Hybrid Search in Machine Learning
Let's talk about a problem every search engineer eventually runs into.
You build a keyword search system using BM25 -- it works great for exact queries like product codes or error messages. Then you add a dense retriever (bi-encoder over a vector index) to handle natural language questions. Both work well on their own. BUT neither one is reliable across all query types.
That's where hybrid search comes in. It's a retrieval strategy that fuses the outputs of two complementary retrieval systems -- typically a sparse lexical retriever (like BM25) and a dense semantic retriever (like a bi-encoder) -- into a single, ranked result list. The fundamental premise? Lexical and semantic signals capture different facets of relevance. BM25 nails exact term matching and handles domain shift like a champ, while dense retrievers capture paraphrase and synonym relationships that keyword systems miss entirely.
Here's the kicker: empirical studies on the BEIR benchmark have consistently shown that neither paradigm dominates across all query distributions. Hybrid combinations outperform either method in isolation on the majority of datasets (Bruch et al., 2023).
In modern retrieval-augmented generation (RAG) pipelines, hybrid search sits in the first-stage retrieval position -- producing the candidate set that downstream re-rankers and language models consume. Its adoption has accelerated with native support in vector databases like Weaviate, Qdrant, Milvus, and managed services like Elasticsearch and OpenSearch. It's no longer a research curiosity -- it's a practical default.
Hybrid search isn't a luxury optimization. It's a reliability mechanism that hedges against the complementary weaknesses of each retrieval paradigm.
Concept Snapshot
- What It Is
- A retrieval method that executes parallel sparse (lexical) and dense (semantic) searches over the same corpus, then merges their ranked result lists using a fusion function such as Reciprocal Rank Fusion or weighted linear combination.
- Category
- RAG Pipeline
- Complexity
- Advanced
- Inputs / Outputs
- **Inputs**: A natural-language query string, a corpus indexed for both sparse (inverted index) and dense (ANN index) retrieval. **Outputs**: A single, fused ranked list of candidate documents with associated scores.
- System Placement
- Sits after query processing and indexing, and before re-ranking or context assembly in a RAG pipeline. Consumes indices built by the embedding model and the text indexer; feeds candidates to the re-ranker or directly to the LLM context window.
- Also Known As
- hybrid retrieval, dense-sparse fusion, multi-signal retrieval, lexical-semantic fusion, combined retrieval
- Typical Users
- ML engineers, search engineers, NLP engineers, RAG system architects, information retrieval researchers
- Prerequisites
- BM25 / inverted index fundamentals, Dense retrieval and bi-encoder models, Vector stores and ANN search, Basic probability and ranking metrics (NDCG, MRR, Recall@k)
- Key Terms
- BM25dense retrievalsparse retrievalReciprocal Rank Fusion (RRF)convex combinationscore normalizationSPLADElearned sparse representationsinverted indexfusion functionalpha weighting
Why This Concept Exists
The keyword search trap
Pure lexical retrieval systems -- built on the BM25 scoring function described by Robertson and Zaragoza (2009) -- match documents to queries through surface-level term overlap. They're fast, interpretable, and require no GPU infrastructure.
BUT they fail silently when users express information needs with vocabulary that differs from the indexed corpus. This is the infamous vocabulary mismatch problem. A user searching for "how to fix GPU memory issues" won't match a document titled "Resolving CUDA OOM errors" -- even though they mean the exact same thing.
The semantic search trap
Dense retrieval systems, exemplified by DPR (Karpukhin et al., 2020), address vocabulary mismatch by encoding queries and documents into a shared embedding space where semantic similarity is measured by vector distance. Sounds perfect, right?
However, dense models struggle with rare entities, exact identifier matching, and out-of-distribution domains where fine-tuning data is scarce. Thakur et al. (2021) demonstrated on the BEIR benchmark that BM25 -- a decades-old algorithm -- outperforms several dense retrievers on specialized corpora such as BioASQ and SciFact.
Let that sink in. A formula from 2009 still beats neural models on certain domains.
Why hybrid search is the answer
Here's the key insight: these failure modes are largely non-overlapping.
When a user searches for CUDA out of memory error RTX 4090, BM25 nails the exact hardware identifier while the dense model captures the semantic concept of GPU memory exhaustion. Fusing both signals yields a result set that neither retriever could produce alone.
Bruch et al. (2023) formalized this intuition, showing that a convex combination of BM25 and dense scores consistently outperforms either individual system across 18 BEIR datasets.
The practical implication is clear: hybrid search is not a luxury -- it's a reliability mechanism that hedges against the complementary weaknesses of each retrieval paradigm.
Core Intuition & Mental Model
I love this analogy, so let me paint a picture.
Two librarians, one library
Imagine two librarians working in parallel. The first librarian (BM25) scans the card catalog for exact title and keyword matches -- she'll find every book that contains your search terms, but she'll miss a relevant book cataloged under a synonym she doesn't recognize.
The second librarian (dense retriever) has read summaries of every book and can recommend titles that discuss the same concept, even if they use entirely different terminology. BUT she occasionally confuses a book about "Java the island" with "Java the programming language" because the embedding space compresses multiple senses into the same region.
How fusion works intuitively
Hybrid search merges both librarians' recommendation lists into a single, superior list. The fusion function determines how to reconcile their rankings.
Think about it: if the first librarian ranks a book at position 3 and the second at position 50, the fusion function must decide -- does the strong lexical signal outweigh the weak semantic signal, or vice versa?
The agreement signal
Here's the most powerful insight:
Agreement between retrievers is a strong relevance signal. A document ranked highly by both BM25 and a dense model is almost certainly relevant.
Disagreement, on the other hand, requires the fusion function to make a judgment call. And the choice of fusion method -- RRF, linear combination, or learned fusion -- determines how gracefully these conflicts are resolved.
That was pretty simple, wasn't it? The hard part is choosing the right fusion function. Let's dive into that next.
Technical Foundations
Alright, let's get precise. I'll explain the intuition first, then show you the math.
Setting up the notation
Let denote the score assigned to document by the sparse retriever for query , and the corresponding dense retriever score. Hybrid search produces a fused score through one of several fusion functions.
Weighted Linear Combination
The simplest approach: normalize both score distributions and take a convex combination.
The intuition? If you have two scores on wildly different scales (BM25 scores can go into the hundreds, while cosine similarity lives in ), you first bring them to the same range, then blend them with a tunable weight.
where controls the balance and is a score normalization function (min-max, z-score, or theoretical bounds).
Bruch et al. (2023) showed that the choice of normalization has limited impact on final ranking quality, but must be tuned per domain.
Reciprocal Rank Fusion (RRF)
What if you don't want to deal with score normalization at all? RRF bypasses it entirely by operating on ranks instead of scores.
The intuition: instead of asking "how high was this document scored?", we ask "what position was this document ranked at?" A document at rank 1 gets more credit than one at rank 10, regardless of the actual score difference.
where is the set of retriever result lists, is the rank of document in list , and is a smoothing constant (typically 60).
RRF is parameter-light and robust, but it discards magnitude information -- a document ranked first by a wide margin is treated identically to one ranked first by a narrow margin.
SPLADE Fusion
Learned sparse models like SPLADE (Formal et al., 2021) produce sparse, high-dimensional representations through vocabulary-level expansion weights. Because SPLADE scores are already in the same term-weight space as BM25, they can be combined with dense scores using the same linear or RRF mechanisms.
Think of SPLADE as a middle ground between pure lexical and pure semantic retrieval -- it expands your query with related terms (semantic understanding) while staying compatible with inverted indices (lexical efficiency).
Key takeaway: Linear combination gives you more expressiveness but requires normalization and tuning. RRF gives you simplicity and robustness. SPLADE bridges the lexical-semantic gap within the sparse retriever itself.
Internal Architecture
A hybrid search system maintains two parallel index structures over the same corpus: a sparse inverted index (for BM25 or learned sparse retrieval) and a dense ANN index (for bi-encoder embeddings). At query time, the query is processed through both retrieval paths simultaneously, and a fusion layer merges the two ranked lists into a single output.
Let's walk through each component.
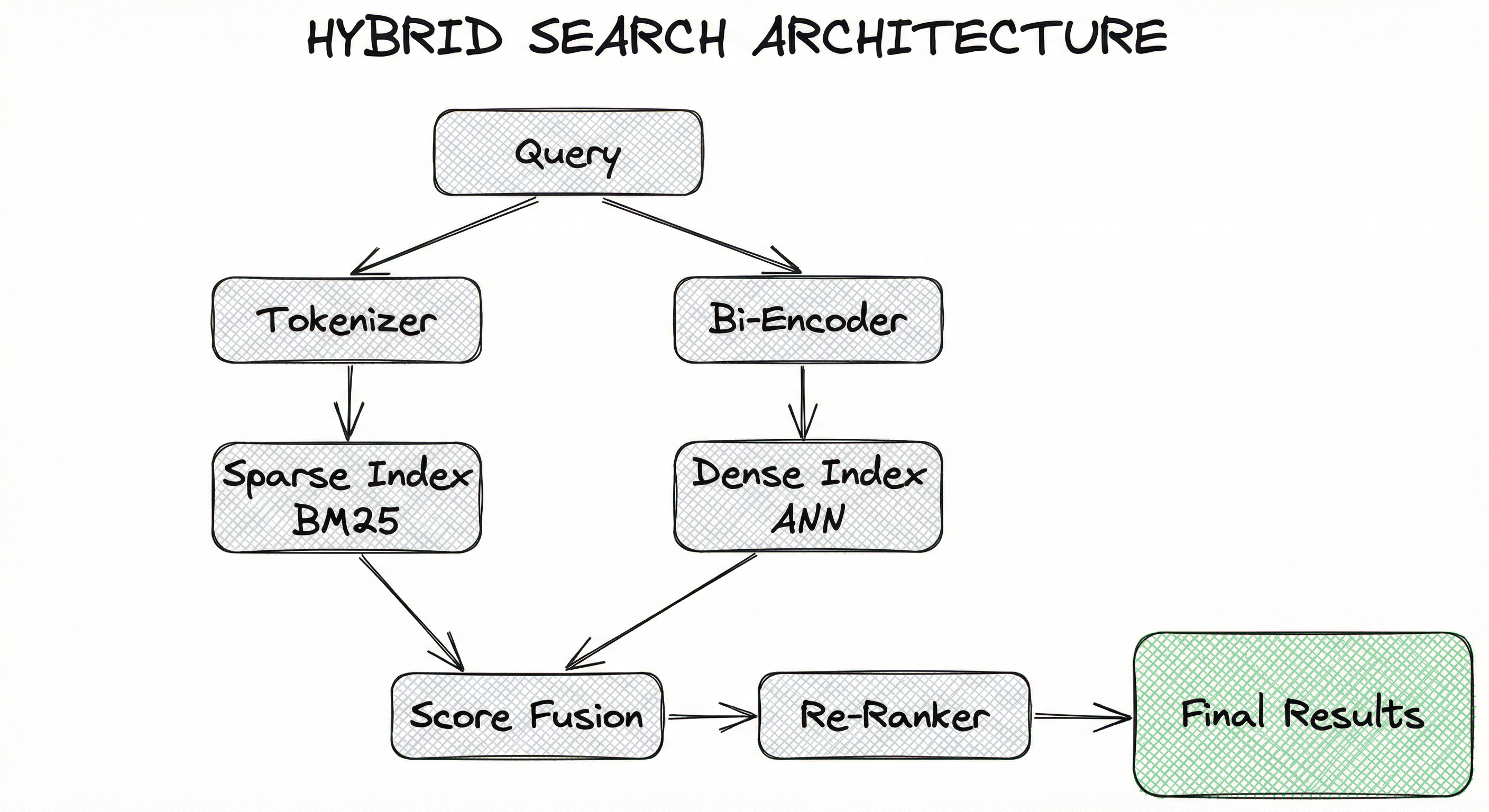
Key Components
Sparse Index (Inverted Index)
Stores term frequencies, document frequencies, and field lengths for BM25 scoring. May alternatively store SPLADE-generated sparse vectors.
Dense Index (ANN Index)
Stores dense embedding vectors produced by a bi-encoder model and supports approximate nearest neighbor retrieval.
Query Encoder
Transforms the raw query string into both a sparse representation (tokenized terms for BM25) and a dense representation (embedding vector from the bi-encoder).
Parallel Retrieval Engine
Executes sparse and dense searches concurrently and returns two independent ranked lists, each with scores and document identifiers.
Score Normalizer
Transforms raw scores from each retriever into a comparable scale before linear fusion. Not required for rank-based methods like RRF.
Fusion Layer
Combines the two ranked lists into a single ranked list using a chosen fusion function (RRF, linear combination, or learned fusion).
Data Flow
Raw query string -> Query Encoder (produces sparse tokens + dense vector) -> [Sparse Index, Dense Index] searched in parallel -> Two ranked lists with scores -> Score Normalizer (for linear fusion) or direct rank extraction (for RRF) -> Fusion Layer merges into single ranked list -> Top-k results forwarded to Re-Ranker or Context Assembler.
A directed flow diagram: 'Query' splits into two parallel paths: (1) 'Tokenizer' -> 'Sparse Index (BM25)' -> 'Sparse Ranked List', and (2) 'Bi-Encoder' -> 'Dense Index (ANN)' -> 'Dense Ranked List'. Both lists converge at a 'Fusion Layer (RRF / Linear)' node, which outputs a single 'Fused Ranked List' -> 'Re-Ranker / LLM'.
How to Implement
Implementing hybrid search boils down to three decisions:
- Which sparse and dense retrievers to use
- Which fusion function to apply
- How to tune the fusion parameters
In practice, most teams start with BM25 + a sentence-transformer bi-encoder fused via RRF, then graduate to weighted linear combination once they have evaluation data to tune .
Production systems increasingly use database-native hybrid search (Weaviate, Qdrant, Elasticsearch) to avoid the operational burden of orchestrating two separate retrieval services.
Let's look at the code.
from collections import defaultdict
from typing import Dict, List, Tuple
def reciprocal_rank_fusion(
ranked_lists: List[List[str]],
k: int = 60
) -> List[Tuple[str, float]]:
"""Fuse multiple ranked lists using RRF (Cormack et al., 2009).
Args:
ranked_lists: List of ranked document ID lists, one per retriever.
k: Smoothing constant. Higher values reduce the influence of
high-ranking documents. Default 60 per original paper.
Returns:
List of (doc_id, rrf_score) tuples sorted by descending score.
"""
rrf_scores: Dict[str, float] = defaultdict(float)
for ranked_list in ranked_lists:
for rank, doc_id in enumerate(ranked_list, start=1):
rrf_scores[doc_id] += 1.0 / (k + rank)
# Sort by RRF score descending
fused = sorted(rrf_scores.items(), key=lambda x: x[1], reverse=True)
return fused
# Example usage
bm25_results = ["doc_3", "doc_1", "doc_7", "doc_12", "doc_5"]
dense_results = ["doc_1", "doc_9", "doc_3", "doc_5", "doc_20"]
fused = reciprocal_rank_fusion([bm25_results, dense_results], k=60)
print(fused[:5])
# doc_1 and doc_3 rank highly in both lists -> boosted to topThis implementation follows the original RRF formulation from Cormack et al. (2009). Notice how elegant it is -- we're operating purely on ranks, not scores. That eliminates the entire score normalization headache.
The smoothing constant was empirically determined in the original paper. Lower values amplify the contribution of top-ranked documents (making the fusion spiky), while higher values flatten the rank distribution (making it more democratic). Documents appearing in multiple lists accumulate score from each, naturally promoting consensus results -- which is exactly what we want.
That was pretty simple, wasn't it?
import numpy as np
from typing import Dict, List, Tuple
def min_max_normalize(scores: Dict[str, float]) -> Dict[str, float]:
"""Normalize scores to [0, 1] range using min-max scaling."""
if not scores:
return {}
values = list(scores.values())
min_s, max_s = min(values), max(values)
if max_s == min_s:
return {doc_id: 0.5 for doc_id in scores}
return {
doc_id: (s - min_s) / (max_s - min_s)
for doc_id, s in scores.items()
}
def linear_hybrid_fusion(
sparse_scores: Dict[str, float],
dense_scores: Dict[str, float],
alpha: float = 0.5
) -> List[Tuple[str, float]]:
"""Fuse sparse and dense scores via convex combination.
S_hybrid = alpha * norm(S_sparse) + (1 - alpha) * norm(S_dense)
Args:
sparse_scores: {doc_id: bm25_score} from sparse retriever.
dense_scores: {doc_id: cosine_similarity} from dense retriever.
alpha: Weight for sparse scores. 0.5 = equal weight.
Returns:
Sorted list of (doc_id, hybrid_score).
"""
norm_sparse = min_max_normalize(sparse_scores)
norm_dense = min_max_normalize(dense_scores)
all_docs = set(norm_sparse.keys()) | set(norm_dense.keys())
hybrid_scores = {}
for doc_id in all_docs:
s_sparse = norm_sparse.get(doc_id, 0.0)
s_dense = norm_dense.get(doc_id, 0.0)
hybrid_scores[doc_id] = alpha * s_sparse + (1 - alpha) * s_dense
return sorted(hybrid_scores.items(), key=lambda x: x[1], reverse=True)
# Example: alpha=0.3 favors dense retrieval
sparse = {"doc_1": 12.5, "doc_3": 9.8, "doc_7": 7.2}
dense = {"doc_1": 0.92, "doc_9": 0.88, "doc_3": 0.71}
results = linear_hybrid_fusion(sparse, dense, alpha=0.3)
print(results[:5])This is the convex combination approach studied by Bruch et al. (2023). Let me highlight the critical detail here: min-max normalization.
BM25 scores can range from 0 to unbounded positive values (I've seen scores of 150+ on long documents), while cosine similarity typically lives in for normalized embeddings. Without normalization, BM25 would completely dominate the fusion regardless of . That's probably the #1 mistake I see teams make.
Notice how documents appearing in only one retriever's results receive a score of 0.0 from the missing retriever -- this naturally penalizes single-source results, which is usually the right behavior.
A common production starting point: , then grid search over in steps of 0.1 using your evaluation set.
import weaviate
from weaviate.classes.query import HybridFusion
# Connect to Weaviate instance
client = weaviate.connect_to_local() # or connect_to_weaviate_cloud()
# Collection must have both vectorizer and inverted index configured
collection = client.collections.get("Document")
# Execute hybrid search with relative score fusion
results = collection.query.hybrid(
query="CUDA out of memory error on large batch sizes",
alpha=0.5, # 0 = pure BM25, 1 = pure vector
fusion_type=HybridFusion.RELATIVE_SCORE, # or RANKED (RRF)
limit=20,
return_metadata=["score", "explain_score"],
)
for obj in results.objects:
print(f"{obj.properties['title']} | score: {obj.metadata.score:.4f}")
client.close()This is where it gets really nice. Weaviate provides first-class hybrid search through a single API call -- it internally executes both BM25 and vector search, then fuses results using either relative score fusion (weighted linear combination with min-max normalization) or ranked fusion (RRF).
The parameter matches the convex combination formulation: is pure BM25, is pure vector search.
The beauty? No need to manage two separate retrieval services, no manual fusion code, no index synchronization headaches. Similar native hybrid search APIs exist in Qdrant, Milvus, and Elasticsearch.
If you're just getting started with hybrid search, I'd strongly recommend using a database-native implementation. You can always switch to a custom fusion layer later when you need more control.
Common Implementation Mistakes
- ●
Using raw, unnormalized scores in linear combination -- BM25 scores can range into the hundreds while cosine similarities are bounded to , causing the higher-magnitude scorer to dominate regardless of . This is the #1 mistake I see in production.
- ●
Setting the RRF smoothing constant too low (e.g., ), which makes fusion extremely sensitive to the top-ranked document and unstable across queries. Stick with unless you have a very good reason to change it.
- ●
Retrieving different candidate pool sizes from each retriever (e.g., top-100 from BM25 and top-20 from dense), which biases fusion toward the retriever with more candidates. Always retrieve the same number from both.
- ●
Failing to tune the parameter on domain-specific evaluation data -- the optimal balance between sparse and dense varies significantly across corpora and query types. Even 50 judged queries suffice (Bruch et al., 2023).
- ●
Assuming hybrid search always outperforms single-retriever baselines -- on corpora where one signal is dominant (e.g., exact-match-heavy technical documentation), the weaker retriever can introduce noise that hurts ranking quality.
- ●
Not indexing the corpus for both retrieval paradigms -- hybrid search requires maintaining both an inverted index and a vector index, which roughly doubles storage and ingestion complexity. Budget for this upfront.
When Should You Use This?
Use When
Your query distribution includes both keyword-heavy queries (product codes, error messages, proper nouns) and natural language questions where semantic understanding is required -- this is extremely common in Indian e-commerce where users mix Hindi/English terms with product SKUs
You are building a RAG pipeline over heterogeneous content where no single retrieval method dominates across all document types
Evaluation on your domain shows that BM25 and dense retrieval have complementary failure modes -- each retrieves relevant documents the other misses
You need robustness to domain shift: BM25 provides a zero-shot baseline that doesn't degrade when the dense model encounters out-of-distribution queries
Your retrieval recall at the first stage is critical because downstream re-rankers cannot recover documents that were never retrieved -- this is a hard ceiling, not a soft one
You are operating in a multilingual or code-mixed environment (e.g., Hinglish, Tanglish) where lexical matching captures language-specific tokens that dense models may underrepresent
Avoid When
Your corpus is small enough (<5K documents) that a single retrieval method with light re-ranking achieves sufficient recall -- hybrid search would be engineering overkill here
All queries are well-formed natural language with minimal jargon -- pure dense retrieval may suffice and is simpler to operate
Latency budget is extremely tight (<10ms) and you cannot afford parallel retrieval from two index types
You lack evaluation data to tune the fusion parameters -- an untuned hybrid system can actually underperform a well-tuned single retriever
Infrastructure cost is a hard constraint and maintaining two index types doubles your storage and compute requirements without proportional quality gains for your specific use case -- for a startup on a tight cloud budget (say, under INR 50,000/month or ~$600/month), this matters
Key Tradeoffs
Let's be honest about the tradeoffs.
Hybrid search increases retrieval quality at the cost of infrastructure complexity and operational overhead. You must maintain two index types (inverted + ANN), which roughly doubles storage requirements. Query latency is bounded by the slower of the two retrievers (typically the dense path) when run in parallel, or their sum when run sequentially.
The fusion function introduces a tunable parameter ( for linear combination, for RRF) that requires evaluation data to optimize. However, Bruch et al. (2023) showed that even a small validation set (50-100 judged queries) is sufficient to tune effectively, making the data requirement quite modest.
The cost tradeoff is straightforward: if hybrid search improves Recall@100 by even 5-10 percentage points over your best single retriever, the downstream improvements in re-ranking and generation quality typically justify the added infrastructure. For a mid-sized RAG deployment on AWS/Azure in India, expect the additional vector index to add roughly INR 15,000-30,000/month (~$180-360/month) on top of your existing search infrastructure.
Alternatives & Comparisons
Pure dense retrieval using models like DPR, E5, or BGE is simpler to operate -- single index, single encoder, single codebase. BUT it's vulnerable to exact-match failures and domain shift.
Hybrid search typically outperforms dense-only retrieval by 5-15% on Recall@100 across diverse benchmarks (Bruch et al., 2023). Choose dense-only when all queries are semantic and infrastructure simplicity is paramount.
BM25 is the most battle-tested retrieval function in production search systems. It excels at exact keyword matching, requires no GPU, and is robust to domain shift.
However, it cannot bridge vocabulary gaps. If a user asks "how to reduce latency in microservices" and your document says "techniques for lowering response time in distributed systems," BM25 will miss it entirely. Hybrid search adds semantic recall on top of BM25's precision. Choose BM25-only when your query-document vocabulary overlap is consistently high.
SPLADE (Formal et al., 2021) and its successors produce learned sparse representations that combine the efficiency of inverted indices with semantic expansion. You can think of SPLADE as a hybrid approach baked into a single model -- it learns to expand queries and documents with related terms.
When used as the sparse component of a hybrid system (replacing BM25), it can further improve recall. However, it requires GPU inference at query time and fine-tuning on in-domain data -- which isn't always feasible.
ColBERTv2 (Santhanam et al., 2022) uses token-level interactions between query and document representations, achieving strong effectiveness without full cross-encoder cost. It's a single-model alternative to hybrid search.
BUT it requires storing per-token embeddings, which is significantly more storage than bi-encoder vectors. For a 10M document corpus, ColBERTv2 might need 50-100GB of storage versus ~5-10GB for a bi-encoder index. Hybrid search with BM25 + bi-encoder is typically more storage-efficient while achieving competitive effectiveness.
A cross-encoder can re-rank results from a single retriever, partially compensating for retrieval gaps. However, here's the fundamental limitation: a re-ranker cannot recover documents that were never retrieved in the first stage.
Hybrid search expands the candidate pool, giving the re-ranker more relevant documents to work with. The best production systems use hybrid search for retrieval followed by cross-encoder re-ranking. They're complementary, not competing.
Pros, Cons & Tradeoffs
Advantages
Captures both exact lexical matches and semantic similarity, covering complementary failure modes of each retrieval paradigm -- this is the core value proposition
Consistently outperforms single-retriever baselines on diverse benchmarks -- Bruch et al. (2023) demonstrated gains across 18 BEIR datasets with an average improvement of 5-15% in Recall@100
RRF provides a strong, nearly parameter-free fusion baseline that requires no training data and works out of the box -- you can ship it in a day
Graceful degradation: if one retriever fails or returns poor results for a query, the other retriever's results still contribute to the fused list -- think of it as built-in redundancy
Natively supported by major vector databases (Weaviate, Qdrant, Milvus, Elasticsearch), reducing implementation complexity to a single API call
Improves first-stage recall, which directly benefits downstream re-rankers and generators that cannot recover missed documents -- this is the recall ceiling argument
Disadvantages
Requires maintaining two index types (inverted + ANN), approximately doubling storage costs and ingestion pipeline complexity -- for a 10M doc corpus, expect ~20-40GB additional storage
Fusion parameters (, ) need tuning on domain-specific evaluation data; untuned fusion can underperform a well-tuned single retriever
Dense retrieval path requires GPU inference for query encoding, adding 10-30ms latency and
INR 25,000-50,000/month ($300-600/month) in compute cost relative to BM25-only systemsScore normalization for linear combination is sensitive to the score distribution of each retriever, which can shift across query types and cause instability
Added architectural complexity increases the surface area for bugs: misaligned document IDs between indices, stale indices, or inconsistent ingestion can cause silent quality degradation
On highly homogeneous corpora where both retrievers return nearly identical results, hybrid search adds cost without meaningful quality improvement -- always validate with an A/B test
Failure Modes & Debugging
Alpha miscalibration
Cause
The fusion weight is set without domain-specific tuning -- for example, using on a corpus where BM25 is significantly stronger or weaker than the dense retriever.
Symptoms
Hybrid search underperforms the stronger individual retriever. Recall@k is lower than the baseline, and users report worse result quality after enabling hybrid search. This is the most embarrassing failure mode because you made things worse by adding complexity.
Mitigation
Tune on a held-out validation set with relevance judgments. Bruch et al. (2023) showed that as few as 50 judged queries suffice. Monitor Recall@k and NDCG@10 for the hybrid system against single-retriever baselines. Consider per-query dynamic if query distributions are heterogeneous (e.g., some queries are keyword-heavy, others are natural language).
Score distribution mismatch in linear fusion
Cause
Raw BM25 scores (unbounded, varies by query length and corpus statistics) are combined with cosine similarity scores (bounded ) without normalization, or normalization is applied incorrectly.
Symptoms
One retriever's scores completely dominate the fused ranking regardless of . The fused list closely mirrors the dominant retriever's list, nullifying the benefit of hybrid search. You've essentially paid for two retrieval systems but are only using one.
Mitigation
Apply min-max or z-score normalization before linear fusion. Alternatively, use RRF, which operates on ranks and is immune to score scale differences. If using min-max, be aware that outlier scores can compress the normalized range for all other documents -- consider using percentile-based clipping.
Index desynchronization
Cause
The sparse and dense indices are updated on different schedules or through different ingestion pipelines, resulting in documents present in one index but absent from the other.
Symptoms
Documents retrieved by one system but missing from the other receive a fusion score of zero from the missing side, causing them to rank lower than expected. In extreme cases, newly ingested documents are invisible to one retrieval path. Users find the document via keyword search but not semantic search, or vice versa.
Mitigation
Use a single ingestion pipeline that writes to both indices atomically. Implement consistency checks that compare document counts across indices and alert on divergence. Database-native hybrid search (e.g., Weaviate, Qdrant) eliminates this issue by managing both indices internally -- this is a strong argument for using managed solutions.
Candidate pool asymmetry
Cause
Different numbers of candidates are retrieved from each system (e.g., top-1000 from BM25 but only top-100 from dense retrieval), biasing fusion toward the retriever with more candidates.
Symptoms
The fused list is dominated by documents from the retriever with the larger candidate pool. Documents from the smaller pool are systematically underrepresented, defeating the purpose of hybrid search.
Mitigation
Retrieve the same number of candidates from both retrievers -- I'd recommend top-100 to top-500 as a starting range. If this is not feasible due to latency constraints, use RRF with a maximum rank cutoff so that documents beyond the cutoff are treated equivalently.
Dense retriever domain drift
Cause
The bi-encoder model was trained on a general-purpose corpus (e.g., MS MARCO) but is deployed on a specialized domain (e.g., legal, biomedical, Indian regulatory documents) without fine-tuning.
Symptoms
The dense retriever contributes noise rather than signal. Hybrid search performs marginally better than BM25 alone, or worse if favors the dense path. The dense retriever returns topically related but irrelevant documents -- close but not close enough.
Mitigation
Fine-tune the dense encoder on in-domain data, even with a small dataset (1K-5K query-passage pairs). Alternatively, shift toward the sparse side when deploying on a new domain, and increase the dense weight only after validating its quality. It's okay to start with (mostly BM25) and gradually reduce it as you improve the dense model.
Latency spike from sequential execution
Cause
Sparse and dense retrievals are executed sequentially rather than in parallel, doubling the end-to-end retrieval latency.
Symptoms
P50 retrieval latency is the sum of both retrieval latencies (e.g., 30ms BM25 + 50ms dense = 80ms) rather than the maximum (50ms). Users experience noticeable slowdown compared to single-retriever systems, especially on high-traffic Indian e-commerce platforms where every millisecond impacts conversion.
Mitigation
Execute both retrievals concurrently using async I/O, threading, or database-native hybrid search that parallelizes internally. Monitor P99 latency to detect tail-latency issues in either path. If one path is consistently slower, consider caching its results or using approximate methods.
Over-retrieval dilution
Cause
Retrieving too many candidates from each system (e.g., top-5000 each) floods the fusion layer with low-quality results, diluting the signal from truly relevant documents.
Symptoms
Precision at low ranks drops. The top-10 fused results contain more noise than a single retriever's top-10. The downstream re-ranker struggles with the enlarged, noisier candidate set and actually performs worse.
Mitigation
Limit candidate retrieval to a reasonable depth (top-100 to top-500 per retriever for most use cases). Profile the marginal recall gain from increasing depth and stop when it plateaus. In my experience, going beyond top-500 rarely helps and often hurts precision.
Placement in an ML System
Hybrid search is the first-stage retriever in a RAG pipeline. It receives a user query, produces two parallel searches over the indexed corpus, and returns a fused candidate set to the downstream re-ranker or directly to the context assembler that formats passages for the LLM.
Why does this stage matter so much? Because the quality of first-stage retrieval sets the recall ceiling for the entire pipeline. A document not retrieved here cannot be recovered by any downstream component -- not by the re-ranker, not by the LLM, not by anyone.
Think of it this way: the re-ranker can reorder the cards you dealt it, but it can't add new cards to the hand.
In recommendation or e-commerce search systems (like those at Flipkart or Amazon India), hybrid search similarly occupies the candidate generation phase, feeding a narrowed set to scoring models.
Pipeline Stage
Retrieval
Upstream
- Document Loader
- Text Chunker
- Embedding Model
- Sparse Index Builder (BM25 / SPLADE)
Downstream
- Re-Ranker
- Context Assembler
- LLM (Generator)
Production Case Studies
Elasticsearch introduced native hybrid search capabilities combining traditional BM25 scoring with k-nearest-neighbor (kNN) vector search in a single query. Their implementation supports both RRF and linear combination fusion methods, enabling e-commerce platforms and enterprise search systems to execute hybrid queries without maintaining separate retrieval services.
The system leverages Lucene's inverted index for BM25 and HNSW graphs for dense vector search, with ACORN-1 enabling efficient filtered kNN at scale. This is probably the most mature hybrid search implementation in the industry, battle-tested at enormous scale.
Production deployments report 15-25% improvements in search relevance metrics (NDCG@10) compared to BM25-only baselines, particularly for queries with ambiguous intent or vocabulary mismatch. The single-service architecture reduced operational overhead compared to multi-service hybrid setups -- a major win for teams that don't want to manage separate vector databases.
Flipkart's product search system combines lexical retrieval (matching product titles, descriptions, and SKU identifiers) with semantic vector search to handle the diverse query patterns of India's multilingual user base.
Here's the challenge they face: users frequently search with code-mixed queries (English-Hindi, like "best phone under 15000 ke saath camera") and use colloquial terms that differ from catalog vocabulary. The hybrid approach ensures that exact product codes and brand names are matched via the lexical path while semantic similarity captures intent behind vernacular queries.
This is a textbook example of why hybrid search matters -- no single retrieval method can handle this level of linguistic diversity.
The hybrid search system improved catalog coverage for long-tail queries by approximately 20%, reducing null-result rates for code-mixed and transliterated queries. Search conversion rates improved measurably on categories with high vocabulary mismatch between user queries and product metadata. For a platform serving 400M+ users, even a 1% improvement in conversion translates to crores in additional GMV.
Airbnb's search system employs embedding-based retrieval alongside traditional structured filters (location, price, availability). The hybrid approach allows the system to balance hard constraint matching (exact dates, location radius) with soft semantic signals (listing similarity, host quality).
Dense embeddings trained via collaborative filtering capture user preference patterns -- "users who booked this listing also liked these listings" -- while structured retrieval ensures business-logic constraints are satisfied. It's a hybrid approach, but between structured filters and embeddings rather than BM25 and dense.
The embedding-based retrieval component expanded the candidate pool with listings that users would not have found through filter-based search alone, contributing to improved booking conversion rates and increased discovery of listings outside the user's initial search parameters. This is particularly impactful for travel destinations in India where listing descriptions vary widely in language and detail.
Vanguard implemented hybrid retrieval combining dense and sparse embeddings (trained in-house using BM25) in Pinecone serverless to power Agent Assist, an AI assistant for customer support representatives. The system uses hybrid search with Alpha set at 0.5 for optimal precision, especially for financial documents with domain-specific terms and abbreviations.
Improved result accuracy by over 12% compared to dense retrieval alone, significantly cut customer wait times, and enabled support for peak periods (e.g., tax season) without additional overhead.
Tooling & Ecosystem
Open-source vector database with built-in hybrid search API. Supports both relative score fusion (linear combination with min-max normalization) and ranked fusion (RRF). The alpha parameter directly controls sparse-dense weighting in a single query call.
High-performance vector database with native hybrid search via query fusion. Supports prefetch-based hybrid retrieval where sparse and dense results are fetched independently and fused using RRF or custom scoring. Written in Rust for low-latency serving.
Industry-standard search engine with hybrid search combining BM25 and kNN vector search. Supports RRF as a built-in retriever and linear combination via scripted scoring. Mature ecosystem for production deployment at scale with distributed sharding.
Cloud-native vector database with hybrid search capabilities combining dense and sparse vector retrieval. Supports multiple index types and distributed deployment. Backed by Zilliz for managed cloud offerings.
AWS-backed open-source search engine forked from Elasticsearch. Provides native hybrid search with a normalization processor that supports min-max and L2 normalization, plus RRF and arithmetic mean combination methods.
LangChain's EnsembleRetriever combines multiple retrievers (e.g., BM25Retriever + FAISS) using RRF or weighted fusion. Provides a quick prototyping path for hybrid search in RAG pipelines without database-native hybrid support.
Fully managed vector database with hybrid search support via sparse-dense vectors. Allows passing both sparse (BM25/SPLADE) and dense vectors in a single upsert and query, with server-side fusion. Zero operational overhead.
Reference implementation of the SPLADE family of learned sparse retrieval models. Produces sparse, high-dimensional representations that can replace or complement BM25 in a hybrid pipeline, offering superior semantic expansion while retaining inverted index compatibility.
Research & References
Robertson & Zaragoza (2009)Foundations and Trends in Information Retrieval, Vol. 3, No. 4
The foundational reference for the BM25 scoring function and the probabilistic relevance framework. Describes the theoretical underpinnings of term frequency saturation, document length normalization, and inverse document frequency weighting that remain the basis of sparse retrieval in every hybrid search system.
Cormack, Clarke & Buettcher (2009)ACM SIGIR 2009
Introduced Reciprocal Rank Fusion (RRF), a simple and effective rank-based fusion method. Demonstrated that RRF outperforms Condorcet fusion and individual rank learning methods across multiple TREC datasets. RRF's parameter-light nature (single constant k) has made it the default fusion baseline in modern hybrid search systems.
Karpukhin, Oguz, Min, Lewis, Wu, Edunov, Chen & Yih (2020)EMNLP 2020
Demonstrated that dense retrieval using a dual-encoder architecture outperforms BM25 by 9-19% on top-20 passage retrieval accuracy for open-domain QA. Established the dual-encoder paradigm that serves as the dense component in most hybrid search systems. Also showed that combining DPR with BM25 via simple score fusion further improves retrieval quality.
Formal, Piwowarski & Clinchant (2021)ACM SIGIR 2021
Introduced SPLADE, a learned sparse retrieval model that produces highly sparse, high-dimensional representations via log-saturation regularization. SPLADE expands documents with semantically related terms while maintaining inverted index compatibility, offering a neural alternative to BM25 that can serve as the sparse component in hybrid systems.
Formal, Lassance, Piwowarski & Clinchant (2021)arXiv preprint (extended in SIGIR 2022)
Extended SPLADE with distillation-based training, hard negative mining, and improved PLM initialization (SPLADE++). Achieved state-of-the-art effectiveness on MS MARCO and BEIR benchmarks while maintaining sparse, inverted-index-compatible representations. Demonstrated that learned sparse models can match or exceed dense retrievers on out-of-domain evaluation.
Bruch, Gai & Ingber (2023)ACM Transactions on Information Systems (TOIS), Vol. 42, No. 1
The most thorough empirical study of fusion functions for hybrid search. Demonstrated that convex combination of normalized scores outperforms RRF in both in-domain and out-of-domain settings. Showed that alpha tuning is sample-efficient (requiring few labeled examples), that the choice of score normalization has limited impact, and that RRF is sensitive to its smoothing parameter k. Essential reading for anyone deploying hybrid search in production.
Santhanam, Khattab, Saad-Falcon, Potts & Zaharia (2022)NAACL 2022
Introduced aggressive residual compression and denoised supervision for late interaction retrieval, achieving strong effectiveness with significantly reduced storage compared to ColBERT. ColBERTv2 represents a single-model alternative to hybrid search that captures both lexical and semantic signals through token-level interactions.
Mandikal & Kothyari (2024)AAAI 2024 Workshop on Scientific Document Understanding
Demonstrated that hybrid dense-sparse retrieval significantly improves scientific document retrieval quality over either method alone. Validated the hybrid approach on domain-specific corpora where vocabulary mismatch between user queries and technical documents is particularly severe.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is hybrid search, and why would you use it instead of pure dense or pure sparse retrieval?
- ●
Explain Reciprocal Rank Fusion. What are its advantages and limitations compared to linear score combination?
- ●
How would you decide the optimal alpha (weight) between BM25 and dense retrieval in a hybrid system?
- ●
What is SPLADE, and how does it differ from BM25 as a sparse retriever in a hybrid pipeline?
- ●
How would you implement hybrid search in a RAG system that needs to handle both technical documentation and conversational queries?
- ●
What happens if the dense and sparse retrievers disagree strongly on the relevance of a document? How does each fusion method handle this?
- ●
How would you evaluate whether hybrid search is actually improving your system compared to a single-retriever baseline?
Key Points to Mention
- ●
Hybrid search exploits the complementary failure modes of lexical and semantic retrieval -- BM25 handles exact matching while dense models capture paraphrase and synonym relationships. Neither dominates across all query types.
- ●
RRF is parameter-light and score-agnostic but discards magnitude information; linear combination is more expressive but requires score normalization and tuning. Know when to use which.
- ●
The optimal varies by domain and must be tuned on held-out relevance judgments -- Bruch et al. (2023) showed this requires as few as 50 labeled queries, making it very sample-efficient.
- ●
First-stage recall is the quality ceiling for the entire pipeline: a document not retrieved here cannot be recovered by any downstream re-ranker or generator. This is non-negotiable.
- ●
SPLADE provides a learned sparse representation that bridges the gap between BM25 and dense retrieval, offering semantic expansion while maintaining inverted index compatibility -- it's the best of both worlds in a single model.
- ●
Production systems should execute sparse and dense retrieval in parallel to avoid doubling latency. The target is , not their sum.
Pitfalls to Avoid
- ●
Claiming hybrid search always outperforms single-retriever baselines -- it requires tuning and can underperform if misconfigured. Say this explicitly in the interview.
- ●
Ignoring the operational cost: hybrid search requires maintaining two index types, which doubles storage and ingestion complexity. Acknowledge this tradeoff.
- ●
Confusing fusion functions -- mixing up score-based (linear combination) and rank-based (RRF) approaches or using them interchangeably without understanding the tradeoffs.
- ●
Forgetting to mention score normalization as a prerequisite for linear combination -- this is the #1 implementation bug and interviewers will test for it.
- ●
Treating hybrid search as a replacement for re-ranking -- they serve different purposes and are complementary in a multi-stage pipeline. Retrieval finds candidates; re-ranking orders them.
Senior-Level Expectation
A senior candidate should articulate the theoretical basis for why hybrid search works (complementary error distributions), compare RRF and linear combination with formal precision, discuss SPLADE and learned sparse retrieval as an evolution beyond BM25, and reason about production concerns: index synchronization, latency parallelism, tuning strategy, cost-quality tradeoffs, and monitoring for recall regression.
They should be able to design a hybrid search evaluation framework that measures marginal gain over single-retriever baselines and justify whether the added complexity is warranted for a given use case. Bonus points for discussing per-query dynamic based on query characteristics and explaining how to handle index desynchronization in distributed systems.
Summary
Let's recap everything we covered.
-
Hybrid search fuses sparse (BM25) and dense (bi-encoder) retrieval signals to exploit their complementary strengths: exact keyword matching and semantic similarity understanding. Neither paradigm dominates alone.
-
The two dominant fusion methods are Reciprocal Rank Fusion (RRF), which operates on ranks and requires no normalization, and weighted linear combination, which operates on normalized scores and offers higher peak performance when is tuned.
-
Bruch et al. (2023) demonstrated that convex combination outperforms RRF on both in-domain and out-of-domain benchmarks -- and is remarkably sample-efficient to tune (50 labeled queries!).
-
SPLADE and learned sparse models offer a neural alternative to BM25 that bridges the lexical-semantic gap through vocabulary expansion while retaining inverted index compatibility.
-
Production systems should execute both retrievals in parallel, use database-native hybrid search when available, and monitor Recall@k to verify the fusion provides measurable gains over single-retriever baselines.
-
First-stage retrieval recall is the quality ceiling for the entire RAG pipeline: hybrid search exists to maximize that ceiling.
Hybrid search is the pragmatic answer to a fundamental tension in information retrieval -- no single retrieval paradigm dominates across all queries and domains. By running lexical and semantic retrieval in parallel and fusing their outputs, we get a robust, complementary first-stage retriever that raises the recall ceiling for everything downstream.
Moving on, once you've nailed hybrid search, the next step in your RAG pipeline is the re-ranker -- which takes the fused candidate set and applies more expensive, fine-grained relevance scoring. But that's a story for another block.