Privacy Filter in Machine Learning
A privacy filter is the gatekeeper of sensitive information in an ML system. It intercepts data at various pipeline stages -- ingestion, training, inference, and output -- to detect, redact, mask, or transform personally identifiable information (PII) before that data reaches components that should never see it.
Why does this matter so much right now? Because modern ML systems are data-hungry by design, and the data they consume is increasingly personal. Names, phone numbers, Aadhaar numbers, medical records, financial transactions -- all of these flow through training pipelines and inference endpoints. Without a privacy filter, a single data breach or model memorization incident can expose millions of individuals and trigger regulatory penalties that can reach up to INR 250 crore (~$30M) under India's DPDP Act or EUR 20 million under GDPR.
Privacy filters combine multiple techniques: rule-based pattern matching (regex for credit card numbers, Aadhaar formats), NLP-based named entity recognition (detecting names, locations, organizations), statistical anonymization (k-anonymity, l-diversity), and mathematical privacy guarantees (differential privacy). The best production systems layer all of these together because no single technique catches everything.
From Aadhaar number masking at Indian fintech companies like Razorpay and PhonePe, to differential privacy in Google's Gboard training, privacy filters have become a non-negotiable component of responsible ML engineering. If your ML system touches personal data -- and it almost certainly does -- you need a privacy filter.
Concept Snapshot
- What It Is
- A pipeline component that detects, classifies, and transforms personally identifiable information (PII) and sensitive data to prevent privacy violations in ML systems.
- Category
- Responsible AI
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: raw text, structured records, or model outputs containing potential PII. Outputs: sanitized data with PII redacted, masked, pseudonymized, or anonymized, plus detection metadata.
- System Placement
- Sits at data ingestion (pre-training), at inference input/output boundaries, and optionally within training loops (differential privacy). Acts as a filter layer between untrusted data sources and privacy-sensitive ML components.
- Also Known As
- PII detector, data anonymizer, privacy gateway, data sanitizer, PII redactor, sensitive data filter
- Typical Users
- ML Engineers, Data Engineers, Privacy Engineers, Compliance Officers, Security Engineers, Data Protection Officers (DPOs)
- Prerequisites
- Named Entity Recognition (NER), Regular expressions and pattern matching, Basic probability and statistics, Data protection regulations (GDPR, DPDP Act), Understanding of ML training pipelines
- Key Terms
- PIIanonymizationpseudonymizationdifferential privacyk-anonymitydata maskingredactionGDPRDPDP ActAadhaar maskingfederated learning
Why This Concept Exists
The Data Privacy Reckoning
For years, the ML community operated under an implicit assumption: more data is always better, and privacy is somebody else's problem. That era is over. A convergence of regulatory pressure, high-profile data breaches, and growing public awareness has made privacy a first-class engineering requirement, not an afterthought.
Consider the scale of the problem. A typical LLM training dataset contains billions of text passages scraped from the web, many of which contain names, email addresses, phone numbers, and even government ID numbers. Without intervention, the model can memorize these verbatim -- a phenomenon documented extensively in research on extraction attacks against GPT-2 and subsequent models. When a user prompts the model and it regurgitates someone's actual phone number, that's not just embarrassing; it's a regulatory violation.
The Regulatory Landscape
Two landmark regulations define the modern privacy landscape:
GDPR (EU, 2018): Established the principles of data minimization, purpose limitation, and the right to erasure. Penalties reach EUR 20 million or 4% of global annual turnover -- whichever is higher. GDPR explicitly distinguishes between anonymized data (not personal data, outside GDPR scope) and pseudonymized data (still personal data, still regulated).
DPDP Act (India, 2023): India's Digital Personal Data Protection Act introduces consent-based processing, mandatory breach notification within 72 hours, and penalties up to INR 250 crore (~$30M). With the DPDP Rules notified in 2025, full compliance is expected by May 2027. For any ML system processing Indian users' data -- think Flipkart, Swiggy, Zomato, IRCTC -- this is now the governing framework.
Why Traditional Security Isn't Enough
Access controls and encryption protect data at rest and in transit, but they don't help when the ML model itself becomes the privacy risk. A model trained on unfiltered data can leak PII through:
- Memorization: The model stores training examples verbatim and reproduces them during inference.
- Membership inference attacks: An adversary determines whether a specific individual's data was in the training set.
- Model inversion attacks: An adversary reconstructs training data from model parameters or outputs.
Privacy filters address these risks at the source, by removing or transforming sensitive information before it enters the ML pipeline. They implement the privacy by design principle that both GDPR and DPDP Act mandate.
Key Takeaway: Privacy filters exist because ML models can memorize and leak personal data, regulations now impose severe penalties for mishandling PII, and traditional security controls don't address the model-as-a-risk-vector problem.
Core Intuition & Mental Model
The Mental Model: A Smart Security Checkpoint
Think of a privacy filter as a security checkpoint at an airport. Every piece of data -- whether it's a training document, an API request, or a model output -- must pass through the checkpoint before proceeding. The checkpoint has multiple detection mechanisms working in parallel: X-ray machines (pattern matching for structured PII like credit card numbers), trained officers (NER models for unstructured PII like names), and behavioral analysis (context-aware detection for ambiguous cases).
Just like a real checkpoint, a privacy filter must balance thoroughness vs. throughput. Checking every molecule would be perfectly secure but would grind everything to a halt. Missing a threat is unacceptable. The art is in layering fast, cheap checks (regex) with slower, more accurate ones (NER models) to achieve both high recall and acceptable latency.
Two Fundamental Strategies
Privacy filters employ two complementary strategies:
Strategy 1: Detect and Transform -- Find the PII and do something to it. This includes redaction (replace with [REDACTED]), masking (replace with XXXX-XXXX-1234), pseudonymization (replace with a consistent fake value), and generalization (replace "age 34" with "age 30-40"). The original data is either destroyed or stored separately under strict access controls.
Strategy 2: Inject Noise Mathematically -- Instead of finding and removing individual PII instances, add calibrated statistical noise to the entire computation so that no single individual's data can influence the output beyond a controlled bound. This is differential privacy, and it's the only approach that provides a formal mathematical guarantee. Everything else is best-effort.
The two strategies are complementary, not competing. Detect-and-transform handles the obvious PII in your data pipeline. Differential privacy handles the subtle leakage that occurs during model training even after obvious PII has been removed.
Expert Note: No detection system achieves 100% recall. Some PII will slip through. That's precisely why defense-in-depth matters -- combine detection-based filtering with differential privacy during training and output filtering at inference time. Three imperfect layers are far better than one.
Technical Foundations
Differential Privacy: The Gold Standard
Let's formalize the strongest privacy guarantee available. Differential privacy is both a definition and a promise: it bounds the maximum information leakage about any single individual in the dataset.
Definition (-Differential Privacy): A randomized mechanism satisfies -differential privacy if, for all datasets and that differ in exactly one record, and for all subsets :
Intuitively, this says: whether or not any single person's data is included in the dataset, the output distribution changes by at most a factor of . A smaller means stronger privacy (less distinguishable outputs), but typically more noise and lower utility.
Approximate DP (-Differential Privacy): In practice, we relax to:
where represents the probability of a catastrophic privacy failure. In practice, is set to be much smaller than where is the dataset size -- typically to .
The Privacy Budget
A critical property of differential privacy is composition: if you run mechanisms, each satisfying -DP, the total privacy cost accumulates. Under basic composition:
Advanced composition (Abadi et al., 2016) gives tighter bounds using the moments accountant, which tracks the privacy loss random variable's moment generating function:
This sublinear growth is what makes training deep neural networks with DP feasible -- without it, the privacy budget would be exhausted after a handful of gradient steps.
K-Anonymity: A Structural Guarantee
For structured/tabular data, k-anonymity provides a different kind of protection:
A dataset satisfies -anonymity if every combination of quasi-identifier values (attributes that could be used for re-identification, like age, gender, zip code) appears in at least records. Formally, for quasi-identifiers , every equivalence class:
K-anonymity is strengthened by l-diversity (each equivalence class contains at least distinct values of the sensitive attribute) and t-closeness (the distribution of the sensitive attribute within each equivalence class is within distance of the overall distribution).
PII Detection as Classification
Formal PII detection is a sequence labeling problem. Given a token sequence , the detector assigns labels using BIO tagging. The detection quality is measured by:
For privacy filters, recall is far more important than precision. A missed PII entity (false negative) is a privacy violation. A falsely flagged non-PII entity (false positive) is merely an inconvenience.
Internal Architecture
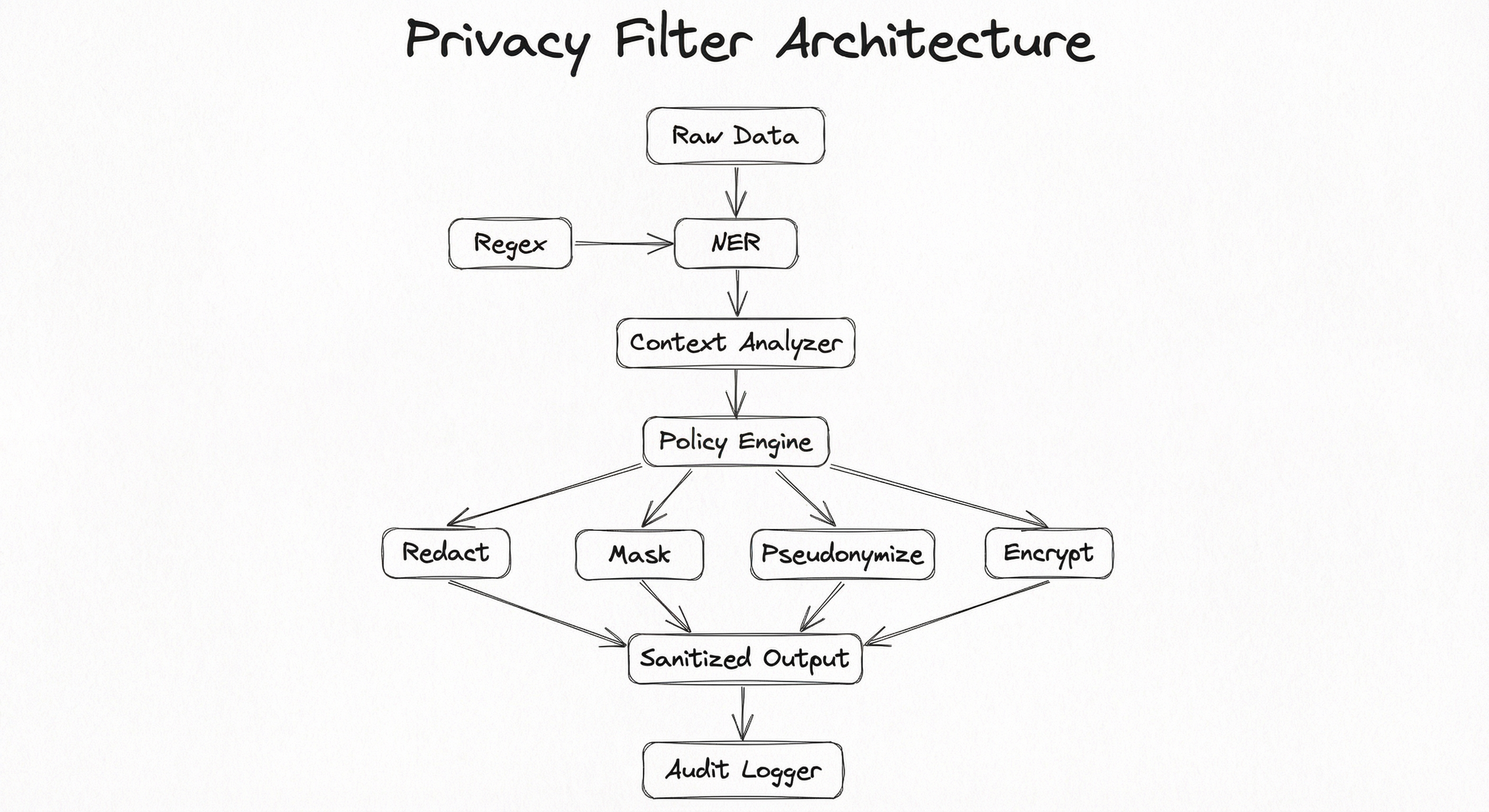
A production privacy filter system consists of five core subsystems: a detection engine that identifies PII entities, a classification module that categorizes detected entities by type and sensitivity level, a transformation engine that applies the appropriate anonymization technique, a policy engine that maps data types and contexts to transformation rules, and an audit logger that records all detections and transformations for compliance reporting.
The architecture follows a layered detection pattern: fast regex-based checks run first (catching structured PII like credit card numbers and Aadhaar numbers), followed by NER-based detection (catching names, locations, organizations), and finally context-aware analysis for ambiguous cases. This layering optimizes for both throughput and detection quality.
For differential privacy integration during model training, a separate DP module wraps the optimizer (DP-SGD) and applies per-sample gradient clipping and noise injection. This operates at the training loop level, complementing the data-level filtering described above.
Key Components
Regex Pattern Matcher
The first detection layer. Uses compiled regular expressions to identify structured PII with known formats: credit card numbers (Luhn-validated), Aadhaar numbers (12-digit, Verhoeff-validated), PAN numbers ([A-Z]{5}[0-9]{4}[A-Z]), email addresses, phone numbers (Indian +91 and international formats), IP addresses, and passport numbers. Extremely fast (microseconds per check) with near-perfect precision for well-defined patterns, but cannot detect unstructured PII like names.
NER Detection Engine
The second detection layer. Uses trained Named Entity Recognition models (typically spaCy's en_core_web_lg or transformer-based models) to identify entity types: PERSON, LOCATION, ORGANIZATION, DATE, NRP (nationalities/religious/political groups). Handles unstructured PII that regex cannot catch. Presidio wraps this with additional context-aware logic and confidence scoring.
Context Analyzer
Resolves ambiguous detections using surrounding context. For example, the word 'Jordan' could be a person name, a country, or a brand. The context analyzer examines neighboring tokens, sentence structure, and domain-specific cues to classify ambiguous entities correctly. Also handles co-reference resolution to track PII mentions across a document.
Policy Engine
Maps detected PII types to transformation rules based on configurable policies. Different PII types may require different treatments: names might be pseudonymized (replaced with consistent fake names), Aadhaar numbers masked (showing only last 4 digits per UIDAI regulations), and email addresses fully redacted. Policies can vary by use case -- training data gets stricter treatment than analytics data.
Transformation Engine
Applies the selected transformation: redaction (replace with [REDACTED] or entity-type tags like [PERSON]), masking (partial obscuring, e.g., xxxx-xxxx-1234), pseudonymization (consistent replacement with realistic fake values using a keyed hash, reversible with the key), generalization (replace specific values with ranges or categories), or format-preserving encryption (encrypt while maintaining the original format for downstream compatibility).
Differential Privacy Module
Operates at the model training level rather than the data level. Implements DP-SGD by clipping per-sample gradients to a maximum norm and adding Gaussian noise with scale . Tracks cumulative privacy budget via the moments accountant and halts training if the budget is exhausted.
Audit Logger
Records all detections, transformations, and policy decisions for compliance reporting. Captures: entity type, confidence score, transformation applied, timestamp, source document ID, and the user/service that triggered the detection. Essential for demonstrating GDPR Article 30 (records of processing) and DPDP Act compliance.
Data Flow
Ingestion-Time Filtering (Pre-Training): Raw data arrives from ingestion sources -> Regex matcher flags structured PII in ~1ms per document -> NER model identifies unstructured PII entities in ~10-50ms per document -> Context analyzer resolves ambiguities -> Policy engine selects transformation -> Transformation engine sanitizes data -> Audit logger records actions -> Sanitized data proceeds to training pipeline.
Inference-Time Filtering (Input/Output): User input arrives at the API gateway -> Privacy filter scans input for PII (to prevent PII from reaching the model) -> Sanitized input is processed by the model -> Model output is scanned by a second privacy filter instance (to catch any PII the model might generate from memorization) -> Sanitized output is returned to the user.
Training-Time DP: Training data (already pre-filtered) enters the training loop -> DP-SGD computes per-sample gradients -> Gradients are clipped to norm -> Gaussian noise is added -> Noisy aggregated gradients update model parameters -> Moments accountant tracks cumulative .
A flowchart showing raw data input flowing through three detection layers (Regex Pattern Matcher, NER Model, Context Analyzer) into a Policy Engine that branches into four transformation options (Redact, Mask, Pseudonymize, Encrypt), all converging to Sanitized Output which feeds into an Audit Logger.
How to Implement
Choosing Your Detection Stack
Implementation approaches range from lightweight regex-only filters (suitable for structured PII in batch pipelines) to full-featured detection frameworks (needed when unstructured text with names, addresses, and contextual PII is involved).
Option A: Microsoft Presidio -- The most mature open-source framework. Combines regex recognizers, spaCy NER, and custom recognizers into a unified detection-and-anonymization pipeline. Supports custom entity types (you can add an Aadhaar recognizer in ~50 lines of Python). Best for general-purpose PII detection across text data.
Option B: Custom NER + Regex Pipeline -- Build your own using spaCy or a fine-tuned transformer model for NER, combined with domain-specific regex patterns. More work upfront, but gives you full control over detection logic and allows fine-tuning on your specific data distribution. Essential when dealing with non-English text (Hindi, Tamil, etc.) or domain-specific PII (medical record numbers, employee IDs).
Option C: Cloud-native Services -- Google Cloud DLP, AWS Macie, or Azure Purview provide managed PII detection with pre-built recognizers and compliance reporting. Higher cost (~$1-3 per GB scanned, INR 84-252 per GB) but zero infrastructure overhead. Good for organizations that need quick compliance wins.
For differential privacy during training, the primary options are Opacus (PyTorch), TensorFlow Privacy, and Google's DP library (for aggregate statistics). These are not alternatives to detection-based filtering -- they're complementary layers.
Cost Note: Presidio is free and open-source. Google Cloud DLP costs approximately 2/GB for de-identification (~INR 84/GB and INR 168/GB respectively). For a startup processing 100 GB/month, that's ~50-100/month or INR 4,200-8,400/month on a basic VM).
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, Pattern
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
# Create a custom Aadhaar number recognizer
aadhaar_pattern = Pattern(
name="aadhaar_pattern",
regex=r"\b[2-9]\d{3}\s?\d{4}\s?\d{4}\b",
score=0.85
)
aadhaar_recognizer = PatternRecognizer(
supported_entity="IN_AADHAAR",
name="Aadhaar Recognizer",
patterns=[aadhaar_pattern],
supported_language="en",
context=["aadhaar", "uid", "uidai", "aadhar"]
)
# Create a custom PAN number recognizer
pan_pattern = Pattern(
name="pan_pattern",
regex=r"\b[A-Z]{5}[0-9]{4}[A-Z]\b",
score=0.80
)
pan_recognizer = PatternRecognizer(
supported_entity="IN_PAN",
name="PAN Recognizer",
patterns=[pan_pattern],
supported_language="en",
context=["pan", "permanent account", "income tax"]
)
# Initialize engines
analyzer = AnalyzerEngine()
analyzer.registry.add_recognizer(aadhaar_recognizer)
analyzer.registry.add_recognizer(pan_recognizer)
anonymizer = AnonymizerEngine()
# Sample text with Indian PII
text = (
"Customer Rajesh Kumar, Aadhaar 9876 5432 1098, "
"PAN ABCDE1234F, email [email protected], "
"mobile +91-98765-43210, lives in Bengaluru."
)
# Detect PII entities
results = analyzer.analyze(
text=text,
entities=["PERSON", "EMAIL_ADDRESS", "PHONE_NUMBER",
"IN_AADHAAR", "IN_PAN", "LOCATION"],
language="en"
)
print(f"Detected {len(results)} PII entities:")
for r in results:
print(f" {r.entity_type}: '{text[r.start:r.end]}' (score={r.score:.2f})")
# Anonymize with type-specific operators
operators = {
"PERSON": OperatorConfig("replace", {"new_value": "[PERSON]"}),
"IN_AADHAAR": OperatorConfig("mask", {
"type": "mask", "masking_char": "X",
"chars_to_mask": 8, "from_end": False
}),
"IN_PAN": OperatorConfig("replace", {"new_value": "[PAN_REDACTED]"}),
"EMAIL_ADDRESS": OperatorConfig("replace", {"new_value": "[EMAIL]"}),
"PHONE_NUMBER": OperatorConfig("replace", {"new_value": "[PHONE]"}),
"LOCATION": OperatorConfig("replace", {"new_value": "[LOCATION]"}),
}
anonymized = anonymizer.anonymize(
text=text, analyzer_results=results, operators=operators
)
print(f"\nAnonymized: {anonymized.text}")
# Output: Customer [PERSON], Aadhaar XXXXXXXX1098, [PAN_REDACTED], ...This example demonstrates a complete Presidio-based PII detection and anonymization pipeline with custom recognizers for Indian PII types (Aadhaar and PAN numbers). The Aadhaar recognizer uses a regex pattern that matches the 12-digit format (starting with 2-9, as UIDAI specifies) with optional spaces, and context words boost the confidence score. The PAN recognizer matches the standard 5-letter-4-digit-1-letter format. Different PII types get different treatments: Aadhaar numbers are masked (showing only last 4 digits, per UIDAI masking regulations), while names and emails are fully replaced with entity-type tags.
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from opacus import PrivacyEngine
from opacus.validators import ModuleValidator
# Define a simple model
model = nn.Sequential(
nn.Linear(768, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 10)
)
# Opacus requires models to be compatible (no BatchNorm, etc.)
model = ModuleValidator.fix(model)
errors = ModuleValidator.validate(model, strict=False)
assert len(errors) == 0, f"Model incompatible with DP: {errors}"
# Create dummy data (replace with real data)
X = torch.randn(10000, 768)
y = torch.randint(0, 10, (10000,))
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size=256, shuffle=True)
# Configure optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# Attach PrivacyEngine with DP guarantees
privacy_engine = PrivacyEngine()
model, optimizer, dataloader = privacy_engine.make_private_with_epsilon(
module=model,
optimizer=optimizer,
data_loader=dataloader,
epochs=10,
target_epsilon=8.0, # Privacy budget
target_delta=1e-5, # Failure probability
max_grad_norm=1.0, # Gradient clipping bound
)
# Training loop with DP
criterion = nn.CrossEntropyLoss()
for epoch in range(10):
total_loss = 0.0
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
output = model(batch_X)
loss = criterion(output, batch_y)
loss.backward()
optimizer.step() # DP noise added automatically
total_loss += loss.item()
# Check current privacy budget spent
epsilon = privacy_engine.get_epsilon(delta=1e-5)
print(f"Epoch {epoch+1}: loss={total_loss/len(dataloader):.4f}, "
f"epsilon={epsilon:.2f}")
print(f"\nFinal privacy guarantee: (epsilon={epsilon:.2f}, delta=1e-5)-DP")This example shows how to train a PyTorch model with formal differential privacy guarantees using Meta's Opacus library. The PrivacyEngine wraps the optimizer to automatically clip per-sample gradients (bounding each individual's influence) and add calibrated Gaussian noise. The make_private_with_epsilon method calculates the required noise scale to achieve the target over the specified number of epochs. After training, get_epsilon reports the actual privacy cost. Note: Opacus requires models without BatchNorm layers (use GroupNorm or LayerNorm instead) -- the ModuleValidator.fix() call handles this automatically.
import pandas as pd
import numpy as np
from typing import Dict, List
def generalize_age(age: int, level: int = 1) -> str:
"""Generalize age into ranges based on level."""
if level == 0:
return str(age)
elif level == 1:
bucket = (age // 5) * 5
return f"{bucket}-{bucket + 4}"
elif level == 2:
bucket = (age // 10) * 10
return f"{bucket}-{bucket + 9}"
else:
return "*"
def generalize_pincode(pincode: str, level: int = 1) -> str:
"""Generalize Indian PIN code by masking trailing digits."""
if level == 0:
return pincode
elif level == 1:
return pincode[:4] + "XX" # e.g., 560001 -> 5600XX
elif level == 2:
return pincode[:3] + "XXX" # e.g., 560001 -> 560XXX
else:
return "XXXXXX"
def check_k_anonymity(df: pd.DataFrame,
quasi_identifiers: List[str],
k: int) -> bool:
"""Check if dataset satisfies k-anonymity."""
group_sizes = df.groupby(quasi_identifiers).size()
return group_sizes.min() >= k
def apply_k_anonymity(df: pd.DataFrame,
quasi_identifiers: List[str],
k: int,
generalizers: Dict) -> pd.DataFrame:
"""Apply k-anonymity through iterative generalization."""
result = df.copy()
levels = {qi: 0 for qi in quasi_identifiers}
while not check_k_anonymity(result, quasi_identifiers, k):
# Find the quasi-identifier with the most unique values
unique_counts = {
qi: result[qi].nunique() for qi in quasi_identifiers
}
target_qi = max(unique_counts, key=unique_counts.get)
# Increase generalization level
levels[target_qi] += 1
if levels[target_qi] > 3:
raise ValueError(
f"Cannot achieve {k}-anonymity without excessive "
f"information loss on {target_qi}"
)
result[target_qi] = result[target_qi].apply(
lambda x: generalizers[target_qi](x, levels[target_qi])
)
print(f"Generalized {target_qi} to level {levels[target_qi]}, "
f"unique values: {result[target_qi].nunique()}")
return result
# Example: Patient records from an Indian hospital
df = pd.DataFrame({
"age": [28, 29, 31, 34, 36, 42, 43, 45, 50, 52],
"gender": ["M", "F", "M", "F", "M", "F", "M", "F", "M", "F"],
"pincode": ["560001", "560034", "560002", "560078",
"400001", "400053", "400012", "110001",
"110045", "110023"],
"diagnosis": ["diabetes", "flu", "diabetes", "cancer",
"flu", "diabetes", "cancer", "flu",
"diabetes", "cancer"]
})
quasi_ids = ["age", "gender", "pincode"]
generalizers = {
"age": generalize_age,
"pincode": generalize_pincode,
"gender": lambda x, l: x if l == 0 else "*"
}
anonymized = apply_k_anonymity(df, quasi_ids, k=2, generalizers=generalizers)
print("\nAnonymized dataset:")
print(anonymized)
print(f"\nK-anonymity satisfied (k=2): "
f"{check_k_anonymity(anonymized, quasi_ids, 2)}")This example implements k-anonymity for tabular data using generalization hierarchies -- a technique commonly applied to structured health, financial, and census datasets. The approach iteratively generalizes quasi-identifiers (age, gender, PIN code) until every combination appears at least times. Indian PIN codes are generalized by masking trailing digits (e.g., 560001 becomes 5600XX). The algorithm greedily selects the quasi-identifier with the most unique values to generalize next, minimizing information loss. In practice, you'd typically use a library like ARX or Amnesia for large datasets, but this implementation illustrates the core logic.
import re
import json
import hashlib
from dataclasses import dataclass, field
from typing import List, Optional, Callable
from datetime import datetime
@dataclass
class PIIEntity:
entity_type: str
value: str
start: int
end: int
confidence: float
transformation: str = ""
transformed_value: str = ""
@dataclass
class AuditRecord:
timestamp: str
document_id: str
entities_detected: int
entity_types: List[str]
transformations_applied: List[str]
class PrivacyFilter:
"""Production-grade privacy filter for streaming pipelines."""
def __init__(self, hmac_key: str = "default-key"):
self.hmac_key = hmac_key.encode()
self.patterns = self._compile_patterns()
self.audit_log: List[AuditRecord] = []
def _compile_patterns(self) -> dict:
return {
"IN_AADHAAR": re.compile(
r"\b[2-9]\d{3}[\s-]?\d{4}[\s-]?\d{4}\b"
),
"IN_PAN": re.compile(
r"\b[A-Z]{5}[0-9]{4}[A-Z]\b"
),
"EMAIL": re.compile(
r"\b[\w.+-]+@[\w-]+\.[\w.-]+\b"
),
"IN_PHONE": re.compile(
r"(?:\+91[\s-]?)?[6-9]\d{4}[\s-]?\d{5}\b"
),
"CREDIT_CARD": re.compile(
r"\b(?:4\d{3}|5[1-5]\d{2}|6011)[-\s]?\d{4}"
r"[-\s]?\d{4}[-\s]?\d{4}\b"
),
"IN_PASSPORT": re.compile(
r"\b[A-Z][1-9]\d{6}\b"
),
}
def _pseudonymize(self, value: str, entity_type: str) -> str:
"""Generate a consistent pseudonym using HMAC."""
h = hashlib.sha256(self.hmac_key + value.encode())
digest = h.hexdigest()[:12]
return f"PSEUDO_{entity_type}_{digest}"
def _mask_aadhaar(self, value: str) -> str:
"""Mask Aadhaar per UIDAI regulations: show only last 4."""
digits = re.sub(r"[\s-]", "", value)
return f"XXXX-XXXX-{digits[-4:]}"
def detect_and_transform(
self, text: str, doc_id: str = "unknown"
) -> tuple:
"""Detect PII and apply transformations."""
entities: List[PIIEntity] = []
for entity_type, pattern in self.patterns.items():
for match in pattern.finditer(text):
entity = PIIEntity(
entity_type=entity_type,
value=match.group(),
start=match.start(),
end=match.end(),
confidence=0.90
)
# Apply type-specific transformation
if entity_type == "IN_AADHAAR":
entity.transformation = "mask"
entity.transformed_value = self._mask_aadhaar(
entity.value
)
elif entity_type in ("EMAIL", "CREDIT_CARD"):
entity.transformation = "redact"
entity.transformed_value = f"[{entity_type}]"
else:
entity.transformation = "pseudonymize"
entity.transformed_value = self._pseudonymize(
entity.value, entity_type
)
entities.append(entity)
# Apply transformations (reverse order to preserve indices)
sanitized = text
for entity in sorted(entities, key=lambda e: e.start,
reverse=True):
sanitized = (
sanitized[:entity.start]
+ entity.transformed_value
+ sanitized[entity.end:]
)
# Log audit record
self.audit_log.append(AuditRecord(
timestamp=datetime.utcnow().isoformat(),
document_id=doc_id,
entities_detected=len(entities),
entity_types=[e.entity_type for e in entities],
transformations_applied=[e.transformation for e in entities]
))
return sanitized, entities
# Usage
filter_instance = PrivacyFilter(hmac_key="my-secret-key-2026")
record = (
"Payment from Aadhaar 9876 5432 1098, card 4111-1111-1111-1111, "
"email [email protected], PAN ABCDE1234F, phone +91-98765-43210"
)
sanitized, entities = filter_instance.detect_and_transform(
record, doc_id="txn-001"
)
print(f"Original: {record}")
print(f"Sanitized: {sanitized}")
print(f"Entities found: {len(entities)}")
for e in entities:
print(f" {e.entity_type}: '{e.value}' -> '{e.transformed_value}' "
f"({e.transformation})")This example implements a production-style privacy filter suitable for streaming data pipelines (inspired by Grab's Flink-based PII masking architecture). Key design decisions: (1) Regex patterns are pre-compiled for performance, (2) Aadhaar numbers are masked per UIDAI regulations (first 8 digits hidden), (3) pseudonymization uses HMAC-SHA256 with a secret key for consistent but irreversible mapping, (4) every detection is logged to an audit trail for compliance. In production, you would add the NER layer (Presidio or spaCy) on top of this regex foundation and deploy it as a Flink/Kafka Streams operator that processes records in real time.
# Privacy filter configuration (YAML)
privacy_filter:
detection:
engines:
- type: regex
entities: [IN_AADHAAR, IN_PAN, EMAIL, CREDIT_CARD, IN_PHONE]
- type: ner
model: en_core_web_trf
entities: [PERSON, LOCATION, ORG, DATE_TIME]
confidence_threshold: 0.60
- type: presidio
language: en
entities: all
transformation_policies:
IN_AADHAAR:
method: mask
mask_char: "X"
chars_to_show: 4
show_from: end # UIDAI regulation
PERSON:
method: pseudonymize
consistency: document # Same name -> same pseudonym within doc
EMAIL:
method: redact
replacement: "[EMAIL]"
CREDIT_CARD:
method: redact
replacement: "[CARD]"
DEFAULT:
method: redact
replacement: "[REDACTED]"
differential_privacy:
enabled: true
target_epsilon: 8.0
target_delta: 1e-5
max_grad_norm: 1.0
noise_multiplier: auto # Computed from epsilon/delta/epochs
audit:
enabled: true
storage: azure_table_storage
table_name: pii_audit_log
retention_days: 365
compliance:
frameworks: [GDPR, DPDP_ACT]
breach_notification_hours: 72
data_retention_policy: minimalCommon Implementation Mistakes
- ●
Relying solely on regex for PII detection: Regex catches structured PII (credit cards, Aadhaar, emails) but completely misses unstructured PII like names, addresses, and contextual references ("my husband's salary"). You need NER models alongside regex for comprehensive coverage.
- ●
Ignoring false negatives in favor of precision: Privacy filters must prioritize recall (catching all PII) over precision (avoiding false alarms). A missed Aadhaar number is a regulatory violation; a falsely redacted city name is just a minor data quality issue. Set your confidence thresholds low and accept some false positives.
- ●
Applying the same transformation to all PII types: Different PII types require different treatments. Aadhaar numbers should be masked per UIDAI regulations, names should be pseudonymized (for analytical continuity), and credit card numbers should be fully redacted. A blanket
[REDACTED]tag destroys data utility unnecessarily. - ●
Forgetting about PII in model outputs: Most teams filter PII from training data but forget that LLMs can generate PII from memorized training examples. You need a privacy filter on both the input and output sides of inference. This is especially critical for customer-facing chatbots.
- ●
Not maintaining an audit trail: GDPR Article 30 and DPDP Act both require records of data processing activities. If you can't demonstrate what PII you detected, how you transformed it, and when -- you're non-compliant, even if your detection is perfect.
- ●
Setting differential privacy epsilon too high or too low: An provides almost no meaningful privacy guarantee. An adds so much noise that the model becomes useless. For most production workloads, is the practical sweet spot. Always validate utility on a held-out evaluation set after DP training.
- ●
Treating pseudonymization as anonymization: Under GDPR, pseudonymized data is still personal data because it can be re-identified with the key. Only truly anonymized data (irreversibly stripped of identifying characteristics) falls outside GDPR scope. This distinction has major legal implications.
When Should You Use This?
Use When
Your ML system ingests or generates data containing personally identifiable information (names, emails, phone numbers, government IDs like Aadhaar or SSN)
You operate under GDPR, DPDP Act, HIPAA, CCPA, or similar data protection regulations
Your model is trained on user-generated content that may contain PII -- chat logs, customer support tickets, medical records, financial transactions
You're building a customer-facing LLM application (chatbot, summarizer, Q&A system) where the model might regurgitate memorized PII
You need to share production data with development/staging environments for model tuning (as Grab's engineering team does)
You're training on sensitive datasets where membership inference or model inversion attacks are a realistic threat
Your organization processes Indian users' data and must comply with Aadhaar masking regulations (UIDAI mandates masking first 8 digits)
Avoid When
Your data is entirely synthetic or public domain with no personal information -- adding a privacy filter introduces unnecessary latency and complexity
You're working with fully anonymized aggregate statistics where no individual can be re-identified (e.g., publicly released census summary tables)
The privacy filter's latency overhead (~10-50ms per document for NER-based detection) is incompatible with ultra-low-latency inference requirements (<5ms)
You're processing structured numerical data with no text fields (consider statistical anonymization methods like k-anonymity directly instead of NER-based detection)
The data never leaves a tightly controlled, audited environment with strong access controls, and regulatory requirements are already met through other mechanisms
You're building a system where the users explicitly intend to share their personal information (e.g., a profile update API) -- filtering there would break functionality
Key Tradeoffs
The Fundamental Tradeoff: Privacy vs. Utility
Every privacy technique reduces data utility. The question is how much, and whether the reduction is acceptable for your use case.
| Technique | Privacy Strength | Utility Impact | Latency Cost | Regulatory Status |
|---|---|---|---|---|
| Redaction | High (data destroyed) | High (information lost) | Low (~1ms) | Accepted by GDPR/DPDP |
| Masking | Medium (partial data visible) | Medium | Low (~1ms) | Accepted (e.g., Aadhaar) |
| Pseudonymization | Medium (reversible with key) | Low (structure preserved) | Low (~2ms) | Still personal data under GDPR |
| K-anonymity | Medium (group-level protection) | Medium-High (generalization) | High (batch process) | Accepted for statistical data |
| Differential Privacy (=8) | High (mathematical guarantee) | Medium (some noise) | Medium (~20% training overhead) | Gold standard |
| Differential Privacy (=1) | Very High | High (significant noise) | Medium | Gold standard |
The Second Axis: Detection Recall vs. Throughput
Regex-only detection runs at ~100K documents/second but misses names and contextual PII. Adding NER drops throughput to ~100-500 documents/second but catches 85-95% of PII entities. Transformer-based NER pushes recall higher but drops throughput further. You need to profile your pipeline and decide what level of recall justifies the compute cost.
The Third Axis: Anonymization vs. Pseudonymization
Anonymization is irreversible -- the original data is gone. This is safest from a privacy perspective and removes the data from GDPR scope entirely. But it also means you can never link records back to individuals, which may be needed for clinical trials, fraud investigations, or customer experience analysis.
Pseudonymization preserves linkability (with the key) and keeps more utility, but the data remains regulated under GDPR. Choose based on your use case: analytics and model training usually favor anonymization, while customer-facing applications may need pseudonymization for personalization.
Rule of Thumb: Start with the least destructive technique that meets your regulatory requirements. Redact only what you must, pseudonymize what you can, and add differential privacy for defense-in-depth.
Alternatives & Comparisons
Guardrails are a broader safety layer that covers toxicity, hallucination, prompt injection, and PII leakage. A privacy filter is a specialized subset of guardrails focused exclusively on PII detection and anonymization. If you need comprehensive LLM safety, use guardrails with a privacy filter as one component. If your primary concern is data privacy in training pipelines (not just inference), a dedicated privacy filter gives you more control and better audit trails.
Content moderators focus on toxicity, hate speech, and inappropriate content. Privacy filters focus on personally identifiable information. They solve different problems and are typically deployed together rather than as alternatives. A content moderator won't catch an Aadhaar number, and a privacy filter won't catch hate speech.
NER extractors identify named entities (persons, organizations, locations) for information extraction use cases. Privacy filters use NER as a detection mechanism but add the transformation/anonymization layer, policy engine, and audit logging. If you just need to find entities, use an NER extractor. If you need to find entities and protect them, use a privacy filter.
Bias detectors identify unfairness in model predictions across protected attributes (gender, race, caste). Privacy filters protect the data itself from leakage. These are complementary responsible AI components: privacy filters protect individuals' data, bias detectors protect groups from discriminatory outcomes. Many organizations deploy both as part of an overall responsible AI framework.
Pros, Cons & Tradeoffs
Advantages
Regulatory compliance out of the box: A well-implemented privacy filter directly addresses GDPR Article 25 (data protection by design), DPDP Act consent requirements, and UIDAI Aadhaar masking regulations. This can save your organization from penalties up to INR 250 crore (~$30M).
Enables safe use of production data for development: Teams can access realistic, sanitized production data for model tuning and debugging without privacy risks -- exactly the pattern Grab uses to give data engineers access to masked production data in staging environments.
Defense-in-depth against model memorization: Even if the upstream embedding model or LLM memorizes some training data, a privacy filter on the inference output catches PII before it reaches end users. Two imperfect layers are far better than one.
Audit trail for incident response: When (not if) a data incident occurs, the audit log from your privacy filter provides timestamped evidence of what PII was processed, how it was handled, and whether proper safeguards were applied. This can be the difference between a warning and a crippling fine.
Differential privacy provides a formal, mathematical privacy guarantee: Unlike heuristic-based approaches, DP gives you a provable bound on information leakage (, ) that holds regardless of the adversary's computational power or auxiliary knowledge.
Composable and layerable: Privacy filters can be deployed at multiple pipeline stages (ingestion, training, inference input, inference output) with different configurations for each. This defense-in-depth approach handles the reality that no single detection point catches everything.
Disadvantages
No detection system achieves 100% recall: NER-based PII detection typically achieves 85-95% recall, meaning 5-15% of PII entities may slip through. Unusual names, misspellings, code-switched text (Hindi-English), and novel PII formats are common failure cases.
Latency overhead in inference pipelines: NER-based detection adds 10-50ms per document. For batch processing this is negligible, but for real-time serving with strict latency SLAs (e.g., <20ms), this overhead can be significant. Regex-only filters are faster but less comprehensive.
Differential privacy degrades model performance: DP-SGD with practical epsilon values () typically reduces model accuracy by 2-10% compared to non-private training. For some use cases (medical diagnosis, fraud detection), this utility loss may be unacceptable.
Pseudonymization is not anonymization under GDPR: Teams frequently confuse the two. Pseudonymized data (where re-identification is possible with a key) remains regulated under GDPR. This creates a false sense of compliance if not properly understood.
Maintenance burden for custom recognizers: PII patterns change -- new government ID formats, evolving phone number formats, new sensitive data types. Custom recognizers (like the Aadhaar pattern) must be actively maintained and tested against new data.
Multilingual and code-switched text is hard: Standard NER models trained on English text perform poorly on Hindi, Tamil, or Marathi text, and even worse on code-switched text (common in Indian contexts). Building robust multilingual PII detection requires significant investment in training data and models.
Failure Modes & Debugging
Incomplete PII detection (false negatives)
Cause
NER model not trained on the specific PII types or languages present in the data. Common with non-English names, code-switched text (Hindi-English), or domain-specific identifiers (hospital patient IDs, employee codes). Regex patterns may also miss variations -- e.g., Aadhaar numbers written without spaces or with hyphens.
Symptoms
PII entities pass through the filter undetected. Downstream models memorize and potentially reproduce them. Data breach occurs when model outputs contain unfiltered PII. Detected during manual audits, user reports, or automated PII scanning of model outputs.
Mitigation
Layer multiple detection methods (regex + NER + dictionary lookup). Fine-tune NER models on domain-specific annotated data. Implement post-hoc scanning of model outputs as a second filter. Run regular PII audits on a sample of filtered data to measure recall. Set up canary PII (known fake PII injected into data) to monitor filter effectiveness.
Overzealous filtering (false positives destroying utility)
Cause
Confidence thresholds set too low, or NER model conflating common words with PII. Example: "Bengaluru" flagged as a person name, or the number sequence "1234 5678 9012" in a technical document flagged as an Aadhaar number.
Symptoms
Excessive data redaction making training data or model outputs unintelligible. Downstream model performance degrades because too much useful information is removed. Users complain that the system is overly censoring legitimate content.
Mitigation
Tune confidence thresholds per entity type (higher for location names, lower for Aadhaar numbers). Implement allowlists for known non-PII terms. Use context-aware detection (Presidio's context enhancement) to reduce false positives. Monitor the false positive rate alongside recall.
Pseudonymization key compromise
Cause
The HMAC key or mapping table used for pseudonymization is stored insecurely, leaked, or accessible to unauthorized personnel. A compromised key means all pseudonymized data can be re-identified.
Symptoms
Pseudonymized data can be reversed by unauthorized parties. Compliance audit reveals inadequate key management. In the worst case, a data breach affecting all records pseudonymized with the compromised key.
Mitigation
Store pseudonymization keys in a dedicated key management service (Azure Key Vault, AWS KMS, HashiCorp Vault). Implement key rotation policies. Limit key access to the privacy filter service only -- no human access. Use format-preserving encryption (FPE) with proper key management instead of simple HMAC for reversible pseudonymization.
Privacy budget exhaustion in differential privacy
Cause
Too many training epochs, too many queries to the model, or epsilon set too low. Each gradient step or query consumes part of the finite privacy budget. Once exhausted, further use of the data violates the DP guarantee.
Symptoms
The moments accountant reports exceeding the target threshold. Model training terminates early before convergence. If budget exhaustion is ignored, the published privacy guarantee becomes invalid.
Mitigation
Plan the privacy budget before training: calculate the number of epochs, batch size, and noise multiplier needed to stay within the target . Use the moments accountant (not basic composition) for tighter tracking. Consider privacy amplification by subsampling. If the budget is exhausted, collect new data with fresh consent rather than continuing to use the existing dataset.
Re-identification through quasi-identifier linkage
Cause
PII entities are individually masked, but the combination of remaining quasi-identifiers (age, gender, PIN code, timestamp, transaction amount) uniquely identifies individuals. This is the classic k-anonymity attack -- Latanya Sweeney demonstrated it by re-identifying the governor of Massachusetts from anonymized hospital data using just zip code, birth date, and gender.
Symptoms
Adversary links anonymized records to external datasets (voter rolls, social media profiles) and re-identifies individuals. Privacy audit reveals that equivalence classes contain fewer than individuals.
Mitigation
Apply k-anonymity (or l-diversity, t-closeness) to structured data after PII removal. Generalize quasi-identifiers: age to ranges, PIN codes to district level, timestamps to date only. Suppress records in equivalence classes smaller than . Use differential privacy for aggregate statistics.
Model memorization bypassing output filter
Cause
The model has memorized verbatim training data containing PII. An adversary crafts prompts that trigger the model to reproduce this memorized data. The output privacy filter fails to detect the PII because it appears in an unusual context or is fragmented across multiple tokens.
Symptoms
Users discover they can extract real names, phone numbers, or email addresses from the model through carefully crafted prompts. Extraction attacks succeed despite output filtering.
Mitigation
Apply differential privacy during training (DP-SGD) to mathematically bound memorization. Implement membership inference tests to detect memorization before deployment. Use output filters with high-sensitivity configurations (lower confidence thresholds). Rate-limit suspicious prompt patterns that resemble extraction attacks.
Placement in an ML System
A Privacy Filter Belongs Everywhere (Almost)
Unlike most ML pipeline components that sit at a single stage, a privacy filter operates at multiple points in the pipeline:
Stage 1: Data Ingestion -- The first and most critical placement. Raw data from sources (web scrapes, user-generated content, database exports) passes through the privacy filter before entering the data lake or feature store. This is where bulk PII removal happens. Think of this as the primary checkpoint.
Stage 2: Training Pipeline -- Even after ingestion-time filtering, differential privacy (DP-SGD) can be applied during model training to provide a mathematical guarantee against memorization. This is the defense-in-depth layer for the training phase.
Stage 3: Inference Input -- User queries to an LLM or ML model may themselves contain PII ("My Aadhaar number is 9876 5432 1098, can you check my application status?"). An input privacy filter sanitizes queries before they reach the model, preventing PII from entering model context or being logged.
Stage 4: Inference Output -- The model's responses are scanned for PII before being returned to the user. This catches memorized training data that the model might reproduce, as well as any PII that was present in retrieved context (in RAG systems).
The upstream components (document loaders, data ingestion, text chunkers) provide the raw data that the privacy filter sanitizes. The downstream components (embedding models, training pipelines, guardrails) consume the sanitized output. In a well-designed system, no component downstream of the privacy filter should ever see raw PII.
Key Insight: A single privacy filter at ingestion is necessary but not sufficient. Defense-in-depth requires filters at ingestion, training (DP), inference input, and inference output. Each layer catches what the previous one missed.
Pipeline Stage
Data Processing / Pre-Training / Serving
Upstream
- document-loader
- data-ingestion
- text-chunker
Downstream
- embedding-model
- model-training
- guardrails
- content-moderator
Scaling Bottlenecks
The primary bottleneck is NER inference throughput. A spaCy en_core_web_trf model (transformer-based) processes ~50-100 documents/second on a CPU, or ~500-1000 on a GPU. For batch processing millions of documents before training, this translates to hours or days of compute. At ~3/hour for a GPU VM (INR 252/hour), filtering 10 million documents costs approximately $15-50 (INR 1,260-4,200) in compute alone.
Regex-only detection scales linearly and can process ~100K documents/second, but misses unstructured PII. A common optimization is to run regex first (as a cheap pre-filter) and only invoke the NER model on documents that pass through regex without any detections -- on the assumption that documents with structured PII likely also contain unstructured PII.
Differential privacy adds ~20-30% training overhead due to per-sample gradient computation and noise addition. For a large model training run that costs 2,000-3,000 (INR 1.68-2.52 lakh) in additional compute.
Production Case Studies
Google trained next-word prediction models for Gboard (the Android keyboard) using federated learning with formal differential privacy guarantees. User typing data never leaves the device -- only differentially private model updates are sent to the server. They used the DP-FTRL algorithm to train a recurrent neural network for Spanish-language Gboard users, achieving the first production neural network with a formal DP guarantee. By 2024, all Gboard production language models trained on user data use federated learning with DP.
Achieved production-quality next-word prediction with formal (epsilon, delta)-DP guarantees, demonstrating that privacy and utility are not fundamentally at odds. Replaced all legacy federated-learning-only models with DP-FL models across all languages.
Apple implemented private federated learning (PFL) for training ML models on user data across iPhone and iPad devices. Their framework ensures user data remains on individual devices, with only essential model updates (protected by differential privacy) transmitted to a central server for aggregation. This powers improvements to Siri, QuickType keyboard suggestions, and other on-device ML features.
Successfully trained production ML models for Siri and keyboard prediction across hundreds of millions of devices while maintaining user privacy. The approach preserves Apple's privacy-first brand positioning while enabling data-driven model improvements.
Grab's data streaming team (Coban) implemented PII masking in their ML data streaming pipelines using a Flink application in the production environment. Production data is mirrored to staging environments for model tuning, with PII masked using deterministic hashing (same input always produces the same masked output). This allows data engineers to tune ML models using realistic data without accessing raw PII.
Enabled data engineers to safely access production-like data for model development. Consistent hashing preserves referential integrity across masked datasets, ensuring that relationships in the data remain analytically useful. Privacy by design culture embedded across the engineering organization.
Google Cloud's Sensitive Data Protection (formerly Cloud DLP) provides a production-grade de-identification and re-identification pipeline for PII in large-scale datasets. The architecture uses a combination of InfoType detectors (regex + ML-based classifiers), transformation methods (redaction, masking, tokenization, bucketing, date shifting), and key management for reversible transformations. It processes data at scale using Dataflow pipelines.
Processes petabytes of data for enterprise customers with configurable privacy policies. Supports over 150 built-in InfoType detectors across 50+ countries. Organizations use it to comply with GDPR, CCPA, HIPAA, and other regulations while maintaining data utility for analytics and ML.
Tooling & Ecosystem
The most mature open-source PII detection and anonymization framework. Combines regex recognizers, NLP-based NER (spaCy), and context-aware detection. Supports custom entity types, multiple anonymization operators (redact, mask, hash, encrypt), and structured data anonymization. Extensible with custom recognizers for Indian PII types (Aadhaar, PAN, Indian phone numbers).
Meta's differential privacy library for PyTorch. Implements DP-SGD with per-sample gradient computation, automatic noise calibration, and privacy budget tracking via the moments accountant. Supports make_private_with_epsilon for easy target-epsilon training. Requires BatchNorm-free models (provides ModuleValidator.fix() for automatic conversion).
Google's collection of DP libraries in C++, Go, and Java. Implements basic noise primitives and differentially private aggregations (count, sum, mean, quantiles). Includes Privacy on Beam for Apache Beam pipelines, PipelineDP for Python/Spark, and DP-Auditorium for auditing DP guarantees with black-box access.
Comprehensive open-source tool for privacy-preserving data publishing. Supports k-anonymity, l-diversity, t-closeness, delta-presence, and differential privacy for tabular data. Features an intuitive GUI, a Java API for programmatic use, risk analysis, and data utility metrics. Handles generalization, suppression, microaggregation, and top/bottom coding.
Industrial-strength NLP library that provides the NER backbone for many PII detection systems, including Presidio. Models like en_core_web_trf (transformer-based) detect PERSON, ORG, GPE, DATE, and other entity types. Can be fine-tuned on custom annotated data for domain-specific PII detection. Essential for detecting unstructured PII that regex cannot catch.
Privacy engineering platform specializing in synthetic data generation with differential privacy guarantees. Generates privacy-safe synthetic versions of datasets that preserve statistical properties without exposing individual records. Useful when you need realistic training data but cannot use the original due to privacy regulations.
Open-source library for generating synthetic tabular, relational, and time-series data using deep learning models (CTGAN, TVAE). Preserves statistical properties and relationships in the original data. Does not include built-in DP, but can be combined with DP techniques for stronger privacy guarantees.
Privacy-preserving machine learning framework that supports federated learning, secure multi-party computation (SMPC), and differential privacy. Extends PyTorch to enable computation on encrypted data and training across decentralized data owners without sharing raw data.
Managed PII detection and de-identification service with 150+ built-in InfoType detectors. Supports redaction, masking, tokenization, bucketing, and date shifting. Integrates with BigQuery, Cloud Storage, and Dataflow for batch and streaming de-identification at scale. ~2/GB for de-identification.
Research & References
Abadi, Chu, Goodfellow, McMahan, Mironov, Talwar & Zhang (2016)ACM CCS 2016
Introduced DP-SGD (differentially private stochastic gradient descent) with per-sample gradient clipping and the moments accountant for tight privacy budget tracking. The foundational paper that made training deep neural networks with differential privacy practical.
Dwork & Roth (2014)Foundations and Trends in Theoretical Computer Science
The definitive textbook on differential privacy. Covers the mathematical framework, composition theorems, the Laplace and Gaussian mechanisms, and applications to data analysis. Essential reading for anyone implementing DP in production.
Sweeney (2002)International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems
Introduced the k-anonymity model and demonstrated re-identification attacks on supposedly anonymized medical data. Sweeney showed that 87% of the U.S. population could be uniquely identified by zip code, birth date, and gender alone.
McMahan, Moore, Ramage, Hampson & Arcas (2017)AISTATS 2017
Introduced the Federated Averaging (FedAvg) algorithm for training deep networks across decentralized data. The foundational paper for federated learning, which enables privacy-preserving model training by keeping raw data on user devices.
Carlini, Tramer, Wallace, Jagielski, Herbert-Voss, Lee, Roberts, Brown, Song, Erlingsson, Oprea & Fredrikson (2021)USENIX Security 2021
Demonstrated that GPT-2 memorizes and regurgitates verbatim training data, including PII like names, phone numbers, and email addresses. This paper is the primary motivation for applying privacy filters to LLM training data and outputs.
Various (2025)arXiv preprint
A comprehensive survey covering the evolution of differential privacy techniques from traditional ML to large language models. Discusses DP-SGD, DP fine-tuning, private inference, and the unique challenges of applying DP to LLMs at scale.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a PII detection pipeline for a multilingual customer support chatbot serving Indian users?
- ●
What is differential privacy, and how does DP-SGD work? Walk me through the math.
- ●
Explain the difference between anonymization and pseudonymization. Which one removes data from GDPR scope?
- ●
How would you handle Aadhaar number masking in a production ML pipeline that processes millions of KYC documents?
- ●
Your LLM is leaking training data containing PII. What are your immediate and long-term mitigations?
- ●
How would you implement k-anonymity for a healthcare dataset while preserving enough utility for disease prediction models?
- ●
What is the privacy-utility tradeoff in differential privacy? How do you choose epsilon?
- ●
Design a privacy-preserving recommendation system for an Indian e-commerce platform.
Key Points to Mention
- ●
Privacy filters should operate at multiple pipeline stages (ingestion, training, inference input, inference output) -- defense-in-depth is essential because no single detection layer achieves 100% recall.
- ●
Recall matters more than precision for PII detection. A missed PII entity is a regulatory violation; a false positive is just data quality noise. Always optimize for recall first.
- ●
The distinction between anonymization (irreversible, outside GDPR scope) and pseudonymization (reversible with key, still personal data under GDPR) has major legal and architectural implications.
- ●
Differential privacy provides the only mathematically rigorous privacy guarantee. Detection-based methods are best-effort. Both are needed: detection for obvious PII, DP for subtle memorization-based leakage.
- ●
India's DPDP Act (2023, rules notified 2025) mandates consent-based processing, 72-hour breach notification, and penalties up to INR 250 crore. UIDAI regulations require Aadhaar masking (first 8 digits hidden) after KYC completion.
- ●
Federated learning + DP is the production pattern at Google (Gboard) and Apple (Siri) for training on user data without centralized data collection. Mention FedAvg + DP-FTRL.
- ●
For practical DP training, epsilon in the range is the sweet spot. Below 1 destroys utility; above 10 provides negligible privacy. Always validate model utility after DP training.
Pitfalls to Avoid
- ●
Claiming that data masking or hashing is 'anonymization' -- deterministic hashing is pseudonymization at best and can be reversed with rainbow tables. True anonymization must be irreversible.
- ●
Ignoring the composition property of differential privacy: running multiple DP mechanisms on the same data accumulates privacy cost. You can't just add DP to every step and assume the guarantee still holds at the original epsilon.
- ●
Treating regex-only PII detection as comprehensive. Names, contextual references ('my husband works at...'), and novel ID formats will be missed. Always layer NER on top of regex.
- ●
Confusing compliance with privacy. Being 'GDPR compliant' on paper (having a privacy policy, appointing a DPO) doesn't mean your ML pipeline is actually protecting personal data. Technical safeguards matter.
- ●
Suggesting federated learning alone provides privacy. Without differential privacy, federated learning is still vulnerable to gradient inversion attacks where an adversary can reconstruct training data from gradient updates.
Senior-Level Expectation
A senior candidate should discuss the end-to-end privacy architecture: detection stack selection (Presidio vs. custom NER), transformation policy design (which PII types get which treatments), differential privacy budget planning (epsilon allocation across training epochs), key management for pseudonymization, audit logging for compliance, and the organizational process around privacy impact assessments. They should demonstrate understanding of the privacy-utility tradeoff with concrete numbers -- not just 'there is a tradeoff' but 'at epsilon=3 on this dataset, we observed a 4% accuracy drop which was acceptable for our use case.' They should also discuss the Indian regulatory context (DPDP Act penalties, Aadhaar masking requirements, data localization) and how it differs from GDPR. Finally, they should address failure modes like quasi-identifier linkage, model memorization, and privacy budget exhaustion, along with concrete mitigations for each.
Summary
A privacy filter is the critical gatekeeper in any ML system that processes personal data. It combines multiple detection techniques -- regex-based pattern matching for structured PII (Aadhaar numbers, credit cards, emails), NER-based entity recognition for unstructured PII (names, addresses), and statistical anonymization (k-anonymity, l-diversity) for tabular quasi-identifiers -- with a policy engine that applies the right transformation (redaction, masking, pseudonymization, or generalization) to each detected entity. The implementation choice depends on your scale and requirements: Microsoft Presidio for general-purpose detection, Google Cloud DLP for managed infrastructure, and custom NER pipelines for domain-specific or multilingual needs.
Beyond detection-based filtering, differential privacy provides the only mathematically rigorous guarantee against information leakage -- including the subtle leakage that occurs through model memorization even after obvious PII has been removed. DP-SGD (per-sample gradient clipping + noise injection) is the standard approach for training neural networks with DP, with practical epsilon values typically in the range . Federated learning complements DP by keeping raw data on user devices, eliminating the need for centralized data collection entirely -- a pattern proven at scale by Google (Gboard) and Apple (Siri).
The regulatory landscape makes privacy filters non-negotiable: GDPR penalties reach EUR 20M, India's DPDP Act penalties reach INR 250 crore (~$30M), and UIDAI mandates Aadhaar masking after KYC completion. But beyond compliance, privacy filters are a defense-in-depth strategy against model memorization, membership inference attacks, and re-identification through quasi-identifier linkage. Deploy them at every pipeline stage -- ingestion, training, inference input, and inference output -- because no single layer catches everything. The organizations that treat privacy as an engineering discipline rather than a legal checkbox will be the ones that maintain user trust while still building powerful ML systems.