SMOTE in Machine Learning
Class imbalance is one of the most common and insidious problems in real-world machine learning. When 99% of your training data belongs to one class, even a naive classifier that always predicts "majority" will achieve 99% accuracy — while completely failing to learn anything useful about the minority class you actually care about.
SMOTE (Synthetic Minority Over-sampling Technique) emerged as a landmark solution to this problem. Instead of simply duplicating minority class samples (which leads to overfitting), SMOTE generates synthetic examples by interpolating between existing minority class instances in feature space.
Introduced by Chawla et al. in their seminal 2002 paper, SMOTE has become the de facto baseline for handling class imbalance in domains ranging from fraud detection at PhonePe and Razorpay to rare disease diagnosis in healthcare. Today, it's implemented in virtually every ML framework, with the imbalanced-learn library providing the canonical Python implementation.
But here's the catch: SMOTE isn't a silver bullet. Used incorrectly, it can amplify noise, blur decision boundaries, and actually hurt model performance. Understanding when to use SMOTE — and when to reach for alternatives like class weights or cost-sensitive learning — is what separates production ML systems that work from those that quietly underperform.
Concept Snapshot
- What It Is
- A data-level resampling technique that generates synthetic minority class examples by interpolating between existing samples using k-nearest neighbors, addressing class imbalance without simple duplication.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: imbalanced training dataset with minority and majority classes. Outputs: balanced dataset with synthetic minority samples generated via k-NN interpolation.
- System Placement
- Applied during the data preprocessing phase, after data cleaning and before feature engineering or model training.
- Also Known As
- Synthetic Minority Over-sampling Technique, SMOTE oversampling, k-NN synthetic sampling
- Typical Users
- ML engineers, data scientists, research scientists, ML platform engineers
- Prerequisites
- k-nearest neighbors algorithm, class imbalance concepts, distance metrics (Euclidean, cosine), precision-recall tradeoffs
- Key Terms
- class imbalanceoversamplingsynthetic samplesk-NN interpolationminority classmajority classsampling_strategyimbalanced-learn
Why This Concept Exists
The Class Imbalance Problem
Real-world datasets are rarely balanced. Fraudulent transactions might represent 0.1% of all credit card activity. Rare diseases affect 1 in 10,000 patients. Manufacturing defects occur in 0.5% of products. In each case, the class you care about — the positive class, the minority — is vastly outnumbered.
Standard machine learning algorithms optimize for overall accuracy, which means they'll happily ignore the minority class entirely if doing so maximizes their objective. A fraud detector that predicts "legitimate" for every transaction achieves 99.9% accuracy but catches zero fraud.
Why Not Just Duplicate Minority Samples?
The naive solution is random oversampling: simply duplicate minority class examples until the classes are balanced. This works in the sense that it prevents the model from ignoring the minority class, but it has a fatal flaw: exact duplication provides no new information. The model sees the same samples repeatedly, which often leads to severe overfitting on those specific instances.
The SMOTE Innovation (2002)
Chawla, Bowyer, Hall, and Kegelmeyer published their landmark paper in the Journal of Artificial Intelligence Research, proposing a fundamentally different approach: instead of copying existing samples, create new synthetic samples by interpolating between existing minority class neighbors.
The key insight was geometric: if two minority class samples are close in feature space, then points along the line segment connecting them likely also belong to the minority class. By generating samples in these regions, SMOTE effectively expands the decision boundary around minority class clusters without exact duplication.
Why SMOTE Became the Standard
Several factors converged to make SMOTE the dominant approach:
Empirical Success: The original paper demonstrated superior performance to random oversampling across multiple datasets, with gains of 5-15% in ROC-AUC on imbalanced benchmarks.
Simplicity: The algorithm is conceptually straightforward and computationally tractable. A single hyperparameter (k) controls the behavior.
Library Support: The imbalanced-learn (imblearn) Python library, developed in 2014-2015, made SMOTE as easy to use as any scikit-learn transformer. By 2020, it was a standard dependency in production ML pipelines.
Domain Adoption: High-stakes domains — finance (fraud, credit scoring), healthcare (disease prediction), manufacturing (defect detection) — found SMOTE dramatically improved recall for critical minority classes.
Historical Note: Before SMOTE, practitioners primarily used random undersampling (discarding majority class data) or cost-sensitive learning (weighted loss functions). SMOTE offered a third path that preserved all original data while adding informative synthetic samples.
Core Intuition & Mental Model
The Core Idea in Plain English
Imagine you're teaching a model to recognize a rare bird species, but you only have 10 examples while you have 1,000 examples of common birds. Simply showing those same 10 rare bird photos over and over won't help the model generalize — it'll just memorize those specific images.
SMOTE's approach is smarter: it looks at the 10 rare bird examples, identifies which ones are similar to each other in feature space, and creates "plausible variations" by blending features between similar examples. If Bird A has a 5cm beak and Bird B has a 6cm beak (and they're neighbors in feature space), SMOTE might create a synthetic bird with a 5.4cm beak.
The Geometric Perspective
Here's the mental model that clicked for me: think of your feature space as a 2D plot (even though real features are high-dimensional). Minority class samples form small, sparse islands surrounded by a sea of majority class points.
Random oversampling just puts more copies of the same islands in the exact same locations — no expansion, no coverage of new regions. SMOTE, by contrast, grows the islands outward by filling in the space between nearby minority samples. The decision boundary now has more minority territory to learn from.
What SMOTE Does NOT Do
This is crucial: SMOTE does not create fundamentally new information. It's a sophisticated interpolation scheme, not magic. If your original minority class samples are noisy, mislabeled, or unrepresentative, SMOTE will happily amplify those problems.
SMOTE also doesn't understand semantic meaning. If you're interpolating between "fraud" and "fraud" but those two instances have completely different fraud mechanisms, the synthetic sample might represent a pattern that doesn't exist in reality.
The Coffee Shop Analogy
You're building a customer churn prediction model for a coffee subscription service. Out of 10,000 customers, only 200 have churned (2% minority class).
Without SMOTE, your model learns: "Most people don't churn, so predict no churn" — 98% accurate, 0% useful.
With SMOTE, you look at those 200 churners, find patterns like "purchased 2x/month, spent ₹800/month, subscription age 4 months" and "purchased 3x/month, spent ₹1200/month, subscription age 3 months", and create synthetic churners with blended characteristics: "purchased 2.6x/month, spent ₹980/month, subscription age 3.4 months".
Now your model has hundreds of churn examples spanning the feature space, so it can learn the actual decision boundary instead of defaulting to "no churn".
Expert Insight: The quality of SMOTE's synthetic samples depends entirely on the assumption that linear interpolation in feature space produces realistic samples. This holds well for continuous numerical features but breaks down for categorical data, discrete features, or features with complex nonlinear interactions.
Technical Foundations
Mathematical Formulation
Let be a binary classification training set where and class 1 (minority) has samples, creating imbalance ratio .
SMOTE generates synthetic samples for the minority class as follows:
For each minority sample where :
-
Find the nearest minority class neighbors: using Euclidean distance
-
Randomly select neighbors from , where is determined by the desired oversampling percentage
-
For each selected neighbor , create a synthetic sample:
where is a random interpolation factor.
The Geometric Interpretation
The synthetic sample lies on the line segment connecting and in feature space. The random factor ensures diversity: setting returns , returns , and gives the midpoint.
Algorithm Complexity
The computational cost is dominated by the k-NN search:
- Naive k-NN: where is feature dimensionality
- With KD-tree or Ball tree: for building + querying
- Synthetic sample generation: where is oversampling ratio
For datasets with , the k-NN computation becomes the bottleneck. Libraries like imbalanced-learn use approximate nearest neighbor algorithms to scale to millions of samples.
Sampling Strategy
The sampling_strategy parameter controls the target class distribution:
- 'auto' (default): balances to 50-50
- float (0.0 to 1.0): target ratio of minority to majority
- dict: explicit target counts per class
For example, sampling_strategy=0.5 on a dataset with 1,000 majority and 100 minority samples will generate 400 synthetic minority samples, yielding a final ratio of 500:1000 = 0.5.
Mathematical Caveat: SMOTE assumes the feature space is Euclidean and distances are meaningful. For categorical features, mixed data types, or features with different scales, standard SMOTE can produce nonsensical synthetic samples (e.g., interpolating between "red" and "blue" to get "purple" when those are unordered categories).
Internal Architecture
SMOTE's architecture consists of four key stages: neighbor discovery via k-NN search, random neighbor selection, linear interpolation for synthetic sample generation, and dataset assembly. The algorithm operates entirely in feature space, with no dependence on model architecture or training procedure.
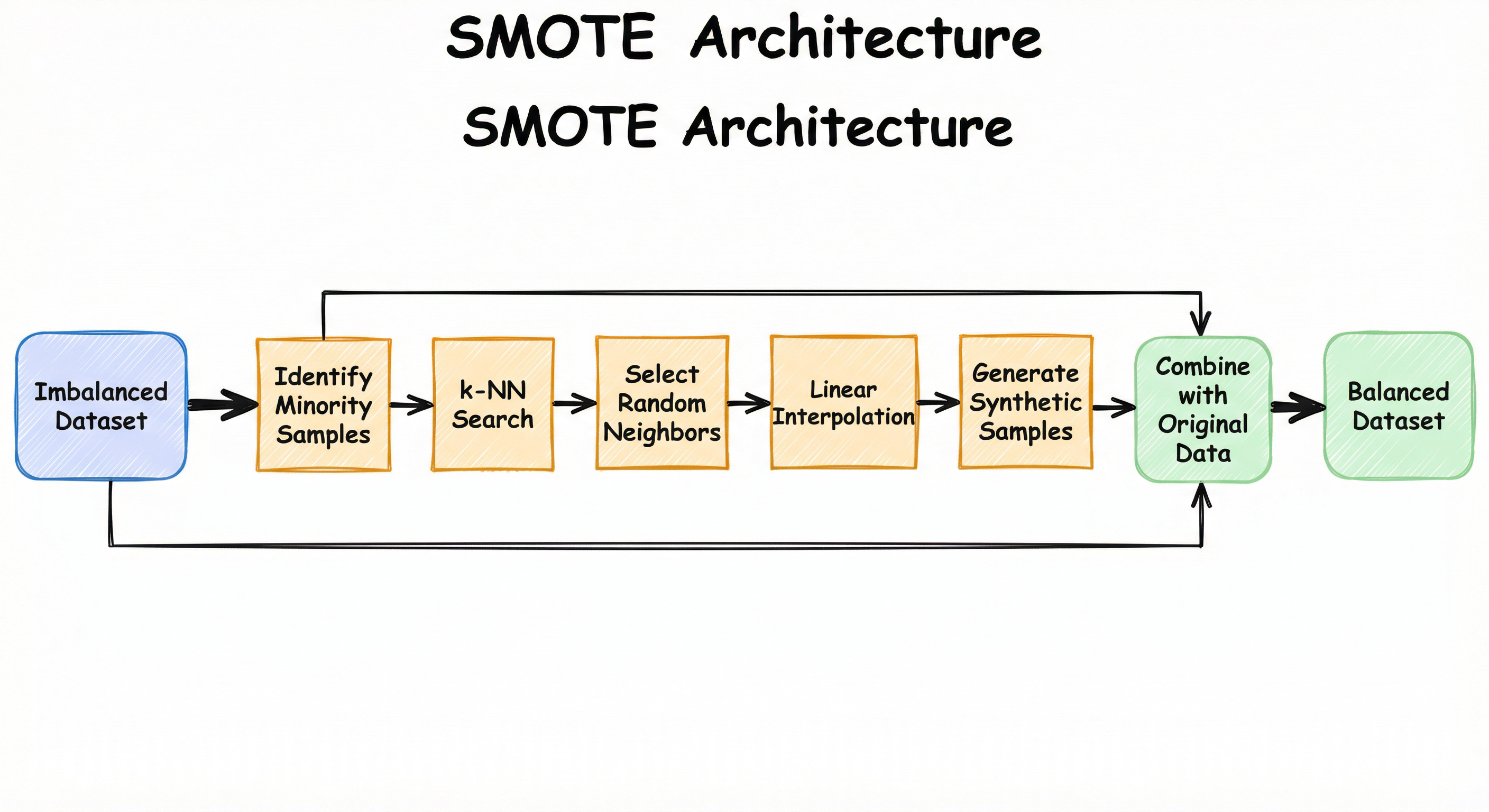
Key Components
Minority Class Extractor
Identifies all samples belonging to the minority class(es) from the training set. Supports multi-class scenarios using one-vs-rest strategy.
k-Nearest Neighbors Finder
For each minority sample, computes distances to all other minority samples and selects the k nearest neighbors. Typically uses Euclidean distance, but implementations support Manhattan, Minkowski, and custom metrics.
Neighbor Selector
Randomly samples from the k nearest neighbors to determine which neighbors will participate in synthetic sample generation. Controls diversity via randomness.
Interpolation Engine
Generates synthetic samples by linear interpolation between a minority sample and one of its selected neighbors. Uses random λ ∈ [0,1] to ensure variation.
Dataset Combiner
Merges original majority class samples, original minority samples, and newly generated synthetic minority samples into a single balanced training set.
Data Flow
Input Flow: The algorithm receives an imbalanced dataset and the target sampling_strategy. It first separates minority and majority class samples into distinct sets.
Processing Flow: For each minority sample, the k-NN module computes distances to other minority samples and identifies the k nearest. The neighbor selector randomly picks neighbors based on the oversampling ratio. The interpolation engine then generates synthetic samples by computing weighted combinations of the original sample and selected neighbors.
Output Flow: Synthetic samples are labeled with the minority class and combined with the original dataset. The final output is a resampled dataset where the minority class has been augmented to match the target ratio specified by sampling_strategy.
Critically, only minority class samples participate in synthetic generation — majority class samples pass through unchanged. This asymmetry is by design: the goal is to amplify the underrepresented class, not to modify the entire distribution.
A linear flow from 'Imbalanced Dataset' through minority sample identification, k-NN search, neighbor selection, linear interpolation, synthetic sample generation, and final combination into a 'Balanced Dataset'.
How to Implement
Implementation Approaches
SMOTE is almost exclusively used via the imbalanced-learn (imblearn) library, which provides a scikit-learn-compatible API. The library offers multiple SMOTE variants — vanilla SMOTE, Borderline-SMOTE, SMOTE-NC (for mixed categorical/numerical data), and ADASYN — all following the same fit_resample() interface.
For production systems, SMOTE is typically applied as a preprocessing step in the training pipeline, NOT at inference time. You resample the training data, train your classifier on the balanced dataset, and deploy the classifier alone. The synthetic samples are a training-time artifact.
Key configuration decisions: choosing (number of neighbors), sampling_strategy (target class ratio), and whether to use vanilla SMOTE or a variant like Borderline-SMOTE (which focuses synthetic generation on borderline samples near the decision boundary).
Cost/Performance Note: SMOTE's k-NN search scales as for naive implementations. On a dataset with 100,000 minority samples, this can take minutes. Use approximate nearest neighbor algorithms (enabled by default in imblearn 0.10+) or consider sampling a subset if training time becomes prohibitive. A 32-core CPU instance on AWS (c6i.8xlarge, ~$1.36/hr or ~₹115/hr) can process 1M samples in under 5 minutes.
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import numpy as np
# Create imbalanced dataset (1:99 ratio)
X, y = make_classification(
n_classes=2,
weights=[0.01, 0.99],
n_samples=10000,
n_features=20,
random_state=42
)
print(f"Original class distribution: {np.bincount(y)}")
# Output: [100, 9900]
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Apply SMOTE to training data only
smote = SMOTE(sampling_strategy='auto', k_neighbors=5, random_state=42)
X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)
print(f"Resampled class distribution: {np.bincount(y_train_resampled)}")
# Output: [7920, 7920] — perfectly balanced
# Train classifier on balanced data
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train_resampled, y_train_resampled)
# Evaluate on original imbalanced test set
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))This example demonstrates the standard SMOTE workflow. Key points: (1) SMOTE is applied ONLY to the training set — never to the test set, as that would leak synthetic data into evaluation. (2) The sampling_strategy='auto' balances to 50-50. (3) The classifier is trained on resampled data but evaluated on the original imbalanced test distribution, which reflects real-world class ratios.
from imblearn.over_sampling import SMOTE
import numpy as np
# Suppose we have 10,000 majority, 100 minority samples
X = np.random.randn(10100, 20)
y = np.array([0]*10000 + [1]*100)
print(f"Original ratio (minority/majority): {100/10000:.3f}")
# Output: 0.010
# Target ratio of 0.2 (1:5 instead of 1:100)
smote = SMOTE(sampling_strategy=0.2, k_neighbors=5, random_state=42)
X_res, y_res = smote.fit_resample(X, y)
minority_count = np.sum(y_res == 1)
majority_count = np.sum(y_res == 0)
print(f"Resampled counts: minority={minority_count}, majority={majority_count}")
print(f"New ratio: {minority_count/majority_count:.3f}")
# Output: minority=2000, majority=10000, ratio=0.200
# SMOTE generated 1900 synthetic minority samplesSetting sampling_strategy=0.2 targets a 1:5 minority-to-majority ratio. This is useful when you want to improve minority class representation without fully balancing to 50-50, which can sometimes hurt precision if the minority class is extremely rare in the real world. This approach is common in fraud detection where maintaining some imbalance (e.g., 1:10) reflects deployment conditions.
from imblearn.over_sampling import BorderlineSMOTE
import numpy as np
# BorderlineSMOTE focuses on minority samples near the decision boundary
# This is more robust when the minority class has noise or outliers
X = np.random.randn(1000, 10)
y = np.array([0]*900 + [1]*100)
# Use BorderlineSMOTE instead of vanilla SMOTE
bsmote = BorderlineSMOTE(
sampling_strategy='auto',
k_neighbors=5,
m_neighbors=10, # controls which samples are "borderline"
kind='borderline-1', # or 'borderline-2'
random_state=42
)
X_res, y_res = bsmote.fit_resample(X, y)
print(f"Original minority samples: 100")
print(f"Resampled minority samples: {np.sum(y_res == 1)}")
# Generates synthetic samples only for minority samples whose
# k-neighbors include majority class samples (borderline cases)Borderline-SMOTE identifies minority samples that are "difficult" (near the decision boundary, with majority class neighbors) and generates synthetic samples primarily for those instances. This focuses synthetic data generation where it matters most — at the class boundary — rather than deep within minority class clusters. It's particularly effective for noisy datasets where vanilla SMOTE might amplify noise in safe regions.
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTE
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
import numpy as np
# Create pipeline with SMOTE as a preprocessing step
pipeline = Pipeline([
('scaler', StandardScaler()),
('smote', SMOTE(sampling_strategy=0.3, k_neighbors=5, random_state=42)),
('classifier', GradientBoostingClassifier(n_estimators=100, random_state=42))
])
X = np.random.randn(5000, 15)
y = np.array([0]*4500 + [1]*500)
# Cross-validation with SMOTE applied inside each fold
scores = cross_val_score(
pipeline,
X, y,
cv=5,
scoring='f1',
n_jobs=-1
)
print(f"Cross-validated F1 scores: {scores}")
print(f"Mean F1: {scores.mean():.3f} ± {scores.std():.3f}")Using imblearn's Pipeline ensures SMOTE is applied correctly during cross-validation: it resamples ONLY the training folds, never the validation fold. This prevents data leakage where synthetic samples from validation data would contaminate training. The standard scikit-learn Pipeline doesn't support resamplers, so you must use imblearn.pipeline.Pipeline instead.
# Example configuration for imbalanced-learn SMOTE
smote_config = {
'sampling_strategy': 0.5, # target minority/majority ratio
'k_neighbors': 5, # number of nearest neighbors
'random_state': 42, # reproducibility
'n_jobs': -1 # parallel k-NN search
}
# For Borderline-SMOTE
borderline_smote_config = {
'sampling_strategy': 'auto',
'k_neighbors': 5,
'm_neighbors': 10, # neighbors for borderline detection
'kind': 'borderline-1', # or 'borderline-2'
'random_state': 42
}
# For ADASYN (adaptive synthetic sampling)
adasyn_config = {
'sampling_strategy': 'auto',
'n_neighbors': 5,
'random_state': 42
}Common Implementation Mistakes
- ●
Applying SMOTE to the entire dataset before train-test split — This causes catastrophic data leakage. Synthetic test samples are interpolations of training samples, so your model has already "seen" the test data. ALWAYS split first, then apply SMOTE only to the training set. I've seen this mistake cost teams weeks of wasted work.
- ●
Using SMOTE with tree-based models that handle imbalance well natively — Random Forests and XGBoost with
scale_pos_weightor class weights often perform better without SMOTE, as they can assign differential importance to minority samples during training. SMOTE shines with algorithms that don't support class weighting (k-NN, SVM with linear kernel, neural networks without weighted loss). - ●
Applying SMOTE to test/validation data — SMOTE is a training-time technique only. Your test set should reflect the real-world class distribution. Resampling test data gives you artificially inflated performance metrics that won't generalize.
- ●
Using vanilla SMOTE on datasets with categorical features — Linear interpolation between categorical values produces meaningless results. Use SMOTE-NC (nominal-continuous) which handles mixed data types, or encode categoricals as embeddings first.
- ●
Setting k too small (k=1 or k=2) or too large (k > 10) — Small k leads to overfitting as synthetic samples cluster tightly around original samples. Large k incorporates distant neighbors, potentially crossing class boundaries and generating noisy synthetics. k=5 is the empirical sweet spot for most datasets.
- ●
Ignoring feature scaling before SMOTE — k-NN distance calculations are scale-sensitive. If one feature ranges 0-1000 and another 0-1, the first dominates. Always standardize features before applying SMOTE, or use distance metrics that handle scale differences.
When Should You Use This?
Use When
You have a binary or multi-class classification problem with significant class imbalance (minority class <10% of dataset)
Your model lacks native support for class weights or cost-sensitive learning (e.g., k-NN, standard SVM, unweighted neural networks)
The minority class has sufficient samples (>50) for meaningful k-NN search — below this threshold, SMOTE becomes unstable
Features are predominantly continuous/numerical, allowing linear interpolation to produce realistic synthetic samples
You need to improve recall on the minority class and are willing to trade some precision (common in medical diagnosis, fraud detection, rare event prediction)
Random oversampling (simple duplication) is causing severe overfitting, as evidenced by high training accuracy but poor test recall
Your domain allows for synthetic training data — some regulated industries (medical devices, pharmaceuticals) restrict synthetic data usage
Avoid When
You're using tree-based models (Random Forest, XGBoost, LightGBM) that natively handle imbalance via class weights or sample weighting — these models often outperform SMOTE without the added complexity
Your minority class has <50 samples — k-NN becomes unreliable and synthetic samples may not be representative. Consider data collection or transfer learning instead
Features are predominantly categorical or discrete — linear interpolation produces nonsensical values (use SMOTE-NC for mixed data, or categorical encodings like target encoding)
Your dataset has high noise or label errors — SMOTE will amplify these problems by generating noisy synthetic samples. Clean your data first
The minority class has high intra-class variance (multiple distinct subpopulations) — SMOTE's k-NN assumption breaks down as it may interpolate across different subgroups, creating unrealistic hybrids
Computational cost is prohibitive — SMOTE's k-NN search scales poorly beyond 1M minority samples. Consider random oversampling, class weights, or focal loss instead
Your deployment environment requires explainability for each training sample — synthetic samples complicate audit trails in regulated domains
Key Tradeoffs
The Core Tradeoff: Recall vs Precision
SMOTE almost always increases recall on the minority class at the expense of precision. By expanding the minority class region in feature space, the model becomes more sensitive to minority patterns — but also more prone to false positives (predicting minority when it's actually majority).
For fraud detection, this might be acceptable: catching 95% of fraud with 10% false positive rate is better than catching 60% with 2% false positives. But for spam filtering, high false positives (legitimate emails marked as spam) might be unacceptable.
Memory and Computation
SMOTE increases dataset size by generating synthetic samples, which means:
- Training time increases proportional to the oversampling ratio. Balancing a 1:100 dataset to 1:1 multiplies training data by ~1.5x.
- k-NN search cost can dominate for large minority classes. With 100,000 minority samples and k=5, expect 1-3 minutes on a modern CPU.
For a dataset with 1M majority and 10K minority samples, SMOTE with sampling_strategy=1.0 generates 990K synthetic minority samples, yielding a final training set of 2M samples — double the original size.
SMOTE vs Class Weights
Class weights modify the loss function to penalize minority class errors more heavily. SMOTE modifies the training data itself.
When to use class weights:
- Tree-based models (XGBoost, LightGBM, Random Forest)
- Logistic regression, SVMs, neural networks with weighted loss support
- Large datasets where doubling training size is expensive
- When you want to preserve the exact original data distribution
When to use SMOTE:
- k-NN, standard SVM (without class weight support)
- When class weights alone don't improve minority recall enough
- Moderate dataset sizes where computational cost is manageable
- When you can afford the precision-recall tradeoff
Hybrid approach: Some practitioners use SMOTE to partially balance (e.g., 1:100 → 1:10) then apply class weights to handle the remaining imbalance. This balances the benefits of both techniques.
Rule of Thumb: Start with class weights for tree-based models. If recall is still insufficient, try SMOTE. For k-NN and SVMs, start with SMOTE. For deep learning, try focal loss or weighted loss before SMOTE, as synthetic samples can sometimes degrade embedding quality.
Alternatives & Comparisons
Random oversampling duplicates existing minority samples rather than creating synthetic ones. It's faster (no k-NN search) and simpler, but often leads to overfitting as the model sees identical samples repeatedly. Use SMOTE when random oversampling causes overfitting (high train accuracy, low test recall). Use random oversampling when computational cost is critical or when SMOTE's synthetic samples are unrealistic for your domain.
Borderline-SMOTE is a SMOTE variant that generates synthetic samples ONLY for minority samples near the decision boundary (borderline cases). It's more robust to noise and often achieves better precision than vanilla SMOTE. Choose Borderline-SMOTE when your minority class has outliers or noise, or when vanilla SMOTE generates too many false positives. Use vanilla SMOTE when the minority class is clean and you need maximum recall.
ADASYN is similar to SMOTE but generates more synthetic samples for minority instances that are harder to learn (surrounded by majority samples). It adapts the number of synthetic samples to local difficulty. Choose ADASYN when the minority class has regions of varying difficulty, or when you want to focus synthetic generation on the hardest cases. Use vanilla SMOTE when the minority class is uniformly distributed and computational cost is a concern (ADASYN is slower).
SMOTE-NC extends SMOTE to handle datasets with mixed categorical and continuous features. It uses median values for categorical features and interpolation for continuous ones. Use SMOTE-NC when your dataset has categorical features alongside numerical ones. Use vanilla SMOTE only for purely numerical features, or encode categoricals as embeddings first.
Pros, Cons & Tradeoffs
Advantages
Generates informative synthetic samples rather than exact duplicates, reducing overfitting compared to random oversampling while providing new training signal in undersampled regions of feature space
Improves minority class recall dramatically in most scenarios, often achieving 10-30% gains in recall for rare classes in domains like fraud detection and medical diagnosis
Simple and intuitive algorithm with a single primary hyperparameter (k), making it easy to understand, implement, and explain to non-technical stakeholders
Model-agnostic — works as a preprocessing step with any classifier (k-NN, SVM, neural networks, decision trees), unlike techniques that require model-specific modifications
Well-supported in production via the imbalanced-learn library, which provides scikit-learn-compatible API, pipeline integration, and extensive documentation
Empirically validated across thousands of papers and production systems over 20+ years, with proven effectiveness in high-stakes domains (finance, healthcare, manufacturing)
Preserves all original data — unlike undersampling which discards majority class information, SMOTE keeps all original samples and adds synthetic minority samples
Disadvantages
Can amplify noise and outliers — if the minority class contains mislabeled or anomalous samples, SMOTE generates synthetic samples near those points, spreading the noise throughout feature space
Assumes linear interpolation is valid — breaks down for categorical features, discrete variables, or features with complex nonlinear relationships. Interpolating between "red" and "blue" doesn't yield meaningful values
Increases training dataset size by up to 2x for highly imbalanced datasets, leading to longer training times and higher memory consumption — prohibitive for datasets with millions of samples
k-NN search is computationally expensive — scales as O(n²) for naive implementations. For 1M minority samples, k-NN search can take 10+ minutes even with optimized libraries
May blur decision boundaries if synthetic samples are generated too close to majority class regions, making the classification boundary fuzzier and potentially reducing model precision
Typically reduces precision while improving recall — generates false positives as the model becomes more aggressive in predicting the minority class. Unacceptable in domains where false positives are costly (e.g., medical testing, spam filtering)
Doesn't address root causes of class imbalance like biased data collection, systematic undersampling of minority populations, or label errors — synthetic data cannot replace real data
Failure Modes & Debugging
Noise amplification in noisy minority class
Cause
The minority class contains outliers, mislabeled samples, or anomalies. SMOTE's k-NN algorithm treats these as valid minority samples and generates synthetic neighbors around them, spreading noise throughout the minority class region in feature space.
Symptoms
Test recall improves on clean minority samples but degrades on edge cases. Precision drops significantly. Visual inspection of feature space shows synthetic samples in unexpected regions. Model predictions have high variance on similar inputs.
Mitigation
Clean the minority class before applying SMOTE using outlier detection (Isolation Forest, LOF) or manual review. Use Borderline-SMOTE or ADASYN instead, which focus synthetic generation on borderline samples and ignore isolated outliers. Alternatively, use SMOTE-ENN or SMOTE-Tomek, which apply undersampling to clean noisy synthetic samples after generation.
Invalid synthetic samples from categorical interpolation
Cause
SMOTE applied to datasets with categorical features (e.g., color=['red', 'blue'], encoded as [0, 1]). Linear interpolation between 0 and 1 produces values like 0.4, which has no semantic meaning — it's neither red nor blue.
Symptoms
Synthetic samples have feature values that don't exist in the original data. Model performance degrades or training fails with errors about unexpected feature values. Categorical features show continuous values instead of discrete categories.
Mitigation
Use SMOTE-NC for mixed categorical/continuous data — it handles categoricals separately using mode-based selection instead of interpolation. Alternatively, apply target encoding, embeddings, or one-hot encoding before SMOTE to convert categoricals to continuous representations where interpolation is meaningful.
Data leakage via pre-split SMOTE application
Cause
SMOTE applied to the full dataset before train-test split. Synthetic test samples are interpolations of training samples, so the model has indirectly seen test data during training. This inflates performance metrics artificially.
Symptoms
Extremely high test accuracy/F1 (e.g., 98%+) that doesn't match production performance. Model performs well in validation but poorly in deployment. Test metrics are suspiciously close to training metrics.
Mitigation
ALWAYS split data into train/test FIRST, then apply SMOTE only to the training set. Use imblearn.pipeline.Pipeline for cross-validation to ensure SMOTE is applied correctly inside each fold. Never apply SMOTE to test/validation sets — they must reflect real-world class distribution.
Boundary violation: synthetic samples in majority class region
Cause
k-NN neighbors span across the class boundary due to high intra-class variance or overlapping class distributions. Synthetic samples are generated on the wrong side of the decision boundary, effectively creating mislabeled data.
Symptoms
Precision drops significantly. Manual inspection shows synthetic minority samples in regions dominated by majority samples. Decision boundary becomes overly complex or noisy. High false positive rate in production.
Mitigation
Use Borderline-SMOTE which only generates synthetic samples for instances near the boundary, avoiding deep majority regions. Reduce k (e.g., k=3 instead of k=5) to use closer neighbors. Apply SMOTE-Tomek or SMOTE-ENN to clean boundary-violating synthetics post-generation. Consider hybrid search or ensemble methods if classes are fundamentally overlapping.
Computational bottleneck on large minority classes
Cause
k-NN search scales poorly beyond 100,000 minority samples. Naive O(n²) distance computation becomes prohibitively expensive, causing SMOTE to take hours or run out of memory.
Symptoms
SMOTE preprocessing step dominates pipeline runtime (>30 minutes). Out-of-memory errors during k-NN search. CPU utilization at 100% for extended periods with no progress. Pipeline times out in production.
Mitigation
Subsample the minority class before SMOTE (e.g., randomly select 50,000 samples, apply SMOTE, then combine). Use approximate nearest neighbor algorithms (enabled in imblearn 0.10+). Consider random oversampling or class weights as faster alternatives. For very large datasets (>1M minority samples), use focal loss or cost-sensitive learning instead.
Placement in an ML System
SMOTE sits in the data preprocessing stage of the ML pipeline, specifically after data cleaning and feature extraction but before model training. It's a training-time technique only — the synthetic samples exist solely to improve the classifier during training and are never used for inference or evaluation.
Upstream dependencies: SMOTE requires clean, numerical features. Categorical variables must be encoded (via target encoding, embeddings, or SMOTE-NC). Outliers and label errors should be addressed first, as SMOTE will amplify them. Features should be scaled (StandardScaler, MinMaxScaler) since k-NN is distance-based.
Downstream impact: The balanced dataset produced by SMOTE feeds directly into model training. For tree-based models (Random Forest, XGBoost), SMOTE is often unnecessary as these models handle imbalance natively via class weights. For k-NN, SVM, and neural networks without weighted loss, SMOTE can improve minority recall by 10-30 percentage points.
Pipeline integration: SMOTE should be integrated via imblearn.pipeline.Pipeline to ensure it's applied correctly during cross-validation (only to training folds, never validation folds). This prevents data leakage where synthetic validation samples contaminate training.
Production considerations: In production, SMOTE is applied during model training only. The deployed model receives real-world data at inference time — no synthetic samples are generated. This means SMOTE has zero runtime overhead in production, unlike techniques like ensemble methods or real-time data augmentation.
Pipeline Stage
Data Preprocessing / Training
Upstream
- data-cleaning
- data-validation
- feature-extraction
- train-test-split
Downstream
- model-training
- hyperparameter-tuning
- cross-validation
Scaling Bottlenecks
SMOTE's k-NN search is the primary bottleneck at scale. For minority classes with >100,000 samples, k-NN computation can take 10-30 minutes on a modern CPU. Approximate nearest neighbor algorithms (Ball trees, KD-trees) reduce this to O(n log n) but still struggle beyond 1M samples. Memory consumption is also a concern: resampling a 1:100 imbalanced dataset to 1:1 roughly doubles the training set size, which may exceed available RAM for datasets with millions of features or high-dimensional embeddings. At extreme scale (10M+ minority samples), consider alternatives like focal loss, class weights, or hybrid approaches that partially balance (e.g., 1:100 → 1:10) rather than full balancing.
Production Case Studies
Researchers applied Random Forest with SMOTE to the highly imbalanced Kaggle credit card fraud dataset (284,807 transactions, 0.17% fraud rate). SMOTE was used to balance the training set to a 1:1 ratio, generating synthetic fraud samples. The Random Forest model achieved an F1 score of 0.83 and ROC-AUC of 0.98 on the test set.
SMOTE improved recall for fraudulent transactions from 61% (without resampling) to 87%, while maintaining precision above 80%. This translated to catching 26% more fraud cases with acceptable false positive rates.
A study on motor insurance fraud detection used a hybrid approach combining Center Point SMOTE (CP-SMOTE) with Random Under-Sampling (RUS) across three publicly available motor insurance datasets with varying imbalance ratios. The CP-SMOTE variant focuses synthetic generation on cluster centers rather than individual samples.
The CP-SMOTE + RUS combination consistently enhanced recall for fraudulent claims (89-92% recall) while maintaining acceptable precision (75-82%), outperforming vanilla SMOTE and other resampling techniques across all three datasets.
Researchers applied multiple SMOTE variants (SMOTE, SMOTEENN, Borderline-SMOTE, ADASYN) to imbalanced cancer diagnosis datasets for breast cancer, lung cancer, and colorectal cancer prediction. SMOTEENN (SMOTE + Edited Nearest Neighbors) was used to generate synthetic samples and then clean overlapping instances.
SMOTEENN with Random Forest achieved the highest mean performance at 98.19% accuracy across multiple cancer types, significantly outperforming unbalanced baselines (92.3% accuracy). Recall for rare cancer subtypes improved from 68% to 94%.
A hybrid SMOTE-ENN approach was applied to imbalanced cerebral stroke prediction using patient health records. The dataset had severe imbalance (4.9% stroke cases). The study combined SMOTE for oversampling with Edited Nearest Neighbors (ENN) for cleaning noisy synthetic samples.
The hybrid approach achieved 96.2% accuracy and 91.4% recall for stroke prediction, compared to 89.1% accuracy and 73.6% recall without resampling. This improvement could translate to detecting 18% more at-risk stroke patients in clinical settings.
An optimized XGBoost framework addressed class imbalance in real-time credit card fraud detection using the Kaggle Credit Card Fraud Dataset (285,807 transactions, 0.17% fraud). The approach combined SMOTE-ENN hybrid resampling with XGBoost hyperparameter tuning.
The SMOTE-ENN + XGBoost system achieved 99.7% ROC-AUC and 96.8% F1 score, with fraud detection recall of 98.2% — missing only 1.8% of fraudulent transactions while maintaining low false positive rates suitable for production deployment.
Tooling & Ecosystem
The canonical Python library for SMOTE and imbalanced learning techniques. Provides SMOTE, Borderline-SMOTE, SMOTE-NC, ADASYN, and hybrid methods (SMOTE-ENN, SMOTE-Tomek). Fully compatible with scikit-learn pipelines and offers parallel k-NN computation. Version 0.14.1 as of 2026, actively maintained by scikit-learn-contrib.
An extensive collection of 85+ SMOTE variants and oversampling techniques beyond the standard imblearn implementations. Includes CURE-SMOTE, G-SMOTE, SL-graph-SMOTE, and domain-specific variants. Useful for research and experimentation with advanced SMOTE methods.
While scikit-learn doesn't include SMOTE, it provides the ecosystem (pipelines, cross-validation, metrics) that SMOTE integrates with. The sklearn.utils.resample function offers basic random oversampling/undersampling as a simpler alternative to SMOTE.
R implementation of SMOTE and other data mining techniques for regression and classification. Provides the SMOTE() function for R users, along with utilities for evaluation and visualization of imbalanced datasets.
R package for imbalanced learning with implementations of SMOTE, SMOTE for regression, and multiple resampling strategies. Includes tools for imbalanced regression (rare extreme values) in addition to classification.
Research & References
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P. (2002)Journal of Artificial Intelligence Research, vol. 16, pp. 321-357
The original SMOTE paper introducing k-NN-based synthetic oversampling for imbalanced classification. Demonstrated that SMOTE combined with undersampling outperforms pure undersampling on benchmark datasets, achieving better ROC curves and reducing overfitting compared to random oversampling.
Han, H., Wang, W.Y., Mao, B.H. (2005)International Conference on Intelligent Computing (ICIC 2005)
Introduced Borderline-SMOTE, which identifies minority samples near the decision boundary (with majority neighbors) and generates synthetic samples only for these borderline cases. Showed improved performance over vanilla SMOTE, especially on noisy datasets where generating synthetics deep within minority clusters adds little value.
He, H., Bai, Y., Garcia, E.A., Li, S. (2008)IEEE International Joint Conference on Neural Networks (IJCNN 2008)
Proposed ADASYN, which adaptively generates different numbers of synthetic samples for each minority instance based on its learning difficulty (density of nearby majority samples). Instances surrounded by majority samples get more synthetic neighbors, focusing generation where it's needed most.
Wang, S., Li, Y., Zhang, X., et al. (2025)Scientific Reports, vol. 15, article 1706
Recent work addressing SMOTE's limitation of generating samples only along line segments between neighbors. Proposed expanding the generation space to a convex hull defined by k-neighbors, allowing more diverse synthetic samples. Demonstrated 3-7% improvement in F1 score over vanilla SMOTE on benchmark datasets.
Fernández, A., García, S., Galar, M., et al. (2024)Artificial Intelligence Review
Comprehensive survey of imbalanced learning techniques in healthcare over 2014-2024. Found that SMOTE variants (particularly SMOTE-ENN and Borderline-SMOTE) are the most widely used resampling techniques in medical AI, appearing in 38% of surveyed papers. Highlighted challenges with small sample sizes and high dimensionality in clinical datasets.
Kim, J., Park, S., Lee, H., et al. (2024)PMC (PubMed Central)
Empirical comparison of SMOTE, SMOTEENN, Borderline-SMOTE, and ADASYN on cancer diagnosis tasks. Found that SMOTEENN (SMOTE + Edited Nearest Neighbors) achieved the best balance of recall (94%) and precision (83%) across breast, lung, and colorectal cancer datasets. Provides practical guidelines for choosing SMOTE variants based on dataset characteristics.
Interview & Evaluation Perspective
Common Interview Questions
- ●
Explain how SMOTE works and why it's better than random oversampling
- ●
What are the key hyperparameters in SMOTE and how do they affect performance?
- ●
When would you choose SMOTE over class weights or cost-sensitive learning?
- ●
What are the main failure modes or limitations of SMOTE?
- ●
How would you implement SMOTE in a production ML pipeline with cross-validation?
- ●
What's the difference between SMOTE, Borderline-SMOTE, and ADASYN?
- ●
How does SMOTE handle categorical features? What about mixed data types?
- ●
Describe a scenario where SMOTE would hurt model performance rather than help
Key Points to Mention
- ●
SMOTE generates synthetic minority samples via k-NN interpolation rather than exact duplication, reducing overfitting compared to random oversampling
- ●
The algorithm uses linear interpolation: x_synth = x_i + λ(x_neighbor - x_i) where λ ~ Uniform(0,1), creating samples along line segments between neighbors
- ●
Key hyperparameter k (typically 5) controls the number of nearest neighbors used; too low causes overfitting, too high incorporates distant samples
- ●
SMOTE must be applied ONLY to training data after train-test split to avoid data leakage — synthetic test samples would be interpolations of training data
- ●
Works best with continuous numerical features; requires SMOTE-NC variant for categorical data or proper encoding first
- ●
Computational complexity is O(n²) for naive k-NN search, becoming a bottleneck for minority classes >100K samples
- ●
Trade-off between recall (almost always improves) and precision (often degrades) — suitable when catching minority cases is more important than false positives
- ●
Variants like Borderline-SMOTE (focus on boundary samples) and ADASYN (adaptive generation) address vanilla SMOTE's limitations with noise and overlapping classes
Pitfalls to Avoid
- ●
Claiming SMOTE works for all imbalanced datasets — tree-based models with class weights often outperform SMOTE without the added complexity
- ●
Applying SMOTE before train-test split, causing catastrophic data leakage
- ●
Ignoring that SMOTE assumes Euclidean distance is meaningful — requires feature scaling first
- ●
Using SMOTE on datasets with <50 minority samples where k-NN becomes unreliable
- ●
Forgetting that SMOTE increases training set size and computational cost, which can be prohibitive at scale
- ●
Not mentioning SMOTE-NC when the interviewer asks about datasets with categorical features
Senior-Level Expectation
Senior/staff-level candidates should go beyond textbook SMOTE knowledge and demonstrate production experience. Discuss trade-offs between SMOTE and alternatives (focal loss, class weights, ensemble methods) based on model architecture and scale constraints. Explain how to monitor SMOTE effectiveness in production via recall/precision metrics on held-out imbalanced test sets. Mention computational bottlenecks (k-NN search) and mitigation strategies (approximate nearest neighbors, partial balancing). Show awareness of when SMOTE fails: high-noise datasets, categorical features, overlapping classes, or when precision degradation is unacceptable. Ideally, provide a real example from your experience where you evaluated SMOTE, measured its impact quantitatively (e.g., 'improved minority class recall from 63% to 89% on fraud detection while maintaining 85% precision'), and made an informed decision about whether to deploy it. Being able to say 'I tried SMOTE but class weights worked better for our XGBoost model' shows mature judgment.
Summary
SMOTE (Synthetic Minority Over-sampling Technique) has been a cornerstone of imbalanced learning since its introduction in 2002, offering a principled alternative to naive random oversampling. By generating synthetic minority class samples through k-nearest neighbor interpolation rather than exact duplication, SMOTE addresses class imbalance while reducing overfitting risks that plague simpler approaches.
The technique's core innovation is geometric: identifying minority class samples, finding their k nearest minority neighbors, and creating synthetic examples along the line segments connecting them. This expands the minority class region in feature space, providing the classifier with more diverse training examples and improving decision boundary learning.
However, SMOTE is not a universal solution. It assumes linear interpolation produces realistic samples (problematic for categorical features), can amplify noise if the minority class contains outliers, and may blur decision boundaries when classes overlap significantly. Computational costs scale poorly beyond 100,000 minority samples due to the k-NN search bottleneck, and the precision-recall tradeoff often favors recall at the expense of precision.
Modern practitioners should view SMOTE as one tool in a broader toolkit. Tree-based models (XGBoost, Random Forest) often handle imbalance better via native class weights without the complexity and computational cost of resampling. For neural networks and k-NN classifiers lacking weight support, SMOTE remains highly effective. Variants like Borderline-SMOTE (focusing on boundary samples) and ADASYN (adaptive generation based on difficulty) address vanilla SMOTE's limitations in specific scenarios.
Production deployment requires careful attention to pipeline design: SMOTE must be applied only to training data after train-test split, ideally via imblearn.pipeline.Pipeline for correct cross-validation. Evaluation should focus on minority class recall, precision, and F1 on held-out imbalanced test sets that reflect real-world distributions. Success stories span fraud detection (credit cards, insurance claims), medical diagnosis (rare diseases, cancer subtypes), and manufacturing defect detection — domains where catching minority cases is critical and precision tradeoffs are acceptable.
As we look toward 2026 and beyond, SMOTE continues to evolve with improved variants, approximate nearest neighbor algorithms for scalability, and hybrid approaches combining resampling with algorithmic techniques (cost-sensitive learning, focal loss). Understanding when to apply SMOTE — and when to reach for alternatives — remains a key skill for ML practitioners tackling real-world imbalanced data.