CTGAN in Machine Learning
CTGAN (Conditional Tabular GAN) is a deep generative model specifically designed for synthesizing realistic tabular data. Introduced by Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni at NeurIPS 2019, CTGAN addresses the fundamental mismatch between standard GAN architectures (built for continuous, image-like data) and the unique structure of tabular datasets -- where columns mix continuous values, categorical labels, and ordinal types, and where distributions are often multimodal, heavily skewed, or severely imbalanced.
The key insight behind CTGAN is threefold. First, mode-specific normalization transforms each continuous column by fitting a Variational Gaussian Mixture Model (VGM), converting multimodal distributions into a representation the generator can actually learn. Second, a conditional generator conditions on discrete column values, enabling the model to produce rows for any category -- even rare ones. Third, training-by-sampling rebalances the training process by sampling discrete column values proportional to their log-frequency, ensuring minority categories receive adequate gradient signal.
Before CTGAN, attempts to apply GANs to structured data consistently failed. Standard GANs would generate continuous columns that clustered around a single mode, ignore rare categorical values entirely, and produce columns with impossible combinations (negative ages, incomes below zero). CTGAN solved these problems systematically and became the first deep generative model to outperform classical Bayesian network approaches on real-world tabular benchmarks.
Today, CTGAN powers the Synthetic Data Vault (SDV) library -- the most widely adopted open-source framework for tabular synthetic data. It is used across industries from healthcare (generating privacy-preserving patient records at AIIMS-style institutions) to fintech (synthesizing transaction data for fraud detection models at companies like Razorpay and PhonePe) to e-commerce (augmenting sparse user-behaviour datasets at Flipkart and Swiggy). Whether you need to share sensitive data without privacy risk, augment imbalanced training sets, or create realistic test fixtures for CI/CD pipelines, CTGAN is the go-to solution for structured data synthesis.
Concept Snapshot
- What It Is
- A GAN architecture purpose-built for tabular data that uses mode-specific normalization, conditional generation, and training-by-sampling to produce high-fidelity synthetic rows preserving the statistical properties of the original dataset.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: real tabular dataset (CSV/DataFrame) with mixed continuous and discrete columns + column metadata. Outputs: synthetic tabular dataset of arbitrary size matching the original data's statistical distribution, column correlations, and category frequencies.
- System Placement
- Sits in the data generation and preprocessing stage of ML pipelines -- upstream of feature engineering, model training, and evaluation. Also used standalone for privacy-preserving data sharing and test data generation.
- Also Known As
- Conditional Tabular GAN, CTGAN, Tabular GAN, SDV CTGAN Synthesizer
- Typical Users
- Data Scientists, ML Engineers, Privacy Engineers, Data Engineers, MLOps Engineers, Compliance Officers
- Prerequisites
- Basic understanding of GANs (generator-discriminator framework), Tabular data concepts (categorical vs continuous columns), Gaussian Mixture Models (conceptual understanding), Python and pandas DataFrames, Basic probability distributions
- Key Terms
- mode-specific normalizationVariational Gaussian Mixture (VGM)conditional vectortraining-by-samplingconditional generatorPacGANWasserstein distancesynthetic data fidelitystatistical similarity
Why This Concept Exists
The Tabular Data Problem
GANs revolutionized synthetic data generation for images starting with DCGAN in 2015, and by 2018 StyleGAN was generating photorealistic faces indistinguishable from real photographs. But when researchers tried to apply the same techniques to tabular data -- the bread and butter of enterprise ML -- the results were disastrous.
The problem is structural. Image pixels are homogeneous: every value is a continuous number between 0 and 255, and neighboring pixels are spatially correlated. Tabular data is fundamentally different. A single row might contain a person's age (continuous, roughly Gaussian), their city (categorical, 500+ values), their income (continuous, heavily right-skewed with multiple modes), and their employment status (binary). No single normalization scheme handles all of these simultaneously.
Standard GANs assumed input features followed roughly Gaussian distributions and used min-max normalization to map values to [-1, 1]. This worked fine for image pixels but destroyed the structure of tabular data. A column like "income" with two modes (salaried employees around ₹6-8 LPA and business owners around ₹25-40 LPA) would be squashed into a unimodal blob, losing the bimodal structure entirely. Categorical columns with 50+ categories were encoded as one-hot vectors so sparse that the generator simply learned to always predict the majority class.
Previous Attempts and Their Limitations
Before CTGAN, several approaches attempted to adapt GANs for tabular data:
- TableGAN (Park et al., 2018) used convolutional architectures borrowed from image GANs, treating each row as a 1D "image." It improved over naive GAN application but still struggled with multimodal continuous columns and rare categories.
- MedGAN (Choi et al., 2017) focused on medical records, using an autoencoder to learn a latent representation before applying GAN training. It worked for binary features but failed on mixed-type datasets.
- Bayesian Networks and copula-based methods handled mixed types naturally but couldn't capture complex nonlinear relationships between columns -- they were limited to pairwise or low-order statistical dependencies.
The gap was clear: the ML community needed a GAN architecture that was tabular-native, designed from the ground up to handle mixed types, multimodal distributions, and class imbalance.
CTGAN's Three Innovations
Xu et al. (2019) identified three specific challenges and proposed targeted solutions:
-
Non-Gaussian multimodal distributions in continuous columns: Solved by mode-specific normalization using Variational Gaussian Mixture Models (VGMs). Each continuous value is represented as a (mode indicator, normalized value) pair, letting the generator learn each mode independently.
-
Imbalanced categorical columns: Solved by conditional generation with a conditional vector that specifies which category to generate, combined with training-by-sampling that ensures all categories receive proportional training signal regardless of their frequency in the data.
-
Complex inter-column dependencies: Addressed through a fully connected generator and discriminator (not convolutional) with residual connections and batch normalization, allowing the model to learn arbitrary nonlinear relationships between columns.
The resulting model, CTGAN, was evaluated on 8 real-world datasets spanning census data, credit card applications, insurance claims, and more. It outperformed all existing deep learning methods and most Bayesian approaches, establishing a new state of the art for tabular synthesis.
Indian Context: The need for synthetic tabular data is particularly acute in India's regulated industries. RBI's data localization requirements, DPDPA (Digital Personal Data Protection Act, 2023) privacy mandates, and IRDAI's data sharing guidelines all create scenarios where organizations need realistic but non-identifiable data for cross-team collaboration, vendor testing, and model development. CTGAN provides a principled solution that preserves statistical utility while breaking the link to real individuals.
Core Intuition & Mental Model
Teaching a Generator to Speak Tabular
Imagine you're training an artist to forge census forms. Each form has fields like age, income, occupation, and city. A standard GAN approach would hand the artist a stack of real forms and say "learn to produce convincing fakes." The artist would quickly discover that most people are aged 25-45, most incomes cluster around the median, and most people live in a few major cities. So the artist produces forms that look plausible on average -- but they're all boringly similar. Every form has a 35-year-old earning ₹7 LPA living in Mumbai. The rare 72-year-old retired professor in Dharwad earning ₹15 LPA from pension and consulting? The artist never learns to produce such forms.
CTGAN fixes this with three complementary tricks:
Trick 1: Mode-Specific Normalization (Teaching the Artist About Multimodality). Before training, CTGAN looks at each continuous column and asks: "How many clusters does this data have?" For income, it might find three modes: students/entry-level (₹0-3 LPA), mid-career salaried (₹6-15 LPA), and high-earners/business owners (₹25+ LPA). Instead of asking the generator to learn one blurry income distribution, CTGAN says: "First decide which income mode you're generating, then decide where within that mode the value falls." The generator outputs a one-hot vector (which mode?) plus a scalar (where in the mode?). This decomposition makes it dramatically easier to learn complex distributions -- the generator handles one simple Gaussian at a time rather than a complex multimodal mixture.
Trick 2: Conditional Generation (Making Sure Every Category Gets Its Turn). In a standard GAN, the generator never learns to produce rare categories because they barely appear in training batches. CTGAN flips this: each training step, we first pick a random discrete column and a random value within it, then condition the generator on that choice. If "occupation = professor" only appears in 2% of the data, it still gets picked as the conditioning value regularly. The generator must learn to produce realistic rows for professors, not just engineers and accountants.
Trick 3: Training-by-Sampling (Rebalancing the Training Diet). Even with conditional generation, the discriminator would still see mostly majority-class rows from the real data. Training-by-sampling fixes this by sampling real training rows to match the conditional vector. When the condition says "occupation = professor," the real training sample is also drawn from professor rows. This keeps the discriminator calibrated across all categories, not just common ones.
Why This Matters in Practice
The beauty of these three tricks is that they're complementary. Mode-specific normalization handles the continuous columns. Conditional generation and training-by-sampling handle the discrete columns. Together, they let CTGAN generate rows where age, income, occupation, and city all make sense together -- a 72-year-old professor in a small city with a moderate pension income, not a random combination of individually plausible but jointly impossible values.
Mental Model: Think of CTGAN as a "guided tour" through your data's distribution. Standard GANs wander randomly and spend most of their time in the crowded tourist spots (majority classes, common value ranges). CTGAN's conditional vector acts as a tour guide that ensures every neighborhood of the data space gets visited, while mode-specific normalization provides a detailed map of each neighborhood's internal structure.
Technical Foundations
Data Representation
Let a tabular dataset have continuous columns and discrete columns. For each continuous column , CTGAN fits a Variational Gaussian Mixture Model (VGM) with modes:
where are the mixture weights, and are the mean and standard deviation of each Gaussian component. Each continuous value in row is transformed into:
- A mode indicator : a one-hot vector of length indicating which Gaussian mode belongs to
- A normalized scalar where is the most likely mode
Each discrete column with unique categories is represented as a one-hot encoded vector of length .
The full row representation becomes: .
Conditional Vector
During training, a conditional vector is constructed by:
- Randomly selecting a discrete column
- Randomly selecting a category within according to log-frequency: where is the frequency of category
- Creating a mask vector with 1 at position and 0 elsewhere, concatenated across all discrete columns:
Generator
The generator takes a noise vector and the conditional vector as input:
The generator architecture uses two fully connected hidden layers with residual connections:
For output activations:
- Continuous scalar : tanh activation (values in [-1, 1])
- Mode indicator : gumbel-softmax (differentiable approximation to argmax)
- Discrete columns : gumbel-softmax
Discriminator
The discriminator evaluates row authenticity using PacGAN (Lin et al., 2018), which packs multiple samples together to prevent mode collapse:
where (typically 10) rows are concatenated and evaluated jointly. This forces the generator to produce diverse samples rather than repeating a single convincing row.
Training Objective
CTGAN uses the WGAN with gradient penalty loss:
where , , and .
Additionally, a conditional loss penalizes the generator if the generated row does not match the conditioning:
This cross-entropy loss ensures the generator respects the conditional vector -- when conditioned on "occupation = professor," the generated row must actually have that occupation value.
Training-by-Sampling
For each training step:
- Sample a conditional vector (random column, random category weighted by log-frequency)
- Sample a real row from the training data that matches the condition (e.g., where occupation = professor)
- Generate a fake row
- Update discriminator with
- Update generator to fool discriminator and satisfy conditional loss
This log-frequency sampling ensures rare categories appear times during training rather than , dramatically improving coverage of minority classes.
Internal Architecture
CTGAN's architecture wraps a standard GAN framework with three tabular-specific preprocessing and training mechanisms. The overall system has four major stages: data transformation (VGM fitting and mode-specific normalization), conditional vector construction (category selection and mask creation), adversarial training (generator and discriminator updates with conditional loss), and inverse transformation (converting generated representations back to original data types).
The generator is a fully connected neural network with residual connections -- not convolutional, since tabular columns have no spatial relationship. It takes concatenated noise and conditional vectors as input and produces a structured output where each segment corresponds to a column's representation (scalar + mode indicator for continuous, one-hot for discrete). The discriminator uses PacGAN architecture, evaluating multiple packed samples simultaneously to detect mode collapse.
The training loop implements the training-by-sampling strategy: each minibatch is constructed by first choosing a conditioning category, then sampling matching real rows and generating conditioned fake rows. This ensures balanced exposure to all categories regardless of their frequency in the original data.
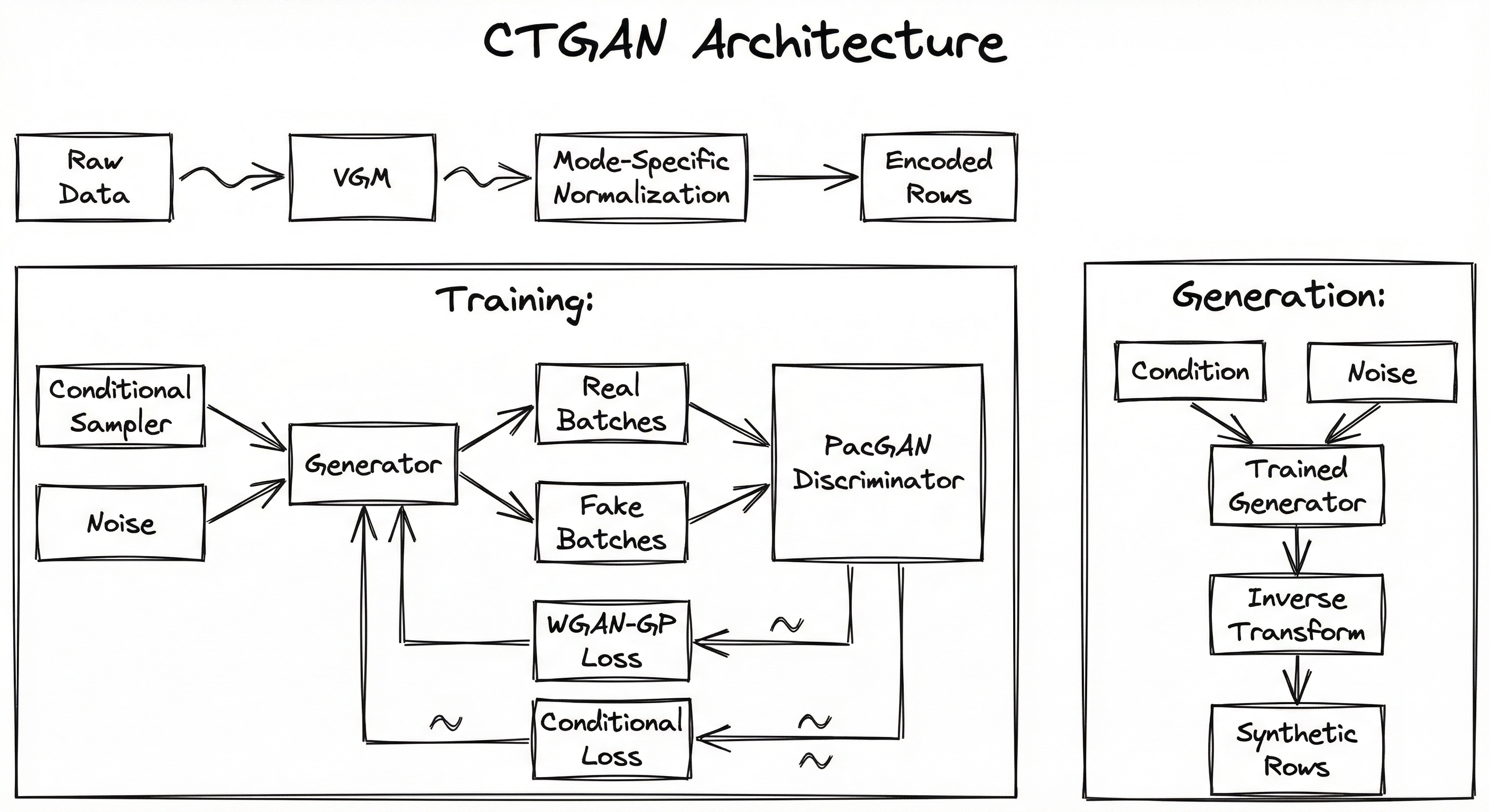
Key Components
Variational Gaussian Mixture Model (VGM)
Fitted independently to each continuous column to discover its mode structure. Uses a Bayesian GMM with a Dirichlet process prior to automatically determine the number of modes . Each value is then decomposed into a mode indicator (which cluster?) and a normalized scalar (where within the cluster?). This is the core of mode-specific normalization and is what allows CTGAN to handle multimodal distributions like income or age.
Mode-Specific Normalization Layer
Transforms raw continuous values into (mode indicator, normalized scalar) pairs using the fitted VGM parameters. The normalized scalar is clipped to [-1, 1] and passed through tanh in the generator output. This decomposition converts a complex multimodal learning problem into multiple simple unimodal problems, dramatically improving generator convergence.
Conditional Vector Constructor
At each training step, randomly selects a discrete column and a category value within it (weighted by log-frequency) to form the conditioning signal. The conditional vector is a concatenation of mask vectors across all discrete columns, with exactly one non-zero entry indicating the target category. This is concatenated with the noise vector as generator input.
Generator Network
A fully connected neural network (default: two hidden layers of 256 units each) with batch normalization and ReLU activations. Uses residual connections -- the output of each hidden layer is added to the input of the next, improving gradient flow. The output layer applies tanh for continuous scalars, gumbel-softmax for mode indicators and discrete columns. Takes as input and produces the full encoded row vector.
PacGAN Discriminator
A fully connected discriminator (default: two hidden layers of 256 units each) that evaluates packs of multiple samples (default pac=10) simultaneously rather than individual rows. By seeing multiple samples at once, the discriminator can detect lack of diversity (mode collapse) -- if all 10 packed samples are suspiciously similar, the discriminator can reject them even if each individually looks realistic. Uses dropout and LeakyReLU activations.
Training-by-Sampling Module
Orchestrates the training loop by coupling real data sampling with the conditional vector. When the conditional vector specifies category of column , this module draws the real training batch exclusively from rows where . This ensures the discriminator compares like with like -- it sees real professors against fake professors, not real samples from all categories against fakes conditioned on professors.
Inverse Transformation
At generation time, converts the generator's encoded output back to original data types. For continuous columns, it selects the mode with highest probability from the mode indicator, then denormalizes the scalar: . For discrete columns, it takes argmax of the softmax output to recover the categorical value. Handles rounding for integer columns and clipping for bounded values.
Data Flow
Data Transformation Phase:
-
VGM Fitting: For each continuous column, fit a Bayesian GMM to discover modes. Store for each mode . Typical columns have 2-10 modes.
-
Row Encoding: Transform each training row into its encoded representation: continuous columns become pairs, discrete columns become one-hot vectors. The encoded row length is .
Training Phase (per iteration):
-
Conditional Sampling: Randomly pick a discrete column and a category with probability . Construct the conditional vector .
-
Real Data Sampling: From the encoded training data, sample a batch of rows where . This is the "training-by-sampling" step.
-
Fake Data Generation: Sample noise , concatenate with , pass through generator to get fake encoded rows.
-
Discriminator Update: Pack real and fake rows into groups of . Compute WGAN-GP loss and update discriminator.
-
Generator Update: Compute WGAN loss (fool discriminator) + conditional cross-entropy loss (match conditioning). Update generator.
-
Repeat for the configured number of epochs (default 300).
Generation Phase:
- Optionally specify conditioning (e.g., "generate rows where city=Bangalore") or sample conditions from the learned distribution.
- Sample , concatenate with , generate encoded row.
- Apply inverse transformation to recover original data types and scales.
- Output synthetic DataFrame.
Key Detail: The generator never directly sees raw data values. It only interacts with the encoded representation, and the VGM parameters act as a fixed bridge between raw and encoded spaces.
A three-stage flowchart. The Preprocessing stage shows raw tabular data flowing through VGM fitting and mode-specific normalization to produce encoded row vectors. The Training stage shows the training-by-sampling loop: a conditional vector sampler feeds into both the generator (along with noise) and the real data sampler. The generator produces fake batches and the sampler produces matched real batches, both feeding into a PacGAN discriminator. WGAN-GP loss and conditional loss jointly update the generator and discriminator. The Generation stage shows how a trained generator takes new noise and conditions to produce synthetic encoded rows, which are inverse-transformed back into synthetic tabular rows.
How to Implement
Implementation Approaches
There are three main paths to implementing CTGAN in production:
Approach 1: SDV Library (Recommended). The Synthetic Data Vault (SDV) library provides CTGANSynthesizer as a high-level API with built-in metadata detection, data preprocessing, quality evaluation, and constraint enforcement. This is the canonical implementation maintained by DataCebo (the company founded by CTGAN's creators). It handles VGM fitting, conditional vector construction, and inverse transformation automatically. Best for most production use cases.
Approach 2: CTGAN Standalone Library. The ctgan PyPI package provides the core CTGAN algorithm without SDV's higher-level features. Use this when you need fine-grained control over hyperparameters or want to integrate CTGAN into a custom pipeline. It exposes the raw CTGAN class with fit() and sample() methods.
Approach 3: Custom Implementation. For research or highly specialized use cases, implement CTGAN from scratch in PyTorch. This requires manually implementing VGM fitting (use sklearn.mixture.BayesianGaussianMixture), conditional vector construction, training-by-sampling, PacGAN, and inverse transformation. Only recommended if you need to modify the core algorithm (e.g., adding differential privacy, changing the generator architecture).
Production Considerations
CTGAN training is GPU-accelerated but not as compute-intensive as image GANs. A dataset with 100K rows and 20 columns typically trains in 5-15 minutes on a single GPU. Key hyperparameters to tune:
- epochs (default 300): More epochs improve quality but risk overfitting. Monitor discriminator loss for convergence.
- batch_size (default 500): Larger batches stabilize training but require more memory.
- generator_dim / discriminator_dim (default (256, 256)): Network capacity. Increase for high-dimensional data (50+ columns).
- discriminator_steps (default 1): Number of discriminator updates per generator update.
- pac (default 10): PacGAN pack size. Higher values catch more mode collapse but increase memory.
Cost Note: Training CTGAN on a 100K-row, 30-column dataset for 300 epochs takes
10 minutes on a single T4 GPU (₹8 / 1.20). This is orders of magnitude cheaper than image GANs.
import pandas as pd
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import SingleTableMetadata
from sdv.evaluation.single_table import evaluate_quality, run_diagnostic
# 1. Load and inspect real data
real_data = pd.read_csv('customer_transactions.csv')
print(f"Real data shape: {real_data.shape}")
print(real_data.dtypes)
# 2. Define metadata (auto-detect + manual overrides)
metadata = SingleTableMetadata()
metadata.detect_from_dataframe(real_data)
# Override detected types for accuracy
metadata.update_column('customer_id', sdtype='id')
metadata.update_column('age', sdtype='numerical',
computer_representation='Int64')
metadata.update_column('annual_income', sdtype='numerical',
computer_representation='Float')
metadata.update_column('city', sdtype='categorical')
metadata.update_column('transaction_date', sdtype='datetime',
datetime_format='%Y-%m-%d')
metadata.update_column('is_fraud', sdtype='boolean')
metadata.set_primary_key('customer_id')
# 3. Initialize CTGAN synthesizer with tuned hyperparameters
synthesizer = CTGANSynthesizer(
metadata,
epochs=500,
batch_size=500,
generator_dim=(256, 256),
discriminator_dim=(256, 256),
generator_lr=2e-4,
discriminator_lr=2e-4,
discriminator_steps=1,
log_frequency=True, # Use log-frequency for training-by-sampling
verbose=True,
cuda=True # Use GPU if available
)
# 4. Train the model
print("Training CTGAN...")
synthesizer.fit(real_data)
# 5. Generate synthetic data
synthetic_data = synthesizer.sample(num_rows=50000)
print(f"Generated {len(synthetic_data)} synthetic rows")
# 6. Evaluate quality
quality_report = evaluate_quality(
real_data, synthetic_data, metadata
)
print(f"\nOverall Quality Score: {quality_report.get_score():.4f}")
# Column shape similarity (marginal distributions)
shape_details = quality_report.get_details(
property_name='Column Shapes'
)
print("\nColumn Shape Scores:")
print(shape_details.to_string())
# Column pair correlations (bivariate relationships)
pair_details = quality_report.get_details(
property_name='Column Pair Trends'
)
print("\nColumn Pair Trend Scores:")
print(pair_details.head(10).to_string())
# 7. Run diagnostic checks
diagnostic = run_diagnostic(
real_data, synthetic_data, metadata
)
print(f"\nDiagnostic Score: {diagnostic.get_score():.4f}")
# 8. Save model for reproducibility
synthesizer.save('models/ctgan_transactions_v1.pkl')
# 9. Later: reload and generate more data
loaded_synth = CTGANSynthesizer.load('models/ctgan_transactions_v1.pkl')
more_data = loaded_synth.sample(num_rows=10000)This is the recommended production workflow using SDV's CTGANSynthesizer. Key points:
- Metadata specification is critical -- CTGAN needs to know which columns are numerical vs categorical vs datetime to apply the correct preprocessing (VGM for continuous, one-hot for discrete)
log_frequency=Trueenables training-by-sampling with log-frequency weighting, the default recommended setting- Quality evaluation via
evaluate_qualitycomputes Column Shapes (marginal distribution similarity using KS-test) and Column Pair Trends (pairwise correlation preservation) - Diagnostic checks via
run_diagnosticcatch issues like data validity (are generated values in valid ranges?) and structure (does the synthetic data have the right schema?) - Model persistence lets you save a trained CTGAN and generate data later without retraining
from ctgan import CTGAN
import pandas as pd
import numpy as np
# Load data
data = pd.read_csv('loan_applications.csv')
# Define discrete columns explicitly
# (CTGAN needs to know which columns are categorical)
discrete_columns = [
'employment_type',
'loan_purpose',
'education_level',
'marital_status',
'default_flag'
]
# Initialize CTGAN with custom hyperparameters
model = CTGAN(
epochs=300,
batch_size=500,
generator_dim=(256, 256),
discriminator_dim=(256, 256),
generator_lr=2e-4,
discriminator_lr=2e-4,
discriminator_steps=1,
log_frequency=True,
verbose=True,
pac=10 # PacGAN pack size
)
# Train
model.fit(data, discrete_columns=discrete_columns)
# Generate synthetic data
synthetic = model.sample(10000)
# Validate: compare distributions
for col in data.columns:
if col in discrete_columns:
# Compare category frequencies
real_freq = data[col].value_counts(normalize=True)
synth_freq = synthetic[col].value_counts(normalize=True)
print(f"\n{col} - Frequency comparison:")
comparison = pd.DataFrame({
'real': real_freq,
'synthetic': synth_freq
}).fillna(0)
comparison['diff'] = abs(
comparison['real'] - comparison['synthetic']
)
print(comparison.to_string())
else:
# Compare mean and std for continuous
print(f"\n{col}:")
print(f" Real: mean={data[col].mean():.2f}, "
f"std={data[col].std():.2f}")
print(f" Synthetic: mean={synthetic[col].mean():.2f}, "
f"std={synthetic[col].std():.2f}")
# Conditional sampling: generate specific subsets
# (Manually filter after generation)
fraud_samples = synthetic[
synthetic['default_flag'] == 1
]
print(f"\nGenerated {len(fraud_samples)} default cases "
f"out of {len(synthetic)} total")The standalone ctgan library provides direct access to the CTGAN algorithm without SDV's metadata and evaluation layers. Key differences from SDV:
- You must manually specify discrete columns as a list (no auto-detection)
- No built-in evaluation -- you need to write your own quality checks
- No constraint enforcement -- SDV can enforce business rules like "age > 18"
- Simpler API -- just
fit()andsample(), easier to integrate into custom pipelines pac=10controls PacGAN pack size directly
Use this when you need maximum control or are integrating CTGAN into a larger custom framework.
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import SingleTableMetadata
from sdv.sampling import Condition
import pandas as pd
# Setup (metadata defined as before)
metadata = SingleTableMetadata()
metadata.detect_from_dataframe(real_data)
synthesizer = CTGANSynthesizer(metadata, epochs=300, verbose=True)
synthesizer.fit(real_data)
# --- Conditional Sampling ---
# Generate 1000 rows where city='Bangalore' and is_fraud=True
bangalore_fraud = Condition(
num_rows=1000,
column_values={
'city': 'Bangalore',
'is_fraud': True
}
)
synthetic_fraud = synthesizer.sample_from_conditions(
conditions=[bangalore_fraud]
)
print(f"Bangalore fraud samples: {len(synthetic_fraud)}")
print(synthetic_fraud.head())
# Generate balanced dataset with equal fraud/non-fraud
non_fraud = Condition(
num_rows=5000,
column_values={'is_fraud': False}
)
fraud = Condition(
num_rows=5000,
column_values={'is_fraud': True}
)
balanced = synthesizer.sample_from_conditions(
conditions=[non_fraud, fraud]
)
print(f"\nBalanced dataset: {balanced['is_fraud'].value_counts()}")
# --- Adding Constraints ---
from sdv.constraints import ScalarRange, FixedCombinations
# Ensure age is between 18 and 100
age_constraint = {
'constraint_class': 'ScalarRange',
'constraint_parameters': {
'column_name': 'age',
'low_value': 18,
'high_value': 100,
'strict_boundaries': False
}
}
# Ensure valid city-state combinations
geo_constraint = {
'constraint_class': 'FixedCombinations',
'constraint_parameters': {
'column_names': ['city', 'state']
}
}
synthesizer.add_constraints(
constraints=[age_constraint, geo_constraint]
)
synthesizer.fit(real_data) # Refit with constraints
constrained_data = synthesizer.sample(num_rows=10000)
print(f"\nAge range: [{constrained_data['age'].min()}, "
f"{constrained_data['age'].max()}]")SDV's CTGAN supports powerful conditional sampling and constraint enforcement:
sample_from_conditions()generates rows matching specific column values -- ideal for creating balanced datasets or generating rare scenarios (e.g., fraud cases for training)ScalarRangeconstraint ensures continuous values stay within valid bounds (no negative ages or impossible incomes)FixedCombinationspreserves valid multi-column relationships (Bangalore is always in Karnataka, not Maharashtra)- These constraints are enforced through reject sampling -- invalid rows are regenerated until constraints are met
This is particularly useful for generating test data with specific properties or augmenting minority classes in imbalanced datasets.
# CTGAN Production Configuration (YAML)
model:
type: ctgan
version: 0.10.0
data:
source: customer_transactions.csv
primary_key: transaction_id
columns:
continuous:
- amount
- age
- account_balance
- credit_score
discrete:
- city
- employment_type
- loan_purpose
- is_fraud
datetime:
- transaction_date
exclude:
- customer_name # PII - exclude entirely
- email # PII - exclude entirely
hyperparameters:
epochs: 500
batch_size: 500
generator_dim: [256, 256]
discriminator_dim: [256, 256]
generator_lr: 0.0002
discriminator_lr: 0.0002
discriminator_steps: 1
log_frequency: true
pac: 10
cuda: true
constraints:
- type: ScalarRange
column: age
low: 18
high: 100
- type: ScalarRange
column: credit_score
low: 300
high: 900
- type: Positive
column: amount
- type: FixedCombinations
columns: [city, state]
generation:
num_rows: 100000
conditions:
- column: is_fraud
value: true
num_rows: 10000 # Oversample fraud cases
evaluation:
quality_threshold: 0.85
diagnostic_threshold: 0.90
downstream_test:
model: xgboost
target: is_fraud
metric: auc_roc
min_score: 0.80
output:
format: parquet
path: data/synthetic/transactions_v1.parquet
model_path: models/ctgan_transactions_v1.pklCommon Implementation Mistakes
- ●
Not specifying discrete columns correctly: CTGAN treats unspecified columns as continuous by default. If a categorical column like 'gender' (encoded as 0/1) is treated as continuous, the VGM will fit Gaussians to binary values, producing nonsensical synthetic values like 0.37 or -0.2. Always explicitly list all categorical, boolean, and ordinal columns as discrete. In SDV, use
metadata.update_column()to setsdtype='categorical'. - ●
Training with too few epochs on complex data: The default 300 epochs works for small datasets (< 10K rows, < 15 columns), but complex datasets with many categories and multimodal continuous columns need 500-1000 epochs. Symptom: generated category frequencies don't match real data, or continuous columns are unimodal when they should be bimodal. Monitor the loss value per epoch -- if it's still decreasing at epoch 300, increase epochs.
- ●
Ignoring high-cardinality categorical columns: Columns with 100+ unique categories (e.g., city names, product IDs) create enormous one-hot vectors that the generator struggles to learn. CTGAN was designed for moderate cardinality (< 50 categories). For high-cardinality columns, either bin/group categories before training, use embedding-based approaches, or exclude the column and fill it post-generation.
- ●
Using CTGAN for very small datasets (< 500 rows): GANs are data-hungry models. With fewer than 500 training rows, CTGAN overfits and essentially memorizes the training data, defeating the purpose of synthetic generation (and creating privacy risks). For small datasets, consider copula-based methods (
GaussianCopulaSynthesizerin SDV) or SMOTE for classification tasks. - ●
Not evaluating synthetic data quality: Generating synthetic data without evaluation is dangerous. The model might produce data that looks reasonable on summary statistics but fails on joint distributions or downstream ML tasks. Always run SDV's
evaluate_quality()(target score > 0.85) andrun_diagnostic(). Additionally, train an ML model on synthetic data and evaluate on real test data to check downstream utility. - ●
Forgetting to handle missing values: CTGAN's core algorithm does not support missing values. SDV wraps CTGAN with Reversible Data Transforms (RDTs) that handle NaN values, but if using the standalone
ctganlibrary, you must impute missing values before training. Failure to do so causes cryptic NaN errors during VGM fitting.
When Should You Use This?
Use When
You need to generate synthetic tabular data that preserves complex statistical relationships between columns, including multimodal distributions, categorical dependencies, and nonlinear correlations
Your tabular data has multimodal continuous columns (e.g., income with multiple clusters for different employment types) that simpler methods like Gaussian Copula cannot capture
You need privacy-preserving data sharing -- sharing synthetic data that statistically resembles the original without containing any real individual's records, for GDPR, HIPAA, DPDPA, or RBI compliance
You have imbalanced categorical columns and need the synthetic data to fairly represent minority categories (CTGAN's training-by-sampling explicitly addresses this)
You want to augment training data for ML models by generating additional synthetic examples, particularly for rare classes like fraud, equipment failure, or rare diseases
You need realistic test data for CI/CD pipelines, development environments, or vendor demos that matches production data characteristics without using actual production data
You have moderate-sized datasets (1K-1M rows) with a manageable number of columns (5-100) where deep learning can provide quality improvements over statistical methods
Avoid When
Your dataset is very small (< 500 rows) -- CTGAN will overfit and memorize the training data, producing synthetic data with privacy risks. Use Gaussian Copula or SMOTE instead
Your tabular data has very high-cardinality categorical columns (100+ unique values) like product IDs, zip codes, or free-text fields -- the one-hot encoding becomes too sparse for the generator to learn effectively
You need guaranteed differential privacy with formal epsilon bounds -- vanilla CTGAN does not provide differential privacy. Use DP-CTGAN or PATE-GAN for formal privacy guarantees
Your data has complex temporal dependencies (time series) -- CTGAN treats each row independently and cannot learn sequential patterns. Use TimeGAN or DoppelGANger for temporal data
You need multi-table relational data with foreign key relationships -- CTGAN operates on single tables only. Use SDV's HMA (Hierarchical Modeling Approach) synthesizer for relational databases
Your data is purely continuous with simple distributions (roughly Gaussian, low dimensionality) -- simpler methods like Gaussian Copula or multivariate normal sampling will be faster and produce comparable quality
You need fast, reproducible synthesis without GPU access -- CTGAN training involves stochastic optimization with variable results across runs. For deterministic output, use statistical methods like copulas
Your primary goal is image, text, or audio generation -- CTGAN is exclusively designed for tabular data. Use standard GANs, diffusion models, or LLMs for unstructured data
Key Tradeoffs
CTGAN vs. Other Tabular Synthesizers
| Aspect | CTGAN | TVAE | Gaussian Copula | Bayesian Network |
|---|---|---|---|---|
| Multimodal Distributions | Excellent (VGM-based) | Good | Poor (assumes Gaussian) | Poor |
| Category Imbalance | Excellent (training-by-sampling) | Moderate | Poor | Moderate |
| Training Stability | Moderate (GAN instability) | Good (VAE loss) | Excellent (no training) | Excellent |
| Training Speed | Moderate (300 epochs typical) | Fast (150 epochs typical) | Very Fast (statistical fit) | Fast |
| Column Correlations | Good (deep network) | Good | Moderate (pairwise only) | Good (DAG structure) |
| High Cardinality | Poor (one-hot explosion) | Poor | Moderate | Moderate |
| Small Data (< 1K) | Poor (overfits) | Moderate | Good | Good |
| Privacy Guarantees | None (without DP) | None (without DP) | None | None |
Quality vs. Speed Tradeoff
CTGAN occupies the "higher quality, slower training" position among tabular synthesizers. Gaussian Copula fits in seconds and handles most simple use cases. CTGAN takes 5-60 minutes but captures complex distributions that statistical methods miss. For most production use cases with datasets > 5K rows and < 100 columns, CTGAN provides the best quality-to-effort ratio.
Compute Cost Comparison
| Method | 10K rows, 20 cols | 100K rows, 20 cols | 1M rows, 20 cols |
|---|---|---|---|
| Gaussian Copula | < 1 sec (₹0) | ~5 sec (₹0) | ~30 sec (₹0) |
| CTGAN (CPU) | ~15 min (₹0) | ~2 hours (₹0) | ~20 hours (₹0) |
| CTGAN (T4 GPU) | ~3 min (₹5) | ~15 min (₹15) | ~2 hours (₹100) |
| TVAE (T4 GPU) | ~2 min (₹3) | ~10 min (₹10) | ~1.5 hours (₹75) |
Rule of Thumb: Start with Gaussian Copula. If quality is insufficient (score < 0.80 on
evaluate_quality), try CTGAN. If CTGAN is too slow or unstable, try TVAE as a middle ground.
Alternatives & Comparisons
TVAE (Tabular VAE) was introduced in the same paper as CTGAN and uses the same mode-specific normalization for continuous columns, but replaces the adversarial training with a variational autoencoder framework. TVAE trains faster and more stably than CTGAN (no mode collapse risk), but CTGAN tends to produce higher-fidelity synthetic data on datasets with complex multimodal distributions and severe class imbalance. Choose TVAE when training stability and speed matter more than marginal quality gains. Choose CTGAN when your data has highly multimodal continuous columns or severely imbalanced categories.
Standard GANs (DCGAN, WGAN-GP, StyleGAN) are designed for homogeneous continuous data like images and audio. They assume all input features have similar scales and distributions, which fails catastrophically on tabular data with mixed types. CTGAN extends the GAN framework specifically for tables by adding mode-specific normalization and conditional generation. Choose generic GANs for image/audio synthesis. Choose CTGAN exclusively for tabular structured data.
Copula-based methods (Gaussian Copula in SDV) model column marginals independently and capture inter-column dependencies through copula functions. They're fast, stable, and require no GPU. However, they assume monotonic dependencies between columns and cannot capture multimodal joint distributions. Choose Copula Generator when you need fast synthesis with simple data, or as a baseline. Choose CTGAN when your data has complex nonlinear relationships, multimodal columns, or when copula quality scores are below 0.80.
SMOTE generates synthetic minority class samples by interpolating between existing k-nearest neighbors. It's designed for class balancing in classification tasks, not full dataset synthesis. SMOTE only generates minority class samples and requires continuous features (or feature-encoded data). Choose SMOTE for targeted class balancing in classification pipelines. Choose CTGAN when you need complete synthetic datasets preserving all columns, categories, and distributions -- not just minority class augmentation.
Pros, Cons & Tradeoffs
Advantages
Handles mixed data types natively: Mode-specific normalization for continuous columns and conditional generation for discrete columns means CTGAN properly handles the fundamental challenge of tabular data -- columns with completely different types and distributions in the same dataset.
Preserves multimodal distributions: Unlike methods that assume Gaussian distributions, CTGAN's VGM-based normalization discovers and preserves multiple modes in continuous columns (e.g., bimodal income distributions, multimodal age patterns). This is critical for data where statistical shape matters.
Addresses class imbalance explicitly: Training-by-sampling with log-frequency weighting ensures rare categories receive adequate training signal. A column with 99% non-fraud and 1% fraud rows will still produce realistic fraud samples, unlike standard GANs that would ignore the minority class entirely.
Production-ready ecosystem: CTGAN is the core of the SDV library, which provides metadata management, quality evaluation, constraint enforcement, conditional sampling, and model persistence. This ecosystem dramatically reduces the engineering effort to go from prototype to production.
Strong downstream ML utility: Synthetic data from CTGAN preserves enough statistical structure that ML models trained on synthetic data achieve 85-95% of the performance of models trained on real data, making it viable for data augmentation and privacy-preserving model development.
Scalable to moderate datasets: Handles datasets up to ~1M rows and ~100 columns with GPU acceleration. Training is typically measured in minutes to hours, not days, making it practical for regular regeneration as source data updates.
Conditional sampling support: Can generate synthetic data conditioned on specific column values (e.g., "generate 10,000 rows where city=Mumbai and age>60"), enabling targeted data augmentation for underrepresented segments.
Disadvantages
GAN training instability: Like all GANs, CTGAN can suffer from mode collapse (generator produces limited diversity), training oscillation, or divergence. The WGAN-GP loss and PacGAN mitigate but don't eliminate these risks. Training results can vary across runs with the same hyperparameters.
Poor performance on small datasets: With fewer than ~500 rows, CTGAN overfits the training data, producing synthetic samples that are essentially noisy copies of real rows. This defeats both the utility purpose and creates privacy risks. Minimum recommended dataset size is 1,000-5,000 rows.
High-cardinality categorical columns are problematic: Columns with 100+ unique categories create very large one-hot encodings that the generator struggles to learn. Categories appearing only once or twice in the training data will be poorly represented in synthetic output.
No built-in differential privacy: Vanilla CTGAN does not provide formal privacy guarantees. While synthetic data is not a direct copy of real data, membership inference attacks can still extract information about training records. Formal DP requires extensions like DP-CTGAN with gradient clipping and noise injection.
Single-table limitation: CTGAN operates on single flat tables only. It cannot model foreign key relationships, hierarchical structures, or multi-table databases. For relational data, you need SDV's HMA synthesizer or custom approaches.
Temporal patterns are not captured: CTGAN treats each row as an independent sample with no ordering. Time series data, session sequences, or any data where row order matters cannot be faithfully synthesized. Use TimeGAN or DoppelGANger for sequential data.
GPU recommended for practical training times: While CTGAN can run on CPU, training on datasets larger than 10K rows becomes impractically slow (hours vs minutes). This creates infrastructure requirements that simpler statistical methods don't have.
Failure Modes & Debugging
Mode Collapse in Generated Continuous Columns
Cause
The generator converges to producing values from only one or two modes of a multimodal continuous column, ignoring other modes. This typically happens when the VGM underestimates the number of modes (too few Gaussian components) or when the discriminator becomes too strong and the generator exploits a single convincing mode.
Symptoms
Histogram of synthetic continuous column shows fewer peaks than the real data. For example, an income column with three modes (low, medium, high) in real data shows only two modes in synthetic data. The Column Shapes quality score for that column drops below 0.70. KS-test between real and synthetic distributions rejects the null hypothesis.
Mitigation
Increase the number of VGM components by adjusting the VGM fitting step (not directly exposed in SDV API -- requires modifying the DataTransformer or using the standalone ctgan library). Reduce discriminator capacity relative to generator. Increase PacGAN pack size to better detect mode collapse. Alternatively, increase training epochs to give the generator more time to discover all modes.
Category Frequency Mismatch
Cause
The generator fails to reproduce the correct frequency distribution of categorical columns, typically overproducing common categories and underproducing rare ones. Occurs when log_frequency=False (no training-by-sampling) or when the dataset has extremely rare categories (< 0.1% frequency) that even log-frequency weighting cannot adequately represent.
Symptoms
Value counts of categorical columns in synthetic data differ significantly from real data. Categories with < 1% real frequency may be completely absent from synthetic data. Chi-squared test between real and synthetic category distributions rejects the null hypothesis. The Column Shapes score for categorical columns drops below 0.75.
Mitigation
Ensure log_frequency=True (default in SDV). For extremely rare categories (< 10 occurrences in training data), consider merging them into an "other" category before CTGAN training and expanding them post-generation. Increase epochs to 500-1000. If the problem persists, use conditional sampling to generate rare categories explicitly: synthesizer.sample_from_conditions([Condition(num_rows=N, column_values={'rare_col': 'rare_value'})]).
Impossible Column Combinations
Cause
CTGAN generates rows with column value combinations that are logically impossible or never occur in reality. For example: age=5 with employment_type='full_time', or city='Chennai' with state='Maharashtra'. The generator learns marginal distributions and pairwise correlations but may miss higher-order constraints.
Symptoms
Manual inspection reveals nonsensical rows. Business rule validation catches impossible combinations. The run_diagnostic() data validity score drops. Downstream ML models trained on synthetic data perform unexpectedly poorly due to learning from impossible examples.
Mitigation
Use SDV's constraints to enforce business rules: ScalarRange for valid value ranges, FixedCombinations for valid column value pairs, Inequality for ordered relationships (start_date < end_date). For complex constraints, implement custom Constraint subclasses. Also consider post-generation filtering to remove rows that violate domain rules.
Training Divergence (Loss Explosion)
Cause
The generator and discriminator losses diverge instead of converging, typically because the learning rates are too high, the batch size is too small, or the data has extreme outliers that destabilize gradient computation. Also occurs when dataset has very few rows (< 300) relative to the number of columns.
Symptoms
Generator loss increases unboundedly over training epochs. Discriminator loss drops to zero (discriminator wins completely). Generated samples contain NaN values or extreme outliers. Training crashes with numerical overflow errors.
Mitigation
Reduce learning rates (try 1e-4 instead of 2e-4). Increase batch size (500-1000). Remove or clip extreme outliers in continuous columns before training. Ensure the dataset has at least 10x more rows than the total number of one-hot encoded features. If divergence persists, switch to TVAE which uses a more stable VAE loss function.
Overfitting / Privacy Leakage on Small Datasets
Cause
When training on small datasets (< 1000 rows), CTGAN memorizes the training data rather than learning the underlying distribution. The generator produces synthetic rows that are near-exact copies of real rows, creating privacy risks -- an adversary could identify real individuals in the synthetic data.
Symptoms
Nearest-neighbor distance between synthetic and real rows is very small (< 0.01 after normalization). The DCR (Distance to Closest Record) metric shows many synthetic rows with a real-data twin. Quality scores are suspiciously high (> 0.98), indicating memorization rather than generalization.
Mitigation
Do not use CTGAN on datasets with fewer than 500 rows. For small datasets, use Gaussian Copula or SMOTE instead. If CTGAN must be used, reduce epochs (50-100), increase noise in the latent space, and always compute DCR metrics to verify that synthetic rows are sufficiently distant from real rows. Consider adding noise post-generation as an additional privacy layer.
Correlation Structure Destruction
Cause
CTGAN preserves marginal distributions well but sometimes fails to capture complex multi-column correlations, especially three-way or higher-order interactions. The conditional vector conditions on single columns, so pairwise and higher-order dependencies must be learned implicitly by the generator network.
Symptoms
Individual column distributions look correct (Column Shapes > 0.90) but Column Pair Trends scores are low (< 0.70). A model trained on real data and applied to synthetic data produces different predictions than expected. Correlation matrices between real and synthetic data show significant differences in off-diagonal entries.
Mitigation
Increase generator and discriminator capacity (try (512, 512) or (512, 256, 512) architectures). Increase epochs. Verify with correlation heatmaps comparing real vs synthetic data. For critical column relationships, use SDV constraints to enforce known dependencies. If correlation preservation is paramount, consider CTAB-GAN+ which adds a classifier loss specifically to preserve downstream ML utility.
Placement in an ML System
CTGAN sits in the data generation and preprocessing layer of ML system architectures, typically invoked in three distinct workflows:
Workflow 1: Privacy-Preserving Data Sharing. Raw sensitive data from production databases (upstream: data lake, feature store) flows into CTGAN, which produces a synthetic dataset that preserves statistical properties without containing real individuals' records. The synthetic data is then shared with downstream teams (data scientists, vendors, partners) for model development, testing, or analytics. This is the most common enterprise use case, driven by regulations like GDPR, HIPAA, India's DPDPA, and RBI data localization requirements.
Workflow 2: Training Data Augmentation. CTGAN receives validated training data (upstream: data validator, feature engineering) and generates additional synthetic samples, particularly for underrepresented classes. The augmented dataset feeds into model training (downstream: model trainer). This is common in fraud detection, rare disease diagnosis, and equipment failure prediction where positive examples are scarce.
Workflow 3: Test Data Generation. CTGAN generates realistic test fixtures for CI/CD pipelines, load testing, and staging environments. Unlike random data generators, CTGAN-produced test data has realistic distributions, correlations, and edge cases, catching bugs that random data would miss. The synthetic test data flows into integration tests, performance benchmarks, and QA environments.
In production ML platforms, CTGAN is typically deployed as a batch job (not real-time) triggered on a schedule or by data pipeline events. The trained model is persisted as a pickle file and the synthetic data is written to a data warehouse or object storage for downstream consumption.
Pipeline Stage
Data Generation / Data Preprocessing
Upstream
- data-validator
- feature-store
- data-lake
Downstream
- feature-engineering
- model-trainer
- bias-detector
- data-validator
Scaling Bottlenecks
CTGAN's primary bottleneck is training time on large datasets. With 1M+ rows, training can take 2-4 hours on a single GPU, and the entire dataset must fit in GPU memory (or be batched). The VGM fitting step uses scikit-learn's BayesianGaussianMixture which is CPU-bound and single-threaded -- for datasets with hundreds of continuous columns, this preprocessing step alone can take 30+ minutes. Generation (sampling) is fast: ~10,000 rows/second on GPU once the model is trained. For production pipelines requiring frequent retraining as source data updates, consider caching the VGM parameters and only retraining the GAN when the underlying distribution shifts significantly (detected via drift monitoring).
Production Case Studies
The original CTGAN paper by Xu et al. (2019) from MIT's Laboratory for Information and Decision Systems (LIDS) evaluated CTGAN on 8 real-world datasets including census data, credit card defaults, insurance claims, and intrusion detection. The authors systematically demonstrated that existing deep learning methods (MedGAN, VeeGAN, TableGAN) failed on tabular data due to inability to handle multimodal distributions and class imbalance.
CTGAN outperformed all deep learning baselines and most Bayesian methods. On the Census dataset, CTGAN achieved an average ML efficacy score of 73.8% (synthetic data used to train classifiers, evaluated on real test data), compared to 54.2% for TableGAN and 69.4% for Bayesian Networks. The CTGAN codebase and SDV library have accumulated 3,500+ GitHub stars and are used by thousands of organizations worldwide.
Researchers used CTGAN-based synthetic data generation for healthcare tabular datasets, employing a divide-and-conquer strategy to handle complex medical record structures. The study generated synthetic patient records for health systems where sharing real data is restricted by patient privacy regulations. CTGAN was used to synthesize patient demographics, clinical measurements, and diagnosis codes while preserving the correlations between symptoms, lab values, and outcomes.
The synthetic healthcare data achieved high statistical similarity to real data (KS-test scores > 0.85 for continuous columns). ML models trained on synthetic data for clinical prediction tasks achieved 88-92% of the AUC-ROC compared to models trained on real data. The approach enabled cross-institutional collaboration on rare disease research without sharing identifiable patient records.
Gretel AI's open-source gretel-synthetics library includes ACTGAN, their fork of CTGAN optimized for high-dimensional tabular datasets. ACTGAN addresses CTGAN's scaling limitations by using binary encoding (instead of pure one-hot encoding) for efficient memory usage, automatic detection and transformation of date-time columns, and improved conditional vector sampling. These changes enable synthesis of datasets with millions of rows without requiring high-memory GPUs.
ACTGAN requires only 16% of CTGAN's GPU memory (835 MB vs 13,769 MB for 5,000 records) and achieves 6.4x speedup. The library is permissively licensed and also includes Timeseries DGAN for temporal data synthesis. Used by enterprise customers across finance, healthcare, and cybersecurity verticals for privacy-preserving synthetic data generation at scale.
Researchers at TU Delft and TU Darmstadt extended CTGAN with differential privacy (DP-CTGAN) for medical data generation. The system adds gradient clipping and calibrated noise injection to the discriminator training, providing formal privacy guarantees (epsilon-delta differential privacy) while preserving CTGAN's tabular synthesis capabilities. Evaluated on medical datasets including heart disease, diabetes, and breast cancer records.
DP-CTGAN outperformed existing differentially private GAN methods (DP-CGAN, PATE-GAN) under the same privacy budget on multiple benchmarks. At a privacy budget of epsilon=1.0, DP-CTGAN achieved 78% downstream classification accuracy compared to 85% for non-private CTGAN -- a reasonable privacy-utility tradeoff. The method also supports federated learning, enabling privacy-preserving synthetic data generation across hospitals without centralizing patient data.
Tooling & Ecosystem
The canonical open-source library for synthetic data generation, maintained by DataCebo (founded by CTGAN's creators). Provides CTGANSynthesizer with full pipeline support: metadata detection, data preprocessing with Reversible Data Transforms, constraint enforcement, conditional sampling, quality evaluation (Column Shapes, Column Pair Trends), and diagnostic checks. Supports single-table, multi-table, and sequential data synthesis.
The standalone CTGAN library providing the core GAN algorithm without SDV's higher-level features. Exposes CTGAN and TVAE classes with fit() and sample() APIs. Useful for integration into custom pipelines or when you need fine-grained control over hyperparameters. Installable via pip install ctgan.
Open-source library providing CTGAN, WGAN-GP, and other GAN variants for tabular and time-series synthetic data. Integrates with YData's data profiling tools for automated quality assessment. Offers a Streamlit-based UI for interactive synthesis workflows and side-by-side comparison of real vs synthetic data distributions.
Enterprise-grade synthetic data library by Gretel AI. Includes ACTGAN (a scalable fork of CTGAN), LSTM-based models, and differential privacy support. The cloud platform provides GUI-based synthesis, automated privacy assessments, and quality metrics. Free tier available for individual researchers; enterprise plans for large-scale production use.
The evaluation library for synthetic data quality, part of the SDV ecosystem. Computes Column Shapes (KS-test, TVD), Column Pair Trends (correlation comparison), and diagnostic checks (data validity, structure). Essential for validating CTGAN output quality. Also provides the NewRowSynthesis privacy metric to detect memorization.
Enterprise synthetic data platform using their proprietary TabularARGN model (an evolution of GAN-based tabular synthesis). Provides GUI-based synthesis, automated privacy risk assessments, and compliance reporting for GDPR and HIPAA. Offers both cloud and on-premises deployment. Best for non-technical teams or organizations requiring enterprise support and compliance certification.
Research & References
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni (2019)NeurIPS 2019
The foundational CTGAN paper. Introduces mode-specific normalization for multimodal continuous columns, conditional generator with training-by-sampling for imbalanced discrete columns, and evaluates on 8 real-world tabular datasets. Establishes the first deep learning method to consistently outperform Bayesian approaches for tabular synthesis.
Zilong Zhao, Aditya Kunar, Robert Birke, Lydia Y. Chen (2021)ACML 2021
Extends CTGAN with a classification loss (auxiliary classifier) and improved encoding for mixed data types. Adds logarithmic transformation for long-tail continuous variables and conditional vector encoding for mixed columns. Outperforms CTGAN on 5 datasets in ML utility, statistical similarity, and privacy metrics.
Zilong Zhao, Aditya Kunar, Robert Birke, Lydia Y. Chen (2022)Frontiers in Big Data 2023
An enhanced version of CTAB-GAN adding type-specific encoding for all column types (Gaussian mixture for continuous, log-transform for skewed, one-hot for categorical), an information loss to preserve column correlations, and Wasserstein loss with downstream classifier regularization. Achieves state-of-the-art on tabular synthesis benchmarks.
Mei Ling Fang, Devendra Singh Dhami, Kristian Kersting (2022)AIME 2022
Integrates differential privacy into CTGAN via gradient clipping and calibrated noise injection during discriminator training. Outperforms DP-CGAN and PATE-GAN under the same privacy budget on medical datasets. Also demonstrates compatibility with federated learning for distributed privacy-preserving synthesis.
Zinan Lin, Ashish Khetan, Giulia Fanti, Sewoong Oh (2018)NeurIPS 2018
Proposes the PacGAN framework used by CTGAN's discriminator. By evaluating packs of multiple samples jointly (rather than individual samples), the discriminator can detect mode collapse -- catching generators that produce limited diversity. Provides theoretical analysis showing pac > 1 provably reduces mode collapse in mixture distributions.
Interview & Evaluation Perspective
Common Interview Questions
- ●
Why can't we use a standard GAN for tabular data? What specific challenges does CTGAN address?
- ●
Explain mode-specific normalization. Why is it necessary for continuous columns in tabular data?
- ●
How does training-by-sampling address class imbalance in CTGAN?
- ●
Compare CTGAN vs TVAE -- when would you choose one over the other?
- ●
How would you evaluate the quality of synthetic tabular data generated by CTGAN?
- ●
What privacy guarantees does CTGAN provide? How would you add differential privacy?
- ●
You have a dataset with 500 rows and 30 columns. Would you use CTGAN? Why or why not?
- ●
How does PacGAN's discriminator help prevent mode collapse in CTGAN?
Key Points to Mention
- ●
CTGAN's three innovations are targeted at three specific tabular data challenges: mode-specific normalization (multimodal continuous), conditional generation (discrete columns), training-by-sampling (class imbalance)
- ●
The VGM uses a Bayesian Gaussian Mixture Model -- it automatically determines the number of modes per column rather than requiring manual specification
- ●
Training-by-sampling uses log-frequency weighting, not uniform sampling -- this provides a balance between equal exposure and preserving natural frequencies
- ●
PacGAN discriminator evaluates packs of samples, providing a structural solution to mode collapse that complements the WGAN-GP loss
- ●
Quality evaluation should check both marginal distributions (Column Shapes via KS-test) and joint distributions (Column Pair Trends via correlation comparison)
- ●
CTGAN does NOT provide differential privacy by default -- vanilla CTGAN can still leak information about training records through membership inference attacks
Pitfalls to Avoid
- ●
Don't claim CTGAN 'preserves privacy' without qualification -- it generates non-identical data but doesn't provide formal DP guarantees
- ●
Don't confuse CTGAN with conditional GANs for images (cGAN) -- CTGAN's conditioning is specifically for tabular category rebalancing
- ●
Don't say CTGAN handles any tabular data -- it struggles with high-cardinality columns (100+ categories), very small datasets, multi-table relationships, and temporal data
- ●
Don't forget to mention the evaluation step -- synthetic data quality must be measured, not assumed
Senior-Level Expectation
Senior and staff-level candidates should be able to discuss CTGAN's position in the broader synthetic data landscape, including comparisons with statistical methods (copulas, Bayesian networks), other deep learning approaches (TVAE, CTAB-GAN, TabDDPM), and enterprise platforms (Gretel, MOSTLY AI). They should articulate the privacy-utility tradeoff quantitatively -- how DP-CTGAN's epsilon parameter affects downstream model performance. They should discuss production deployment patterns: when to retrain CTGAN as source data drifts, how to monitor synthetic data quality over time, and how to handle the latency between data ingestion and synthetic data availability in pipeline architectures. Senior candidates should also understand limitations: CTGAN's inability to handle multi-table relationships, its sensitivity to hyperparameter choices (epochs, pac, learning rate), and when simpler methods like Gaussian Copula are actually the right choice.
Summary
CTGAN (Conditional Tabular GAN) is a deep generative model purpose-built for synthesizing realistic tabular data. Introduced at NeurIPS 2019 by Xu et al. from MIT, it addresses the three fundamental challenges that prevented standard GANs from working on structured data: multimodal continuous distributions (via mode-specific normalization using Variational Gaussian Mixture Models), imbalanced categorical columns (via conditional generation with a conditional vector), and inadequate minority class representation (via training-by-sampling with log-frequency weighting). These innovations, combined with a PacGAN discriminator and WGAN-GP training objective, enable CTGAN to generate synthetic tabular rows that faithfully preserve the statistical properties, column correlations, and category frequencies of the original dataset.
In practice, CTGAN is most commonly accessed through the Synthetic Data Vault (SDV) library, which wraps the core algorithm with metadata management, constraint enforcement, conditional sampling, and quality evaluation tools. It excels on datasets with 1,000-1,000,000 rows and 5-100 columns containing mixed data types, making it suitable for privacy-preserving data sharing (GDPR, DPDPA, HIPAA compliance), training data augmentation for imbalanced classification, and realistic test data generation for CI/CD pipelines. Notable limitations include poor performance on small datasets (< 500 rows), inability to handle high-cardinality categorical columns (100+ unique values), lack of built-in differential privacy guarantees, and exclusion of temporal patterns.
For ML system design interviews and production architecture decisions, the key tradeoff to understand is CTGAN vs. simpler alternatives. Gaussian Copula is faster and more stable but cannot capture multimodal distributions. TVAE (from the same paper) trades marginal quality for training stability. CTAB-GAN+ adds downstream utility optimization. The pragmatic recommendation is to start with Gaussian Copula as a baseline, and upgrade to CTGAN when the quality gap matters -- particularly for datasets with complex, multimodal, imbalanced structure where statistical fidelity is critical for downstream model performance or regulatory compliance.