SMOTE-NC in Machine Learning
Real-world ML datasets rarely consist of purely numerical features. Credit scoring models ingest income (continuous) alongside employment type (categorical). Healthcare systems combine blood pressure readings (continuous) with diagnosis codes (categorical). Churn prediction pipelines merge monthly spend (continuous) with subscription tier (categorical). When these mixed-type datasets are also class-imbalanced, vanilla SMOTE fails catastrophically on the categorical dimensions because you cannot meaningfully interpolate between "full-time" and "part-time" the way you interpolate between 50,000 and 70,000.
SMOTE-NC (Synthetic Minority Over-sampling Technique for Nominal and Continuous features) was introduced in the same seminal 2002 paper by Chawla et al. that gave us vanilla SMOTE. It extends SMOTE to handle datasets containing a mix of categorical (nominal) and continuous features by treating each type differently during both distance computation and synthetic sample generation.
The key insight is elegant: for continuous features, SMOTE-NC uses the same linear interpolation as vanilla SMOTE. For categorical features, it assigns the most frequent category among the k-nearest neighbors rather than interpolating. To compute distances across mixed types, it introduces a penalty term equal to the median of standard deviations of all continuous features whenever two samples disagree on a categorical value.
Today, SMOTE-NC is implemented as SMOTENC in the imbalanced-learn library and is a critical component in any production ML pipeline where tabular data contains both feature types. It sits at the intersection of data preprocessing and class balancing, enabling ML engineers to handle the messy reality of mixed-type imbalanced datasets without resorting to brittle categorical encoding hacks.
Concept Snapshot
- What It Is
- An extension of SMOTE that generates synthetic minority class samples for datasets containing both numerical (continuous) and categorical (nominal) features, using interpolation for continuous features and mode-based selection for categorical ones.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: imbalanced dataset with mixed continuous and categorical features, specification of which columns are categorical. Outputs: balanced dataset with synthetic minority samples preserving valid categorical values.
- System Placement
- Applied during the data preprocessing phase, after data cleaning and feature extraction but before model training. Must be applied only to training data, never test/validation sets.
- Also Known As
- SMOTE Nominal-Continuous, SMOTENC, SMOTE for mixed data, SMOTE for categorical data
- Typical Users
- ML engineers, data scientists, ML platform engineers, risk modelers, healthcare informaticists
- Prerequisites
- SMOTE (vanilla) algorithm, k-nearest neighbors, Euclidean distance, Categorical vs continuous feature distinction, Standard deviation and median statistics, Class imbalance concepts
- Key Terms
- nominal featurescontinuous featuresmedian of standard deviationsmode-based categorical selectionmixed data typescategorical distance penaltySMOTENCimbalanced-learn
Why This Concept Exists
The Mixed Data Problem
Vanilla SMOTE operates by finding k-nearest neighbors in feature space and generating synthetic samples via linear interpolation: where . This works beautifully for continuous features: interpolating between salary=50,000 and salary=70,000 to get salary=62,000 is perfectly valid.
But consider a dataset with a department feature encoded as: engineering=0, marketing=1, finance=2. If SMOTE interpolates between 0 and 2, it produces 1.3 -- which maps to... nothing meaningful. It is neither engineering nor marketing nor finance. The linear interpolation assumption that underpins SMOTE breaks down entirely for categorical features.
The naive workaround -- one-hot encode all categoricals before applying SMOTE -- creates its own problems. Interpolating between [1,0,0] (engineering) and [0,0,1] (finance) produces [0.4, 0, 0.6], which is not a valid one-hot vector. You need post-processing (e.g., argmax) to recover a valid category, and the resulting distribution may not match the original data.
Chawla's Solution: Treat Feature Types Differently (2002)
In the same 2002 JAIR paper that introduced vanilla SMOTE, Chawla et al. proposed SMOTE-NC as a direct extension for mixed-type datasets. The core idea is pragmatic:
- For continuous features: Use standard SMOTE interpolation.
- For categorical features: Instead of interpolating, assign the most frequent category among the k-nearest neighbors of the sample being oversampled.
- For distance computation: Use Euclidean distance on continuous features, and add a fixed penalty (the median of standard deviations of all continuous features in the minority class) for each categorical feature where the two samples disagree.
This approach preserves valid categorical values while still generating diverse synthetic samples for continuous dimensions.
Why It Matters in Practice
The need for SMOTE-NC is pervasive in real-world ML. Consider these common scenarios:
- Credit scoring at Razorpay or Lendingkart: Features include annual income (continuous), loan amount (continuous), employment type (categorical: salaried/self-employed/freelance), education level (categorical: graduate/postgraduate/diploma), and city tier (categorical: tier-1/tier-2/tier-3). The default rate is typically 3-5%, creating severe imbalance.
- Healthcare at Apollo or Narayana Health: Patient records combine blood pressure (continuous), age (continuous), diagnosis code (categorical: ICD-10), medication type (categorical), and admission type (categorical: emergency/elective/urgent). Rare conditions create extreme imbalance.
- E-commerce churn at Flipkart or Myntra: User features include monthly spend (continuous), session duration (continuous), subscription tier (categorical: free/premium/enterprise), payment method (categorical: UPI/card/wallet), and preferred category (categorical: electronics/fashion/groceries). Churn rates of 5-15% are common.
In each case, vanilla SMOTE on the raw data would produce nonsensical categorical values, and encoding-then-SMOTE introduces distribution artifacts. SMOTE-NC handles these datasets natively.
Historical Context: While SMOTE-NC was part of the original 2002 paper, it received far less attention than vanilla SMOTE for over a decade. It was not until the
imbalanced-learnlibrary addedSMOTENCin 2017-2018 that mixed-type oversampling became accessible to the broader ML community. The subsequent rise of tabular ML (XGBoost, LightGBM, CatBoost) further increased demand for techniques that handle categorical features natively.
Core Intuition & Mental Model
The Core Idea: Different Rules for Different Feature Types
Imagine you are a chef creating new recipes by blending existing ones. For quantitative ingredients (200g flour, 3 eggs), you can blend freely: a recipe with 200g flour and one with 300g flour might yield a valid recipe with 240g flour. But for categorical choices (oven-baked vs. pan-fried, vegetarian vs. non-vegetarian), blending makes no sense. You cannot "interpolate" between oven-baked and pan-fried to get something 40% oven-baked.
SMOTE-NC's solution is exactly this: blend the quantities, but vote on the categories. When creating a new synthetic sample, it interpolates the continuous features (like vanilla SMOTE) but for each categorical feature, it looks at the k-nearest neighbors and picks the most popular category -- a majority vote.
The Distance Problem
Before generating anything, SMOTE-NC must find the k-nearest neighbors. But how do you measure "distance" between two samples when some features are numbers and others are categories?
SMOTE-NC introduces a clever penalty system. First, it computes the standard deviation of each continuous feature across the minority class and takes the median of all those standard deviations. Call this value . Now, when computing the Euclidean distance between two samples:
- For continuous features: use the standard squared difference
- For each categorical feature where the two samples disagree: add to the distance
- For each categorical feature where they agree: add nothing
The intuition is elegant: represents a "typical spread" in the continuous feature space. A disagreement on a categorical feature is penalized as if the two samples were one standard deviation apart on a typical continuous feature. This puts categorical differences on a comparable scale to continuous differences without overweighting or underweighting them.
A Concrete Example
Consider two loan applicants (minority class = default):
- Applicant A: income=$50,000, credit_score=620, employment=salaried, city=tier-1
- Applicant B: income=$55,000, credit_score=640, employment=self-employed, city=tier-1
Suppose the median of standard deviations of all continuous minority features is .
Distance computation:
- income:
- credit_score:
- employment: salaried != self-employed, so add
- city: tier-1 == tier-1, so add
Total squared distance:
Notice how the categorical disagreement on employment contributes more to the distance than the income difference. This reflects the intuition that switching employment types is a "bigger" change than a modest income variation.
When generating a synthetic sample from Applicant A using Applicant B as a neighbor:
- income: (interpolated)
- credit_score: (interpolated)
- employment: majority vote among k neighbors (say 3 of 5 are "salaried") => salaried
- city: majority vote among k neighbors (all are "tier-1") => tier-1
Key Mental Model: Think of SMOTE-NC as two parallel systems running simultaneously: a continuous interpolation engine (identical to vanilla SMOTE) and a categorical voting engine (picks the most popular category from the neighborhood). The distance metric glues them together by making categorical disagreements contribute a fixed, calibrated penalty to the overall distance.
Technical Foundations
Mathematical Formulation
Let be a training set with continuous features and nominal (categorical) features, where . Let denote the minority class with .
Step 1: Compute the Categorical Distance Penalty
For each continuous feature , compute the standard deviation across minority class samples:
Then compute the median of these standard deviations:
This value serves as the fixed distance penalty for each disagreeing categorical feature.
Step 2: Modified Distance Metric
The distance between two minority samples and is:
where is the indicator function that equals 1 when the categorical values differ and 0 when they agree.
Step 3: k-Nearest Neighbor Search
For each minority sample , find the nearest minority class neighbors using the modified distance metric:
Step 4: Synthetic Sample Generation
For each minority sample and a randomly selected neighbor :
Continuous features ():
Categorical features ():
where returns the most frequent category among the k-nearest neighbors. In the case of ties, a random selection is made among the tied categories.
Complexity Analysis
- Penalty computation: for standard deviations + for median
- k-NN search: for naive implementation, with spatial indexing
- Synthetic generation: where is the number of synthetic samples and the term accounts for the mode computation on categorical features
Constraint
SMOTE-NC requires at least one continuous feature () because the distance penalty is derived from continuous feature standard deviations. For purely categorical datasets, use SMOTEN (SMOTE for Nominal features) instead.
Mathematical Subtlety: The choice of the median (rather than the mean) of standard deviations for makes the penalty robust to outlier features with extremely high or low variance. A single continuous feature with very high variance (e.g., income in rupees vs. age in years) would inflate the mean but not the median, keeping the categorical penalty calibrated to the typical feature spread.
Internal Architecture
SMOTE-NC's architecture extends vanilla SMOTE with two critical modifications: a modified distance metric that handles mixed feature types, and a dual-mode generation engine that applies interpolation to continuous features and majority voting to categorical features.
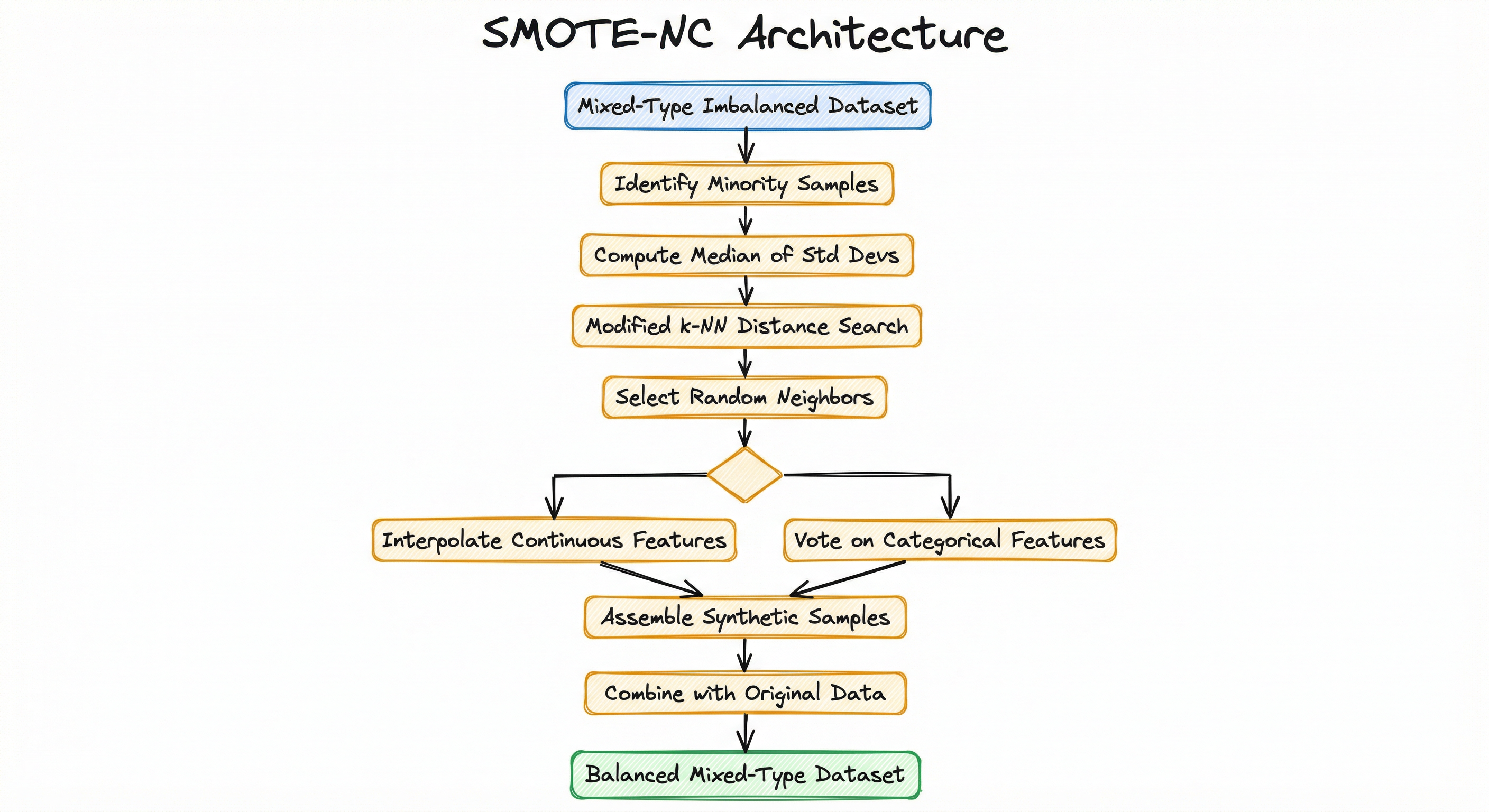
The architecture divides neatly into three phases: calibration (computing the median standard deviation penalty), search (finding neighbors using the modified distance metric), and generation (producing synthetic samples with type-aware feature handling).
Key Components
Feature Type Classifier
Identifies which features are categorical and which are continuous, either from explicit user specification (indices or column names) or automatic detection via pandas CategoricalDtype. This classification determines how each feature is treated during distance computation and synthetic generation.
Median Standard Deviation Calculator
Computes the standard deviation of each continuous feature across minority class samples, then takes the median of all standard deviations to produce the categorical penalty value . This value calibrates the contribution of categorical disagreements to be on par with typical continuous feature variation.
Modified Distance Engine
Computes pairwise distances between minority class samples using a hybrid metric: Euclidean distance for continuous features plus penalty for each disagreeing categorical feature. This metric unifies continuous and categorical dimensions into a single distance measure for k-NN search.
k-Nearest Neighbor Finder
For each minority sample, identifies the k nearest minority class neighbors using the modified distance metric. Returns neighbor indices and distances for use in the generation phase.
Continuous Feature Interpolator
Generates continuous feature values for synthetic samples using standard SMOTE interpolation: where . Operates independently on each continuous feature dimension.
Categorical Feature Voter
For each categorical feature of a synthetic sample, performs a majority vote across the k-nearest neighbors of the source sample. Assigns the most frequent category. Handles ties by random selection among tied categories.
Sample Assembler
Combines interpolated continuous features and voted categorical features into complete synthetic samples. Labels each synthetic sample with the minority class. Merges synthetic samples with the original dataset to produce the final balanced output.
Data Flow
Input Flow: The algorithm receives a mixed-type imbalanced dataset along with the specification of which features are categorical (via indices, column names, or automatic detection). It separates minority and majority class samples.
Calibration Flow: The Median Standard Deviation Calculator processes only the continuous features of minority class samples. It computes per-feature standard deviations and derives the penalty value . This is a one-time computation that parameterizes the rest of the algorithm.
Search Flow: The Modified Distance Engine computes pairwise distances between all minority samples, incorporating both continuous Euclidean distances and categorical penalty terms. The k-NN Finder uses these distances to identify neighbors for each minority sample. This is the most computationally expensive phase.
Generation Flow: For each synthetic sample to generate, the algorithm selects a source minority sample and a random neighbor from its k nearest. The continuous and categorical paths diverge: the Continuous Feature Interpolator produces interpolated values, while the Categorical Feature Voter polls the neighborhood for each categorical feature. The Sample Assembler merges these into complete synthetic records.
Output Flow: Synthetic minority samples are combined with original data. The majority class passes through unchanged. The final output is a balanced dataset where all categorical features contain only valid, existing category values -- never interpolated nonsense.
A flow diagram starting with a mixed-type imbalanced dataset, passing through minority sample identification, median standard deviation computation, modified k-NN distance search, neighbor selection, then splitting into parallel paths for continuous feature interpolation and categorical feature voting, which converge at synthetic sample assembly and combine with original data to produce a balanced mixed-type dataset.
How to Implement
Implementation via imbalanced-learn
SMOTE-NC is implemented as SMOTENC in the imbalanced-learn (imblearn) library, providing a scikit-learn-compatible API. The class accepts a categorical_features parameter that specifies which columns are categorical -- either as integer indices, feature name strings (for pandas DataFrames), a boolean mask, or 'auto' for automatic detection via pandas.CategoricalDtype.
Key implementation decisions:
- Feature specification: You must tell SMOTENC which features are categorical. Unlike CatBoost or LightGBM, it does not infer this automatically from data inspection (unless using the
'auto'option with properly typed pandas DataFrames). - One-hot encoding internally: The imblearn implementation internally one-hot encodes categorical features for distance computation, applying the median standard deviation as a scaling factor. This is transparent to the user.
- At least one continuous feature required: SMOTENC will raise an error if all features are categorical. For purely categorical datasets, use
SMOTENinstead.
Cost/Performance Note: SMOTENC's computational cost is similar to vanilla SMOTE, dominated by the k-NN search. For a dataset with 100,000 minority samples and 50 features (30 continuous + 20 categorical), expect 2-5 minutes on a modern CPU. The categorical penalty computation is negligible. A standard compute instance on AWS (m6i.xlarge, ~$0.192/hr or ~₹16/hr) handles most tabular ML workloads comfortably.
import numpy as np
import pandas as pd
from imblearn.over_sampling import SMOTENC
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Create a mixed-type imbalanced dataset
np.random.seed(42)
n_samples = 5000
data = pd.DataFrame({
'income': np.random.normal(50000, 15000, n_samples).astype(int),
'credit_score': np.random.normal(650, 80, n_samples).astype(int),
'age': np.random.normal(35, 10, n_samples).astype(int),
'employment': np.random.choice(
['salaried', 'self_employed', 'freelance'], n_samples, p=[0.6, 0.3, 0.1]
),
'city_tier': np.random.choice(
['tier_1', 'tier_2', 'tier_3'], n_samples, p=[0.4, 0.35, 0.25]
),
'education': np.random.choice(
['graduate', 'postgraduate', 'diploma', 'high_school'], n_samples
),
})
# Create imbalanced target (5% minority)
y = np.zeros(n_samples, dtype=int)
y[np.random.choice(n_samples, size=int(0.05 * n_samples), replace=False)] = 1
print(f"Class distribution: {np.bincount(y)}")
# Output: [4750, 250]
# Split data
X_train, X_test, y_train, y_test = train_test_split(
data, y, test_size=0.2, random_state=42, stratify=y
)
# Specify categorical feature indices
# employment=3, city_tier=4, education=5
categorical_features = [3, 4, 5]
# Apply SMOTE-NC
smote_nc = SMOTENC(
categorical_features=categorical_features,
sampling_strategy='auto',
k_neighbors=5,
random_state=42
)
X_train_res, y_train_res = smote_nc.fit_resample(X_train, y_train)
print(f"Resampled class distribution: {np.bincount(y_train_res)}")
# Categorical features preserve valid values:
print(f"Unique employment values: {X_train_res['employment'].unique()}")
# Output: ['salaried', 'self_employed', 'freelance'] -- no interpolated garbage
# Train and evaluate
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train_res, y_train_res)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))This example demonstrates the standard SMOTE-NC workflow with mixed-type data. Key points: (1) The categorical_features parameter explicitly identifies which columns are categorical. (2) After resampling, categorical features contain only valid category values from the original data -- never interpolated values. (3) SMOTE-NC is applied only to the training set, preserving the original imbalanced distribution in the test set for realistic evaluation.
import numpy as np
import pandas as pd
from imblearn.over_sampling import SMOTENC
# Create DataFrame with explicit CategoricalDtype
np.random.seed(42)
n = 2000
df = pd.DataFrame({
'amount': np.random.exponential(5000, n),
'duration_days': np.random.randint(1, 365, n),
'payment_method': pd.Categorical(
np.random.choice(['upi', 'credit_card', 'debit_card', 'wallet'], n)
),
'merchant_category': pd.Categorical(
np.random.choice(['electronics', 'food', 'travel', 'fashion', 'utilities'], n)
),
'is_international': pd.Categorical(
np.random.choice([True, False], n, p=[0.1, 0.9])
),
})
y = np.zeros(n, dtype=int)
y[:60] = 1 # 3% fraud rate
np.random.shuffle(y)
# Use 'auto' to detect CategoricalDtype columns
smote_nc = SMOTENC(
categorical_features='auto', # Detects pd.CategoricalDtype columns
sampling_strategy=0.3, # Target 30% minority ratio
k_neighbors=5,
random_state=42
)
X_res, y_res = smote_nc.fit_resample(df, y)
minority_count = np.sum(y_res == 1)
majority_count = np.sum(y_res == 0)
print(f"Original minority: {np.sum(y == 1)}, majority: {np.sum(y == 0)}")
print(f"Resampled minority: {minority_count}, majority: {majority_count}")
print(f"New ratio: {minority_count / majority_count:.3f}")
# Verify categorical integrity
print(f"Payment methods: {X_res['payment_method'].unique()}")
print(f"Merchant categories: {X_res['merchant_category'].unique()}")
# All values are valid categories from the original dataWhen using pandas DataFrames with pd.CategoricalDtype columns, SMOTENC can automatically detect categorical features via categorical_features='auto'. This avoids manually specifying column indices and reduces errors when columns are reordered. The sampling_strategy=0.3 targets a 30% minority-to-majority ratio rather than full 1:1 balancing, which is common in fraud detection where some imbalance is realistic.
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTENC
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OrdinalEncoder
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
import numpy as np
import pandas as pd
# Sample dataset with mixed types
np.random.seed(42)
n = 3000
df = pd.DataFrame({
'monthly_spend': np.random.lognormal(8, 1.5, n),
'tenure_months': np.random.randint(1, 60, n),
'support_tickets': np.random.poisson(2, n),
'plan_type': np.random.choice(['basic', 'standard', 'premium'], n),
'payment_method': np.random.choice(['auto', 'manual', 'upi'], n),
'region': np.random.choice(['north', 'south', 'east', 'west'], n),
})
y = np.zeros(n, dtype=int)
y[:300] = 1 # 10% churn rate
np.random.shuffle(y)
# Categorical feature indices: plan_type=3, payment_method=4, region=5
cat_features = [3, 4, 5]
# Build imblearn pipeline (NOT sklearn pipeline)
pipeline = Pipeline([
('smote_nc', SMOTENC(
categorical_features=cat_features,
sampling_strategy=0.5,
k_neighbors=5,
random_state=42
)),
('classifier', GradientBoostingClassifier(
n_estimators=100,
random_state=42
))
])
# Cross-validation with SMOTE-NC applied inside each fold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(
pipeline, df, y,
cv=cv,
scoring='f1',
n_jobs=-1
)
print(f"Cross-validated F1 scores: {scores}")
print(f"Mean F1: {scores.mean():.3f} +/- {scores.std():.3f}")Using imblearn.pipeline.Pipeline ensures SMOTE-NC is applied correctly during cross-validation: it resamples ONLY the training folds, never the validation fold, preventing data leakage. Note: you must use imblearn.pipeline.Pipeline, not sklearn.pipeline.Pipeline, because the standard scikit-learn pipeline does not support resamplers. The StratifiedKFold preserves class ratios in each fold, ensuring consistent imbalance for the resampler.
import numpy as np
import pandas as pd
from imblearn.over_sampling import SMOTENC
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, recall_score, precision_score
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler, LabelEncoder
# Healthcare dataset with mixed features
np.random.seed(42)
n_patients = 4000
df = pd.DataFrame({
'age': np.random.normal(55, 15, n_patients).clip(18, 90).astype(int),
'bmi': np.random.normal(27, 5, n_patients).clip(15, 50),
'blood_pressure_systolic': np.random.normal(130, 20, n_patients).clip(80, 200).astype(int),
'blood_glucose': np.random.normal(110, 30, n_patients).clip(60, 300),
'gender': np.random.choice(['male', 'female', 'other'], n_patients, p=[0.48, 0.48, 0.04]),
'smoking_status': np.random.choice(
['never', 'former', 'current'], n_patients, p=[0.5, 0.3, 0.2]
),
'diagnosis_category': np.random.choice(
['cardiovascular', 'respiratory', 'metabolic', 'neurological'], n_patients
),
'admission_type': np.random.choice(
['emergency', 'elective', 'urgent'], n_patients, p=[0.3, 0.5, 0.2]
),
})
# Rare adverse event (2.5% occurrence)
y = np.zeros(n_patients, dtype=int)
y[:100] = 1
np.random.shuffle(y)
# Specify categorical features by NAME (requires pandas DataFrame)
categorical_feature_names = [
'gender', 'smoking_status', 'diagnosis_category', 'admission_type'
]
# Split
X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.2, stratify=y, random_state=42
)
# Apply SMOTE-NC using feature names
smote_nc = SMOTENC(
categorical_features=categorical_feature_names,
sampling_strategy='auto',
k_neighbors=5,
random_state=42
)
X_train_res, y_train_res = smote_nc.fit_resample(X_train, y_train)
# Encode categoricals for LogisticRegression
le_dict = {}
for col in categorical_feature_names:
le = LabelEncoder()
X_train_res[col] = le.fit_transform(X_train_res[col])
X_test[col] = le.transform(X_test[col])
le_dict[col] = le
# Scale continuous features
cont_features = ['age', 'bmi', 'blood_pressure_systolic', 'blood_glucose']
scaler = StandardScaler()
X_train_res[cont_features] = scaler.fit_transform(X_train_res[cont_features])
X_test[cont_features] = scaler.transform(X_test[cont_features])
# Train and evaluate
clf = LogisticRegression(max_iter=1000, random_state=42)
clf.fit(X_train_res, y_train_res)
y_pred = clf.predict(X_test)
print(f"Recall (adverse events): {recall_score(y_test, y_pred):.3f}")
print(f"Precision: {precision_score(y_test, y_pred):.3f}")
print(f"F1: {f1_score(y_test, y_pred):.3f}")This healthcare example demonstrates specifying categorical features by column name instead of index, which is more readable and robust to column reordering. The workflow shows SMOTE-NC generating balanced training data with valid categorical values (e.g., only 'emergency'/'elective'/'urgent' for admission type), then encoding and scaling for a logistic regression model. In clinical settings, improving recall for rare adverse events (even at some precision cost) can be life-saving.
# SMOTE-NC configuration for imbalanced-learn SMOTENC
smotenc_config = {
'categorical_features': [3, 4, 5], # indices of categorical columns
'sampling_strategy': 'auto', # balance to 1:1
'k_neighbors': 5, # nearest neighbors for generation
'random_state': 42, # reproducibility
'n_jobs': -1 # parallel k-NN search
}
# Alternative: specify by column name (pandas DataFrame)
smotenc_config_names = {
'categorical_features': ['employment', 'city_tier', 'education'],
'sampling_strategy': 0.3, # target 30% minority ratio
'k_neighbors': 5,
'random_state': 42
}
# Alternative: automatic detection (pandas CategoricalDtype)
smotenc_config_auto = {
'categorical_features': 'auto', # detects pd.CategoricalDtype
'sampling_strategy': 'auto',
'k_neighbors': 5,
'random_state': 42
}Common Implementation Mistakes
- ●
Passing all categorical features without any continuous features -- SMOTE-NC requires at least one continuous feature to compute the median standard deviation penalty. If all features are categorical, use
SMOTENinstead. The algorithm will raise aValueErrorif no continuous features are detected. - ●
Forgetting to specify which features are categorical -- If you pass a numpy array to SMOTENC without setting
categorical_features, it assumes ALL features are continuous and applies vanilla SMOTE interpolation. This silently produces nonsensical categorical values (e.g., employment=1.37). Always explicitly specify categorical features. - ●
One-hot encoding categorical features before SMOTE-NC -- If you one-hot encode first, SMOTE-NC treats the resulting binary columns as continuous and interpolates them, producing values like 0.6 that are invalid. Feed the raw categorical values to SMOTE-NC and let it handle them internally.
- ●
Applying SMOTE-NC to the full dataset before train-test split -- Same data leakage risk as vanilla SMOTE. Synthetic test samples are influenced by training samples, inflating performance metrics. Always split first, then apply SMOTE-NC only to the training set.
- ●
Not scaling continuous features before SMOTE-NC -- The k-NN search uses Euclidean distance on continuous features. If income ranges 0-1,000,000 and age ranges 18-90, income dominates the distance computation. Standardize continuous features before applying SMOTE-NC, or use the pipeline approach.
- ●
Using SMOTE-NC when categorical features have very high cardinality -- With hundreds of unique categories (e.g., zip codes, product IDs), the mode-based voting produces categories that are poorly representative of the neighborhood. Consider grouping high-cardinality categoricals into broader categories (e.g., zip code -> city tier) before applying SMOTE-NC.
- ●
Mismatching categorical_features indices after column operations -- If you drop, reorder, or add columns after defining the categorical indices but before calling fit_resample, the indices will point to the wrong columns. Use column names with pandas DataFrames instead of integer indices for robustness.
When Should You Use This?
Use When
Your dataset contains a mix of continuous and categorical features with class imbalance -- the primary and most common use case for SMOTE-NC
Categorical features represent meaningful domain concepts (employment type, diagnosis code, subscription tier) that should not be interpolated or encoded before oversampling
The minority class has sufficient samples (>50-100) for reliable k-NN search, and the majority of features are not purely categorical
Your model lacks native support for class weights with mixed data types (e.g., k-NN, standard SVM, certain neural network architectures)
You need to improve minority class recall for datasets like credit risk scoring, healthcare adverse events, or insurance fraud where the data is inherently mixed-type
Random oversampling (simple duplication) is causing overfitting on the minority class, evidenced by high training accuracy but poor generalization
One-hot encoding followed by vanilla SMOTE produces distribution artifacts (e.g., interpolated one-hot vectors that don't decode cleanly to valid categories)
Avoid When
All your features are categorical -- SMOTE-NC requires at least one continuous feature. Use SMOTEN (SMOTE for Nominal features) instead
All your features are continuous -- vanilla SMOTE is simpler, faster, and equally effective for purely numerical datasets
You are using tree-based models (XGBoost, LightGBM, CatBoost) that natively handle both categorical features and class imbalance via class weights and native categorical support
Categorical features have very high cardinality (>100 unique values) -- the mode-based voting becomes unreliable as the probability of any single category being the mode decreases
Your minority class has fewer than 30-50 samples -- with extreme data scarcity, k-NN neighbors may be unreliable and the median standard deviation is poorly estimated
The categorical features are ordinal with meaningful ordering (e.g., education levels: high school < bachelor < master < PhD) -- SMOTE-NC treats them as nominal, ignoring the ordering. Consider ordinal encoding and vanilla SMOTE instead
Computational constraints are tight and your dataset is very large (>500K minority samples) -- the modified distance computation adds overhead vs. vanilla SMOTE, and class weights or focal loss may be more efficient alternatives
Key Tradeoffs
Continuous vs. Categorical Feature Handling
The fundamental tradeoff in SMOTE-NC is between categorical fidelity and synthetic diversity. Continuous features get diverse synthetic values through interpolation, but categorical features are limited to the most popular existing category in the neighborhood. This means synthetic samples may have lower diversity on categorical dimensions than on continuous ones.
For example, if 4 out of 5 neighbors have employment=salaried, every synthetic sample from that neighborhood will also be salaried, regardless of the source sample's employment type. This can exaggerate majority categories within the minority class, subtly shifting the categorical distribution of synthetic samples toward the dominant category.
The Median Penalty Calibration
The choice of the median of standard deviations as the categorical distance penalty is a pragmatic compromise, not an optimal solution:
| Scenario | Effect |
|---|---|
| Few categoricals, many continuous | Categorical penalties are small relative to total distance -- categoricals have minimal influence on neighbor selection |
| Many categoricals, few continuous | Categorical penalties dominate -- neighbors are primarily selected by categorical similarity, with continuous features having little influence |
| High-variance continuous features | Median penalty is large -- categorical disagreements are heavily penalized, potentially over-separating samples that differ only on categories |
| Low-variance continuous features | Median penalty is small -- categorical disagreements are underweighted, potentially grouping samples with different categories as neighbors |
SMOTE-NC vs. Encode-Then-SMOTE
A common alternative workflow is to encode categorical features (one-hot, target, ordinal) and then apply vanilla SMOTE. This avoids the median penalty mechanism entirely but introduces different issues:
- One-hot + SMOTE: Produces non-binary one-hot values (e.g., [0.3, 0.7]) requiring post-processing. Can distort the categorical distribution.
- Target encoding + SMOTE: Introduces target leakage risk if not done carefully within each CV fold. The encoding creates a continuous proxy for the categorical feature that SMOTE can interpolate meaningfully.
- Ordinal encoding + SMOTE: Only appropriate for ordinal features. Interpolating between rank 1 and rank 3 to get 2.4 may or may not be meaningful depending on the feature.
SMOTE-NC sidesteps all of these by handling categoricals natively, at the cost of reduced diversity on categorical dimensions.
Computational Overhead
Compared to vanilla SMOTE, SMOTE-NC adds the median standard deviation computation (negligible) and the categorical penalty evaluation during distance computation (moderate). For a dataset with categorical features, each pairwise distance requires additional equality checks and conditional additions. On a dataset with 50 features (30 continuous + 20 categorical) and 10,000 minority samples, this adds roughly 10-20% to the k-NN search time.
Rule of Thumb: Use SMOTE-NC when you have 2-20 categorical features alongside continuous features. For >20 categorical features, consider dimensionality reduction on the categoricals (e.g., embedding them) before applying vanilla SMOTE. For purely categorical data, switch to SMOTEN.
Alternatives & Comparisons
Vanilla SMOTE only handles continuous features via linear interpolation. If your dataset has categorical features, vanilla SMOTE will produce meaningless interpolated values (e.g., employment=1.37). Use SMOTE for purely numerical datasets. Use SMOTE-NC whenever categorical features are present and you want to avoid encoding-before-resampling artifacts.
Borderline-SMOTE focuses synthetic generation on minority samples near the decision boundary, ignoring those deep in safe regions. However, it only supports continuous features natively. If you need both boundary-focused generation AND categorical feature handling, you would need to encode categoricals first (with associated trade-offs) or look for custom implementations. Use Borderline-SMOTE for purely numerical noisy datasets; use SMOTE-NC for mixed-type datasets.
ADASYN adaptively generates more synthetic samples for harder-to-learn minority instances (those surrounded by majority samples). Like Borderline-SMOTE, it only supports continuous features natively. ADASYN is preferable when minority class difficulty varies significantly across the feature space and all features are numerical. For mixed-type datasets with varying difficulty, consider using SMOTE-NC and then applying an undersampling technique (like ENN) to clean boundary-violating synthetics.
Random oversampling duplicates existing minority samples regardless of feature type, making it universally applicable to any data type. It requires no distance metric or feature type specification. However, it provides no new information and often leads to overfitting. Use random oversampling as a quick baseline or when SMOTE-NC's computational cost is prohibitive. Use SMOTE-NC when you need diverse synthetic samples with valid categorical values.
SMOTE + ENN combines oversampling (SMOTE) with undersampling (Edited Nearest Neighbors) to generate synthetic samples and then remove noisy or borderline samples. The imblearn implementation uses vanilla SMOTE, so it does not natively support categorical features. However, combining SMOTE-NC with a separate ENN cleaning step can produce cleaner synthetic samples for mixed-type datasets.
Pros, Cons & Tradeoffs
Advantages
Handles mixed data types natively -- generates valid categorical values (via majority voting) and meaningful continuous values (via interpolation), eliminating the need for error-prone encoding-before-resampling workflows
Preserves categorical integrity -- synthetic samples only contain category values that exist in the original data, unlike one-hot-then-SMOTE which produces non-binary one-hot vectors requiring post-processing
Calibrated distance metric -- the median standard deviation penalty provides a principled way to compare categorical and continuous features in a unified distance space, robust to outlier features via the median (not mean)
scikit-learn compatible API -- fully integrated with
imblearn.pipeline.Pipeline, cross-validation, and the fit_resample interface. Supports pandas DataFrames with automatic categorical detection viaCategoricalDtypeWidely applicable to real-world tabular data -- most production ML datasets (credit scoring, healthcare, churn prediction, fraud detection) contain mixed feature types, making SMOTE-NC more broadly useful than vanilla SMOTE for tabular ML
Model-agnostic preprocessing -- works as a data-level resampling step before any classifier. Particularly valuable for models that do not natively handle class imbalance (k-NN, SVM, vanilla neural networks)
Preserves all original data -- unlike undersampling, SMOTE-NC keeps all original samples (both majority and minority) and only adds synthetic minority instances, retaining maximum information
Disadvantages
Reduced categorical diversity in synthetic samples -- mode-based voting produces homogeneous categorical values within neighborhoods. If 4/5 neighbors are 'salaried', all synthetic samples from that neighborhood will be 'salaried', potentially exaggerating majority categories within the minority class
Requires at least one continuous feature -- the median standard deviation penalty is undefined without continuous features. For purely categorical datasets, you must use SMOTEN instead, fragmenting your resampling strategy
Fixed penalty for all categorical features -- a single value penalizes all categorical disagreements equally, ignoring that some categorical features may be more or less important. Disagreeing on 'gender' is penalized identically to disagreeing on 'diagnosis_code', even though they may have very different semantic significance
Sensitive to continuous feature scaling -- the median standard deviation (and thus the categorical penalty) depends on the scale of continuous features. Unstandardized features with large ranges (e.g., income in rupees) inflate the penalty, potentially overweighting categorical disagreements
Does not consider categorical feature semantics -- treats all categories as equally distant from each other. 'tier_1' and 'tier_2' cities are penalized the same as 'tier_1' and 'tier_3', even though tier_1 and tier_2 may be more similar. No concept of ordinal relationships or category embeddings
k-NN search overhead for high-cardinality categoricals -- with many categorical features, the penalty computation adds comparisons per distance evaluation. For 50+ categorical features, this can noticeably slow the neighbor search compared to vanilla SMOTE
Mode ties are resolved randomly -- when multiple categories are equally frequent among neighbors, the chosen category is random, introducing non-determinism even with a fixed random seed (depending on implementation). This can affect reproducibility in edge cases
Failure Modes & Debugging
Categorical homogenization in skewed minority subgroups
Cause
When the minority class has a dominant category for a particular feature (e.g., 80% of fraud cases involve payment_method=credit_card), the mode-based voting nearly always selects the dominant category for synthetic samples. Over successive rounds of generation, the synthetic minority distribution becomes increasingly skewed toward the dominant category, amplifying existing biases.
Symptoms
After resampling, the minority class shows less categorical diversity than the original. Synthetic samples disproportionately represent one category (e.g., 95% credit card fraud instead of the original 80%). Model learns to associate the minority class almost exclusively with the dominant category, failing to detect minority instances with other categories (e.g., UPI-based fraud).
Mitigation
Monitor categorical distributions before and after SMOTE-NC to detect homogenization. If detected, consider stratified SMOTE-NC: split the minority class by the skewed categorical feature, apply SMOTE-NC to each subgroup independently, then combine. Alternatively, use undersampling techniques (ENN, Tomek links) post-SMOTE-NC to remove the most homogeneous synthetic samples.
Median penalty miscalibration from extreme-variance continuous features
Cause
When one or a few continuous features have extremely high variance (e.g., income ranging from 10,000 to 10,000,000 in the minority class) while others have low variance (e.g., age 20-60), the median standard deviation may be inflated or deflated depending on which side of the median the extreme features fall. This makes categorical disagreements either too costly or too cheap in the distance computation.
Symptoms
Neighbors are selected primarily based on categorical agreement (if penalty is too high) or primarily based on continuous proximity (if penalty is too low), ignoring the other dimension. Synthetic samples cluster unnaturally in feature space. Model performance degrades compared to vanilla SMOTE with encoded categoricals.
Mitigation
Standardize all continuous features before applying SMOTE-NC (StandardScaler or MinMaxScaler). This ensures each continuous feature contributes a standard deviation close to 1.0, making the median penalty approximately 1.0 -- a balanced contribution for categorical disagreements. If standardization is not possible, manually inspect the computed median and consider whether it appropriately weighs categorical differences.
High-cardinality categorical features producing meaningless modes
Cause
When a categorical feature has hundreds of unique values (e.g., 500 product IDs, 800 zip codes), the k=5 nearest neighbors are unlikely to share any single category. The mode computation may yield categories with only 1 or 2 votes out of 5, producing synthetic samples with essentially random categorical assignments.
Symptoms
Synthetic samples have categorical values that appear arbitrary and not representative of the local neighborhood. No clear pattern between the source sample's category and the synthetic sample's category. Model trained on resampled data performs worse than random oversampling for high-cardinality categorical features.
Mitigation
Group high-cardinality categoricals into broader categories before applying SMOTE-NC (e.g., zip code to city tier, product ID to product category). Alternatively, embed high-cardinality categoricals into dense continuous representations (using target encoding, entity embeddings, or learned embeddings) and treat them as continuous features in SMOTE-NC. For k=5, any categorical feature with >20 unique values in the minority class is at risk.
Feature type misspecification leading to silent corruption
Cause
Categorical features are not specified (or incorrectly specified) to SMOTENC, causing them to be treated as continuous. This is especially insidious when categorical features are integer-encoded (e.g., city_tier: 1, 2, 3) and look numerical to the algorithm.
Symptoms
No errors are raised because the data is technically numeric. But synthetic samples contain interpolated categorical values (e.g., city_tier=1.7, education_level=2.4) that have no semantic meaning. Model may still train without errors but learns on corrupted data, leading to subtle performance degradation that is hard to diagnose.
Mitigation
Always explicitly specify categorical features via the categorical_features parameter. Use column names (not indices) with pandas DataFrames for clarity. After resampling, validate that categorical columns contain only original category values: assert set(X_resampled['city_tier'].unique()).issubset(set(X_original['city_tier'].unique())). Add this assertion as a pipeline validation step.
Memory exhaustion from internal one-hot encoding
Cause
The imbalanced-learn implementation internally one-hot encodes categorical features for the distance computation. With high-cardinality categoricals (e.g., 500 categories), this expands the feature space dramatically. A dataset with 10 continuous + 5 categorical features (each with 100 categories) becomes 10 + 500 = 510 dimensions internally.
Symptoms
Out-of-memory errors during fit_resample(). Unexpectedly slow k-NN search times. System swapping heavily. The error message may reference distance matrix computation or nearest neighbor construction rather than explicitly mentioning one-hot encoding.
Mitigation
Reduce categorical cardinality before applying SMOTE-NC by grouping rare categories (e.g., categories with <1% frequency into an 'other' bucket). For datasets with many high-cardinality categoricals, consider using target encoding to convert them to continuous features and then applying vanilla SMOTE. Monitor memory usage during resampling: if the internal one-hot expansion exceeds 1,000 features, expect significant memory overhead.
Placement in an ML System
SMOTE-NC occupies the same pipeline position as vanilla SMOTE: it sits in the data preprocessing stage, after data cleaning, validation, and feature extraction but before model training. It is exclusively a training-time technique -- synthetic samples are used only to balance the training set and are never generated or used during inference.
Upstream dependencies: SMOTE-NC requires that categorical features are clearly identified and that continuous features are reasonably clean (no extreme outliers that would skew the median standard deviation). Feature scaling (standardization) should be applied to continuous features before SMOTE-NC to ensure the median penalty is well-calibrated. Missing value imputation should be completed upstream, as SMOTE-NC cannot handle NaN values.
Downstream impact: The balanced dataset produced by SMOTE-NC feeds into model training. Because synthetic samples contain valid categorical values, downstream models that handle categoricals natively (CatBoost, LightGBM with categorical support) can consume the output directly. For models requiring encoded features (logistic regression, standard neural networks), encoding should happen after SMOTE-NC to avoid the one-hot interpolation problem.
Production deployment: Like all SMOTE variants, SMOTE-NC has zero inference-time overhead. The deployed model receives real-world mixed-type data and makes predictions without any resampling. SMOTE-NC's contribution exists entirely in the model weights learned during training on the balanced dataset.
Pipeline integration: SMOTE-NC should be wrapped in an imblearn.pipeline.Pipeline for cross-validation. It integrates with standard MLOps tools (MLflow, Kubeflow, Airflow) as a preprocessing step in the training DAG. Typical placement: data loading -> cleaning -> splitting -> SMOTE-NC (training only) -> encoding -> scaling -> model training.
Pipeline Stage
Data Preprocessing / Training
Upstream
- data-cleaning
- data-validation
- feature-extraction
- train-test-split
Downstream
- model-training
- hyperparameter-tuning
- cross-validation
Scaling Bottlenecks
SMOTE-NC's scalability bottleneck is the k-NN search with the modified distance metric. The additional categorical penalty evaluation adds comparisons per distance computation, where is the number of categorical features. For a dataset with 100,000 minority samples and 50 features (30 continuous + 20 categorical), expect the k-NN phase to take 3-8 minutes on a modern CPU -- roughly 20-30% slower than vanilla SMOTE on the same dataset. The internal one-hot encoding for distance computation can also be memory-intensive: 20 categorical features with an average of 50 categories each creates 1,000 additional dimensions, requiring proportionally more memory for the distance matrix. At scale (>500K minority samples), the combined CPU and memory overhead may necessitate approximate nearest neighbor algorithms, dimensionality reduction on categoricals, or switching to class weights.
Production Case Studies
A study on data-driven loan default prediction used SMOTENC to handle mixed categorical and continuous features in lending datasets. The research built a structured ML pipeline including data preprocessing, feature engineering, class imbalance handling via SMOTENC and class weighting, and evaluated XGBoost, Gradient Boosting, Random Forest, and LightGBM models.
Gradient Boosting achieved the highest classification performance (accuracy=0.889, F1=0.808, recall=0.802) on the SMOTENC-balanced dataset. The study demonstrated that SMOTENC effectively preserved categorical feature integrity (employment type, loan purpose, home ownership) while generating meaningful synthetic minority samples for the default class.
Researchers developed NOTE (Non-parametric Oversampling Technique for Explainable credit scoring) to address SMOTE and SMOTE-NC's limitations with high-dimensional, non-linear credit data. The study benchmarked against SMOTE-NC and other variants on mixed-type credit scoring datasets containing both continuous financial features (income, debt ratio) and categorical features (employment type, loan grade).
The study found that SMOTE-NC improved baseline model accuracy from 78% to 84% ROC-AUC on mixed-type credit datasets. The NOTE approach further improved to 89% by addressing SMOTE-NC's fixed-penalty limitation. Both methods validated that categorical-aware oversampling significantly outperforms vanilla SMOTE on mixed-type financial data.
A study on enhancing customer retention in the telecom industry used SMOTE-based techniques to handle imbalanced churn datasets with mixed features (monthly charges as continuous, contract type and payment method as categorical). The research evaluated Random Forest, XGBoost, CatBoost, and LightGBM on balanced datasets with churn-to-non-churn ratios around 1:5.39.
The Random Forest model achieved 91.66% predictive accuracy, 82.2% precision, and 81.8% recall on the SMOTE-balanced dataset. The study highlighted that proper handling of categorical features during oversampling was critical for maintaining realistic customer profiles in synthetic churn data, particularly for features like contract type ('month-to-month', 'one-year', 'two-year') and internet service type ('DSL', 'fiber-optic').
An employee attrition prediction study used SMOTE techniques on the IBM HR Analytics dataset (1,470 observations, 35 attributes) where approximately 84% of instances belonged to the non-resignation class. The dataset contained mixed features: continuous features (monthly income, years at company, distance from home) and categorical features (department, job role, marital status, education field). SMOTENC was used to properly handle the categorical dimensions.
Without oversampling, models achieved <60% recall for attrition cases. After applying SMOTE-based balancing with categorical-aware handling, recall for attrition prediction improved to 78-85% while maintaining >75% precision. The study demonstrated that preserving valid categorical values (department, job role) in synthetic samples was essential for learning meaningful attrition patterns.
Tooling & Ecosystem
The canonical Python implementation of SMOTE-NC, part of the imbalanced-learn (imblearn) library. Provides a scikit-learn-compatible API with fit_resample(), supports categorical feature specification via indices, names, boolean mask, or automatic detection ('auto' with pandas CategoricalDtype). Version 0.14.1 as of 2026. Includes pipeline integration via imblearn.pipeline.Pipeline.
Companion tool for purely categorical datasets where SMOTE-NC cannot be used (requires at least one continuous feature). SMOTEN uses Value Difference Metric (VDM) for distance computation on categorical features and mode-based generation. Use SMOTEN when all features are nominal; switch to SMOTENC when at least one continuous feature exists.
A comprehensive collection of 85+ SMOTE variants including advanced mixed-type oversampling techniques beyond the standard imblearn implementation. Includes G-SMOTE-NC, CURE-SMOTE, and domain-specific variants. Useful for research and experimentation when standard SMOTENC does not perform well.
The foundational ML library that provides the ecosystem (pipelines, cross-validation, metrics, preprocessing) that SMOTENC integrates with. scikit-learn's StandardScaler, LabelEncoder, and ColumnTransformer are essential upstream and downstream components in SMOTE-NC workflows.
An R package providing SMOTE-NC implementation for R users working with mixed-type tabular data. Implements the original Chawla et al. algorithm with median standard deviation penalty for categorical features. Part of the broader RSBID framework for imbalanced dataset resampling.
An advanced variant that combines Geometric SMOTE's broader generation region (using geometric regions instead of line segments) with SMOTENC's categorical handling. Generates more diverse synthetic samples for continuous features while maintaining valid categorical values. Published in Expert Systems with Applications (2023).
Research & References
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P. (2002)Journal of Artificial Intelligence Research, vol. 16, pp. 321-357
The original paper that introduced both vanilla SMOTE and SMOTE-NC. Section 5 describes the SMOTE-NC algorithm for handling datasets with mixed nominal and continuous features, including the median standard deviation distance penalty and mode-based categorical generation.
Mukherjee, M., Khushi, M. (2021)Applied System Innovation, vol. 4, no. 1, p. 18 (MDPI)
Proposed SMOTE-ENC as an improvement over SMOTE-NC, encoding nominal features as numeric values where the difference reflects the change in association with the minority class. Demonstrated better performance than SMOTE-NC when datasets have a substantial number of nominal features (>25% of total features).
Fonseca, J., Bacao, F. (2023)Expert Systems with Applications, vol. 234, p. 121053
Combined Geometric SMOTE's broader data generation regions with SMOTENC's categorical handling to create G-SMOTE-NC. Used one-hot encoding for nominal features with the median standard deviation divided by two as the non-zero constant. Demonstrated improved classification performance over standard SMOTENC on 66 benchmark datasets.
Tripathi, D., Edla, D.R., et al. (2024)Scientific Reports, vol. 14, article 25419
Addressed SMOTE and SMOTE-NC's limitations with high-dimensional non-linear credit data by proposing a non-parametric approach combining stacked autoencoders with conditional WGAN. Benchmarked against SMOTE-NC and showed that while SMOTE-NC improved credit scoring AUC from 78% to 84%, NOTE further improved to 89% by capturing non-linear patterns.
Limeng, L., et al. (2025)PLOS ONE
Proposed Cluster-Based Reduced Noise SMOTE (CRN-SMOTE) to address noise amplification in SMOTE variants. The approach clusters minority samples, identifies and removes noisy instances, then applies SMOTE within clean clusters. Demonstrated reduced noise amplification compared to vanilla SMOTE and SMOTE-NC on 15 benchmark datasets.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is SMOTE-NC and how does it differ from vanilla SMOTE?
- ●
How does SMOTE-NC handle categorical features during synthetic sample generation?
- ●
Explain the median standard deviation penalty in SMOTE-NC's distance computation
- ●
Why can't you just one-hot encode categorical features and use vanilla SMOTE?
- ●
When would you use SMOTE-NC vs. SMOTEN vs. vanilla SMOTE?
- ●
What happens if you forget to specify categorical features in SMOTENC?
- ●
How does SMOTE-NC handle ordinal features like education level or income bracket?
- ●
Describe a failure mode specific to SMOTE-NC that doesn't apply to vanilla SMOTE
Key Points to Mention
- ●
SMOTE-NC extends SMOTE for mixed-type data: interpolation for continuous features, majority voting (mode) for categorical features among k-nearest neighbors
- ●
Distance metric adds the median of standard deviations of continuous features as a penalty for each disagreeing categorical feature, putting categoricals on a comparable scale to continuous features
- ●
Requires at least one continuous feature -- for purely categorical data, use SMOTEN instead
- ●
The categorical_features parameter must be explicitly specified (indices, names, or 'auto' with pandas CategoricalDtype) -- failing to specify it silently treats categoricals as continuous
- ●
Synthetic samples always contain valid category values from the original data, unlike one-hot + SMOTE which produces non-binary vectors
- ●
The median (not mean) is used for robustness to outlier features with extreme variance
- ●
Same data leakage risks as vanilla SMOTE: must apply only to training data after train-test split, use imblearn Pipeline for cross-validation
- ●
Mode-based voting can homogenize categorical distributions in synthetic samples when one category dominates within the minority class
Pitfalls to Avoid
- ●
Confusing SMOTE-NC with SMOTEN -- SMOTE-NC handles mixed types (continuous + categorical), SMOTEN handles purely categorical data
- ●
Claiming SMOTE-NC works with purely categorical features -- it requires at least one continuous feature for the median standard deviation computation
- ●
Forgetting to mention the fixed penalty limitation: all categorical features get the same M penalty regardless of their semantic importance
- ●
Not recognizing that one-hot encoding before SMOTE-NC is counterproductive -- it defeats the purpose of having a categorical-aware algorithm
- ●
Overlooking the categorical homogenization problem: mode-based voting reduces categorical diversity in synthetic samples
- ●
Failing to mention that feature scaling affects the median standard deviation and thus the categorical penalty calibration
Senior-Level Expectation
Senior/staff-level candidates should demonstrate deep understanding of SMOTE-NC's trade-offs beyond textbook knowledge. Discuss the median penalty mechanism critically: explain why a single penalty value for all categorical features is a limitation and propose alternatives (per-feature penalties based on chi-squared tests or mutual information). Compare SMOTE-NC to modern alternatives like entity embeddings followed by vanilla SMOTE, or CatBoost's native handling of both imbalance and categoricals. Show awareness of the categorical homogenization problem and propose mitigations (stratified SMOTE-NC, post-generation diversity checks). Ideally, share a concrete production experience: 'We used SMOTE-NC for credit risk scoring at [company] because our features included employment type and loan purpose alongside income and credit score. It improved minority recall from 58% to 81%, but we noticed synthetic samples over-represented salaried employment because it was the majority category within defaults. We mitigated this by stratifying the minority class by employment type before applying SMOTE-NC.' This demonstrates practical judgment, not just theoretical knowledge.
Summary
SMOTE-NC (Synthetic Minority Over-sampling Technique for Nominal and Continuous features) addresses a fundamental limitation of vanilla SMOTE: the inability to handle datasets containing both categorical and continuous features. Introduced alongside vanilla SMOTE in Chawla et al.'s seminal 2002 paper, SMOTE-NC provides a principled approach to generating synthetic minority samples for the mixed-type tabular data that dominates real-world ML applications -- from credit scoring with employment type and income, to healthcare with diagnosis codes and blood pressure, to churn prediction with subscription tier and monthly spend.
The algorithm's key innovations are twofold. First, it introduces a modified distance metric that bridges the gap between categorical and continuous features: the median of standard deviations of all continuous features in the minority class serves as a fixed penalty for each categorical disagreement, putting categorical differences on a comparable scale to continuous variation. Second, it uses a dual-mode generation strategy: continuous features are interpolated (like vanilla SMOTE), while categorical features are assigned the most frequent category among k-nearest neighbors (majority voting). This ensures synthetic samples always contain valid category values, unlike the nonsensical interpolations produced by applying vanilla SMOTE to encoded categoricals.
However, SMOTE-NC is not without trade-offs. The mode-based categorical assignment can homogenize synthetic samples when one category dominates within the minority class. The fixed penalty treats all categorical features equally, ignoring their varying discriminative power. The algorithm requires at least one continuous feature, fragmenting the resampling strategy for purely categorical datasets (which require SMOTEN instead). For high-cardinality categoricals, mode-based voting becomes unreliable as no single category achieves a meaningful majority among neighbors.
In production, SMOTE-NC is implemented as SMOTENC in the imbalanced-learn library with full scikit-learn pipeline compatibility. It sits in the training preprocessing stage with zero inference-time overhead. Modern alternatives like SMOTE-ENC (which uses class-conditional encoding for categoricals) and G-SMOTE-NC (which generates in geometric regions rather than line segments) address some of SMOTE-NC's limitations, but SMOTE-NC remains the most widely used and battle-tested approach for mixed-type imbalanced data. For practitioners working with tabular data in domains like fintech, healthcare, HR analytics, and telecommunications -- where mixed feature types and class imbalance are the norm rather than the exception -- SMOTE-NC is an essential tool in the data balancing arsenal.