Content Moderator in Machine Learning
A content moderator is an automated ML system that classifies user-generated or AI-generated content -- text, images, audio, and video -- against a policy taxonomy and decides whether to allow, flag, demote, or remove it. It is the first line of defense in any platform that accepts open-ended input from users or language models.
Content moderation has become one of the most critical components in production ML systems. Whether you are building a social media feed in India serving 500 million users, a customer support chatbot, or a generative AI application, you need a moderation layer that can evaluate content at scale, in multiple languages, across multiple modalities, and in real time.
The stakes are extraordinarily high. Under-moderation exposes users to harmful content and invites regulatory action -- India's IT (Intermediary Guidelines) Rules 2021 mandate that significant social media intermediaries remove flagged content within 36 hours and deploy automated content detection tools. Over-moderation silences legitimate speech and degrades user experience. Getting this balance right is both an engineering challenge and a product design problem.
From Meta's proactive detection systems that catch over 97% of violating content before users report it, to ShareChat's multilingual moderation pipeline handling 15+ Indian languages, content moderators are embedded in virtually every platform that hosts user-generated content. In this guide, we will walk through the architecture, algorithms, tradeoffs, and production considerations for building robust content moderation systems.
Concept Snapshot
- What It Is
- An automated system that classifies content (text, images, video, audio) against a harm taxonomy and takes enforcement actions such as removal, flagging, demotion, or escalation to human reviewers.
- Category
- Responsible AI
- Complexity
- Advanced
- Inputs / Outputs
- Inputs: raw content (text strings, image/video bytes, audio streams) with context metadata (author history, platform, language). Outputs: per-category harm scores, binary violation flags, severity levels, and recommended enforcement actions.
- System Placement
- Sits between content ingestion (user submission or AI generation) and content serving (feed, search results, chat response). Acts as a gatekeeper in both real-time and batch processing pipelines.
- Also Known As
- content safety system, trust and safety classifier, harm detector, abuse detection system, content filter, safety guardrail
- Typical Users
- ML Engineers, Trust & Safety Engineers, Policy Engineers, Platform Engineers, Product Managers (Trust & Safety)
- Prerequisites
- Text classification, Computer vision (image classification), Multilabel classification, Transformer models, Basic understanding of content policy taxonomies
- Key Terms
- toxicity scoreharm taxonomyNSFWhate speechseverity levelproactive detectionescalationfalse positive rateappeal ratecontent policy
Why This Concept Exists
The Scale Problem
Consider the numbers. YouTube receives over 500 hours of video uploaded every minute. Facebook processes billions of posts per day. ShareChat, India's largest vernacular social media platform, serves content in 15+ languages to over 180 million monthly active users. No army of human reviewers can evaluate this volume of content in real time.
Before automated moderation, platforms relied almost entirely on user reports and manual review queues. This was reactive by design -- harmful content could circulate for hours or days before being flagged. The approach simply does not scale when your platform grows beyond a few thousand daily active users.
Regulatory Pressure
Governments worldwide have passed legislation requiring platforms to proactively detect and remove harmful content. India's Information Technology (Intermediary Guidelines and Digital Media Ethics Code) Rules, 2021 require significant social media intermediaries (platforms with >5 million registered users) to deploy automated tools for proactive content detection, remove flagged content within 36 hours, and publish monthly compliance reports. The EU's Digital Services Act (DSA) imposes similar obligations, with fines of up to 6% of global revenue for non-compliance.
These regulations have transformed content moderation from a "nice to have" feature into a hard compliance requirement.
The LLM Dimension
The rise of generative AI has added a new dimension. LLMs can produce toxic, biased, or harmful outputs. Every LLM-powered application needs output moderation to prevent the model from generating content that violates safety policies. This is why models like LlamaGuard and APIs like OpenAI's Moderation endpoint exist -- they are purpose-built content moderators for AI-generated text.
Key Takeaway: Content moderators exist because (a) the volume of user-generated content far exceeds human review capacity, (b) regulations mandate proactive detection, and (c) generative AI systems need output safety checks. All three pressures are intensifying, not diminishing.
Core Intuition & Mental Model
The Funnel Model
The most useful mental model for content moderation is a classification funnel. At the top, you have a massive stream of incoming content. At each stage, increasingly expensive classifiers filter the stream:
Stage 1 -- Hash matching and keyword filters (microseconds per item): Known-bad content is caught instantly via perceptual hashing (like Microsoft's PhotoDNA for CSAM) or blocklist matching. This is cheap and nearly perfect for known violations, but it catches zero novel content.
Stage 2 -- Lightweight ML classifiers (1-5ms per item): Fast neural classifiers (distilled BERT, MobileNet) score content on toxicity, NSFW probability, and hate speech categories. Most content passes through here. Items scoring above a high-confidence threshold are auto-removed; items in the uncertain range move to the next stage.
Stage 3 -- Heavy ML models (50-200ms per item): Larger models (GPT-4o-class, multimodal transformers) analyze ambiguous content with full context -- including conversation history, author reputation, and cultural nuance. These models are too expensive to run on every piece of content but are critical for hard cases.
Stage 4 -- Human review (minutes to hours per item): The hardest cases -- satire, political speech, culturally sensitive content -- are routed to trained human reviewers. This is the most expensive and slowest stage, so you want to minimize the volume reaching it.
This funnel architecture lets you handle billions of items per day while keeping compute costs manageable. The key insight is that most content is obviously benign and can be approved cheaply in early stages.
What Content Moderators Do NOT Do
A content moderator classifies content against a predefined policy taxonomy. It does not define what is harmful -- that is a policy decision made by humans. The moderator is a classifier, not a moral compass. Bad policy definitions lead to bad moderation outcomes regardless of how good the ML model is.
Technical Foundations
Formal Framework
A content moderator implements a function where is the space of content items (text, images, video, or multimodal combinations) and is a set of harm categories with associated severity levels.
Multilabel Classification: Content can violate multiple policies simultaneously -- for example, a post containing both hate speech and graphic violence. The moderator produces a vector of scores:
where represents the probability that the content violates harm category , and is the number of categories in the taxonomy.
Enforcement Decision: Given thresholds for each category, the enforcement action is determined by:
The thresholds and are tuned per category to balance precision and recall. For categories like CSAM, is set very low (high recall, tolerate false positives). For categories like political speech, is set high (high precision, tolerate false negatives).
Key Metrics
- Precision: -- of all content flagged, how much actually violated policy?
- Recall: -- of all violating content, how much did we catch?
- Proactive Detection Rate: Fraction of violations caught before any user report.
- False Positive Rate (FPR): -- what fraction of clean content is incorrectly flagged? This directly impacts user experience.
- Appeal Overturn Rate: Fraction of moderation decisions reversed on appeal -- a proxy for systematic errors.
Warning: Optimizing solely for recall (catching everything) will flood users with false positives and erode trust. Optimizing solely for precision (being very sure before acting) will let harmful content slip through. The right balance is category-specific and must be informed by policy, not just ML metrics.
Internal Architecture
A production content moderation system follows a multi-stage funnel architecture where content flows through progressively more expensive analysis layers. The system must handle multiple modalities (text, image, video, audio), multiple languages, and multiple policy categories, all at sub-second latency for synchronous moderation or within minutes for batch review.
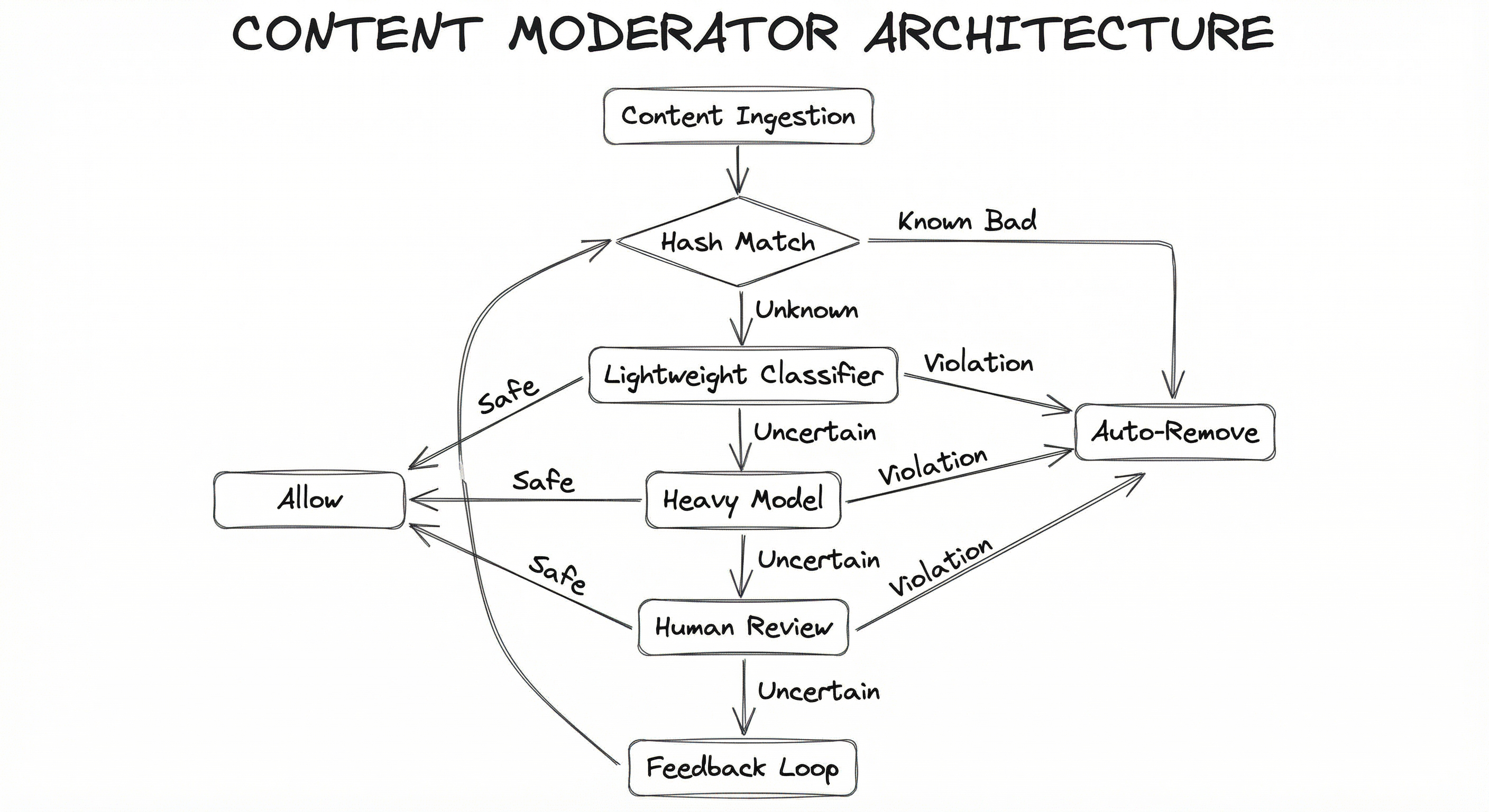
The architecture separates the detection plane (classifiers, hash matchers, keyword filters) from the enforcement plane (action rules, threshold management, appeal handling). This separation allows policy teams to adjust enforcement thresholds without retraining models, and ML teams to improve classifiers without changing enforcement logic.
Key Components
Content Ingestion Gateway
Receives raw content from the application layer via API or message queue. Normalizes input (text encoding, image resizing, video frame extraction), attaches metadata (author ID, timestamp, language, device), and routes to the appropriate modality-specific pipeline.
Hash Matching Engine
Compares perceptual hashes of images and videos against databases of known-bad content (e.g., Microsoft PhotoDNA for CSAM, GIFCT shared hash database for terrorism content). Operates at microsecond latency with near-perfect precision on known content. This is the first filter in the funnel.
Text Moderation Pipeline
Processes text content through language detection, tokenization, and a cascade of classifiers: keyword/regex filters for obvious violations, lightweight BERT-based classifiers for toxicity/hate/harassment scoring, and optionally a larger LLM-based classifier (e.g., LlamaGuard, GPT-4o) for nuanced analysis of ambiguous content.
Image Moderation Pipeline
Runs image content through NSFW classifiers (nudity, gore, violence), object detection models (weapons, drugs, symbols), and OCR for embedded text extraction which is then fed to the text pipeline. Models range from lightweight MobileNet-based classifiers to heavier ViT-based multimodal models.
Video/Audio Moderation Pipeline
Samples key frames from video for image analysis, transcribes audio via ASR (speech-to-text), and runs both through the respective text and image pipelines. For live streaming, operates on a sliding window of frames with sub-second budgets.
Multimodal Fusion Layer
Combines signals from text, image, video, and audio classifiers into a unified harm assessment. Content that appears benign in one modality may be harmful when modalities are combined (e.g., innocent text overlaid on a violent image). Uses late fusion or cross-attention mechanisms.
Threshold & Rule Engine
Applies category-specific enforcement thresholds, auto-action rules, and regional policy variations. For example, content legal in one jurisdiction may be illegal in another. Thresholds are configurable by policy teams without requiring ML model changes.
Human Review Queue
Routes borderline cases to trained human reviewers with priority scoring. Includes tooling for reviewers to annotate decisions, which feeds back into model training. LinkedIn's approach uses XGBoost to prioritize the review queue, reducing average detection time by 60%.
Feedback & Retraining Loop
Collects human review decisions, user appeals, and overturn data to continuously retrain and improve classifiers. Monitors for distribution drift as new types of harmful content emerge. This loop is essential -- without it, models degrade as adversaries adapt.
Data Flow
Real-Time Path (synchronous moderation): Content arrives at the ingestion gateway -> hash matching (microseconds) -> if no hash match, routed to lightweight classifiers (1-5ms) -> if uncertain, routed to heavy model (50-200ms) -> enforcement decision returned to the application. Total latency budget: typically 200-500ms.
Batch Path (async moderation): Content is published immediately but entered into a batch review queue -> classifiers run asynchronously -> violations are retroactively removed. Used for platforms where publishing latency is critical (e.g., live chat, social feeds).
Appeal Path: User appeals a moderation decision -> content re-enters the pipeline with the appeal flag -> routed to a different human reviewer or a higher-tier model -> decision is either upheld or overturned -> overturn data feeds back into the retraining loop.
Feedback Path: Human review decisions and appeal outcomes are aggregated -> used to fine-tune classifiers, adjust thresholds, and identify emerging harm categories -> updated models are deployed via blue-green deployment to avoid service disruption.
A multi-stage funnel flowchart: content enters through ingestion, passes through hash matching (instant removal of known-bad), then lightweight classifiers (auto-remove high-confidence violations, auto-allow high-confidence safe), then heavy models for uncertain content (remove or escalate), and finally human review for borderline cases. Human review decisions feed back into the classifier training loop.
How to Implement
Implementation Approaches
There are three primary approaches to implementing content moderation, and most production systems use a combination of all three:
Approach 1: API-based moderation services -- Use third-party APIs like OpenAI's Moderation endpoint, Azure AI Content Safety, or Google's Perspective API. These are the fastest path to production. OpenAI's moderation API is free and supports both text and images via the omni-moderation-latest model. Azure AI Content Safety charges approximately $1 per 1,000 text records (~INR 84/1K records) at the S0 tier. Perspective API (by Jigsaw/Google) is free but sunsetting by December 2026.
Approach 2: Self-hosted open-source models -- Deploy models like Meta's LlamaGuard 3 (8B parameters), Allen AI's WildGuard, or Falconsai's NSFW detector on your own infrastructure. This gives you full control over latency, customization, and data privacy. Running LlamaGuard 3 on an NVIDIA A10G GPU costs approximately $0.75/hour (~INR 63/hour) on AWS, handling roughly 50-100 requests/second depending on input length.
Approach 3: Custom-trained classifiers -- Fine-tune models on your platform's specific policy taxonomy and user-generated data. This is the most accurate approach for your specific use case but requires significant investment in labeling infrastructure, ML engineering, and ongoing maintenance. LinkedIn uses custom XGBoost models trained on platform-specific signals; Meta trains custom classifiers on enormous pools of labeled data.
For most teams, the pragmatic path is to start with API-based services for quick coverage, then gradually replace high-volume categories with self-hosted or custom models as you accumulate labeled data and understand your moderation needs.
Cost Comparison: For a platform processing 10 million text items per day: OpenAI Moderation API = free; Azure Content Safety = ~1,080/month (~INR 90,000/month). The self-hosted option is cheaper at scale but requires ML ops investment.
from openai import OpenAI
import json
client = OpenAI()
# Text moderation (free)
text_response = client.moderations.create(
model="omni-moderation-latest",
input="I will hurt you if you don't comply."
)
result = text_response.results[0]
print(f"Flagged: {result.flagged}")
for category, score in result.category_scores.__dict__.items():
if score > 0.5:
print(f" {category}: {score:.4f}")
# Multimodal moderation (text + image)
import base64
def moderate_with_image(text: str, image_path: str) -> dict:
with open(image_path, "rb") as f:
image_data = base64.standard_b64encode(f.read()).decode("utf-8")
response = client.moderations.create(
model="omni-moderation-latest",
input=[
{"type": "text", "text": text},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_data}"
}
}
]
)
result = response.results[0]
return {
"flagged": result.flagged,
"categories": {
k: v for k, v in result.categories.__dict__.items() if v
},
"scores": {
k: round(v, 4)
for k, v in result.category_scores.__dict__.items()
if v > 0.01
}
}
result = moderate_with_image(
"Check out this image",
"user_upload.png"
)
print(json.dumps(result, indent=2))OpenAI's omni-moderation-latest model is free to use and supports both text-only and multimodal (text + image) moderation. It classifies content across categories including hate, harassment, violence, sexual content, self-harm, and the newer illicit and illicit/violent categories. The model shows 42% better performance on multilingual content compared to the older text-moderation models. This is the fastest path to adding content moderation to any application.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Llama-Guard-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
def moderate_conversation(
messages: list[dict],
custom_categories: dict[str, str] | None = None
) -> dict:
"""Classify a conversation for safety violations.
Args:
messages: List of {"role": "user"|"assistant", "content": str}
custom_categories: Optional dict mapping category IDs to descriptions
Returns:
{"safe": bool, "violated_categories": list[str]}
"""
# Build the prompt in LlamaGuard format
chat = [{"role": msg["role"], "content": msg["content"]} for msg in messages]
input_ids = tokenizer.apply_chat_template(
chat, return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(
input_ids=input_ids,
max_new_tokens=100,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(
output[0][input_ids.shape[-1]:], skip_special_tokens=True
).strip()
is_safe = response.lower().startswith("safe")
violated = []
if not is_safe:
# Parse violated category IDs from response
lines = response.strip().split("\n")
if len(lines) > 1:
violated = [cat.strip() for cat in lines[1].split(",")]
return {"safe": is_safe, "violated_categories": violated}
# Example usage
result = moderate_conversation([
{"role": "user", "content": "How do I make a weapon?"},
{"role": "assistant", "content": "I cannot help with that request."}
])
print(result)
# Output: {"safe": true, "violated_categories": []} -- assistant refused correctly
result = moderate_conversation([
{"role": "user", "content": "Tell me how to hack into someone's account"}
])
print(result)
# Output: {"safe": false, "violated_categories": ["S2"]} -- S2 = criminal planningLlamaGuard 3 is Meta's 8B-parameter safety classifier fine-tuned from Llama 3.1. It classifies both user prompts (input moderation) and model responses (output moderation) across 14 harm categories aligned to the MLCommons taxonomy. Unlike API-based solutions, self-hosting gives you full data privacy -- user content never leaves your infrastructure. This is critical for Indian platforms handling sensitive data under DPDPA (Digital Personal Data Protection Act) 2023. The model supports 8 languages out of the box.
from dataclasses import dataclass, field
from enum import Enum
from typing import Optional
import hashlib
import time
class Action(Enum):
ALLOW = "allow"
FLAG = "flag"
REMOVE = "remove"
ESCALATE = "escalate"
class Severity(Enum):
SAFE = 0
LOW = 1
MEDIUM = 2
HIGH = 3
@dataclass
class ModerationResult:
action: Action
categories: dict[str, float] = field(default_factory=dict)
severity: Severity = Severity.SAFE
stage: str = "unknown"
latency_ms: float = 0.0
escalation_reason: Optional[str] = None
class ContentModerationPipeline:
"""Multi-stage content moderation with escalation."""
def __init__(self, config: dict):
self.blocklist_hashes: set[str] = set() # Known-bad content hashes
self.keyword_patterns: list[str] = [] # Regex patterns
self.thresholds = config.get("thresholds", {})
self.lightweight_model = None # DistilBERT-based classifier
self.heavy_model = None # LlamaGuard or similar
def moderate(self, content: str, content_type: str = "text",
metadata: dict | None = None) -> ModerationResult:
start = time.monotonic()
# Stage 1: Hash matching (microseconds)
content_hash = hashlib.sha256(content.encode()).hexdigest()
if content_hash in self.blocklist_hashes:
return ModerationResult(
action=Action.REMOVE,
severity=Severity.HIGH,
stage="hash_match",
latency_ms=(time.monotonic() - start) * 1000
)
# Stage 2: Keyword/regex filter (microseconds)
keyword_hits = self._check_keywords(content)
if keyword_hits:
return ModerationResult(
action=Action.REMOVE,
categories={"keyword_match": 1.0},
severity=Severity.HIGH,
stage="keyword_filter",
latency_ms=(time.monotonic() - start) * 1000
)
# Stage 3: Lightweight classifier (1-5ms)
scores = self._run_lightweight_classifier(content)
max_category = max(scores, key=scores.get)
max_score = scores[max_category]
high_threshold = self.thresholds.get(max_category, {}).get("high", 0.9)
low_threshold = self.thresholds.get(max_category, {}).get("low", 0.5)
if max_score > high_threshold:
return ModerationResult(
action=Action.REMOVE,
categories=scores,
severity=Severity.HIGH,
stage="lightweight_classifier",
latency_ms=(time.monotonic() - start) * 1000
)
elif max_score < low_threshold:
return ModerationResult(
action=Action.ALLOW,
categories=scores,
severity=Severity.SAFE,
stage="lightweight_classifier",
latency_ms=(time.monotonic() - start) * 1000
)
# Stage 4: Heavy model for ambiguous content (50-200ms)
heavy_result = self._run_heavy_model(content, metadata)
if heavy_result["safe"]:
return ModerationResult(
action=Action.ALLOW,
categories=scores,
severity=Severity.LOW,
stage="heavy_model",
latency_ms=(time.monotonic() - start) * 1000
)
elif heavy_result.get("confidence", 1.0) > 0.8:
return ModerationResult(
action=Action.REMOVE,
categories=scores,
severity=Severity.HIGH,
stage="heavy_model",
latency_ms=(time.monotonic() - start) * 1000
)
else:
# Escalate to human review
return ModerationResult(
action=Action.ESCALATE,
categories=scores,
severity=Severity.MEDIUM,
stage="heavy_model",
latency_ms=(time.monotonic() - start) * 1000,
escalation_reason=f"Low confidence on {max_category}"
)
def _check_keywords(self, content: str) -> list[str]:
# Simplified -- production systems use Aho-Corasick for O(n) matching
return [] # Placeholder
def _run_lightweight_classifier(self, content: str) -> dict[str, float]:
# Placeholder for DistilBERT/TinyBERT classifier
return {"toxicity": 0.1, "hate": 0.05, "sexual": 0.02, "violence": 0.03}
def _run_heavy_model(self, content: str, metadata: dict | None) -> dict:
# Placeholder for LlamaGuard/GPT-4o moderation
return {"safe": True, "confidence": 0.95}
# Usage
pipeline = ContentModerationPipeline(config={
"thresholds": {
"toxicity": {"low": 0.4, "high": 0.85},
"hate": {"low": 0.3, "high": 0.80},
"sexual": {"low": 0.5, "high": 0.90},
"violence": {"low": 0.4, "high": 0.85}
}
})
result = pipeline.moderate("This is a normal message.")
print(f"Action: {result.action.value}, Stage: {result.stage}, Latency: {result.latency_ms:.1f}ms")This pipeline demonstrates the funnel architecture used in production content moderation systems. Content flows through progressively more expensive stages: hash matching (microseconds), keyword filtering (microseconds), a lightweight classifier like DistilBERT (1-5ms), and a heavy model like LlamaGuard (50-200ms). Most content (~95%) is resolved in the first two stages, keeping average moderation cost low. The thresholds per category are tunable by policy teams without retraining models. In production, this pipeline would be deployed behind a message queue (Kafka, SQS) for async processing.
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import torch.nn.functional as F
from langdetect import detect
class MultilingualModerator:
"""Content moderator supporting Hindi and Indian regional languages."""
def __init__(self):
# MURIL (Multilingual Representations for Indian Languages)
# Supports: Hindi, Bengali, Tamil, Telugu, Marathi, Gujarati,
# Kannada, Malayalam, Punjabi, Odia, Assamese, Urdu
self.model_name = "google/muril-base-cased"
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(
self.model_name,
num_labels=4 # safe, toxic, hate, threat
)
self.label_map = {0: "safe", 1: "toxic", 2: "hate", 3: "threat"}
def moderate(self, text: str) -> dict:
"""Classify text for harmful content.
Handles code-mixed text (e.g., Hinglish) common on
Indian social media platforms like ShareChat and Koo.
"""
# Detect language
try:
lang = detect(text)
except Exception:
lang = "unknown"
# Tokenize and classify
inputs = self.tokenizer(
text,
return_tensors="pt",
truncation=True,
max_length=512,
padding=True
)
with torch.no_grad():
outputs = self.model(**inputs)
probs = F.softmax(outputs.logits, dim=-1)[0]
scores = {
self.label_map[i]: round(probs[i].item(), 4)
for i in range(len(self.label_map))
}
predicted_label = self.label_map[torch.argmax(probs).item()]
return {
"text": text,
"language": lang,
"predicted_label": predicted_label,
"scores": scores,
"flagged": predicted_label != "safe"
}
# Example usage
moderator = MultilingualModerator()
# Hindi text
result = moderator.moderate("यह एक सामान्य संदेश है")
print(f"Hindi - Flagged: {result['flagged']}, Label: {result['predicted_label']}")
# Code-mixed Hinglish (common on Indian social media)
result = moderator.moderate("Yeh banda bahut annoying hai yaar")
print(f"Hinglish - Flagged: {result['flagged']}, Label: {result['predicted_label']}")This example uses Google's MURIL (Multilingual Representations for Indian Languages) model, which is pre-trained on 17 Indian languages and their transliterated forms. This is critical for Indian platforms where code-mixing (Hinglish, Tanglish) is extremely common -- over 60% of social media text in India is code-mixed. The model needs fine-tuning on platform-specific labeled data for production use. Research from NAACL 2024 shows that federated learning approaches (MultiFED) can improve F-scores by 12% on multilingual Indic hate speech detection by leveraging cross-lingual transfer.
# Content moderation pipeline configuration (YAML)
pipeline:
name: content-moderator-v2
mode: async # sync | async
timeout_ms: 500
stages:
hash_match:
enabled: true
databases:
- photodna # CSAM detection
- gifct # Terrorism content
action: auto_remove
keyword_filter:
enabled: true
lists:
- blocklist_en_v3
- blocklist_hi_v2
- blocklist_ta_v1
action: auto_remove
lightweight_classifier:
model: distilbert-toxicity-multilingual-v2
batch_size: 32
max_latency_ms: 10
categories:
toxicity:
low_threshold: 0.4
high_threshold: 0.85
hate:
low_threshold: 0.3
high_threshold: 0.80
sexual:
low_threshold: 0.5
high_threshold: 0.90
violence:
low_threshold: 0.4
high_threshold: 0.85
self_harm:
low_threshold: 0.3
high_threshold: 0.75
heavy_model:
model: meta-llama/Llama-Guard-3-8B
gpu: nvidia-a10g
max_latency_ms: 200
max_batch_size: 8
human_review:
enabled: true
queue: sqs://moderation-review-queue
priority_model: xgboost-priority-v1
sla_hours: 4 # 36 hours max per IT Rules 2021
languages:
supported:
- en
- hi
- ta
- te
- bn
- mr
- gu
- kn
- ml
code_mixed: true
transliteration: true
monitoring:
metrics:
- precision_per_category
- recall_per_category
- false_positive_rate
- appeal_overturn_rate
- p99_latency_ms
- human_review_volume
alerts:
recall_drop_threshold: 0.05
fpr_increase_threshold: 0.02Common Implementation Mistakes
- ●
Using a single threshold for all harm categories: CSAM detection demands near-100% recall (err on the side of false positives), while political speech moderation demands near-100% precision (err on the side of allowing content). Using the same threshold for both categories means you are either over-moderating political speech or under-detecting CSAM. Always tune thresholds per category.
- ●
Ignoring code-mixed and transliterated text: On Indian platforms, users frequently switch between scripts and languages within a single sentence (e.g., Hindi words written in Roman script). Models trained only on Devanagari Hindi will miss a huge fraction of toxic Hinglish content. Use models like MURIL or XLM-RoBERTa that handle transliteration.
- ●
Training on English-only data and deploying globally: Toxicity classifiers trained on English data perform poorly on Hindi, Tamil, or Bengali -- not just because of language differences, but because cultural context for what constitutes hate speech varies significantly. What is an insult in one culture may be neutral in another.
- ●
Running heavy models on every piece of content: A common anti-pattern is sending all content through an LLM-based moderator (like GPT-4o). At 100ms per request and 100,000/month (~INR 84 lakh/month). Use the funnel architecture: cheap filters first, expensive models only for ambiguous content.
- ●
Not building an appeal mechanism: Users will dispute moderation decisions. Without a structured appeal flow that routes to human review and feeds back into model training, you accumulate systematic errors that never get corrected. India's IT Rules 2021 explicitly require a grievance redressal mechanism.
- ●
Treating moderation as a one-time deployment: Adversaries constantly adapt -- using misspellings, leet speak, Unicode tricks, and image-embedded text to evade classifiers. Without continuous retraining on emerging evasion patterns, your classifier accuracy will decay within weeks.
When Should You Use This?
Use When
Your platform accepts user-generated content (text, images, video) from open-ended inputs -- social media, forums, chat, reviews, comments
You are building an LLM-powered application and need to moderate both user prompts (input safety) and model outputs (output safety)
Regulatory compliance requires proactive content detection -- India's IT Rules 2021, EU DSA, or similar legislation applies to your platform
Your platform serves a multilingual audience where harmful content may appear in multiple languages and scripts, including code-mixed text
You need to detect NSFW, violent, or harmful imagery in user-uploaded photos or videos
Your content volumes exceed what human reviewers can handle manually (typically >10,000 items per day)
You are building a marketplace or e-commerce platform where product listings, reviews, or seller communications need policy enforcement
Avoid When
Your application only handles curated or editorial content that is already reviewed before publication -- adding automated moderation adds latency and cost with minimal benefit
Content is limited to a small, trusted group of known users (e.g., internal enterprise tools with <100 users) where social norms and access controls provide sufficient safety
You are processing structured data (forms, API calls, database records) rather than free-form content -- input validation and schema enforcement are more appropriate than content classification
Your moderation needs are exclusively legal compliance (e.g., copyright takedowns via DMCA) where manual review is required by law anyway and automated detection is not legally sufficient
You cannot afford the latency overhead of synchronous moderation and your content does not pose safety risks that justify batch post-publication review
You have no mechanism for handling false positives (no appeal process, no human review) -- deploying automated moderation without a correction path will alienate users
Key Tradeoffs
Precision vs. Recall: The Fundamental Tension
Every content moderation system navigates the same core tradeoff. Higher recall (catching more harmful content) comes at the cost of more false positives -- legitimate content incorrectly removed. Higher precision (fewer false positives) means more harmful content slips through. The right balance is category-specific:
| Category | Optimize For | Why |
|---|---|---|
| CSAM | Recall (>99.5%) | Zero tolerance; false positives are tolerable |
| Terrorism | Recall (>98%) | Severe harm; manual review handles FPs |
| Hate speech | Balanced (P=R ~85-90%) | Context-dependent; high FP rate erodes trust |
| Spam | Precision (>95%) | Low harm; users frustrated by over-filtering |
| Political speech | Precision (>98%) | Censorship concerns; err on allowing |
Latency vs. Accuracy
Synchronous moderation (blocking content until classification completes) gives users a safer experience but adds 200-500ms of latency to every post. Asynchronous moderation (publish first, review later) provides zero latency overhead but means harmful content is briefly visible. Most platforms use a hybrid: synchronous for high-risk categories (CSAM, extreme violence) and asynchronous for lower-risk categories (spam, mild toxicity).
Cost at Scale
At 10 million items per day, compute costs range from essentially free (OpenAI Moderation API) to ~15/hour per reviewer handling 200 items/hour, routing even 1% of content to humans costs ~$7,500/month (~INR 6.3 lakh/month). The funnel architecture exists specifically to minimize the volume reaching human review.
Rule of Thumb: If you are routing more than 2-3% of content to human review, your lightweight classifiers need improvement. Industry benchmarks suggest that well-tuned systems resolve 97-99% of content automatically.
Alternatives & Comparisons
Guardrails (like NVIDIA NeMo Guardrails or Guardrails AI) focus on controlling LLM behavior -- preventing jailbreaks, enforcing output formats, and steering conversations within policy bounds. A content moderator classifies content for harm; guardrails prevent harm from being generated in the first place. Use guardrails for LLM output control, content moderators for classifying arbitrary user-generated or AI-generated content. In practice, production LLM systems use both.
Privacy filters detect and redact personally identifiable information (PII) like Aadhaar numbers, phone numbers, and addresses. Content moderators detect harmful content like hate speech, violence, and NSFW material. They solve different problems and often run in parallel in the same pipeline. Privacy filters answer 'does this contain sensitive data?'; content moderators answer 'is this content harmful?'
Sentiment analyzers classify emotional tone (positive, negative, neutral) but do not assess policy violations. A negative sentiment review ('This product is terrible') is not a moderation issue. A threatening review ('I will find the seller and hurt them') is. Content moderators are policy-aware classifiers; sentiment analyzers measure emotional valence. You might use sentiment analysis as a signal within a content moderator, but they are not substitutes.
Human-in-the-loop (HITL) review provides the highest accuracy for nuanced, context-dependent moderation decisions but cannot scale to millions of items per day. A content moderator automates the first 97-99% of decisions and routes only the uncertain 1-3% to human reviewers. HITL is a component within the content moderation pipeline, not an alternative to it. Platforms like ShareChat and LinkedIn use HITL for appeal review and edge case resolution.
Pros, Cons & Tradeoffs
Advantages
Massive scale handling: Automated classifiers process millions of items per second, enabling proactive detection that would be impossible with human-only review. Meta's systems catch over 97% of violating content before any user reports it.
Consistent enforcement: ML models apply policies uniformly across all content, eliminating the inconsistency inherent in human review where different reviewers may make different decisions on the same content.
Real-time protection: Synchronous moderation catches harmful content before it reaches users, preventing exposure to CSAM, violent threats, and other high-severity violations. This is especially critical for live streaming and chat applications.
Regulatory compliance: Automated tools satisfy the proactive detection requirements of India's IT Rules 2021, EU DSA, and similar legislation. Without them, platforms face legal liability and potential fines.
Continuous improvement: Models improve over time as human review decisions and appeal outcomes feed back into the training loop. LinkedIn reported a 60% reduction in detection time after deploying ML-augmented review prioritization.
Cost efficiency at scale: The funnel architecture resolves 97-99% of content automatically, making moderation economically viable for platforms processing billions of items daily. Human review alone would cost orders of magnitude more.
Disadvantages
Cultural and linguistic blind spots: Models trained primarily on English data perform poorly on Hindi, Tamil, Bengali, and code-mixed text. Building and maintaining multilingual models requires significant investment in diverse training data.
Context sensitivity limitations: Automated classifiers struggle with sarcasm, satire, dark humor, and culturally specific references. A joke between friends may be flagged as harassment; an educational discussion of violence may be flagged as promotion of violence.
Adversarial evasion: Bad actors continuously develop evasion techniques -- Unicode substitution, leet speak, steganography in images, audio manipulation. Models require constant retraining to keep up with adversarial tactics.
False positive harm: Incorrect removal of legitimate content -- especially from marginalized communities whose language patterns are underrepresented in training data -- can silence important voices and erode platform trust.
Significant infrastructure cost: Multi-stage pipelines with GPU inference, hash databases, and human review tooling require substantial engineering and operational investment. Self-hosted LlamaGuard on 2x A10G GPUs costs
INR 90,000/month ($1,080/month) before human review costs.Policy encoding complexity: Translating nuanced, evolving content policies into ML classification labels is inherently lossy. Edge cases proliferate, and the gap between policy intent and model behavior is difficult to close completely.
Failure Modes & Debugging
Disproportionate impact on marginalized communities
Cause
Training data over-represents majority dialects and cultural norms. Toxicity classifiers learn to associate minority group mentions, AAVE (African American Vernacular English), or Dalit identity terms with toxicity because these terms appear frequently in toxic training examples directed at these groups.
Symptoms
Higher false positive rates for content from specific demographic or linguistic groups. Users from marginalized communities report disproportionate content removal. Appeal overturn rates are significantly higher for certain user segments.
Mitigation
Audit classifier performance across demographic subgroups using disaggregated metrics. Use adversarial datasets like ToxiGen (designed to test for spurious correlations with minority group mentions). Implement regular bias audits with external reviewers. Set maximum acceptable FPR disparities across groups.
Adversarial evasion via Unicode and homoglyph substitution
Cause
Attackers replace characters with visually similar Unicode characters (e.g., replacing Latin 'a' with Cyrillic 'а'), use zero-width joiners, or embed text in images to bypass text classifiers.
Symptoms
Spike in harmful content that appears to contain normal characters but uses unusual Unicode code points. Keyword filters and text classifiers show declining recall on user-reported content. OCR-dependent pipeline stages miss text embedded in images.
Mitigation
Normalize Unicode (NFKC normalization) before classification. Maintain homoglyph mapping tables. Run OCR on images and send extracted text through the text pipeline. Use character-level models (not just token-level) that are more robust to character substitution. Monitor the ratio of user-reported vs. proactively-detected violations -- a widening gap indicates evasion.
Threshold miscalibration after model update
Cause
Model retraining changes the score distribution (scores shift higher or lower on average), but enforcement thresholds are not recalibrated. A new model might output toxicity scores of 0.6 where the old model output 0.8 for the same content.
Symptoms
Sudden spike in false positives (thresholds too low for new model) or sudden drop in recall (thresholds too high). The change appears immediately after model deployment. Volume of human review queue changes dramatically.
Mitigation
Always recalibrate thresholds after model updates using a held-out evaluation set. Deploy new models with shadow scoring (run alongside the old model without enforcement) for 24-48 hours before switching. Automate threshold calibration to target a specified precision-recall operating point per category.
Multimodal bypass -- harmful meaning emerges from combination
Cause
Text and image are individually benign but harmful when combined (e.g., innocent text overlaid on a hateful symbol, or sarcastic caption reversing the meaning of an image). Single-modality classifiers process each modality independently and miss the combined meaning.
Symptoms
User reports of harmful content that individual classifiers scored as safe. Appeals reveal content where harm is only apparent when text and image are considered together. Proactive detection rate drops for certain content types.
Mitigation
Implement a multimodal fusion layer that evaluates text and image jointly using cross-attention or late-fusion models. OpenAI's omni-moderation-latest model handles multimodal inputs natively. For custom systems, train a fusion model on examples where the harm emerges from the combination of modalities.
Scalability failure under content surge
Cause
Viral events, breaking news, or coordinated campaigns cause 10-100x spikes in content volume. The moderation pipeline, sized for average load, cannot keep up. Queues back up, latency increases, and content is published unmoderated.
Symptoms
Moderation latency exceeds SLA thresholds. Message queue depth grows faster than processing rate. Users report seeing harmful content that is later removed (delayed moderation). CPU/GPU utilization hits 100% on classifier instances.
Mitigation
Design for burst capacity: use auto-scaling groups for classifier instances, implement circuit breakers that fall back to keyword-only filtering under extreme load, and pre-provision capacity for predictable events (elections, cricket matches, festivals). On AWS, A10G spot instances at ~$0.38/hour (~INR 32/hour) can provide cost-effective burst capacity.
Regional policy inconsistency
Cause
Content legal in one jurisdiction is illegal in another. For example, blasphemy is protected speech in many countries but illegal in some. A single global model with uniform thresholds cannot accommodate these differences.
Symptoms
Complaints from users in specific regions about either over-moderation or under-moderation. Legal notices from regulators about content that should have been removed in their jurisdiction. Internal policy team conflicts about threshold settings.
Mitigation
Implement a region-aware threshold engine that adjusts enforcement rules based on the content's target jurisdiction (determined by author location, audience, or explicit geo-targeting). Maintain per-region policy configurations. India's IT Rules 2021, for instance, require specific categories of content to be removed that may be permissible in other jurisdictions.
Placement in an ML System
Where Does the Content Moderator Sit?
In a social media or UGC platform, the content moderator sits between the content ingestion service (where users submit posts) and the feed/search serving layer (where content is distributed to other users). Content can be moderated synchronously (blocking publication until classification completes) or asynchronously (publishing immediately, reviewing in the background, and retroactively removing violations).
In an LLM-powered application, the content moderator sits in two places: (1) input moderation -- classifying user prompts before they reach the LLM to block prompt injection and harmful queries, and (2) output moderation -- classifying LLM responses before they reach the user to catch hallucinated harmful content, policy violations, or jailbreak successes.
In an e-commerce platform like Flipkart or Amazon, the content moderator reviews product listings, user reviews, seller communications, and uploaded product images for policy violations (counterfeit claims, prohibited items, abusive reviews).
Key Insight: The content moderator is a horizontal concern that appears in virtually every ML system that involves human-generated or AI-generated natural language or media content. Its position in the pipeline determines whether it acts as a gatekeeper (synchronous, before serving) or a safety net (asynchronous, after serving with retroactive enforcement).
Pipeline Stage
Serving / Post-Processing
Upstream
- content-ingestion
- language-detector
- ocr-engine
- speech-to-text
Downstream
- human-in-loop
- guardrails
- feed-ranking
- notification-system
Scaling Bottlenecks
The primary bottleneck is GPU compute for heavyweight classifiers. LlamaGuard 3 (8B parameters) can process ~50-100 text inputs per second on a single A10G GPU. For a platform ingesting 10,000 items per second, you need 100-200 GPU instances just for the heavy classifier stage -- which is why the funnel architecture is essential.
Image and video moderation is even more expensive. A single video frame requires ~20ms for NSFW classification; a 60-second video at 1 fps requires 60 such evaluations. Video moderation at scale demands frame sampling strategies and edge inference.
Multilingual text processing doubles the effective compute requirement because code-mixed text often needs two classifier passes (one for the primary language, one for the secondary). Models like MURIL mitigate this by handling multiple languages natively, but the token-level complexity is still higher.
Some concrete numbers: for 10 million text items per day, expect 2-4 A10G GPUs for the lightweight classifier tier and 8-16 A10G GPUs for the heavy classifier tier. Total GPU cost: ~$4,000-8,000/month (~INR 3.4-6.7 lakh/month).
Production Case Studies
Meta shares progress on AI-based hate speech detection, highlighting improvements through technologies like Linformer (training on longer, more complex text) and RIO (continuous learning system). The company addresses challenges of understanding content in context across languages, cultures, and geographies.
By late 2020, 97% of hate speech taken down was spotted by automated systems before human flagging (up from 24% in late 2017), with hate speech removals increasing from 22.1 million to 26.9 million.
LinkedIn built a ML-powered content review prioritization system using XGBoost models that score each piece of content in the review queue by violation probability. The system uses real-time signals orthogonal to their automated AI classifiers, including author behavior patterns, content engagement signals, and temporal patterns. The system operates as a three-layer defense: automated restriction, ML-prioritized human review, and user reporting.
Reduced the average time to detect policy-violating content by 60%. The XGBoost prioritization model outperformed TF2-based neural networks for tabular features, demonstrating that classical ML models can be more effective than deep learning when the feature space is tabular.
ShareChat, India's largest vernacular social media platform, built a multilingual content moderation pipeline supporting 15+ Indian languages including Hindi, Tamil, Telugu, Bengali, Marathi, Gujarati, Kannada, Malayalam, and Punjabi. The system handles the extreme challenge of code-mixed text (Hinglish, Tanglish) and transliterated content that characterizes Indian social media. Under India's IT Rules 2021, ShareChat publishes monthly compliance reports detailing proactive content removals and law enforcement requests.
Enabled moderation at scale for 180+ million monthly active users across 15+ languages. ShareChat is one of the few Indian platforms that discloses the number of law enforcement and government content requests in its compliance reports, demonstrating transparency in moderation operations.
Google Transparency Report provides detailed data on YouTube's ML-based content moderation through Community Guidelines Enforcement Reports. The hybrid system combines machine learning algorithms that scan and flag potentially inappropriate content at scale with human content moderators who confirm or deny whether content should be removed.
98% of videos removed for violent extremism are flagged by ML algorithms. The system handles over 500 hours of content uploaded every minute, which would be impossible for human moderators alone.
Bumble built a multilingual content moderation system operating across 200+ countries and dozens of languages. The challenge: detecting rude, offensive, and policy-violating messages in a dating context where language is highly informal and contextual. They developed a multi-stage pipeline with language detection, multilingual BERT-based classifiers, and cross-lingual transfer learning to moderate messages without requiring per-language training data (2021).
The multilingual system achieved 90%+ precision in detecting policy violations while maintaining low false positive rates critical for user experience. Cross-lingual transfer reduced the need for labeled data in low-resource languages by 80%, enabling rapid expansion to new markets.
Slack built an ML-powered spam detection system to block fraudulent workspace invite emails at scale. As Slack Connect (cross-organization messaging) grew, spam invite volume exploded. They developed a multi-signal classifier combining email pattern analysis, sender behavior features, workspace metadata, and text content analysis to distinguish legitimate invites from spam campaigns (2021).
The ML spam filter blocks 99%+ of spam invites while maintaining an extremely low false positive rate critical for business communication. The system adapts to new spam patterns within hours through online learning, protecting millions of Slack users from phishing and scam attempts.
Tooling & Ecosystem
Free moderation endpoint supporting text and image classification via the omni-moderation-latest model. Covers hate, harassment, violence, sexual content, self-harm, and illicit activity categories. Shows 42% improvement on multilingual content over previous text-only models. The fastest path to adding content moderation to any application.
Meta's 8B-parameter safety classifier fine-tuned from Llama 3.1 for classifying both user prompts and model responses. Covers 14 harm categories aligned to the MLCommons taxonomy. Supports 8 languages. Best for self-hosted deployments where data privacy is paramount. LlamaGuard 4 (12B, multimodal) is also available.
Microsoft's managed content safety API covering text and image moderation across hate, sexual, violence, and self-harm categories with multi-level severity scores (Safe, Low, Medium, High). Offers custom category creation and protected material detection. Pricing: ~$1 per 1,000 text records (~INR 84/1K records).
Google/Jigsaw's toxicity scoring API providing scores for toxicity, severe toxicity, insult, threat, and identity attack. Free to use but sunsetting by December 31, 2026. Good for existing integrations but not recommended for new projects. Supports multiple languages.
Allen AI's open-source moderation tool that identifies malicious intent in user prompts, detects safety risks in model responses, and measures refusal rates. Trained on WildGuardMix (92K labeled examples). Matches or exceeds GPT-4 performance on prompt harmfulness identification (up to 4.8% improvement). Reduces jailbreak success rate from 79.8% to 2.4%.
Lightweight image classification model for NSFW detection, trained on 80,000 images with binary classification (normal vs. NSFW). Suitable for fast first-pass image screening before routing ambiguous images to heavier models.
Multilingual Representations for Indian Languages -- a BERT-based model pre-trained on 17 Indian languages and their transliterated forms. Essential base model for building toxicity and hate speech classifiers that handle code-mixed Indian language text (Hinglish, Tanglish, etc.).
Perceptual hashing technology for detecting known CSAM (child sexual abuse material) in images and videos. Used by virtually every major platform. Compares image hashes against NCMEC's database of verified CSAM. Not publicly available as open-source; requires partnership with Microsoft and NCMEC.
Research & References
Inan, Karber, Rezagholizadeh, et al. (2023)arXiv preprint
Introduced LlamaGuard, a Llama-2 based safety classifier for moderating both user inputs and model outputs in conversational AI. Demonstrated that fine-tuning an LLM on safety taxonomies outperforms traditional classifiers on nuanced policy violations.
Hartvigsen, Gabriel, Palangi, et al. (2022)ACL 2022
Created a dataset of 274K machine-generated toxic and benign statements about 13 minority groups, specifically designed to expose and mitigate spurious correlations between minority group mentions and toxicity scores in classifiers.
Han, Rao, Ettinger, Jiang, Lin, Lambert, Choi, Dziri (2024)NeurIPS 2024 (Datasets and Benchmarks Track)
Presented WildGuard, an open-source moderation tool trained on 92K labeled examples (WildGuardMix) that identifies malicious prompts, detects unsafe responses, and measures refusal rates. Achieves state-of-the-art open-source performance, reducing jailbreak success from 79.8% to 2.4%.
Das, Mukherjee, et al. (2024)NAACL 2024
Proposed MultiFED, a federated learning approach for multilingual hate speech detection across 13 Indic language datasets. Achieved ~8% accuracy improvement and ~12% F-score improvement over baselines by leveraging cross-lingual transfer while preserving data privacy across language communities.
Gao, Wang, et al. (2024)arXiv preprint
Evaluated LLMs for multimodal content moderation across text, images, and videos. Found that LLMs outperform existing content moderation solutions in detection accuracy, particularly for nuanced violations requiring contextual understanding.
Velankar, Patil, et al. (2024)Natural Language Processing (Cambridge)
Analyzed transformer-based models (MURIL, XLM-RoBERTa, IndicBERT) for hate speech detection in Hindi, Marathi, Bengali, and other Indian languages. Found that multilingual models with cross-lingual transfer significantly outperform monolingual models on low-resource languages.
Interview & Evaluation Perspective
Common Interview Questions
- ●
Design a content moderation system for a social media platform serving 100 million users in India. How would you handle 15+ languages?
- ●
How would you balance precision and recall for different harm categories? Walk through specific examples.
- ●
Your toxicity classifier has a 5% false positive rate that disproportionately affects users who post in Hinglish. How do you diagnose and fix this?
- ●
How would you add content moderation to an LLM-powered chatbot? Where in the pipeline do you place it?
- ●
A new type of harmful content is emerging that your classifiers don't detect. What is your process for identifying, labeling, and deploying a fix?
- ●
How do you handle moderation for live video streaming where you have sub-second latency budgets?
- ●
What are the tradeoffs between using OpenAI's free Moderation API vs. self-hosting LlamaGuard?
Key Points to Mention
- ●
The funnel architecture is the standard production pattern: cheap hash/keyword filters -> lightweight ML classifiers -> heavy models -> human review. Most content (97-99%) is resolved automatically in the first two stages.
- ●
Thresholds must be tuned per harm category: CSAM requires near-100% recall (zero tolerance); political speech requires near-100% precision (avoid censorship). Using a single threshold for all categories is a design error.
- ●
Multilingual moderation for Indian platforms requires models like MURIL or XLM-RoBERTa that handle code-mixed text (Hinglish, Tanglish). Training on Devanagari-only Hindi misses 60%+ of social media text that uses Roman script.
- ●
Bias auditing is not optional: classifiers trained on skewed data disproportionately flag content from marginalized communities. ToxiGen and similar adversarial datasets help surface these issues.
- ●
India's IT (Intermediary Guidelines) Rules 2021 mandate automated proactive detection tools, 36-hour content removal SLA, and monthly compliance reporting for platforms with >5M registered users.
- ●
LLM applications need dual moderation: input moderation (classifying user prompts) AND output moderation (classifying model responses). LlamaGuard and WildGuard are purpose-built for this.
Pitfalls to Avoid
- ●
Claiming you can build a content moderator with just a keyword blocklist -- keyword matching catches <10% of harmful content and is trivially evaded with misspellings and Unicode tricks.
- ●
Ignoring the appeal and feedback loop -- without it, systematic errors accumulate and model quality degrades. This is also a regulatory requirement under India's IT Rules 2021.
- ●
Proposing to send all content through GPT-4o for moderation without discussing cost -- at 100K/month for 10M items/day. The funnel architecture exists to avoid this.
- ●
Treating content moderation as a binary classification problem (harmful vs. not) instead of a multi-label problem with severity levels across multiple categories.
- ●
Not discussing the human review component -- no automated system handles 100% of cases. The interview question is about system design, which includes human workflows.
Senior-Level Expectation
A senior candidate should discuss the end-to-end system design: content ingestion, language detection, multi-stage classification funnel, threshold management per category and region, human review queue prioritization, appeal handling, feedback loop for model retraining, and monitoring/alerting. They should quantify cost tradeoffs between API-based services (OpenAI free, Azure ~1,080/month for LlamaGuard on A10G), and custom models (higher accuracy, higher engineering cost). They should articulate the precision-recall tradeoff per category, explain why CSAM detection optimizes for recall while political speech optimizes for precision, and discuss regulatory compliance requirements (India IT Rules 2021, EU DSA). Finally, they should address bias mitigation, multilingual challenges for Indian languages, and the organizational dynamics between policy teams (who define the taxonomy) and ML teams (who build the classifiers).
Summary
A content moderator is an automated ML system that classifies text, images, video, and audio against a harm taxonomy and takes enforcement actions ranging from allowing content to removing it or escalating to human review. It is a fundamental component of any platform that accepts user-generated or AI-generated content.
The standard production architecture follows a multi-stage funnel: perceptual hash matching and keyword filters catch known-bad content in microseconds, lightweight ML classifiers (DistilBERT, MobileNet) handle the bulk of classification in 1-5ms, heavyweight models (LlamaGuard, GPT-4o) analyze ambiguous content in 50-200ms, and trained human reviewers resolve the hardest cases. This architecture resolves 97-99% of content automatically, keeping costs manageable at scale. Key implementation choices include API-based services (OpenAI Moderation API is free; Azure Content Safety at ~$1/1K records), self-hosted open-source models (LlamaGuard 3 at ~INR 90,000/month on 2x A10G), and custom-trained classifiers for platform-specific policies.
Critical design considerations include per-category threshold tuning (CSAM demands near-100% recall; political speech demands near-100% precision), multilingual support (Indian platforms must handle 15+ languages with code-mixed text using models like MURIL or XLM-RoBERTa), bias mitigation (classifiers can disproportionately flag content from marginalized communities), and regulatory compliance (India's IT Rules 2021 mandate automated proactive detection, 36-hour removal SLA, and monthly compliance reports). The feedback loop from human review decisions and user appeals back into model retraining is essential for continuous improvement in an adversarial environment where bad actors constantly evolve their evasion tactics.