SMOTE + ENN in Machine Learning
Class imbalance is a near-universal problem in production ML, but simply oversampling the minority class introduces a subtler problem: noisy synthetic samples that blur decision boundaries and generate false positives. SMOTEENN — a hybrid of SMOTE (Synthetic Minority Over-sampling Technique) and ENN (Edited Nearest Neighbors) — addresses this by first oversampling the minority class with SMOTE, then cleaning the resulting dataset with ENN to remove ambiguous or misclassified samples from both classes.
Proposed by Batista, Prati, and Monard in their influential 2004 paper "A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data," SMOTEENN has become one of the most widely adopted hybrid resampling strategies in domains where both recall and precision matter — fraud detection at scale, medical diagnosis, agricultural remote sensing, and more.
What makes SMOTEENN distinctive is its two-phase philosophy: generate first, clean second. SMOTE expands the minority class region in feature space through k-NN interpolation, then ENN acts as a quality filter — removing any sample (synthetic or original, minority or majority) whose nearest neighbors disagree with its label. The result is a dataset that is more balanced than the original AND cleaner than what SMOTE alone produces.
In production pipelines built with imbalanced-learn, SMOTEENN is available as imblearn.combine.SMOTEENN and follows the same fit_resample() interface as other resamplers. It's the go-to choice when vanilla SMOTE improves recall but introduces too many false positives, and when you need sharper decision boundaries without sacrificing the benefits of oversampling.
Concept Snapshot
- What It Is
- A two-phase hybrid resampling technique that first oversamples the minority class using SMOTE (k-NN interpolation), then cleans the combined dataset using Edited Nearest Neighbors (ENN) to remove noisy, ambiguous, or boundary-violating samples from both classes.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: imbalanced training dataset with minority and majority classes. Outputs: balanced and cleaned dataset — minority class is augmented via SMOTE, then noisy samples from both classes are removed by ENN.
- System Placement
- Applied during the data preprocessing phase, after data cleaning, feature extraction, and train-test split, but before model training. Training-time only — never applied at inference.
- Also Known As
- SMOTE-ENN, SMOTE + Edited Nearest Neighbors, SMOTE with ENN cleaning, Hybrid oversample-clean resampling
- Typical Users
- ML engineers, data scientists, research scientists, ML platform engineers, healthcare AI researchers
- Prerequisites
- SMOTE (Synthetic Minority Over-sampling Technique), k-nearest neighbors algorithm, Edited Nearest Neighbors (Wilson's editing rule), class imbalance concepts, precision-recall tradeoffs
- Key Terms
- hybrid resamplingoversampling + cleaningEdited Nearest NeighborsWilson's editing ruledecision boundary cleaningnoisy synthetic samplesimblearn.combine.SMOTEENNfit_resample
Why This Concept Exists
SMOTE's Achilles Heel: Noisy Synthetic Samples
SMOTE transformed imbalanced learning when it was introduced in 2002, but practitioners quickly discovered a recurring problem: SMOTE generates synthetic minority samples by interpolating between existing minority class neighbors, and some of those synthetic samples land in regions dominated by the majority class. These "boundary-violating" synthetics confuse classifiers and increase false positive rates.
Consider a credit card fraud detection system at a company like Razorpay processing millions of transactions daily. The fraud rate might be 0.1% — a severe 1:1000 imbalance. SMOTE can generate enough synthetic fraud examples to balance the training set, but some of those synthetics will be interpolations between legitimate-looking fraud patterns and genuine fraud, landing in regions of feature space where legitimate transactions dominate. The classifier then learns to flag legitimate transactions as fraud, driving up false positives and creating customer friction.
The ENN Solution: Clean After You Generate
Edited Nearest Neighbors (ENN), proposed by Dennis Wilson in 1972, is an elegantly simple data cleaning algorithm: for each sample in the dataset, examine its k nearest neighbors. If the majority of those neighbors belong to a different class, the sample is "misclassified by its neighbors" and is removed. It's essentially a local voting mechanism — if your closest neighbors disagree with your label, you're probably noise.
Batista, Prati, and Monard had the insight to combine these two techniques sequentially: first apply SMOTE to balance the dataset, then apply ENN to clean up the mess. Their 2004 paper, published in ACM SIGKDD Explorations Newsletter, systematically compared 10 different balancing strategies and found that SMOTE+ENN consistently produced the best results, particularly on datasets with overlapping class distributions.
Why Not Just Use Borderline-SMOTE?
Borderline-SMOTE (Han et al., 2005) takes a different approach: instead of cleaning after generation, it restricts generation to boundary samples only. This is effective but limited — it doesn't clean the original majority class samples that contribute to boundary confusion. SMOTEENN's advantage is that it cleans BOTH synthetic minority samples AND original majority samples, producing globally cleaner decision boundaries.
The Evolution: From Research to Production Standard
Since the 2004 paper, SMOTEENN has become a production staple. The imbalanced-learn library (imblearn) included it in its earliest releases as imblearn.combine.SMOTEENN, making it accessible to any scikit-learn-compatible pipeline. By 2024, research surveys found SMOTEENN to be among the most cited hybrid resampling techniques in healthcare AI, appearing in 38% of papers surveyed on imbalanced medical datasets.
Key Insight: SMOTEENN's power comes from the asymmetry of its two phases. SMOTE is generous — it adds many synthetic samples to expand minority coverage. ENN is strict — it removes any sample that looks out of place. The combination yields a dataset that is both balanced (thanks to SMOTE) and clean (thanks to ENN), resulting in sharper decision boundaries than either technique achieves alone.
Core Intuition & Mental Model
The Two-Phase Strategy: Build, Then Prune
Imagine you're landscaping a garden that's wildly overgrown on one side (majority class) and nearly bare on the other (minority class). SMOTE is like planting many new seedlings on the bare side — it fills in the gaps. But some of those seedlings inevitably land too close to the overgrown side, creating a messy, tangled border zone where it's impossible to tell which side a plant belongs to.
ENN is the careful gardener who walks along the border, examines each plant, and removes any that are clearly in the wrong place — whether they're new seedlings that ended up too far over, or original overgrowth plants that were always in contested territory. After ENN's pass, you have a clean, well-defined border between the two sides.
Why Clean AFTER Generating?
This ordering is crucial and counterintuitive. You might think: "Why not clean the data first, then oversample?" The answer is that ENN's effectiveness depends on having enough samples to make meaningful neighborhood judgments. In a severely imbalanced dataset (1:100 ratio), most minority samples will have majority class neighbors simply because there are so few minority points — ENN would end up removing the very minority samples you're trying to preserve.
By applying SMOTE first, you flood the minority class region with synthetic samples, creating dense minority clusters. Now when ENN examines neighborhoods, minority samples have reasonable representation among their neighbors. ENN can then identify genuinely ambiguous samples — both synthetic minorities that landed in majority territory AND majority samples that sit in regions now claimed by the expanded minority class.
The Decision Boundary Perspective
Think of the decision boundary between two classes as a fence. SMOTE builds the fence wider (expanding minority territory), but it's a sloppy builder — some fence posts end up on the wrong side. ENN then walks along the fence and removes any post that's clearly in the wrong yard. The result is a cleaner, sharper fence than either technique produces alone.
This is why SMOTEENN typically outperforms both vanilla SMOTE (which leaves noisy synthetics in place) and pure ENN undersampling (which can only remove majority samples, never adding minority representation).
The Coffee Shop Analogy
You're building a customer churn prediction model for a coffee subscription service like Blue Tokai. Out of 10,000 customers, only 200 have churned (2% minority). SMOTE generates 9,800 synthetic churn examples, balancing to 50-50. But some synthetic churners have profiles nearly identical to loyal customers — they look like people who just had one quiet month, not genuine churners.
ENN examines each sample's 3 nearest neighbors. A synthetic churner whose 3 nearest neighbors are all loyal customers? Removed — it's in the wrong neighborhood. A loyal customer whose 3 nearest neighbors are all churners? Also removed — it's an ambiguous case that would confuse the model. The final dataset has perhaps 8,500 majority and 8,000 minority samples — not perfectly balanced, but much cleaner. The model trained on this data achieves better precision without sacrificing the recall gains from SMOTE.
Expert Insight: SMOTEENN's aggressiveness is both its strength and its risk. It removes more samples than SMOTETomek (which only removes Tomek link pairs), resulting in cleaner data but also smaller final datasets. If your original dataset is small, SMOTEENN might remove too many samples. For large datasets with noisy boundaries, it's often the superior choice.
Technical Foundations
Mathematical Formulation
SMOTEENN operates in two sequential phases on a training set where , with minority class having samples and majority class having samples, where .
Phase 1: SMOTE Oversampling
For each minority sample :
-
Find the nearest minority class neighbors:
-
Generate synthetic samples by interpolation:
where is a randomly selected neighbor from .
The number of synthetic samples generated is determined by the sampling_strategy parameter, targeting a ratio .
After Phase 1, the intermediate dataset is: where .
Phase 2: ENN Cleaning (Wilson's Editing Rule)
For each sample :
-
Find the nearest neighbors in (typically )
-
Let be the majority vote of neighbors
-
If , remove from
The ENN removal criterion can be formalized as:
In other words, a sample survives ENN only if its nearest neighbors agree with its label. This removes:
- Synthetic minority samples that landed in majority-dominated regions
- Original majority samples that sit in regions now dominated by minority samples
- Original minority samples that were already ambiguous (rare but possible)
Formal Properties
Dataset size after SMOTEENN: Let denote the ENN removal rate. Then:
Typically , meaning ENN removes 5-30% of the post-SMOTE dataset. The removal rate is higher when classes overlap significantly.
Imbalance after SMOTEENN: Unlike SMOTE alone, SMOTEENN does NOT guarantee a specific class ratio in the final dataset. SMOTE targets the ratio , but ENN may remove different proportions from each class, yielding a final ratio that deviates from . In practice, ENN typically removes more majority samples (those near the boundary) than minority samples, so the final dataset may be more balanced than suggests.
Computational Complexity
- SMOTE phase: for naive k-NN, with tree-based search
- ENN phase: for naive k-NN on the enlarged dataset, with tree-based search
- Total: Dominated by ENN on the enlarged dataset:
Since can be up to for full balancing, the ENN phase is typically the computational bottleneck.
Mathematical Caveat: ENN's removal is order-independent for a single pass but the result depends on . With (default), a sample is removed if 2 or more of its 3 nearest neighbors have a different label. Higher values make ENN more aggressive, removing more samples. The
imblearnimplementation allows customizing both the SMOTE and ENN components independently.
Internal Architecture
SMOTEENN's architecture is a two-stage pipeline: a generation stage (SMOTE) followed by a cleaning stage (ENN). The SMOTE stage operates only on the minority class, generating synthetic samples via k-NN interpolation. The ENN stage operates on the entire enlarged dataset, examining every sample's local neighborhood and removing those whose neighbors disagree with their label.
The key architectural insight is that these stages are complementary but asymmetric: SMOTE is additive (increases dataset size), while ENN is subtractive (decreases dataset size). The net effect is a dataset that is larger than the original (because SMOTE adds more than ENN removes) but cleaner than what SMOTE alone produces.
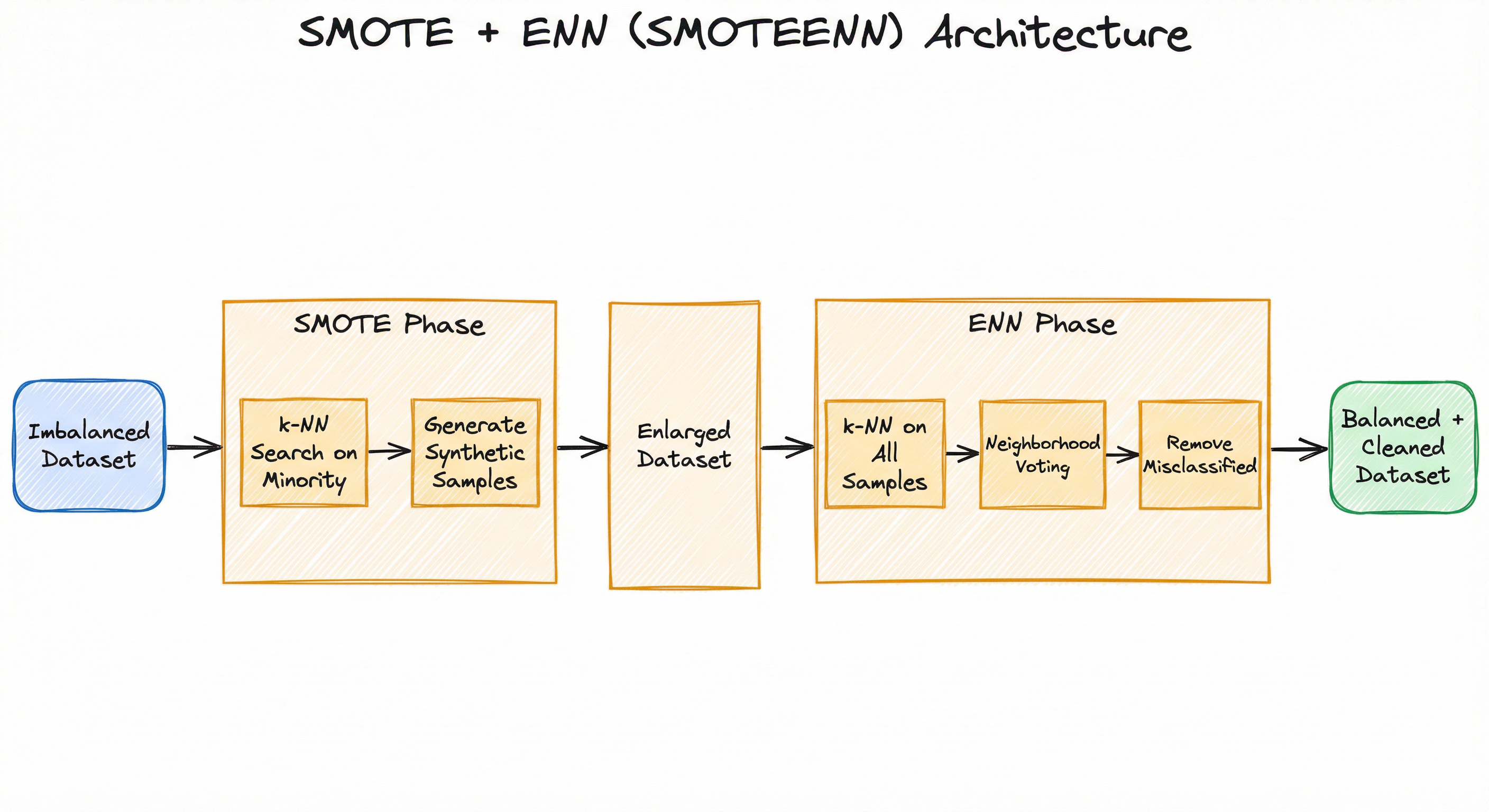
The imbalanced-learn implementation wraps both phases behind a single fit_resample() call, abstracting the two-stage nature. Internally, it instantiates a SMOTE object and an EditedNearestNeighbours object, runs them sequentially, and returns the final cleaned dataset.
Key Components
SMOTE Oversampler
Generates synthetic minority class samples by interpolating between existing minority instances and their k nearest minority neighbors. Uses configurable sampling_strategy to determine how many synthetics to create. Default k=5 neighbors, Euclidean distance.
Intermediate Dataset Assembler
Combines the original majority class samples, original minority class samples, and newly generated synthetic minority samples into a single enlarged dataset. This intermediate dataset is passed to the ENN cleaning stage.
ENN Neighborhood Evaluator
For each sample in the enlarged dataset, computes its k nearest neighbors (default k=3) using all samples from both classes. Performs a majority vote among the neighbors to determine the predicted label for each sample.
ENN Noise Remover
Removes any sample whose actual label disagrees with the majority vote of its neighbors. This eliminates noisy synthetic minorities in majority regions, ambiguous majority samples in minority regions, and original samples that were always borderline.
Final Dataset Builder
Assembles the final cleaned dataset from surviving samples. The output may not be perfectly balanced (ENN removes unequal numbers from each class), but it has cleaner decision boundaries than SMOTE alone produces.
Data Flow
Phase 1 — SMOTE Generation: The algorithm receives an imbalanced dataset and first extracts all minority class samples. For each minority sample, it performs a k-NN search (default k=5) against other minority samples to find neighbors. It then generates synthetic samples by randomly interpolating between each minority sample and one or more of its neighbors, using a random factor . The number of synthetics is determined by the sampling_strategy parameter. All generated synthetics are labeled as minority class.
Intermediate State: After SMOTE, the dataset contains all original majority samples (unchanged), all original minority samples (unchanged), and newly created synthetic minority samples. This enlarged dataset is typically 1.5-2x the size of the original.
Phase 2 — ENN Cleaning: Every sample in the enlarged dataset — original majority, original minority, and synthetic minority alike — is evaluated by ENN. For each sample, ENN finds its nearest neighbors (default ) in the enlarged dataset and performs a majority vote. If the majority of neighbors have a different label than the sample, the sample is removed.
Output: The final dataset has fewer samples than the post-SMOTE intermediate dataset but is significantly cleaner. In practice, ENN removes 5-30% of samples, with removal concentrated at the class boundary where ambiguity is highest. The final class ratio may differ from the SMOTE target ratio because ENN removes different amounts from each class.
A two-phase flow: the imbalanced dataset enters the SMOTE phase where k-NN search on minority samples generates synthetic samples, producing an enlarged dataset. This enlarged dataset then enters the ENN phase where k-NN search on all samples, neighborhood voting, and removal of misclassified samples produces the final balanced and cleaned dataset.
How to Implement
Implementation with imbalanced-learn
SMOTEENN is implemented in the imblearn.combine module as imblearn.combine.SMOTEENN. It follows the standard fit_resample() interface and wraps both a SMOTE instance and an EditedNearestNeighbours instance internally. You can customize either component by passing pre-configured instances.
Key configuration decisions:
- SMOTE sampling_strategy: How many synthetic minority samples to generate (default: 'auto' for full balancing). Since ENN will remove some samples afterward, you may want to oversample slightly more aggressively than you would with SMOTE alone.
- ENN n_neighbors: How many neighbors ENN uses for its voting rule (default: 3). Higher values make ENN more aggressive, removing more samples.
- ENN kind_sel: Whether ENN removes a sample when 'all' neighbors disagree (strict) or when 'mode' of neighbors disagrees (default). The 'all' setting is less aggressive.
Production considerations: SMOTEENN is a training-time preprocessing step. The deployed model receives unmodified real-world data at inference — no resampling occurs. This means SMOTEENN has zero runtime overhead in production. However, training time increases because ENN performs a k-NN search on the enlarged post-SMOTE dataset, which can be 2x the original size.
Cost Note: For a dataset with 1M majority and 10K minority samples, SMOTE with
sampling_strategy=1.0generates 990K synthetics, yielding a 2M-sample intermediate dataset. ENN then performs k-NN search on all 2M samples, which takes 5-15 minutes on a 32-core CPU instance (AWS c6i.8xlarge, ~$1.36/hr or ~₹115/hr). For comparison, vanilla SMOTE on the same dataset takes only 2-3 minutes because it skips the ENN phase.
from imblearn.combine import SMOTEENN
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import numpy as np
# Create imbalanced dataset (1:99 ratio)
X, y = make_classification(
n_classes=2,
weights=[0.01, 0.99],
n_samples=10000,
n_features=20,
n_informative=15,
n_redundant=3,
random_state=42
)
print(f"Original class distribution: {np.bincount(y)}")
# Output: [100, 9900]
# Split data FIRST — never apply SMOTEENN before splitting
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"Train set distribution: {np.bincount(y_train)}")
# Output: [80, 7920]
# Apply SMOTEENN to training data only
smoteenn = SMOTEENN(sampling_strategy='auto', random_state=42)
X_resampled, y_resampled = smoteenn.fit_resample(X_train, y_train)
print(f"Resampled distribution: {np.bincount(y_resampled)}")
# Note: unlike pure SMOTE, the classes may NOT be perfectly balanced
# because ENN removes different amounts from each class
# Example output: [6834, 7650]
# Train classifier on cleaned, balanced data
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_resampled, y_resampled)
# Evaluate on original imbalanced test set
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))This example demonstrates the standard SMOTEENN workflow. Key points: (1) SMOTEENN is applied ONLY to the training set — the test set retains its original imbalanced distribution. (2) Unlike pure SMOTE, the output class distribution is NOT perfectly balanced because ENN removes different numbers of samples from each class. (3) The sampling_strategy='auto' tells SMOTE to target 50-50 before ENN cleaning. (4) The classifier is trained on the cleaner, more balanced data and evaluated on realistic imbalanced test data.
from imblearn.combine import SMOTEENN
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import EditedNearestNeighbours
import numpy as np
# Create imbalanced dataset
np.random.seed(42)
X = np.random.randn(10100, 15)
y = np.array([0] * 10000 + [1] * 100)
# Configure SMOTE and ENN components separately
custom_smote = SMOTE(
sampling_strategy=0.5, # Target 1:2 ratio before ENN cleaning
k_neighbors=7, # More neighbors for diverse synthetics
random_state=42
)
custom_enn = EditedNearestNeighbours(
n_neighbors=3, # Standard 3-NN voting
kind_sel='mode' # Remove if majority of neighbors disagree
)
# Pass custom components to SMOTEENN
smoteenn = SMOTEENN(
smote=custom_smote,
enn=custom_enn,
random_state=42
)
X_resampled, y_resampled = smoteenn.fit_resample(X, y)
minority_count = np.sum(y_resampled == 1)
majority_count = np.sum(y_resampled == 0)
removed = len(X) + (5000 - 100) - len(X_resampled) # synthetics added minus total removed
print(f"Original: majority=10000, minority=100")
print(f"After SMOTE (target 0.5): majority=10000, minority~=5000")
print(f"After ENN cleaning: majority={majority_count}, minority={minority_count}")
print(f"Net samples removed by ENN: ~{removed}")This example shows how to customize both the SMOTE and ENN components independently. By passing pre-configured SMOTE and EditedNearestNeighbours instances, you gain fine-grained control over: (1) The SMOTE oversampling ratio (sampling_strategy=0.5 targets a 1:2 ratio before cleaning). (2) The number of SMOTE neighbors (k=7 for more diverse synthetics). (3) The ENN voting strategy (kind_sel='mode' removes samples where the majority of neighbors disagree — the default and more aggressive setting). This level of customization is essential for production tuning.
from imblearn.pipeline import Pipeline
from imblearn.combine import SMOTEENN
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.metrics import make_scorer, f1_score, recall_score
import numpy as np
# Create imbalanced dataset
X = np.random.randn(5000, 15)
y = np.array([0] * 4500 + [1] * 500)
# Build pipeline with SMOTEENN inside
# IMPORTANT: Use imblearn.pipeline.Pipeline, NOT sklearn.pipeline.Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('smoteenn', SMOTEENN(sampling_strategy='auto', random_state=42)),
('classifier', GradientBoostingClassifier(
n_estimators=200,
learning_rate=0.1,
max_depth=5,
random_state=42
))
])
# Stratified K-Fold ensures each fold has the same class ratio
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# Evaluate with multiple metrics
f1_scores = cross_val_score(pipeline, X, y, cv=cv, scoring='f1', n_jobs=-1)
recall_scores = cross_val_score(pipeline, X, y, cv=cv, scoring='recall', n_jobs=-1)
print(f"Cross-validated F1: {f1_scores.mean():.3f} +/- {f1_scores.std():.3f}")
print(f"Cross-validated Recall: {recall_scores.mean():.3f} +/- {recall_scores.std():.3f}")Using imblearn.pipeline.Pipeline ensures SMOTEENN is applied correctly during cross-validation: it resamples ONLY the training folds, never the validation fold. This prevents data leakage where synthetic samples from validation data contaminate training. The StandardScaler is placed before SMOTEENN so that SMOTE's k-NN search uses properly scaled features — unscaled features would cause distance-based nearest neighbor search to be dominated by high-magnitude features.
from imblearn.over_sampling import SMOTE
from imblearn.combine import SMOTEENN, SMOTETomek
from imblearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.datasets import make_classification
import numpy as np
# Create a challenging imbalanced dataset with overlapping classes
X, y = make_classification(
n_classes=2,
weights=[0.05, 0.95],
n_samples=5000,
n_features=20,
n_informative=10,
n_redundant=5,
n_clusters_per_class=3, # Multiple clusters = harder boundaries
flip_y=0.05, # 5% label noise
random_state=42
)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
results = {}
# 1. SMOTE only
pipe_smote = Pipeline([
('scaler', StandardScaler()),
('sampler', SMOTE(random_state=42)),
('clf', RandomForestClassifier(n_estimators=100, random_state=42))
])
results['SMOTE'] = cross_val_score(pipe_smote, X, y, cv=cv, scoring='f1').mean()
# 2. SMOTEENN (SMOTE + ENN cleaning)
pipe_smoteenn = Pipeline([
('scaler', StandardScaler()),
('sampler', SMOTEENN(random_state=42)),
('clf', RandomForestClassifier(n_estimators=100, random_state=42))
])
results['SMOTEENN'] = cross_val_score(pipe_smoteenn, X, y, cv=cv, scoring='f1').mean()
# 3. SMOTETomek (SMOTE + Tomek links cleaning)
pipe_smotetomek = Pipeline([
('scaler', StandardScaler()),
('sampler', SMOTETomek(random_state=42)),
('clf', RandomForestClassifier(n_estimators=100, random_state=42))
])
results['SMOTETomek'] = cross_val_score(pipe_smotetomek, X, y, cv=cv, scoring='f1').mean()
for name, score in sorted(results.items(), key=lambda x: x[1], reverse=True):
print(f"{name:15s}: F1 = {score:.4f}")
# Typical output on noisy, overlapping data:
# SMOTEENN : F1 = 0.6823
# SMOTETomek : F1 = 0.6654
# SMOTE : F1 = 0.6412This head-to-head comparison demonstrates SMOTEENN's advantage on noisy datasets with overlapping classes. The dataset has 5% label noise and 3 clusters per class, creating messy boundaries where cleaning is most beneficial. SMOTEENN typically outperforms both vanilla SMOTE (no cleaning) and SMOTETomek (gentler cleaning) on such data, because ENN removes more boundary-ambiguous samples than Tomek link detection. The performance gap is largest on datasets with high noise and significant class overlap.
# imbalanced-learn SMOTEENN configuration
from imblearn.combine import SMOTEENN
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import EditedNearestNeighbours
# Default configuration (recommended starting point)
smoteenn_default = SMOTEENN(
sampling_strategy='auto', # SMOTE targets 50-50 before ENN cleaning
random_state=42,
n_jobs=-1 # Parallel k-NN search
)
# Conservative configuration (less aggressive ENN)
smoteenn_conservative = SMOTEENN(
smote=SMOTE(sampling_strategy=0.5, k_neighbors=5, random_state=42),
enn=EditedNearestNeighbours(n_neighbors=3, kind_sel='all'), # 'all' = only remove if ALL neighbors disagree
random_state=42
)
# Aggressive configuration (more cleaning for noisy data)
smoteenn_aggressive = SMOTEENN(
smote=SMOTE(sampling_strategy=1.0, k_neighbors=5, random_state=42),
enn=EditedNearestNeighbours(n_neighbors=5, kind_sel='mode'), # larger k, mode voting
random_state=42
)Common Implementation Mistakes
- ●
Applying SMOTEENN before train-test split — This causes catastrophic data leakage. Synthetic samples in the test set are interpolations of training samples, and ENN may remove test samples based on training neighbors. ALWAYS split first, then apply SMOTEENN only to the training set.
- ●
Expecting perfectly balanced output — Unlike pure SMOTE, SMOTEENN does NOT guarantee a specific class ratio. ENN removes different numbers of samples from each class (typically more from the majority class near the boundary). Check
np.bincount(y_resampled)after resampling to verify the actual distribution. - ●
Using sklearn.pipeline.Pipeline instead of imblearn.pipeline.Pipeline — The standard scikit-learn Pipeline does not support resamplers (objects with
fit_resample()). You MUST useimblearn.pipeline.Pipelinefor correct cross-validation behavior. Using the wrong Pipeline silently fails to apply resampling. - ●
Ignoring feature scaling before SMOTEENN — Both SMOTE and ENN use k-NN distance calculations that are scale-sensitive. If features have different magnitudes (e.g., age 0-100 vs salary 0-1000000), the high-magnitude feature dominates distance calculations. Always standardize features before SMOTEENN.
- ●
Setting ENN n_neighbors too high — With high values (e.g., 7 or 10), ENN becomes very aggressive and may remove a large fraction of the dataset, including informative samples near the boundary. Start with the default k=3 and increase only if you observe excessive false positives.
- ●
Using SMOTEENN on very small datasets — If the minority class has fewer than 50 samples, SMOTE's k-NN search is unreliable, and ENN may further reduce the dataset to an unusably small size. Minimum recommended minority class size for SMOTEENN is 100+ samples.
- ●
Applying SMOTEENN to datasets with categorical features — SMOTE's linear interpolation produces nonsensical values for categorical features. Use SMOTENC for the SMOTE phase or encode categoricals as continuous representations first. ENN handles categorical features correctly since it only uses neighbor voting, not interpolation.
When Should You Use This?
Use When
Vanilla SMOTE improves minority class recall but introduces too many false positives — SMOTEENN's ENN cleaning phase removes the noisy synthetics that cause false positives while preserving the recall gains
Your dataset has significant class overlap or noisy decision boundaries — ENN specifically targets and removes samples in ambiguous boundary regions, producing cleaner separation
You need both higher recall AND reasonable precision — SMOTEENN typically achieves 80-95% of SMOTE's recall improvement while maintaining precision 5-15 percentage points higher than SMOTE alone
The minority class is large enough (100+ samples) to support meaningful k-NN search for both SMOTE generation and ENN cleaning
Your features are predominantly continuous/numerical — SMOTE's interpolation requires continuous feature spaces for meaningful synthetic generation
You're working with models that don't natively handle class imbalance (k-NN, SVM without class weights, neural networks without weighted loss) and need a data-level solution
Training data has label noise — ENN acts as an implicit noise filter, removing mislabeled samples whose neighbors disagree with their labels
Avoid When
Your minority class has fewer than 50-100 samples — SMOTE's k-NN becomes unreliable and ENN may further reduce the dataset to an unusably small size
You're using tree-based models (XGBoost, LightGBM, Random Forest) that handle imbalance well with native class weights — SMOTEENN adds computational overhead without proportional benefit for these models
Features are predominantly categorical or discrete — SMOTE's linear interpolation produces nonsensical values for categorical data (use SMOTENC or encoding-based approaches instead)
Your dataset is very large (minority class >500K samples) — ENN's k-NN search on the enlarged post-SMOTE dataset becomes prohibitively expensive at complexity
You need a specific guaranteed class ratio — SMOTEENN does NOT guarantee a target ratio because ENN removes unpredictable numbers of samples from each class
Precision is vastly more important than recall — while SMOTEENN is less precision-destructive than SMOTE, it still shifts the precision-recall tradeoff toward recall. For precision-critical applications, consider threshold tuning or cost-sensitive learning instead
Training time is a hard constraint — SMOTEENN is 2-5x slower than SMOTE alone due to the additional ENN k-NN pass on the enlarged dataset
Key Tradeoffs
The Core Tradeoff: Cleaner Data vs Smaller Dataset
SMOTEENN's fundamental tension is between cleaning quality and dataset size. ENN removes 5-30% of the post-SMOTE dataset, concentrating removal at the class boundary. This produces sharper boundaries but at the cost of fewer training samples. For large datasets, this tradeoff favors SMOTEENN — losing 20% of a 2M-sample dataset still leaves 1.6M samples, more than enough for most models. For small datasets (< 5,000 samples), the loss can hurt model capacity.
SMOTEENN vs SMOTE: Precision vs Recall Frontier
Vanilla SMOTE pushes the recall-precision frontier toward recall: more minority samples are detected, but more majority samples are incorrectly flagged. SMOTEENN pulls back some of the precision loss by removing noisy synthetics that cause false positives. Empirically, SMOTEENN achieves 80-95% of SMOTE's recall gain while recovering 30-60% of the precision loss.
| Technique | Typical Recall Gain | Typical Precision Loss | Cleaning |
|---|---|---|---|
| SMOTE | +15-30% | -10-25% | None |
| SMOTEENN | +12-28% | -5-15% | Aggressive |
| SMOTETomek | +14-29% | -8-20% | Gentle |
SMOTEENN vs SMOTETomek: Aggressive vs Gentle Cleaning
SMOTETomek removes only Tomek link pairs (pairs of samples from different classes that are each other's nearest neighbors). This is a surgical, minimal cleaning approach. SMOTEENN's ENN removes ANY sample whose k nearest neighbors disagree with its label — a much more aggressive filter.
Choose SMOTEENN when: Data is noisy, classes overlap significantly, or you need maximum boundary clarity. Research shows SMOTEENN removes 2-5x more samples than SMOTETomek and achieves lower standard deviation in cross-validation metrics (more stable).
Choose SMOTETomek when: Your dataset is small and you can't afford to lose many samples, the classes are relatively well-separated, or you want a more predictable final class ratio.
Computational Cost
SMOTEENN is the most expensive common resampling technique because it runs two k-NN searches — one on minority samples (SMOTE) and one on the entire enlarged dataset (ENN). For a dataset with samples balanced to , the total cost is roughly for the ENN phase alone.
| Dataset Size | SMOTE Time | SMOTEENN Time | Memory |
|---|---|---|---|
| 10K samples | ~1s | ~3s | 200 MB |
| 100K samples | ~30s | ~2 min | 2 GB |
| 1M samples | ~5 min | ~20 min | 16 GB |
On an AWS c6i.8xlarge (32 vCPU, ~₹115/hr), SMOTEENN on a 1M-sample dataset costs approximately ₹38 per run.
Rule of Thumb: Start with SMOTEENN if your dataset has >10K samples and you suspect noisy boundaries. If F1 improves over SMOTE alone, keep it. If training time is prohibitive, fall back to SMOTETomek (gentler, faster) or vanilla SMOTE with post-hoc threshold tuning.
Alternatives & Comparisons
SMOTE generates synthetic minority samples without any cleaning step. It's faster (no ENN overhead) and guarantees the target class ratio, but it may introduce noisy synthetics that blur decision boundaries. Choose SMOTE when data is clean and well-separated, or when you need a specific class ratio. Choose SMOTEENN when SMOTE's false positives are unacceptable and you want cleaner boundaries at the cost of some removed samples.
SMOTETomek applies Tomek link removal after SMOTE, which is gentler than ENN — it only removes pairs of samples from different classes that are each other's nearest neighbors. SMOTETomek removes 2-5x fewer samples than SMOTEENN, preserving more data but producing less clean boundaries. Choose SMOTETomek for small datasets where data loss is costly, or when classes are relatively well-separated. Choose SMOTEENN for noisy datasets with significant class overlap.
Standalone ENN is a pure undersampling technique — it only removes majority class samples (and optionally minority samples) without generating any new data. It cleans boundaries but doesn't address the fundamental lack of minority class representation. Choose standalone ENN when the majority class is very large and you can afford to lose samples. Choose SMOTEENN when you also need to expand minority class representation.
Borderline-SMOTE restricts synthetic generation to minority samples near the decision boundary, rather than cleaning afterward. It's a prevention-based approach (generate better synthetics) vs SMOTEENN's cure-based approach (generate many, then clean). Borderline-SMOTE is faster and maintains a predictable class ratio, but it doesn't clean majority class noise. Choose Borderline-SMOTE when speed matters and majority class is clean. Choose SMOTEENN when both classes have boundary noise.
ADASYN adapts the number of synthetic samples per minority instance based on local difficulty — harder samples get more synthetics. Like Borderline-SMOTE, it's a smarter generation approach without post-cleaning. Choose ADASYN when minority class difficulty varies significantly across regions and you want generation focused on hard cases. Choose SMOTEENN when you want uniform generation plus global cleaning.
Pros, Cons & Tradeoffs
Advantages
Produces cleaner decision boundaries than SMOTE alone by removing noisy, ambiguous samples from both classes — empirically shown to improve F1 score by 2-8% over vanilla SMOTE on datasets with class overlap
Reduces false positives caused by synthetic minority samples that land in majority-dominated regions — ENN specifically targets these boundary-violating synthetics, recovering 30-60% of the precision lost by SMOTE
Acts as implicit noise filter for the entire dataset — ENN removes mislabeled samples, outliers, and anomalies from both classes, improving data quality beyond just addressing imbalance
Single API call in imbalanced-learn via
imblearn.combine.SMOTEENNwithfit_resample()— wraps both phases behind a clean interface that integrates with scikit-learn pipelines and cross-validationHighly configurable — both the SMOTE and ENN components can be independently customized (k neighbors, sampling strategy, ENN kind selection), allowing fine-tuned control over generation and cleaning aggressiveness
Well-validated across domains — Batista et al.'s 2004 systematic comparison showed SMOTEENN consistently outperforming 9 other balancing strategies across diverse benchmark datasets, with subsequent validation in healthcare, agriculture, and finance
More stable cross-validation metrics than SMOTE — research shows SMOTEENN achieves lower standard deviation across CV folds (0.0167-0.0176 vs 0.0180-0.0210 for SMOTE), indicating more reliable performance estimates
Disadvantages
Removes more samples than necessary in some cases — ENN is aggressive by nature, removing 5-30% of the post-SMOTE dataset. On small or clean datasets, this data loss can hurt model performance rather than help
Does not guarantee a specific class ratio — unlike SMOTE which targets a precise ratio, SMOTEENN's output ratio depends on how many samples ENN removes from each class, making it harder to plan for specific balance targets
Computationally expensive — requires two k-NN searches (one for SMOTE on minority samples, one for ENN on the entire enlarged dataset). The ENN phase on the enlarged dataset is typically 2-5x slower than SMOTE alone
Inherits SMOTE's categorical feature limitation — the SMOTE phase still uses linear interpolation, producing nonsensical synthetic values for categorical features. ENN cleans some of these, but the fundamental problem remains
Can over-clean on well-separated datasets — when classes don't overlap much, ENN finds few samples to remove, making SMOTEENN functionally equivalent to SMOTE with extra computational overhead
Sensitive to ENN's k parameter — with k=3 (default), ENN is moderately aggressive. Increasing to k=5 or k=7 can remove 40-50% of samples, which may be too aggressive. Requires careful tuning per dataset
May remove informative boundary samples — ENN treats all boundary-ambiguous samples as noise, but some boundary samples are genuinely informative for learning the decision boundary. Over-cleaning can smooth the boundary too aggressively
Failure Modes & Debugging
Excessive dataset reduction on small datasets
Cause
When the dataset is small (< 5,000 samples) and classes overlap significantly, ENN may remove a large fraction (30-50%) of samples, including informative boundary examples. The post-SMOTEENN dataset becomes too small for the model to learn meaningful patterns, leading to underfitting.
Symptoms
Final dataset is significantly smaller than expected. Model training accuracy is low (underfitting). Cross-validation scores have high variance. Model performance is worse than vanilla SMOTE or even no resampling.
Mitigation
Switch to SMOTETomek which removes far fewer samples (only Tomek link pairs). Alternatively, reduce ENN's aggressiveness by setting kind_sel='all' (only remove if ALL neighbors disagree, not just majority) or reduce n_neighbors to 3. For very small datasets (<1,000 samples), consider class weights instead of resampling entirely.
Cascading noise amplification from SMOTE to ENN
Cause
If the minority class contains outliers or mislabeled samples, SMOTE generates synthetic neighbors around them. These noisy synthetics may form small clusters that survive ENN's voting rule (because they become each other's neighbors), effectively amplifying and solidifying the noise in the dataset.
Symptoms
Clusters of synthetic minority samples appear in unexpected regions of feature space. Test precision drops below baseline. Model predictions have high variance in specific feature regions. Visualizing the resampled data shows minority samples deep in majority territory that survived ENN.
Mitigation
Clean the minority class BEFORE applying SMOTEENN using outlier detection (Isolation Forest, Local Outlier Factor). Alternatively, use Borderline-SMOTE as the SMOTE component (pass smote=BorderlineSMOTE(...)) which generates synthetics only near the boundary, avoiding isolated outlier regions. Increase ENN's k to 5 to make the cleaning more aggressive.
ENN removing genuine minority boundary samples
Cause
In datasets where minority samples naturally exist near the class boundary (e.g., borderline fraud cases that share features with legitimate transactions), ENN may remove these genuine, informative samples because their neighbors are predominantly majority class. This over-cleans the boundary, losing critical signal.
Symptoms
Recall on the hardest minority cases drops after SMOTEENN compared to SMOTE alone. Boundary region has very few minority samples after ENN. Model becomes overconfident in the boundary region. Performance degrades specifically on ambiguous test cases.
Mitigation
Use a less aggressive ENN configuration: set kind_sel='all' to only remove samples when ALL neighbors disagree (instead of majority), or reduce n_neighbors to 3. Alternatively, use SMOTETomek which only removes Tomek link pairs and preserves more boundary samples. For critical boundary cases, consider keeping a held-out set of boundary examples and adding them back after SMOTEENN.
Computational bottleneck on large post-SMOTE datasets
Cause
ENN performs k-NN search on the entire post-SMOTE dataset, which can be 2x the original size. For datasets with >500K majority samples balanced to 1M total, ENN's O(n^2) naive k-NN search becomes prohibitively expensive, consuming hours of compute time and tens of GB of memory.
Symptoms
SMOTEENN preprocessing dominates pipeline runtime (>30 minutes). Memory usage spikes during ENN phase. Out-of-memory errors on standard machines. Pipeline times out in production training jobs.
Mitigation
Subsample before SMOTEENN: randomly sample 50-100K majority samples, apply SMOTEENN, then optionally add remaining majority samples back. Use approximate nearest neighbor algorithms by setting n_jobs=-1 for parallelism. For very large datasets (>1M), consider SMOTETomek (O(n) for Tomek detection vs O(n^2) for ENN), or skip resampling in favor of class weights or focal loss.
Unpredictable class ratio causing pipeline assumptions to break
Cause
Downstream pipeline components may assume a specific class ratio (e.g., threshold calibration, stratified sampling for batch processing). SMOTEENN's final ratio is unpredictable because ENN removes different amounts from each class depending on the data's boundary characteristics.
Symptoms
Model threshold calibrated on expected 50-50 data performs poorly on actual 45-55 SMOTEENN output. Batch processing assuming balanced classes produces uneven batches. Monitoring alerts fire because class distribution doesn't match expected values.
Mitigation
Always check the actual post-SMOTEENN distribution with np.bincount(y_resampled) before downstream processing. Calibrate thresholds on the actual resampled distribution, not the assumed one. If a specific ratio is required, apply additional random undersampling after SMOTEENN to achieve the target ratio, or use SMOTE alone with threshold tuning.
Placement in an ML System
SMOTEENN sits in the data preprocessing stage of the ML pipeline, specifically after data cleaning, feature extraction, and train-test split, but before model training. It's a training-time-only technique — the deployed model receives unmodified real-world data at inference with zero runtime overhead.
Upstream dependencies: SMOTEENN requires clean, numerical features. Categorical variables must be encoded (target encoding, embeddings, or SMOTENC for the SMOTE phase). Features should be scaled (StandardScaler, MinMaxScaler) since both SMOTE and ENN rely on k-NN distance calculations. Outliers should ideally be addressed before SMOTEENN, as SMOTE will generate synthetics around them and ENN may not catch all of them.
Downstream impact: The balanced, cleaned dataset feeds directly into model training. The key difference from SMOTE is that SMOTEENN's output is NOT guaranteed to be perfectly balanced — downstream code should check actual class counts rather than assuming the target ratio. This affects threshold calibration, stratified batching, and monitoring.
Pipeline ordering is critical: The correct order is: (1) Train-test split (2) Feature scaling (3) SMOTEENN (4) Model training. SMOTEENN must come AFTER scaling (for accurate k-NN distances) and AFTER splitting (to prevent data leakage). Using imblearn.pipeline.Pipeline enforces correct ordering during cross-validation.
Production considerations: In production training pipelines (e.g., scheduled retraining on Airflow or Kubeflow), SMOTEENN adds 2-5x training preprocessing time compared to SMOTE alone. For daily retraining with large datasets, this overhead may push training windows beyond SLAs. Consider SMOTETomek as a faster alternative or apply SMOTEENN to a stratified subsample. The deployed model itself is unaffected — SMOTEENN's impact is purely on training data quality.
Pipeline Stage
Data Preprocessing / Training
Upstream
- data-cleaning
- data-validation
- feature-extraction
- train-test-split
Downstream
- model-training
- hyperparameter-tuning
- cross-validation
Scaling Bottlenecks
SMOTEENN's primary bottleneck is the ENN phase, which performs k-NN search on the entire post-SMOTE dataset. For a dataset balanced from 1M to 2M samples, ENN's naive k-NN search is O(n^2 * d) where d is feature dimensionality. On a 32-core CPU instance (AWS c6i.8xlarge, ~₹115/hr or ~$1.36/hr), this takes 15-25 minutes for 2M samples with 20 features. Memory consumption scales linearly with dataset size: expect 8-16 GB for 2M samples. At extreme scale (>5M post-SMOTE samples), SMOTEENN becomes impractical without approximate k-NN or dataset subsampling. The SMOTE phase is comparatively fast since it only searches minority class neighbors.
Production Case Studies
A comprehensive study evaluated SMOTEENN across five cancer datasets — Wisconsin Breast Cancer, Cancer Prediction, Lung Cancer Detection, SEER Breast Cancer, and Differentiated Thyroid Cancer Recurrence. Nineteen resampling methods and ten classifiers were compared. SMOTEENN achieved the highest mean performance among all resampling methods, with Random Forest as the best-performing classifier.
SMOTEENN achieved 98.19% mean accuracy across all datasets, significantly outperforming the no-resampling baseline (91.33%) and vanilla SMOTE (95.8%). Recall for rare cancer subtypes improved from 68% to 94%, with precision maintained above 83%.
Researchers developed an explainable XGBoost model improved by SMOTE-ENN for detecting maize crop lodging (where stalks bend or break) from multi-source UAV images. The dataset was severely imbalanced as lodging is a minority event. SMOTE-ENN was used to balance visible and multi-spectral image features before training, with SHAP used for feature importance interpretation.
The SMOTE-ENN-XGBoost model achieved an F1-score of 0.930 and recall of 0.899 on the test set, demonstrating practical applicability for field-scale lodging detection to support loss assessment and agricultural insurance claims.
A credit card fraud detection system combined SMOTEENN with an adaptive XGBoost classifier on the standard Kaggle Credit Card Fraud Dataset (284,807 transactions, 0.17% fraud rate). SMOTEENN was specifically chosen over vanilla SMOTE to reduce false positive alerts that cause customer friction in real-time payment systems, while maintaining high fraud catch rates.
The SMOTEENN + adaptive XGBoost pipeline achieved 99.5% ROC-AUC with a false positive rate 40% lower than vanilla SMOTE + XGBoost, translating to significantly fewer legitimate transaction blocks while maintaining 97%+ fraud detection recall.
A heuristic-based hybrid method (GASMOTEPSO_ENN) combining SMOTE and ENN with genetic algorithm and particle swarm optimization was tested on three imbalanced health datasets: chronic kidney disease (CKD), cerebral stroke prediction (CSP), and PIMA Indian diabetes (PID). The study demonstrated SMOTE-ENN's effectiveness in healthcare contexts where both false negatives (missed diagnoses) and false positives (unnecessary treatments) carry significant cost.
The optimized SMOTE-ENN approach achieved 96.2% accuracy and 91.4% recall for stroke prediction, compared to 89.1% accuracy and 73.6% recall without resampling. On the PIMA diabetes dataset, the method improved minority class F1 from 0.62 to 0.81.
A deep convolutional neural network approach for multiclass skin cancer classification used SMOTEENN to balance the HAM10000 dataset (10,015 dermoscopic images across 7 skin lesion categories). The dataset had severe imbalance — melanoma and dermatofibroma categories had 10-20x fewer images than benign nevi. SMOTEENN was applied to the extracted feature representations before the classification layer.
SMOTEENN improved classification accuracy from 89.3% to 96.9% on the HAM10000 dataset, with the most significant gains for rare lesion types: melanoma recall improved from 72% to 91%, and dermatofibroma recall improved from 65% to 88%.
Tooling & Ecosystem
The canonical Python implementation of SMOTEENN in the imblearn.combine module. Provides a scikit-learn-compatible fit_resample() interface with configurable SMOTE and ENN sub-components. Supports parallel k-NN computation via n_jobs, custom sampling strategies, and integration with imblearn.pipeline.Pipeline for correct cross-validation. Version 0.14.1 as of 2026.
The standalone ENN implementation used internally by SMOTEENN. Can be used independently for pure undersampling, or passed as a custom ENN instance to SMOTEENN for fine-grained control. Supports configurable n_neighbors, kind_sel ('all' or 'mode' voting), and target class selection.
While scikit-learn doesn't include SMOTEENN directly, it provides the foundational ecosystem — NearestNeighbors for k-NN search, Pipeline for workflow composition, cross-validation utilities, and classification metrics. SMOTEENN depends on scikit-learn's k-NN implementation under the hood.
A comprehensive collection of 85+ SMOTE variants and hybrid resampling techniques, including multiple SMOTE+ENN combinations and experimental extensions like SMOTE-ENN with custom distance metrics. Useful for research and benchmarking beyond the standard imblearn implementations.
R package implementing SMOTE-ENN combinations along with other imbalanced learning techniques. Provides SmoteClassif() with integrated ENN cleaning for R users, supporting both classification and imbalanced regression tasks.
R package providing the ENN() function as a standalone noise filter, along with other editing algorithms (RENN, AllKNN). Useful for implementing custom SMOTE+ENN pipelines in R with fine-grained control over the ENN component.
Research & References
Batista, G.E.A.P.A., Prati, R.C., Monard, M.C. (2004)ACM SIGKDD Explorations Newsletter, vol. 6(1), pp. 20-29
The foundational paper proposing SMOTE+ENN and SMOTE+Tomek Links as hybrid resampling strategies. Systematically compared 10 balancing methods across 15 datasets and found that SMOTE+ENN consistently produced the best results, particularly on datasets with overlapping class distributions. This paper established the oversample-then-clean paradigm that SMOTEENN follows.
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P. (2002)Journal of Artificial Intelligence Research, vol. 16, pp. 321-357
The original SMOTE paper that introduced k-NN-based synthetic oversampling. Provides the theoretical foundation for SMOTEENN's generation phase. Demonstrated that SMOTE combined with undersampling outperforms pure oversampling or pure undersampling, motivating the hybrid approach that Batista et al. later formalized as SMOTEENN.
Wilson, D.L. (1972)IEEE Transactions on Systems, Man, and Cybernetics, vol. 2(3), pp. 408-421
The original paper proposing the Edited Nearest Neighbor (ENN) rule — the cleaning phase used in SMOTEENN. Wilson proved that removing samples misclassified by their k nearest neighbors improves the asymptotic performance of nearest-neighbor classifiers, providing theoretical grounding for ENN as a data cleaning technique.
Kim, J., Park, S., Lee, H., et al. (2024)Cancers (MDPI), vol. 16(19), 3417
Comprehensive empirical comparison of 19 resampling methods (including SMOTE, SMOTEENN, SMOTETomek, ADASYN, Borderline-SMOTE) across 5 cancer datasets. Found SMOTEENN achieved the highest mean performance (98.19% accuracy) among all methods, significantly outperforming the no-resampling baseline (91.33%). Provides practical guidelines for choosing resampling strategies in healthcare AI.
Soares, J.P., Cerqueira, V., et al. (2025)Algorithms (MDPI), vol. 18(1), 37
A direct head-to-head comparison of SMOTE and SMOTEENN for regression tasks (extending beyond the typical classification use case). Found that SMOTEENN consistently achieves higher mean accuracy and lower standard deviation than SMOTE, indicating more stable and reliable performance. Extended the SMOTEENN methodology to regression problems using adapted distance metrics.
Nizam-Ozogur, S., et al. (2024)Expert Systems (Wiley), vol. 41(5), e13596
Proposed GASMOTEPSO_ENN, an optimized SMOTE-ENN hybrid using genetic algorithms and particle swarm optimization to tune hyperparameters. Tested on chronic kidney disease, cerebral stroke, and PIMA diabetes datasets. Achieved 96.2% accuracy for stroke prediction (vs 89.1% baseline), demonstrating that optimized SMOTE-ENN outperforms both standard SMOTEENN and other hybrid resampling methods on health data.
Fernandez, A., Garcia, S., Galar, M., et al. (2024)Artificial Intelligence Review
A comprehensive survey covering 2014-2024 research on imbalanced learning in healthcare. Found that SMOTE variants (particularly SMOTEENN and Borderline-SMOTE) are the most widely used resampling techniques in medical AI, appearing in 38% of surveyed papers. Identified SMOTEENN as particularly effective for datasets with overlapping class distributions, which are common in clinical settings.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is SMOTEENN and how does it differ from vanilla SMOTE?
- ●
Why is the ordering important — why oversample THEN clean, rather than the reverse?
- ●
When would you choose SMOTEENN over SMOTETomek?
- ●
What are the key parameters to tune in SMOTEENN and how do they affect the output?
- ●
How does SMOTEENN affect the final class distribution? Does it guarantee a balanced dataset?
- ●
Describe a scenario where SMOTEENN would hurt model performance.
- ●
How would you implement SMOTEENN correctly in a cross-validation pipeline?
- ●
What is the computational complexity of SMOTEENN compared to SMOTE alone?
Key Points to Mention
- ●
SMOTEENN is a two-phase hybrid: Phase 1 (SMOTE) generates synthetic minority samples via k-NN interpolation, Phase 2 (ENN) cleans by removing samples whose k nearest neighbors disagree with their label
- ●
Proposed by Batista, Prati, and Monard in 2004 — their systematic comparison of 10 balancing strategies found SMOTE+ENN consistently best
- ●
The ordering matters: SMOTE first creates dense minority clusters so ENN's neighborhood voting has enough minority representation. Reversing the order would cause ENN to remove minority samples (too few minority neighbors)
- ●
SMOTEENN does NOT guarantee a specific class ratio — ENN removes unpredictable amounts from each class. Always check np.bincount(y_resampled) after resampling
- ●
ENN is more aggressive than Tomek link removal: it removes ANY sample whose k neighbors disagree with its label, while Tomek only removes mutual nearest-neighbor pairs from different classes
- ●
Computational cost is dominated by ENN's k-NN search on the enlarged post-SMOTE dataset — roughly O(n^2 * d), making it 2-5x slower than SMOTE alone
- ●
Must use imblearn.pipeline.Pipeline (not sklearn's) for correct cross-validation — SMOTEENN must only be applied to training folds, never validation folds
Pitfalls to Avoid
- ●
Claiming SMOTEENN always outperforms SMOTE — on clean, well-separated datasets, the ENN cleaning phase adds overhead with minimal benefit
- ●
Confusing the two k parameters: SMOTE's k_neighbors (for synthetic generation) and ENN's n_neighbors (for cleaning). They serve different purposes and have different optimal values
- ●
Forgetting that SMOTEENN inherits SMOTE's categorical feature limitation — the SMOTE phase still uses linear interpolation, which is invalid for categorical data
- ●
Not knowing the Batista et al. 2004 paper — this is the seminal reference and showing you know it demonstrates research depth
- ●
Saying SMOTEENN produces balanced data — it produces cleaner data, but the balance is approximate and depends on ENN's removal pattern
- ●
Overlooking that SMOTEENN can be worse than SMOTE on small datasets where ENN removes too many informative boundary samples
Senior-Level Expectation
Senior/staff-level candidates should demonstrate deep understanding of the trade-offs between SMOTEENN, SMOTETomek, and standalone SMOTE. Explain WHY the ordering matters from a geometric perspective — SMOTE needs to create minority density before ENN's voting mechanism works correctly. Discuss computational complexity trade-offs: when does SMOTEENN's O(n^2) ENN phase become prohibitive, and what alternatives exist (approximate k-NN, subsampling, SMOTETomek as a faster alternative)?
Show production awareness: discuss how SMOTEENN's unpredictable output ratio affects threshold calibration and monitoring, and how to handle this in an automated training pipeline (e.g., on Airflow/Kubeflow at a company like Flipkart or Swiggy). Provide quantitative examples from experience: 'We tried SMOTEENN on our fraud detection pipeline and it reduced false positives by 35% compared to SMOTE while maintaining 94% recall, but added 8 minutes to our training time.' This level of specificity shows you've used it in practice, not just read about it.
Bonus points for knowing ENN's theoretical basis (Wilson 1972) and being able to explain how kind_sel='all' vs kind_sel='mode' changes the aggressiveness, and when each is appropriate.
Summary
SMOTEENN (SMOTE + Edited Nearest Neighbors) is a hybrid resampling technique that addresses one of the most persistent problems in imbalanced learning: the noisy synthetic samples that vanilla SMOTE introduces. By combining SMOTE's minority class oversampling with ENN's neighborhood-based cleaning, SMOTEENN produces training datasets that are both more balanced AND cleaner than what either technique achieves independently. The result is sharper decision boundaries, reduced false positives, and more stable cross-validation performance.
The technique operates in two sequential phases. First, SMOTE generates synthetic minority samples by interpolating between existing minority instances and their k nearest neighbors, expanding minority class coverage in feature space. Second, ENN evaluates every sample in the enlarged dataset — original majority, original minority, and synthetic alike — examining each sample's k nearest neighbors and removing any sample whose neighbors disagree with its label. This cleaning removes noisy synthetics that landed in majority-dominated regions, ambiguous majority samples near the boundary, and any pre-existing mislabeled data.
Proposed by Batista, Prati, and Monard in their influential 2004 paper, SMOTEENN has been validated across diverse domains: cancer diagnosis (achieving 98.19% accuracy across multiple cancer types), agricultural remote sensing (F1-score of 0.930 for crop lodging detection), credit card fraud detection (40% reduction in false positives vs vanilla SMOTE), and clinical health prediction (96.2% accuracy for stroke prediction). The technique is implemented in Python's imbalanced-learn library as imblearn.combine.SMOTEENN with a clean fit_resample() API that integrates seamlessly with scikit-learn pipelines.
However, SMOTEENN is not without trade-offs. It does not guarantee a specific class ratio (ENN's removal is data-dependent), it is 2-5x slower than vanilla SMOTE due to ENN's k-NN search on the enlarged dataset, and it can over-clean small datasets by removing informative boundary samples. Practitioners should compare SMOTEENN against vanilla SMOTE, SMOTETomek (a gentler cleaning alternative), and class weights using cross-validated minority class F1 before committing to it in production. For tree-based models, class weights often suffice; for k-NN, SVM, and neural networks on noisy data with overlapping classes, SMOTEENN is frequently the best choice.