Semantic Search in Machine Learning
Let's start with a question that sounds deceptively simple: how do you find the right document when the user doesn't use the right words?
Semantic search is the practice of retrieving documents, passages, or data records based on meaning rather than surface-level keyword overlap. In ML systems, we implement it as a dense retrieval pipeline — an encoder model maps both queries and corpus items into a shared embedding space, and the system returns items whose vectors are closest to the query vector under a chosen similarity metric.
This approach supersedes the lexical matching paradigm (BM25, TF-IDF) that dominated information retrieval for decades. Why? Because it enables retrieval even when queries and relevant documents share zero common terms.
How the Pipeline Works
The architecture has three stages:
- Offline encoding — the corpus is converted into vectors and stored in an index
- Online encoding — the user's query is encoded into a vector at request time
- ANN search — approximate nearest neighbor search identifies the top- candidates in sub-linear time
Semantic search is the critical retrieval component in retrieval-augmented generation (RAG), conversational AI, enterprise knowledge systems, and e-commerce product discovery. Its quality ceiling is determined jointly by the embedding model's representational fidelity and the ANN index's recall-throughput characteristics.
Modern implementations, validated on benchmarks such as BEIR (Thakur et al., NeurIPS 2021), routinely outperform lexical baselines on queries involving paraphrase, synonymy, or abstract intent. That said, we'll see later why you almost always want to combine semantic search with lexical methods rather than relying on it alone.
Concept Snapshot
- What It Is
- An end-to-end retrieval pipeline that encodes queries and documents into dense vector representations and retrieves relevant items by vector similarity — enabling meaning-based search that transcends exact keyword matching.
- Category
- RAG Pipeline
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: a natural-language query string and a pre-indexed corpus of document embeddings. Outputs: a ranked list of the top-$k$ most semantically similar documents with similarity scores.
- System Placement
- Sits after the embedding model and vector store have been populated during ingestion, and before the re-ranker or context assembler during query-time retrieval in a RAG pipeline.
- Also Known As
- dense retrieval, neural search, vector search, embedding-based retrieval, neural information retrieval
- Typical Users
- ML engineers, search/retrieval engineers, NLP engineers, RAG system architects, product search engineers
- Prerequisites
- Embedding models (bi-encoders), Vector stores and ANN indexing, Distance metrics (cosine, dot product, L2), Tokenization and text preprocessing
- Key Terms
- dense passage retrievalbi-encoderlate interactionapproximate nearest neighborrecall@kHNSWIVFproduct quantizationhard negativesin-batch negativeshybrid searchre-ranking
Why This Concept Exists
The Problem with Keywords
Classical information retrieval systems rely on sparse lexical representations: a query is decomposed into tokens, each token is matched against an inverted index, and documents are scored by term-frequency statistics.
BM25 — the dominant algorithm for three decades — is fast, interpretable, and requires no training data. That's pretty great, right?
BUT here's the fundamental limitation: BM25 is structurally incapable of bridging the vocabulary mismatch between how users phrase questions and how authors write answers.
Consider this: the query "affordable sedan with good mileage" and the passage "budget-friendly compact car offering excellent fuel economy" are semantically equivalent — but they share zero lexical overlap. BM25 would score this match at zero. A Swiggy user searching for "chiken biriyani" would miss perfectly relevant results listed as "Hyderabadi chicken biryani" because the spelling doesn't match.
Early Attempts (and Why They Fell Short)
Early approaches to close this gap — query expansion, synonym dictionaries, latent semantic analysis — offered marginal improvements at considerable engineering cost. You'd spend weeks building synonym dictionaries only to discover that language is far too creative to capture in static mappings.
The Breakthrough: Neural Encoders
The real breakthrough came with transformer-based encoders trained with contrastive objectives that learn to project semantically similar text into proximate regions of a continuous vector space.
Karpukhin et al. (EMNLP 2020) demonstrated with Dense Passage Retrieval (DPR) that a dual-encoder trained on question-answer pairs outperformed BM25 by 9-19 points of top-20 retrieval accuracy on multiple open-domain QA benchmarks — without any term-matching heuristics.
Why This Matters for Production Systems
Semantic search exists because production systems need meaning-level retrieval at scale:
- Search engines must understand intent, not just keywords
- RAG systems must ground LLMs in contextually relevant passages, not merely string-matched fragments
- E-commerce platforms like Flipkart and Amazon must surface items that satisfy latent user preferences even when the query is vague ("something cozy for winter evenings")
- Food delivery apps like Swiggy and Zomato must handle multilingual, misspelled, transliterated queries across 500+ Indian cities
Dense retrieval, powered by learned representations and efficient ANN indexing, is the enabling technology for all of these capabilities.
Core Intuition & Mental Model
The Geometric Insight
The core intuition behind semantic search is beautifully geometric: if you train a neural network to place semantically similar texts near each other in a high-dimensional space, retrieval reduces to finding the nearest points to the query vector.
That's it. That's the entire idea.
How the Model Learns This
Training uses contrastive learning — the model sees triplets of (query, positive passage, negative passages) and adjusts its parameters so that:
- Positive pairs have high cosine similarity
- Negative pairs are pushed apart
After training, the encoder produces a fixed-length vector for any text input, and all the semantic understanding the model has learned is compressed into the distances between these vectors.
The Offline-Online Trick
Here's the architectural insight that makes semantic search practical at scale: we decouple document encoding from query encoding.
- Document encoding happens offline, once per corpus update. You can take your time — run it on a batch of GPUs overnight.
- Query encoding happens online, per request. This is a single encoder forward pass — typically 5-20ms on a GPU.
- ANN lookup finds the nearest neighbors in the pre-built index — another 1-10ms.
Total online cost per query? Under 50 milliseconds, irrespective of corpus size. Whether you have 10,000 documents or 10 billion, the query-time cost stays roughly the same. That was pretty simple, wasn't it?
Key Insight: This offline-online decoupling is what separates bi-encoder semantic search from cross-encoder approaches. A cross-encoder scores each query-document pair jointly — accurate, but per query. A bi-encoder does the heavy lifting offline.
What Determines Quality?
The quality of semantic search is bounded by two independent factors:
- Embedding model quality — its ability to capture nuanced meaning (determined by architecture, training data, and objective function)
- ANN index quality — its ability to find true nearest neighbors efficiently (determined by index type, parameters, and the recall-throughput tradeoff)
Improving either factor independently improves the end-to-end system. This modularity is one of the reasons semantic search is such a popular architecture.
Technical Foundations
Let's build up the math step by step. I'll explain the intuition first, then give the formal notation.
The Retrieval Problem
We want to find the most relevant documents for a given query. Semantic search formalizes this as a maximum inner product search (MIPS) or nearest neighbor search in a learned embedding space.
Let be an encoder parameterized by that maps a text input from token space to a -dimensional real-valued vector.
Given a query and a corpus , semantic search retrieves the top- documents:
where is typically cosine similarity:
The Training Objective
How does the encoder learn to place similar texts nearby? Through the InfoNCE loss — a contrastive objective.
Given a batch of queries with corresponding positive passages and negative passages :
where is a temperature hyperparameter (controls how sharply the model discriminates) and is the batch size.
Intuitively, this loss says: "Make the positive pair's similarity high relative to all the negative pairs." It's essentially a softmax classification where the model must pick the correct passage out of a crowd of distractors.
Variants
- DPR (Karpukhin et al., 2020) uses separate encoders for queries and passages with in-batch negatives.
- ColBERT (Khattab & Zaharia, 2020) refines this with token-level late interaction:
where and are per-token embeddings. This enables finer-grained matching while retaining the ability to pre-compute document representations.
Complexity
At inference, exact search over documents requires operations per query — impractical for large corpora. Approximate nearest neighbor algorithms reduce this to:
- for graph-based methods like HNSW (Malkov & Yashunin, 2018)
- for partition-based methods like IVF
For a corpus of 100 million documents, that's the difference between 100,000,000 comparisons and roughly 17 comparisons (HNSW). That's a 1,000,000x speedup.
Internal Architecture
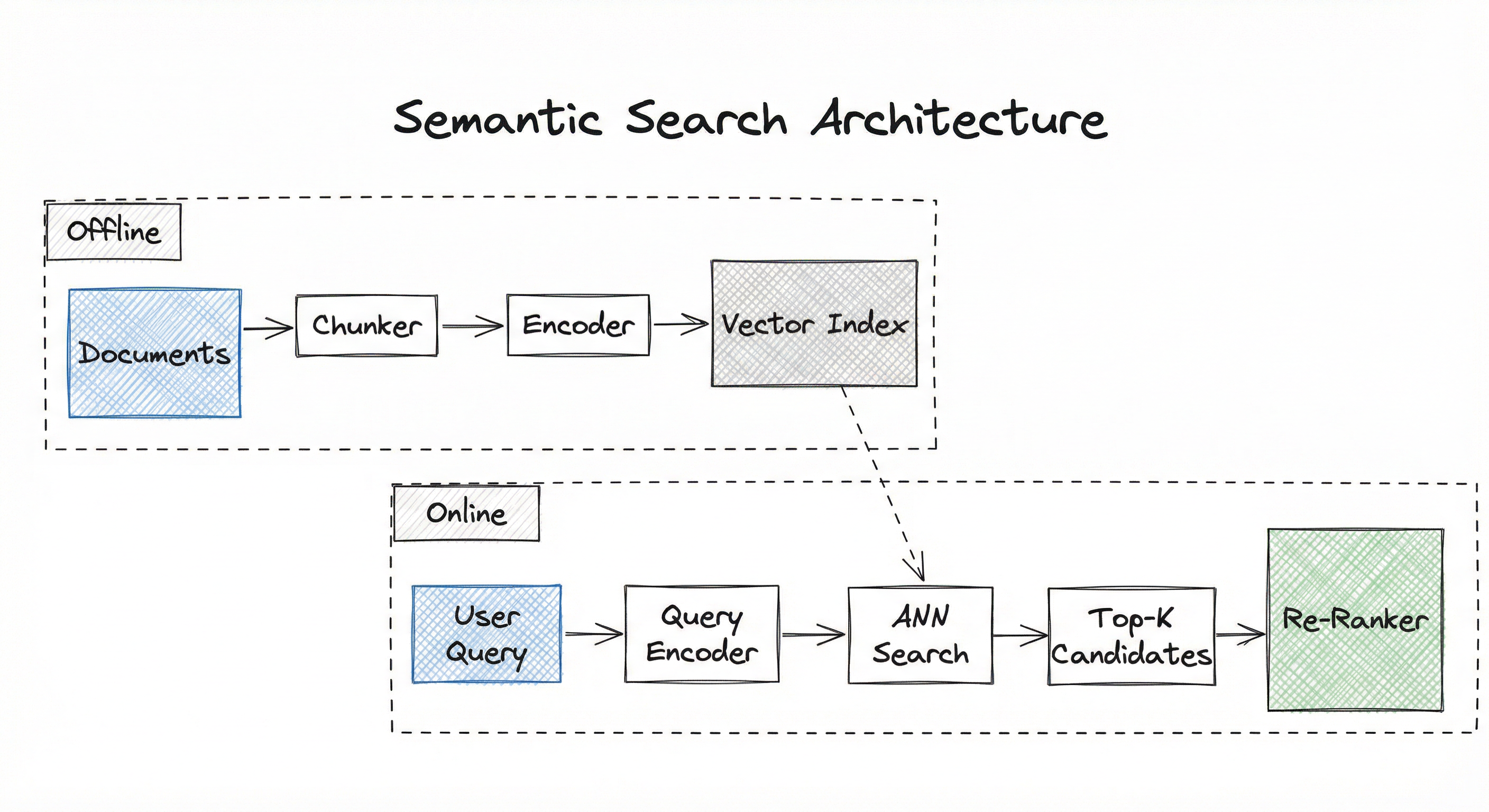
A semantic search system consists of two decoupled pipelines that meet at a shared index. Let's walk through each.
The Offline Indexing Pipeline
This runs once per corpus update (or incrementally as new documents arrive). Its job: encode every document into a vector and build a searchable index.
The Online Serving Pipeline
This runs per query. Its job: encode the query, search the index, and return results — all within a strict latency budget (typically p99 < 200ms).
The Optional Re-Ranking Stage
For applications where precision matters more than raw speed, a cross-encoder re-ranker can refine the top- candidates from the ANN search. This adds 50-200ms but can significantly boost relevance.
Architecture Principle: The offline-online separation is not just an optimization — it's the fundamental design insight. It makes query-time cost independent of corpus size.
Key Components
Query Encoder
A bi-encoder (typically a transformer) that converts the user's natural-language query into a dense vector at request time. In DPR, this is a separate BERT-base model; in single-encoder systems (SBERT, E5), the same model encodes both queries and documents.
Document Encoder
Encodes corpus documents (or chunks) into dense vectors during the offline indexing phase. The same architecture as the query encoder, though DPR uses independently parameterized encoders for queries and passages.
ANN Index
Stores pre-computed document vectors and supports sub-linear similarity search. Implements algorithms such as HNSW, IVF, or product quantization to trade a small amount of recall for orders-of-magnitude speedup over brute-force search.
Retrieval Engine
Orchestrates the query flow: receives the query vector from the query encoder, executes ANN search with optional metadata filters, and returns the top-k candidate documents with similarity scores.
Re-Ranker (Optional)
A cross-encoder that jointly processes the query and each retrieved candidate to produce a refined relevance score. Improves precision at the cost of additional latency.
Result Formatter
Maps internal document IDs back to source content, attaches metadata (source URL, chunk position, timestamp), and returns the final ranked list to the calling system.
Data Flow
Offline Path: Raw Documents --> Text Chunker --> Document Encoder --> Document Vectors --> ANN Index (persisted to disk/storage).
Online Path: User Query --> Query Encoder --> Query Vector --> ANN Index Search --> Top- Candidate IDs + Scores --> (Optional) Re-Ranker --> Final Ranked Results --> Context Assembler / Application.
The ANN Index is the meeting point where the offline and online paths converge. Everything before the index is about preparation; everything after is about retrieval and refinement.
Two parallel flows converging at the ANN index. The offline path runs top-to-bottom: Documents --> Chunker --> Document Encoder --> Vectors --> ANN Index. The online path runs left-to-right: Query --> Query Encoder --> Query Vector --> ANN Index --> Top-K Results --> Re-Ranker --> Output. The ANN Index is the shared node where both paths meet.
How to Implement
Implementing semantic search requires three core decisions — and I'd recommend making them in this order:
Decision 1: Embedding Model
Start with a pretrained model (SBERT, E5-v2, BGE, or OpenAI text-embedding-3-small). Don't fine-tune until you've established a baseline and measured where quality falls short.
Decision 2: ANN Index Backend
For prototyping, FAISS is unbeatable — it's free, runs locally, and supports every index type you'd want to try. For production, consider a managed vector database like Qdrant, Pinecone, or Weaviate that handles scaling, replication, and metadata filtering out of the box.
Decision 3: Re-Ranking
Skip the re-ranker initially. Add a cross-encoder re-ranker only when your baseline retrieval quality plateaus and you need the extra precision boost.
Practical Tip: This "start simple, measure, then optimize" approach saves weeks of premature optimization. I've seen teams spend a month fine-tuning an encoder when the real issue was their chunking strategy.
For most applications, a pretrained model + managed vector DB + no re-ranker provides a strong baseline that you can iterate from with confidence.
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
# 1. Load encoder
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# 2. Encode corpus (offline)
corpus = [
"The Eiffel Tower is a wrought-iron lattice tower in Paris.",
"Photosynthesis converts sunlight into chemical energy in plants.",
"The Python programming language was created by Guido van Rossum.",
"Dense retrieval uses neural encoders for semantic matching.",
"The Great Wall of China stretches over 13,000 miles."
]
corpus_embeddings = model.encode(corpus, normalize_embeddings=True)
# 3. Build FAISS index (HNSW for sub-linear search)
d = corpus_embeddings.shape[1] # 384 dimensions
index = faiss.IndexHNSWFlat(d, 32) # 32 neighbors per node
index.hnsw.efConstruction = 200
index.add(corpus_embeddings.astype('float32'))
# 4. Encode query and search (online)
query = "How does dense passage retrieval work?"
query_embedding = model.encode([query], normalize_embeddings=True)
index.hnsw.efSearch = 100 # search-time precision parameter
scores, indices = index.search(query_embedding.astype('float32'), k=3)
print("Top-3 results:")
for rank, (score, idx) in enumerate(zip(scores[0], indices[0])):
print(f" {rank+1}. (score={score:.4f}) {corpus[idx]}")
# Output: Dense retrieval passage ranked first despite no keyword overlap with queryThis example demonstrates the full semantic search pipeline: encode a corpus with a pretrained bi-encoder (Sentence-BERT's MiniLM variant), build an HNSW index in FAISS for sub-linear retrieval, and query with a natural-language string. The query 'How does dense passage retrieval work?' matches the passage about dense retrieval despite minimal lexical overlap. The efConstruction and efSearch parameters control the recall-throughput tradeoff: higher values improve recall at the cost of build time and query latency respectively.
from transformers import DPRQuestionEncoder, DPRContextEncoder
from transformers import DPRQuestionEncoderTokenizer, DPRContextEncoderTokenizer
import torch
import numpy as np
# Load DPR dual encoders (separate models for query and passage)
q_encoder = DPRQuestionEncoder.from_pretrained(
'facebook/dpr-question_encoder-single-nq-base'
)
q_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained(
'facebook/dpr-question_encoder-single-nq-base'
)
ctx_encoder = DPRContextEncoder.from_pretrained(
'facebook/dpr-ctx_encoder-single-nq-base'
)
ctx_tokenizer = DPRContextEncoderTokenizer.from_pretrained(
'facebook/dpr-ctx_encoder-single-nq-base'
)
# Encode passages
passages = [
"Albert Einstein developed the theory of general relativity.",
"Quantum computing uses qubits to perform parallel computations.",
"Relativity theory describes gravity as spacetime curvature."
]
ctx_inputs = ctx_tokenizer(passages, return_tensors='pt', padding=True,
truncation=True, max_length=256)
with torch.no_grad():
ctx_embeddings = ctx_encoder(**ctx_inputs).pooler_output.numpy()
# Encode query
question = "Who formulated the theory of relativity?"
q_inputs = q_tokenizer(question, return_tensors='pt', max_length=64,
truncation=True)
with torch.no_grad():
q_embedding = q_encoder(**q_inputs).pooler_output.numpy()
# Compute dot-product similarity (DPR uses dot product, not cosine)
scores = np.dot(ctx_embeddings, q_embedding.T).squeeze()
ranked = np.argsort(-scores)
for i, idx in enumerate(ranked):
print(f"{i+1}. (score={scores[idx]:.2f}) {passages[idx]}")
# Einstein passage and relativity passage ranked highestDPR (Karpukhin et al., EMNLP 2020) uses independently parameterized encoders for questions and passages, trained with in-batch negatives on Natural Questions. The query encoder and context encoder are separate BERT-base models. Note the use of dot product (not cosine) as the similarity metric, matching DPR's training objective. In production, the ctx_embeddings would be pre-computed and stored in a FAISS index; only the query encoding happens at request time.
from qdrant_client import QdrantClient
from qdrant_client.models import (
Distance, VectorParams, PointStruct,
Filter, FieldCondition, MatchValue, Range
)
from sentence_transformers import SentenceTransformer
import uuid
# Initialize encoder and vector DB client
model = SentenceTransformer('intfloat/e5-base-v2')
client = QdrantClient(host='localhost', port=6333)
# Create collection with HNSW indexing
client.recreate_collection(
collection_name='knowledge_base',
vectors_config=VectorParams(size=768, distance=Distance.COSINE),
)
# Index documents with metadata
documents = [
{"text": "HNSW provides logarithmic search complexity.",
"source": "arxiv", "year": 2018, "topic": "indexing"},
{"text": "Product quantization compresses vectors for memory efficiency.",
"source": "ieee", "year": 2011, "topic": "compression"},
{"text": "DPR outperforms BM25 on open-domain QA benchmarks.",
"source": "arxiv", "year": 2020, "topic": "retrieval"},
]
points = []
for doc in documents:
embedding = model.encode(f"passage: {doc['text']}",
normalize_embeddings=True)
points.append(PointStruct(
id=str(uuid.uuid4()),
vector=embedding.tolist(),
payload={"text": doc["text"], "source": doc["source"],
"year": doc["year"], "topic": doc["topic"]}
))
client.upsert(collection_name='knowledge_base', points=points)
# Semantic search with metadata filter
query = "query: How does approximate nearest neighbor search work?"
query_vec = model.encode(query, normalize_embeddings=True).tolist()
results = client.search(
collection_name='knowledge_base',
query_vector=query_vec,
query_filter=Filter(must=[
FieldCondition(key='year', range=Range(gte=2015))
]),
limit=5
)
for r in results:
print(f"Score: {r.score:.4f} | {r.payload['text']}")This example shows a production-grade semantic search implementation with Qdrant. Key features demonstrated: (1) using E5 embeddings with required 'query:' and 'passage:' prefixes, (2) storing documents with structured metadata (source, year, topic), (3) combining vector similarity with metadata filtering to constrain results to papers published after 2015. This pattern is essential for multi-tenant RAG systems where retrieval must be scoped by user, organization, or time range.
Common Implementation Mistakes
- ●
Using raw BERT or GPT embeddings without contrastive fine-tuning — these models were not trained for semantic similarity and produce unreliable retrieval rankings. Reimers & Gurevych (EMNLP 2019) showed that BERT CLS embeddings actually underperform GloVe averages on semantic textual similarity tasks. Always use models explicitly trained for retrieval (SBERT, E5, BGE).
- ●
Ignoring the vocabulary mismatch in evaluation — lexical metrics like BLEU or ROUGE do not measure retrieval quality. Use recall@, MRR, or NDCG. I've seen teams celebrate high BLEU scores while their retrieval was actually broken.
- ●
Training only with random negatives — the model learns trivial distinctions and fails on challenging queries where irrelevant passages are topically similar. Xiong et al. (ICLR 2021) showed ANCE with dynamic hard negatives outperforms random-negative training by 5-10 points on TREC DL. Use BM25-retrieved hard negatives at minimum.
- ●
Not normalizing embeddings when using cosine similarity — unnormalized dot products conflate vector magnitude with semantic relevance, producing incorrect rankings. Always set
normalize_embeddings=Trueor L2-normalize manually. - ●
Deploying without a recall evaluation set — silent recall degradation is the most common failure mode in production semantic search. Without a golden set, you cannot detect when quality drops. Build one before you ship.
- ●
Over-relying on semantic search alone — hybrid search (dense + BM25) consistently outperforms pure dense retrieval on benchmarks like BEIR (Thakur et al., NeurIPS 2021). Don't throw away BM25 — combine it with dense retrieval using reciprocal rank fusion.
When Should You Use This?
Use When
Queries and documents frequently use different vocabulary to express the same concepts (synonymy, paraphrase, multilingual queries)
Building a RAG pipeline where the LLM needs contextually relevant passages, not just keyword-matched fragments
The corpus exceeds 10K documents and brute-force pairwise comparison is infeasible at query time
User queries are natural-language questions or conversational, not keyword lists
You need cross-lingual retrieval where queries may be in a different language than the documents (e.g., Hindi queries retrieving English docs)
Product or content discovery requires understanding latent intent (e.g., 'something cozy for winter evenings' matching a specific product on Flipkart or Amazon)
Avoid When
Exact keyword matching is the requirement (e.g., searching for specific error codes, product SKUs, or legal statute numbers) — use BM25 or structured search
The corpus is very small (<1K items) and simple TF-IDF or BM25 already meets quality requirements
Retrieval must be fully explainable at the token level — dense vectors are opaque, and users or regulators require visibility into why a result was returned
Latency budget is extremely tight (<2ms) and even cached ANN lookups exceed the budget — consider pre-computed candidate lists or lexical indices
The domain has no overlap with the embedding model's training data and you lack labeled pairs for fine-tuning — the model may produce meaningless embeddings for highly specialized jargon
Cost constraints prohibit GPU inference or API calls for query encoding — BM25 runs on CPU with negligible cost
Key Tradeoffs
The primary tradeoff axis in semantic search is accuracy vs. latency vs. cost. Let me break this down with concrete numbers.
Accuracy vs. Latency
Bi-encoder retrieval is fast (single forward pass per query, ANN lookup in <10ms) but less precise than cross-encoder scoring. Adding a cross-encoder re-ranker improves precision but adds 50-200ms per query. You're essentially paying latency for accuracy.
Model Size vs. Quality
Larger embedding models (768d, 1024d) capture more nuance but increase encoding latency, storage, and ANN search cost. A 384d MiniLM model runs 3x faster than a 768d E5-large model, but you'll see 3-5% lower recall on nuanced queries.
Index Type vs. Memory
HNSW indices provide the best recall-throughput profile but consume 2-4x more memory than IVF+PQ. Compressed indices save memory at the expense of 3-5% recall. For a 100M-vector index at 768 dimensions: HNSW needs ~120GB RAM, while IVF+PQ can fit in ~15GB.
Cost Realities
At scale, embedding API costs can dominate the total cost of ownership. OpenAI text-embedding-3-small costs 0.13 per million tokens (~INR 11 per million tokens). For a Jio-scale platform processing 10M+ queries/day, self-hosted open-source models (E5, BGE) on Mumbai/Chennai data center GPUs become significantly more cost-effective than API calls.
Rule of Thumb: If you're under 100K queries/day, API-based embeddings are simpler and cheaper. Above that, self-hosted models start saving money — and give you control over latency and model updates.
Alternatives & Comparisons
BM25 scores documents by term frequency and inverse document frequency. It excels at exact keyword matching — for queries containing specific named entities, product codes, or technical terms, BM25 often outperforms dense retrieval. Surprised? Many people are.
BM25 requires no training data, no GPU infrastructure, and is fully interpretable. You can see exactly which terms contributed to the score.
However, it fails entirely when queries and documents use different vocabulary for the same concept. The query "best budget phone for college students" won't match a listing titled "affordable smartphone for young professionals" in a BM25 system.
For many workloads, the best approach is hybrid — combine BM25 + semantic search with score fusion. This consistently outperforms either method alone, as demonstrated on the BEIR benchmark (Thakur et al., NeurIPS 2021).
Hybrid search combines dense retrieval (semantic search) with sparse retrieval (BM25) using reciprocal rank fusion or weighted score combination. It captures both lexical precision and semantic recall, consistently achieving the best results across diverse query types.
The additional complexity is minimal — most vector databases (Weaviate, Qdrant, Milvus) now support hybrid search natively with a single API call.
I'd go so far as to say: use hybrid search as the default unless your queries are exclusively natural-language (favoring dense) or exclusively keyword-based (favoring sparse). It's the pragmatic engineer's choice.
Cross-encoders concatenate the query and document, process them jointly through a transformer, and output a scalar relevance score. They achieve higher accuracy than bi-encoders because they model fine-grained token-level interactions between query and document.
BUT — and this is a critical but — they cannot pre-compute document representations. Every (query, document) pair must be scored at query time. For a corpus of 10M documents, that's 10M forward passes per query. Completely infeasible.
In practice, cross-encoders serve as a second-stage re-ranker applied to the top 20-100 candidates from semantic search. Think of it as a precision refinement layer on top of a recall-oriented retrieval layer.
ColBERT (Khattab & Zaharia, SIGIR 2020) bridges the gap between bi-encoders and cross-encoders with a clever trick: late interaction.
Instead of compressing each document into a single vector, ColBERT preserves per-token embeddings. At query time, each query token is matched against all document tokens via MaxSim — the maximum similarity between each query token and its best-matching document token.
This captures richer token-level interactions than single-vector bi-encoders while retaining the ability to pre-compute document representations. ColBERT achieves within 3% of full cross-encoder accuracy at 170x lower latency.
The tradeoff? Storage. ColBERT stores one vector per token rather than one per document — roughly 20-50x more storage. ColBERTv2 mitigates this with residual compression, bringing storage overhead to a more manageable 6-10x.
Pros, Cons & Tradeoffs
Advantages
Bridges the vocabulary gap — retrieves semantically relevant documents even when queries and documents share no common keywords. This is the killer feature that BM25 simply cannot replicate.
Sub-linear retrieval at scale — pre-computable document representations enable ANN indices that scale to billions of documents with single-digit millisecond latency. Corpus of 1 billion docs? Still under 10ms per query.
Multilingual by default — naturally supports multilingual and cross-lingual retrieval when the encoder is trained on multilingual data (e.g., multilingual E5, Cohere multilingual). A user in Chennai can query in Tamil and retrieve English documents.
Improves with better models — the same ANN infrastructure benefits from upgraded embedding models without architectural changes. Swap the encoder, re-index, and you're done.
Mature open-source ecosystem — FAISS, Sentence-Transformers, DPR, ColBERT, and multiple vector databases provide production-ready components. You don't have to build anything from scratch.
Handles latent intent — enables queries that lexical search cannot handle. "Something for a rainy afternoon" can match books, movies, or recipes depending on the corpus context.
Disadvantages
GPU/API cost for query encoding — requires GPU or high-end CPU for real-time query encoding, introducing infrastructure cost that BM25 does not. BM25 runs on commodity hardware with <1ms latency; semantic search needs at minimum an API call or a beefy CPU.
Opaque retrieval — unlike BM25 where matched terms are highlighted, dense retrieval provides no human-interpretable explanation for why a document was returned. In regulated industries (banking, healthcare), this can be a blocker.
Out-of-distribution degradation — performance drops on rare named entities, domain-specific jargon, or neologisms not seen during training. A medical encoder won't understand new drug names; a legal encoder won't know about recent legislation.
Re-indexing on model update — changing the embedding model requires re-encoding and re-indexing the entire corpus. At 100M+ documents, that's a multi-hour, GPU-intensive operation. Plan model updates carefully.
ANN recall is imperfect — approximate nearest neighbor search inherently trades recall for speed. A small fraction (typically 2-5%) of truly relevant documents will be missed by the ANN index.
Training data dependency — training effective dense retrievers requires large-scale supervision. Unsupervised dense retrieval (Contriever, Izacard et al., TMLR 2022) narrows the gap but still lags supervised approaches on most benchmarks.
Failure Modes & Debugging
Vocabulary mismatch with the embedding model's training domain
Cause
The query or corpus contains domain-specific terminology, abbreviations, or jargon that the encoder never encountered during pre-training. Medical queries with ICD codes, legal queries with statute references, or engineering queries with component part numbers produce embeddings in poorly calibrated regions of the vector space. In India, this also surfaces with vernacular terms — queries in Hinglish, Tamil technical jargon, or Marathi colloquialisms that weren't in the training data.
Symptoms
Generic or out-of-domain queries return reasonable results, but domain-specific queries return irrelevant passages. Recall@10 on domain evaluation sets is significantly lower than on general benchmarks.
Mitigation
Fine-tune the embedding model on domain-specific (query, passage) pairs. Even 5K-10K labeled pairs significantly improve domain retrieval quality. Alternatively, use hybrid search to let BM25 handle exact-match domain terms while the dense retriever covers semantic queries. For Indic language domains, consider models like IndicSBERT or fine-tune multilingual-E5 on your domain data.
Embedding space collapse due to poor negative sampling
Cause
The encoder was trained exclusively with random negatives (or easy in-batch negatives), causing it to learn only coarse topic-level distinctions. It cannot differentiate between topically similar but semantically irrelevant passages — for example, distinguishing between passages about 'Python the programming language' and 'Python the snake' when both contain the word 'Python'.
Symptoms
High recall on easy benchmarks but significant quality drop on hard evaluation sets. The model groups all documents about a broad topic together without fine-grained ranking within the topic. You'll notice this when users complain that "all results look the same."
Mitigation
Incorporate hard negative mining into training. Use BM25 to retrieve plausible but irrelevant passages as hard negatives, or adopt ANCE (Xiong et al., ICLR 2021) which dynamically mines hard negatives from the model's own index during training. Even adding just one BM25 hard negative per query (as DPR does) makes a measurable difference.
ANN index recall degradation at scale
Cause
Index parameters (HNSW ef_search, IVF nprobe) tuned for a smaller corpus are not recalibrated as the index grows. Alternatively, the data distribution shifts (new document types added) and the existing index structure becomes suboptimal.
Symptoms
Retrieval latency remains acceptable, but the quality of returned results decreases over time. A/B tests show declining click-through rates or RAG answer quality without any model changes. This is insidious because your dashboards look fine — latency is green — but quality is silently dropping.
Mitigation
Implement continuous recall monitoring against a golden evaluation set. Re-tune index parameters whenever the corpus size doubles. Periodically rebuild indices rather than relying solely on incremental inserts. Set up automated alerts when recall@10 drops below your threshold (typically 0.90).
Query-document length asymmetry
Cause
Queries are short (5-15 tokens) while documents are long (200-500 tokens). The encoder produces embeddings of different quality for short and long inputs — short queries may be underspecified, and long documents may dilute their main topic across the embedding.
Symptoms
Retrieval quality is better for longer, more specific queries than for short, vague ones. Long documents tend to be retrieved less frequently than short ones, regardless of relevance.
Mitigation
Use passage-level chunking to reduce document length variance (300-500 tokens per chunk is a good starting point). Train or fine-tune with examples that reflect the actual query-document length distribution. Consider a query expansion step using an LLM to add context to short queries before encoding — turning "ML latency" into "How to reduce inference latency in machine learning models."
Stale embeddings after corpus update without re-indexing
Cause
New documents are added to the corpus but encoded with a different model version, or existing documents are updated in the source system but their embeddings in the index are not refreshed.
Symptoms
Newly added documents never appear in results (if not indexed) or appear with anomalous scores (if encoded with a different model). Updated documents return outdated content. Users see stale information even though the source has been updated.
Mitigation
Implement an incremental indexing pipeline that detects corpus changes and re-encodes affected documents. Use embedding model versioning and enforce that all vectors in an index are produced by the same model version. A CDC (Change Data Capture) pipeline that triggers re-encoding on document updates is the production-grade solution.
False confidence from high-similarity irrelevant results
Cause
The embedding model assigns high similarity scores to passages that are topically related but factually incorrect or contextually irrelevant. This is especially dangerous when the corpus contains near-duplicate passages with subtle but critical differences (e.g., contradictory medical advice, outdated regulatory information).
Symptoms
RAG system generates confident but incorrect answers grounded in retrieved passages that are semantically close but factually wrong. No obvious signal in similarity scores to distinguish correct from incorrect passages. Your users trust the system and act on wrong information.
Mitigation
Add a cross-encoder re-ranking stage to refine the top- candidates. Implement fact-checking or consistency-checking downstream of retrieval. For high-stakes domains (medical, legal, financial), supplement semantic search with structured knowledge bases or curated sources. Never assume that high cosine similarity equals factual correctness.
Catastrophic performance on multilingual queries without multilingual encoder
Cause
A monolingual (English-only) encoder is deployed in a setting where users issue queries in other languages, or the corpus contains documents in multiple languages. This is especially common in India, where users naturally switch between English, Hindi, and regional languages within a single query.
Symptoms
Non-English queries return English-only results with near-zero relevance. Queries in languages using non-Latin scripts (Hindi, Tamil, Bengali, Arabic) produce essentially random retrieval behavior.
Mitigation
Deploy a multilingual encoder (multilingual-E5, Cohere multilingual, LaBSE). Evaluate retrieval quality per language separately. For Indian language support, consider models specifically fine-tuned on Indic languages (IndicSBERT, MuRIL) or use translation as a preprocessing step. Swiggy's approach of building a custom tri-gram tokenizer for handling transliterated queries is worth studying.
Placement in an ML System
Semantic search is the retrieval execution layer in a RAG pipeline. Think of it as the bridge between your indexed corpus and your downstream generation model.
It consumes the infrastructure built by upstream components — the embedding model provides the encoder, the vector store provides the index, the text chunker provides appropriately sized passage units, and the document loader provides the raw content.
At query time, semantic search orchestrates the query encoding and ANN lookup, producing a ranked candidate set that downstream components refine (re-ranker), format (context assembler), and consume (LLM generator).
In non-RAG applications, semantic search serves as the primary retrieval interface for product discovery (Flipkart, Amazon), knowledge base search (Notion, Confluence), customer support ticket routing (Freshdesk, Zendesk), and content recommendation (Spotify, YouTube).
Critical Point: The quality of semantic search determines the recall ceiling for the entire downstream pipeline. The LLM can only generate answers from what the retriever surfaces. If the retriever misses a relevant passage, no amount of prompt engineering will recover it.
Pipeline Stage
Retrieval
Upstream
- Embedding Model
- Vector Store
- Text Chunker
- Document Loader
Downstream
- Re-Ranker
- Context Assembler
- LLM Generator
- Response Synthesizer
Production Case Studies
Google integrated dense retrieval into its core search ranking pipeline, supplementing the traditional inverted index with neural retrieval. The system uses dual-encoder models related to the REALM architecture (Guu et al., ICML 2020) to encode web pages and queries into dense representations, enabling retrieval of relevant pages even when no query terms appear in the document.
What's interesting here is that Google didn't replace BM25 — they added neural retrieval alongside the existing lexical system in a hybrid configuration. Even at Google's scale, lexical signals remain valuable.
Google reported that neural retrieval improved search quality for approximately 10% of queries — particularly those involving natural-language questions, conversational phrasing, and queries in underserved languages. The system processes billions of queries daily with strict latency constraints, demonstrating that dense retrieval scales to web-scale corpora when properly engineered.
Spotify implemented semantic search for podcast discovery using dense retrieval over transcript-based content embeddings. They fine-tuned a BART transformer model on MS MARCO to generate synthetic query-episode pairs, then trained a CMLM (Conditional Masked Language Model) on multilingual corpora covering 100+ languages.
Rather than replacing their existing Elasticsearch-based retrieval, Spotify made natural language search an additional retrieval source. A final-stage reranking algorithm takes top candidates from each retrieval source (lexical + semantic) to produce the final ranking — a textbook hybrid architecture.
Semantic search enabled discovery of long-tail podcast content that keyword-based search missed entirely. Natural-language queries like "podcasts about starting a business in your 30s" now surface relevant episodes despite never containing those exact phrases. The system retrieves the top 30 semantic candidates from Vespa with retrieval latency under 50ms, serving 600M+ users at production scale.
Swiggy transitioned their restaurant and dish search from fuzzy text matching to semantic search using Siamese network embeddings and custom tri-gram tokenizers. The system encodes user queries — which routinely mix English, Hindi, and regional languages, and include informal spellings like "chiken biriyani" or "paneer tikka" — alongside restaurant menus and dish descriptions into a shared embedding space.
They evaluated models including all-mpnet-base-v2 and all-MiniLM-L6-v2 from the Sentence-Transformers library, applying a two-stage fine-tuning approach: first unsupervised training with TSDAE (Transformers and Sequential Denoising AutoEncoder), then supervised fine-tuning on their hyperlocal food search data. A key constraint was keeping query embedding latency under 100ms to support their CPU-based infrastructure.
Semantic search improved dish retrieval relevance by over 20% compared to the previous fuzzy-matching approach, particularly for queries in regional languages and colloquial spellings. The system handles millions of daily searches across 500+ cities in India with p99 latency under 100ms, significantly reducing null search results for misspelled or transliterated queries.
Flipkart evolved their product search from a purely lexical approach to a multi-modal semantic search system. The platform uses dense retrieval to encode product titles, descriptions, and images into a shared embedding space, enabling queries like "comfortable work-from-home chair under 10000" (INR) to surface relevant products even when catalog listings use entirely different terminology.
Their Product2Vec approach (MRNet-Product2Vec) uses a multi-task recurrent neural network to generate generic product embeddings that capture semantic relationships across categories. They also leverage semantic embeddings for visual similarity search and duplicate product detection across millions of SKUs.
More recently, Flipkart's Flippi conversational assistant uses bi-encoder semantic text similarity models trained with contrastive loss on proprietary e-commerce user-generated content, integrating semantic search with query reformulation and RAG for natural-language product discovery.
The transition to semantic search increased search-to-purchase conversion rates, particularly for long-tail queries where users describe desired product attributes rather than searching for specific brand names. Duplicate product detection using embedding similarity reduced redundant listings by approximately 30% in high-volume categories, improving catalog quality. The system serves 100M+ monthly active users with sub-200ms search latency.
Notion built its AI Q&A feature using semantic search over workspace content. Documents, databases, and wiki pages are chunked and encoded into embeddings using OpenAI's embedding API, stored in a per-workspace vector index powered by TurboPuffer (a serverless vector database handling 10B+ vectors across millions of namespaces).
When a user asks a question, the query is encoded and matched against the workspace index to retrieve relevant context, which is then fed to an LLM for answer generation. Metadata filtering ensures retrieval is scoped to content the user has permission to access — a critical requirement for multi-tenant enterprise software.
The semantic search layer enables Notion AI to answer questions about workspace content with sub-200ms retrieval latency across millions of documents per workspace. Users can ask natural-language questions like "What was the decision on the Q3 pricing proposal?" and receive answers grounded in their actual documents, even when the exact terms differ from the query.
Scribd, the digital reading platform with 100M+ documents, implemented embedding-based retrieval to power content recommendations. They trained document embeddings using a two-tower neural network that maps user reading history and document features into a shared embedding space. The system uses approximate nearest neighbor (ANN) search to retrieve candidates from millions of documents in under 50ms (2021).
Embedding-based retrieval doubled recommendation click-through rates compared to the previous collaborative filtering approach. The system handles Scribd's massive catalog of books, audiobooks, documents, and articles, scaling to serve personalized results for millions of users.
Tooling & Ecosystem
Meta's open-source library for efficient similarity search and clustering of dense vectors. Supports GPU acceleration, composable index types (Flat, HNSW, IVF, PQ, and combinations), and billion-scale indexing. FAISS is the de facto standard for ANN search in research and production ML systems. Based on the foundational work of Johnson, Douze & Jegou (IEEE TBD, 2019).
Python framework for computing sentence, paragraph, and image embeddings. Wraps HuggingFace Transformers with a simple encode() API, pre-built contrastive training losses (MultipleNegativesRankingLoss, CosineSimilarityLoss), and hundreds of pretrained models. Based on the original Sentence-BERT work (Reimers & Gurevych, EMNLP 2019, 15K+ citations).
Implements the late-interaction retrieval paradigm where per-token embeddings are precomputed for documents and matched via MaxSim at query time. ColBERTv2 adds residual compression to reduce storage by 6-10x while maintaining retrieval quality. Achieves near-cross-encoder accuracy with bi-encoder-like latency.
High-performance vector database written in Rust, supporting HNSW indexing, payload-based filtering, scalar and product quantization, and distributed deployment. Provides native hybrid search (dense + sparse vectors) and multi-tenancy support. Offers both open-source self-hosted and managed cloud options.
Fully managed vector database service with zero operational overhead. Handles indexing, sharding, replication, and scaling automatically. Supports metadata filtering and hybrid search. Pricing starts at $0.096/hr for a single pod (~INR 8/hr), with serverless options for lower-traffic workloads.
Open-source vector database with built-in vectorization modules (can embed text during ingestion), GraphQL and REST APIs, and native hybrid search combining BM25 with dense vectors. Supports HNSW indexing with product quantization for memory-efficient large-scale deployments.
Managed vector search service built on Google's ScaNN algorithm (Guo et al., ICML 2020). Supports billion-scale deployments with automatic scaling and low-latency retrieval. Integrates with Vertex AI's RAG Engine for end-to-end retrieval-augmented generation pipelines.
Lightweight, header-only C++ library implementing the HNSW algorithm (Malkov & Yashunin, IEEE TPAMI 2018) with Python bindings. Ideal for embedding directly in application code when a full database is unnecessary. Used internally by Chroma and other lightweight vector stores.
Research & References
Reimers & Gurevych (2019)EMNLP 2019
Established the bi-encoder paradigm for sentence embeddings by fine-tuning BERT with siamese and triplet networks. Demonstrated that BERT CLS-token embeddings without contrastive training are worse than GloVe averages for semantic similarity. Reduced pairwise sentence comparison from 65 hours (BERT cross-encoder over 10K sentences) to 5 seconds (pre-computed SBERT vectors with cosine similarity). The foundational architecture underlying modern semantic search encoders. Over 15,000 citations.
Karpukhin, Oguz, Min, Lewis, Wu, Edunov, Chen & Yih (2020)EMNLP 2020
Introduced DPR, a dual-encoder retrieval system that trains separate BERT encoders for questions and passages using in-batch negatives and one BM25 hard negative per question. DPR outperformed BM25 by 9-19 points in top-20 retrieval accuracy on five open-domain QA datasets. Established the retriever-reader paradigm that underpins modern RAG architectures. Over 4,700 citations.
Khattab & Zaharia (2020)SIGIR 2020
Proposed late interaction: pre-compute per-token document embeddings, then at query time compute MaxSim between query and document tokens. This captures richer token-level interactions than single-vector bi-encoders while retaining the ability to pre-compute document representations. ColBERT achieves within 3% of full cross-encoder accuracy at 170x lower latency. ColBERTv2 added residual compression for practical storage. Over 1,700 citations.
Guu, Lee, Tung, Pasupat & Chang (2020)ICML 2020
Introduced end-to-end pre-training of a knowledge retriever jointly with a language model. REALM uses a dense retriever to select Wikipedia passages during pre-training, demonstrating that retrieval-augmented pre-training improves downstream QA accuracy. Established the conceptual foundation for modern RAG systems by showing that retrieval and generation can be jointly optimized.
Thakur, Reimers, Ruckte, Srivastava & Gurevych (2021)NeurIPS 2021
Created a benchmark of 18 diverse retrieval datasets spanning bio-medical, financial, scientific, and web domains to evaluate zero-shot generalization of retrieval models. Revealed that dense retrievers trained on a single dataset (e.g., MS MARCO) often fail to generalize to out-of-domain corpora, while BM25 remains competitive across domains. Motivated research on domain-robust dense retrieval.
Xiong, Xiong, Li, Tang, Liu, Bennett, Ahmed & Overwijk (2021)ICLR 2021
Introduced ANCE, a training method that dynamically mines hard negatives from the model's own ANN index during training. By periodically refreshing the index and selecting the highest-scoring non-relevant passages as negatives, ANCE trains the retriever to make fine-grained distinctions. Outperformed DPR and BM25+BERT re-ranking on TREC DL 2019 and Natural Questions.
Izacard, Caron, Hosseini, Riedel, Bojanowski, Joulin & Grave (2022)Transactions on Machine Learning Research (TMLR) 2022
Presented Contriever, an unsupervised dense retriever trained with contrastive learning on unlabeled text using independent cropping as positive pair generation. Demonstrated competitive retrieval performance without any labeled query-passage pairs, narrowing the gap between unsupervised and supervised dense retrieval. Particularly strong on out-of-domain generalization evaluated on BEIR.
Malkov & Yashunin (2018)IEEE TPAMI, Vol. 42, No. 4
Introduced the HNSW algorithm: a multi-layer proximity graph where each layer contains a subset of elements, enabling greedy search from coarse upper layers to fine-grained lower layers in O(log N) time. HNSW achieves state-of-the-art recall-throughput tradeoffs and is now the dominant ANN algorithm in production vector databases (Qdrant, Weaviate, pgvector, Chroma).
Johnson, Douze & Jegou (2019)IEEE Transactions on Big Data, Vol. 7, No. 3
Presented GPU-optimized implementations of brute-force search, IVF, and product quantization that form the algorithmic core of the FAISS library. Achieved 8.5x speedup over prior GPU state-of-the-art for k-nearest-neighbor search. Demonstrated billion-scale similarity search on commodity GPU hardware, enabling practical dense retrieval at web scale.
Jegou, Douze & Schmid (2011)IEEE TPAMI, Vol. 33, No. 1
Introduced product quantization (PQ): decomposing high-dimensional vectors into sub-vectors and quantizing each independently. PQ enables compact codes (8-64 bytes per vector vs. 3072 bytes for a 768-dim float32 vector) and efficient distance estimation via lookup tables. Foundational compression technique used in FAISS IVF+PQ and most production ANN indices for memory-constrained deployments.
Interview & Evaluation Perspective
Common Interview Questions
- ●
Explain how semantic search works end-to-end. Walk through the offline indexing and online query paths.
- ●
What is the difference between semantic search (dense retrieval) and BM25 (lexical search)? When would you use each?
- ●
How does DPR (Dense Passage Retrieval) train its dual encoders? What role do in-batch negatives play?
- ●
Your semantic search system has low recall on domain-specific queries. How would you diagnose and fix this?
- ●
Explain the recall-latency tradeoff in ANN search. How do HNSW and IVF+PQ differ in this regard?
- ●
How does ColBERT's late interaction differ from standard bi-encoder retrieval? What are the tradeoffs?
- ●
Design a semantic search system for a product catalog with 50M items. Walk through your architecture decisions.
Key Points to Mention
- ●
Semantic search encodes queries and documents into a shared embedding space; retrieval is a vector similarity lookup, not keyword matching. The encoder is trained with contrastive objectives (InfoNCE loss) using positive and negative pairs.
- ●
The offline-online separation is the key architectural insight: documents are encoded once during ingestion, query encoding happens per request. This makes retrieval cost independent of corpus size for the encoding step.
- ●
Hard negative mining (BM25-retrieved negatives, ANCE-style dynamic negatives) is critical for training discriminative retrievers. Random negatives produce models that learn only coarse topic distinctions.
- ●
HNSW provides the best recall-throughput tradeoff for most workloads (recall@10 > 0.95 at <5ms) but is memory-intensive. IVF+PQ reduces memory by 8-16x at the cost of 3-5% recall loss. The choice depends on your infrastructure budget.
- ●
Hybrid search (dense + BM25 with reciprocal rank fusion) consistently outperforms pure dense or pure lexical retrieval on diverse benchmarks like BEIR. This should be your default recommendation unless there's a strong reason to use a single signal.
- ●
Production semantic search requires: (1) recall monitoring against a golden evaluation set, (2) embedding model versioning with blue-green re-indexing, (3) metadata filtering for multi-tenant access control, and (4) latency budgeting for query encoding + ANN search.
Pitfalls to Avoid
- ●
Claiming semantic search always outperforms BM25 — lexical search remains competitive for keyword-heavy queries, exact entity matching, and out-of-domain generalization (as shown by BEIR). Interviewers will test whether you understand both sides.
- ●
Forgetting that embedding quality bounds retrieval quality — the best ANN index cannot compensate for a poorly trained encoder. If your embeddings are bad, making search faster doesn't help.
- ●
Ignoring the re-indexing cost when the embedding model changes — this is a major operational consideration that many candidates overlook. At 100M docs, re-indexing takes hours and requires careful blue-green deployment.
- ●
Conflating similarity score magnitude with relevance probability — a cosine similarity of 0.8 does not mean 80% probability of relevance. Thresholds are dataset-dependent and must be calibrated empirically.
- ●
Not mentioning the re-ranking stage — production systems almost always combine a fast retriever (bi-encoder) with a precise re-ranker (cross-encoder) for optimal quality. Leaving this out suggests a gap in production experience.
Senior-Level Expectation
A senior candidate should articulate the full system design: model selection (SBERT, DPR, ColBERT, or proprietary API), training strategy (contrastive objectives, hard negative mining, data collection and labeling), ANN index selection with quantitative justification (HNSW ef parameters, recall@ targets, memory budget), hybrid retrieval architecture (dense + sparse fusion), re-ranking strategy (cross-encoder model selection, candidate pool size), infrastructure considerations (GPU serving for query encoding, vector database selection and capacity planning), monitoring and evaluation (recall regression testing, A/B testing retrieval quality against downstream metrics), and cost analysis (embedding API costs vs. self-hosted GPU costs at INR-level granularity, storage costs scaling with corpus size).
They should discuss failure modes proactively and propose mitigation strategies. Bonus points for mentioning multilingual considerations (critical for India-focused products), CDC-based incremental indexing, and the tradeoff between model quality and inference cost.
Summary
Let me wrap up everything we've covered about semantic search.
-
Semantic search retrieves documents based on meaning, not keyword overlap. Neural encoders map queries and documents into a shared dense vector space where similarity is computed geometrically —
-
The offline-online split is the key architectural insight: documents are encoded once during ingestion; only the query encoding (-ms on GPU) and ANN lookup (-ms) happen per request. This makes query latency independent of corpus size.
-
Three seminal works established the field: Sentence-BERT (Reimers & Gurevych, EMNLP 2019) provided the bi-encoder training framework, DPR (Karpukhin et al., EMNLP 2020) established the dual-encoder paradigm, and ColBERT (Khattab & Zaharia, SIGIR 2020) introduced fine-grained late interaction.
-
Hard negative mining is essential — training with BM25-retrieved or ANCE-style dynamically mined negatives produces encoders that make fine-grained semantic distinctions, not just coarse topic-level groupings.
-
HNSW dominates production deployments: recall@10 > 0.95 at <5ms per query. IVF+PQ provides 8-16x memory savings when RAM is constrained.
-
Hybrid search is the recommended default — combining dense retrieval with BM25 via reciprocal rank fusion consistently outperforms either method alone. Pure dense retrieval can underperform BM25 on out-of-domain queries (BEIR benchmark).
-
Production essentials: recall monitoring against golden evaluation sets, embedding model versioning with blue-green re-indexing, metadata filtering for access control, and cost-aware choices between API-based (OpenAI at $0.02-0.13/million tokens, ~INR 1.7-11/million tokens) and self-hosted encoders.
Semantic search is the retrieval backbone of modern RAG systems, knowledge-base search, and content discovery. Its quality ceiling is jointly determined by the embedding model's representational fidelity and the ANN index's recall-throughput characteristics — improving either factor independently lifts the entire system. Moving on from here, the natural next steps are understanding re-ranking (downstream) and hybrid search (a complementary pattern).