Train/Test Split in Machine Learning
The train/test split is one of the most deceptively simple concepts in machine learning -- and one of the most consequential to get wrong. At its core, it is the practice of partitioning a dataset into mutually exclusive subsets so that a model is trained on one portion and evaluated on data it has never seen.
Why does this matter so much? Because without a proper split, you have no trustworthy way to estimate how your model will perform in production. A model that scores 99% accuracy on data it was trained on tells you exactly nothing. That number could drop to 60% the moment it encounters real-world inputs. The split is your only honest mirror.
In practice, most teams use a three-way split: training (to learn parameters), validation (to tune hyperparameters and make architectural decisions), and test (to get a final, unbiased performance estimate). The ratios vary -- 70/15/15 and 80/10/10 are common -- but the principle is universal: the test set is sacred. You touch it once, at the very end, and you report whatever number it gives you.
This guide covers everything from the basic holdout method to advanced strategies like stratified splitting, time-series splitting, and group-aware splitting. We will also spend significant time on data leakage -- the silent killer that has invalidated more ML experiments than any other single mistake. Whether you are building a fraud detector at Razorpay or a recommendation engine at Flipkart, getting the split right is non-negotiable.
Concept Snapshot
- What It Is
- The process of partitioning a dataset into disjoint training, validation, and test subsets to enable unbiased model evaluation and hyperparameter tuning.
- Category
- Model Training
- Complexity
- Beginner
- Inputs / Outputs
- Input: a labeled (or unlabeled) dataset. Output: two or three disjoint subsets -- training set, validation set (optional), and test set -- with controlled proportions and statistical properties.
- System Placement
- Sits between data preprocessing/feature engineering (upstream) and model training/hyperparameter tuning (downstream) in the ML pipeline.
- Also Known As
- holdout method, data splitting, train-val-test split, dataset partitioning, data holdout
- Typical Users
- ML Engineers, Data Scientists, Applied Researchers, MLOps Engineers
- Prerequisites
- Basic statistics (distributions, sampling), Supervised learning fundamentals, Understanding of overfitting and generalization
- Key Terms
- stratified splitdata leakageholdoutcross-validationtemporal splitgroup spliti.i.d. assumptiongeneralization error
Why This Concept Exists
The Fundamental Problem: Overfitting Is Invisible Without a Split
Imagine training a model on every data point you have and then reporting its accuracy on the same data. You could get 100% by simply memorizing the dataset -- a lookup table would suffice. This is not learning; it is rote memorization. The model has captured noise, not signal.
The train/test split exists to solve this fundamental evaluation problem. By withholding a portion of data that the model never sees during training, we get an honest estimate of generalization error -- how well the model will perform on new, unseen data. This is arguably the single most important concept in applied ML.
A Brief History
The idea of holding out data for evaluation dates back to the early days of statistical model selection. In 1931, Larson proposed using independent samples for model validation. But the practice became formalized in the ML community through Stone (1974) and Geisser (1975), who established the theoretical foundations of cross-validation. Ron Kohavi's landmark 1995 study at Stanford systematically compared holdout, bootstrap, and k-fold cross-validation on real datasets, establishing the practical guidelines that the community still follows today.
Why Three Sets, Not Two?
The two-set split (train/test) has a subtle flaw: if you use the test set to make any decision -- choosing between models, tuning a threshold, selecting features -- you have effectively "peeked" at the test data. Each decision contaminates your test estimate.
The solution is the three-way split: train on the training set, make all intermediate decisions using the validation set, and reserve the test set for a single final evaluation. This gives you two layers of protection against overfitting:
- The validation set catches overfitting to the training data.
- The test set catches overfitting to the validation data (yes, this happens).
Key Takeaway: The train/test split is not just a convenience -- it is the mechanism that makes empirical ML science possible. Without it, every performance number is a fiction.
Core Intuition & Mental Model
The Restaurant Analogy
Think of training a model like a chef preparing for a restaurant opening. The training set is the kitchen during practice -- the chef experiments with recipes, adjusts seasoning, and iterates freely. The validation set is a soft launch with trusted friends who give honest feedback -- the chef uses this to refine the menu. The test set is opening night with real food critics. You get one shot. You cannot go back and adjust the recipes based on the critics' scores and then claim those scores represent an unbiased review.
If the chef tastes the critics' plates beforehand and tweaks the recipes accordingly, the review is meaningless. That is exactly what happens when you use the test set for anything other than final evaluation. This is data leakage by another name.
The Core Guarantee
Here is the statistical guarantee that makes the split work: if the test set is drawn independently and identically distributed (i.i.d.) from the same population as the training data, then the model's performance on the test set is an unbiased estimate of its performance on future data from that population.
The phrase "from that population" is doing a lot of work. If the production data distribution shifts -- and it usually does -- your test estimate is only as good as the overlap between your test distribution and the real world. This is why temporal splits exist for time-dependent data, and why domain adaptation is such a hot research area.
Why Randomness Matters
A common beginner mistake is splitting data sequentially -- "first 80% for training, last 20% for testing." If the data has any temporal ordering, seasonal patterns, or was sorted by some attribute, this creates a biased split. Random shuffling ensures that both sets are representative samples of the underlying distribution.
But randomness alone is not always enough. If your dataset has 95% negative examples and 5% positive, a random split could give you a test set with 0% positives by sheer bad luck. That is where stratified splitting comes in -- preserving the class distribution across all subsets.
Technical Foundations
Mathematical Framework
Let be a dataset of samples drawn i.i.d. from an unknown distribution . A train/test split partitions into disjoint subsets:
with , , , and .
Generalization Error Estimation
The test set provides an estimate of the true risk (generalization error):
The empirical risk on the test set:
is an unbiased estimator of if and only if was chosen independently of .
Confidence Interval for the Test Estimate
By the Central Limit Theorem, for large , the test error has a confidence interval:
where is the critical value for confidence level . For classification accuracy with and , the 95% confidence interval is approximately . This tells you how much to trust that test number.
Stratified Sampling Formulas
For a classification problem with classes, let be the proportion of class in the full dataset. A stratified split ensures that each subset preserves these proportions:
Formally, stratified sampling minimizes the total variation distance between the class distribution of each subset and the population distribution:
Data Leakage Detection (Formal)
Data leakage can be formally detected by testing mutual information between train and test sets beyond what is expected under i.i.d. sampling:
In practice, this manifests as test accuracy significantly exceeding cross-validation estimates, or as a model performing far better on the test set than on truly new production data. A practical heuristic: if your test accuracy is more than 5 percentage points above your cross-validation estimate, investigate for leakage.
Internal Architecture
The train/test split sits within a larger data preparation pipeline. In production ML systems, splitting is not a one-time operation -- it is a reproducible, versioned step that must handle data updates, class imbalance, temporal ordering, and group constraints.
A well-designed splitting architecture has three layers: a strategy selector that chooses the splitting method based on data characteristics, a split executor that performs the actual partitioning with appropriate randomness controls, and a validation checker that verifies split quality (class balance, leakage detection, coverage).
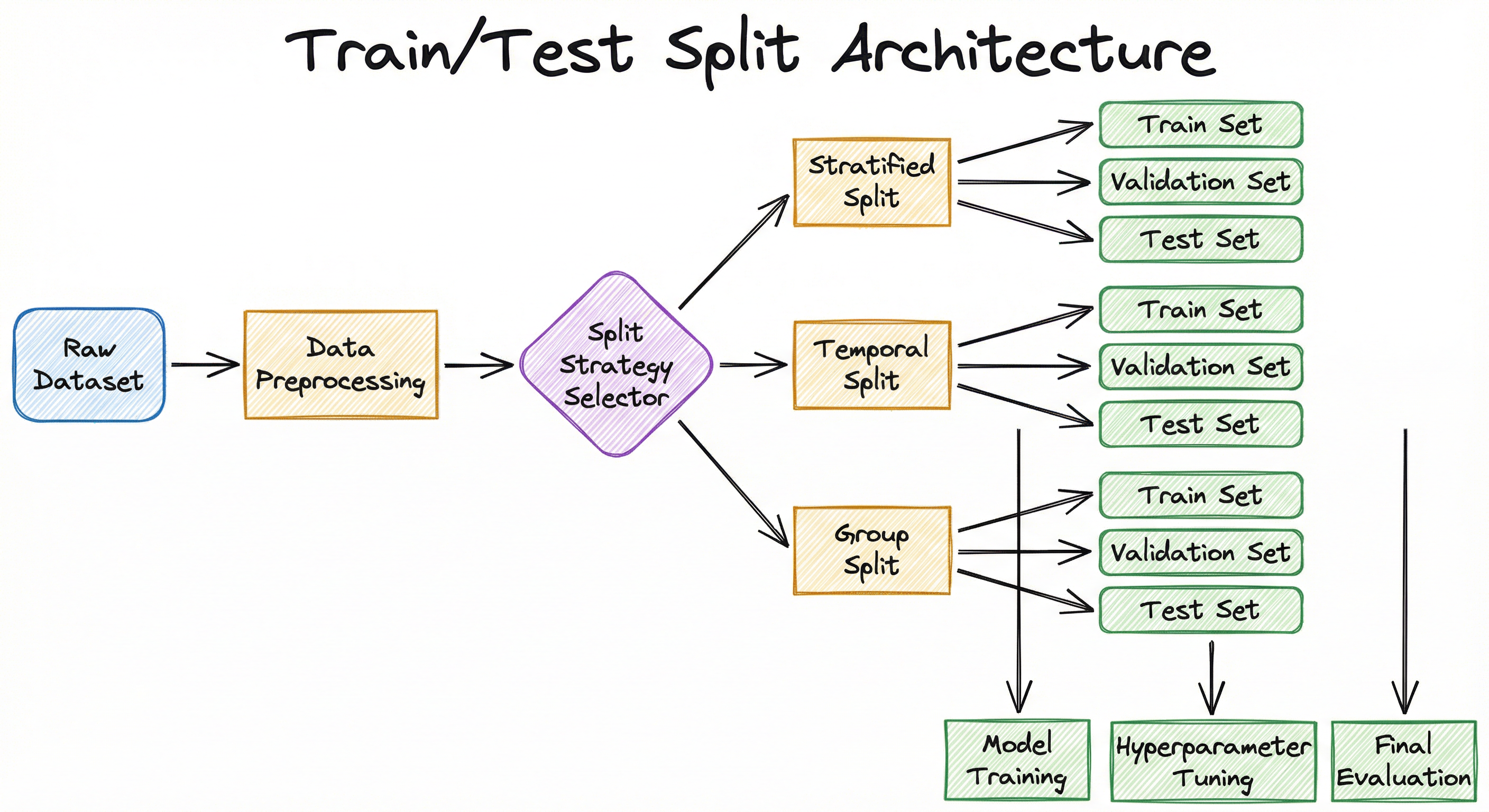
The split strategy is determined by the nature of the data. For classification tasks with imbalanced classes, stratified splitting is essential. For time-series forecasting, temporal splitting prevents future information from leaking into training. For medical studies or A/B test data where multiple records belong to the same entity (patient, user, session), group splitting ensures all records from an entity stay in the same subset.
Key Components
Split Strategy Selector
Analyzes dataset characteristics (class distribution, temporal ordering, group structure) and selects the appropriate splitting strategy. This is often a manual decision, but can be automated in mature ML platforms.
Stratified Splitter
Partitions data while preserving the target variable's distribution across all subsets. Uses iterative stratification for multi-label problems. Essential when dealing with class imbalance -- for example, fraud detection at Razorpay where fraudulent transactions may be <0.1% of all data.
Temporal Splitter
Splits data along the time axis, ensuring training data is strictly before validation data, which is strictly before test data. Prevents temporal leakage in time-series forecasting, stock prediction, or demand forecasting at e-commerce platforms.
Group Splitter
Ensures all samples belonging to the same group (patient, user, device, geographic region) are assigned to the same subset. Prevents information leakage when samples within a group are correlated.
Leakage Detector
Validates the split by checking for duplicate samples across subsets, feature overlap that should not exist, and statistical anomalies that suggest information leakage. Can be implemented as a post-split validation step.
Split Registry
Stores split indices or hashes alongside dataset versions for reproducibility. Enables re-creating exact splits for experiment comparison and audit trails. Critical for regulated industries like healthcare and finance.
Data Flow
Data Flow Through the Splitting Pipeline:
- Input: Preprocessed dataset with features, labels, and optional metadata (timestamps, group IDs).
- Strategy Selection: The system examines the dataset for class distribution, temporal structure, and group membership to choose the splitting method.
- Partitioning: The selected splitter divides the data into train/val/test subsets using the chosen strategy with a fixed random seed for reproducibility.
- Validation: The leakage detector checks for duplicates, verifies class proportions, and ensures no information bleeding between subsets.
- Output: Three disjoint datasets are output along with split metadata (indices, strategy used, random seed, class distributions per split).
The split indices are registered in the split registry so that any future experiment can recreate the exact same partition. This is especially important for companies like Zerodha building financial models where regulatory audits may require reproducing historical experiments.
A flowchart showing a raw dataset flowing through data preprocessing into a split strategy selector, which branches into stratified, temporal, or group splitting methods. Each method produces train, validation, and test sets that feed into model training, hyperparameter tuning, and final evaluation respectively.
How to Implement
Implementation Approaches
The train/test split can be implemented at several levels of sophistication:
Level 1: Basic holdout using sklearn.model_selection.train_test_split. This is appropriate for tabular datasets where samples are i.i.d. and the dataset is large enough that a single split provides a reliable estimate.
Level 2: Stratified holdout using train_test_split with the stratify parameter. Essential for classification with imbalanced classes. If your positive class is 5% of the data, a random split could give you a test set with anywhere from 2% to 8% positives. Stratification guarantees approximately 5% in every subset.
Level 3: Advanced splits using TimeSeriesSplit, GroupShuffleSplit, or StratifiedGroupKFold for data with temporal ordering, group structure, or both. These are the methods that separate production ML from Kaggle notebooks.
Level 4: Production-grade splitting with data versioning (DVC, LakeFS), split registries, and automated leakage detection. At this level, the split is a versioned, reproducible artifact in your ML pipeline -- not a throwaway cell in a Jupyter notebook.
Cost Context for Indian Startups: For a team of 3 ML engineers in Bengaluru (average CTC ~INR 25-35 lakh/year or ~$30,000-42,000/year), investing 2-3 days in building a proper splitting pipeline pays for itself the first time it prevents a data leakage bug from reaching production. We have seen Indian fintech startups lose months of work because a leaky split inflated their model's apparent performance.
import numpy as np
from sklearn.model_selection import train_test_split
def stratified_train_val_test_split(
X, y,
train_ratio=0.7, val_ratio=0.15, test_ratio=0.15,
random_state=42
):
"""Split data into train/val/test with stratification.
Args:
X: Feature matrix (n_samples, n_features)
y: Target vector (n_samples,)
train_ratio: Fraction for training (default 0.7)
val_ratio: Fraction for validation (default 0.15)
test_ratio: Fraction for testing (default 0.15)
random_state: Seed for reproducibility
Returns:
X_train, X_val, X_test, y_train, y_val, y_test
"""
assert abs(train_ratio + val_ratio + test_ratio - 1.0) < 1e-6, \
f"Ratios must sum to 1, got {train_ratio + val_ratio + test_ratio}"
# First split: separate test set
X_temp, X_test, y_temp, y_test = train_test_split(
X, y,
test_size=test_ratio,
stratify=y,
random_state=random_state
)
# Second split: separate train and validation from remaining
val_fraction_of_remaining = val_ratio / (train_ratio + val_ratio)
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp,
test_size=val_fraction_of_remaining,
stratify=y_temp,
random_state=random_state
)
print(f"Train: {len(X_train)} ({len(X_train)/len(X):.1%})")
print(f"Val: {len(X_val)} ({len(X_val)/len(X):.1%})")
print(f"Test: {len(X_test)} ({len(X_test)/len(X):.1%})")
# Verify stratification
for name, subset_y in [("Train", y_train), ("Val", y_val), ("Test", y_test)]:
unique, counts = np.unique(subset_y, return_counts=True)
dist = dict(zip(unique, counts / len(subset_y)))
print(f" {name} class distribution: {dist}")
return X_train, X_val, X_test, y_train, y_val, y_test
# Usage
X_train, X_val, X_test, y_train, y_val, y_test = stratified_train_val_test_split(
X, y, train_ratio=0.7, val_ratio=0.15, test_ratio=0.15
)This function performs a two-step stratified split to create three subsets. The key insight is in the second step: we compute the validation fraction relative to the remaining data (after removing the test set), not the total data. This ensures the final proportions match the requested ratios. The stratify=y parameter ensures class distributions are preserved in every subset -- critical for imbalanced datasets like fraud detection or medical diagnosis.
import pandas as pd
from typing import Tuple
def temporal_train_val_test_split(
df: pd.DataFrame,
time_column: str,
train_end: str,
val_end: str,
gap: str = "0D"
) -> Tuple[pd.DataFrame, pd.DataFrame, pd.DataFrame]:
"""Split time-series data chronologically with an optional gap.
Args:
df: DataFrame with a datetime column
time_column: Name of the timestamp column
train_end: Cutoff date for training data (exclusive)
val_end: Cutoff date for validation data (exclusive)
gap: Gap duration between sets to prevent leakage from
rolling features (e.g., '7D' for 7 days)
Returns:
df_train, df_val, df_test
"""
df = df.sort_values(time_column).reset_index(drop=True)
train_cutoff = pd.Timestamp(train_end)
val_cutoff = pd.Timestamp(val_end)
gap_delta = pd.Timedelta(gap)
df_train = df[df[time_column] < train_cutoff]
df_val = df[
(df[time_column] >= train_cutoff + gap_delta) &
(df[time_column] < val_cutoff)
]
df_test = df[df[time_column] >= val_cutoff + gap_delta]
# Warn if gap dropped samples
total_used = len(df_train) + len(df_val) + len(df_test)
if total_used < len(df):
dropped = len(df) - total_used
print(f"Warning: {dropped} samples fell in gap periods and were excluded.")
print(f"Train: {len(df_train)} samples "
f"({df_train[time_column].min()} to {df_train[time_column].max()})")
print(f"Val: {len(df_val)} samples "
f"({df_val[time_column].min()} to {df_val[time_column].max()})")
print(f"Test: {len(df_test)} samples "
f"({df_test[time_column].min()} to {df_test[time_column].max()})")
return df_train, df_val, df_test
# Example: Splitting stock market or UPI transaction data
df_train, df_val, df_test = temporal_train_val_test_split(
df=transactions,
time_column="timestamp",
train_end="2025-07-01",
val_end="2025-10-01",
gap="7D" # 7-day gap to prevent rolling feature leakage
)This function splits data strictly by time, ensuring no future information leaks into training. The gap parameter is crucial: if you compute rolling features (e.g., 7-day moving average), data points near the boundary can implicitly contain information from the other set. A gap of at least the rolling window size prevents this. This pattern is essential for financial models (stock prediction at Zerodha), demand forecasting (inventory planning at Flipkart), or any temporal prediction task.
import numpy as np
from sklearn.model_selection import GroupShuffleSplit
from collections import Counter
def group_train_val_test_split(
X, y, groups,
train_size=0.7, val_size=0.15, test_size=0.15,
random_state=42
):
"""Split data ensuring all samples from a group stay together.
Use this when multiple samples belong to the same entity
(patient, user, device, session) and are correlated.
Args:
X: Feature matrix
y: Target vector
groups: Group labels (e.g., patient_id, user_id)
train_size, val_size, test_size: Split fractions
random_state: Seed for reproducibility
Returns:
Split indices and data for train/val/test
"""
unique_groups = np.unique(groups)
n_groups = len(unique_groups)
# Shuffle groups, not samples
rng = np.random.RandomState(random_state)
shuffled_indices = rng.permutation(n_groups)
train_end = int(n_groups * train_size)
val_end = int(n_groups * (train_size + val_size))
train_groups = set(unique_groups[shuffled_indices[:train_end]])
val_groups = set(unique_groups[shuffled_indices[train_end:val_end]])
test_groups = set(unique_groups[shuffled_indices[val_end:]])
train_mask = np.isin(groups, list(train_groups))
val_mask = np.isin(groups, list(val_groups))
test_mask = np.isin(groups, list(test_groups))
# Verify no group overlap
assert len(train_groups & val_groups) == 0, "Group leak: train-val overlap!"
assert len(train_groups & test_groups) == 0, "Group leak: train-test overlap!"
assert len(val_groups & test_groups) == 0, "Group leak: val-test overlap!"
print(f"Unique groups -> Train: {len(train_groups)}, "
f"Val: {len(val_groups)}, Test: {len(test_groups)}")
print(f"Samples -> Train: {train_mask.sum()}, "
f"Val: {val_mask.sum()}, Test: {test_mask.sum()}")
return (
X[train_mask], X[val_mask], X[test_mask],
y[train_mask], y[val_mask], y[test_mask]
)
# Example: Medical imaging where each patient has multiple scans
X_train, X_val, X_test, y_train, y_val, y_test = group_train_val_test_split(
X=features, y=labels, groups=patient_ids,
train_size=0.7, val_size=0.15, test_size=0.15
)This function splits by groups rather than individual samples. If patient A has 10 X-ray images, all 10 go into the same subset. Without group splitting, images from the same patient could appear in both train and test, and the model would learn patient-specific features (bone structure, imaging device) rather than disease indicators. This is one of the most common sources of data leakage in medical ML -- and it regularly appears in Kaggle competitions with misleadingly high leaderboard scores.
import pandas as pd
import numpy as np
from typing import List, Dict, Any
def detect_leakage(
train_df: pd.DataFrame,
test_df: pd.DataFrame,
id_columns: List[str] = None,
feature_columns: List[str] = None
) -> Dict[str, Any]:
"""Detect common forms of data leakage between train and test sets.
Checks for:
1. Duplicate rows across sets
2. Shared IDs (entity leakage)
3. Feature distribution anomalies
4. Target leakage indicators
Returns:
Dictionary with leakage report
"""
report = {"leakage_detected": False, "issues": []}
# Check 1: Exact duplicate rows
if feature_columns:
cols = feature_columns
else:
cols = [c for c in train_df.columns if c not in (id_columns or [])]
train_hashes = set(train_df[cols].apply(lambda r: hash(tuple(r)), axis=1))
test_hashes = set(test_df[cols].apply(lambda r: hash(tuple(r)), axis=1))
duplicates = train_hashes & test_hashes
if duplicates:
report["leakage_detected"] = True
report["issues"].append(
f"Found {len(duplicates)} duplicate row hashes across train/test"
)
# Check 2: Shared entity IDs
if id_columns:
for col in id_columns:
train_ids = set(train_df[col].unique())
test_ids = set(test_df[col].unique())
overlap = train_ids & test_ids
if overlap:
report["leakage_detected"] = True
report["issues"].append(
f"Column '{col}': {len(overlap)} shared IDs "
f"({len(overlap)/len(test_ids):.1%} of test IDs)"
)
# Check 3: Suspiciously similar distributions
# (Low KL divergence can indicate overlap)
numeric_cols = train_df[cols].select_dtypes(include=[np.number]).columns
for col in numeric_cols[:10]: # Check first 10 numeric columns
train_mean, test_mean = train_df[col].mean(), test_df[col].mean()
train_std = train_df[col].std()
if train_std > 0:
z_score = abs(train_mean - test_mean) / train_std
if z_score < 0.01: # Suspiciously identical
report["issues"].append(
f"Column '{col}': means nearly identical "
f"(z={z_score:.4f}) -- possible data overlap"
)
if not report["issues"]:
report["issues"].append("No obvious leakage detected.")
return report
# Usage
report = detect_leakage(
train_df, test_df,
id_columns=["user_id", "session_id"],
feature_columns=["feat_1", "feat_2", "feat_3"]
)
print(report)This utility performs basic leakage detection by checking for duplicate rows, shared entity IDs, and suspiciously similar feature distributions. In production, this should be run as an automated validation step after every split. The entity ID check is particularly important: if user_id appears in both train and test, the model may learn user-specific patterns rather than generalizable features. We have seen this exact issue in recommendation systems at Indian e-commerce companies where transaction data from the same user leaked across splits.
# DVC pipeline stage for reproducible splitting
# dvc.yaml
stages:
split_data:
cmd: python src/split.py
deps:
- src/split.py
- data/processed/features.parquet
params:
- split.train_ratio
- split.val_ratio
- split.test_ratio
- split.strategy # stratified | temporal | group
- split.random_seed
- split.group_column # optional: for group splits
- split.time_column # optional: for temporal splits
outs:
- data/splits/train.parquet
- data/splits/val.parquet
- data/splits/test.parquet
metrics:
- data/splits/split_report.json:
cache: false
# params.yaml
split:
train_ratio: 0.70
val_ratio: 0.15
test_ratio: 0.15
strategy: stratified
random_seed: 42
group_column: null
time_column: nullCommon Implementation Mistakes
- ●
Splitting before preprocessing: Fitting a scaler or imputer on the entire dataset before splitting leaks information from the test set into training. Always split first, then fit transformations on the training set only and apply (transform) them to val/test. This is the #1 leakage bug in Kaggle notebooks and production codebases alike.
- ●
Using the test set for hyperparameter tuning: Every time you evaluate a hyperparameter configuration on the test set and use that result to choose a better configuration, you contaminate the test estimate. Use the validation set for all intermediate decisions. The test set is for the final number only.
- ●
Ignoring class imbalance during splitting: A random 80/20 split on a dataset with 1% positive rate might give you a test set with 0 positives. Always use
stratify=yfor classification tasks. The risk is especially acute with small datasets common in Indian healthcare ML projects (<10,000 samples). - ●
Not using a fixed random seed: Without
random_state=42(or any fixed seed), your split changes every run, making experiments non-reproducible. This sounds trivial but causes real debugging nightmares when model performance fluctuates between runs. - ●
Sequential splitting of time-series data: Using
train_test_split(which shuffles randomly) on data with temporal ordering. Future data leaks into the training set, making your model appear clairvoyant. Always use temporal splitting for time-ordered data. - ●
Splitting after data augmentation: If you augment images and then split, augmented versions of training images may end up in the test set. Always split the original data first, then augment only the training set.
- ●
Ignoring group structure: In medical data, multiple samples from the same patient are correlated. A random split can put some scans from patient A in training and others in test. The model learns patient-specific features, not disease features. This has led to retracted papers.
When Should You Use This?
Use When
You are training any supervised ML model and need an unbiased estimate of generalization performance -- this is essentially always
Your dataset is large enough (>10,000 samples) that a single holdout split provides a stable performance estimate
You have imbalanced classes and need stratification to ensure all subsets are representative (fraud detection, medical diagnosis, churn prediction)
Your data has temporal ordering and you need to simulate real-world deployment where the model only sees past data (financial forecasting, demand prediction, weather modeling)
Your data has group structure (multiple samples per entity) and you need to prevent entity leakage (medical imaging, user behavior modeling, multi-device tracking)
You are deploying to production and need a held-out test set to validate the final model before launch -- this is the go/no-go gate
Regulatory or audit requirements mandate documented, reproducible evaluation methodology (healthcare, finance, insurance in India under IRDAI/RBI guidelines)
Avoid When
Your dataset is very small (<1,000 samples) and you cannot afford to hold out 20-30% of data for evaluation -- use k-fold cross-validation instead to maximize both training data utilization and evaluation stability
You are in an active learning or online learning setting where the data distribution shifts continuously and a static split is meaningless
You are doing unsupervised learning (clustering, dimensionality reduction) where there is no target variable to stratify on and evaluation requires different methodology
Your entire dataset is a time-series with strong autocorrelation and you need multiple evaluation windows -- use TimeSeriesSplit with expanding or sliding windows instead
You are performing transfer learning with a pre-trained foundation model and only have a handful of labeled examples (<100) for fine-tuning -- every sample is too precious to hold out
You need to evaluate model stability and variance across different data subsets -- a single split gives you a point estimate, not a distribution. Use cross-validation.
Key Tradeoffs
Split Ratio: The Bias-Variance Tradeoff of Evaluation
The split ratio controls a bias-variance tradeoff -- not of the model, but of the evaluation estimate:
| Split | Train Data | Eval Reliability | Best For |
|---|---|---|---|
| 90/5/5 | Maximum | High variance | Very large datasets (>1M samples) |
| 80/10/10 | High | Moderate variance | Large datasets (100K-1M) |
| 70/15/15 | Moderate | Low variance | Medium datasets (10K-100K) |
| 60/20/20 | Lower | Lowest variance | Smaller datasets (5K-10K) |
With a small test set, the performance estimate has high variance -- run the experiment 10 times with different random seeds and you will get wildly different numbers. With a large test set, the estimate is stable but you have less training data, which may hurt model performance.
The Deep Learning Exception
For deep learning with millions of parameters and massive datasets (ImageNet, Common Crawl), the standard practice is 98/1/1 or even 99/0.5/0.5. When your test set is 50,000 images, the variance of the performance estimate is already negligible.
Cost Considerations for Indian Startups
Labeled data is expensive. For an Indian startup paying INR 5-15 (~6,000-18,000). Holding out 20% for testing means INR 1-3 lakh ($1,200-3,600) of labeled data that never trains the model. This is a real cost. Cross-validation can help extract more value from the same labeled data, but the test set remains non-negotiable for the final evaluation.
Rule of Thumb: If your test set has fewer than 1,000 samples, the confidence interval on accuracy will be uncomfortably wide (>3 percentage points for 95% CI). Either collect more data or use k-fold cross-validation for intermediate evaluation.
Alternatives & Comparisons
Cross-validation uses all data for both training and evaluation by rotating through folds. It produces a lower-variance performance estimate than a single holdout split and is preferred when data is scarce (<10,000 samples). However, it is times more expensive computationally and still requires a separate held-out test set for final evaluation. Use cross-validation for model selection, holdout for final reporting.
Hyperparameter tuning often uses an inner cross-validation loop within the training set, making the validation set implicit. If you use nested cross-validation for both model selection and hyperparameter tuning, you may not need an explicit validation set -- but you still need a held-out test set. The train/test split is complementary to hyperparameter tuning, not a replacement.
Feature selection must happen after the train/test split, using only training data. If you select features on the entire dataset, you introduce leakage because the selection is informed by test data statistics. The split is a prerequisite for proper feature selection, not an alternative to it.
Pros, Cons & Tradeoffs
Advantages
Simple and universally understood -- every ML practitioner knows what a train/test split is, making it the lingua franca of model evaluation. No explanation needed in code reviews or papers.
Computationally cheap -- a single split is O(N) time and O(N) space. Even for datasets with millions of rows, splitting takes seconds. Compare this to 10-fold cross-validation which requires training 10 separate models.
Provides an unbiased generalization estimate when done correctly -- the test set performance is a statistically valid estimate of real-world performance, assuming the i.i.d. assumption holds.
Enables reproducible evaluation -- with a fixed random seed, the exact same split can be recreated on any machine, enabling fair comparison across experiments and teams.
Supports stratification, temporal, and group constraints -- the basic holdout method extends naturally to handle class imbalance, time-series data, and grouped/hierarchical data structures.
Essential for regulatory compliance -- in regulated industries (banking under RBI, insurance under IRDAI, healthcare), auditors require documented evaluation on held-out data. A train/test split is the minimum acceptable standard.
Scales to any dataset size -- from 1,000-sample medical datasets to billion-row recommendation datasets, the split methodology adapts through ratio adjustment.
Disadvantages
High variance estimate with small datasets -- on a dataset with 1,000 samples and a 20% test set (200 samples), the accuracy estimate can vary by 5-10 percentage points across different random seeds. This makes it unreliable for small-data regimes.
Wastes labeled data -- holding out 20-30% of expensive labeled data means those labels never contribute to model training. For domains where labeling costs INR 50-200 per sample (medical imaging, legal document review), this is a significant expense.
Single point estimate, not a distribution -- a single split gives you one number. You do not know if that number is unusually high or low. Cross-validation gives you numbers, providing a confidence interval.
Does not detect all forms of leakage -- the split itself does not prevent preprocessing leakage, feature leakage, or temporal leakage. It is a necessary but not sufficient condition for valid evaluation.
Can mislead if data is non-i.i.d. -- if training and test data come from different distributions (domain shift, temporal drift, population shift), the test estimate will not reflect real-world performance. The split assumes the test set is representative of deployment conditions.
Sensitive to split randomness in imbalanced data -- even with stratification, rare classes with very few examples (e.g., 10 positive samples in 10,000) may have all positives concentrated in one set by chance.
Failure Modes & Debugging
Preprocessing leakage (fit-before-split)
Cause
Fitting a scaler, imputer, encoder, or PCA on the entire dataset before splitting. The test set's statistics (mean, standard deviation, principal components) influence the training data transformations.
Symptoms
Model performs suspiciously well on the test set -- often 2-10% better than on genuinely new data. The gap between test performance and production performance is the leakage signature. Cross-validation scores are consistently lower than the holdout test score.
Mitigation
Always follow the split-then-fit rule: split the data first, fit all transformations on the training set only, and use .transform() (not .fit_transform()) on val/test. Use sklearn.pipeline.Pipeline to enforce this automatically. Add a CI check that greps for .fit( calls on full datasets.
Temporal leakage (future data in training)
Cause
Randomly shuffling time-series data before splitting, allowing future observations to leak into the training set. Common in demand forecasting, stock prediction, and fraud detection.
Symptoms
Model accuracy drops dramatically in production compared to offline evaluation. The model appears to predict the future during evaluation but fails on truly future data. Performance degrades over time as the model's training window becomes stale.
Mitigation
Use strict temporal splitting: training data must precede validation data, which must precede test data. Add a gap period between splits equal to the longest rolling feature window. Validate using TimeSeriesSplit from sklearn for cross-validation.
Entity leakage (group contamination)
Cause
Multiple correlated samples from the same entity (patient, user, device) appearing in both train and test sets. The model memorizes entity-specific patterns rather than learning generalizable features.
Symptoms
High test accuracy that drops when the model encounters new entities. In medical imaging, this manifests as a model that recognizes patients rather than pathologies. In user modeling, the model predicts based on user history rather than behavioral patterns.
Mitigation
Use GroupShuffleSplit or StratifiedGroupKFold from sklearn. Identify all entity identifiers in your data and ensure no entity appears in more than one subset. Document group columns in your data schema.
Target leakage (label information in features)
Cause
Features that are computed from or highly correlated with the target variable, or that would not be available at inference time. Example: including "loan_default_date" as a feature when predicting loan default.
Symptoms
Unrealistically high accuracy (often >99%) on both train and test sets. A simple model (logistic regression, decision tree) achieves near-perfect performance. Feature importance analysis reveals a single dominant feature that is suspiciously predictive.
Mitigation
Review every feature and ask: "Would I have this information at the time of prediction?" If not, remove it. Compute correlation between each feature and the target -- any feature with correlation >0.95 is suspicious. Build a feature availability timeline that maps each feature to its earliest available timestamp.
Insufficient test set size
Cause
Using a very small test set (e.g., 50-100 samples) that produces unstable performance estimates with wide confidence intervals.
Symptoms
Test accuracy varies by 5-15 percentage points across different random seeds. Different team members report wildly different results for the same model because they used different splits. Performance appears to fluctuate randomly between model versions.
Mitigation
Calculate the required test set size for your desired confidence interval. For binary classification at 95% accuracy with a 95% CI of 1%, you need samples. If you cannot afford this, use cross-validation for variance reduction.
Distribution mismatch between splits
Cause
Random splitting on non-i.i.d. data where certain subpopulations or conditions are underrepresented in the test set. For example, splitting customer data from a Swiggy-like platform where urban and rural users have very different ordering patterns.
Symptoms
Model performs well on the test set but poorly on specific subpopulations in production. Fairness metrics reveal disparate performance across demographic groups. Sliced evaluation on the test set shows high variance across subgroups.
Mitigation
Use stratified splitting on the most important segmentation variable (or multi-label stratification for multiple variables). Perform sliced evaluation on every relevant subpopulation. Consider oversampling underrepresented groups in the test set if you need precise estimates for each group.
Placement in an ML System
Where Does the Split Sit in the Pipeline?
The train/test split is the gateway between data preparation and model training. It is the last step in the data pipeline and the first step in the evaluation pipeline. Everything upstream (ingestion, cleaning, feature engineering) produces the dataset. Everything downstream (training, tuning, evaluation) consumes the split subsets.
In a well-architected ML system, the split is a versioned artifact. When you change your feature engineering pipeline, you re-run the split. When you add new data, you re-run the split. The split indices (or manifest files) are stored alongside the dataset version in a tool like DVC, MLflow, or a custom metadata store.
The split also defines the contract between the training and evaluation stages. The training pipeline receives train.parquet and val.parquet. The evaluation pipeline receives test.parquet and a trained model. These stages should be independently executable -- you should be able to re-evaluate a model on a new test set without retraining it.
Production Pattern: At scale (Flipkart, Swiggy, PhonePe), splits are often defined by date ranges rather than random indices. This naturally handles temporal ordering and makes the split deterministic across runs. The split configuration (date cutoffs, stratification columns) lives in the pipeline configuration, not in a Jupyter notebook.
Pipeline Stage
Training / Data Preparation
Upstream
- feature-extraction
- feature-engineering
- feature-store
- data-validation
Downstream
- model-training
- hyperparameter-tuning
- cross-validation
- model-evaluation
Scaling Bottlenecks
The split operation itself is computationally trivial -- it is essentially a shuffle and index partition, both O(N). The real scaling bottlenecks are downstream:
-
Memory: For very large datasets (>100GB), the split must be performed out-of-core. You cannot load 100GB into memory, shuffle, and split. Use Dask, Spark, or file-based splitting where indices are written to a manifest file rather than materializing separate datasets.
-
Storage: A naive split that copies data into three separate directories triples your storage cost. For a startup storing 500GB of training images on S3 at 23/month (~INR 1,930/month) just for the split copies. Use index files or symbolic links instead.
-
Reproducibility at scale: With 1 billion rows, even a different sort order can change the split. Use deterministic hashing of row IDs rather than random shuffling to ensure reproducibility across distributed systems.
-
Stratification with rare classes: When a class has only 50 examples in a billion-row dataset, stratified splitting requires careful handling to ensure at least some examples appear in each subset.
Production Case Studies
Google's ML Crash Course dedicates an entire module to train/test splitting, emphasizing that randomization is essential and that test data must never influence training decisions. They recommend the 80/20 split for most use cases and explicitly warn against using the test set for hyperparameter tuning. Their internal ML platform (TFX) enforces split integrity through data validation components.
The TFX data validation component has prevented numerous data leakage incidents in Google's production ML pipelines. Their documentation has become the de facto reference for ML practitioners globally, with millions of page views.
Netflix's recommendation system uses temporal splitting for evaluating personalization models. Training data consists of user interactions before a cutoff date, and evaluation uses interactions after the cutoff. They account for cold-start users (new users with no history in the training period) as a separate evaluation cohort. Their A/B testing infrastructure validates that offline metrics computed on the temporal split correlate with online engagement metrics.
Netflix's personalization algorithms, validated through rigorous temporal splitting, drive approximately 80% of content watched on the platform. Their correlation between offline temporal-split metrics and online A/B test results is a benchmark for the industry.
UIDAI developed AI and machine learning-based Aadhaar Face Authentication solutions in-house, processing over 130.5 crore transactions. The system introduced an AI/ML-based FIR model to check fingerprint liveness, working with biometric data from over a billion people.
Since October 2022, UIDAI's AI-powered face authentication has processed over 130.5 crore cumulative transactions, with close to 102 crore in FY 2024-25 alone (78% of total transactions). The in-house AI/ML models revolutionize biometric verification at unprecedented scale in India.
Razorpay's fraud detection system uses temporal splitting with a gap period to evaluate models. Since fraudulent transactions are often reported days or weeks after occurrence, training on recent data without a gap would include unconfirmed fraud labels. They use a 30-day gap between training and test periods to ensure all fraud labels in the test set are confirmed. The split is also stratified by fraud type (card-not-present, account takeover, friendly fraud) to ensure each type is evaluated.
By using temporal-stratified splitting with a gap period, Razorpay's fraud model evaluation correlates within 2% of actual production performance. This accuracy in offline evaluation has reduced the time to deploy new fraud models from weeks to days.
Tooling & Ecosystem
The gold standard for data splitting in Python. Provides train_test_split (basic and stratified), StratifiedShuffleSplit, TimeSeriesSplit, GroupShuffleSplit, StratifiedGroupKFold, and more. The stratify parameter on train_test_split handles class-balanced splitting in a single line.
Version control for datasets and ML pipelines. DVC tracks split configurations alongside data versions, ensuring reproducible splits. The dvc repro command re-runs the split pipeline when data or parameters change. Essential for teams that need audit trails for their data splits.
While not a splitting tool per se, Pandas provides the foundation for custom splitting logic -- sample(frac=...), groupby, datetime filtering for temporal splits, and merge for leakage detection. Most custom splitting functions are built on Pandas operations.
For datasets too large for single-machine splitting, Spark's randomSplit method distributes the partitioning across a cluster. Supports stratified splitting via sampleBy. Used by Indian companies like Flipkart, PhonePe, and Swiggy for splitting datasets with billions of rows.
Identifies label errors and data quality issues that can corrupt train/test splits. If your labels are noisy (common in crowd-sourced annotation), Cleanlab can help you identify and correct mislabeled samples before splitting, improving the reliability of your evaluation.
Data validation framework that can enforce post-split quality checks: class distribution in each subset, no duplicate IDs across sets, feature range consistency, and more. Can be integrated into ML pipelines as a split validation gate.
Research & References
Ron Kohavi (1995)IJCAI 1995
The landmark study comparing holdout, cross-validation, and bootstrap methods on real datasets. Found that stratified 10-fold cross-validation provides the best bias-variance tradeoff for model selection. Established that the holdout method has high variance for small datasets and recommended cross-validation as the default.
M. Stone (1974)Journal of the Royal Statistical Society, Series B
One of the foundational papers on cross-validation theory. Established the theoretical connection between cross-validation and model selection, proving that leave-one-out cross-validation is asymptotically equivalent to AIC (Akaike Information Criterion).
Yoshua Bengio, Yves Grandvalet (2004)Journal of Machine Learning Research (JMLR)
Proved that there is no unbiased estimator of the variance of k-fold cross-validation, because the training sets across folds overlap. This means confidence intervals from cross-validation are approximate. The paper influenced how practitioners report uncertainty in model evaluation.
Shachar Kaufman, Saharon Rosset, Claudia Perlich, Ori Stitelman (2012)ACM TKDD
Formalized the concept of data leakage in ML, taxonomized leakage types (target leakage, train-test contamination, temporal leakage), and proposed detection methods. This paper is the definitive reference for understanding why splits fail and how to fix them.
Sarah Nogueira, Gavin Brown (2016)JMLR
Demonstrated that feature selection stability is heavily influenced by the train/test split. Different random splits can produce radically different selected features, especially with small datasets. Proposed stability measures that account for split randomness.
Yuji Roh, Geon Heo, Steven Euijong Whang (2021)IEEE TKDE
Comprehensive survey covering data splitting in the broader context of ML data management. Discusses how split strategy interacts with data collection, labeling, and augmentation -- providing a systems-level view of why splitting is not an isolated step.
Interview & Evaluation Perspective
Common Interview Questions
- ●
Why do we need a separate validation set in addition to the test set?
- ●
How would you split time-series data for training a demand forecasting model?
- ●
What is data leakage and how does the train/test split help prevent it?
- ●
Your model achieves 98% accuracy on the test set but only 72% in production. What went wrong?
- ●
How would you handle a dataset with 99.9% negative and 0.1% positive examples when splitting?
- ●
Explain the difference between stratified splitting and group splitting. When would you use each?
- ●
How would you design a splitting strategy for a medical imaging dataset with multiple scans per patient?
Key Points to Mention
- ●
The test set must be touched exactly once -- after all model selection and tuning is complete. Using it for any intermediate decision biases the final estimate.
- ●
Split before preprocess: all transformations (scaling, encoding, imputation) must be fit on training data only. This is the single most common source of leakage in practice.
- ●
For imbalanced data, always use stratified splitting to preserve class proportions. For time-series, always use temporal splitting with a gap. For grouped data, always use group splitting.
- ●
Quantify the reliability of your test estimate: with samples and accuracy , the 95% confidence interval is approximately .
- ●
In production, splits should be versioned artifacts (via DVC, MLflow, or custom metadata) so that experiments are reproducible and auditable.
Pitfalls to Avoid
- ●
Saying "I always use 80/20" without considering dataset size, class balance, or data structure. The ratio should be justified, not defaulted.
- ●
Forgetting to mention temporal splitting when discussing time-dependent data -- this is a red flag for interviewers evaluating production experience.
- ●
Claiming that a good test accuracy means the model is ready for production. The test set only validates performance under the assumption of identical distribution -- distribution shift in production is the norm, not the exception.
- ●
Not mentioning reproducibility (fixed random seeds, versioned splits). This signals that you have only worked in Jupyter notebooks, not production systems.
- ●
Confusing validation and test sets -- using the terms interchangeably suggests a lack of rigor.
Senior-Level Expectation
A senior/staff-level candidate should discuss the full lifecycle of data splitting in a production ML system: choosing the split strategy based on data characteristics (temporal, grouped, imbalanced), integrating the split into a versioned pipeline (DVC, Kubeflow, Vertex AI), implementing automated leakage detection as a CI/CD check, monitoring for distribution drift between training data and production data, and designing re-splitting strategies when new data arrives. They should also discuss the failure modes -- preprocessing leakage, entity leakage, temporal leakage -- with specific examples from their experience. At the staff level, expect a discussion of how split design interacts with the broader system: how the split strategy affects A/B testing design, how production feedback loops can contaminate future splits, and how to handle regulatory requirements for model validation in regulated industries.
Summary
Let us recap what we have covered about the train/test split and why it matters so much in ML systems.
The train/test split is the foundational mechanism for honest model evaluation. Without it, every performance metric is fiction -- a number that reflects memorization, not generalization. The three-way split (train/validation/test) provides two layers of protection: the validation set for intermediate decisions (hyperparameter tuning, model selection, early stopping) and the test set for a single, final, unbiased estimate of real-world performance. The ratios (typically 70/15/15 or 80/10/10) should be chosen based on dataset size, not habit -- what matters is the absolute size of the test set and the confidence interval it affords.
Beyond the basic holdout, production ML systems require stratified splitting (to preserve class distributions in imbalanced data), temporal splitting (to prevent future leakage in time-series problems), and group splitting (to prevent entity leakage when samples are correlated). Data leakage -- the silent killer of ML projects -- can occur at multiple points: preprocessing before splitting, random shuffling of time-ordered data, entity contamination across subsets, and features that encode target information. Every team we have worked with has encountered at least one leakage bug. The question is not whether you will face it, but whether you will catch it before production.
The train/test split is deceptively simple in concept but demanding in execution. Master it -- and especially master its failure modes -- and you will avoid the most common and costly mistakes in applied ML. Whether you are building a recommendation engine at Flipkart, a fraud detector at Razorpay, or a diagnostic model at an Indian healthtech startup, the integrity of your split determines the trustworthiness of every metric you report.