APM in Machine Learning
Application Performance Monitoring (APM) is the discipline of instrumenting, measuring, and analyzing the runtime behavior of software services -- and in the ML world, that includes everything from feature stores to inference endpoints to GPU utilization during batch training.
Why does APM matter specifically for ML systems? Because ML services fail in ways traditional web applications don't. A recommendation endpoint might return HTTP 200 with perfect latency while serving stale embeddings from a corrupted cache. A fraud detection model might silently degrade from 98% precision to 72% because an upstream feature pipeline started producing nulls. APM is your first line of defense against these invisible failures.
Modern APM goes far beyond simple uptime checks. It encompasses distributed tracing (following a single request through dozens of microservices), latency profiling (understanding p50, p95, and p99 response times), resource monitoring (CPU, memory, GPU utilization, network I/O), and dependency mapping (which services call which). For ML systems, you add layers like inference latency breakdowns (preprocessing vs. model forward pass vs. postprocessing), GPU memory profiling, batch queue depths, and model version tracking.
From Razorpay tracing payment fraud detection pipelines across hundreds of microservices to Uber using Jaeger to trace ride-matching ML models across global data centers -- APM is the connective tissue that makes complex ML systems operable. Without it, you're flying blind in production.
Concept Snapshot
- What It Is
- A monitoring discipline that instruments, collects, and analyzes performance telemetry (traces, metrics, and profiling data) from application services to diagnose latency, errors, and resource bottlenecks in real time.
- Category
- Monitoring
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: instrumented application code emitting spans, metrics, and logs. Outputs: service maps, latency distributions (p50/p95/p99), error rate dashboards, flame graphs, and automated alerts.
- System Placement
- Sits as an observability layer alongside (not inline with) the ML serving pipeline, collecting telemetry from model-serving, feature-store, and preprocessing services.
- Also Known As
- application performance management, distributed tracing, service observability, request tracing, performance profiling
- Typical Users
- ML Engineers, SRE / Platform Engineers, DevOps Engineers, Backend Engineers, Infrastructure Engineers
- Prerequisites
- HTTP and gRPC fundamentals, Microservices architecture basics, Basic statistics (percentiles, distributions), Container orchestration (Kubernetes)
- Key Terms
- spantracetrace context propagationOpenTelemetryp50/p95/p99 latencyflame graphservice mapSLI/SLO/SLADCGMtail latency
Why This Concept Exists
The Observability Crisis in ML Systems
Traditional web applications have a relatively straightforward failure model: either the server responds or it doesn't. You check HTTP status codes, measure response times, and you're mostly covered. ML systems shatter this simplicity.
Consider a typical ML inference pipeline: a request hits an API gateway, gets routed to a preprocessing service that fetches features from a feature store, passes through an embedding model, hits a vector store for retrieval, feeds results to a re-ranker, and finally returns a response. That's six services minimum. When p99 latency spikes from 200ms to 2 seconds, where is the bottleneck? Without distributed tracing, you're reduced to guessing.
The Evolution from Logs to Observability
The journey started with logs -- plain text files dumped to disk. Teams would SSH into servers and grep through log files when something went wrong. This worked for monoliths but collapsed spectacularly when organizations moved to microservices.
Google's Dapper paper (Sigelman et al., 2010) introduced the foundational concept of distributed tracing -- assigning a unique trace ID to each request and propagating it across service boundaries. This single idea transformed observability. Twitter open-sourced Zipkin in 2012 based on Dapper's principles. Uber built and open-sourced Jaeger in 2016. By 2019, the OpenTelemetry project merged OpenTracing and OpenCensus into a vendor-neutral standard that now dominates the industry.
Why ML Systems Need Specialized APM
Standard APM tools were built for request-response web services. ML systems introduce unique challenges:
- GPU resource monitoring: Traditional APM doesn't understand GPU utilization, VRAM allocation, or CUDA kernel execution times. You need specialized exporters like NVIDIA DCGM.
- Model version correlation: When latency changes, was it the new model deployment or an infrastructure issue? APM must track model versions as first-class metadata.
- Batch vs. real-time asymmetry: Training jobs run for hours on GPUs. Inference requests complete in milliseconds. The same APM system must handle both time scales.
- Silent quality degradation: A model returning wrong predictions at low latency looks perfectly healthy to standard APM. You need ML-specific signals (prediction distributions, feature drift scores) alongside infrastructure metrics.
Key Insight: APM for ML systems is not just "regular APM plus a GPU dashboard." It requires fundamentally rethinking what "healthy" means -- a fast, available service that returns garbage predictions is worse than a slow service that returns correct ones.
Core Intuition & Mental Model
The Three Pillars Mental Model
Think of APM as providing three complementary lenses into your system:
- Metrics tell you what is happening: request rate is 5,000 QPS, p99 latency is 180ms, GPU utilization is 73%. Metrics are cheap, aggregated, and great for dashboards and alerts.
- Traces tell you where it's happening: this specific request spent 12ms in preprocessing, 45ms waiting for the feature store, 80ms in model inference, and 15ms in postprocessing. Traces are per-request and expensive at scale.
- Profiles tell you why it's happening: 60% of inference time is spent in the attention layer, memory allocation is the bottleneck in the preprocessing service. Profiles are deep but heavyweight.
No single pillar is sufficient. Metrics without traces give you averages that hide outliers. Traces without metrics give you anecdotes without trends. Profiles without traces give you local optimization without understanding the system.
The Restaurant Analogy
Imagine you run a large restaurant (your ML system). Metrics are like knowing your average wait time is 15 minutes and you served 200 customers today. Traces are like following a single customer's journey: they waited 5 minutes for a table, 10 minutes for their order to be taken, the kitchen took 20 minutes, and food was served in 2 minutes. Profiles are like watching the kitchen chef and seeing that 70% of their time is spent chopping vegetables because the knives are dull.
A Swiggy delivery partner experiencing a slow order routing can be traced through the recommendation model, the restaurant matching service, and the delivery optimization engine -- each span in the trace revealing exactly where time was spent.
Expert Note: In practice, you'll use metrics for alerting ("something is wrong"), traces for diagnosis ("here's where it's wrong"), and profiles for optimization ("here's why it's slow"). Build your APM strategy around this workflow, not around a single tool.
Technical Foundations
Formalizing Latency Measurement
APM systems fundamentally measure latency distributions. Let be the random variable representing request latency. The percentile function gives the value below which of observations fall:
where is the cumulative distribution function.
In practice, we care about three percentiles:
- p50 (median): The "typical" request. Half are faster, half are slower.
- p95: The experience of your worst 5% of users.
- p99: The experience of your worst 1% of users -- the tail latency that drives SLA violations.
Why Tail Latency Matters Disproportionately
For a system making sequential service calls, the probability that at least one call hits the p99 tail is:
For services (common in ML pipelines): -- roughly 10% of end-to-end requests will experience at least one tail-latency hop. For : -- nearly 40% of requests. This is why Jeff Dean famously said "the tail at scale" is the dominant challenge.
Apdex Score
The Application Performance Index (Apdex) provides a normalized satisfaction score:
where = satisfied requests (latency threshold ), = tolerating requests ( latency ), and = total requests. An Apdex of 0.94+ is considered "excellent," while below 0.50 is "unacceptable."
SLI, SLO, and SLA
APM enables the formal definition of service reliability:
- Service Level Indicator (SLI): A quantitative measure, e.g., "proportion of requests completed in under 200ms."
- Service Level Objective (SLO): A target for the SLI, e.g., "99.9% of requests under 200ms over a 30-day window."
- Service Level Agreement (SLA): A contractual commitment with consequences, e.g., "if uptime drops below 99.95%, customer receives credits."
The error budget is:
For a 99.9% SLO over 30 days: minutes of allowed downtime per month.
Internal Architecture
A production APM system for ML services consists of four layers: an instrumentation layer embedded in application code, a collection layer that aggregates and ships telemetry, a storage and processing layer that indexes traces and computes metrics, and a visualization and alerting layer that surfaces insights to engineers.
The architecture follows a push model: instrumented services emit telemetry to a collector (typically the OpenTelemetry Collector), which batches, processes, and exports data to one or more backends. This decouples instrumentation from storage, allowing you to switch backends (e.g., from Jaeger to Grafana Tempo) without changing application code.
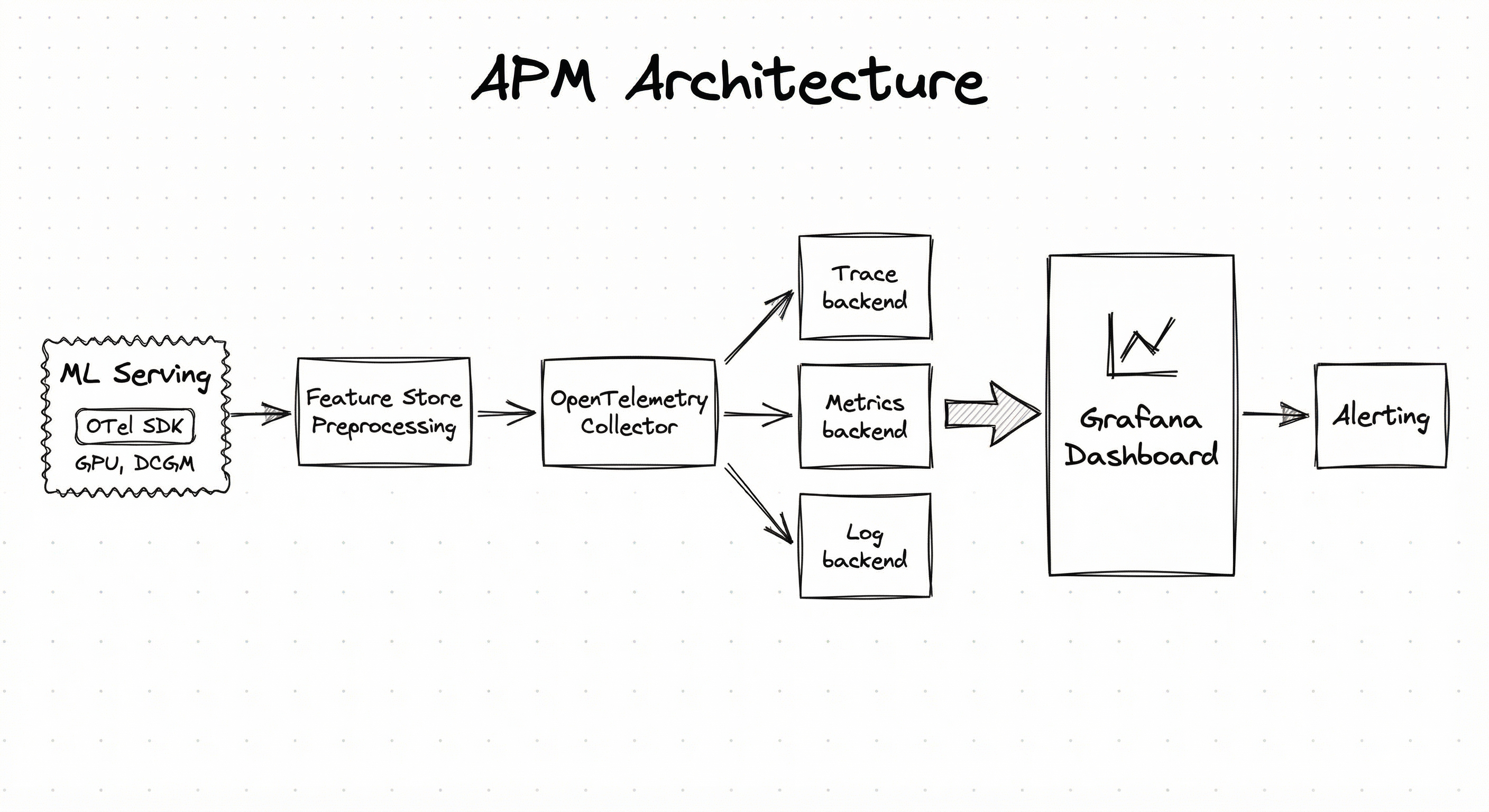
For ML-specific monitoring, the architecture extends with NVIDIA DCGM Exporter for GPU telemetry, custom span attributes for model version and batch size metadata, and continuous profiling agents (like Pyroscope or Datadog Continuous Profiler) that capture flame graphs without manual instrumentation.
Key Components
Instrumentation Layer (OTel SDK)
Embeds in application code to create spans (units of work with start time, duration, and metadata), record metrics (counters, histograms, gauges), and attach context (trace ID, span ID, baggage) that propagates across service boundaries via HTTP headers or gRPC metadata.
OpenTelemetry Collector
A vendor-neutral telemetry pipeline that receives data from instrumented services via OTLP (OpenTelemetry Protocol), applies processors (batching, sampling, attribute enrichment), and exports to one or more backends. Runs as a sidecar or daemonset in Kubernetes.
Trace Backend (Jaeger / Grafana Tempo)
Stores and indexes distributed traces. Provides query APIs for searching traces by service name, operation, duration, tags, and trace ID. Supports trace comparison and critical path analysis.
Metrics Backend (Prometheus / Mimir)
Collects and stores time-series metrics using a pull (Prometheus) or push (OTLP) model. Supports PromQL for querying, alerting rules, and recording rules for pre-aggregation. Grafana Mimir provides long-term storage and horizontal scaling.
GPU Telemetry Exporter (NVIDIA DCGM)
NVIDIA Data Center GPU Manager exports GPU metrics (utilization, memory usage, temperature, power draw, ECC errors, SM clock frequency) in Prometheus format. Essential for monitoring ML inference and training workloads on GPU nodes.
Continuous Profiler
Captures stack-level profiling data (CPU, memory, wall-clock time) continuously with low overhead (~2-5%). Enables engineers to correlate hot code paths with specific traces and identify the why behind latency spikes.
Visualization and Alerting Layer
Grafana dashboards, Datadog APM views, or New Relic interfaces that render service maps, latency heatmaps, error rate charts, and GPU utilization graphs. Alerting integrations with PagerDuty, OpsGenie, and Slack notify on-call engineers when SLOs are breached.
Data Flow
Trace Propagation Path: When a request enters the ML serving gateway, the OTel SDK generates a trace ID and root span. As the request moves to the preprocessing service, the trace context is propagated via W3C Traceparent headers. Each downstream service (feature store, model inference, postprocessing) creates child spans under the same trace ID. GPU execution time is captured as a span attribute on the inference span.
Metrics Path: Each service emits metrics (request count, latency histogram, error count) to the OTel Collector, which batches and exports them to Prometheus or a remote-write compatible backend every 15-60 seconds. DCGM Exporter runs as a daemonset on GPU nodes and exposes GPU metrics on port 9400, which the OTel Collector scrapes.
Alert Path: Alerting rules in Prometheus or the APM backend evaluate conditions (e.g., p99_latency > 500ms for 5 minutes) and fire alerts to PagerDuty or Slack via webhooks. Critical alerts page the on-call engineer; warnings create tickets.
A layered architecture showing ML services (serving, feature store, preprocessing) instrumented with OTel SDKs, plus a GPU node with DCGM Exporter, all feeding into a central OpenTelemetry Collector. The collector fans out to three backends: a trace store (Jaeger/Tempo), a metrics store (Prometheus/Mimir), and a log store (Loki/Elasticsearch). All three backends feed into a unified dashboard (Grafana/Datadog) which connects to an alerting system (PagerDuty/Slack).
How to Implement
Two Implementation Philosophies
You can approach APM for ML systems in two ways:
Philosophy A: Vendor-managed APM (Datadog, New Relic, Dynatrace) -- you install an agent, configure auto-instrumentation, and get dashboards, traces, and alerts out of the box. This is the fastest path to value but comes with significant cost at scale. Datadog APM pricing starts at ~40-75/host/month (~INR 3,350-6,300/host/month) with full-suite features. For a team running 50 hosts, that's $1,550-3,750/month (~INR 1.3-3.15 lakh/month).
Philosophy B: Open-source stack (OpenTelemetry + Prometheus + Grafana Tempo + Grafana) -- you own the entire stack. Initial setup is more involved (2-4 weeks for a small team), but ongoing costs are limited to infrastructure. An Indian startup like SigNoz (YC W21, based in Bengaluru) offers an open-source, OpenTelemetry-native alternative to Datadog that can be self-hosted or used as a managed service with data residency in India.
For ML-specific monitoring, both approaches require additional instrumentation: custom span attributes for model version, batch size, and feature counts; NVIDIA DCGM integration for GPU metrics; and application-level metrics for prediction distributions and feature statistics.
Cost Note for Indian Teams: Datadog's Enterprise plan for a 20-host ML platform costs approximately 3,000-5,000/year (~INR 2.5-4.2 lakh/year) in cloud costs, but requires 0.5-1 FTE of operational investment.
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.resources import Resource
from opentelemetry.semconv.resource import ResourceAttributes
import time
import numpy as np
# Configure the tracer
resource = Resource.create({
ResourceAttributes.SERVICE_NAME: "ml-inference-service",
ResourceAttributes.SERVICE_VERSION: "1.4.2",
"ml.model.name": "fraud-detector-v3",
"ml.model.version": "3.1.0",
"deployment.environment": "production",
})
provider = TracerProvider(resource=resource)
exporter = OTLPSpanExporter(endpoint="http://otel-collector:4317", insecure=True)
provider.add_span_processor(BatchSpanProcessor(exporter))
trace.set_tracer_provider(provider)
tracer = trace.get_tracer("ml.inference")
def predict(request_data: dict) -> dict:
"""Run inference with full APM instrumentation."""
with tracer.start_as_current_span("inference.predict") as root_span:
root_span.set_attribute("ml.request.batch_size", len(request_data["inputs"]))
root_span.set_attribute("ml.model.name", "fraud-detector-v3")
# Phase 1: Feature preprocessing
with tracer.start_as_current_span("inference.preprocess") as preprocess_span:
start = time.perf_counter()
features = preprocess(request_data["inputs"])
duration_ms = (time.perf_counter() - start) * 1000
preprocess_span.set_attribute("ml.preprocess.duration_ms", duration_ms)
preprocess_span.set_attribute("ml.preprocess.feature_count", features.shape[1])
preprocess_span.set_attribute("ml.preprocess.null_count", int(np.isnan(features).sum()))
# Phase 2: Model forward pass
with tracer.start_as_current_span("inference.forward_pass") as model_span:
start = time.perf_counter()
predictions = model.predict(features)
duration_ms = (time.perf_counter() - start) * 1000
model_span.set_attribute("ml.inference.duration_ms", duration_ms)
model_span.set_attribute("ml.inference.gpu_used", True)
model_span.set_attribute("ml.inference.model_version", "3.1.0")
# Phase 3: Postprocessing and thresholding
with tracer.start_as_current_span("inference.postprocess") as post_span:
start = time.perf_counter()
results = postprocess(predictions, threshold=0.85)
duration_ms = (time.perf_counter() - start) * 1000
post_span.set_attribute("ml.postprocess.duration_ms", duration_ms)
post_span.set_attribute("ml.postprocess.flagged_count", sum(results["flags"]))
root_span.set_attribute("ml.predict.total_duration_ms",
root_span.end_time - root_span.start_time if hasattr(root_span, 'end_time') else 0)
return resultsThis example instruments an ML inference function with OpenTelemetry, creating a parent span for the entire prediction and child spans for each phase (preprocessing, forward pass, postprocessing). Custom attributes like ml.model.version, ml.preprocess.null_count, and ml.postprocess.flagged_count provide ML-specific observability that standard APM auto-instrumentation misses. The trace context propagates automatically to downstream services (feature store, etc.) via W3C Traceparent headers.
from prometheus_client import Histogram, Counter, Gauge, start_http_server
import time
# Define ML-specific metrics
INFERENCE_LATENCY = Histogram(
"ml_inference_latency_seconds",
"Latency of model inference in seconds",
labelnames=["model_name", "model_version", "endpoint"],
buckets=[0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0, 2.5, 5.0, 10.0],
)
PREPROCESS_LATENCY = Histogram(
"ml_preprocess_latency_seconds",
"Latency of feature preprocessing in seconds",
labelnames=["model_name"],
buckets=[0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5],
)
PREDICTION_COUNT = Counter(
"ml_predictions_total",
"Total number of predictions served",
labelnames=["model_name", "model_version", "result_class"],
)
MODEL_LOAD_TIME = Gauge(
"ml_model_load_duration_seconds",
"Time taken to load the model into memory",
labelnames=["model_name", "model_version"],
)
GPU_MEMORY_USED = Gauge(
"ml_gpu_memory_used_bytes",
"GPU memory used by the model",
labelnames=["gpu_id", "model_name"],
)
# Start metrics server on port 8000
start_http_server(8000)
def serve_prediction(request):
model_name = "fraud-detector"
model_version = "v3.1"
# Time preprocessing
with PREPROCESS_LATENCY.labels(model_name=model_name).time():
features = preprocess(request)
# Time inference
with INFERENCE_LATENCY.labels(
model_name=model_name,
model_version=model_version,
endpoint="/predict",
).time():
prediction = model.predict(features)
# Record prediction class
result_class = "fraud" if prediction > 0.85 else "legitimate"
PREDICTION_COUNT.labels(
model_name=model_name,
model_version=model_version,
result_class=result_class,
).inc()
return {"prediction": float(prediction), "class": result_class}This example sets up Prometheus histograms for inference and preprocessing latency with ML-appropriate bucket boundaries (10ms to 10s for inference, 5ms to 500ms for preprocessing). Counters track predictions by class, enabling you to monitor prediction distribution drift. Gauges track model load time and GPU memory -- critical for capacity planning. The histogram buckets are chosen to give meaningful percentile resolution around typical ML inference latencies.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: dcgm-exporter
namespace: monitoring
labels:
app: dcgm-exporter
spec:
selector:
matchLabels:
app: dcgm-exporter
template:
metadata:
labels:
app: dcgm-exporter
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9400"
spec:
nodeSelector:
nvidia.com/gpu.present: "true"
containers:
- name: dcgm-exporter
image: nvcr.io/nvidia/k8s/dcgm-exporter:3.3.8-3.6.0-ubuntu22.04
ports:
- containerPort: 9400
name: metrics
securityContext:
capabilities:
add: ["SYS_ADMIN"]
env:
- name: DCGM_EXPORTER_COLLECTORS
value: "/etc/dcgm-exporter/dcp-metrics-included.csv"
volumeMounts:
- name: dcgm-config
mountPath: /etc/dcgm-exporter
volumes:
- name: dcgm-config
configMap:
name: dcgm-metrics-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: dcgm-metrics-config
namespace: monitoring
data:
dcp-metrics-included.csv: |
DCGM_FI_DEV_GPU_UTIL, gauge, GPU utilization (%)
DCGM_FI_DEV_MEM_COPY_UTIL, gauge, Memory utilization (%)
DCGM_FI_DEV_FB_USED, gauge, Framebuffer memory used (MiB)
DCGM_FI_DEV_FB_FREE, gauge, Framebuffer memory free (MiB)
DCGM_FI_DEV_GPU_TEMP, gauge, GPU temperature (C)
DCGM_FI_DEV_POWER_USAGE, gauge, Power usage (W)
DCGM_FI_DEV_SM_CLOCK, gauge, SM clock frequency (MHz)
DCGM_FI_DEV_MEM_CLOCK, gauge, Memory clock frequency (MHz)
DCGM_FI_DEV_PCIE_TX_THROUGHPUT, counter, PCIe TX throughput (KB/s)
DCGM_FI_DEV_PCIE_RX_THROUGHPUT, counter, PCIe RX throughput (KB/s)This Kubernetes DaemonSet deploys NVIDIA DCGM Exporter on every GPU node in your cluster. It exposes GPU metrics (utilization, memory, temperature, power, PCIe throughput) in Prometheus format on port 9400. The nodeSelector ensures it only runs on nodes with GPUs. The ConfigMap customizes which DCGM metrics to export -- you should include at minimum GPU utilization, memory usage, and temperature for ML workloads. Prometheus or the OTel Collector then scrapes these metrics alongside your application metrics.
# Prometheus alerting rules for ML inference SLOs
groups:
- name: ml_inference_slos
interval: 30s
rules:
# P99 latency SLO: inference must complete within 500ms
- alert: InferenceP99LatencyHigh
expr: |
histogram_quantile(0.99,
sum(rate(ml_inference_latency_seconds_bucket{
model_name="fraud-detector"
}[5m])) by (le, model_version)
) > 0.5
for: 5m
labels:
severity: critical
team: ml-platform
annotations:
summary: "P99 inference latency exceeds 500ms SLO"
description: |
Model {{ $labels.model_version }} p99 latency is
{{ $value | humanizeDuration }}. SLO threshold: 500ms.
Check GPU utilization and model batch size.
runbook_url: "https://wiki.internal/runbooks/ml-latency-slo"
# Error rate SLO: less than 0.1% of predictions should fail
- alert: InferenceErrorRateHigh
expr: |
sum(rate(ml_predictions_total{result_class="error"}[5m]))
/
sum(rate(ml_predictions_total[5m]))
> 0.001
for: 3m
labels:
severity: warning
team: ml-platform
annotations:
summary: "Inference error rate exceeds 0.1% SLO"
description: |
Current error rate: {{ $value | humanizePercentage }}.
Check preprocessing pipeline and model health.
# GPU memory pressure: alert before OOM
- alert: GPUMemoryPressure
expr: |
(DCGM_FI_DEV_FB_USED / (DCGM_FI_DEV_FB_USED + DCGM_FI_DEV_FB_FREE))
> 0.90
for: 2m
labels:
severity: warning
team: infrastructure
annotations:
summary: "GPU memory usage exceeds 90%"
description: |
GPU {{ $labels.gpu }} on node {{ $labels.instance }}
is at {{ $value | humanizePercentage }} memory utilization.
Risk of OOM for inference workloads.
# Error budget burn rate (multi-window)
- alert: SLOErrorBudgetBurnRate
expr: |
(
sum(rate(ml_inference_latency_seconds_count{
model_name="fraud-detector"
}[1h]))
-
sum(rate(ml_inference_latency_seconds_bucket{
model_name="fraud-detector",le="0.5"
}[1h]))
)
/
sum(rate(ml_inference_latency_seconds_count{
model_name="fraud-detector"
}[1h]))
> 14.4 * (1 - 0.999)
for: 5m
labels:
severity: critical
team: ml-platform
annotations:
summary: "SLO error budget burning too fast (14.4x rate)"
description: |
At this burn rate, the monthly error budget will be
exhausted in less than 2 hours. Immediate action required.These Prometheus alerting rules implement SLO-based alerting for an ML inference service. The first rule alerts when p99 latency exceeds the 500ms SLO. The second monitors error rates. The third catches GPU memory pressure before it causes OOM kills. The fourth implements multi-window burn rate alerting from the Google SRE book -- alerting not on absolute thresholds but on the rate at which your error budget is being consumed. This prevents alert fatigue from brief spikes while catching sustained degradation early.
# OpenTelemetry Collector config for ML inference monitoring
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
prometheus:
config:
scrape_configs:
- job_name: 'dcgm-exporter'
scrape_interval: 15s
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app]
regex: dcgm-exporter
action: keep
processors:
batch:
send_batch_size: 1024
timeout: 5s
memory_limiter:
check_interval: 5s
limit_mib: 512
spike_limit_mib: 128
attributes:
actions:
- key: deployment.environment
value: production
action: upsert
tail_sampling:
decision_wait: 10s
policies:
- name: error-traces
type: status_code
status_code:
status_codes: [ERROR]
- name: slow-traces
type: latency
latency:
threshold_ms: 500
- name: probabilistic-sampling
type: probabilistic
probabilistic:
sampling_percentage: 10
exporters:
otlp/tempo:
endpoint: tempo:4317
tls:
insecure: true
prometheusremotewrite:
endpoint: http://mimir:9009/api/v1/push
loki:
endpoint: http://loki:3100/loki/api/v1/push
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, tail_sampling, batch]
exporters: [otlp/tempo]
metrics:
receivers: [otlp, prometheus]
processors: [memory_limiter, batch, attributes]
exporters: [prometheusremotewrite]
logs:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [loki]Common Implementation Mistakes
- ●
Averaging latencies instead of tracking percentiles: Mean latency hides tail behavior. A service with 10ms mean but 5-second p99 looks great on average while 1% of users have terrible experiences. Always instrument with histograms that support percentile computation, not simple averages.
- ●
Over-instrumenting in the hot path: Adding synchronous trace export or heavy attribute computation inside the inference loop can add 5-15ms of overhead per request. Use async/batched exporters (like
BatchSpanProcessor) and keep span attribute computation lightweight. - ●
Ignoring trace context propagation across service boundaries: If the preprocessing service doesn't forward the
traceparentheader to the feature store, you'll get disconnected trace fragments instead of end-to-end visibility. Test propagation explicitly in integration tests. - ●
Setting uniform histogram buckets for all services: ML inference latency (10-500ms) and training job duration (minutes to hours) need completely different bucket distributions. Using default buckets designed for web requests (25ms, 50ms, 100ms, ...) will give you poor resolution for both ML workloads.
- ●
Not correlating model version with performance metrics: When you deploy model v3.2 and p99 latency increases, you need to prove the correlation. Always add
model_nameandmodel_versionas labels or span attributes to every ML metric and trace. - ●
Alerting on symptoms without runbooks: A "p99 latency high" alert without a runbook that says "check GPU utilization, then check batch queue depth, then check feature store latency" forces the on-call engineer to improvise at 3 AM. Every alert must link to a runbook.
When Should You Use This?
Use When
Your ML system spans multiple microservices (preprocessing, feature store, model serving, postprocessing) and you need end-to-end latency visibility across the entire request path
You have production SLAs on inference latency (e.g., p99 under 200ms) that require continuous monitoring and alerting
You're deploying models on GPUs and need to monitor utilization, memory pressure, and thermal throttling to prevent resource waste or OOM failures
You're running A/B tests or canary deployments of new model versions and need to compare performance metrics between versions in real time
Your team is larger than 3-5 engineers and diagnosing production issues requires understanding cross-service dependencies rather than reading a single log file
You need to track error budgets and SLO compliance for ML services as part of organizational reliability commitments
You're operating in a regulated industry (fintech, healthcare) where audit trails of system behavior are required
Avoid When
You have a single monolithic ML service with no microservice dependencies -- simple logging and basic Prometheus metrics are likely sufficient at this stage
Your ML system is offline-only (batch processing, periodic retraining) with no real-time serving requirements -- batch job monitoring tools like Airflow metrics or MLflow are more appropriate
Your team is under 3 engineers and operational overhead of maintaining an APM stack would exceed the value it provides -- consider starting with a managed service like Datadog's free tier
Your inference latency requirements are very relaxed (seconds, not milliseconds) and detailed latency profiling provides minimal value -- focus on correctness monitoring instead
You're in the prototyping phase and the ML system architecture is changing weekly -- invest in APM once the architecture stabilizes, or you'll spend more time updating instrumentation than writing ML code
Key Tradeoffs
The Fundamental Tradeoff: Observability Depth vs. Overhead
Every piece of telemetry you collect has a cost: CPU cycles to instrument, network bandwidth to ship, and storage to retain. A fully instrumented ML inference service with per-request tracing, detailed span attributes, and continuous profiling can add 3-8% latency overhead and significant storage costs (1 TB of traces per month is not unusual for a high-QPS service at $0.10-0.30/GB storage).
Sampling is the primary mechanism to manage this tradeoff. Head-based sampling (decide at ingestion time) is simple but misses interesting traces. Tail-based sampling (decide after the full trace is collected) lets you keep 100% of error and slow traces while sampling 5-10% of normal traffic. This is the recommended approach for ML systems where rare failure modes are the most valuable signals.
Cost Comparison Table
| Approach | Monthly Cost (50 hosts) | Setup Time | Operational Overhead |
|---|---|---|---|
| Datadog APM Suite | $1,550-3,750 (~INR 1.3-3.15L) | 1-2 days | Low (managed) |
| New Relic Full Platform | $1,250-3,000 (~INR 1.05-2.52L) | 1-2 days | Low (managed) |
| SigNoz Cloud (India region) | $500-1,200 (~INR 42K-1.01L) | 2-3 days | Low (managed) |
| Self-hosted LGTM Stack | $200-500 (~INR 16.8K-42K) infra | 2-4 weeks | High (self-managed) |
The Second Axis: Vendor Lock-in vs. Flexibility
Vendor APM tools (Datadog, New Relic) provide excellent UX but create lock-in through proprietary agents, query languages, and dashboard formats. OpenTelemetry-native approaches preserve flexibility -- you can switch backends without re-instrumenting your code. For Indian startups watching runway carefully, starting with OTel + SigNoz or the Grafana stack and migrating to a vendor only if self-management becomes untenable is often the pragmatic path.
Alternatives & Comparisons
A metrics collector focuses on aggregate time-series data (counters, gauges, histograms) without trace-level per-request visibility. Use a standalone metrics collector when you only need dashboards and alerts on aggregate service health. Choose full APM when you need to drill into individual slow requests and trace them across service boundaries.
Logging provides detailed, human-readable event records but lacks the structured parent-child relationships of distributed traces. Logs are essential for debugging application logic errors but poor at diagnosing cross-service latency issues. APM traces are the inverse: excellent for latency analysis but poor at capturing business logic details. Most production systems need both.
Alerting systems are the consumer of APM data, not a replacement. They receive alerts generated by APM tools and route them to on-call engineers. APM tells you what's wrong; alerting tells the right person about it. You always need both -- APM without alerting is a dashboard nobody watches.
Model serving platforms handle the execution of inference. APM provides visibility into that execution. Modern serving platforms like Triton Inference Server and KServe emit OpenTelemetry traces and Prometheus metrics natively, making them instrumentation sources for APM rather than alternatives to it.
Pros, Cons & Tradeoffs
Advantages
End-to-end request visibility across ML pipeline services -- a single trace shows exactly where time is spent across preprocessing, feature retrieval, inference, and postprocessing, eliminating guesswork during incident diagnosis
SLO-based alerting enables proactive reliability management -- error budget burn rate alerts catch degradation hours before users notice, giving teams time to react instead of firefight
GPU-aware monitoring via DCGM integration reveals hardware-level bottlenecks (thermal throttling, memory pressure, PCIe bandwidth saturation) that pure software metrics miss entirely
Model version correlation with performance metrics enables data-driven deployment decisions -- you can quantify whether model v3.2 is 15% slower than v3.1 before it reaches 100% of traffic
OpenTelemetry standardization eliminates vendor lock-in -- instrument once, export to any backend (Datadog, Grafana, SigNoz, custom), and switch providers without changing application code
Tail-based sampling captures 100% of error and slow traces while sampling normal traffic, giving you full visibility into failures without the cost of storing every trace
Disadvantages
Instrumentation overhead adds 3-8% latency in the hot path for fully traced services -- at p99 targets of 50ms, this overhead may be unacceptable without careful optimization
Storage costs scale with traffic: a service handling 10K QPS generates roughly 25-50 GB of trace data per day at 100% sampling; even with 10% sampling, that's 2.5-5 GB/day or 75-150 GB/month of trace storage
Operational complexity of self-hosted stacks (Prometheus, Tempo, Loki, Grafana) requires dedicated SRE attention -- expect 0.5-1 FTE of operational investment for a medium-scale deployment
Alert fatigue from poorly tuned thresholds is a real risk -- teams new to APM often set overly sensitive alerts that fire on normal variance, training engineers to ignore them
Context propagation gaps in heterogeneous systems -- if one service in the chain doesn't propagate trace headers (common with legacy services or third-party APIs), you get broken traces that mislead more than they help
Cardinality explosion from high-cardinality labels (user IDs, request IDs, model input hashes) can crash Prometheus or inflate Datadog bills -- label design requires upfront planning
Failure Modes & Debugging
Trace context propagation failure
Cause
A service in the ML pipeline does not forward the traceparent / tracestate HTTP headers (or gRPC metadata) to downstream services. Common when integrating legacy services, third-party APIs, or message queues without instrumented consumers.
Symptoms
Traces appear fragmented -- you see isolated spans for each service but no end-to-end trace connecting them. Service maps show disconnected nodes. Root cause analysis becomes impossible because you can't follow a request across boundaries.
Mitigation
Enforce trace context propagation in integration tests. Use OTel auto-instrumentation libraries that handle propagation automatically for HTTP/gRPC clients. For message queues (Kafka, RabbitMQ), inject trace context into message headers and extract on the consumer side. Audit propagation gaps monthly by querying for orphan spans.
Cardinality explosion in metrics
Cause
Adding high-cardinality labels to Prometheus metrics -- e.g., user_id, request_id, or input_hash as metric labels. Each unique label combination creates a new time series. With 1M unique users, a single metric becomes 1M time series.
Symptoms
Prometheus OOM kills, drastically increased query latency, Grafana dashboards timing out, Datadog bills spiking unexpectedly (Datadog charges per custom metric). At 10M+ active time series, Prometheus becomes effectively unusable without horizontal scaling (Thanos/Mimir).
Mitigation
Never use unbounded values (user IDs, trace IDs, IP addresses) as metric labels. Use trace span attributes for high-cardinality data instead -- traces are designed for per-request cardinality, metrics are not. Set Prometheus sample_limit per scrape target. Use recording rules to pre-aggregate high-cardinality metrics into lower-cardinality summaries.
Sampling bias hiding failures
Cause
Head-based probabilistic sampling (e.g., sample 5% of traces) uniformly drops 95% of traces, including error traces and slow traces that are the most diagnostically valuable.
Symptoms
Error rates and p99 latencies appear lower than reality in trace-based dashboards. Intermittent bugs that affect 0.1% of traffic become nearly invisible because the sampler discards most instances. The team concludes "we can't reproduce the issue" when traces of the issue were simply not retained.
Mitigation
Switch to tail-based sampling using the OTel Collector's tail_sampling processor. Configure policies that always retain error traces (status_code: ERROR), slow traces (latency > threshold), and traces matching specific attributes (e.g., a particular model version under canary). Sample normal traffic at 5-10%.
Dashboard sprawl and alert fatigue
Cause
Teams create dozens of dashboards without a clear hierarchy or ownership. Alerts are set on raw metrics with static thresholds that don't account for normal variance (time-of-day patterns, weekly seasonality, traffic spikes during sales events).
Symptoms
On-call engineers receive 20-50 alerts per shift, most of which are false positives. They start ignoring alerts, missing real incidents. Dashboards proliferate to the point where nobody knows which one to check during an incident. MTTR increases instead of decreasing.
Mitigation
Implement a dashboard hierarchy: one service overview dashboard (golden signals: traffic, errors, latency, saturation), one detailed dashboard per service, and ad-hoc investigation dashboards as needed. Use SLO-based alerting with multi-window burn rates instead of raw threshold alerts. Review and prune alerts quarterly -- any alert that fires more than once a week without leading to action should be tuned or removed.
GPU metrics blind spot
Cause
DCGM Exporter not deployed on GPU nodes, or OTel Collector not configured to scrape the DCGM endpoint. Common when the ML platform team and the infrastructure team have separate monitoring stacks.
Symptoms
ML inference latency spikes with no visible cause in application metrics. GPU thermal throttling reduces clock speeds by 20-30%, increasing inference latency proportionally, but without GPU temperature metrics this correlation is invisible. GPU OOM kills are attributed to "random crashes" because memory utilization was never tracked.
Mitigation
Deploy DCGM Exporter as a DaemonSet on all GPU nodes (see implementation example above). Include GPU metrics in the same Grafana dashboard as application metrics. Set alerts for GPU temperature > 85C, memory utilization > 90%, and GPU utilization < 10% (idle GPU waste). Correlate GPU metrics with inference latency using Grafana's panel linking.
Clock skew corrupting trace timelines
Cause
Services running on different nodes have unsynchronized clocks (NTP drift). Span timestamps become inconsistent -- a child span may appear to start before its parent span.
Symptoms
Trace timelines in Jaeger or Grafana Tempo show negative durations or parent-child ordering violations. Latency calculations based on span timestamps are incorrect. Automated root cause analysis tools produce nonsensical results.
Mitigation
Ensure NTP (or PTP for sub-millisecond accuracy) is configured on all nodes. In Kubernetes, the kubelet syncs with the node's clock -- ensure node NTP is properly configured. Use monotonic clocks (time.perf_counter() in Python, process.hrtime() in Node.js) for duration measurements within a single process, and wall clocks only for cross-process timestamp correlation.
Placement in an ML System
APM's Position in the ML System
APM operates as a cross-cutting concern rather than a sequential pipeline stage. It doesn't sit before or after model serving in the data flow -- it sits alongside every component, passively collecting telemetry.
In a typical ML system architecture:
- The API gateway is the first instrumentation point -- it creates the root span and sets the trace context.
- Preprocessing services add child spans with feature engineering metadata.
- The feature store adds spans for feature retrieval latency and cache hit/miss rates.
- The model serving layer (TFServing, Triton, vLLM) adds inference-specific spans with model version, batch size, and GPU execution time.
- Postprocessing adds spans for result formatting, business logic application, and response serialization.
APM data feeds into three downstream consumers: alerting systems (PagerDuty, OpsGenie) for real-time incident notification, logging platforms (for trace-correlated log queries), and incident management tools (for post-mortem analysis). The feedback loop is critical: APM data informs capacity planning, which influences infrastructure decisions, which changes the performance characteristics that APM measures.
Key Insight: APM is the "nervous system" of your ML platform. Just as your nervous system doesn't process food or pump blood but monitors everything, APM doesn't serve predictions but watches everything that does.
Pipeline Stage
Monitoring / Observability
Upstream
- model-serving
- feature-store
- api-gateway
Downstream
- alerting
- logging
- incident-management
Scaling Bottlenecks
The primary scaling bottleneck is trace storage. At 10,000 QPS with an average of 8 spans per trace and 2 KB per span, you generate approximately:
At Grafana Tempo's storage cost on S3 (~310/day (~INR 26,000/day) for raw trace storage alone. Tail-based sampling at 10% reduces this to ~$31/day -- a critical optimization.
The second bottleneck is metrics cardinality. Prometheus handles 10-20 million active time series on a single instance. Beyond that, you need horizontal scaling via Thanos, Mimir, or VictoriaMetrics. Each additional time series costs ~1-3 KB of RAM in Prometheus.
The third bottleneck is the OpenTelemetry Collector itself. A single Collector instance can process ~30,000-50,000 spans/second. For high-QPS ML services, deploy the Collector as a horizontally scaled deployment behind a load balancer, or use the Gateway pattern (agent collectors on each node forwarding to a central gateway fleet).
Production Case Studies
Uber built and open-sourced Jaeger, a distributed tracing platform inspired by Google's Dapper paper. Jaeger traces requests across Uber's thousands of microservices, including ML-powered ride matching, ETA prediction, and fraud detection models. The system processes billions of spans per day and uses adaptive sampling to manage volume while retaining diagnostically valuable traces.
Jaeger reduced Uber's mean time to resolution (MTTR) for cross-service latency issues from hours to minutes. It became a CNCF graduated project and is now used by thousands of organizations worldwide. Uber's observability stack (Jaeger + M3 metrics + XYS sampling) handles tracing for services processing millions of requests per second.
Razorpay documented their transition from paid APM tools to an open-source observability stack. With hundreds of microservices processing millions of transactions monthly (including ML-powered fraud detection and risk scoring), they built a distributed tracing infrastructure capable of handling 100K+ spans per second. The team evaluated cost vs. capability tradeoffs critical for an Indian fintech managing growth while watching burn rate.
Razorpay achieved full end-to-end tracing across their payment processing pipeline, including ML fraud detection services. Moving to open-source tools significantly reduced their APM costs while scaling to handle India's growing digital payment volume, which crossed 13 billion UPI transactions per month in 2024.
Netflix built Atlas, a custom in-memory dimensional time-series database for near real-time operational monitoring. Atlas handles millions of time series across Netflix's ML-heavy infrastructure -- from content recommendation models to streaming quality optimization. Netflix also built ML Observability modules for monitoring, logging, and explaining ML model behavior in production.
Atlas processes millions of metrics data points per second with sub-second query latency. Netflix's ML observability framework enabled transparency into payment fraud models, content personalization models, and streaming optimization systems, reducing debugging time for ML-specific issues from days to hours.
Netflix designed a dedicated ML Observability framework with three interconnected modules: logging (capturing model inputs, outputs, and decisions), monitoring (tracking prediction distributions and performance metrics), and explaining (providing interpretability for model decisions). This was applied to their payment fraud detection pipeline and extended to other ML services.
The framework provided real-time visibility into ML model behavior, enabling Netflix to detect data quality issues and model degradation within minutes rather than waiting for downstream business metric changes. The approach has been adopted across multiple ML use cases at Netflix.
Tooling & Ecosystem
The CNCF standard for vendor-neutral instrumentation. Provides SDKs for 11+ languages, auto-instrumentation agents, and the OTel Collector for telemetry processing and routing. The foundational layer for any modern APM strategy -- instrument with OTel, export to any backend.
Enterprise APM platform with auto-instrumentation, distributed tracing, continuous profiling, and Watchdog AI-powered anomaly detection. Native integrations with ML platforms. Pricing: ~$31-75/host/month (~INR 2,600-6,300/host/month).
Open-source, high-scale distributed tracing backend that stores traces in object storage (S3, GCS). Part of the Grafana LGTM stack (Loki, Grafana, Tempo, Mimir). Cost-effective for high-volume tracing with support for TraceQL query language.
CNCF graduated distributed tracing platform originally built at Uber. Supports multiple storage backends (Cassandra, Elasticsearch, Kafka). Excellent for organizations already running Elasticsearch or Cassandra. Native OpenTelemetry compatibility.
The de facto standard for metrics collection in Kubernetes environments. Pull-based model with PromQL query language, built-in alerting (Alertmanager), and extensive ecosystem of exporters. Handles 10-20M active time series per instance.
Open-source, OpenTelemetry-native observability platform built in India (YC W21, Bengaluru). Provides logs, traces, and metrics in a single application using ClickHouse as the storage backend. Self-hosted or managed cloud with India data residency option. A cost-effective Datadog alternative for Indian startups.
Exports NVIDIA GPU metrics (utilization, memory, temperature, power, PCIe throughput, ECC errors) in Prometheus format. Essential for monitoring ML inference and training workloads on GPU nodes. Deploys as a Kubernetes DaemonSet.
Full-stack observability platform with APM, infrastructure monitoring, browser monitoring, and AI-powered insights. Offers a perpetual free tier (100 GB/month data ingest). Good for teams wanting a single vendor with broad coverage.
Enterprise APM with Davis AI for automated root cause analysis and anomaly detection. Automatic topology mapping discovers microservice dependencies. Strong in complex enterprise environments with extensive compliance requirements.
Open-source continuous profiling platform that captures CPU, memory, and wall-clock flame graphs with minimal overhead (~2-5%). Integrates with Grafana for correlating profiles with traces and metrics -- essential for understanding why ML inference is slow, not just that it's slow.
Research & References
Sigelman, Barroso, Burrows, Stephenson, Plakal, Beaver, Jaspan, Shanbhag (2010)Google Technical Report
The foundational paper on distributed tracing. Introduced trace context propagation, span-based trace representation, and adaptive sampling -- concepts that underpin every modern APM system from Jaeger to OpenTelemetry.
Various authors (2025)arXiv preprint
Empirical study of ML monitoring practices through focus group sessions. Catalogs what practitioners actually capture across ML systems and identifies gaps between current tooling and the observability needs of production ML pipelines.
Shankar, Parameswaran, et al. (2022)arXiv preprint
Proposes an end-to-end observability system for ML pipelines with assisted detection, diagnosis, and reaction to ML-related bugs -- addressing the unique challenge that ML systems fail silently through wrong predictions rather than crashing.
Various authors (2025)arXiv preprint
Comprehensive literature review of ML system monitoring approaches, identifying Grafana, Prometheus, Evidently, and MLflow as the most commonly used tools and categorizing monitoring concerns across data, model, and infrastructure layers.
Various authors (2025)arXiv preprint
Describes three design patterns for cloud-native monitoring: Distributed Tracing for request flow visibility, Application Metrics for performance indicators, and Infrastructure Metrics for environment monitoring -- providing a pattern language for APM architecture decisions.
Various authors (2024)arXiv preprint
Introduces a scalable streaming trace sampler using Locality-Sensitive Hashing to project traces into low-dimensional space while preserving similarity -- addressing the critical problem of trace volume management in high-QPS systems.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design an APM system for an ML inference pipeline serving 50,000 QPS across 20 microservices?
- ●
Explain the difference between p50, p95, and p99 latency. Why does p99 matter more than mean latency for user experience?
- ●
How do you monitor GPU utilization and memory for ML model serving in Kubernetes?
- ●
What is the difference between head-based and tail-based trace sampling? When would you choose each?
- ●
How would you set up SLOs for an ML recommendation service? What SLIs would you track?
- ●
Your ML inference p99 latency suddenly doubled after a deployment. Walk me through your debugging process using APM tools.
- ●
How do you prevent cardinality explosion in Prometheus when monitoring ML services with many model versions?
Key Points to Mention
- ●
The three pillars of observability (metrics, traces, profiles) serve different purposes: metrics for alerting, traces for diagnosis, profiles for optimization. No single pillar is sufficient.
- ●
Tail-based sampling is essential for ML systems because head-based sampling uniformly drops traces including the rare error and slow traces that are most diagnostically valuable.
- ●
SLO-based alerting with error budget burn rates (from the Google SRE book) prevents alert fatigue by alerting on the rate of budget consumption rather than raw thresholds -- the same technique Google uses for its ML-powered services.
- ●
GPU monitoring requires NVIDIA DCGM Exporter because standard APM agents have no visibility into GPU utilization, memory, or thermal state. This is a common blind spot in ML platform monitoring.
- ●
Cardinality management is the #1 operational challenge in APM at scale. Use trace attributes (not metric labels) for high-cardinality data like user IDs, request IDs, and model input features.
- ●
OpenTelemetry is the vendor-neutral standard -- always instrument with OTel and export to your backend of choice. This prevents vendor lock-in and reduces migration cost.
Pitfalls to Avoid
- ●
Citing mean latency as a meaningful metric -- means hide tail behavior. Always discuss percentiles (p50, p95, p99) and explain the tail-at-scale problem with the formula for service calls.
- ●
Suggesting logging as a substitute for distributed tracing -- logs capture events, traces capture causal relationships between events across services. They're complementary, not interchangeable.
- ●
Ignoring the cost dimension of APM -- at scale, trace storage and metrics cardinality dominate operational costs. Always discuss sampling strategies and cardinality management.
- ●
Forgetting GPU monitoring when discussing ML system APM -- this immediately signals lack of hands-on ML platform experience.
- ●
Treating APM as a set-and-forget installation rather than an ongoing practice -- instrumentation must evolve with the system, alerts must be tuned regularly, and dashboards must be pruned.
Senior-Level Expectation
A senior/staff-level candidate should articulate a complete APM strategy covering: (1) instrumentation design -- what to trace, what to metric, what to profile, and what to sample, with justification for each choice; (2) SLO definition tied to business impact -- not just "p99 < 200ms" but why 200ms (e.g., because recommendation latency above 200ms reduces click-through rate by 12% based on A/B test data); (3) cost modeling -- expected storage costs for traces and metrics at target QPS, with sampling strategy to stay within budget; (4) organizational process -- on-call rotations, runbook standards, alert review cadence, and incident post-mortem practices; (5) ML-specific considerations -- model version tracking, prediction distribution monitoring, GPU resource optimization, and correlation between infrastructure metrics and model quality metrics. The ability to discuss how Indian-scale systems (Flipkart during Big Billion Days, IRCTC during Tatkal booking, Razorpay during payment festivals) handle traffic spikes from an APM perspective demonstrates real-world depth.
Summary
Wrapping Up: APM for ML Systems
Application Performance Monitoring is the observability backbone that makes complex ML systems operable in production. At its core, APM provides three complementary lenses -- metrics (what is happening), traces (where it is happening), and profiles (why it is happening) -- that together give engineers the visibility needed to diagnose latency issues, prevent SLO violations, and optimize resource utilization.
For ML systems specifically, APM must extend beyond standard web application monitoring to include GPU telemetry (via NVIDIA DCGM), model version correlation (tracking which model served which request), inference phase breakdowns (preprocessing vs. forward pass vs. postprocessing), and prediction distribution monitoring (catching silent quality degradation that HTTP status codes miss). The mathematical foundation revolves around latency percentiles (, , ) and the tail-at-scale problem: with sequential service calls, the probability of hitting at least one tail-latency hop is , which approaches 40% for typical ML pipelines.
The implementation landscape offers a spectrum from fully managed vendors (Datadog at ~$31-75/host/month, New Relic, Dynatrace) to open-source stacks (OpenTelemetry + Prometheus + Grafana Tempo + SigNoz). For Indian teams, SigNoz -- a Bengaluru-based, YC-backed, OpenTelemetry-native alternative -- offers a compelling combination of cost efficiency and data residency compliance. Regardless of which backend you choose, always instrument with OpenTelemetry for vendor neutrality, use tail-based sampling to retain diagnostically valuable traces, implement SLO-based alerting to prevent alert fatigue, and deploy DCGM Exporter on every GPU node. APM is not a one-time setup -- it's an ongoing practice that evolves with your ML system.