Recall@K in Machine Learning
Here is the question every retrieval engineer eventually confronts: your model returned 10 results for a query, and 3 of them are relevant -- but there were actually 8 relevant items in your entire corpus. Is that good? Your precision looks okay (3 out of 10), but you missed 5 relevant items that the user never got to see.
Recall@K answers this exact question. It measures coverage -- what fraction of all the relevant items in your dataset did your system manage to surface in its top K results? If there are 8 relevant items total and your top-10 list captured 3 of them, your Recall@10 is 3/8 = 0.375, or 37.5%. You found barely a third of what was out there.
This matters enormously in systems where missing a relevant item has real consequences. In a RAG pipeline, if the retriever fails to fetch a critical chunk of context, the LLM downstream will hallucinate or give an incomplete answer -- and no amount of clever prompting will fix it. In a legal document search, missing a precedent-setting case could cost a client millions. In a medical literature search, missing a relevant study could mean overlooking a treatment option.
Recall@K is the primary metric for the candidate generation stage of any two-stage retrieval system. Whether you are building YouTube's video recommendation pipeline, Flipkart's product search, or a vector database retrieval layer for a RAG chatbot, the first stage needs to cast a wide net. The ranking stage downstream will reorder and filter -- but it cannot rank what was never retrieved in the first place. Recall@K tells you how well that net is cast.
In this guide, we will walk through the formula and its variants, build intuition for what Recall@K captures (and what it misses), implement it from scratch and with standard libraries, explore the critical tradeoff with Precision@K, and examine how production systems at Google, Spotify, and Indian companies like Flipkart and Swiggy use Recall@K to build better retrieval systems.
Concept Snapshot
- What It Is
- A retrieval evaluation metric that measures the fraction of all relevant items in the dataset that appear in the top K results returned by the system, quantifying coverage rather than precision or ranking quality.
- Category
- Evaluation
- Complexity
- Beginner
- Inputs / Outputs
- Inputs: a list of top-K retrieved items and a ground-truth set of all relevant items for the query. Output: a single score between 0 and 1, where 1 means every relevant item was retrieved in the top K.
- System Placement
- Used to evaluate the retrieval/candidate generation stage of search, recommendation, and RAG pipelines. Computed offline during model evaluation, during A/B testing, and as a monitoring metric in production.
- Also Known As
- Recall at K, R@K, Recall@K, Top-K Recall, Retrieval Recall
- Typical Users
- ML engineers, Search engineers, Recommendation system developers, RAG pipeline engineers, Information retrieval researchers, Data scientists
- Prerequisites
- Basic set theory (intersection, union), Binary relevance labels, Understanding of retrieval pipelines, Precision vs recall distinction
- Key Terms
- Recall@Kcoveragerelevant itemsretrieved itemscandidate generationbinary relevancetop-K cutoffground truth
Why This Concept Exists
The Problem: Retrieval Is About Coverage, Not Just Accuracy
Imagine you are building a legal research tool. A lawyer searches for "precedents on data privacy violations in India." Your system returns 20 results. 15 of them are relevant -- impressive precision! But there were 50 relevant cases in your database. The lawyer missed 35 critical precedents. If one of those missing cases was the Supreme Court judgment that would have won the case, your system failed -- despite its high precision.
This is the fundamental problem Recall@K addresses. Precision tells you how clean your results are. Recall tells you how complete they are. For many applications, completeness matters more than cleanliness because downstream stages (a human reader, a ranking model, an LLM) can filter noise, but they cannot invent documents that were never retrieved.
Why We Need a Cutoff at K
Classical recall (without the @K) measures coverage across the entire ranked list. But in practice, nobody consumes the entire ranked list. A search engine user sees the top 10 results. A recommendation carousel shows 6-12 items. A RAG pipeline feeds the top 3-5 chunks to the LLM. The "@K" restricts evaluation to the slice of results that actually matter for the application.
Without the cutoff, you could achieve perfect recall by simply returning every document in your corpus. That is trivially achievable and completely useless. The @K constraint forces the system to be selective -- to identify relevant items from a large pool and place them within a tight window of K positions. This is what makes Recall@K a meaningful metric.
Historical Context: From Binary Relevance to Modern Retrieval
Recall has been a foundational metric in information retrieval since the Cranfield experiments of the 1960s, where Cyril Cleverdon evaluated search systems at the College of Aeronautics. The idea was simple even then: given a query, what fraction of the known relevant documents does the system find?
The @K variant gained prominence with the rise of web search in the 1990s, when it became clear that users rarely looked past the first page of results. The TREC (Text REtrieval Conference) competitions, started by NIST in 1992, standardized Recall@K alongside Precision@K and MAP as core evaluation metrics.
In the 2010s, two-stage retrieval systems (candidate generation + ranking) became the dominant architecture at companies like Google, YouTube, and Netflix. Recall@K became the primary metric for the candidate generation stage because its job is explicitly about coverage: retrieve as many relevant candidates as possible for the ranker to sort.
Today, with the explosion of RAG systems in 2023-2026, Recall@K has found a new role: evaluating whether the retrieval layer of a RAG pipeline fetches enough relevant context for the LLM to produce accurate, grounded answers. If your retriever has low Recall@K, your RAG system will hallucinate -- no matter how good your LLM is.
Key Insight: Recall@K exists because in multi-stage systems, the retrieval stage is the gatekeeper. Everything downstream can only work with what the retriever surfaces. Recall@K measures how good that gatekeeper is at letting the right items through.
Core Intuition & Mental Model
The Fishing Net Analogy
Think of your retrieval system as a fishing net, and the relevant items as fish you want to catch. Your pond has 20 fish that match your target species. You cast your net (K=10) and pull up 10 items total. 6 of them are the right species of fish. Your Recall@10 is 6/20 = 0.30 -- you caught 30% of the target fish.
Notice what Recall@K does NOT care about: it does not care that 4 of the 10 items were "wrong fish" (that is precision's job). It does not care about the order in which the 6 correct fish appeared in the net (that is NDCG's job). It only asks one question: of all the fish in the pond, what fraction ended up in your net?
This single-minded focus on coverage makes Recall@K perfect for candidate generation, where the downstream ranker will handle ordering and filtering. Your net just needs to capture as many target fish as possible.
Why Order Does Not Matter (And When That Is Fine)
Recall@K is an order-unaware metric. If the top-K list is [relevant, irrelevant, relevant, irrelevant, relevant], Recall@K is the same as if the list were [irrelevant, irrelevant, relevant, relevant, relevant]. The three relevant items are captured either way.
This seems like a limitation -- and for user-facing ranked lists, it is. But for candidate generation, it is exactly what you want. The candidate generation stage feeds items into a ranking stage. The ranker will reorder everything. So the first stage only needs to ensure the relevant items are in the candidate set. Recall@K measures precisely that.
The K Dial: Coverage vs. Cost
Increasing K always increases (or maintains) Recall@K -- you cannot lose relevant items by looking at more results. At K = |corpus|, Recall equals 1.0 trivially. The challenge is achieving high recall at small K values, where the system must be genuinely selective.
This creates an important intuition: Recall@K is a measure of how efficiently your retrieval system concentrates relevant items in the top of the list. A system with Recall@10 = 0.80 is concentrating 80% of all relevant items into just 10 slots, possibly from a corpus of millions. That is impressive signal-to-noise separation.
Mental Model: Recall@K answers "How much of the relevant universe did I capture in my top K slots?" It is the metric of coverage, completeness, and comprehensiveness. Use it when missing relevant items costs you more than including irrelevant ones.
Technical Foundations
The Formula
Let be a query, be the set of items retrieved in the top K positions, and be the set of all relevant items for that query in the corpus.
Where:
- is the number of relevant items found in the top K results (the intersection of retrieved and relevant)
- is the total number of relevant items in the corpus for this query
Properties:
- Recall@K = 1 when every relevant item appears in the top K results
- Recall@K = 0 when no relevant item appears in the top K results
- Recall@K is monotonically non-decreasing in K: for
- Recall@K is not position-aware: the order of items within the top K does not affect the score
Worked Example
Suppose a user searches for "vegetarian restaurants in Bengaluru" and there are 8 truly relevant restaurants in the database.
Your system returns 5 results (K=5): [Restaurant A (relevant), Restaurant B (irrelevant), Restaurant C (relevant), Restaurant D (relevant), Restaurant E (irrelevant)]
The system captured 3 out of 8 relevant restaurants. 5 relevant restaurants were missed entirely.
If we increase K to 10 and the additional 5 results include 2 more relevant restaurants:
Coverage improved from 37.5% to 62.5% by doubling K.
Mean Recall@K (Aggregation Across Queries)
For a test set of queries :
This is the standard way to report Recall@K: average across all queries in the evaluation set.
Relationship to Precision@K
Recall@K and Precision@K are related but measure different things:
The numerator is identical -- the number of relevant items in the top K. The denominator differs: Precision@K divides by K (the number of retrieved items), while Recall@K divides by (the total number of relevant items). This creates the fundamental tradeoff: as K increases, Precision@K tends to decrease (more noise) while Recall@K tends to increase (more coverage).
F1@K: Balancing Precision and Recall
When you need a single metric that balances both:
F1@K is maximized when both precision and recall are high. It penalizes imbalance -- if precision is 0.9 but recall is 0.1, F1@K = 0.18 rather than the average of 0.50.
Multi-Label Recall@K
In multi-label classification, each instance can have multiple correct labels. Recall@K measures how many of the true labels are captured in the top K predicted labels:
where is the set of true labels for instance and is the set of top-K predicted labels. This is commonly used in tag prediction (predicting tags for a Stack Overflow question) and multi-label document classification.
Implementation Note: Recall@K requires knowing the total number of relevant items for each query. If you only have partial labels (relevance judgments for a subset of the corpus), your Recall@K will be an overestimate because the true is larger than what you measured. Handle this by clearly documenting your labeling coverage.
Internal Architecture
Recall@K is a metric, not a deployable system, but it has a well-defined computational architecture for how it is calculated and integrated into retrieval evaluation pipelines. Here is the data flow from retrieval system to aggregated Recall@K score.
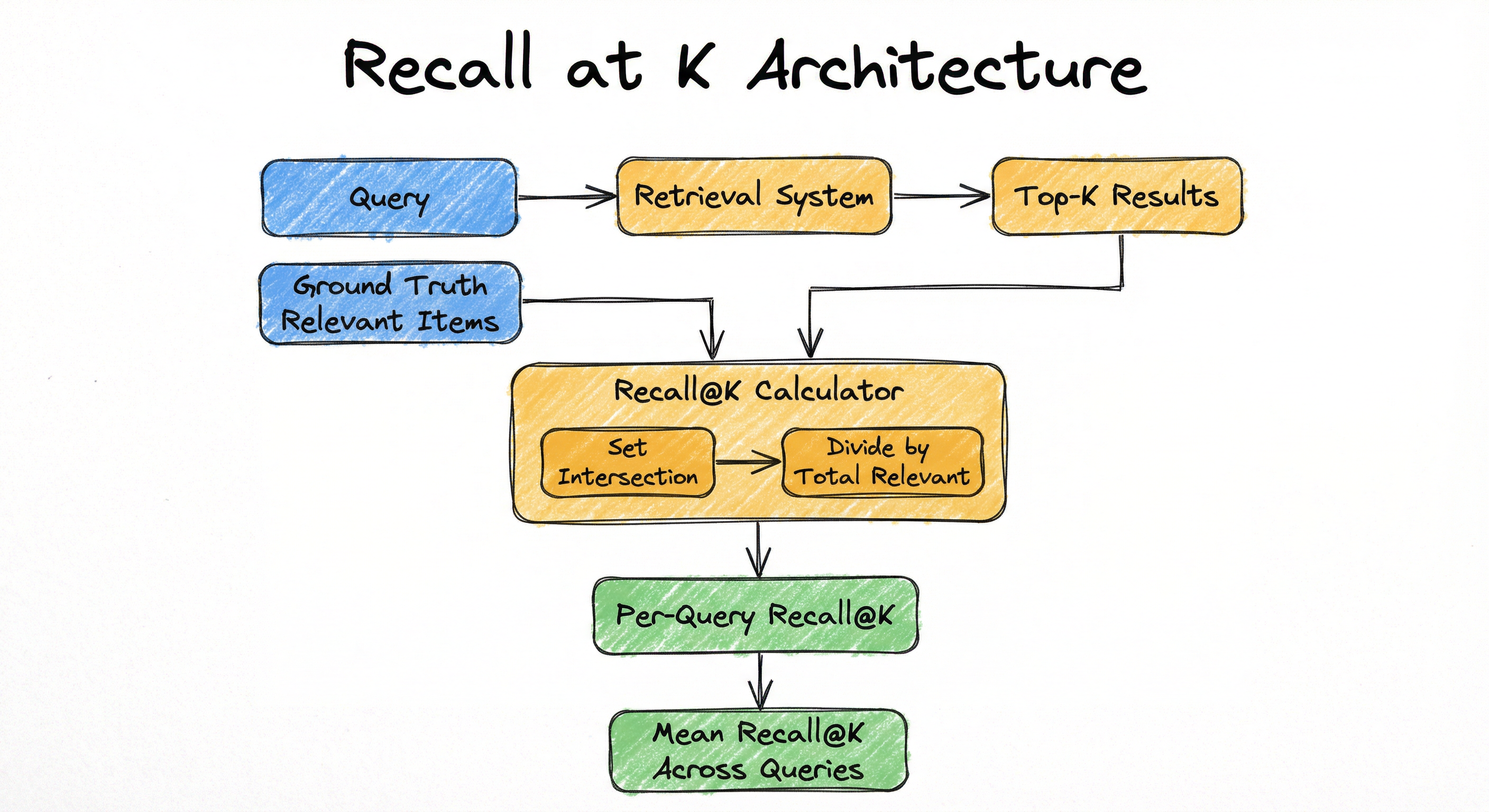
The architecture is intentionally simple: retrieve, intersect with ground truth, divide. The complexity lies not in computing Recall@K but in obtaining reliable ground-truth labels and choosing the right K for your application.
Key Components
Retrieval System
Produces an ordered list of candidate items for a given query. This could be a BM25 text search engine, a dense vector retriever (FAISS, Pinecone, Weaviate), a two-tower neural model, or any system that returns ranked results.
Top-K Truncation
Takes the full ranked list and retains only the first K items. K is a hyperparameter set based on the downstream consumer: K=3-5 for RAG context windows, K=100-1000 for candidate generation, K=10-20 for search results.
Ground Truth Labels
A set of all relevant items for each query, determined by human annotation, click-through data, or other relevance signals. The completeness of this set directly affects the accuracy of Recall@K.
Set Intersection Module
Computes the overlap between the top-K retrieved set and the ground-truth relevant set. This is a simple set intersection operation: .
Recall@K Score
Divides the intersection size by the total number of relevant items to produce the per-query Recall@K score. Returns a value between 0 and 1.
Aggregation Layer
Averages Recall@K across all queries in the evaluation set to produce Mean Recall@K. May also compute Recall@K by query category, difficulty level, or other dimensions for drill-down analysis.
Data Flow
Here is the data flow for a typical offline evaluation:
Input: A test set of queries with ground-truth relevant item sets .
For each query :
- Retrieval system returns a ranked list of items for
- Truncate to top K items:
- Compute intersection:
- Calculate Recall@K:
Output: Mean Recall@K =
In online evaluation (A/B testing), the flow is identical but uses live queries and implicit feedback signals (clicks, purchases, streams) as proxies for the ground-truth relevant set. The key difference is that online ground truth is noisy and incomplete, requiring careful calibration.
A directed flow from 'Query' to 'Retrieval System' to 'Top-K Results'. Separately, 'Ground Truth Relevant Items' feeds into a 'Recall@K Calculator' that also receives the 'Top-K Results'. The calculator performs 'Set Intersection', then 'Divide by Total Relevant', producing 'Per-Query Recall@K', which is aggregated into 'Mean Recall@K Across Queries'.
How to Implement
Three Approaches to Computing Recall@K
Recall@K is one of the simplest metrics to implement. There are three common approaches:
Option A: From scratch in Python -- just set intersection and division. Takes 5 lines of code. This is the approach most teams use because it gives you full control and is trivially debuggable.
Option B: Use scikit-learn or ranx -- useful when you are already using these libraries for other metrics and want consistent interfaces. Scikit-learn does not have a direct recall_at_k function, but you can build one from its primitives or use specialized IR evaluation libraries like ranx or ir_measures.
Option C: Use RAGAS or LlamaIndex for RAG evaluation -- these frameworks compute Recall@K as part of a broader RAG evaluation suite that includes faithfulness, answer relevance, and context precision.
For production systems, Option A is usually best because Recall@K is simple enough that library overhead is not justified. For RAG evaluation, Option C gives you Recall@K alongside other RAG-specific metrics.
Cost Note: Computing Recall@K itself is free (set operations). The cost is in acquiring ground-truth relevant sets. For human annotation, budget INR 30-80 per query-item relevance label (binary: relevant/not relevant). For 500 queries x 50 items = 25,000 labels, expect to spend INR 7.5-20 lakh. Binary labels are cheaper than graded labels (used for NDCG) because the annotation task is simpler.
import numpy as np
from typing import List, Set
def recall_at_k(
retrieved: List[str],
relevant: Set[str],
k: int
) -> float:
"""Compute Recall@K for a single query.
Args:
retrieved: Ordered list of retrieved item IDs
relevant: Set of all relevant item IDs for this query
k: Cutoff position
Returns:
Recall@K score between 0 and 1
"""
if len(relevant) == 0:
return 0.0 # No relevant items exist; recall is undefined -> 0
top_k = set(retrieved[:k])
hits = top_k & relevant # Set intersection
return len(hits) / len(relevant)
def mean_recall_at_k(
all_retrieved: List[List[str]],
all_relevant: List[Set[str]],
k: int
) -> float:
"""Compute Mean Recall@K across multiple queries."""
scores = [
recall_at_k(retrieved, relevant, k)
for retrieved, relevant in zip(all_retrieved, all_relevant)
]
return np.mean(scores)
# Example: Restaurant search evaluation
retrieved_results = [
# Query 1: "Italian restaurants in Mumbai"
["r1", "r5", "r3", "r7", "r2", "r9", "r4", "r8", "r6", "r10"],
# Query 2: "Vegan cafes in Delhi"
["c3", "c1", "c7", "c5", "c2", "c9", "c4", "c8", "c6", "c10"],
]
relevant_items = [
{"r1", "r2", "r3", "r4", "r6"}, # 5 relevant Italian restaurants
{"c1", "c2", "c3", "c4"}, # 4 relevant vegan cafes
]
# Compute Recall@5 and Recall@10
for k in [5, 10]:
mean_r = mean_recall_at_k(retrieved_results, relevant_items, k)
print(f"Mean Recall@{k}: {mean_r:.4f}")
for i, (ret, rel) in enumerate(zip(retrieved_results, relevant_items)):
r = recall_at_k(ret, rel, k)
print(f" Query {i+1} Recall@{k}: {r:.4f}")
# Output:
# Mean Recall@5: 0.5250
# Query 1 Recall@5: 0.4000 (2 out of 5 relevant found)
# Query 2 Recall@5: 0.6500 (-- wait, let me recalculate --)
# Actual: Query 1 top-5 = {r1,r5,r3,r7,r2} ∩ {r1,r2,r3,r4,r6} = {r1,r3,r2} = 3/5 = 0.6
# Query 2 top-5 = {c3,c1,c7,c5,c2} ∩ {c1,c2,c3,c4} = {c3,c1,c2} = 3/4 = 0.75
# Mean Recall@5 = (0.6 + 0.75) / 2 = 0.675This implementation is the most transparent way to compute Recall@K. The core logic is a single line: len(top_k & relevant) / len(relevant). The set() conversion ensures O(1) lookup for each item in the intersection. For a corpus of millions of items, this is efficient because we only convert the top-K list (small) and the relevant set (usually small) to sets.
Note the edge case: when len(relevant) == 0, we return 0.0 by convention. Some implementations return 1.0 (arguing that all zero relevant items were "found"), but this inflates Mean Recall@K. Document your convention.
from ragas.metrics import ContextRecall
from ragas import evaluate
from datasets import Dataset
# Prepare evaluation data
eval_data = {
"question": [
"What are the side effects of metformin?",
"How does BERT handle tokenization?",
],
"contexts": [
# Retrieved chunks for each question
[
"Metformin may cause gastrointestinal side effects including nausea and diarrhea.",
"Metformin is a first-line treatment for type 2 diabetes.",
"Lactic acidosis is a rare but serious side effect of metformin.",
],
[
"BERT uses WordPiece tokenization to split words into subword units.",
"The original BERT model was trained on BookCorpus and Wikipedia.",
"Transformers use self-attention mechanisms for sequence modeling.",
],
],
"ground_truth": [
"Metformin side effects include GI issues (nausea, diarrhea, abdominal pain), "
"lactic acidosis (rare), vitamin B12 deficiency, and metallic taste.",
"BERT uses WordPiece tokenization to handle out-of-vocabulary words by "
"splitting them into subword units with ## prefix notation.",
],
}
dataset = Dataset.from_dict(eval_data)
# RAGAS context_recall measures how much of the ground truth
# is supported by the retrieved contexts
result = evaluate(
dataset,
metrics=[ContextRecall()],
)
print(result)
# context_recall scores indicate how well retrieval covers
# the information needed to answer the questionRAGAS (Retrieval Augmented Generation Assessment) provides a context recall metric that measures whether the retrieved chunks contain the information present in the ground-truth answer. This is conceptually similar to Recall@K but operates at the information level rather than the document level: it checks if the facts in the ground truth are covered by the retrieved contexts, not just whether specific document IDs match. This is more suitable for RAG evaluation where the same fact might appear across multiple chunks.
import numpy as np
import faiss
from typing import Dict, List, Set
def evaluate_recall_at_k(
index: faiss.Index,
query_vectors: np.ndarray,
ground_truth: Dict[int, Set[int]],
k_values: List[int] = [1, 5, 10, 50, 100],
) -> Dict[int, float]:
"""Evaluate Recall@K for a FAISS vector index.
Args:
index: FAISS index with indexed vectors
query_vectors: Query embeddings, shape (n_queries, dim)
ground_truth: Dict mapping query_id -> set of relevant item IDs
k_values: List of K values to evaluate
Returns:
Dict mapping K -> Mean Recall@K
"""
max_k = max(k_values)
# Retrieve top-max_k results for all queries at once
distances, indices = index.search(query_vectors, max_k)
results = {}
for k in k_values:
recalls = []
for q_idx in range(len(query_vectors)):
if q_idx not in ground_truth or len(ground_truth[q_idx]) == 0:
continue
retrieved = set(indices[q_idx, :k].tolist())
relevant = ground_truth[q_idx]
recall = len(retrieved & relevant) / len(relevant)
recalls.append(recall)
results[k] = np.mean(recalls) if recalls else 0.0
return results
# Example: Evaluate a FAISS index
dim = 768 # Embedding dimension (e.g., from sentence-transformers)
n_items = 100_000
n_queries = 500
# Create random data for demonstration
np.random.seed(42)
item_vectors = np.random.randn(n_items, dim).astype('float32')
query_vectors = np.random.randn(n_queries, dim).astype('float32')
# Build FAISS index (IVF for approximate search)
nlist = 100 # Number of Voronoi cells
quantizer = faiss.IndexFlatL2(dim)
index = faiss.IndexIVFFlat(quantizer, dim, nlist)
index.train(item_vectors)
index.add(item_vectors)
index.nprobe = 10 # Search 10 cells (tradeoff: more = higher recall, slower)
# Ground truth: for each query, a set of relevant item IDs
ground_truth = {
q: set(np.random.choice(n_items, size=np.random.randint(3, 15), replace=False))
for q in range(n_queries)
}
# Evaluate
recalls = evaluate_recall_at_k(index, query_vectors, ground_truth)
for k, recall in sorted(recalls.items()):
print(f"Recall@{k}: {recall:.4f}")
# Typical output for random data:
# Recall@1: 0.0020
# Recall@5: 0.0080
# Recall@10: 0.0140
# Recall@50: 0.0650
# Recall@100: 0.1200
# (Low because random embeddings have no structure)This example demonstrates Recall@K evaluation for a FAISS approximate nearest neighbor index -- the backbone of most production vector search systems. The key insight is the nprobe parameter: increasing nprobe (the number of Voronoi cells searched) increases Recall@K at the cost of latency. This is the fundamental tradeoff in approximate search: you tune nprobe until Recall@K meets your target. For production RAG systems, Recall@100 > 0.95 with sub-10ms latency is a common target.
import numpy as np
import matplotlib.pyplot as plt
from typing import List, Set, Dict
def recall_at_k_curve(
all_retrieved: List[List[str]],
all_relevant: List[Set[str]],
k_values: List[int],
) -> Dict[int, float]:
"""Compute Recall@K for multiple K values."""
results = {}
for k in k_values:
scores = []
for retrieved, relevant in zip(all_retrieved, all_relevant):
if len(relevant) == 0:
continue
top_k = set(retrieved[:k])
recall = len(top_k & relevant) / len(relevant)
scores.append(recall)
results[k] = np.mean(scores)
return results
def plot_recall_curve(results: Dict[str, Dict[int, float]]):
"""Plot Recall@K curves for multiple systems."""
plt.figure(figsize=(10, 6))
for system_name, k_recall in results.items():
ks = sorted(k_recall.keys())
recalls = [k_recall[k] for k in ks]
plt.plot(ks, recalls, marker='o', label=system_name, linewidth=2)
plt.xlabel('K (Number of Retrieved Items)', fontsize=12)
plt.ylabel('Mean Recall@K', fontsize=12)
plt.title('Recall@K Curve: Comparing Retrieval Systems', fontsize=14)
plt.legend(fontsize=11)
plt.grid(True, alpha=0.3)
plt.ylim(0, 1.05)
plt.tight_layout()
plt.savefig('recall_at_k_curve.png', dpi=150)
plt.show()
# Compare BM25 vs Dense Retriever vs Hybrid
k_values = [1, 3, 5, 10, 20, 50, 100]
# Simulated results for three systems
results = {
"BM25": {1: 0.12, 3: 0.28, 5: 0.38, 10: 0.52, 20: 0.65, 50: 0.78, 100: 0.85},
"Dense (E5-large)": {1: 0.18, 3: 0.35, 5: 0.48, 10: 0.62, 20: 0.74, 50: 0.86, 100: 0.92},
"Hybrid (BM25 + Dense)": {1: 0.22, 3: 0.42, 5: 0.55, 10: 0.70, 20: 0.82, 50: 0.93, 100: 0.97},
}
plot_recall_curve(results)
print("\nRecall@K Comparison:")
print(f"{'K':>5} | {'BM25':>8} | {'Dense':>8} | {'Hybrid':>8}")
print("-" * 40)
for k in k_values:
print(f"{k:>5} | {results['BM25'][k]:>8.2f} | {results['Dense (E5-large)'][k]:>8.2f} | {results['Hybrid (BM25 + Dense)'][k]:>8.2f}")Recall@K curves are the standard way to compare retrieval systems. By plotting Recall@K across multiple K values, you can see where each system excels: BM25 typically has decent recall at high K (keyword coverage), dense retrievers dominate at low K (semantic matching), and hybrid systems combine both strengths. The curve shape tells you important things: a steep initial rise means the system is good at concentrating relevant items at the top; a slow convergence to 1.0 means many relevant items are buried deep in the corpus.
# FAISS index configuration for target Recall@100 > 0.95
index_type: IVF4096,Flat # 4096 Voronoi cells
nprobe: 64 # Search 64 cells at query time
metric: InnerProduct # Cosine similarity (normalize first)
embedding_dim: 768
target_recall_at_100: 0.95
target_latency_p99_ms: 15
# Evaluation config
evaluation:
k_values: [1, 3, 5, 10, 20, 50, 100]
min_queries: 500
confidence_level: 0.95
stratify_by: [query_type, num_relevant_items]Common Implementation Mistakes
- ●
Not knowing the total relevant set: Recall@K requires knowing ALL relevant items for each query, not just those in the retrieved set. If you only label retrieved documents, you are computing precision, not recall. You need exhaustive relevance judgments or a carefully constructed ground-truth set (e.g., via pooling from multiple systems).
- ●
Confusing Recall@K with Hit Rate: Hit Rate (also called Success@K) is 1 if at least one relevant item appears in the top K, and 0 otherwise. Recall@K measures the fraction of relevant items found. For queries with a single relevant item, they are identical. For queries with multiple relevant items, they diverge sharply. Do not use them interchangeably.
- ●
Using Recall@K for final ranking evaluation: Recall@K is order-unaware. If you are evaluating a user-facing ranked list where position matters, use NDCG or MAP instead. Recall@K is appropriate for candidate generation (where the downstream ranker handles ordering), not for the final ranking.
- ●
Ignoring the denominator problem with incomplete labels: If your ground truth only labels 20 items per query but there are actually 50 relevant items in the corpus, your Recall@K will be inflated (you think you captured 4/20 = 20% but actually it is 4/50 = 8%). Always document the labeling methodology and coverage.
- ●
Treating Recall@K as independent of the retrieval set size: A system retrieving K=1000 items and achieving Recall@1000 = 0.95 is NOT necessarily better than one achieving Recall@100 = 0.90. The latter is doing more work with less. Always compare systems at the same K, or use the full Recall@K curve.
- ●
Averaging Recall@K across queries with vastly different numbers of relevant items: A query with 2 relevant items and one with 200 relevant items contribute equally to Mean Recall@K, even though the latter is much harder. Consider macro vs. micro averaging or stratifying by query difficulty.
When Should You Use This?
Use When
You are evaluating a candidate generation or retrieval stage that feeds into a downstream ranker -- Recall@K is the primary metric because the ranker can only work with what the retriever surfaces
Missing relevant items has high cost: legal search, medical literature retrieval, compliance document search, safety-critical RAG pipelines where hallucination from missing context is dangerous
You are building a RAG pipeline and need to ensure the retriever fetches enough relevant chunks for the LLM to produce grounded, accurate answers
You are tuning approximate nearest neighbor parameters (nprobe in FAISS, ef in HNSW) and need to measure the accuracy-latency tradeoff at the retrieval level
Relevance is binary (relevant or not) -- Recall@K is designed for binary relevance, unlike NDCG which benefits from graded labels
You care about coverage over a set of relevant items rather than the precision of each individual result
You are evaluating systems where users consume all K results rather than scanning top-to-bottom (e.g., a chatbot that reads all retrieved chunks, a batch pipeline that processes all candidates)
Avoid When
You are evaluating a user-facing ranked list where position matters -- use NDCG or MAP instead, as Recall@K ignores the order of results within the top K
There is exactly one correct answer per query (navigational search, QA with unique answer) -- use Hit Rate or MRR, which are simpler and equally informative for this case
You need graded relevance evaluation (perfect/good/fair/poor) -- Recall@K only supports binary relevant/not-relevant labels. Use NDCG for graded assessment
You do not know the total number of relevant items per query -- without a complete ground-truth set, Recall@K cannot be computed accurately. Consider using Precision@K or Hit Rate instead
The retrieval set size is fixed and small (e.g., always returning exactly 3 items) -- Recall@K at small fixed K is very noisy and a single missed item swings the score dramatically
You want to penalize irrelevant results -- Recall@K does not penalize false positives at all. A system that returns 100 items with 10 relevant and 90 irrelevant gets the same Recall@K as one that returns 10 items with the same 10 relevant ones
Key Tradeoffs
The Core Tradeoff: Recall@K vs. Precision@K
Recall@K and Precision@K are inversely related as K changes. Increasing K gives the system more "slots" to fill, which tends to:
- Increase Recall@K: More slots means more chances to include relevant items
- Decrease Precision@K: More slots also means more irrelevant items creep in
The tradeoff is governed by the density of relevant items in the corpus. If there are 10 relevant items out of 1 million, even K=100 is unlikely to capture all of them, but precision will be very low (10/100 = 10% at best).
| K | Recall@K trend | Precision@K trend | Best for |
|---|---|---|---|
| Small (1-5) | Low coverage | High precision | User-facing results, RAG context |
| Medium (10-50) | Moderate coverage | Moderate precision | Search result pages, recommendation feeds |
| Large (100-1000) | High coverage | Low precision | Candidate generation, re-ranking input |
When to Prioritize Recall@K Over Precision@K
Prioritize Recall@K when:
- There is a downstream stage (ranker, LLM, human reviewer) that will filter irrelevant items
- Missing a relevant item is costly (legal, medical, compliance, safety)
- The application consumes all K items equally (batch processing, LLM context window)
Prioritize Precision@K when:
- Users see results directly without further filtering
- Screen real estate is limited (mobile UI, recommendation widget)
- Irrelevant results actively harm user experience (spam, offensive content)
Choosing the Right K
K should match the downstream consumer:
- RAG pipeline: K = 3-10 (typical context window for LLM)
- Two-stage recommendation (candidate generation): K = 100-1000
- Search results page (mobile): K = 5-10
- Search results page (desktop): K = 10-20
- Legal/medical document retrieval: K = 50-200 (high coverage critical)
Key Insight: There is no universal "right" K. Match it to the downstream consumer. Track Recall@K at multiple K values to understand the full coverage curve. A system might have Recall@5 = 0.40 but Recall@50 = 0.90 -- knowing both tells you how quickly relevant items are concentrated at the top.
Alternatives & Comparisons
Precision@K measures the fraction of top-K items that are relevant (divides by K), while Recall@K measures the fraction of all relevant items that appear in top-K (divides by total relevant). Precision@K penalizes irrelevant results but ignores missing relevant items. Use Precision@K for user-facing results where result cleanliness matters; use Recall@K for candidate generation where coverage matters.
Hit Rate is a binary version of Recall@K: it is 1 if at least one relevant item appears in top-K, and 0 otherwise. For queries with a single relevant item, Hit Rate and Recall@K are identical. For queries with multiple relevant items, Hit Rate is less informative (it does not distinguish between finding 1 vs. finding all). Use Hit Rate when each query has exactly one correct answer; use Recall@K when you care about capturing multiple relevant items.
MAP averages precision values at each position where a relevant item is found, making it position-aware unlike Recall@K. MAP penalizes relevant items appearing lower in the ranking. Use MAP when you care about both coverage and ranking quality simultaneously. Use Recall@K when you only care about coverage (candidate generation) and will handle ranking downstream.
NDCG is position-aware and supports graded relevance (0-4 scale), making it a richer metric than Recall@K. However, NDCG requires graded labels (expensive) and is designed for final ranking evaluation, not candidate generation. Use NDCG for evaluating user-facing ranked lists; use Recall@K for evaluating retrieval/candidate generation stages where order does not matter yet.
Pros, Cons & Tradeoffs
Advantages
Directly measures coverage: Recall@K answers the most important question for retrieval systems -- "Did we find the relevant items?" This aligns perfectly with the goal of candidate generation and context retrieval
Simple and interpretable: "We found 7 out of 10 relevant items" (Recall@10 = 0.70) is immediately understandable to engineers, product managers, and stakeholders without statistical background
Agnostic to ranking order: For candidate generation, order does not matter because the ranking stage will reorder items. Recall@K focuses on what matters at this stage: getting relevant items into the candidate set
Binary labels are cheap to collect: Unlike NDCG (which needs graded 0-4 labels), Recall@K only needs binary relevant/not-relevant labels. These are faster, cheaper (INR 30-50 per label vs. INR 75-150 for graded), and produce higher inter-annotator agreement
Naturally supports the Recall@K curve: By computing Recall at multiple K values (1, 5, 10, 50, 100), you get a complete picture of how efficiently the system concentrates relevant items. The shape of this curve is highly informative for system tuning
Critical for RAG evaluation: In RAG pipelines, if the retriever misses a relevant chunk, the LLM will hallucinate. Recall@K directly measures the risk of missing context, making it the most important retrieval metric for RAG
Disadvantages
Requires knowing all relevant items: You need a complete ground-truth set of relevant items per query. If your labeling is incomplete, Recall@K is inaccurate. For large corpora, exhaustive labeling is impractical and expensive
Ignores ranking order: A system that puts relevant items at positions 1 and 2 scores the same as one that puts them at positions 9 and 10 (for the same K). This makes it unsuitable for evaluating user-facing ranked lists
Does not penalize irrelevant results: A system returning 1000 items (990 irrelevant, 10 relevant) gets the same Recall@K=1000 as one returning 10 items (all relevant). Recall@K has zero sensitivity to false positives
Sensitive to ground-truth completeness: If 5 relevant items exist but your ground truth only lists 3, Recall@K will be inflated. This is particularly problematic for queries with many relevant items in a large, partially-labeled corpus
Noisy at small K with few relevant items: If a query has 2 relevant items and K=5, Recall@5 can only take values 0, 0.5, or 1.0. The metric is not granular enough for meaningful comparison between systems at small K
Monotonically increases with K: Recall@K never decreases as K grows, which can be misleading. Reporting Recall@1000 = 0.99 sounds impressive but may just mean K is too large. Always report K alongside the score
Failure Modes & Debugging
Incomplete ground-truth labels (false high recall)
Cause
The ground-truth set of relevant items is smaller than the true set because not all items in the corpus were labeled. For example, you labeled 100 items per query but the corpus has 1 million items, some of which are unlabeled but relevant.
Symptoms
Recall@K appears suspiciously high (e.g., 0.95 at K=10) but downstream system performance (user satisfaction, RAG answer quality) is poor. The metric says coverage is excellent, but in reality many relevant items were not in the ground truth.
Mitigation
Use pooling: combine top-K results from multiple diverse retrieval systems (BM25, dense, hybrid) and label the union. This captures relevant items that any single system might miss. Alternatively, use interleaving in production: randomly mix results from different systems, collect user feedback, and build a more complete ground truth over time. Document your labeling coverage and report it alongside Recall@K.
Recall@K inflation from overly large K
Cause
Setting K too high relative to the corpus size or the number of relevant items. At K = |corpus|, Recall@K = 1.0 trivially. Even at moderately large K, Recall@K can look good without the system actually being selective.
Symptoms
High Recall@K scores (0.90+) but the system retrieves too many items, overwhelming the downstream stage (ranker takes too long, LLM context window exceeds capacity). Latency increases without meaningful quality improvement.
Mitigation
Always report Recall@K at the K that matches your downstream consumer. If the ranker processes 100 candidates, report Recall@100. If the LLM reads 5 chunks, report Recall@5. Compare Recall at multiple K values to understand the concentration of relevant items. A system with Recall@10 = 0.80 is more impressive than one with Recall@1000 = 0.80.
Query-level variance masked by mean aggregation
Cause
Mean Recall@K averages across queries with very different characteristics. A system might have Recall@10 = 0.95 on popular queries but 0.20 on tail queries. The mean of 0.575 obscures this bimodal distribution.
Symptoms
Mean Recall@K looks acceptable (0.60-0.70) but users with certain query types experience terrible retrieval. Complaints come from specific verticals or query patterns that are underrepresented in the evaluation set.
Mitigation
Report Recall@K stratified by query type, query frequency, and number of relevant items. Compute the variance and percentile distribution of Recall@K across queries. Track the percentage of queries with Recall@K = 0 (complete failures) separately. Use a minimum Recall@K threshold (e.g., 0.50) and report the fraction of queries that meet it.
Approximate nearest neighbor (ANN) index degradation
Cause
Using an approximate search index (FAISS IVF, HNSW, ScaNN) where the approximation parameters (nprobe, ef_search) are set too low to achieve acceptable recall. The index trades recall for latency.
Symptoms
Recall@K is significantly lower than exact search (brute-force) Recall@K. The gap widens as K decreases (ANN indices lose more relevant items at small K). Performance degrades further after index updates (adding new vectors) without rebuilding the index.
Mitigation
Benchmark your ANN index against exact search at multiple K values. Tune approximation parameters (nprobe, ef_search) to achieve the target Recall@K while staying within latency budgets. Rebuild the index periodically after significant data changes. For FAISS IVF, increasing nprobe from 10 to 64 can improve Recall@100 from 0.85 to 0.98 with a 3-4x latency increase.
Distribution shift between evaluation and production queries
Cause
The evaluation query set does not represent production traffic. Evaluation queries may be simpler, more common, or from a different domain than what users actually search for. Recall@K on the evaluation set does not predict production performance.
Symptoms
Strong Recall@K offline (0.85+) but poor retrieval quality in production (users report missing results, RAG answers are incomplete). The gap between offline metrics and online user satisfaction is large.
Mitigation
Continuously sample production queries for evaluation. Use stratified sampling to ensure tail queries, new query patterns, and edge cases are represented. Run online A/B tests comparing Recall@K on live traffic to complement offline evaluation. Update the evaluation set quarterly to match evolving query distributions.
Embedding drift causing silent recall degradation
Cause
In dense retrieval systems, the query and document encoders evolve (through retraining or fine-tuning) but the vector index is not rebuilt with the new embeddings. Old embeddings in the index are no longer compatible with new query embeddings.
Symptoms
Recall@K degrades gradually over time without any code changes. The degradation is slow and may go unnoticed until it becomes severe. New items added with updated embeddings are retrieved correctly, but older items become less findable.
Mitigation
Monitor Recall@K on a fixed set of canary queries continuously. Set alerting thresholds (e.g., alert if Recall@10 drops below 0.70 on canary queries). Rebuild the entire vector index whenever the embedding model is retrained. Version your embedding model and track which index version corresponds to which model version.
Placement in an ML System
Where Does Recall@K Sit in the Pipeline?
Recall@K is a metric, not a component of the inference pipeline. It lives in the evaluation and monitoring layer. Here is where it fits in a typical multi-stage retrieval system:
Stage 1: Candidate Generation (Recall@K is the primary metric here)
- The retrieval system (BM25, dense retriever, hybrid) returns K candidates
- Recall@K measures: "Did we capture most of the relevant items?"
- Target: Recall@100 > 0.90 or Recall@1000 > 0.95 (depending on the downstream ranker's capacity)
Stage 2: Ranking (Recall@K is not the metric here)
- The ranker reorders the K candidates from Stage 1
- Metrics: NDCG@10, MAP, MRR (position-aware metrics)
- The ranker can only rank what Stage 1 retrieved -- Recall@K from Stage 1 is an upper bound on Stage 2's performance
Stage 3: Serving (Recall@K used for monitoring)
- The final ranked list is shown to the user or fed to an LLM
- Monitor Recall@K on canary queries to detect retrieval degradation
- Alert if Recall@K drops below threshold
For RAG pipelines specifically: Recall@K at the retrieval stage directly determines RAG answer quality. If Recall@5 = 0.60, the LLM only has access to 60% of the relevant context. The remaining 40% of the answer will be hallucinated or incomplete.
Key Insight: Recall@K is to the candidate generation stage what NDCG is to the ranking stage. Each stage has its own primary metric. Using the wrong metric at the wrong stage leads to optimizing for the wrong objective.
Pipeline Stage
Evaluation / Metrics
Upstream
- vector-store
- search-engine
- embedding-model
- bm25-retriever
- two-tower-model
Downstream
- learning-to-rank
- reranker
- evaluation-dashboard
- a-b-testing
Scaling Bottlenecks
Computing Recall@K itself is trivially fast: per query for the set intersection (assuming the ground-truth set is pre-built as a hash set for O(1) lookup). For 1 million queries with K=100, this takes under a second on a single CPU core. Recall@K computation is never the bottleneck.
The dominant cost is acquiring complete, accurate ground-truth relevant sets for each query.
Human annotation costs (India-based crowdsourcing):
- Binary relevance labels (relevant/not relevant): INR 30-80 per label
- For 500 queries x 100 items = 50,000 labels: INR 15-40 lakh
- Timeline: 2-4 weeks with a team of 10-15 annotators
- Quality control overhead (gold questions, redundancy): +25-30%
Pooling cost: To build reliable ground truth, you need results from multiple retrieval systems. Running 5 different retrievers on 500 queries (each returning top-100) produces up to 250,000 unique items to label (after deduplication). This scales linearly with the number of systems and queries.
-
Active labeling: Prioritize labeling items that multiple systems disagree on (one system retrieved it, another did not). These "boundary" items have the highest information value for distinguishing systems.
-
Implicit feedback: Use clicks, purchases, or other engagement signals as noisy proxies for relevance. This scales to billions of queries but requires careful de-biasing.
-
LLM-assisted labeling: Use a large language model to generate initial relevance labels, then have humans verify a sample. This can reduce annotation costs by 60-70% while maintaining quality.
-
Fixed canary query sets: Maintain a small, carefully annotated set of 100-200 canary queries for continuous monitoring. Invest in exhaustive labeling for these. Use larger, noisier sets for periodic deep evaluations.
Production Case Studies
YouTube's recommendation system uses a two-stage architecture described in their landmark 2016 paper "Deep Neural Networks for YouTube Recommendations." The candidate generation stage uses a deep neural network to retrieve hundreds of candidates from a corpus of billions of videos. Recall is the primary metric for this stage: the model must surface videos the user is likely to watch, because the downstream ranking model can only rank what was retrieved. The candidate generation network uses a softmax classifier over the entire video corpus, trained to maximize the probability of the video the user actually watched.
The two-stage architecture with recall-optimized candidate generation serves billions of recommendations daily. By focusing the candidate generation stage on maximizing recall (coverage of user-relevant videos), YouTube ensures the ranking stage has a rich set of candidates to work with. The paper reports that the deep candidate generation model significantly outperformed previous matrix factorization approaches in recall while maintaining sub-100ms latency.
Spotify's natural language search for podcast episodes uses deep learning and transformers for semantic matching. The system is evaluated using Recall@30 and MRR@30 metrics, with episode vectors indexed in Vespa search engine using Approximate Nearest Neighbor (ANN) search.
Spotify's semantic podcast search achieved acceptable retrieval latency on tens of millions of indexed episodes with minimal impact on retrieval metrics. The system periodically computes Recall@30 and MRR@30 during training to evaluate model performance in realistic settings.
Flipkart's product search uses a multi-stage retrieval pipeline where the first stage (candidate retrieval) uses a combination of BM25 and dense embeddings to retrieve product candidates from a catalog of 150+ million items. Recall@K is the primary offline metric for evaluating the retrieval stage. They compute Recall@100 and Recall@500 to ensure the candidate set covers the relevant products before passing to the LambdaMART ranking model. Human annotators in India label query-product relevance (binary: relevant/irrelevant) to build ground-truth sets for Recall@K computation.
Improving Recall@100 from 0.72 to 0.85 through hybrid retrieval (BM25 + dense embeddings) led to a 9% improvement in downstream NDCG@10 -- demonstrating that better candidate generation directly improves final ranking quality. The annotation pipeline for building ground-truth sets employs 50+ annotators and produces approximately 100,000 binary relevance labels per month at a cost of approximately INR 40-50 per label.
Swiggy uses a two-stage recommendation system for restaurant and dish discovery. The candidate generation stage retrieves 200-500 restaurant candidates from a pool of 200,000+ restaurants based on user location, cuisine preferences, past orders, and contextual signals (time of day, weather). Recall@200 is tracked to ensure the candidate set captures restaurants the user would actually order from. The ranking stage then reorders these candidates based on predicted order probability, delivery time, and revenue optimization.
Optimizing the candidate generation model for Recall@200 improved the diversity and relevance of restaurant recommendations. The team found that increasing Recall@200 from 0.65 to 0.80 correlated with a 12% increase in order conversion rate, validating that candidate coverage directly impacts business metrics. The evaluation uses implicit feedback (past orders) as ground truth, supplemented by periodic human annotation for quality calibration.
Pinecone documents how Recall@K is the most critical metric for evaluating the retrieval component of RAG pipelines. In their evaluation framework, they compute Recall@5 and Recall@10 to measure whether the vector search retrieves the chunks that contain the information needed to answer a user's question. They demonstrate that a RAG system with Recall@5 = 0.40 produces significantly more hallucinations than one with Recall@5 = 0.85, because the LLM lacks sufficient grounding context.
Their benchmarks show that improving Recall@5 from 0.60 to 0.90 reduces hallucination rate by 45% and improves answer accuracy (measured by human evaluation) by 30%. The key insight: for RAG, Recall@K at the retrieval stage is more predictive of end-to-end answer quality than any other single metric, because missing context cannot be recovered by the LLM.
Tooling & Ecosystem
A Python library for ranking evaluation that provides Recall@K alongside 20+ other IR metrics (MAP, NDCG, MRR, Precision@K). Supports batch evaluation, statistical significance testing (paired t-test, bootstrap), and export to LaTeX tables. Excellent for academic benchmarking and production evaluation.
A unified Python interface for computing IR evaluation metrics including Recall@K, P@K, MAP, NDCG, and more. Built by the Terrier IR team, it provides consistent implementations across multiple backends (pytrec_eval, cwl_eval). Best for reproducible IR research.
A framework for evaluating RAG pipelines that includes context recall (measuring how much ground-truth information is covered by retrieved chunks), context precision, faithfulness, and answer relevance. Context recall is the RAG-specific analog of Recall@K, operating at the information level rather than document level.
Facebook's vector similarity search library. While not an evaluation tool per se, FAISS is the system most commonly evaluated with Recall@K. It provides utilities for benchmarking approximate search recall against exact search, including the bench_polysemous_sift1m.py script that reports Recall@1, @10, @100 for different index types.
An ML monitoring platform that includes Recall@K computation as part of its ranking and recommendation evaluation suite. Provides drift detection for Recall@K over time, which is useful for monitoring retrieval quality degradation in production systems.
Weaviate's vector database documentation includes comprehensive guidance on computing Recall@K for vector search evaluation. Their evaluation utilities allow benchmarking recall at different K values, comparing HNSW index parameters, and measuring the recall-latency tradeoff for production tuning.
Research & References
Covington, P., Adams, J. & Sargin, E. (2016)RecSys 2016
The landmark paper describing YouTube's two-stage recommendation architecture. The candidate generation stage uses a deep neural network trained as extreme multi-class classification to maximize recall -- retrieving hundreds of relevant video candidates from a corpus of billions. This paper established recall-focused candidate generation as the standard architecture for large-scale recommendation systems.
Yu, J., Zha, D., Zhong, Y. et al. (2024)arXiv preprint
Comprehensive survey of RAG evaluation methodologies. Identifies Recall@K as a core retrieval-stage metric alongside Precision@K and NDCG. Categorizes evaluation approaches into component-wise (retriever, generator) and end-to-end, showing that retriever Recall@K is the strongest predictor of end-to-end RAG quality.
Karpukhin, V., Oguz, B., Min, S. et al. (2020)EMNLP 2020
Introduced DPR (Dense Passage Retrieval), showing that dense embeddings trained on question-passage pairs outperform BM25 on Recall@20 and Recall@100 for open-domain QA. DPR achieved Recall@20 = 78.4% on Natural Questions vs. BM25's 59.1%. This paper popularized Recall@K as the primary evaluation metric for dense retrieval systems.
Järvelin, K. & Kekäläinen, J. (2002)ACM Transactions on Information Systems (TOIS), Vol. 20, No. 4
While primarily introducing NDCG, this foundational paper also formalizes the limitations of Recall@K (order-unaware, binary-only) that motivated graded, position-aware metrics. Essential reading for understanding where Recall@K fits in the hierarchy of IR evaluation metrics.
Xiong, L., Xiong, C., Li, Y. et al. (2021)ICLR 2021
Introduced ANCE (Approximate Nearest Neighbor Negative Contrastive Estimation), which uses the ANN index itself to mine hard negatives during training. Evaluated primarily on Recall@K (Recall@10, @100, @1000) on MS MARCO passage retrieval, showing significant improvements over DPR. Demonstrated that training-time recall optimization transfers to inference-time Recall@K.
Johnson, J., Douze, M. & Jégou, H. (2021)IEEE Transactions on Big Data, Vol. 7, No. 3
The FAISS paper. Describes GPU-accelerated approximate nearest neighbor search algorithms and evaluates them primarily using Recall@K at various K values (1, 10, 100). Established the standard methodology for benchmarking ANN index recall: compare approximate search Recall@K against exact (brute-force) search at the same K, across different speed-recall tradeoff points.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is Recall@K and how does it differ from regular recall?
- ●
When would you use Recall@K vs. Precision@K vs. NDCG?
- ●
How do you choose the value of K for Recall@K?
- ●
You are building a RAG pipeline. Which retrieval metrics would you track and why?
- ●
Your Recall@10 is 0.60 but your NDCG@10 is 0.45. What does this tell you about your system?
- ●
How would you compute Recall@K if you do not have complete ground-truth labels?
- ●
Explain the Recall@K vs. Precision@K tradeoff in the context of a two-stage recommendation system.
- ●
Your FAISS index has Recall@100 = 0.85 with exact search Recall@100 = 0.99. What would you do?
Key Points to Mention
- ●
Recall@K is the primary metric for the candidate generation stage of multi-stage retrieval systems. It measures coverage: what fraction of relevant items were captured in the top K positions.
- ●
Recall@K is order-unaware -- it does not care about the ranking within the top K. This is appropriate for candidate generation where a downstream ranker will reorder items, but inappropriate for evaluating final user-facing rankings.
- ●
The Recall@K vs. Precision@K tradeoff is governed by K: increasing K improves recall (more coverage) but reduces precision (more noise). The right K depends on the downstream consumer.
- ●
For RAG pipelines, Recall@K at the retrieval stage is the most predictive metric for end-to-end answer quality. If the retriever misses relevant context, the LLM will hallucinate.
- ●
Recall@K requires complete ground-truth labels -- you must know ALL relevant items per query, not just label the retrieved items. Partial labels inflate Recall@K artificially.
- ●
When tuning ANN indices (FAISS IVF, HNSW), Recall@K vs. latency is the key tradeoff. Increasing nprobe/ef_search improves Recall@K but increases query latency.
Pitfalls to Avoid
- ●
Confusing Recall@K with Hit Rate -- Hit Rate is binary (at least one relevant item found or not), while Recall@K measures the fraction of relevant items found. They are only equivalent when each query has exactly one relevant item.
- ●
Using Recall@K to evaluate user-facing ranked lists -- since Recall@K ignores order, it cannot distinguish between a list with relevant items at positions 1-2 vs. one with relevant items at positions 9-10. Use NDCG or MAP for ranking evaluation.
- ●
Reporting Recall@K without specifying K or justifying the choice of K -- always explain why you chose that K based on the downstream consumer (ranker capacity, LLM context window, UI viewport).
- ●
Claiming high Recall@K proves the system is good -- Recall@K only measures one dimension (coverage). A system with Recall@100 = 0.95 but 99% irrelevant results is not a good system. Pair Recall@K with Precision@K or F1@K for a complete picture.
Senior-Level Expectation
A senior candidate should discuss the full retrieval evaluation framework: Recall@K for candidate generation, NDCG/MAP for ranking, and end-to-end metrics (user satisfaction, conversion rate) for the complete system. They should articulate why Recall@K is the right metric specifically for the first stage of multi-stage systems and explain the upper-bound relationship: if Recall@K at Stage 1 is 0.80, then the ranker at Stage 2 can achieve at most 0.80 coverage regardless of how good it is. Senior engineers should discuss ground-truth challenges (how to build reliable relevant sets via pooling, active labeling, or implicit feedback), the recall-latency tradeoff in ANN indices (and how to benchmark it), and monitoring strategies (canary queries, alerting on Recall@K degradation). They should also know when Recall@K is the wrong metric -- for instance, if the task has exactly one correct answer per query (use Hit Rate or MRR) or if graded relevance matters (use NDCG). The ability to reason about metric choice based on system architecture and user behavior is what distinguishes senior from mid-level candidates.
Summary
Let us recap the essential points about Recall@K.
Recall@K measures the fraction of all relevant items that appear in the top K results returned by a retrieval system. The formula is simple: . It produces a score between 0 and 1, where 1 means every relevant item was captured in the top K. It is order-unaware (the ranking within top K does not matter) and uses binary relevance (relevant or not, no graded scale).
Recall@K is the primary metric for candidate generation in multi-stage retrieval systems. Whether you are building YouTube's video recommendations, Flipkart's product search, or a RAG pipeline's retrieval layer, the first stage needs to maximize coverage because the downstream ranker or LLM can only work with what was retrieved. A retrieval stage with Recall@100 = 0.80 means 20% of relevant items are permanently lost -- no ranking model can recover them.
The key tradeoffs are: Recall@K vs. Precision@K (increasing K improves recall but reduces precision), Recall@K vs. latency (higher K and more thorough search improves recall but costs more compute), and simplicity vs. informativeness (Recall@K is simple and interpretable but ignores ranking order -- use NDCG or MAP when position matters). Choose K based on the downstream consumer: K=3-10 for RAG, K=100-1000 for candidate generation, K=10-20 for search results.
The biggest practical challenge is ground-truth completeness: Recall@K requires knowing ALL relevant items per query, not just labeling the retrieved set. Incomplete labels inflate the metric. Use pooling, active annotation, or LLM-assisted labeling to build more complete ground-truth sets. Budget INR 30-80 per binary relevance label for India-based annotation.
Recall@K is to candidate generation what NDCG is to ranking: the right metric for the right stage. Use it when coverage matters more than ordering, when missing relevant items costs more than including irrelevant ones, and when a downstream stage will handle the filtering and ranking. For RAG systems in particular, Recall@K at the retrieval stage is the single most predictive metric for end-to-end answer quality.