LLM Data Generator in Machine Learning
LLM Data Generator refers to the practice of using large language models themselves to produce synthetic training data -- instruction-response pairs, classification examples, question-answer datasets, conversational transcripts, or even entire textbooks -- that can then be used to train or fine-tune other (typically smaller) models. It is one of the most transformative ideas in modern machine learning: the notion that you can use the output of one model as the input for training another.
The technique exploded into mainstream ML practice in early 2023 when Stanford's Alpaca project demonstrated that 52,000 instruction-response pairs generated by GPT-3.5 for under $500 (~INR 42,000) could fine-tune a 7B LLaMA model to near-ChatGPT quality on many tasks. Within months, the field produced a cascade of follow-ups: Vicuna (trained on real ChatGPT conversations), WizardLM (using Evol-Instruct to increase instruction complexity), Orca (distilling GPT-4 reasoning traces), and dozens more.
Today, LLM-based data generation is not just an academic curiosity -- it is the dominant strategy for building instruction-tuned models. NVIDIA's Nemotron-4 pipeline reported that over 98% of its alignment data was synthetically generated. Microsoft's Phi-3 was trained on billions of synthetic textbook-quality tokens. HuggingFace's Cosmopedia dataset contains 25 billion tokens of synthetic educational content produced by Mixtral.
But the technique comes with serious risks. Model collapse -- where training on synthetic data from the same or similar models causes progressive quality degradation -- is a well-documented phenomenon. Synthetic data can also encode biases, stylistic artifacts, and factual hallucinations from the teacher model. Understanding when and how to use LLM data generation, and critically, when to stop, is essential knowledge for any ML engineer building production systems in 2026.
Concept Snapshot
- What It Is
- A data generation technique that uses large language models to produce synthetic training examples -- instructions, responses, classifications, dialogues, or structured data -- for training or fine-tuning downstream models.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: generation prompts (templates, seed examples, schemas) + optional few-shot examples. Outputs: synthetic datasets (instruction-response pairs, labeled examples, structured records).
- System Placement
- Sits at the very beginning of the ML pipeline, upstream of data preprocessing, model training, and fine-tuning. Typically used when real labeled data is scarce, expensive, or privacy-sensitive.
- Also Known As
- LLM-based synthetic data, synthetic instruction generation, AI data generation, model distillation data, teacher-student data synthesis, LLM data factory
- Typical Users
- ML Engineers, NLP Researchers, Data Scientists, LLM Alignment Engineers, AI Startup Founders, Applied AI Scientists
- Prerequisites
- Prompt engineering fundamentals, LLM API usage (OpenAI, Anthropic, or open-source inference), Basic understanding of instruction tuning, JSON/structured output parsing, Data quality assessment methods
- Key Terms
- Self-InstructEvol-Instructteacher modelstudent modelseed tasksquality filteringmodel collapseknowledge distillationsynthetic data diversityLLM-as-judge
Why This Concept Exists
The Data Bottleneck in ML
Every supervised ML system needs labeled training data, and getting enough of it has always been the hardest part of building production models. Human annotation is expensive (INR 50-500 per example depending on complexity), slow (a skilled annotator produces 50-200 labeled examples per day for complex tasks), and difficult to scale. For instruction tuning alone, you need thousands to hundreds of thousands of diverse, high-quality instruction-response pairs covering dozens of task categories.
Before LLM data generators existed, teams had three options: (1) pay for human annotation at enormous cost, (2) scrape and clean existing datasets with all their noise and licensing issues, or (3) use rule-based augmentation techniques that could increase volume but not truly create new knowledge or task diversity.
The Self-Instruct Breakthrough
The idea that LLMs could generate their own training data crystallized with the Self-Instruct paper (Wang et al., 2022). The key insight was deceptively simple: if you give a language model a handful of seed instruction-response examples and ask it to generate new instructions and responses, it can produce surprisingly diverse and high-quality training data. The original Self-Instruct pipeline used just 175 human-written seed tasks to generate 52,000+ instruction pairs from GPT-3.
Stanford's Alpaca project (March 2023) proved this idea was practical: they used GPT-3.5 (text-davinci-003) to generate 52K instruction-response pairs for under $500, then fine-tuned LLaMA-7B on this synthetic data. The resulting model matched text-davinci-003 on many benchmarks. The cost-to-quality ratio was revolutionary -- what previously required months of annotation and hundreds of thousands of dollars could now be done in a weekend for the price of a few API calls.
The Explosion of Techniques
Alpaca opened the floodgates. Within months, the field produced:
- Evol-Instruct (WizardLM): Instead of generating instructions from scratch, take existing simple instructions and evolve them into more complex versions through in-depth, in-breadth, and constraint additions. This produced instructions that human evaluators rated as more complex and diverse than human-written ones.
- Orca: Distill not just answers but reasoning traces from GPT-4, including step-by-step explanations. This transferred reasoning capabilities far more effectively than simple Q&A pairs.
- Magpie (ICLR 2025): Extract instructions directly from an aligned model's auto-regressive generation by feeding it only the chat template prefix -- no prompting needed at all.
- Cosmopedia: Generate entire synthetic textbooks and educational content at scale (25B tokens from Mixtral).
Why It Became Indispensable
The economics are compelling. Consider an Indian startup building a domain-specific chatbot for legal advice in Hindi:
| Approach | Cost for 10K examples | Timeline | Quality |
|---|---|---|---|
| Human annotation (legal experts) | INR 10-25 lakh ($12K-30K) | 2-3 months | Highest |
| LLM generation + human review | INR 10,000-50,000 ($120-600) + review cost | 1-2 days + review | High |
| LLM generation + LLM filtering | INR 15,000-75,000 ($180-900) | 2-4 hours | Medium-High |
| Rule-based templates | INR 0 (compute only) | Days of engineering | Low |
The 100x cost reduction with LLM generation, combined with 10-100x speed improvement, made it the default starting point for any data-scarce ML project.
Key Insight: LLM data generators didn't just reduce cost -- they fundamentally changed the development cycle. Instead of "collect data, then build models," teams can now "generate data, build models, evaluate, regenerate better data" in tight iterative loops.
Core Intuition & Mental Model
The Teacher-Student Mental Model
Think of LLM data generation as hiring a brilliant but expensive tutor (GPT-4, Claude) to create a curriculum for a cheaper, faster student (your 7B model). The tutor doesn't teach the student directly at inference time -- that would be too expensive at $0.01-0.06 per query. Instead, the tutor creates thousands of worked examples that capture their knowledge and reasoning patterns. The student then studies these examples through fine-tuning and internalizes the patterns.
This is why the technique is sometimes called knowledge distillation through synthetic data -- you're distilling the teacher's capabilities into a smaller model via the medium of generated training examples.
Why It Works Better Than You'd Expect
Here's the counterintuitive part: synthetic data from an LLM often works better than equivalent amounts of real data scraped from the internet. Why?
- Consistency: An LLM generates examples in a consistent format with consistent quality. Real-world data is noisy, inconsistently formatted, and varies wildly in quality.
- Control: You can precisely specify the distribution of topics, difficulty levels, and task types. With real data, you're at the mercy of what exists.
- Coverage: You can generate examples for rare edge cases and underrepresented categories that are hard to find in real data. Need 500 examples of Hindi-English code-mixed medical queries? An LLM can generate them in minutes.
- Privacy: Synthetic data contains no real personal information, sidestepping privacy regulations like India's Digital Personal Data Protection Act (DPDPA) and GDPR.
The Fundamental Limitation
An LLM data generator cannot create knowledge that the teacher model doesn't have. If GPT-4 doesn't understand a niche medical procedure or a rare programming language, the synthetic data about that topic will contain hallucinations. This is why LLM-generated data works best for common knowledge, well-established tasks, and general instruction following -- domains where the teacher model is reliably accurate.
For highly specialized or rapidly evolving domains, LLM-generated data should be treated as a starting point that needs human expert review, not a finished product.
Practitioner's Rule of Thumb: Use LLM data generation when the teacher model can answer the questions correctly with >90% reliability. Below that threshold, you're amplifying errors, not creating useful training signal.
Technical Foundations
Mathematical Framework
Let be a teacher model with parameters and be a student model with parameters where . LLM data generation constructs a synthetic dataset by sampling from the teacher:
where is a generated instruction (possibly itself sampled from ), is the teacher's response, and is optional context (system prompt, few-shot examples, constraints).
Self-Instruct Generation Process
The Self-Instruct pipeline operates in three phases:
Phase 1: Instruction Generation. Given seed tasks (typically ), new instructions are generated by sampling a subset and prompting the teacher:
where is a random subset of indices.
Phase 2: Response Generation. For each generated instruction, the teacher produces a response:
Phase 3: Quality Filtering. A filter function removes low-quality pairs:
Common filter criteria include ROUGE-L deduplication ( for all ), length constraints, and LLM-as-judge quality scores.
Evol-Instruct Complexity Evolution
Evol-Instruct (Xu et al., 2023) defines evolution operators (deepen), (broaden), (add constraints), and (increase reasoning). For an instruction , an evolved instruction is:
The process is applied iteratively for rounds, producing a difficulty-stratified dataset. WizardLM showed this yields a more uniform difficulty distribution compared to Self-Instruct, which tends to cluster at low-to-medium complexity.
Model Collapse Risk
When the student model trained on is itself used as a teacher for the next generation , the error accumulates. Shumailov et al. (2023) showed that after generations of recursive training:
where is the true data distribution and is the distribution of generation . The tail of the distribution collapses first -- rare examples and minority modes vanish, and the model's output distribution becomes progressively narrower and more peaked.
However, Gerstgrasser et al. (2024) showed that model collapse can be avoided if synthetic data is accumulated alongside real data rather than replacing it:
This accumulation strategy preserves the tails of the distribution and prevents collapse.
Formal Property: LLM data generation is a form of amortized knowledge distillation -- instead of distilling at inference time (as in standard knowledge distillation with KL divergence on logits), the distillation happens once at data generation time and is amortized over all subsequent training runs on the synthetic dataset.
Internal Architecture
An LLM data generation pipeline has a modular architecture with distinct stages for prompt construction, data generation, quality assurance, and output formatting. The pipeline must handle API rate limits, cost tracking, deduplication, and quality filtering at scale.
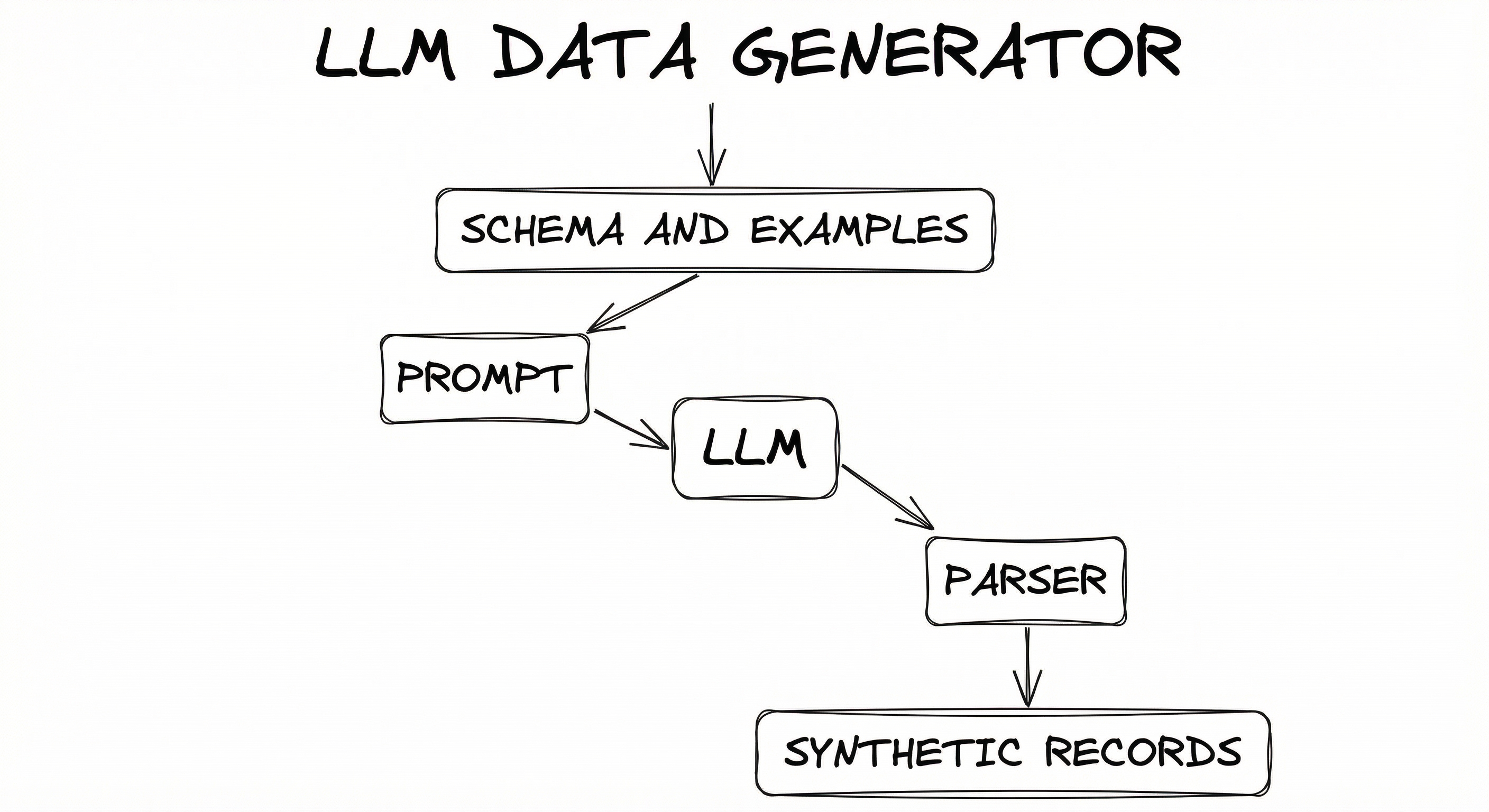
The pipeline is designed for batch processing, typically generating thousands to millions of examples in parallel. Cost tracking is critical because a single poorly configured generation run can consume thousands of dollars in API credits. Modern pipelines include circuit breakers, per-batch quality sampling, and incremental cost estimates.
Key Components
Seed Task Pool
A curated collection of 50-500 high-quality, human-written instruction-response examples that serve as the bootstrap for generation. The diversity and quality of seeds directly determines the diversity of generated data. Seeds should cover the target task taxonomy: different instruction types (open-ended, classification, extraction, creative, reasoning), varying complexity levels, and multiple output formats. For domain-specific generation, seeds must include domain expertise.
Prompt Builder
Constructs the generation prompt from seed examples, task specifications, and optional constraints. Supports multiple generation strategies: random seed sampling (Self-Instruct), complexity evolution (Evol-Instruct), topic-conditioned generation (specify a topic or domain), and schema-constrained generation (output must match a JSON schema). The prompt builder is the primary lever for controlling data diversity and quality.
LLM Teacher API
The teacher model that generates synthetic data. Can be a proprietary API (GPT-4, Claude, Gemini) or a self-hosted open model (Llama-3, Mixtral, Qwen). The choice of teacher model is the single biggest quality lever -- GPT-4 produces higher-quality data than GPT-3.5, which produces higher-quality data than a 7B model. For cost optimization, teams often use GPT-4 for complex reasoning examples and GPT-4o-mini or GPT-3.5 for simpler instruction-response pairs.
Response Parser
Extracts structured instruction-response pairs from the LLM's raw text output. Handles JSON parsing, markdown extraction, and format normalization. Must be robust to malformed outputs -- LLMs frequently produce invalid JSON, miss required fields, or embed explanatory text outside the expected format. A good parser recovers 85-95% of outputs; the remainder are discarded.
Quality Filter Pipeline
A multi-stage filter that removes low-quality, duplicate, toxic, or off-topic examples. Stages include: (1) LLM-as-judge scoring -- a model (often GPT-4o-mini) rates each example on a 1-5 scale for instruction clarity, response accuracy, and helpfulness; (2) length filtering -- remove extremely short or excessively long responses; (3) format validation -- ensure the output matches the expected schema; (4) toxicity screening -- flag and remove unsafe content; (5) factual consistency -- for fact-dependent tasks, cross-check key claims. Typically 20-50% of raw generated data is filtered out.
Deduplication Engine
Removes near-duplicate instructions using ROUGE-L similarity, embedding-based cosine similarity, or MinHash locality-sensitive hashing. LLMs tend to produce many paraphrased variants of the same instruction, especially at higher temperatures. Deduplication typically removes an additional 5-15% of examples and is critical for preventing the student model from overfitting to repeated patterns.
Evolution Operator (Optional)
Implements Evol-Instruct-style complexity evolution. Takes existing instructions and rewrites them to be more complex, more constrained, or broader in scope. Evolution operators include: deepen (add more reasoning steps), broaden (generalize to related topics), constrain (add format/length/style constraints), and concretize (make abstract instructions specific). This component is used iteratively to produce difficulty-stratified datasets.
Format Converter & Cost Tracker
Converts filtered data into standard training formats: Alpaca JSON ({instruction, input, output}), ShareGPT JSON (multi-turn conversations), JSONL for streaming, or HuggingFace Datasets format. The cost tracker maintains running tallies of API tokens consumed, cost per example, and projected total cost. This component prevents budget overruns -- a common failure mode when generation pipelines run unmonitored.
Data Flow
The data generation pipeline operates in configurable batch cycles:
1. Prompt Construction: The prompt builder samples seed examples, applies optional evolution operators, and constructs the generation prompt. For Self-Instruct, this samples 3-8 seeds and asks for a new, diverse instruction-response pair. For Evol-Instruct, this takes an existing instruction and applies a random evolution operator.
2. Parallel Generation: Prompts are sent to the teacher LLM in parallel batches (typically 10-50 concurrent requests, respecting rate limits). Each API call generates 1-20 examples depending on the prompt design. Temperature is set to 0.7-1.0 for diversity.
3. Parsing and Validation: Raw LLM outputs are parsed into structured records. Malformed outputs are logged and discarded. Valid outputs enter the quality filter pipeline.
4. Quality Filtering: Examples pass through the multi-stage filter: LLM-as-judge scoring, length checks, format validation, toxicity screening, and optional factual consistency checks. Examples scoring below the threshold (typically 4/5 from the judge) are discarded.
5. Deduplication: Surviving examples are compared against all previously generated examples using ROUGE-L or embedding similarity. Near-duplicates are removed.
6. Output: Deduplicated, filtered examples are written to the output dataset in the target format. Running statistics (total examples, cost, filter rates) are logged.
This cycle repeats until the target dataset size is reached. A typical run generating 50K high-quality examples from GPT-4o-mini takes 2-6 hours and costs $50-300 (~INR 4,200-25,000).
A directed flow from Seed Examples through Prompt Builder, LLM Teacher API, Response Parser, Quality Filter Pipeline (with sub-components for LLM-as-Judge, Format Validator, Toxicity Filter, and Factual Consistency), Deduplication Engine, and Format Converter, producing the final Synthetic Dataset. An optional feedback loop from the output back through an Evol-Instruct Operator feeds into the Prompt Builder for iterative complexity evolution.
How to Implement
Practical Implementation Approaches
LLM data generation implementation varies based on your budget, quality requirements, and the type of data you need:
Tier 1: API-based generation (most common) -- Use GPT-4, Claude, or Gemini APIs to generate data. Highest quality, easiest to implement, but per-example costs of $0.005-0.10 (~INR 0.4-8.4) add up at scale. Best for datasets under 100K examples.
Tier 2: Open-model generation -- Use self-hosted Llama-3-70B, Mixtral, or Qwen-72B to generate data. Lower per-example cost (~$0.001 on rented GPUs), but requires inference infrastructure. Quality is 70-85% of GPT-4 depending on the task. Best for datasets over 100K examples or when data privacy prevents API usage.
Tier 3: Specialized tool-based -- Use purpose-built tools like DataDreamer, Bonito, or Gretel that abstract away the prompt engineering and pipeline management. Fastest to set up, but less customizable.
Cost Context for India: Generating 50K instruction-response pairs with GPT-4o-mini costs approximately $50-100 (~INR 4,200-8,400) in API credits. Using self-hosted Llama-3-70B on an Indian cloud provider like E2E Networks (A100 at ~INR 150/hr) costs approximately INR 2,000-4,000 for the same volume. The quality gap between API-based and open-model generation has narrowed significantly with Llama-3 and Qwen-2.5, making self-hosted generation increasingly viable for budget-conscious Indian startups.
The most important implementation decision is not which model to use for generation -- it is how you filter and validate the generated data. Teams that invest 20% of their budget in generation and 80% in quality assurance consistently outperform teams that do the reverse.
import openai
import json
import random
import time
from typing import List, Dict, Optional
from concurrent.futures import ThreadPoolExecutor, as_completed
client = openai.OpenAI() # Uses OPENAI_API_KEY env var
# Seed tasks: 8-15 diverse, high-quality human-written examples
SEED_TASKS = [
{
"instruction": "Write a Python function that checks if a string is a valid palindrome, ignoring spaces and punctuation.",
"input": "",
"output": "def is_palindrome(s: str) -> bool:\n cleaned = ''.join(c.lower() for c in s if c.isalnum())\n return cleaned == cleaned[::-1]\n\n# Examples:\n# is_palindrome('A man, a plan, a canal: Panama') -> True\n# is_palindrome('hello') -> False"
},
{
"instruction": "Classify the sentiment of the following product review as positive, negative, or neutral.",
"input": "The delivery was super fast but the product quality is disappointing. Wouldn't buy again.",
"output": "Negative. While the reviewer acknowledges fast delivery (positive aspect), the overall sentiment is negative due to disappointing product quality and stated intent not to repurchase."
},
{
"instruction": "Explain the concept of database sharding to a junior developer.",
"input": "",
"output": "Database sharding is splitting a large database into smaller, faster pieces called shards. Imagine a library so big that one building can't hold all the books -- so you build multiple buildings, each holding books for certain categories. Each shard holds a subset of the data (e.g., users A-M in shard 1, N-Z in shard 2). This improves performance because queries only search one shard instead of the entire database. The tricky part is choosing a good shard key and handling queries that span multiple shards."
},
]
GENERATION_PROMPT = """Below are examples of instruction-input-output triples for training an AI assistant.
{examples}
Generate a NEW, creative instruction-input-output triple that is DIFFERENT from the examples above.
Requirements:
- The instruction should be clear, specific, and self-contained
- Cover a different topic or skill than the examples
- The output should be detailed and high-quality
- Vary the format: some with input, some without
- Include diverse task types: coding, analysis, explanation, creative writing, math, etc.
Respond with ONLY a valid JSON object:
{{"instruction": "...", "input": "...", "output": "..."}}"""
def generate_single_example(
task_pool: List[Dict],
model: str = "gpt-4o-mini",
temperature: float = 0.9,
) -> Optional[Dict]:
"""Generate one instruction-response pair using Self-Instruct."""
# Sample 3-5 diverse examples from the pool
n_demos = min(random.randint(3, 5), len(task_pool))
demos = random.sample(task_pool, n_demos)
examples_text = "\n\n".join([
f"Example {i+1}:\n"
f"Instruction: {d['instruction']}\n"
f"Input: {d.get('input', '')}\n"
f"Output: {d['output']}"
for i, d in enumerate(demos)
])
prompt = GENERATION_PROMPT.format(examples=examples_text)
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
max_tokens=2048,
)
content = response.choices[0].message.content.strip()
# Handle markdown code blocks
if content.startswith("```"):
content = content.split("```")[1]
if content.startswith("json"):
content = content[4:]
parsed = json.loads(content)
# Validate required fields
if not all(k in parsed for k in ["instruction", "output"]):
return None
if len(parsed["instruction"]) < 10 or len(parsed["output"]) < 20:
return None
parsed.setdefault("input", "")
return parsed
except (json.JSONDecodeError, KeyError, IndexError):
return None
def generate_dataset(
n_examples: int = 1000,
model: str = "gpt-4o-mini",
max_workers: int = 10,
output_path: str = "synthetic_data.json",
) -> List[Dict]:
"""Generate a synthetic instruction dataset using Self-Instruct."""
task_pool = SEED_TASKS.copy()
generated = []
failed = 0
print(f"Generating {n_examples} examples with {model}...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# Submit all generation tasks
futures = []
for _ in range(int(n_examples * 1.3)): # Over-generate by 30% for filtering
futures.append(
executor.submit(generate_single_example, task_pool, model)
)
for future in as_completed(futures):
result = future.result()
if result is not None:
generated.append(result)
task_pool.append(result) # Grow the pool for diversity
if len(generated) % 100 == 0:
print(f" Generated: {len(generated)}/{n_examples}")
if len(generated) >= n_examples:
break
else:
failed += 1
print(f"\nGeneration complete: {len(generated)} examples ({failed} failed)")
with open(output_path, "w") as f:
json.dump(generated, f, indent=2, ensure_ascii=False)
return generated
# Generate 1000 synthetic instruction pairs
dataset = generate_dataset(n_examples=1000, model="gpt-4o-mini")
print(f"Estimated cost: ~${len(dataset) * 0.003:.2f}")This implements the Self-Instruct pipeline with practical production enhancements. Key design decisions: (1) Growing task pool -- each generated example is added to the sampling pool, increasing diversity over time; (2) Over-generation by 30% -- accounts for parsing failures and quality filtering; (3) Parallel execution with ThreadPoolExecutor for 10x throughput; (4) Robust parsing that handles markdown code blocks and validates required fields. At 30 (~INR 2,500). For GPT-4o, multiply cost by ~10x but expect higher quality, especially for complex reasoning tasks.
import openai
import json
import random
from typing import List, Dict, Optional
client = openai.OpenAI()
# Evolution operator prompts (from WizardLM methodology)
EVOL_OPERATORS = {
"deepen": """Rewrite the following instruction to require deeper thinking and multi-step reasoning.
Add complexity by requiring analysis, comparison, or synthesis of multiple concepts.
Original: {instruction}
Rewrite the instruction to be MORE COMPLEX (deeper reasoning required).
Respond with ONLY the rewritten instruction, nothing else.""",
"broaden": """Rewrite the following instruction to cover a broader scope or relate to additional topics.
Expand the scope while keeping it answerable.
Original: {instruction}
Rewrite the instruction to be BROADER in scope.
Respond with ONLY the rewritten instruction, nothing else.""",
"constrain": """Add specific constraints or requirements to the following instruction.
Examples: word limits, format requirements, specific perspectives, language style.
Original: {instruction}
Rewrite the instruction with ADDED CONSTRAINTS (format, length, perspective, etc.).
Respond with ONLY the rewritten instruction, nothing else.""",
"concretize": """Make the following instruction more specific and concrete.
Replace general concepts with specific examples, real-world scenarios, or particular technologies.
Original: {instruction}
Rewrite the instruction to be MORE SPECIFIC and CONCRETE.
Respond with ONLY the rewritten instruction, nothing else.""",
}
def evolve_instruction(
instruction: str,
operator: Optional[str] = None,
model: str = "gpt-4o-mini",
) -> Optional[str]:
"""Apply an evolution operator to an instruction."""
if operator is None:
operator = random.choice(list(EVOL_OPERATORS.keys()))
prompt = EVOL_OPERATORS[operator].format(instruction=instruction)
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=512,
)
evolved = response.choices[0].message.content.strip()
# Sanity checks
if len(evolved) < 10 or len(evolved) > 2000:
return None
if evolved.lower() == instruction.lower():
return None # No evolution happened
return evolved
except Exception:
return None
def generate_response(
instruction: str,
model: str = "gpt-4o",
) -> Optional[str]:
"""Generate a high-quality response for an evolved instruction."""
system_msg = (
"You are a helpful AI assistant. Provide detailed, accurate, "
"and well-structured responses. Use examples where appropriate."
)
try:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_msg},
{"role": "user", "content": instruction},
],
temperature=0.3, # Lower temp for response quality
max_tokens=2048,
)
return response.choices[0].message.content.strip()
except Exception:
return None
def evol_instruct_pipeline(
seed_instructions: List[str],
n_rounds: int = 3,
model_evolve: str = "gpt-4o-mini",
model_respond: str = "gpt-4o",
) -> List[Dict]:
"""Run multi-round Evol-Instruct on seed instructions."""
results = []
current_instructions = seed_instructions.copy()
for round_num in range(n_rounds):
print(f"\n=== Evolution Round {round_num + 1}/{n_rounds} ===")
evolved_instructions = []
for i, instr in enumerate(current_instructions):
evolved = evolve_instruction(instr, model=model_evolve)
if evolved:
evolved_instructions.append(evolved)
# Generate response with stronger model
response = generate_response(evolved, model=model_respond)
if response:
results.append({
"instruction": evolved,
"input": "",
"output": response,
"evolution_round": round_num + 1,
"source_instruction": instr,
})
if (i + 1) % 10 == 0:
print(f" Processed {i + 1}/{len(current_instructions)}")
current_instructions = evolved_instructions
print(f" Round {round_num + 1}: {len(evolved_instructions)} evolved instructions")
print(f"\nTotal examples generated: {len(results)}")
return results
# Example usage
seeds = [
"Explain what a REST API is.",
"Write a function to sort a list.",
"What is the difference between SQL and NoSQL?",
"Summarize the benefits of cloud computing.",
]
evolved_data = evol_instruct_pipeline(seeds, n_rounds=3)
# Save results
with open("evolved_instructions.json", "w") as f:
json.dump(evolved_data, f, indent=2, ensure_ascii=False)
print(f"\nSample evolved instruction (round 3):")
round3 = [d for d in evolved_data if d["evolution_round"] == 3]
if round3:
print(f" {round3[0]['instruction'][:150]}...")This implements the Evol-Instruct methodology from WizardLM. Four evolution operators (deepen, broaden, constrain, concretize) are applied iteratively to seed instructions over multiple rounds. Key design choices: (1) Separate models for evolution and response -- use a cheaper model (GPT-4o-mini) for instruction evolution and a stronger model (GPT-4o) for response generation, optimizing cost while maintaining response quality; (2) Multi-round evolution produces a difficulty-stratified dataset where round 1 is easier and round 3 is more complex; (3) Metadata tracking records the evolution round and source instruction, enabling analysis of how complexity affects downstream model performance. A typical 3-round run on 100 seed instructions produces ~300 evolved examples at varying difficulty levels.
import openai
import json
import numpy as np
from typing import List, Dict, Tuple
from concurrent.futures import ThreadPoolExecutor, as_completed
from collections import defaultdict
client = openai.OpenAI()
JUDGE_PROMPT = """You are evaluating the quality of an instruction-response pair for training an AI assistant.
Rate this example on THREE criteria (1-5 each):
1. **Instruction Quality**: Is the instruction clear, specific, and non-trivial?
2. **Response Accuracy**: Is the response correct, complete, and helpful?
3. **Educational Value**: Would training on this example improve an AI assistant?
Instruction: {instruction}
Input: {input}
Response: {response}
Respond with ONLY a JSON object:
{{"instruction_quality": <1-5>, "response_accuracy": <1-5>, "educational_value": <1-5>, "overall": <1-5>, "reason": "<brief explanation>"}}"""
def score_example(example: Dict, model: str = "gpt-4o-mini") -> Tuple[Dict, Dict]:
"""Score a single example using LLM-as-judge."""
prompt = JUDGE_PROMPT.format(
instruction=example["instruction"],
input=example.get("input", ""),
response=example["output"],
)
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
max_tokens=300,
)
scores = json.loads(response.choices[0].message.content)
return example, scores
except Exception:
return example, {"overall": 0, "reason": "scoring_failed"}
def rouge_l_similarity(text1: str, text2: str) -> float:
"""Compute ROUGE-L F1 similarity between two texts."""
words1 = text1.lower().split()
words2 = text2.lower().split()
if not words1 or not words2:
return 0.0
# LCS computation
m, n = len(words1), len(words2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
if words1[i-1] == words2[j-1]:
dp[i][j] = dp[i-1][j-1] + 1
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
lcs_len = dp[m][n]
precision = lcs_len / n if n > 0 else 0
recall = lcs_len / m if m > 0 else 0
if precision + recall == 0:
return 0.0
return 2 * precision * recall / (precision + recall)
def deduplicate(
examples: List[Dict],
threshold: float = 0.7,
) -> List[Dict]:
"""Remove near-duplicate instructions using ROUGE-L similarity."""
deduplicated = []
for example in examples:
is_duplicate = False
for existing in deduplicated:
sim = rouge_l_similarity(
example["instruction"], existing["instruction"]
)
if sim > threshold:
is_duplicate = True
break
if not is_duplicate:
deduplicated.append(example)
return deduplicated
def filter_and_deduplicate(
dataset: List[Dict],
min_score: int = 4,
rouge_threshold: float = 0.7,
max_workers: int = 15,
) -> List[Dict]:
"""Full quality filtering and deduplication pipeline."""
print(f"Starting with {len(dataset)} examples")
# Stage 1: Basic length and format filters
length_filtered = [
ex for ex in dataset
if 10 < len(ex["instruction"]) < 2000
and 20 < len(ex["output"]) < 10000
and not ex["instruction"].strip().startswith("As an AI")
]
print(f"After length/format filter: {len(length_filtered)}")
# Stage 2: LLM-as-judge quality scoring
scored = []
score_distribution = defaultdict(int)
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {
executor.submit(score_example, ex): ex
for ex in length_filtered
}
for future in as_completed(futures):
example, scores = future.result()
overall = scores.get("overall", 0)
score_distribution[overall] += 1
if overall >= min_score:
example["quality_scores"] = scores
scored.append(example)
print(f"After quality filter (>={min_score}): {len(scored)}")
print(f"Score distribution: {dict(sorted(score_distribution.items()))}")
# Stage 3: Deduplication
final = deduplicate(scored, threshold=rouge_threshold)
print(f"After deduplication (ROUGE-L < {rouge_threshold}): {len(final)}")
retention_rate = len(final) / len(dataset) * 100
print(f"\nOverall retention: {retention_rate:.1f}%")
return final
# Usage
raw_dataset = json.load(open("synthetic_data.json"))
clean_dataset = filter_and_deduplicate(raw_dataset, min_score=4)
json.dump(clean_dataset, open("clean_synthetic_data.json", "w"), indent=2)This implements a production-grade quality filtering pipeline with three stages: (1) Basic format/length filters remove obviously bad examples (too short, too long, or starting with known LLM artifacts like 'As an AI'); (2) LLM-as-judge scoring uses GPT-4o-mini to evaluate instruction quality, response accuracy, and educational value on a 1-5 scale, keeping only examples scoring 4+; (3) ROUGE-L deduplication removes near-duplicate instructions with similarity above 0.7. The pipeline typically retains 40-65% of raw generated data. The AlpaGasus paper showed that filtering Alpaca's 52K examples down to 9K high-quality ones produced a better model -- quality over quantity is the key principle.
import openai
import json
from typing import List, Dict, Optional
from pydantic import BaseModel, Field
from enum import Enum
client = openai.OpenAI()
# Define schema for domain-specific generation
class DifficultyLevel(str, Enum):
easy = "easy"
medium = "medium"
hard = "hard"
class DomainExample(BaseModel):
instruction: str = Field(description="The user's question or task")
context: str = Field(default="", description="Optional context or background")
response: str = Field(description="Detailed expert response")
domain: str = Field(description="Specific sub-domain")
difficulty: DifficultyLevel
tags: List[str] = Field(description="Topic tags for categorization")
# Domain-specific generation for Indian e-commerce customer support
DOMAIN_CONFIG = {
"name": "Indian E-commerce Customer Support",
"sub_domains": [
"order tracking", "returns and refunds", "payment issues",
"product quality", "delivery complaints", "account management",
"COD (cash on delivery)", "EMI and financing", "seller disputes",
],
"system_prompt": """You are generating training data for an AI customer support
assistant for an Indian e-commerce platform (similar to Flipkart/Amazon India).
Generate realistic customer queries and expert responses that:
- Use natural Indian English (include common phrases like "kindly", "do the needful")
- Reference INR amounts, Indian addresses, PIN codes
- Cover real scenarios: COD issues, UPI payment failures, festival sale problems
- Include both polite and frustrated customer tones
- Responses should be empathetic, solution-oriented, and policy-aware""",
"few_shot_examples": [
{
"instruction": "My order #FKT892341 was supposed to arrive yesterday but tracking shows it's stuck in Bangalore hub for 3 days. I paid extra for express delivery. This is very frustrating.",
"context": "Customer ordered electronics worth INR 15,999 with express delivery (INR 99 extra). Order placed 5 days ago.",
"response": "I completely understand your frustration, and I sincerely apologize for the delay with your order #FKT892341. Express delivery delays are unacceptable, and I want to help resolve this right away.\n\nI can see your package is currently at our Bangalore hub. Let me take these steps:\n1. I'm escalating this to our logistics team for priority dispatch today\n2. I'm initiating a full refund of the INR 99 express delivery charge\n3. You'll receive an updated tracking link within 2 hours\n\nIf the package doesn't reach you within 24 hours, I'll also apply a INR 500 store credit to your account as compensation. Would you like me to proceed with this?",
"domain": "delivery complaints",
"difficulty": "medium",
"tags": ["express delivery", "logistics delay", "refund", "escalation"]
}
]
}
def generate_domain_examples(
config: Dict,
n_examples: int = 100,
model: str = "gpt-4o",
) -> List[Dict]:
"""Generate domain-specific training examples with schema validation."""
results = []
schema_str = json.dumps(DomainExample.model_json_schema(), indent=2)
for i in range(n_examples):
sub_domain = config["sub_domains"][i % len(config["sub_domains"])]
difficulty = ["easy", "medium", "hard"][i % 3]
few_shot = json.dumps(config["few_shot_examples"][0], indent=2)
prompt = f"""Generate a realistic {config['name']} training example.
Sub-domain: {sub_domain}
Difficulty: {difficulty}
Here's an example of the format:
{few_shot}
Generate a NEW example that is different from the above.
The output MUST be valid JSON matching this schema:
{schema_str}
Respond with ONLY the JSON object."""
try:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": config["system_prompt"]},
{"role": "user", "content": prompt},
],
temperature=0.8,
max_tokens=1500,
)
content = response.choices[0].message.content.strip()
if content.startswith("```"):
content = content.split("```")[1]
if content.startswith("json"):
content = content[4:]
content = content.strip()
parsed = json.loads(content)
validated = DomainExample(**parsed)
results.append(validated.model_dump())
if (i + 1) % 20 == 0:
print(f"Generated {i + 1}/{n_examples} examples")
except Exception as e:
print(f" Failed example {i + 1}: {e}")
continue
print(f"\nSuccessfully generated {len(results)}/{n_examples} examples")
return results
# Generate domain-specific dataset
dataset = generate_domain_examples(DOMAIN_CONFIG, n_examples=100)
with open("ecommerce_support_data.json", "w") as f:
json.dump(dataset, f, indent=2, ensure_ascii=False)
# Analyze distribution
from collections import Counter
domains = Counter(ex["domain"] for ex in dataset)
print(f"\nDomain distribution: {dict(domains)}")This demonstrates domain-specific LLM data generation with schema constraints using Pydantic for validation. Key features: (1) Domain configuration defines sub-domains, system prompts, and few-shot examples specific to the target use case (here, Indian e-commerce support); (2) Pydantic schema validation ensures every generated example has the correct structure and types, rejecting malformed outputs at generation time rather than during training; (3) Controlled difficulty distribution cycles through easy/medium/hard to create a balanced dataset; (4) Indian context includes INR amounts, Indian addresses, COD scenarios, and culturally appropriate language. This pattern is used by companies like Flipkart, Swiggy, and Razorpay to generate domain-specific training data for their customer-facing AI systems.
# DataDreamer configuration for synthetic data generation
# pip install datadreamer
from datadreamer import DataDreamer
from datadreamer.llms import OpenAI
from datadreamer.steps import (
DataFromPrompt,
ProcessWithPrompt,
FilterByScore,
)
with DataDreamer("./output"):
# Step 1: Generate instructions
llm = OpenAI(model_name="gpt-4o-mini")
instructions = DataFromPrompt(
name="Generate Instructions",
llm=llm,
n=5000,
prompt=(
"Generate a unique instruction for an AI assistant. "
"Cover diverse topics: coding, writing, analysis, math, science. "
"Output ONLY the instruction, nothing else."
),
temperature=0.9,
)
# Step 2: Generate responses with stronger model
strong_llm = OpenAI(model_name="gpt-4o")
responses = ProcessWithPrompt(
name="Generate Responses",
llm=strong_llm,
inputs=instructions,
prompt="{instruction}",
temperature=0.3,
)
# Step 3: Quality filtering
filtered = FilterByScore(
name="Quality Filter",
llm=llm,
inputs=responses,
min_score=4,
scoring_prompt=(
"Rate this instruction-response pair 1-5 for quality. "
"Respond with only a number."
),
)
# Export
filtered.export_to_hf_dataset("./synthetic_dataset")Common Implementation Mistakes
- ●
Using the same model for generation and training: If you generate data with GPT-3.5 and then fine-tune GPT-3.5 on it, you're essentially training the model on its own outputs -- a recipe for model collapse. Always use a stronger teacher model (e.g., GPT-4 generating data for a 7B student). The quality gap between teacher and student is what creates useful training signal.
- ●
Ignoring generation temperature: Using temperature=0 produces repetitive, low-diversity data. Using temperature=1.5 produces incoherent gibberish. The sweet spot is 0.7-0.9 for instruction generation and 0.2-0.5 for response generation. Many practitioners set the same temperature for both, which is suboptimal.
- ●
Not tracking costs in real-time: A generation pipeline running overnight with GPT-4 can easily consume $500-2,000 (~INR 42,000-1.7 lakh) in API credits. Always implement per-batch cost tracking and set hard budget limits before starting. Use GPT-4o-mini for prototyping and switch to GPT-4o only for final production runs.
- ●
Skipping deduplication: LLMs generate many near-duplicate instructions, especially when using Self-Instruct with a small seed pool. Without deduplication, 10-20% of your dataset may be paraphrased copies, causing the student model to overfit to repeated patterns. ROUGE-L or embedding-based dedup is essential.
- ●
Generating too much data without quality filtering: More data is not always better. The AlpaGasus paper showed that 9K filtered examples outperformed 52K unfiltered ones. Always allocate budget for quality filtering (LLM-as-judge scoring costs ~$0.001 per example with GPT-4o-mini). The optimal strategy is: over-generate by 2-3x, then aggressively filter.
- ●
Not diversifying the seed pool: Starting Self-Instruct with only 5-10 seeds in a narrow domain produces a dataset that's diverse in surface form but narrow in substance. Use 50-200 diverse seeds covering your full task taxonomy. The initial investment in seed quality has an outsized impact on the final dataset.
When Should You Use This?
Use When
You need instruction-response pairs for fine-tuning but have fewer than 1,000 labeled examples -- LLM generation can produce 10K+ examples in hours at minimal cost
You are building a domain-specific assistant (legal, medical, e-commerce) and need training data that reflects domain terminology and scenarios
Real training data contains PII or sensitive information that cannot be used directly -- synthetic data preserves patterns without exposing real individuals
You need to bootstrap a new task or language where no public datasets exist (e.g., instruction data for underserved Indian languages like Telugu or Kannada)
You want to create a difficulty-stratified dataset with controlled complexity levels for curriculum learning
You are distilling capabilities from a large proprietary model (GPT-4, Claude) into a smaller, self-hosted model for cost reduction at inference time
You need to augment an existing dataset with more diverse examples to reduce overfitting and improve generalization
Avoid When
The target domain requires specialized factual accuracy that the teacher model lacks (e.g., cutting-edge medical research, proprietary internal knowledge) -- synthetic data will contain hallucinations
You already have abundant, high-quality labeled data (100K+ examples) -- the marginal benefit of synthetic data decreases rapidly when real data is plentiful
The teacher model's terms of service prohibit using outputs for training competitive models -- check OpenAI, Anthropic, and Google's latest policies before generating
You need ground-truth labels for safety-critical applications (autonomous driving, medical diagnosis) where synthetic labels could be dangerously wrong
The task requires real-world distribution matching (e.g., fraud detection where the true positive rate matters) -- synthetic data may not reflect actual class distributions
You are training on the same model architecture and size as the teacher -- this creates a model collapse feedback loop rather than useful distillation
Key Tradeoffs
Quality vs. Cost
The primary tradeoff is between the strength of the teacher model and the cost per example. Here's the practical landscape in 2026:
| Teacher Model | Cost per 1K examples | Quality Level | Best Use Case |
|---|---|---|---|
| GPT-4o | $5-15 (~INR 420-1,260) | Highest | Complex reasoning, nuanced responses |
| GPT-4o-mini | $0.50-2 (~INR 42-170) | High | General instruction following, most tasks |
| Claude 3.5 Haiku | $0.30-1.50 (~INR 25-125) | High | Long-form content, analysis |
| Llama-3-70B (self-hosted) | $0.10-0.50 (~INR 8-42) | Medium-High | Privacy-sensitive, high volume |
| Llama-3-8B (self-hosted) | $0.02-0.10 (~INR 2-8) | Medium | Prototyping, low budget |
Volume vs. Quality
The AlpaGasus result is the most important finding in this space: 9K high-quality examples > 52K unfiltered examples. This means your budget allocation should be roughly:
- 30-40% on data generation (over-generate by 2-3x)
- 40-50% on quality filtering and scoring
- 10-20% on deduplication and post-processing
Teams that spend 90% on generation and 10% on filtering consistently underperform.
Synthetic vs. Real Data
Synthetic data is not a replacement for real data -- it is a supplement. The optimal strategy for most production systems is a mixed dataset: 20-50% real human-written examples (for distribution grounding) + 50-80% high-quality synthetic examples (for volume and diversity). The real examples anchor the distribution and prevent the model from learning synthetic artifacts, while the synthetic examples provide breadth and volume.
Single-Source vs. Multi-Source
Generating all synthetic data from a single teacher model risks encoding that model's biases and stylistic quirks. Using multiple teachers (e.g., GPT-4 for reasoning, Claude for analysis, Gemini for creative tasks) produces more diverse and robust training data, at the cost of increased pipeline complexity.
Alternatives & Comparisons
Faker generates structured fake data (names, addresses, phone numbers, emails) using rule-based templates -- deterministic, fast, and free. Use Faker when you need structured PII-safe data at massive scale (millions of records) or when the data schema is well-defined. Use LLM Data Generator when you need semantic diversity: natural language instructions, realistic conversations, nuanced responses, or domain-specific content that rule-based templates cannot produce.
Text augmentation (synonym replacement, back-translation, EDA) modifies existing text to create variations while preserving meaning. It's cheaper and faster than LLM generation but cannot create new knowledge, tasks, or instruction types. Use text augmentation to expand a small labeled dataset for classification/NER tasks. Use LLM Data Generator when you need entirely new instruction-response pairs, multi-turn conversations, or data for tasks not present in your existing dataset.
GANs generate synthetic data by training a generator-discriminator pair on real data. GANs excel at generating tabular, image, and time-series data that preserves statistical properties. For text generation, LLMs have entirely supplanted GANs -- modern LLMs produce far more coherent, diverse, and controllable text than any GAN-based text generator. Use GANs for non-text modalities; use LLM Data Generator for all text and instruction data.
CTGAN is specialized for generating synthetic tabular data with mixed column types. It learns the joint distribution of columns from real data. Use CTGAN when you need tabular data that preserves column correlations and statistical properties. Use LLM Data Generator when you need text-heavy data, instruction-response pairs, or when no real training data exists to learn a distribution from -- LLMs can generate from a prompt specification alone.
Diffusion models excel at generating high-fidelity images, audio, and continuous data through iterative denoising. For text data generation, LLMs are strictly superior to diffusion models in both quality and controllability. Use diffusion generators for image/audio synthetic data and LLM Data Generator for all text-based synthetic data needs.
Pros, Cons & Tradeoffs
Advantages
100x cost reduction vs. human annotation: Generating 10K instruction-response pairs costs 6K-30K) for human annotation. This makes ML accessible to teams with limited budgets, including Indian startups and academic labs.
Speed: hours instead of months: A complete synthetic dataset can be generated, filtered, and ready for training in 4-12 hours, compared to 1-3 months for human annotation campaigns. This enables rapid experimentation and iteration.
Controllable diversity and distribution: You can precisely specify the topic distribution, difficulty levels, output formats, and languages. Need 500 examples each of coding, math, writing, and analysis? An LLM produces exactly that distribution. Human annotation campaigns always have imbalanced coverage.
Privacy-safe by construction: Synthetic data contains no real personal information, making it inherently compliant with DPDPA (India), GDPR (EU), and CCPA (US). This is critical for healthcare, finance, and government applications where real data cannot be shared.
Supports rare and underrepresented categories: LLMs can generate examples for edge cases, minority languages, and niche domains that are expensive or impossible to collect naturally. Need Hindi-English code-mixed customer support data? Generate it directly.
Iterative improvement: Unlike static datasets, synthetic data pipelines can be re-run with improved prompts, new seed examples, or different teacher models. Each iteration produces better data, enabling continuous improvement of the downstream model.
Multi-format output: The same LLM pipeline can generate single-turn instructions, multi-turn conversations, structured JSON, code examples, and more -- no separate annotation interfaces needed for each format.
Disadvantages
Teacher model hallucinations propagate to student: If GPT-4 generates a factually incorrect response in the synthetic data, the student model will learn that incorrect fact as truth. This is especially dangerous for medical, legal, and financial domains where factual accuracy is critical.
Stylistic artifacts and uniformity: LLM-generated text has distinctive patterns: hedging phrases ('It is important to note...'), formulaic structures, and artificially balanced perspectives. Student models trained on such data inherit these quirks, making them sound 'synthetic' to experienced users.
Model collapse risk with recursive generation: Using a model trained on synthetic data to generate the next round of synthetic data causes progressive quality degradation. Each generation loses tail diversity and amplifies biases from the previous round.
Terms-of-service and legal uncertainty: Using outputs from proprietary models (GPT-4, Claude) to train competing models may violate terms of service. The legal status of synthetic data for model training remains unsettled, creating risk for commercial applications.
Hidden cost of quality filtering: Raw synthetic data requires significant filtering -- typically 30-50% is discarded. The cost of LLM-as-judge scoring and human spot-checking adds 30-100% to the generation cost. Teams often underestimate this hidden expense.
Doesn't create new knowledge: An LLM cannot generate accurate data about topics it doesn't understand. For cutting-edge research, proprietary processes, or rapidly evolving domains, synthetic data will contain plausible-sounding but incorrect information. Human expertise remains essential for these cases.
Difficulty calibration is hard: Generating a balanced distribution of easy, medium, and hard examples is more difficult than it appears. LLMs tend to cluster around medium difficulty, making it hard to produce truly challenging examples without explicit Evol-Instruct-style complexity evolution.
Failure Modes & Debugging
Model Collapse from Recursive Synthetic Training
Cause
The student model, trained on synthetic data from teacher model , is used to generate synthetic data for the next student model . Over multiple generations, the data distribution narrows and tail modes disappear. This is especially severe when the student and teacher are the same architecture/size.
Symptoms
Each successive model generation produces less diverse outputs. Rare topics, minority perspectives, and edge cases disappear from generated text. The model's vocabulary shrinks. Output quality degrades gradually -- often imperceptibly at first -- until the model produces only generic, repetitive responses.
Mitigation
Always preserve real data in the training mix. Use the accumulation strategy from Gerstgrasser et al. (2024): rather than replacing real data with synthetic. Maintain a significant gap between teacher and student model sizes. Never use a model to generate its own training data without mixing in real examples. Monitor diversity metrics (distinct n-grams, topic distribution entropy) across training generations.
Hallucination Amplification
Cause
The teacher model generates factually incorrect information in a small percentage of synthetic examples (typically 5-15%). When the student model trains on this data, it learns the incorrect facts as authoritative truths. Because the errors are embedded in otherwise high-quality, confident-sounding text, quality filters often miss them.
Symptoms
The student model confidently states incorrect facts, produces plausible-sounding but wrong calculations, or cites non-existent sources. The error rate is higher for niche topics where the teacher model is less reliable. Users report factual errors that don't appear in standard evaluation benchmarks (which test common knowledge).
Mitigation
For fact-dependent domains, implement factual consistency checking in the quality pipeline: cross-reference key claims against knowledge bases, use NLI models to check for contradictions, or use a separate model to verify factual claims. For high-stakes domains (medical, legal), require human expert review of a random 5-10% sample. Consider using RAG-augmented generation where the teacher has access to authoritative sources during data generation.
Distribution Mismatch with Real-World Data
Cause
The synthetic data distribution does not match the real-world distribution of user queries. LLMs tend to generate 'textbook-quality' instructions that are well-formed, grammatically correct, and precisely specified -- unlike real user queries that are often ambiguous, typo-ridden, colloquial, or poorly structured.
Symptoms
The student model performs well on clean, well-formed inputs (benchmark evaluations) but poorly on real user traffic. It struggles with typos, slang, code-mixed language (e.g., Hinglish), incomplete sentences, and ambiguous instructions. There's a persistent gap between benchmark performance and user satisfaction scores.
Mitigation
Include noisy and realistic examples in the synthetic dataset: deliberately generate examples with typos, informal language, code-mixing, and ambiguous instructions. Mix synthetic data with even a small amount (5-20%) of real user queries (anonymized). For Indian applications, explicitly generate examples in Hinglish, regional English variants, and with typical Indian English patterns.
Teacher Model Artifact Leakage
Cause
The teacher model's distinctive style, safety training artifacts, and behavioral quirks leak into the synthetic data. GPT-4 tends to produce responses starting with 'Certainly!', 'Great question!', or 'I'd be happy to help'. Claude tends to add disclaimers and caveats. These artifacts get encoded into the student model.
Symptoms
The student model adopts the teacher model's distinctive conversational patterns: excessive hedging, specific refusal phrases, characteristic opening/closing phrases, and safety-related over-refusals. Users recognize the output as 'sounding like ChatGPT' even when using a different model.
Mitigation
Post-process synthetic data to remove known teacher model artifacts. Use regex or simple classifiers to strip phrases like 'As an AI language model', 'Certainly!', 'I cannot and will not'. Mix data from multiple teacher models to dilute any single model's artifacts. Include a small percentage of human-written examples (10-20%) to anchor the style distribution. Consider style-transfer prompting: instruct the teacher to respond in a specific tone rather than its default style.
Budget Overrun from Unmonitored Generation
Cause
Generation pipelines running with expensive teacher models (GPT-4o at 500-2,000 (~INR 42,000-1.7 lakh) -- often more than expected.
Symptoms
API bills arrive that are 5-10x the expected amount. The team realizes too late that they used GPT-4o for a job that GPT-4o-mini could handle. A single misconfigured pipeline run (e.g., max_tokens set too high, or no dedup causing regeneration of existing examples) consumes the month's API budget.
Mitigation
Implement per-batch cost tracking that logs token usage and estimated cost after every 100 examples. Set hard budget limits in the pipeline that abort generation when the threshold is reached. Use a tiered generation strategy: prototype with GPT-4o-mini (10x cheaper), then switch to GPT-4o only for the final production run on validated prompts. Always estimate total cost before starting: (n_examples * avg_tokens_per_example * price_per_token).
Seed Pool Bias Leading to Narrow Data
Cause
The Self-Instruct seed pool is too small (< 20 examples) or too homogeneous (all seeds are from the same task type or topic domain). Since the LLM generates new examples by analogy to the seeds, a narrow seed pool produces a narrow dataset, even with high generation temperature.
Symptoms
The generated dataset appears diverse at the surface level (different wordings) but covers only 3-4 task types when analyzed. The student model performs well on the task types represented in the seeds but fails on other task types. Topic distribution analysis reveals heavy clustering around seed topics.
Mitigation
Invest in a diverse seed pool of 100-200 examples covering at least 10-15 distinct task categories: open QA, closed QA, classification, extraction, summarization, creative writing, code generation, math reasoning, analysis, role-play, multi-step instructions, and domain-specific tasks. Audit the generated dataset's topic distribution before training and regenerate underrepresented categories with targeted prompts.
Placement in an ML System
Where LLM Data Generation Fits in the ML System
LLM data generation sits at the very beginning of the ML pipeline -- before data cleaning, preprocessing, or model training. It is fundamentally a data curation component, not a model training component.
In a typical LLM fine-tuning pipeline:
- Data Generation (this block): Produce raw synthetic instruction-response pairs from a teacher model
- Data Cleaning: Remove malformed, toxic, or low-quality examples
- Deduplication: Eliminate near-duplicate entries
- Data Mixing: Combine synthetic data with real human-written data and existing public datasets
- Instruction Tuning / Fine-tuning: Train the student model on the curated dataset
- Evaluation: Assess the student model on held-out benchmarks
For production systems at Indian tech companies, LLM data generation typically serves two use cases:
Use Case 1: Cold-start bootstrapping. A team building a new chatbot for, say, Razorpay's merchant support has zero training data. They use GPT-4 to generate 10K merchant support conversations, filter to 5K high-quality ones, and fine-tune a Llama-3-8B model. The synthetic data gets them to a functional v1 in days, which then collects real user feedback for v2.
Use Case 2: Long-tail augmentation. A team at Flipkart has 50K real customer support conversations but very few examples for rare categories (e.g., international returns, cryptocurrency refunds). They use LLM generation to produce 2K examples specifically for these underrepresented categories, improving coverage without waiting for rare events to accumulate naturally.
Pipeline Stage
Data Generation / Data Curation
Upstream
- api-endpoint
- data-validation
Downstream
- data-cleaning
- deduplication
- instruction-tuning
- full-fine-tuning
- lora-fine-tuning
Scaling Bottlenecks
The primary scaling bottleneck for API-based generation is tokens per minute (TPM) and requests per minute (RPM) limits. OpenAI's GPT-4o allows 30K-800K TPM depending on your tier. At 500 tokens per example, Tier 3 (30K TPM) allows ~60 examples/minute, meaning 50K examples takes ~14 hours. Higher tiers or self-hosted models remove this bottleneck.
LLM-as-judge quality scoring is itself an API-intensive operation. Scoring 100K examples with GPT-4o-mini at 300 tokens per scoring call takes 30M tokens (~$4.50 / ~INR 375). The scoring step often takes as long as the generation step.
Naive ROUGE-L deduplication is in dataset size. For datasets above 50K examples, use MinHash LSH or embedding-based approximate nearest neighbor search (FAISS) to reduce dedup time from hours to minutes.
Synthetic datasets of 100K+ examples with metadata (quality scores, evolution rounds, source models) can reach 500MB-2GB. Version control becomes critical as prompts evolve and generation runs accumulate. Use DVC or HuggingFace Datasets for versioned dataset management.
Production Case Studies
Stanford's Alpaca project used GPT-3.5 (text-davinci-003) to generate 52,000 instruction-response pairs via the Self-Instruct pipeline, bootstrapped from just 175 human-written seed tasks. The generated data was used to fine-tune LLaMA-7B into an instruction-following assistant. The total data generation cost was under 100.
Alpaca-7B matched text-davinci-003 on the Self-Instruct evaluation set in blind human evaluations. The project proved that LLM-generated synthetic data could produce competitive assistants at a tiny fraction of the cost of human annotation, catalyzing the entire open-source instruction-tuning movement.
Microsoft researchers developed Evol-Instruct, which takes existing simple instructions and evolves them through LLM-powered rewriting into more complex, nuanced instructions. Starting with Alpaca's 52K examples as seeds, they produced 250K evolved instruction-response pairs across multiple complexity levels. The method was published at ICLR 2024.
Human evaluators rated WizardLM's evolved instructions as more complex and diverse than human-written ones. WizardLM-7B achieved 90%+ of ChatGPT's quality and was preferred over ChatGPT on several task categories. Evol-Instruct became the standard technique for generating difficulty-stratified training data.
NVIDIA's Nemotron-4 340B pipeline demonstrated industrial-scale LLM data generation for model alignment. The Nemotron-4-340B-Instruct model generated synthetic training data, which was then scored by the Nemotron-4-340B-Reward model. The pipeline synthesized over 98% of all data used in the alignment process (SFT + DPO), with only ~20K human-annotated examples in the entire mix.
The 98% synthetic data ratio is the highest reported for a production-quality LLM alignment pipeline. The resulting model achieved competitive performance on standard benchmarks, proving that carefully generated and filtered synthetic data can almost entirely replace human annotation at industrial scale. Total human data needed: just 20K examples out of millions.
Microsoft's Phi-3 series of small language models (3.8B parameters) was trained on 3.3 trillion tokens, heavily leveraging synthetic 'textbook-quality' data generated by larger LLMs. The synthetic data included educational content covering math, coding, common sense reasoning, and general knowledge, following the 'Textbooks Are All You Need' philosophy from the earlier Phi-1 work.
Phi-3-mini (3.8B) matched or exceeded the performance of models 10-15x its size (Mixtral 8x7B, Llama-3-8B) on many benchmarks, directly attributable to the quality of its synthetic training data. The project demonstrated that synthetic data quality can compensate for massive reductions in model size -- a key insight for deploying LLMs on mobile devices and in resource-constrained environments.
HuggingFace created Cosmopedia, the largest open synthetic dataset, containing over 30 million files and 25 billion tokens of synthetic textbooks, blog posts, stories, and educational articles generated by Mixtral-8x7B-Instruct. Topics were seeded from Stanford courses, Khan Academy, OpenStax, and WikiHow to ensure educational quality and breadth.
Cosmopedia was generated in over 10,000 H100 GPU hours. The dataset achieved less than 1% duplication rate after MinHash filtering. It was used to train SmolLM, demonstrating that massive-scale synthetic data generation is viable with open-source models -- a critical finding for teams that cannot use proprietary APIs due to data sovereignty or budget constraints.
Tooling & Ecosystem
An open-source Python library for synthetic data generation and reproducible LLM workflows. Provides a high-level API for multi-step generation pipelines with built-in caching, resumability, and support for both API-based and self-hosted models. Published at ACL 2024. The most complete open-source tool for LLM data generation in 2026.
An open-source model fine-tuned from Mistral-7B specifically for conditional task generation -- converting unannotated text into instruction-tuning datasets. Unlike API-based approaches, Bonito runs locally and doesn't require proprietary model access. Trained on 1.65M examples from the CTGA dataset. Published at ACL 2024 Findings.
The original Self-Instruct codebase from the ACL 2023 paper. Includes the seed task pool, generation scripts, filtering logic, and evaluation code. While newer tools (DataDreamer, Magpie) have improved upon it, the original codebase remains a clear and well-documented reference implementation for understanding the core algorithm.
A novel alignment data synthesis method (ICLR 2025) that generates instructions by exploiting the auto-regressive nature of aligned LLMs. Instead of prompting a model to generate instructions, Magpie feeds only the chat template prefix and lets the model generate a user query naturally. Produced 4M instruction-response pairs from Llama-3-Instruct, with 300K high-quality instances selected.
A commercial synthetic data platform offering APIs for generating anonymized and safe synthetic data. Supports tabular, text, and time-series generation with built-in privacy metrics (differential privacy, k-anonymity) and quality assessment. Enterprise-focused with SOC 2 compliance. Pricing starts at free tier for small projects.
An open-source data curation platform that integrates with LLM data generation pipelines. Provides annotation interfaces for human review of synthetic data, quality scoring dashboards, and dataset versioning. While not a generation tool itself, Argilla is the best open-source option for the human-in-the-loop quality review step that should follow any LLM generation pipeline.
Research & References
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirhi (2023)ACL 2023
The foundational paper introducing the Self-Instruct framework: bootstrap instruction-response pairs from a language model using a small seed pool of human-written examples. Showed a 33% improvement on Super-NaturalInstructions over vanilla GPT-3, establishing the viability of LLM-generated training data.
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Daxin Jiang (2024)ICLR 2024
Introduces Evol-Instruct, a method for evolving simple instructions into complex ones through LLM-powered rewriting. Demonstrates that evolved instructions produce better instruction-tuned models than human-written ones of equivalent volume. The deepening, broadening, and constraining operators became standard tools for synthetic data generation.
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson (2024)Nature 2024
Demonstrates that model collapse -- progressive degradation of model quality -- occurs when models are recursively trained on synthetic data from previous generations. The tail of the distribution collapses first, erasing rare and minority modes. A foundational warning for LLM data generation practitioners.
Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey, Rafael Rafailov, et al. (2024)arXiv 2024
Shows that model collapse can be avoided by accumulating synthetic data alongside original real data rather than replacing it. When , the model preserves the tails of the distribution across generations. A critical practical guideline for safe LLM data generation.
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, Bill Yuchen Lin (2025)ICLR 2025
Introduces a zero-prompt method for extracting instruction data from aligned LLMs by feeding only the chat template prefix. Produced 4M instruction-response pairs from Llama-3-Instruct. Models fine-tuned on Magpie data perform comparably to official Llama-3-8B-Instruct despite the latter using 10M human-curated data points.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you generate synthetic training data for a domain-specific chatbot using LLMs? Walk through the full pipeline.
- ●
What is Self-Instruct, and how does it differ from Evol-Instruct?
- ●
You need to build an instruction-tuned model but have no labeled data. How would you bootstrap the training dataset?
- ●
What is model collapse, and how do you prevent it when using synthetic data?
- ●
How would you ensure quality in a synthetically generated dataset? What filtering steps would you apply?
- ●
GPT-4 costs $10 per 1M output tokens. You need 100K training examples. How would you optimize the cost of synthetic data generation?
- ●
When should you NOT use LLM-generated synthetic data?
Key Points to Mention
- ●
The quality vs. quantity tradeoff: cite AlpaGasus (9K filtered > 52K unfiltered) to demonstrate understanding of data curation principles
- ●
Multi-stage quality pipeline: generation -> LLM-as-judge scoring -> deduplication -> human spot-check. Most candidates mention generation but forget the filtering stages
- ●
Model collapse risk and the accumulation mitigation strategy from Gerstgrasser et al. -- show awareness of recursive training dangers
- ●
Cost-quality tradeoff: use cheaper models (GPT-4o-mini) for generation and expensive models (GPT-4o) only for quality scoring or complex reasoning examples
- ●
The importance of seed pool diversity: narrow seeds produce narrow data, even at high temperature
- ●
Distribution mismatch: synthetic data tends to be cleaner than real user queries, requiring intentional noise injection
Pitfalls to Avoid
- ●
Claiming synthetic data is 'as good as' real data -- it's a supplement, not a replacement. The optimal strategy is always a mix of real and synthetic data
- ●
Ignoring the legal/ToS implications of using proprietary model outputs for training. Always mention this risk and suggest alternatives (open-source teacher models)
- ●
Focusing only on generation volume without discussing quality filtering -- this signals a beginner-level understanding
- ●
Not mentioning model collapse when discussing iterative/recursive synthetic data generation
Senior-Level Expectation
Senior and staff-level candidates should discuss the economics of synthetic data pipelines (cost-per-example across different teacher models, budget allocation between generation and filtering), the data mixing strategy (optimal ratio of real to synthetic data, how to handle distribution shift), multi-teacher diversification (using multiple LLMs to reduce single-source bias), and evaluation methodology (how to measure whether synthetic data actually improves the downstream model vs. just inflating benchmark scores). They should also discuss organizational considerations: when to build a reusable synthetic data platform vs. one-off generation scripts, how to version and audit synthetic datasets, and the governance implications of training on AI-generated content.
Summary
LLM Data Generator represents one of the most impactful developments in modern machine learning: the ability to use large language models to produce synthetic training data for downstream model development. From Stanford Alpaca's demonstration that $500 worth of GPT-3.5 outputs could fine-tune a competitive assistant, to NVIDIA Nemotron's pipeline where 98% of alignment data is synthetic, to Microsoft Phi-3's proof that synthetic textbook data can compensate for 10x model size reductions, LLM-based data generation has become indispensable.
The core techniques -- Self-Instruct (bootstrapping from seed examples), Evol-Instruct (evolving instructions for complexity), and Magpie (extracting instructions from aligned model auto-regression) -- each serve different needs in the data generation toolkit. The critical success factor is not the generation method itself but the quality filtering pipeline: LLM-as-judge scoring, deduplication, and human spot-checking that transforms raw synthetic outputs into clean, diverse, high-quality training data. The AlpaGasus finding (9K filtered > 52K unfiltered) is the most important practical insight in this space.
For Indian ML teams, LLM data generation is especially valuable: it reduces training data costs from lakhs of rupees to thousands, enables rapid bootstrapping of models for underserved Indian languages, and sidesteps privacy concerns by generating data that never contained real PII. The risks -- model collapse from recursive training, hallucination propagation, teacher model stylistic artifacts, and legal uncertainty around proprietary model outputs -- are real but manageable with proper practices: maintain real data in the mix, use multi-teacher diversification, implement factual consistency checks, and prefer open-source teacher models for legally unambiguous use.