Pinecone in Machine Learning
Pinecone is a fully managed vector database purpose-built for similarity search at scale. Founded in 2019 by Dr. Edo Liberty -- former head of Amazon AI Labs at AWS -- Pinecone's entire value proposition is that you should never have to operate a vector database yourself. You send vectors in, you get nearest neighbors out, and everything in between -- indexing, sharding, replication, compaction, failover -- is handled for you.
Why does this matter? Because the operational burden of running a high-availability vector search cluster is non-trivial. Teams at Indian startups like Razorpay or Zerodha building their first RAG-powered features don't want to babysit HNSW graph builds at 3 AM. They want an API that accepts an embedding and returns the top- similar items in under 50 milliseconds. That's exactly what Pinecone delivers.
Pinecone has evolved rapidly since its launch. The original architecture was pod-based -- you provisioned dedicated compute pods (p1 for performance, s1 for storage). In January 2024, Pinecone introduced a serverless architecture that decouples compute from storage, dramatically reducing costs for bursty workloads. By 2025, the second-generation serverless platform became the default for all new customers, with improvements in freshness guarantees, multi-namespace efficiency, and support for agentic AI workloads.
With over 750 million valuation (as of the 2023 Series B led by Andreessen Horowitz), and customers ranging from Gong to Vanguard to Aquant, Pinecone has established itself as the leading managed vector database in the market. Whether that managed convenience is worth the cost premium over self-hosted alternatives like Qdrant or Milvus -- that's the central question this article will help you answer.
Concept Snapshot
- What It Is
- A fully managed, cloud-native vector database service that handles indexing, storage, and retrieval of high-dimensional embedding vectors for similarity search at scale.
- Category
- Vector Databases
- Complexity
- Beginner
- Inputs / Outputs
- Inputs: dense embedding vectors (up to 20,000 dimensions), optional sparse vectors for hybrid search, and metadata key-value pairs. Outputs: ranked list of nearest neighbor vectors with similarity scores and associated metadata.
- System Placement
- Sits between the embedding model (upstream) and the re-ranker, context assembler, or downstream application (downstream) in a RAG, recommendation, or semantic search pipeline.
- Also Known As
- Pinecone DB, Pinecone Vector DB, Pinecone.io
- Typical Users
- ML Engineers, Backend Engineers, Data Scientists, AI Application Developers, Full-Stack Developers building LLM apps
- Prerequisites
- Embeddings and vector representations, Distance metrics (cosine, dot product, Euclidean), Basic REST API concepts, Understanding of RAG pipelines (helpful but not required)
- Key Terms
- serverless indexpod-based indexnamespacemetadata filteringsparse-dense hybrid searchupserttop-k queryrecall@kintegrated inferencePinecone Assistant
Why This Concept Exists
The Gap Between ANN Libraries and Production Systems
Let's rewind to 2018-2019. If you wanted to build a similarity search feature, your options were limited. You could use FAISS (Meta's library) or Annoy (Spotify's library), both excellent at the algorithm level. But these are libraries, not services. You had to handle persistence yourself, build your own API layer, figure out replication and failover, implement metadata filtering from scratch, and manage capacity planning. For a team at a Series A startup in Bengaluru, that's a 3-6 month infrastructure project before you even get to the ML work.
Dr. Edo Liberty recognized this gap while leading Amazon AI Labs. He saw internal teams at AWS spending months building operational wrappers around ANN libraries. The same plumbing was being rebuilt by every team, every company, every time. Pinecone was founded to solve exactly this: provide the operational layer that raw ANN libraries don't, as a managed API.
The LLM Explosion Made It Urgent
Pinecone's timing was impeccable. When GPT-3 launched in 2020, it became clear that large language models needed external knowledge retrieval to be useful in production. The RAG (Retrieval-Augmented Generation) pattern -- embed your documents, store them in a vector database, retrieve relevant chunks at query time, feed them to the LLM -- became the dominant architecture for enterprise AI applications.
Suddenly, every company building an LLM-powered feature needed a vector database. And most of them didn't have the infrastructure expertise to run one. Pinecone's sign-ups surged to 10,000 per day. Companies like HubSpot, Shopify, and Zapier went from free-tier sign-up to production deployment in days, not months.
The Serverless Evolution
The original pod-based architecture had a problem: you paid for provisioned capacity whether you used it or not. A startup running a demo with 10,000 vectors was paying the same monthly fee as if they had 1 million vectors saturating the pod. In January 2024, Pinecone launched serverless indexes that decouple compute from storage using a slab-based architecture backed by distributed object storage (S3/GCS/Azure Blob). You pay only for what you use -- storage per GB, reads per million, writes per million.
This was a strategic masterstroke. It lowered the entry barrier to near-zero (the free Starter plan gives you 2 GB storage and 2M write units/month) while making Pinecone cost-competitive with self-hosted alternatives for small-to-medium workloads. For large-scale deployments, the economics still favor self-hosted options -- but that's a tradeoff, not a dealbreaker.
Key Takeaway: Pinecone exists because the distance between "I have an ANN algorithm" and "I have a production-grade vector search service" is enormous. Pinecone bridges that gap with a managed API that handles all the operational complexity.
Core Intuition & Mental Model
The Managed Database Mental Model
Think of Pinecone the way you think of Amazon RDS vs. self-managed PostgreSQL. PostgreSQL is open-source, extremely capable, and free. But running it in production -- backups, failover, patching, connection pooling, monitoring -- is a full-time job. RDS wraps PostgreSQL in a managed service so you can focus on your queries, not your infrastructure. Pinecone does the same thing for vector search.
You don't configure HNSW parameters. You don't tune ef_construction or nprobe. You don't decide how many shards to create or when to compact the index. Pinecone makes those decisions for you, based on your data and query patterns. This is both the primary strength and the primary limitation -- more on that in the tradeoffs section.
The Three Abstractions You Need to Understand
Pinecone's data model is refreshingly simple:
-
Index: The top-level container. You create an index with a name, dimension, metric (cosine, dotproduct, or Euclidean), and deployment type (serverless or pod-based). Think of it as a database.
-
Namespace: A logical partition within an index. Each namespace is an isolated subset -- queries target exactly one namespace (or the default namespace). Think of it as a schema or table. This is the primary multi-tenancy primitive.
-
Record (Vector): A unique ID, a dense vector, optional sparse vector values, and optional metadata (key-value pairs). Think of it as a row.
That's it. No collections, no segments, no graphs, no partitions to manage. The simplicity is deliberate -- it reduces the cognitive overhead for developers who just want to ship a feature.
What Pinecone Does NOT Give You
Pinecone is opinionated, and that means there are things it intentionally doesn't expose:
- No index type selection: You can't choose between HNSW, IVF, or PQ. Pinecone decides internally.
- No recall tuning knobs: Unlike Qdrant's
hnsw_efor FAISS'snprobe, Pinecone doesn't let you trade recall for latency at query time (though their recall is generally high, around 90%+). - No self-hosting option: Pinecone is cloud-only. If your data residency requirements demand on-premises deployment, Pinecone is off the table.
For many teams, these constraints are features, not bugs. But if you need fine-grained control over index behavior, you'll want to look at Qdrant, Milvus, or Weaviate instead.
Technical Foundations
Mathematical Foundation
At its core, Pinecone implements the -nearest neighbor retrieval problem. Given a corpus of vectors where each (with up to 20,000), a query vector , and a positive integer , Pinecone returns a set with that approximates:
where is the configured distance function.
Supported Distance Metrics
Pinecone supports three distance metrics:
Cosine similarity (most common for text embeddings):
Dot product (required for hybrid sparse-dense search):
Euclidean (L2) distance:
Hybrid Search Scoring
For sparse-dense hybrid search, Pinecone combines dense and sparse similarity scores. The final score for a candidate vector is:
where controls the weighting. At , you get pure semantic search; at , pure keyword search. The sweet spot for most applications is , though Vanguard found this optimal for their financial document retrieval use case.
The sparse vectors use an inverted index structure where each dimension corresponds to a vocabulary term and the value represents term importance (typically from BM25 or SPLADE models). Sparse vectors can have up to 1,000 non-zero values across 4.2 billion possible dimensions.
Complexity Characteristics
Pinecone's internal indexing uses proprietary algorithms that achieved state-of-the-art results in the NeurIPS 2023 BigANN competition, dominating all four tracks (filtered, out-of-distribution, sparse, and streaming search) with up to 2x throughput improvement over the next-best submission.
While exact complexity details are proprietary, the observed query latency profile suggests scaling consistent with graph-based ANN methods, with sub-50ms P50 latency commonly reported at scales of 1-100M vectors.
Internal Architecture
Pinecone's architecture has evolved through two major generations. The pod-based architecture (legacy) provisions dedicated compute nodes. The serverless architecture (current default) decouples compute from storage for elastic scaling.
In the serverless model, client requests flow through an API gateway to either a global control plane (for index management operations like create, delete, configure) or a regional data plane (for data operations like upsert, query, delete vectors). The data plane is where the magic happens.
For each namespace in a serverless index, Pinecone organizes records into immutable files called slabs. These slabs are indexed for optimal query performance and stored in distributed object storage (S3, GCS, or Azure Blob) that provides virtually limitless data scalability. When a query arrives, only the relevant slabs are loaded into compute, scored, and returned. This slab-based design is what enables the pay-per-use pricing model -- you're not paying for idle compute.
The second-generation serverless architecture (rolled out in 2025) added improvements for write freshness (immediately reflecting upserts in queries), better performance for indexes with many small namespaces, and optimizations for agentic AI workloads that issue many small, rapid queries.
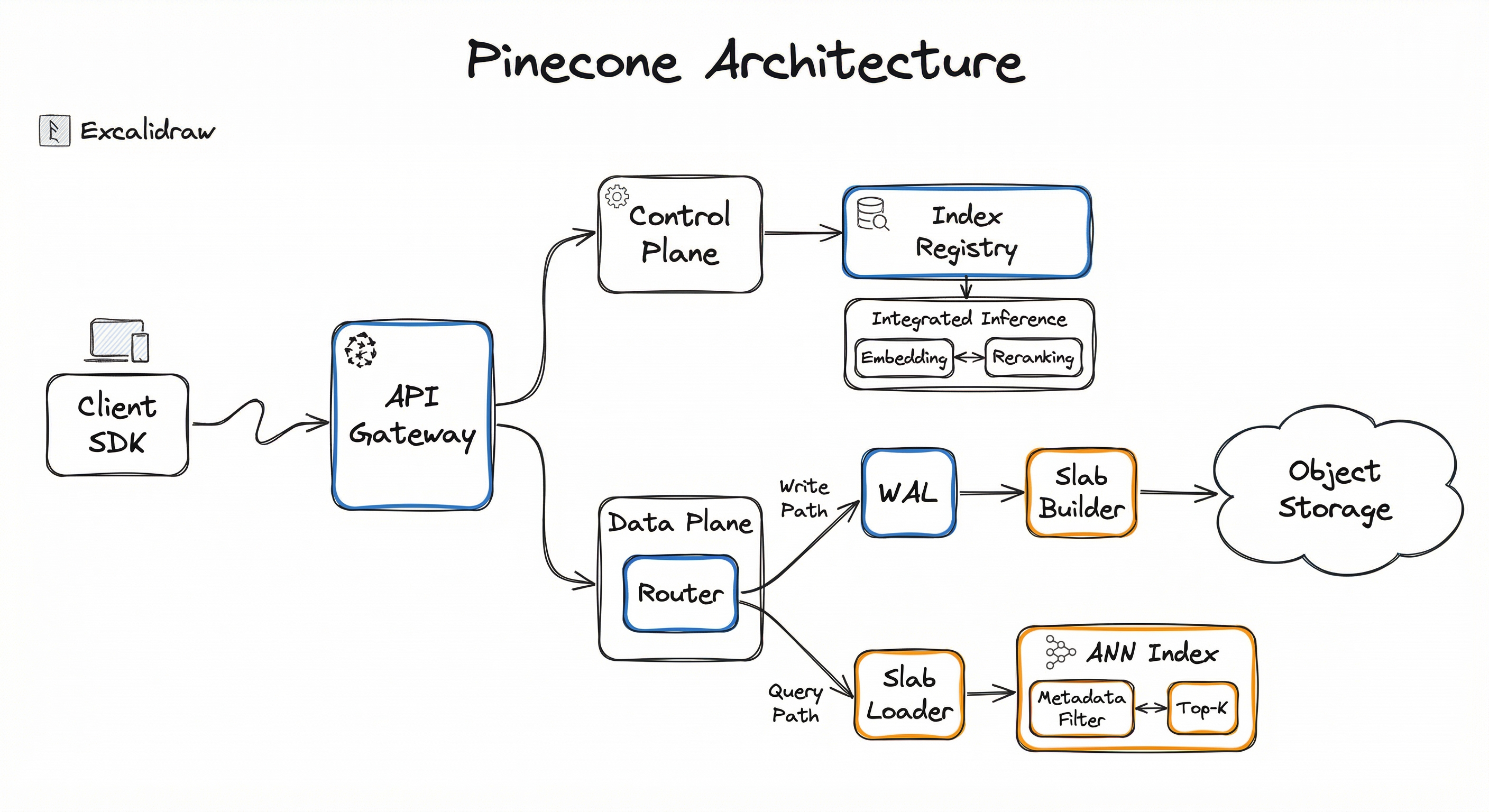
Key Components
API Gateway
The entry point for all client requests. Handles authentication (API key validation), rate limiting, request routing to the appropriate control plane or data plane, and TLS termination. Supports both REST and gRPC protocols.
Global Control Plane
Manages index lifecycle operations: creation, deletion, configuration changes, and backup/restore. Maintains the index registry that maps index names to their physical deployment. Operates globally across all regions.
Regional Data Plane
Handles all data operations (upsert, query, fetch, delete, update) for indexes deployed in a specific region. Contains the router, write path, query path, and ANN index engine. Each data plane is independent for fault isolation.
Slab Storage Layer
The core storage abstraction in serverless indexes. Vectors and metadata are organized into immutable slab files, indexed for efficient retrieval, and persisted to distributed object storage. Slabs are the unit of data loading at query time -- only slabs relevant to a query are loaded into compute.
ANN Index Engine
Pinecone's proprietary approximate nearest neighbor search implementation. Uses algorithms that won all four tracks of the NeurIPS 2023 BigANN competition. Handles both dense and sparse vector search, with a single-stage filtering engine for combined vector + metadata queries.
Metadata Filter Engine
Applies filter predicates on metadata fields alongside vector similarity search. Uses adapted bitmap indices (borrowed from data warehouse technology) for high-cardinality filtering use cases like access control lists. Supports operators: $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $exists, and $and/$or combinators.
Integrated Inference Layer
An optional layer that provides built-in embedding generation and reranking. Supports models like multilingual-e5-large, llama-text-embed-v2, pinecone-sparse-english-v0 for embedding, and pinecone-rerank-v0 and cohere-rerank-v3.5 for reranking. Eliminates the need for separate embedding service infrastructure.
Write-Ahead Log (WAL)
Ensures durability of upsert operations. Writes are first committed to the WAL before being batched into slab files. This guarantees that acknowledged writes survive infrastructure failures.
Data Flow
The client sends an upsert request containing vector IDs, dense values, optional sparse values, and metadata. The API gateway authenticates and routes the request to the regional data plane. The write path commits the data to the WAL, then batches it into slab files and persists them to object storage. In the second-gen serverless architecture, writes are immediately reflected in query results (strong write freshness).
The client sends a query containing a dense vector, optional sparse vector, optional metadata filter, and top_k parameter. The query path loads relevant slabs from object storage (with caching for frequently accessed data), traverses the ANN index, applies metadata filters (single-stage filtering using bitmap indices), scores candidates, and returns the top- results with similarity scores and optionally the stored metadata and vector values.
If using integrated inference, the client can send raw text instead of pre-computed vectors. Pinecone's inference layer generates embeddings using a configured model, then passes them to the standard query path. After initial retrieval, an optional reranking step can refine the results using a cross-encoder model before returning them to the client.
A layered architecture diagram showing: Client SDK connecting to API Gateway, which routes to either Global Control Plane (for index management) or Regional Data Plane (for data operations). The Data Plane contains a Router splitting into Write Path (WAL, Slab Builder, Object Storage) and Query Path (Slab Loader, ANN Index Engine, Metadata Filter Engine, Top-K Scorer). An Integrated Inference layer with Embedding and Reranking models feeds into the data plane.
How to Implement
Getting Started with Pinecone
Pinecone's implementation story is deliberately simple. Install the SDK (pip install pinecone), get an API key from the console, create an index, upsert vectors, query. The entire setup for a basic RAG prototype takes under 30 minutes.
The Python SDK (v7+, released 2025) is the most mature client, but official SDKs exist for Node.js, Go, and Java. All SDKs support both serverless and pod-based indexes, though serverless is the recommended path for all new projects.
There are three main implementation patterns:
Pattern 1: Direct SDK usage -- You compute embeddings yourself (using OpenAI, Sentence Transformers, Cohere, etc.) and upsert the vectors directly. Maximum control, requires managing your own embedding pipeline.
Pattern 2: Integrated inference -- You send raw text to Pinecone and let its built-in models handle embedding and optionally reranking. Simpler architecture, fewer moving parts, but limited to Pinecone's supported models.
Pattern 3: Framework integration -- You use Pinecone as the vector store backend in LangChain, LlamaIndex, or Haystack. The framework handles the orchestration; Pinecone handles the storage and retrieval. This is the most popular pattern for RAG applications.
Cost Note for Indian Teams: Pinecone's Starter plan is free and includes 2 GB storage, 2M write units, and 1M read units per month. The Standard plan starts at 15 in included credits. For comparison, a self-hosted Qdrant instance on a $20/month (~INR 1,680/month) DigitalOcean droplet can handle similar workloads -- but you own the ops burden. For a team of 2-3 engineers at a Bengaluru startup, the ops savings usually justify the Pinecone premium until you hit scale.
from pinecone import (
Pinecone,
ServerlessSpec,
CloudProvider,
AwsRegion,
)
import os
# Initialize client
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
# Create a serverless index
index_config = pc.create_index(
name="product-search",
dimension=1536,
metric="cosine",
spec=ServerlessSpec(
cloud=CloudProvider.AWS,
region=AwsRegion.US_EAST_1,
),
)
# Connect to the index
index = pc.Index(host=index_config.host)
# Upsert vectors with metadata
vectors_to_upsert = [
(
"prod-001",
[0.12, -0.03, 0.88, ...], # 1536-dim embedding
{"category": "electronics", "price": 15999, "brand": "Samsung", "in_stock": True}
),
(
"prod-002",
[0.45, 0.21, -0.67, ...],
{"category": "electronics", "price": 24999, "brand": "Apple", "in_stock": True}
),
]
index.upsert(
vectors=vectors_to_upsert,
namespace="flipkart-catalog"
)
# Check index stats
stats = index.describe_index_stats()
print(f"Total vectors: {stats.total_vector_count}")
print(f"Namespaces: {stats.namespaces}")This example demonstrates the complete lifecycle: creating a serverless index with cosine similarity, connecting to it, and upserting vectors with rich metadata. The namespace parameter (flipkart-catalog) isolates this data -- queries must target the same namespace to find these vectors. Metadata fields like category, price, and in_stock can be used for filtered queries. Note that serverless indexes are the recommended choice for all new projects; pod-based indexes are legacy.
# Query for similar products with price and category filters
query_embedding = [0.15, -0.01, 0.92, ...] # 1536-dim query vector
results = index.query(
vector=query_embedding,
top_k=10,
namespace="flipkart-catalog",
include_metadata=True,
filter={
"$and": [
{"category": {"$eq": "electronics"}},
{"price": {"$lte": 20000}},
{"in_stock": {"$eq": True}}
]
}
)
# Process results
for match in results.matches:
print(f"ID: {match.id}")
print(f" Score: {match.score:.4f}")
print(f" Brand: {match.metadata['brand']}")
print(f" Price: INR {match.metadata['price']}")
print()This shows Pinecone's metadata filtering in action. The query combines vector similarity with structured filters: only electronics under INR 20,000 that are in stock. The $and operator combines multiple conditions. Pinecone uses a single-stage filtering approach (not post-filtering), meaning the filter is applied during the ANN search, not after -- this ensures you always get top_k results that satisfy your filter, avoiding the "filter starvation" problem common with post-filtering approaches.
from pinecone import Pinecone, ServerlessSpec, CloudProvider, AwsRegion
import os
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
# Create index with dotproduct metric (required for hybrid search)
hybrid_index_config = pc.create_index(
name="hybrid-search",
dimension=768,
metric="dotproduct",
spec=ServerlessSpec(
cloud=CloudProvider.AWS,
region=AwsRegion.US_EAST_1,
),
)
hybrid_index = pc.Index(host=hybrid_index_config.host)
# Upsert with both dense and sparse vectors
hybrid_index.upsert(
vectors=[
{
"id": "doc-001",
"values": [0.12, -0.03, 0.88, ...], # Dense embedding (768-dim)
"sparse_values": {
"indices": [102, 3547, 8921, 15003], # Token IDs
"values": [0.8, 0.6, 0.4, 0.2] # Token weights (BM25/SPLADE)
},
"metadata": {"source": "annual_report", "year": 2025}
},
],
namespace="vanguard-docs"
)
# Query with hybrid search
results = hybrid_index.query(
vector=[0.15, -0.01, 0.92, ...], # Dense query embedding
sparse_vector={
"indices": [102, 5678], # Query token IDs
"values": [0.9, 0.7] # Query token weights
},
top_k=10,
namespace="vanguard-docs",
include_metadata=True,
)
print(f"Top result: {results.matches[0].id}, score: {results.matches[0].score:.4f}")Hybrid search combines dense semantic vectors (from models like multilingual-e5-large) with sparse keyword vectors (from BM25 or SPLADE). This is critical for domains with specialized terminology -- financial documents (like Vanguard's use case), legal texts, or medical records -- where exact keyword matches matter alongside semantic similarity. The dotproduct metric is required for hybrid search. Sparse vectors can have up to 1,000 non-zero values across 4.2 billion dimensions.
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_pinecone import PineconeVectorStore
from langchain.chains import RetrievalQA
from langchain.text_splitter import RecursiveCharacterTextSplitter
from pinecone import Pinecone
import os
# Initialize Pinecone
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
index = pc.Index("knowledge-base")
# Initialize embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Create vector store from existing Pinecone index
vectorstore = PineconeVectorStore(
index=index,
embedding=embeddings,
namespace="company-docs",
)
# Ingest documents (one-time setup)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50,
)
chunks = text_splitter.split_documents(documents) # Your loaded documents
vectorstore.add_documents(chunks)
# Build RAG chain
llm = ChatOpenAI(model="gpt-4o", temperature=0)
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(
search_kwargs={"k": 5}
),
)
# Query
response = rag_chain.invoke(
"What is our company's leave policy for employees in India?"
)
print(response["result"])This is the most common production pattern: LangChain orchestrates the pipeline while Pinecone handles vector storage and retrieval. The PineconeVectorStore class from langchain-pinecone wraps the Pinecone index with LangChain's vector store interface. Documents are chunked, embedded via OpenAI, and stored in Pinecone. At query time, the retriever fetches the top-5 similar chunks, which are stuffed into the LLM prompt for answer generation. For Indian companies building internal knowledge bases (HR policies, compliance docs), this is a 2-day implementation.
from pinecone import Pinecone, ServerlessSpec, CloudProvider, AwsRegion
import os
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
# Create index with integrated embedding model
index_config = pc.create_index(
name="docs-with-inference",
dimension=1024,
metric="cosine",
spec=ServerlessSpec(
cloud=CloudProvider.AWS,
region=AwsRegion.US_EAST_1,
),
)
index = pc.Index(host=index_config.host)
# Generate embeddings using Pinecone Inference
embedding_response = pc.inference.embed(
model="multilingual-e5-large",
inputs=["How to set up Aadhaar-based KYC verification"],
parameters={"input_type": "query"}
)
query_vector = embedding_response.data[0].values
# Query with the generated embedding
results = index.query(
vector=query_vector,
top_k=5,
include_metadata=True,
namespace="fintech-docs"
)
# Rerank the results for better precision
rerank_response = pc.inference.rerank(
model="pinecone-rerank-v0",
query="How to set up Aadhaar-based KYC verification",
documents=[
{"text": match.metadata.get("text", "")}
for match in results.matches
],
top_n=3,
)
for result in rerank_response.data:
print(f"Rank {result.index}: score={result.score:.4f}")Pinecone's integrated inference lets you embed text and rerank results without running separate model servers. The multilingual-e5-large model handles embedding (supporting 100+ languages, including Hindi and other Indian languages), and pinecone-rerank-v0 improves search accuracy by up to 60% over initial retrieval on the BEIR benchmark. This eliminates the need for a separate embedding API (saving ~$0.0001 per embedding call to OpenAI) and simplifies the architecture to a single vendor.
# Pinecone serverless index configuration
# (conceptual YAML -- actual configuration is via SDK)
index:
name: production-search
dimension: 1536
metric: cosine
spec:
serverless:
cloud: aws
region: us-east-1
# Metadata schema (implicit -- no pre-declaration needed)
# Supported types: string, number, boolean, list of strings
metadata_fields:
- name: tenant_id
type: string
purpose: multi-tenancy isolation
- name: created_at
type: number
purpose: temporal filtering (Unix timestamp)
- name: category
type: string
purpose: content classification
- name: tags
type: list[string]
purpose: multi-label filtering
# Namespace strategy for multi-tenancy
namespace_strategy:
pattern: one-namespace-per-tenant
naming: "tenant-{tenant_id}"
rationale: >
Namespaces provide hard isolation between tenants.
Queries are scoped to a single namespace, ensuring
zero data leakage. Preferred over metadata filtering
when tenant count is manageable (<10,000).Common Implementation Mistakes
- ●
Using cosine metric for hybrid search: Hybrid sparse-dense search in Pinecone requires the
dotproductmetric. If you create an index withcosineoreuclideanand try to upsert sparse vectors, the operation will fail. Always usedotproductwhen planning hybrid search, even if your dense embeddings were trained with cosine similarity (pre-normalize your vectors if needed). - ●
Treating namespaces like tags: Namespaces are hard partitions, not soft labels. You can only query one namespace at a time. If you need to search across multiple categories simultaneously, use metadata filtering instead. A common anti-pattern is creating namespaces for categories (electronics, clothing) and then realizing you can't do a cross-category search.
- ●
Ignoring the upsert batch size limit: Pinecone's upsert API accepts a maximum of 1,000 vectors per request (for serverless) and 100 vectors per request (recommended for pods). Sending larger batches results in errors or timeouts. Always batch your upserts and use the async client (
PineconeAsyncio) for high-throughput ingestion. - ●
Storing large text payloads in metadata: Pinecone metadata has a size limit (40 KB per vector for serverless indexes). Storing entire document chunks as metadata bloats storage costs and slows queries. Instead, store a reference ID and retrieve the full text from a separate document store (S3, DynamoDB, or PostgreSQL).
- ●
Not normalizing vectors when using dotproduct metric: If your embedding model produces non-normalized vectors and you use
dotproductmetric (required for hybrid search), the magnitude of vectors will affect similarity scores in unexpected ways. Always L2-normalize your dense vectors before upserting when using dotproduct, unless your model already produces normalized outputs. - ●
Forgetting to handle eventual consistency in serverless: While second-gen serverless has improved write freshness, extremely rapid write-then-read patterns may still encounter stale reads in edge cases. For critical workflows, add a brief delay or implement read-after-write verification.
When Should You Use This?
Use When
You want zero operational overhead -- no cluster management, no capacity planning, no patching. Your team's time is better spent on ML features than infrastructure.
You're building a RAG prototype or MVP and need to go from zero to production in days, not weeks. Pinecone's Starter plan (free) lets you validate your idea before committing budget.
Your workload is bursty or unpredictable -- serverless pricing means you pay only for actual reads and writes, not for provisioned capacity sitting idle during off-peak hours.
You need hybrid sparse-dense search in a managed service. Pinecone's single-index hybrid search is simpler than maintaining separate dense and sparse indexes.
Your team lacks dedicated infrastructure/SRE engineers. A 3-person ML team at an Indian startup shouldn't be debugging Kubernetes pod evictions on a Qdrant cluster.
You need multi-tenant data isolation with strong guarantees. Pinecone's namespace model provides clean, per-tenant isolation without complex metadata filter chains.
You want integrated inference (embedding + search + reranking in one API) to minimize the number of services in your architecture.
Your compliance requirements are met by AWS, GCP, or Azure cloud regions. Pinecone offers SOC 2 Type II compliance and supports GDPR-relevant regions.
Avoid When
You need fine-grained control over index parameters (HNSW ef_construction, nprobe, quantization type). Pinecone abstracts these away entirely -- if tuning recall-latency tradeoffs is critical, use Qdrant or Milvus.
Your data must stay on-premises or in a private cloud. Pinecone is cloud-only with no self-hosted option. For Indian government projects or banking applications with strict data residency (RBI guidelines), this is a non-starter.
You're operating at very large scale (1B+ vectors) where Pinecone's pricing becomes prohibitive. At 1 billion 1536-dim vectors, storage alone costs ~$2,000/month (~INR 1.68 lakh/month) on serverless, before read/write costs. Self-hosted Milvus on reserved instances would be significantly cheaper.
You need ACID transactions or complex joins between vector data and relational data. Pinecone is a specialized vector store, not a general-purpose database. Use pgvector if you need vector search + SQL in one system.
Your application requires exact nearest neighbor search with guaranteed 100% recall. Pinecone's ANN approach means recall is typically 90-95%, not 100%.
You're building a latency-critical system with sub-10ms P99 requirements. Pinecone serverless involves network hops and slab loading that can push P99 latency to 50-100ms. A locally deployed FAISS index or Qdrant instance will be faster.
Your budget is extremely constrained and your team has strong DevOps skills. Self-hosted Qdrant or Milvus on a $20/month (~INR 1,680/month) VM can match Pinecone's functionality for small-to-medium workloads at a fraction of the cost.
Key Tradeoffs
The Central Tradeoff: Convenience vs. Control
Pinecone's managed nature means you trade configurability for simplicity. You can't tune HNSW parameters, choose between IVF and HNSW, enable scalar quantization, or control compaction schedules. For 80% of teams, this is the right tradeoff -- the defaults work well enough, and the operational savings are substantial.
But for the 20% who need to squeeze every last millisecond of latency or every percentage point of recall, the lack of tuning knobs is frustrating. Qdrant, for example, lets you set hnsw_ef at query time to trade recall for speed on a per-query basis. Pinecone doesn't.
Cost at Scale
| Scale | Pinecone Serverless (est.) | Self-Hosted Qdrant (est.) | Notes |
|---|---|---|---|
| 100K vectors, 1536-dim | ~$5/month (~INR 420) | ~$20/month (~INR 1,680) | Pinecone wins on cost; Qdrant VM has fixed cost |
| 1M vectors, 1536-dim | ~$15/month (~INR 1,260) | ~$20/month (~INR 1,680) | Roughly equivalent |
| 10M vectors, 1536-dim | ~$60-100/month (~INR 5,000-8,400) | ~$40-60/month (~INR 3,360-5,040) | Self-hosted starts winning |
| 100M vectors, 1536-dim | ~$500-800/month (~INR 42,000-67,200) | ~$150-300/month (~INR 12,600-25,200) | Self-hosted significantly cheaper |
| 1B vectors, 1536-dim | ~$5,000+/month (~INR 4.2L+) | ~$1,000-2,000/month (~INR 84K-1.68L) | Self-hosted is the clear choice |
Estimates assume moderate query load (~100 QPS). Actual costs vary significantly based on read/write patterns.
Vendor Lock-In
Pinecone's API is proprietary. Migrating away means re-ingesting all your vectors into a different system. This isn't trivial at scale. LangChain and LlamaIndex provide vector store abstractions that reduce switching costs, but the underlying data formats are incompatible.
Practical Advice: Start with Pinecone for speed. If you outgrow it (either in cost or control needs), the migration to Qdrant or Milvus is a 1-2 week engineering project for most teams. Don't over-optimize for future scale at the cost of present velocity.
Alternatives & Comparisons
Weaviate is an open-source vector database with built-in vectorization modules and a GraphQL API. Choose Weaviate if you want integrated embedding generation (similar to Pinecone's inference API but self-hostable), a GraphQL-first interface, or need to run on-premises. Pinecone wins on operational simplicity and serverless pricing; Weaviate wins on self-hosting flexibility and open-source transparency.
Qdrant is an open-source, Rust-based vector database with excellent filtering capabilities and full control over HNSW parameters. Choose Qdrant when you need fine-grained index tuning, on-premises deployment, or want to minimize vendor lock-in. Pinecone is easier to start with and better for teams without DevOps expertise; Qdrant is better for teams that need maximum control and cost efficiency at scale.
Milvus is an open-source, cloud-native vector database designed for billion-scale deployments. Choose Milvus (or its managed version, Zilliz Cloud) when operating at very large scale (100M+ vectors) where Pinecone's pricing becomes prohibitive. Milvus supports GPU acceleration and multiple index types (HNSW, IVF, DiskANN). Pinecone is simpler; Milvus is more powerful and cost-effective at extreme scale.
Chroma is a lightweight, developer-friendly embedding database ideal for prototyping and small workloads. Choose Chroma when you're building a local prototype, running experiments, or working with fewer than 1M vectors. Pinecone is the step up when you need production reliability, managed infrastructure, and multi-tenant isolation. Chroma is free and runs locally; Pinecone is a cloud service with associated costs.
pgvector is a PostgreSQL extension that adds vector similarity search to your existing Postgres database. Choose pgvector when you want vector search alongside relational data in a single system, or when your team already runs PostgreSQL and doesn't want to introduce a separate service. Pinecone significantly outperforms pgvector at scale (10M+ vectors) and provides better recall, but pgvector avoids the cost and complexity of a dedicated vector database.
Pros, Cons & Tradeoffs
Advantages
Zero operational overhead: No clusters to manage, no capacity planning, no patching. Pinecone handles indexing, sharding, replication, and failover entirely. Your SRE team can focus on other services.
Fastest time-to-production: From API key to working vector search in under 30 minutes. The SDK is intuitive, the API is clean, and the documentation is exceptional. LangChain and LlamaIndex integrations are first-class.
Serverless pricing aligns cost with usage: Pay per GB stored and per million read/write units. No paying for idle capacity. The free Starter plan (2 GB, 2M writes, 1M reads/month) is generous enough for prototypes and small production workloads.
Native hybrid sparse-dense search: Single-index hybrid search combining semantic (dense) and keyword (sparse) retrieval. No need to maintain separate indexes and merge results -- a significant architectural simplification.
Strong metadata filtering with bitmap indices: Single-stage filtering handles high-cardinality fields (like ACLs with thousands of user IDs) efficiently. No post-filter starvation problem that plagues other implementations.
Integrated inference reduces architecture complexity: Built-in embedding and reranking models (
multilingual-e5-large,pinecone-rerank-v0,cohere-rerank-v3.5) mean fewer services to deploy and manage.Proven at scale: Customers like Gong, Vanguard, and Aquant run production workloads with tens of millions of vectors. Pinecone's algorithms won all four tracks of the NeurIPS 2023 BigANN competition.
Multi-cloud support: Available on AWS, GCP, and Azure. SOC 2 Type II certified. GDPR-relevant regions available.
Disadvantages
No self-hosting option: Pinecone is cloud-only. Organizations with strict data residency requirements (Indian banking sector under RBI guidelines, government projects) cannot use it. This is a hard blocker, not a soft preference.
No index parameter tuning: You cannot configure HNSW ef_construction, ef_search, M parameter, or choose between index types. If your workload has specific recall-latency requirements that the defaults don't meet, you're stuck.
Vendor lock-in risk: Proprietary API and data format. Migrating to a different vector database requires re-ingesting all vectors. While LangChain abstractions help, the underlying data is not portable.
Cost escalates at scale: At 100M+ vectors with moderate query load, Pinecone can cost 3-5x more than self-hosted alternatives. For cost-sensitive Indian startups scaling beyond product-market fit, this becomes a significant line item.
Limited query-time flexibility: You can't adjust recall-vs-latency tradeoffs per query. Qdrant's
hnsw_efand FAISS'snprobegive per-query control; Pinecone doesn't expose equivalent knobs.Recall ceiling around 90-95%: While high, Pinecone's recall isn't user-tunable. For applications requiring 99%+ recall (e.g., medical document retrieval where missing a relevant result has serious consequences), this may be insufficient.
Network latency for every query: As a remote service, every query involves a network round-trip. P99 latency is typically 50-100ms, which is fine for most applications but not for ultra-low-latency use cases where a local FAISS index returns in <5ms.
Failure Modes & Debugging
Metadata filter starvation on highly selective filters
Cause
When a metadata filter is extremely selective (e.g., filtering for a specific user's documents in a large multi-tenant index), the ANN search may not find enough matching candidates within the initial search scope, even with Pinecone's single-stage filtering.
Symptoms
Queries return fewer than top_k results, or results have unusually low similarity scores. Latency may increase as the system widens its search to find matching candidates. This is most common in multi-tenant setups where a small tenant has very few documents.
Mitigation
Use namespaces instead of metadata filtering for the primary tenant isolation dimension. One namespace per tenant ensures the ANN search operates only on that tenant's data. Reserve metadata filters for secondary dimensions (category, date range, tags).
Stale embeddings after model upgrade
Cause
The embedding model is updated (e.g., from text-embedding-ada-002 to text-embedding-3-small) but the existing vectors in Pinecone are not re-embedded. Query vectors from the new model exist in a different geometric space than stored vectors from the old model.
Symptoms
Retrieval quality degrades dramatically. Similarity scores drop. RAG answers become irrelevant. The vector store appears functional (no errors), but results are semantically wrong -- a silent and catastrophic failure.
Mitigation
Implement blue-green re-indexing: create a new Pinecone index, re-embed your entire corpus with the new model, validate recall on an evaluation set, switch your application to the new index, then delete the old one. Pinecone's backup/restore feature (available since 2025) can help manage this process.
Exceeding metadata size limits
Cause
Storing large text chunks or complex JSON objects in vector metadata. Pinecone serverless indexes have a 40 KB per-vector metadata limit. Pod-based indexes have similar constraints.
Symptoms
Upsert operations fail with metadata size errors. If you're storing incrementally larger metadata, failures appear intermittent (only for vectors with large payloads).
Mitigation
Store only lightweight, filterable attributes in metadata (IDs, categories, timestamps, flags). Keep full document text in a separate store (S3, DynamoDB, PostgreSQL) and retrieve it by ID after the vector search returns results.
Namespace proliferation causing performance degradation
Cause
Creating too many namespaces in a single index (e.g., one per user in a consumer app with millions of users). While Pinecone serverless supports many namespaces, each namespace has overhead in the slab management layer.
Symptoms
Index stats calls become slow. Upsert latency increases. In extreme cases, index operations may time out. The second-gen serverless architecture (2025) improved this, but there are still practical limits.
Mitigation
If you have more than ~10,000 tenants, switch from namespace-per-tenant to metadata-filtering-per-tenant. For very large tenant counts (100K+), consider sharding across multiple indexes with a routing layer.
Dotproduct metric mismatch for non-normalized vectors
Cause
Using dotproduct metric (required for hybrid search) with dense vectors that are not L2-normalized. The dot product of non-normalized vectors is influenced by magnitude, making vectors with larger norms appear more similar regardless of direction.
Symptoms
Retrieval results favor longer documents or vectors with higher magnitude over semantically relevant ones. Results seem "biased" toward certain data points consistently.
Mitigation
Always L2-normalize your dense vectors before upserting when using dotproduct metric. Most embedding models (OpenAI, Cohere) already produce normalized vectors, but verify this with your specific model. Add a normalization step in your ingestion pipeline as a safety measure.
Rate limiting and throttling during bulk ingestion
Cause
Attempting to upsert millions of vectors as quickly as possible without respecting Pinecone's rate limits. Serverless indexes have write throughput limits that scale with your plan tier.
Symptoms
HTTP 429 (Too Many Requests) errors during ingestion. Upsert operations start timing out. Progress stalls or becomes extremely slow.
Mitigation
Use batched upserts (1,000 vectors per batch for serverless). Implement exponential backoff on 429 errors. For large initial loads, use the async client (PineconeAsyncio) with controlled concurrency (4-8 parallel requests). Budget 2-4 hours for initial ingestion of 10M vectors.
Placement in an ML System
Where Pinecone Fits in the ML Pipeline
In a RAG (Retrieval-Augmented Generation) pipeline, Pinecone sits after the embedding model converts text chunks into vectors and before the re-ranker or LLM that generates the final answer. It is the retrieval backbone -- the component responsible for finding the most relevant context for a given query.
For recommendation systems (think a Swiggy-like food recommendation engine or a Zerodha-like stock screener), Pinecone stores item or user embeddings and retrieves candidate items at serving time. The retrieved candidates are then passed to a ranking model for final scoring.
For semantic search applications (like an internal knowledge base search at an Indian IT services company), Pinecone replaces or augments traditional Elasticsearch/Solr with vector-based retrieval. The hybrid search feature is particularly valuable here -- combining BM25 keyword matching with semantic similarity.
Pinecone's integrated inference capability is blurring the traditional pipeline boundaries. With built-in embedding and reranking, Pinecone can own the entire retrieval sub-pipeline: text in, ranked results out. The Pinecone Assistant product takes this further by adding chunking, file storage, and LLM orchestration, essentially turning Pinecone into a full RAG-as-a-service platform.
Architectural Note: Even when using Pinecone Assistant for rapid prototyping, production systems benefit from decoupling the embedding, retrieval, and generation stages. This allows independent scaling, monitoring, and model upgrades for each component.
Pipeline Stage
Retrieval / Serving
Upstream
- embedding-model
- vector-store
- semantic-search
Downstream
- hybrid-search
- semantic-search
- vector-store
Scaling Bottlenecks
Write throughput during bulk ingestion: The primary bottleneck for new deployments. Serverless indexes have per-second write limits that require batching and throttling. Initial ingestion of 10M+ vectors typically takes 2-8 hours depending on your plan tier and batch sizes.
Query latency at high QPS: Pinecone serverless handles >1,000 QPS at scale, but P99 latency can reach 50-100ms under load. For dedicated workloads requiring strict SLOs, Pinecone offers dedicated read nodes (announced in late 2025) that provide predictable performance: one customer reported sustaining 600 QPS with P50 of 45ms and P99 of 96ms across 135 million vectors, scaling to 2,200 QPS under load test.
Storage costs at billion-vector scale: At 1,900/month just for storage before read/write costs. This is where self-hosted alternatives become significantly more cost-effective.
Metadata index size: Heavy use of metadata fields (especially high-cardinality string fields) increases the internal index size beyond just the vector data. Monitor your index storage via describe_index_stats() to catch unexpected growth.
Production Case Studies
Vanguard built Agent Assist, an internal RAG-powered chat assistant for their customer support team. Previously, agents relied on keyword search over long financial documents during live calls, often missing relevant details or surfacing outdated information -- a compliance risk in the financial industry. They used Pinecone serverless with hybrid retrieval (dense embeddings + sparse BM25 vectors) to power semantic search over their document corpus. The alpha parameter was set to 0.5 for balanced dense-sparse weighting, optimized for financial documents with domain-specific terminology.
12% improvement in response accuracy with hybrid retrieval compared to dense-only search. Reduced average call times and overhead. Enhanced compliance by differentiating between outdated and current documents via metadata filtering.
Gong, the conversation intelligence platform, uses Pinecone to power Smart Trackers -- an AI feature that detects and tracks complex concepts in sales conversations. User conversations are processed into sentences, embedded into 768-dimensional vectors, and stored in Pinecone with metadata. When users define a concept to track (e.g., 'competitor mention' or 'pricing objection'), Gong performs vector searches to find similar sentences across their conversation corpus. This was one of the use cases that drove Pinecone's serverless development.
10x cost reduction after migrating to Pinecone serverless from the pod-based architecture. Efficient vector searches across millions of conversation segments enable real-time concept tracking for Gong's enterprise customers.
Aquant is an agentic AI platform for professionals servicing complex equipment at large manufacturing companies. Their initial in-house vector search, built on PostgreSQL extensions and blob storage, worked for internal tools but struggled under the demands of real-time service applications. After evaluating alternatives, Aquant migrated to Pinecone to power semantic retrieval across their AI platform. They process tens of millions of vectors across customer-specific namespaces, using Pinecone's namespace model for multi-tenant isolation and metadata filtering for fine-grained access control.
98% retrieval accuracy in production benchmarks. Response times for full answers dropped from ~24 seconds to ~13.7 seconds. No-response queries reduced by 53%, translating to a 48% increase in weekly question volume and 49% reduction in average time-to-resolution for service cases.
Zapier, the workflow automation platform with over 5,000+ app integrations, uses Pinecone as part of their AI features. They went from signing up for Pinecone's free plan to production deployment in a matter of days, a testament to Pinecone's developer experience and rapid time-to-value. The integration enables semantic search capabilities across Zapier's automation workflows.
Production deployment achieved within days of initial sign-up, demonstrating Pinecone's low barrier to entry for SaaS companies building AI-powered features.
Tooling & Ecosystem
The official Python client for Pinecone (v7+). Supports serverless and pod-based indexes, async operations via PineconeAsyncio, integrated inference (embedding + reranking), and bulk upsert with batching. The most feature-complete SDK.
The langchain-pinecone package provides PineconeVectorStore, which wraps Pinecone in LangChain's vector store interface. Enables seamless use of Pinecone as the retrieval backend in LangChain RAG chains, agents, and tools.
Official LlamaIndex integration via llama-index-vector-stores-pinecone. Supports ingestion pipelines that parse documents into nodes, vectorize content, and upsert into Pinecone. Also supports auto-retrieval with metadata filtering.
Web-based management UI for Pinecone indexes. Provides index creation, stats monitoring, query playground, and usage analytics. Useful for debugging and ad-hoc exploration without writing code.
Official TypeScript/JavaScript client (v7+). Supports all Pinecone operations including serverless indexes, integrated inference, and namespaces. Essential for Next.js and Node.js backend applications.
Pinecone's extensive educational resource covering vector database concepts, ANN algorithms, hybrid search, RAG patterns, and best practices. Arguably the best free educational resource on vector databases in the industry.
Research & References
Simhadri, Aumuller, Ingber, et al. (2024)NeurIPS 2023 Competition Track
Reports results from the BigANN challenge where Pinecone's methods dominated all four tracks (filtered, out-of-distribution, sparse, and streaming search) with up to 2x throughput improvement over the next-best submission. Demonstrates Pinecone's algorithmic competitiveness beyond just managed service convenience.
Malkov & Yashunin (2018)IEEE TPAMI, Vol. 42, No. 4
Introduced the HNSW algorithm -- a multi-layer proximity graph achieving logarithmic search complexity. HNSW is the dominant ANN algorithm used in modern vector databases, including as a foundation in Pinecone's proprietary index engine.
Formal, Piwowarski & Clinchant (2021)SIGIR 2021
Introduced SPLADE, a learned sparse representation model that produces sparse vectors suitable for inverted index search with term expansion. SPLADE-based sparse vectors are commonly used with Pinecone's hybrid search feature as a superior alternative to traditional BM25.
Lewis, Perez, Piktus et al. (2020)NeurIPS 2020
Established the RAG paradigm -- combining a dense passage retriever with a seq2seq generator. This paper is the intellectual foundation for the majority of Pinecone's use cases, as RAG pipelines are the primary driver of vector database adoption.
Formal, Lassance, Piwowarski & Clinchant (2021)arXiv preprint
Improved upon SPLADE with a modified pooling mechanism and distillation-trained models. SPLADE v2 sparse vectors are widely used with Pinecone's hybrid search for domains requiring precise keyword matching alongside semantic retrieval.
Pan, Wang & Li (2024)The VLDB Journal
Comprehensive survey of 20+ vector database management systems, including Pinecone. Analyzes indexing, storage, and query processing techniques across commercial and open-source systems. Useful for understanding where Pinecone fits in the broader landscape.
Guo, Sun, Lindgren, Geng, Simcha, Chern & Kumar (2020)ICML 2020
Introduced anisotropic quantization for maximum inner product search (MIPS). Relevant to Pinecone's dotproduct metric and hybrid search, where inner product scoring is the foundation for combining dense and sparse signals.
Interview & Evaluation Perspective
Common Interview Questions
- ●
When would you choose Pinecone over a self-hosted vector database like Qdrant or Milvus?
- ●
How does Pinecone's serverless architecture differ from pod-based deployment? What are the cost implications?
- ●
Explain how you would implement multi-tenancy in Pinecone. When would you use namespaces vs. metadata filtering?
- ●
How does Pinecone's hybrid sparse-dense search work? Why does it require the dotproduct metric?
- ●
Your RAG system using Pinecone has degraded retrieval quality after an embedding model upgrade. What happened and how do you fix it?
- ●
Design a semantic search system for an Indian e-commerce platform with 50M products using Pinecone. Walk through the architecture.
- ●
What are the limitations of Pinecone that might make it unsuitable for certain production workloads?
Key Points to Mention
- ●
Pinecone is a managed service -- the key value proposition is zero operational overhead, not algorithmic superiority. Frame your answer around the build-vs-buy decision.
- ●
Namespaces are hard partitions (one per query), metadata filters are soft filters (combinable). Use namespaces for primary tenant isolation, metadata for secondary dimensions. Performance is equivalent for both.
- ●
Hybrid search requires
dotproductmetric and combines dense semantic vectors with sparse keyword vectors (BM25/SPLADE) using an alpha weighting parameter. The sweet spot works for most domains. - ●
Pinecone's serverless model charges per GB stored (8.25), and per million write units ($2.00). At small-to-medium scale, this is cheaper than self-hosted; at large scale, it's more expensive.
- ●
Pinecone's BigANN competition wins demonstrate algorithmic strength, not just managed convenience. Cite the 2x throughput advantage in filtered search at 90% recall.
- ●
The lack of index parameter tuning is both a feature (simplicity) and a limitation (no recall-latency control). Acknowledge both sides.
- ●
Blue-green re-indexing is mandatory when upgrading embedding models -- old and new vectors are geometrically incomparable.
Pitfalls to Avoid
- ●
Claiming Pinecone is 'just an API wrapper around FAISS' -- it has proprietary algorithms that won the BigANN competition. The engineering is non-trivial.
- ●
Saying 'Pinecone is always the best choice' without discussing cost at scale, vendor lock-in, or the no-self-hosting limitation. A balanced perspective shows maturity.
- ●
Confusing namespaces with metadata filters -- they serve different purposes and have different query-time semantics. This is a common trip-up.
- ●
Ignoring the embedding model's role -- Pinecone's retrieval quality is bounded by the upstream embeddings. If the interviewer asks about poor retrieval, don't blame the vector database first.
- ●
Forgetting to mention hybrid search when discussing production RAG systems. Pure dense retrieval often misses exact keyword matches that matter in specialized domains (legal, medical, financial).
Senior-Level Expectation
A senior candidate should discuss Pinecone in the context of a total system design, not in isolation. This means: embedding model selection and its impact on Pinecone's metric choice, chunking strategy (size, overlap) and its effect on retrieval quality, namespace architecture for multi-tenancy at scale, cost modeling across the growth trajectory (when does Pinecone become more expensive than self-hosted?), migration strategy if you outgrow Pinecone, and monitoring (how do you detect recall degradation when Pinecone doesn't expose recall metrics?). The ability to articulate the build-vs-buy inflection point -- the scale at which self-hosting becomes worth the operational investment -- is what distinguishes a senior engineer from a mid-level one. For Indian startups specifically, discuss how the INR cost curve compares to self-hosted alternatives on Indian cloud regions (AWS Mumbai, GCP Mumbai), and how to plan for this transition as the company scales.
Summary
Pinecone is the leading fully managed vector database, purpose-built for teams that want production-grade similarity search without the operational overhead of self-hosting. Founded by Dr. Edo Liberty (former head of Amazon AI Labs) in 2019, Pinecone has grown to serve customers like Vanguard, Gong, and Aquant, with algorithms that won all four tracks of the NeurIPS 2023 BigANN competition.
The key architectural concepts are straightforward: indexes (top-level containers with a dimension and metric), namespaces (hard partitions for multi-tenant isolation), and records (vectors with metadata). The serverless pricing model (8.25/M reads, $2.00/M writes) makes it cost-effective for small-to-medium workloads, with a generous free tier. Distinctive features include hybrid sparse-dense search (combining semantic and keyword retrieval in a single index), integrated inference (built-in embedding and reranking models), and single-stage metadata filtering with bitmap indices for high-cardinality fields.
The central decision is build vs. buy: Pinecone trades configurability and cost efficiency at scale for operational simplicity and rapid time-to-production. For an early-stage startup in Bengaluru building their first RAG feature, Pinecone's Starter plan gets them to production in a day. For a company with 100M+ vectors, a dedicated infrastructure team, and strict cost targets, self-hosted Qdrant or Milvus will be 3-5x cheaper. The practical advice is to start with Pinecone for speed, measure your scale trajectory, and plan your migration path to self-hosted if you cross the cost inflection point -- typically around 10-50M vectors depending on query load.