Bias Detector in Machine Learning
A bias detector is a component in ML systems that systematically identifies and quantifies unfair treatment of individuals or groups based on protected attributes -- race, gender, caste, religion, age, disability, or any other characteristic that should not influence a model's decision.
Why does this matter so much? Because ML models learn from historical data, and historical data is drenched in the biases of the societies that produced it. Amazon's recruiting tool learned to penalize resumes containing the word "women's." The COMPAS recidivism algorithm falsely flagged Black defendants as high-risk at nearly twice the rate of white defendants. In India, large language models reproduce caste stereotypes -- completing "Do not touch the ____" with "Dalit" and "The learned man is ____" with "Brahmin."
Bias detection is not just an ethical imperative -- it is increasingly a legal requirement. The EU AI Act (fully enforceable by August 2026) mandates bias testing for high-risk AI systems, with penalties up to 35 million EUR or 7% of global turnover. India's Digital Personal Data Protection Act and the emerging AI governance framework similarly push organizations toward proactive fairness auditing.
In modern ML pipelines, a bias detector sits after model training (or during inference) and before deployment, acting as a quality gate that prevents discriminatory models from reaching production. Think of it as the smoke detector of your ML system -- you hope it never goes off, but you absolutely need it wired in before something catches fire.
Concept Snapshot
- What It Is
- A systematic module that measures, quantifies, and reports unfair disparities in ML model predictions or training data distributions across protected demographic groups.
- Category
- Responsible AI
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: model predictions (or dataset labels), ground truth labels, and protected attribute annotations. Outputs: fairness metric scores (demographic parity difference, equalized odds difference, disparate impact ratio), per-group performance breakdowns, and bias audit reports.
- System Placement
- Sits after model training and evaluation but before deployment in a typical ML pipeline. Can also be applied to raw training data during the data validation stage and continuously during model monitoring in production.
- Also Known As
- fairness auditor, bias auditor, algorithmic fairness checker, discrimination detector, equity evaluator, fairness monitor
- Typical Users
- ML Engineers, Data Scientists, Responsible AI teams, Compliance officers, Product managers, Legal/policy teams
- Prerequisites
- Binary and multi-class classification fundamentals, Confusion matrix (TP, FP, TN, FN), Basic probability and statistics, Understanding of protected attributes and discrimination law
- Key Terms
- demographic parityequalized oddsdisparate impactstatistical paritycalibrationprotected attributeprivileged groupunprivileged groupfour-fifths ruleintersectional fairness
Why This Concept Exists
The Problem: ML Models Inherit Society's Biases
Machine learning models don't generate bias from thin air -- they absorb it from training data. If historical hiring decisions favored men, a model trained on that data will learn to favor men. If loan approval data reflects decades of redlining, the model will replicate those patterns. The model is an optimization machine: it finds the signal in your data, and if that signal is contaminated with discrimination, the model will faithfully amplify it.
This isn't a theoretical concern. ProPublica's 2016 investigation of the COMPAS recidivism prediction system revealed that Black defendants were nearly twice as likely as white defendants to be falsely flagged as high-risk. Amazon's internal recruiting AI, trained on a decade of predominantly male resumes, learned to penalize resumes that included phrases like "women's chess club" or graduates of all-women's colleges. In India, researchers at IIT have documented that GPT models reproduce caste hierarchies, associating Dalits with impurity and Brahmins with learning.
The Impossibility Theorem: You Can't Have It All
Here's what makes bias detection genuinely hard: different fairness definitions are mathematically incompatible. Researchers at Stanford, Cornell, and Carnegie Mellon proved that a risk score cannot simultaneously satisfy calibration (equal accuracy across groups) and equalized odds (equal error rates across groups) unless the base rates are identical across groups. This is the fundamental impossibility of algorithmic fairness.
This means every deployment requires a deliberate choice about which fairness criterion matters most for the specific context. A medical diagnosis system might prioritize equalized odds (equal false negative rates) to ensure no demographic group is disproportionately denied treatment. A hiring system might prioritize demographic parity to ensure equal opportunity. There is no universal "fair" -- only contextually appropriate tradeoffs.
The Regulatory Push
Regulators worldwide are codifying these concerns into law:
- EU AI Act (August 2026 full enforcement): Mandates bias testing and documentation for high-risk AI systems in employment, credit scoring, law enforcement, and education. Violations carry penalties up to EUR 35 million or 7% of global annual turnover.
- NYC Local Law 144 (2023): Requires annual bias audits for automated employment decision tools, with published impact ratios by sex and race/ethnicity.
- India's emerging AI governance: The Digital Personal Data Protection Act (2023) and NITI Aayog's Responsible AI framework emphasize non-discrimination, though enforcement mechanisms are still developing.
Bias detectors exist because hoping your model is fair is not a strategy. You need to measure it, prove it, and monitor it continuously.
Core Intuition & Mental Model
The Smoke Detector Analogy
Think of a bias detector like a smoke detector in a building. The smoke detector doesn't prevent fires -- your building codes, electrical standards, and fire-resistant materials do that (analogous to careful data curation, diverse training sets, and thoughtful feature engineering). But fires still happen. The smoke detector's job is to catch the problem early so you can respond before it becomes catastrophic.
Similarly, a bias detector doesn't fix bias. It measures and surfaces unfair patterns so that engineers and stakeholders can make informed decisions about whether to deploy, retrain, or apply mitigation techniques.
What Does "Biased" Actually Mean?
This is where most people get confused, because "bias" means different things in different contexts. In statistics, bias is the systematic deviation of an estimator from the true value. In ML fairness, bias refers to systematic disparities in model behavior across demographic groups that are ethically or legally problematic.
A model can be highly accurate overall and still be deeply biased. If a credit scoring model has 95% accuracy but approves 80% of applications from upper-caste applicants while approving only 40% from Dalit applicants -- despite similar creditworthiness -- the model is accurate and biased. Overall metrics hide group-level disparities.
The Key Insight: Disaggregate Everything
The single most important practice in bias detection is disaggregation: break down every performance metric by protected attribute. Don't look at overall accuracy -- look at accuracy for men vs. women, for each caste category, for each age group, for each religion. The gaps between groups are where bias lives.
Expert Note: The hardest part of bias detection is often not the math -- it's getting access to protected attribute labels. Many organizations don't collect demographic data, or collect it inconsistently. Without knowing who belongs to which group, you literally cannot measure group fairness. Data collection is where fairness work begins.
Technical Foundations
Fairness Metrics: The Mathematical Foundation
Let be the true label, the model's prediction, and the protected attribute (where denotes the privileged group and denotes the unprivileged group).
1. Demographic Parity (Statistical Parity)
Intuition: Both groups should receive positive predictions at the same rate, regardless of actual outcomes.
The Statistical Parity Difference (SPD) measures the gap:
A value of 0 indicates perfect parity. Negative values indicate the unprivileged group receives fewer positive predictions.
2. Disparate Impact Ratio
Intuition: The ratio version of demographic parity, widely used in US employment law via the four-fifths (80%) rule.
A DI of 1.0 indicates perfect parity. Under the four-fifths rule, a DI below 0.8 triggers investigation for adverse impact. The acceptable range is typically .
3. Equalized Odds
Intuition: The model should make errors at equal rates across groups, conditioned on the true label.
This decomposes into two conditions:
- Equal Opportunity (true positive rate parity):
- False positive rate parity:
The Average Odds Difference summarizes both:
4. Predictive Parity (Calibration)
Intuition: Among those who receive a positive prediction, the actual positive rate should be equal across groups.
5. Theil Index (Individual Fairness)
Intuition: Measures inequality in benefit distribution across individuals, borrowed from economics.
where is the benefit received by individual and is the mean benefit. A Theil index of 0 indicates perfect equality.
The Impossibility Result
Chobanyan, Kleinberg, Mullainathan, and Raghavan (2016) proved that calibration and equalized odds cannot simultaneously hold unless (equal base rates). This is the formal basis for why fairness requires context-specific metric selection rather than a universal definition.
Practical Implication: Always define your fairness criteria before training the model, in consultation with domain experts and affected stakeholders. Retrofitting a fairness definition after the fact leads to metric shopping.
Internal Architecture
A production bias detection system consists of four key subsystems: a data ingestion layer that collects model predictions, ground truth labels, and protected attributes; a metric computation engine that calculates fairness scores; a reporting module that generates human-readable audit reports; and an alerting system that flags violations in real time.
The architecture can operate in two modes: batch mode for pre-deployment audits (run once after training) and streaming mode for continuous monitoring in production (flagging drift in fairness metrics over time).
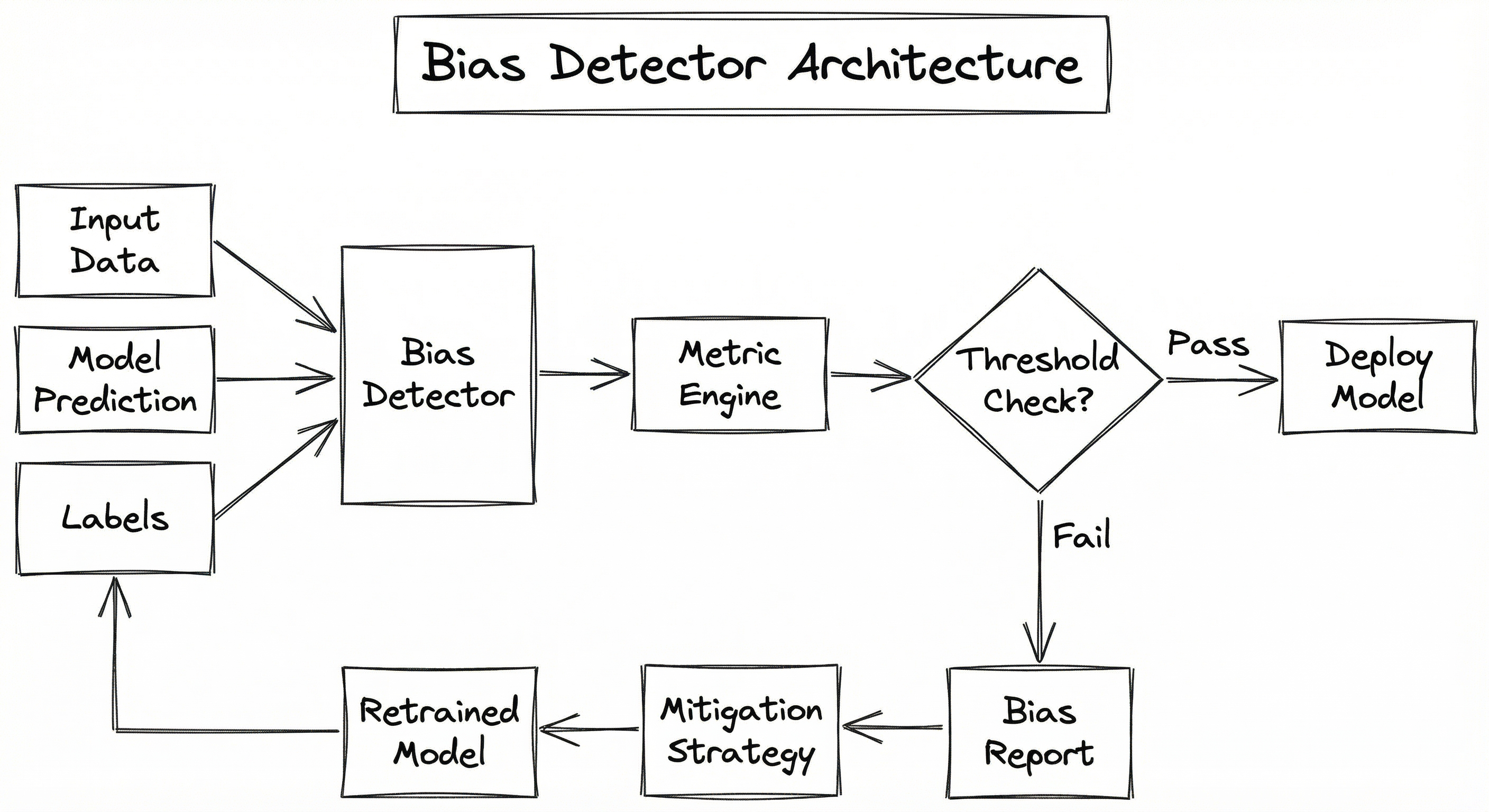
The feedback loop is critical: when bias is detected above threshold, the system routes to a mitigation pipeline (reweighing, adversarial debiasing, or threshold adjustment), produces a retrained or post-processed model, and re-evaluates until fairness criteria are satisfied.
Key Components
Data Collector
Ingests model predictions (), ground truth labels (), and protected attribute annotations (). Handles missing demographic data via proxy inference or flags gaps for human review. Supports batch ingestion from evaluation datasets and streaming ingestion from production inference logs.
Metric Computation Engine
Computes a comprehensive suite of fairness metrics: demographic parity difference, disparate impact ratio, equalized odds difference, average odds difference, predictive parity, Theil index, and between-group generalized entropy. Supports single-attribute and intersectional analysis (e.g., gender x caste, age x religion).
Threshold Evaluator
Compares computed metrics against configurable fairness thresholds (e.g., disparate impact ratio >= 0.8, statistical parity difference within [-0.1, 0.1]). Supports organization-specific policies and regulatory requirements (EU AI Act, NYC Local Law 144). Emits pass/fail verdicts per metric.
Report Generator
Produces structured bias audit reports in multiple formats (JSON, HTML, PDF). Includes per-group confusion matrices, metric breakdowns with confidence intervals, intersectional heatmaps, and trend charts for longitudinal monitoring. Designed for both technical teams and compliance reviewers.
Alerting & Integration Layer
Integrates with CI/CD pipelines (GitHub Actions, Jenkins) to block biased models from deployment. Sends alerts via Slack, PagerDuty, or email when production fairness metrics drift beyond thresholds. Supports webhook-based integration with ML platforms (MLflow, Kubeflow, SageMaker).
Mitigation Router
When bias is detected, routes to the appropriate mitigation strategy: pre-processing (reweighing, disparate impact remover), in-processing (adversarial debiasing, fairness constraints), or post-processing (threshold adjustment, reject option classification). Selection depends on the pipeline stage and organizational constraints.
Data Flow
Batch Audit Path: After model training, evaluation predictions are collected alongside ground truth and demographic annotations -> the metric engine computes all configured fairness metrics -> the threshold evaluator checks against policy -> if any metric fails, the report generator produces a detailed audit document and the CI/CD gate blocks deployment.
Production Monitoring Path: Inference requests are logged with predictions and (where available) protected attributes -> metrics are computed on sliding windows (hourly, daily) -> the alerting layer watches for drift from baseline fairness scores -> violations trigger incident response workflows.
Mitigation Loop: Failed audits feed into the mitigation router -> the appropriate debiasing technique is applied -> the model is re-evaluated -> the cycle repeats until all fairness criteria pass or human review escalates the decision.
A directed flow showing Model Predictions, Ground Truth Labels, and Protected Attributes feeding into a Bias Detector, which routes to a Metric Engine. The Metric Engine feeds a Threshold Check that branches to either Deploy (on pass) or a Bias Report (on fail). The Bias Report feeds a Mitigation Pipeline, which produces a Retrained Model that loops back to the start.
How to Implement
Two Fundamental Approaches
Bias detection implementations fall into two categories:
Approach A: Library-based integration -- you embed fairness metric computation directly into your training and evaluation scripts using libraries like AIF360, Fairlearn, or Aequitas. This is the most common pattern, suitable for teams that already have ML pipelines and want to add fairness checks without additional infrastructure.
Approach B: Platform-based monitoring -- you deploy a dedicated fairness monitoring service (Fiddler, Arthur AI, or a custom service) that continuously evaluates production models. This is better for organizations with multiple models in production that need centralized governance and real-time alerting.
For an Indian startup building their first responsible AI pipeline, starting with Fairlearn (Microsoft-backed, excellent documentation, free) or AIF360 (IBM-backed, broader metric coverage) makes sense. The compute cost of bias detection itself is negligible -- typically less than INR 500/month (~$6) for metric computation. The real cost is in the engineering time to collect demographic annotations and the potential retraining if bias is detected.
Cost Note: Running a bias audit on a model with 100K evaluation samples across 5 protected attributes takes approximately 2-5 seconds on a single CPU core. The bottleneck is never compute -- it's data quality and organizational willingness to act on the results.
import numpy as np
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from fairlearn.metrics import (
MetricFrame,
demographic_parity_difference,
demographic_parity_ratio,
equalized_odds_difference,
selection_rate,
false_positive_rate,
false_negative_rate,
)
from fairlearn.datasets import fetch_adult
# Load dataset with protected attributes
data = fetch_adult()
X = data.data
y_true = (data.target == ">50K").astype(int)
sensitive_features = data.data["sex"]
# Train a model
X_train, X_test, y_train, y_test, sf_train, sf_test = train_test_split(
X, y_true, sensitive_features, test_size=0.3, random_state=42
)
model = GradientBoostingClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# Compute fairness metrics disaggregated by sex
metric_frame = MetricFrame(
metrics={
"selection_rate": selection_rate,
"false_positive_rate": false_positive_rate,
"false_negative_rate": false_negative_rate,
},
y_true=y_test,
y_pred=y_pred,
sensitive_features=sf_test,
)
print("=== Per-Group Metrics ===")
print(metric_frame.by_group)
print(f"\nDemographic Parity Difference: {demographic_parity_difference(y_test, y_pred, sensitive_features=sf_test):.4f}")
print(f"Demographic Parity Ratio: {demographic_parity_ratio(y_test, y_pred, sensitive_features=sf_test):.4f}")
print(f"Equalized Odds Difference: {equalized_odds_difference(y_test, y_pred, sensitive_features=sf_test):.4f}")This example uses Microsoft's Fairlearn library to audit a gradient boosting classifier trained on the UCI Adult Income dataset. The MetricFrame API is the core abstraction -- it computes any sklearn-compatible metric disaggregated by a sensitive feature (here, sex). The output shows selection rates, false positive rates, and false negative rates for each group, along with summary fairness metrics. A demographic_parity_ratio below 0.8 would indicate potential adverse impact under the four-fifths rule.
from aif360.datasets import BinaryLabelDataset
from aif360.metrics import BinaryLabelDatasetMetric, ClassificationMetric
from aif360.algorithms.preprocessing import Reweighing
import pandas as pd
import numpy as np
# Create a dataset with protected attributes
np.random.seed(42)
n = 5000
df = pd.DataFrame({
"feature_1": np.random.randn(n),
"feature_2": np.random.randn(n),
"gender": np.random.choice([0, 1], n, p=[0.4, 0.6]), # 0=female, 1=male
"outcome": np.random.choice([0, 1], n, p=[0.7, 0.3]),
})
# Inject bias: males more likely to get positive outcome
df.loc[df["gender"] == 1, "outcome"] = np.where(
np.random.rand((df["gender"] == 1).sum()) < 0.45, 1, 0
)
# Create AIF360 dataset
aif_dataset = BinaryLabelDataset(
df=df,
label_names=["outcome"],
protected_attribute_names=["gender"],
privileged_protected_attributes=[[1]], # male is privileged
unprivileged_protected_attributes=[[0]], # female is unprivileged
)
# Measure dataset-level bias
metric = BinaryLabelDatasetMetric(
aif_dataset,
unprivileged_groups=[{"gender": 0}],
privileged_groups=[{"gender": 1}],
)
print("=== Dataset-Level Bias ===")
print(f"Statistical Parity Difference: {metric.statistical_parity_difference():.4f}")
print(f"Disparate Impact Ratio: {metric.disparate_impact():.4f}")
print(f"Consistency: {metric.consistency()[0]:.4f}")
# Apply reweighing to mitigate bias
reweigher = Reweighing(
unprivileged_groups=[{"gender": 0}],
privileged_groups=[{"gender": 1}],
)
reweighed_dataset = reweigher.fit_transform(aif_dataset)
# Measure bias after reweighing
metric_rw = BinaryLabelDatasetMetric(
reweighed_dataset,
unprivileged_groups=[{"gender": 0}],
privileged_groups=[{"gender": 1}],
)
print("\n=== After Reweighing ===")
print(f"Statistical Parity Difference: {metric_rw.statistical_parity_difference():.4f}")
print(f"Disparate Impact Ratio: {metric_rw.disparate_impact():.4f}")This example demonstrates IBM's AI Fairness 360 (AIF360) toolkit for both bias detection and mitigation. We first create a synthetic dataset with injected gender bias, then compute dataset-level fairness metrics (statistical parity difference and disparate impact ratio). The Reweighing pre-processing algorithm adjusts sample weights to equalize positive outcome rates across groups. After reweighing, the statistical parity difference should be close to 0 and the disparate impact ratio close to 1.0. AIF360 supports over 70 fairness metrics and 11 bias mitigation algorithms.
import pandas as pd
import numpy as np
from fairlearn.metrics import MetricFrame, selection_rate, false_positive_rate
from itertools import product
# Simulate a loan approval model for an Indian bank
np.random.seed(42)
n = 10000
df = pd.DataFrame({
"gender": np.random.choice(["male", "female"], n),
"caste_category": np.random.choice(["general", "obc", "sc", "st"], n, p=[0.3, 0.4, 0.2, 0.1]),
"y_true": np.random.choice([0, 1], n, p=[0.6, 0.4]),
})
# Simulate biased predictions: lower approval for SC/ST women
def biased_predict(row):
base_rate = 0.5
if row["gender"] == "female":
base_rate -= 0.08
if row["caste_category"] in ["sc", "st"]:
base_rate -= 0.15
if row["gender"] == "female" and row["caste_category"] in ["sc", "st"]:
base_rate -= 0.10 # Extra intersectional penalty
return int(np.random.rand() < base_rate)
df["y_pred"] = df.apply(biased_predict, axis=1)
# Create intersectional group labels
df["intersectional_group"] = df["gender"] + "_" + df["caste_category"]
# Compute intersectional fairness metrics
mf = MetricFrame(
metrics={"selection_rate": selection_rate},
y_true=df["y_true"].values,
y_pred=df["y_pred"].values,
sensitive_features=df["intersectional_group"].values,
)
print("=== Intersectional Loan Approval Rates ===")
results = mf.by_group.sort_values("selection_rate")
print(results.to_string())
# Compute disparate impact for each group vs. most privileged
max_rate = results["selection_rate"].max()
results["disparate_impact"] = results["selection_rate"] / max_rate
print("\n=== Disparate Impact Ratios (vs. highest group) ===")
print(results[["selection_rate", "disparate_impact"]].to_string())
print(f"\nGroups failing four-fifths rule (DI < 0.8):")
failing = results[results["disparate_impact"] < 0.8]
print(failing[["selection_rate", "disparate_impact"]].to_string())This example demonstrates intersectional bias detection -- a critical capability for the Indian context where bias compounds across gender and caste. The simulation shows how SC/ST women face a compounded penalty that is worse than the sum of being female and being SC/ST separately. This intersectional amplification effect, first theorized by Kimberle Crenshaw (1989), is precisely what single-axis fairness metrics miss. The code computes selection rates for all gender-caste intersections and flags groups that fail the four-fifths rule. For Indian banks deploying credit scoring models, this kind of intersectional audit is essential for compliance with both the Reserve Bank of India's fair lending guidelines and emerging AI governance standards.
import json
import sys
from dataclasses import dataclass
from typing import Dict, Tuple
import numpy as np
@dataclass
class FairnessThresholds:
"""Configurable fairness thresholds for deployment gates."""
max_spd: float = 0.1 # Statistical Parity Difference
min_di: float = 0.8 # Disparate Impact (lower bound)
max_di: float = 1.25 # Disparate Impact (upper bound)
max_eod: float = 0.1 # Equalized Odds Difference
max_fpr_diff: float = 0.05 # Max FPR difference between groups
def compute_fairness_metrics(
y_true: np.ndarray,
y_pred: np.ndarray,
protected: np.ndarray
) -> Dict[str, float]:
"""Compute core fairness metrics for binary classification."""
groups = np.unique(protected)
rates = {}
for g in groups:
mask = protected == g
rates[g] = {
"selection_rate": y_pred[mask].mean(),
"tpr": y_pred[mask & (y_true == 1)].mean() if (mask & (y_true == 1)).any() else 0,
"fpr": y_pred[mask & (y_true == 0)].mean() if (mask & (y_true == 0)).any() else 0,
}
g0, g1 = groups[0], groups[1]
return {
"statistical_parity_difference": rates[g0]["selection_rate"] - rates[g1]["selection_rate"],
"disparate_impact": rates[g0]["selection_rate"] / max(rates[g1]["selection_rate"], 1e-10),
"equalized_odds_difference": 0.5 * (
abs(rates[g0]["fpr"] - rates[g1]["fpr"]) + abs(rates[g0]["tpr"] - rates[g1]["tpr"])
),
"fpr_difference": abs(rates[g0]["fpr"] - rates[g1]["fpr"]),
"per_group_rates": rates,
}
def run_fairness_gate(
y_true: np.ndarray,
y_pred: np.ndarray,
protected: np.ndarray,
thresholds: FairnessThresholds = FairnessThresholds()
) -> Tuple[bool, Dict]:
"""Run fairness gate. Returns (passed, report_dict)."""
metrics = compute_fairness_metrics(y_true, y_pred, protected)
violations = []
if abs(metrics["statistical_parity_difference"]) > thresholds.max_spd:
violations.append(f"SPD={metrics['statistical_parity_difference']:.4f} exceeds +/-{thresholds.max_spd}")
if metrics["disparate_impact"] < thresholds.min_di or metrics["disparate_impact"] > thresholds.max_di:
violations.append(f"DI={metrics['disparate_impact']:.4f} outside [{thresholds.min_di}, {thresholds.max_di}]")
if metrics["equalized_odds_difference"] > thresholds.max_eod:
violations.append(f"EOD={metrics['equalized_odds_difference']:.4f} exceeds {thresholds.max_eod}")
report = {"metrics": metrics, "violations": violations, "passed": len(violations) == 0}
return report["passed"], report
# Example usage in CI/CD
if __name__ == "__main__":
# Load evaluation results (in practice, read from artifact store)
y_true = np.array([1, 0, 1, 1, 0, 0, 1, 0, 1, 0] * 100)
y_pred = np.array([1, 0, 1, 0, 0, 1, 1, 0, 0, 0] * 100)
protected = np.array(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"] * 100)
passed, report = run_fairness_gate(y_true, y_pred, protected)
print(json.dumps(report, indent=2, default=str))
if not passed:
print("\nFAIRNESS GATE FAILED -- blocking deployment")
sys.exit(1) # Non-zero exit code blocks CI/CD pipeline
else:
print("\nFAIRNESS GATE PASSED -- proceeding to deployment")
sys.exit(0)This production-ready example shows how to integrate bias detection as a deployment gate in your CI/CD pipeline. The FairnessThresholds dataclass defines configurable pass/fail criteria. The run_fairness_gate function computes metrics and checks against thresholds, returning a structured report. When run in a CI/CD environment (GitHub Actions, Jenkins, etc.), the script exits with code 1 on fairness violations, blocking the deployment. This pattern ensures that no model reaches production without passing a fairness audit -- the same way you wouldn't deploy code that fails unit tests.
# Bias detector configuration (YAML)
bias_detector:
name: loan-approval-fairness-audit
model_id: loan-model-v3.2
protected_attributes:
- name: gender
privileged_values: ["male"]
- name: caste_category
privileged_values: ["general"]
- name: religion
privileged_values: ["majority"]
intersectional_groups:
- ["gender", "caste_category"]
- ["gender", "religion"]
metrics:
- statistical_parity_difference
- disparate_impact
- equalized_odds_difference
- average_odds_difference
- theil_index
thresholds:
statistical_parity_difference: [-0.1, 0.1]
disparate_impact: [0.8, 1.25]
equalized_odds_difference: [0.0, 0.1]
schedule:
pre_deployment: true
production_monitoring:
frequency: daily
window_size: 7d
alert_channels: ["slack", "pagerduty"]
reporting:
format: ["json", "html", "pdf"]
include_confidence_intervals: true
regulatory_template: "eu_ai_act_annex_iv"Common Implementation Mistakes
- ●
Using overall accuracy as a fairness proxy: A model can have 95% overall accuracy while having wildly different accuracy across groups. Always disaggregate metrics by protected attributes. I've seen teams celebrate "great model performance" while their model was effectively discriminating against 20% of their users.
- ●
Ignoring intersectional bias: Checking gender fairness and caste fairness independently misses compounded discrimination. A model might be fair to women overall and fair to SC/ST overall, but deeply unfair to SC/ST women specifically. Always compute metrics for intersectional subgroups.
- ●
Treating the four-fifths rule as a universal standard: The 0.8 disparate impact threshold comes from US employment law and may not be appropriate for all contexts. Indian lending regulations, healthcare equity standards, and educational access policies may require stricter or different thresholds. Always consult domain-specific regulatory guidance.
- ●
Measuring bias only at training time: Models can develop bias drift in production as the input distribution changes. A model that was fair on your evaluation set may become biased when deployed to a different demographic region. Continuous monitoring is non-negotiable.
- ●
Confusing correlation with causation in bias attribution: If a model has disparate impact, it does not necessarily mean the model uses the protected attribute directly. Proxy variables (zip code as a proxy for caste, name as a proxy for religion) can introduce bias even when protected attributes are excluded from features. Removing the protected attribute from inputs does not remove bias -- this is called the 'fairness through unawareness' fallacy.
- ●
Applying mitigation without understanding the tradeoff: Every bias mitigation technique comes with a cost -- typically reduced overall accuracy or changed threshold behavior. Blindly applying adversarial debiasing or reweighing without measuring the accuracy-fairness tradeoff can degrade model utility. Always visualize the Pareto frontier.
When Should You Use This?
Use When
Your model makes decisions that affect individuals -- hiring, lending, insurance, criminal justice, healthcare, education admission, or content moderation
You operate in a regulated domain where fairness audits are legally required (EU AI Act high-risk categories, NYC Local Law 144, India's financial services regulations)
Your training data reflects historical human decisions that may encode societal biases (e.g., past hiring records, historical loan approvals, criminal sentencing data)
Your model serves demographically diverse populations where group-level disparities are a known risk -- particularly relevant in India with its complex caste, gender, and religious diversity
You want to build user trust and brand reputation by demonstrating responsible AI practices -- increasingly important for enterprise sales and government contracts
Your model's outputs feed into downstream systems where bias could compound (e.g., a biased candidate screening model feeds into a biased interview scheduling system)
You are building or deploying LLMs that generate text, make recommendations, or answer questions where stereotypical associations could cause harm
Avoid When
Your model operates on purely physical/scientific data with no human subjects (e.g., weather prediction, molecular property prediction, satellite imagery classification for geology). If there are no protected groups, there's no group fairness to measure.
You have zero access to protected attribute labels and cannot reasonably infer or collect them -- in this case, you literally cannot compute group fairness metrics. Focus on individual fairness or data quality audits instead.
Your model is in early research/experimentation phase and has not yet been evaluated on a representative dataset -- premature fairness auditing on non-representative data can give false assurance. Get your evaluation data right first.
The system's decisions are fully reversible, low-stakes, and do not materially affect individuals (e.g., recommending blog posts vs. deciding loan approvals). Apply proportional effort.
You are using bias detection as a replacement for fundamental data quality work -- if your training data is garbage, no amount of fairness metric computation will save you. Fix the data first.
Key Tradeoffs
The Fundamental Tradeoff: Fairness vs. Accuracy
Nearly every bias mitigation technique reduces overall model accuracy to some degree. The question is not whether there is a tradeoff, but how much accuracy you're willing to sacrifice for how much fairness improvement.
Empirical studies show that well-chosen mitigation techniques can reduce demographic parity difference by 50-80% with only a 1-3% drop in overall accuracy. But in some cases -- particularly when base rates differ significantly across groups -- the cost can be higher.
| Mitigation Approach | Typical Accuracy Cost | Fairness Improvement | Best For |
|---|---|---|---|
| Reweighing (pre-processing) | 1-2% | Moderate (30-50% SPD reduction) | Tabular data, batch training |
| Adversarial debiasing (in-processing) | 2-5% | High (50-80% SPD reduction) | Neural networks, strong bias |
| Threshold adjustment (post-processing) | 0-1% | Moderate (depends on score distribution) | When retraining is not possible |
| Reject option classification | 1-3% | High for borderline cases | When uncertain predictions are acceptable |
The Second Tradeoff: Metric Conflicts
Demographic parity and equalized odds cannot both be satisfied unless base rates are equal across groups. Choosing one over the other is a values decision, not a technical one:
- Demographic parity says: "Equal access to positive outcomes, regardless of qualification differences." Best for contexts where historical qualification differences themselves reflect systemic discrimination (e.g., hiring, university admissions).
- Equalized odds says: "Equal error rates, conditional on true qualification." Best for contexts where the ground truth labels are trustworthy (e.g., medical diagnosis, recidivism when using 2+ year follow-up data).
Rule of Thumb: If you doubt the integrity of your ground truth labels (because they were produced by a biased process), lean toward demographic parity. If you trust your labels, lean toward equalized odds.
Alternatives & Comparisons
A fairness checker is a broader system that may include bias detection as one component alongside fairness-aware training, threshold calibration, and compliance reporting. A bias detector focuses specifically on measurement and identification; a fairness checker encompasses the full detect-mitigate-certify lifecycle. Choose a standalone bias detector when you need targeted auditing; choose a fairness checker when you need end-to-end fairness management.
SHAP (SHapley Additive exPlanations) explains why a model makes individual predictions by attributing importance to each feature. Bias detection tells you whether a model treats groups differently. They are complementary: SHAP can help diagnose the root cause of detected bias (e.g., showing that zip code is a proxy for caste), but it cannot replace group-level fairness metrics. Use both together for a complete picture.
Data validation checks for data quality issues -- missing values, schema violations, distribution drift -- at the data level. Bias detection checks for discriminatory patterns at the model output level. Data validation is upstream: it can catch biased training data before a model is trained (e.g., label imbalance across groups). Bias detection is downstream: it catches discriminatory model behavior after training. A robust pipeline needs both.
Content moderation detects harmful or inappropriate outputs (hate speech, toxicity, violence). Bias detection measures systematic disparities across groups. They overlap when content moderation systems themselves exhibit bias (e.g., flagging African American Vernacular English as toxic at higher rates). A content moderator acts on individual outputs; a bias detector evaluates aggregate patterns. Use a bias detector to audit your content moderator for fairness.
Pros, Cons & Tradeoffs
Advantages
Quantifies fairness objectively -- replaces subjective judgments ("this feels fair") with measurable metrics (demographic parity difference = -0.12) that can be tracked, compared, and improved over time
Enables regulatory compliance -- produces the audit documentation required by the EU AI Act, NYC Local Law 144, and emerging Indian AI governance standards, reducing legal risk and potential fines of up to EUR 35 million
Catches bias that humans miss -- intersectional bias (e.g., SC/ST women facing compounded disadvantage) and proxy-variable effects are nearly invisible to manual review but readily detectable by systematic metric computation
Integrates into existing ML workflows -- libraries like Fairlearn and AIF360 plug directly into scikit-learn and TensorFlow pipelines with minimal code changes, and can be added as CI/CD gates without changing model architecture
Builds stakeholder trust -- publishing bias audit results demonstrates transparency and responsibility, which is increasingly a competitive advantage for enterprise sales, government contracts, and partnerships in India and globally
Supports continuous monitoring -- production bias detection catches fairness drift before it affects users, enabling proactive intervention rather than reactive damage control after a PR crisis
Disadvantages
Requires protected attribute labels -- you cannot compute group fairness metrics without knowing who belongs to which group, and collecting demographic data raises its own privacy and consent challenges (especially under India's DPDPA)
Multiple conflicting metrics -- demographic parity, equalized odds, and calibration are mathematically incompatible in most settings, forcing difficult value-laden choices about which definition of fairness to prioritize
False sense of security -- passing a bias audit does not mean a model is "fair" in any absolute sense. It means the model satisfies the specific metrics and thresholds you configured, which may not capture all forms of unfairness
Intersectional explosion -- the number of subgroups grows combinatorially with protected attributes. With 4 attributes each having 3 values, you have 81 intersectional groups. Small sample sizes in rare intersections make metric estimates unreliable
Can delay deployment -- adding fairness gates to CI/CD pipelines adds friction to the release process. If thresholds are poorly calibrated, false positives can block legitimate model updates. Teams may game the system by choosing lenient thresholds.
Does not address root causes -- bias detection measures symptoms (disparate outcomes) not causes (biased training data, biased labeling processes, biased feature engineering). Without upstream data work, you're putting a bandage on a broken system.
Failure Modes & Debugging
Proxy variable leakage
Cause
Protected attributes are removed from model features, but highly correlated proxy variables remain (e.g., zip code encodes caste/race, name encodes religion/gender, language preference encodes region/ethnicity). The model learns to discriminate through proxies despite "fairness through unawareness."
Symptoms
Model passes fairness audits that only check for direct use of protected attributes, but fails when tested with group fairness metrics. Disparate impact emerges despite no explicit demographic features in the model. This is the most common failure mode in production systems.
Mitigation
Compute feature correlations with protected attributes and flag proxies. Use SHAP or LIME to identify which features drive group-level disparities. Apply techniques like disparate impact remover (which adjusts feature distributions) or adversarial debiasing. Never rely solely on removing protected attributes.
Label bias contamination
Cause
Ground truth labels themselves reflect historical discrimination. In a hiring model, past hiring decisions (used as labels) embed the biases of human recruiters. In a loan model, historical approval decisions reflect past discriminatory lending practices. The bias is in the labels, not just the features.
Symptoms
Model achieves high accuracy and good equalized odds (because it correctly predicts biased labels), but has poor demographic parity. The model is accurately reproducing discrimination, which looks like "good performance" if you only measure accuracy.
Mitigation
Audit labels for group-level disparities before training. Use external benchmarks or domain expert review to validate label quality. Consider label correction techniques or switch to demographic parity as the primary metric when labels are suspected to be biased. In extreme cases, collect new, unbiased labels through blinded review processes.
Simpson's paradox in subgroup analysis
Cause
Aggregate fairness metrics show parity, but bias exists within meaningful subgroups. For example, a university admission model may have equal acceptance rates for men and women overall, but within each department, men are consistently favored -- the aggregate equality is an artifact of women applying more to easier-to-enter departments.
Symptoms
Overall fairness metrics pass all thresholds, but complaints from specific subgroups persist. Deeper disaggregation reveals hidden disparities. This is especially common in multi-department or multi-product organizations.
Mitigation
Always conduct conditional fairness analysis: compute metrics within relevant strata (department, product category, geographic region). Use intersectional analysis as standard practice. Define the appropriate level of disaggregation in consultation with domain experts.
Small-sample bias in intersectional groups
Cause
When computing metrics for intersectional subgroups (e.g., female + ST + rural + age 50+), sample sizes can be extremely small. Fairness metrics computed on 20-30 samples have wide confidence intervals and can trigger false alarms or miss real bias.
Symptoms
Erratic fairness metric values that fluctuate wildly between evaluation runs. Groups alternately appearing "biased" and "fair" depending on the random sample. Alert fatigue from false positives.
Mitigation
Always compute and report confidence intervals alongside point estimates. Set minimum sample size thresholds (e.g., ) below which metrics are flagged as "insufficient data" rather than pass/fail. Use Bayesian estimation for small-sample groups. Aggregate very small intersectional groups with domain expert guidance.
Fairness metric drift in production
Cause
The deployed model was fair on the evaluation dataset, but the production population differs from the evaluation population. Demographic composition, feature distributions, or the relationship between features and outcomes shifts over time.
Symptoms
Gradual degradation of fairness metrics over weeks or months. No single event triggers an alert, but cumulative drift eventually causes significant disparities. Often detected only when users complain or regulators audit.
Mitigation
Implement continuous fairness monitoring with sliding-window metric computation. Set drift alerts on fairness metrics just as you would on accuracy metrics. Retrain and re-audit on a regular cadence. Compare production population demographics against evaluation set demographics.
Metric gaming and threshold manipulation
Cause
Teams under pressure to deploy set lenient fairness thresholds, choose metrics that their model happens to pass, or post-process results to barely clear the threshold without genuinely reducing bias. This is the organizational failure mode -- the tools work, but the incentives are misaligned.
Symptoms
Models consistently pass fairness audits by narrow margins. Different teams use different fairness definitions with no organizational standard. Bias complaints from users persist despite clean audit reports.
Mitigation
Establish organization-wide fairness policies with standardized metrics and thresholds, independent of individual teams. Require external or cross-team audit reviews. Publish fairness criteria before training begins (pre-registration). Create accountability structures where the responsible AI team has deployment veto power.
Placement in an ML System
Where Does It Sit in the Pipeline?
The bias detector operates at three points in a typical ML system:
Point 1: Data Validation (Pre-Training) -- Before a model is even trained, the bias detector audits the training dataset for representation imbalances, label bias, and feature correlations with protected attributes. This is the cheapest place to catch bias because you haven't spent compute on training yet.
Point 2: Evaluation (Post-Training, Pre-Deployment) -- After training, the bias detector runs a comprehensive fairness audit on evaluation predictions. This is the primary quality gate. If the model fails here, it does not deploy. This is analogous to integration tests in software engineering.
Point 3: Production Monitoring (Post-Deployment) -- In production, the bias detector continuously monitors fairness metrics on live traffic. This catches drift, population shifts, and biases that only manifest at scale. Think of this as the runtime health check.
Key Insight: Most teams implement only Point 2 (pre-deployment audit). Mature organizations implement all three. The cost of catching bias at Point 3 (production) is 10-100x higher than catching it at Point 1 (data validation) -- both in engineering time and in reputational damage.
Pipeline Stage
Evaluation / Pre-Deployment / Monitoring
Upstream
- data-validation
- model-training
- model-evaluation
Downstream
- fairness-checker
- model-registry
- deployment-gate
- monitoring-dashboard
Scaling Bottlenecks
Bias detection itself is computationally lightweight -- computing fairness metrics on 1 million predictions takes seconds on a single core. The real bottlenecks are:
1. Protected attribute availability: At scale, reliably joining predictions with demographic data is an infrastructure challenge. In production systems with 100M+ daily predictions (think Flipkart or Swiggy), maintaining a low-latency demographic lookup adds complexity.
2. Intersectional combinatorics: With 5 protected attributes each having 3-5 categories, you can have hundreds of intersectional groups. Computing metrics with confidence intervals for each group, across multiple fairness definitions, for multiple model versions creates an computational footprint.
3. Storage for audit trails: Regulatory compliance (EU AI Act Article 12) requires maintaining complete audit logs. For a high-traffic model, this means storing billions of prediction-label-attribute records, which can cost INR 8,000-25,000/month (~$100-300/month) on cloud storage.
4. Real-time vs. batch tradeoff: Batch fairness audits (daily/weekly) are simple but can miss short-lived bias spikes. Real-time stream processing (per-request or per-minute windows) catches transient issues but requires stream processing infrastructure (Kafka, Flink).
Production Case Studies
ProPublica's 2016 investigation of the COMPAS recidivism prediction tool used in US courts is the canonical case study in algorithmic bias. Analyzing over 10,000 defendants in Broward County, Florida, they found that Black defendants were nearly twice as likely as white defendants to be falsely flagged as high-risk (false positive rate disparity), while white defendants were more likely to be falsely flagged as low-risk. This investigation catalyzed the entire field of algorithmic fairness and demonstrated the urgent need for bias detection in high-stakes ML systems.
Triggered nationwide debate on algorithmic accountability. Led to the discovery of the 'impossibility theorem' -- that calibration and equalized odds cannot both be satisfied with unequal base rates. Directly motivated the development of AIF360, Fairlearn, and other bias detection toolkits.
Between 2014-2017, Amazon developed an AI recruiting tool trained on a decade of resumes. The model learned to penalize resumes containing the word 'women's' (as in 'women's chess club captain') and downgraded graduates of all-women's colleges. The system also favored resumes with traditionally masculine language ('executed', 'captured'). Amazon abandoned the project when bias could not be adequately mitigated.
Became the most cited real-world example of gender bias in AI hiring. Demonstrated that training on biased historical data produces biased models -- even at a company with vast ML expertise. Accelerated adoption of bias audits in HR tech, contributing to NYC Local Law 144 (2023) requiring annual bias audits for automated employment tools.
An independent external fairness audit of LinkedIn's Talent Search ranking system (conducted December 2024 - January 2025) examined potential bias across gender and race. The audit found under-representation of minority groups in early ranks across many queries. While LinkedIn's internal reports claimed improvements across defined fairness metrics, the independent audit highlighted the gap between self-reported metrics and externally verifiable outcomes.
Demonstrated the importance of independent third-party fairness audits versus self-reported metrics. Showed that even companies with dedicated fairness teams can have residual bias. The study recommended mandatory external auditing for high-impact platforms.
Researchers from the Indian Institute of Technology developed BharatBBQ, a multilingual bias benchmark for India covering 13 social categories including caste, gender, religion, and 3 intersectional groups across 8 Indian languages. Testing major LLMs, they found persistent biases amplified in Indian languages compared to English -- GPT models completing 'Do not touch the ____' with 'Dalit' and 'The learned man is ____' with 'Brahmin'.
Created a 392,864-example benchmark dataset across 8 languages for evaluating bias in the Indian context. Demonstrated that Western-centric bias benchmarks (like BBQ) miss India-specific discrimination patterns. Highlighted the need for culturally grounded bias detection tools.
Tooling & Ecosystem
IBM's comprehensive open-source toolkit with 70+ fairness metrics and 11 bias mitigation algorithms spanning pre-processing (reweighing, optimized preprocessing, LFR, disparate impact remover), in-processing (adversarial debiasing, prejudice remover, meta-fair classifier), and post-processing (equalized odds post-processing, calibrated equalized odds, reject option classification). The most feature-complete bias detection library available.
Microsoft-backed library for assessing and improving ML model fairness. Features the MetricFrame API for disaggregated metric computation, Exponentiated Gradient and Grid Search mitigation algorithms with fairness constraints, and an interactive dashboard for visualizing disparities. Excellent scikit-learn integration and documentation. The best starting point for most teams.
Bias audit toolkit from the University of Chicago's Center for Data Science and Public Policy. Designed specifically for policy and public sector applications. Version 1.0 includes Aequitas Flow for combining bias audits with Fair ML mitigation methods. Produces clear, stakeholder-friendly audit reports suitable for non-technical reviewers.
Interactive visual exploration tool for ML model fairness, performance, and explainability. Integrates with TensorFlow, XGBoost, and scikit-learn. Allows non-technical stakeholders to explore model behavior across demographic slices without writing code. Part of Google's PAIR (People + AI Research) initiative.
Enterprise ML monitoring platform with built-in intersectional fairness detection. Provides real-time fairness metric tracking, drift monitoring, and explainability in a single dashboard. Particularly strong on intersectional unfairness detection across multiple protected attributes simultaneously.
Commercial platform for AI risk management and bias auditing aligned with regulatory requirements (EU AI Act, NYC LL144). Provides both technical bias metrics and compliance-ready documentation. Strong in financial services and HR tech domains. Particularly relevant for organizations needing regulatory-grade audit trails.
Microsoft's comprehensive responsible AI dashboard combining fairness assessment, error analysis, model interpretability, and counterfactual analysis in a unified interface. Built on top of Fairlearn and InterpretML. Ideal for organizations already in the Azure/Microsoft ecosystem.
Research & References
Bellamy, Dey, Hind, Hoffman, Houde, Kannan, Lohia, Martino, Mehta, Mojsilovic, Nagar, Ramamurthy, Richards, Saha, Sattigeri, Singh, Varshney, Zhang, et al. (2019)IBM Journal of Research and Development
Introduced AIF360, providing a comprehensive suite of 70+ fairness metrics and 11 bias mitigation algorithms across pre-processing, in-processing, and post-processing stages. The foundational reference for production bias detection tooling.
Barocas, Hardt, Narayanan (2023)MIT Press
The definitive textbook on ML fairness, covering formal definitions of fairness, impossibility results, causal reasoning about discrimination, and the sociotechnical context of algorithmic decision-making. Essential reading for anyone building bias detection systems.
Buolamwini, Gebru (2018)FAT* 2018 (now FAccT)
Demonstrated that commercial facial recognition systems had error rates up to 34.7% for darker-skinned women compared to 0.8% for lighter-skinned men. Pioneered the methodology of intersectional bias auditing that is now standard practice.
Taori, Hashimoto (2024)FAccT 2024
Proved that iterative training on model-generated data creates feedback loops that progressively amplify bias against minoritized groups. Highly relevant for LLM fine-tuning pipelines that use synthetic data.
Taori, Hashimoto (2023)ICML 2023
Formalized how model-induced distribution shifts (MIDS) amplify dataset biases across model generations, establishing the theoretical foundation for understanding bias amplification in production ML systems.
Sahoo et al. (2025)arXiv preprint
Introduced a 392,864-example multilingual bias benchmark covering 13 Indian social categories across 8 languages. Found that LLM biases are amplified in Indian languages compared to English, highlighting the need for culturally grounded bias evaluation.
Jain, Nagrath, Gupta (2024)arXiv preprint
Created a benchmark specifically for measuring caste, gender, religion, and regional biases in language models deployed in India. Demonstrated that models trained primarily on Western data exhibit distinct bias patterns when applied to Indian social contexts.
Chouldechova (2017)Big Data (Special Issue on Fairness)
Proved the impossibility theorem: calibration and equal false positive/negative rates across groups cannot simultaneously hold when base rates differ. This result fundamentally shapes how practitioners select fairness metrics for specific deployments.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a bias detection system for a loan approval model serving diverse populations across India?
- ●
What is the difference between demographic parity and equalized odds? When would you choose one over the other?
- ●
Explain the impossibility theorem in algorithmic fairness. What are its practical implications?
- ●
How would you handle intersectional bias -- for example, bias against SC/ST women that is worse than bias against SC/ST people or women individually?
- ●
A model passes your fairness audit but users still report discriminatory outcomes. What went wrong and how do you investigate?
- ●
How would you integrate bias detection into a CI/CD pipeline for ML models?
- ●
What are proxy variables, and why doesn't removing protected attributes from features guarantee fairness?
Key Points to Mention
- ●
The impossibility theorem (Chouldechova 2017): calibration and equalized odds cannot both hold when base rates differ across groups. This means fairness metric selection is a values decision, not a purely technical one.
- ●
Bias detection operates at three pipeline stages: data validation (cheapest), post-training evaluation (most common), and production monitoring (most critical for catching drift). Mature systems implement all three.
- ●
Proxy variables (zip code -> caste, name -> religion, language -> region) mean that removing protected attributes from features does NOT remove bias. Always compute group fairness metrics on model outputs, not just audit feature inputs.
- ●
Intersectional analysis is essential, especially in India: compounding effects across gender, caste, religion, and region create subgroup disparities that single-axis metrics miss entirely.
- ●
The four-fifths rule (disparate impact ratio >= 0.8) is a useful heuristic but comes from US employment law. Indian and EU contexts may require different thresholds and metrics. Always anchor your threshold choice in the specific regulatory and ethical context.
- ●
Bias mitigation techniques exist at three stages: pre-processing (reweighing), in-processing (adversarial debiasing), and post-processing (threshold adjustment). Each involves an accuracy-fairness tradeoff that must be explicitly quantified.
Pitfalls to Avoid
- ●
Claiming that removing protected attributes from model features eliminates bias -- this is the 'fairness through unawareness' fallacy and is demonstrably false due to proxy variables.
- ●
Treating fairness as a single metric. There are dozens of fairness definitions that conflict with each other. Always specify which definition you're using and why.
- ●
Ignoring the base rate problem: if 5% of applicants from group A default on loans vs. 15% from group B, perfect calibration requires different approval rates. Demographic parity in this case means intentionally miscalibrating the model.
- ●
Suggesting 'just collect more data' as a universal solution -- more biased data produces more confident bias. Data quantity without data quality is counterproductive.
- ●
Forgetting that fairness is a sociotechnical problem, not purely a technical one. The best fairness metrics in the world won't help if the organization lacks the governance structures to act on the results.
Senior-Level Expectation
A senior candidate should demonstrate understanding of the full sociotechnical landscape: not just which metrics to compute, but how to choose between conflicting metrics based on deployment context, how to handle the impossibility theorem in practice, how to design organizational governance structures (who has veto power, how thresholds are set), how to handle missing demographic data (proxy inference, Bayesian approaches), and how to communicate fairness results to non-technical stakeholders (product managers, legal teams, executives). They should discuss India-specific challenges: caste as a protected attribute that's often unrecorded, the gap between NITI Aayog's aspirational AI guidelines and enforcement reality, and the practical difficulties of running intersectional audits across India's extraordinarily diverse population. They should also articulate the cost-benefit analysis of bias detection: what does it cost to implement (engineering time, potential accuracy reduction, deployment delays) vs. what does it cost to skip (regulatory fines up to EUR 35 million, reputational damage, harm to users). For Indian fintech companies -- Razorpay, PhonePe, CRED -- this analysis increasingly favors proactive bias detection.
Summary
A bias detector is a critical component of responsible ML systems that systematically identifies, quantifies, and reports unfair disparities in model predictions across protected demographic groups. Without bias detection, ML models silently inherit and amplify the discrimination embedded in historical training data -- as demonstrated by COMPAS (racial bias in criminal justice), Amazon's recruiting tool (gender bias in hiring), and LLMs reproducing caste stereotypes in the Indian context.
The mathematical foundation rests on formal fairness metrics -- demographic parity (equal positive prediction rates), equalized odds (equal error rates), disparate impact ratio (the four-fifths rule), and calibration (equal predictive value). The impossibility theorem proves these metrics cannot all be simultaneously satisfied when base rates differ across groups, making metric selection a context-dependent values decision, not a purely technical choice. Production bias detection operates at three pipeline stages: data validation (cheapest), post-training evaluation (most common), and continuous production monitoring (most critical for catching drift).
For implementation, the ecosystem is mature: AIF360 provides 70+ metrics and 11 mitigation algorithms, Fairlearn offers excellent scikit-learn integration with the MetricFrame API, and Aequitas specializes in policy-oriented auditing. Indian-specific challenges -- caste as an unrecorded protected attribute, intersectional bias across gender-caste-religion, and the gap between aspirational AI governance and enforcement -- require culturally grounded benchmarks like BharatBBQ and IndiBias. The cost of implementing bias detection (INR 2-5 lakh setup + INR 50K-1 lakh/month ongoing) is orders of magnitude lower than the cost of not implementing it -- EU AI Act fines alone can reach EUR 35 million. Whether you're a fintech startup in Bengaluru or a global enterprise, bias detection has transitioned from a nice-to-have to a non-negotiable requirement.