ADASYN in Machine Learning
When you apply SMOTE to an imbalanced dataset, every minority sample gets the same number of synthetic neighbors — regardless of whether it sits safely inside a minority cluster or teeters on the edge of a majority-dominated region. That uniform treatment is precisely what ADASYN (Adaptive Synthetic Sampling) was designed to fix.
Introduced by He, Bai, Garcia, and Li at IEEE IJCNN 2008, ADASYN is a density-aware extension of SMOTE that allocates more synthetic samples to minority instances that are harder to learn — those surrounded by majority-class neighbors. The result is an adaptive oversampling strategy that concentrates synthetic data generation where it matters most: at the fuzzy, contested boundary between classes.
In practice, ADASYN has become a standard tool in the imbalanced-learning toolkit, available through the imbalanced-learn library with a one-line API identical to SMOTE. It is widely deployed in fraud detection at Indian fintech companies like Razorpay and PhonePe, medical diagnosis pipelines, network intrusion detection, and credit scoring systems. Yet ADASYN is not without trade-offs: its focus on hard-to-learn regions can amplify noise, its density computation adds overhead, and choosing when to prefer it over vanilla SMOTE or Borderline-SMOTE requires understanding the geometry of your data.
This guide covers the algorithm's mathematical foundations, architecture, implementation patterns, failure modes, and practical decision frameworks — everything you need to deploy ADASYN correctly in a production ML system.
Concept Snapshot
- What It Is
- An adaptive oversampling algorithm that generates more synthetic minority-class samples in regions where the minority class is harder to learn (surrounded by majority-class neighbors), using a density distribution to weight sample generation per instance.
- Category
- Data Generation
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: imbalanced training dataset with minority and majority classes. Outputs: resampled dataset where harder-to-learn minority regions receive proportionally more synthetic samples.
- System Placement
- Applied during data preprocessing, after data cleaning and feature scaling, before model training. Training-time only — never used at inference.
- Also Known As
- Adaptive Synthetic Sampling, ADASYN oversampling, Density-adaptive SMOTE
- Typical Users
- ML engineers, Data scientists, Research scientists, ML platform engineers, Applied scientists
- Prerequisites
- k-nearest neighbors algorithm, Class imbalance concepts, SMOTE fundamentals, Distance metrics (Euclidean, Minkowski), Precision-recall tradeoffs
- Key Terms
- density ratioadaptive oversamplingminority classmajority classk-nearest neighborshard-to-learn samplesimbalanced-learnsampling_strategy
Why This Concept Exists
The Uniform Treatment Problem in SMOTE
SMOTE was a breakthrough when Chawla et al. introduced it in 2002. Instead of duplicating minority samples (which causes overfitting), it generates synthetic examples by interpolating between a minority instance and its k-nearest minority neighbors. But SMOTE treats every minority sample identically — each one produces the same number of synthetic neighbors, regardless of its position in feature space.
Consider a fraud detection dataset at a fintech company. Some fraudulent transactions cluster tightly together in a well-separated region of feature space (easy cases). Others sit in ambiguous zones where legitimate and fraudulent transactions are interleaved (hard cases). Vanilla SMOTE generates equal synthetic samples for both regions. This means you waste synthetic capacity on safe regions where the classifier already performs well, while under-generating in the contested regions where the classifier actually struggles.
The Insight: Adapt Generation to Local Difficulty
He et al. recognized this fundamental limitation and proposed a solution in their 2008 IEEE IJCNN paper: weight the number of synthetic samples per minority instance by its local difficulty. The intuition is straightforward — if a minority sample has mostly majority-class neighbors (high local difficulty), it needs more synthetic support. If it sits safely within a minority cluster (low local difficulty), it needs less.
This adaptive allocation has two concrete effects:
-
Bias reduction: By generating more samples in under-represented minority regions, ADASYN reduces the classification bias introduced by imbalanced data more effectively than uniform oversampling.
-
Decision boundary improvement: By concentrating synthetic samples near the class boundary, ADASYN shifts the learned decision boundary toward the difficult examples — precisely the region where the classifier's accuracy matters most.
Why ADASYN Became a Standard Tool
Several factors drove ADASYN's adoption into the mainstream:
Empirical validation: The original paper demonstrated improvements across five evaluation metrics on benchmark datasets, showing consistent gains over both SMOTE and random oversampling.
Natural extension of SMOTE: ADASYN uses the same k-NN interpolation mechanism as SMOTE for generating individual synthetic samples. The only difference is how many samples each minority instance generates. This made it easy to implement and integrate into existing SMOTE-based pipelines.
Library support: The imbalanced-learn library included ADASYN from its early versions, providing a drop-in replacement for SMOTE with an identical fit_resample() API. No code changes beyond swapping the class name.
Domain adoption: High-stakes domains like healthcare, finance, and cybersecurity — where minority-class detection is critical and the minority class often has regions of varying difficulty — found ADASYN's adaptive approach particularly valuable.
Historical Note: ADASYN was published six years after the original SMOTE paper (2002) and three years after Borderline-SMOTE (2005). While Borderline-SMOTE restricts synthetic generation to boundary samples (a binary decision), ADASYN takes a softer approach — it generates samples for all minority instances but in proportion to their difficulty. This continuous weighting scheme often yields more nuanced results than Borderline-SMOTE's binary filtering.
Core Intuition & Mental Model
The Classroom Analogy
Imagine you are a teacher with 30 students, but only 3 are struggling with the material. You have limited time for extra tutoring sessions. Vanilla SMOTE would give each struggling student exactly one extra session — equal treatment. But ADASYN looks at each student's situation: the student who sits next to strong peers and gets help naturally needs less intervention, while the student who is completely isolated and surrounded by students who cannot help needs much more support.
ADASYN is that adaptive teacher — it allocates more resources (synthetic samples) to the minority instances that need the most help (those surrounded by majority neighbors) and fewer to those that are already in safe territory.
The Geometric Perspective
Picture your feature space as a 2D landscape. Minority class samples form small islands in a sea of majority class points. Some islands are large and well-separated from the sea (easy regions). Others are tiny, almost submerged, with majority points lapping at their edges (hard regions).
Vanilla SMOTE grows all islands equally — adding the same amount of land to each. ADASYN grows the near-submerged islands much more aggressively than the safe ones. The result is that the classifier's decision boundary gets the most support precisely where it is most contested.
The mechanism is a simple ratio: for each minority sample, count how many of its k nearest neighbors belong to the majority class. Divide by k. That ratio (call it ) measures local difficulty. High means the sample is surrounded by enemies — it needs more synthetic support. Low means the sample is surrounded by friends — it needs less.
What ADASYN Gets Right (and What It Doesn't)
The adaptive allocation is ADASYN's superpower: it focuses synthetic data where the model struggles most. But this same focus creates a vulnerability — if a minority sample is surrounded by majority neighbors because it is noise (a mislabeled or anomalous point), ADASYN will generate the most synthetic samples precisely around that noisy point. This noise amplification is ADASYN's Achilles' heel and the primary reason practitioners sometimes prefer Borderline-SMOTE, which can be more conservative.
The Spice Shop Analogy
Think of a spice shop in a crowded Indian bazaar. Some spice stalls are on the main road with heavy foot traffic from other vendors (majority class — those vendors crowd the space). Other stalls are tucked in quiet lanes with plenty of room. ADASYN is like a city planner who opens more branch stalls near the crowded main road (where your spice shop is hardest to find) and fewer in the quiet lanes (where customers can already find you easily). The goal is to make the spice shop discoverable everywhere, but especially in the noisy, contested areas.
Key Insight: ADASYN doesn't change how synthetic samples are generated (it still uses SMOTE's interpolation). It changes where and how many samples are generated. This makes it a meta-strategy on top of SMOTE rather than a fundamentally different algorithm.
Technical Foundations
Mathematical Formulation
Let be a binary classification dataset where , with minority samples and majority samples, such that .
Step 1: Compute the degree of class imbalance
where . A preset threshold (typically 1.0) determines whether resampling is needed: if , proceed.
Step 2: Calculate total synthetic samples needed
where controls the desired balance level. Setting fully balances to 1:1; setting balances to 1:2 (minority:majority).
Step 3: Compute the density ratio for each minority sample
For each minority sample (), find its nearest neighbors (from the entire dataset, not just minority) and compute:
where is the number of majority-class samples among the nearest neighbors of . Note that .
Step 4: Normalize the density ratios
so that . The vector is a probability distribution over minority samples.
Step 5: Compute per-instance synthetic sample count
where is the (possibly fractional) number of synthetic samples to generate for minority sample . Samples with high (hard-to-learn, majority-dominated neighborhoods) get more synthetic neighbors; samples with low (safe, minority-dominated neighborhoods) get fewer.
Step 6: Generate synthetic samples (SMOTE interpolation)
For each minority sample , generate synthetic samples. For each synthetic sample, randomly select a minority neighbor from the nearest minority neighbors and compute:
where is a random interpolation factor.
Key Differences from SMOTE
| Property | SMOTE | ADASYN |
|---|---|---|
| Synthetic count per instance | Equal for all | Proportional to |
| k-NN search scope | Minority class only | Entire dataset (for density) |
| Density awareness | None | Majority-neighbor density |
| Total synthetic samples | Exactly | Approximately (rounding) |
Computational Complexity
- Density ratio computation: where is total dataset size and is feature dimensionality (k-NN search over entire dataset)
- Synthetic generation: where is total synthetic count
- Overall:
Compared to SMOTE (), ADASYN's density computation is more expensive when because it searches the entire dataset, not just the minority class.
Mathematical Caveat: The density ratio depends on the choice of . For small , the ratio is noisy (high variance). For large , it smooths over local structure. The default provides a reasonable trade-off for most datasets. Additionally, the rounding of fractional values means the actual total synthetic count may differ slightly from .
Internal Architecture
ADASYN's architecture extends SMOTE's pipeline by inserting a density estimation and adaptive weighting phase between the k-NN search and synthetic sample generation. The key architectural difference is the two-pass k-NN search: a first pass over the entire dataset to compute density ratios, and a second pass over minority samples only to select interpolation partners.
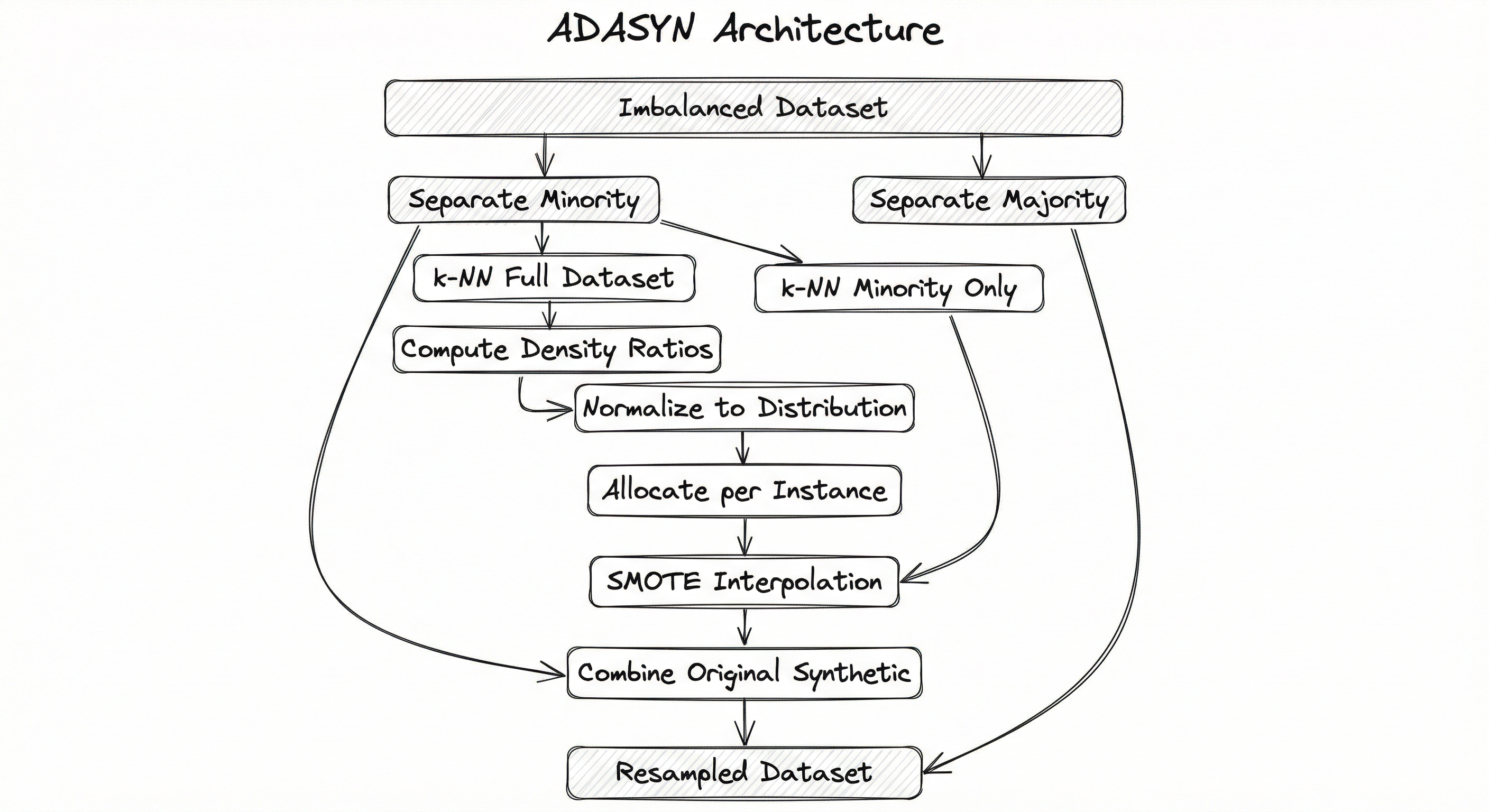
The first k-NN search (Step C) queries the entire dataset to determine how many majority neighbors surround each minority sample. This is the density estimation step that distinguishes ADASYN from SMOTE. The second k-NN search (Step G) queries only minority samples to find interpolation partners for synthetic generation — identical to SMOTE's mechanism.
Key Components
Class Separator
Splits the input dataset into minority and majority subsets. Computes the imbalance ratio and determines the total number of synthetic samples needed to achieve the target balance.
Full-Dataset k-NN Engine
For each minority sample, computes k nearest neighbors from the entire dataset (both classes). This is the critical difference from SMOTE — by searching the full dataset, ADASYN can measure how many majority-class neighbors surround each minority instance.
Density Ratio Calculator
Computes for each minority sample, where is the count of majority-class neighbors among its k nearest neighbors. High indicates a hard-to-learn sample in a majority-dominated neighborhood.
Distribution Normalizer
Normalizes density ratios so they sum to 1.0, converting them into a proper probability distribution . This distribution governs how many synthetic samples each minority instance receives.
Adaptive Allocator
Computes — the number of synthetic samples for each minority instance. Handles rounding so the total is approximately . Instances in majority-dominated regions receive the largest allocations.
Minority-Only k-NN Engine
For each minority sample that needs synthetic generation, finds its k nearest minority-class neighbors as interpolation partners. This is the same k-NN search used in standard SMOTE.
SMOTE Interpolation Engine
Generates synthetic samples for each minority instance by randomly selecting one of its minority-class neighbors and interpolating: with .
Dataset Combiner
Merges original majority samples, original minority samples, and newly generated synthetic minority samples into the final resampled training set.
Data Flow
Input Flow: The algorithm receives an imbalanced dataset, a target sampling_strategy, and the number of neighbors n_neighbors. It first separates the dataset into minority and majority subsets and computes the imbalance ratio.
Density Estimation Flow: For each of the minority samples, a k-NN search over the entire dataset (both classes) identifies how many majority-class neighbors are present. This produces a density ratio per minority instance — the fraction of neighbors that belong to the majority class.
Adaptive Allocation Flow: Density ratios are normalized into a distribution that sums to 1. Multiplying by the total target count yields per-instance allocations . A minority sample with (4 out of 5 neighbors are majority) will receive 4x more synthetic samples than one with .
Generation Flow: For each minority sample, synthetic samples are generated using standard SMOTE interpolation with randomly selected minority-class neighbors.
Output Flow: Synthetic samples are labeled as minority class and combined with the original dataset. The final output is a resampled dataset where hard-to-learn minority regions have been disproportionately augmented.
A linear pipeline from 'Imbalanced Dataset' through class separation, full-dataset k-NN search, density ratio computation, normalization into a distribution, adaptive allocation of synthetic counts, minority-only k-NN for interpolation partners, SMOTE interpolation, and final combination into a 'Resampled Dataset'.
How to Implement
Implementation Approaches
ADASYN is available through the imbalanced-learn (imblearn) library as a drop-in replacement for SMOTE. The API is nearly identical — you swap SMOTE(...) with ADASYN(...) and everything else stays the same. Internally, imblearn's implementation handles the two-pass k-NN search, density computation, and adaptive allocation automatically.
Key configuration decisions: The primary parameter is n_neighbors (default 5), which controls both the density estimation (how many neighbors to check for majority presence) and the interpolation (how many minority neighbors to consider for synthetic generation). The sampling_strategy parameter works identically to SMOTE's — 'auto' for full balancing, a float for partial balancing, or a dict for explicit per-class targets.
Production deployment pattern: Like SMOTE, ADASYN is a training-time technique only. You apply it to the training set, train your model on the resampled data, and deploy the model alone. No synthetic samples are generated at inference time. This means ADASYN adds zero latency to your production serving pipeline.
Cost Note: ADASYN's density computation requires a k-NN search over the entire dataset for each minority sample, which is more expensive than SMOTE's minority-only k-NN search. For a dataset with 100K minority samples and 1M total samples, ADASYN's density step can take 5-10 minutes on a 32-core CPU (AWS c6i.8xlarge, ~$1.36/hr or ~₹115/hr). SMOTE on the same data takes 2-3 minutes because it only searches minority samples.
from imblearn.over_sampling import ADASYN
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import numpy as np
# Create imbalanced dataset (1:99 ratio)
X, y = make_classification(
n_classes=2,
weights=[0.01, 0.99],
n_samples=10000,
n_features=20,
n_informative=10,
random_state=42
)
print(f"Original class distribution: {np.bincount(y)}")
# Output: [100, 9900]
# Split FIRST — never apply ADASYN before splitting
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Apply ADASYN to training data only
adasyn = ADASYN(
sampling_strategy='auto', # balance to 1:1
n_neighbors=5, # k for density estimation
random_state=42
)
X_train_res, y_train_res = adasyn.fit_resample(X_train, y_train)
print(f"Resampled distribution: {np.bincount(y_train_res)}")
# Output: [7920, ~7920] — approximately balanced
# Note: ADASYN total may differ slightly from exact balance due to rounding
# Train classifier on resampled data
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train_res, y_train_res)
# Evaluate on ORIGINAL imbalanced test set
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))This example demonstrates the standard ADASYN workflow. Key points: (1) ADASYN is applied ONLY to the training set after the train-test split — applying it before causes data leakage. (2) The sampling_strategy='auto' targets approximate 1:1 balance, though ADASYN's rounding of per-instance allocations means the final count may differ slightly from exact balance. (3) The n_neighbors=5 parameter controls both the density estimation and interpolation. (4) Evaluation is on the original imbalanced test set, reflecting real-world class ratios.
from imblearn.over_sampling import SMOTE, ADASYN
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score, recall_score, precision_score
import numpy as np
# Create dataset with clusters of varying difficulty
X, y = make_classification(
n_classes=2,
weights=[0.05, 0.95],
n_samples=5000,
n_features=15,
n_informative=8,
n_clusters_per_class=3, # Multiple subclusters
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Compare SMOTE vs ADASYN
results = {}
for name, sampler in [
('No resampling', None),
('SMOTE', SMOTE(sampling_strategy='auto', k_neighbors=5, random_state=42)),
('ADASYN', ADASYN(sampling_strategy='auto', n_neighbors=5, random_state=42)),
]:
if sampler:
X_res, y_res = sampler.fit_resample(X_train, y_train)
else:
X_res, y_res = X_train, y_train
clf = LogisticRegression(max_iter=1000, random_state=42)
clf.fit(X_res, y_res)
y_pred = clf.predict(X_test)
results[name] = {
'recall': recall_score(y_test, y_pred, pos_label=0),
'precision': precision_score(y_test, y_pred, pos_label=0),
'f1': f1_score(y_test, y_pred, pos_label=0),
}
for name, metrics in results.items():
print(f"{name:20s} | Recall: {metrics['recall']:.3f} | "
f"Precision: {metrics['precision']:.3f} | F1: {metrics['f1']:.3f}")This example compares ADASYN against SMOTE and a no-resampling baseline on a dataset with multiple subclusters (varying difficulty regions). ADASYN typically shows stronger recall improvements on datasets with heterogeneous minority class distributions, because it allocates more synthetic samples to the hard-to-learn subclusters near the decision boundary. On datasets with uniform minority distributions, SMOTE and ADASYN perform similarly.
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import ADASYN
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
import numpy as np
# Create pipeline: scale -> ADASYN -> classify
pipeline = Pipeline([
('scaler', StandardScaler()),
('adasyn', ADASYN(
sampling_strategy=0.3, # target 3:10 minority:majority ratio
n_neighbors=5,
random_state=42
)),
('classifier', GradientBoostingClassifier(
n_estimators=100,
random_state=42
))
])
# Example data
X = np.random.randn(5000, 15)
y = np.array([0] * 4500 + [1] * 500)
# Cross-validation with ADASYN applied INSIDE each fold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(
pipeline,
X, y,
cv=cv,
scoring='f1',
n_jobs=-1
)
print(f"Cross-validated F1 scores: {scores}")
print(f"Mean F1: {scores.mean():.3f} +/- {scores.std():.3f}")Using imblearn.pipeline.Pipeline (not sklearn's Pipeline) ensures ADASYN is applied correctly during cross-validation: it resamples ONLY the training folds, never the validation fold. This prevents data leakage where synthetic validation samples would contaminate training. The StandardScaler is applied before ADASYN because k-NN distance calculations are scale-sensitive. Setting sampling_strategy=0.3 targets a 3:10 minority-to-majority ratio rather than full 1:1 balance — a common production pattern that improves recall without over-committing to precision loss.
from imblearn.over_sampling import ADASYN
from sklearn.neighbors import NearestNeighbors
import numpy as np
# Create toy dataset: 2 clusters of minority samples
np.random.seed(42)
# Cluster 1: safe minority region (far from majority)
min_safe = np.random.randn(30, 2) + np.array([5.0, 5.0])
# Cluster 2: hard minority region (overlapping with majority)
min_hard = np.random.randn(20, 2) + np.array([0.5, 0.5])
# Majority class
maj = np.random.randn(500, 2)
X = np.vstack([min_safe, min_hard, maj])
y = np.array([1]*50 + [0]*500)
# Manually compute density ratios to understand ADASYN's allocation
k = 5
nn = NearestNeighbors(n_neighbors=k + 1) # +1 because query point is included
nn.fit(X)
minority_indices = np.where(y == 1)[0]
density_ratios = []
for idx in minority_indices:
distances, neighbors = nn.kneighbors(X[idx:idx+1])
neighbor_labels = y[neighbors[0][1:]] # exclude self
majority_count = np.sum(neighbor_labels == 0)
ratio = majority_count / k
density_ratios.append(ratio)
density_ratios = np.array(density_ratios)
# Show difference between safe and hard clusters
print(f"Safe cluster avg density ratio: {density_ratios[:30].mean():.3f}")
print(f"Hard cluster avg density ratio: {density_ratios[30:].mean():.3f}")
# Safe cluster: low ratio (few majority neighbors)
# Hard cluster: high ratio (many majority neighbors)
# -> ADASYN will generate more synthetics for the hard cluster
# Apply ADASYN and verify
adasyn = ADASYN(n_neighbors=5, random_state=42)
X_res, y_res = adasyn.fit_resample(X, y)
print(f"\nOriginal minority: {np.sum(y == 1)}")
print(f"Synthetic samples added: {np.sum(y_res == 1) - np.sum(y == 1)}")This example exposes ADASYN's internal adaptive allocation mechanism. We create a toy dataset with two minority clusters: one safe (far from majority) and one hard (overlapping with majority). By manually computing density ratios, you can verify that ADASYN assigns higher ratios to the hard cluster, meaning it will receive proportionally more synthetic samples. This demonstrates the core value proposition: ADASYN automatically detects and reinforces the most vulnerable regions of the minority class.
# ADASYN configuration for imbalanced-learn
adasyn_config = {
'sampling_strategy': 'auto', # target balance (or float for partial)
'n_neighbors': 5, # k for density estimation + interpolation
'random_state': 42, # reproducibility
}
# Partial balancing (recommended for production)
adasyn_partial_config = {
'sampling_strategy': 0.3, # target 3:10 minority:majority ratio
'n_neighbors': 5,
'random_state': 42,
}
# Custom NearestNeighbors for large datasets
from sklearn.neighbors import NearestNeighbors
adasyn_optimized_config = {
'sampling_strategy': 'auto',
'n_neighbors': NearestNeighbors(
n_neighbors=5,
algorithm='ball_tree', # faster for high-dimensional data
n_jobs=-1 # parallel computation
),
'random_state': 42,
}Common Implementation Mistakes
- ●
Applying ADASYN before train-test split — This is the most catastrophic mistake. Synthetic samples in the test set are interpolations of training samples, so the model has indirectly 'seen' test data. ALWAYS split first, then apply ADASYN only to the training set.
- ●
Using ADASYN on noisy minority data without cleaning first — ADASYN's adaptive mechanism assigns the MOST synthetic samples to noisy or mislabeled minority instances (since they tend to be surrounded by majority neighbors). This amplifies noise more aggressively than vanilla SMOTE. Clean your data with outlier detection (Isolation Forest, LOF) before applying ADASYN.
- ●
Ignoring that ADASYN requires the entire dataset for density estimation — Unlike SMOTE which only does k-NN within the minority class, ADASYN's density step searches the full dataset. This makes it significantly slower on large datasets. A dataset with 10K minority and 1M majority samples will have ADASYN spending most of its time on the density k-NN pass.
- ●
Using ADASYN with categorical features — ADASYN inherits SMOTE's linear interpolation, which produces nonsensical values for categorical data. Use SMOTE-NC for mixed data types, or apply proper encoding before ADASYN.
- ●
Setting n_neighbors too large on small minority classes — If your minority class has 50 samples and you set n_neighbors=20, the density ratios become overly smoothed and lose local sensitivity. Keep n_neighbors at 5 for most datasets, and never exceed sqrt(m_s).
- ●
Expecting ADASYN to always outperform SMOTE — On datasets with uniform minority class distribution (no hard/easy distinction), ADASYN degenerates to approximately uniform allocation, matching SMOTE's behavior but with higher computational cost. ADASYN shines specifically when the minority class has heterogeneous difficulty regions.
When Should You Use This?
Use When
Your minority class has heterogeneous difficulty — some regions are well-separated from the majority while others are interleaved or boundary-adjacent. ADASYN's adaptive allocation provides the most benefit when difficulty varies across the minority class.
You want to shift the decision boundary toward hard-to-learn examples rather than uniformly expanding the minority class region. ADASYN's density-weighted generation concentrates synthetic samples at the boundary.
The minority class has sufficient samples (>50) for meaningful density estimation — below this threshold, the density ratios become unreliable and ADASYN degenerates to noisy allocation.
Features are predominantly continuous/numerical, allowing meaningful k-NN distance computation and linear interpolation for synthetic generation.
You are building a fraud detection, medical diagnosis, or intrusion detection system where the cost of missing a minority-class instance (false negative) is much higher than the cost of a false positive.
Vanilla SMOTE's uniform allocation is demonstrably insufficient — you've tried SMOTE and recall on hard minority subpopulations remains low.
Your dataset is moderately sized (minority class <100K, total <5M) so ADASYN's additional k-NN pass over the full dataset is computationally feasible.
Avoid When
The minority class contains significant noise or mislabeled samples — ADASYN will generate the most synthetic samples around noisy points (which appear hard-to-learn), amplifying the problem more aggressively than SMOTE. Use Borderline-SMOTE or clean the data first.
You are using tree-based models (XGBoost, Random Forest, LightGBM) that handle imbalance natively via class weights — these models often outperform resampling without the added complexity and computation.
The minority class has fewer than 50 samples — density estimation with k=5 neighbors is unreliable, and k-NN search becomes dominated by noise. Consider data collection, transfer learning, or few-shot learning instead.
Features are predominantly categorical or discrete — linear interpolation produces meaningless values. Use SMOTE-NC for mixed data or apply embeddings first.
Computational cost is a constraint — ADASYN's full-dataset k-NN search is more expensive than SMOTE's minority-only search. For datasets with >5M total samples, consider random oversampling, class weights, or focal loss.
The minority class distribution is uniform (no hard/easy regions) — ADASYN provides no benefit over SMOTE in this case but adds computational overhead.
Your application is precision-critical — ADASYN typically improves recall at the cost of precision. If false positives are expensive (e.g., unnecessary medical procedures, spam filtering), the tradeoff may be unacceptable.
Key Tradeoffs
The Core Tradeoff: Targeted Recall vs Noise Amplification
ADASYN's greatest strength is its greatest vulnerability. By generating more synthetic samples in majority-dominated neighborhoods, it focuses the classifier's attention on the hardest-to-learn regions — exactly where you want it for fraud detection or disease diagnosis. But those same majority-dominated neighborhoods may contain minority samples that are noise rather than genuinely difficult cases. A mislabeled data point surrounded by majority neighbors looks exactly like a hard-to-learn sample to ADASYN's density calculator.
The practical impact: on clean datasets with heterogeneous difficulty, ADASYN typically outperforms SMOTE by 2-5% in minority-class recall. On noisy datasets, ADASYN can underperform SMOTE because it over-generates around noisy points.
ADASYN vs SMOTE vs Borderline-SMOTE
| Criterion | SMOTE | Borderline-SMOTE | ADASYN |
|---|---|---|---|
| Generation uniformity | Uniform | Boundary only | Density-weighted |
| Noise sensitivity | Moderate | Low | High |
| Computational cost | Low | Medium | Medium-High |
| Best for | Uniform minority | Noisy data | Heterogeneous difficulty |
| Precision impact | Moderate decrease | Smaller decrease | Moderate decrease |
| Recall improvement | Good | Good | Best (on clean data) |
Computational Cost
ADASYN's density estimation requires a k-NN search over the entire dataset for each minority sample, while SMOTE only searches the minority class. For a dataset with 10K minority and 1M majority samples:
- SMOTE k-NN cost: Searches 10K minority samples = fast
- ADASYN density k-NN cost: Searches 1.01M total samples per minority instance = significantly slower
In practice, ADASYN takes 2-5x longer than SMOTE on the same dataset. For a pipeline running on AWS (c6i.4xlarge, ~$0.68/hr or ~₹58/hr), this might mean 10 minutes vs 3 minutes — acceptable for batch training but worth considering if you retrain frequently.
Partial Balancing Strategy
Full 1:1 balancing is rarely optimal. Recent research (Chia, 2025) found that for credit scoring with ~7% default rate, ADASYN with 1x multiplication (doubling the minority class to achieve ~6.6:1 ratio) outperformed both no resampling and full 1:1 balancing. The recommendation: start with sampling_strategy=0.3 (3:10 ratio) and tune based on cross-validated F1.
Rule of Thumb: Use ADASYN when you've verified that your minority class is clean (no significant noise/mislabels) AND has regions of varying difficulty. If you're unsure about noise levels, start with Borderline-SMOTE. If the minority class is uniformly distributed, start with vanilla SMOTE. All three are available in imbalanced-learn with identical APIs, so switching is trivial.
Alternatives & Comparisons
SMOTE generates synthetic samples uniformly for all minority instances, while ADASYN adapts the count based on local difficulty. On datasets with uniform minority distribution, both perform similarly, but SMOTE is faster because it only searches within the minority class. Choose SMOTE when computational cost matters, the minority class is uniformly distributed, or you want a simpler baseline. Choose ADASYN when the minority class has regions of varying difficulty and the data is clean.
Borderline-SMOTE applies a binary filter: it only generates synthetic samples for minority instances near the decision boundary (those with some majority neighbors) and ignores safe interior instances entirely. ADASYN uses a continuous weighting: all minority instances get some synthetic samples, but boundary instances get more. Borderline-SMOTE is more robust to noise (it ignores isolated outlier minority points), while ADASYN provides more nuanced density-based allocation. Choose Borderline-SMOTE for noisy datasets; choose ADASYN when the minority class is clean and you want maximum adaptive coverage.
SMOTE-NC handles datasets with mixed categorical and continuous features — something neither ADASYN nor vanilla SMOTE can do correctly. If your dataset has categorical features, SMOTE-NC is the necessary choice regardless of whether ADASYN's adaptive allocation would be beneficial. For purely numerical datasets, ADASYN provides adaptive density-based oversampling that SMOTE-NC lacks.
Random oversampling duplicates existing minority samples without creating new synthetic data. It's orders of magnitude faster than ADASYN (no k-NN search) and trivially simple, but leads to overfitting since the model sees identical copies. Use random oversampling when ADASYN's computational cost is prohibitive (>1M minority samples) or as a quick baseline. Use ADASYN when you can afford the computation and want informative synthetic samples.
SMOTE+ENN first oversamples with SMOTE, then cleans the result by removing samples misclassified by their nearest neighbors (Edited Nearest Neighbors). This two-phase approach addresses SMOTE's noise amplification problem. ADASYN tries to address noise by differential allocation, while SMOTE+ENN addresses it by post-generation cleaning. SMOTE+ENN is often more robust to noisy data than ADASYN because it explicitly removes problematic synthetics.
Pros, Cons & Tradeoffs
Advantages
Adaptive density-based allocation generates more synthetic samples in hard-to-learn regions (majority-dominated neighborhoods), concentrating synthetic data where the classifier struggles most — unlike SMOTE's uniform generation
Shifts the decision boundary toward difficult examples, which is precisely the region where classifier accuracy has the most impact on minority-class recall in production systems
Drop-in replacement for SMOTE in imbalanced-learn with identical API (
fit_resample()), requiring only a class name change in existing pipelines — zero integration overheadReduces classification bias more effectively than SMOTE on datasets with heterogeneous minority difficulty, as shown in the original He et al. 2008 paper and subsequent empirical studies
Preserves all original training data — unlike undersampling which discards majority class information, ADASYN adds synthetic minority samples while keeping the full original dataset
Model-agnostic — works as a preprocessing step with any classifier (SVM, k-NN, neural networks, logistic regression), without requiring model-specific modifications
Supports multi-class imbalanced learning via one-vs-rest decomposition in imbalanced-learn, handling datasets with more than two classes automatically
Disadvantages
Amplifies noise more aggressively than SMOTE — mislabeled or anomalous minority samples surrounded by majority neighbors receive the most synthetic samples, since they appear maximally hard-to-learn to the density calculator
Higher computational cost than SMOTE — the density estimation step requires k-NN search over the entire dataset (both classes) rather than just the minority class, adding 2-5x overhead on large datasets
Approximate total synthetic count — because per-instance allocations are rounded to integers, the actual total synthetic samples may differ from the target , making exact balance unreachable
No benefit on uniformly distributed minority classes — when all minority samples have similar difficulty (similar density ratios), ADASYN degenerates to approximately uniform allocation, matching SMOTE's behavior at higher computational cost
Inherits SMOTE's categorical feature limitation — linear interpolation produces nonsensical values for categorical data. Requires SMOTE-NC or prior encoding for mixed-type datasets
Float sampling_strategy only works for binary classification — multi-class problems require dict-based sampling strategy or 'auto' mode, limiting fine-grained control in multi-class scenarios
May blur safe minority regions — even with adaptive allocation, ADASYN still generates some synthetic samples in safe regions (just fewer). On very clean datasets, these unnecessary synthetics can introduce minor noise
Failure Modes & Debugging
Noise amplification in majority-dominated neighborhoods
Cause
A minority sample is mislabeled, an outlier, or anomalous. Because it sits in a majority-dominated region, its density ratio is high, and ADASYN allocates the maximum number of synthetic samples around it. The noisy point becomes a nucleus for a cluster of equally noisy synthetic samples.
Symptoms
Precision drops sharply after applying ADASYN. Visual inspection shows clusters of synthetic minority samples in unexpected majority-dominated regions. False positive rate increases in production. The model makes confident but wrong minority predictions in specific feature regions.
Mitigation
Clean the minority class before applying ADASYN using outlier detection (Isolation Forest, LOF, or DBSCAN). Alternatively, switch to Borderline-SMOTE which is more conservative about isolated minority points. A hybrid approach is ADASYN followed by Edited Nearest Neighbors (ENN) cleaning to remove noisy synthetics post-generation.
Density ratio instability with small minority classes
Cause
When the minority class has fewer than ~50 samples, the k-NN density estimation becomes unreliable. With k=5 neighbors, a single noisy neighbor can swing the density ratio by 20% (1/5), leading to highly variable and non-representative allocations. The normalized distribution becomes dominated by a few high-ratio samples.
Symptoms
Synthetic samples are heavily concentrated around 2-3 minority instances while others receive zero synthetics. Model performance is unstable across cross-validation folds. The resampled training set has poor coverage of the minority class feature space.
Mitigation
For minority classes with <50 samples, prefer vanilla SMOTE (uniform allocation is more stable with few samples), random oversampling, or data collection. If ADASYN is required, reduce k to 3 and verify allocation stability across multiple random seeds.
Data leakage via pre-split ADASYN application
Cause
ADASYN applied to the full dataset before train-test split. Synthetic test samples are interpolations of training data, and the density ratios are computed using majority samples that appear in both train and test sets. This creates two forms of leakage: synthetic samples leak training information into the test set, and the density estimation uses test-set majority samples.
Symptoms
Extremely high test metrics (98%+ accuracy/F1) that don't match production performance. Shadow deployment reveals a 10-20 percentage point gap between offline and online metrics. Cross-validation scores are suspiciously close to training scores.
Mitigation
ALWAYS split data first, then apply ADASYN only to the training set. Use imblearn.pipeline.Pipeline for cross-validation to ensure ADASYN is applied correctly inside each fold. Test set must reflect the real-world imbalanced distribution with zero synthetic samples.
Excessive generation in overlapping class regions
Cause
When minority and majority classes have significant overlap in feature space, many minority samples have high density ratios (many majority neighbors). ADASYN generates large numbers of synthetic samples in these overlapping regions, but the synthetics are as ambiguous as the originals — they don't provide clean signal for the classifier.
Symptoms
High recall but very low precision. The decision boundary becomes noisy and unstable. Synthetic minority samples appear deep in majority-class territory. The model predicts minority class too aggressively in ambiguous regions.
Mitigation
Use partial balancing (sampling_strategy=0.3) instead of full balancing to limit the total number of synthetics. Apply Borderline-SMOTE which is more conservative in overlapping regions. Consider cost-sensitive learning (focal loss, weighted cross-entropy) as an alternative that doesn't inject synthetic data into ambiguous regions.
Computational timeout on large datasets
Cause
ADASYN's density estimation performs k-NN search over the entire dataset for each minority sample. With 100K minority samples and 5M total samples, this requires 100K queries against a 5M-sample index. Even with Ball tree optimization, this can take 30-60 minutes, causing pipeline timeouts in production training jobs.
Symptoms
ADASYN preprocessing step dominates pipeline runtime. Training jobs timeout or exceed SLA. CPU utilization at 100% during the density k-NN pass. Memory pressure as the full-dataset k-NN index must fit in RAM.
Mitigation
Subsample the dataset before density estimation: randomly sample 100K majority samples, compute density ratios on the reduced dataset, then generate synthetics using the full minority set. Use approximate nearest neighbor algorithms by passing a custom NearestNeighbors(algorithm='ball_tree', n_jobs=-1) instance. For extreme scale (>5M samples), switch to class weights or focal loss.
Placement in an ML System
ADASYN sits in the data preprocessing stage of the ML pipeline, specifically after data cleaning, feature extraction, and train-test split, but before model training and hyperparameter tuning. It is a training-time technique only — no synthetic samples are generated at inference time.
Upstream dependencies: ADASYN requires clean, scaled, numerical features. Categorical variables must be encoded (ADASYN inherits SMOTE's linear interpolation limitation). Outliers and label errors should be addressed before applying ADASYN, because its adaptive mechanism will amplify noise by over-generating around noisy points. Feature scaling (StandardScaler, MinMaxScaler) is critical because the k-NN search is distance-based.
Downstream impact: The resampled dataset feeds into model training. For models that natively handle imbalance (XGBoost, LightGBM, Random Forest with class weights), ADASYN is often unnecessary. For models without native imbalance support (k-NN, SVM, logistic regression, unweighted neural networks), ADASYN can improve minority-class recall by 10-30 percentage points.
Pipeline integration: ADASYN must be integrated via imblearn.pipeline.Pipeline (not sklearn's Pipeline) to ensure correct application during cross-validation — only to training folds, never validation folds. This prevents data leakage from synthetic samples.
Production considerations: ADASYN adds zero runtime overhead in production because it's applied only during training. The deployed model receives real-world data at inference time. However, ADASYN does increase training pipeline duration by 2-5x compared to SMOTE due to the full-dataset density estimation step. For retraining pipelines that run daily (common at Indian fintech companies like Razorpay, PhonePe), this additional training time should be budgeted into the pipeline SLA.
Pipeline Stage
Data Preprocessing / Training
Upstream
- data-cleaning
- data-validation
- feature-extraction
- train-test-split
Downstream
- model-training
- hyperparameter-tuning
- cross-validation
Scaling Bottlenecks
ADASYN's primary bottleneck is the full-dataset k-NN search for density estimation. Unlike SMOTE which only searches within the minority class (), ADASYN searches the entire dataset () where . For a dataset with 50K minority and 2M majority samples with 100 features, the density k-NN pass takes ~15 minutes on a 32-core CPU even with Ball tree indexing. Memory consumption includes the full-dataset k-NN index plus the resampled dataset (which can be up to 2x the original size). At extreme scale (minority >500K, total >10M), ADASYN becomes impractical — switch to class weights, focal loss, or partial random oversampling combined with class weights.
Production Case Studies
A comprehensive study evaluated ADASYN alongside SMOTE, MWMOTE, and ROSE for handling data imbalance in health insurance fraud detection. Six classification models (Decision Tree, Random Forest, XGBoost, Naive Bayes, GBM, GLM) were tested across multiple resampling strategies. The study also integrated business rule triggers to boost model performance.
XGBoost combined with ADASYN was selected as the optimal combination, achieving the highest F2 score. The integration of business rule triggers with ADASYN-resampled models further improved fraud detection performance by prioritizing recall for fraudulent claims.
An ADASYN-Random Forest based intrusion detection model was tested on the CICIDS 2017 and UNSW-NB15 network intrusion datasets. ADASYN was used to address severe class imbalance in attack types, where some attack categories had <1% representation. The resampled training data was fed to a Random Forest classifier optimized for multi-class detection.
The ADASYN-RF model achieved accuracy, precision, recall, and F1 scores of 99.99% on the UNSW-NB15 dataset. On CICIDS 2017, it outperformed traditional ML methods and random forest with other sampling methods, demonstrating higher prediction performance, efficiency, and robustness for rare attack detection.
ADASYN was applied to the multi-class imbalanced EEG signal classification problem for epilepsy event detection. An OVA (One-Against-All) approach created five separate binary classification datasets from five-class EEG data. ADASYN balanced each dataset before Random Forest classification, with a majority voting scheme combining all classifiers.
The ADASYN + Random Forest approach achieved 91.72% classification success on five-class EEG signals, outperforming three alternative approaches (71.90%, 89%, 91.08%). The method showed particular strength in detecting rare epileptic event categories that were severely underrepresented in the original data.
A systematic study evaluated the optimal data augmentation ratio for ADASYN in credit scoring, using the Give Me Some Credit dataset (97,243 observations, 7% default rate). Ten augmentation scenarios were compared using SMOTE, Borderline-SMOTE, and ADASYN at different multiplication factors (1x, 2x, 3x) with XGBoost classification.
ADASYN with 1x multiplication (doubling the minority class to a 6.6:1 ratio) achieved the optimal AUC of 0.6778, outperforming both full 1:1 balancing and no resampling. The study demonstrated that moderate imbalance ratios (6-7:1) outperform full balancing for credit scoring, challenging the common practice of balancing to 1:1.
Tooling & Ecosystem
The canonical Python library for ADASYN and imbalanced learning. Provides imblearn.over_sampling.ADASYN with full scikit-learn compatibility, pipeline integration, and multi-class support via one-vs-rest. Version 0.14.1 as of 2026. Parameters: sampling_strategy, n_neighbors, random_state. Supports custom NearestNeighbors instances for optimized k-NN search.
Extensive collection of 85+ oversampling techniques including ADASYN, KernelADASYN, M-ADASYN, and AR-ADASYN variants. Useful for benchmarking ADASYN against specialized variants and exploring advanced adaptive sampling methods not available in imbalanced-learn.
While scikit-learn doesn't include ADASYN directly, it provides the ecosystem (NearestNeighbors, pipelines, cross-validation, metrics) that ADASYN integrates with. Custom NearestNeighbors instances with Ball tree or KD-tree algorithms can be passed to ADASYN for optimized density estimation on large datasets.
R implementation of ADASYN via the SMOTEWB package, providing an ADASYN() function for R-based ML pipelines. Includes additional variants like SMOTE-WB (within-between) alongside standard ADASYN functionality.
A standalone Python implementation of the original ADASYN algorithm by He et al. (2008). Useful for understanding the algorithm's internals — the codebase is minimal and readable, making it ideal for educational purposes and custom modifications. Not recommended for production use (use imbalanced-learn instead).
Research & References
He, H., Bai, Y., Garcia, E.A., Li, S. (2008)IEEE International Joint Conference on Neural Networks (IJCNN 2008)
The original ADASYN paper proposing adaptive density-based synthetic sampling. Demonstrated that weighting synthetic generation by local difficulty (majority-neighbor density) reduces classification bias and shifts the decision boundary toward difficult examples. Validated on benchmark datasets across five evaluation metrics, showing consistent improvements over both SMOTE and random oversampling.
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P. (2002)Journal of Artificial Intelligence Research, vol. 16, pp. 321-357
The foundational SMOTE paper that ADASYN extends. Introduced k-NN interpolation for synthetic minority oversampling, establishing the baseline algorithm that ADASYN enhances with adaptive density-based allocation. Understanding SMOTE is essential context for understanding ADASYN's innovation.
Han, H., Wang, W.Y., Mao, B.H. (2005)International Conference on Intelligent Computing (ICIC 2005)
Introduced Borderline-SMOTE, the primary alternative to ADASYN for adaptive oversampling. Uses a binary filter (boundary vs interior) rather than ADASYN's continuous density weighting. Understanding both approaches is critical for choosing between them based on data characteristics.
Gnana Sheela, K., Varma, G.P.S. (2023)IEEE International Conference on Intelligent Systems for Communication, IoT and Security (ICISCoIS 2023)
Systematic comparison of SMOTE, Borderline-SMOTE, and ADASYN across multiple classifiers and datasets. Found that no single method consistently dominates — ADASYN performs best on datasets with heterogeneous minority difficulty, while Borderline-SMOTE is more robust to noise. Provides practical guidelines for method selection.
Hou, Z., et al. (2024)Statistics and Computing
Proposed AR-ADASYN, which extends ADASYN by considering both distance and angle between minority samples during synthetic generation, better preserving the distribution of minority classes. Results showed superior classification performance compared to standard ADASYN and other oversampling techniques.
Chia, L.H. (2025)arXiv preprint
Systematic evaluation of ADASYN augmentation ratios for credit scoring. Found that ADASYN with 1x multiplication (moderate imbalance ratio of 6.6:1) outperforms full 1:1 balancing, challenging the common practice of complete class balance. Provides empirical evidence for partial balancing strategies in financial applications.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How does ADASYN differ from SMOTE, and when would you choose one over the other?
- ●
Explain the density ratio computation in ADASYN and what it represents geometrically.
- ●
What happens when you apply ADASYN to a dataset with noisy minority samples?
- ●
How would you implement ADASYN correctly in a cross-validation pipeline?
- ●
When would ADASYN hurt model performance rather than help?
- ●
How does ADASYN handle multi-class imbalanced datasets?
- ●
Compare the computational cost of ADASYN vs SMOTE on a dataset with 10K minority and 1M majority samples.
- ●
You've applied ADASYN and recall improved but precision dropped significantly. What would you do?
Key Points to Mention
- ●
ADASYN generates more synthetic samples for harder-to-learn minority instances (those surrounded by majority neighbors), using a normalized density distribution to weight per-instance allocation
- ●
The density ratio r_i = (majority neighbors in k-NN) / k measures local difficulty — high r_i means the sample is in a contested region and gets more synthetic support
- ●
ADASYN's k-NN search spans the ENTIRE dataset (for density estimation), not just the minority class, making it more expensive than SMOTE
- ●
ADASYN inherits SMOTE's linear interpolation mechanism but changes WHERE and HOW MANY samples are generated, making it a meta-strategy on top of SMOTE
- ●
The algorithm's main vulnerability is noise amplification: noisy minority points appear hard-to-learn (high r_i) and receive the most synthetic samples
- ●
Partial balancing (sampling_strategy=0.3) often outperforms full 1:1 balancing in production systems
- ●
For multi-class problems, imbalanced-learn uses one-vs-rest decomposition, but float sampling_strategy is restricted to binary classification
Pitfalls to Avoid
- ●
Saying ADASYN always outperforms SMOTE — on uniform minority distributions, they perform identically but ADASYN is slower
- ●
Forgetting that ADASYN amplifies noise more than SMOTE due to its adaptive mechanism
- ●
Not mentioning that ADASYN's density estimation searches the entire dataset, not just the minority class
- ●
Applying ADASYN before train-test split (data leakage) or to test/validation sets
- ●
Claiming ADASYN works for categorical features — it inherits SMOTE's linear interpolation limitation
- ●
Ignoring tree-based models' native imbalance handling (class weights, scale_pos_weight) which often eliminates the need for resampling
Senior-Level Expectation
Senior/staff candidates should demonstrate understanding of ADASYN's density estimation mechanism at the mathematical level — specifically how the density ratio r_i is computed, normalized, and used for adaptive allocation. They should articulate when ADASYN provides genuine value over SMOTE (heterogeneous difficulty, clean data) vs when it hurts (noisy data, uniform difficulty). A strong answer includes a real production example: 'In our fraud detection pipeline at [company], we compared SMOTE, Borderline-SMOTE, and ADASYN. ADASYN improved recall on hard-to-detect fraud patterns (card-not-present transactions near the decision boundary) by 8% over SMOTE, but we had to first remove mislabeled transactions using Isolation Forest because ADASYN was amplifying label noise.' Senior candidates should also discuss partial balancing strategies (not always 1:1), computational cost considerations for production pipelines, and when to skip resampling entirely in favor of class weights or focal loss.
Summary
ADASYN (Adaptive Synthetic Sampling) extends SMOTE with a critical innovation: density-based adaptive allocation of synthetic samples. Instead of generating equal synthetic neighbors for every minority instance (as SMOTE does), ADASYN measures the local difficulty of each minority sample — specifically, what fraction of its k nearest neighbors belong to the majority class — and allocates more synthetic samples to harder-to-learn instances. This adaptive mechanism concentrates synthetic data generation at the contested class boundary, where the classifier's accuracy matters most.
The algorithm's mathematical core is a normalized density distribution computed from majority-neighbor ratios, which governs per-instance synthetic allocation. A minority sample with 80% majority neighbors receives 4x more synthetic samples than one with 20% majority neighbors. The actual synthetic generation uses SMOTE's standard k-NN interpolation — ADASYN changes how many samples are generated, not how they are generated.
In practice, ADASYN excels on datasets where the minority class has heterogeneous difficulty — some regions safely separated from the majority, others deeply contested. Fraud detection, intrusion detection, and medical diagnosis are canonical applications where ADASYN's adaptive allocation provides measurable gains (2-8% recall improvement over SMOTE) on hard-to-learn subpopulations. However, ADASYN's focus on hard-to-learn regions creates a critical vulnerability: it amplifies noise more aggressively than SMOTE, because noisy or mislabeled minority samples appear maximally hard-to-learn (surrounded by majority neighbors) and receive the most synthetic samples.
For production ML systems, ADASYN is available as a drop-in SMOTE replacement via imbalanced-learn with identical API. Key deployment considerations include: cleaning minority data before application (outlier detection), using partial balancing (sampling_strategy=0.3) rather than full 1:1 balancing, budgeting for 2-5x higher preprocessing time compared to SMOTE (due to full-dataset density estimation), and evaluating whether tree-based models with native class weights might eliminate the need for resampling entirely. Recent research (Chia, 2025) demonstrates that moderate imbalance ratios (6-7:1) often outperform full balancing, reinforcing the recommendation to start with conservative resampling and tune based on cross-validated metrics.