CI/CD Pipeline in Machine Learning
A CI/CD pipeline for machine learning extends the principles of continuous integration and continuous delivery -- battle-tested in traditional software engineering -- to the unique challenges of building, testing, and deploying ML models. But here is the catch: ML systems are not just code. They are code plus data plus model artifacts, and all three axes can change independently. That fundamental difference is why you cannot simply bolt Jenkins onto a training script and call it a day.
In a traditional CI/CD pipeline, you test code, build a binary, and deploy it. In an ML CI/CD pipeline, you must also validate data quality, verify model performance against baseline metrics, check for training-serving skew, ensure reproducibility across environments, and orchestrate the promotion of model artifacts through staging gates -- all before a single prediction reaches production.
The stakes are high. A silent regression in model accuracy can cost real money. Imagine a fraud detection model at Razorpay that starts letting through 0.5% more fraudulent transactions because someone pushed a feature engineering change without running the evaluation suite. Or a recommendation model at Flipkart that degrades during Big Billion Days because the training data pipeline drifted and nobody caught it. CI/CD for ML exists to catch these failures before they reach users.
Today, ML CI/CD pipelines are the backbone of production MLOps at companies like Google, Uber, Netflix, Airbnb, and increasingly at Indian tech companies like Swiggy, Zerodha, and PhonePe. If you are building ML systems at any meaningful scale, you need one.
Concept Snapshot
- What It Is
- An automated pipeline that continuously integrates code, data, and model changes, validates them through quality gates, and deploys verified model artifacts to production environments.
- Category
- Orchestration
- Complexity
- Advanced
- Inputs / Outputs
- Inputs: source code commits, data updates, training configurations, model artifacts. Outputs: validated, versioned, deployed model serving endpoints with rollback capability.
- System Placement
- Sits at the center of the MLOps lifecycle, connecting model training, evaluation, registry, and serving infrastructure. It orchestrates the flow from experiment to production.
- Also Known As
- ML CI/CD, MLOps pipeline, continuous delivery for ML, CD4ML, model deployment pipeline, ML release pipeline
- Typical Users
- ML Engineers, MLOps Engineers, Platform Engineers, Data Scientists, DevOps Engineers, SRE teams
- Prerequisites
- Version control (Git), Basic CI/CD concepts, Docker and containerization, Model training and evaluation, Infrastructure as Code basics
- Key Terms
- continuous trainingdata validation gatemodel quality gateartifact registrypipeline triggertraining-serving skewblue-green deploymentcanary releaseshadow modeGitOps
Why This Concept Exists
The Problem: ML in Production Is Not a One-Shot Deploy
Traditional software is deterministic. Given the same code and inputs, you get the same outputs. You can write unit tests, run them in CI, and be reasonably confident that what passes tests in staging will behave the same in production.
ML systems break this assumption in three ways:
-
Data changes independently of code. A feature pipeline that worked perfectly last month might produce subtly different distributions today because upstream data sources shifted. This is not a bug -- it is the nature of real-world data.
-
Model quality is probabilistic. You cannot unit-test a model the way you test a REST endpoint. A model that achieves 94% accuracy on your test set might degrade to 91% on next week's data. Catching this requires evaluation pipelines, not just test suites.
-
Artifacts are large and expensive to produce. A trained model might take 8 hours of GPU time to produce. You cannot just "rebuild from source" on every commit the way you rebuild a Go binary. Caching, versioning, and incremental re-training become essential.
The Famous Paper That Started It All
In 2015, Sculley et al. published "Hidden Technical Debt in Machine Learning Systems" at NeurIPS, arguing that ML systems accumulate technical debt at an alarming rate because the actual ML code is a tiny fraction of the overall system. Configuration, data collection, feature extraction, monitoring, and serving infrastructure dwarf the model code itself. The paper's diagram showing the small "ML Code" box surrounded by a vast sea of infrastructure became one of the most cited images in MLOps.
This paper made the industry realize that treating ML deployments as ad-hoc, manual processes was unsustainable. CI/CD for ML emerged as the engineering discipline to manage this complexity.
Google's MLOps Maturity Model
Google formalized the progression with their MLOps maturity levels:
- Level 0 (Manual): Data scientists train models in notebooks, hand off artifacts to engineers, who manually deploy them. No automation, no reproducibility.
- Level 1 (ML Pipeline Automation): Training is automated and triggered by schedules or data changes. Continuous training exists, but deployment is still manual.
- Level 2 (CI/CD Pipeline Automation): Full automation -- code changes trigger CI, which validates data, trains models, runs evaluation suites, and promotes artifacts through staging to production. This is the target state.
Most teams today are somewhere between Level 0 and Level 1. Getting to Level 2 is what this block is about.
Key Takeaway: CI/CD for ML exists because ML systems have three axes of change (code, data, model), each requiring its own validation strategy. Traditional CI/CD only handles one axis -- code.
Core Intuition & Mental Model
Think of It Like a Three-Lane Highway
Here is an analogy that I find helpful. In traditional CI/CD, you have a single-lane highway: code changes flow from commit to build to test to deploy. Simple, linear, well-understood.
ML CI/CD is a three-lane highway running in parallel:
- Lane 1 (Code): Source code changes to feature engineering, training scripts, serving logic. This lane looks like traditional CI -- linting, unit tests, integration tests.
- Lane 2 (Data): Changes to training data, feature distributions, schema evolution. This lane runs data validation checks, schema tests, and distribution drift detection.
- Lane 3 (Model): The trained artifact itself, evaluated against performance baselines, fairness criteria, latency constraints, and business metrics.
All three lanes must converge at a quality gate before anything reaches production. If any lane has a red signal -- a failing unit test, a schema violation, or a model regression -- the entire release is blocked.
The Core Guarantee
A well-built ML CI/CD pipeline guarantees one thing: no model reaches production without passing every automated check you have defined. That includes code correctness, data integrity, model quality, infrastructure readiness, and deployment safety.
This sounds obvious, but the reality is that most ML teams today deploy models by running a notebook, eyeballing some metrics, and copying a model file to S3. The gap between "it works on my machine" and "it works in production, reliably, at 3 AM on a Saturday" is exactly what CI/CD closes.
What ML CI/CD Does NOT Do
It does not replace good ML engineering. If your features are poorly designed, your training data is biased, or your model architecture is wrong, CI/CD will faithfully automate the deployment of a bad model. CI/CD is a delivery mechanism, not a quality oracle. The quality comes from the checks you define within the pipeline.
Technical Foundations
Formalizing ML CI/CD
Let us define an ML CI/CD pipeline formally. Consider an ML system state as a tuple:
where is the code version, is the data version, is the model architecture, and is the trained parameter set.
A pipeline run is a function:
where is the evaluation report for the resulting model. The pipeline maps a specific code and data version to a trained model and its evaluation.
Quality Gate Function
The quality gate is a boolean predicate over the evaluation report:
where is the set of metrics (accuracy, latency, fairness, etc.) and is the threshold for metric . The model is promoted only if .
For example, a quality gate might require:
- Accuracy
- P99 inference latency
- Demographic parity gap
- No data schema violations (boolean)
Reproducibility Constraint
A pipeline is reproducible if:
meaning re-running the same code and data versions produces statistically equivalent results (within a tolerance for stochastic training). Achieving this requires pinning random seeds, library versions, and hardware configurations -- which is why containerization is non-negotiable.
Pipeline Trigger Space
The trigger set defines when the pipeline runs:
- : Git push, PR merge
- : New data batch arrival, schema change detected
- : Cron-based retraining (daily, weekly)
- : Performance drift alert from monitoring system
Practical Note: Most production ML CI/CD pipelines trigger on for fast feedback during development and for ongoing production freshness.
Internal Architecture
An ML CI/CD pipeline consists of several interconnected stages that validate, build, and deploy ML artifacts. The architecture is designed around the principle of progressive confidence -- each stage increases confidence that the change is safe to ship.
The pipeline typically begins with a trigger (code push, data update, or schedule), flows through validation and testing stages, and terminates with a deployment to production or a rejection with diagnostic feedback.
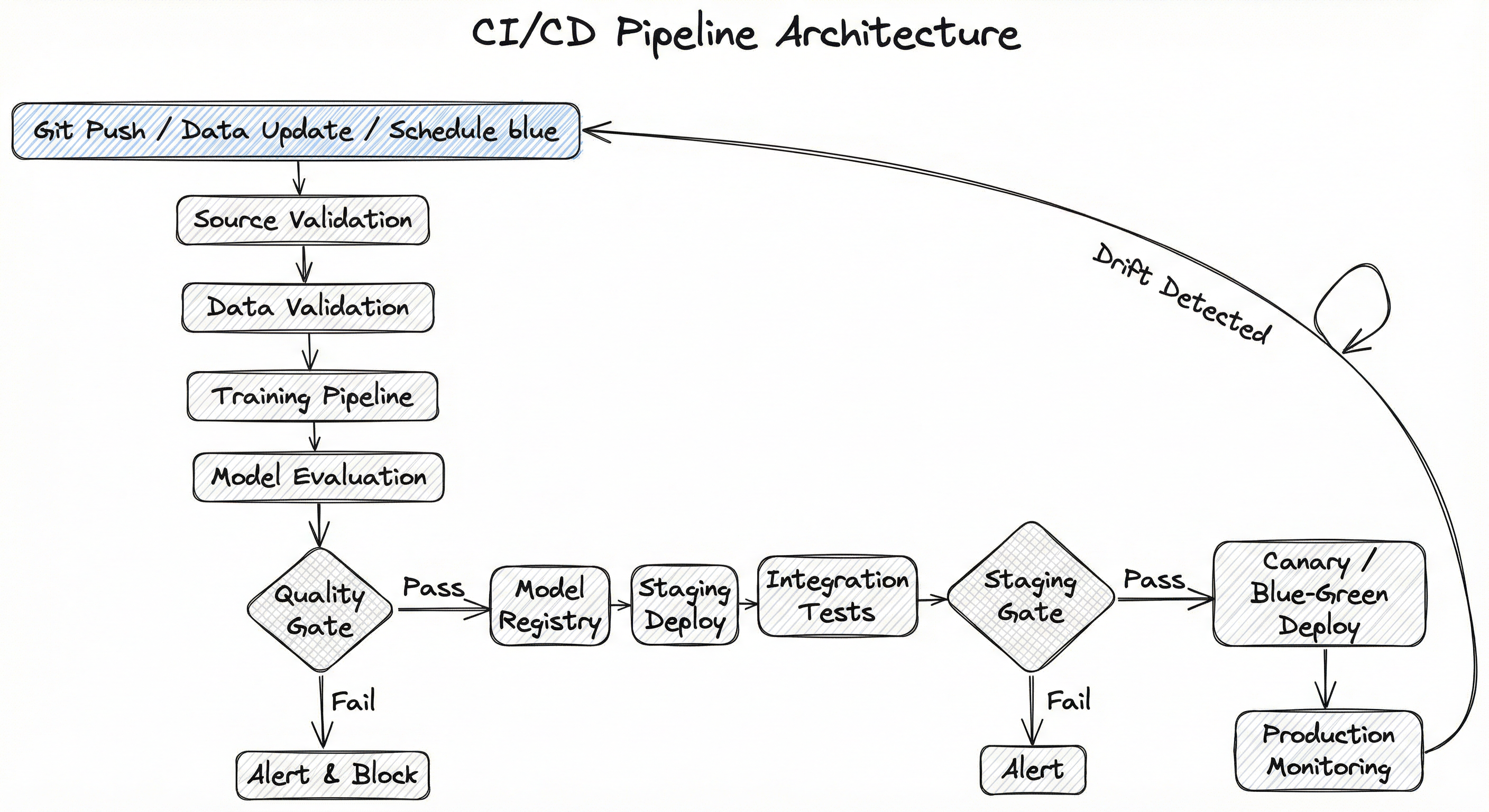
The feedback loop from production monitoring back to the trigger is what makes this a continuous pipeline rather than a one-shot deployment. When monitoring detects performance degradation or data drift, it can automatically trigger a retraining cycle -- this is what Google calls Continuous Training (CT), the third pillar alongside CI and CD.
Key Components
Trigger Manager
Listens for pipeline triggers including Git webhooks (push, PR), data arrival events, cron schedules, and drift alerts from monitoring. Determines which pipeline stages to execute based on the type of change (code-only changes may skip data validation; data-only changes may skip unit tests).
Source Validation Stage
Runs traditional CI checks on ML code: linting (flake8, ruff), type checking (mypy), unit tests for feature engineering functions, and integration tests for pipeline components. Also validates pipeline configuration files (YAML/JSON) and infrastructure-as-code definitions.
Data Validation Stage
Validates training data against defined expectations: schema checks (column types, ranges), distribution drift detection, completeness checks, and referential integrity. Tools like Great Expectations or TensorFlow Data Validation (TFDV) power this stage. Blocks the pipeline if data quality falls below thresholds.
Training Pipeline
Executes the ML training workflow: data preprocessing, feature engineering, model training, and hyperparameter tuning. Runs in a containerized environment with pinned dependencies. Logs metrics, parameters, and artifacts to an experiment tracker (MLflow, Weights & Biases). Produces a versioned model artifact.
Model Evaluation Stage
Evaluates the trained model against a held-out test set and the current production model (champion-challenger comparison). Computes metrics across multiple dimensions: accuracy, latency, fairness, robustness, and resource consumption. Generates an evaluation report for the quality gate.
Quality Gate
The critical decision point. Compares evaluation metrics against predefined thresholds and the current production baseline. Requires all metrics to pass before promotion. Can be configured for auto-promotion (full automation) or human-in-the-loop approval for high-risk models.
Model Registry
Stores versioned model artifacts with metadata (training data version, code commit, evaluation metrics, lineage). Manages model lifecycle stages: development -> staging -> production -> archived. MLflow Model Registry, Vertex AI Model Registry, and SageMaker Model Registry are common implementations.
Deployment Orchestrator
Manages the actual deployment to serving infrastructure. Supports multiple strategies: canary (gradual traffic shift), blue-green (instant switchover with rollback), and shadow (parallel execution without user impact). Integrates with Kubernetes, Seldon Core, KServe, or cloud-native serving (SageMaker Endpoints, Vertex AI).
Monitoring & Feedback Loop
Continuously monitors deployed model performance: prediction distributions, latency, throughput, data drift, and concept drift. Triggers retraining when metrics breach alerting thresholds. Closes the loop from production back to pipeline triggers.
Data Flow
Write Path (Code Change): Developer pushes code -> trigger manager fires -> source validation (lint, test) -> if training code changed, data validation runs -> training pipeline produces new model artifact -> evaluation stage compares against baseline -> quality gate approves/rejects -> approved artifacts registered in model registry -> deployment orchestrator rolls out via canary/blue-green -> monitoring watches production metrics.
Write Path (Data Change): New data batch arrives -> trigger manager fires -> data validation checks schema and distributions -> if validation passes, training pipeline runs with new data -> same evaluation and quality gate flow -> deployment.
Write Path (Scheduled Retraining): Cron fires at configured interval (e.g., daily 2 AM IST) -> full pipeline run with latest data -> evaluation against current production model -> only deploy if new model improves metrics (otherwise, current model stays).
Feedback Path: Monitoring detects drift/degradation -> alert triggers retraining -> pipeline runs automatically -> if new model passes gates, deployed; if not, alert escalated to on-call ML engineer.
A top-to-bottom flowchart showing: trigger sources (Git push, data update, schedule) feeding into source validation, then data validation, then training, then model evaluation, branching at a quality gate to either model registry (pass) or alert and block (fail), then continuing through staging deployment, integration tests, staging gate, production deployment via canary/blue-green, and production monitoring with a feedback loop back to the trigger.
How to Implement
Choosing Your Stack
Implementation approaches for ML CI/CD fall on a spectrum from lightweight to enterprise-grade:
Lightweight (startup/small team): GitHub Actions + DVC + CML + MLflow. Low cost (~$0, or ~INR 0 for open-source tooling on self-hosted runners), fast to set up, but requires manual infrastructure management. Perfect for a 3-person ML team at an Indian startup burning through seed funding.
Mid-scale (growth-stage): GitLab CI/CD + Kubeflow Pipelines + MLflow + Seldon Core. Moderate operational overhead but highly flexible. Requires a Kubernetes cluster -- budget ~$200-500/month (~INR 16,800-42,000/month) for a modest GKE/EKS cluster.
Enterprise (large org): Vertex AI Pipelines (GCP) / SageMaker Pipelines (AWS) / Azure ML Pipelines. Fully managed, integrated with cloud ecosystems. Higher cost ($500-5,000+/month, ~INR 42,000-4.2 lakh/month) but minimal ops burden. This is what teams at Flipkart, Swiggy, and large Indian enterprises typically adopt.
Regardless of the stack, the core implementation pattern is the same: define pipeline stages as code, version everything, automate execution, and enforce quality gates.
The Three CI Pillars for ML
Every ML CI/CD pipeline must implement three types of continuous integration that traditional CI does not cover:
- CI for Code: Standard linting, testing, and building. Nothing new here.
- CI for Data: Validate that training data meets schema expectations, distributions are stable, and no data leakage has occurred.
- CI for Model: Validate that the trained model meets performance, fairness, and latency requirements before promotion.
name: ML CI/CD Pipeline
on:
push:
branches: [main, develop]
pull_request:
branches: [main]
schedule:
- cron: '0 20 * * 0' # Weekly Sunday 1:30 AM IST (8 PM UTC)
jobs:
code-quality:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: '3.11'
- run: pip install ruff mypy pytest
- run: ruff check src/
- run: mypy src/ --ignore-missing-imports
- run: pytest tests/unit/ -v --tb=short
data-validation:
runs-on: ubuntu-latest
needs: code-quality
steps:
- uses: actions/checkout@v4
- uses: iterative/setup-dvc@v1
- run: dvc pull data/
- run: pip install great-expectations
- run: python scripts/validate_data.py
- run: python scripts/check_schema.py
train-and-evaluate:
runs-on: ubuntu-latest
needs: data-validation
steps:
- uses: actions/checkout@v4
- uses: iterative/setup-cml@v2
- uses: iterative/setup-dvc@v1
- run: pip install -r requirements.txt
- run: dvc pull
- run: dvc repro # Reproduce the full DVC pipeline
- name: Generate CML Report
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
echo "## Model Evaluation Report" >> report.md
echo "### Metrics" >> report.md
dvc metrics show --md >> report.md
echo "### Metrics Diff vs Main" >> report.md
dvc metrics diff main --md >> report.md
echo "### Plots" >> report.md
dvc plots diff --targets plots/ --out plots_diff
echo '' >> report.md
cml comment create report.md
quality-gate:
runs-on: ubuntu-latest
needs: train-and-evaluate
steps:
- uses: actions/checkout@v4
- run: pip install -r requirements.txt
- name: Check model quality thresholds
run: |
python scripts/quality_gate.py \
--min-accuracy 0.92 \
--max-latency-p99-ms 50 \
--max-fairness-gap 0.05 \
--compare-to production
deploy-staging:
runs-on: ubuntu-latest
needs: quality-gate
if: github.ref == 'refs/heads/main'
steps:
- uses: actions/checkout@v4
- run: pip install -r requirements.txt
- run: python scripts/register_model.py --stage staging
- run: python scripts/deploy.py --env staging --strategy blue-green
- run: pytest tests/integration/ -v --env staging
deploy-production:
runs-on: ubuntu-latest
needs: deploy-staging
environment: production # Requires manual approval
steps:
- run: python scripts/deploy.py --env production --strategy canary --canary-pct 10
- run: python scripts/monitor_canary.py --duration 30m --rollback-on-regressionThis GitHub Actions workflow implements a full ML CI/CD pipeline. It triggers on code pushes, PRs, and a weekly schedule (for automated retraining). The pipeline flows through code quality checks, data validation with DVC and Great Expectations, model training with DVC reproducible pipelines, CML report generation on PRs (with metrics diffs and confusion matrix plots), quality gate enforcement, and staged deployment with canary release. The environment: production directive enables manual approval gates for production deployments.
import great_expectations as gx
import sys
def validate_training_data(data_path: str) -> bool:
"""Validate training data before pipeline proceeds."""
context = gx.get_context()
# Define the data source
data_source = context.data_sources.add_pandas(name="training_data")
data_asset = data_source.add_csv_asset(
name="train_csv",
filepath_or_buffer=data_path,
)
batch_definition = data_asset.add_batch_definition_whole_dataframe(
name="full_batch"
)
# Create expectation suite
suite = context.suites.add(
gx.ExpectationSuite(name="training_data_suite")
)
# Schema checks
suite.add_expectation(
gx.expectations.ExpectTableColumnsToMatchOrderedList(
column_list=["feature_1", "feature_2", "feature_3", "label"]
)
)
# Completeness checks
suite.add_expectation(
gx.expectations.ExpectColumnValuesToNotBeNull(
column="label", mostly=0.99
)
)
# Distribution checks
suite.add_expectation(
gx.expectations.ExpectColumnMeanToBeBetween(
column="feature_1", min_value=-1.0, max_value=1.0
)
)
# Range checks
suite.add_expectation(
gx.expectations.ExpectColumnValuesToBeBetween(
column="feature_2", min_value=0, max_value=1000
)
)
# Row count check (detect data pipeline issues)
suite.add_expectation(
gx.expectations.ExpectTableRowCountToBeBetween(
min_value=10000, max_value=10000000
)
)
# Run validation
validation_definition = context.validation_definitions.add(
gx.ValidationDefinition(
name="training_validation",
data=batch_definition,
suite=suite,
)
)
result = validation_definition.run()
if not result.success:
print("DATA VALIDATION FAILED")
for r in result.results:
if not r.success:
print(f" FAILED: {r.expectation_config.type}")
print(f" Details: {r.result}")
return False
print("Data validation passed. All expectations met.")
return True
if __name__ == "__main__":
success = validate_training_data("data/processed/train.csv")
sys.exit(0 if success else 1)This script implements a data validation gate using Great Expectations (GX Core). It checks schema compliance (columns match expected order), completeness (labels are non-null), distribution stability (feature means within range), value ranges, and row counts. If any expectation fails, the script exits with code 1, which causes the CI pipeline to fail and block the training stage. This is the data lane of our three-lane highway.
import json
import argparse
import mlflow
import sys
from typing import Dict
def load_metrics(run_id: str) -> Dict[str, float]:
"""Load metrics from an MLflow run."""
client = mlflow.tracking.MlflowClient()
run = client.get_run(run_id)
return run.data.metrics
def get_production_metrics(model_name: str) -> Dict[str, float]:
"""Get metrics from the current production model."""
client = mlflow.tracking.MlflowClient()
# Get the model version with 'production' alias
mv = client.get_model_version_by_alias(model_name, "production")
return load_metrics(mv.run_id)
def run_quality_gate(
candidate_run_id: str,
model_name: str,
min_accuracy: float = 0.92,
max_latency_p99_ms: float = 50.0,
max_fairness_gap: float = 0.05,
min_improvement: float = 0.0,
) -> bool:
"""Evaluate candidate model against thresholds and production baseline."""
candidate = load_metrics(candidate_run_id)
production = get_production_metrics(model_name)
checks = []
# Absolute threshold checks
checks.append((
"accuracy >= threshold",
candidate.get("accuracy", 0) >= min_accuracy,
f"{candidate.get('accuracy', 0):.4f} vs {min_accuracy}"
))
checks.append((
"p99_latency <= threshold",
candidate.get("p99_latency_ms", 999) <= max_latency_p99_ms,
f"{candidate.get('p99_latency_ms', 999):.1f}ms vs {max_latency_p99_ms}ms"
))
checks.append((
"fairness_gap <= threshold",
candidate.get("demographic_parity_gap", 1.0) <= max_fairness_gap,
f"{candidate.get('demographic_parity_gap', 1.0):.4f} vs {max_fairness_gap}"
))
# Relative improvement check (candidate must not regress vs production)
prod_acc = production.get("accuracy", 0)
cand_acc = candidate.get("accuracy", 0)
improvement = cand_acc - prod_acc
checks.append((
"accuracy improvement >= minimum",
improvement >= min_improvement,
f"improvement={improvement:+.4f} vs min={min_improvement}"
))
# Print results
print("=" * 60)
print("QUALITY GATE RESULTS")
print("=" * 60)
all_passed = True
for name, passed, detail in checks:
status = "PASS" if passed else "FAIL"
print(f" [{status}] {name}: {detail}")
if not passed:
all_passed = False
print("=" * 60)
print(f"Overall: {'PASSED' if all_passed else 'FAILED'}")
print("=" * 60)
return all_passed
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--candidate-run-id", required=True)
parser.add_argument("--model-name", default="fraud-detector")
parser.add_argument("--min-accuracy", type=float, default=0.92)
parser.add_argument("--max-latency-p99-ms", type=float, default=50.0)
parser.add_argument("--max-fairness-gap", type=float, default=0.05)
parser.add_argument("--min-improvement", type=float, default=0.0)
args = parser.parse_args()
passed = run_quality_gate(
candidate_run_id=args.candidate_run_id,
model_name=args.model_name,
min_accuracy=args.min_accuracy,
max_latency_p99_ms=args.max_latency_p99_ms,
max_fairness_gap=args.max_fairness_gap,
min_improvement=args.min_improvement,
)
sys.exit(0 if passed else 1)This quality gate script implements the champion-challenger pattern: it loads metrics for the candidate model (from the latest training run) and the current production model (the champion) from MLflow, then checks absolute thresholds (accuracy, latency, fairness) and relative improvement. If any check fails, the pipeline is blocked. This is the critical decision point that prevents model regressions from reaching production.
# dvc.yaml - Reproducible ML pipeline definition
stages:
preprocess:
cmd: python src/preprocess.py --input data/raw/ --output data/processed/
deps:
- src/preprocess.py
- data/raw/
outs:
- data/processed/
params:
- preprocess.min_samples
- preprocess.max_null_ratio
feature_engineering:
cmd: python src/features.py --input data/processed/ --output data/features/
deps:
- src/features.py
- data/processed/
outs:
- data/features/
params:
- features.embedding_dim
- features.categorical_encoding
train:
cmd: python src/train.py --data data/features/ --model models/model.pkl
deps:
- src/train.py
- data/features/
outs:
- models/model.pkl
params:
- train.learning_rate
- train.n_estimators
- train.max_depth
metrics:
- metrics/train_metrics.json:
cache: false
evaluate:
cmd: python src/evaluate.py --model models/model.pkl --data data/features/test.csv
deps:
- src/evaluate.py
- models/model.pkl
- data/features/test.csv
metrics:
- metrics/eval_metrics.json:
cache: false
plots:
- plots/confusion_matrix.csv:
x: predicted
y: actual
- plots/roc_curve.csv:
x: fpr
y: tprThis DVC pipeline definition (dvc.yaml) declares a four-stage ML pipeline with explicit dependencies. DVC tracks which stages need to re-run based on what changed -- if only train.py changed, preprocessing is skipped. The dvc repro command in CI ensures only necessary stages execute, saving compute costs. Metrics and plots are tracked in Git for PR-level comparison via CML.
# Kubeflow Pipelines CI/CD trigger configuration
apiVersion: pipelines.kubeflow.org/v1
kind: PipelineRun
metadata:
name: ml-cicd-run-{{ .Values.runId }}
namespace: ml-pipelines
spec:
pipeline:
name: fraud-detection-pipeline
params:
- name: data_version
value: "v2.3.1"
- name: code_commit
value: "{{ .Values.gitSha }}"
- name: min_accuracy
value: "0.92"
- name: max_latency_p99_ms
value: "50"
- name: deploy_strategy
value: "canary"
- name: canary_traffic_pct
value: "10"
- name: mlflow_tracking_uri
value: "https://mlflow.internal.example.com"
resources:
- name: training
resourceSpec:
requests:
cpu: "8"
memory: "32Gi"
nvidia.com/gpu: "1"
limits:
cpu: "16"
memory: "64Gi"
nvidia.com/gpu: "1"Common Implementation Mistakes
- ●
Training in CI runners without GPU support: Attempting to train deep learning models on standard CI runners (2 vCPU, 7 GB RAM) leads to timeouts and failures. Use self-hosted runners with GPU access, or offload training to a cloud service (SageMaker, Vertex AI) and poll for completion.
- ●
Not versioning data alongside code: Committing code changes without tracking the corresponding data version makes runs non-reproducible. Use DVC, LakeFS, or Delta Lake to version datasets and ensure every pipeline run can be traced to a specific code + data snapshot.
- ●
Skipping the champion-challenger comparison: Setting only absolute thresholds without comparing to the current production model means you can deploy a model that technically passes all checks but is worse than what is already serving. Always compare against the production baseline.
- ●
Hardcoding secrets and credentials in pipeline configs: Storing API keys, database passwords, or cloud credentials in YAML files or scripts that get committed to Git. Use CI/CD secret management (GitHub Secrets, Vault, AWS Secrets Manager) instead.
- ●
Running the full pipeline on every commit: Not differentiating between code-only and data-only changes leads to unnecessary GPU hours and slow feedback loops. Use dependency tracking (DVC) or conditional stages to skip irrelevant steps.
- ●
Ignoring training-serving skew: Your CI pipeline trains with pandas on batch data but your serving environment uses a different feature computation path. Always test the serving path in CI to ensure training and serving feature computations are identical.
When Should You Use This?
Use When
You have ML models in production that require regular updates (retraining, feature changes, or architecture changes) and you need to ensure quality does not regress with each update
Multiple team members (data scientists, ML engineers, platform engineers) contribute to the same ML codebase and you need automated quality checks to prevent bad merges
Your organization requires audit trails and reproducibility for model deployments (common in regulated industries like fintech -- Razorpay, PhonePe -- or healthcare)
Model retraining frequency is weekly or more often, making manual validation unsustainable -- the human review bottleneck becomes a deployment bottleneck
You are operating at a scale where a model regression can cause significant business impact (revenue loss, customer churn, compliance violations)
Your ML system involves multiple connected models or pipelines where a change in one component can cascade to others, requiring integration testing
Avoid When
You are in the early exploration phase with a single data scientist prototyping in notebooks -- adding CI/CD overhead too early slows experimentation velocity. Get the model working first, then automate the delivery.
Your model is trained once and never updated (e.g., a one-time data migration classifier). The overhead of a full CI/CD pipeline is not justified for a deploy-once artifact.
You have no production serving infrastructure yet -- CI/CD for ML assumes you have a target deployment environment. Build the serving layer first.
The model training takes many hours and you cannot afford the compute cost of running it on every PR. In this case, consider a lighter CI pipeline that runs fast checks (data validation, unit tests) on PRs and defers full training to merge-to-main.
Your team is a single person working on a side project. The complexity of setting up and maintaining CI/CD pipelines outweighs the risk of manual deployment for a solo developer.
The model output is not customer-facing and errors are easily reversible (e.g., an internal analytics dashboard that is checked weekly). The cost of CI/CD may exceed the cost of occasional manual fixes.
Key Tradeoffs
The Fundamental Tradeoff: Velocity vs. Safety
Every CI/CD pipeline sits on a spectrum between deployment speed and deployment safety. More quality gates mean more confidence but slower releases. Fewer gates mean faster iteration but higher risk.
For a startup building their first ML product, a lightweight pipeline (code lint + basic data validation + accuracy threshold) provides 80% of the value with 20% of the effort. For a fintech company like Razorpay running fraud detection models, you want the full suite: data validation, fairness checks, latency benchmarks, champion-challenger comparison, canary deployment, and automated rollback.
The Cost Axis
| Pipeline Tier | Monthly Cost (Cloud) | Setup Time | Best For |
|---|---|---|---|
| Lightweight (GitHub Actions + DVC) | $0-50 (~INR 0-4,200) | 1-2 days | Startups, small teams |
| Mid-scale (GitLab CI + Kubeflow) | $200-800 (~INR 16,800-67,200) | 1-2 weeks | Growth-stage companies |
| Enterprise (Vertex AI / SageMaker) | $500-5,000+ (~INR 42,000-4.2L+) | 2-4 weeks | Large orgs, regulated industries |
The compute cost of running training in CI can be significant. A single training run on a V100 GPU instance costs approximately 100/month just for CI training compute. Scale to 100 runs/week across multiple models and you are looking at $4,000-10,000/month (~INR 3.4-8.4 lakh/month).
Human-in-the-Loop vs. Full Automation
Not every deployment should be fully automated. A sensible middle ground: auto-deploy for low-risk models (recommendations, content ranking) and require manual approval for high-risk models (fraud detection, credit scoring, medical diagnosis). GitHub Actions environments with required reviewers make this easy to implement.
Rule of Thumb: Start with the lightest pipeline that catches your most common failure modes. Add gates incrementally as you encounter new failure modes in production.
Alternatives & Comparisons
A pipeline scheduler orchestrates the execution of ML workflows (training, feature computation, data processing) on a schedule or trigger. CI/CD pipelines orchestrate the validation and deployment of artifacts produced by those workflows. In practice, you need both: Airflow schedules your daily training job, and your CI/CD pipeline validates the resulting model and promotes it to production. They are complementary, not alternatives.
A model registry stores and versions model artifacts with metadata and lifecycle stages. It is a component within a CI/CD pipeline, not a replacement for one. The registry provides the artifact management that CI/CD needs, but it does not enforce quality gates, run tests, or orchestrate deployments on its own. Think of the registry as the warehouse and CI/CD as the supply chain.
Canary deployment is a deployment strategy used within the CD (continuous delivery) stage of a CI/CD pipeline. It gradually routes a small percentage of traffic to the new model while monitoring for regressions. It is one option at the deployment stage alongside blue-green and shadow deployment, not an alternative to the full CI/CD pipeline.
Blue-green deployment maintains two identical production environments and switches traffic atomically between them. Like canary, it is a deployment strategy within the CD stage. Blue-green is preferred when you need instant rollback capability; canary is preferred when you want gradual exposure and statistical validation before full rollout.
Pros, Cons & Tradeoffs
Advantages
Automated quality enforcement prevents model regressions from reaching production -- no more 'it looked good in the notebook' surprises. Quality gates catch issues that manual review consistently misses.
Full reproducibility through versioned code, data, and configurations means any historical model can be exactly recreated, which is essential for debugging, auditing, and regulatory compliance (RBI guidelines for fintech, SEBI for trading systems).
Faster iteration cycles -- once the pipeline is set up, deploying a new model version takes minutes instead of days. Teams at Google report that Level 2 MLOps reduces deployment time from weeks to hours.
Multi-team collaboration becomes safe because CI catches conflicts and regressions automatically. Five data scientists can push changes to the same model without stepping on each other's work.
Auditability and governance -- every model deployment has a traceable lineage from code commit to data version to evaluation metrics to deployment timestamp. Essential for enterprise customers and regulated industries.
Continuous training (CT) enables models to automatically adapt to new data, keeping predictions fresh without manual intervention. Critical for systems where data distributions shift frequently (e-commerce, ride-sharing, fraud detection).
Disadvantages
Significant upfront investment in infrastructure, tooling, and pipeline development. A production-grade ML CI/CD pipeline can take 2-4 weeks to build and requires ongoing maintenance. For a small team, this is a real opportunity cost.
Compute costs scale with pipeline frequency. Running GPU-intensive training in CI on every PR can be expensive. A single A100 GPU hour costs ~700/week just on CI training.
Pipeline complexity becomes its own maintenance burden. Pipeline code, configuration, and infrastructure can accumulate technical debt just like model code. The pipeline itself needs testing and monitoring -- meta-CI for CI.
False sense of security -- passing all automated checks does not guarantee the model will perform well in production. Edge cases, distribution shifts, and adversarial inputs may not be covered by your test suite. CI/CD is necessary but not sufficient.
Steep learning curve for data scientists who are used to notebook-based workflows. Transitioning from 'run cells and check output' to 'write testable code, define pipeline stages, manage configurations' requires cultural change and training.
Debugging pipeline failures is harder than debugging model code -- when a pipeline stage fails at 3 AM, the error could be in the code, the data, the infrastructure, or the pipeline configuration itself. Observability and logging are essential.
Failure Modes & Debugging
Flaky data validation gates
Cause
Data validation thresholds set too tight on naturally variable distributions. For example, setting a hard range on a feature that has seasonal variation (e-commerce transaction volume during Diwali vs. regular days). The validation passes in November but fails in January because the distribution shifted back.
Symptoms
Pipeline fails intermittently on data validation stages despite no actual data quality issues. Team starts ignoring or disabling validation checks, defeating their purpose. Increased pipeline noise leads to alert fatigue.
Mitigation
Use dynamic thresholds based on rolling statistics rather than hard-coded values. Implement seasonal adjustments. Distinguish between hard failures (schema violations, null keys) and soft warnings (distribution shifts within tolerance). Use a two-tier system: hard gates that block and soft gates that warn.
Training-serving skew undetected
Cause
CI pipeline validates model accuracy on batch data using pandas-based feature engineering, but production serving uses a different feature computation path (e.g., real-time features from a feature store). Differences in floating-point precision, missing value handling, or feature ordering between training and serving cause silent prediction errors.
Symptoms
Model passes all CI checks but performs worse in production than the evaluation metrics suggest. A/B test results do not match offline evaluation. Predictions are subtly wrong but not catastrophically so, making the issue hard to detect.
Mitigation
Run integration tests that exercise the serving path with representative inputs and compare outputs against the training path. Implement a consistency test that feeds the same input through both paths and asserts outputs match within a tolerance. Include serving-path latency benchmarks in CI.
Stale champion model in quality gate
Cause
The quality gate compares the candidate model against the production champion, but the champion's metrics were recorded at deployment time and do not reflect current performance on recent data. The production model may have degraded due to drift, making the comparison misleading.
Symptoms
New models consistently pass the quality gate because they are being compared against stale metrics. In reality, even the champion has degraded and the threshold should have triggered retraining much earlier. You deploy a model that is better than the degraded champion but worse than what the champion was when it was fresh.
Mitigation
Periodically re-evaluate the champion model on recent data and update its metrics in the registry. Include a freshness check in the quality gate that flags if the champion's evaluation is older than a configured threshold (e.g., 7 days). Better yet, run both champion and challenger on the same recent holdout set during the quality gate.
Pipeline resource exhaustion
Cause
Training jobs triggered too frequently (e.g., on every commit to a busy repository) exhaust CI compute budget, GPU quotas, or cloud spending limits. Common when multiple data scientists merge PRs rapidly during a sprint.
Symptoms
Pipeline queues grow, training jobs wait hours for runners, deployments are delayed. Cloud bills spike unexpectedly. In the worst case, hitting spending limits causes all pipelines to fail, blocking even critical hotfixes.
Mitigation
Implement pipeline deduplication (merge multiple triggers into a single run), compute budgets with alerts, and tiered pipelines (fast checks on every PR, full training only on merge to main or on schedule). Use spot/preemptible instances for training to reduce costs by 60-70%.
Secret leakage in pipeline logs
Cause
Pipeline logs capture environment variables, API responses, or error messages that contain secrets (database credentials, API keys, model endpoint URLs). Logs are stored in CI systems that may have broader access than the secrets themselves.
Symptoms
Secrets visible in CI/CD logs accessible to team members or, worse, in public repository action logs. May not be discovered until a security audit or incident.
Mitigation
Use secret masking features in your CI platform (GitHub Actions automatically masks secrets in logs). Never print environment variables in pipeline scripts. Implement log scrubbing for known secret patterns. Run security scanning tools (e.g., truffleHog, detect-secrets) as a CI stage.
Non-reproducible training runs
Cause
Random seeds not pinned, library versions not locked (using >= instead of == in requirements), or non-deterministic GPU operations cause different results on each pipeline run with the same inputs.
Symptoms
The same code and data produce different metrics on successive runs. Quality gate becomes unreliable because model performance appears to fluctuate randomly. Debugging becomes impossible because you cannot reproduce a specific result.
Mitigation
Pin all library versions in requirements.txt or poetry.lock. Set random seeds for Python, NumPy, and framework-specific seeds (PyTorch, TensorFlow). Use Docker containers with pinned base images. For GPU non-determinism, set CUBLAS_WORKSPACE_CONFIG=:4096:8 and torch.use_deterministic_algorithms(True).
Placement in an ML System
Where It Sits in the ML System
The CI/CD pipeline is the central nervous system of an MLOps platform. It does not produce models or serve predictions itself -- instead, it orchestrates the flow of artifacts between all other components.
Upstream, it depends on the model registry (for artifact storage and versioning), the experiment tracker (for training metrics), the feature store (for consistent feature definitions), and data validation tools (for quality checks). These components produce the inputs that the CI/CD pipeline validates and promotes.
Downstream, it feeds into deployment infrastructure (canary, blue-green, shadow deployments), model serving (the actual prediction endpoints), and monitoring systems (which close the feedback loop by triggering retraining).
In a typical flow at a company like Swiggy: a data scientist trains a restaurant recommendation model locally, pushes code to GitHub, the CI/CD pipeline runs data validation and model evaluation, the quality gate compares against the current production model, and if approved, the pipeline deploys a canary to 5% of traffic in Bengaluru before rolling out nationally.
Key Insight: The CI/CD pipeline is the enforcer of quality standards across the ML lifecycle. Without it, quality becomes a manual, inconsistent process that degrades as the team and system grow.
Pipeline Stage
Orchestration / Deployment
Upstream
- model-registry
- experiment-tracker
- feature-store
- data-validation
Downstream
- canary-deploy
- blue-green-deploy
- model-serving
- monitoring-dashboard
Scaling Bottlenecks
The primary bottleneck is training compute in CI. Each full pipeline run may require GPU hours, and at scale (multiple models, frequent retraining), this becomes the dominant cost center. A team managing 20 models with daily retraining might need 20+ GPU-hours per day just for CI -- roughly $70/day (~INR 5,900/day) on AWS spot instances.
The second bottleneck is pipeline orchestration latency. As the number of pipeline stages grows, the total wall-clock time from trigger to deployment increases. A 10-stage pipeline with 5 minutes per stage takes 50 minutes if stages are sequential. Parallelizing independent stages (data validation + code tests can run simultaneously) is essential.
The third bottleneck is artifact storage. Each pipeline run produces model artifacts (often 100 MB - 10 GB each). With daily retraining across 20 models, you accumulate 2-200 GB/day. After a year, that is 0.7-73 TB of model artifacts. Implement retention policies to purge old artifacts and use compressed storage.
At enterprise scale (Uber's Michelangelo processes 20,000+ training jobs monthly), you need dedicated pipeline infrastructure with autoscaling, job queuing, and priority-based scheduling.
Production Case Studies
Google Cloud outlines the key requirements for building an MLOps foundation, emphasizing that MLOps aims to unify ML system development and operations through automation and monitoring at all steps of ML system construction. The article covers continuous integration, continuous delivery, continuous training, and continuous monitoring as critical properties unique to ML systems.
Establishes MLOps maturity framework with 3 levels, from manual processes to fully automated CI/CD pipelines for ML, enabling organizations to operationalize machine learning at scale.
Uber's Michelangelo platform implements comprehensive ML CI/CD with automated model validation, shadow testing (running new models in parallel with production without affecting users), and gradual rollout. Over 75% of critical online use cases at Uber use shadow testing as part of their deployment pipeline. The platform processes 20,000+ training jobs monthly and serves 15 million real-time predictions per second at peak.
Automated deployment safety checks and shadow testing significantly reduced production incidents from model deployments. Gradual rollout with automatic rollback limits the blast radius of any model regression to a small percentage of traffic.
Netflix built Metaflow (now open-source) to standardize the path from notebook experimentation to production deployment. Their ML infrastructure supports diverse model types across recommendations, content delivery, and A/B testing. Metaflow integrates with Argo Workflows for CI/CD orchestration and AWS Step Functions for production scheduling, reducing the median project-to-deployment time from four months to one week.
Metaflow and associated CI/CD infrastructure reduced median project deployment time from 4 months to 1 week -- an 16x improvement. The framework is now used by hundreds of data scientists at Netflix and has been open-sourced for community use.
Razorpay uses ML models extensively for fraud detection, risk scoring, and payment routing optimization. Given the financial regulatory requirements in India (RBI compliance), their ML CI/CD pipeline includes mandatory fairness checks, audit logging of all model deployments, and champion-challenger testing before any model touches live transaction flows. Models are deployed via canary releases to limit exposure during rollout.
Automated CI/CD with strict quality gates reduced fraudulent transaction pass-through rates while maintaining compliance with RBI guidelines. The audit trail from their pipeline satisfies regulatory requirements for model explainability and deployment traceability.
Airbnb's Bighead ML platform standardizes the ML lifecycle from feature engineering to deployment. The platform includes an ML Automator that uses Airflow for orchestrating retraining pipelines and DeepThought for online model serving. Automated retraining ensures their pricing model stays current with market dynamics, and all model deployments go through automated validation gates.
Bighead reduced the time from ML project ideation to production deployment from weeks/months to days/weeks, enabling more teams across Airbnb to deploy ML models safely and independently.
Mozilla built an ML-powered bug triage system that automatically classifies and assigns new Firefox bug reports to the correct engineering team. With thousands of new bugs filed monthly across dozens of components, manual triage was a bottleneck. The system uses gradient-boosted decision trees trained on features extracted from bug report text, component history, and reporter metadata (2019).
The automated triage system correctly assigns 85%+ of new bugs to the right component, significantly reducing the manual triage burden. This freed up engineering time previously spent on bug routing and reduced the time-to-first-response for critical issues.
Tooling & Ecosystem
General-purpose CI/CD platform with native Git integration. Free tier offers 2,000 minutes/month for public repos. Supports self-hosted runners for GPU workloads. The ecosystem includes CML and DVC actions for ML-specific workflows. Most accessible entry point for ML CI/CD.
Open-source library by Iterative.ai that brings ML-specific CI/CD capabilities to GitHub Actions and GitLab CI. Generates rich PR reports with metrics comparisons, plots, and model performance summaries. Supports cloud runner provisioning (AWS, GCP, Azure) for GPU training jobs directly from CI.
Open-source tool for versioning data and ML pipelines. Defines reproducible pipeline stages in dvc.yaml and tracks data/model artifacts in remote storage (S3, GCS, Azure Blob). The dvc repro command in CI ensures only changed stages re-run, saving compute. Essential companion to CML for ML CI/CD.
Kubernetes-native ML pipeline orchestrator. Define pipelines as Python code using the KFP SDK, run them on Kubernetes clusters with resource isolation. Supports caching, artifact tracking, and visualization. Best for teams already invested in Kubernetes infrastructure.
Open-source platform for the ML lifecycle: experiment tracking, model registry, and model serving. The Model Registry component provides model versioning, stage transitions (staging -> production), and webhook-based CI/CD integration. Supports environment-based model management for dev/staging/prod separation.
Open-source data validation framework. Define expectations (tests) for your data as code, run them in CI to catch schema violations, distribution drift, and data quality issues before they pollute model training. Provides a dedicated GitHub Action for seamless CI integration.
Open-source MLOps framework that provides a unified API for building portable ML pipelines. Integrates with experiment trackers (W&B, MLflow), orchestrators (Airflow, Kubeflow), and deployment targets. Supports GitHub Actions-based CI/CD workflows and end-to-end lineage tracking.
GitOps continuous delivery tool for Kubernetes. Automatically synchronizes Kubernetes cluster state with Git repository definitions. Used with Seldon Core or KServe to implement GitOps-style ML model deployments where model serving manifests are version-controlled and auto-synced.
Fully managed ML pipeline service on GCP. Supports KFP and TFX pipeline definitions, built-in model evaluation, and integration with Vertex AI Model Registry. Pricing starts at $0.03/run + compute costs. Best for GCP-native teams wanting minimal infrastructure management.
AWS-native ML pipeline service with built-in model registry, A/B testing, and endpoint deployment. Supports condition steps, quality checks, and integration with AWS Step Functions. Pricing is based on pipeline execution time and compute. Popular among Indian enterprises using AWS.
Research & References
Sculley, Holt, Golovin, Davydov, Phillips, et al. (2015)NeurIPS 2015
The seminal paper arguing that ML systems accumulate technical debt at an alarming rate because the ML code is a tiny fraction of the total system. Configuration, data pipelines, and serving infrastructure dominate. Motivated the entire MLOps movement and CI/CD for ML.
Kreuzberger, Kuhl, Hirschl (2023)IEEE Access
Comprehensive academic definition of MLOps covering principles, components, roles, and architecture. Provides a unified framework for understanding CI/CD, CT, and CM (continuous monitoring) in ML systems.
Testi, Farias, Silva (2022)arXiv preprint
Detailed analysis of CI/CD practices specific to ML model deployment, covering pipeline architecture, testing strategies, and automation patterns for MLOps workflows.
Tamburri, et al. (2024)arXiv preprint
Tertiary analysis encompassing 33 reviews and 1,397 primary studies on MLOps. Identifies key challenges in CI/CD for ML including reproducibility, testing adequacy, and organizational adoption barriers.
Ruf, Kiening, Manini, et al. (2023)arXiv preprint
Practical guide to enterprise MLOps adoption covering pipeline architecture, CI/CD patterns, model governance, and organizational challenges. Bridges the gap between academic MLOps definitions and industrial practice.
Various (2025)arXiv preprint
Introduces a unified MLOps lifecycle framework incorporating LLMOps. Addresses challenges in integrating large language models into CI/CD pipelines, a growing concern as LLM-based applications proliferate.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a CI/CD pipeline for an ML model that is retrained daily on new data?
- ●
What are the key differences between CI/CD for traditional software and CI/CD for ML systems?
- ●
How do you handle the quality gate -- what metrics would you check before deploying a model?
- ●
Explain the champion-challenger pattern for model deployment. How would you implement it?
- ●
How would you handle a situation where training takes 8 hours but you need fast CI feedback on PRs?
- ●
What is training-serving skew and how do you test for it in CI?
- ●
How would you design CI/CD for a system with 50 different ML models that share a common feature store?
Key Points to Mention
- ●
ML CI/CD has three axes of change (code, data, model) unlike traditional CI/CD which only has one (code). Each axis needs its own validation strategy.
- ●
The quality gate is the most critical component -- it should enforce absolute thresholds (accuracy >= X) AND relative comparisons against the current production model (no regression). Include latency, fairness, and business metrics, not just accuracy.
- ●
Reproducibility requires pinning everything: code version, data version, library versions, random seeds, and hardware. Docker containers with pinned base images are non-negotiable for production ML CI/CD.
- ●
Tiered pipelines solve the velocity-cost tradeoff: fast checks (lint, unit tests, data validation) on every PR, full training only on merge-to-main or scheduled triggers. This keeps PR feedback fast (<10 min) while still doing thorough validation.
- ●
Reference Google's MLOps maturity levels (0: manual, 1: pipeline automation, 2: CI/CD automation) to demonstrate you understand the progression from ad-hoc to fully automated.
- ●
Always discuss deployment strategies (canary, blue-green, shadow) as part of the CD stage, and explain when to use each one. Shadow mode for high-risk models, canary for gradual rollout, blue-green for instant switchover with rollback.
Pitfalls to Avoid
- ●
Describing ML CI/CD as identical to traditional CI/CD -- if you do not mention the data and model validation dimensions, the interviewer will probe deeper and you will look shallow.
- ●
Forgetting about compute costs -- training in CI is expensive. A senior candidate should proactively discuss cost optimization strategies (spot instances, tiered pipelines, caching).
- ●
Ignoring the human element -- not every deployment should be fully automated. Discuss when human-in-the-loop approval is appropriate (high-risk models, regulatory requirements).
- ●
Overlooking monitoring as part of CI/CD -- the feedback loop from production monitoring to retraining triggers is what makes it continuous. Without monitoring, you have a deployment pipeline, not a CI/CD pipeline.
- ●
Not discussing rollback -- if a deployed model regresses in production, how do you roll back? Mention canary auto-rollback, blue-green instant switch, and model version management in the registry.
Senior-Level Expectation
A senior/staff-level candidate should be able to design a complete ML CI/CD system from scratch, covering: pipeline architecture (triggers, stages, gates), tooling choices with justification (not just 'I would use Kubeflow' but 'I would use Kubeflow because we are already on Kubernetes and need resource isolation for multi-tenant training'), cost analysis (compute cost per pipeline run, monthly budget for CI training, spot instance savings), organizational considerations (who owns the pipeline, how data scientists interact with it, approval workflows for different risk levels), and failure mode analysis (what happens when the pipeline breaks at 3 AM, how you debug training-serving skew, how you handle non-reproducible runs). The candidate should also discuss the tradeoff between pipeline maturity and team velocity -- over-engineering CI/CD for a 3-person team is as much of a failure as under-engineering it for a 50-person team. Reference real-world systems (Google TFX, Uber Michelangelo, Netflix Metaflow) to demonstrate breadth.
Summary
An ML CI/CD pipeline is the automated backbone that bridges the gap between experimental model development and reliable production deployment. Unlike traditional software CI/CD, which validates a single axis of change (code), ML CI/CD must validate three axes: code (linting, unit tests), data (schema validation, distribution checks, completeness), and model (performance evaluation, fairness, latency). The quality gate -- which enforces both absolute thresholds and champion-challenger comparisons -- is the critical decision point that prevents regressions from reaching production.
The architecture follows a pattern of progressive confidence: each stage (source validation, data validation, training, evaluation, quality gate, staging, canary/blue-green deployment, monitoring) increases confidence that the change is safe to ship. The feedback loop from production monitoring back to pipeline triggers enables continuous training (CT) -- the ability to automatically retrain and redeploy models when data shifts or performance degrades. This closed loop is what distinguishes a CI/CD pipeline from a one-time deployment script.
Implementation ranges from lightweight setups (GitHub Actions + DVC + CML, costing ~500-5,000+/month) used by large organizations. The right choice depends on team size, model count, retraining frequency, and regulatory requirements. Regardless of the stack, the core principles remain the same: version everything, automate validation, enforce quality gates, deploy progressively, and monitor continuously. Start with the lightest pipeline that catches your most common failure modes, and add complexity only as your scale and risk profile demand it.