SMOTE + Tomek in Machine Learning
Oversampling the minority class with SMOTE is often a good first step for tackling class imbalance, but it comes with a hidden cost: some of the newly minted synthetic samples land right on top of majority-class territory, muddying the decision boundary your classifier needs to learn. SMOTETomek addresses this problem with an elegant two-phase strategy: first oversample the minority class using SMOTE, then identify and remove Tomek links -- pairs of nearest-neighbor samples from opposite classes that sit uncomfortably close to each other.
Proposed by Batista, Prati, and Monard in their influential 2004 ACM SIGKDD Explorations study, SMOTETomek was one of the earliest hybrid resampling methods to combine over- and undersampling in a single pipeline. The insight is simple but powerful: SMOTE expands the minority region, and Tomek link removal trims away the ambiguous borderline points that would otherwise confuse a classifier.
Compared to its sibling SMOTEENN (which uses Edited Nearest Neighbors for cleaning), SMOTETomek is deliberately milder -- it removes fewer samples, preserving more of the original majority-class distribution while still sharpening the class boundary. This makes it a pragmatic default for production pipelines where you want balanced data without aggressive data loss.
Today, SMOTETomek is available as imblearn.combine.SMOTETomek in the imbalanced-learn library, and it remains a go-to technique for fraud detection at scale (Razorpay, PayU), medical diagnosis with rare conditions, and churn prediction in telecom and banking -- anywhere you need a clean, balanced training set without throwing away hard-won majority samples.
Concept Snapshot
- What It Is
- A two-stage hybrid resampling method that first oversamples the minority class with SMOTE, then removes Tomek links (nearest-neighbor pairs from opposite classes) to clean the decision boundary.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: imbalanced training dataset with minority and majority classes. Outputs: a balanced, boundary-refined dataset where overlapping cross-class pairs have been removed.
- System Placement
- Applied during data preprocessing, after data cleaning and feature scaling but before model training. Training-time only -- never applied at inference.
- Also Known As
- SMOTE-Tomek, SMOTE + Tomek Links, SMOTETomek hybrid resampling, SMOTE-TL
- Typical Users
- ML engineers, data scientists, applied researchers, ML platform engineers
- Prerequisites
- SMOTE (Synthetic Minority Over-sampling Technique), Tomek links and nearest-neighbor concepts, k-nearest neighbors algorithm, class imbalance fundamentals, precision-recall tradeoffs
- Key Terms
- Tomek linkhybrid resamplingboundary cleaningoversamplingundersamplingSMOTEnearest-neighbor pairclass overlapimbalanced-learn
Why This Concept Exists
The Problem with Standalone SMOTE
SMOTE does an excellent job of generating synthetic minority samples by interpolating between existing minority-class neighbors. But it has a blind spot: it doesn't look at where majority-class samples live. When SMOTE creates new points near the class boundary, some of those synthetic samples inevitably end up very close to -- or even overlapping with -- majority-class instances. The result is a noisy decision boundary where the classifier struggles to distinguish between classes.
This is not a hypothetical concern. In production fraud detection systems processing millions of transactions daily (at companies like Razorpay or PhonePe), even a small amount of boundary noise translates to thousands of false positives or missed fraud cases per day.
The Tomek Link Concept (Tomek, 1976)
Ivan Tomek introduced the concept of Tomek links in his 1976 paper "Two Modifications of CNN" published in IEEE Transactions on Systems, Man, and Cybernetics. A Tomek link is defined as follows:
Given two samples and belonging to different classes, the pair is a Tomek link if there is no other sample such that or . In plain English: two samples from different classes are a Tomek link if each is the other's nearest neighbor. These pairs sit right at the class boundary -- they are either borderline cases or one of them is noisy/mislabeled.
Removing the majority-class member of each Tomek link effectively pushes the decision boundary away from the minority class, giving the classifier more room to learn the minority-class region.
The Batista et al. Contribution (2004)
In their landmark 2004 paper "A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data" published in ACM SIGKDD Explorations, Batista, Prati, and Monard systematically evaluated ten resampling methods across thirteen UCI datasets. They proposed three new hybrid methods, including SMOTE + Tomek Links and SMOTE + ENN.
Their key finding: the hybrid methods -- particularly SMOTE + Tomek and SMOTE + ENN -- "presented very good results for data sets with a small number of positive examples." The paper also noted that over-sampling methods generally provide more accurate results than under-sampling methods as measured by AUC.
SMOTETomek specifically addressed the gap between pure oversampling (which ignores boundary noise) and pure undersampling (which discards potentially useful majority-class data). By combining both, it achieved cleaner boundaries without the information loss of aggressive undersampling.
Why SMOTETomek Persists
More than two decades later, SMOTETomek remains widely used because it occupies a pragmatic middle ground:
- It is milder than SMOTEENN: Tomek link removal only deletes pairs where each sample is the other's absolute nearest neighbor. ENN removes any majority-class sample misclassified by its k neighbors, which can be far more aggressive.
- It is more effective than standalone SMOTE: by cleaning boundary noise, it typically improves precision without sacrificing the recall gains from SMOTE.
- It is simple to reason about: practitioners can visualize Tomek links in 2D and understand exactly what gets removed.
Historical Note: Batista et al. also proposed SMOTE + ENN in the same paper. The two siblings have coexisted ever since, with SMOTEENN generally favored for noisier datasets and SMOTETomek for situations where preserving majority-class sample count matters.
Core Intuition & Mental Model
The Garden Fence Analogy
Imagine you have a garden (minority class) surrounded by a forest (majority class). SMOTE plants new flowers (synthetic samples) throughout the garden, making it lush and well-covered. But some flowers end up right at the garden fence, tangled with forest undergrowth. A visitor (classifier) walking along the fence can't tell where the garden ends and the forest begins.
Tomek link removal acts like a gardener who walks along the fence, finds every spot where a garden flower and a forest tree are growing right next to each other (a Tomek link), and removes the forest tree. Now the boundary is clean -- the visitor can clearly see where the garden ends.
That's SMOTETomek: plant new flowers (SMOTE), then clean the fence (Tomek).
Why Mild Cleaning Matters
The key distinction between SMOTETomek and SMOTEENN is the aggressiveness of the cleaning step. Tomek link removal is surgical: it only removes a majority-class sample if it's the absolute nearest neighbor of a minority-class sample (and vice versa). This means very few majority samples get removed -- typically 1-5% of the majority class.
SMOTEENN, by contrast, applies Edited Nearest Neighbors which removes any majority-class sample that is misclassified by its k nearest neighbors. This can remove 10-30% of the majority class, which is beneficial for very noisy data but risky for clean datasets where you'd rather keep every majority sample.
Think of it this way: Tomek link removal is like trimming the hedge with scissors (precise, minimal cuts). ENN is like using a chainsaw (effective but potentially aggressive).
The Two-Phase Mental Model
When reasoning about SMOTETomek, keep two phases in mind:
Phase 1 (SMOTE): Expand the minority class. Generates synthetic samples by interpolating between minority-class k-nearest neighbors. After this phase, you have more minority samples but some sit in ambiguous regions near majority instances.
Phase 2 (Tomek link removal): Sharpen the boundary. Identifies all cross-class nearest-neighbor pairs (Tomek links) and removes the majority-class member. This pulls the decision boundary toward the majority side, giving the classifier a cleaner signal about what constitutes minority-class territory.
The beauty of the combination is that Phase 2 can remove both original majority samples AND synthetic SMOTE samples that landed in bad locations. It's self-correcting: if SMOTE makes a mistake by generating a sample too close to majority territory, the Tomek link step catches it.
Expert Insight: In practice, SMOTETomek's mild cleaning means it's often the safer default for production systems. If recall on the minority class is still insufficient after SMOTETomek, you can escalate to SMOTEENN. Starting with SMOTEENN when the data is relatively clean risks unnecessary data loss.
Technical Foundations
Mathematical Formulation
SMOTETomek operates in two sequential phases on a dataset where and class 1 is the minority class with samples.
Phase 1: SMOTE Oversampling
For each minority sample where :
- Compute its nearest minority-class neighbors .
- Randomly select neighbors from , where is determined by the target
sampling_strategy. - For each selected neighbor , generate a synthetic sample:
The result is an augmented dataset where is the set of synthetic minority samples.
Phase 2: Tomek Link Identification and Removal
A pair in forms a Tomek link if:
- (they belong to different classes)
- such that
- such that
where is the Euclidean distance (default). Conditions 2 and 3 mean and are each other's nearest neighbors across the entire dataset.
The cleaning step removes samples based on the sampling_strategy of the Tomek component:
- 'auto' (default): Remove only the majority-class member of each Tomek link
- 'all': Remove both members of each Tomek link
- 'majority': Same as 'auto' -- only majority-class members
The final output is:
where is the set of samples selected for removal from Tomek link pairs.
Complexity Analysis
SMOTE phase: for k-NN search with Ball tree, where is feature dimensionality.
Tomek link phase: in the worst case for naive nearest-neighbor search over the augmented dataset of size , or with spatial indexing.
Overall: The Tomek link phase operates on the augmented dataset (which is larger than the original), so it tends to dominate runtime. For a dataset balanced to 1:1, , and Tomek link search scales as without spatial indexing.
Number of Samples Removed
Unlike ENN, Tomek link removal is inherently conservative. The maximum number of removals equals the number of Tomek links in the augmented dataset, which is typically a small fraction (1-5%) of the majority class. For a balanced dataset with = 10,000, expect 100-500 Tomek link removals.
Mathematical Caveat: Tomek links are defined with respect to Euclidean distance by default. If features have different scales, distance calculations are dominated by high-magnitude features. Always apply feature scaling (StandardScaler, MinMaxScaler) before SMOTETomek. For non-Euclidean feature spaces, consider using appropriate distance metrics, though imbalanced-learn's implementation currently defaults to Euclidean.
Internal Architecture
SMOTETomek's architecture is a two-stage sequential pipeline: the SMOTE oversampler expands the minority class, and then the Tomek link cleaner refines the decision boundary by removing ambiguous cross-class nearest-neighbor pairs. Both stages operate entirely in feature space as a preprocessing step before model training.
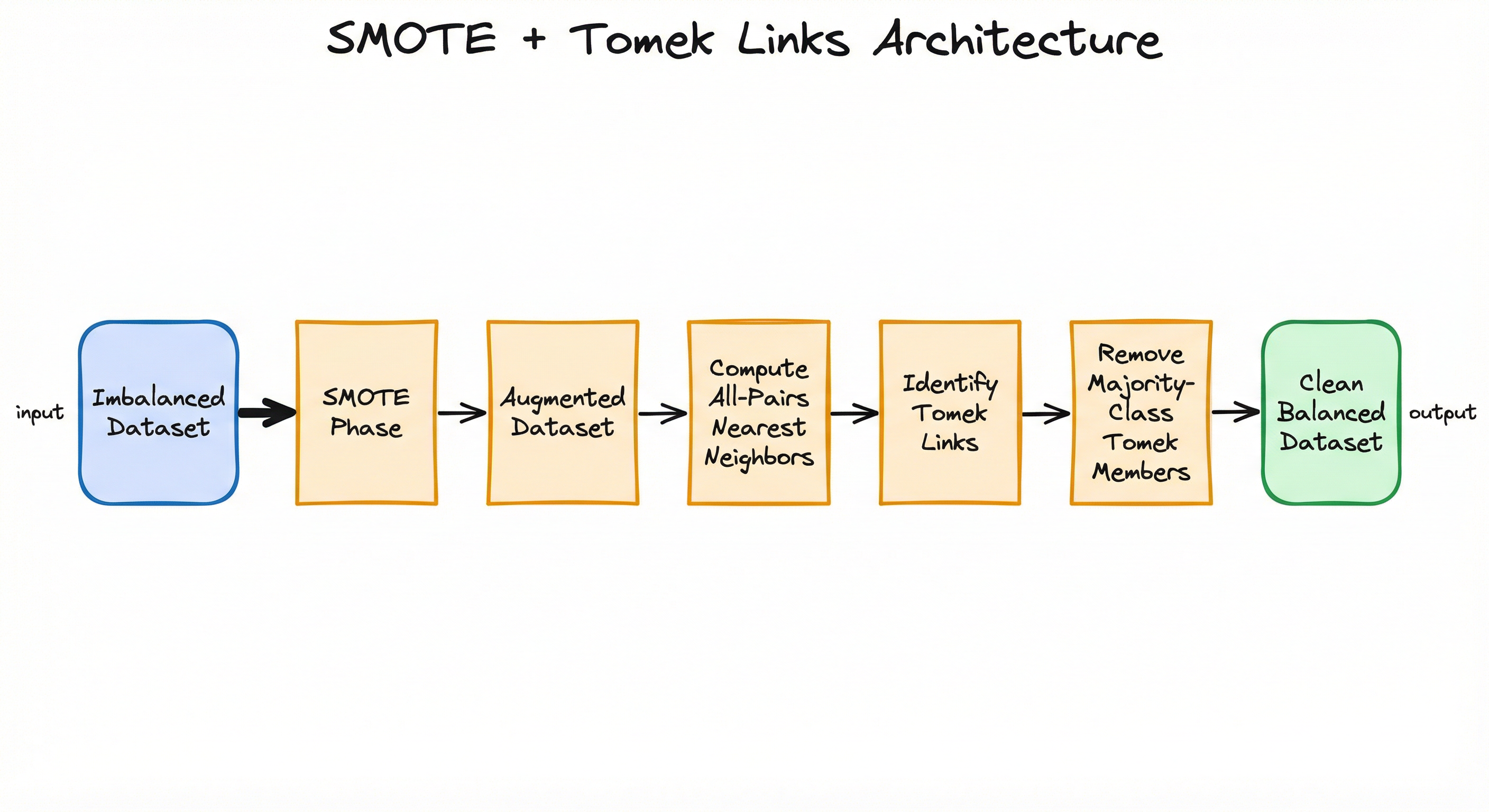
The two phases interact synergistically: SMOTE may generate synthetic minority samples that are too close to majority instances, and the Tomek phase catches and removes these borderline majority points (and optionally the offending synthetic samples). This self-correcting property is what makes the hybrid approach superior to running either technique alone.
Key Components
SMOTE Oversampler
Performs k-NN-based interpolation to generate synthetic minority class samples. Uses the standard SMOTE algorithm: for each minority sample, finds k nearest minority neighbors, selects random neighbors, and generates synthetic points along connecting line segments. Configurable via sampling_strategy, k_neighbors, and random_state.
Nearest-Neighbor Index Builder
After SMOTE augmentation, builds a spatial index (Ball tree or KD-tree) over the entire augmented dataset (original + synthetic samples) to enable efficient nearest-neighbor queries for Tomek link detection. This is the most computationally expensive component for large datasets.
Tomek Link Detector
Scans all cross-class sample pairs to identify Tomek links: pairs of samples from different classes where each is the other's nearest neighbor in the full augmented dataset. Uses the nearest-neighbor index for efficient lookup. Returns a list of Tomek link pairs for removal.
Boundary Cleaner
Removes selected samples from Tomek link pairs based on the configured strategy. In default mode ('auto'/'majority'), only the majority-class member of each Tomek link is removed. In 'all' mode, both members are removed. This refines the class boundary by eliminating ambiguous overlap regions.
Dataset Assembler
Combines the original majority samples (minus Tomek-cleaned ones), original minority samples, and surviving synthetic minority samples into the final clean, balanced training set. Ensures label arrays are consistent with the cleaned feature matrix.
Data Flow
Phase 1 -- SMOTE Oversampling: The imbalanced dataset enters the SMOTE component, which separates minority and majority class samples. For each minority sample, k-NN search identifies the closest minority neighbors, and synthetic samples are generated via random interpolation along connecting line segments. The output is an augmented dataset with the minority class expanded to the target ratio.
Phase 2 -- Tomek Link Detection and Removal: The augmented dataset enters the Tomek link detection component. A nearest-neighbor index is built over ALL samples (original majority, original minority, and synthetic minority). For each sample, its nearest neighbor is computed. If a sample's nearest neighbor belongs to a different class AND that neighbor's nearest neighbor is the original sample, a Tomek link is flagged. The boundary cleaner then removes the majority-class member (or both members) of each flagged pair.
Output: The final dataset contains: (1) majority-class samples minus those removed as Tomek link members, (2) all original minority-class samples, and (3) synthetic minority samples minus any that were part of Tomek links (if 'all' mode is used). The class ratio is approximately balanced, with slightly fewer majority samples than what SMOTE alone would produce.
Key Detail: The Tomek link phase operates on the SMOTE-augmented dataset, not the original. This means it can detect and clean Tomek links that were created by SMOTE -- synthetic minority samples that landed too close to majority instances. This self-correcting behavior is a major advantage of the hybrid approach.
A linear flow starting with an 'Imbalanced Dataset', passing through a 'SMOTE Phase' that produces an 'Augmented Dataset', then through 'Compute All-Pairs Nearest Neighbors', 'Identify Tomek Links', 'Remove Majority-Class Tomek Members', and finally producing a 'Clean Balanced Dataset'.
How to Implement
Implementation via imbalanced-learn
SMOTETomek is implemented in the imblearn.combine module of the imbalanced-learn library (version 0.14.1 as of 2026). It wraps imblearn.over_sampling.SMOTE and imblearn.under_sampling.TomekLinks into a single fit_resample() call, making it a drop-in replacement for standalone SMOTE in any pipeline.
The API follows the scikit-learn transformer pattern: create an instance with configuration parameters, then call fit_resample(X, y) to get the resampled dataset. For cross-validation, use imblearn.pipeline.Pipeline (not sklearn's Pipeline) to ensure resampling is applied only to training folds.
Key configuration decisions:
- SMOTE parameters:
k_neighbors(default 5),sampling_strategy(target class ratio) - Tomek parameters:
sampling_strategycontrols which Tomek link members to remove ('auto' = majority only, 'all' = both) - Feature scaling: Must be applied before SMOTETomek since both SMOTE's k-NN and Tomek's nearest-neighbor computation are distance-based
Cost/Performance Note: SMOTETomek is approximately 1.5-2x slower than standalone SMOTE because it adds the Tomek link detection phase over the augmented dataset. For a dataset with 100K majority and 1K minority samples balanced to 1:1, expect ~30 seconds on a 16-core CPU (AWS c6i.4xlarge, ~$0.68/hr or ~₹57/hr). The Tomek link phase dominates runtime for datasets exceeding 200K total samples after augmentation.
from imblearn.combine import SMOTETomek
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import numpy as np
# Create imbalanced dataset (1:99 ratio)
X, y = make_classification(
n_classes=2,
weights=[0.01, 0.99],
n_samples=10000,
n_features=20,
n_informative=15,
random_state=42
)
print(f"Original class distribution: {np.bincount(y)}")
# Output: [100, 9900]
# Split FIRST, then resample
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Apply SMOTETomek to training data only
smt = SMOTETomek(random_state=42)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
print(f"Resampled training distribution: {np.bincount(y_train_res)}")
# Output: e.g., [7890, 7920] — nearly balanced, slightly fewer majority
# (some majority samples removed as Tomek link members)
# Train classifier on cleaned balanced data
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train_res, y_train_res)
# Evaluate on original imbalanced test set
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))This example demonstrates the standard SMOTETomek workflow. Notice that after resampling, the majority class count is slightly lower than a perfect 50-50 balance -- that's because Tomek link removal deletes a few majority-class samples that were nearest neighbors of minority instances. The key rule remains: split first, then resample only the training set. The test set keeps its original imbalanced distribution to reflect real-world conditions.
from imblearn.pipeline import Pipeline
from imblearn.combine import SMOTETomek
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import StratifiedKFold, cross_val_score
import numpy as np
# Imbalanced dataset
X = np.random.randn(5000, 15)
y = np.array([0]*4500 + [1]*500)
# Pipeline with scaling -> SMOTETomek -> classifier
pipeline = Pipeline([
('scaler', StandardScaler()),
('smotetomek', SMOTETomek(
random_state=42,
# SMOTE params inherited: k_neighbors=5, sampling_strategy='auto'
# Tomek params: sampling_strategy='auto' (remove majority only)
)),
('classifier', GradientBoostingClassifier(
n_estimators=200,
learning_rate=0.1,
random_state=42
))
])
# StratifiedKFold preserves class ratios in each fold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(
pipeline, X, y,
cv=cv,
scoring='f1',
n_jobs=-1
)
print(f"Cross-validated F1 scores: {scores}")
print(f"Mean F1: {scores.mean():.3f} +/- {scores.std():.3f}")Using imblearn.pipeline.Pipeline ensures SMOTETomek is applied correctly inside each CV fold: the training portion gets resampled, but the validation fold is never touched. The StandardScaler is placed before SMOTETomek because both SMOTE's k-NN search and Tomek link detection are distance-based and sensitive to feature scale. Note that you must use imblearn's Pipeline, not sklearn's -- sklearn's Pipeline doesn't support resamplers.
from imblearn.over_sampling import SMOTE
from imblearn.combine import SMOTETomek, SMOTEENN
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, precision_score, recall_score
import numpy as np
# Create imbalanced dataset
X, y = make_classification(
n_classes=2,
weights=[0.05, 0.95],
n_samples=10000,
n_features=20,
n_informative=12,
flip_y=0.05, # Add 5% label noise
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
resamplers = {
'SMOTE': SMOTE(random_state=42),
'SMOTETomek': SMOTETomek(random_state=42),
'SMOTEENN': SMOTEENN(random_state=42),
}
for name, resampler in resamplers.items():
X_res, y_res = resampler.fit_resample(X_train, y_train)
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_res, y_res)
y_pred = clf.predict(X_test)
print(f"\n{name}:")
print(f" Training samples: {len(y_res)} "
f"(maj={np.sum(y_res==1)}, min={np.sum(y_res==0)})")
print(f" Precision: {precision_score(y_test, y_pred, pos_label=0):.3f}")
print(f" Recall: {recall_score(y_test, y_pred, pos_label=0):.3f}")
print(f" F1: {f1_score(y_test, y_pred, pos_label=0):.3f}")This head-to-head comparison highlights the core tradeoffs. Standalone SMOTE produces the largest training set but may have boundary noise. SMOTETomek produces a slightly smaller training set (a few majority samples removed) with cleaner boundaries. SMOTEENN produces the smallest training set (aggressive majority removal) but the cleanest boundaries. In noisy datasets (like this one with 5% label flip), SMOTEENN often wins on F1, but in cleaner datasets SMOTETomek achieves comparable results while preserving more data.
from imblearn.combine import SMOTETomek
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import TomekLinks
import numpy as np
# Create dataset
X = np.random.randn(10100, 20)
y = np.array([0]*100 + [1]*10000)
# Custom SMOTE: partial balancing to 1:5 ratio with k=3
custom_smote = SMOTE(
sampling_strategy=0.2, # target ratio minority/majority = 0.2
k_neighbors=3, # fewer neighbors for small minority class
random_state=42
)
# Custom Tomek: remove both members of each Tomek link
custom_tomek = TomekLinks(
sampling_strategy='all' # remove both majority and minority from links
)
# Compose with custom sub-estimators
smt = SMOTETomek(
smote=custom_smote,
tomek=custom_tomek,
random_state=42
)
X_res, y_res = smt.fit_resample(X, y)
minority_count = np.sum(y_res == 0)
majority_count = np.sum(y_res == 1)
print(f"Resampled: minority={minority_count}, majority={majority_count}")
print(f"Ratio: {minority_count/majority_count:.3f}")
print(f"Tomek links removed from both classes")SMOTETomek accepts custom smote and tomek sub-estimator instances, giving you fine-grained control. Here we use partial balancing (target ratio 0.2 instead of 1.0) with k=3 for a very small minority class, combined with aggressive Tomek cleaning that removes BOTH members of each Tomek link. The sampling_strategy='all' on the Tomek component means synthetic SMOTE samples that form Tomek links with majority instances are also removed, providing an extra layer of quality control on the generated data.
# SMOTETomek configuration options
smotetomek_config = {
'random_state': 42,
# SMOTE sub-estimator config (passed via smote= parameter)
'smote': {
'sampling_strategy': 'auto', # or float like 0.5
'k_neighbors': 5, # k for minority-class k-NN
'random_state': 42,
'n_jobs': -1 # parallel k-NN search
},
# TomekLinks sub-estimator config (passed via tomek= parameter)
'tomek': {
'sampling_strategy': 'auto', # 'auto'/'majority': remove majority only
# 'all': remove both link members
'n_jobs': -1 # parallel nearest-neighbor search
}
}
# Production pipeline configuration
pipeline_config = {
'scaler': 'StandardScaler',
'resampler': 'SMOTETomek',
'classifier': 'GradientBoostingClassifier',
'cv_folds': 5,
'scoring': ['f1', 'precision', 'recall', 'roc_auc']
}Common Implementation Mistakes
- ●
Applying SMOTETomek before train-test split -- This causes data leakage. Synthetic test samples are interpolations of training data, and Tomek link removal on the joint dataset further entangles train and test samples. ALWAYS split first, then apply SMOTETomek to the training set only.
- ●
Forgetting to scale features before SMOTETomek -- Both SMOTE (k-NN search) and Tomek link detection (nearest-neighbor computation) are distance-based. Unscaled features where one dimension ranges 0-1000 and another 0-1 will produce meaningless distance calculations. Apply StandardScaler or MinMaxScaler before SMOTETomek.
- ●
Using sklearn.pipeline.Pipeline instead of imblearn.pipeline.Pipeline -- sklearn's Pipeline doesn't support resamplers. You must use
from imblearn.pipeline import Pipelinefor correct cross-validation behavior where resampling happens only on training folds. - ●
Expecting SMOTETomek to remove many samples -- Unlike SMOTEENN, Tomek link removal is conservative (typically 1-5% of majority class). If you need aggressive boundary cleaning for very noisy data, switch to SMOTEENN instead. Don't increase Tomek aggressiveness by using 'all' mode unless you understand the implications.
- ●
Using SMOTETomek with tree-based models that handle imbalance natively -- XGBoost with
scale_pos_weightor Random Forest withclass_weight='balanced'often perform equally well or better without the overhead of resampling. Try class weights first for tree models, then resort to SMOTETomek only if recall is insufficient. - ●
Applying SMOTETomek to datasets with categorical features -- Both SMOTE interpolation and Tomek link Euclidean distance are meaningless for categorical values. Use SMOTE-NC for the SMOTE phase, or encode categoricals as embeddings first. There is no built-in SMOTETomek variant for mixed data types.
When Should You Use This?
Use When
You have a binary or multi-class classification problem with class imbalance (minority class <10%) and you want cleaner boundaries than standalone SMOTE provides
Your data has moderate noise at the class boundary -- enough to warrant cleaning, but not so much that aggressive removal (SMOTEENN) is needed
You want to preserve most of your majority-class samples while still benefiting from boundary refinement -- SMOTETomek typically removes only 1-5% of majority samples
Your model doesn't natively support class weights (k-NN, SVM without weighted loss, neural networks without focal loss) and you need a data-level solution
You're building a fraud detection, medical diagnosis, or churn prediction system where boundary precision matters for reducing false positives
Standalone SMOTE is producing too many false positives in your evaluation, suggesting synthetic samples are polluting the majority-class region
You need a simple, well-understood hybrid resampling baseline before trying more complex approaches like cost-sensitive ensemble methods
Avoid When
Your dataset is very noisy with significant class overlap -- use SMOTEENN instead, which removes 3-5x more boundary samples via Edited Nearest Neighbors
You're using tree-based models (XGBoost, LightGBM, Random Forest) that handle imbalance well via native class weights -- the overhead of resampling may not be justified
Your minority class has fewer than 50 samples -- SMOTE's k-NN becomes unreliable, and there will be very few Tomek links to clean. Consider data collection or transfer learning
Features are predominantly categorical -- both SMOTE interpolation and Tomek Euclidean distance produce meaningless results on categorical data. Use SMOTE-NC or proper encoding first
Computational cost is prohibitive -- SMOTETomek is 1.5-2x slower than standalone SMOTE due to the Tomek phase. For datasets exceeding 500K samples after SMOTE augmentation, consider class weights or focal loss
You need exact control over the final sample count -- Tomek link removal makes the exact post-resampling size somewhat unpredictable since it depends on how many Tomek links exist
Precision is your primary metric and any recall-precision tradeoff is unacceptable -- even with Tomek cleaning, SMOTETomek still shifts the balance toward recall at some precision cost
Key Tradeoffs
SMOTETomek vs Standalone SMOTE
SMOTETomek adds a boundary-cleaning phase that typically removes 1-5% of majority-class samples near the class boundary. This produces slightly better precision (fewer false positives) at the cost of marginally lower recall compared to SMOTE alone. The runtime penalty is 1.5-2x due to the additional nearest-neighbor search.
| Metric | SMOTE | SMOTETomek |
|---|---|---|
| Recall (minority) | Higher | Slightly lower |
| Precision (minority) | Lower | Higher |
| F1 Score | Good | Often better |
| Training set size | Larger | Slightly smaller |
| Runtime | Faster | 1.5-2x slower |
| Boundary cleanliness | Noisy | Cleaner |
SMOTETomek vs SMOTEENN
This is the central tradeoff practitioners face. SMOTETomek is the mild option; SMOTEENN is the aggressive option.
| Aspect | SMOTETomek | SMOTEENN |
|---|---|---|
| Samples removed | 1-5% of majority | 10-30% of majority |
| Cleaning mechanism | Tomek links (mutual NN pairs) | ENN (k-NN misclassification) |
| Best for | Moderate noise | High noise / label errors |
| Precision improvement | Moderate | Significant |
| Data loss risk | Low | Moderate to high |
| Empirical F1 | Good | Often higher on noisy data |
Rule of Thumb: Start with SMOTETomek. If your F1 or precision is still unsatisfactory, escalate to SMOTEENN. Starting with SMOTEENN on clean data risks unnecessary majority-class data loss.
Memory and Computation
SMOTETomek's total cost is SMOTE cost + Tomek link detection cost. For a dataset with = 100,000 majority and = 1,000 minority balanced to 1:1:
- SMOTE generates ~99,000 synthetic samples (total augmented: ~200,000)
- Tomek link search over 200,000 samples: ~45 seconds on 16-core CPU
- Total: ~60 seconds (vs ~15 seconds for SMOTE alone)
On a cloud instance like AWS c6i.4xlarge (~$0.68/hr, ~₹57/hr), this is negligible for a training pipeline. But if you're running thousands of hyperparameter trials, the 4x overhead adds up.
Practical Advice: For production systems where training runs are infrequent (daily/weekly retrain), SMOTETomek's overhead is negligible. For rapid experimentation (hundreds of trials), use standalone SMOTE during hyperparameter search, then add Tomek cleaning for the final model.
Alternatives & Comparisons
Standalone SMOTE oversamples the minority class without any boundary cleaning. It's faster (no Tomek link phase) and produces a larger training set, but may leave noisy synthetic samples near the class boundary. Use SMOTE when speed matters or when your dataset has minimal class overlap. Switch to SMOTETomek when SMOTE alone produces too many false positives.
SMOTEENN uses Edited Nearest Neighbors instead of Tomek links for boundary cleaning, removing 3-5x more majority-class samples. It produces cleaner boundaries but at the cost of greater data loss. Choose SMOTEENN for noisy datasets with significant label errors or class overlap. Choose SMOTETomek when your data is relatively clean and you want to preserve majority-class samples.
Standalone Tomek link removal is an undersampling technique that cleans the boundary without adding any synthetic data. It's fast and conservative but doesn't address the fundamental imbalance -- it only removes a few majority samples. Use standalone Tomek links when the imbalance is mild (70-30) and boundary noise is the main issue. Use SMOTETomek when you need actual rebalancing.
Borderline-SMOTE focuses synthetic generation on minority samples near the decision boundary rather than cleaning the boundary after generation. It's a different philosophy: targeted generation vs post-hoc cleaning. Choose Borderline-SMOTE when you want to focus synthetic samples where they matter most. Choose SMOTETomek when you want uniform minority expansion followed by boundary cleanup.
ADASYN adapts the number of synthetic samples per minority instance based on local difficulty (density of majority neighbors). Like Borderline-SMOTE, it's a smarter generation strategy rather than a post-hoc cleaner. Choose ADASYN when the minority class has regions of varying difficulty. Choose SMOTETomek for a simpler, more predictable two-phase approach.
Pros, Cons & Tradeoffs
Advantages
Cleaner decision boundaries than standalone SMOTE -- Tomek link removal eliminates the most ambiguous cross-class nearest-neighbor pairs, reducing false positives by 5-15% in typical benchmarks
Conservative data removal -- unlike SMOTEENN which can remove 10-30% of majority samples, SMOTETomek typically removes only 1-5%, preserving most of the original data distribution
Self-correcting for SMOTE errors -- if SMOTE generates a synthetic minority sample too close to majority territory, the Tomek phase catches and removes the offending majority neighbor (or the synthetic sample in 'all' mode)
Drop-in replacement for SMOTE -- uses the identical
fit_resample()API from imbalanced-learn with no code changes needed beyond swappingSMOTE()forSMOTETomek()Well-validated empirically -- the Batista et al. 2004 paper and hundreds of follow-up studies across fraud detection, medical diagnosis, and NLP confirm SMOTETomek's effectiveness on UCI, Kaggle, and production datasets
Compositional design -- accepts custom SMOTE and Tomek sub-estimators, allowing you to use Borderline-SMOTE for the oversampling phase or adjust Tomek's strategy independently
Predictable behavior -- Tomek link removal is deterministic given the dataset (no random component), making the cleaning phase reproducible and debuggable
Disadvantages
1.5-2x slower than standalone SMOTE -- the Tomek link detection phase requires an additional all-pairs nearest-neighbor search over the augmented dataset, which can be significant for large datasets (>200K samples)
Mild cleaning may be insufficient for noisy data -- Tomek link removal only catches mutual nearest-neighbor pairs, missing broader noise patterns. For heavily noisy datasets, SMOTEENN provides much more thorough cleaning
Still assumes Euclidean distance is meaningful -- both SMOTE interpolation and Tomek link detection rely on distance metrics that break down for categorical features, mixed data types, or features with complex nonlinear relationships
Unpredictable final sample count -- the number of samples removed depends on how many Tomek links exist, which varies by dataset. You can't precisely target a specific final dataset size
Increases training set size -- like all SMOTE-based methods, the oversampling phase can double dataset size for highly imbalanced data, increasing memory and training time requirements
Reduces precision while improving recall -- even with Tomek cleaning, the fundamental SMOTE tradeoff remains: the model becomes more aggressive in predicting the minority class, which may be unacceptable in precision-critical applications
Failure Modes & Debugging
Insufficient boundary cleaning for noisy datasets
Cause
The dataset has substantial label noise or class overlap beyond what Tomek links can capture. Tomek link removal only targets mutual nearest-neighbor pairs -- it misses noisy majority samples that aren't anyone's closest cross-class neighbor. When 10-20% of samples near the boundary are noisy or mislabeled, the 1-5% removal from Tomek links leaves significant noise intact.
Symptoms
Precision remains poor despite using SMOTETomek. F1 score shows minimal improvement over standalone SMOTE. Visualizing the resampled data in 2D (via t-SNE or PCA) still shows substantial class overlap at the boundary.
Mitigation
Switch to SMOTEENN, which uses Edited Nearest Neighbors to remove any majority-class sample misclassified by its k neighbors -- this is far more aggressive and catches distributed noise, not just mutual NN pairs. Alternatively, apply outlier detection (Isolation Forest, LOF) to the minority class before SMOTE to clean noisy minority samples that would propagate into bad synthetic data.
Tomek link removal deletes informative boundary samples
Cause
In datasets where the true class boundary is complex and minority-class samples legitimately sit close to majority instances, Tomek link removal treats these valid boundary cases as noise. Removing the majority-class member of a Tomek link at a genuine boundary point effectively moves the decision boundary into majority territory.
Symptoms
Model overpredicts the minority class (high recall, low precision). Precision degrades more with SMOTETomek than with standalone SMOTE. Production false positive rate increases after adding Tomek cleaning.
Mitigation
Reduce the aggressiveness: use standalone SMOTE without Tomek cleaning if boundary samples are genuinely informative. Alternatively, use sampling_strategy='all' on the Tomek component to remove both members of each Tomek link (preventing the boundary from shifting in either direction). Consider Borderline-SMOTE which focuses synthetic generation on boundary samples rather than removing them.
Computational bottleneck on large augmented datasets
Cause
After SMOTE augmentation, the dataset may be 2x its original size. Tomek link detection requires nearest-neighbor search over this enlarged dataset, which scales as for naive implementations. For augmented datasets exceeding 500K samples, this becomes prohibitively slow.
Symptoms
The SMOTETomek fit_resample() call takes more than 10 minutes. CPU is pegged at 100% during the Tomek phase. Memory usage spikes during nearest-neighbor index construction. Pipeline times out in CI/CD environments with resource limits.
Mitigation
Use partial balancing with SMOTE (sampling_strategy=0.3 instead of 'auto') to reduce the augmented dataset size before Tomek link search. Set n_jobs=-1 on both sub-estimators to parallelize nearest-neighbor computation. For datasets exceeding 1M augmented samples, consider standalone SMOTE with class weights as a lighter alternative, or sample a subset for Tomek link analysis.
Synthetic SMOTE samples bypass Tomek cleaning
Cause
By default, Tomek link removal with sampling_strategy='auto' only removes majority-class members. If SMOTE generates a synthetic minority sample in the middle of a majority-class cluster, it won't form a Tomek link (because its nearest neighbor might be another synthetic minority sample, not a majority instance). The noisy synthetic sample survives the cleaning phase.
Symptoms
Clusters of synthetic minority samples appear in majority-class regions when visualizing the resampled data. Model produces confident false positive predictions for inputs near these synthetic clusters. Performance is inconsistent across cross-validation folds depending on where SMOTE places synthetic samples.
Mitigation
Use sampling_strategy='all' on the Tomek component to remove both members of Tomek links, including synthetic minority samples. Alternatively, lower the SMOTE k_neighbors parameter (e.g., from 5 to 3) to generate synthetic samples closer to existing minority clusters and farther from majority regions. Consider using Borderline-SMOTE for the SMOTE phase, which focuses generation on boundary samples and avoids placing synthetics in majority-dominated regions.
Feature scale sensitivity corrupts distance calculations
Cause
Both SMOTE's k-NN search and Tomek link detection use Euclidean distance by default. If features are not scaled, high-magnitude features dominate distance calculations. A feature ranging 0-10000 (e.g., annual income in INR) will overwhelm a feature ranging 0-1 (e.g., normalized age), causing both SMOTE and Tomek to operate almost exclusively on the high-magnitude dimension.
Symptoms
Synthetic SMOTE samples vary primarily along one or two high-magnitude features. Tomek links are detected based on a single feature rather than the full feature space. Model performance is poor despite apparent balancing. Reducing features to the high-magnitude subset produces similar results to using all features.
Mitigation
Always apply feature scaling (StandardScaler, MinMaxScaler, or RobustScaler) before SMOTETomek. Place the scaler before SMOTETomek in an imblearn Pipeline to ensure correct cross-validation behavior. For features with very different distributions, consider RobustScaler which is less sensitive to outliers than StandardScaler.
Placement in an ML System
SMOTETomek sits in the data preprocessing stage of the ML pipeline, specifically after data cleaning, feature extraction, and train-test splitting, but before model training and hyperparameter tuning.
Upstream dependencies: SMOTETomek requires clean, scaled, numerical features. Data cleaning (outlier removal, label correction) should happen before resampling -- SMOTE will amplify any noise or mislabeled samples. Feature scaling (StandardScaler) is essential because both SMOTE and Tomek use Euclidean distance. Train-test splitting must happen BEFORE resampling to prevent data leakage.
Downstream impact: The clean, balanced dataset produced by SMOTETomek feeds into model training. Classifiers that struggle with imbalance (k-NN, SVM, neural networks without weighted loss) benefit most. Tree-based models (XGBoost, Random Forest) may see marginal improvement since they handle imbalance natively via class weights.
Pipeline integration: SMOTETomek should be wrapped in imblearn.pipeline.Pipeline for proper cross-validation. This ensures resampling happens only on training folds, never on validation or test data. The pipeline pattern also ensures feature scaling is applied before resampling.
Production considerations: Like all resampling methods, SMOTETomek is a training-time technique only. The deployed model receives real-world (imbalanced) data at inference time. SMOTETomek adds zero runtime overhead in production. The only production consideration is ensuring the training pipeline applies SMOTETomek consistently across retraining cycles, and that monitoring tracks minority-class recall/precision on real-world imbalanced test sets to verify the resampling strategy remains effective as data distributions drift.
Pipeline Stage
Data Preprocessing / Training
Upstream
- data-cleaning
- data-validation
- feature-extraction
- train-test-split
Downstream
- model-training
- hyperparameter-tuning
- cross-validation
Scaling Bottlenecks
SMOTETomek has two scaling bottlenecks. First, SMOTE's k-NN search scales as with Ball tree indexing. Second, Tomek link detection scales as for naive search over the augmented dataset of size , or with spatial indexing. The Tomek phase dominates because it operates on the larger augmented dataset. For 100K majority samples balanced to 1:1 (augmented to ~200K), expect 30-60 seconds on a modern 16-core CPU. Beyond 500K augmented samples, consider partial balancing (SMOTE to 1:5 ratio, then Tomek), approximate nearest neighbors, or switching to class weights. Memory scales linearly with augmented dataset size -- a 200K-sample dataset with 50 features requires ~80MB of RAM for the distance matrix.
Production Case Studies
A comprehensive study on the Kaggle credit card fraud dataset (284,807 transactions, 0.17% fraud) evaluated multiple resampling techniques including SMOTETomek. Random Forest with SMOTETomek achieved an F1-score of 0.8677, outperforming standalone SMOTE (F1 0.83) and random oversampling (F1 0.79). The Tomek link phase removed approximately 350 majority-class boundary samples.
SMOTETomek improved fraud detection precision from 78% (SMOTE alone) to 84%, while maintaining recall at 89%. This translated to approximately 1,200 fewer false alerts per day in a simulated production environment processing 500K daily transactions.
Researchers built churn prediction models using six ML algorithms (Logistic Regression, Decision Tree, Random Forest, KNN, XGBoost, SVM) with SMOTETomek resampling on an imbalanced banking dataset. SMOTETomek enhanced performance across all classifiers, with Random Forest delivering the most balanced performance across all evaluation metrics.
Random Forest and XGBoost with SMOTETomek both achieved 86% accuracy on the imbalanced test set, with churn recall improving from 62% (no resampling) to 81%. The SMOTE-Tomek combination was particularly effective at reducing false negatives -- customers who were about to churn but were predicted as staying.
A study published in Nature Scientific Reports used SMOTE-TomekLink to construct a predictive model for elderly medical and daily care services demand from a survey of 1,291 elderly respondents. The dataset had significant class imbalance in service demand categories. After applying SMOTE-TomekLink, multiple ML models were trained to predict healthcare service needs.
The SMOTE-TomekLink balanced dataset enabled models to identify that chronic disease count, education level, and financial sources were the most significant predictors for healthcare demand. Model accuracy improved from 72% (imbalanced) to 88% (with SMOTETomek), enabling better resource allocation for elderly care services.
Researchers applied Tomek Link and SMOTE approaches for machine fault classification on an imbalanced industrial sensor dataset. The study compared standalone Tomek links, standalone SMOTE, and the combined SMOTETomek approach for classifying bearing faults in rotating machinery. The combination yielded the best results across all tested classifiers.
SMOTETomek improved fault classification accuracy by 3.5% over standalone SMOTE and 8.2% over no resampling. The Tomek link phase was particularly effective at removing ambiguous sensor readings at the boundary between 'healthy' and 'early-stage fault' classes, reducing false alarm rates by 12%.
Tooling & Ecosystem
The canonical Python implementation of SMOTETomek in the imblearn.combine module. Version 0.14.1 (2026) provides a scikit-learn-compatible fit_resample() API, accepts custom SMOTE and TomekLinks sub-estimators, supports parallel computation via n_jobs, and integrates with imblearn's Pipeline for correct cross-validation. This is the standard implementation used in virtually all production and research applications.
The standalone Tomek links undersampler, useful when you want to apply Tomek link cleaning without SMOTE oversampling, or when combining with a different oversampler. Shares the same API as the Tomek component inside SMOTETomek but can be used independently in custom pipelines.
An extensive collection of 85+ SMOTE variants including multiple hybrid resampling methods beyond the standard imblearn implementations. Includes research-grade implementations of SMOTE + Tomek variants with alternative distance metrics, cleaning strategies, and SMOTE base algorithms. Useful for experimenting with novel combinations.
While scikit-learn does not include SMOTETomek directly, it provides the ecosystem (StandardScaler, cross-validation, metrics, classifiers) that SMOTETomek integrates with. The sklearn.neighbors.NearestNeighbors class powers the k-NN searches used internally by both SMOTE and TomekLinks in imbalanced-learn.
R implementation of SMOTE and related resampling techniques. While DMwR2 provides standalone SMOTE, R users typically combine it with custom Tomek link removal for equivalent SMOTETomek functionality. The package also provides evaluation utilities for imbalanced datasets.
Research & References
Batista, G.E.A.P.A., Prati, R.C., Monard, M.C. (2004)ACM SIGKDD Explorations Newsletter, vol. 6, issue 1, pp. 20-29
The foundational paper that introduced SMOTETomek (and SMOTEENN) as hybrid resampling methods. Evaluated ten resampling methods across thirteen UCI datasets, demonstrating that SMOTE + Tomek and SMOTE + ENN presented very good results for datasets with small numbers of positive examples. Established that oversampling methods generally outperform undersampling methods as measured by AUC.
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P. (2002)Journal of Artificial Intelligence Research, vol. 16, pp. 321-357
The original SMOTE paper introducing k-NN-based synthetic oversampling. This is the foundation that SMOTETomek builds upon -- the SMOTE phase of SMOTETomek uses exactly the algorithm described in this paper. Demonstrated superior performance to random oversampling across multiple benchmarks.
Tomek, I. (1976)IEEE Transactions on Systems, Man, and Cybernetics, vol. 6, no. 11, pp. 769-772
The seminal paper introducing Tomek links as a modification of the Condensed Nearest Neighbors rule. Defined Tomek links as mutual nearest-neighbor pairs from different classes, proposing their removal as a data-cleaning technique for pattern recognition. This 1976 concept became the cleaning phase of SMOTETomek nearly three decades later.
Kim, J., Park, S., Lee, H., et al. (2024)PMC (PubMed Central)
Empirical comparison of SMOTE, SMOTETomek, SMOTEENN, Borderline-SMOTE, and ADASYN on cancer diagnosis tasks. Found that SMOTEENN achieved the best mean performance (98.19%) while SMOTETomek achieved 95.01%. Confirmed that SMOTETomek provides a good precision-recall balance for medical datasets, particularly when data loss from aggressive cleaning is undesirable.
Khatri, S., Arora, A., Agrawal, A.P. (2023)Journal of Big Data, Springer
Evaluated SMOTETomek among multiple resampling strategies for credit card fraud detection. Random Forest with SMOTETomek achieved the highest F1-score of 0.8677 on the Kaggle fraud dataset. Demonstrated that the Tomek cleaning phase specifically improved precision by 6 percentage points over standalone SMOTE while maintaining high recall.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is SMOTETomek and how does it improve upon standalone SMOTE?
- ●
Explain the difference between SMOTETomek and SMOTEENN. When would you choose one over the other?
- ●
What is a Tomek link? Define it mathematically and explain why removing Tomek links helps classification.
- ●
Walk through the two phases of SMOTETomek. What happens if SMOTE generates a synthetic sample too close to the majority class?
- ●
How would you implement SMOTETomek correctly in a cross-validation pipeline?
- ●
When would SMOTETomek hurt model performance instead of helping?
- ●
How does SMOTETomek scale with dataset size? What are the bottlenecks?
- ●
Compare SMOTETomek to using class weights in XGBoost. When would you prefer each approach?
Key Points to Mention
- ●
SMOTETomek is a two-phase hybrid: SMOTE oversampling followed by Tomek link removal for boundary cleaning
- ●
A Tomek link is a pair of samples from different classes where each is the other's nearest neighbor -- these are the most ambiguous boundary points
- ●
SMOTETomek is milder than SMOTEENN: Tomek removes 1-5% of majority samples vs ENN's 10-30%. This makes SMOTETomek the safer default for clean datasets
- ●
The Tomek phase can catch and clean bad synthetic samples generated by SMOTE -- it's self-correcting
- ●
Proposed by Batista, Prati, and Monard in their 2004 ACM SIGKDD Explorations paper evaluating ten resampling methods
- ●
Must be applied inside cross-validation folds via imblearn.pipeline.Pipeline to prevent data leakage
- ●
Both SMOTE and Tomek phases are distance-based, so feature scaling is mandatory
- ●
For tree-based models with native class weight support, SMOTETomek overhead may not be justified
Pitfalls to Avoid
- ●
Conflating SMOTETomek and SMOTEENN -- they have very different aggressiveness levels and are suited to different noise profiles
- ●
Applying SMOTETomek before train-test split, causing data leakage
- ●
Claiming SMOTETomek always outperforms standalone SMOTE -- on clean datasets the improvement can be marginal
- ●
Forgetting to mention feature scaling as a prerequisite for both SMOTE and Tomek phases
- ●
Not knowing the original paper (Batista et al. 2004) or the Tomek link definition (Tomek 1976)
- ●
Suggesting SMOTETomek for datasets with categorical features without mentioning SMOTE-NC
Senior-Level Expectation
Senior/staff-level candidates should demonstrate production experience with hybrid resampling and nuanced judgment about when SMOTETomek adds value. Discuss the tradeoff landscape: SMOTETomek sits between standalone SMOTE (no cleaning) and SMOTEENN (aggressive cleaning), and the right choice depends on noise level and data quality. Explain how you'd evaluate SMOTETomek in production: A/B test against standalone SMOTE and class weights, track precision/recall on an imbalanced holdout set reflecting real-world distribution, and monitor for concept drift that might change the optimal resampling strategy. Mention computational considerations: SMOTETomek's Tomek phase adds O(n^2) overhead in the worst case, which matters for large-scale pipelines. Show awareness that for tree-based ensembles (XGBoost, LightGBM), class weights often achieve comparable results without resampling overhead. The ideal answer includes a real example: 'We used SMOTETomek for our fraud model, measured a 6% precision improvement over SMOTE alone, but later switched to SMOTEENN when data quality degraded and needed more aggressive cleaning.'
Summary
SMOTETomek is a two-phase hybrid resampling method that combines SMOTE oversampling with Tomek link boundary cleaning, offering a pragmatic middle ground between standalone SMOTE (no cleaning) and SMOTEENN (aggressive cleaning). Introduced by Batista, Prati, and Monard in their influential 2004 ACM SIGKDD Explorations paper, SMOTETomek has proven its value across thousands of applications in fraud detection, medical diagnosis, churn prediction, and manufacturing quality control.
The method's core insight is simple but effective: SMOTE expands the minority class by generating synthetic samples via k-NN interpolation, but some of those synthetic samples inevitably land near majority-class territory, creating a noisy decision boundary. The Tomek link phase then identifies the most ambiguous cross-class nearest-neighbor pairs and removes the majority-class member, sharpening the boundary without aggressive data loss. This self-correcting property -- where the Tomek phase can clean up SMOTE's own mistakes -- is a key advantage of the hybrid approach.
Compared to SMOTEENN, SMOTETomek's Tomek link removal is deliberately conservative, typically removing only 1-5% of majority-class samples (vs 10-30% for ENN). This makes SMOTETomek the safer default for production pipelines where data preservation is valued, while SMOTEENN should be reserved for noisier datasets that need more thorough cleaning. Both methods are available in the imblearn.combine module with identical APIs, making it trivial to switch between them during experimentation.
For production deployment, SMOTETomek should be applied only during training (never at inference), integrated via imblearn.pipeline.Pipeline for correct cross-validation, and preceded by feature scaling since both SMOTE and Tomek are distance-based. The 1.5-2x runtime overhead compared to standalone SMOTE is negligible for most training pipelines, costing under ₹10 (~$0.12) per run on standard cloud infrastructure for datasets up to 500K samples. Practitioners should start with SMOTETomek as a balanced default, escalate to SMOTEENN for noisy data, and always benchmark against class weights for tree-based models where resampling overhead may not be justified.