NER Extractor in Machine Learning
Named Entity Recognition (NER) is the task of locating and classifying named entities in unstructured text into predefined categories such as person names, organizations, locations, dates, monetary amounts, and more. It is one of the oldest and most practically useful tasks in Natural Language Processing, sitting at the foundation of virtually every information extraction pipeline.
In modern ML systems, NER goes far beyond simple rule-based pattern matching. Today's NER extractors leverage deep learning architectures -- from BiLSTM-CRF models to fine-tuned BERT transformers to zero-shot approaches with large language models -- to handle ambiguous, multilingual, and domain-specific text with remarkable accuracy. Whether you are building a KYC document processor for Razorpay, extracting medical entities from clinical notes at Apollo Hospitals, or parsing Aadhaar addresses for identity verification, NER is the component that transforms raw text into structured, actionable fields.
This guide covers everything you need to build, deploy, and scale NER extractors in production ML systems: from core algorithms and formal definitions to architecture patterns, implementation code, failure modes, and interview preparation. We will pay special attention to challenges unique to Indian names, addresses, and multilingual text -- problems that off-the-shelf English NER models handle poorly.
Concept Snapshot
- What It Is
- A pipeline component that identifies spans of text corresponding to named entities (persons, organizations, locations, dates, etc.) and assigns each span a category label.
- Category
- NLP
- Complexity
- Intermediate
- Inputs / Outputs
- Input: raw or tokenized text (string or token sequence). Output: list of entity spans, each with start/end offsets, text, and entity type label (e.g., PER, ORG, LOC, DATE).
- System Placement
- Sits after tokenization and (optionally) part-of-speech tagging, and before downstream tasks like relation extraction, entity linking, knowledge graph construction, or privacy filtering.
- Also Known As
- named entity recognition, entity extractor, sequence labeler, token classifier, entity tagger, NE recognizer
- Typical Users
- ML Engineers, NLP Engineers, Data Scientists, Backend Engineers, Compliance/Legal Tech Teams
- Prerequisites
- Tokenization, Word embeddings / contextual embeddings, Sequence labeling basics (BIO tagging), Basic deep learning (RNNs or Transformers)
- Key Terms
- BIO taggingIOB2 formatCoNLL formatentity spantoken classificationCRF layersequence labelingnested NERfew-shot NERentity linking
Why This Concept Exists
The Problem: Unstructured Text Is Useless to Machines
Consider this sentence: "Sundar Pichai announced that Google will invest 10 billion), the location (India), and the date (2026). But to a computer, this is just a sequence of characters. NER bridges this gap -- it transforms unstructured text into structured records that databases, APIs, and downstream ML models can actually consume.
Without NER, you cannot build:
- Search engines that understand queries about specific people or places
- Compliance systems that detect PII (personally identifiable information) for GDPR or India's DPDP Act
- Financial pipelines that extract company names and monetary values from news feeds
- Healthcare NLP that identifies drug names, dosages, and symptoms from doctor's notes
A Brief History: From Rules to Transformers
The earliest NER systems (1990s) were entirely rule-based -- handcrafted gazetteers (dictionaries of known entities) combined with regular expressions. These worked for narrow domains but were brittle and expensive to maintain.
The CoNLL-2003 shared task was a watershed moment. It standardized the NER benchmark format (four entity types: PER, ORG, LOC, MISC) and the BIO tagging scheme, giving the research community a common evaluation framework. Early statistical approaches like Hidden Markov Models (HMMs) and Conditional Random Fields (CRFs) dominated through the 2000s.
The deep learning revolution arrived with BiLSTM-CRF models around 2015-2016. Lample et al. (2016) showed that a bidirectional LSTM with a CRF output layer could achieve state-of-the-art results without any hand-crafted features -- a paradigm shift that eliminated years of feature engineering.
Then came BERT (2018). Fine-tuning BERT for token classification pushed CoNLL-2003 F1 scores above 93, and subsequent models like RoBERTa, XLNet, and DeBERTa pushed it past 94. Today, ModernBERT (2024) achieves F1 of 0.93 on CoNLL-2003 with architectural improvements like rotary positional embeddings.
The latest frontier is few-shot and zero-shot NER using large language models. Models like GLiNER (NAACL 2024) and prompt-based approaches with GPT-4 can extract entities from arbitrary categories without any training data -- a game-changer for domain-specific applications where labeled data is scarce.
Key Takeaway: NER has evolved from brittle rule-based systems to powerful neural models that can generalize across domains and languages. But the fundamental job remains the same: find the entities in text and tell me what type they are.
Core Intuition & Mental Model
Think of It as Highlighting a Document
Imagine you are reading a news article with a set of colored highlighters. You use yellow for person names, green for organizations, blue for locations, and pink for dates. As you read, you highlight each entity you encounter. That is exactly what an NER model does -- except it processes thousands of documents per second and never gets tired.
The key challenge is ambiguity. The word "Apple" could be a fruit, a company, or a record label. "Washington" could be a person, a city, or a state. The NER model must use context -- the surrounding words -- to resolve these ambiguities. This is why modern NER models use contextual embeddings (BERT, RoBERTa) rather than static word vectors (Word2Vec, GloVe): the same word gets different representations depending on its context.
The BIO Tagging Mental Model
At its core, NER is a token classification task. Each token in the input gets assigned one of several labels. The most common labeling scheme is BIO (Beginning-Inside-Outside):
- B-PER: Beginning of a person entity
- I-PER: Inside (continuation of) a person entity
- O: Outside any entity (not part of an entity)
So "Sundar Pichai works at Google" becomes: Sundar/B-PER Pichai/I-PER works/O at/O Google/B-ORG. This framing turns NER into a standard sequence labeling problem that any token classifier can solve.
Why Context Windows Matter
Here is an intuition that separates good NER engineers from great ones: the context window determines how much surrounding text the model can see when deciding whether a token is an entity. A CRF sees only immediate neighbors. A BiLSTM sees the entire sentence. A Transformer (BERT) sees 512 tokens of context. And an LLM can see thousands of tokens. More context generally means better disambiguation -- but also higher compute cost. The art is finding the right balance for your use case and budget.
Technical Foundations
Mathematical Formulation
Let be an input sequence of tokens. NER is the task of predicting a label sequence where each , and is the set of BIO labels. For example, with entity types , we have:
This gives labels for entity types.
The CRF Objective
In a BiLSTM-CRF model, the BiLSTM produces emission scores for each token . The CRF layer adds transition scores where is the score of transitioning from label to label . The score of a label sequence given input is:
The CRF loss maximizes the log-probability of the correct label sequence:
where is the set of all valid label sequences. The partition function (second term) is computed efficiently via the forward algorithm in time.
Why the CRF Matters
Without a CRF, a token classifier might predict I-PER immediately after O -- a label transition that is structurally invalid (you cannot be inside an entity without starting one). The CRF's transition matrix learns that , enforcing valid BIO sequences at decode time. This is why adding a CRF layer on top of any encoder (BiLSTM or BERT) almost always improves entity-level F1 by 1-3 points.
Evaluation Metric: Entity-Level F1
NER is evaluated at the entity level, not the token level. An entity is considered correct only if both the span boundaries (start and end tokens) and the entity type match the gold annotation exactly. The standard metric is micro-averaged F1:
where Precision = (correct entities predicted) / (total entities predicted) and Recall = (correct entities predicted) / (total entities in gold).
Warning: Token-level accuracy can be misleadingly high (often >97%) because most tokens are
O(outside any entity). Always report entity-level F1, which is the standard metric for NER evaluation.
Internal Architecture
A production NER system typically has four stages: text preprocessing (tokenization, normalization), feature extraction (embeddings), sequence labeling (the NER model itself), and post-processing (span extraction, entity linking, deduplication). The NER model can be swapped between different architectures depending on accuracy, latency, and cost requirements.
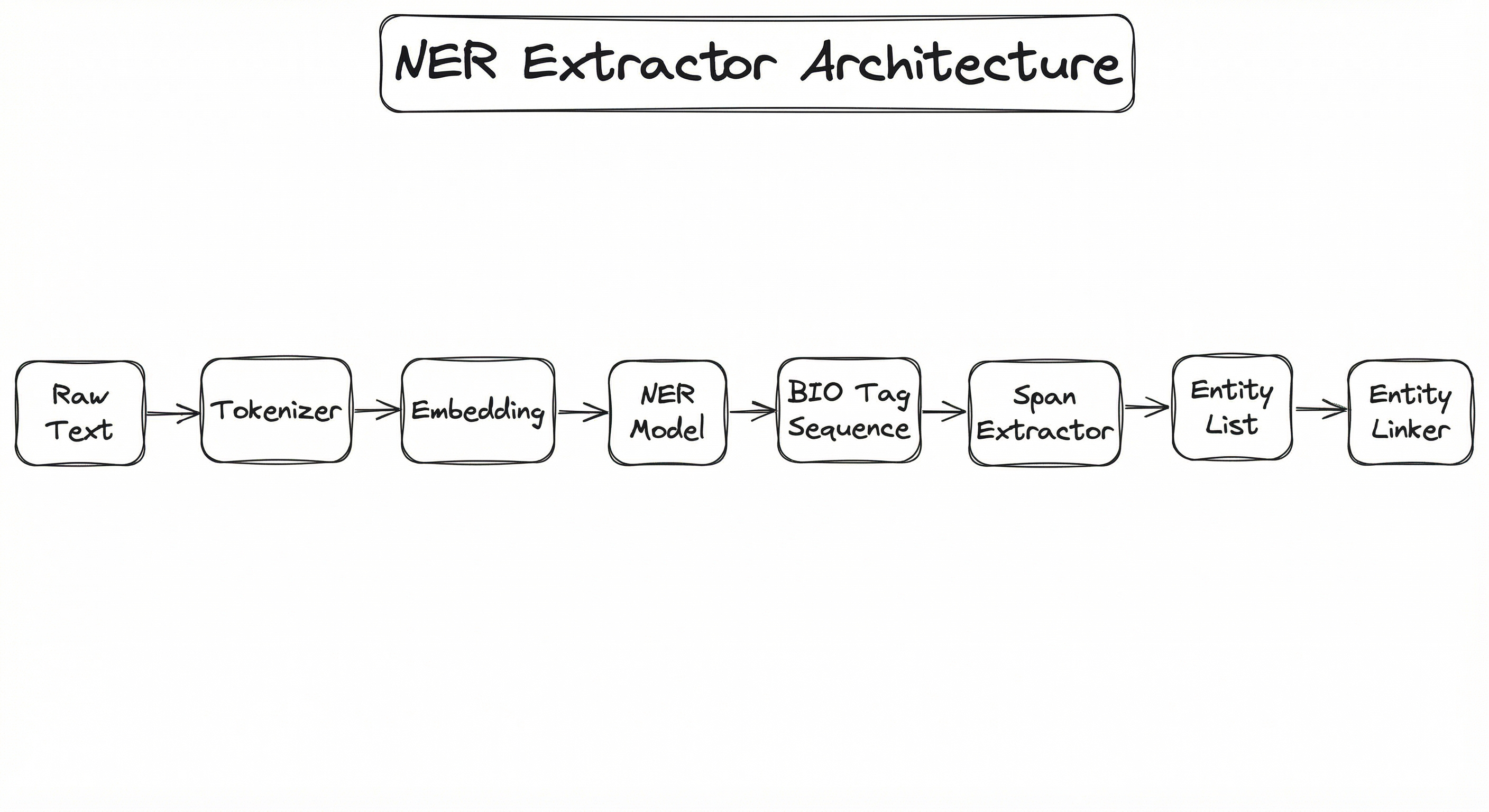
The architecture follows a classic encoder-decoder pattern for sequence labeling. The encoder converts tokens into contextual representations (via BiLSTM or Transformer). The decoder assigns a label to each token (via a linear classification head, optionally with a CRF layer). Post-processing extracts contiguous BIO spans into discrete entity objects.
For production systems, this pipeline is typically wrapped in a serving framework (FastAPI, TorchServe, or Triton Inference Server) with batching, caching, and monitoring. The choice of model architecture determines the latency-accuracy tradeoff: spaCy's built-in NER processes ~10,000 tokens/sec on CPU, while BERT-based models process ~500-1,000 tokens/sec on CPU but achieve 3-5 F1 points higher accuracy.
Key Components
Tokenizer
Splits raw text into tokens. For Transformer-based NER, this is a subword tokenizer (WordPiece for BERT, BPE for RoBERTa). For BiLSTM-CRF, word-level tokenization is typical. Critically, the tokenizer must preserve character offsets so that entity spans can be mapped back to the original text -- dropping this information is a common source of bugs.
Embedding Layer
Converts tokens into dense vector representations. Options range from static embeddings (GloVe, fastText) to contextual embeddings (BERT, RoBERTa, DeBERTa). Contextual embeddings capture polysemy (e.g., 'Apple' the company vs. the fruit), which is critical for disambiguation. For Indian languages, MuRIL (Multilingual Representations for Indian Languages) provides strong multilingual embeddings trained on 17 Indian languages.
Sequence Labeling Head
The core NER model component. A linear layer maps each token's embedding to a score vector over the label set . Optionally, a CRF layer sits on top to enforce valid BIO transition constraints and jointly decode the optimal label sequence via the Viterbi algorithm.
Span Extractor
Converts the BIO tag sequence back into entity spans with start offset, end offset, text, and label. Handles edge cases like incomplete BIO sequences (e.g., I-PER without a preceding B-PER). This is where you apply heuristic fixes for model output errors.
Entity Linker / Normalizer
Maps extracted entity strings to canonical forms or knowledge base entries. For example, normalizing 'Mumbai', 'Bombay', and 'Bambai' to the same location ID. For person names, this might involve fuzzy matching against a directory. For dates, it involves parsing '15th Aug 1947' into a structured date object.
Post-Processing & Validation
Applies domain-specific rules after model inference: merging adjacent entities of the same type, filtering low-confidence predictions, deduplicating entities, and validating entity formats (e.g., checking that a detected PAN number matches the [A-Z]{5}[0-9]{4}[A-Z] pattern). In production, the glue logic here often takes more engineering time than model training itself.
Data Flow
Training Path: Annotated text in CoNLL format (token-per-line with BIO tags) -> tokenized and aligned with subword tokens (for Transformer models) -> batched into training examples -> forward pass through encoder + classification head -> CRF loss computed -> backpropagation.
Inference Path: Raw text -> tokenized with character offset tracking -> batched for GPU inference -> forward pass through encoder + CRF Viterbi decode -> BIO tags extracted -> spans assembled from contiguous B/I tags -> entities normalized and linked -> structured output (JSON with entity type, text, start, end, confidence).
The critical data alignment step happens between word-level and subword-level tokens. BERT's WordPiece tokenizer may split 'Bengaluru' into ['Ben', '##gal', '##uru']. Only the first subword token receives the BIO label; the rest are masked during training and aggregated during inference. Getting this alignment wrong is one of the most common bugs in Transformer-based NER implementations.
A directed flow from 'Raw Text' through 'Tokenizer', 'Embedding Layer', 'NER Model' (with options for BiLSTM-CRF, BERT+Linear, BERT+CRF, LLM Few-Shot, GLiNER), producing 'BIO Tag Sequence', then through 'Span Extractor' to 'Entity List', and finally 'Entity Linker/Normalizer' for structured output.
How to Implement
Three Implementation Tiers
NER implementation approaches fall into three tiers based on accuracy, cost, and engineering effort:
Tier 1: Off-the-shelf models -- Use spaCy's pre-trained NER (en_core_web_lg), HuggingFace's dslim/bert-base-NER, or Flair's ner-english. Zero training required. Best for prototyping or when your entity types match standard categories (PER, ORG, LOC, DATE). Accuracy: F1 ~85-90 on general text.
Tier 2: Fine-tuned Transformers -- Fine-tune BERT/RoBERTa/DeBERTa on your domain-specific annotated data using HuggingFace Transformers or spaCy v3 with transformer backend. Requires 500-5,000 annotated sentences for good results. Accuracy: F1 ~90-95 on domain text. Training cost: ~INR 500-2,000 (24) on a single GPU for a few hours.
Tier 3: LLM-based few-shot or zero-shot -- Use GPT-4, Claude, or GLiNER with carefully crafted prompts for entity extraction. No training required, but higher per-inference cost. Best for custom entity types where labeled data does not exist. Accuracy: F1 ~75-88 depending on prompt engineering quality.
Cost Comparison for 1M documents/month: spaCy on CPU: ~INR 2,500/month (150). GPT-4 API: ~INR 42,000-84,000/month (1,000). Choose wisely based on your accuracy requirements and budget.
For most Indian startups building NER pipelines -- whether for fintech document processing at Razorpay-like companies, healthcare NLP at Practo-like platforms, or e-commerce product extraction at Flipkart-like marketplaces -- Tier 2 (fine-tuned Transformers) offers the best accuracy-cost tradeoff. Start with Tier 1 to validate the use case, then move to Tier 2 when you have enough annotated data.
import spacy
# Load the large English model (includes NER)
nlp = spacy.load("en_core_web_lg")
text = "Mukesh Ambani, chairman of Reliance Industries, announced a \u20b975,000 crore investment in Jamnagar on 15 January 2026."
doc = nlp(text)
# Extract entities with their labels and character offsets
for ent in doc.ents:
print(f"{ent.text:30s} {ent.label_:10s} [{ent.start_char}:{ent.end_char}]")
# Output:
# Mukesh Ambani PERSON [0:14]
# Reliance Industries ORG [29:49]
# 75,000 crore MONEY [64:76]
# Jamnagar GPE [91:99]
# 15 January 2026 DATE [103:119]
# For batch processing (much faster)
texts = ["Text 1...", "Text 2...", "Text 3..."]
for doc in nlp.pipe(texts, batch_size=64, n_process=4):
entities = [(ent.text, ent.label_) for ent in doc.ents]
print(entities)spaCy's pre-trained models provide a fast, no-training-required NER solution. The en_core_web_lg model recognizes 18 entity types including PERSON, ORG, GPE (geo-political entity), DATE, MONEY, and more. The nlp.pipe() method enables efficient batch processing with multiprocessing -- essential for production throughput. On a modern CPU, this processes ~10,000 tokens/second. For Indian text, note that spaCy's English models struggle with Indian names and locations not present in their training data.
from transformers import (
AutoTokenizer,
AutoModelForTokenClassification,
TrainingArguments,
Trainer,
DataCollatorForTokenClassification,
)
from datasets import load_dataset
import numpy as np
import evaluate
# Load CoNLL-2003 dataset
dataset = load_dataset("eriktks/conll2003")
label_list = dataset["train"].features["ner_tags"].feature.names
# ['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
# Load pre-trained model and tokenizer
model_name = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(
model_name, num_labels=len(label_list)
)
# Tokenize and align labels with subword tokens
def tokenize_and_align_labels(examples):
tokenized = tokenizer(
examples["tokens"],
truncation=True,
is_split_into_words=True,
)
labels = []
for i, label in enumerate(examples["ner_tags"]):
word_ids = tokenized.word_ids(batch_index=i)
label_ids = []
previous_word_id = None
for word_id in word_ids:
if word_id is None:
label_ids.append(-100) # Special tokens
elif word_id != previous_word_id:
label_ids.append(label[word_id]) # First subword gets label
else:
label_ids.append(-100) # Other subwords masked
previous_word_id = word_id
labels.append(label_ids)
tokenized["labels"] = labels
return tokenized
tokenized_datasets = dataset.map(tokenize_and_align_labels, batched=True)
# Setup evaluation
seqeval = evaluate.load("seqeval")
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
true_labels = [
[label_list[l] for l, p in zip(label_row, pred_row) if l != -100]
for label_row, pred_row in zip(labels, predictions)
]
true_predictions = [
[label_list[p] for l, p in zip(label_row, pred_row) if l != -100]
for label_row, pred_row in zip(labels, predictions)
]
results = seqeval.compute(predictions=true_predictions, references=true_labels)
return {"f1": results["overall_f1"], "precision": results["overall_precision"], "recall": results["overall_recall"]}
# Training
training_args = TrainingArguments(
output_dir="./ner-bert",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
num_train_epochs=3,
weight_decay=0.01,
save_strategy="epoch",
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
data_collator=DataCollatorForTokenClassification(tokenizer),
compute_metrics=compute_metrics,
)
trainer.train()
# Expected: F1 ~91-93 on CoNLL-2003 test set after 3 epochsThis is a complete, runnable fine-tuning script for BERT-based NER on CoNLL-2003. The critical step is tokenize_and_align_labels -- it handles the mismatch between word-level annotations and subword-level tokens by assigning labels only to the first subword of each word and masking the rest with -100. Training on a single NVIDIA T4 GPU takes ~20 minutes and costs roughly INR 50-100 (1.20) on cloud providers. The resulting model achieves F1 ~91-93, which is strong baseline performance.
from gliner import GLiNER
# Load the pre-trained GLiNER model
model = GLiNER.from_pretrained("urchade/gliner_medium-v2.1")
text = "Ratan Tata invested INR 50 crore in Ola Electric through Tata Trusts. "
"The deal was signed in Mumbai on 10 March 2024."
# Define custom entity types -- no training needed!
labels = ["person", "organization", "money", "city", "date", "investment_vehicle"]
# Predict entities
entities = model.predict_entities(text, labels, threshold=0.5)
for entity in entities:
print(f"{entity['text']:25s} {entity['label']:22s} score={entity['score']:.3f}")
# Output (approximate):
# Ratan Tata person score=0.987
# INR 50 crore money score=0.923
# Ola Electric organization score=0.961
# Tata Trusts investment_vehicle score=0.845
# Mumbai city score=0.978
# 10 March 2024 date score=0.965GLiNER (NAACL 2024) is a generalist NER model that works with arbitrary entity type labels specified at inference time -- no fine-tuning required. It frames NER as a matching problem between entity type embeddings and text span representations. This is invaluable for domain-specific applications where you need custom entity types (like 'investment_vehicle' or 'drug_dosage') but lack annotated training data. The model is compact (~400MB) and runs on CPU, making it practical for production use. It outperforms GPT-3.5 on zero-shot NER benchmarks while being orders of magnitude cheaper to run.
import torch
import torch.nn as nn
from torchcrf import CRF
class BiLSTMCRF(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_tags, padding_idx=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=padding_idx)
self.lstm = nn.LSTM(
embedding_dim, hidden_dim // 2,
num_layers=2, bidirectional=True,
batch_first=True, dropout=0.3,
)
self.hidden2tag = nn.Linear(hidden_dim, num_tags)
self.crf = CRF(num_tags, batch_first=True)
self.dropout = nn.Dropout(0.5)
def forward(self, input_ids, labels=None, mask=None):
embeds = self.dropout(self.embedding(input_ids))
lstm_out, _ = self.lstm(embeds)
emissions = self.hidden2tag(self.dropout(lstm_out))
if labels is not None:
# Training: return negative log-likelihood
loss = -self.crf(emissions, labels, mask=mask, reduction="mean")
return loss
else:
# Inference: Viterbi decode
return self.crf.decode(emissions, mask=mask)
# Usage
model = BiLSTMCRF(
vocab_size=30000,
embedding_dim=300, # GloVe 300d or fastText
hidden_dim=512,
num_tags=9, # BIO tags for 4 entity types
)
# Training loop (simplified)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(20):
for batch in train_loader:
loss = model(batch["input_ids"], batch["labels"], batch["mask"])
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 5.0)
optimizer.step()
optimizer.zero_grad()This is the classic BiLSTM-CRF architecture that dominated NER before Transformers. The BiLSTM captures bidirectional context, the linear layer produces emission scores for each tag, and the CRF layer ensures valid BIO tag sequences. While Transformer-based models now achieve higher accuracy, BiLSTM-CRF remains relevant for resource-constrained deployments: it trains in minutes (vs. hours for BERT), has a much smaller model footprint (~10MB vs. ~400MB), and runs efficiently on CPU. The torchcrf library provides a clean CRF implementation compatible with PyTorch.
import json
from openai import OpenAI
client = OpenAI() # Uses OPENAI_API_KEY env var
def extract_entities_llm(text: str, entity_types: list[str], examples: list[dict] = None) -> list[dict]:
"""Extract entities using GPT-4 with few-shot prompting."""
system_prompt = f"""You are a Named Entity Recognition system. Extract entities from the given text.
Entity types to extract: {', '.join(entity_types)}
Return a JSON array of objects with keys: "text", "type", "start", "end".
Only return the JSON array, no other text.
If no entities found, return an empty array []."""
messages = [{"role": "system", "content": system_prompt}]
# Add few-shot examples if provided
if examples:
for ex in examples:
messages.append({"role": "user", "content": ex["text"]})
messages.append({"role": "assistant", "content": json.dumps(ex["entities"])})
messages.append({"role": "user", "content": text})
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0,
response_format={"type": "json_object"},
)
result = json.loads(response.choices[0].message.content)
return result if isinstance(result, list) else result.get("entities", [])
# Example: Extract Indian-specific entities
examples = [
{
"text": "Narayana Murthy founded Infosys in Pune in 1981.",
"entities": [
{"text": "Narayana Murthy", "type": "PERSON", "start": 0, "end": 15},
{"text": "Infosys", "type": "ORGANIZATION", "start": 24, "end": 31},
{"text": "Pune", "type": "LOCATION", "start": 35, "end": 39},
{"text": "1981", "type": "DATE", "start": 43, "end": 47},
]
}
]
text = "Nithin Kamath launched Zerodha from Bengaluru, processing over INR 15 lakh crore in trades annually."
entities = extract_entities_llm(
text,
entity_types=["PERSON", "ORGANIZATION", "LOCATION", "DATE", "MONETARY_VALUE"],
examples=examples,
)
print(json.dumps(entities, indent=2))LLM-based NER is ideal for bootstrapping new entity types or handling long-tail entities that fine-tuned models miss. By providing a few examples in the prompt, GPT-4 can extract entities it was never explicitly trained on. The trade-off is cost and latency: GPT-4o processes ~1,000 tokens/sec and costs roughly INR 1.25-2.50 (0.030) per 1K input tokens. For high-volume production use, this approach is best used as a labeling assistant to generate training data for a fine-tuned model, rather than as the primary inference engine.
# spaCy NER training config (config.cfg)
[system]
seed = 42
gpu_allocator = "pytorch"
[nlp]
lang = "en"
pipeline = ["transformer", "ner"]
batch_size = 128
[components.transformer]
factory = "transformer"
[components.transformer.model]
@architectures = "spacy-transformers.TransformerModel.v3"
name = "roberta-base"
tokenizer_config = {"use_fast": true}
[components.ner]
factory = "ner"
[components.ner.model]
@architectures = "spacy.TransitionBasedParser.v2"
state_type = "ner"
hidden_width = 64
maxout_pieces = 2
use_upper = true
[training]
accumulate_gradient = 3
max_epochs = 20
patience = 5
max_steps = 20000
eval_frequency = 200
[training.optimizer]
@optimizers = "Adam.v1"
learn_rate = 5e-5Common Implementation Mistakes
- ●
Subword-label misalignment: When using BERT/RoBERTa, failing to properly align word-level BIO labels with subword tokens. If 'Bengaluru' is split into ['Ben', '##gal', '##uru'], only the first subword should receive the B-LOC label -- the rest must be masked (-100) during training. Getting this wrong silently corrupts your training signal.
- ●
Reporting token-level accuracy instead of entity-level F1: Token-level accuracy is inflated because ~85% of tokens are 'O' (outside any entity). A model that predicts 'O' for everything achieves 85%+ token accuracy but 0% entity F1. Always use
seqevalfor proper entity-level evaluation. - ●
Training on text that looks nothing like your inference data: If your model will process OCR output from scanned Aadhaar cards (noisy, with spelling errors), training on clean Wikipedia text will produce poor results. Always make your training distribution match your inference distribution.
- ●
Ignoring class imbalance: Entity tokens are rare compared to 'O' tokens. Without addressing this (via weighted loss, oversampling entity-rich sentences, or focal loss), the model learns to predict 'O' for borderline cases. This hurts recall significantly.
- ●
Not handling overlapping or nested entities: Standard BIO tagging cannot represent nested entities like 'Reserve Bank of India' (ORG) containing 'India' (LOC). If your use case involves nested entities, you need a span-based or multi-layer approach instead of flat BIO tagging.
- ●
Applying English NER models to Indian text without adaptation: Pre-trained English NER models have poor coverage of Indian names (Aishwarya, Subramaniam, Venkatanarasimharajuvaripeta), Indian organizations (IRCTC, SEBI, DRDO), and Indian location formats ('Koramangala 4th Block, Bengaluru'). Fine-tuning on Indian-specific data is essential.
When Should You Use This?
Use When
You need to extract structured entity information (names, dates, amounts, locations) from unstructured text at scale
Your pipeline requires PII detection for compliance with GDPR, India's DPDP Act 2023, or HIPAA regulations
You are building a search system that needs to index and filter by entity types (e.g., finding all news articles mentioning a specific company)
Document processing workflows (invoices, contracts, KYC documents, medical records) need automated field extraction
Your downstream tasks (relation extraction, knowledge graph construction, question answering) depend on first identifying entities in text
You need to auto-tag or categorize content based on mentioned entities for recommendation or content management systems
Avoid When
Your text is already structured (CSV, JSON, database records) -- NER is for unstructured text extraction, not data transformation
Simple pattern matching (regex) suffices for your entity types -- if all your entities follow fixed formats (email addresses, phone numbers, PAN numbers), regex is simpler, faster, and more reliable
You only need to classify the entire document rather than extract specific spans -- use a text classifier instead
Your entities are highly domain-specific with no existing training data and you cannot invest in annotation -- though GLiNER and LLM-based approaches are reducing this barrier
Real-time latency requirements are extreme (<1ms) and your text is long -- even optimized NER models add 5-50ms per document
Your primary need is entity resolution or deduplication rather than extraction -- NER extracts mentions, entity linking resolves them
Key Tradeoffs
Accuracy vs. Latency vs. Cost
This is the fundamental three-way tradeoff in NER system design:
| Approach | F1 (CoNLL) | Latency (per doc) | Cost (1M docs/mo) | Training Data Needed |
|---|---|---|---|---|
| spaCy (rule + statistical) | ~85-88 | 1-5ms | ~INR 2,500 ($30) | 0 (pre-trained) |
| BiLSTM-CRF | ~89-91 | 5-15ms | ~INR 5,000 ($60) | 5K-20K sentences |
| BERT fine-tuned | ~91-93 | 20-80ms (CPU) / 5-15ms (GPU) | ~INR 12,500 ($150) GPU | 1K-5K sentences |
| DeBERTa-v3 fine-tuned | ~93-94 | 30-100ms (CPU) / 8-20ms (GPU) | ~INR 16,500 ($200) GPU | 1K-5K sentences |
| GLiNER (zero-shot) | ~80-88 | 15-40ms | ~INR 8,000 ($100) | 0 |
| GPT-4 (few-shot) | ~78-86 | 500-2000ms | ~INR 42,000+ ($500+) | 3-10 examples |
When to Upgrade
Start with spaCy or a pre-trained HuggingFace model. Measure entity-level F1 on a manually annotated test set of ~200 sentences from your actual data distribution. If F1 is below your threshold (typically 90+ for production), move to fine-tuning. If fine-tuning data is scarce, use GLiNER or LLM-based labeling to bootstrap annotations.
The Indian Text Challenge
Indian names and addresses present unique challenges. Names like 'Rajesh Kumar Singh' follow different patterns than Western names. Addresses like 'H.No. 12-5-149/3, Tarnaka, Secunderabad, Telangana - 500017' combine numbers, location names, and postal codes in formats that Western-trained models have never seen. Plan for Indian-specific training data if your use case involves Indian documents.
Alternatives & Comparisons
A text classifier assigns a single label to an entire document or sentence, while NER identifies and labels individual spans within the text. Use a text classifier when you need document-level categorization ('Is this a complaint?'). Use NER when you need to extract specific entities from within the text ('Who complained about what product?'). They are often used together -- classify first, then extract entities from relevant documents.
Privacy filters use NER as a core building block but add additional logic for PII-specific entity types (SSN, Aadhaar, PAN, credit card numbers) and redaction/masking capabilities. If your sole goal is PII detection and redaction, a dedicated privacy filter (like Microsoft Presidio or AWS Comprehend PII) is more appropriate. If you need general entity extraction beyond PII, use NER directly.
Tokenization is a prerequisite step for NER, not an alternative. The tokenizer splits text into tokens; the NER model assigns entity labels to those tokens. However, for very simple extraction tasks (splitting text into words and looking up each word in a gazetteer), tokenization alone with dictionary lookup can approximate NER without a trained model.
Sentiment analysis determines the emotional tone of text (positive, negative, neutral), while NER identifies named entities within text. They solve different problems but are often used together in pipelines -- for example, extracting brand names with NER and then determining sentiment toward each brand with a sentiment analyzer.
Pros, Cons & Tradeoffs
Advantages
Transforms unstructured text into structured data -- the single most valuable preprocessing step for any downstream NLP pipeline, enabling search, filtering, aggregation, and analytics over entity mentions
Mature ecosystem with multiple accuracy tiers -- from spaCy's 1ms CPU inference to BERT's 93+ F1, you can always find a model that fits your latency and accuracy requirements
Transfer learning dramatically reduces data requirements -- fine-tuning BERT for NER requires only 500-2,000 annotated sentences to achieve production-quality results, compared to 50,000+ sentences for training from scratch
Zero-shot approaches (GLiNER, LLMs) eliminate the cold-start problem -- you can extract custom entity types with zero training data, making NER accessible for any domain from day one
Language-agnostic architectures -- the same BiLSTM-CRF or Transformer architecture works for English, Hindi, Tamil, or any other language given appropriate training data; multilingual models like XLM-RoBERTa and MuRIL handle code-mixed text natively
Composable with other NLP tasks -- NER output feeds directly into relation extraction, entity linking, knowledge graph construction, and question answering, making it a foundational pipeline component
Disadvantages
Entity boundary detection remains imperfect -- even state-of-the-art models struggle with complex entity boundaries like 'Reserve Bank of India's monetary policy committee' (where does the ORG entity end?)
Nested and overlapping entities are poorly handled by standard BIO tagging -- 'Bank of India' (ORG) inside 'Reserve Bank of India' (ORG) requires specialized architectures that add complexity
Domain transfer degrades performance significantly -- a model trained on news text drops 10-20 F1 points when applied to medical notes, legal contracts, or social media text without domain-specific fine-tuning
Annotation is expensive and subjective -- NER annotation requires entity-level span marking which is slower than document-level labeling; inter-annotator agreement on entity boundaries is often only 85-90%, creating a ceiling on model performance
High sensitivity to tokenization and text preprocessing -- OCR errors, inconsistent capitalization, missing spaces, and Unicode normalization issues all degrade NER accuracy, requiring robust preprocessing pipelines
Indian names and addresses remain a hard problem -- models trained on Western text consistently fail on Indian names with patronymics, Indian addresses with inconsistent formats, and Hindi-English code-mixed text
Failure Modes & Debugging
Entity boundary errors
Cause
The model correctly identifies that an entity exists but gets the start or end boundary wrong. For example, predicting 'Bank of India' instead of 'Reserve Bank of India', or 'Bengaluru, Karnataka' instead of just 'Bengaluru'. This is especially common with compound names, prepositional phrases, and Indian addresses.
Symptoms
Entity-level F1 is significantly lower than token-level F1. Manual inspection reveals truncated or over-extended entity spans. Downstream systems receive partial or noisy entity strings.
Mitigation
Add more training examples with diverse boundary patterns. Use a CRF layer to enforce valid BIO transitions. Implement post-processing rules for known entity patterns (e.g., always include 'Reserve' before 'Bank of India'). Evaluate with both strict and relaxed (partial overlap) matching to understand the extent of the problem.
Entity type confusion
Cause
The model detects the entity span correctly but assigns the wrong type. Classic examples: 'Washington' classified as PER instead of LOC, 'Apple' as ORG instead of MISC. In Indian context: 'Tata' could be a person (Ratan Tata), organization (Tata Group), or location (Tata Nagar).
Symptoms
Per-entity-type F1 scores vary widely -- one type has 95+ F1 while another has 75. Confusion matrix shows systematic misclassification between specific entity type pairs.
Mitigation
Add more training examples for ambiguous entities with diverse contexts. Consider using entity linking (mapping to a knowledge base) to disambiguate. Use ensemble models or confidence thresholds to flag ambiguous predictions for human review.
Missing entities (low recall)
Cause
The model fails to detect entities entirely, especially rare or domain-specific entities not well-represented in training data. Indian names with unusual spellings, newly formed startups, Tier-2/3 city names, and technical jargon are common victims.
Symptoms
Overall recall is significantly lower than precision. Users report that important entities are being missed. Analysis shows that entity coverage correlates with training data frequency.
Mitigation
Augment training data with gazetteer-based weak supervision (use lists of Indian names, cities, and organizations to auto-annotate unlabeled text). Use active learning to prioritize annotating sentences where the model is least confident. Consider GLiNER or LLM-based extraction as a fallback for the long tail.
False positives (low precision)
Cause
The model over-predicts entities, marking common words or phrases as entities when they are not. This often happens when the model is over-fitted on a small training set or when entity-rich training data biases the model toward predicting entities everywhere.
Symptoms
Precision drops, especially on text that is entity-sparse (e.g., instructional text, disclaimers, boilerplate). Downstream systems are flooded with spurious entities that increase noise.
Mitigation
Balance training data to include entity-sparse examples. Apply confidence thresholds (discard predictions below a score cutoff). Implement post-processing validation rules (e.g., verify that detected MONEY entities contain a number, that DATE entities parse as valid dates).
Degradation on OCR/noisy text
Cause
NER models trained on clean text fail dramatically when applied to OCR output from scanned documents (Aadhaar cards, PAN cards, invoices). OCR introduces character-level errors ('Bangalor€' instead of 'Bangalore'), missing spaces ('MukeshAmbani'), and garbled text that breaks tokenization.
Symptoms
F1 drops by 15-30 points compared to clean text. Entity extraction from scanned documents is unreliable. Downstream processes reject extracted entities due to formatting errors.
Mitigation
Train (or fine-tune) on synthetically noised data that simulates OCR errors. Implement a text correction / normalization layer before NER. Use character-level embeddings (CNN over characters or Flair embeddings) that are more robust to spelling variations. Build a post-processing pipeline that validates and corrects extracted entities.
Catastrophic forgetting during fine-tuning
Cause
When fine-tuning a pre-trained NER model on domain-specific data, the model forgets how to recognize general entity types it previously handled well. For example, fine-tuning on medical NER data causes the model to forget how to detect person names and locations.
Symptoms
Domain-specific entity types improve dramatically, but general entity type F1 drops by 10+ points. The model works well on the new domain but poorly on general text.
Mitigation
Use a mixed training set that combines domain-specific and general NER data. Apply elastic weight consolidation (EWC) or other continual learning techniques. Alternatively, run multiple NER models in parallel -- one general, one domain-specific -- and merge results.
Placement in an ML System
Where NER Sits in the Pipeline
In a document processing pipeline (KYC, invoice processing, contract analysis), NER sits after OCR and text cleaning, and before entity linking and downstream business logic. It is the component that converts a wall of text into structured fields.
In a RAG pipeline, NER can be used to enrich chunks with entity metadata before indexing. For example, tagging each chunk with the organizations and people mentioned in it enables metadata-filtered retrieval -- the user asks about 'Infosys Q3 results' and the system retrieves chunks specifically tagged with the ORG entity 'Infosys'.
In a search and recommendation system (like Flipkart product search or Zomato restaurant discovery), NER extracts entities from user queries ('biryani near Koramangala') to drive intent classification and entity-based filtering.
In a compliance and privacy pipeline, NER is the first step in PII detection -- identifying person names, Aadhaar numbers, PAN numbers, and addresses so they can be masked or redacted before the data is shared or stored.
Key Insight: NER is a foundational component that rarely runs alone. Its value is realized through the downstream systems it feeds. A 2-point improvement in NER F1 can translate to a 5-10% improvement in end-to-end pipeline accuracy, because every missed entity cascades through the entire system.
Pipeline Stage
Feature Extraction / Preprocessing
Upstream
- tokenizer
- text-classifier
Downstream
- privacy-filter
- sentiment-analyzer
- knowledge-graph
Scaling Bottlenecks
The primary bottleneck is inference throughput. A BERT-based NER model on a single GPU processes ~500-1,000 documents/sec (depending on document length). For a Swiggy-scale system processing millions of restaurant reviews daily, you would need 4-8 GPU instances to keep up.
Batching is critical: processing documents one-at-a-time wastes 80%+ of GPU compute. Dynamic batching (grouping documents of similar length) maximizes throughput. Tools like NVIDIA Triton Inference Server handle this automatically.
Model distillation offers a 3-5x speedup with minimal accuracy loss. DistilBERT-based NER achieves ~90 F1 (vs. BERT's ~92) at 2x the throughput and half the memory. For spaCy pipelines, using the en_core_web_sm model (instead of _lg) gives 5x throughput at 3-4 F1 points cost.
At very high scale (>10M documents/day), consider a tiered architecture: fast regex/rule-based extraction for common patterns (dates, amounts, emails), spaCy for standard entity types, and BERT only for ambiguous or high-value documents. This reduces GPU cost by 60-70%.
Production Case Studies
John Snow Labs benchmarked their clinical NER models against AWS Comprehend Medical, Google Healthcare NLP API, and Azure Text Analytics for Health. Their Spark NLP models, fine-tuned on biomedical corpora, achieved the highest F1 scores for extracting medical entities (drugs, dosages, procedures, diagnoses) from clinical notes. This demonstrates the critical importance of domain-specific fine-tuning -- general-purpose NER models from cloud providers consistently underperformed specialized models.
Spark NLP's clinical NER achieved F1 scores 5-15 points higher than general-purpose cloud NER APIs on clinical text, demonstrating that domain-specific fine-tuning is essential for production healthcare NLP.
Explosion integrated Transformer models (BERT, RoBERTa, XLNet) directly into spaCy v3's pipeline architecture. This allowed users to combine the accuracy of Transformer-based NER with spaCy's production-grade tokenization, rule-based matching, and entity linking components. The integration supports multi-task learning where the Transformer backbone is shared across NER, POS tagging, and dependency parsing, amortizing the cost of the expensive Transformer forward pass.
spaCy v3 with Transformer backends achieves within 0.5 F1 of pure HuggingFace Transformer models while providing a complete production pipeline (tokenization, NER, entity linking) in a single library.
Creative Dock deployed an NER system for HGS, one of the largest marine insurance houses globally. The system extracts entity information (vessel names, policy numbers, coverage dates, monetary values) from thousands of complex insurance documents with diverse formats. The NER pipeline was combined with OCR and document classification to automate underwriting workflows that previously required manual data entry.
Achieved 97% accuracy over all document types, automating the extraction of key insurance entities and reducing manual data entry time by over 60%.
Google Cloud's Natural Language API provides production-grade NER as a managed service, supporting entity extraction in 12+ languages. Their Healthcare Natural Language API extends this with medical entity recognition trained on thousands of clinical documents. The API identifies entities like medications, dosages, procedures, and medical conditions, mapping them to standard medical vocabularies (SNOMED CT, ICD-10). This is used by hospitals and health-tech companies across India and globally for clinical document processing.
Processes millions of documents daily for enterprise customers, with healthcare NER supporting extraction of 200+ medical entity types mapped to standard clinical vocabularies.
Stitch Fix used BERT for entity extraction from unstructured customer style notes to understand what clients actually want. Customers write free-text notes like 'Give me jeans not shoes' or 'I need something for a beach wedding.' The NER system extracts intent entities (want/don't-want), item categories, occasions, and style preferences from these notes using a fine-tuned BERT model trained on stylist-annotated customer feedback (2019).
The NER system improved style recommendation accuracy by 25% by extracting structured preferences from freeform text. This reduced the frequency of sending unwanted items and improved the human-in-the-loop workflow where stylists review AI-extracted preferences before curating shipments.
Tooling & Ecosystem
Industrial-strength NLP library with built-in NER pipeline. Supports pre-trained models for 25+ languages, custom training via spacy train, and Transformer backends via spacy-transformers. The go-to choice for production NER in Python. Processes ~10,000 tokens/sec on CPU with the statistical model.
Provides AutoModelForTokenClassification for fine-tuning any Transformer model (BERT, RoBERTa, DeBERTa, ModernBERT) on NER tasks. The HuggingFace Hub hosts hundreds of pre-trained NER models including dslim/bert-base-NER (CoNLL-2003) and domain-specific variants for biomedical, legal, and multilingual text.
Generalist and lightweight model for zero-shot NER. Extracts any entity type specified at inference time without fine-tuning. Published at NAACL 2024. Outperforms ChatGPT on zero-shot NER benchmarks while being compact enough to run on CPU. Ideal for bootstrapping NER on custom entity types.
PyTorch-based NLP framework by Zalando Research. Features contextual string embeddings (character-level language models), stacked embeddings, and state-of-the-art NER models. Supports 12+ languages out of the box. Also provides the CleanCoNLL dataset, a corrected version of CoNLL-2003 with fixed annotation errors.
Neural NLP pipeline from Stanford, supporting 70+ languages. Provides pre-trained NER models with BiLSTM-CRF architecture. Particularly strong for multilingual NER and academic research. Supports Hindi and other Indian languages via Universal Dependencies models.
PII detection and anonymization framework that uses NER as its core engine. Combines spaCy NER with pattern matching for detecting PII entities (names, addresses, phone numbers, Aadhaar numbers, PAN numbers). Ideal when NER is used specifically for privacy and compliance use cases.
Distributed NLP library built on Apache Spark. Provides NER models that scale to billions of documents via Spark's distributed computing. Includes specialized healthcare and legal NER models. Best for organizations already using Spark for big data processing.
Open-source data labeling tool with a dedicated NER annotation interface. Supports BIO/IOB tagging, span-level annotation, and export to CoNLL, spaCy, and HuggingFace formats. Essential tooling for building custom NER training datasets.
Research & References
Lample, Ballesteros, Subramanian, Kawakami, Dyer (2016)NAACL 2016
Introduced the BiLSTM-CRF architecture for NER that eliminated the need for hand-crafted features. Combined character-level and word-level embeddings with a CRF output layer. This paper established the dominant NER architecture for the next three years.
Devlin, Chang, Lee, Toutanova (2019)NAACL 2019
Introduced BERT, which achieved state-of-the-art results on NER by fine-tuning a pre-trained bidirectional Transformer for token classification. Pushed CoNLL-2003 F1 above 92 and established the transfer learning paradigm for NER.
Zaratiana, Nouri, Arias, Stepanov, Farahani (2024)NAACL 2024
Proposed a compact model for zero-shot NER that frames entity recognition as a matching problem between entity type embeddings and text span representations. Outperforms ChatGPT on zero-shot NER benchmarks while being orders of magnitude smaller and cheaper to run.
Li, Sun, Han, Li (2020)IEEE TKDE
Comprehensive survey covering distributed representations, neural architectures (CNN, RNN, Transformer), and evaluation methodologies for NER. Catalogs the evolution from feature-engineered CRFs to deep learning approaches.
Keraghel, Morbieu, Striegel (2024)arXiv preprint
The most recent comprehensive NER survey covering Transformer-based methods, LLM-based approaches, few-shot learning, and low-resource scenarios. Provides comparative evaluation across multiple datasets and paradigms.
Ashok, Lipton (2023)arXiv preprint
Proposed a prompt-based approach for few-shot NER using large language models. Demonstrated that carefully designed prompts with entity type definitions and examples can achieve competitive NER performance without any gradient updates.
Chen, Li, Wang (2024)EMNLP 2024
Investigated LLM capabilities for nested NER -- detecting entities that contain other entities. Found that output format critically influences performance and that label descriptions are crucial for eliciting LLM NER capabilities, though BERT-based models still outperform LLMs on nested NER.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How does NER differ from text classification, and when would you use each?
- ●
Explain the BIO tagging scheme and why the CRF layer improves NER performance.
- ●
How would you handle NER for a domain (e.g., medical or legal) where you have limited annotated data?
- ●
What are the challenges of applying NER to Indian languages and how would you address them?
- ●
How would you design an NER pipeline that processes 10 million documents per day?
- ●
What is the difference between flat NER and nested NER? When does nested NER matter?
- ●
How do you evaluate NER models and what metrics do you use?
- ●
Describe the tradeoff between spaCy NER, BERT-based NER, and LLM-based NER for production use.
- ●
How would you handle entity extraction from noisy OCR text (e.g., scanned Aadhaar cards)?
Key Points to Mention
- ●
Always evaluate at the entity level (using seqeval or conlleval), not the token level. Token accuracy is misleading because most tokens are 'O'.
- ●
The CRF layer enforces valid BIO transitions and typically improves entity-level F1 by 1-3 points over a bare linear classification head. The improvement comes from jointly decoding the entire sequence rather than making independent per-token predictions.
- ●
Subword alignment is the critical implementation detail for Transformer-based NER. Only the first subword of each word receives a label; the rest are masked. Getting this wrong corrupts training silently.
- ●
For low-resource domains, use GLiNER for zero-shot extraction or LLM-based labeling to bootstrap training data, then fine-tune a BERT model on the generated annotations.
- ●
Indian NER requires domain-specific training data because pre-trained English models have poor coverage of Indian names, organizations, and address formats. Models like MuRIL (trained on 17 Indian languages) provide a better starting point for multilingual Indian NER.
- ●
At production scale, use a tiered architecture: regex for structured patterns (dates, PAN numbers), spaCy for standard entities, BERT for ambiguous cases. This reduces GPU cost by 60-70% while maintaining accuracy.
Pitfalls to Avoid
- ●
Claiming that NER is a 'solved problem' -- entity-level F1 on real-world data is typically 85-92, far from perfect, especially for domain-specific or multilingual text.
- ●
Ignoring the distinction between entity extraction (NER) and entity linking/resolution (mapping 'Reliance' to a specific knowledge base entry) -- these are different tasks with different architectures.
- ●
Reporting token-level metrics instead of entity-level F1 -- this is a red flag in interviews that suggests lack of hands-on NER experience.
- ●
Forgetting to mention the CRF layer when discussing BiLSTM-CRF or BERT-CRF architectures -- the CRF is the component that makes the model NER-aware rather than just a generic token classifier.
- ●
Not considering the practical challenges of annotation (cost, inter-annotator agreement, annotation tools) when discussing NER pipeline design.
Senior-Level Expectation
A senior candidate should discuss the full lifecycle: data annotation strategy (active learning, weak supervision with gazetteers, LLM-assisted labeling), model selection with quantitative justification (not just 'I would use BERT'), subword alignment implementation details, evaluation methodology (entity-level F1, per-type analysis, error categorization), deployment architecture (batching, model serving, latency SLAs), monitoring (F1 drift detection, entity distribution tracking), and continuous improvement (error analysis pipeline, annotation flywheel). They should also be able to reason about cost -- for example, explaining why a Tier-2 Indian startup processing 1M documents/month should use spaCy with custom rules rather than BERT on GPU, saving INR 10,000/month while meeting the 88 F1 threshold. The ability to discuss nested NER, cross-lingual transfer, and few-shot approaches demonstrates depth beyond standard NER implementations.
Summary
Wrapping Up: NER in Production ML Systems
Named Entity Recognition is one of the most foundational components in any NLP pipeline. It transforms unstructured text into structured entity records -- person names, organizations, locations, dates, monetary values -- that downstream systems can search, filter, aggregate, and reason over. Without NER, most information extraction, compliance, and search applications simply cannot function.
The NER landscape in 2026 offers a clear progression of approaches: spaCy for fast, low-cost extraction of standard entity types (~85-88 F1, 1-5ms/doc); fine-tuned BERT/RoBERTa/DeBERTa for high-accuracy domain-specific extraction (~91-94 F1, 5-80ms/doc); and GLiNER or LLM-based few-shot for zero-training extraction of custom entity types (~78-88 F1, 15-2000ms/doc). The CRF layer remains a valuable addition to any architecture, improving entity-level F1 by 1-3 points through valid BIO sequence enforcement.
For teams building NER systems in India, three challenges deserve special attention: (1) Indian names with patronymics, initials, and non-Western patterns require domain-specific training data; (2) Indian addresses with variable formats need robust post-processing and validation; and (3) multilingual and code-mixed text (Hindi-English, Tamil-English) benefits from multilingual models like MuRIL rather than English-only models. Start with spaCy to validate the use case, move to fine-tuned Transformers when you have 500+ annotated sentences, and use GLiNER or LLM labeling to bootstrap when annotation is scarce. Monitor entity-level F1 continuously in production, and remember: NER is only as good as the text it receives -- invest in preprocessing (OCR correction, normalization) to maximize extraction quality.