Sentiment Analyzer in Machine Learning
A sentiment analyzer is an NLP component that takes raw text as input and produces a structured assessment of the emotional tone, polarity, and opinion expressed within it. At its simplest, it answers the question: is this text positive, negative, or neutral? At its most sophisticated, it decomposes text into aspect-level opinions, detects sarcasm, handles code-mixed languages like Hinglish, and quantifies emotional intensity on a continuous scale.
Sentiment analysis sits at the heart of virtually every customer-facing product that processes user-generated content. From Flipkart's product review summaries to Zomato's restaurant rating insights, from Twitter trend monitoring during IPL seasons to Razorpay's merchant feedback pipeline -- sentiment analyzers convert unstructured human language into structured signals that downstream systems can act upon.
The field has evolved dramatically: from hand-crafted lexicons (VADER, SentiWordNet) through classical ML classifiers (Naive Bayes, SVM with TF-IDF) to modern transformer-based models (BERT, RoBERTa, DeBERTa) that capture nuance, negation, and context in ways that were impossible a decade ago. Today, the frontier includes zero-shot sentiment classification with large language models, aspect-based sentiment analysis (ABSA), and handling the unique challenges of emoji-heavy, multilingual social media text.
Whether you are building a brand monitoring dashboard, a content moderation pipeline, or a recommendation system that incorporates user sentiment signals, understanding sentiment analyzers -- their architectures, tradeoffs, and failure modes -- is essential knowledge for any ML engineer working with text data.
Concept Snapshot
- What It Is
- An NLP component that classifies the emotional polarity (positive, negative, neutral) and optionally the intensity, subjectivity, and aspect-level opinions expressed in a given text.
- Category
- NLP
- Complexity
- Intermediate
- Inputs / Outputs
- Input: raw text (reviews, tweets, comments, chat messages). Output: polarity label (positive/negative/neutral), confidence score, and optionally aspect-sentiment pairs, emotion labels, or continuous valence scores.
- System Placement
- Sits after text preprocessing (tokenization, cleaning) and before downstream decision systems (recommendation engines, alert triggers, dashboards, content moderators).
- Also Known As
- sentiment classifier, opinion mining engine, sentiment detection model, polarity classifier, emotion analyzer, tone detector
- Typical Users
- ML Engineers, Data Scientists, NLP Engineers, Product Analysts, Customer Experience Teams, Brand Monitoring Analysts
- Prerequisites
- Text preprocessing and tokenization, Classification fundamentals (precision, recall, F1), Word embeddings and contextual representations, Basic understanding of transformer architectures
- Key Terms
- polarityvalencesubjectivityaspect-based sentimentcompound scorefine-grained sentimentnegation handlingsarcasm detectioncode-mixing
Why This Concept Exists
The Explosion of Unstructured Opinion Data
Humans express opinions constantly -- in product reviews, social media posts, support tickets, survey responses, and app store ratings. By some estimates, over 500 million tweets are posted daily, and platforms like Amazon India and Flipkart collectively host hundreds of millions of product reviews. No team of human analysts can read all of that. Sentiment analysis automates the extraction of opinion signals from this firehose of unstructured text.
Before sentiment analyzers existed, businesses relied on proxy signals: star ratings, NPS scores, or manually coded survey responses. But a 3-star review that says "decent product but terrible packaging" carries very different information than one that says "average in every way." Star ratings lose nuance; sentiment analyzers recover it.
From Lexicons to Transformers: A Brief History
The earliest approaches were lexicon-based: curate a dictionary of words with associated sentiment scores (e.g., "excellent" = +3, "terrible" = -3), sum up the scores in a document, and call it a day. The General Inquirer (1960s) was among the first such systems. SentiWordNet (2006) and VADER (2014) refined this approach with better coverage of informal language, emoticons, and intensity modifiers.
The next wave brought machine learning classifiers -- Naive Bayes, SVMs, and logistic regression trained on labeled datasets like the Stanford Sentiment Treebank (SST). These models could learn domain-specific patterns that lexicons missed, but they required extensive feature engineering (TF-IDF, n-grams, POS tags).
The transformer revolution changed everything. BERT (2019) and its variants (RoBERTa, DistilBERT, XLNet) demonstrated that a pre-trained language model fine-tuned on a few thousand labeled examples could outperform years of feature engineering. Today, models like cardiffnlp/twitter-roberta-base-sentiment-latest on Hugging Face achieve state-of-the-art accuracy on social media sentiment with minimal setup.
Why It Still Isn't "Solved"
Despite the progress, sentiment analysis remains surprisingly hard. Sarcasm ("Oh great, another delayed delivery"), negation ("not bad at all"), implicit sentiment ("the battery lasted 2 hours" -- negative for a laptop, positive for a concert), and code-mixed text ("yeh phone bahut accha hai but camera is worst") all challenge even the best models. Domain transfer is another issue: a model trained on movie reviews will struggle with financial earnings calls. These unsolved challenges are exactly why understanding the architecture and tradeoffs matters.
Key Takeaway: Sentiment analyzers exist because humans generate vastly more opinion text than any team can manually process, and simple proxies like star ratings lose the nuance that businesses need for actionable insights.
Core Intuition & Mental Model
The Mental Model: A Human Reader at Scale
Imagine you are reading a product review on Amazon India: "Camera quality is outstanding in daylight but night mode is disappointing. Battery backup is decent for the price." As a human, you instantly parse this into three opinions: camera-daylight (positive), camera-night (negative), battery (mildly positive). A sentiment analyzer does exactly this, but at the rate of thousands of reviews per second.
The simplest version just gives you an overall polarity -- "this review is mostly positive." A more sophisticated version (aspect-based sentiment analysis) breaks it down by aspect, which is far more useful for product teams who need to know what specifically customers love or hate.
Why Context Is Everything
Consider the word "sick." In a medical context, it is negative. In slang ("this beat is sick!"), it is positive. A lexicon-based tool will always treat "sick" the same way. A transformer-based model, because it reads the surrounding context, can distinguish between the two. This is the fundamental advantage of contextual models: they don't just look up word scores -- they understand how words interact in a sentence.
The same principle applies to negation. "Not good" is obviously negative, but "not bad" is mildly positive, and "not bad at all" is quite positive. Simple negation-flipping rules (multiply by -1 when "not" appears) fail here. Contextual models learn these subtleties from data.
The Spectrum, Not the Binary
Sentiment is rarely binary. Most real-world opinions fall on a continuous spectrum. The Stanford Sentiment Treebank introduced five-class fine-grained sentiment (very negative, negative, neutral, positive, very positive), and modern systems often output a continuous score from -1.0 to +1.0. VADER's compound score, for example, ranges from -1 (maximally negative) to +1 (maximally positive), with the magnitude indicating intensity.
This continuous view is critical for production systems. A review with a sentiment score of -0.2 might need no action, but one at -0.9 might trigger an automatic escalation to customer support. The difference between -0.2 and -0.9 is lost if you collapse everything into a binary positive/negative label.
Expert Note: Always prefer continuous or fine-grained sentiment scores over binary labels in production. Binary labels discard intensity information that is almost always useful downstream.
Technical Foundations
Formal Framing
Sentiment analysis can be formalized as a classification or regression task. Let denote a text input (a sentence, document, or text span) and denote the sentiment label or score.
Classification formulation: Given a text , assign a label . For fine-grained sentiment, (mapping to very negative through very positive).
where is the set of sentiment classes and are the model parameters.
Regression formulation: Map text to a continuous sentiment score :
Lexicon-Based Scoring (VADER)
VADER computes sentiment as a normalized weighted sum of lexicon scores. For a text with tokens :
where is the valence score of word (adjusted for modifiers, capitalization, punctuation, and negation), and is a normalization constant (default 15) that bounds the output to .
Transformer-Based Sentiment Classification
For a BERT-based sentiment classifier, the input text is tokenized into subwords . The model produces contextual embeddings , and the token representation is passed through a classification head:
where and are learned parameters.
Aspect-Based Sentiment Analysis (ABSA)
ABSA extends the task to a tuple extraction problem. Given text , extract a set of tuples:
where is the aspect term (e.g., "battery"), is the opinion term (e.g., "excellent"), and is the sentiment polarity toward that aspect.
Evaluation Metrics
Sentiment classifiers are evaluated with standard classification metrics:
- Accuracy:
- Macro F1: , which weights each class equally regardless of frequency
- Cohen's Kappa: , measuring agreement above chance -- particularly important given class imbalance in sentiment datasets
Note: For fine-grained (5-class) sentiment, macro F1 is the standard metric because class distributions are typically skewed toward neutral.
Internal Architecture
A production sentiment analysis system typically comprises a preprocessing pipeline, one or more sentiment models, a post-processing layer, and an output formatter. Let's look at the architecture for a system that handles multiple languages, domains, and granularities.
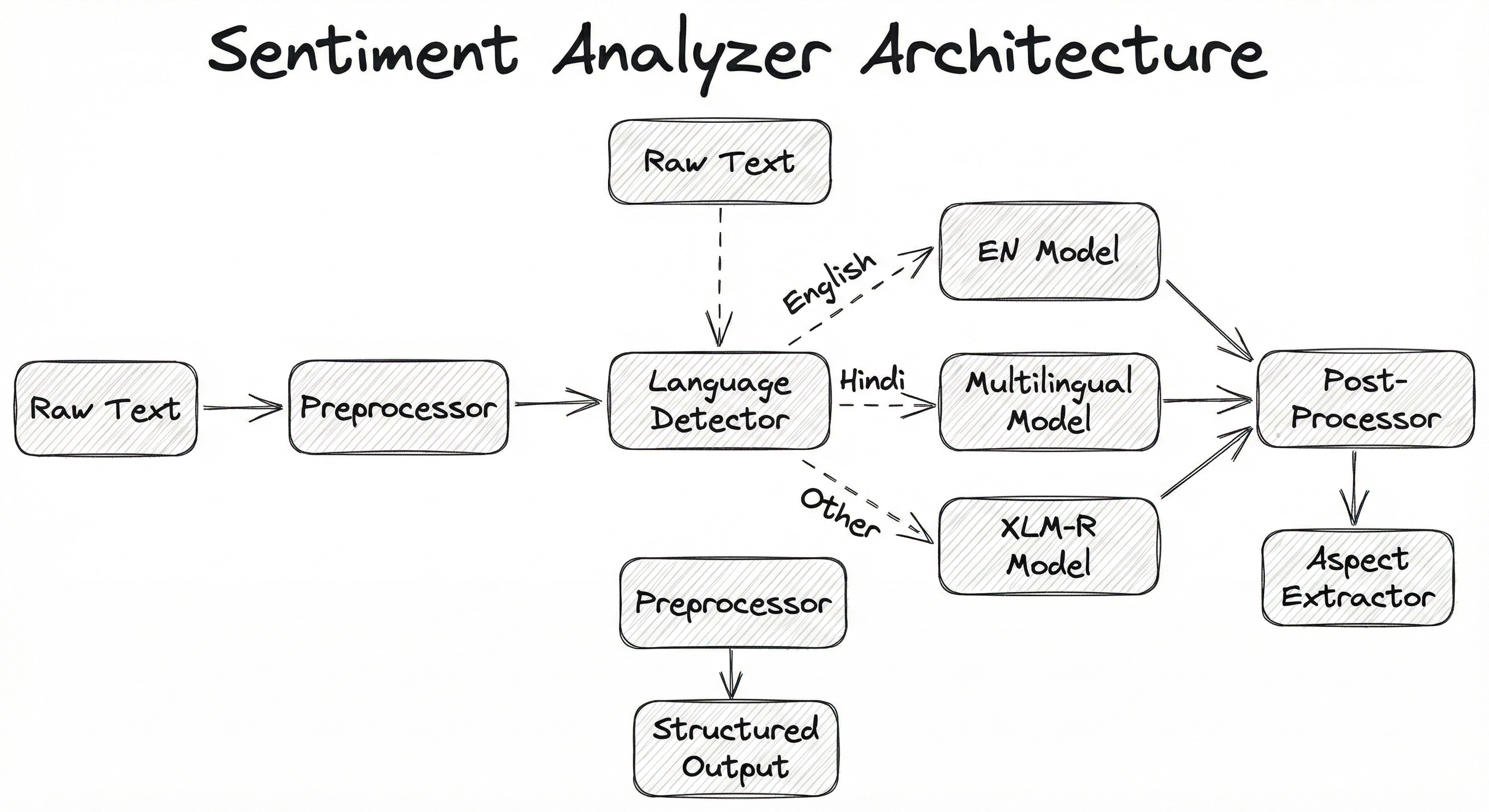
The preprocessing stage handles text normalization: cleaning HTML entities, expanding contractions, converting emojis to textual descriptions (or embedding them), handling URLs and mentions, and performing language detection. This is critical because real-world text -- especially from Indian e-commerce platforms -- is messy, multilingual, and full of non-standard tokens.
The core sentiment model can be a lexicon-based system (VADER, TextBlob), a fine-tuned transformer (BERT, RoBERTa), or an ensemble that routes to different models based on text characteristics. The post-processor applies calibration, confidence thresholding, and optionally feeds into an aspect extraction module for fine-grained analysis.
Key Components
Text Preprocessor
Normalizes raw text by cleaning HTML, expanding contractions, handling emojis (converting to text descriptions via the emoji library or demoji), normalizing Unicode, removing or replacing URLs/mentions, and performing language detection. For Indian text, this includes handling Devanagari script and romanized Hindi.
Language Router
Detects the input language and routes to the appropriate sentiment model. For code-mixed text (e.g., Hinglish), routes to a multilingual model like XLM-RoBERTa or a specialized code-mixed model. Uses libraries like langdetect or fastText language identification.
Sentiment Classification Model
The core component that assigns polarity labels and confidence scores. Can be a lexicon-based engine (VADER), a fine-tuned transformer (e.g., cardiffnlp/twitter-roberta-base-sentiment-latest), or an ensemble. Outputs a probability distribution over sentiment classes.
Aspect Extractor
Identifies specific aspects or features mentioned in the text (e.g., 'camera quality', 'battery life', 'delivery speed') and assigns per-aspect sentiment. Typically uses a sequence labeling model (token classification) or an instruction-tuned LLM.
Post-Processor & Calibrator
Applies temperature scaling or Platt scaling to calibrate confidence scores, enforces business rules (e.g., texts containing profanity are flagged regardless of polarity score), and formats output into the structured schema expected by downstream consumers.
Aggregation Engine
Aggregates individual text-level sentiment scores into entity-level summaries (e.g., average sentiment for a product, trend over time for a brand). Computes statistics like sentiment distribution, aspect-level breakdowns, and temporal trends.
Data Flow
Analysis Path: Raw text arrives via API or message queue -> the preprocessor cleans and normalizes it -> the language router identifies the language and selects the appropriate model -> the sentiment model produces polarity scores and confidence -> the post-processor calibrates and applies business rules -> the aspect extractor (if enabled) identifies aspect-sentiment pairs -> structured results are written to the output store (database, cache, or event stream).
Batch Path: For historical analysis, documents are loaded from a data lake (S3, Azure Blob), processed in parallel using Spark or Ray, and results are stored in a data warehouse for BI dashboards.
The real-time and batch paths share the same model artifacts but differ in infrastructure: real-time uses a model server (TorchServe, Triton) behind an API gateway, while batch uses distributed compute frameworks.
A directed flow from 'Raw Text Input' through 'Preprocessor' to a 'Language Detector' that branches to three model paths (EN Sentiment Model, Multilingual Model, XLM-R Model), all converging at a 'Post-Processor', then flowing through 'Aspect Extractor' to 'Structured Output'.
How to Implement
Three Tiers of Implementation
Sentiment analysis implementations fall into three tiers of complexity and capability:
Tier 1: Lexicon-based (VADER, TextBlob) -- Zero training data required, fast inference, interpretable scores. Perfect for prototyping, social media monitoring, and domains where labeled data is scarce. VADER handles emojis, slang, and capitalization out of the box. TextBlob adds subjectivity detection. But both struggle with sarcasm, domain-specific language, and non-English text.
Tier 2: Fine-tuned transformers (BERT, RoBERTa, DistilBERT) -- Requires a labeled dataset (typically 5K-50K examples), but delivers dramatically better accuracy, especially on nuanced text. Models like cardiffnlp/twitter-roberta-base-sentiment-latest are pre-fine-tuned on millions of tweets and can be used zero-shot or further fine-tuned on your domain data. This is the sweet spot for most production systems.
Tier 3: LLM-based (GPT-4, Claude, Llama) -- Use instruction-tuned LLMs for zero-shot or few-shot sentiment analysis, especially for aspect-based sentiment or complex reasoning tasks (sarcasm, implicit sentiment). Higher latency and cost, but unmatched flexibility. A single prompt can extract aspects, sentiments, and even reasoning chains.
Cost Comparison (India context): VADER is free and runs on a single CPU. A fine-tuned DistilBERT model on a
g4dn.xlargeGPU instance costs ~2.50 per 1M input tokens (~INR 210 per 1M tokens). For 10M reviews/month, that's approximately: VADER on 2-vCPU VM = INR 1,500/month, DistilBERT on GPU = INR 8,000-15,000/month, GPT-4o API = INR 50,000-80,000/month.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
import nltk
nltk.download('vader_lexicon', quiet=True)
analyzer = SentimentIntensityAnalyzer()
reviews = [
"This phone is absolutely amazing! Best purchase ever 😍",
"Terrible customer service. Never buying again.",
"The product is okay, nothing special.",
"Not bad at all, surprisingly decent for the price.",
"Oh great, another delayed delivery from Flipkart 🙄", # sarcasm
]
for review in reviews:
scores = analyzer.polarity_scores(review)
compound = scores['compound']
if compound >= 0.05:
label = 'POSITIVE'
elif compound <= -0.05:
label = 'NEGATIVE'
else:
label = 'NEUTRAL'
print(f"[{label:>8}] (compound={compound:+.4f}) {review[:60]}")VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based tool specifically attuned to social media text. It handles emoji natively, understands capitalization as emphasis (e.g., "GREAT" is stronger than "great"), and applies grammatical rules for negation and degree modifiers. The compound score ranges from -1 (most negative) to +1 (most positive). The thresholds of +/-0.05 are VADER's recommended defaults for three-class classification. Note that VADER will misclassify sarcastic text like the last example -- this is a fundamental limitation of lexicon-based approaches.
from textblob import TextBlob
reviews = [
"The camera quality is outstanding in daylight.",
"Battery life is terrible, barely lasts 4 hours.",
"I think this might be the best phone under 15000 INR.",
"The phone weighs 185 grams and has a 6.5 inch display.",
]
for review in reviews:
blob = TextBlob(review)
polarity = blob.sentiment.polarity # [-1.0, 1.0]
subjectivity = blob.sentiment.subjectivity # [0.0, 1.0]
print(f"Polarity={polarity:+.3f} Subjectivity={subjectivity:.3f} "
f"{'Subjective' if subjectivity > 0.5 else 'Objective':>10} {review[:55]}")TextBlob provides both polarity (emotional direction) and subjectivity (opinion vs. fact). The subjectivity score is particularly useful for filtering out factual statements that shouldn't be treated as opinions. In the example above, "The phone weighs 185 grams" is objective and should have low subjectivity, while "I think this might be the best phone" is subjective. This distinction is valuable in review analysis pipelines where you want to separate factual product descriptions from actual user opinions.
from transformers import AutoModelForSequenceClassification, AutoTokenizer, AutoConfig
import torch
import numpy as np
from scipy.special import softmax
MODEL_NAME = "cardiffnlp/twitter-roberta-base-sentiment-latest"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
config = AutoConfig.from_pretrained(MODEL_NAME)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME)
def preprocess(text: str) -> str:
"""Preprocess text for twitter-roberta models."""
new_text = []
for t in text.split():
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
def analyze_sentiment(text: str) -> dict:
preprocessed = preprocess(text)
encoded = tokenizer(preprocessed, return_tensors='pt', truncation=True, max_length=512)
with torch.no_grad():
output = model(**encoded)
scores = softmax(output.logits[0].numpy())
ranking = np.argsort(scores)[::-1]
results = {}
for i in ranking:
label = config.id2label[i]
results[label] = float(scores[i])
return results
# Example usage
texts = [
"Loving the new iPhone camera! Portrait mode is insane 📸",
"@flipkart your delivery is 5 days late. Worst experience ever.",
"The new MacBook has an M3 chip with 8 cores.",
]
for text in texts:
result = analyze_sentiment(text)
print(f"\nText: {text[:60]}")
for label, score in result.items():
print(f" {label}: {score:.4f}")The cardiffnlp/twitter-roberta-base-sentiment-latest model is a RoBERTa-base model trained on approximately 124 million tweets and fine-tuned for three-class sentiment classification (negative, neutral, positive). This is the go-to model for social media sentiment analysis in production. The preprocessing step replaces usernames with @user and URLs with http to match the model's training distribution. This model outputs calibrated probabilities, making it suitable for both hard classification and soft scoring. For Indian social media text in English, this model works well out of the box; for Hindi or code-mixed content, use cardiffnlp/twitter-xlm-roberta-base-sentiment instead.
from datasets import load_dataset, Dataset
from transformers import (
AutoTokenizer, AutoModelForSequenceClassification,
TrainingArguments, Trainer
)
import numpy as np
from sklearn.metrics import accuracy_score, f1_score
# Load a pre-trained model
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name, num_labels=3 # negative, neutral, positive
)
# Assume you have domain-specific labeled data
# Example: Flipkart/Amazon India product reviews
# train_df has columns: 'text', 'label' (0=neg, 1=neu, 2=pos)
train_dataset = Dataset.from_pandas(train_df)
val_dataset = Dataset.from_pandas(val_df)
def tokenize_fn(examples):
return tokenizer(
examples['text'], padding='max_length',
truncation=True, max_length=256
)
train_dataset = train_dataset.map(tokenize_fn, batched=True)
val_dataset = val_dataset.map(tokenize_fn, batched=True)
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=-1)
return {
'accuracy': accuracy_score(labels, preds),
'macro_f1': f1_score(labels, preds, average='macro'),
}
training_args = TrainingArguments(
output_dir='./sentiment_model',
num_train_epochs=3,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
learning_rate=2e-5,
weight_decay=0.01,
eval_strategy='epoch',
save_strategy='epoch',
load_best_model_at_end=True,
metric_for_best_model='macro_f1',
fp16=True, # Mixed precision for faster training
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
# Save the fine-tuned model
trainer.save_model('./flipkart_sentiment_model')
tokenizer.save_pretrained('./flipkart_sentiment_model')This example demonstrates fine-tuning DistilBERT for domain-specific sentiment analysis -- a common requirement when deploying sentiment models for e-commerce platforms like Flipkart or Amazon India. DistilBERT is 40% smaller and 60% faster than BERT-base while retaining 97% of its accuracy, making it ideal for production deployments where latency matters. Key decisions: (1) max_length=256 is usually sufficient for reviews; longer wastes compute. (2) macro_f1 as the best-model metric ensures the model doesn't just optimize for the majority class. (3) Mixed precision (fp16=True) cuts training time nearly in half on NVIDIA GPUs. (4) Three epochs is typically the sweet spot -- more can overfit, especially on small datasets. Fine-tuning on 10K labeled reviews takes approximately 20-30 minutes on a single T4 GPU (cost: ~INR 30 on AWS Mumbai spot instances).
from transformers import pipeline
import spacy
# Load spaCy for aspect extraction
nlp = spacy.load("en_core_web_sm")
# Load sentiment classifier
sentiment_pipe = pipeline(
"sentiment-analysis",
model="cardiffnlp/twitter-roberta-base-sentiment-latest",
top_k=None
)
def extract_aspects_with_sentiment(text: str) -> list[dict]:
"""Extract aspect-sentiment pairs from a review."""
doc = nlp(text)
# Split into sentences for per-sentence analysis
sentences = [sent.text.strip() for sent in doc.sents if len(sent.text.strip()) > 5]
results = []
for sent in sentences:
# Extract noun chunks as potential aspects
sent_doc = nlp(sent)
aspects = [chunk.text for chunk in sent_doc.noun_chunks]
# Get sentiment for the sentence
sent_scores = sentiment_pipe(sent)[0]
top_label = max(sent_scores, key=lambda x: x['score'])
results.append({
'sentence': sent,
'aspects': aspects,
'sentiment': top_label['label'].lower(),
'confidence': round(top_label['score'], 4)
})
return results
# Example: Flipkart product review
review = (
"The camera quality is superb in daylight conditions. "
"However, the night mode is quite disappointing. "
"Battery backup is decent and lasts a full day. "
"Build quality feels premium for a phone under 20000 rupees."
)
for r in extract_aspects_with_sentiment(review):
print(f"Aspects: {r['aspects']}")
print(f"Sentiment: {r['sentiment']} ({r['confidence']})")
print(f"Sentence: {r['sentence']}\n")This is a practical approach to aspect-based sentiment analysis (ABSA) that combines spaCy's noun chunk extraction with a transformer sentiment classifier. By splitting reviews into sentences and extracting noun phrases as aspects, we get a lightweight ABSA pipeline without needing dedicated ABSA training data. The approach works well for product reviews where aspects are explicitly mentioned (e.g., 'camera quality', 'battery backup', 'build quality'). For more sophisticated ABSA -- where aspects are implicit or where you need opinion term extraction -- consider using dedicated ABSA models or an instruction-tuned LLM with structured output.
# Sentiment Analyzer Service Configuration (YAML)
service:
name: sentiment-analyzer
version: 2.1.0
port: 8080
models:
primary:
name: cardiffnlp/twitter-roberta-base-sentiment-latest
device: cuda:0
max_length: 512
batch_size: 64
multilingual:
name: cardiffnlp/twitter-xlm-roberta-base-sentiment
device: cuda:0
max_length: 512
batch_size: 32
fallback:
type: vader # CPU-based fallback when GPU is unavailable
preprocessing:
emoji_handling: convert_to_text # options: remove, keep, convert_to_text
url_handling: replace # replace with <URL> token
mention_handling: replace # replace with @user token
max_text_length: 1000
language_detection: true
postprocessing:
calibration: temperature_scaling
confidence_threshold: 0.6 # below this, return 'uncertain'
aspect_extraction: true
caching:
enabled: true
backend: redis
ttl_seconds: 3600
max_cache_size: 100000Common Implementation Mistakes
- ●
Using a generic model without domain fine-tuning: A sentiment model trained on movie reviews will misclassify financial text where "volatile" is negative and "bullish" is positive. Always evaluate on your target domain before deploying, and fine-tune when domain accuracy drops below your threshold.
- ●
Stripping emojis during preprocessing: Emojis carry strong sentiment signals. Research shows that including emojis improves sentiment classification accuracy by 2-5% on social media text. Instead of removing them, convert emojis to text descriptions (e.g., fire emoji to 'fire') or use models that natively handle emoji tokens.
- ●
Ignoring class imbalance in training data: Real-world sentiment distributions are heavily skewed -- product reviews on Indian e-commerce sites are typically 60-70% positive. Training on imbalanced data produces a model that predicts 'positive' for everything. Use stratified sampling, class weights, or focal loss.
- ●
Treating compound/mixed sentiment as neutral: A review that says 'Great product but terrible service' is not neutral -- it contains both positive and negative opinions about different aspects. Binary or three-class models collapse this into 'neutral', losing critical information. Use aspect-based analysis for reviews with mixed sentiment.
- ●
Not handling negation properly in lexicon-based systems: VADER handles common negation patterns, but domain-specific negation ('fails to impress', 'leaves much to be desired') requires custom rules or a learned model. Always test your system on negation test cases.
- ●
Assuming English-only input in Indian production systems: A significant fraction of social media and review text in India is Hindi, code-mixed Hinglish, or regional languages. Deploy multilingual models (XLM-RoBERTa) or language-specific models alongside your English pipeline.
When Should You Use This?
Use When
You need to monitor brand perception across social media, review platforms, or customer support channels at scale -- manually reading millions of texts is not feasible
Your product team requires aspect-level feedback (what specifically do customers like or dislike?) rather than just overall star ratings
You are building a content moderation pipeline and need to flag toxic, hateful, or extremely negative content for review
Your recommendation system can benefit from sentiment signals -- e.g., downranking products with consistently negative recent reviews on Flipkart or Amazon India
You need real-time alerting for sudden sentiment shifts (brand crisis detection, viral complaints, stock-moving news sentiment)
You are analyzing customer support transcripts to assess agent performance and customer satisfaction trends, as Airbnb does with their AI-based sentiment scoring
Your application processes multilingual or code-mixed text (Hindi-English, Tamil-English) common in Indian social media and needs automated opinion extraction
Avoid When
Your text data is primarily factual/technical with minimal opinion content (e.g., scientific papers, legal documents, API documentation) -- sentiment analyzers will produce noisy, meaningless scores on such text
You need causal reasoning about why sentiment changed, not just what the sentiment is -- sentiment analyzers detect polarity but don't explain root causes without additional analysis
Your accuracy requirements exceed 95% on adversarial or sarcastic text -- current models still struggle significantly with sarcasm, irony, and implicit sentiment
The volume is low enough (<100 texts/day) that a human analyst can read everything -- the setup cost of a sentiment pipeline isn't justified at this scale
You need to classify very domain-specific emotions (e.g., distinguishing 'frustrated' from 'angry' from 'disappointed' in healthcare patient feedback) without investing in custom labeled data and fine-tuning
Your text is extremely short (1-2 words) without sufficient context for meaningful sentiment analysis -- even transformers need some context to work with
Key Tradeoffs
The Accuracy-Latency-Cost Triangle
Every sentiment analysis system navigates three competing dimensions:
| Approach | Accuracy (F1) | Latency (p50) | Cost per 1M texts | Best For |
|---|---|---|---|---|
| VADER | 0.65-0.75 | <1ms | ~INR 0 (CPU) | Social media, prototyping |
| TextBlob | 0.60-0.70 | <2ms | ~INR 0 (CPU) | Quick analysis, subjectivity |
| DistilBERT (fine-tuned) | 0.85-0.92 | 5-15ms | ~INR 500-1,500 (GPU) | Production, balanced |
| RoBERTa-base (fine-tuned) | 0.88-0.94 | 10-25ms | ~INR 1,000-3,000 (GPU) | High accuracy needs |
| GPT-4o (API) | 0.90-0.95 | 200-500ms | ~INR 50,000-80,000 | Complex/ABSA/zero-shot |
| AWS Comprehend | 0.80-0.88 | 50-100ms | ~INR 8,400 ($1/1M chars) | Managed, no ML team |
The Domain Generalization Tradeoff
General-purpose models (Twitter-RoBERTa, VADER) work across domains but underperform on specific ones. Domain-fine-tuned models are 5-15% more accurate on their target domain but require labeled data and maintenance. The practical question is: do you have 3K-10K labeled examples in your domain? If yes, fine-tune. If no, start with a general model and build a labeling pipeline in parallel.
Continuous vs. Categorical Tradeoff
Continuous scores preserve intensity information but are harder to interpret and set thresholds for. Categorical labels (3-class or 5-class) are easier to act on but lose nuance. Most production systems output continuous scores internally and apply thresholds at the application layer -- this gives you the best of both worlds.
Recommendation for Indian startups: Start with VADER for your MVP (free, instant), migrate to a fine-tuned DistilBERT when you have labeled data and need better accuracy, and selectively use GPT-4o for complex cases like aspect extraction or sarcasm-heavy text. This staged approach keeps costs under INR 15,000/month for most workloads.
Alternatives & Comparisons
A general text classifier can be trained for sentiment analysis, but also handles any other label schema (topic classification, intent detection, spam detection). Choose a dedicated sentiment analyzer when you need pre-built sentiment features (lexicons, aspect extraction, intensity scoring) and don't want to build from scratch. Choose a general text classifier when sentiment is just one of several classification tasks you need to support with a unified pipeline.
Content moderation focuses on detecting harmful content (toxicity, hate speech, profanity), while sentiment analysis focuses on opinion polarity. There's overlap -- extremely negative sentiment often correlates with toxic content -- but they serve different purposes. In practice, many teams run both in parallel: the sentiment analyzer feeds product analytics, while the content moderator feeds safety systems.
NER extracts what is being talked about (entities: products, people, locations), while sentiment analysis determines how the author feels about it. They are complementary: combine NER + sentiment to get entity-level sentiment (e.g., 'users feel positive about Brand X but negative about Brand Y'). This combination is the foundation of brand monitoring and competitive analysis systems.
Pros, Cons & Tradeoffs
Advantages
Scales human judgment infinitely: A sentiment analyzer processes millions of texts per hour with consistent scoring, eliminating the bottleneck of human annotators who can handle perhaps 200-500 texts per hour with inter-annotator agreement of only 70-80%.
Enables real-time opinion monitoring: Detect sentiment shifts as they happen -- a sudden spike in negative reviews about a Flipkart sale event, or a viral complaint about Zomato delivery, can be flagged within minutes rather than days.
Rich ecosystem of pre-trained models: Hugging Face alone hosts 10,000+ sentiment models across 100+ languages. For most use cases, you can get 85%+ accuracy without training a single model -- just pick the right pre-trained checkpoint.
Aspect-level granularity recovers insights lost in star ratings: A 3-star review might contain strong positive sentiment about product quality and strong negative sentiment about delivery. Aspect-based sentiment surfaces both signals, enabling targeted improvements.
Low barrier to entry with lexicon-based tools: VADER and TextBlob require zero labeled data, zero GPU compute, and can be integrated in under 10 lines of Python. This makes sentiment analysis accessible to teams without ML infrastructure.
Multilingual capabilities via XLM-RoBERTa: Modern multilingual models handle 100+ languages including Hindi, Tamil, Bengali, and code-mixed Hinglish, making them practical for the linguistically diverse Indian market.
Disadvantages
Sarcasm and irony remain unsolved: "Oh wonderful, my order arrived a week late" will be classified as positive by most models. Sarcasm detection is an active research area, but production-grade solutions remain elusive -- expect 15-30% error rate on sarcastic text.
Domain transfer degrades accuracy significantly: A model fine-tuned on movie reviews achieves 92% F1 on movies but may drop to 75% on financial text or medical records. Every new domain potentially requires fresh labeled data and fine-tuning.
Cultural and linguistic bias in training data: Most sentiment models are trained predominantly on English text from Western contexts. Sentiment expressions in Indian languages, cultural norms ('not bad' is strong praise in some Indian English dialects), and code-mixed text are underrepresented.
Annotation subjectivity introduces a quality ceiling: Human annotators agree on sentiment only 70-85% of the time for fine-grained tasks. This means models are evaluated against noisy ground truth, and reported accuracy numbers may be optimistic.
Context window limitations for long documents: Most transformer models truncate at 512 tokens. A long product review or support ticket may contain sentiment shifts that are lost when the text is truncated. Strategies like splitting into chunks and aggregating add complexity.
Adversarial manipulation is trivial: Users can game sentiment scores by adding invisible positive words, using letter substitutions ("terr1ble"), or crafting inputs that exploit model blind spots. This matters for any system where users have incentive to manipulate sentiment scores (e.g., fake reviews).
Failure Modes & Debugging
Sarcasm and Irony Misclassification
Cause
Sarcastic statements use positive words with negative intent ('great job breaking my order in transit'). Both lexicon-based and transformer models rely heavily on surface-level token polarity and struggle when the literal meaning diverges from the intended meaning.
Symptoms
Consistently positive predictions on texts that humans would label as negative. Particularly prevalent in social media monitoring for brands, where frustrated customers often use sarcasm. Evaluation datasets with sarcasm labels show 15-40% error rates on sarcastic text specifically.
Mitigation
Train or fine-tune on datasets that include labeled sarcastic examples (e.g., the iSarcasm dataset). Use ensemble approaches where a dedicated sarcasm detector flags potential sarcasm before sentiment classification. For high-stakes decisions, route texts with low confidence to human review. Consider multimodal signals (e.g., a text with positive words and a negative emoji may indicate sarcasm).
Negation Scope Errors
Cause
The model fails to correctly identify the scope of negation. 'The product is not bad at all' should be positive, but naive negation handling (flipping the sign of 'bad') produces incorrect results. Complex negation patterns like 'I wouldn't say it's not worth buying' confound even transformer models.
Symptoms
Reviews with double negatives or qualified negations are consistently misclassified. VADER handles simple negation ('not good') but fails on complex patterns. Fine-tuned BERT is better but still makes errors on approximately 8-12% of negated sentences.
Mitigation
Include diverse negation patterns in your training data. Use constituency or dependency parsing to determine negation scope. For lexicon-based systems, implement negation window rules (VADER uses a 3-word window by default). Test your model specifically on a negation test suite before deployment.
Domain Mismatch Degradation
Cause
The sentiment model was trained on one domain (e.g., movie reviews, tweets) but deployed on a different domain (e.g., financial reports, healthcare surveys, legal documents) where the same words carry different sentiment. 'Volatile' is neutral/descriptive in chemistry but negative in finance.
Symptoms
Gradual or sudden drop in precision and recall when the model encounters domain-specific vocabulary. Often discovered only after users report inaccurate results or when running periodic quality audits against human labels.
Mitigation
Always evaluate on a held-out set from your target domain before deployment. Maintain a domain-specific validation set of 200-500 labeled examples and run weekly regression checks. When domain accuracy falls below your threshold (typically 80% macro F1), trigger a fine-tuning cycle with domain-specific data.
Code-Mixed and Multilingual Text Failures
Cause
Input text contains multiple languages within a single sentence (e.g., 'yeh phone bahut accha hai but camera quality is terrible'). English-only models cannot interpret the Hindi tokens, and even multilingual models may underperform on code-mixed text compared to monolingual text.
Symptoms
Systematically lower accuracy on reviews or social media posts from Indian users who code-mix Hindi and English. The model may classify the sentiment based only on the English tokens, ignoring Hindi-language sentiment signals.
Mitigation
Deploy multilingual models like cardiffnlp/twitter-xlm-roberta-base-sentiment which supports Hindi among other languages. For critical applications, fine-tune on code-mixed datasets like the SemEval-2020 SentiMix Hindi-English dataset. Implement language detection at the sentence level to route to appropriate models.
Emoji and Emoticon Misinterpretation
Cause
The model either strips emojis (losing signal) or misinterprets them. Context-dependent emojis like the skull emoji (can mean 'dead laughing' or actual death) and the fire emoji (can be praise or literal fire) are particularly problematic.
Symptoms
Texts containing only or primarily emojis receive neutral or incorrect sentiment scores. Social media texts where emojis reverse or amplify the textual sentiment are misclassified.
Mitigation
Convert emojis to textual descriptions using the emoji or demoji Python packages before feeding to the model. For transformer models, ensure the tokenizer includes emoji tokens in its vocabulary (many do). Build a curated emoji-to-sentiment mapping for domain-specific emoji usage patterns.
Confidence Miscalibration
Cause
The model outputs high confidence scores even when its predictions are wrong. Neural networks, especially fine-tuned transformers, are notoriously overconfident. A model may predict 'positive' with 95% confidence on a sarcastic text.
Symptoms
High confidence threshold filtering still lets through incorrect predictions. Downstream systems that rely on confidence scores for routing or escalation make poor decisions.
Mitigation
Apply post-hoc calibration using temperature scaling or Platt scaling on a held-out calibration set. Monitor the Expected Calibration Error (ECE) metric alongside accuracy. In production, implement a 'low confidence' pathway that routes uncertain predictions to human review rather than acting on uncalibrated scores.
Placement in an ML System
Where Does the Sentiment Analyzer Sit?
In a customer feedback pipeline, the sentiment analyzer sits after text preprocessing (cleaning, tokenization) and before aggregation and dashboarding. It often runs in parallel with a named entity recognizer (to identify what entities the sentiment is about) and a topic classifier (to categorize the type of feedback).
In a recommendation system (e.g., Flipkart or Amazon India), sentiment scores from recent reviews serve as real-time features that modulate item rankings. A product with a sudden spike in negative sentiment might be temporarily downranked, even if its historical rating is high.
In a content moderation pipeline (e.g., for a social media platform like ShareChat or Koo), the sentiment analyzer runs alongside toxicity and hate speech classifiers. Extreme negative sentiment flags are one input to the moderation decision, though toxicity classifiers are typically the primary signal.
In a financial NLP pipeline (e.g., for a fintech like Zerodha or Groww), sentiment analysis of news headlines and earnings call transcripts feeds into trading signal generation. Here, latency requirements are extreme (sub-10ms) and the stakes of misclassification are measured in rupees.
Key Insight: The sentiment analyzer is rarely the final consumer of its output. It produces signals that are consumed by downstream decision systems -- rankers, moderators, alerting engines, and dashboards. Design it as a composable building block, not an end-to-end solution.
Pipeline Stage
Feature Extraction / Inference
Upstream
- tokenizer
- text-classifier
- ner-extractor
Downstream
- content-moderator
- text-classifier
Scaling Bottlenecks
For transformer-based sentiment models, the primary bottleneck is GPU inference throughput. A single BERT-base model on a T4 GPU processes roughly 200-500 texts/second (depending on sequence length). Scaling to 10K texts/second requires model parallelism, batching optimization, or model distillation.
Batching is the single most impactful optimization: processing 64 texts in one batch is 10-20x faster than processing them one at a time due to GPU parallelism. Dynamic batching (accumulating requests over a short window) is essential for real-time services.
Model distillation offers a permanent speedup: DistilBERT is 2x faster than BERT-base with only 3% accuracy loss. TinyBERT and MobileBERT push this further for edge deployment.
For lexicon-based systems (VADER, TextBlob), the bottleneck shifts to I/O and network -- the models themselves are CPU-bound and extremely fast (>10K texts/second on a single core).
BERT-base requires ~420MB of GPU memory for the model weights. With batch processing and attention caching, peak memory can reach 2-4GB. This limits the number of concurrent models on a single GPU. For multi-model deployments (English + multilingual + domain-specific), plan for 8-16GB GPU memory.
Production Case Studies
Airbnb built an AI-based sentiment model to assess customer service quality by analyzing support conversation transcripts. They developed customized rating guidelines for customer support messages, handling challenges like heavily skewed negative distributions (most people contact support when something goes wrong) and multilingual input across 14+ languages.
The sentiment model complemented and improved upon traditional NPS (Net Promoter Score) by providing per-interaction granularity rather than per-stay aggregates, enabling real-time quality monitoring of support agents and automated escalation of severely negative interactions.
Researchers implemented sentiment analysis on Flipkart product customer reviews using machine learning and NLP techniques. The system analyzes millions of product reviews across categories (electronics, fashion, home appliances) to extract actionable insights about customer satisfaction, product quality, and delivery experience. Feature extraction with TF-IDF and word embeddings fed classifiers including SVM, Random Forest, and deep learning models.
Achieved approximately 90% accuracy on Flipkart review classification, demonstrating that automated sentiment analysis can reliably replace manual review reading for product quality monitoring at scale across Indian e-commerce.
Goldman Sachs deployed a sentiment analysis system to analyze earnings call transcripts, detecting subtle shifts in executive language around supply chain issues and business outlook. The system processes thousands of earnings calls per quarter, identifying sentiment changes that precede market-moving events. When executives discussed supply chain projections, the system detected increased uncertainty despite an overall positive tone.
Portfolios incorporating sentiment signals from earnings call analysis outperformed traditional counterparts by an average of 3.2% annually over a five-year period, demonstrating the value of NLP-derived sentiment as a financial alpha signal.
Sentiment analysis was applied to 50,000+ tweets from official Swiggy and Zomato handles and user-generated mentions. The study used lexicon-based (VADER, TextBlob) and ML approaches to compare brand perception between India's two largest food delivery platforms. Critical sentiment topics identified included 'restaurant quality', 'refund process', 'delivery waiting time', and 'customer support responsiveness'.
The analysis revealed that Swiggy gained more favorable sentiment on Twitter compared to Zomato, with 'refund' and 'waiting time' being the most influential negative sentiment drivers. This demonstrated practical application of aspect-level sentiment analysis for competitive brand monitoring in the Indian food-tech sector.
Tooling & Ecosystem
A lexicon and rule-based sentiment analysis tool specifically attuned to social media text. Handles emojis, slang, capitalization, and common internet language patterns. Part of NLTK. Outputs compound, positive, negative, and neutral scores without requiring any training data.
A simplified NLP library that provides both polarity (sentiment direction from -1 to +1) and subjectivity (opinion vs. fact from 0 to 1) scores. Uses a pattern-based approach with a pre-built lexicon. Excellent for quick prototyping and when subjectivity detection is needed alongside sentiment.
The central hub for pre-trained sentiment models. Hosts 10,000+ text classification models including cardiffnlp/twitter-roberta-base-sentiment-latest (social media), nlptown/bert-base-multilingual-uncased-sentiment (multilingual 1-5 star), and domain-specific models. The pipeline('sentiment-analysis') API enables two-line inference.
A state-of-the-art NLP framework that provides pre-trained sentiment models using contextual string embeddings. The standard sentiment model uses DistilBERT embeddings trained on the Amazon review corpus. Supports both fast (RNN-based) and accurate (transformer-based) sentiment analysis variants.
A fully managed NLP service from AWS that provides sentiment analysis as an API call. Supports 12+ languages. Pricing is $0.0001 per unit (100 characters), with a free tier of 5M characters/month. Best for teams that want sentiment analysis without managing ML infrastructure. Available in the Mumbai (ap-south-1) region.
Provides entity-level sentiment analysis out of the box -- not just document-level polarity but sentiment toward specific entities mentioned in the text. Supports 10+ languages. Pricing is per 1,000-character unit. Particularly strong for extracting entity-sentiment pairs (e.g., sentiment about 'camera' vs. 'battery' in a product review).
spaCy provides industrial-strength NLP pipelines with extensions like spacytextblob for sentiment analysis. Excellent for building pipelines that combine sentiment with entity recognition, dependency parsing, and other NLP tasks in a single pass. Highly optimized for production throughput.
Research & References
Hutto, C.J. & Gilbert, E. (2014)ICWSM 2014
Introduced VADER, a lexicon and rule-based model that combines a sentiment lexicon with grammatical and syntactical heuristics (capitalization, degree modifiers, conjunctions). Outperformed individual human raters on social media text and remains the most widely used lexicon-based sentiment tool a decade later.
Socher, R., Peres, A., Manning, C.D. et al. (2013)EMNLP 2013
Introduced the Stanford Sentiment Treebank (SST) -- a dataset of 215,154 phrases with fine-grained (5-class) sentiment labels from movie reviews. Also proposed the Recursive Neural Tensor Network (RNTN) for compositional sentiment. SST remains the standard benchmark for sentiment analysis research.
Gupta, V. et al. (2024)arXiv / Artificial Intelligence Review (Springer)
Comprehensive survey of 727 ABSA studies, identifying trends in methods (shift from RNNs to transformers and LLMs), domains (restaurant and electronics dominate), and challenges (cross-domain transfer, implicit aspects, and multilingual ABSA). Highlights the systemic lack of dataset diversity as a key research gap.
Liu, H. et al. (2024)arXiv preprint
Proposes SentiSys, an edge-enhanced Graph Convolutional Network that navigates syntactic dependency graphs to capture aspect-opinion relationships. Demonstrates improved performance on SemEval ABSA benchmarks by preserving syntactic structure information during message passing.
Li, Y. et al. (2024)arXiv preprint
First systematic evaluation of LLMs (GPT-4, Claude, Llama) on sarcasm detection using three prompting strategies. Finds that while LLMs outperform traditional models on some sarcasm benchmarks, they still struggle with context-dependent and cultural sarcasm, identifying key failure modes.
Muhammad, S.H. et al. (2023)SemEval 2023 (ACL Workshop)
Organized a shared task for sentiment analysis in 14 African languages, demonstrating the challenges of low-resource multilingual sentiment. BERT-like models and ensembles dominated the leaderboard. Relevant for understanding the multilingual sentiment challenge that Indian languages also face.
Singh, G. (2021)arXiv preprint
Addresses sentiment analysis of Hindi-English code-mixed (Hinglish) text from Indian social media. Evaluates sub-word level LSTM representations and multilingual BERT (mBERT) on code-mixed datasets, achieving F1 scores of up to 66% -- highlighting the difficulty of code-mixed sentiment compared to monolingual text.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a sentiment analysis pipeline for a platform like Flipkart that receives millions of product reviews in multiple languages?
- ●
What are the key differences between lexicon-based (VADER) and transformer-based (BERT) approaches to sentiment analysis, and when would you choose each?
- ●
How do you handle sarcasm in sentiment analysis? What are the current limitations?
- ●
Explain aspect-based sentiment analysis. How would you implement it for a restaurant review platform like Zomato?
- ●
How would you evaluate a sentiment analysis model? What metrics would you use, and why might accuracy be misleading?
- ●
How do you handle code-mixed (Hindi-English) text in a sentiment analysis pipeline deployed in India?
- ●
What happens to your sentiment model when you deploy it on a domain it wasn't trained on? How do you detect and fix this?
Key Points to Mention
- ●
Always start with the use case: document-level polarity (simple), aspect-based sentiment (more useful for product teams), or emotion detection (more specific). The architecture differs significantly for each.
- ●
Lexicon-based approaches (VADER) are zero-shot, fast, and interpretable, but top out at ~0.70 F1. Fine-tuned transformers achieve 0.88-0.94 F1 but require labeled data and GPU compute. The choice is a function of data availability and accuracy requirements.
- ●
Evaluation must use macro F1 (not accuracy) due to class imbalance. A model that predicts 'positive' for everything gets 65% accuracy on a dataset that's 65% positive -- but it's useless.
- ●
Sarcasm detection is the hardest open problem in sentiment analysis. Acknowledge this honestly and discuss mitigation strategies: ensemble with dedicated sarcasm detectors, confidence thresholding, and human-in-the-loop for uncertain cases.
- ●
For multilingual systems, XLM-RoBERTa is the workhorse. For code-mixed Hinglish text specifically, you need either a dedicated code-mixed model or a transliteration pipeline + language-specific model.
- ●
In production, calibration matters as much as accuracy. Overconfident wrong predictions are worse than uncertain correct ones, because downstream systems trust the confidence scores.
Pitfalls to Avoid
- ●
Claiming that VADER or TextBlob are sufficient for production-grade sentiment analysis -- they are great for prototypes but their accuracy ceiling is too low for most real applications.
- ●
Ignoring class imbalance: real-world sentiment data is heavily skewed (60-70% positive on e-commerce platforms). Not addressing this in model training and evaluation is a red flag.
- ●
Treating sentiment analysis as a solved problem. It isn't -- sarcasm, implicit sentiment, cultural context, and domain transfer remain active research challenges.
- ●
Not discussing evaluation beyond accuracy. Interviewers expect you to know about macro F1, confusion matrices, and calibration metrics like Expected Calibration Error.
- ●
Failing to mention the preprocessing pipeline (emoji handling, language detection, text normalization) -- the model is only one part of the system.
Senior-Level Expectation
A senior candidate should discuss the full system design: preprocessing pipeline with language detection and emoji handling, model selection based on quantitative evaluation (not vibes), training infrastructure (GPU provisioning, data labeling pipeline with inter-annotator agreement monitoring), serving architecture (batched inference, model distillation for latency, A/B testing framework), monitoring (drift detection using reference dataset evaluation, confidence distribution monitoring, and feedback loops from downstream consumers), and cost optimization (VADER for low-stakes text, transformer for high-stakes, LLM for complex cases). The ability to design a multi-model system that routes text to the appropriate analyzer based on language, domain, and complexity -- and to articulate the cost and accuracy tradeoffs for an Indian market context where compute budgets are constrained -- separates senior engineers from mid-level ones.
Summary
A sentiment analyzer is the NLP component responsible for extracting opinion polarity, intensity, and aspect-level assessments from unstructured text. It transforms raw human language -- product reviews on Flipkart, tweets about IPL matches, customer support transcripts at Airbnb, financial earnings call transcripts analyzed by Goldman Sachs -- into structured signals that downstream systems can act upon.
The implementation spectrum ranges from lexicon-based tools (VADER, TextBlob) that require zero training data and run on CPU at >10K texts/second, through fine-tuned transformers (DistilBERT, RoBERTa) that achieve 88-94% macro F1 with domain-specific labeled data, to LLM-based approaches (GPT-4o, Claude) that handle complex tasks like aspect extraction and sarcasm reasoning at higher cost and latency. The right choice depends on your accuracy requirements, latency budget, and available labeled data -- most production systems in India achieve the best cost-accuracy balance with a fine-tuned DistilBERT at INR 10,000-15,000/month for 10M texts.
The key challenges that separate production-grade sentiment analysis from toy demos are: sarcasm detection (15-40% error rates on sarcastic text), domain transfer (5-15% accuracy drop when switching domains without fine-tuning), code-mixed multilingual text (common in Indian markets, where Hindi-English mixing reduces accuracy by 20-30% compared to monolingual baselines), confidence calibration (overconfident wrong predictions mislead downstream systems), and emoji/emoticon handling (stripping them loses 2-5% accuracy). A well-designed sentiment pipeline addresses each of these with dedicated preprocessing, model routing, and post-processing stages rather than relying on a single model to handle everything.