Face Detection in Machine Learning
Face detection is the foundational computer vision task of locating human faces within images or video frames -- answering the question "where are the faces?" before any downstream analysis can begin. It is the mandatory first step in virtually every face-related ML pipeline: recognition, verification, emotion analysis, gaze tracking, virtual try-on, and more.
The field has evolved dramatically from Viola-Jones cascades in 2001 to modern deep learning detectors like RetinaFace and MediaPipe that achieve near-perfect accuracy on benchmarks while running in real time on mobile devices. Yet face detection remains far from a solved problem. Occlusion, extreme pose, tiny faces in crowds, lighting variation, and -- critically -- demographic bias continue to challenge even the best models.
At production scale, face detection powers everything from India's Aadhaar facial authentication system (which crossed 100 crore transactions in FY 2024-25) to Apple's Face ID, Snapchat's AR filters, and airport e-gates worldwide. Getting it right is not just a technical challenge but an ethical imperative: a face detector that fails on certain skin tones or age groups causes real harm.
This guide covers the full landscape: classical and deep learning architectures, the critical distinction between detection and recognition, landmark localization, liveness detection, bias considerations, production deployment patterns, and the Indian regulatory context. Whether you are building a KYC verification system for a fintech startup in Bengaluru or designing a safety monitoring pipeline for a manufacturing plant, this is your reference.
Concept Snapshot
- What It Is
- A computer vision model that localizes human faces in images or video by predicting bounding boxes (and optionally landmarks) around each face present in the input.
- Category
- Computer Vision
- Complexity
- Intermediate
- Inputs / Outputs
- Input: raw image or video frame (RGB tensor). Output: list of bounding boxes with confidence scores, optionally with facial landmark coordinates (eyes, nose, mouth corners).
- System Placement
- Sits at the very front of any face-analysis pipeline -- upstream of alignment, embedding, recognition, attribute analysis, and liveness detection.
- Also Known As
- face localization, face finder, face bounding box detector, facial detection
- Typical Users
- ML Engineers, Computer Vision Engineers, Product Engineers (AR/VR), Security & Surveillance Teams, Identity Verification (KYC) Teams
- Prerequisites
- Convolutional Neural Networks (CNNs), Object detection fundamentals (anchors, NMS), Image preprocessing (resizing, normalization), Basic understanding of bounding boxes and IoU
- Key Terms
- bounding boxfacial landmarksNMS (Non-Maximum Suppression)anchor-free detectionmulti-scale feature pyramidface alignmentIoU (Intersection over Union)WIDER FACE benchmark
Why This Concept Exists
The Need: Faces Are Everywhere, and Machines Need to Find Them
Humans are extraordinarily good at spotting faces -- our brains have a dedicated neural region (the fusiform face area) for exactly this purpose. But for machines, a face is just a pattern of pixel intensities, and detecting it requires solving several hard sub-problems simultaneously: scale variation (a face can occupy 10 pixels or 1000 pixels), pose variation (frontal, profile, tilted), occlusion (sunglasses, masks, hands), and illumination changes (harsh shadows, backlit scenes).
The practical demand for automated face detection exploded alongside three converging trends:
Trend 1: Digital Identity at Scale
India's Aadhaar program -- the world's largest biometric identity system with 1.4 billion enrollees -- illustrates the scale. In FY 2024-25, Aadhaar face authentication crossed 100 crore (1 billion) transactions, with over 100 government and private entities using it for service delivery. This scale is only possible because face detection can run reliably on commodity smartphones. Every single one of those billion transactions begins with a face detector locating the user's face in a phone camera frame.
Trend 2: Consumer AR and Social Media
Snapchat processes over 6 billion Snaps per day, many with AR face filters that require real-time face detection and landmark localization at 30+ FPS on mobile GPUs. Instagram, TikTok, and Indian apps like Meesho and ShareChat all rely on face detection for filters, stickers, and content moderation.
Trend 3: Security and Surveillance
From airport e-gates to smart city CCTV networks (India's AFRS -- Automated Facial Recognition System -- is deployed by multiple state police forces), face detection is the gateway to identification. This trend raises profound ethical questions that we'll address later.
Evolution of the Technology
The journey from classical to modern face detection spans two decades:
- 2001: Viola-Jones introduced Haar cascades with AdaBoost -- the first real-time face detector, running at 15 FPS on a 700 MHz Pentium. Revolutionary for its time, but brittle on non-frontal faces.
- 2010-2015: Deformable Part Models (DPM) and HOG+SVM approaches improved robustness but remained slow.
- 2016: MTCNN (Multi-task Cascaded Convolutional Networks) brought deep learning to face detection with a three-stage cascade (P-Net, R-Net, O-Net) that jointly performed detection and landmark localization.
- 2019: RetinaFace achieved state-of-the-art on WIDER FACE (91.4% AP on the hard set) by adding dense landmark regression and self-supervised mesh decoding to a single-stage detector.
- 2020-present: MediaPipe Face Mesh (468 3D landmarks in real time on mobile), YOLO-based face detectors, and lightweight architectures for edge deployment have pushed the frontier toward ubiquitous, always-on face detection.
Key Takeaway: Face detection exists because every face-related ML application -- from Aadhaar e-KYC to Snapchat filters -- needs to first answer "where are the faces?" before it can do anything else. The technology evolved from fragile cascade classifiers to robust deep detectors that work across scales, poses, and devices.
Core Intuition & Mental Model
Detection vs. Recognition: The Critical Distinction
Before we go deeper, let's nail down a distinction that trips up many engineers (and interviewers):
- Face detection answers: "Are there faces in this image, and where are they?" Output: bounding boxes + confidence scores.
- Face recognition answers: "Whose face is this?" Output: an identity label or embedding vector.
Detection is a prerequisite for recognition, but detection alone does not identify anyone. A face detector on a CCTV camera can count the number of people in a frame without knowing who any of them are. This distinction matters enormously for privacy: detection is generally privacy-preserving; recognition is where the surveillance concerns arise.
The Core Intuition: Sliding Windows on Steroids
At its heart, a face detector is asking: "For every possible rectangular region in this image, does it contain a face?" The naive approach -- sliding a classifier window across every position and scale -- is computationally explosive. A 1080p image has roughly 2 million pixels; checking every possible rectangle at every scale would require billions of evaluations.
Modern face detectors solve this with three key ideas:
- Feature pyramids: Process the image at multiple resolutions simultaneously using a Feature Pyramid Network (FPN), so small and large faces are detected by different layers of the network.
- Anchor-based or anchor-free proposals: Instead of sliding a window, predict face locations directly from feature map cells, either by refining pre-defined anchor boxes or by predicting center points.
- Multi-task learning: Simultaneously predict bounding boxes, confidence scores, and facial landmarks in a single forward pass -- the landmark predictions actually help regularize and improve detection accuracy.
A Useful Analogy
Think of face detection like a security guard scanning a crowd. A novice guard would examine every single person one by one (brute force). An experienced guard develops a spatial intuition -- they quickly scan the crowd at different distances (multi-scale), focus attention on head-height regions (feature maps), and use contextual cues like hair and shoulders to confirm a face (multi-task learning). That's essentially what a modern face detector does, except it processes the entire scene in one "glance" (a single forward pass through the neural network).
Expert Note: When your face detector misses faces, the problem is almost always at specific scales (tiny faces or extreme close-ups) or specific poses (profile, looking down). Understanding the multi-scale architecture tells you exactly where to look for the fix.
Technical Foundations
Mathematical Formulation
Face detection can be formalized as a special case of object detection restricted to the "face" class. Given an input image , a face detector outputs a set of detections:
where:
- is the bounding box (center coordinates, width, height)
- is the confidence score
- is an optional set of facial landmark coordinates
- is the number of detected faces
Detection Quality Metrics
The standard metrics for evaluating face detectors follow from object detection:
Intersection over Union (IoU):
A detection is considered correct (true positive) if with a ground-truth box.
Average Precision (AP): The area under the precision-recall curve, computed per difficulty level on WIDER FACE (easy, medium, hard).
Precision and Recall:
The Multi-Task Loss (MTCNN / RetinaFace Style)
Modern face detectors optimize a multi-task objective that jointly trains detection, bounding box regression, and landmark localization:
where:
- is the classification loss (binary cross-entropy: face vs. not-face)
- is the bounding box regression loss (smooth L1 or IoU-based)
- is the landmark regression loss (L2 distance between predicted and ground-truth landmark coordinates)
The weighting factors control the relative importance of each task. RetinaFace uses in its default configuration.
ArcFace Loss (Downstream Recognition)
While ArcFace is a recognition (not detection) loss, it's worth understanding because face detection and recognition pipelines are tightly coupled. ArcFace introduces an additive angular margin to the softmax loss:
where is the angle between the feature vector and the weight vector for the ground-truth class, is the angular margin penalty, and is a scaling factor. This pushes embeddings of different identities apart on a hypersphere, creating highly discriminative face representations.
Why This Matters for Detection: The quality of your face detector directly determines the quality of the crops fed to the recognition model. A poorly detected face with a tight or offset bounding box degrades ArcFace embedding quality, even if the recognition model is perfect.
Internal Architecture
A production face detection system typically follows a multi-stage architecture, even when the core detector is a single-stage network. The full pipeline includes preprocessing, detection, post-processing (NMS), and optional landmark refinement.
The most influential architectures in the field are:
MTCNN (2016): A three-stage cascade of increasingly complex CNNs. P-Net (Proposal Network) generates candidate windows at 12x12 resolution. R-Net (Refine Network) filters candidates at 24x24. O-Net (Output Network) produces final detections with 5 landmarks at 48x48. Each stage progressively eliminates false positives while refining bounding boxes.
RetinaFace (2019): A single-stage detector built on a Feature Pyramid Network (FPN) backbone (typically ResNet-50 or MobileNet). It performs dense face localization with multi-task branches for classification, bounding box regression, 5-point landmarks, and optionally a self-supervised 3D mesh decoder. Achieves 91.4% AP on WIDER FACE hard set.
MediaPipe Face Mesh (2020): Google's real-time pipeline uses BlazeFace (a lightweight SSD-style detector) for initial face detection, followed by a landmark regression model that predicts 468 3D landmarks. Designed for mobile and edge deployment with sub-5ms inference on modern smartphones.
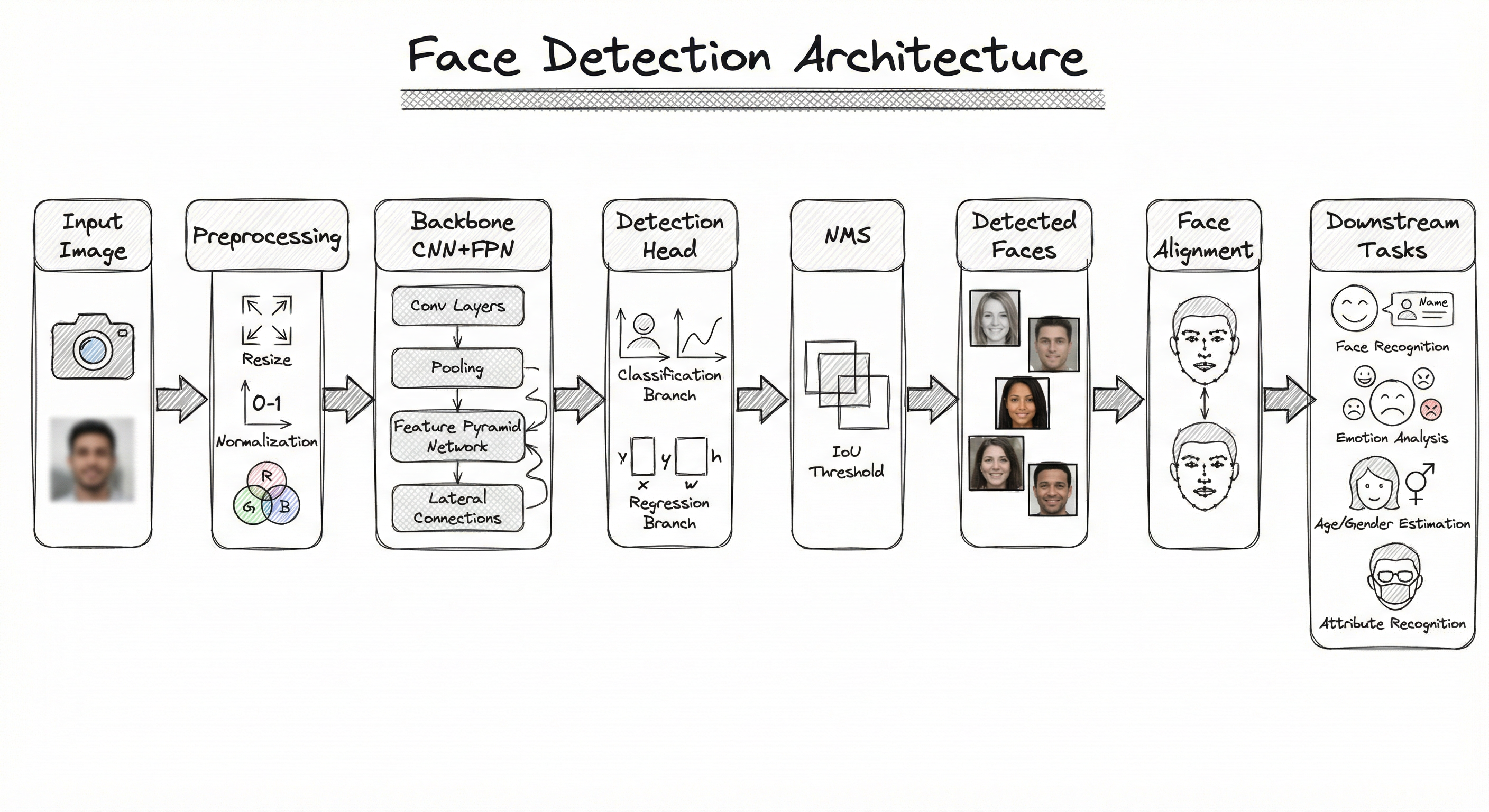
The backbone extracts multi-scale features. The detection head operates on each FPN level to predict faces of different sizes -- low-resolution feature maps detect large faces, high-resolution maps detect small faces. NMS eliminates duplicate detections. The aligned face crops are then passed to downstream models.
Key Components
Image Preprocessor
Resizes input to the detector's expected resolution, normalizes pixel values (typically to [0,1] or [-1,1]), and optionally applies image pyramids for multi-scale detection. For video pipelines, handles frame extraction and temporal sampling.
Backbone Network (Feature Extractor)
Extracts hierarchical visual features from the input image. Common choices: ResNet-50 (high accuracy, ~25M params), MobileNetV2 (mobile-friendly, ~3.4M params), or ShuffleNetV2 (ultra-lightweight). The backbone feeds into a Feature Pyramid Network (FPN) to produce multi-scale feature maps.
Detection Head
Multi-task head that operates on each FPN level. Produces three outputs per anchor/cell: (1) face/not-face classification score, (2) bounding box regression offsets , and (3) facial landmark coordinates. Uses anchor-based (RetinaFace) or anchor-free (CenterFace) formulations.
Non-Maximum Suppression (NMS)
Eliminates duplicate detections by keeping only the highest-confidence box among overlapping predictions. Standard IoU threshold is 0.4-0.5. Variants include Soft-NMS (decays scores instead of hard removal) and DIoU-NMS (considers center distance).
Face Aligner
Uses detected landmarks (typically 5 points: 2 eyes, nose tip, 2 mouth corners) to compute a similarity transform (rotation + scale + translation) that warps the face crop to a canonical frontal orientation. Critical for downstream recognition accuracy -- alignment alone improves recognition by up to 6%.
Liveness Detector (Optional)
Verifies that the detected face belongs to a live person, not a photo, video replay, or 3D mask. Techniques include texture analysis (detecting moire patterns from screens), depth estimation, infrared checks, and challenge-response (blink/head-turn prompts). Essential for KYC and authentication applications.
Data Flow
Detection Path: Raw image -> preprocessor (resize to 640x640 or image pyramid) -> backbone CNN extracts multi-scale features -> FPN merges features across scales -> detection heads predict boxes + scores + landmarks at each scale -> NMS filters duplicates -> final detections output.
Alignment Path: For each detected face -> extract 5 landmarks from detection head -> compute similarity transform to canonical template (e.g., 112x112 ArcFace input) -> apply affine warp -> output aligned face crop.
Video Path: Frame extraction (every Nth frame or based on motion detection) -> detection on selected frames -> optional tracking (SORT, DeepSORT) to propagate detections across frames without re-running the detector every frame, reducing compute by 3-5x.
The detection and alignment paths are typically fused into a single pipeline call. In production video systems, tracking reduces the need to run the full detector on every frame, bringing per-frame cost down from ~15ms to ~2ms for tracked faces.
A left-to-right flow: Input Image -> Preprocessing -> Backbone CNN with FPN -> Detection Head (classification, bounding box, landmarks) -> NMS -> Detected Faces -> Face Alignment -> Downstream Tasks (recognition, analysis). Multi-scale features flow from the backbone through the FPN, with separate detection heads at each scale level.
How to Implement
Choosing an Implementation Approach
Face detection implementations fall into three tiers:
Tier 1: Pre-built libraries -- Use deepface, insightface, or mediapipe directly. Zero model training, instant results. Best for prototyping and applications where the pre-trained model's accuracy is sufficient.
Tier 2: Fine-tuned detectors -- Start with a pre-trained RetinaFace or YOLO-Face model and fine-tune on your domain data (e.g., faces with surgical masks, faces in industrial safety helmets, or faces captured by specific camera hardware). This is the sweet spot for most production systems.
Tier 3: Cloud APIs -- AWS Rekognition, Azure Face API, or Google Cloud Vision. No infrastructure to manage, pay-per-call pricing. AWS Rekognition charges ~$1 per 1,000 images (~INR 0.084 per image). Azure Face API has similar consumption-based pricing. Good for low-volume applications or when you want to avoid ML infrastructure entirely.
Cost Comparison (India context): Processing 1 million face detections per month:
- Self-hosted RetinaFace on a single NVIDIA T4 GPU (AWS g4dn.xlarge in Mumbai): ~$380/month (~INR 31,900/month), can handle ~50M detections/month
- AWS Rekognition: ~$1,000/month (~INR 84,000/month) for 1M images
- MediaPipe on CPU: Free (open source), runs on a c5.xlarge at ~$124/month (~INR 10,400/month) for 1M+ detections
For Indian startups building KYC/eKYC solutions, self-hosted models are almost always more cost-effective at scale. The break-even point versus cloud APIs is typically around 100K-200K detections per month.
from retinaface import RetinaFace
import cv2
import numpy as np
# Load image
img_path = "group_photo.jpg"
img = cv2.imread(img_path)
# Detect faces (returns dict of faces with landmarks)
detections = RetinaFace.detect_faces(img_path)
for face_id, face_data in detections.items():
# Bounding box: [x1, y1, x2, y2]
bbox = face_data["facial_area"]
confidence = face_data["score"]
# 5 facial landmarks
landmarks = face_data["landmarks"]
right_eye = landmarks["right_eye"]
left_eye = landmarks["left_eye"]
nose = landmarks["nose"]
mouth_right = landmarks["mouth_right"]
mouth_left = landmarks["mouth_left"]
# Draw bounding box
cv2.rectangle(img, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)
cv2.putText(img, f"{confidence:.2f}", (bbox[0], bbox[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
# Draw landmarks
for point in landmarks.values():
cv2.circle(img, (int(point[0]), int(point[1])), 3, (0, 0, 255), -1)
cv2.imwrite("detected_faces.jpg", img)
print(f"Detected {len(detections)} faces")This example uses the retinaface Python package (a wrapper around the RetinaFace model). It returns both bounding boxes and 5 facial landmarks per face. The landmarks are critical for the downstream alignment step -- without proper alignment, recognition accuracy can drop by 5-10%. Install with pip install retinaface.
import mediapipe as mp
import cv2
import numpy as np
mp_face_mesh = mp.solutions.face_mesh
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
# Initialize face mesh (max 3 faces, min confidence 0.5)
with mp_face_mesh.FaceMesh(
max_num_faces=3,
refine_landmarks=True, # Adds iris landmarks (478 total)
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
) as face_mesh:
cap = cv2.VideoCapture(0) # Webcam
while cap.isOpened():
success, frame = cap.read()
if not success:
break
# Convert BGR to RGB for MediaPipe
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = face_mesh.process(rgb_frame)
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
# Draw the face mesh tesselation
mp_drawing.draw_landmarks(
image=frame,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_tesselation_style(),
)
# Access individual landmarks (468 points)
h, w, _ = frame.shape
nose_tip = face_landmarks.landmark[1]
nose_x, nose_y = int(nose_tip.x * w), int(nose_tip.y * h)
print(f"Nose tip at: ({nose_x}, {nose_y})")
cv2.imshow("Face Mesh", frame)
if cv2.waitKey(5) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()MediaPipe Face Mesh provides 468 3D landmarks (478 with iris refinement) in real time. This is far more detailed than the 5 landmarks from MTCNN or RetinaFace, enabling applications like facial expression tracking, head pose estimation, and AR effects. On a modern smartphone, inference takes ~3-5ms per frame. Install with pip install mediapipe.
from deepface import DeepFace
import json
# 1. Face detection with multiple backend options
faces = DeepFace.extract_faces(
img_path="group_photo.jpg",
detector_backend="retinaface", # Options: opencv, ssd, mtcnn, retinaface, mediapipe, yolov8
align=True,
enforce_detection=True,
)
for i, face in enumerate(faces):
print(f"Face {i}: confidence={face['confidence']:.3f}, "
f"region={face['facial_area']}")
# 2. Face verification (are these the same person?)
result = DeepFace.verify(
img1_path="person_a_1.jpg",
img2_path="person_a_2.jpg",
model_name="ArcFace", # Recognition model
detector_backend="retinaface", # Detection model
distance_metric="cosine",
)
print(f"Same person: {result['verified']}, distance: {result['distance']:.4f}")
# 3. Facial attribute analysis (age, gender, emotion, race)
analysis = DeepFace.analyze(
img_path="portrait.jpg",
actions=["age", "gender", "emotion"],
detector_backend="retinaface",
)
for face_analysis in analysis:
print(f"Age: {face_analysis['age']}, "
f"Gender: {face_analysis['dominant_gender']}, "
f"Emotion: {face_analysis['dominant_emotion']}")The deepface library (MIT licensed) wraps multiple detection backends (OpenCV, SSD, MTCNN, RetinaFace, MediaPipe, YOLOv8) and recognition models (VGG-Face, FaceNet, ArcFace, etc.) into a unified API. It handles the full pipeline: detect -> align -> represent -> verify/analyze. This is the fastest path from zero to a working face analysis system. Install with pip install deepface.
import insightface
from insightface.app import FaceAnalysis
import cv2
import numpy as np
# Initialize the face analysis pipeline
# buffalo_l: large model (best accuracy)
# buffalo_s: small model (faster, mobile-friendly)
app = FaceAnalysis(
name="buffalo_l",
providers=["CUDAExecutionProvider", "CPUExecutionProvider"],
)
app.prepare(ctx_id=0, det_size=(640, 640))
# Load and analyze image
img = cv2.imread("group_photo.jpg")
faces = app.get(img)
for face in faces:
# Detection results
bbox = face.bbox.astype(int) # [x1, y1, x2, y2]
det_score = face.det_score # Detection confidence
landmarks = face.kps # 5 key points (2x5 array)
# Recognition embedding (512-dim ArcFace vector)
embedding = face.embedding # np.ndarray of shape (512,)
# Attributes
age = face.age
gender = "Male" if face.gender == 1 else "Female"
print(f"Face: bbox={bbox}, score={det_score:.3f}, "
f"age={age}, gender={gender}")
# Draw on image
cv2.rectangle(img, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)
# Compare two faces by cosine similarity
if len(faces) >= 2:
sim = np.dot(faces[0].embedding, faces[1].embedding) / (
np.linalg.norm(faces[0].embedding) * np.linalg.norm(faces[1].embedding)
)
print(f"Similarity between face 0 and face 1: {sim:.4f}")
cv2.imwrite("insightface_output.jpg", img)InsightFace is the reference implementation for ArcFace and RetinaFace from the original authors. The buffalo_l model bundle includes RetinaFace detection + ArcFace recognition in a single pipeline. It produces 512-dimensional face embeddings that can be compared with cosine similarity for verification (threshold ~0.4) or searched in a vector store for identification. This is the gold standard for production face recognition systems. Install with pip install insightface onnxruntime-gpu.
# Production face detection pipeline config (YAML)
pipeline:
name: face-detection-v2
model: retinaface-resnet50
input:
max_resolution: 1920x1080
resize_to: 640x640
color_space: RGB
normalization: imagenet # mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]
detection:
confidence_threshold: 0.5
nms_iou_threshold: 0.4
max_faces: 50
min_face_size: 20 # pixels (in resized image)
landmarks:
enabled: true
num_points: 5 # eyes, nose, mouth corners
alignment:
enabled: true
output_size: 112x112 # ArcFace input size
template: arcface # canonical landmark positions
video:
tracker: bytetrack
detect_interval: 5 # run detector every N frames
track_confidence_threshold: 0.3
liveness:
enabled: true
method: texture_analysis
threshold: 0.7
hardware:
device: cuda:0
precision: fp16 # TensorRT optimization
batch_size: 8Common Implementation Mistakes
- ●
Not aligning faces before recognition: Feeding raw bounding box crops to a recognition model (ArcFace, FaceNet) without first performing landmark-based alignment. Alignment alone improves recognition accuracy by up to 6%. Always use the detected landmarks to compute a similarity transform before cropping.
- ●
Using a single detection threshold for all scenarios: A threshold of 0.5 may work for close-up selfies but will miss small or occluded faces in crowd scenes. Use lower thresholds (0.3-0.4) for recall-critical applications (surveillance, attendance) and higher thresholds (0.7-0.9) for precision-critical ones (KYC verification).
- ●
Ignoring image preprocessing: Many face detectors expect specific input formats (RGB vs BGR, specific normalization). OpenCV reads images in BGR; MediaPipe expects RGB. Forgetting this conversion is a silent accuracy killer.
- ●
Running the detector on every video frame: In video pipelines, running RetinaFace at 640x640 on every frame at 30 FPS consumes ~450ms/frame on CPU. Use a tracker (DeepSORT, ByteTrack) to propagate detections and only re-run the detector every 5-10 frames or when the tracker loses confidence.
- ●
Neglecting demographic bias testing: Deploying a face detector without evaluating performance across skin tones, age groups, and genders. The Gender Shades study showed up to 35% error rate on darker-skinned females for commercial systems. Always benchmark with diverse evaluation sets.
- ●
Confusing detection with recognition in privacy assessments: Telling stakeholders that your system "only does face detection" while actually storing face embeddings downstream. Face embeddings are biometric data and subject to data protection regulations regardless of what you call the pipeline.
When Should You Use This?
Use When
You need to locate faces in images or video as the first step of any face-related pipeline (recognition, verification, attribute analysis, AR effects)
Building a KYC/eKYC identity verification system (Aadhaar-based authentication, fintech onboarding in India)
Implementing attendance tracking, access control, or visitor management systems
Content moderation requiring detection of faces for blurring or anonymization before public release
AR/VR applications that need real-time facial landmark tracking for filters, avatars, or gaze estimation
Crowd counting or occupancy monitoring where you need to count faces without identifying them
Building a face search engine or similar-face retrieval system (detection is the prerequisite for embedding extraction)
Avoid When
Your task is purely person detection (full body) without face-specific analysis -- use a general object detector (YOLOv8, Detectron2) instead, as these handle occluded faces where only the body is visible
The faces in your images are always in the same, controlled position (e.g., passport photo cropping) -- a simple fixed crop may suffice without a neural network detector
You need to identify people primarily by gait, posture, or body shape rather than facial features -- face detection won't help when faces are obscured or too distant
Privacy regulations in your jurisdiction prohibit biometric data collection, and your downstream pipeline stores face embeddings -- address the legal framework first before deploying any face detection
Your compute budget is extremely constrained (e.g., a Raspberry Pi Zero) and even lightweight models like BlazeFace exceed your latency budget -- consider motion detection or simple skin-color segmentation as cheaper alternatives
The problem can be solved with simpler presence/absence detection (e.g., PIR motion sensor) without the need for computer vision
Key Tradeoffs
Accuracy vs. Speed
This is the primary tradeoff. The landscape looks roughly like this:
| Model | WIDER FACE Hard AP | Inference (GPU) | Inference (CPU) | Params |
|---|---|---|---|---|
| RetinaFace-ResNet50 | 91.4% | ~15ms | ~120ms | ~30M |
| RetinaFace-MobileNet | 82.5% | ~5ms | ~30ms | ~1M |
| MTCNN | 84.8% | ~20ms | ~80ms | ~0.5M |
| BlazeFace (MediaPipe) | ~79% | ~2ms | ~8ms | ~0.1M |
| YOLOv8n-Face | ~85% | ~4ms | ~25ms | ~3M |
For KYC/verification (single face, controlled environment): BlazeFace or MTCNN is sufficient. Speed matters because users are waiting.
For surveillance/crowd detection (many small faces, uncontrolled): RetinaFace-ResNet50 is worth the compute cost. Missing a face in a security context is more expensive than a few extra milliseconds.
For mobile AR (real-time, 30+ FPS required): BlazeFace or MediaPipe Face Mesh. Nothing else is fast enough on mobile GPUs while maintaining acceptable landmark quality.
The Bias Tradeoff
More accurate models (trained on larger, more diverse datasets) tend to exhibit less demographic bias, but no model is perfectly fair. You must explicitly evaluate and report per-demographic performance. The cost of bias is not just ethical -- it's business-critical. A KYC system that rejects legitimate users from specific demographics loses customers and invites regulatory scrutiny.
Cloud vs. Self-Hosted
Cloud APIs (AWS Rekognition at ~INR 0.084/image, Azure Face API at similar rates) offer zero operational overhead but become expensive at scale and introduce latency (~100-300ms round-trip). Self-hosted models on a GPU instance (INR 31,900/month for an NVIDIA T4) can process millions of images for a fixed cost. The break-even is around 200K-400K images/month.
Alternatives & Comparisons
General object detectors can detect faces as one of many classes, but face-specific detectors (RetinaFace, MTCNN) significantly outperform them on challenging face scenarios -- small faces, heavy occlusion, extreme pose. Use a general detector when you need to detect faces alongside other objects (people, vehicles) in a unified pipeline. Use a dedicated face detector when face detection accuracy is the priority.
Image preprocessors handle resizing, normalization, and augmentation but do not perform detection. They are upstream of the face detector. If your face detector is underperforming, improving preprocessing (better resolution, denoising, histogram equalization) can yield significant gains without changing the detector itself.
Privacy filters blur, pixelate, or replace detected faces to anonymize images/video. They depend on face detection as an upstream step -- you can't anonymize what you haven't detected. If your goal is to remove faces rather than analyze them, pair a fast detector (BlazeFace) with a privacy filter for an efficient anonymization pipeline.
Pros, Cons & Tradeoffs
Advantages
Mature ecosystem: Multiple production-ready open-source implementations (RetinaFace, MTCNN, MediaPipe, InsightFace) with pre-trained weights, extensive documentation, and active communities. You can go from zero to a working detector in under 30 minutes.
Real-time performance on edge devices: Lightweight models like BlazeFace achieve sub-5ms inference on mobile phones, enabling on-device face detection without cloud round-trips -- critical for privacy-sensitive applications and offline scenarios.
Multi-task learning provides free extras: Modern detectors output landmarks and head pose alongside bounding boxes at negligible additional cost, eliminating the need for separate landmark detection models.
Transfer learning friendly: Pre-trained face detectors can be fine-tuned on domain-specific data (masked faces, specific camera angles, industrial helmets) with relatively small datasets (1,000-10,000 annotated images) and converge quickly.
Well-established benchmarks: WIDER FACE, FDDB, and AFW provide standardized evaluation, making it straightforward to compare models and track progress objectively.
Scales from mobile to cloud: The same model family (e.g., RetinaFace with MobileNet vs. ResNet backbone) spans mobile to server deployment, allowing a single codebase with configurable accuracy-speed tradeoffs.
Disadvantages
Demographic bias is pervasive: The Gender Shades study found up to 35% error rates on darker-skinned females for commercial systems. Even modern models trained on more diverse data still exhibit measurable disparities. Continuous bias auditing is required, not optional.
Occlusion and extreme pose remain hard: Faces obscured by masks, hands, or objects -- and faces in extreme profile or looking straight down -- still cause significant accuracy drops, even for state-of-the-art models.
Small face detection is unreliable: Faces smaller than ~20x20 pixels (common in wide-angle surveillance or crowd scenes) are frequently missed. Higher input resolution helps but proportionally increases compute cost.
Liveness detection adds significant complexity: Preventing spoofing attacks (printed photos, screen replays, 3D masks) requires additional models, hardware (IR sensors), or challenge-response protocols that complicate the user experience and increase latency.
Ethical and legal landmines: Deploying face detection in public spaces without consent raises GDPR, India's DPDP Act, and other regulatory concerns. India lacks comprehensive facial recognition regulation as of 2025, creating legal uncertainty.
Annotation cost for custom datasets: Building a domain-specific face detection dataset with bounding boxes and landmarks requires skilled annotators. Expect INR 5-15 (~0.18-0.36) per image with 5-point landmarks.
Failure Modes & Debugging
Demographic bias causing disparate false negative rates
Cause
Training data skewed toward lighter-skinned, younger faces. Most popular face detection datasets (WIDER FACE, CelebA) have demographic imbalances. The model learns to detect overrepresented groups more reliably.
Symptoms
Higher miss rates for darker skin tones, older individuals, and women -- particularly darker-skinned women (the intersection effect documented in Gender Shades). In a KYC system, this manifests as specific user demographics being asked to retry verification more often.
Mitigation
Evaluate per-demographic recall using balanced test sets (e.g., BFW -- Balanced Faces in the Wild). Fine-tune on demographically balanced data. Use data augmentation to simulate diverse lighting and skin tones. Report disaggregated metrics, not just aggregate AP. Consider tools like IBM's AI Fairness 360 for bias auditing.
Spoofing / presentation attacks bypassing liveness checks
Cause
A printed photo, video replay on a phone screen, or a 3D-printed mask is presented to the camera. Basic face detectors cannot distinguish live faces from spoofs -- they will happily detect a face in a photograph.
Symptoms
Unauthorized access in authentication systems. False acceptance of spoofed identities during KYC onboarding. In India's Aadhaar context, this could enable fraudulent benefit claims.
Mitigation
Deploy a dedicated liveness detection module: passive liveness (texture analysis detecting moire patterns, screen reflections) or active liveness (challenge-response: blink detection, head turn, smile). For high-security applications, use multi-modal checks (IR depth sensor + RGB). UIDAI's Aadhaar face authentication includes liveness measures built into the specification.
Small face miss rate in crowd / surveillance scenes
Cause
Faces occupying fewer than ~20x20 pixels in the input image fall below the detector's effective resolution. FPN feature maps at the highest resolution still represent these faces with too few feature cells.
Symptoms
Significant drop in recall for distant subjects in wide-angle cameras. Crowd counting underestimates by 20-40% in large venues. Security systems fail to detect persons at the periphery of camera view.
Mitigation
Use tiled inference: split the high-resolution image into overlapping tiles, run the detector on each tile, and merge results with NMS. Alternatively, increase input resolution (from 640 to 1280 or higher) at the cost of ~4x compute. RetinaFace with an image pyramid achieves better small-face recall but at 3-5x latency cost.
NMS over-suppression in dense face scenarios
Cause
When faces are tightly packed (concert crowds, group photos), standard NMS with a fixed IoU threshold can suppress correct detections of adjacent faces that have high bounding box overlap.
Symptoms
Missing faces in group photos or crowd scenes despite high per-face confidence. Detection count plateaus below the actual face count. One face in a cluster is detected while adjacent overlapping faces are suppressed.
Mitigation
Lower the NMS IoU threshold (from 0.5 to 0.3) for dense-face scenarios. Use Soft-NMS which decays confidence scores instead of hard removal. Alternatively, use anchor-free detectors (CenterFace, FCOS-Face) which are inherently more robust to dense overlap.
Motion blur and low-light degradation in video
Cause
Fast subject movement causes blur that destroys facial texture. Low-light cameras produce noisy, low-contrast images where faces blend into backgrounds. Both effects compound in night-time surveillance.
Symptoms
Intermittent detection failures during fast motion sequences. Consistent low confidence scores in night-time or indoor footage. Tracking systems lose face IDs and create fragmented tracks.
Mitigation
Use cameras with higher shutter speeds and IR illumination. Apply super-resolution or denoising preprocessing (Real-ESRGAN, SwinIR) before detection. Fine-tune the detector on low-light/blurry training data. In tracking pipelines, use Kalman filter prediction to maintain tracks through brief detection gaps.
Model drift with changing face appearance patterns
Cause
The COVID-19 pandemic dramatically demonstrated this: when populations started wearing masks en masse, face detectors trained on unmasked faces experienced significant accuracy drops. Similar drift occurs with changing fashion (face coverings, oversized sunglasses) or camera hardware changes.
Symptoms
Gradual decline in detection recall over time without any system changes. Spike in detection failures correlated with external events (mask mandates, seasonal fashion changes).
Mitigation
Implement continuous monitoring of detection metrics against a golden evaluation set. Retrain or fine-tune periodically with recent data. For mask detection specifically, fine-tune on masked face datasets (MaskedFace-Net, MAFA). Build an alerting system that flags when recall drops below threshold.
Placement in an ML System
Where Face Detection Sits in the ML Pipeline
Face detection is the gateway of any face-analysis system. It sits immediately after image acquisition and preprocessing, and its output feeds into every downstream face-related task:
- Face recognition/verification: Detection -> Alignment -> Embedding (ArcFace) -> Comparison
- Face attribute analysis: Detection -> Alignment -> Attribute classifier (age, gender, emotion)
- Face anonymization: Detection -> Privacy filter (blur/pixelate/replace)
- AR face effects: Detection -> Landmark mesh (MediaPipe) -> 3D overlay rendering
- Liveness detection: Detection -> Anti-spoofing classifier -> Accept/reject
The critical insight is that face detection determines the quality ceiling for everything downstream. If the detector misses a face, no amount of downstream processing can recover it. If the detector produces a poor bounding box (too tight, offset, or including background), the alignment step produces a distorted crop that degrades recognition accuracy.
Rule of Thumb: In a face recognition pipeline, approximately 80% of errors trace back to detection or alignment failures, not the recognition model itself. Invest in your detector before upgrading your recognition model.
In production systems at scale (e.g., India's DigiYatra airport face recognition system), face detection runs on edge devices (cameras with embedded GPUs) to minimize data transfer, with only the aligned face crops sent to centralized recognition servers.
Pipeline Stage
Preprocessing / Feature Extraction
Upstream
- image-preprocessor
Downstream
- object-detector
- bias-detector
- privacy-filter
Scaling Bottlenecks
Face detection is typically the most compute-intensive step per frame in a video pipeline. A RetinaFace-ResNet50 model at 640x640 input requires ~12 GFLOPs per image. For a 100-camera video surveillance system at 5 FPS each, that's 500 detections/second requiring ~6 TFLOPs sustained -- roughly 2 NVIDIA T4 GPUs dedicated just to detection.
- Batch processing: Accumulate frames and process in batches of 8-32 on GPU. Increases throughput by 3-5x over single-image inference.
- Model quantization: FP16 inference halves memory and doubles throughput on Tensor Cores. INT8 quantization (via TensorRT or OpenVINO) provides another 2x speedup with minimal accuracy loss (<0.5% AP).
- Tracking-based frame skipping: Run the detector every 5th frame and use a lightweight tracker (ByteTrack) on intermediate frames. Reduces effective compute by 4-5x.
- Hierarchical detection: Run a lightweight detector (BlazeFace) on full frames, then run a heavy detector (RetinaFace) only on regions of interest. Reduces per-frame cost by 60-80% in sparse scenes.
At India-scale deployments like Aadhaar (processing 100 crore face authentications in a year), the infrastructure requires distributed GPU clusters with load balancing, model serving via Triton Inference Server, and careful batching to maintain sub-500ms end-to-end latency per authentication request.
Production Case Studies
India's Aadhaar system, operated by UIDAI, deployed face authentication as a modality alongside fingerprint and iris. In FY 2024-25, face authentication transactions crossed 100 crore (1 billion), with over 100 government and private entities using it. The system runs on smartphone cameras, requiring robust face detection across diverse lighting, skin tones, and device quality. UIDAI received the PM's Award for Excellence in Public Administration for this innovation.
1 billion face authentication transactions in a single fiscal year, enabling Aadhaar-based KYC and benefit delivery for 1.4 billion citizens. Face auth now accounts for a significant share of total Aadhaar authentications, reducing dependency on fingerprint scanners.
Apple's Face ID uses a TrueDepth camera (structured light IR projector + IR camera) combined with a neural network face detector to authenticate users on iPhone and iPad. The system projects 30,000 IR dots to create a 3D depth map of the face, enabling robust face detection and liveness verification that defeats printed photos and masks. The detection model runs entirely on-device via the Neural Engine.
Face ID has a false acceptance rate of 1 in 1,000,000 (compared to 1 in 50,000 for Touch ID). It works in complete darkness (IR-based) and adapts to gradual appearance changes (glasses, beards, aging). Used by over 1 billion iPhone users daily.
Snapchat's AR Lens platform relies on real-time face detection and dense landmark tracking to overlay filters, masks, and 3D effects on user faces. The detector must achieve consistent 30+ FPS on mobile devices across the full range of smartphone hardware. Snap processes over 6 billion Snaps per day, many involving face detection for AR effects.
Real-time face mesh tracking with sub-5ms detection latency on mobile GPUs, enabling seamless AR experiences. The technology drove Snapchat's AR platform to become a $500M+ annual business, with 250M+ daily AR Lens users.
India's DigiYatra program deploys face detection and recognition at airports for seamless, paperless passenger processing. Passengers register their face with their boarding pass, and face detection systems at entry gates, security checkpoints, and boarding gates verify identity without manual document checks. Deployed at 24+ Indian airports including Delhi, Bengaluru, Mumbai, and Hyderabad.
Reduced average passenger processing time from 45 seconds to under 10 seconds at each checkpoint. Over 70 lakh (7 million) passengers processed through DigiYatra as of early 2025, with plans for pan-India rollout.
Tooling & Ecosystem
Standalone Python implementation of RetinaFace for face detection with 5-point landmark localization. Achieves state-of-the-art accuracy on WIDER FACE. Easy to install via pip, wraps TensorFlow backend.
Comprehensive 2D and 3D face analysis library from the original ArcFace/RetinaFace authors. Includes detection (RetinaFace, SCRFD), recognition (ArcFace), alignment, and attribute analysis. Production-grade with ONNX Runtime support for deployment. MIT licensed.
Google's real-time face detection and 468-landmark mesh solution. Optimized for mobile and edge devices with sub-5ms inference. Includes BlazeFace detector, face mesh, and blendshape coefficients (52 facial expressions). Cross-platform: Python, JavaScript, Android, iOS.
Lightweight Python library wrapping multiple face detection backends (OpenCV, MTCNN, RetinaFace, MediaPipe, YOLOv8) and recognition models (ArcFace, FaceNet, VGG-Face). Unified API for detection, verification, recognition, and attribute analysis. MIT licensed.
PyTorch implementation of MTCNN face detection + FaceNet/InceptionResNet recognition. Pre-trained models included. The MTCNN implementation supports batched detection for efficient video processing. Well-documented with extensive examples.
Fully managed cloud API for face detection, analysis, comparison, and search. Detects up to 100 faces per image with attributes (age range, gender, emotions, landmarks). Pay-per-use: ~$1 per 1,000 images (~INR 84 per 1,000 images). No ML expertise required.
Microsoft's cloud face detection and recognition service. Provides face detection, verification, identification, and grouping. Consumption-based pricing with free tier for development. Includes liveness detection capabilities.
YOLOv8 adapted for face detection with landmark regression. Pre-trained on WIDER FACE dataset. Offers nano to large model variants (3M to 43M params). Excellent speed-accuracy tradeoff for real-time applications.
Research & References
Zhang, Zhang, Li, Qiao (2016)IEEE Signal Processing Letters
Introduced MTCNN, the three-stage cascaded detector (P-Net, R-Net, O-Net) that performs joint face detection and landmark alignment. Became the de facto standard face detector for years and remains widely used.
Deng, Guo, Zhou, Yu, Kotsia, Zafeiriou (2020)CVPR 2020
Proposed RetinaFace, achieving 91.4% AP on WIDER FACE hard set via multi-task learning with extra-supervised 5-point landmarks and self-supervised 3D mesh decoding. Current state-of-the-art for single-stage face detection.
Deng, Guo, Xue, Zafeiriou (2019)CVPR 2019
Introduced the ArcFace angular margin loss that produces highly discriminative face embeddings on a hypersphere. The standard loss function for modern face recognition systems, achieving state-of-the-art on LFW, CFP-FP, and AgeDB benchmarks.
Buolamwini, Gebru (2018)FAT* 2018 (now FAccT)
Landmark study revealing dramatic accuracy disparities in commercial face analysis systems: up to 34.7% error on darker-skinned females vs. <1% on lighter-skinned males. Catalyzed the AI fairness movement and led to policy changes by IBM, Microsoft, and Amazon.
Bazarevsky, Kartynnik, Vakunov, Raveendran, Grundmann (2019)CVPR Workshop on Computer Vision for AR/VR 2019
Presented BlazeFace, a lightweight face detector achieving sub-millisecond inference on mobile GPUs. Uses a modified SSD architecture with depthwise separable convolutions. Powers Google's MediaPipe face detection pipeline.
Yang, Luo, Loy, Tang (2016)CVPR 2016
Introduced the WIDER FACE benchmark with 32,203 images and 393,703 annotated faces across 61 event categories. Established the standard evaluation protocol (easy/medium/hard splits) used by all subsequent face detection research.
Ahn, Kim (2024)arXiv preprint
Explored Vision Transformer architectures fine-tuned with DINO-based self-supervised learning for face anti-spoofing. Demonstrated improved generalization to unseen attack types compared to CNN-based liveness detectors.
Albiero, Bowyer (2025)arXiv preprint
Comprehensive 2025 survey of demographic bias in face recognition and detection systems. Reviews causes (dataset imbalance, feature representation gaps), measurement methodologies, and mitigation strategies across commercial and academic systems.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is the difference between face detection and face recognition? Where does each sit in the pipeline?
- ●
How does MTCNN's three-stage cascade architecture work? Why use a cascade instead of a single-stage detector?
- ●
How would you design a face detection system for a KYC application serving 10 million users in India?
- ●
What is the WIDER FACE benchmark and how is performance measured on it?
- ●
How do you handle demographic bias in face detection systems?
- ●
Explain how RetinaFace achieves multi-scale face detection using Feature Pyramid Networks.
- ●
How would you implement liveness detection to prevent spoofing attacks?
- ●
What are the tradeoffs between running face detection on-device vs. in the cloud?
Key Points to Mention
- ●
Face detection finds faces (bounding boxes + landmarks); face recognition identifies whose face it is (embeddings + matching). Detection is the prerequisite for recognition, not a substitute.
- ●
RetinaFace achieves 91.4% AP on WIDER FACE hard set by combining FPN-based multi-scale detection with multi-task learning (classification + box regression + 5-point landmarks + optional 3D mesh).
- ●
MTCNN's three-stage cascade (P-Net -> R-Net -> O-Net) progressively refines detections, trading compute for accuracy. Early stages are cheap and eliminate easy negatives; later stages are expensive but only process remaining candidates.
- ●
Demographic bias is not a niche concern -- Gender Shades showed up to 35% error on darker-skinned females in commercial systems. Always report disaggregated metrics and use balanced evaluation sets.
- ●
In production video pipelines, use tracking (DeepSORT, ByteTrack) to avoid running the detector on every frame. This reduces compute by 4-5x while maintaining detection continuity.
- ●
Liveness detection is mandatory for any authentication application. Passive methods (texture analysis) are less intrusive; active methods (blink/head turn) are more robust but hurt UX.
- ●
Face alignment using detected landmarks improves downstream recognition accuracy by up to 6% -- it is not optional in production pipelines.
Pitfalls to Avoid
- ●
Conflating face detection with face recognition -- they are distinct tasks with different outputs, privacy implications, and technical requirements.
- ●
Claiming a face detector has 'solved' the problem based on WIDER FACE easy/medium scores while ignoring the hard subset (which represents real-world challenges like small, occluded, and atypical faces).
- ●
Ignoring the ethical dimension entirely -- any senior-level discussion of face detection should proactively address bias, consent, and regulatory considerations.
- ●
Assuming one detection threshold works for all applications -- KYC verification and crowd surveillance require very different precision-recall operating points.
- ●
Forgetting that face detection quality is the ceiling for the entire downstream pipeline -- optimizing the recognition model while the detector produces poor crops is wasted effort.
Senior-Level Expectation
A senior/staff-level candidate should discuss the full system design, not just the model. This includes: (1) multi-scale detection architecture choices with quantitative justification (RetinaFace for accuracy vs. BlazeFace for latency, with actual numbers), (2) the detection-alignment-embedding pipeline as an integrated system where each stage's quality bounds the next, (3) bias evaluation methodology with specific metrics and datasets (BFW, demographic-stratified recall), (4) liveness detection strategy appropriate to the threat model, (5) production scaling patterns (batching, quantization, tracking-based frame skipping, tiled inference for small faces), (6) cost analysis in both USD and INR with break-even calculations for cloud vs. self-hosted, and (7) regulatory awareness -- GDPR biometric data requirements, India's DPDP Act implications, and the distinction between detection (generally acceptable) and recognition (requires consent). The ability to reason about the ethical tradeoffs -- not just dismiss them -- separates truly senior engineers.
Summary
Recap
Face detection -- the task of locating human faces in images and video -- is the foundational gate of every face-analysis ML pipeline. Whether you're building Aadhaar-scale identity verification (1 billion face authentications in FY 2024-25), Snapchat-style AR filters (6 billion Snaps/day), or airport boarding with DigiYatra, the face detector is where it all begins. A missed face means a failed pipeline; a poorly cropped face degrades everything downstream.
The technology has matured from Viola-Jones cascades (2001) through MTCNN's three-stage deep cascade (2016) to RetinaFace's single-stage FPN architecture (91.4% AP on WIDER FACE hard) and MediaPipe's real-time 468-landmark face mesh on mobile devices. Modern detectors jointly predict bounding boxes, confidence scores, and facial landmarks in a single forward pass, trained with multi-task losses that combine classification (), box regression (), and landmark regression ().
But accuracy on benchmarks is only half the story. Demographic bias remains a critical challenge -- the Gender Shades study exposed 35x error rate disparities across skin tones and genders, and while the gap has narrowed, it has not closed. Liveness detection is mandatory for any authentication application to prevent spoofing attacks. Privacy and ethical considerations -- particularly around consent, surveillance, and India's evolving regulatory landscape -- must be addressed at design time, not as an afterthought. The tools are ready (InsightFace, DeepFace, MediaPipe are all open source and production-grade), the costs are manageable (self-hosted detection at INR 32K/month handles millions of images), and the demand is enormous. The challenge for ML engineers is to deploy this technology responsibly, with rigorous bias evaluation, robust liveness checks, and genuine respect for the faces in the frame.