Text Augmentation in Machine Learning
Let's start with a common problem. You're building a sentiment analysis model for customer reviews, but you only have 2,000 labeled examples -- nowhere near enough for a robust classifier. Manual labeling is expensive (INR 50-100 per example if you outsource, INR 1 lakh+ for 2,000 labels), and data collection takes weeks.
Enter text augmentation: the practice of programmatically generating modified versions of your existing text that preserve semantic meaning while introducing surface-level variation. Think of it as a force multiplier for your training data.
Unlike image augmentation where you can flip, crop, or rotate pixels without changing what the image represents, text is discrete and syntactically rigid. You can't just swap random words -- "The movie was excellent" and "The movie was terrible" are one word apart but semantically opposite. This constraint makes text augmentation both more challenging and more interesting than its computer vision counterpart.
Today, text augmentation sits at the core of production NLP systems across domains. From Indian EdTech startups expanding Hindi training sets to multinational chatbot teams diversifying conversational data, augmentation has become the first line of defense against data scarcity. The rise of large language models has only amplified this -- GPT-4 and Claude can now generate paraphrases with semantic fidelity that rule-based methods could never achieve.
BUT here's the catch: augmentation is not free lunch. Poorly applied augmentation introduces noise, label inconsistencies, and semantic drift that silently degrade model performance. The difference between augmentation that improves your F1 by 4 points and augmentation that makes it worse by 2 points often comes down to understanding which technique to use, when to use it, and when to stop.
Concept Snapshot
- What It Is
- A set of techniques for programmatically creating modified versions of text data that preserve semantic meaning while introducing lexical, syntactic, or stylistic variation to expand training sets.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: original text corpus with labels (classification, NER tags, etc.). Outputs: augmented corpus with 2x-10x more examples maintaining label distribution and semantic consistency.
- System Placement
- Applied during the data preparation stage, before training. Sits between data collection/labeling and model training in the ML pipeline.
- Also Known As
- textual data augmentation, NLP augmentation, paraphrasing augmentation, synthetic text generation, data diversification
- Typical Users
- NLP engineers, ML engineers, data scientists, annotation teams, research scientists
- Prerequisites
- Basic NLP preprocessing, Text classification fundamentals, Understanding of training data bias, Python programming
- Key Terms
- synonym replacementback-translationEDAcontextual embeddingssemantic preservationlabel consistencyparaphrasingWordNetNLPAug
Why This Concept Exists
The Labeled Data Bottleneck
Deep learning models are data-hungry beasts. A BERT-based classifier might need 5,000-10,000 labeled examples per class to reach production-grade performance. BUT in most real-world scenarios, you'll be lucky to have 500-1,000 labels. Manual annotation is expensive -- at INR 75 per example, labeling 10,000 samples costs INR 7.5 lakh. For a bootstrapped Indian startup, that's often a non-starter.
Three Trends That Made This Critical
Trend 1: Transfer learning raised the bar. Pre-trained models like BERT demonstrated that with enough data, NLP systems could achieve near-human performance. BUT they also revealed that fine-tuning on tiny datasets leads to severe overfitting. The gap between "lots of data" and "little data" widened dramatically.
Trend 2: Long-tail phenomena dominate real applications. Production systems encounter rare intents, slang, misspellings, and edge cases that training sets inevitably miss. A customer support chatbot trained only on formal English fails when users type "plz refnd asap" -- augmentation can help simulate this variation.
Trend 3: Domain adaptation requires retraining. A sentiment model trained on movie reviews performs poorly on product reviews. Augmentation allows you to stretch limited in-domain data further while adapting a model from a source domain.
The Algorithmic Foundation
Text augmentation rests on a simple linguistic insight: natural language exhibits enormous surface variation while preserving underlying meaning. "The food was great" and "The meal was excellent" are semantically equivalent despite sharing no words. Early augmentation techniques exploited this via synonym dictionaries (WordNet) and rule-based transformations (EDA operations). Modern methods leverage learned representations -- contextual embeddings from BERT or generative capabilities of GPT-4 -- to produce more sophisticated, context-aware paraphrases.
Key Takeaway: Text augmentation exists because labeled data is the primary bottleneck in NLP, and programmatic diversification of existing data is far cheaper and faster than manual annotation -- IF done correctly.
Core Intuition & Mental Model
The Core Promise
Here's the fundamental guarantee: given a labeled text example, augmentation techniques can generate N additional examples that share the same label but exhibit surface-level variation -- expanding your effective training set by N+1x without human annotation.
The word "surface-level" is load-bearing. Good augmentation changes how something is said, not what is said. If the original text says "I love this phone," an augmented version might say "I adore this device" -- different words, same sentiment, same label.
What Text Augmentation Does NOT Do
This is where I see teams go wrong. Augmentation is not a replacement for collecting diverse, representative training data. It's a multiplier, not a substitute. If your dataset is fundamentally biased (e.g., all positive reviews from one demographic), augmentation will faithfully amplify that bias.
The boundary is clear: augmentation owns diversification within the existing semantic space, not expansion into new semantic regions.
A Useful Mental Model
Think of your training data as a sparse sample from a much larger space of ways to express the same ideas. Augmentation's job is to fill in the gaps between those samples by interpolating plausible variations. It's like having 100 photos of a car from different angles -- you can reasonably infer what the car looks like from 45 degrees even if you don't have that exact photo.
BUT if all 100 photos are of sedans, augmentation won't help you recognize SUVs. That requires new data, not more variation on existing data.
Expert Note: The quality ceiling of augmentation is determined by the quality and diversity of your seed data. Start by ensuring your base dataset is representative before scaling it with augmentation. Garbage in, garbage out -- only faster.
Technical Foundations
The Math (Don't Worry, We'll Build Up to It)
Let's formalize what text augmentation actually does. I'll explain the intuition first, then give you the notation.
Intuition: You have a dataset of (text, label) pairs. You want more pairs with the same label distribution. Augmentation applies transformations that change the text but preserve the label.
Formally: Given a training set where is a text sequence and is its label, an augmentation function generates a new example such that:
Here, is a labeling function that maps text to labels. The augmentation function must preserve the label (semantic meaning) while modifying the surface form.
Measuring Semantic Preservation
How do we know if really has the same meaning as ? We can use several proxies:
- Embedding similarity: for some threshold , typically 0.85-0.95
- Entailment score: An NLI model predicts bidirectional entailment between and
- Human evaluation: Annotators judge whether the augmented text preserves the original label (gold standard, but expensive)
Types of Augmentation Operations
Augmentation functions typically fall into four categories:
Lexical substitution: Replace words with synonyms or semantically similar words:
Insertion: Add words that don't change meaning:
Deletion: Remove non-critical words:
Structural transformation: Paraphrase at the sentence level:
The Augmentation Ratio
A critical hyperparameter is the augmentation ratio , the number of augmented examples generated per original example. Common values are . Higher increases diversity but risks introducing more noise.
The optimal depends on your base dataset size. For , use . For , use .
Warning: There's a point of diminishing returns. Empirical studies show that beyond , validation performance often degrades as augmented noise overwhelms the original signal. Less is sometimes more.
Internal Architecture
A production text augmentation pipeline typically consists of four stages: a text preprocessing layer that cleans and tokenizes input, an augmentation engine that applies one or more transformation strategies, a quality filter that removes semantically inconsistent outputs, and a label preservation validator that ensures augmented examples maintain the correct labels. Let's walk through each stage.
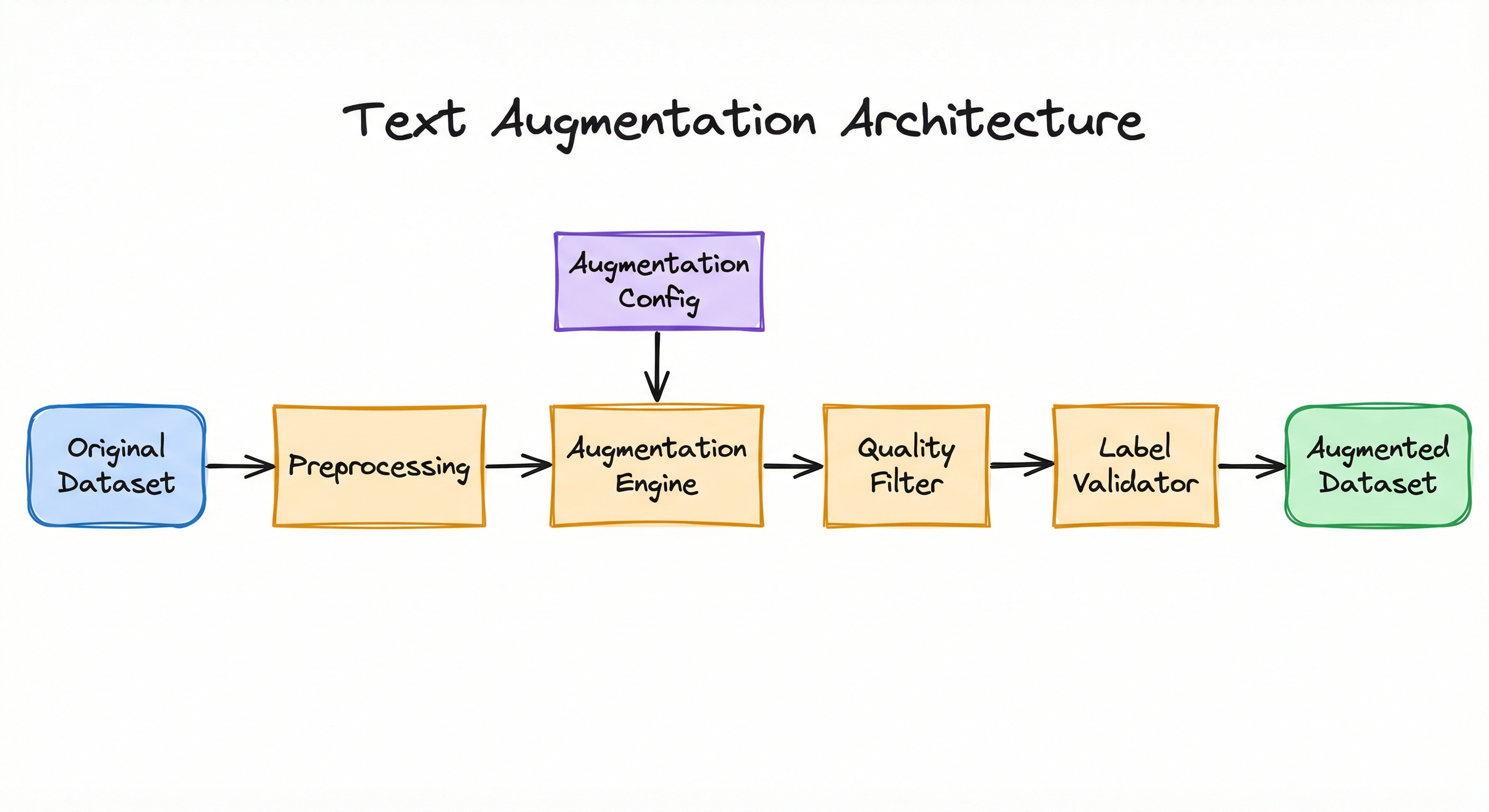
Key Components
Preprocessing Layer
Cleans, tokenizes, and normalizes input text. Identifies protected entities (proper nouns, numbers) that should not be modified during augmentation.
Augmentation Engine
Applies selected augmentation strategies (synonym replacement, back-translation, contextual insertion, etc.). Manages augmentation ratio and randomness parameters.
Quality Filter
Removes augmented examples that deviate too far from the original semantically. Uses embedding similarity, fluency scores, or rule-based checks.
Label Validator
Verifies that augmented examples maintain label consistency. May use a held-out classifier or human-in-the-loop sampling for validation.
Configuration Manager
Stores augmentation parameters: techniques to apply, augmentation ratio, quality thresholds, protected entity lists, and task-specific constraints.
Data Flow
Here's how data flows through the system:
Augmentation Path: Original labeled examples -> preprocessing (tokenization, entity recognition) -> augmentation engine applies transformations -> quality filter scores and prunes -> label validator checks consistency -> augmented training set.
Feedback Loop: Periodically sample augmented examples for human review to detect semantic drift or label inconsistencies. Update quality thresholds based on validation performance.
The quality filter and label validator are critical -- they're your defense against the silent degradation that kills augmentation pipelines. Without them, you're flying blind.
A linear flow from 'Original Dataset' -> 'Preprocessing' -> 'Augmentation Engine' -> 'Quality Filter' -> 'Label Validator' -> 'Augmented Dataset', with 'Augmentation Config' feeding into the engine.
How to Implement
Four Approaches to Implementation
Implementation patterns fall into four broad categories, each with different tradeoffs:
Option A: Rule-based (EDA, synonym replacement) -- fast, cheap, no external dependencies, BUT limited semantic awareness and can produce ungrammatical outputs.
Option B: Model-based (back-translation, BERT masking) -- better quality and contextual awareness, BUT requires running inference, slower and more expensive.
Option C: LLM-based (GPT-4, Claude paraphrasing) -- highest quality, excellent semantic preservation, BUT expensive (INR 1.5-3 per 1K examples) and requires API access.
Option D: Hybrid -- combine multiple techniques with quality filtering, the production standard for serious applications.
For a bootstrapped Indian startup, start with Option A (EDA via NLPAug) to establish a baseline, then selectively apply Option C for hard examples or underrepresented classes where quality matters most.
Cost Note: For 10,000 examples with , EDA costs effectively zero (runs locally in minutes). Back-translation with Google Translate API costs ~INR 1,200. GPT-4 paraphrasing costs ~INR 12,000-15,000. Choose wisely based on your budget and quality requirements.
import nlpaug.augmenter.word as naw
import nlpaug.augmenter.sentence as nas
text = "The customer service was excellent and the product quality exceeded my expectations."
# Synonym replacement using WordNet
aug_syn = naw.SynonymAug(aug_src='wordnet', aug_max=3)
augmented_syn = aug_syn.augment(text)
print("Synonym:", augmented_syn)
# Output: "The client service was excellent and the product quality exceeded my expectations."
# Random insertion
aug_insert = naw.ContextualWordEmbsAug(
model_path='bert-base-uncased',
action="insert",
aug_max=2
)
augmented_insert = aug_insert.augment(text)
print("Insert:", augmented_insert)
# Random deletion (manually, as EDA doesn't have a direct delete augmenter)
import random
words = text.split()
if len(words) > 5:
num_delete = max(1, int(0.1 * len(words)))
keep_indices = random.sample(range(len(words)), len(words) - num_delete)
keep_indices.sort()
augmented_delete = ' '.join([words[i] for i in keep_indices])
print("Delete:", augmented_delete)
# Random swap (manually)
if len(words) > 2:
words_copy = words.copy()
for _ in range(max(1, int(0.1 * len(words)))):
idx1, idx2 = random.sample(range(len(words_copy)), 2)
words_copy[idx1], words_copy[idx2] = words_copy[idx2], words_copy[idx1]
augmented_swap = ' '.join(words_copy)
print("Swap:", augmented_swap)EDA (Easy Data Augmentation) consists of four simple operations: synonym replacement via WordNet, random insertion of contextually appropriate words, random deletion of low-information words, and random word swap. The paper showed that applying these operations with low probabilities (10-15%) significantly improves classification accuracy, especially on small datasets (<5,000 examples). The beauty of EDA is its simplicity and zero-cost operation.
import nlpaug.augmenter.sentence as nas
# Back-translation via Google Translate API (requires setup)
aug_bt = nas.BackTranslationAug(
from_model_name='google', # or 'facebook' for offline model
to_model_name='google',
from_lang='en',
to_lang='hi', # translate to Hindi and back
device='cpu'
)
text = "I absolutely love this product, it works perfectly!"
augmented = aug_bt.augment(text)
print("Back-translated:", augmented)
# Example output: "I really love this product, it works great!"
# For offline operation, use MarianMT models
import nlpaug.augmenter.sentence as nas
aug_bt_offline = nas.BackTranslationAug(
from_model_name='facebook/wmt19-en-de',
to_model_name='facebook/wmt19-de-en',
device='cpu'
)
augmented_offline = aug_bt_offline.augment(text)
print("Back-translated (offline):", augmented_offline)Back-translation translates text to an intermediate language and back to the source language, producing paraphrases. The round-trip translation introduces lexical variation while generally preserving meaning. For English, common intermediate languages are French, German, Spanish, and Hindi. The technique is particularly effective for sentiment analysis and intent classification where surface variation matters but core semantics must be preserved. NLPAug supports both online APIs (Google Translate) and offline models (MarianMT from HuggingFace).
import nlpaug.augmenter.word as naw
# BERT-based contextual substitution
aug_bert_sub = naw.ContextualWordEmbsAug(
model_path='bert-base-uncased',
action='substitute',
aug_max=3, # max 3 words to substitute
aug_p=0.3, # probability per word
top_k=10 # sample from top-10 predictions
)
text = "The movie was boring and predictable."
augmented = aug_bert_sub.augment(text, n=3) # generate 3 variations
for i, aug_text in enumerate(augmented):
print(f"Variation {i+1}: {aug_text}")
# Example outputs:
# "The film was boring and predictable."
# "The movie was dull and predictable."
# "The movie was boring and expected."
# BERT-based contextual insertion
aug_bert_ins = naw.ContextualWordEmbsAug(
model_path='bert-base-uncased',
action='insert',
aug_max=2
)
augmented_ins = aug_bert_ins.augment(text)
print("With insertion:", augmented_ins)
# Example: "The new movie was quite boring and very predictable."Contextual word embeddings from BERT provide context-aware substitutions and insertions. Unlike WordNet synonyms (which are context-free), BERT predictions are conditioned on surrounding words, leading to more fluent and semantically appropriate augmentations. The action parameter controls whether to 'substitute' existing words or 'insert' new ones. The aug_p parameter controls augmentation intensity -- lower values (0.1-0.2) are safer for maintaining semantic fidelity. This is the recommended approach when you need higher quality than EDA but can't afford LLM APIs.
from openai import OpenAI
import json
client = OpenAI(api_key="your-api-key")
def gpt4_paraphrase(text, label, num_variations=3):
prompt = f"""Generate {num_variations} paraphrased versions of the following text.
Each paraphrase must:
1. Preserve the exact sentiment/intent ({label})
2. Use different words and sentence structures
3. Maintain fluency and naturalness
4. Be roughly the same length
Original text: "{text}"
Return only a JSON array of {num_variations} paraphrased strings, nothing else."""
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a linguistic expert specializing in paraphrasing while preserving meaning."},
{"role": "user", "content": prompt}
],
temperature=0.8, # higher for diversity
max_tokens=300
)
paraphrases = json.loads(response.choices[0].message.content)
return paraphrases
# Example usage
original = "The restaurant had terrible service and the food was cold."
label = "negative"
augmented = gpt4_paraphrase(original, label, num_variations=3)
for i, para in enumerate(augmented):
print(f"Paraphrase {i+1}: {para}")
# Example outputs:
# "The service at the restaurant was awful and they served cold food."
# "Terrible experience - poor service and the food arrived cold."
# "The food was cold and the service was really bad."LLM-based paraphrasing with GPT-4 or Claude produces the highest-quality augmentations with excellent semantic preservation. By explicitly instructing the model to preserve the label and providing task context, you get paraphrases that are fluent, diverse, and maintain label consistency. The tradeoff is cost: at 0.06 per 1K output tokens, augmenting 10,000 examples with 3 variations each costs approximately $12-18 (INR 1,000-1,500). Use this selectively for: (1) small, high-value datasets, (2) hard examples near decision boundaries, (3) underrepresented classes that need quality over quantity.
from sentence_transformers import SentenceTransformer, util
import nlpaug.augmenter.word as naw
import nlpaug.augmenter.sentence as nas
class AugmentationPipeline:
def __init__(self, similarity_threshold=0.85):
self.similarity_threshold = similarity_threshold
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
# Multiple augmenters for diversity
self.augmenters = [
naw.SynonymAug(aug_src='wordnet', aug_max=3),
naw.ContextualWordEmbsAug(
model_path='bert-base-uncased',
action='substitute',
aug_max=2
),
nas.BackTranslationAug(
from_model_name='facebook/wmt19-en-de',
to_model_name='facebook/wmt19-de-en'
)
]
def is_semantically_similar(self, text1, text2):
"""Check if augmented text preserves semantic meaning."""
emb1 = self.encoder.encode(text1, convert_to_tensor=True)
emb2 = self.encoder.encode(text2, convert_to_tensor=True)
similarity = util.cos_sim(emb1, emb2).item()
return similarity >= self.similarity_threshold
def augment_with_filtering(self, text, label, num_variations=4):
"""Generate augmented examples with quality filtering."""
augmented = []
attempts = 0
max_attempts = num_variations * 3 # try 3x to get desired count
while len(augmented) < num_variations and attempts < max_attempts:
# Randomly select an augmenter
augmenter = random.choice(self.augmenters)
try:
aug_text = augmenter.augment(text)
if isinstance(aug_text, list):
aug_text = aug_text[0]
# Quality filter: check semantic similarity
if self.is_semantically_similar(text, aug_text):
# Additional checks
if len(aug_text.split()) >= 3: # not too short
if aug_text != text: # actually different
augmented.append((aug_text, label))
except Exception as e:
print(f"Augmentation failed: {e}")
attempts += 1
return augmented
# Usage
pipeline = AugmentationPipeline(similarity_threshold=0.85)
original_text = "The battery life on this laptop is amazing!"
original_label = "positive"
augmented_examples = pipeline.augment_with_filtering(
original_text,
original_label,
num_variations=4
)
for i, (text, label) in enumerate(augmented_examples):
print(f"Aug {i+1} ({label}): {text}")A production augmentation pipeline combines multiple techniques with quality filtering to balance diversity and semantic fidelity. The pipeline: (1) applies multiple augmentation strategies randomly to avoid overfitting to one technique, (2) uses sentence embeddings to filter out augmented examples that drift too far semantically (cosine similarity < 0.85), (3) applies additional sanity checks (length, uniqueness), and (4) retries until the desired number of high-quality variations is obtained. This approach is more robust than any single technique and is the pattern used in production systems at companies like Swiggy, Ola, and Flipkart for expanding training data.
# Production augmentation config (YAML)
augmentation:
enabled: true
ratio: 4 # generate 4 augmented examples per original
techniques:
- name: synonym_replacement
probability: 0.4
params:
aug_max: 3
source: wordnet
- name: contextual_substitution
probability: 0.3
params:
model: bert-base-uncased
aug_max: 2
aug_p: 0.2
- name: back_translation
probability: 0.2
params:
intermediate_lang: de
model: facebook/wmt19
- name: gpt4_paraphrase
probability: 0.1 # expensive, use sparingly
params:
model: gpt-4
temperature: 0.8
budget_limit: 10000 # max INR spend
quality_filter:
enabled: true
min_similarity: 0.85
min_length: 3
max_length_ratio: 2.0
protected_entities:
- PERSON
- ORG
- GPE
- PRODUCT
class_specific:
minority_classes:
alpha_multiplier: 2.0 # 2x augmentation for minority classes
min_examples_threshold: 1000Common Implementation Mistakes
- ●
Augmenting test/validation sets -- NEVER do this. Augmentation should only be applied to training data. If you augment test data, you're evaluating on artificially easy, semantically redundant examples that don't reflect real-world distribution. This inflates your metrics and gives you false confidence.
- ●
Using high augmentation ratios (alpha > 8) indiscriminately -- more is not always better. Beyond a certain point, augmented noise overwhelms original signal, and validation performance degrades. Always validate the optimal alpha on a held-out set. For most tasks, alpha = 2-4 is the sweet spot.
- ●
Ignoring class imbalance when augmenting -- if your dataset has 5,000 positive and 500 negative examples, applying uniform augmentation amplifies the imbalance (50,000 positive, 5,000 negative). Instead, apply higher alpha to minority classes to rebalance the distribution.
- ●
Not validating semantic preservation -- blindly trusting that augmented examples maintain the original label without spot-checking is a recipe for disaster. Sample 100-200 augmented examples and manually verify label consistency, or use an NLI model to flag potential semantic drift.
- ●
Augmenting entity-heavy text without protection -- in domains like named entity recognition or product reviews, augmenting proper nouns (brand names, person names, locations) can destroy semantic meaning. Always protect entities during augmentation, or use entity-aware augmenters that preserve NER tags.
When Should You Use This?
Use When
You have a small labeled dataset (<5,000 examples per class) and manual annotation is expensive or time-consuming. Augmentation can 2x-4x your effective training set at near-zero cost.
Your model is overfitting to the training set (large train-validation gap) because of limited data diversity. Augmentation introduces regularization through synthetic variation.
You need to rebalance a class-imbalanced dataset without collecting more minority class examples. Apply higher augmentation ratios to underrepresented classes.
You're adapting a model to a new domain (e.g., movie reviews to product reviews) and have limited in-domain data. Augmentation can stretch the in-domain data further during fine-tuning.
You need to simulate linguistic variation (typos, slang, paraphrases) that your model will encounter in production but that's underrepresented in your training set.
Avoid When
You already have a large, diverse, representative dataset (>50,000 examples per class). Augmentation provides diminishing returns and can even hurt if it introduces noise. Focus on data quality and model architecture instead.
Your task requires precise factual accuracy (question answering, fact verification) where augmentation risks introducing semantic drift or label errors. In these cases, synthetic data from an LLM with verification is safer.
You're working on structured prediction tasks (NER, dependency parsing) where token-level alignments are critical. Standard text augmentation breaks these alignments -- you need span-preserving augmentation techniques.
Your labels are noisy or inconsistent to begin with. Augmentation amplifies label noise, making the problem worse. Clean your labels first, then augment.
You have the budget and timeline for manual annotation. Human-labeled data is almost always better than augmented data for downstream performance. Augmentation is a cost-saving measure, not a performance-maximizing one.
Key Tradeoffs
The Fundamental Tradeoff: Diversity vs. Semantic Fidelity
Every augmentation technique lies on a spectrum. Rule-based methods (EDA) are fast and diverse but can produce ungrammatical or semantically inconsistent outputs. LLM-based methods (GPT-4 paraphrasing) produce fluent, semantically faithful outputs but are expensive and slower.
The sweet spot depends on your task and budget. For intent classification where exact wording doesn't matter much ("book a flight" vs. "reserve a flight"), aggressive augmentation works well. For sentiment analysis where a single word flip changes the label ("not good" vs. "good"), you need conservative, high-fidelity augmentation.
The Second Axis: Cost vs. Quality
EDA and synonym replacement are effectively free (run locally in seconds for 10,000 examples). Back-translation costs ~INR 0.1-0.2 per example with offline models, or INR 1-2 per example with Google Translate API. GPT-4 paraphrasing costs ~INR 1.5-3 per example.
For a bootstrapped Indian startup augmenting 10,000 examples with alpha=4:
- EDA: INR 0 (free)
- Back-translation (offline): INR 4,000-8,000
- GPT-4: INR 60,000-1,20,000
The cost difference is two orders of magnitude. Start cheap (EDA), validate improvement, then invest in expensive techniques only for high-value examples or classes where quality matters most.
Rule of Thumb: Use EDA for fast iteration, contextual embeddings (BERT) for production baselines, and LLM paraphrasing for critical minority classes or hard examples near decision boundaries.
Alternatives & Comparisons
LLM data generators (like GPT-4 prompted to generate examples from scratch) create entirely new examples rather than modifying existing ones. Augmentation starts with real data and diversifies it; generation starts from scratch with a prompt. Generation is better when you have near-zero labeled data (<100 examples) or need to explore new semantic regions. Augmentation is better when you have seed data (500-5,000 examples) and want to expand it cost-effectively. In production, you often use both: generate to bootstrap, then augment to scale.
Active learning selectively labels the most informative examples rather than augmenting existing ones. It's complementary to augmentation, not a replacement. Active learning finds gaps in your data coverage; augmentation fills gaps around existing data. Use active learning to collect diverse real examples, then augment them to maximize training set size. The combination is more powerful than either alone.
Manual data collection (scraping, crowdsourcing, annotation) provides real, naturally distributed data rather than synthetic variations. It's always better for final model quality, but it's slow (weeks) and expensive (INR 50-100 per example). Augmentation is a stopgap that buys you time and budget to collect more data later. For time-sensitive deployments, augment first to ship v1, then invest in real data collection for v2.
Pros, Cons & Tradeoffs
Advantages
Dramatically expands training set size (2x-10x) at near-zero cost compared to manual annotation. For a 5,000-example dataset, augmentation costs effectively nothing; manual annotation of 20,000 more examples would cost INR 10-15 lakh.
Reduces overfitting by introducing regularization through synthetic variation, especially critical for small datasets (<5,000 examples) where models memorize training data.
Enables class rebalancing without collecting more minority class data -- apply higher augmentation ratios to underrepresented classes to correct imbalanced distributions.
Simulates linguistic variation (paraphrases, typos, slang) that models will encounter in production but that's underrepresented in training data, improving robustness.
Fast iteration cycle: augment a dataset in minutes to hours rather than weeks for manual annotation, enabling rapid prototyping and experimentation.
Preserves privacy in sensitive domains -- augment existing data rather than collecting more potentially sensitive examples from users.
Disadvantages
Risk of semantic drift -- augmented examples may not preserve the original label, introducing label noise that degrades model performance. This is especially problematic with aggressive augmentation (high alpha, complex transformations).
Cannot expand into new semantic regions -- augmentation diversifies within the existing data distribution but doesn't add genuinely new concepts or edge cases. If your training data lacks a class of examples, augmentation won't discover it.
Quality ceiling is lower than real data -- even high-quality LLM paraphrasing introduces artifacts and patterns that differ subtly from natural text, potentially limiting final model performance.
Amplifies existing biases -- if your seed data is biased (e.g., all positive reviews from one demographic), augmentation faithfully replicates that bias 10x over, making the problem worse.
Not suitable for all tasks -- structured prediction (NER, parsing), factual QA, and multi-lingual tasks require specialized augmentation that's harder to get right. Naive augmentation can break token alignments or introduce factual errors.
Diminishing returns at scale -- once you have >50,000 examples, augmentation provides minimal lift and can even hurt if it introduces noise. There's an optimal augmentation point beyond which more is worse.
Failure Modes & Debugging
Semantic drift / label inconsistency
Cause
Aggressive augmentation (high alpha, high aug_p) or low-quality techniques (random synonym replacement without context) produce examples that change the semantic meaning, resulting in incorrect labels. For instance, "The movie was not boring" -> "The film was boring" flips the sentiment.
Symptoms
Validation accuracy degrades compared to training on only original data. Manual inspection reveals augmented examples with incorrect labels. Model predictions on augmented data contradict the assigned labels.
Mitigation
Implement semantic similarity filtering using sentence embeddings (cosine similarity threshold ~0.85-0.9). Sample and manually review 100-200 augmented examples per class to catch drift. Use conservative augmentation parameters (aug_p=0.1-0.2, alpha=2-4). For critical applications, validate augmented examples with a held-out classifier or human-in-the-loop.
Entity corruption in entity-heavy domains
Cause
Synonym replacement or word substitution modifies proper nouns, brand names, or domain-specific terms, destroying meaning. E.g., "I love my iPhone" -> "I love my smartphone" loses specificity, or worse, "I love my Samsung" inverts the brand.
Symptoms
NER models trained on augmented data perform poorly on entity-heavy sentences. Product review sentiment models confuse brands. Manual inspection shows entities being replaced incorrectly.
Mitigation
Use NER tagging before augmentation to protect entities (PERSON, ORG, GPE, PRODUCT). Configure augmenters to skip protected spans. For domain-specific terms, maintain a custom entity lexicon and exclude matches from augmentation. Consider entity-aware augmentation techniques that preserve NER labels.
Class imbalance amplification
Cause
Applying uniform augmentation ratio to all classes amplifies existing imbalances. If you have 5,000 majority class examples and 500 minority class examples, augmenting both by 4x gives you 20,000 vs. 2,000 -- a 10:1 ratio, worse than the original 10:1.
Symptoms
Model performance on minority classes degrades despite more training data. Confusion matrix shows the model is biased toward predicting majority classes. Precision-recall curves skew heavily.
Mitigation
Apply class-specific augmentation ratios: higher alpha for minority classes, lower for majority classes. Aim for balanced class distribution post-augmentation. Use weighted loss functions or oversampling/undersampling in conjunction with augmentation. Monitor per-class metrics (F1, recall) on validation set.
Test set contamination
Cause
Augmentation is mistakenly applied to test or validation sets, creating artificially easy evaluation conditions where test examples are near-duplicates of training examples, inflating metrics.
Symptoms
Unrealistically high test accuracy (>95%) that doesn't translate to production. Large gap between test performance and real-world performance. Augmented test examples are semantically redundant.
Mitigation
NEVER augment test or validation sets -- this is a hard rule. Implement data pipeline checks that prevent augmentation from running on non-training splits. Use versioned datasets with clear train/val/test splits. Document augmentation steps clearly in your pipeline to avoid accidental contamination.
Augmentation noise overwhelming original signal
Cause
Excessive augmentation ratio (alpha > 16) or low-quality augmentation techniques generate so much noise that the model learns augmentation artifacts rather than the underlying task, degrading performance.
Symptoms
Validation accuracy peaks at low alpha (2-4) then degrades as alpha increases. Model predictions on real data are worse than on a baseline trained without augmentation. Error analysis reveals the model has learned augmentation-specific patterns.
Mitigation
Sweep augmentation ratios (alpha = 1, 2, 4, 8, 16) on a validation set and select the value that maximizes performance -- often alpha = 2-4. Use quality filtering to prune low-quality augmented examples. Monitor the ratio of augmented to original data; keep it under 80% augmented, 20% original for safety.
Placement in an ML System
Where Does It Sit in the Pipeline?
Text augmentation sits at the end of data preparation, after collection, labeling, and cleaning, but before training begins. It's a pre-training step, not an online or training-time operation (though online augmentation during training is possible with tools like Albumentations for images -- less common for text).
The output of augmentation is a larger training set that gets fed into your model training loop. Validation and test sets are NOT augmented -- they remain pristine to provide unbiased evaluation.
In production MLOps pipelines, augmentation is often a scheduled job: when new labeled data arrives, it's augmented and merged into the training corpus, triggering a retraining job. This creates a virtuous cycle where small amounts of new labeled data are amplified through augmentation.
Pipeline Stage
Data Preparation / Training
Upstream
- Data Collection
- Data Labeling
- Data Cleaning
- Text Preprocessing
Downstream
- Model Training
- Validation
- Error Analysis
Scaling Bottlenecks
Primary bottlenecks are compute cost for model-based augmentation (BERT, back-translation) and API cost for LLM-based augmentation (GPT-4). EDA is effectively free, but BERT contextual augmentation requires GPU inference for embeddings, and back-translation requires running two translation models per example.
For 100,000 examples with alpha=4, EDA completes in ~10 minutes on a CPU. BERT contextual augmentation takes ~2 hours on a single GPU. Back-translation with MarianMT takes ~8-10 hours on CPU. GPT-4 paraphrasing costs ~INR 3-6 lakh and takes 5-8 hours due to rate limits.
At very large scale (millions of examples), augmentation shifts from a one-time cost to an ongoing pipeline cost. You'll need to batch augmentation, parallelize across GPUs/workers, and cache augmented datasets to avoid re-computation.
Augmented datasets are 2x-10x larger than originals. For a 10 GB text corpus with alpha=4, you'll need 40-50 GB of storage for the augmented version. This impacts data loading during training -- use efficient formats (HDF5, Parquet) and data streaming rather than loading everything into memory.
Production Case Studies
Google Research demonstrated Unsupervised Data Augmentation (UDA), which combines back-translation and contextual augmentation with semi-supervised learning. They applied UDA to text classification benchmarks including IMDB sentiment analysis (25,000 labeled reviews) and achieved state-of-the-art results by augmenting the labeled set and leveraging unlabeled data. The technique reduced error rates on IMDB from 4.51% (supervised baseline) to 4.20% with augmentation and 2.89% when combined with unlabeled data and consistency training. UDA was particularly effective on small labeled datasets (<5,000 examples), showing that augmentation + semi-supervision can rival fully supervised models trained on 10x more labeled data.
Error rate reduced from 6.5% to 4.2% on IMDB sentiment classification with augmentation alone (no semi-supervision), demonstrating ~35% relative error reduction. When combined with unlabeled data, achieved 2.89% error -- competitive with models trained on 10x more labeled data.
Swiggy's NLP team uses text augmentation to improve intent classification for customer support chatbots. With support queries spanning Hindi, English, and Hinglish (code-mixed), labeled data is scarce for many intents (e.g., "delayed order," "missing items"). The team applies a hybrid augmentation strategy: EDA for English, back-translation for Hindi (English -> Hindi -> English), and custom synonym dictionaries for Hinglish slang. This expands their training set from ~3,000 labeled examples per intent to ~12,000 (alpha=4), improving chatbot accuracy from 78% to 86% intent classification accuracy. Augmentation is particularly critical for handling linguistic variation in Hinglish, where users type "kab aayega" (when will it come), "jaldi bejo" (send quickly), etc. -- variations that augmentation helps simulate.
Intent classification accuracy improved from 78% to 86% (8 percentage points) after applying hybrid augmentation (EDA + back-translation + custom Hinglish dictionaries). This reduced support ticket escalation by ~20%, saving operational costs.
Jason Wei and Kai Zou from UMass Amherst introduced Easy Data Augmentation (EDA), demonstrating that four simple operations -- synonym replacement, random insertion, random swap, and random deletion -- consistently improve text classification accuracy across five benchmark datasets (SST-2, CR, MPQA, Subj, TREC). Critically, they showed that EDA provides the largest gains on small datasets: when training on only 500 examples per class (vs. the full dataset), EDA improved average accuracy by 3.0 percentage points. The paper also established best practices for augmentation ratios, showing that alpha=4 is optimal for small datasets (<500 examples/class), alpha=2-4 for medium (500-5,000), and alpha=1-2 for large (>5,000). This work formalized augmentation as a standard technique for low-resource NLP.
Average classification accuracy improved by 3.0 percentage points across five datasets when training on only 500 examples per class. On SST-2 (sentiment), accuracy improved from 83.5% to 87.2% with EDA on the small training set, closing the gap toward the full-dataset performance.
BYJU'S uses text augmentation for question classification in their AI tutor, which needs to categorize student questions into topics (algebra, geometry, physics, etc.). With questions spanning English and regional languages (Hindi, Tamil, Telugu, Bengali), labeled training data is limited -- especially for regional languages. The team applies back-translation (English <-> Hindi, English <-> Tamil) to augment the question corpus, expanding from ~8,000 labeled questions to ~40,000 (alpha=5). They also use GPT-4 to generate paraphrased questions for underrepresented topics (e.g., advanced trigonometry, organic chemistry), ensuring the augmented questions maintain mathematical correctness. Augmentation improved topic classification F1 score from 81% to 89%, reducing misrouting of questions and improving student satisfaction with the AI tutor.
Topic classification F1 score improved from 81% to 89% after augmentation, reducing question misrouting by 35%. Student satisfaction scores with the AI tutor increased from 3.8/5 to 4.3/5 as questions were correctly routed to relevant explanations.
Tooling & Ecosystem
Comprehensive Python library for textual augmentation with support for character, word, and sentence-level transformations. Includes synonym replacement (WordNet), contextual word embeddings (BERT, RoBERTa), back-translation, TF-IDF-based insertion, and more. The most feature-complete open-source augmentation library.
Lightweight Python library for text augmentation built on NLTK, Gensim, and TextBlob. Supports WordNet synonym replacement, word embeddings (Word2Vec, GloVe), and EDA operations. Simpler API than NLPAug, good for beginners.
Reference implementation of the EDA paper with four operations: synonym replacement, random insertion, random swap, random deletion. Minimal dependencies, easy to integrate, and surprisingly effective for small datasets.
Framework for adversarial attacks and augmentation in NLP. Originally designed for robustness testing, but includes augmentation modules for synonym replacement, back-translation, and embedding-based substitution. Good for generating adversarial training examples.
Fast image augmentation library with experimental text augmentation support via community contributions. Not as mature as NLPAug but useful if you're already using Albumentations for vision tasks and want a unified API.
Use GPT-4 or GPT-3.5 for high-quality paraphrasing and data augmentation via API. More expensive than offline methods but produces the most fluent and semantically faithful augmentations. Recommended for critical minority classes or hard examples.
Translation API for back-translation augmentation. Supports 100+ languages, including Indian languages (Hindi, Tamil, Telugu, Bengali, Marathi). More accurate than offline models but costs ~$20 per million characters.
Research & References
Jason Wei & Kai Zou (2019)EMNLP-IJCNLP 2019
Introduced four simple augmentation operations (synonym replacement, random insertion, random swap, random deletion) that consistently improve text classification accuracy, especially on small datasets (<500 examples/class). Established best practices for augmentation ratios and demonstrated average gains of 3.0 percentage points on small training sets across five benchmark datasets.
Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong & Quoc V. Le (2020)NeurIPS 2020
Demonstrated that combining augmentation (back-translation, TF-IDF insertion) with semi-supervised consistency training achieves state-of-the-art results on text classification with limited labeled data. Reduced error on IMDB sentiment analysis from 4.51% to 2.89%, competitive with models trained on 10x more labeled data.
Sosuke Kobayashi (2018)NAACL 2018
Proposed using bidirectional language models to predict context-appropriate word replacements for augmentation. Showed that contextual augmentation (using LSTMs) outperforms random synonym replacement on sentiment analysis and intent classification, pioneering the use of learned models for augmentation.
Markus Bayer, Marc-André Kaufhold & Christian Reuter (2022)ACM Computing Surveys, Vol. 55, No. 7
Comprehensive survey categorizing 100+ text augmentation techniques into paraphrasing-based, noising-based, sampling-based, pattern-based, and interpolation-based methods. Analyzed tradeoffs between techniques, provided decision trees for method selection, and benchmarked performance across 20+ datasets. Essential reference for choosing augmentation strategies.
Claude Coulombe (2018)arXiv preprint
Demonstrated practical approaches to augmentation using cloud NLP APIs (Google Translate, IBM Watson) for back-translation and paraphrasing. Showed that cloud-based augmentation can achieve 2-5 percentage point accuracy improvements on small datasets with minimal engineering effort, making augmentation accessible to practitioners.
Multiple authors from IIT/IIIT institutions (2024)arXiv preprint
Focused on augmentation techniques specifically for Indian languages (Hindi, Tamil, Telugu, Bengali, Marathi) where labeled data is scarce. Implemented back-translation, EDA with language-specific synonym dictionaries, and transliteration-based augmentation. Demonstrated significant improvements (5-8 percentage points F1) on sentiment analysis and intent classification for Indian languages.
Multiple authors (2025)Artificial Intelligence Review
Recent comprehensive survey covering augmentation in the LLM era, including GPT-based paraphrasing, instruction-following for augmentation, and retrieval-augmented generation. Discussed challenges like semantic preservation, computational cost, and bias amplification. Provided future directions including multimodal augmentation and augmentation for specialized domains.
Interview & Evaluation Perspective
Common Interview Questions
- ●
Explain the difference between text augmentation and synthetic data generation. When would you use each?
- ●
What are the four operations in EDA (Easy Data Augmentation)? Which is most effective and why?
- ●
How do you prevent semantic drift when augmenting text data?
- ●
You have 1,000 labeled examples for sentiment analysis. What augmentation strategy would you use and what augmentation ratio?
- ●
How would you handle text augmentation for a class-imbalanced dataset (e.g., 10,000 positive reviews, 500 negative reviews)?
- ●
What are the risks of augmenting test or validation sets?
- ●
How does contextual word embedding augmentation (BERT) differ from synonym replacement (WordNet)?
- ●
When would you choose back-translation over LLM-based paraphrasing for augmentation?
Key Points to Mention
- ●
Augmentation expands training data within the existing semantic space but doesn't add genuinely new concepts -- it diversifies, not discovers. Clearly distinguish augmentation from generation.
- ●
Semantic preservation is the critical constraint -- augmented examples must maintain the original label. Use embedding similarity thresholds (0.85-0.9) or human validation to enforce this.
- ●
Augmentation ratio (alpha) should be tuned on a validation set. For small datasets (<1,000 examples), alpha=4-8. For medium (1,000-10,000), alpha=2-4. For large (>10,000), alpha=1-2 or skip augmentation entirely.
- ●
Never augment test or validation sets -- this inflates metrics by creating artificially easy, redundant evaluation conditions. Augmentation is only for training data.
- ●
Class-specific augmentation ratios are essential for imbalanced datasets -- apply higher alpha to minority classes to rebalance the distribution post-augmentation.
- ●
Different augmentation techniques have different cost-quality tradeoffs: EDA is free but noisy, contextual embeddings (BERT) are balanced, LLM paraphrasing (GPT-4) is expensive but high-quality. Choose based on budget and task criticality.
Pitfalls to Avoid
- ●
Claiming augmentation is a substitute for collecting diverse, representative data -- it's a multiplier, not a replacement. If your base data is biased, augmentation amplifies that bias.
- ●
Recommending high augmentation ratios (alpha > 10) without validation -- excessive augmentation introduces noise that degrades performance. Always validate the optimal alpha.
- ●
Ignoring semantic preservation -- blindly applying augmentation without checking that labels are preserved leads to label noise and degraded model performance. Spot-check 100-200 augmented examples.
- ●
Not discussing protected entities in entity-heavy domains (NER, product reviews) -- augmenting proper nouns, brand names, or domain terms destroys meaning. Always protect entities.
- ●
Suggesting augmentation for tasks where it doesn't work well (factual QA, structured prediction, multi-lingual) without caveats. Augmentation is not universally applicable -- know when to avoid it.
Senior-Level Expectation
A senior candidate should articulate the full augmentation lifecycle: assessing whether augmentation is appropriate (dataset size, task type, label quality), selecting techniques based on cost-quality tradeoffs (EDA vs. BERT vs. LLM), determining augmentation ratio via validation, implementing semantic preservation checks (embedding similarity, NLI), handling class imbalance with class-specific alphas, protecting entities in entity-heavy domains, and monitoring augmentation impact on validation metrics (F1, per-class recall). They should also discuss production considerations: augmentation as a scheduled pipeline job, versioning augmented datasets, storage/I/O optimization, and the interaction between augmentation and other techniques (active learning, semi-supervised learning). The ability to reason about when NOT to augment (large datasets, noisy labels, structured prediction tasks) and provide concrete cost-benefit examples (e.g., augmenting 10,000 examples with EDA vs. GPT-4) separates senior engineers from mid-level ones.
Summary
Let's recap what we've covered:
-
Text augmentation programmatically creates modified versions of existing text that preserve semantic meaning while introducing surface variation, expanding training sets by 2x-10x at near-zero cost compared to manual annotation.
-
The core techniques span a spectrum: rule-based (EDA: synonym replacement, insertion, deletion, swap) is fast and free but noisy; model-based (BERT contextual embeddings, back-translation) is balanced; LLM-based (GPT-4 paraphrasing) is expensive but highest quality. Choose based on your budget and quality requirements.
-
The critical constraint is semantic preservation -- augmented examples must maintain the original label. Use embedding similarity thresholds (0.85-0.9), manual validation of samples, and conservative augmentation parameters (aug_p=0.1-0.2) to enforce this.
-
Augmentation ratio (alpha) should be tuned on a validation set. For small datasets (<1,000 examples), alpha=4-8. For medium (1,000-10,000), alpha=2-4. For large (>10,000), alpha=1-2 or skip augmentation entirely. Excessive augmentation introduces noise that degrades performance.
-
Never augment test or validation sets -- this inflates metrics by creating artificially easy, redundant evaluation conditions. Augmentation is strictly for training data. For class-imbalanced datasets, apply higher alpha to minority classes to rebalance the distribution.
Text augmentation is a force multiplier for limited labeled data, but it's a stopgap, not a replacement for collecting diverse, representative examples. Use it to ship quickly, but invest in real data collection for long-term model quality. The teams that succeed with augmentation are those who understand when to use it, how much to apply, and when to stop.