Cluster Centroids in Machine Learning
When your dataset has a severe class imbalance -- say 98% legitimate transactions and 2% fraud -- one natural instinct is to throw away some majority class samples until things even out. That's undersampling. But random undersampling is a blunt instrument: it discards majority class samples indiscriminately, and with them, potentially valuable information about the structure of the majority class distribution.
Cluster Centroids offers a smarter approach. Instead of randomly deleting majority class samples, it applies K-Means clustering to the majority class and replaces each cluster with its centroid. The result is a compact, representative summary of the majority class that preserves its global structure while dramatically reducing its size.
This is a prototype generation technique -- the undersampled majority class contains newly generated points (the centroids) rather than a subset of original samples. That distinction has profound implications for how the resampled data behaves with different classifiers, and understanding it is key to using Cluster Centroids effectively.
From credit card fraud detection at Razorpay to churn prediction at Jio, Cluster Centroids has found its way into production ML pipelines across India and globally. But it comes with real tradeoffs -- computational cost, sensitivity to K-Means assumptions, and the risk of generating centroids that fall in ambiguous decision regions. This guide covers all of that and more.
Concept Snapshot
- What It Is
- An undersampling technique that reduces the majority class by clustering its samples using K-Means and replacing each cluster with its centroid, producing a compact representative summary of the majority distribution.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: imbalanced dataset with majority and minority classes. Outputs: balanced dataset where majority class samples are replaced by K-Means cluster centroids.
- System Placement
- Applied during data preprocessing, after data cleaning and before feature engineering or model training. Typically used in the resampling stage of an imbalanced learning pipeline.
- Also Known As
- ClusterCentroids, K-Means undersampling, centroid-based undersampling, cluster-based prototype generation, KMeans majority reduction
- Typical Users
- ML engineers, data scientists, research scientists, ML platform engineers, fraud analytics teams
- Prerequisites
- K-Means clustering algorithm, class imbalance concepts, prototype generation vs prototype selection, distance metrics (Euclidean), precision-recall tradeoffs
- Key Terms
- K-Meanscentroidprototype generationundersamplingimbalance ratiovoting (hard/soft)cluster assignmentinformation lossmajority class reduction
Why This Concept Exists
The Problem with Random Undersampling
Random undersampling is the simplest way to handle class imbalance: just randomly remove majority class samples until the classes are balanced. It's fast, trivial to implement, and often surprisingly effective. But there's a fundamental problem: random removal is information-destroying in a structurally blind way.
Imagine your majority class has three distinct clusters -- say, three types of legitimate transactions (small retail, recurring subscriptions, large one-time purchases). Random undersampling might disproportionately wipe out one of these clusters, leaving the classifier with a distorted view of what "legitimate" looks like. The classifier then misclassifies that entire subpopulation as fraudulent.
The Insight: Compress, Don't Delete
Cluster Centroids emerged from a key insight: instead of selecting which samples to keep and which to discard, why not summarize the majority class? If you cluster the majority class into groups and represent each group by its centroid, you get exactly representative points that capture the overall shape of the distribution.
This is analogous to image compression. A JPEG doesn't randomly throw away pixels; it transforms the image into a compact representation that preserves the important structure. Cluster Centroids does the same thing for your majority class.
The Prototype Generation Lineage
Cluster Centroids belongs to the prototype generation family of undersampling methods. Unlike prototype selection methods (like Condensed Nearest Neighbours or Tomek Links) that keep a subset of original samples, prototype generation creates entirely new synthetic points. This distinction dates back to Hart's 1968 work on the Condensed Nearest Neighbor rule and has been refined through decades of research.
The specific application of K-Means clustering for undersampling was formalized in the context of Yen and Lee's 2009 work on cluster-based undersampling approaches, which demonstrated that clustering-aware methods consistently outperform random undersampling on standard benchmarks.
Key Takeaway: Cluster Centroids exists because random undersampling is structurally blind. By clustering the majority class and replacing clusters with centroids, we preserve the macro-structure of the majority distribution while achieving aggressive data reduction.
Core Intuition & Mental Model
The Mental Model: Summary Statistics for Your Data
Here's the simplest way to think about Cluster Centroids. Imagine you have 10,000 majority class samples and 200 minority class samples. You want to balance the dataset to a 1:1 ratio, so you need to reduce the majority class to approximately 200 samples.
Random undersampling says: "Pick 200 random samples from the 10,000." That's like summarizing a 300-page book by tearing out 200 random pages and keeping only 6 of them. You might get lucky and keep the important pages, but you probably won't.
Cluster Centroids says: "Group those 10,000 samples into 200 clusters, then represent each cluster by its center point." That's like asking 200 expert readers to each summarize a different chapter. You lose the fine-grained details, but you preserve the book's overall structure.
What Makes It Work (and When It Doesn't)
The technique works well when the majority class has a multimodal distribution -- multiple distinct subclusters that K-Means can identify. In this case, the centroids genuinely capture the essential structure.
But here's the flip side: if your majority class data lives near the decision boundary with the minority class, the centroids can drift toward the boundary and create overlapping regions. This is because a centroid is the mean of its cluster -- and means are pulled toward dense regions, which might include samples right on the boundary. This is the single most important failure mode to understand.
Prototype Generation: You're Creating New Data
A subtle but critical point: unlike random undersampling or Tomek Links, Cluster Centroids produces samples that did not exist in the original dataset. The centroids are synthetic points -- weighted averages of real samples. This means:
- The resampled data may not be consistent with the original data-generating distribution at a local level
- Classifiers that rely on exact distances (like k-NN) may behave differently than expected
- The centroids can fall in low-density regions between subclusters, creating "phantom" majority class samples
Understanding this distinction between prototype generation and prototype selection is what separates practitioners who use Cluster Centroids effectively from those who get bitten by its edge cases.
Technical Foundations
Problem Setup
Let be a training set where and . Define the majority class as with and the minority class as with , where .
The Algorithm
Cluster Centroids reduces the majority class to representative points, where is typically set to (to achieve a 1:1 ratio) or determined by the sampling_strategy parameter.
Step 1: Cluster the majority class. Apply K-Means clustering to , partitioning it into clusters by minimizing the within-cluster sum of squares:
where is the centroid of cluster .
Step 2: Generate replacement samples. The replacement strategy depends on the voting parameter:
- Soft voting: Use the centroids directly as the new majority class samples.
- Hard voting: For each centroid , find its nearest neighbor in the original majority class and use that original sample instead:
Step 3: Form the resampled dataset. The final dataset is:
for soft voting, or equivalently with replacing for hard voting.
Complexity Analysis
The computational cost is dominated by K-Means:
- Time complexity: where is the number of K-Means iterations (typically 100-300)
- Space complexity: for storing the majority class during clustering
For large datasets, this can be substantially more expensive than random undersampling which is .
Important: The
voting='auto'parameter in imbalanced-learn defaults to'soft'for dense data and'hard'for sparse data. Sparse data gets hard voting because centroids of sparse vectors are dense, which would change the data representation fundamentally.
Internal Architecture
The Cluster Centroids pipeline is conceptually straightforward but involves several important decision points. The architecture consists of a class separator that splits the dataset by label, a K-Means clustering engine that operates on the majority class, a centroid extractor with soft/hard voting, and a dataset assembler that recombines the reduced majority class with the untouched minority class.
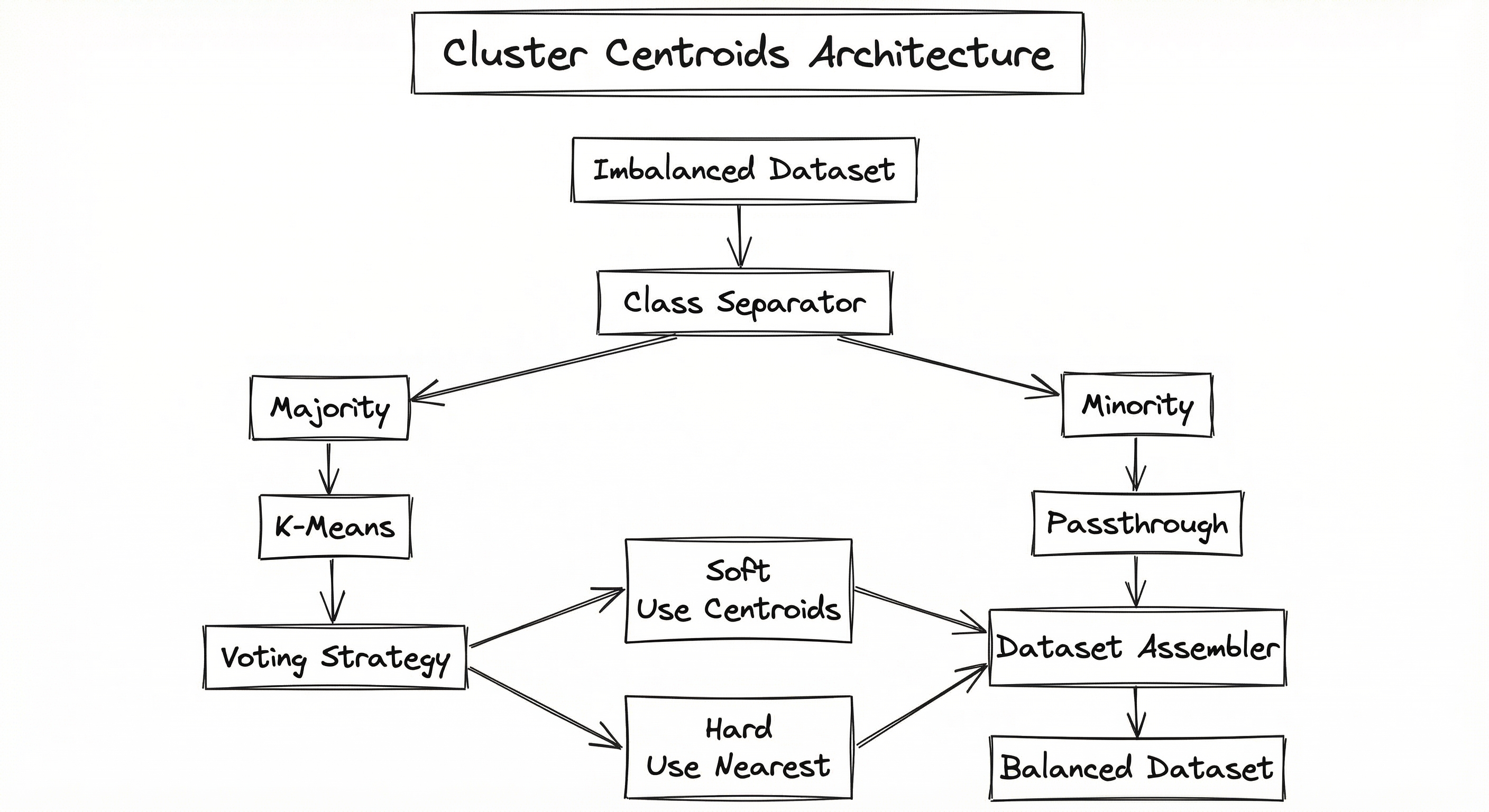
The minority class passes through completely unchanged -- only the majority class is modified. This is an important invariant: Cluster Centroids never touches minority class samples, which means minority class integrity is always preserved.
Key Components
Class Separator
Splits the input dataset by class label, routing majority class samples to the clustering pipeline and minority class samples through a passthrough path. Also determines the target sample count based on the sampling_strategy parameter.
K-Means Clustering Engine
Runs the K-Means algorithm on majority class samples with clusters (where equals the desired number of majority samples post-resampling). Supports custom estimators -- any scikit-learn compatible clustering algorithm with n_clusters and cluster_centers_ attributes can be substituted.
Voting Strategy Selector
Determines how cluster results are converted to samples. Soft voting uses the computed centroids directly (synthetic points). Hard voting maps each centroid to its nearest original sample (prototype selection fallback). The auto setting chooses based on data sparsity.
Centroid Extractor
Extracts the cluster centroids from the fitted K-Means model. For soft voting, these become the new majority samples directly. For hard voting, they serve as query points for nearest-neighbor lookup against original majority samples.
Dataset Assembler
Recombines the reduced majority class (centroids or nearest originals) with the unchanged minority class to produce the final balanced dataset. Handles index alignment and optional metadata preservation.
Data Flow
Step 1: The imbalanced dataset enters the class separator, which identifies majority and minority classes based on label frequencies.
Step 2: Majority class samples are passed to the K-Means clustering engine, which fits clusters. The number is determined by the sampling_strategy -- typically equal to for 1:1 balancing.
Step 3: The voting strategy selector examines data sparsity (for auto mode) or applies the user-specified strategy (soft or hard).
Step 4: For soft voting, centroids are extracted directly. For hard voting, each centroid is mapped to its nearest original majority class sample.
Step 5: The dataset assembler combines the majority representatives with the full minority class, producing the final balanced dataset.
Note: The entire pipeline is deterministic given a fixed
random_statefor K-Means initialization. This is critical for reproducibility in production pipelines.
A directed flow from 'Imbalanced Dataset' through 'Class Separator' which splits into two paths: the majority class goes through 'K-Means Clustering' then a 'Voting Strategy' decision (soft uses centroids, hard uses nearest originals), while the minority class passes through unchanged. Both paths converge at 'Dataset Assembler' producing the final 'Balanced Dataset'.
How to Implement
Two Implementation Paths
The most common way to use Cluster Centroids is through the imbalanced-learn library (imblearn), which provides a ClusterCentroids class that integrates seamlessly with scikit-learn pipelines. For custom requirements -- such as using a different clustering algorithm, applying per-cluster weighting, or handling very large datasets -- you can implement the approach from scratch using scikit-learn's K-Means.
The key implementation decisions are:
- Choosing the number of clusters (): defaults to the minority class count for 1:1 balancing, but you can specify any ratio via
sampling_strategy - Selecting the voting strategy:
softfor synthetic centroids (better information preservation, but generates non-real samples),hardfor nearest-original-sample (preserves data realism, but slightly less representative) - Configuring K-Means:
n_init,max_iter, andrandom_stateall affect reproducibility and quality
Cost Note: For a dataset with 1M majority class samples and 100 features, K-Means clustering to 10K centroids takes roughly 2-5 minutes on a 4-core machine (~₹50,000 / $600 cloud instance). Random undersampling would take milliseconds. This cost difference is the primary practical concern at scale.
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.under_sampling import ClusterCentroids
# Create a synthetic imbalanced dataset
X, y = make_classification(
n_samples=10000,
n_features=20,
n_informative=15,
n_redundant=3,
n_classes=2,
weights=[0.95, 0.05],
random_state=42
)
print(f"Original distribution: {Counter(y)}")
# Output: Counter({0: 9500, 1: 500})
# Apply Cluster Centroids undersampling
cc = ClusterCentroids(
sampling_strategy='auto', # Balance to 1:1
random_state=42,
voting='soft' # Use centroid points directly
)
X_resampled, y_resampled = cc.fit_resample(X, y)
print(f"Resampled distribution: {Counter(y_resampled)}")
# Output: Counter({0: 500, 1: 500})This is the simplest usage pattern. The sampling_strategy='auto' parameter tells ClusterCentroids to balance the dataset to a 1:1 ratio, so it clusters the 9,500 majority samples into 500 clusters and uses the centroids as replacement samples. The voting='soft' setting means we use the actual centroid coordinates, not the nearest original sample.
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score, make_scorer
from imblearn.pipeline import Pipeline as ImbPipeline
from imblearn.under_sampling import ClusterCentroids
# Build an imbalanced-learn pipeline
# (imblearn.pipeline.Pipeline supports resamplers; sklearn's doesn't)
pipeline = ImbPipeline([
('scaler', StandardScaler()),
('undersampler', ClusterCentroids(
sampling_strategy=0.5, # Majority = 2x minority (not full 1:1)
random_state=42,
voting='soft',
estimator=None # Uses default KMeans
)),
('classifier', RandomForestClassifier(
n_estimators=200,
random_state=42
))
])
# Evaluate with stratified cross-validation
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scorer = make_scorer(f1_score)
scores = cross_val_score(pipeline, X, y, cv=cv, scoring=scorer)
print(f"F1 scores: {scores}")
print(f"Mean F1: {scores.mean():.4f} (+/- {scores.std():.4f})")This example demonstrates proper pipeline integration. Key points: (1) Use imblearn.pipeline.Pipeline, not sklearn.pipeline.Pipeline -- the latter does not support resamplers. (2) The sampling_strategy=0.5 means the majority class will be reduced to twice the minority class count, not a full 1:1 balance -- partial undersampling often works better. (3) Resampling happens inside cross-validation, so the test fold is never contaminated with resampled data.
from sklearn.cluster import MiniBatchKMeans
from imblearn.under_sampling import ClusterCentroids
import numpy as np
# Use MiniBatchKMeans for large datasets (much faster than standard KMeans)
# MiniBatchKMeans uses mini-batches of size 'batch_size' for each iteration
cc_fast = ClusterCentroids(
sampling_strategy='auto',
random_state=42,
voting='hard', # Use nearest original samples
estimator=MiniBatchKMeans(
n_init=3,
batch_size=1024,
random_state=42
)
)
# For very large datasets, this is 5-10x faster than default KMeans
X_resampled, y_resampled = cc_fast.fit_resample(X, y)
# Verify that hard voting returns actual original samples
# (not synthetic centroids)
def check_samples_are_original(X_resampled, X_original, y_resampled):
"""Check if resampled majority samples exist in original data."""
majority_mask = y_resampled == 0
X_majority_resampled = X_resampled[majority_mask]
for sample in X_majority_resampled:
distances = np.linalg.norm(X_original - sample, axis=1)
assert distances.min() < 1e-10, "Sample not found in original data!"
print("All resampled majority samples are from original data.")
# This assertion passes with hard voting, fails with soft voting
check_samples_are_original(X_resampled, X, y_resampled)This example shows two important patterns: (1) Using MiniBatchKMeans as a drop-in replacement for large datasets -- it processes data in batches rather than loading everything into memory. (2) Using voting='hard' to ensure the resampled majority class contains only real data points. The verification function confirms that hard voting preserves original samples, which is critical for domains where synthetic data points are not acceptable (e.g., regulated financial services).
import time
import numpy as np
from collections import Counter
from sklearn.datasets import make_classification
from sklearn.model_selection import RepeatedStratifiedKFold, cross_validate
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import make_scorer, f1_score, recall_score
from imblearn.pipeline import Pipeline as ImbPipeline
from imblearn.under_sampling import ClusterCentroids, RandomUnderSampler
# Create imbalanced dataset
X, y = make_classification(
n_samples=20000, n_features=30, n_informative=20,
weights=[0.97, 0.03], random_state=42
)
print(f"Distribution: {Counter(y)}")
# Define scoring metrics
scoring = {
'f1': make_scorer(f1_score),
'recall': make_scorer(recall_score),
}
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=42)
# Pipeline 1: ClusterCentroids
pipe_cc = ImbPipeline([
('sampler', ClusterCentroids(random_state=42, voting='soft')),
('clf', GradientBoostingClassifier(n_estimators=100, random_state=42))
])
# Pipeline 2: Random Undersampler
pipe_ru = ImbPipeline([
('sampler', RandomUnderSampler(random_state=42)),
('clf', GradientBoostingClassifier(n_estimators=100, random_state=42))
])
# Evaluate both
for name, pipe in [('ClusterCentroids', pipe_cc), ('RandomUnderSampler', pipe_ru)]:
start = time.time()
results = cross_validate(pipe, X, y, cv=cv, scoring=scoring)
elapsed = time.time() - start
print(f"\n{name}:")
print(f" F1: {results['test_f1'].mean():.4f} (+/- {results['test_f1'].std():.4f})")
print(f" Recall: {results['test_recall'].mean():.4f} (+/- {results['test_recall'].std():.4f})")
print(f" Time: {elapsed:.1f}s")This head-to-head comparison is the experiment you should run before committing to Cluster Centroids. In practice, Cluster Centroids often achieves 2-5% higher F1 than random undersampling on structured/tabular data, but takes 10-50x longer. The variance (standard deviation) is also worth watching -- Cluster Centroids tends to produce more stable results because the centroid-based summary is deterministic given the same K-Means initialization.
# imbalanced-learn ClusterCentroids configuration
# Typical production settings for tabular fraud detection
undersampler:
class: imblearn.under_sampling.ClusterCentroids
params:
sampling_strategy: 0.3 # majority = ~3x minority (not full 1:1)
random_state: 42
voting: soft # soft for dense data, hard for sparse
estimator:
class: sklearn.cluster.MiniBatchKMeans
params:
n_init: 5
max_iter: 300
batch_size: 1024
random_state: 42
# Pipeline order:
# 1. StandardScaler (required before K-Means)
# 2. ClusterCentroids (undersampling)
# 3. Classifier (e.g., GradientBoosting, XGBoost)Common Implementation Mistakes
- ●
Forgetting to scale features before clustering: K-Means uses Euclidean distance, so features with larger magnitudes dominate the clustering. Always apply
StandardScalerorMinMaxScalerupstream of ClusterCentroids. Without scaling, the centroids will be biased toward high-variance features. - ●
Using soft voting with distance-based classifiers: When
voting='soft', the centroids are synthetic points that may not lie on the data manifold. k-NN classifiers and SVMs with RBF kernels can produce unexpected decision boundaries because they're reasoning about distances to points that never existed in the real data. - ●
Applying ClusterCentroids after train/test split on the wrong side: Resampling must happen only on the training set, never on the test set. A common bug is applying ClusterCentroids to the full dataset before splitting, which causes data leakage. Use
imblearn.pipeline.Pipelineto avoid this. - ●
Not tuning the sampling_strategy parameter: The default 1:1 ratio is often too aggressive. For datasets with extreme imbalance (>100:1), reducing the majority class to a 3:1 or 5:1 ratio can preserve more majority class information while still helping the classifier focus on the minority class.
- ●
Ignoring K-Means convergence warnings: If K-Means does not converge within
max_iteriterations, the centroids may not be representative. This is especially common when is large relative to the number of majority samples. Increasemax_iteror useMiniBatchKMeanswith moren_initrestarts. - ●
Using ClusterCentroids on categorical or mixed-type data: K-Means is designed for continuous numerical features. Applying it to one-hot encoded categorical features produces centroids with fractional values (e.g., 0.3 for a binary feature), which are meaningless. Use K-Prototypes or encode categoricals differently.
When Should You Use This?
Use When
Your majority class has clear subclusters or multimodal structure that K-Means can capture -- Cluster Centroids shines when the majority class is not uniformly distributed
You need a more informative undersampling approach than random undersampling but don't want the complexity of ensemble methods like EasyEnsemble or BalanceCascade
Your dataset is tabular with continuous numerical features (the sweet spot for K-Means)
The imbalance ratio is moderate (10:1 to 100:1) and you want to preserve the global shape of the majority class distribution
Reproducibility matters -- given the same random seed, Cluster Centroids produces deterministic results, unlike random undersampling which varies across runs
You are building a pipeline where downstream classifiers benefit from representative majority class summaries (e.g., logistic regression, naive Bayes)
You have sufficient compute budget for the K-Means step -- if clustering is feasible, the quality improvement over random undersampling usually justifies the cost
Avoid When
Your dataset is very large (>1M majority samples) and training time is constrained -- the K-Means step can take minutes to hours, whereas random undersampling is instant
Your features are categorical, mixed-type, or high-cardinality sparse -- K-Means centroids of categorical features are meaningless (e.g., a centroid with gender=0.4)
The minority class samples lie close to or interleaved with the majority class -- centroids may drift into the minority class region, increasing overlap and hurting classifier performance
You need interpretable or auditable resampled data (e.g., in regulated industries) -- soft voting produces synthetic points that never existed in the original data, which can complicate regulatory compliance
Your majority class is uniformly distributed with no cluster structure -- K-Means will produce arbitrary clusters and the centroids won't be more representative than random samples
You are using a tree-based ensemble (Random Forest, XGBoost, LightGBM) that already handles imbalance well via
class_weightorscale_pos_weight-- the added complexity of Cluster Centroids may not yield improvement
Key Tradeoffs
The Core Tradeoff: Information Preservation vs. Computational Cost
Cluster Centroids sits on a tradeoff curve between random undersampling (fast, lossy) and no undersampling with cost-sensitive learning (slow training, no data loss). The K-Means step costs -- for a 500K-sample majority class with 50 features and 200 K-Means iterations, that's roughly 5 billion distance computations. In comparison, random undersampling is -- essentially free.
Soft vs. Hard Voting: A Subtle Choice
| Aspect | Soft Voting | Hard Voting |
|---|---|---|
| Sample type | Synthetic centroids | Original data points |
| Representativeness | Higher (mean of cluster) | Slightly lower (nearest to mean) |
| Data realism | Lower (points may not exist on manifold) | Higher (real observations) |
| Sparse data | Problematic (dense centroids from sparse data) | Works well |
| Regulatory compliance | May require justification | Easier to audit |
For most tabular ML tasks, soft voting is preferred because the centroids better represent the cluster. But for applications where auditability matters -- think credit scoring under RBI guidelines or insurance underwriting -- hard voting is the safer choice because every sample in the resampled dataset is a real observation.
How Much to Undersample?
Full 1:1 balancing (the default sampling_strategy='auto') is often too aggressive. Empirically, ratios of 3:1 to 5:1 (majority to minority) tend to produce better downstream classifier performance because they retain more majority class information while still giving the classifier enough minority class signal. Start with sampling_strategy=0.3 (majority ~3x minority) and tune from there.
Cost Estimate: On an AWS
m5.2xlargeinstance (~₹5,000 / $60 per month), clustering 1M samples with 50 features into 10K centroids takes roughly 3-5 minutes. For a daily retraining pipeline, this is usually acceptable. For real-time resampling, it's not.
Alternatives & Comparisons
Random Undersampler is dramatically faster ( vs ) and requires no hyperparameter tuning beyond the sampling ratio. Choose Random Undersampler when you need speed, when your majority class has no clear cluster structure, or when combined with ensemble methods (e.g., BalancedRandomForest) that already mitigate random removal variance. Choose Cluster Centroids when you need structurally informed undersampling and can afford the compute cost.
NearMiss selects majority samples based on their distance to minority class samples (keeping those closest or farthest, depending on the version). It's a prototype selection method -- it keeps original samples rather than generating new ones. NearMiss is better when the decision boundary region is critical; Cluster Centroids is better for preserving the overall majority class distribution. NearMiss versions 1 and 2 are computationally expensive due to pairwise distance calculations, often comparable to Cluster Centroids.
Tomek Links removes majority class samples that form Tomek links with minority class samples -- i.e., pairs of opposite-class samples that are each other's nearest neighbors. It's a conservative cleaning method, often removing only a few samples. Choose Tomek Links for gentle boundary cleaning (often combined with SMOTE); choose Cluster Centroids when you need aggressive majority class reduction. They are complementary and can be used together.
ENN removes majority class samples that are misclassified by their k nearest neighbors, effectively cleaning noisy boundary regions. ENN is a prototype selection method (keeps originals) and typically removes fewer samples than Cluster Centroids. Use ENN for noise cleaning; use Cluster Centroids for bulk reduction. They address different aspects of the imbalance problem and can be combined in a pipeline.
SMOTE addresses imbalance from the opposite direction: it generates synthetic minority class samples via k-NN interpolation. Cluster Centroids reduces the majority class; SMOTE augments the minority class. Combining both (SMOTE + undersampling) via techniques like SMOTEENN or SMOTETomek is a common and effective strategy. SMOTE alone risks overfitting to the minority class; Cluster Centroids alone risks losing majority class information.
Pros, Cons & Tradeoffs
Advantages
Preserves majority class structure: Unlike random undersampling, centroids capture the global distribution shape -- subclusters, modes, and overall geometry are retained rather than randomly sampled
Deterministic output: Given the same
random_state, Cluster Centroids produces identical results every time, making it ideal for reproducible ML pipelines and A/B testingFlexible target ratio: The
sampling_strategyparameter allows any target ratio, not just 1:1 -- you can reduce the majority class by 50%, 80%, or to an exact countPluggable clustering algorithm: Any scikit-learn compatible clustering estimator can replace the default K-Means -- MiniBatchKMeans for speed, K-Medoids for robustness to outliers, or even DBSCAN-derived methods
Integrates with scikit-learn pipelines: Through
imblearn.pipeline.Pipeline, Cluster Centroids slots cleanly into cross-validation and hyperparameter search workflows with zero data leakageReduces training time for downstream classifiers: By reducing the majority class to samples, subsequent model training is faster -- important when the classifier itself is expensive (e.g., SVMs, deep networks)
Hard voting provides an audit trail: With
voting='hard', every sample in the resampled dataset maps to a real original observation, which matters for regulated industries
Disadvantages
Computationally expensive: K-Means clustering on the full majority class costs , making it 100-1000x slower than random undersampling for large datasets
Centroid drift near decision boundaries: Centroids can shift toward the minority class region when majority samples near the boundary dominate a cluster, blurring the decision surface
Soft voting creates synthetic data: The centroids are weighted averages, not real observations -- this can be problematic for distance-based classifiers and for regulatory audits
K-Means assumptions may not hold: K-Means assumes spherical, equally-sized clusters with Euclidean distance. If the majority class has irregular shapes, elongated clusters, or varying densities, centroids may be poor representatives
Not suitable for categorical or mixed-type features: K-Means centroids of categorical features are meaningless -- a centroid of one-hot encoded features produces fractional values that break the encoding semantics
Sensitive to K-Means initialization: Different random seeds can produce different clusterings, leading to different centroids and potentially different downstream model performance -- use
n_init > 1to mitigateNo consideration of minority class proximity: Cluster Centroids clusters the majority class in isolation, without awareness of where minority class samples lie -- this can place centroids right on top of minority class regions
Failure Modes & Debugging
Centroid drift into minority class territory
Cause
When a majority class cluster spans the decision boundary and contains samples near the minority class region, the centroid (being the mean) is pulled toward the minority class. This is exacerbated when boundary-adjacent majority samples are dense.
Symptoms
The classifier's precision on the majority class drops because centroids in the boundary region look similar to minority class samples. ROC-AUC may appear stable, but the precision-recall curve deteriorates, especially at high-recall operating points.
Mitigation
Use voting='hard' to avoid synthetic boundary points. Alternatively, combine Cluster Centroids with Tomek Links removal as a post-processing step to clean up the boundary region. Another approach is to increase K (use a milder sampling_strategy like 0.3) so that boundary clusters are smaller and their centroids drift less.
Catastrophic information loss from over-aggressive undersampling
Cause
Setting sampling_strategy='auto' on an extremely imbalanced dataset (e.g., 1000:1 ratio) reduces the majority class to match the minority class count -- compressing, say, 100,000 samples into 100 centroids. This is like compressing an image to 0.1% of its original size.
Symptoms
The classifier underfits the majority class: it cannot distinguish majority class subpopulations and produces high false positive rates. Majority class recall drops below 90%, indicating the model frequently misclassifies legitimate instances as the minority class.
Mitigation
Use a less aggressive sampling_strategy -- values of 0.2 to 0.5 (majority = 2-5x minority) are usually safer than full 1:1. Monitor majority class recall alongside minority class metrics to detect information loss early.
K-Means convergence failure on high-dimensional data
Cause
K-Means struggles in high-dimensional spaces (the curse of dimensionality). When features exceed ~50-100 dimensions, Euclidean distances become less meaningful and K-Means may not converge or produces degenerate clusters.
Symptoms
Scikit-learn raises ConvergenceWarning: Number of distinct clusters found smaller than n_clusters. The resulting centroids may be duplicates or near-duplicates, producing a degenerate resampled dataset with effectively fewer unique majority samples than intended.
Mitigation
Apply dimensionality reduction (PCA, UMAP) before clustering, or reduce the feature space through feature selection. Alternatively, use MiniBatchKMeans with more n_init restarts. For very high-dimensional data, consider whether Cluster Centroids is the right tool -- random undersampling may perform comparably with far less cost.
Semantic corruption of sparse/categorical features
Cause
When applied to sparse data (e.g., TF-IDF vectors, one-hot encoded categoricals), voting='soft' computes centroids that are dense vectors with fractional values. A centroid of sparse TF-IDF vectors produces a dense vector where every word has a small positive weight -- this is semantically meaningless.
Symptoms
Model performance is worse than random undersampling. Feature importance analysis shows that many previously zero-valued features now contribute to predictions, introducing noise. For text data, the "average document" centroid looks like gibberish.
Mitigation
Use voting='hard' for sparse data (imbalanced-learn does this automatically when voting='auto'). Alternatively, switch to a different undersampling method entirely for text/categorical data -- NearMiss or Random Undersampler preserve the original data representation.
Pipeline ordering error: scaling after resampling
Cause
If the feature scaler is placed after ClusterCentroids in the pipeline, K-Means operates on unscaled features. Features with larger magnitudes dominate the distance calculation, producing biased clusters and unrepresentative centroids.
Symptoms
Clusters are determined almost entirely by a few high-magnitude features. Centroids do not represent the multivariate distribution accurately. Downstream model performance is inconsistent and varies significantly when feature scales change.
Mitigation
Always place StandardScaler (or equivalent) before ClusterCentroids in the pipeline. Verify by inspecting centroid coordinates -- they should have comparable magnitudes across features.
Non-reproducible results in distributed training
Cause
When training is distributed across multiple workers (e.g., Spark MLlib, Dask), the K-Means algorithm may produce different results depending on data partitioning, even with the same random_state. This breaks reproducibility guarantees.
Symptoms
Model performance metrics fluctuate between training runs despite identical hyperparameters and random seeds. Resampled datasets differ between runs, making debugging and A/B test analysis unreliable.
Mitigation
Centralize the resampling step on a single worker (K-Means is relatively cheap compared to model training). Alternatively, use MiniBatchKMeans with a large batch_size and fixed seed, which is more stable across data orderings. Save the resampled dataset to disk for reproducibility.
Placement in an ML System
Where Does It Sit in the ML Pipeline?
Cluster Centroids operates in the data preprocessing stage, specifically during the resampling phase that sits between feature engineering and model training. In a typical imbalanced classification pipeline:
- Data ingestion and cleaning
- Feature engineering (encoding, transformations)
- Feature scaling (StandardScaler -- must happen before ClusterCentroids)
- Resampling with Cluster Centroids (this block)
- Model training on the balanced dataset
- Evaluation on the original (unsampled) test set
Critically, Cluster Centroids must run inside the cross-validation loop, not before the train/test split. If you resample the entire dataset before splitting, majority class information leaks from test to train through the centroid computation. The imblearn.pipeline.Pipeline class handles this correctly.
Integration with the Broader ML System
In production systems at companies like Flipkart (fraud detection), Zerodha (anomaly detection in trading), or IRCTC (ticket scalping detection), the resampling step is typically part of a feature store pipeline that runs on a schedule (daily or weekly). The resampled dataset is materialized and versioned, not computed on-the-fly. This amortizes the K-Means cost over many model training iterations.
Key Insight: Cluster Centroids is a preprocessing transformation, not a model component. It should be treated like feature scaling or encoding -- a fixed step that transforms the training data before any model touches it.
Pipeline Stage
Data Preprocessing / Resampling
Upstream
- data-validation
- feature-engineering
- data-cleaning
Downstream
- model-training
- cross-validation
- hyperparameter-tuning
Scaling Bottlenecks
The primary bottleneck is the K-Means clustering step, which scales as . For a dataset with 10M majority samples, 100 features, and a target of 100K centroids, this translates to roughly distance computations -- about 30-60 minutes on a single machine.
Memory is the second constraint. K-Means requires the full majority class in memory during clustering. For 10M samples with 100 features at 8 bytes (float64), that's ~8 GB just for the data matrix, plus overhead for cluster assignments and intermediate calculations.
Practical scaling strategies:
- Use
MiniBatchKMeansfor >500K samples (5-10x speedup with minimal quality loss) - Apply PCA to reduce dimensionality before clustering (reduces in the complexity equation)
- Consider sampling a representative subset, clustering that, and using the centroids as the final result (meta-undersampling)
- For distributed settings, run K-Means on a single node -- the resampling step is a fixed preprocessing cost, not a per-epoch cost
Production Case Studies
Researchers evaluated clustering-based undersampling approaches for credit card fraud detection using the European credit card transactions dataset (284,807 transactions, 0.17% fraud). They combined hybrid neural networks with cluster-based undersampling to address the extreme 578:1 imbalance ratio, comparing multiple undersampling strategies including centroid-based methods.
The clustering-based undersampling approach achieved F1 scores exceeding 0.85 on the minority (fraud) class, significantly outperforming random undersampling (F1 ~0.78) and approaching the performance of more complex hybrid oversampling+undersampling pipelines while maintaining faster training times.
Researchers from Indian universities developed a class balancing framework for credit card fraud detection that uses K-Means clustering combined with similarity-based selection (SBS). The framework clusters the majority class and selects representative samples based on similarity to cluster centroids, directly extending the Cluster Centroids concept with a boundary-aware selection mechanism.
The proposed framework improved fraud detection recall from 0.62 (no resampling) to 0.91 while maintaining precision above 0.85 on standard Indian banking transaction datasets. Training time was reduced by 65% compared to training on the full imbalanced dataset.
A medical informatics study applied clustering-based undersampling with random oversampling and SVM for breast cancer diagnosis from imbalanced histopathological data. The approach used K-Means to cluster the benign (majority) class and replaced clusters with centroids before training the classifier, addressing the typical 3:1 benign-to-malignant imbalance in breast cancer datasets.
The clustering-based undersampling approach achieved 97.2% accuracy and 96.8% sensitivity (recall) for malignant class detection, outperforming random undersampling by 3.1% in sensitivity. Critically, specificity (benign class recall) remained above 95%, indicating the centroids preserved enough benign class structure to avoid excessive false positives.
A study on intelligent systems for class imbalance combined clustering-based undersampling with ensemble methods (AdaBoost, Bagging, Random Forest) across multiple domains including telecom churn prediction. The approach clustered the non-churning majority class and used centroid representatives with ensemble classifiers to predict customer churn.
The combination of cluster-based undersampling with Random Forest achieved the best results: AUC of 0.94 and G-mean of 0.89, outperforming standalone ensemble methods (AUC 0.87) and random undersampling + ensemble (AUC 0.91). The cluster-based approach was particularly effective at preserving the substructure within the non-churning class (e.g., high-value vs low-value loyal customers).
Tooling & Ecosystem
The canonical Python implementation of ClusterCentroids. Part of the scikit-learn-contrib ecosystem, it provides a fit_resample API that integrates with scikit-learn pipelines. Supports custom clustering estimators, soft/hard voting, and multi-class balancing. Version 0.14.1 is the latest stable release.
The default clustering backend used by ClusterCentroids. Provides standard K-Means and MiniBatchKMeans for large datasets. Essential for understanding and tuning the clustering parameters (n_init, max_iter, algorithm) that directly affect centroid quality.
An extension library that combines imbalanced-learn samplers (including ClusterCentroids) with ensemble classifiers. Provides SelfPacedEnsembleClassifier, BalanceCascade, and other meta-learners that use ClusterCentroids as an internal resampling component.
A comprehensive library implementing 85+ oversampling and undersampling variants, including multiple cluster-based undersampling methods. Useful for benchmarking Cluster Centroids against a wide range of alternatives in a consistent API.
A Java-based ML experimentation framework that includes implementations of cluster-based undersampling methods, Tomek Links, NearMiss, and many other resampling techniques. Widely used in academic research for benchmarking imbalanced learning methods. Includes 66 imbalanced datasets for evaluation.
The successor to R's mlr framework. Through the mlr3pipelines package, it supports resampling operations including cluster-based undersampling that can be combined with any learner. Useful for R-centric data science teams.
Research & References
Yen, S.J. & Lee, Y.S. (2009)Expert Systems with Applications, Vol. 36, No. 3
The foundational paper proposing five cluster-based undersampling approaches for imbalanced data. Demonstrated that clustering the majority class and selecting representative samples based on distance to minority class neighbors consistently outperforms random undersampling across multiple benchmark datasets.
Chawla, N.V., Bowyer, K.W., Hall, L.O. & Kegelmeyer, W.P. (2002)Journal of Artificial Intelligence Research, Vol. 16
The seminal paper on SMOTE, which established that combining minority oversampling with majority undersampling improves classifier performance in ROC space. Directly motivates the use of informed undersampling methods like Cluster Centroids as the undersampling component.
Mishra, A. et al. (2024)SN Computer Science, Springer
Proposes an iterative clustering-based undersampling approach that refines cluster assignments over multiple rounds, improving centroid quality. Demonstrates 3-7% improvement in G-mean over single-pass Cluster Centroids on 20 benchmark datasets.
Arafat, M.Y. et al. (2023)Journal of King Saud University - Computer and Information Sciences
Extends the Cluster Centroids concept with adaptive K selection that automatically determines the optimal number of clusters based on majority class structure, removing the need to manually tune the sampling ratio.
Lin, W.C., Tsai, C.F., Hu, Y.H. & Jhang, J.S. (2017)Information Sciences, Vol. 409-410
Introduces cluster-based instance selection (CBIS) that combines clustering analysis with instance selection, preserving boundary samples while reducing redundant interior points. Provides a theoretical framework for why centroid-based methods work and when they fail.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How does Cluster Centroids differ from random undersampling, and when would you prefer one over the other?
- ●
What is the difference between prototype generation and prototype selection in the context of undersampling?
- ●
Explain the soft vs hard voting parameter in ClusterCentroids. When would you use each?
- ●
What are the computational implications of using Cluster Centroids on a dataset with 10 million majority class samples?
- ●
How would you handle class imbalance in a fraud detection system at a payment company like PhonePe or Razorpay?
- ●
Why shouldn't you apply Cluster Centroids to categorical features?
- ●
How does the choice of distance metric in K-Means affect the quality of Cluster Centroids undersampling?
Key Points to Mention
- ●
Cluster Centroids is a prototype generation method -- it creates new synthetic majority class samples (centroids), unlike random undersampling or Tomek Links which select from existing samples. This distinction affects downstream classifier behavior, especially for distance-based models.
- ●
The computational cost is for K-Means, which is the dominant bottleneck. For large datasets,
MiniBatchKMeansprovides a 5-10x speedup with minimal quality loss. - ●
Feature scaling is mandatory before Cluster Centroids because K-Means uses Euclidean distance. Without scaling, high-magnitude features dominate cluster formation.
- ●
The
sampling_strategydefault of 1:1 balancing is usually too aggressive. Ratios of 3:1 to 5:1 (majority to minority) often perform better because they retain more majority class information. - ●
In production, resampling should happen inside cross-validation, not before the train/test split. The
imblearn.pipeline.Pipelinehandles this correctly;sklearn.pipeline.Pipelinedoes not support resamplers.
Pitfalls to Avoid
- ●
Claiming Cluster Centroids is always better than random undersampling -- on high-dimensional or uniformly distributed data, random undersampling often performs comparably at a fraction of the cost.
- ●
Forgetting to mention that soft voting produces synthetic points that never existed in the original data -- this has real implications for model interpretability and regulatory compliance.
- ●
Overlooking the fact that K-Means assumes spherical, equally-sized clusters -- if the majority class has irregular cluster shapes, centroids may be poor representatives.
- ●
Not mentioning the centroid drift problem near decision boundaries -- this is the most common failure mode and interviewers expect you to identify it proactively.
Senior-Level Expectation
A senior candidate should discuss the full tradeoff landscape: when Cluster Centroids adds value over simpler methods (multimodal majority class, reproducibility requirements), when it doesn't (high-dimensional data, categorical features, extreme imbalance), and how it compares to modern alternatives like cost-sensitive learning, class_weight in tree-based models, and focal loss. They should quantify computational costs (), recommend practical scaling strategies (MiniBatchKMeans, PCA preprocessing), and articulate why sampling_strategy=0.3 often outperforms 'auto'. Bonus points for discussing the soft-vs-hard voting decision through the lens of regulatory compliance -- a concern highly relevant to Indian fintech companies operating under RBI and SEBI guidelines.
Summary
What We Covered
Cluster Centroids is a prototype generation undersampling technique that reduces the majority class by clustering it with K-Means and replacing the original samples with cluster centroids. It represents a thoughtful middle ground between the simplicity of random undersampling and the complexity of ensemble-based imbalanced learning methods.
The technique works by fitting clusters to the majority class (where is typically the desired post-resampling count) and using the centroids as representative summary points. With soft voting, the centroids themselves become the new samples; with hard voting, the nearest original samples to each centroid are selected instead. This distinction matters for distance-based classifiers and regulatory compliance.
Key Takeaways
-
Cluster Centroids preserves the global structure of the majority class distribution, unlike random undersampling which is structurally blind. This makes it particularly effective when the majority class has multimodal distributions with distinct subclusters.
-
The computational cost () is the primary practical limitation. For large datasets,
MiniBatchKMeansis essentially mandatory, providing 5-10x speedup. -
Feature scaling is non-negotiable -- K-Means uses Euclidean distance, so unscaled features will produce biased centroids. Always apply
StandardScalerbefore ClusterCentroids in the pipeline. -
The most dangerous failure mode is centroid drift near the decision boundary. When majority class clusters span the boundary region, centroids are pulled toward the minority class, increasing overlap and hurting precision.
-
For production systems, start with
sampling_strategy=0.3(3:1 ratio) rather than full 1:1 balancing, and useimblearn.pipeline.Pipelineto ensure resampling happens correctly inside cross-validation. At Indian fintech companies handling fraud detection (Razorpay, PhonePe, Paytm), this technique is part of the standard resampling toolkit alongside SMOTE and class weights.