Data Validation in Machine Learning
Here is the uncomfortable truth about machine learning systems: your model is only as good as the data it ingests. Data validation is the disciplined practice of verifying that incoming data conforms to expected schemas, statistical distributions, and business rules before it is allowed to enter training or serving pipelines.
In production ML systems, data validation sits at the very front gate of the pipeline. It answers three critical questions: Is the data shaped correctly (schema validation)? Is the data complete (null and missing-value checks)? Is the data reasonable (outlier and distribution checks)? When any of these checks fail, the pipeline should halt, alert, and prevent garbage from propagating downstream.
Why does this matter so much? Because ML models fail silently. A corrupted feature column does not throw an exception during model.predict() -- it just produces subtly wrong predictions that erode user trust over days and weeks. Google's own research found that data-related bugs are the most common source of production ML failures, dwarfing code bugs by a wide margin. From Flipkart's product recommendation engine to IRCTC's dynamic pricing, every Indian-scale ML deployment needs automated data validation to operate reliably.
Data validation has evolved from ad-hoc assertions scattered through ETL scripts into a formal engineering discipline with dedicated frameworks (Great Expectations, Pandera, TFDV, Deequ), standardized metrics, and the emerging concept of data contracts that encode producer-consumer agreements as executable validation suites.
Concept Snapshot
- What It Is
- A systematic process of verifying that data conforms to expected schemas, value constraints, statistical distributions, and business rules before it enters ML training or serving pipelines.
- Category
- Data Processing
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: raw data batches or streaming records with a reference schema and constraint suite. Outputs: validation report (pass/fail per expectation), data quality metrics, and optionally filtered/quarantined invalid records.
- System Placement
- Sits immediately after data ingestion and before data cleaning, feature engineering, or model training in an ML pipeline. Also applied at serving time to validate inference requests.
- Also Known As
- data quality checks, data testing, data contracts enforcement, schema enforcement, data assertions, data unit testing
- Typical Users
- ML Engineers, Data Engineers, Data Scientists, Platform Engineers, MLOps Engineers
- Prerequisites
- Basic statistics (mean, standard deviation, quantiles), Data types and schema concepts, ETL/ELT pipeline fundamentals, Python or Spark basics
- Key Terms
- schema validationnull checkoutlier detectiondata contractexpectation suitedata quality metricdistribution driftIQRZ-scoreisolation forestcompletenessuniqueness
Why This Concept Exists
The Silent Killer of ML Systems
In traditional software engineering, bad input causes a crash, an exception, a stack trace -- something observable. In machine learning, bad input causes bad predictions that look perfectly normal on the surface. The model doesn't raise an error when a feature that should be a price in INR suddenly arrives in USD, or when a column that's normally 98% non-null drops to 40% because an upstream API changed its response format over a weekend deployment.
This is why Google's famous paper on ML technical debt identifies data dependencies as the most expensive and dangerous form of technical debt in production ML systems. The authors at Google found that data-related issues -- schema changes, feature corruption, distribution shifts -- caused more production incidents than model or code bugs combined.
From Ad-Hoc Assertions to Engineering Discipline
In the early days, data validation meant sprinkling assert df['price'] > 0 statements through Jupyter notebooks. This approach fails at scale for three reasons:
- No centralized registry: Assertions are scattered across scripts with no way to track what's being validated.
- No historical tracking: You can't see whether data quality is improving or degrading over time.
- No separation of concerns: The validation logic is tangled with the transformation logic.
The turning point came with two developments. First, Google published their work on TensorFlow Data Validation (TFDV) in 2018, demonstrating that automated schema inference and anomaly detection could catch data bugs at petabyte scale. Second, Great Expectations emerged as an open-source framework that brought software engineering practices (version-controlled test suites, CI/CD integration, human-readable reports) to data validation.
The Data Contract Revolution
More recently, the concept of data contracts has gained traction. A data contract is a formal agreement between a data producer (e.g., a backend service emitting events) and a data consumer (e.g., an ML pipeline) that specifies exactly what the data should look like: column names, types, allowed ranges, freshness SLAs, and more. Think of it as an API contract, but for data.
This matters especially in large organizations. At a company like Flipkart or Razorpay, dozens of microservices produce data that feeds into ML pipelines. Without data contracts, any upstream change can silently break downstream models. With contracts, violations are caught at the boundary and the offending producer is notified -- before bad data reaches the model.
Key Takeaway: Data validation exists because ML models fail silently on bad data. Formalizing validation into schemas, expectation suites, and data contracts transforms data quality from a hope into an engineering guarantee.
Core Intuition & Mental Model
The Bouncer at the Club
Here's the simplest way to think about data validation: it's the bouncer at the door of your ML pipeline. Just as a bouncer checks IDs, dress codes, and guest lists before letting anyone into the venue, data validation checks schemas, null rates, and value ranges before letting any data into your model.
The bouncer doesn't care about what happens inside the club (that's the model's job). The bouncer's only job is to ensure that everyone who enters meets the minimum requirements. If they don't, they're turned away at the door -- not after they've already caused a scene inside.
Three Layers of Defense
Production data validation operates in three concentric layers, from cheapest to most expensive:
Layer 1 -- Schema Validation (structural checks): Does the data have the right columns, in the right types, in the right order? This is the fastest check and catches the most catastrophic failures. If your training data suddenly has 15 columns instead of 20, you want to know immediately.
Layer 2 -- Constraint Validation (value-level checks): Are values within expected ranges? Are null rates below acceptable thresholds? Are categorical columns limited to known categories? This catches data corruption and upstream API changes.
Layer 3 -- Statistical Validation (distribution-level checks): Does the distribution of values match what we've seen historically? Are there unexpected outliers? Has the mean shifted? This catches subtle drift that individual value checks would miss.
The key insight is that each layer catches a different class of bug, and you need all three for robust coverage. Schema validation without statistical validation catches format changes but misses distribution drift. Statistical validation without schema validation catches drift but misses structural breaks.
Mental Model: Think of these three layers as progressively finer sieves. Layer 1 catches boulders (wrong schema). Layer 2 catches pebbles (out-of-range values). Layer 3 catches sand (statistical drift). You need all three to keep the water clean.
Technical Foundations
Formalizing Data Validation
Let's put some mathematical rigor behind the intuition. Data validation can be formally defined as a function that maps a dataset and a set of constraints to a validation report :
Each constraint is a predicate over the dataset or a specific column. Let's formalize the three layers.
Layer 1: Schema Validation
A schema defines the expected structure: where is the expected data type. Schema validation checks:
Layer 2: Constraint Validation
Completeness (null check): For column with maximum allowed null fraction :
Range constraints: For numeric column with bounds :
Uniqueness: For column that should be unique:
Layer 3: Statistical Validation
Z-score outlier detection: A value is flagged as an outlier if:
where is typically 3.0. However, Z-scores are sensitive to outliers themselves (the mean and standard deviation are affected by extreme values).
IQR-based outlier detection: More robust than Z-scores. A value is an outlier if:
where (interquartile range).
Distribution divergence (for drift detection): The Kullback-Leibler divergence between the current batch distribution and the reference distribution :
In practice, the Population Stability Index (PSI) is more commonly used because it's symmetric:
where is the number of bins. A PSI > 0.25 typically indicates significant distribution shift.
Composite Data Quality Score
Many organizations compute a single aggregate data quality score across all constraints:
where is the weight (criticality) assigned to each constraint. A score below a threshold (e.g., 0.95) triggers a pipeline halt.
Internal Architecture
A production data validation system consists of five major subsystems: a schema registry that stores and versions expected data schemas, a constraint engine that evaluates validation rules against incoming data, a statistical profiler that computes distributional summaries, an alerting layer that notifies stakeholders of failures, and a quarantine store for rejected records. Here's how they connect:
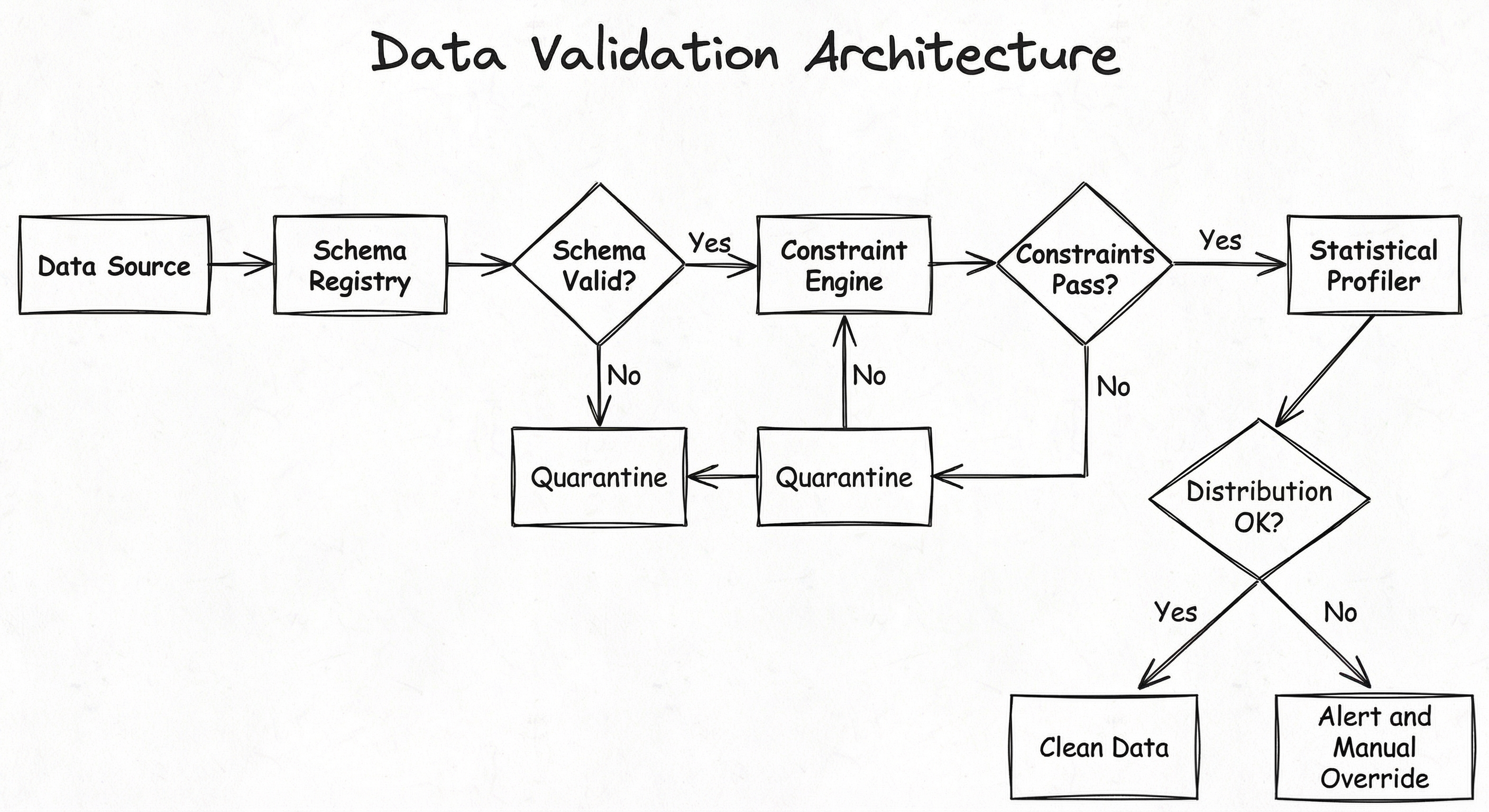
The architecture follows a fail-fast principle: the cheapest checks (schema) run first, and data that fails early checks never reaches the expensive statistical profiling stage. This design minimizes wasted compute on clearly invalid data.
In a streaming context (e.g., Kafka-based ingestion at a company like Swiggy processing millions of order events per hour), the schema validation and constraint checks run synchronously on each micro-batch, while the statistical profiling runs asynchronously on windowed aggregates. This separation ensures that validation doesn't become a latency bottleneck in the streaming pipeline.
Key Components
Schema Registry
Stores versioned data schemas that define expected column names, data types, nullable flags, and structural constraints. Supports schema evolution (adding optional columns, widening types) while preventing breaking changes. Often implemented using tools like Confluent Schema Registry, or as expectation suites in Great Expectations.
Constraint Engine
Evaluates a suite of declarative validation rules (expectations) against incoming data. Handles null checks, range checks, uniqueness checks, regex pattern matching, referential integrity, and custom business rules. Returns a structured validation report with pass/fail per constraint and associated metrics.
Statistical Profiler
Computes distributional summaries of incoming data (mean, standard deviation, quantiles, histograms, cardinality) and compares them against a reference profile from training data. Detects outliers using Z-score, IQR, or Isolation Forest methods. Identifies distribution drift using PSI, KL divergence, or Kolmogorov-Smirnov tests.
Quarantine Store
Holds records or batches that failed validation, along with the specific failure reasons. Enables data engineers to inspect, correct, and replay quarantined data. Prevents bad data from silently entering the pipeline while preserving it for debugging.
Alert & Notification Layer
Routes validation failures to appropriate channels (Slack, PagerDuty, email) based on severity. Critical failures (schema breaks) trigger immediate alerts. Statistical anomalies may trigger review workflows rather than hard blocks. Integrates with incident management systems.
Validation Metadata Store
Persists historical validation results, data quality metrics, and profiling snapshots. Powers dashboards showing data quality trends over time. Enables root-cause analysis when model performance degrades by correlating quality dips with prediction errors.
Data Flow
Batch Pipeline Flow: Raw data lands in a staging area (S3, GCS, or Azure Blob) -> the schema registry validates structure -> the constraint engine runs all expectations -> the statistical profiler compares distributions against the training reference -> passing data moves to the feature store or training pipeline -> failing data goes to quarantine with a detailed report.
Serving/Inference Flow: An inference request arrives at the model serving endpoint -> Pydantic or a lightweight schema validator checks the request payload -> range and null checks are applied to each feature -> outlier detection flags extreme values -> valid requests proceed to the model -> invalid requests return a structured error response with the specific validation failure.
Continuous Monitoring Flow: On a scheduled cadence (hourly, daily), the statistical profiler compares recent production data distributions against the training baseline. If PSI exceeds thresholds or if null rates spike, alerts fire. This provides early warning of upstream data pipeline changes before model performance degrades.
A sequential flow from Data Source through Schema Registry, Constraint Engine, and Statistical Profiler, with branching paths to either Clean Data (on pass) or Quarantine Store (on fail). Alerts are triggered on statistical anomalies.
How to Implement
Choosing Your Validation Strategy
Implementation approaches for data validation fall along two axes: declarative vs. programmatic and batch vs. streaming.
Declarative frameworks (Great Expectations, Deequ) let you define validation rules as configuration rather than code. You write expectations like expect_column_values_to_be_between(column='price', min_value=0, max_value=1000000) and the framework handles execution, reporting, and documentation. This approach scales well across teams because non-engineers can read and contribute expectations.
Programmatic libraries (Pandera, Pydantic) embed validation logic directly in Python code using decorators and type annotations. This approach is more natural for ML engineers who already write Python and want validation tightly coupled with data processing logic.
For batch validation (training data, daily ETL outputs), Great Expectations or Deequ are the standard choices. Great Expectations integrates with Airflow, Dagster, and Prefect. Deequ runs natively on Spark, making it ideal for large-scale data lakes on AWS.
For serving-time validation (inference requests), Pydantic is the gold standard. Its type-annotation-based validation is fast (microsecond-scale), integrates natively with FastAPI, and produces clear error messages. For DataFrame-level validation in feature pipelines, Pandera provides pandas-native schema enforcement.
Cost Note: Great Expectations is free and open source. Running validation on a daily pipeline processing 100 million rows on an AWS
r5.2xlargeinstance costs roughly 1,500/month (~INR 1.26 lakh/month).
import great_expectations as gx
# Initialize context
context = gx.get_context()
# Connect to data source
data_source = context.data_sources.add_pandas("my_data_source")
data_asset = data_source.add_dataframe_asset(name="training_data")
batch_definition = data_asset.add_batch_definition_whole_dataframe(
"full_batch"
)
# Create expectation suite
suite = context.suites.add(
gx.ExpectationSuite(name="ml_training_data_suite")
)
# Schema validations
suite.add_expectation(
gx.expectations.ExpectTableColumnsToMatchOrderedList(
column_list=["user_id", "age", "income", "city", "purchase_amount", "label"]
)
)
# Null checks
suite.add_expectation(
gx.expectations.ExpectColumnValuesToNotBeNull(
column="user_id"
)
)
suite.add_expectation(
gx.expectations.ExpectColumnValuesToNotBeNull(
column="label", mostly=0.99 # allow 1% nulls
)
)
# Range checks
suite.add_expectation(
gx.expectations.ExpectColumnValuesToBeBetween(
column="age", min_value=13, max_value=120
)
)
suite.add_expectation(
gx.expectations.ExpectColumnValuesToBeBetween(
column="income", min_value=0, max_value=50000000 # up to 5 crore INR
)
)
# Categorical checks
suite.add_expectation(
gx.expectations.ExpectColumnDistinctValuesToBeInSet(
column="city",
value_set=["Mumbai", "Delhi", "Bengaluru", "Chennai", "Hyderabad",
"Pune", "Kolkata", "Ahmedabad", "Jaipur", "Lucknow"]
)
)
# Uniqueness check
suite.add_expectation(
gx.expectations.ExpectColumnValuesToBeUnique(column="user_id")
)
# Run validation
import pandas as pd
df = pd.read_parquet("training_data.parquet")
batch = batch_definition.get_batch(batch_parameters={"dataframe": df})
validation_definition = context.validation_definitions.add(
gx.ValidationDefinition(
name="ml_training_validation",
data=batch_definition,
suite=suite
)
)
results = validation_definition.run()
print(f"Validation success: {results.success}")
for result in results.results:
if not result.success:
print(f" FAILED: {result.expectation_config.type}: {result.result}")This example demonstrates a complete Great Expectations validation workflow for ML training data. The suite includes schema validation (column order), null checks with tolerance (mostly=0.99 allows up to 1% nulls in the label column -- useful when some labels are legitimately missing), range checks appropriate for Indian demographics and income ranges, categorical value set enforcement for Indian cities, and uniqueness checks for identifiers. The mostly parameter is particularly important for ML: you rarely want zero tolerance on nulls because real-world data has legitimate gaps.
import pandera as pa
from pandera.typing import DataFrame, Series
import pandas as pd
import numpy as np
class TrainingDataSchema(pa.DataFrameModel):
"""Schema for ML training data with Indian e-commerce context."""
user_id: Series[str] = pa.Field(unique=True, nullable=False)
age: Series[int] = pa.Field(ge=13, le=120, nullable=False)
income: Series[float] = pa.Field(
ge=0, le=5e7, nullable=True, # income can be missing
description="Annual income in INR"
)
city: Series[str] = pa.Field(
isin=["Mumbai", "Delhi", "Bengaluru", "Chennai", "Hyderabad",
"Pune", "Kolkata", "Ahmedabad"],
nullable=False
)
purchase_amount: Series[float] = pa.Field(ge=0, nullable=False)
label: Series[int] = pa.Field(isin=[0, 1], nullable=False)
class Config:
strict = True # no extra columns allowed
coerce = True # attempt type coercion before validation
@pa.check("income", name="income_outlier_check")
def income_within_3_sigma(cls, series: Series[float]) -> Series[bool]:
"""Flag values beyond 3 standard deviations as invalid."""
mean = series.mean()
std = series.std()
return (series - mean).abs() <= 3 * std
@pa.dataframe_check
def label_distribution_check(cls, df: pd.DataFrame) -> bool:
"""Ensure label is not excessively imbalanced (>95:5)."""
label_ratio = df["label"].mean()
return 0.05 <= label_ratio <= 0.95
@pa.check_types
def train_model(data: DataFrame[TrainingDataSchema]) -> dict:
"""Function with automatic input validation via decorator."""
# Training logic here -- data is guaranteed to be valid
print(f"Training on {len(data)} validated records")
return {"status": "trained", "n_records": len(data)}
# Usage
df = pd.read_csv("training_data.csv")
try:
result = train_model(df) # validation happens automatically
except pa.errors.SchemaErrors as exc:
print(f"Validation failed with {len(exc.failure_cases)} errors")
print(exc.failure_cases.head(10))Pandera takes a code-first approach to validation using Python type annotations and class-based schemas. The @pa.check_types decorator automatically validates function arguments, making validation invisible to callers. The custom income_within_3_sigma check demonstrates how to embed statistical outlier detection directly in the schema. The label_distribution_check is a dataframe-level check that prevents severely imbalanced datasets from entering training -- a common issue that causes models to learn trivial solutions.
from pydantic import BaseModel, Field, field_validator, model_validator
from typing import Optional
from enum import Enum
import numpy as np
class City(str, Enum):
MUMBAI = "Mumbai"
DELHI = "Delhi"
BENGALURU = "Bengaluru"
CHENNAI = "Chennai"
HYDERABAD = "Hyderabad"
class PredictionRequest(BaseModel):
"""Validates inference requests before they reach the model."""
user_id: str = Field(..., min_length=1, max_length=64)
age: int = Field(..., ge=13, le=120)
income: Optional[float] = Field(None, ge=0, le=50_000_000)
city: City
purchase_amount: float = Field(..., ge=0, le=10_000_000)
@field_validator("user_id")
@classmethod
def user_id_alphanumeric(cls, v: str) -> str:
if not v.replace("-", "").replace("_", "").isalnum():
raise ValueError("user_id must be alphanumeric (hyphens/underscores allowed)")
return v
@model_validator(mode="after")
def purchase_income_sanity(self) -> "PredictionRequest":
"""Catch cases where purchase > income (likely data error)."""
if self.income is not None and self.purchase_amount > self.income:
raise ValueError(
f"purchase_amount ({self.purchase_amount}) exceeds "
f"income ({self.income}) -- likely a data error"
)
return self
class PredictionResponse(BaseModel):
prediction: int = Field(..., ge=0, le=1)
confidence: float = Field(..., ge=0.0, le=1.0)
validation_warnings: list[str] = []
# FastAPI integration
from fastapi import FastAPI, HTTPException
app = FastAPI()
@app.post("/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
warnings = []
# Soft validation: flag unusual but not invalid values
if request.age > 100:
warnings.append(f"Unusual age: {request.age}")
if request.income and request.income > 10_000_000:
warnings.append(f"High income: {request.income} INR")
# Model inference (placeholder)
prediction = 1
confidence = 0.87
return PredictionResponse(
prediction=prediction,
confidence=confidence,
validation_warnings=warnings
)Pydantic validation runs at the API boundary, catching malformed requests before they reach the model. The field_validator for user_id prevents injection attacks. The model_validator implements cross-field business logic (purchase cannot exceed income). Notice the distinction between hard validation (Pydantic raises a 422 error) and soft validation (warnings returned in the response for unusual-but-valid values). This pattern is common in production: you block clearly invalid data but flag edge cases for monitoring.
import tensorflow_data_validation as tfdv
import pandas as pd
# Generate statistics from training data
train_df = pd.read_csv("train.csv")
train_stats = tfdv.generate_statistics_from_dataframe(train_df)
# Infer schema from training statistics
schema = tfdv.infer_schema(statistics=train_stats)
# Customize schema constraints
tfdv.set_domain(
schema, "city",
tfdv.utils.schema_util.schema_pb2.StringDomain(
value=["Mumbai", "Delhi", "Bengaluru", "Chennai", "Hyderabad"]
)
)
tfdv.get_feature(schema, "user_id").not_null = (
tfdv.utils.schema_util.schema_pb2.FixedShape()
)
# Validate new serving data against the training schema
serving_df = pd.read_csv("serving_batch.csv")
serving_stats = tfdv.generate_statistics_from_dataframe(serving_df)
# Detect anomalies (schema violations + distribution skew)
anomalies = tfdv.validate_statistics(
statistics=serving_stats,
schema=schema,
previous_statistics=train_stats # enables drift detection
)
# Display results
tfdv.display_anomalies(anomalies)
# Programmatic access to anomaly results
if anomalies.anomaly_info:
for feature_name, anomaly in anomalies.anomaly_info.items():
print(f"Feature: {feature_name}")
print(f" Severity: {anomaly.severity}")
print(f" Description: {anomaly.description}")
print(f" Short description: {anomaly.short_description}")TFDV takes a unique approach: instead of manually writing expectations, it infers a schema from your training data and then validates new data against that schema. This catches not just constraint violations but also training-serving skew -- the subtle but devastating difference between what your model was trained on and what it sees in production. The previous_statistics parameter enables drift detection by comparing the serving batch's distributional statistics against the training baseline. TFDV is used at Google scale, validating petabytes of data daily across hundreds of ML pipelines.
import numpy as np
import pandas as pd
from scipy import stats
from sklearn.ensemble import IsolationForest
from typing import Tuple
def detect_outliers_zscore(
series: pd.Series, threshold: float = 3.0
) -> pd.Series:
"""Z-score based outlier detection. Simple but sensitive to outliers."""
z_scores = np.abs(stats.zscore(series.dropna()))
mask = pd.Series(False, index=series.index)
mask[series.dropna().index] = z_scores > threshold
return mask
def detect_outliers_iqr(
series: pd.Series, multiplier: float = 1.5
) -> pd.Series:
"""IQR-based outlier detection. More robust to existing outliers."""
Q1 = series.quantile(0.25)
Q3 = series.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - multiplier * IQR
upper_bound = Q3 + multiplier * IQR
return (series < lower_bound) | (series > upper_bound)
def detect_outliers_modified_zscore(
series: pd.Series, threshold: float = 3.5
) -> pd.Series:
"""Modified Z-score using median and MAD. Best for skewed distributions."""
median = series.median()
mad = np.median(np.abs(series - median)) # Median Absolute Deviation
modified_z = 0.6745 * (series - median) / (mad + 1e-10)
return np.abs(modified_z) > threshold
def detect_outliers_isolation_forest(
df: pd.DataFrame,
feature_columns: list,
contamination: float = 0.05
) -> pd.Series:
"""Isolation Forest for multivariate outlier detection."""
clf = IsolationForest(
contamination=contamination,
random_state=42,
n_estimators=100
)
features = df[feature_columns].dropna()
predictions = clf.fit_predict(features)
# IsolationForest returns -1 for outliers, 1 for inliers
mask = pd.Series(False, index=df.index)
mask[features.index] = predictions == -1
return mask
def comprehensive_outlier_report(
df: pd.DataFrame,
numeric_columns: list
) -> pd.DataFrame:
"""Generate a complete outlier report across multiple methods."""
results = []
for col in numeric_columns:
series = df[col].dropna()
n_total = len(series)
z_outliers = detect_outliers_zscore(series).sum()
iqr_outliers = detect_outliers_iqr(series).sum()
mz_outliers = detect_outliers_modified_zscore(series).sum()
results.append({
"column": col,
"n_records": n_total,
"z_score_outliers": z_outliers,
"z_score_pct": round(z_outliers / n_total * 100, 2),
"iqr_outliers": iqr_outliers,
"iqr_pct": round(iqr_outliers / n_total * 100, 2),
"modified_z_outliers": mz_outliers,
"modified_z_pct": round(mz_outliers / n_total * 100, 2)
})
return pd.DataFrame(results)
# Example usage with Indian e-commerce data
df = pd.DataFrame({
"order_value": [250, 300, 1500, 99999, 450, 200, 350, 175000, 600, 280],
"delivery_time_hrs": [2, 3, 48, 4, 5, 2, 72, 3, 6, 4],
"items_count": [1, 2, 3, 1, 5, 1, 2, 100, 3, 2]
})
report = comprehensive_outlier_report(
df, ["order_value", "delivery_time_hrs", "items_count"]
)
print(report.to_string(index=False))
# Multivariate outlier detection
if_outliers = detect_outliers_isolation_forest(
df, ["order_value", "delivery_time_hrs", "items_count"]
)
print(f"\nIsolation Forest flagged {if_outliers.sum()} multivariate outliers")This example implements four complementary outlier detection methods. Z-score is fast but assumes normality and is influenced by existing outliers. IQR is more robust because it uses the median-based interquartile range. Modified Z-score uses the Median Absolute Deviation (MAD) instead of standard deviation, making it ideal for skewed distributions common in e-commerce data (like order values in INR where most orders are small but a few are very large). Isolation Forest handles multivariate outliers -- records that are normal in each individual column but abnormal when columns are considered together (e.g., a delivery taking 72 hours for a nearby location).
# Great Expectations checkpoint config (YAML)
name: ml_training_checkpoint
validations:
- batch_request:
datasource_name: training_data_source
data_asset_name: daily_training_batch
expectation_suite_name: ml_training_data_suite
actions:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
- name: slack_notification
action:
class_name: SlackNotificationAction
slack_webhook: ${SLACK_WEBHOOK_URL}
notify_on: failure
renderer:
class_name: SlackRenderer
runtime_configuration:
result_format:
result_format: COMPLETE
include_unexpected_rows: true
partial_unexpected_count: 20Common Implementation Mistakes
- ●
Validating only at training time, not at serving time: If your training pipeline has schema checks but your inference API accepts raw JSON without validation, a client can send invalid data that produces silently wrong predictions. Always validate at both boundaries.
- ●
Using absolute thresholds for outlier detection on evolving data: Hardcoding
income > 10000000 is outlierbreaks when inflation or market conditions change. Use statistical methods (IQR, Z-score) relative to recent data distributions, and update reference profiles periodically. - ●
Treating all validation failures as hard blockers: Not every failed check should halt the pipeline. Schema violations and null-in-required-columns are hard failures. A minor shift in mean value might just warrant a warning. Design your system with severity levels: CRITICAL (halt), WARNING (alert), and INFO (log).
- ●
Not versioning your validation schemas alongside your model: When you retrain a model, the expected data distribution changes. If your validation suite still references the old distribution, you'll get false positives. Version schemas alongside model artifacts.
- ●
Writing validation rules that are too strict for production data: A test dataset might have zero nulls, but production data will always have some. Setting
expect_column_values_to_not_be_nullwithout amostlyparameter on real-world data will cause constant failures. Be realistic about data quality in production. - ●
Ignoring the cost of validation at scale: Running 500 expectations on a 1 billion row dataset takes non-trivial compute. Profile your validation suite's execution time and parallelize where possible. Great Expectations supports checkpoint-level parallelism; Deequ leverages Spark's distributed execution.
When Should You Use This?
Use When
You are building any ML pipeline that will run in production -- data validation is not optional, it's infrastructure
Your training data comes from multiple upstream sources (APIs, databases, third-party vendors) that you don't fully control
You need to detect training-serving skew before it degrades model performance
Regulatory or compliance requirements mandate data quality auditing (common in fintech, healthcare, and government ML applications in India -- think Aadhaar-linked systems or RBI-regulated models at Razorpay)
Your team is scaling beyond 2-3 ML models and needs standardized data quality practices across projects
You are implementing data contracts between data-producing microservices and data-consuming ML pipelines
Model debugging is difficult because you can't determine if poor predictions stem from bad data or bad model logic
Avoid When
You are running a quick experiment in a Jupyter notebook with a known, clean dataset -- adding full validation infrastructure adds overhead without benefit at this stage
Your data source is completely static and immutable (e.g., a published benchmark dataset like ImageNet or SQuAD) -- validate once, not repeatedly
The validation overhead exceeds the cost of occasional bad predictions in a low-stakes, non-production context
You are in the earliest prototype phase and the schema is changing daily -- wait until the schema stabilizes before investing in formal validation suites
Real-time latency requirements are extreme (<1ms per request) and even lightweight validation adds unacceptable overhead -- though this is rare; Pydantic validates in microseconds
Key Tradeoffs
Strictness vs. Availability
The core tradeoff in data validation is between data quality and pipeline availability. Strict validation catches more issues but also blocks more data, potentially starving your model of training examples or causing serving outages.
Consider a practical example: Swiggy processes millions of order events daily. If validation is too strict (rejecting any batch with a single null in any column), the recommendation model might not get updated for hours during a data pipeline hiccup. If validation is too loose (accepting anything that parses), corrupted data silently degrades recommendations.
The resolution is tiered validation:
| Tier | Check Type | Action on Failure | Example |
|---|---|---|---|
| Critical | Schema, required nulls | Hard block | Missing user_id column |
| Major | Range violations, type coercion failures | Block + alert | Age = -5, price in wrong currency |
| Minor | Outlier detection, distribution drift | Alert + log | Mean order value shifted 15% |
| Info | Freshness, row count variance | Log only | 5% fewer rows than yesterday |
Validation Cost vs. Coverage
More validation rules mean more compute and more maintenance. A suite of 500 expectations on a 100M row dataset can take 30-60 minutes to run. You need to balance coverage with execution time.
A reasonable target: validate 100% of schema and null constraints (cheap), sample-based statistical checks on 10% of data (moderate cost), and full distribution profiling on a daily cadence (expensive but infrequent).
Build vs. Buy
Open-source tools (Great Expectations, Pandera, TFDV) are free but require engineering investment for setup, maintenance, and integration. Managed solutions (Monte Carlo, Anomalo, Soda) cost $1,500-10,000/month (~INR 1.26-8.4 lakh/month) but provide out-of-the-box dashboards, ML-powered anomaly detection, and incident workflows. For a mid-stage Indian startup, the open-source path is typically more cost-effective; for a large enterprise like Flipkart or Jio, managed solutions can be justified by engineering time saved.
Alternatives & Comparisons
Data validation detects problems; data cleaning fixes them. Validation tells you 'this column has 15% nulls'; cleaning imputes those nulls with the median or drops the rows. In a pipeline, validation runs first (to decide if the data is usable at all), then cleaning runs on data that passed validation. They are complementary, not substitutes.
Drift detection is a specialized subset of data validation focused specifically on distribution shifts between training and serving data. Data validation is broader: it includes schema checks, null handling, and business rules that drift detection does not cover. Use standalone drift detection when you already have robust schema/constraint validation and need deeper statistical monitoring.
Data transformation reshapes data (normalization, encoding, aggregation) while data validation verifies data. Transformation changes data; validation inspects it without modification. A common anti-pattern is embedding implicit validation inside transformation logic (e.g., silently clipping outliers during normalization). Keep them separate for auditability.
Feature stores (Feast, Tecton) manage feature computation and serving, and some include built-in validation (schema enforcement, freshness checks). However, their validation is typically limited to the features they manage. Use a dedicated validation layer for raw data before it enters the feature store, and rely on the feature store's built-in checks for feature-level quality.
Pros, Cons & Tradeoffs
Advantages
Catches silent data bugs that would otherwise propagate through the pipeline and degrade model performance without any error or warning -- the single biggest risk in production ML
Enables confident pipeline automation: when validation gates are in place, you can safely automate retraining without a human manually inspecting every data batch
Creates a living documentation of data expectations that new team members can read to understand what the data should look like -- Great Expectations literally generates HTML data docs
Reduces debugging time dramatically: when model performance drops, the first question is 'did the data change?' -- validation history answers this immediately with timestamped reports
Supports regulatory compliance: in regulated industries (BFSI, healthcare), audit trails of data quality checks are often mandatory -- Razorpay and PhonePe-scale fintech systems need this
Enables data contracts between teams, creating clear ownership boundaries: the team that produces data is responsible for meeting the contract, the consuming team trusts validated data
Disadvantages
Adds pipeline latency and compute cost: running hundreds of expectations on large datasets takes time and resources -- on a tight training schedule, this overhead matters
Requires ongoing maintenance: as data schemas evolve, validation suites must be updated. Stale validation rules generate false positives that lead teams to ignore alerts (the 'alert fatigue' problem)
Can create a false sense of security: passing all validations does not guarantee data quality. Validation can only check for known failure modes; novel data issues will slip through until you add new rules
Initial setup cost is significant: defining comprehensive expectation suites for a new dataset takes 2-5 engineering days per data source, and the ROI isn't visible until the first bug is caught
Over-strict validation causes pipeline blockages: if thresholds are set too tight, pipelines halt on normal data variance, leading teams to either loosen checks excessively or bypass validation entirely
Failure Modes & Debugging
Alert Fatigue Leading to Ignored Warnings
Cause
Validation thresholds set too aggressively, causing frequent false-positive alerts. Over time, engineers start ignoring or auto-dismissing validation failures because most turn out to be noise. This is a classic 'cry wolf' failure pattern.
Symptoms
Slack channels full of unacknowledged validation alerts. Team members muting notification channels. Real data quality issues discovered days or weeks after they occurred, by the time model performance has already degraded.
Mitigation
Implement severity tiers (critical/major/minor/info) with different notification channels and escalation paths. Only page on-call for critical failures. Conduct monthly reviews of alert frequency and tune thresholds. Target fewer than 5 false-positive alerts per week.
Schema Drift Without Contract Enforcement
Cause
An upstream data producer (e.g., a backend API) adds, removes, or renames columns without coordinating with the ML team. Without formal data contracts, the ML pipeline silently receives data with a different schema than expected.
Symptoms
Columns suddenly become null, new unknown columns appear, type mismatches cause downstream errors. Often manifests as a spike in model prediction errors that correlates with an upstream deployment timestamp.
Mitigation
Implement data contracts with automated schema validation at the ingestion boundary. Use a schema registry (e.g., Confluent Schema Registry, or Great Expectations suites stored in version control) that both producer and consumer reference. Require contract review for any upstream schema change.
Validation Bypass in Emergency Deployments
Cause
During production incidents, engineers bypass validation gates to push data or models faster. 'We'll fix it later' becomes permanent. This is especially common during high-traffic events like Flipkart Big Billion Days or Diwali sales.
Symptoms
Validation is disabled or set to warn-only mode and never re-enabled. Unvalidated data enters the pipeline. Model quality degrades but isn't noticed until the emergency is over.
Mitigation
Design bypass mechanisms with automatic expiry (e.g., validation bypass token expires after 4 hours). Log all bypasses with the engineer's identity and justification. Run a post-incident review that includes re-enabling validation gates.
Outlier Detection Masking Legitimate Distribution Shifts
Cause
Outlier detection thresholds calibrated on old data flag legitimate new patterns as anomalies. For example, after a successful marketing campaign, a surge in new user sign-ups with different demographics is flagged as outliers and quarantined.
Symptoms
Valid data is quarantined or discarded. Model becomes stale because new data patterns are rejected. Business metrics improve (more users, more transactions) but the model doesn't reflect this growth.
Mitigation
Use adaptive reference profiles that are updated periodically (weekly or monthly) rather than fixed to the original training data. Implement a human review workflow for quarantined data before permanent deletion. Distinguish between 'anomalous' and 'novel' data.
Insufficient Serving-Time Validation
Cause
Team validates training data rigorously but neglects to validate inference requests. Malformed, adversarial, or out-of-distribution inputs reach the model at serving time.
Symptoms
Model returns confident but nonsensical predictions on malformed input. API doesn't return helpful error messages, just wrong results. In extreme cases, adversarial inputs can exploit model vulnerabilities.
Mitigation
Implement Pydantic validation on all inference endpoints. Add both hard validation (schema, type, range) and soft validation (outlier flags, distribution checks). Return structured error responses for invalid inputs. Log and monitor rejection rates.
Validation Suite Staleness After Model Retraining
Cause
Model is retrained on new data with different distributional characteristics, but the validation suite still references the old training data's profile. New data that matches the retrained model's expectations fails validation against the stale profile.
Symptoms
Validation failure rate spikes after model retraining. Pipeline blocks despite data being correct for the new model version. Engineers manually override validation to unblock the pipeline.
Mitigation
Version validation suites alongside model artifacts. When a new model is deployed, its corresponding validation profile should be deployed simultaneously. Automate profile regeneration as part of the retraining pipeline.
Placement in an ML System
The First Gate in the Pipeline
Data validation occupies the first quality gate in any ML pipeline. It sits directly after data ingestion (whether from a batch source like S3/GCS or a streaming source like Kafka) and before any data transformation, cleaning, or feature engineering.
The placement is deliberate: you want to catch bad data before you spend compute on transforming, cleaning, and training on it. Running an hour-long feature engineering pipeline on corrupted data is pure waste.
In a typical production setup at an Indian e-commerce company, the flow looks like this: raw clickstream and transaction data lands in S3 -> an Airflow DAG triggers Great Expectations validation -> if validation passes, data flows to the feature engineering pipeline -> computed features are validated again (using Pandera) before entering the feature store -> at serving time, Pydantic validates each inference request.
This defense-in-depth pattern -- validating at multiple pipeline stages with different tools optimized for each context -- is the standard architecture at companies operating at scale. Each validation layer catches different failure modes, and the cost of each layer is proportional to its specificity.
Key Insight: Data validation is not a single checkpoint; it's a series of gates throughout the pipeline. The raw data gate catches structural problems, the feature gate catches transformation bugs, and the serving gate catches request-level anomalies.
Pipeline Stage
Data Processing / Ingestion
Upstream
- batch-data-source
- streaming-data-source
- data-ingestion
Downstream
- data-cleaning
- data-transformation
- feature-engineering
- model-training
Scaling Bottlenecks
The primary bottleneck is compute cost for statistical profiling on large datasets. Computing exact quantiles, histograms, and distribution statistics on a 1 billion row dataset requires a full data scan. On a single machine, this can take hours; on Spark, it's manageable but still costs real money.
Some concrete numbers: running a Great Expectations suite with 50 expectations on 100 million rows (pandas on a 64 GB machine) takes approximately 8-15 minutes. The same suite on Deequ (Spark cluster with 10 executors) takes 3-5 minutes but costs more in cluster resources (~$2-4 per run, or INR 170-340).
For serving-time validation, the bottleneck is per-request latency. Pydantic validation adds ~50-200 microseconds per request, which is negligible. However, if you add statistical outlier checks (e.g., comparing each request against a stored distribution), latency can increase to 1-5 milliseconds -- significant at high QPS.
The scaling strategy is clear: run expensive statistical checks asynchronously on batches, and keep synchronous per-request validation lightweight (schema + range checks only).
Production Case Studies
Google developed TensorFlow Data Validation (TFDV) as part of the TFX platform to address the challenge of validating data in continuous ML pipelines at massive scale. The system automatically infers schemas from training data and detects anomalies in new data by comparing statistical properties against the learned schema. TFDV is deployed across hundreds of product teams at Google, validating several petabytes of data per day across trillions of training and serving examples.
TFDV catches training-serving skew, feature drift, and schema violations before they reach models. Google reports that automated data validation prevented numerous production incidents that would have degraded model quality across Search, Ads, and YouTube recommendation systems.
Amazon developed Deequ, an open-source library built on Apache Spark, for defining 'unit tests for data' in ML pipelines. The system computes data quality metrics (completeness, uniqueness, distribution statistics), verifies user-defined constraints, and automatically suggests constraints by profiling data. Deequ is used internally at Amazon to validate data feeding into product recommendation, fraud detection, and supply chain optimization models.
Deequ enabled Amazon to scale data quality verification across thousands of datasets and ML pipelines. The automated constraint suggestion feature reduced the effort needed to bootstrap validation suites for new datasets from days to minutes, as described in the VLDB 2018 paper.
Netflix implemented a multi-layered data validation system that includes circuit breakers (functioning as unit tests for data), data canaries (deploying new data to a small subset before full rollout), and staggered rollout techniques for data pipeline changes. Their approach treats data validation as a production reliability practice, not just a quality metric. Netflix's RAD (Robust Anomaly Detection) system uses Robust Principal Component Analysis (RPCA) to detect anomalies in payment and signup data streams.
Netflix's data validation infrastructure helps maintain reliable ML-powered personalization for 250M+ subscribers globally. The circuit breaker pattern prevents bad data from propagating to downstream ML models, while data canaries catch issues during gradual rollouts before they affect all users.
Uber built a comprehensive data quality platform that predefines validation rules (tests) and executes them periodically across their massive data estate. Their test-expression model allows the execution engine to handle a limitless number of assertions with flexibility in adding new test types. Uber also developed the Model Excellence Scores (MES) framework that includes data quality as a core dimension of ML model quality, measuring and monitoring data health across each stage of the ML lifecycle.
Uber achieved operational excellence in data quality by standardizing validation across their data platform, enabling hundreds of ML models (pricing, ETA prediction, fraud detection, driver matching) to operate reliably on validated data.
Tooling & Ecosystem
The most widely adopted open-source data validation framework. Provides a declarative API for defining expectations (validation rules), generates human-readable data documentation, integrates with Airflow, Dagster, Spark, and cloud storage. Supports 300+ built-in expectation types covering schema, null, range, distribution, and custom checks. Best for batch validation in data pipelines.
DataFrame validation library that uses Python type annotations and class-based schemas. Supports pandas, Polars, Dask, and Modin DataFrames. Provides decorators for automatic function input/output validation and custom statistical checks. Ideal for ML engineers who want validation tightly integrated with Python code. Published as a SciPy proceedings paper.
Google's data validation library within the TFX ecosystem. Automatically infers schemas from data statistics, detects anomalies by comparing new data against the schema, and identifies training-serving skew and distribution drift. Scales to petabytes using Apache Beam. Best for TensorFlow-based ML pipelines with strong schema inference needs.
Python data validation library using type annotations. Extremely fast (Rust-powered core in v2), integrates natively with FastAPI for API validation. Best for serving-time validation of inference requests. Supports custom validators, nested models, and serialization. The de facto standard for runtime data validation in Python microservices.
Amazon's data quality library built on Apache Spark. Provides declarative constraint verification, automated constraint suggestion via data profiling, and incremental metrics computation. Best for large-scale data lake validation on AWS. Python wrapper available via PyDeequ.
Holistic ML validation library that covers data integrity, distribution checks, and model performance in a single framework. Provides pre-built test suites for tabular, NLP, and vision data. Generates visual HTML reports. Useful for research-to-production validation covering both data and model quality.
Data quality testing framework that uses a YAML-based configuration language (SodaCL) for defining checks. Connects directly to databases and warehouses (BigQuery, Snowflake, Postgres, Redshift) without requiring data extraction. Good for data engineers validating data in-place without moving it to Python.
Lightweight, dependency-free Python data validation library for dictionaries and JSON documents. Supports custom validation rules and type coercion. Best for validating configuration files, API payloads, and simple data structures where Pydantic's type-annotation approach is overkill.
Research & References
Breck, Polyzotis, Roy, Whang, Zinkevich (2019)MLSys 2019
The foundational paper on automated data validation for ML. Describes Google's system for detecting data anomalies at scale, including schema inference, feature drift detection, and training-serving skew identification. Directly led to the development of TFDV.
Caveness, Smith, Chung, Polyzotis, Zinkevich (2020)ACM SIGMOD 2020
Describes the production implementation of TFDV at Google, validating several petabytes of data per day across hundreds of ML pipelines. Covers scalable statistics computation, automatic schema inference, and anomaly detection for continuous pipelines.
Schelter, Lange, Schmidt, Celikel, Biessmann, Grafberger (2018)VLDB 2018
Introduces Amazon's Deequ system for declarative, scalable data quality verification. Proposes the concept of 'unit tests for data' -- composable quality constraints verified on Apache Spark. Includes automated constraint suggestion via data profiling.
Various (2024)arXiv preprint
Comprehensive survey tracing the evolution of data quality management from traditional databases to modern ML systems. Covers data profiling, validation, cleaning, and monitoring with emphasis on how ML introduces new quality challenges like distribution drift and feature store consistency.
Niels Bantilan et al. (2022)SciPy Proceedings
Describes the design and implementation of Pandera, a statistical data validation toolkit. Covers the type-annotation-based schema definition approach, integration with multiple DataFrame backends (pandas, Polars, Dask), and the hypothesis testing framework for statistical validation.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a data validation system for an ML pipeline that processes 100 million records daily?
- ●
What is the difference between schema validation, constraint validation, and statistical validation? When do you use each?
- ●
How do you handle data validation for streaming ML pipelines versus batch pipelines?
- ●
Describe how you would implement data contracts between a backend engineering team and an ML team.
- ●
How would you detect and handle training-serving skew using data validation?
- ●
What outlier detection method would you use for highly skewed numerical features like transaction amounts?
- ●
How do you avoid alert fatigue when running hundreds of data quality checks in production?
Key Points to Mention
- ●
Data validation operates in three layers: schema (structural), constraint (value-level), and statistical (distribution-level). Each catches a different class of bug. Always mention all three to show breadth.
- ●
Use Great Expectations or Deequ for batch validation, Pandera for DataFrame-level validation in feature pipelines, and Pydantic for serving-time request validation. Knowing which tool fits which context demonstrates practical experience.
- ●
Training-serving skew is the most dangerous data quality issue in ML systems because it's invisible at training time. Use TFDV's schema-plus-statistics approach or compute PSI between training and serving distributions to detect it.
- ●
Design validation with severity tiers (critical/major/minor/info) to avoid alert fatigue. Only hard-block the pipeline on critical failures; alert-and-log for minor issues.
- ●
For outlier detection on skewed distributions (common in financial data), prefer IQR or Modified Z-score over standard Z-score, because Z-score assumes normality and is sensitive to existing outliers.
- ●
Data contracts formalize the agreement between data producers and consumers, turning data quality from an informal expectation into an enforceable engineering contract.
Pitfalls to Avoid
- ●
Saying 'I would check if the data looks right' without specifying concrete validation strategies, tools, or metrics. Be specific: name the tools, the check types, and the thresholds.
- ●
Ignoring serving-time validation entirely and only discussing training data quality. Production ML systems need validation at both boundaries.
- ●
Conflating data validation with data cleaning -- they are different pipeline stages with different responsibilities. Validation detects; cleaning fixes.
- ●
Proposing to manually inspect data quality rather than automating checks. At scale (millions of records), manual inspection is impossible.
- ●
Not discussing the cost-performance tradeoff of validation: more checks = better coverage but higher latency and compute cost. Senior candidates should articulate how they'd balance this.
Senior-Level Expectation
A senior/staff candidate should discuss the full validation architecture: multi-layer checks (schema, constraint, statistical) with severity-based routing, data contracts between teams with schema registries, automated profile regeneration tied to model retraining, integration with CI/CD (validation as a pipeline gate in Airflow/Dagster), monitoring dashboards tracking DQ metrics over time, and cost-performance optimization (sampling strategies for expensive statistical checks, async profiling for streaming pipelines). They should also discuss organizational challenges: getting upstream teams to adopt data contracts, managing alert fatigue across dozens of pipelines, and building a culture where data quality is a shared responsibility rather than an afterthought. Bonus points for discussing how data validation interacts with feature stores, experiment tracking, and model monitoring to form a holistic MLOps platform.
Summary
Data validation is the immune system of your ML pipeline. Without it, corrupted data enters silently, degrades predictions gradually, and causes failures that are extraordinarily difficult to diagnose after the fact. With it, you catch schema breaks, null spikes, range violations, and distribution drift at the pipeline boundary -- before they can propagate downstream.
The practice operates in three layers: schema validation catches structural problems (wrong columns, wrong types), constraint validation catches value-level issues (out-of-range values, excessive nulls, uniqueness violations), and statistical validation catches distributional anomalies (outliers, drift, training-serving skew). Each layer uses different tools: Great Expectations and Deequ for batch pipeline validation, Pandera for DataFrame-level enforcement in Python, Pydantic for serving-time request validation, and TFDV for automated schema inference and skew detection.
The field has matured from ad-hoc assertions in notebooks to formalized data contracts between producer and consumer teams, with automated validation suites versioned alongside model artifacts. The key engineering challenge is balancing thoroughness with availability -- overly strict validation blocks the pipeline on normal data variance, while overly loose validation lets bad data through. The solution is tiered severity levels (critical/major/minor/info) with appropriate routing: hard-block on critical schema failures, alert on statistical anomalies, and log informational drift metrics for trend analysis. Whether you're validating Aadhaar-linked data at a government agency, transaction streams at Razorpay, or clickstream data at Flipkart, robust data validation is not a nice-to-have -- it's the foundation upon which reliable ML systems are built.