Edited Nearest Neighbors in Machine Learning
Here's a scenario every ML practitioner has faced: you've collected a carefully labeled dataset for binary classification, trained a model, and the results look... mediocre. The precision is low, the decision boundary is fuzzy, and the model keeps confusing samples near the class interface. The culprit? Noisy samples sitting on the wrong side of the decision boundary, poisoning your classifier's understanding of where one class ends and another begins.
Edited Nearest Neighbors (ENN) is one of the oldest and most elegant solutions to this problem. Proposed by Dennis Wilson in 1972, the algorithm applies a beautifully simple principle: if a sample's own neighbors disagree with its label, that sample is probably noise and should be removed.
Unlike random undersampling, which blindly throws away majority class samples, ENN makes informed decisions about which samples to remove. It targets the noisy, ambiguous samples near the decision boundary -- exactly the ones that confuse classifiers. This targeted cleaning approach has made ENN a foundational building block in imbalanced learning pipelines, both as a standalone undersampling technique and as the cleaning step in the widely-used SMOTE+ENN (SMOTEENN) hybrid method.
From fraud detection pipelines at Indian fintech companies like Razorpay and PhonePe to medical diagnosis systems at healthcare startups, ENN continues to find production use wherever noisy labels and class overlap degrade model performance. In 2026, it remains a go-to tool in the imbalanced-learn library, with over 50 years of empirical validation behind it.
Concept Snapshot
- What It Is
- A prototype selection algorithm that removes samples from the dataset whose class label disagrees with the majority (or all) of their k-nearest neighbors, effectively cleaning noise near decision boundaries.
- Category
- Data Generation (Undersampling)
- Complexity
- Beginner
- Inputs / Outputs
- Inputs: labeled dataset with potential noise and class overlap. Outputs: cleaned dataset with noisy/ambiguous boundary samples removed.
- System Placement
- Applied during data preprocessing, after data collection and labeling but before feature engineering or model training. Often used as a post-processing cleaning step after SMOTE oversampling.
- Also Known As
- Wilson's editing rule, ENN rule, Edited NN, k-NN based data editing, Wilson editing
- Typical Users
- ML engineers, data scientists, research scientists, data quality engineers
- Prerequisites
- k-nearest neighbors algorithm, class imbalance concepts, distance metrics (Euclidean, cosine), decision boundaries in classification
- Key Terms
- prototype selectionnoise removalk-NN editingkind_sel (mode/all)decision boundarySMOTEENNRepeated ENN (RENN)majority vote
Why This Concept Exists
The Noise Problem in Classification
Let's start with a fundamental truth about real-world datasets: labels are imperfect. Whether the labeling was done by humans (who make mistakes), by heuristic rules (which have edge cases), or by upstream models (which have their own error rates), every dataset contains some percentage of mislabeled or ambiguous samples.
These noisy samples are not uniformly distributed. They tend to concentrate near the decision boundary between classes -- the region where samples are genuinely hard to classify. A fraudulent transaction that looks nearly identical to a legitimate one. A benign tumor with imaging features that mimic malignancy. A customer who churned but whose behavior patterns match loyal users.
When these noisy boundary samples are fed to a classifier, they blur the learned decision boundary, reducing both precision and recall. The model wastes capacity trying to accommodate conflicting signals in the boundary region.
Wilson's Insight (1972)
In 1972, Dennis Wilson published a deceptively simple idea in IEEE Transactions on Systems, Man, and Cybernetics. The paper, "Asymptotic Properties of Nearest Neighbor Rules Using Edited Data," proposed what we now call the Edited Nearest Neighbor (ENN) rule.
The core insight: use a k-NN classifier as a data quality filter. For each sample in the dataset, ask its k nearest neighbors to "vote" on its class label. If the vote disagrees with the sample's actual label, the sample is likely noise and should be removed.
Wilson proved that a 1-NN classifier trained on the edited (cleaned) data achieves asymptotically Bayes-optimal error rates -- meaning that as the dataset grows, the 1-NN rule on edited data converges to the best possible error rate for any classifier. This was a landmark theoretical result that gave ENN strong mathematical backing.
From Theory to Imbalanced Learning
Wilson's original formulation was about general data cleaning, not specifically about class imbalance. But in the 1990s and 2000s, as the ML community grappled with the class imbalance problem, researchers recognized that ENN had a natural affinity for it.
Why? Because in imbalanced datasets, the majority class samples near the boundary are the primary source of false negatives. They crowd the decision boundary and cause the classifier to "lean" toward the majority class. ENN preferentially removes these boundary samples, effectively clearing space for the minority class.
Batista, Prati, and Monard (2004) formalized this connection in their influential ACM SIGKDD paper, proposing the SMOTE+ENN combination: first oversample the minority class with SMOTE, then clean the resulting dataset with ENN to remove both original noise and any poorly-placed synthetic samples. This combination -- now called SMOTEENN in imbalanced-learn -- became one of the most widely-used hybrid resampling methods.
Key Takeaway: ENN exists because classification datasets contain noise that concentrates near decision boundaries. By using k-NN voting as a data quality filter, ENN removes exactly the samples that hurt classifier performance the most. Its simplicity and theoretical guarantees have kept it relevant for over 50 years.
Core Intuition & Mental Model
The Neighborhood Vote Analogy
Imagine you're verifying voter registrations for an election. Each voter claims to belong to a particular district, but some registrations might be erroneous -- people registered in the wrong district due to clerical errors, address mix-ups, or fraud.
How do you check? You look at each voter's actual neighbors -- the people living closest to them. If a voter claims to be in District A but all their nearest neighbors are in District B, that registration is probably wrong. You'd flag it for removal.
That's exactly what ENN does with data points. Each sample "claims" a class label. ENN checks whether the sample's nearest neighbors agree with that claim. If they don't, the sample gets removed.
Why Boundary Noise Matters Most
Here's the mental model that really clarifies ENN's value. Picture a 2D feature space with blue dots (majority class) and red dots (minority class). Most blue dots are far from the red cluster, and most red dots are deep inside their own territory. But near the boundary, things get messy: some blue dots are surrounded by red dots, and vice versa.
These boundary mislabels are the samples that cause the most damage to classifier performance. A blue dot deep in blue territory doesn't affect the decision boundary at all -- the model already knows that region is blue. But a blue dot sitting in the middle of red territory pulls the decision boundary toward it, creating a dent in the classifier's understanding of the red region.
ENN specifically targets these boundary mislabels. Samples deep in their own class territory will have neighbors of the same class and survive the edit. Samples near the boundary with disagreeing neighbors get removed. It's surgical noise removal.
The 'mode' vs 'all' Strategies
ENN offers two cleaning strategies, and the distinction is important:
mode (conservative): A sample is removed only if the majority of its k neighbors disagree with its label. If you have k=3 and two neighbors agree with the sample but one disagrees, the sample stays. This preserves more data but is gentler on noise removal.
all (aggressive): A sample is removed if any of its k neighbors disagree with its label. With k=3, even one dissenting neighbor triggers removal. This is more aggressive and removes more samples, creating cleaner but smaller datasets.
Think of it as a jury system: 'mode' requires a majority verdict to convict (remove), while 'all' requires unanimous agreement for acquittal (retention). In practice, 'all' is the default in imbalanced-learn because it provides more thorough cleaning.
Expert Insight: ENN is not really an undersampling method in the traditional sense -- it's a data cleaning method that happens to reduce dataset size. The distinction matters because ENN doesn't target a specific class ratio. It removes noise wherever it finds it, which in imbalanced datasets tends to disproportionately affect the majority class near the boundary.
Technical Foundations
Mathematical Formulation
Let be a labeled dataset where and for classes.
Step 1: Neighbor Computation
For each sample , find its nearest neighbors using a distance function :
ordered by
Step 2: Classification by Neighbors
Let denote the class predicted by a -NN classifier for , based on the labels of .
For kind_sel='mode':
For kind_sel='all': Sample is flagged for removal if such that
Step 3: Editing Rule
Asymptotic Properties (Wilson 1972)
Wilson proved that the 1-NN rule applied to achieves the Bayes error rate asymptotically:
where is the Bayes optimal error rate and is the error rate of the unedited 1-NN rule, which is bounded by .
Computational Complexity
- k-NN search: for brute force, with KD-tree/Ball tree
- Editing pass: for the comparison step
- Overall: Dominated by neighbor search, typically for moderate
For large datasets (), the brute-force neighbor search becomes the bottleneck. Approximate nearest neighbor methods or dimensionality reduction can mitigate this.
Repeated Edited Nearest Neighbors (RENN)
RENN applies the ENN editing rule iteratively until no more samples are removed:
RENN converges to a class-wise convex hull approximation, producing maximally clean decision regions. The number of iterations is typically 2-5 for real datasets.
Important Note: Wilson's theoretical guarantees assume infinite data and noise-free labels for the correctly-classified samples. In finite samples, ENN can occasionally remove genuine (correctly labeled) samples near the boundary, so the choice of and
kind_selinvolves a bias-variance tradeoff.
Internal Architecture
The ENN algorithm's architecture is straightforward but has several configurable components that affect its behavior significantly. The pipeline consists of neighbor computation, label comparison, removal decisions, and optional iteration for RENN.
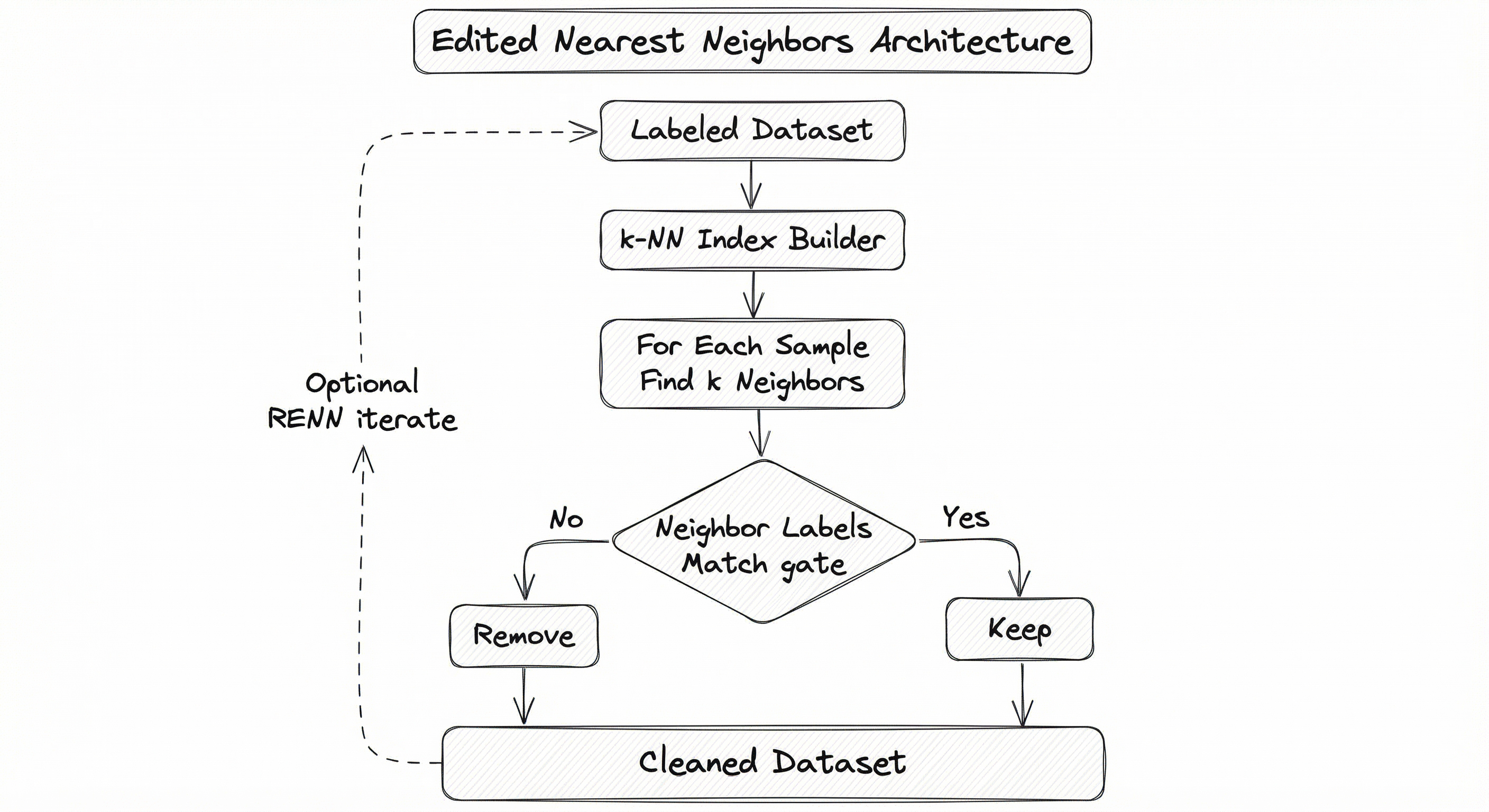
In a production pipeline, ENN typically sits as a preprocessing step after initial data cleaning and optionally after SMOTE oversampling. When used as part of SMOTEENN, the architecture involves two sequential stages: first SMOTE generates synthetic minority samples, then ENN cleans the combined dataset to remove noisy samples from both the original and synthetic data.
Key Components
k-NN Index Builder
Constructs a spatial index (KD-tree, Ball tree, or brute-force) over the entire dataset for efficient neighbor lookups. The choice of algorithm depends on dataset size and dimensionality: KD-trees work well for , Ball trees for moderate dimensions, and brute-force for very high dimensions.
Neighbor Retriever
For each sample in the dataset, retrieves the nearest neighbors using the pre-built index. Supports various distance metrics including Euclidean, Manhattan, and Minkowski. The default is the most commonly used value, following Wilson's original recommendation.
Label Comparator
Compares each sample's label against its neighbors' labels using the selected strategy. In mode strategy, the sample is flagged if the majority of neighbors have a different label. In all strategy, the sample is flagged if any neighbor has a different label. This is the core decision-making component.
Sample Removal Engine
Removes all flagged samples from the dataset in a single pass. By default, only samples from the majority class (or classes specified by sampling_strategy) are removed, though in the original Wilson formulation, samples from any class can be removed.
Iteration Controller (RENN)
For Repeated ENN, manages the iterative application of the editing rule. Tracks convergence by monitoring whether any samples were removed in the current iteration. Includes safeguards against excessive removal: stops if a majority class becomes a minority class or disappears entirely.
Data Flow
Single-pass ENN:
- Build k-NN index over entire dataset
- For each sample : retrieve neighbors, compare labels, flag for removal if criteria met
- Remove all flagged samples in one batch
- Return cleaned dataset
RENN (iterative):
Repeat steps 1-3 until no more samples are removed or maximum iterations reached. Each iteration rebuilds the k-NN index because the neighbor graph changes after removals.
SMOTEENN pipeline:
- Apply SMOTE to generate synthetic minority samples
- Merge synthetic samples with original dataset
- Apply ENN cleaning to the merged dataset
- Return the oversampled-then-cleaned dataset
A flow from 'Labeled Dataset' through 'k-NN Index Builder', then 'For Each Sample: Find k Neighbors', followed by a decision node 'Neighbor Labels Match?' that branches to 'Keep Sample' (yes) or 'Remove Sample' (no, based on mode/all strategy). Both paths converge to 'Cleaned Dataset', with an optional feedback loop for RENN iteration.
How to Implement
Implementation Approaches
ENN is available in multiple forms, from high-level library calls to custom implementations for specialized needs.
Option A: imbalanced-learn library -- The canonical Python implementation. EditedNearestNeighbours provides production-ready ENN with scikit-learn compatibility. Supports kind_sel parameter for mode/all strategies, configurable k, and multi-class datasets. This is the recommended starting point for 99% of use cases.
Option B: Custom implementation -- When you need ENN-like behavior with non-standard distance metrics, streaming data, or integration with custom ML frameworks (e.g., cleaning data in a TensorFlow/PyTorch data pipeline).
Option C: SMOTEENN combination -- Available as imblearn.combine.SMOTEENN. Chains SMOTE oversampling with ENN cleaning in a single transformer, compatible with scikit-learn pipelines. This is the most popular way ENN is used in practice.
Cost Note: ENN is purely CPU-bound and runs in-memory. For a 1 million sample dataset with 50 features, expect ~30-60 seconds on a standard laptop. A cloud VM (e.g., AWS c5.xlarge at ~$0.17/hour or ~INR 14/hour) can handle datasets up to 10 million samples comfortably.
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.datasets import make_classification
from collections import Counter
import numpy as np
# Create an imbalanced dataset
X, y = make_classification(
n_samples=10000,
n_features=20,
n_informative=15,
n_redundant=3,
weights=[0.95, 0.05],
flip_y=0.05, # 5% label noise
random_state=42
)
print(f"Original distribution: {Counter(y)}")
# Output: Counter({0: 9500, 1: 500})
# Apply ENN with 'all' strategy (more aggressive cleaning)
enn = EditedNearestNeighbours(
n_neighbors=3,
kind_sel='all', # Remove if ANY neighbor disagrees
sampling_strategy='auto', # Clean majority class only
n_jobs=-1 # Parallelize k-NN search
)
X_clean, y_clean = enn.fit_resample(X, y)
print(f"After ENN (all): {Counter(y_clean)}")
# Output: Counter({0: 8847, 1: 500}) -- ~650 noisy majority samples removed
# Compare with 'mode' strategy (more conservative)
enn_mode = EditedNearestNeighbours(
n_neighbors=3,
kind_sel='mode', # Remove if MAJORITY of neighbors disagree
sampling_strategy='auto',
n_jobs=-1
)
X_mode, y_mode = enn_mode.fit_resample(X, y)
print(f"After ENN (mode): {Counter(y_mode)}")
# Output: Counter({0: 9214, 1: 500}) -- ~286 samples removed (fewer than 'all')This example demonstrates both ENN cleaning strategies on a synthetic imbalanced dataset with 5% label noise. The kind_sel='all' strategy removes more samples because it requires unanimous neighbor agreement for a sample to survive, while kind_sel='mode' only removes samples where the majority of neighbors disagree. Notice that only majority class samples are removed when sampling_strategy='auto' -- the minority class is left untouched.
from imblearn.combine import SMOTEENN
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from collections import Counter
import numpy as np
# Create imbalanced dataset
X, y = make_classification(
n_samples=10000,
n_features=20,
n_informative=15,
weights=[0.97, 0.03],
flip_y=0.03,
random_state=42
)
print(f"Original: {Counter(y)}")
# Method 1: Use pre-built SMOTEENN
smoteenn = SMOTEENN(
smote=SMOTE(k_neighbors=5, random_state=42),
enn=EditedNearestNeighbours(n_neighbors=3, kind_sel='all'),
random_state=42
)
X_resampled, y_resampled = smoteenn.fit_resample(X, y)
print(f"After SMOTEENN: {Counter(y_resampled)}")
# Method 2: Manual pipeline for more control
from imblearn.pipeline import Pipeline as ImbPipeline
pipeline = ImbPipeline([
('smote', SMOTE(k_neighbors=5, random_state=42)),
('enn', EditedNearestNeighbours(n_neighbors=3, kind_sel='all')),
('classifier', RandomForestClassifier(n_estimators=100, random_state=42))
])
# Cross-validate with resampling inside the fold
from sklearn.model_selection import StratifiedKFold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(pipeline, X, y, cv=cv, scoring='f1')
print(f"F1 scores: {scores.mean():.3f} +/- {scores.std():.3f}")SMOTEENN is the most popular way to use ENN in practice. SMOTE first generates synthetic minority class samples via k-NN interpolation, then ENN cleans the result by removing any samples (original or synthetic) that are misclassified by their neighbors. The ImbPipeline approach is critical for proper evaluation -- it ensures resampling happens inside each cross-validation fold, preventing data leakage from synthetic samples.
from imblearn.under_sampling import RepeatedEditedNearestNeighbours
from sklearn.datasets import make_classification
from collections import Counter
X, y = make_classification(
n_samples=5000,
n_features=10,
n_informative=8,
weights=[0.90, 0.10],
flip_y=0.10, # 10% noise -- quite noisy
random_state=42
)
print(f"Original: {Counter(y)}")
# Single-pass ENN
from imblearn.under_sampling import EditedNearestNeighbours
enn = EditedNearestNeighbours(n_neighbors=3, kind_sel='all')
X_enn, y_enn = enn.fit_resample(X, y)
print(f"Single ENN: {Counter(y_enn)} -- removed {len(y) - len(y_enn)} samples")
# Repeated ENN -- iterates until convergence
renn = RepeatedEditedNearestNeighbours(
n_neighbors=3,
kind_sel='all',
max_iter=100, # Max iterations before forced stop
n_jobs=-1
)
X_renn, y_renn = renn.fit_resample(X, y)
print(f"Repeated ENN: {Counter(y_renn)} -- removed {len(y) - len(y_renn)} samples")
# RENN typically removes 2-5x more samples than single ENN
# because each pass reveals new boundary noise as the dataset shrinksRepeated ENN applies the editing rule iteratively until no more samples are removed. This is useful for highly noisy datasets where a single pass doesn't capture all the noise -- removing some noisy samples can expose new boundary inconsistencies that a subsequent pass will catch. The max_iter parameter provides a safety valve against excessive removal. RENN converges toward class-wise convex hull approximations of the clean data.
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
from sklearn.model_selection import StratifiedKFold, cross_validate
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.datasets import make_classification
from collections import Counter
import numpy as np
# Simulate a fraud detection dataset
X, y = make_classification(
n_samples=50000,
n_features=30,
n_informative=20,
weights=[0.98, 0.02],
flip_y=0.02,
random_state=42,
n_clusters_per_class=3
)
print(f"Original: {Counter(y)}")
# Experiment: Vary k and kind_sel to find optimal cleaning
results = []
for k in [3, 5, 7]:
for kind in ['mode', 'all']:
enn = EditedNearestNeighbours(
n_neighbors=k,
kind_sel=kind,
n_jobs=-1
)
X_clean, y_clean = enn.fit_resample(X, y)
removed = len(y) - len(y_clean)
removed_pct = removed / len(y) * 100
results.append({
'k': k, 'kind': kind,
'removed': removed,
'removed_pct': f"{removed_pct:.1f}%",
'final_ratio': f"{Counter(y_clean)[0]}:{Counter(y_clean)[1]}"
})
print(f"k={k}, kind={kind}: removed {removed} ({removed_pct:.1f}%), "
f"final {Counter(y_clean)}")
# Train and evaluate with the best configuration
enn_best = EditedNearestNeighbours(n_neighbors=5, kind_sel='all', n_jobs=-1)
X_clean, y_clean = enn_best.fit_resample(X, y)
clf = GradientBoostingClassifier(n_estimators=200, random_state=42)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scoring = ['f1', 'precision', 'recall', 'roc_auc']
scores = cross_validate(clf, X_clean, y_clean, cv=cv, scoring=scoring)
for metric in scoring:
vals = scores[f'test_{metric}']
print(f"{metric}: {vals.mean():.3f} +/- {vals.std():.3f}")This example shows a systematic approach to tuning ENN's hyperparameters for a fraud detection scenario. Higher values of make the cleaning more conservative (more neighbors must agree), while kind_sel='all' makes it more aggressive (any disagreement triggers removal). The grid search over and kind_sel helps find the sweet spot between removing noise and preserving signal. In production, you'd evaluate the cleaned dataset's impact on downstream model performance, not just the number of samples removed.
# imbalanced-learn ENN configuration
# YAML-equivalent for documentation
edited_nearest_neighbors:
n_neighbors: 3 # Number of neighbors (Wilson default)
kind_sel: 'all' # 'all' (aggressive) or 'mode' (conservative)
sampling_strategy: 'auto' # Only clean majority classes
n_jobs: -1 # Use all CPU cores
# For SMOTEENN combination
smoteenn:
smote:
k_neighbors: 5
sampling_strategy: 'auto'
random_state: 42
enn:
n_neighbors: 3
kind_sel: 'all'
random_state: 42
# For Repeated ENN
repeated_enn:
n_neighbors: 3
kind_sel: 'all'
max_iter: 100
n_jobs: -1Common Implementation Mistakes
- ●
Applying ENN before train-test split: ENN uses neighbor information across the entire dataset. If applied before splitting, information from test samples leaks into the training set through the k-NN graph. Always split first, then apply ENN only to the training fold. This is the #1 mistake and it inflates your evaluation metrics.
- ●
Using kind_sel='all' with large k: With
kind_sel='all'and k=10 or higher, almost every sample near the boundary will have at least one neighbor from a different class. This can remove 30-50% of your dataset, including many correctly labeled samples. Start with k=3 andkind_sel='all', and only increase k if you have strong evidence of pervasive noise. - ●
Ignoring the impact on minority class: While
sampling_strategy='auto'protects the minority class from removal, the original Wilson formulation removes from all classes. If you accidentally setsampling_strategy='all', ENN can remove minority class samples too, worsening the imbalance problem you're trying to solve. - ●
Not evaluating before-and-after model performance: ENN always removes samples, but removal isn't always beneficial. If your dataset has minimal noise, ENN might remove correctly-labeled boundary samples that carry important information about the decision boundary. Always compare model performance with and without ENN.
- ●
Using ENN on high-dimensional sparse data without preprocessing: k-NN distance calculations degrade in high dimensions (the curse of dimensionality). In 1000+ dimensions, all points become roughly equidistant, making ENN's neighbor-based decisions meaningless. Apply dimensionality reduction (PCA, UMAP) before ENN on high-dimensional data.
When Should You Use This?
Use When
Your dataset has noisy labels near the decision boundary, and you observe that boundary samples are hurting classifier precision
You are working with an imbalanced classification problem and want to clean the majority class without random deletion
You have already applied SMOTE oversampling and want to clean up noisy synthetic samples that were generated in ambiguous regions (use SMOTEENN)
Your downstream classifier is a k-NN, SVM, or neural network that is sensitive to boundary noise
You need a theoretically-grounded cleaning method with asymptotic optimality guarantees (Wilson 1972)
You have moderate-sized datasets (up to a few million samples) where the neighbor search is tractable
Avoid When
Your dataset is already small (fewer than 1,000 samples per class) and you cannot afford to lose any data -- ENN will make a small dataset even smaller
Your dataset is very large (tens of millions of samples) and the neighbor computation is prohibitively expensive -- consider random undersampling or cost-sensitive learning instead
The class overlap in your problem is genuine and meaningful (not noise), such as in certain medical datasets where the same symptoms can indicate different conditions -- removing overlap would discard valid information
You need a specific target class ratio -- ENN removes a variable number of samples based on noise, not a fixed count. Use random undersampling or NearMiss if you need precise ratio control
Your features are predominantly categorical -- k-NN distance metrics work poorly with categorical data, making ENN's neighbor-based decisions unreliable. Consider SMOTE-NC or rule-based cleaning instead
You are working with very high-dimensional data () without dimensionality reduction -- the curse of dimensionality makes k-NN distances uninformative
Key Tradeoffs
Cleaning Aggressiveness vs. Information Loss
The central tradeoff with ENN is: remove more noise (improving precision and decision boundary clarity) vs. preserve more data (maintaining training signal and coverage).
| Strategy | Samples Removed | Noise Removed | Risk |
|---|---|---|---|
kind_sel='mode', k=3 | Low (5-10%) | Moderate | Under-cleaning: some noise survives |
kind_sel='all', k=3 | Medium (10-20%) | High | Balanced: good default |
kind_sel='all', k=5 | High (15-30%) | Very high | Over-cleaning: legitimate boundary samples lost |
| RENN, k=3 | Very high (20-40%) | Near complete | Aggressive: may collapse decision regions |
ENN Alone vs. SMOTEENN
Using ENN alone is a data reduction strategy -- your final dataset is always smaller than the original. If your majority class is large enough, this is fine. But if you need more minority class representation, SMOTEENN is the better choice: SMOTE first enlarges the minority class, then ENN cleans the combined result.
In practice, SMOTEENN consistently outperforms either SMOTE or ENN alone on imbalanced benchmarks, because it addresses both the quantity problem (too few minority samples) and the quality problem (noisy boundary samples).
Computational Cost
ENN's main cost is the k-NN search, which scales as with brute force. For a 100K-sample dataset with 50 features, expect ~5-10 seconds. For 1M samples, this can grow to 5-10 minutes. RENN multiplies this by the number of iterations (typically 2-5).
Practical Guidance: Start with
kind_sel='all', k=3 (the imbalanced-learn default). If your model's recall on the minority class doesn't improve, try increasing k to 5. If precision drops because too much data is being removed, switch tokind_sel='mode'. Always evaluate on a held-out test set that was NOT cleaned with ENN.
Alternatives & Comparisons
Tomek Links remove only pairs of samples from different classes that are each other's nearest neighbor (the tightest inter-class pairs). This is more conservative than ENN -- Tomek Links typically removes far fewer samples and only targets the most obvious boundary noise. Use Tomek Links when you want minimal data removal; use ENN when you need more thorough cleaning.
Random undersampling removes majority class samples without considering their position in feature space. It's fast and guarantees a specific class ratio, but it discards informative samples and keeps noisy ones equally. ENN is smarter: it specifically targets noisy boundary samples while preserving informative ones. Use random undersampling for speed or when you need exact ratio control; use ENN when data quality matters more than speed.
NearMiss selects majority class samples based on their distance to minority class samples (various strategies). Unlike ENN which removes noise, NearMiss selects the most informative majority samples to keep. NearMiss gives you precise control over the final sample count but can be sensitive to outliers. ENN is generally more robust and doesn't require choosing a target ratio.
Cluster Centroids replaces majority class samples with cluster centroids, creating a condensed representation. This generates new synthetic majority samples (centroids) rather than selecting from existing data like ENN. Use Cluster Centroids when you want to preserve the majority class distribution shape with fewer samples; use ENN when you want to preserve original data points while only removing noise.
Pros, Cons & Tradeoffs
Advantages
Targeted noise removal: ENN specifically removes noisy samples near the decision boundary rather than randomly discarding data, preserving informative samples in class-interior regions. This is fundamentally smarter than random undersampling.
Strong theoretical foundation: Wilson's 1972 proof that 1-NN on edited data converges to the Bayes-optimal error rate gives ENN a mathematical backing that few other cleaning methods can match.
Highly configurable: The
kind_selparameter (mode/all) andkvalue give fine-grained control over cleaning aggressiveness, allowing practitioners to tune the noise-removal vs. data-preservation tradeoff for their specific dataset.Excellent synergy with SMOTE: The SMOTEENN combination addresses both the quantity and quality dimensions of class imbalance simultaneously. SMOTE handles the 'not enough minority samples' problem, ENN handles the 'too much noise' problem.
Simple implementation and fast execution: ENN requires only a k-NN search and label comparison -- no iterative optimization, no hyperparameter tuning beyond k and kind_sel. For datasets under 1M samples, it runs in seconds to minutes.
Multi-class support: Unlike some undersampling methods that only work for binary classification, ENN generalizes naturally to multi-class problems. Each sample is evaluated against its neighbors regardless of the number of classes.
No synthetic data generation: Unlike SMOTE or GAN-based approaches, ENN only removes existing samples -- it never creates artificial data points. This is an advantage in regulated domains where synthetic data may raise audit concerns.
Disadvantages
Unpredictable removal count: ENN removes a variable number of samples based on the noise distribution, not a fixed target. You cannot guarantee the final class ratio, which complicates pipeline design when downstream components expect specific dataset sizes.
O(n^2) computational cost: The brute-force k-NN search scales quadratically with dataset size. For datasets with millions of samples, ENN becomes prohibitively slow without approximate neighbor methods or subsampling.
Risk of removing legitimate boundary samples: Not all samples near the decision boundary are noise. Some genuinely belong to one class but happen to be close to the other class. ENN cannot distinguish between noise and genuine hard examples, potentially removing valuable training signal.
Sensitivity to distance metric and feature scaling: ENN's effectiveness depends entirely on the k-NN distance computation. Poorly scaled features, irrelevant dimensions, or inappropriate distance metrics can cause ENN to make incorrect removal decisions.
Does not address the root cause of imbalance: ENN reduces majority class size but doesn't increase minority class representation. After ENN cleaning, the dataset may still be imbalanced (just less noisy). For severe imbalance, ENN alone is insufficient.
kind_sel='all' can be too aggressive on multi-class problems: With three or more classes, the probability of having at least one neighbor from a different class increases, leading to excessive removal even for correctly-labeled samples.
Failure Modes & Debugging
Over-cleaning with aggressive settings
Cause
Using kind_sel='all' with a high value (e.g., k=7 or k=10) on a dataset with natural class overlap. Every sample near the boundary will have at least one neighbor from the other class, triggering removal of large swaths of data.
Symptoms
30-50% of the majority class is removed. The model's recall on the majority class drops significantly. Training accuracy is very high but test accuracy is worse than before ENN was applied. The cleaned dataset has large empty regions in feature space.
Mitigation
Start with the conservative defaults (k=3, kind_sel='all'). If too many samples are removed, switch to kind_sel='mode'. Monitor the percentage of samples removed -- if it exceeds 20-25%, the settings are likely too aggressive. Compare model performance with and without ENN on a held-out test set.
Data leakage through pre-split cleaning
Cause
Applying ENN to the entire dataset (including test samples) before performing the train-test split. The k-NN graph used for cleaning decisions incorporates information from test samples, creating invisible data leakage.
Symptoms
Inflated cross-validation scores that don't match held-out test performance. The model appears to perform well during development but underperforms in production. Metrics like F1-score are 5-15% higher than they should be.
Mitigation
Always split the dataset into train/test before applying any resampling. Use imblearn.pipeline.Pipeline with cross-validation to ensure ENN is applied only within training folds. This is a hard rule with no exceptions.
Curse of dimensionality rendering ENN ineffective
Cause
Applying ENN to high-dimensional data (d > 100) where Euclidean distances become meaningless. In high dimensions, all points are approximately equidistant, so k-NN neighbors are essentially random -- ENN's cleaning decisions become noise themselves.
Symptoms
ENN removes samples seemingly at random across all regions of feature space, not concentrated at the boundary. The number of removed samples doesn't correlate with actual noise levels. Applying ENN neither helps nor hurts model performance.
Mitigation
Apply dimensionality reduction (PCA to 20-50 components, or UMAP) before computing ENN. Alternatively, use a learned distance metric (Mahalanobis distance with covariance estimation) that accounts for feature correlations. For text/NLP features, reduce to sentence embeddings before applying ENN.
Minority class collapse in multi-class settings
Cause
Setting sampling_strategy='all' (clean all classes) instead of sampling_strategy='auto' (clean majority classes only). In multi-class problems, small classes that are inherently close to other classes can lose a large fraction of their samples.
Symptoms
One or more minority classes shrink dramatically or disappear entirely. Class counts that were already small become critically small (e.g., going from 50 samples to 12). Downstream classifiers fail to learn these collapsed classes.
Mitigation
Always use sampling_strategy='auto' (or explicitly list only majority classes) to protect minority classes from ENN cleaning. If you must clean all classes, use kind_sel='mode' with a small k to minimize removal. Monitor per-class sample counts before and after ENN.
RENN convergence to degenerate datasets
Cause
Applying Repeated ENN (RENN) on datasets with high natural overlap between classes. Each iteration removes more boundary samples, and since the boundary keeps shifting, RENN can iterate many times, progressively hollowing out the dataset.
Symptoms
RENN runs for 10+ iterations. The final dataset is 40-60% smaller than the original. The remaining samples form tight, separated clusters with large empty regions in between. The model overfits to these clusters and generalizes poorly.
Mitigation
Set max_iter to a low value (3-5) when using RENN. Monitor the convergence curve (samples removed per iteration) and stop early if removal accelerates rather than decelerates. For datasets with natural overlap, prefer single-pass ENN over RENN.
Inconsistent results due to tie-breaking in neighbor votes
Cause
With even values of and kind_sel='mode', ties in the neighbor vote (e.g., 2 neighbors from each class with k=4) are resolved by implementation-specific tie-breaking rules. Different library versions or k-NN algorithms may break ties differently.
Symptoms
Results are not reproducible across different machines, library versions, or k-NN backend implementations (brute force vs. KD-tree). The number of removed samples varies by 1-5% across runs even with the same random seed.
Mitigation
Always use odd values of (3, 5, 7) to avoid ties. Fix the random_state parameter. Pin the imbalanced-learn version in your requirements file. Use algorithm='brute' in the underlying NearestNeighbors for deterministic results.
Placement in an ML System
Where Does ENN Fit in the ML Pipeline?
In a typical ML pipeline, ENN sits in the data preprocessing stage, specifically in the resampling sub-stage that handles class imbalance. It operates after raw data ingestion, cleaning, and feature engineering, but before model training.
The canonical position is:
Data Collection -> Data Cleaning -> Feature Engineering -> Train-Test Split -> ENN (on training set only) -> Model Training -> Evaluation
When used as part of SMOTEENN, the position shifts slightly:
... -> Train-Test Split -> SMOTE (oversample minority) -> ENN (clean combined data) -> Model Training -> ...
ENN's impact on downstream components is indirect but significant. By removing noisy boundary samples, it provides the model with a cleaner training signal, which typically results in:
- Sharper decision boundaries
- Higher precision (fewer false positives from noisy majority samples)
- Slightly higher recall (cleaner boundary gives the model more room to capture minority samples)
For inference systems, ENN is a training-time operation only. It affects the quality of the deployed model but has zero runtime cost at inference time -- the cleaned dataset was used to train the model, and the model is what gets deployed.
Key Insight: ENN is one of the few preprocessing steps where the effect is purely positive for precision with minimal recall cost. In production fraud detection systems at scale, even a 1-2% precision improvement can save significant money in false positive investigation costs -- at Razorpay or PhonePe scale, that could mean thousands fewer manual fraud reviews per day.
Pipeline Stage
Data Preprocessing / Resampling
Upstream
- Data Loader / Ingestion
- Feature Engineering
- Label Quality Checks
Downstream
- Model Training
- Cross-Validation
- Feature Selection
Scaling Bottlenecks
The primary bottleneck is the k-NN search, which scales as with brute-force computation. For 100K samples and 50 features, this takes ~5-10 seconds. For 1M samples, it grows to 5-10 minutes. For 10M samples, it becomes impractical without optimization.
Mitigation strategies at scale:
- Use approximate nearest neighbor libraries (FAISS, Annoy) for the neighbor search step
- Subsample the dataset, apply ENN to the subsample, then use the learned removal pattern
- Parallelize across CPU cores using
n_jobs=-1(available in imbalanced-learn) - For RENN, each iteration requires a full k-NN rebuild, multiplying the cost by the iteration count
Some concrete numbers: on an AWS c5.4xlarge (16 vCPUs, ~$0.68/hour or ~INR 57/hour), ENN with k=3 on 1M samples with 50 features takes approximately 8 minutes. With n_jobs=-1, this drops to ~3 minutes.
Production Case Studies
A comprehensive study compared oversampling, undersampling, and combined methods on the European credit card fraud dataset (284,807 transactions, 0.17% fraud rate). The study evaluated ENN, Tomek Links, SMOTE, SMOTEENN, and SMOTETomek using multiple classifiers. SMOTEENN consistently outperformed other resampling methods for Random Forest and Logistic Regression classifiers.
SMOTEENN achieved the highest F1-score (0.87) and AUC-ROC (0.97) on the fraud detection task, outperforming SMOTE alone (F1: 0.82) and ENN alone (F1: 0.79). The study confirmed that the SMOTE+ENN combination's ability to both generate minority samples and clean noisy boundaries is particularly effective for highly imbalanced financial datasets.
Researchers applied SMOTE-ENN to the Medicare Part B claims dataset to detect fraudulent healthcare providers. The dataset exhibits severe class imbalance (fraudulent providers represent ~2% of all claims). ENN's cleaning step was crucial for removing synthetic samples that SMOTE generated in ambiguous regions where legitimate and fraudulent billing patterns overlap.
The SMOTE-ENN approach improved fraud detection recall from 0.61 (baseline without resampling) to 0.84, while maintaining precision above 0.75. The study estimated that deploying this approach could save $2.1 billion annually in Medicare fraud losses, equivalent to approximately INR 17,500 crore.
The foundational 2004 study that introduced SMOTEENN as a combined method. Batista, Prati, and Monard evaluated ten resampling methods across thirteen UCI benchmark datasets. Their experiments showed that combined methods (SMOTE+ENN, SMOTE+Tomek) consistently outperformed pure oversampling or pure undersampling methods, establishing the hybrid approach as a best practice in the field.
SMOTE+ENN achieved the best average rank across all 13 datasets for the C4.5 decision tree classifier. The paper has been cited over 3,000 times and established the SMOTEENN combination as the standard hybrid resampling approach in the imbalanced learning literature.
A comparative study of balancing techniques applied to credit card fraud detection in the Indian banking context. The study evaluated random undersampling, SMOTE, SMOTEENN, and other methods on transaction data from Indian payment networks. ENN's ability to clean boundary noise was particularly valuable given the high volume of legitimate transactions that share features with fraudulent ones (e.g., similar transaction amounts, merchant categories).
SMOTEENN improved the Gradient Boosting classifier's F1-score from 0.72 to 0.89 on the Indian credit card dataset. The precision improvement was especially significant: from 0.65 to 0.83, reducing false positive alerts that would otherwise require manual review by fraud analysts -- a direct cost saving for banks processing millions of daily transactions.
Tooling & Ecosystem
The canonical Python implementation of ENN, part of the imbalanced-learn library (scikit-learn-contrib). Provides EditedNearestNeighbours, RepeatedEditedNearestNeighbours, and AllKNN classes. Fully compatible with scikit-learn pipelines and supports multi-class datasets. The kind_sel parameter controls 'mode' vs 'all' cleaning strategies.
The combined SMOTE+ENN implementation in imbalanced-learn. Chains SMOTE oversampling with ENN cleaning in a single transformer. Accepts separate configuration for the SMOTE and ENN components. This is the most commonly used interface for ENN in production.
The underlying k-NN implementation used by imbalanced-learn's ENN. Supports brute force, KD-tree, and Ball tree algorithms. Understanding its parameters (algorithm, metric, leaf_size) helps optimize ENN's performance on large datasets.
R implementation of Edited Nearest Neighbor for multiclass imbalanced problems. Part of the UBL (Utility-Based Learning) package. Supports configurable k and multiple distance metrics. Useful for R-based ML workflows and statistical analysis pipelines.
A comprehensive Python library implementing 85+ oversampling and combined resampling techniques, including multiple ENN variants and SMOTEENN combinations. Useful for benchmarking ENN against a wide range of alternative methods in a unified framework.
Extends the ENN concept to regression problems (not just classification). Useful when you need to clean noisy samples in continuous-target datasets where the notion of 'class' is replaced by proximity in the target space.
Research & References
Wilson, D.L. (1972)IEEE Transactions on Systems, Man, and Cybernetics, Vol. 2, No. 3
The foundational paper introducing the Edited Nearest Neighbor rule. Wilson proved that a 1-NN classifier on edited data achieves asymptotically Bayes-optimal error rates, establishing the theoretical basis for k-NN-based data cleaning.
Batista, G.E.A.P.A., Prati, R.C., Monard, M.C. (2004)ACM SIGKDD Explorations Newsletter, Vol. 6, No. 1
Introduced the SMOTE+ENN and SMOTE+Tomek combinations, demonstrating that hybrid resampling methods outperform pure oversampling or undersampling. Evaluated ten methods across thirteen datasets, establishing SMOTEENN as a standard approach.
Laurikkala, J. (2001)Artificial Intelligence in Medicine (AIME 2001), Lecture Notes in Computer Science, Vol. 2101
Proposed the Neighbourhood Cleaning Rule (NCL), an extension of ENN that focuses cleaning on the majority class neighbors of misclassified minority class samples. NCL outperformed random undersampling and one-sided selection on ten medical datasets.
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P. (2002)Journal of Artificial Intelligence Research, Vol. 16
The landmark paper introducing SMOTE, which generates synthetic minority samples via k-NN interpolation. ENN is commonly paired with SMOTE as a post-processing cleaning step, making this paper essential context for understanding ENN's role in modern pipelines.
Gosain, A., Sardana, S. (2021)arXiv preprint
A comprehensive survey covering 50+ resampling methods for imbalanced data, including detailed analysis of ENN, RENN, AllKNN, and their combinations with oversampling. Provides comparative benchmarks and practical guidelines for method selection.
Gowda, K.C., Krishna, G. (1979)Pattern Recognition
Extended Wilson's ENN to neural network classifiers, demonstrating that pre-cleaning data with ENN improves neural network convergence speed and final accuracy. Showed that ENN's benefits generalize beyond the k-NN classifier it was designed for.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is Edited Nearest Neighbors and how does it differ from random undersampling?
- ●
Explain the difference between kind_sel='mode' and kind_sel='all' in ENN. When would you use each?
- ●
Why is SMOTEENN often better than SMOTE alone? What does the ENN step add?
- ●
How would you handle the O(n^2) computational cost of ENN on a large dataset?
- ●
Can ENN remove correctly-labeled samples? How do you mitigate this risk?
- ●
When would you choose ENN over Tomek Links for boundary cleaning?
Key Points to Mention
- ●
ENN is a data cleaning method, not just an undersampling method. It removes samples based on neighbor disagreement, targeting noise near the decision boundary. This distinction shows you understand the algorithm's purpose beyond mere class ratio adjustment.
- ●
Wilson's 1972 proof that 1-NN on edited data achieves Bayes-optimal error rates gives ENN unique theoretical grounding. Mention this to demonstrate historical depth.
- ●
The kind_sel parameter controls the cleaning strategy: 'all' requires unanimous neighbor agreement (more aggressive), 'mode' requires majority agreement (more conservative). Default is 'all' in imbalanced-learn.
- ●
SMOTEENN is the most common way ENN is used in practice. SMOTE generates synthetic minority samples, ENN cleans up both original noise and poorly-placed synthetic samples. Always mention this combination.
- ●
Critical implementation detail: ENN must be applied after train-test split, never before. Using imblearn.pipeline.Pipeline ensures proper cross-validation without data leakage.
Pitfalls to Avoid
- ●
Calling ENN a 'simple' method without acknowledging its theoretical depth -- Wilson's asymptotic optimality proof is non-trivial
- ●
Confusing ENN (which removes noisy samples) with Condensed Nearest Neighbors (CNN, which removes redundant samples). They solve different problems despite similar names.
- ●
Claiming ENN solves class imbalance -- it reduces noise but doesn't guarantee balanced classes. You need SMOTE or another oversampling method for that.
- ●
Forgetting to mention the data leakage risk when ENN is applied before train-test split -- this is a red flag for interviewers testing production ML knowledge
Senior-Level Expectation
A senior candidate should discuss ENN in the context of a complete imbalanced learning pipeline, covering: (1) the theoretical foundation (Wilson 1972, Bayes optimality), (2) practical parameter tuning (k, kind_sel, and their interaction), (3) the SMOTEENN combination and why it works, (4) computational scaling strategies for large datasets, (5) the distinction between noise removal and legitimate boundary samples, and (6) proper evaluation methodology (resampling inside CV folds, never before split). They should also be able to compare ENN with alternatives (Tomek Links, NCL, AllKNN) and explain when each is appropriate. Bonus points for discussing ENN's role in regulated industries like Indian fintech, where model interpretability and audit trails make ENN's transparent 'keep or remove' decision preferable to black-box resampling methods.
Summary
Edited Nearest Neighbors (ENN) is a foundational data cleaning algorithm that removes noisy samples from classification datasets by leveraging k-nearest neighbor voting. Proposed by Dennis Wilson in 1972, the algorithm's core principle is elegant: if a sample's neighbors disagree with its label, that sample is likely noise and should be removed. Wilson's proof that this editing rule produces asymptotically Bayes-optimal classification provided a theoretical foundation that has kept ENN relevant for over five decades.
In modern ML systems, ENN serves two primary roles. First, as a standalone undersampling technique that cleans majority class noise near decision boundaries in imbalanced datasets. Second -- and more commonly -- as the cleaning step in the SMOTEENN hybrid method, where SMOTE first generates synthetic minority samples and ENN then removes any noisy or poorly-placed samples from the combined dataset. The kind_sel parameter offers two strategies: 'all' (aggressive, any disagreeing neighbor triggers removal) and 'mode' (conservative, majority must disagree). The default 'all' strategy with k=3 works well for most datasets.
For production ML pipelines -- whether it's fraud detection at Razorpay, medical diagnosis systems, or recommendation engines at Flipkart -- ENN provides a computationally tractable way to improve training data quality without the risks of synthetic data generation. The key implementation requirements are: apply ENN after the train-test split to prevent data leakage, start with default parameters (k=3, kind_sel='all') and adjust based on the percentage of samples removed, and always validate the downstream model performance change. ENN's main limitation is its computational cost for the k-NN search, which becomes impractical beyond a few million samples without approximate neighbor methods.