Model Registry in Machine Learning
A model registry is the central, versioned repository where trained ML models go to be cataloged, governed, and prepared for production deployment. Think of it as the single source of truth that answers: which model versions exist, which one is currently serving traffic, who approved it, what data was it trained on, and how does it perform across evaluation slices?
In mature ML organizations -- whether it's Google managing thousands of models across Search, Ads, and YouTube, or Flipkart running hundreds of fraud detection and recommendation models during Big Billion Days -- the model registry is the connective tissue between experimentation and production. Without it, teams resort to ad-hoc model storage (shared drives, S3 buckets with inconsistent naming, or worse, Slack messages with model file attachments), leading to reproducibility nightmares and deployment incidents.
The model registry solves three fundamental problems simultaneously: versioning (tracking every model iteration with its lineage), governance (enforcing approval workflows before models reach production), and discoverability (letting any team member find, compare, and understand any model in the organization). As ML systems scale from a handful of models to hundreds or thousands, the registry transforms from a "nice to have" into load-bearing infrastructure that determines whether your MLOps practice is disciplined or chaotic.
Concept Snapshot
- What It Is
- A centralized, versioned catalog that stores trained ML model artifacts alongside their metadata, lineage, evaluation metrics, and lifecycle state to enable governed promotion from development through staging to production.
- Category
- Deployment
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: trained model artifacts (serialized weights, ONNX files, TorchScript), training metadata (hyperparameters, dataset version, code commit), evaluation metrics. Outputs: versioned model packages ready for deployment, model cards, lineage graphs, approval audit trails.
- System Placement
- Sits between model training (upstream) and model serving/deployment (downstream) in the ML pipeline. It is the handoff point where experimental models become production candidates.
- Also Known As
- model store, model catalog, model repository, model management system, ML artifact registry
- Typical Users
- ML Engineers, Data Scientists, MLOps Engineers, ML Platform Engineers, Governance/Compliance Officers
- Prerequisites
- Model training pipelines, Model serialization formats (pickle, ONNX, TorchScript, SavedModel), Basic CI/CD concepts, Experiment tracking fundamentals
- Key Terms
- model versionmodel stagemodel lineagemodel cardmodel artifactstage transitionapproval workflowmodel aliasmodel signatureregistered model
Why This Concept Exists
The Problem: Models as Unmanaged Artifacts
In the early days of production ML, models were treated like any other build artifact -- serialized to a file, uploaded to cloud storage, and referenced by a path in a config file. This works surprisingly well when you have three models and two data scientists. It falls apart catastrophically when you have three hundred models and fifty data scientists.
Here's what goes wrong without a registry: a data scientist trains an improved fraud detection model, uploads it to s3://models/fraud-v2-final-FINAL.pkl, sends the path over Slack, and an ML engineer deploys it on Friday afternoon. Monday morning, the model is flagging 40% of legitimate transactions. Which training run produced this model? What data was it trained on? Who approved the deployment? Nobody knows. There's no audit trail, no rollback path, and no way to reproduce the model. This is not a hypothetical scenario -- it's the lived reality of teams operating without a model registry.
The Regulatory Push
Beyond operational pain, regulatory pressure has made model governance non-negotiable. The EU AI Act, India's proposed Digital India Act, and RBI guidelines for AI in financial services all require organizations to demonstrate traceability and accountability for AI systems. A model registry provides the audit trail that regulators demand: who trained the model, on what data, with what evaluation results, and who approved its deployment.
For Indian fintech companies like Razorpay, PhonePe, and Paytm, where ML models make decisions about fraud scoring, credit underwriting, and transaction routing, the ability to trace any production model back to its training data and approval chain isn't just good engineering -- it's a compliance requirement.
Evolution: From File Systems to First-Class Registries
The evolution followed a predictable path:
-
Phase 1 (2015-2017): Models stored as files in shared storage. Version tracking via filename conventions (
model_v1.pkl,model_v2_johns_fix.pkl). No metadata, no governance. -
Phase 2 (2018-2020): Experiment trackers like MLflow Tracking and Weights & Biases began capturing training metadata. But tracking experiments and managing production model lifecycle were still separate concerns.
-
Phase 3 (2020-2023): Dedicated model registry abstractions emerged -- MLflow Model Registry, SageMaker Model Registry, Vertex AI Model Registry. These unified versioning, staging, and governance into a single system.
-
Phase 4 (2024-present): Registries expanded to handle foundation model management, model cards for responsible AI, and integration with LLMOps workflows. MLflow deprecated the traditional stage-based model lifecycle in favor of more flexible aliases and tags.
Key Insight: A model registry is not an experiment tracker. Experiment tracking records what you tried. A model registry manages what you deploy. The boundary between "research artifact" and "production asset" is exactly where the registry sits.
Core Intuition & Mental Model
The Library Analogy
Imagine a university library. Researchers produce papers (models), and the library doesn't just dump them in a pile -- it catalogs each one with metadata (title, authors, date, abstract, citations), assigns a unique identifier, and organizes them so anyone can find what they need. The library also tracks different editions of the same work and can tell you which edition is currently on the recommended reading list (production) versus which ones are archived.
A model registry does exactly this for ML models. Each "registered model" is like a library entry, and each "model version" is like an edition. The registry tracks which version is currently recommended for use (production), which is being evaluated (staging), and which has been retired (archived).
Why Not Just Use Git?
This is the most common pushback, and it's a fair question. Git is brilliant for versioning code, but models are fundamentally different artifacts. A model's behavior is determined by three things: the code that defines its architecture, the data it was trained on, and the hyperparameters used during training. Git can version the code, but model weights are often hundreds of megabytes to hundreds of gigabytes -- far beyond what Git (even with LFS) handles gracefully.
More importantly, a model's identity isn't just its weights. It includes the training data lineage, evaluation metrics across multiple slices, the environment it was trained in, and its deployment history. A model registry captures all of this as first-class metadata, not as comments in a commit message.
The State Machine Mental Model
The clearest way to think about a model registry is as a state machine for model lifecycle. Each model version transitions through states -- from None (just registered) to Staging (being evaluated) to Production (serving traffic) to Archived (retired). Each transition has a trigger (an approval, an automated test pass, a manual decision), and the registry records who triggered it and when. This state machine is the governance backbone of your entire deployment pipeline.
Technical Foundations
Formal Model
A model registry can be formalized as a tuple where:
- is the set of registered models (logical model names, e.g., "fraud-detector", "recommendation-ranker")
- maps each registered model to its set of version numbers
- is the set of lifecycle stages
- maps each (model, version) pair to its current stage
- maps each (model, version) pair to its metadata record
Metadata Record
Each metadata record contains:
where is the artifact URI (location of serialized model weights), is the set of hyperparameters, is the training data reference (dataset version or hash), is the evaluation metrics dictionary, is the provenance record (experiment ID, run ID, code commit), and is the model card (documentation for responsible AI).
Version Ordering and Promotion
The promotion function defines valid stage transitions. In a typical registry:
where is the minimum evaluation threshold and indicates whether human or automated approval has been granted.
Storage Efficiency
For model families derived via fine-tuning from a common base, storage can be optimized using delta encoding. If model version is fine-tuned from , we store only the parameter delta:
MGit (Hao et al., 2024) demonstrated that this approach reduces storage by up to for lineage graphs of fine-tuned models. This is particularly relevant in the era of foundation models, where the base model may be 70B+ parameters and fine-tuned variants differ by a small fraction of weights.
Internal Architecture
A production model registry is built around four core subsystems: a metadata store that tracks model versions, stages, and lineage; an artifact store that persists serialized model weights and associated files; a governance engine that enforces approval workflows and access controls; and an API layer that exposes registration, querying, and promotion operations to both humans and CI/CD pipelines.
The architecture separates metadata from artifacts for good reason. Metadata (model name, version, metrics, stage, lineage pointers) is small, frequently queried, and benefits from relational storage with indexing. Artifacts (model weights, ONNX files, config files) are large, rarely read (only at deployment time), and benefit from blob storage with content-addressable hashing. Conflating the two would either make metadata queries slow or artifact storage expensive.
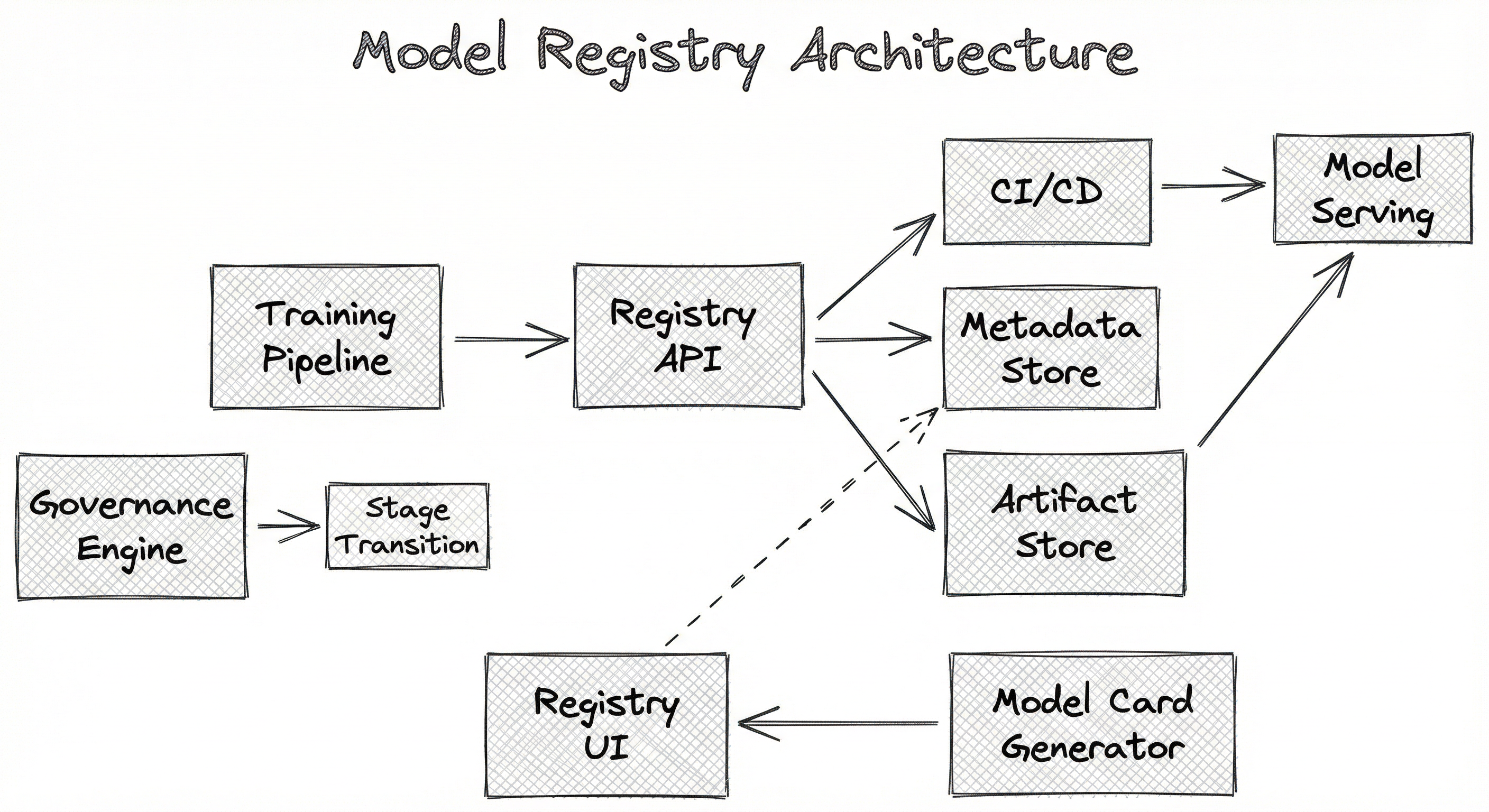
The flow is straightforward: training pipelines register models via the API, which stores metadata and artifacts separately. Users or automated systems query the registry, trigger approvals through the governance engine, and downstream CI/CD pipelines react to stage transitions by fetching artifacts and deploying them to serving infrastructure.
Key Components
Metadata Store
Persists structured metadata for registered models: version numbers, lifecycle stages, tags, aliases, evaluation metrics, hyperparameters, data lineage pointers, and model signatures (input/output schema). Typically backed by a relational database (PostgreSQL, MySQL) or a managed metadata service. Supports efficient querying -- e.g., "find all production models trained on dataset v3.2" or "list all versions of fraud-detector with AUC > 0.95".
Artifact Store
Stores the actual model files -- serialized weights (.pkl, .pt, .onnx, .savedmodel), configuration files, preprocessing pipelines, and any bundled dependencies. Backed by object storage (S3, GCS, Azure Blob) with content-addressable hashing for deduplication. Artifacts are immutable once registered -- you never overwrite a version, you create a new one.
Governance Engine
Enforces lifecycle policies: who can promote a model from staging to production, what automated checks must pass before promotion, and how rollbacks are handled. Implements approval workflows (manual review, automated gate checks), role-based access control (RBAC), and audit logging of all state transitions. In regulated industries (banking, healthcare), this component must produce compliance-ready audit trails.
Model Card Generator
Produces standardized documentation for each model version following the Model Cards framework (Mitchell et al., 2019). Includes intended use cases, evaluation metrics across demographic and data slices, known limitations, ethical considerations, and training data provenance. Can be auto-generated from registry metadata or manually authored and attached.
Lineage Tracker
Records the full provenance chain: which experiment run produced this model, which dataset version was used, which code commit defined the architecture, which base model was fine-tuned (if applicable). Enables forward and backward tracing -- from a production incident, trace back to the training data; from a data quality issue, trace forward to all affected models.
Registry API / CLI
Exposes programmatic access for model registration, version querying, stage transitions, metadata updates, and artifact retrieval. Supports both synchronous operations (register a model, query versions) and event-driven patterns (webhooks triggered on stage transitions for CI/CD integration). Most registries provide both a REST API and language-specific SDKs (Python, Java).
Data Flow
Registration Path: A training pipeline completes a run and calls the registry API to register a new model version. The API validates the model signature, stores the artifact in blob storage (receiving a content-addressed URI), writes metadata (version, metrics, hyperparameters, lineage pointers) to the metadata store, and returns a version identifier.
Promotion Path: A user or automated pipeline requests a stage transition (e.g., staging -> production). The governance engine checks prerequisites: Did the model pass all required evaluation gates? Does the requester have the appropriate RBAC permissions? If checks pass, the metadata store is updated with the new stage, an audit log entry is created, and a webhook fires to notify downstream systems (CI/CD pipelines, model serving infrastructure).
Deployment Path: The model serving system receives a deployment trigger (via webhook or polling), queries the registry for the artifact URI of the production model version, fetches the artifact from blob storage, loads it into the serving runtime, and begins serving predictions. The serving system reports back deployment status to the registry.
Rollback Path: If a production model degrades, an operator triggers a rollback through the registry. The current production version is moved to Archived, the previous production version is promoted back, and the serving system is notified to swap artifacts.
A directed flow diagram showing: Training Pipeline -> Registry API -> (Metadata Store, Artifact Store). Registry UI/CLI queries Metadata Store and triggers the Governance Engine for stage transitions. Governance Engine updates Metadata Store, which triggers CI/CD Pipeline. CI/CD Pipeline deploys to Model Serving, which fetches artifacts from the Artifact Store. A Model Card Generator feeds documentation into the Metadata Store.
How to Implement
Implementation Approaches
There are three main approaches to implementing a model registry, each with different tradeoffs:
Option A: Open-source registry (MLflow, DVC) -- Self-hosted, full control, no licensing cost but significant ops overhead. MLflow Model Registry is the most widely adopted open-source option, with a mature API, UI, and integrations with major ML frameworks. DVC takes a Git-native approach, using Git branches and tags for versioning with model files stored in remote storage.
Option B: Cloud-managed registry (SageMaker Model Registry, Vertex AI Model Registry, Azure ML Model Registry) -- Fully managed, integrated with the cloud provider's ML ecosystem, but creates vendor lock-in. AWS SageMaker Model Registry is particularly strong on approval workflows, supporting multi-environment promotion with human-in-the-loop approvals via EventBridge and Lambda.
Option C: Platform registry (Weights & Biases Registry, Neptune.ai, Comet ML) -- Managed SaaS platforms with rich experiment tracking integration, but introduce a third-party dependency for critical infrastructure. W&B Registry provides particularly strong lineage tracking and model card generation.
For a startup in Bengaluru building their first ML platform, MLflow on a single EC2 instance (or ECS container) is often the best starting point -- it costs around $50-100/month (~INR 4,200-8,400/month) for the infrastructure and provides 90% of what you need. As you scale to 50+ models and need audit-grade governance, migrating to a cloud-managed registry or adding governance tooling on top of MLflow becomes worthwhile.
Cost Comparison: Self-hosted MLflow on AWS (t3.medium + RDS PostgreSQL + S3) runs approximately 150/month (~INR 12,600/month). SageMaker Model Registry is included in SageMaker pricing with no additional charge for the registry itself. W&B Teams starts at 50/user/month (~INR 4,200/user/month). Databricks Managed MLflow is included in the Databricks platform cost, with DBUs billed at $0.07-0.55/DBU depending on tier.
import mlflow
from mlflow.tracking import MlflowClient
# Set tracking URI (local or remote)
mlflow.set_tracking_uri("http://mlflow-server:5000")
client = MlflowClient()
# Step 1: Log a model during training
with mlflow.start_run(run_name="fraud-detector-v3") as run:
# ... training code ...
mlflow.log_params({"learning_rate": 0.001, "epochs": 50, "batch_size": 256})
mlflow.log_metrics({"auc": 0.974, "precision": 0.921, "recall": 0.889})
# Log model with signature and input example
from mlflow.models import infer_signature
signature = infer_signature(X_train, model.predict(X_train))
mlflow.sklearn.log_model(
model,
artifact_path="model",
signature=signature,
input_example=X_train[:5],
registered_model_name="fraud-detector" # Auto-registers
)
# Step 2: Set alias for the new version (MLflow 2.9+ pattern)
model_version = client.get_latest_versions("fraud-detector")[0]
client.set_registered_model_alias(
name="fraud-detector",
alias="staging",
version=model_version.version
)
# Step 3: Add model description and tags
client.update_model_version(
name="fraud-detector",
version=model_version.version,
description="XGBoost fraud detector trained on Jan 2026 transaction data. "
"Improved recall on high-value transactions (>INR 50,000)."
)
client.set_model_version_tag(
name="fraud-detector",
version=model_version.version,
key="validation_status",
value="passed"
)
# Step 4: Promote to production (after validation)
client.set_registered_model_alias(
name="fraud-detector",
alias="production",
version=model_version.version
)
# Step 5: Load model by alias in serving code
production_model = mlflow.pyfunc.load_model("models:/fraud-detector@production")
predictions = production_model.predict(new_transactions_df)This example demonstrates the modern MLflow Model Registry workflow (post-2.9, using aliases instead of deprecated stages). The key pattern is: log the model during training with registered_model_name to auto-register, then use aliases (staging, production) to mark lifecycle state. Loading by alias (models:/fraud-detector@production) ensures your serving code always picks up the right version without hardcoding version numbers. Note the use of infer_signature to capture input/output schema -- this is critical for downstream serving systems to validate inputs.
import boto3
from sagemaker import ModelPackage
from sagemaker.session import Session
sagemaker_client = boto3.client("sagemaker")
session = Session()
# Step 1: Create a Model Package Group (logical model name)
sagemaker_client.create_model_package_group(
ModelPackageGroupName="fraud-detector",
ModelPackageGroupDescription="Fraud detection models for transaction scoring"
)
# Step 2: Register a model version with PendingManualApproval
model_package_input = {
"ModelPackageGroupName": "fraud-detector",
"ModelPackageDescription": "XGBoost v3 - trained on Jan 2026 data",
"ModelApprovalStatus": "PendingManualApproval",
"InferenceSpecification": {
"Containers": [{
"Image": "123456789.dkr.ecr.ap-south-1.amazonaws.com/fraud-model:v3",
"ModelDataUrl": "s3://ml-models-mumbai/fraud-detector/v3/model.tar.gz"
}],
"SupportedContentTypes": ["text/csv", "application/json"],
"SupportedResponseMIMETypes": ["application/json"]
},
"ModelMetrics": {
"ModelQuality": {
"Statistics": {
"ContentType": "application/json",
"S3Uri": "s3://ml-models-mumbai/fraud-detector/v3/metrics.json"
}
}
},
"CustomerMetadataProperties": {
"training_dataset_version": "txn-data-2026-01",
"code_commit": "abc123def",
"trained_by": "[email protected]"
}
}
response = sagemaker_client.create_model_package(**model_package_input)
model_package_arn = response["ModelPackageArn"]
print(f"Registered: {model_package_arn}")
# Step 3: Approve the model (after review)
sagemaker_client.update_model_package(
ModelPackageArn=model_package_arn,
ModelApprovalStatus="Approved",
ApprovalDescription="Reviewed by ML Lead. AUC 0.974 exceeds threshold 0.95. "
"Bias audit passed for all demographic slices."
)
# Step 4: Query for approved models
approved_models = sagemaker_client.list_model_packages(
ModelPackageGroupName="fraud-detector",
ModelApprovalStatus="Approved",
SortBy="CreationTime",
SortOrder="Descending",
MaxResults=5
)
print(f"Latest approved version: {approved_models['ModelPackageSummaryList'][0]}")This demonstrates AWS SageMaker's approval-first model registry pattern. Models are registered with PendingManualApproval status by default, creating a mandatory review gate before deployment. The CustomerMetadataProperties field captures lineage information (dataset version, code commit, author). Note the use of ap-south-1 region (Mumbai) -- for Indian companies, keeping model artifacts in the Mumbai region minimizes latency and satisfies data residency requirements. SageMaker's EventBridge integration can trigger automated deployment pipelines when a model is approved.
import wandb
# Step 1: Log model artifact during training
run = wandb.init(project="fraud-detection", job_type="training")
# Log model as an artifact
model_artifact = wandb.Artifact(
name="fraud-detector",
type="model",
description="XGBoost fraud detector v3",
metadata={
"framework": "xgboost",
"auc": 0.974,
"training_data": "txn-data-2026-01",
"hyperparameters": {
"learning_rate": 0.001,
"max_depth": 8,
"n_estimators": 500
}
}
)
model_artifact.add_file("model.xgb")
model_artifact.add_file("preprocessor.pkl")
run.log_artifact(model_artifact)
run.finish()
# Step 2: Link artifact to the W&B Registry
run = wandb.init(project="fraud-detection", job_type="registry-link")
model_artifact = run.use_artifact("fraud-detector:latest")
run.link_artifact(
artifact=model_artifact,
target_path="ml-team/model-registry/fraud-detector"
)
run.finish()
# Step 3: Consume from registry in deployment pipeline
run = wandb.init(project="fraud-detection", job_type="deployment")
model_artifact = run.use_artifact(
"ml-team/model-registry/fraud-detector:latest"
)
model_dir = model_artifact.download()
print(f"Model downloaded to: {model_dir}")
run.finish()
# Webhook automation (configured in W&B UI):
# When a new version is linked to the registry,
# W&B fires a webhook to your CI/CD endpoint:
# POST https://your-ci-cd.com/deploy
# {
# "event_type": "LINK_ARTIFACT",
# "artifact_name": "fraud-detector",
# "artifact_version": "v3",
# "registry_path": "ml-team/model-registry/fraud-detector"
# }Weights & Biases takes an artifact-centric approach to the model registry. Models are first logged as artifacts during training, then explicitly linked to the W&B Registry for lifecycle management. The webhook automation is particularly powerful -- it enables GitOps-style workflows where linking a model to the registry automatically triggers validation tests, canary deployments, and production rollouts without manual intervention. The metadata dictionary captures everything needed for reproducibility and governance.
import torch
import onnx
import onnxruntime as ort
import mlflow
import numpy as np
# Step 1: Export PyTorch model to ONNX
class FraudDetector(torch.nn.Module):
def __init__(self, input_dim=128):
super().__init__()
self.layers = torch.nn.Sequential(
torch.nn.Linear(input_dim, 256),
torch.nn.ReLU(),
torch.nn.Dropout(0.3),
torch.nn.Linear(256, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
return self.layers(x)
model = FraudDetector(input_dim=128)
# ... training code ...
# Export to ONNX
dummy_input = torch.randn(1, 128)
torch.onnx.export(
model,
dummy_input,
"fraud_detector.onnx",
input_names=["transaction_features"],
output_names=["fraud_probability"],
dynamic_axes={
"transaction_features": {0: "batch_size"},
"fraud_probability": {0: "batch_size"}
},
opset_version=17
)
# Step 2: Validate ONNX model
onnx_model = onnx.load("fraud_detector.onnx")
onnx.checker.check_model(onnx_model)
# Verify inference matches
session = ort.InferenceSession("fraud_detector.onnx")
test_input = np.random.randn(5, 128).astype(np.float32)
onnx_output = session.run(None, {"transaction_features": test_input})
torch_output = model(torch.tensor(test_input)).detach().numpy()
assert np.allclose(onnx_output[0], torch_output, atol=1e-5)
# Step 3: Register ONNX model in MLflow
with mlflow.start_run(run_name="fraud-detector-onnx"):
mlflow.onnx.log_model(
onnx_model=onnx_model,
artifact_path="model",
registered_model_name="fraud-detector-onnx"
)
mlflow.log_params({"opset_version": 17, "framework": "pytorch->onnx"})
mlflow.log_metric("inference_latency_ms", 2.3)ONNX (Open Neural Network Exchange) is the lingua franca for model interoperability. By exporting to ONNX before registering, you decouple the training framework (PyTorch, TensorFlow, scikit-learn) from the serving runtime. This is critical in organizations where the training team uses PyTorch but the serving team runs ONNX Runtime for its superior inference performance. The dynamic_axes parameter ensures the exported model handles variable batch sizes at inference time. Always validate that ONNX output matches the original framework output before registering.
# MLflow Model Registry Configuration (docker-compose.yml)
version: '3.8'
services:
mlflow-server:
image: ghcr.io/mlflow/mlflow:v2.10.0
ports:
- "5000:5000"
environment:
- MLFLOW_BACKEND_STORE_URI=postgresql://mlflow:password@postgres:5432/mlflow
- MLFLOW_DEFAULT_ARTIFACT_ROOT=s3://ml-artifacts-mumbai/mlflow/
- AWS_DEFAULT_REGION=ap-south-1
command: >
mlflow server
--host 0.0.0.0
--port 5000
--backend-store-uri postgresql://mlflow:password@postgres:5432/mlflow
--default-artifact-root s3://ml-artifacts-mumbai/mlflow/
depends_on:
- postgres
postgres:
image: postgres:15
environment:
POSTGRES_DB: mlflow
POSTGRES_USER: mlflow
POSTGRES_PASSWORD: password
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:Common Implementation Mistakes
- ●
Registering models without signatures: Skipping input/output schema capture means downstream serving systems cannot validate inference requests. MLflow's
infer_signaturetakes seconds to add but prevents entire classes of deployment failures. Always define what goes in and what comes out. - ●
Using filenames as version identifiers: Naming models
model_final_v2_fixed.pklinstead of using the registry's built-in versioning. This defeats the purpose of having a registry and makes lineage tracking impossible. Let the registry assign version numbers. - ●
Skipping evaluation metrics during registration: Registering a model without logging its evaluation metrics makes comparison between versions impossible. How can a reviewer approve a model they can't evaluate? Always log at least accuracy/AUC and latency metrics alongside the model.
- ●
One giant registered model for everything: Registering all model types under a single registered model name (e.g., "production-model") instead of creating separate entries per use case ("fraud-detector", "recommendation-ranker", "search-embedder"). This destroys the ability to independently version and promote models.
- ●
Ignoring model size in artifact storage: Registering 50GB foundation models without compression or delta encoding, then wondering why your S3 bill tripled. Use quantized or ONNX-optimized versions for the registry, and keep full-precision checkpoints in a separate training artifact store.
- ●
No rollback plan: Promoting to production without documenting how to rollback. The registry should always maintain a pointer to the previous production version. Test your rollback procedure regularly -- your 3 AM production incident is not the time to learn it.
When Should You Use This?
Use When
Your team manages more than 5 ML models in production and needs a systematic way to track which version is deployed where
Regulatory or compliance requirements demand audit trails for model deployment decisions (financial services, healthcare, government)
Multiple data scientists contribute models and you need a shared catalog with search, comparison, and governance capabilities
You are implementing CI/CD for ML (MLOps) and need a programmatic interface to trigger deployments based on model promotion events
Your organization requires model cards or documentation for responsible AI practices before models can enter production
You operate in a multi-environment setup (dev/staging/production) and need controlled promotion between environments
Models are frequently retrained (daily, weekly) and you need automated registration and evaluation gates to prevent regressions
Avoid When
You have a single model in production managed by one person -- a well-organized S3 bucket with a naming convention may suffice for now. Don't over-engineer the tooling before the problem demands it.
Your ML work is purely research/experimental with no production deployment intent -- an experiment tracker (MLflow Tracking, W&B) without the registry component is sufficient
You are using a fully managed ML API (e.g., OpenAI API, Google Gemini API) where you don't own the model artifacts -- there's nothing to register
Your models are stateless transformations embedded in application code (e.g., simple rule-based scoring) rather than trained artifacts with weights
You are in the earliest prototype phase and deploying models by manually copying files -- get the prototype working first, then add registry infrastructure
Key Tradeoffs
Self-Hosted vs. Managed
| Factor | Self-Hosted (MLflow) | Cloud-Managed (SageMaker) | SaaS Platform (W&B) |
|---|---|---|---|
| Cost (10 users, 50 models) | ~$150/mo (~INR 12,600) | Included in SageMaker | ~$500/mo (~INR 42,000) |
| Ops Overhead | High (backups, upgrades, HA) | None | None |
| Vendor Lock-in | None | High (AWS-specific APIs) | Medium (data export available) |
| Governance Features | Basic (manual) | Strong (EventBridge + Lambda) | Strong (webhooks + RBAC) |
| Customization | Full control | Limited to AWS patterns | Limited to W&B patterns |
Stages vs. Aliases
MLflow's migration from stages (Staging, Production, Archived) to aliases (arbitrary string labels like champion, challenger, shadow) reflects a fundamental tradeoff. Stages are simple and opinionated -- every team uses the same lifecycle. Aliases are flexible but require teams to agree on conventions. For smaller teams, stages provide sufficient structure. For larger organizations with complex deployment patterns (A/B testing, shadow mode, multi-region rollouts), aliases offer the flexibility needed.
Artifact Storage: Co-located vs. Separated
Storing model artifacts alongside metadata (in the registry's database) simplifies architecture but limits scalability. Storing them in external blob storage (S3, GCS) adds a network hop but allows petabyte-scale artifact management and leverages cloud storage's built-in durability (11 nines for S3). The industry has converged on separated storage for any production deployment.
Alternatives & Comparisons
A model serving platform (KServe, BentoML, Seldon Core) handles the deployment and inference side -- loading models, scaling replicas, managing traffic. The registry handles the versioning and governance side. They are complementary: the registry decides which model version should be deployed, and the serving platform decides how to deploy it. Most production systems need both.
Generic CI/CD tools (GitHub Actions, Jenkins, GitLab CI) can version and deploy artifacts, but they lack ML-specific features: model signatures, evaluation metric tracking, stage-based lifecycle management, and lineage to training data. You can build a model registry on top of CI/CD, but you'll end up reimplementing most registry features. Use CI/CD as the automation layer triggered by registry events, not as the registry itself.
Experiment trackers (MLflow Tracking, W&B Experiments) record all training runs, including failed ones. A model registry curates the best runs and manages their lifecycle toward production. Using an experiment tracker as your registry means every team member must sift through hundreds of runs to find the production model. The registry provides the curated, governed layer on top of the experiment tracker.
Pros, Cons & Tradeoffs
Advantages
Single source of truth for which model version is in production, eliminating the 'which model is deployed?' ambiguity that plagues teams without a registry. When someone asks at 3 AM during an incident, the registry has the answer.
Reproducibility by design: every registered model version links back to its training run, dataset version, code commit, and hyperparameters. Reproducing any model from history is a single API call, not a forensic investigation.
Governance and compliance: built-in approval workflows, audit logs, and model cards satisfy regulatory requirements (EU AI Act, RBI AI guidelines) without building custom compliance tooling. The audit trail is automatic, not manual.
Automated deployment pipelines: stage transitions (or alias assignments) can trigger webhooks and CI/CD pipelines, enabling fully automated model deployment with human approval gates where needed. No more manual deployment scripts.
Cross-team discoverability: a searchable catalog lets any team member find, compare, and understand models across the organization. The recommendation team can discover that the search team already trained an embedding model that meets their needs.
Safe rollbacks: since every version is immutable and the previous production version is always available, rolling back a bad deployment is a single API call to reassign the production alias. Recovery time drops from hours to minutes.
Disadvantages
Operational overhead for self-hosted registries: running MLflow or a custom registry requires database management, backup procedures, high-availability configuration, and version upgrades. For a 3-person ML team, this overhead may not be justified initially.
Learning curve and workflow friction: introducing a registry adds steps to the data scientist's workflow (register, tag, document, request approval). Without buy-in, teams will bypass the registry and deploy models directly, defeating its purpose.
Registry-serving integration complexity: connecting the registry to downstream serving infrastructure (KServe, SageMaker Endpoints, custom serving) requires custom glue code. No two organizations have the same deployment target, so this integration is rarely plug-and-play.
Artifact storage costs scale linearly: each model version stores a full copy of model weights. For organizations training daily and keeping 90 days of versions for rollback, storage costs can grow quickly. A 2GB model with 90 versions = 180GB of artifact storage (~$4/month on S3, but much more for larger models).
Schema evolution is painful: if you change the input schema of a registered model (adding or removing features), the registry may not enforce backward compatibility. Downstream consumers that relied on the old schema will break silently unless you implement explicit schema validation.
False sense of governance: having a registry doesn't automatically mean you have good governance. If approval workflows are rubber-stamped, if model cards are template-filled without real analysis, and if evaluation metrics don't cover critical slices, the registry becomes compliance theater rather than genuine safety infrastructure.
Failure Modes & Debugging
Orphaned production model
Cause
A model is deployed to production outside the registry (e.g., a data scientist manually copies weights to the serving system), creating a discrepancy between what the registry says is in production and what is actually serving traffic.
Symptoms
Registry shows model v5 in production, but serving logs show predictions consistent with v3. Rollback attempts via the registry have no effect on actual serving behavior. Incident response teams waste time investigating the wrong model version.
Mitigation
Enforce that the serving system only loads models fetched from the registry by artifact URI. Implement a reconciliation check that periodically compares the serving system's loaded model hash against the registry's production model hash. Alert on mismatches. Restrict direct access to the artifact store.
Approval workflow bypass
Cause
Time pressure during incidents or launches leads teams to promote models directly to production without completing the approval workflow. Once bypassed, the precedent makes it easier to bypass again. Common in fast-moving Indian startups where 'ship fast' culture clashes with governance requirements.
Symptoms
Audit logs show stage transitions without corresponding approval records. Models in production lack model cards or evaluation reports. Post-deployment issues are harder to debug because lineage information is incomplete.
Mitigation
Make the approval workflow the only path to production -- remove the ability to bypass it, even for admins. If emergency deployments are needed, create a fast-track approval path with post-hoc documentation requirements rather than no approval at all. Use RBAC to separate 'can register' from 'can promote to production' permissions.
Registry metadata rot
Cause
Model descriptions, tags, and documentation become stale as models evolve. Initial registration includes detailed metadata, but subsequent versions copy the previous description without updating it. Over time, the registry's metadata diverges from reality.
Symptoms
Model cards reference outdated training data versions. Tags indicate 'experimental' for models that have been in production for months. Description says 'initial prototype' for a model serving 10M requests/day. Teams stop trusting the registry and maintain separate spreadsheets.
Mitigation
Implement metadata freshness checks: require description updates when registering a new version of an existing model. Auto-generate metadata from training run artifacts where possible (dataset version, metrics). Periodically audit registry entries and flag stale metadata. Make metadata quality a team KPI.
Artifact store corruption or unavailability
Cause
The blob storage backend (S3, GCS) experiences an outage, data corruption, or accidental deletion. Since the registry's metadata store and artifact store are separate, the metadata may reference artifacts that no longer exist.
Symptoms
Model deployment fails with 'artifact not found' or checksum mismatch errors. The registry shows valid model versions, but the serving system cannot load them. This is catastrophic during rollback scenarios -- you can't roll back to a version whose artifacts are gone.
Mitigation
Enable versioning and cross-region replication on the artifact store bucket. Implement artifact integrity checks (SHA-256 hash verification) during both registration and retrieval. Maintain at least two copies of production model artifacts in separate availability zones. Test artifact recovery procedures quarterly.
Version explosion and storage bloat
Cause
Automated retraining pipelines register a new model version on every training run (e.g., daily retraining), without any cleanup policy. Over months, the registry accumulates thousands of versions, most of which will never be deployed.
Symptoms
Registry UI becomes sluggish due to thousands of versions per model. Artifact storage costs grow linearly without bound. Searching for relevant versions becomes a needle-in-a-haystack problem. S3 bills spike unexpectedly.
Mitigation
Implement a retention policy: only register model versions that pass a minimum quality threshold. Automatically archive (and eventually delete artifacts for) versions older than a defined retention window (e.g., 90 days for non-production versions). Use tags to distinguish 'candidate' registrations from 'validated' registrations.
Lineage chain breakage
Cause
Upstream data sources or feature pipelines are modified without updating the registry's lineage references. The model's recorded training data version no longer exists or has been overwritten in the data lake.
Symptoms
Attempting to reproduce a model from its registry entry fails because the training data version cannot be resolved. Root cause analysis during incidents is blocked because you cannot trace the model back to its training conditions.
Mitigation
Use immutable, content-addressed references for training data (e.g., DVC hashes, Delta Lake version numbers). Validate lineage references during model registration -- reject registration if the referenced data version cannot be resolved. Integrate the model registry with the data catalog to maintain bidirectional lineage links.
Placement in an ML System
The Handoff Point
The model registry sits at the boundary between the development world (experimentation, training, evaluation) and the production world (serving, monitoring, rollback). It is the formal handoff point where a model transitions from 'something a data scientist built' to 'something the organization operates.'
Upstream, the model registry receives model artifacts from training pipelines (Kubeflow, SageMaker Pipelines, Metaflow) and evaluation results from validation pipelines. The registry does not care how the model was trained -- it accepts any serialized artifact with the required metadata.
Downstream, the registry feeds into model serving infrastructure (KServe, TorchServe, Triton, SageMaker Endpoints) via deployment pipelines. It also connects to canary deployment and blue-green deployment systems that control how traffic is shifted from the old model version to the new one.
Key Insight: The model registry is where organizational trust is established. By the time a model version has a 'production' alias in the registry, it should have passed evaluation gates, received governance approval, and been documented with a model card. The registry doesn't serve predictions -- it serves confidence that the right model is being deployed.
Pipeline Stage
Deployment / Model Management
Upstream
- model-training
- ci-cd-pipeline
Downstream
- model-serving
- canary-deploy
- blue-green-deploy
Scaling Bottlenecks
The primary bottleneck is metadata query latency as the number of registered models and versions grows. A registry with 500 models and 10,000 total versions generates complex queries when filtering by tags, metrics thresholds, or lineage. PostgreSQL-backed registries handle this well up to ~100K versions; beyond that, consider read replicas or caching.
The second bottleneck is artifact transfer throughput during deployment. When a model serving system fetches a 5GB model artifact from S3 during a deployment, the transfer time (10-30 seconds depending on network) adds to deployment latency. For latency-sensitive deployments (canary rollouts that need to complete in under a minute), pre-staging artifacts on the serving nodes or using a CDN for artifact distribution becomes necessary.
The third bottleneck is concurrent registration during automated retraining. If 50 models are retrained simultaneously and all try to register at the same time, the registry's metadata store can become a contention point. Connection pooling and write batching help, but at extreme scale (1000+ concurrent registrations), you may need to shard the metadata store.
Production Case Studies
Uber built Gallery, a model lifecycle management system within its Michelangelo ML platform. Gallery provides model saving, searching, serving, performance monitoring, and orchestration across lifecycle stages. It serves as the centralized registry for all ML models at Uber, enabling teams across ETA prediction, fraud detection, and dynamic pricing to discover, reuse, and deploy models with full lineage tracking.
Gallery manages thousands of models across Uber's platform, enabling the Marketplace Forecasting and Simulation teams to iterate on models with full provenance tracking. The centralized registry reduced model discovery time from days to minutes and eliminated duplicate model training efforts across teams.
Netflix's ML platform includes Runway, a model management system that tracks deployed models, their upstream dependencies (feature pipelines, training data), and downstream consumers (services that use the model's predictions). Runway provides full lineage from data source to production endpoint, enabling impact analysis when any component changes. Combined with Metaflow for workflow orchestration, Netflix manages thousands of ML models across content recommendations, search ranking, and artwork personalization.
Runway enables Netflix to manage over 3,000 ML models, with Metaflow executing hundreds of millions of compute jobs. The centralized model management system ensures that any change to an upstream feature pipeline is automatically flagged to all downstream model owners.
Flipkart operates hundreds of ML models for product recommendations, search ranking, fraud detection, and logistics optimization. During high-traffic events like Big Billion Days (serving 100M+ users), the ability to rapidly roll back models that degrade under load is critical. Flipkart's ML platform uses a registry-based approach to manage model versions, enabling quick switching between model versions when real-time monitoring detects performance degradation. Their fraud detection models, which evaluate millions of transactions per day, require strict governance with audit trails for RBI compliance.
Registry-based model management enables sub-minute rollbacks during peak traffic events, preventing revenue loss from degraded model performance. The governance framework satisfies financial regulatory requirements for AI-driven fraud scoring systems.
Google's Vertex AI Model Registry provides a unified interface for managing AutoML models, custom-trained models, and models imported from external frameworks. The registry integrates with Model Cards (following Google's own Model Cards for Model Reporting framework) to attach responsible AI documentation to every registered model. Vertex AI supports automatic model evaluation, comparison between versions, and deployment to endpoints with traffic splitting for canary releases.
The Vertex AI Model Registry serves as the backbone for thousands of enterprise ML deployments on Google Cloud, with native integration to the entire Vertex AI suite including Pipelines, Endpoints, and Model Monitoring.
Tooling & Ecosystem
The most widely adopted open-source model registry. Provides versioning, aliases (replacing deprecated stages), tags, model signatures, and a UI for model comparison. Integrates with all major ML frameworks (PyTorch, TensorFlow, scikit-learn, XGBoost). Backend can be SQLite (dev) or PostgreSQL/MySQL (production). Free and self-hosted.
SaaS-based registry with deep integration to W&B's experiment tracking platform. Provides artifact versioning, lineage graphs, model cards, webhook automation for CI/CD triggers, and role-based access control. Strong collaboration features for teams. Pricing starts at $50/user/month (~INR 4,200/user/month).
AWS-managed registry with native approval workflows (PendingManualApproval -> Approved -> Rejected), EventBridge integration for event-driven deployments, and model package groups for organizing versions. No additional cost beyond SageMaker usage. Strong governance features for enterprise deployments.
GCP-managed registry supporting AutoML, custom, and imported models. Integrates with Vertex AI Pipelines for automated model evaluation and deployment. Supports model versioning, labeling, and deployment to endpoints with traffic splitting.
Git-native model registry that uses Git branches and tags for versioning, with model files stored in remote storage (S3, GCS, Azure). Follows GitOps principles -- model promotion is a Git tag operation. Ideal for teams that want their model lifecycle managed alongside code in Git.
The de facto registry for transformer and foundation models. Provides Git-based versioning, model cards (README.md with YAML metadata), community features, and direct integration with the transformers library. Hosts 630K+ models. Free for public models; enterprise plans for private repos.
BentoML bundles models with their serving logic into 'Bentos' -- deployable units that include the model, preprocessing code, and API definition. Yatai is BentoML's model registry and deployment platform for Kubernetes. Good for teams that want a tightly coupled registry-to-serving pipeline.
Experiment tracking and model registry platform with strong metadata management. Provides custom fields, comparison dashboards, and integration with CI/CD systems. Particularly good for tracking complex experiment-to-registry workflows with rich metadata.
Research & References
Mitchell, Wu, Zaldivar, Barnes, Vasserman, Hutchinson, Spitzer, Raji, Gebru (2019)FAT* 2019 (Conference on Fairness, Accountability, and Transparency)
Proposed the model card framework -- standardized documentation that accompanies trained models with details on intended use, evaluation across demographic groups, ethical considerations, and limitations. Now a foundational component of model registries worldwide.
Hao, Mendoza, da Silva, Narayanan, Phanishayee (2024)ICML 2024
Introduced MGit, a Git-inspired versioning system for ML models that exploits parameter sharing between fine-tuned model derivatives. Achieves up to 7x storage reduction for lineage graphs through delta encoding of model weights. Particularly relevant for managing foundation model families.
Paleyes, Urma, Lawrence (2022)ACM Computing Surveys
Comprehensive survey of ML deployment challenges across industry, identifying model management and versioning as a critical pain point. Provides taxonomy of deployment challenges including model validation, monitoring, and lifecycle management.
Castano, Serebrenik, Fernandes, Mens (2024)ICSE 2025
Analyzed model integration patterns across thousands of ML-enabled systems on GitHub. Found that model management and versioning practices vary widely, with many systems lacking formal registry infrastructure, leading to reproducibility and maintenance challenges.
Sculley, Holt, Golovin, Davydov, Phillips, Ebner, Chaudhary, Young, Crespo, Dennison (2015)NeurIPS 2015
The foundational paper on ML systems technical debt. Identified configuration management, model staleness, and pipeline dependencies as major debt sources -- all problems that a well-designed model registry directly addresses.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a model registry for an organization with 200+ ML models across 10 teams?
- ●
What metadata should a model registry capture for each model version?
- ●
How do you handle model rollback in production when using a registry?
- ●
Explain the difference between an experiment tracker and a model registry. When do you need both?
- ●
How would you implement an approval workflow for model promotion from staging to production?
- ●
What happens to your model registry when the upstream training data schema changes?
- ●
How do you handle model versioning for A/B testing and canary deployments?
Key Points to Mention
- ●
A model registry is the single source of truth for production models -- it answers 'what is deployed, who approved it, and how to roll back' at any moment. Lead with this purpose, not with tooling names.
- ●
Every registered model version must capture: artifact URI, training data version, hyperparameters, evaluation metrics, model signature (input/output schema), code commit, and approver identity. This is the minimum viable metadata.
- ●
The registry implements a state machine for model lifecycle: None -> Staging -> Production -> Archived, with governance gates at each transition. Modern systems (MLflow 2.9+) use flexible aliases instead of fixed stages.
- ●
Lineage tracking is bidirectional: from a production incident, trace back to training data; from a data quality issue, trace forward to all affected models. This capability is non-negotiable for regulated industries.
- ●
Storage optimization via delta encoding (storing only parameter differences between fine-tuned variants) can reduce storage costs by 5-7x for foundation model families -- mention MGit's approach.
- ●
Model cards (Mitchell et al., 2019) should be a required artifact for every registered model, documenting intended use, evaluation slices, limitations, and ethical considerations.
Pitfalls to Avoid
- ●
Confusing an experiment tracker with a model registry -- they serve different purposes. The tracker records all runs; the registry curates production candidates. Conflating them suggests shallow understanding.
- ●
Suggesting that a shared S3 bucket with naming conventions is an adequate model registry. It lacks metadata querying, governance, lineage, and atomic state transitions. This answer signals 'I haven't operated ML systems at scale.'
- ●
Ignoring the governance and compliance dimension. In interviews for Indian fintech or healthcare companies, demonstrating awareness of regulatory requirements (RBI, DPDP Act) alongside technical architecture shows maturity.
- ●
Describing model versioning without mentioning how to handle rollback. If your registry can promote but can't demote, it's only half-built.
- ●
Forgetting about artifact immutability -- registered model artifacts should never be overwritten. If someone can silently replace the weights behind version v3, your entire audit trail is worthless.
Senior-Level Expectation
A senior or staff-level candidate should discuss the model registry not as an isolated component but as the governance backbone of the entire ML platform. They should cover: multi-tenancy design (how different teams share the registry with access controls), integration with CI/CD (webhooks, event-driven deployment), model card generation automation, storage optimization strategies (delta encoding, retention policies), disaster recovery for the registry itself (what happens when the metadata store goes down), and the organizational change management required to get data scientists to actually use the registry instead of bypassing it. They should also discuss how the registry interfaces with model monitoring -- when monitoring detects drift, does the system automatically trigger retraining and registration of a new version? This closed-loop thinking separates platform engineers from tool operators. Bonus points for discussing cost modeling: at 1,000 model versions averaging 2GB each, what does artifact storage cost on S3 (40/month), and how do retention policies bring that down?
Summary
The model registry is the governance backbone of production ML systems -- a centralized, versioned catalog that manages the full lifecycle of trained models from registration through staging, production deployment, and eventual archival. It solves three critical problems that every scaling ML organization faces: versioning (tracking every model iteration with full provenance), governance (enforcing approval workflows and audit trails before models reach production), and discoverability (enabling any team member to find, compare, and understand any model in the organization).
At its core, a model registry implements a state machine for model lifecycle, with metadata storage, artifact storage, and a governance engine as its primary subsystems. The architecture separates lightweight metadata (version numbers, metrics, lineage pointers) from heavyweight artifacts (model weights, config files) for efficient querying and scalable storage. Tools range from open-source self-hosted options like MLflow and DVC (starting at ~INR 5,700/month for infrastructure) to cloud-managed solutions like SageMaker Model Registry and Vertex AI Model Registry, to SaaS platforms like Weights & Biases and Neptune.ai.
The model registry is not a luxury or a nice-to-have -- it is the formal boundary between experimentation and production. Without it, organizations accumulate technical debt in the form of untraceable deployments, impossible rollbacks, and compliance gaps. With it, teams gain reproducibility by design, safe rollbacks in minutes, automated deployment pipelines triggered by model promotion events, and the audit trails that regulators increasingly demand. For Indian companies operating under RBI AI guidelines and the upcoming Digital India Act, the governance capabilities of a model registry are not just good engineering -- they are a compliance requirement.