Deduplication in Machine Learning
Deduplication is the process of identifying and removing duplicate or near-duplicate records from a dataset before it enters an ML pipeline. It sounds deceptively simple -- just delete the copies, right? -- but in practice, deduplication is one of the most impactful and underappreciated stages in data processing.
Why does it matter so much? Because duplicates silently corrupt everything downstream. They inflate training set sizes without adding information, cause models to memorize repeated patterns instead of generalizing, leak test set examples into training data, and waste compute on redundant processing. Google's research showed that the C4 dataset contained a single 61-word English sentence repeated over 60,000 times. Cerebras found that 49.6% of the 1.2 trillion token RedPajama dataset was duplicate or near-duplicate content.
Deduplication spans a spectrum from exact matching (byte-identical records) through fuzzy matching (near-duplicates with minor edits) to semantic deduplication (conceptually identical but differently worded content). Each level requires different algorithms, different compute budgets, and different quality tradeoffs. In this guide, we will walk through all of them -- from simple MD5 hashing to embedding-based semantic dedup -- with production-ready code, real case studies, and the math that makes it all work.
Concept Snapshot
- What It Is
- A data processing step that identifies and removes duplicate or near-duplicate records from datasets to improve data quality, reduce redundancy, and prevent data leakage in ML pipelines.
- Category
- Data Processing
- Complexity
- Intermediate
- Inputs / Outputs
- Input: raw dataset with potential duplicates (text, tabular records, images, code). Output: deduplicated dataset with duplicates removed or flagged, plus optional duplicate cluster mappings.
- System Placement
- Sits after data ingestion and initial cleaning, before feature engineering and model training. Often run as part of a data validation pipeline alongside schema checks and outlier detection.
- Also Known As
- duplicate removal, duplicate detection, near-duplicate detection, record deduplication, data dedup, entity resolution, record linkage
- Typical Users
- Data Engineers, ML Engineers, Data Scientists, Data Quality Analysts, NLP Engineers
- Prerequisites
- Hashing fundamentals (MD5, SHA-256), Set similarity metrics (Jaccard similarity), Basic probability (hash collisions, false positives), Text preprocessing (tokenization, n-grams)
- Key Terms
- MinHashLSHSimHashJaccard similarityn-gram shinglingexact dedupfuzzy dedupsemantic dedupentity resolutionrecord linkageblockingdata leakage
Why This Concept Exists
The Hidden Cost of Duplicates
Duplicates are not just wasted disk space. In ML systems, they are active saboteurs. When a training dataset contains duplicate examples, the model effectively sees those examples more often, causing it to overfit to duplicated patterns rather than learning generalizable representations. This is not a theoretical concern -- Lee et al. (2022) demonstrated that language models trained on deduplicated data emit memorized text ten times less frequently and achieve the same accuracy with fewer training steps.
The problem is worse than most teams realize. When Cerebras deduplicated the 1.2 trillion token RedPajama dataset to create SlimPajama, they removed 49.6% of the data -- nearly half the dataset was redundant. The resulting 627 billion token dataset produced models with higher downstream accuracy using less compute. That is the fundamental promise of deduplication: better results with fewer resources.
Data Leakage: The Silent Evaluation Killer
Beyond training efficiency, duplicates create a more insidious problem: train-test leakage. If the same document appears in both your training and evaluation sets, your evaluation metrics are artificially inflated -- the model appears to perform better than it actually does on unseen data. Lee et al. found that over 4% of validation examples in standard NLP benchmarks overlapped with training data. Deduplication across dataset splits is not optional; it is a prerequisite for trustworthy evaluation.
The Evolution from Simple to Sophisticated
Early deduplication was straightforward: hash every record, group by hash, keep one copy. This handles exact duplicates but misses near-duplicates -- records that differ by a few characters, whitespace variations, or minor formatting changes. The field evolved through several waves:
- Exact hashing (MD5/SHA-256): Fast, deterministic, but misses any variation
- N-gram fingerprinting (SimHash, MinHash): Catches near-duplicates via probabilistic similarity
- Record linkage and entity resolution (Dedupe, Zingg): Handles structured data with field-level fuzzy matching
- Embedding-based semantic dedup (SemDeDup): Uses neural embeddings to catch conceptual duplicates that share meaning but not surface form
Each generation expanded the definition of "duplicate" and the compute cost of finding them. The right level depends on your data type, quality requirements, and budget.
Key Insight: Deduplication is not a one-size-fits-all operation. The appropriate algorithm depends on what kind of duplicates you're hunting: byte-identical copies, surface-level near-duplicates, or semantically equivalent reformulations.
Core Intuition & Mental Model
The Spectrum of Sameness
Here is the mental model that will save you hours of confusion: duplicates exist on a spectrum of similarity, and every deduplication method draws a line somewhere on that spectrum.
At one end, you have exact duplicates -- two records that are bit-for-bit identical. A cryptographic hash catches these trivially. At the other end, you have semantic duplicates -- two paragraphs that say the same thing in completely different words. Catching these requires understanding meaning, which means embeddings and neural models.
In between, you have the vast middle ground of near-duplicates: documents that share 80-95% of their content but differ in whitespace, formatting, timestamps, minor edits, or boilerplate additions. This is where MinHash LSH and SimHash live, and this is where most practical deduplication effort is spent.
The Library Analogy
Think of deduplication like organizing a library. Exact dedup is finding two identical copies of the same book with the same ISBN -- easy, just check the barcode. Fuzzy dedup is finding the hardcover and paperback editions of the same book, or the same article republished in two different newspapers with different headlines -- you need to actually look at the content. Semantic dedup is finding two books that cover the same topic but were written by different authors -- you need to understand what the books are about.
Each level of detection requires more intelligence and more compute. The trick is knowing which level your problem actually requires. For LLM pre-training data, fuzzy dedup (MinHash LSH) is the standard. For a product catalog with variant listings, entity resolution is more appropriate. For a research corpus where the same finding is described in multiple papers, you might need semantic dedup.
Rule of Thumb: Start with exact dedup (it is essentially free), then assess whether fuzzy dedup is needed by sampling your data for near-duplicates. Only invest in semantic dedup if you have evidence that paraphrased duplicates are significantly impacting model quality.
Technical Foundations
Jaccard Similarity: The Foundation
Most deduplication algorithms build on Jaccard similarity, which measures the overlap between two sets. Given two documents and represented as sets of shingles (n-grams):
A Jaccard similarity of 1.0 means the documents are identical (as sets of shingles); 0.0 means they share no shingles at all. In practice, a threshold of is commonly used to flag near-duplicates.
The Computational Challenge
The naive approach -- computing pairwise Jaccard similarity for all document pairs -- has complexity , which is catastrophic at scale. For a corpus of million documents, that is comparisons. Even at 1 microsecond per comparison, this would take over 1.5 years.
MinHash: Estimating Jaccard Without Pairwise Comparison
MinHash provides an unbiased estimator of Jaccard similarity using compact signatures. For each document, we apply independent hash functions to its shingle set and record the minimum hash value for each:
The key theorem: the probability that two documents have the same MinHash value under a random hash function equals their Jaccard similarity:
With hash functions, we estimate Jaccard similarity as the fraction of matching signature positions:
This reduces each document from a variable-size set to a fixed-size signature of integers.
LSH Banding: Sublinear Candidate Generation
Even with compact signatures, comparing all pairs is still . Locality-Sensitive Hashing (LSH) solves this by dividing each signature into bands of rows each (where ) and hashing each band into buckets. Two documents become candidates only if they hash to the same bucket in at least one band.
The probability that two documents with Jaccard similarity become candidates is:
This S-curve provides a tunable threshold. For example, with bands and rows, documents with have a ~97% chance of being identified as candidates, while documents with have only a ~0.3% chance -- an effective separation.
SimHash: Cosine-Based Fingerprinting
While MinHash estimates Jaccard similarity, SimHash (Charikar, 2002) produces a single -bit fingerprint per document that preserves cosine similarity. Two documents' similarity is estimated by the fraction of matching bits:
SimHash is more memory-efficient (one -bit hash per document) but offers less flexibility in threshold tuning compared to MinHash LSH.
Semantic Deduplication
SemDeDup (Abbas et al., 2023) operates on pre-trained embeddings. For each document pair with embeddings :
To avoid comparisons, documents are first clustered (e.g., via k-means), and deduplication is performed within clusters. This reduces the effective comparison space from to where .
Internal Architecture
A production deduplication pipeline typically operates in three phases: preprocessing (normalization, tokenization, shingling), candidate generation (blocking or LSH to avoid all-pairs comparison), and verification (precise similarity computation on candidate pairs). Here is how these components connect:
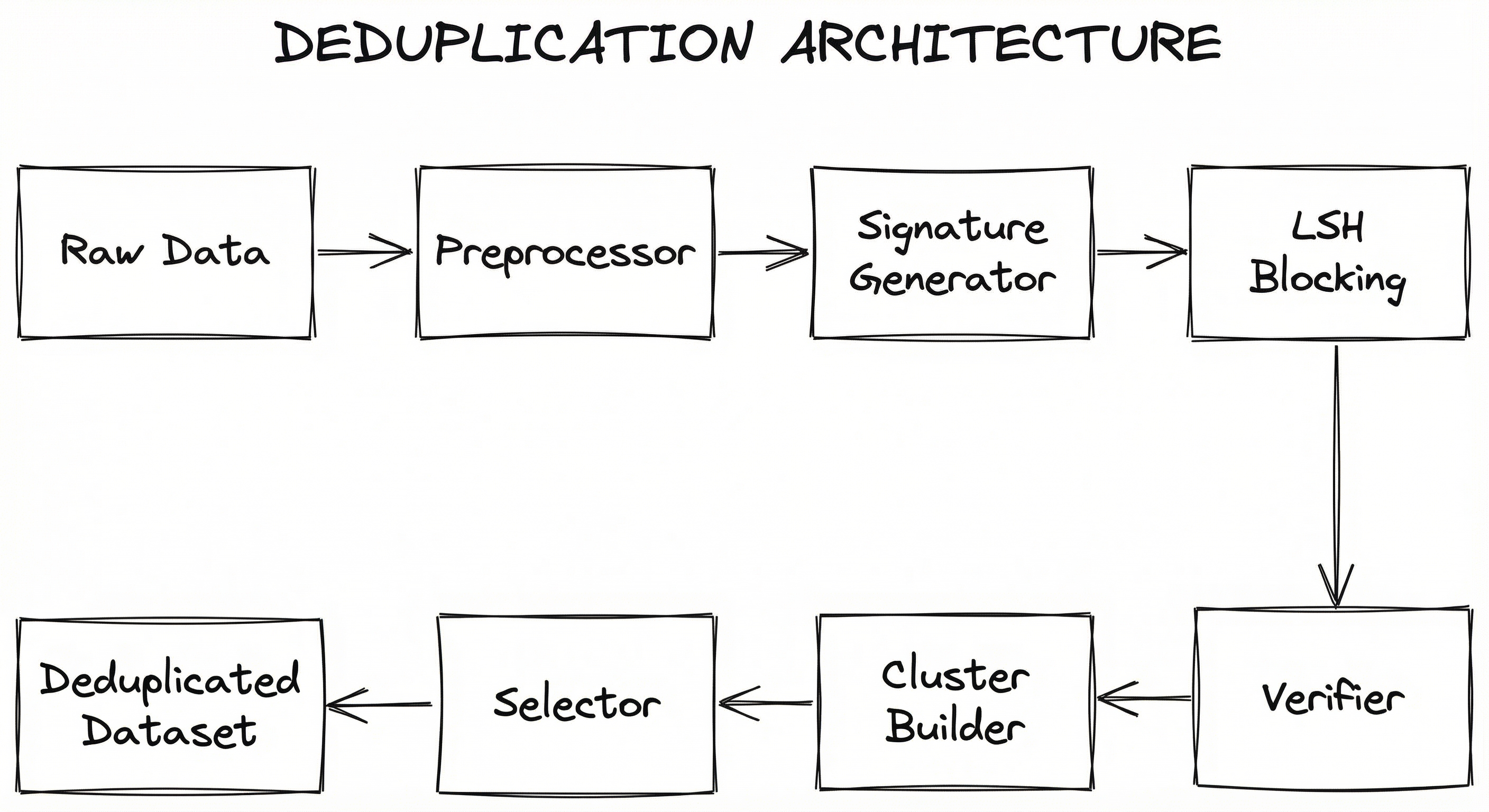
The architecture scales horizontally at each stage. Preprocessing and signature generation are embarrassingly parallel -- each document can be processed independently. LSH banding requires a shared hash table (or distributed equivalent), making it the primary coordination point. Verification and clustering operate on candidate pairs, which are typically 1-5% of all pairs after effective blocking.
For exact deduplication, the pipeline simplifies dramatically: hash each document, group by hash, keep one per group. This can be implemented as a single MapReduce pass or a SQL GROUP BY query. The full architecture above is needed only for fuzzy and semantic deduplication.
Key Components
Preprocessor
Normalizes raw text (lowercasing, whitespace normalization, Unicode canonicalization) and converts documents into shingle sets (overlapping n-grams, typically 5-grams or 13-grams for text). For structured data, concatenates and normalizes relevant fields.
Signature Generator
Computes compact fingerprints for each document. For MinHash, applies permutation hash functions to the shingle set and records the minimum hash per function. For SimHash, computes a weighted bit-vector fingerprint. For semantic dedup, generates dense embeddings via a pre-trained encoder model.
LSH / Blocking Engine
Reduces the comparison space from to near-linear by grouping likely duplicates. MinHash LSH splits signatures into bands and hashes each band; documents sharing a bucket in any band become candidates. For structured data, blocking on key attributes (e.g., first three characters of name + zip code) serves the same purpose.
Pairwise Verifier
Computes precise similarity scores (Jaccard, cosine, edit distance, or field-level comparisons) on candidate pairs generated by LSH/blocking. Filters out false positives that passed the approximate screening.
Cluster Builder
Groups verified duplicate pairs into connected components or clusters using Union-Find or graph-based clustering. Handles transitive duplicates: if A matches B and B matches C, all three are grouped together even if A and C were not directly compared.
Representative Selector
Chooses one canonical record from each duplicate cluster to retain. Selection criteria may include: longest document, most recent timestamp, highest quality score, or source priority ranking.
Data Flow
Write / Batch Path: Raw documents enter the preprocessor, which normalizes and shingles each document in parallel. The signature generator produces MinHash signatures (or embeddings), which are passed to the LSH engine. LSH groups candidate pairs, which the verifier scores precisely. The cluster builder forms connected components of duplicates, and the selector outputs the deduplicated dataset.
Incremental Path: For streaming or incremental dedup, new documents are hashed and queried against an existing LSH index. If a new document matches existing entries above the threshold, it is flagged as duplicate. Otherwise, its signature is added to the index. This is the pattern used for real-time deduplication in data ingestion pipelines.
Execution Model: At scale (>100M documents), the pipeline runs on distributed compute -- Spark, Dask, or Ray. The LSH index is partitioned across workers, with each band assigned to a reducer. NVIDIA NeMo Curator uses GPU-accelerated MinHash computation with RAPIDS for trillion-token scale.
A linear flow from Raw Data through Preprocessor, Signature Generator, LSH/Blocking, Pairwise Verifier, Cluster Builder, and Representative Selector, producing a Deduplicated Dataset. The first three stages operate per-document; the last three operate on candidate pairs and clusters.
How to Implement
Three Tiers of Implementation
Deduplication implementations fall into three tiers, each matching a different scale and complexity requirement:
Tier 1: Exact Dedup -- Hash each record (MD5 or SHA-256), group by hash, keep one. This handles byte-identical duplicates and runs in time. For a dataset of 10 million records, this completes in seconds. Always run this first -- it is cheap and catches the lowest-hanging fruit.
Tier 2: Fuzzy Dedup (MinHash LSH) -- Convert documents to shingle sets, compute MinHash signatures, apply LSH banding to find candidate pairs, verify with precise Jaccard computation. This catches near-duplicates (documents that share ~80%+ content). For SlimPajama, this step removed 49.6% of the 1.2T token dataset. The standard approach used by BigCode, Cerebras, and NVIDIA NeMo Curator.
Tier 3: Semantic Dedup -- Embed documents using a pre-trained model (e.g., sentence-transformers), cluster embeddings, and deduplicate within clusters using cosine similarity. This catches paraphrased content that shares meaning but not surface form. SemDeDup showed that removing 50% of LAION data this way caused minimal performance loss.
For structured data (customer records, product catalogs), record linkage with the Dedupe library or Zingg provides field-level fuzzy matching with active learning. This is the standard approach for CRM deduplication, Aadhaar-style identity matching, and e-commerce catalog cleanup.
Cost Guideline: Exact dedup on 1B records costs virtually nothing (~50-200 / INR 4,200-16,800 on cloud CPUs, or 100-500 / INR 8,400-42,000 for 1B documents depending on model size.
import hashlib
from collections import defaultdict
from typing import List, Dict, Tuple
def exact_dedup(documents: List[str]) -> Tuple[List[str], Dict[str, List[int]]]:
"""Remove exact duplicates using MD5 hashing.
Returns:
- Deduplicated list of documents
- Mapping of hash -> list of original indices (for audit trail)
"""
hash_to_indices = defaultdict(list)
for idx, doc in enumerate(documents):
# Normalize whitespace before hashing
normalized = " ".join(doc.split()).strip().lower()
doc_hash = hashlib.md5(normalized.encode("utf-8")).hexdigest()
hash_to_indices[doc_hash].append(idx)
# Keep the first occurrence of each unique document
deduplicated = []
duplicate_clusters = {}
for doc_hash, indices in hash_to_indices.items():
deduplicated.append(documents[indices[0]])
if len(indices) > 1:
duplicate_clusters[doc_hash] = indices
n_duplicates = len(documents) - len(deduplicated)
print(f"Removed {n_duplicates} exact duplicates "
f"({100 * n_duplicates / len(documents):.1f}% of dataset)")
return deduplicated, duplicate_clusters
# Example usage
documents = [
"The quick brown fox jumps over the lazy dog.",
"Machine learning is transforming industries worldwide.",
"The quick brown fox jumps over the lazy dog.", # exact dup
" The quick brown fox jumps over the lazy dog. ", # whitespace variant
"A completely different document about data science.",
]
deduped, clusters = exact_dedup(documents)
# Output: Removed 2 exact duplicates (40.0% of dataset)This is the simplest and fastest deduplication method. We normalize whitespace and case before hashing to catch trivial formatting variations. The duplicate_clusters output provides an audit trail -- essential for compliance and debugging. MD5 is used here for speed; SHA-256 can be substituted if collision resistance matters (though for dedup, MD5 collisions are not a practical concern).
from datasketch import MinHash, MinHashLSH
from typing import List, Set, Tuple
import re
def create_shingles(text: str, k: int = 5) -> Set[str]:
"""Convert text to a set of character-level k-shingles."""
text = re.sub(r"\s+", " ", text.lower().strip())
return {text[i:i+k] for i in range(len(text) - k + 1)}
def build_minhash(shingles: Set[str], num_perm: int = 128) -> MinHash:
"""Build a MinHash signature from a shingle set."""
m = MinHash(num_perm=num_perm)
for shingle in shingles:
m.update(shingle.encode("utf-8"))
return m
def fuzzy_dedup(
documents: List[str],
threshold: float = 0.8,
num_perm: int = 128,
shingle_size: int = 5,
) -> Tuple[List[str], List[Set[int]]]:
"""Deduplicate documents using MinHash LSH.
Args:
documents: List of document strings
threshold: Jaccard similarity threshold for duplicates
num_perm: Number of MinHash permutations (higher = more accurate)
shingle_size: Character n-gram size for shingling
Returns:
- Deduplicated documents
- List of duplicate clusters (sets of original indices)
"""
# Initialize LSH index
lsh = MinHashLSH(threshold=threshold, num_perm=num_perm)
minhashes = {}
# Build signatures and insert into LSH
for idx, doc in enumerate(documents):
shingles = create_shingles(doc, k=shingle_size)
if len(shingles) == 0:
continue
mh = build_minhash(shingles, num_perm=num_perm)
minhashes[idx] = mh
try:
lsh.insert(str(idx), mh)
except ValueError:
pass # Duplicate MinHash signature already in index
# Find duplicate clusters using Union-Find
parent = list(range(len(documents)))
def find(x):
while parent[x] != x:
parent[x] = parent[parent[x]] # path compression
x = parent[x]
return x
def union(x, y):
px, py = find(x), find(y)
if px != py:
parent[px] = py
# Query each document against LSH index
for idx in minhashes:
candidates = lsh.query(minhashes[idx])
for cand in candidates:
cand_idx = int(cand)
if cand_idx != idx:
# Verify with actual Jaccard estimate
sim = minhashes[idx].jaccard(minhashes[cand_idx])
if sim >= threshold:
union(idx, cand_idx)
# Build clusters and select representatives
from collections import defaultdict
clusters = defaultdict(set)
for idx in range(len(documents)):
clusters[find(idx)].add(idx)
# Keep the first document in each cluster
deduplicated = []
duplicate_groups = []
for root, members in clusters.items():
representative = min(members) # keep earliest
deduplicated.append(documents[representative])
if len(members) > 1:
duplicate_groups.append(members)
n_removed = len(documents) - len(deduplicated)
print(f"Removed {n_removed} near-duplicates "
f"({100 * n_removed / len(documents):.1f}% of dataset)")
return deduplicated, duplicate_groupsThis is the workhorse algorithm for text deduplication at scale. The pipeline follows three steps: (1) shingle each document into overlapping character n-grams, (2) compute MinHash signatures that compactly represent each shingle set, and (3) use LSH banding to efficiently find candidate pairs. Union-Find groups transitive duplicates into clusters. The threshold parameter controls the Jaccard similarity cutoff -- 0.8 is the standard for LLM training data (used by SlimPajama and BigCode). For more aggressive dedup, lower it to 0.7; for conservative dedup that only catches very close matches, raise it to 0.9.
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.cluster import MiniBatchKMeans
from sklearn.metrics.pairwise import cosine_similarity
from typing import List, Tuple, Set
from collections import defaultdict
def semantic_dedup(
documents: List[str],
model_name: str = "all-MiniLM-L6-v2",
n_clusters: int = 100,
similarity_threshold: float = 0.9,
batch_size: int = 256,
) -> Tuple[List[str], List[Set[int]]]:
"""Deduplicate using embedding-based semantic similarity.
Uses SemDeDup approach: cluster embeddings, then deduplicate
within clusters to avoid O(n^2) pairwise comparison.
Args:
documents: List of document strings
model_name: Sentence transformer model name
n_clusters: Number of k-means clusters (controls granularity)
similarity_threshold: Cosine similarity threshold for duplicates
batch_size: Encoding batch size
"""
# Step 1: Generate embeddings
model = SentenceTransformer(model_name)
embeddings = model.encode(
documents, batch_size=batch_size, show_progress_bar=True,
normalize_embeddings=True # for cosine similarity
)
# Step 2: Cluster embeddings to reduce comparison space
kmeans = MiniBatchKMeans(
n_clusters=min(n_clusters, len(documents) // 2),
batch_size=1024, random_state=42
)
cluster_labels = kmeans.fit_predict(embeddings)
# Step 3: Deduplicate within each cluster
parent = list(range(len(documents)))
def find(x):
while parent[x] != x:
parent[x] = parent[parent[x]]
x = parent[x]
return x
def union(x, y):
px, py = find(x), find(y)
if px != py:
parent[px] = py
cluster_to_docs = defaultdict(list)
for idx, label in enumerate(cluster_labels):
cluster_to_docs[label].append(idx)
for label, doc_indices in cluster_to_docs.items():
if len(doc_indices) < 2:
continue
cluster_embeds = embeddings[doc_indices]
sim_matrix = cosine_similarity(cluster_embeds)
for i in range(len(doc_indices)):
for j in range(i + 1, len(doc_indices)):
if sim_matrix[i, j] >= similarity_threshold:
union(doc_indices[i], doc_indices[j])
# Step 4: Build clusters and select representatives
clusters = defaultdict(set)
for idx in range(len(documents)):
clusters[find(idx)].add(idx)
deduplicated = []
duplicate_groups = []
for root, members in clusters.items():
representative = min(members)
deduplicated.append(documents[representative])
if len(members) > 1:
duplicate_groups.append(members)
n_removed = len(documents) - len(deduplicated)
print(f"Removed {n_removed} semantic duplicates "
f"({100 * n_removed / len(documents):.1f}% of dataset)")
return deduplicated, duplicate_groupsThis implements the SemDeDup approach from Meta Research. The key insight is clustering embeddings first (via k-means) to avoid all-pairs comparison. Within each cluster, we compute a full cosine similarity matrix and group documents exceeding the threshold. The similarity_threshold of 0.9 is conservative -- it catches close paraphrases while avoiding false positives. The embedding model choice matters: all-MiniLM-L6-v2 is fast and lightweight; for higher quality, use all-mpnet-base-v2 or domain-specific models. Note that this catches duplicates that MinHash would miss entirely -- two documents expressing the same idea in different words.
import dedupe
import csv
from collections import OrderedDict
def load_data(filepath: str) -> dict:
"""Load structured records for deduplication."""
data = OrderedDict()
with open(filepath, "r") as f:
reader = csv.DictReader(f)
for i, row in enumerate(reader):
data[i] = {k: v.strip() if v else None for k, v in row.items()}
return data
def deduplicate_records(data: dict) -> list:
"""Deduplicate structured records using the Dedupe library.
Uses active learning to train a matching model.
"""
# Define fields and their types for comparison
fields = [
{"field": "name", "type": "String", "has missing": True},
{"field": "address", "type": "String", "has missing": True},
{"field": "city", "type": "ShortString", "has missing": True},
{"field": "phone", "type": "String", "has missing": True},
{"field": "email", "type": "String", "has missing": True},
]
# Initialize deduper
deduper = dedupe.Dedupe(fields)
# Prepare training data (sample pairs for active learning)
deduper.prepare_training(data, sample_size=15000)
# In production, you would use:
# dedupe.console_label(deduper) # Interactive labeling
# Or load pre-labeled training data:
# with open("training.json", "r") as f:
# deduper.prepare_training(data, training_file=f)
# Train the matching model
deduper.train()
# Find duplicate clusters
# threshold: probability threshold for considering a match
clustered_dupes = deduper.partition(data, threshold=0.5)
# Process results
cluster_membership = {}
for cluster_id, (records, scores) in enumerate(clustered_dupes):
for record_id, score in zip(records, scores):
cluster_membership[record_id] = {
"cluster_id": cluster_id,
"confidence": score,
}
n_clusters = len(clustered_dupes)
n_duplicates = len(data) - n_clusters
print(f"Found {n_clusters} unique entities from {len(data)} records")
print(f"Identified {n_duplicates} duplicate records")
return clustered_dupesThe Dedupe library is the gold standard for deduplicating structured records (customer databases, product catalogs, CRM data). Unlike hash-based methods, it uses active learning -- you label a small sample of record pairs as matches/non-matches, and the library trains a logistic regression model that generalizes to the full dataset. It handles messy real-world data: typos in names, different address formats, missing phone numbers. This is the approach used for entity resolution in contexts like Aadhaar deduplication, voter roll cleanup, and e-commerce catalog matching. The prepare_training step uses blocking (TF-IDF on field values) to efficiently sample informative pairs.
# Deduplication pipeline configuration (YAML)
pipeline:
name: training-data-dedup
stages:
- name: exact_dedup
method: md5
normalize:
lowercase: true
strip_whitespace: true
unicode_nfkc: true
- name: fuzzy_dedup
method: minhash_lsh
params:
num_permutations: 128
jaccard_threshold: 0.8
shingle_size: 5
bands: 20
rows_per_band: 5
backend: spark # or 'ray', 'dask', 'gpu'
- name: semantic_dedup
enabled: false # enable for high-value datasets
method: semdedup
params:
model: all-MiniLM-L6-v2
n_clusters: 1000
cosine_threshold: 0.92
output:
deduplicated_path: s3://data-lake/deduped/
duplicate_log_path: s3://data-lake/dedup-audit/
format: parquet
compression: snappyCommon Implementation Mistakes
- ●
Skipping exact dedup before fuzzy dedup: Exact dedup is essentially free () and removes the easiest duplicates. Running MinHash LSH without it wastes compute on pairs that a simple hash comparison would catch. Always run exact dedup first.
- ●
Using too few MinHash permutations: With permutations, your Jaccard estimates have a standard error of . For reliable dedup at a 0.8 threshold, use at least 128 permutations (standard error ~0.088). BigCode uses 256.
- ●
Deduplicating within splits but not across them: If you dedup your train and test sets independently, the same document can appear in both -- creating train-test leakage. Always dedup across the combined dataset first, then split.
- ●
Normalizing too aggressively: Over-normalization (e.g., removing all punctuation, stemming, lowercasing everything) can cause semantically different documents to hash identically. A legal clause that differs by a single 'not' is a very different document. Be thoughtful about what you normalize.
- ●
Ignoring transitive closure: If document A matches B, and B matches C, then A and C should be in the same duplicate cluster -- even if they were not directly compared or fall below the threshold when compared directly. Use Union-Find to handle transitive duplicates.
- ●
Setting the Jaccard threshold too low: A threshold of 0.5 will flag documents that share only half their content as duplicates. For most ML training data, 0.7-0.8 is appropriate. Going lower risks removing legitimately distinct documents.
- ●
Not preserving an audit trail: When you remove duplicates, record which documents were removed and which cluster they belonged to. You will need this for debugging, compliance, and understanding downstream quality changes.
When Should You Use This?
Use When
You are curating training data for LLM pre-training and need to remove redundant web-crawled content (the single most impactful use case -- SlimPajama removed 49.6% of RedPajama)
Your dataset was assembled from multiple sources that may overlap (e.g., combining Common Crawl, Wikipedia, and domain-specific crawls)
You need to prevent train-test data leakage by ensuring evaluation examples do not appear in training data
Your product catalog or CRM database has grown organically with variant entries for the same entity (common in Indian e-commerce with transliterated names, multiple address formats)
You are building a RAG knowledge base and want to avoid retrieving redundant chunks that waste context window space
Your data pipeline ingests real-time streams where the same event may arrive multiple times from different sources
You want to reduce storage costs and training compute by removing redundant data without losing information diversity
Avoid When
Your dataset is small enough (<10K records) that manual inspection is feasible and more reliable than automated dedup
Duplicates are intentional -- e.g., data augmentation where you deliberately create variations of training examples
The 'duplicates' carry different labels or annotations that reflect legitimate disagreement (removing them would bias the model)
You are working with time-series data where repeated patterns are natural signals, not redundancy
The cost of false positives (incorrectly removing unique records) exceeds the cost of retaining duplicates -- this happens in medical records and legal documents where every variant may be legally significant
Your embeddings are not well-calibrated for the domain, making semantic dedup unreliable (garbage embeddings produce garbage dedup decisions)
Key Tradeoffs
Precision vs. Recall in Dedup
Every deduplication algorithm faces a precision-recall tradeoff. Lowering the similarity threshold catches more true duplicates (higher recall) but also flags more false positives (lower precision). Raising the threshold preserves more unique documents but misses subtle duplicates.
For LLM training data, the community has converged on Jaccard threshold 0.8 with MinHash LSH as a good balance. BigCode, Cerebras (SlimPajama), and NVIDIA NeMo Curator all use this setting.
Compute Cost vs. Dedup Quality
| Method | Compute Cost (1B docs) | Duplicates Caught | False Positive Rate |
|---|---|---|---|
| Exact (MD5) | ~$5 / INR 420 | Byte-identical only | ~0% |
| MinHash LSH (128 perm) | ~$100 / INR 8,400 | Near-duplicates (>80% overlap) | 1-3% |
| MinHash LSH (256 perm) | ~$180 / INR 15,120 | Near-duplicates (more accurate) | <1% |
| SimHash (64-bit) | ~$60 / INR 5,040 | Near-duplicates (cosine-based) | 2-5% |
| Semantic (SemDeDup) | ~$300 / INR 25,200 | Paraphrases + near-duplicates | 3-8% |
Surface vs. Semantic Duplicates
MinHash LSH catches documents that share surface-level content (same words, same order). It will not catch two news articles about the same event written by different journalists, or two code functions implementing the same algorithm in different styles. If these semantic duplicates matter for your use case, you need embedding-based dedup -- but at significantly higher cost and false positive rates.
Practical Advice: Run exact dedup (free) + MinHash LSH (cheap) on all datasets. Only add semantic dedup for high-value, curated datasets where you have evidence of paraphrase-level duplication and can afford to verify false positives.
Alternatives & Comparisons
Data cleaning encompasses a broader set of operations (handling missing values, fixing inconsistencies, removing noise) of which deduplication is one component. If your primary issue is duplicate records, deduplication is the targeted solution. If your data has multiple quality problems, a full cleaning pipeline -- with deduplication as one stage -- is more appropriate.
Data validation checks whether data conforms to expected schemas, ranges, and constraints. It can flag duplicates as a validation rule but is not optimized for the fuzzy and semantic matching that dedicated deduplication provides. Use validation for schema enforcement and constraint checking; use deduplication for duplicate-specific detection.
Data transformation changes the representation of data (encoding, normalization, feature extraction). While normalization is a prerequisite for effective deduplication, transformation itself does not identify or remove duplicates. These are complementary stages in a data processing pipeline.
Embedding models produce the dense vector representations used by semantic deduplication (SemDeDup). The embedding model is a dependency of semantic dedup, not an alternative to it. For surface-level dedup (exact + MinHash), no embedding model is needed. For semantic dedup, embedding quality directly determines dedup quality.
Pros, Cons & Tradeoffs
Advantages
Dramatic training efficiency gains: Cerebras showed that deduplicating RedPajama removed 49.6% of data while improving model accuracy -- literally better results from less data and less compute
Prevents data memorization: Models trained on deduplicated data emit memorized text 10x less frequently (Lee et al., 2022), reducing privacy and copyright risks
Eliminates train-test leakage: Cross-split deduplication ensures evaluation metrics reflect true generalization, not memorization of leaked examples
Reduces storage and compute costs: Removing 40-50% of a dataset saves proportional storage and a significant fraction of training compute -- at trillion-token scale, this translates to hundreds of thousands of dollars (lakhs of rupees) in GPU costs
Improves data diversity: By removing redundant copies, the remaining data budget can be filled with more diverse examples, improving model robustness
Scales to internet-scale corpora: MinHash LSH operates in near-linear time, and GPU-accelerated implementations (NVIDIA NeMo Curator, FED) can dedup 1.2 trillion tokens in hours
Catches data pipeline errors: Unexpected duplicate rates often signal upstream bugs -- broken dedup alerting has caught ingestion pipeline failures at multiple companies
Disadvantages
False positives remove legitimate content: Aggressive deduplication can remove documents that are similar but contain meaningfully different information -- legal documents, product variants, news updates. Careful threshold tuning is essential.
Compute cost scales with corpus size: While sub-quadratic, MinHash LSH on trillion-token datasets still requires significant infrastructure. GPU acceleration helps but adds hardware cost (~$20-50 / INR 1,680-4,200 per run).
Threshold sensitivity: The choice of Jaccard threshold (0.7 vs. 0.8 vs. 0.9) significantly affects outcomes, and the optimal threshold varies by data type. There is no universal right answer.
Does not catch semantic duplicates: MinHash LSH and SimHash only detect surface-level overlap. Two documents expressing the same information in different words will not be flagged. Semantic dedup addresses this but at much higher cost.
Ordering effects matter: Which document you keep from a duplicate cluster affects downstream model behavior. Keeping the longest vs. the most recent vs. the highest quality version can produce meaningfully different results.
Incremental dedup is harder: Deduplicating a static dataset is well-understood, but deduplicating a continuously growing dataset requires maintaining an LSH index and handling deletions -- significantly more complex engineering.
Failure Modes & Debugging
False positive explosion
Cause
Jaccard/cosine threshold set too low, or shingle size too large (capturing less document-specific information). Common when teams copy-paste default parameters without tuning for their data distribution.
Symptoms
Excessive data removal (>60% of corpus), loss of important variant documents, degraded model performance on underrepresented topics. Manual inspection reveals clearly distinct documents being grouped as duplicates.
Mitigation
Start with a conservative threshold (0.85-0.9) and lower gradually while monitoring downstream metrics. Always sample 100-200 duplicate pairs and manually verify before running full dedup. Use precision@k on a labeled sample to quantify false positive rate.
Train-test leakage despite dedup
Cause
Deduplication applied independently to train and test splits instead of across the combined dataset. Near-duplicates that fall just below the threshold still leak information across splits.
Symptoms
Evaluation metrics are optimistically biased. Model performs significantly worse on truly held-out data compared to the "deduplicated" test set. Performance gap between validation and production is unexpectedly large.
Mitigation
Always dedup across the full dataset before splitting into train/test/validation. For additional safety, run cross-split contamination checks at a lower threshold (e.g., 0.6) to detect borderline leakage.
LSH index memory exhaustion
Cause
MinHash LSH index grows with the number of documents and the number of bands. At 1B+ documents with 128 permutations and 20 bands, the LSH hash tables can require hundreds of GB of RAM.
Symptoms
OOM errors during LSH construction, extremely slow query times due to OS paging, or Spark/Dask executors crashing. On Kubernetes, pods enter CrashLoopBackOff.
Mitigation
Use distributed backends (Spark, Dask, Ray) to partition the LSH index across workers. NVIDIA NeMo Curator uses GPU memory and RAPIDS for efficient index construction. For very large corpora, use LSHBloom (Bloom filter-based LSH) which requires 12x less memory than traditional MinHashLSH.
Encoding-sensitive duplicate misses
Cause
Unicode normalization not applied before hashing. Documents that look identical to humans but differ in Unicode representation (e.g., precomposed vs. decomposed characters, different quotation marks, em-dashes vs. hyphens) produce different hashes.
Symptoms
Known duplicates survive exact dedup. Especially common with multilingual data or content scraped from different platforms (which use different Unicode conventions).
Mitigation
Apply NFKC Unicode normalization before any hashing or shingling. Normalize quotation marks, dashes, and whitespace characters to canonical forms. For Indian languages (Hindi, Tamil, etc.), be especially careful with Devanagari and other Indic script normalization.
Catastrophic loss of minority-class data
Cause
Minority classes often have fewer unique examples and higher internal similarity. Deduplication disproportionately removes these, exacerbating class imbalance.
Symptoms
Model performance on minority classes degrades after dedup. Class distribution shifts significantly (e.g., rare disease descriptions or low-resource language content is preferentially removed).
Mitigation
Monitor per-class or per-category duplicate rates. Apply stratified deduplication that respects class distribution. Set different thresholds for different content types if warranted.
Stale dedup on growing datasets
Cause
Deduplication run once on a snapshot, but new data ingested afterward is not checked against the existing corpus. Over time, duplicates accumulate again.
Symptoms
Duplicate rate in production data gradually increases over months. Periodic audits reveal duplication levels returning to pre-dedup baselines.
Mitigation
Implement incremental deduplication: maintain a persistent LSH index and query new documents against it at ingestion time. Periodically re-run full dedup to catch any drift. datasketch supports Redis-backed MinHash LSH for persistent indices.
Placement in an ML System
Where Deduplication Fits in the ML Pipeline
Deduplication sits squarely in the data processing stage, after raw data has been ingested and undergone initial cleaning (encoding fixes, language filtering, basic quality checks) but before feature engineering, embedding generation, or model training.
In a typical LLM pre-training pipeline, the flow is: Web Crawl -> Language Detection -> Quality Filtering -> Exact Dedup -> Fuzzy Dedup (MinHash LSH) -> Tokenization -> Training. This is the exact order used by Cerebras for SlimPajama, by BigCode for The Stack, and by most open-source LLM training efforts.
For RAG pipelines, deduplication serves a different purpose: ensuring that the knowledge base does not contain redundant chunks that waste context window space during retrieval. Here, dedup happens after document chunking but before embedding and indexing in the vector store.
For structured data systems (CRM, e-commerce catalogs), deduplication is part of the ETL pipeline, running after extraction and basic transformation but before loading into the production database. In Indian e-commerce, where the same product may appear with different transliterations of its name ("Dettol" vs "Detol" vs "Dettal"), fuzzy dedup or entity resolution is essential for catalog quality.
Key Insight: Deduplication is a force multiplier -- every downstream component (training, retrieval, serving) benefits from cleaner data, making it one of the highest-ROI investments in the entire pipeline.
Pipeline Stage
Data Processing
Upstream
- batch-data-source
- data-cleaning
- data-validation
Downstream
- data-transformation
- embedding-model
- batch-data-source
Scaling Bottlenecks
The primary bottleneck is the LSH index construction and query phase. For MinHash LSH, memory grows linearly with document count and number of bands. At 1 billion documents with 128 permutations and 20 bands, expect ~200-400 GB of RAM for the index alone.
The second bottleneck is pairwise verification on candidate pairs. While LSH reduces the comparison space from to roughly where is the average number of candidates per document, highly duplicated corpora produce large candidate sets that still require significant compute.
GPU acceleration is transformative here. NVIDIA NeMo Curator processes 1.2 trillion tokens in ~6 hours on a GPU cluster. The FED framework (2025) achieves 107x speedup over CPU-based MinHash LSH using just 4 GPUs. For organizations with GPU infrastructure, this is the path forward.
For semantic dedup, the bottleneck shifts to embedding generation -- encoding 1 billion documents with a sentence transformer at 256 docs/sec on a single GPU takes ~45 days. Scaling to 8 GPUs brings this down to ~6 days. The clustering and within-cluster comparison steps are comparatively fast.
Production Case Studies
Cerebras created SlimPajama by applying MinHash LSH deduplication (Jaccard threshold 0.8, 13-gram shingles) to the 1.21 trillion token RedPajama dataset. The global deduplication strategy -- deduplicating across all source domains simultaneously rather than within each domain -- was critical for removing cross-source duplicates that local dedup would miss.
Removed 49.6% of the dataset (from 1.21T to 627B tokens), producing the largest open deduplicated LLM training corpus. Models trained on SlimPajama achieved higher accuracy with roughly half the compute budget.
BigCode applied near-deduplication using MinHash with 256 permutations to The Stack, a massive code dataset for training StarCoder. The pipeline processed terabytes of source code across 358 programming languages, computing document-level MinHash signatures and using LSH banding to identify near-duplicate code files.
Approximately 40% of permissively licensed files were identified as exact or near-duplicates. The deduplicated dataset (The Stack Dedup, 3TB) produced StarCoder models with improved code generation quality and reduced verbatim reproduction of training data.
Lee et al. studied deduplication in the C4, Wiki-40B, and LM1B datasets used for training major language models. They developed exact and near-duplicate detection tools and discovered extreme redundancy -- including a single 61-word sentence repeated 60,000+ times in C4. The paper established that deduplication is not just a data quality concern but directly improves model training dynamics.
Models trained on deduplicated C4 emitted memorized text 10x less frequently, required fewer training steps to reach the same perplexity, and showed more accurate evaluation metrics due to reduced train-test overlap (which affected >4% of validation examples).
India's Aadhaar program -- the world's largest biometric ID system covering 1.3+ billion residents -- uses biometric deduplication to ensure each person receives only one unique ID. The deduplication engine compares fingerprints, iris scans, and facial photographs against the entire enrolled population to detect duplicate enrollments. This is entity resolution at nation-scale, running multi-modal matching across biometric and demographic fields.
The system processes millions of deduplication requests daily, maintaining a unique identity database of over 1.3 billion records. The deduplication process has detected and prevented millions of duplicate enrollments, saving the government significant resources in welfare distribution.
Meta developed SemDeDup (Semantic Deduplication), which uses pre-trained model embeddings to identify and remove semantic duplicates from web-scale datasets. Applied to LAION (a massive image-text dataset), SemDeDup identified semantically redundant examples that surface-level methods like exact hashing or MinHash would miss -- pairs that express the same visual or textual concept in different surface forms.
SemDeDup removed 50% of LAION data with minimal performance loss on downstream vision-language tasks, effectively halving training time. The method outperformed random subsampling and traditional dedup methods in maintaining model quality per training compute dollar.
Coupang, South Korea's largest e-commerce platform, built a duplicate item matching system to improve catalog quality. With millions of products listed by different sellers, the same item often appears with different titles, images, and descriptions. They developed a multimodal deduplication pipeline combining text similarity (TF-IDF + BERT embeddings), image similarity (CNN feature vectors), and attribute matching to identify duplicate listings at scale (2022).
The deduplication system identified and merged millions of duplicate product listings, improving search relevance and enabling accurate price comparisons. Catalog quality improvements led to higher conversion rates and better customer trust in product pages.
Tooling & Ecosystem
Python library implementing MinHash, MinHash LSH, LSH Forest, Weighted MinHash, HyperLogLog, and LSH Ensemble. The go-to library for probabilistic deduplication. Supports Redis and Cassandra backends for persistent indices. Used internally by many teams for production dedup pipelines.
GPU-accelerated data curation toolkit for LLM training data. Provides exact dedup (MD5), fuzzy dedup (MinHash LSH), and semantic dedup -- all GPU-accelerated using RAPIDS. Designed for trillion-token scale. Used in the production pipeline for NVIDIA's NeMo LLM training.
Python library for fuzzy matching, deduplication, and entity resolution on structured data. Uses active learning to train a matching model from user-labeled examples. Handles missing data, typos, and variant spellings. The gold standard for CRM and catalog deduplication.
Google's tool for exact and near-duplicate detection in text datasets, developed alongside the seminal "Deduplicating Training Data Makes Language Models Better" paper. Implements suffix array-based exact substring dedup and MinHash-based near-duplicate detection.
Fast multimodal semantic deduplication and filtering library. Uses embedding-based similarity to detect semantic duplicates across text and other modalities. Designed as a practical tool for dataset curation with a clean API.
Toolkit for record linkage and deduplication in Python. Provides tools for indexing (blocking), comparing records, classifying matches, and evaluating results. Good for structured data dedup when you need more control than Dedupe provides.
Argilla's Distilabel framework includes a MinHashDedup step for integrating MinHash-based deduplication directly into synthetic data generation and curation pipelines. Useful for deduplicating LLM-generated training data.
Research & References
Lee, Ippolito, Nystrom, Zhang, Eck, Callison-Burch, Carlini (2022)ACL 2022 (Long Papers)
The foundational paper showing that LLM training data is heavily duplicated (a single sentence repeated 60,000+ times in C4) and that deduplication reduces memorization 10x while improving training efficiency. Released dedup tooling at Google Research.
Abbas, Tirumala, Simig, Ganguli, Morcos (2023)arXiv preprint (Meta AI)
Introduced embedding-based semantic deduplication that uses pre-trained model representations to identify conceptual duplicates missed by surface-level methods. Removed 50% of LAION with minimal performance loss.
Tirumala, Simig, Harchaoui, Morcos (2023)NeurIPS 2023
Demonstrated that combining deduplication with diversity-aware data selection yields 20% training efficiency gains and up to 2% accuracy improvement on 16 NLP tasks at the 6.7B model scale. Challenges the assumption that training on more data is always better.
Khan (2024)arXiv preprint
Proposed replacing traditional LSH hash tables with Bloom filters for MinHash signature matching, achieving 12x speedup over standard MinHashLSH by using efficient bit array operations instead of tree-based data structures.
Various (2025)arXiv preprint
GPU-accelerated deduplication framework that achieves up to 107x speedup over CPU-based SlimPajama dedup and 6.3x over NVIDIA NeMo Curator. Deduplicates 1.2 trillion tokens in 6 hours on 16 GPUs using optimized non-cryptographic hash functions.
Dell Research (Harvard) (2022)ICLR 2023
Evaluated hashing, n-gram, bi-encoder, and cross-encoder approaches for dedup in noisy text. The neural bi-encoder approach significantly outperformed MinHash on noisy corpora and scales to 10M documents on a single GPU. Released the NEWS-COPY benchmark dataset.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a deduplication pipeline for a dataset with 1 billion web-crawled documents?
- ●
Explain the difference between exact, fuzzy (MinHash LSH), and semantic deduplication. When would you use each?
- ●
What is MinHash and how does LSH banding help scale it? Walk through the math.
- ●
How do you prevent train-test data leakage in an ML pipeline? What role does deduplication play?
- ●
How would you deduplicate a product catalog where the same product appears with different names and descriptions?
- ●
What happens if you skip deduplication when training a large language model?
- ●
How do you handle deduplication in a continuously growing dataset (streaming dedup)?
Key Points to Mention
- ●
Always run exact dedup first (free, O(n)), then fuzzy dedup (MinHash LSH), and only invest in semantic dedup if you have evidence of paraphrase-level duplication. This layered approach is what production systems use.
- ●
MinHash provides an unbiased estimator of Jaccard similarity: P[min_hash(A) = min_hash(B)] = J(A,B). LSH banding creates an S-curve that separates high-similarity pairs from low-similarity pairs in sublinear time.
- ●
The standard configuration for LLM training data dedup is: Jaccard threshold 0.8, 128-256 MinHash permutations, 5-13 character n-gram shingles. This is used by Cerebras (SlimPajama), BigCode (The Stack), and NVIDIA NeMo Curator.
- ●
Deduplication must be applied across train/test splits, not within each split independently, to prevent data leakage. Lee et al. found >4% of validation examples in standard benchmarks overlapped with training data.
- ●
For structured data, record linkage with blocking and active learning (Dedupe library) is more appropriate than hash-based methods. Field-level comparisons (Levenshtein distance, phonetic matching, address normalization) are essential.
Pitfalls to Avoid
- ●
Claiming deduplication is just 'removing exact copies' -- in practice, near-duplicates and semantic duplicates are the harder and more impactful problem
- ●
Ignoring the quadratic scaling problem: naive pairwise comparison on 1M documents requires 500 billion comparisons. Always mention LSH or blocking as the solution.
- ●
Forgetting about transitive closure: if A matches B and B matches C, all three are duplicates. Union-Find is the standard algorithm for this.
- ●
Not discussing the precision-recall tradeoff: lower thresholds catch more duplicates but also produce more false positives. The optimal threshold depends on the data and use case.
Senior-Level Expectation
A senior or staff-level candidate should discuss the full dedup lifecycle: data profiling (measuring duplicate rate before and after), normalization strategy (Unicode, whitespace, domain-specific rules), algorithm selection with quantitative justification (MinHash permutation count, LSH band/row configuration, expected false positive/negative rates), distributed execution strategy (Spark partitioning, GPU acceleration trade-offs), incremental dedup for growing datasets (persistent LSH index, Redis-backed datasketch), impact measurement (downstream model quality A/B test, not just dedup rate), and cost analysis. They should be able to reason about Indian-specific challenges: transliteration variants ("Bengaluru" vs "Bangalore"), mixed-script content (Hindi in Devanagari vs romanized Hindi), and entity resolution for names with varying conventions ("Kumar, Rajesh" vs "Rajesh Kumar" vs "R. Kumar"). The ability to discuss when not to dedup -- intentional data augmentation, label-carrying variants, minority class preservation -- separates senior engineers from juniors who treat dedup as a checkbox.
Summary
Wrapping Up
Deduplication is one of the highest-ROI operations in any ML data pipeline. Here is what you should take away:
-
The impact is massive: Cerebras removed 49.6% of RedPajama through deduplication, and the resulting SlimPajama dataset produced better models with half the compute. Google found a single sentence repeated 60,000 times in C4. If you are not deduplicating your training data, you are almost certainly wasting compute and degrading model quality.
-
Layer your approach: Start with exact dedup (MD5 hashing, , essentially free), then apply fuzzy dedup (MinHash LSH with Jaccard threshold 0.8, the industry standard), and optionally add semantic dedup (SemDeDup with embedding clustering) for high-value datasets. Each layer catches duplicates the previous one missed.
-
The math matters: MinHash provides an unbiased estimator of Jaccard similarity via the probability that minimum hash values match. LSH banding creates an S-curve that enables sublinear candidate generation, making trillion-scale dedup feasible. Understanding the band/row configuration and its effect on the false positive/negative tradeoff is essential for production tuning.
-
Always dedup across splits: Applying deduplication within train and test sets independently does not prevent data leakage. Dedup the combined dataset first, then split. Lee et al. found >4% leakage in standard benchmarks.
-
For structured data, use record linkage: Hash-based methods do not work well for customer databases, product catalogs, or identity systems. The Dedupe library with active learning and field-level comparison is the right tool for entity resolution on structured records.
Deduplication is the bridge between raw, redundant data and efficient, high-quality ML training. It costs pennies per gigabyte and saves dollars per GPU-hour. There is no good reason to skip it.