API Endpoint in Machine Learning
An API endpoint is the front door of any ML system that needs to accept data from the outside world. Whether you are ingesting training samples, receiving real-time feature updates, or serving predictions back to clients, the API endpoint is where raw HTTP requests become structured data that your pipeline can consume.
In ML systems, API endpoints serve a dual purpose that traditional web APIs rarely face: they must handle both data ingestion (accepting new data for training, fine-tuning, or enrichment) and inference serving (returning predictions with strict latency SLAs). This dual mandate creates unique design constraints around payload validation, request batching, authentication, and throughput management.
The choice of protocol -- REST, GraphQL, or gRPC -- is not cosmetic. It has measurable implications for serialization overhead, streaming support, and client compatibility. A REST endpoint returning JSON might add 30-50% payload overhead compared to a gRPC endpoint using Protocol Buffers, and at scale, that overhead translates directly into bandwidth costs and latency.
From Flipkart's centralized API gateway handling millions of product catalog updates to Razorpay processing thousands of payment-related ML scoring requests per second, API endpoints are the critical interface between business systems and ML pipelines. Get them wrong, and your pipeline starves for data or drowns in malformed requests. Get them right, and you have a clean, versioned, rate-limited contract that both producers and consumers can depend on.
Concept Snapshot
- What It Is
- A network-accessible interface (REST, GraphQL, or gRPC) that accepts structured data payloads for ingestion into an ML pipeline or returns model predictions to clients.
- Category
- Data Ingestion
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: HTTP/gRPC requests with JSON, Protocol Buffer, or multipart payloads containing data samples, features, or prediction requests. Outputs: validated, parsed data records routed to downstream pipeline stages, or prediction responses returned to clients.
- System Placement
- Sits at the outermost boundary of the ML system, upstream of data validation, feature stores, and training/inference pipelines. Typically behind a load balancer and API gateway.
- Also Known As
- ingestion API, prediction endpoint, serving endpoint, data API, inference API, model endpoint, REST endpoint
- Typical Users
- ML Engineers, Backend Engineers, Platform Engineers, Data Engineers, DevOps / SRE
- Prerequisites
- HTTP protocol basics, REST API design principles, JSON / Protocol Buffers serialization, Authentication and authorization (OAuth2, API keys), Basic networking (DNS, load balancing)
- Key Terms
- RESTgRPCGraphQLrate limitingrequest validationAPI versioningidempotencybackpressurepayload schemaOpenAPIProtocol Buffers
Why This Concept Exists
The Problem: ML Pipelines Need Structured Input
ML systems do not exist in isolation. They consume data from mobile apps, web frontends, IoT sensors, third-party services, internal microservices, and batch ETL jobs. Each of these producers speaks a different dialect -- different serialization formats, different authentication mechanisms, different payload structures. Without a well-defined API endpoint, your ML pipeline would need custom integration code for every data source. That does not scale.
The API endpoint imposes a contract: "Send me data in this exact format, authenticated with these credentials, at this rate, and I will guarantee it enters the pipeline correctly." That contract is the boundary between chaos and order in a data-driven system.
Two Historical Tracks That Converged
Track 1: Web API maturity. REST APIs became the lingua franca of the web in the 2010s. Every SaaS product, every mobile app, every microservice spoke REST+JSON. When ML teams needed to accept data from these systems, REST was the natural choice -- not because it was optimal for ML workloads, but because it was already everywhere.
Track 2: ML serving infrastructure. As ML moved from offline batch processing to real-time inference, frameworks like TensorFlow Serving (2017) and Clipper (2017) introduced purpose-built prediction APIs. These used gRPC and Protocol Buffers for efficiency, recognizing that JSON serialization was a bottleneck for high-throughput inference. Google's TF Serving demonstrated that gRPC could achieve 75% lower latency than REST for image classification payloads.
These two tracks converged into the modern pattern: REST for external-facing ingestion, gRPC for internal service-to-service communication and high-throughput inference. Most production ML systems now expose both.
Why Not Just Use a Message Queue Directly?
A common question, especially from backend engineers: "Why not skip the API and have producers write directly to Kafka or RabbitMQ?" The answer is separation of concerns. The API endpoint handles validation, authentication, rate limiting, and schema enforcement -- none of which a raw message queue provides. The API endpoint writes validated data to the queue; it does not replace the queue.
Key Takeaway: API endpoints exist because ML systems need a standardized, validated, rate-limited interface between the messy outside world and the structured internal pipeline. They are the contract layer that makes data ingestion at scale possible.
Core Intuition & Mental Model
The Mental Model: A Customs Checkpoint
Think of an API endpoint as a customs checkpoint at a country's border. Goods (data) arrive from many different origins, in different packaging (formats), carried by different vehicles (protocols). The customs checkpoint inspects each shipment: Is the documentation valid (authentication)? Does the cargo match the declaration (schema validation)? Is the quantity within allowed limits (rate limiting)? Only after passing all checks does the cargo enter the country (pipeline).
Just like a busy port needs multiple lanes for trucks, ships, and aircraft, a production API endpoint often exposes multiple interfaces: a REST endpoint for external partners, a gRPC endpoint for internal services, and a bulk upload endpoint for batch data. Same destination, different entry points optimized for different traffic patterns.
What an API Endpoint Does NOT Do
This is where confusion creeps in. The API endpoint is not responsible for feature engineering, model inference, or data storage. It receives, validates, and routes data. The moment you start embedding business logic or ML inference directly in your API handler, you have created a monolith that will be painful to scale and impossible to test independently.
The boundary is clear: the API endpoint owns the contract and the routing, not the computation.
The Throughput-Latency Duality
Here is the core tension that makes API endpoint design for ML systems uniquely challenging. For ingestion endpoints, you optimize for throughput -- how many records per second can you accept? Latency per request matters less because the data will be processed asynchronously. For prediction endpoints, you optimize for latency -- how fast can you return a response? Throughput matters, but the P99 latency SLA is king.
This duality means a single API service often needs two completely different optimization strategies running side by side. Understanding which mode each endpoint operates in is the first decision you make.
Expert Note: When a stakeholder says "we need an API for our ML system," the first question is not "REST or gRPC?" It is "ingestion or inference?" The answer determines everything downstream: sync vs. async, batching strategy, timeout configuration, and scaling policy.
Technical Foundations
Formalizing the API Endpoint
Let us define an API endpoint formally to establish precise vocabulary.
Definition: An API endpoint is a tuple where:
- is the URL path (e.g.,
/api/v2/ingest) - is the HTTP method or RPC method (e.g.,
POST,Predict) - is the request schema (a set of typed fields with validation constraints)
- is the response schema
- is the authentication/authorization policy
- is the rate limiting policy
Throughput and Latency Modeling
For a synchronous endpoint with processing time per request and concurrency level (number of worker threads/coroutines), the theoretical maximum throughput is:
For example, with async workers and per request, the theoretical max throughput is 10,000 requests per second (RPS).
In practice, throughput is bounded by the bottleneck resource -- CPU for validation-heavy endpoints, network I/O for large payloads, or downstream queue capacity for ingestion endpoints.
Rate Limiting: Token Bucket Algorithm
The most common rate limiting algorithm for ML API endpoints is the token bucket. A bucket with capacity (burst size) is refilled at rate tokens per second. Each request consumes one token. A request is allowed if the bucket has at least one token; otherwise it is rejected (HTTP 429).
The bucket state at time is:
This allows short bursts of up to requests while enforcing a sustained average rate of RPS. For an ML ingestion endpoint accepting training data, you might set RPS and to handle periodic bulk uploads.
Payload Size and Serialization Overhead
For a feature vector of floating-point values:
- JSON serialization: approximately bytes (due to decimal text representation and delimiters)
- Protocol Buffers: approximately bytes (native float32 encoding)
- Compression ratio:
At (a typical embedding dimension), JSON encodes the vector in ~7.5 KB while Protobuf uses ~3 KB. At 10,000 RPS, that difference is 45 MB/s of saved bandwidth -- meaningful at scale.
Warning: These are theoretical bounds. Real-world throughput depends on network conditions, downstream backpressure, garbage collection pauses, and connection pool exhaustion. Always benchmark with production-like traffic.
Internal Architecture
A production ML API endpoint is not a single Flask route handler. It is a layered system with distinct responsibilities at each tier. Let us walk through the architecture from the outside in.
At the outermost layer, a load balancer (AWS ALB, Nginx, or Envoy) distributes incoming requests across multiple API server instances. Behind the load balancer, an API gateway (Kong, APISIX, or AWS API Gateway) handles cross-cutting concerns: authentication, rate limiting, request logging, and TLS termination. The gateway routes requests to the appropriate API server instances, which run the application code -- typically FastAPI, Flask, or a gRPC server. The API server validates the payload against the schema, applies any transformation or enrichment, and writes the validated data to a message queue (Kafka, RabbitMQ, or SQS) for asynchronous downstream processing, or forwards it to the inference service for synchronous prediction.
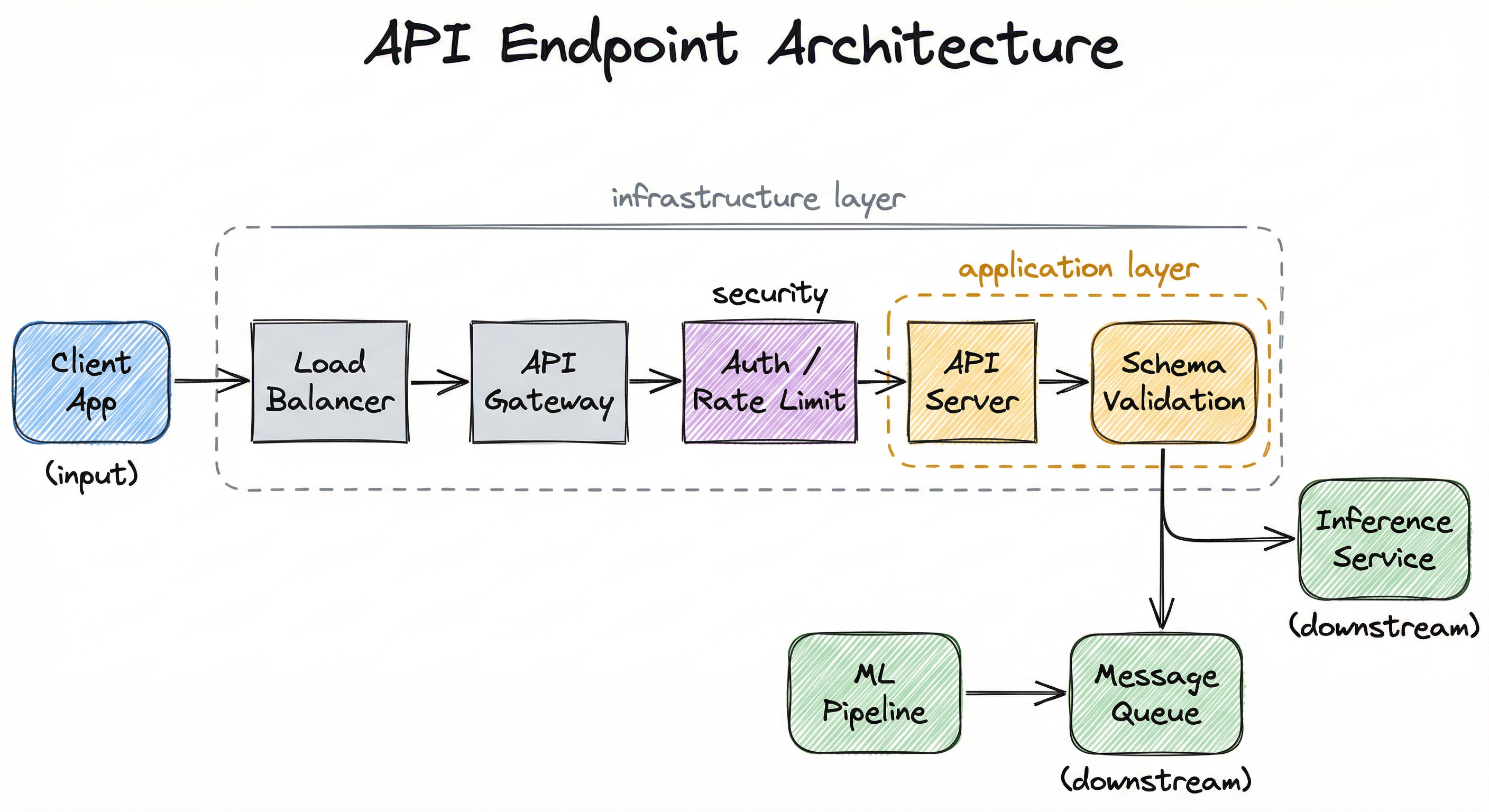
This layered design ensures that each concern -- security, throttling, validation, routing -- is handled by the component best suited for it. The API server itself stays lean: validate, route, respond. No business logic, no model loading, no heavy computation.
Key Components
Load Balancer
Distributes incoming traffic across API server instances using round-robin, least-connections, or weighted algorithms. Handles health checks and automatic failover. Examples: AWS ALB, Nginx, HAProxy, Envoy.
API Gateway
Centralized entry point that enforces authentication (API keys, OAuth2, JWT), rate limiting, request/response transformation, and routing rules. Provides observability (access logs, metrics). Examples: Kong, Apache APISIX, AWS API Gateway, Apigee.
API Server (Application Layer)
Runs the endpoint handler code. Validates request payloads against the schema using Pydantic (FastAPI) or Protocol Buffer definitions (gRPC). Routes validated data to the appropriate downstream system. Handles serialization/deserialization and error formatting.
Schema Validator
Enforces the data contract: checks field types, value ranges, required fields, and custom constraints (e.g., embedding dimension must equal 768). Rejects malformed requests with descriptive error messages before they reach the pipeline.
Message Queue / Buffer
Decouples the API endpoint from downstream processing. Ingested data is written to Kafka, SQS, or RabbitMQ, allowing the pipeline to consume at its own pace. Provides durability (data survives API server crashes) and backpressure management.
Inference Service
For prediction endpoints, the inference service loads the ML model and computes predictions. Typically a separate process (TensorFlow Serving, Triton, TorchServe, or a custom Ray Serve deployment) to isolate compute-heavy inference from lightweight API handling.
Monitoring & Observability
Collects request metrics (latency P50/P95/P99, error rates, throughput), traces (distributed tracing via OpenTelemetry), and logs. Feeds dashboards and alerting systems. Critical for detecting degradation before users notice.
Data Flow
Ingestion Path (Async):
- Client sends POST request with data payload
- Load balancer routes to an available API server
- API gateway authenticates the request and checks rate limits
- API server validates the payload schema
- Validated data is published to a Kafka topic (or SQS queue)
- Client receives HTTP 202 Accepted with a tracking ID
- Downstream consumers (feature pipeline, training pipeline) process the data asynchronously
Prediction Path (Sync):
- Client sends POST request with features for prediction
- Same auth + rate limiting as above
- API server validates input features
- Request is forwarded to the inference service (TF Serving, Triton, etc.)
- Inference service returns prediction
- API server formats and returns HTTP 200 with prediction result
- Total latency budget: typically 50-200ms end-to-end
The ingestion path optimizes for throughput and durability; the prediction path optimizes for latency and availability. Both paths share the same authentication and validation infrastructure, which is why they often live in the same API service.
A left-to-right flow diagram showing: Client App -> Load Balancer -> API Gateway (with Auth/Rate Limit) -> API Server (FastAPI/gRPC) -> Schema Validation, which then branches to either a Message Queue (Kafka/SQS) leading to the ML Pipeline, or an Inference Service returning a Prediction Response.
How to Implement
Choosing Your Stack
The implementation of an ML API endpoint begins with a framework choice, and in 2026 the landscape is clear:
FastAPI is the default choice for Python-based ML teams. It is built on ASGI (Starlette + Uvicorn), supports async/await natively, auto-generates OpenAPI documentation, and uses Pydantic for request validation. FastAPI benchmarks show it handling 15,000-25,000 RPS on a single instance for lightweight endpoints -- competitive with Node.js and Go.
gRPC (with Protocol Buffers) is the choice for internal service-to-service communication and high-throughput inference. It uses HTTP/2 for multiplexed streams, binary serialization for compact payloads, and bidirectional streaming for real-time data feeds. TensorFlow Serving and Triton both expose gRPC interfaces natively.
Flask remains popular for simpler deployments but lacks native async support, making it unsuitable for high-concurrency ingestion endpoints. If you see Flask in a production ML API, it is probably legacy code.
GraphQL (via Strawberry or Ariadne in Python) is occasionally used when clients need flexible data querying -- for instance, a dashboard that queries different model metrics dynamically. But for standard ingestion and prediction, REST or gRPC is almost always the better fit.
Cost Note: Running a FastAPI service on AWS (2 vCPU, 4 GB RAM,
t3.medium) costs approximately 150/month (~INR 12,500/month) and can handle 50,000+ RPS. On Azure, equivalent B2s VMs cost ~$35/month (~INR 2,900/month).
from fastapi import FastAPI, HTTPException, Depends, BackgroundTasks
from pydantic import BaseModel, Field, validator
from typing import List, Optional
from datetime import datetime
import uuid
import aiokafka
app = FastAPI(title="ML Data Ingestion API", version="2.0.0")
# --- Schema Definition ---
class DataRecord(BaseModel):
"""Schema for a single ingestion record."""
record_id: str = Field(default_factory=lambda: str(uuid.uuid4()))
timestamp: datetime = Field(default_factory=datetime.utcnow)
features: List[float] = Field(..., min_length=1, max_length=2048)
label: Optional[float] = None
metadata: dict = Field(default_factory=dict)
@validator("features")
def validate_feature_dimensions(cls, v):
if len(v) not in [128, 256, 512, 768]:
raise ValueError(
f"Feature dimension {len(v)} not supported. "
f"Expected one of: 128, 256, 512, 768"
)
return v
class BatchIngestRequest(BaseModel):
"""Batch ingestion request containing multiple records."""
source: str = Field(..., description="Data source identifier")
records: List[DataRecord] = Field(..., min_length=1, max_length=1000)
class IngestResponse(BaseModel):
tracking_id: str
records_accepted: int
records_rejected: int
errors: List[dict] = []
# --- Kafka Producer (initialized at startup) ---
producer = None
@app.on_event("startup")
async def startup():
global producer
producer = aiokafka.AIOKafkaProducer(
bootstrap_servers="kafka:9092",
value_serializer=lambda v: json.dumps(v).encode("utf-8"),
)
await producer.start()
@app.on_event("shutdown")
async def shutdown():
await producer.stop()
# --- Ingestion Endpoint ---
@app.post(
"/api/v2/ingest",
response_model=IngestResponse,
status_code=202,
summary="Ingest batch data for ML pipeline",
)
async def ingest_data(request: BatchIngestRequest):
tracking_id = str(uuid.uuid4())
accepted, rejected, errors = 0, 0, []
for i, record in enumerate(request.records):
try:
await producer.send_and_wait(
topic="ml-ingestion",
value=record.dict(),
key=record.record_id.encode("utf-8"),
)
accepted += 1
except Exception as e:
rejected += 1
errors.append({"index": i, "error": str(e)})
return IngestResponse(
tracking_id=tracking_id,
records_accepted=accepted,
records_rejected=rejected,
errors=errors,
)This example demonstrates a production-grade ingestion endpoint with several key patterns:
- Pydantic validation enforces the data contract at the API boundary -- invalid feature dimensions are rejected before reaching Kafka.
- Async Kafka producer (
aiokafka) enables non-blocking writes, so the API server can handle concurrent requests without thread exhaustion. - Batch ingestion accepts up to 1,000 records per request, reducing HTTP overhead for bulk uploads.
- Partial success handling -- individual record failures do not fail the entire batch; the response reports both accepted and rejected counts.
- HTTP 202 Accepted signals asynchronous processing -- the client knows the data is queued, not yet processed.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
from typing import List
from functools import lru_cache
import numpy as np
import joblib
import time
app = FastAPI(title="ML Prediction API", version="2.0.0")
# --- Request / Response Schemas ---
class PredictionRequest(BaseModel):
features: List[float] = Field(..., min_length=10, max_length=768)
model_version: str = Field(default="v2.1")
class PredictionResponse(BaseModel):
prediction: float
confidence: float
model_version: str
latency_ms: float
# --- Model Loading (cached singleton) ---
@lru_cache(maxsize=4)
def load_model(version: str):
"""Load and cache model artifacts. Supports 4 concurrent versions."""
model_path = f"/models/{version}/model.joblib"
try:
return joblib.load(model_path)
except FileNotFoundError:
raise HTTPException(
status_code=404,
detail=f"Model version '{version}' not found"
)
# --- Prediction Endpoint ---
@app.post("/api/v2/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
start = time.perf_counter()
model = load_model(request.model_version)
features = np.array(request.features).reshape(1, -1)
prediction = model.predict(features)[0]
confidence = float(np.max(model.predict_proba(features)))
latency_ms = (time.perf_counter() - start) * 1000
return PredictionResponse(
prediction=float(prediction),
confidence=confidence,
model_version=request.model_version,
latency_ms=round(latency_ms, 2),
)
# --- Health Check ---
@app.get("/health")
async def health():
return {"status": "healthy", "models_cached": len(load_model.cache_info())}This prediction endpoint illustrates several production patterns:
- Model caching via
lru_cacheavoids reloading the model from disk on every request. The cache holds up to 4 model versions simultaneously, enabling A/B testing and gradual rollouts. - Latency instrumentation in the response helps clients and monitoring systems track performance without external tracing.
- Model versioning in the request allows clients to pin to a specific model version during canary deployments.
- Structured error handling -- a missing model version returns a clean 404, not an unhandled exception.
# prediction.proto
# syntax = "proto3";
# package ml_serving;
#
# service PredictionService {
# rpc Predict (PredictRequest) returns (PredictResponse);
# rpc PredictStream (stream PredictRequest) returns (stream PredictResponse);
# }
#
# message PredictRequest {
# repeated float features = 1;
# string model_version = 2;
# }
#
# message PredictResponse {
# float prediction = 1;
# float confidence = 2;
# string model_version = 3;
# float latency_ms = 4;
# }
import grpc
from concurrent import futures
import numpy as np
import prediction_pb2
import prediction_pb2_grpc
class PredictionServicer(prediction_pb2_grpc.PredictionServiceServicer):
def __init__(self):
self.models = {} # version -> model
def _load_model(self, version: str):
if version not in self.models:
import joblib
self.models[version] = joblib.load(f"/models/{version}/model.joblib")
return self.models[version]
def Predict(self, request, context):
import time
start = time.perf_counter()
try:
model = self._load_model(request.model_version)
except FileNotFoundError:
context.abort(grpc.StatusCode.NOT_FOUND, "Model version not found")
features = np.array(request.features).reshape(1, -1)
pred = model.predict(features)[0]
conf = float(np.max(model.predict_proba(features)))
latency = (time.perf_counter() - start) * 1000
return prediction_pb2.PredictResponse(
prediction=float(pred),
confidence=conf,
model_version=request.model_version,
latency_ms=latency,
)
def PredictStream(self, request_iterator, context):
"""Bidirectional streaming for batch predictions."""
for request in request_iterator:
yield self.Predict(request, context)
def serve():
server = grpc.server(
futures.ThreadPoolExecutor(max_workers=16),
options=[
("grpc.max_receive_message_length", 10 * 1024 * 1024), # 10MB
("grpc.max_send_message_length", 10 * 1024 * 1024),
],
)
prediction_pb2_grpc.add_PredictionServiceServicer_to_server(
PredictionServicer(), server
)
server.add_insecure_port("[::]:50051")
server.start()
server.wait_for_termination()
if __name__ == "__main__":
serve()This gRPC implementation demonstrates the high-performance alternative to REST:
- Protocol Buffers define a strict, language-agnostic schema with binary serialization -- approximately 2.5x smaller payloads than JSON for float arrays.
- Bidirectional streaming (
PredictStream) enables clients to send a continuous stream of prediction requests without the overhead of establishing a new HTTP connection per request. This is ideal for real-time feature pipelines. - HTTP/2 multiplexing means multiple concurrent RPCs share a single TCP connection, reducing connection overhead at high concurrency.
- Thread pool executor with 16 workers handles concurrent predictions. For CPU-bound inference, match this to your core count.
from fastapi import FastAPI, APIRouter
from pydantic import BaseModel, Field
from typing import List, Optional
app = FastAPI(title="ML API with Versioning")
# --- V1 Schema (legacy, deprecated) ---
class V1PredictRequest(BaseModel):
features: List[float]
class V1PredictResponse(BaseModel):
result: float
# --- V2 Schema (current) ---
class V2PredictRequest(BaseModel):
features: List[float] = Field(..., min_length=1)
model_version: str = Field(default="latest")
request_id: Optional[str] = None
class V2PredictResponse(BaseModel):
prediction: float
confidence: float
model_version: str
request_id: Optional[str]
# --- V1 Router (deprecated, maintained for backward compat) ---
v1_router = APIRouter(prefix="/api/v1", tags=["v1-deprecated"])
@v1_router.post("/predict", response_model=V1PredictResponse,
deprecated=True)
async def v1_predict(request: V1PredictRequest):
# Internally delegate to V2 logic
v2_result = await _predict_core(request.features, "v1-default")
return V1PredictResponse(result=v2_result["prediction"])
# --- V2 Router (current) ---
v2_router = APIRouter(prefix="/api/v2", tags=["v2-current"])
@v2_router.post("/predict", response_model=V2PredictResponse)
async def v2_predict(request: V2PredictRequest):
result = await _predict_core(request.features, request.model_version)
return V2PredictResponse(
prediction=result["prediction"],
confidence=result["confidence"],
model_version=result["model_version"],
request_id=request.request_id,
)
async def _predict_core(features, model_version):
"""Shared prediction logic across versions."""
# ... model loading and inference ...
return {
"prediction": 0.87,
"confidence": 0.94,
"model_version": model_version,
}
app.include_router(v1_router)
app.include_router(v2_router)API versioning is critical for ML systems because model schemas evolve frequently. This example demonstrates:
- URL-based versioning (
/api/v1/,/api/v2/) -- the most explicit and widely adopted strategy. - Backward compatibility -- V1 endpoints delegate to V2 logic internally, so a single codebase serves both versions.
- Deprecation marking -- the
deprecated=Trueflag shows in auto-generated OpenAPI docs, signaling to consumers that V1 will be removed. - Shared core logic -- the
_predict_corefunction prevents code duplication between versions.
# docker-compose.yml for ML API with ingestion
version: '3.8'
services:
api:
image: ml-api:v2.1
ports:
- "8000:8000" # REST
- "50051:50051" # gRPC
environment:
- KAFKA_BROKERS=kafka:9092
- MODEL_PATH=/models
- RATE_LIMIT_RPS=5000
- MAX_BATCH_SIZE=1000
- LOG_LEVEL=INFO
- OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4317
deploy:
replicas: 4
resources:
limits:
cpus: '2'
memory: 4G
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 10s
timeout: 5s
retries: 3
kafka:
image: confluentinc/cp-kafka:7.6.0
ports:
- "9092:9092"
environment:
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
inference:
image: nvcr.io/nvidia/tritonserver:24.01-py3
ports:
- "8001:8001" # gRPC
- "8002:8002" # Metrics
volumes:
- ./models:/models
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]Common Implementation Mistakes
- ●
Synchronous blocking in async handlers: Using
requests.post()ortime.sleep()inside anasync defendpoint blocks the event loop. Usehttpx.AsyncClientorasyncio.sleep()instead. This mistake can reduce your throughput by 10-50x. - ●
No request validation: Accepting raw JSON without Pydantic models or protobuf schemas means malformed data reaches your pipeline. A single record with
NaNfeatures can corrupt an entire training batch. Validate at the boundary, always. - ●
Embedding model inference in the API handler: Loading a PyTorch model directly in your FastAPI route handler creates a monolith. The API server scales differently from the inference server (I/O-bound vs. compute-bound). Separate them.
- ●
Missing idempotency for ingestion endpoints: If a client retries a failed request (network timeout), you ingest the same data twice. Use
record_idorrequest_idas idempotency keys with a deduplication layer (Redis SET or Kafka exactly-once). - ●
Ignoring backpressure from downstream systems: If Kafka is slow or the inference service is overloaded, your API server will accumulate pending requests in memory until it OOMs. Implement circuit breakers (e.g.,
circuitbreakerlibrary or Envoy's built-in) and return HTTP 503 when the downstream is unhealthy. - ●
Hardcoding model paths and configuration: Model versions, feature dimensions, and service URLs change frequently in ML systems. Use environment variables or a configuration service (Consul, AWS Parameter Store) instead of hardcoded values.
- ●
No content-type negotiation: Returning JSON when the client sent
Accept: application/protobufwastes bandwidth. For internal services, negotiate the serialization format based on headers.
When Should You Use This?
Use When
External systems (mobile apps, partner services, web frontends) need to push data into your ML pipeline through a standardized interface
You need real-time or near-real-time prediction serving with latency SLAs (sub-200ms P99)
Multiple data producers with different authentication levels need to submit data to the same pipeline (multi-tenant ingestion)
You require request validation, rate limiting, and audit logging at the ingestion boundary -- features that raw message queues do not provide
Your ML system needs API versioning to support gradual model schema evolution without breaking existing consumers
You are building a platform that exposes ML capabilities as a service (MLaaS) to internal or external teams
Regulatory requirements (GDPR, India's DPDP Act) mandate audit trails and access controls on data ingestion
Avoid When
Data is already flowing through a well-established streaming infrastructure (Kafka, Kinesis) and adding an API layer would just add latency without benefit -- connect your pipeline directly to the stream
The data volume is exclusively batch (daily ETL from a data warehouse) and the overhead of maintaining a real-time API is unjustified -- use a batch data source block instead
Internal services with high trust and no rate-limiting needs communicate over a service mesh -- direct gRPC or queue-based communication may be simpler than a formal API layer
You are prototyping and the data producer is a single script you control -- reading from a local file or database is simpler
The payload size exceeds 10 MB per request (e.g., raw video or high-res images) -- use a presigned URL upload pattern with S3/GCS instead of streaming through the API
Key Tradeoffs
REST vs. gRPC vs. GraphQL
| Criterion | REST + JSON | gRPC + Protobuf | GraphQL |
|---|---|---|---|
| Payload size | Large (~10 bytes/float) | Compact (~4 bytes/float) | Large (JSON) |
| Latency (P50) | 5-15ms | 2-8ms | 8-20ms |
| Streaming | Limited (SSE, WebSocket) | Native bidirectional | Subscriptions (complex) |
| Browser support | Native | Requires grpc-web proxy | Native |
| Schema enforcement | Optional (OpenAPI) | Mandatory (proto files) | Mandatory (SDL) |
| Tooling maturity | Excellent | Good (growing) | Good |
| Best for | External APIs, public-facing | Internal services, high-throughput | Flexible querying, dashboards |
Sync vs. Async Ingestion
The second major tradeoff is synchronous vs. asynchronous ingestion. Synchronous endpoints process the data inline and return a result (HTTP 200) -- necessary for predictions but expensive for ingestion. Asynchronous endpoints accept the data, queue it, and return immediately (HTTP 202) -- ideal for ingestion because it decouples the API from pipeline processing speed.
For a Swiggy-scale system processing 100K+ order events per minute, async ingestion via Kafka is the only viable pattern. Synchronous ingestion would require the API server to wait for the downstream feature pipeline, creating a fragile coupling that breaks under load.
Cost Considerations (India Context)
Running a FastAPI cluster on AWS Mumbai (ap-south-1) for a mid-size ML API:
- 2x t3.medium instances (auto-scaling to 6): ~INR 5,000/month ($60/month) base
- ALB: ~INR 2,000/month ($25/month)
- Kafka (MSK 2-broker): ~INR 25,000/month ($300/month)
- Total for a 10K RPS ingestion API: ~INR 32,000/month ($385/month)
Compare this to AWS API Gateway (managed): 350/month) at 10K RPS sustained. Self-hosted is cheaper only if you have the ops capacity.
Rule of Thumb: Use REST for anything client-facing, gRPC for anything service-to-service, and async ingestion (Kafka-backed) for anything where data volume exceeds 1K records/second.
Alternatives & Comparisons
A webhook is an inverted API -- instead of the consumer polling your endpoint, your system pushes data to the consumer's URL. Use webhooks for event notifications (model training complete, drift detected) but not for high-volume data ingestion. Webhooks lack built-in rate limiting, retry logic, and backpressure handling that a proper API endpoint provides. Think of webhooks as fire-and-forget signals, not data transport.
Batch data sources (S3 file drops, database exports, scheduled ETL) trade latency for throughput. A batch source can ingest millions of records in a single job without the per-request overhead of an API endpoint. Use batch sources when data freshness requirements are hours, not seconds. For real-time ingestion or when producers need immediate validation feedback, an API endpoint is necessary.
A streaming source provides continuous, ordered data flow with built-in durability and replay. It excels when data producers are internal services that can write directly to the stream. An API endpoint is preferable when external producers need authentication, validation, and a standard HTTP interface. In many production systems, the API endpoint writes to the stream -- they are complementary, not competing.
Pros, Cons & Tradeoffs
Advantages
Standardized interface that any HTTP client can call -- mobile apps, curl, Postman, partner services -- with zero custom integration code. REST is the lingua franca of the internet.
Built-in validation at the boundary via Pydantic or Protocol Buffers ensures only well-formed data enters the pipeline. This eliminates an entire class of downstream data quality issues.
Fine-grained access control through API keys, OAuth2 scopes, and JWT claims enables multi-tenant ingestion where different clients have different permissions and rate limits.
Automatic documentation (OpenAPI/Swagger for REST, proto files for gRPC) makes the API self-documenting. New team members and external partners can onboard without reading source code.
Version management allows gradual schema evolution -- critical in ML systems where model input schemas change with every model iteration. Old clients continue working while new clients adopt the latest schema.
Observable by default -- every request generates a log entry, latency metric, and optional trace span. This observability is far richer than what you get from direct queue writes or file drops.
Ecosystem maturity means battle-tested middleware for rate limiting, caching, compression, CORS, and authentication is available off-the-shelf. You are not building from scratch.
Disadvantages
Per-request overhead from HTTP parsing, JSON serialization, and TLS adds 2-10ms of latency compared to direct queue writes. At ultra-high throughput (100K+ RPS), this overhead matters.
Synchronous coupling risk -- if the API endpoint is synchronous and the downstream system is slow, request queues build up and the API server becomes a bottleneck. Requires careful async design.
Operational complexity of running API servers, load balancers, and API gateways adds infrastructure surface area. Each component needs monitoring, scaling policies, and incident response runbooks.
Payload size limitations -- most API gateways enforce 1-10 MB request limits. Large files (images, audio, video) need alternative upload patterns (presigned URLs, chunked upload).
State management overhead -- API keys, rate limit counters, session tokens, and idempotency keys all require shared state (typically Redis), which introduces its own failure modes.
Cold start latency in serverless deployments (AWS Lambda, Cloud Functions) can add 500ms-2s to the first request, violating latency SLAs for prediction endpoints.
Failure Modes & Debugging
Cascading timeout failure
Cause
The API endpoint calls a downstream inference service that becomes slow (model loading, GPU contention). The API server holds connections open waiting for responses, exhausting its connection pool. New requests queue up, and the entire API becomes unresponsive.
Symptoms
P99 latency spikes from 50ms to 30s. HTTP 504 Gateway Timeout errors propagate to clients. Health checks fail, triggering unnecessary restarts that make the problem worse. Monitoring shows connection pool utilization at 100%.
Mitigation
Implement circuit breakers (Hystrix pattern, or circuitbreaker Python library) that trip after N consecutive failures and return HTTP 503 immediately instead of waiting. Set aggressive timeouts on downstream calls (e.g., 200ms for inference, 500ms for Kafka writes). Use bulkhead isolation so a slow downstream does not exhaust the entire server's capacity.
Silent data corruption through schema drift
Cause
An upstream producer starts sending features in a different order or with different semantics (e.g., swapping normalized and raw feature values) without updating the API schema. The data passes validation because the types are correct, but the values are semantically wrong.
Symptoms
Model accuracy degrades gradually over days or weeks. Feature distributions shift in monitoring dashboards. Retraining on the corrupted data produces worse models. By the time the issue is detected, weeks of training data may be compromised.
Mitigation
Implement semantic validation beyond type checking: statistical range checks (feature values within expected min/max), distribution drift detection on incoming data (compare rolling statistics against a reference distribution), and automated data quality tests that flag anomalies. Use tools like Great Expectations or Evidently AI at the validation layer.
Rate limit bypass via distributed clients
Cause
Rate limiting is applied per API key, but a single logical client uses multiple API keys (one per microservice instance) to circumvent the limit. The aggregate load exceeds what the pipeline can handle.
Symptoms
Total ingestion throughput exceeds capacity despite per-key limits being within bounds. Kafka consumer lag increases. Pipeline processing falls behind, and data freshness degrades.
Mitigation
Implement hierarchical rate limiting: per-key limits for burst control, plus per-tenant (organization) limits for aggregate control. Use a centralized rate limit store (Redis) that tracks both dimensions. Add global circuit breakers that throttle all traffic when pipeline health degrades.
Deserialization denial-of-service (DeS-DoS)
Cause
An attacker or misconfigured client sends deeply nested JSON, extremely long strings, or arrays with millions of elements. The API server spends excessive CPU and memory deserializing the payload before validation can reject it.
Symptoms
CPU spikes to 100% on API servers. Memory usage grows rapidly. Legitimate requests timeout. In extreme cases, the server OOMs.
Mitigation
Set request body size limits at the load balancer level (e.g., 1 MB max). Configure JSON parser depth limits. Use streaming JSON parsers for large payloads. Add WAF rules (AWS WAF, Cloudflare) to block malformed payloads before they reach the API server.
Idempotency failure causing duplicate ingestion
Cause
Client retries a request after a network timeout, but the original request was already processed. Without idempotency keys, the data is ingested twice. For training data, duplicates skew the model. For prediction endpoints, duplicate charges or actions may occur.
Symptoms
Duplicate records in the training dataset. Data counts exceed expected volumes. Model performance degrades due to overrepresentation of duplicated samples.
Mitigation
Require a client-generated idempotency_key (UUID) in every request. Store processed keys in Redis with a TTL (e.g., 24 hours). Before processing, check if the key exists; if so, return the cached response. Kafka's exactly-once semantics can also help at the queue level.
TLS certificate expiry causing total outage
Cause
The API endpoint's TLS certificate expires without automated renewal. All HTTPS connections fail with certificate errors. In ML systems where the API is the sole ingestion path, this halts all data flow.
Symptoms
Sudden 100% error rate. Clients report SSL/TLS handshake failures. No data enters the pipeline. Dashboards show zero ingestion.
Mitigation
Use automated certificate management (Let's Encrypt with certbot auto-renewal, AWS ACM, or cert-manager in Kubernetes). Set monitoring alerts for certificates expiring within 30 days. Maintain a runbook for emergency certificate rotation.
Placement in an ML System
Where Does It Sit in the Pipeline?
The API endpoint sits at the outermost boundary of the ML system. It is the first component that data touches and the last component that predictions leave through. Everything upstream is infrastructure (DNS, CDN, load balancer); everything downstream is ML-specific (validation, feature engineering, training, inference).
In an ingestion pipeline, the API endpoint feeds data into a message queue (Kafka, SQS), which is consumed by data validation, feature engineering, and ultimately the training pipeline. The endpoint's job ends the moment validated data enters the queue.
In an inference pipeline, the API endpoint sits between the client and the model serving infrastructure (TensorFlow Serving, Triton, Ray Serve). It handles request formatting, schema validation, and response packaging, while the actual inference happens in a separate service.
For platforms like Flipkart's Nexus gateway that handle both ingestion and inference across hundreds of ML models, the API gateway tier becomes a critical shared infrastructure layer. Flipkart uses Apache APISIX to route requests to the appropriate downstream ML service based on URL path and headers, handling authentication and rate limiting centrally.
Key Insight: The API endpoint is the system's immune system -- it protects the pipeline from malformed data, unauthorized access, and traffic surges. Every request that bypasses the API endpoint is an unvalidated vector into your ML system.
Pipeline Stage
Data Ingestion / Serving
Upstream
- load-balancer
- api-gateway
Downstream
- data-validation
- batch-data-source
- feature-store
- rate-limiter
Scaling Bottlenecks
The primary bottleneck for ingestion endpoints is downstream queue throughput -- if Kafka or SQS cannot keep up with the API's write rate, backpressure propagates upstream. For prediction endpoints, the bottleneck is inference latency -- a slow model means the API server holds connections longer, reducing effective concurrency.
At 10K+ RPS, connection pool exhaustion becomes a real concern. Each concurrent request consumes a connection to the downstream service. A FastAPI server with 100 workers calling an inference service with a 50ms response time can handle ~2,000 concurrent requests. Beyond that, you need horizontal scaling (more API instances) or connection multiplexing (gRPC's HTTP/2).
JSON serialization itself becomes measurable at very high throughput. Parsing a 10 KB JSON payload takes ~0.1ms, but at 50K RPS that is 5 seconds of CPU per second -- a full core just for JSON parsing. This is why high-throughput internal APIs switch to Protocol Buffers.
Some concrete numbers: A single FastAPI instance on a 4-core machine can sustain ~8,000 RPS for lightweight validation-only endpoints, ~3,000 RPS for endpoints that write to Kafka, and ~500 RPS for endpoints that call an inference service synchronously. Scale horizontally for higher throughput.
Production Case Studies
Uber's Michelangelo platform serves 10 million real-time predictions per second at peak through its Online Prediction Service (OPS). The platform exposes both REST and gRPC API endpoints for model inference, with API versioning to support gradual model rollouts across 5,000+ production models. Michelangelo's API layer handles request routing, feature hydration from the feature store (Palette), and response formatting -- cleanly separating the API contract from model computation.
Reduced model deployment time from weeks to minutes. The standardized API interface enabled 400+ active ML projects to share serving infrastructure, with the API layer handling authentication, rate limiting, and model version routing centrally.
Flipkart built Nexus, a centralized API gateway leveraging Apache APISIX, to unify their fragmented API landscape. Previously, each team maintained its own API entry points for ML services (search ranking, recommendation, fraud detection), leading to inconsistent authentication, rate limiting, and monitoring. Nexus standardized all API traffic through a single gateway with dynamic configuration and a plugin-driven architecture.
Consolidated API management across the organization, achieving 10x scaling headroom. APISIX's radix tree routing handles tens of thousands of routes efficiently, with configuration changes propagating in milliseconds via etcd. The unified gateway provides consistent observability across all ML API endpoints.
Razorpay's payment processing infrastructure handles ML-powered fraud detection scoring via API endpoints that must maintain 99.9% uptime and sub-100ms latency. Their API gateway performs real-time fraud scoring on every payment request by routing features to an ML inference endpoint, with rate limiting that adapts to merchant-level traffic patterns. Load testing with Gatling and JMeter simulates millions of requests to validate API reliability before peak events like Diwali sales.
Maintains 99.9% API uptime during peak payment processing (Big Billion Days, festive season sales). The ML-backed fraud detection API processes thousands of scoring requests per second with P99 latency under 100ms, preventing fraudulent transactions worth crores annually.
Spotify's ML gateway (ML Home) manages 220+ active ML projects, exposing prediction APIs for recommendations, search ranking, and content moderation. Their Event Delivery Infrastructure (EDI) ingests up to 8 million events per second through API endpoints that feed features into real-time ML pipelines via Kafka. Each user interaction (play, skip, save) is a data point ingested through a structured API and processed by Apache Beam for downstream model training.
The structured API ingestion layer enabled consistent data quality across 500 billion events processed daily. ML model iteration velocity increased as standardized APIs allowed new models to be deployed without changing the data ingestion contract.
Tooling & Ecosystem
Modern Python web framework built on ASGI with native async support, automatic Pydantic validation, and OpenAPI doc generation. The de facto standard for Python ML API endpoints. Benchmarks at 15-25K RPS for lightweight endpoints.
High-performance RPC framework using HTTP/2 and Protocol Buffers. Supports bidirectional streaming, binary serialization (2.5x smaller payloads than JSON), and code generation in 10+ languages. Preferred for internal ML service-to-service communication.
Production model serving system with both REST and gRPC endpoints. Supports model versioning, A/B testing, and hot-swapping. Benchmarks show 75% lower latency via gRPC vs REST for image payloads. Part of the TFX ecosystem.
Multi-framework model serving with REST and gRPC APIs. Supports dynamic batching, model ensembles, and GPU scheduling. Used by Uber's Michelangelo for next-generation inference serving.
Cloud-native API gateway with plugins for rate limiting, authentication, logging, and traffic control. Available as open-source (Kong OSS) or managed (Kong Konnect). Widely used to front ML API endpoints.
High-performance API gateway with dynamic routing and plugin architecture. Used by Flipkart (Nexus) for centralizing ML API traffic. Supports rate limiting, auth, and observability out of the box. Recently added AI gateway capabilities.
ML model serving framework that packages models with their API definitions into deployable 'Bentos.' Generates REST and gRPC endpoints automatically from model signatures. Supports adaptive batching and multi-model serving.
Scalable model serving library built on Ray. Supports FastAPI integration, dynamic request batching, multi-model composition, and fractional GPU allocation. Ideal for complex inference graphs with multiple models.
Research & References
Crankshaw, Wang, Zhou, Franklin, Gonzalez, Stoica (2017)NSDI 2017
Introduced a modular prediction serving architecture that interposes an API layer between applications and ML frameworks, achieving low-latency prediction serving through caching, batching, and adaptive model selection.
Crankshaw, Sela, Mo, Zumar, Stoica, Gonzalez, Tumanov (2020)ACM SoCC 2020
Addressed provisioning and scaling of multi-stage ML prediction API pipelines with end-to-end latency SLAs, achieving up to 7.6x cost reduction compared to existing approaches.
Paleyes, Cabrera, Lawrence (2024)arXiv preprint
Benchmarked five model serving frameworks (TensorFlow Serving, TorchServe, MLServer, MLflow, BentoML) across four ML tasks, finding that TF Serving outperforms for deep learning and that framework overhead can be 2-10x the raw inference time.
Miao, Oliaro, Zhang, Cheng, Jin, Wang, et al. (2024)arXiv preprint
Comprehensive survey of LLM serving systems covering API design patterns, continuous batching (vLLM), PagedAttention, speculative decoding, and disaggregated serving architectures.
Miao, Oliaro, Zhang, Cheng, Wang, Wong, et al. (2024)arXiv preprint
Surveyed the full stack of LLM serving from algorithmic optimizations (quantization, pruning) to system-level innovations (memory management, scheduling), providing a taxonomy of API serving patterns for generative models.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design an API endpoint to ingest 50,000 records per second for an ML training pipeline?
- ●
What is the difference between REST, gRPC, and GraphQL for ML serving? When would you choose each?
- ●
How would you handle API versioning when the ML model input schema changes?
- ●
Design a prediction API that serves multiple model versions simultaneously for A/B testing.
- ●
How would you implement rate limiting for a multi-tenant ML API where different customers have different SLAs?
- ●
What happens when the downstream inference service becomes slow? How does your API handle backpressure?
- ●
How would you ensure idempotency for a data ingestion API that receives retried requests?
Key Points to Mention
- ●
Distinguish between ingestion endpoints (optimize for throughput, use async + Kafka) and prediction endpoints (optimize for latency, use sync + gRPC). This immediately shows you understand the dual nature of ML APIs.
- ●
gRPC achieves 75% lower latency and 2.5x smaller payloads than REST+JSON for typical ML workloads -- cite TensorFlow Serving benchmarks. Use gRPC internally, REST externally.
- ●
Pydantic validation at the API boundary prevents malformed data from entering the pipeline. This is cheaper than fixing bad data downstream.
- ●
Circuit breakers (Hystrix pattern) prevent cascading failures when the inference service is slow. The API should fail fast (HTTP 503) rather than hold connections indefinitely.
- ●
Idempotency keys with Redis deduplication prevent duplicate data ingestion on retries. This is critical for training data quality.
- ●
API versioning via URL prefixes (
/api/v1/,/api/v2/) with backward-compatible adapters is the most explicit and maintainable strategy for ML systems where schemas evolve frequently.
Pitfalls to Avoid
- ●
Saying you would put model inference directly in the API handler -- this creates a monolith. Always separate the API server from the inference server.
- ●
Ignoring rate limiting and assuming all clients are well-behaved. In production, one misconfigured client can DDoS your entire ingestion pipeline.
- ●
Designing a synchronous ingestion endpoint without mentioning Kafka or a message queue. At scale, synchronous ingestion is a single point of failure.
- ●
Not mentioning API versioning when the question involves model schema changes. Unversioned APIs break every client on every model update.
- ●
Assuming REST is always the answer. Interviewers expect you to discuss when gRPC or even direct queue writes are more appropriate.
Senior-Level Expectation
A senior candidate should architect the full request lifecycle: DNS resolution, TLS termination at the load balancer, API gateway for auth and rate limiting, API server for validation and routing, message queue for ingestion durability, and inference service for predictions. They should discuss capacity planning -- how many API instances for N RPS, connection pool sizing, Kafka partition count for the ingestion topic. They should mention observability (OpenTelemetry distributed tracing, P99 latency dashboards, error rate alerts) and graceful degradation (circuit breakers, fallback responses, load shedding). They should also discuss security at depth: input sanitization against injection attacks, request signing for tamper detection, and audit logging for compliance (especially under India's DPDP Act for user data). The hallmark of a senior answer is discussing what happens when things go wrong, not just the happy path.
Summary
Let us recap the essential points about API endpoints in ML systems.
An API endpoint is the contract layer between the outside world and your ML pipeline. It handles two fundamentally different workloads: data ingestion (high-throughput, async, Kafka-backed) and prediction serving (low-latency, sync, inference-backed). The protocol choice matters: REST+JSON for external consumers, gRPC+Protobuf for internal services (2.5x smaller payloads, 75% lower latency). Every endpoint needs Pydantic or Protobuf schema validation at the boundary, rate limiting to protect downstream capacity, and idempotency keys to handle retries safely.
The architecture follows a layered pattern: load balancer -> API gateway (auth, rate limiting) -> API server (validation, routing) -> message queue or inference service. This separation of concerns ensures each component scales independently and fails gracefully. Circuit breakers prevent cascading failures when downstream services degrade. API versioning via URL prefixes enables schema evolution without breaking existing clients -- critical in ML systems where model input schemas change frequently.
From Uber serving 10 million predictions per second through Michelangelo to Flipkart's APISIX-powered Nexus gateway handling unified ML API traffic at 10x scale, the patterns are consistent: validate early, route intelligently, decouple ingestion from processing, version explicitly, and monitor relentlessly. The API endpoint may seem like "just a web server," but in an ML system it is the immune system that determines data quality, system reliability, and ultimately model performance.
The best API endpoint is one that your ML pipeline never notices -- it just works, data flows in clean and fast, and predictions flow out within SLA. The worst API endpoint is one that becomes the headline in your post-mortem.