Webhook in Machine Learning
A webhook is an HTTP callback mechanism that pushes data from an external source to your ML system the moment an event occurs -- no polling required. Instead of your pipeline repeatedly asking "is there new data yet?", the data source tells you proactively by firing an HTTP POST request to a URL you control.
In machine learning systems, webhooks serve as the entry point for real-time data ingestion. They receive payment events from Razorpay that feed fraud detection models, accept GitHub push notifications that trigger model retraining, ingest labeling completions from annotation platforms like Label Studio, and capture user activity events from SaaS products that power recommendation engines.
Webhooks occupy a unique position in the ML stack: they sit at the boundary between the outside world and your internal pipeline. This boundary role makes them simultaneously simple in concept and tricky in production. You need to handle authentication, validate payloads, guarantee idempotency, buffer against traffic spikes, and do all of this while returning a 200 OK within a few seconds -- because the sender is waiting.
Getting webhooks right is the difference between an ML system that reacts to the real world in real time and one that operates on stale batch data. This guide covers everything from HMAC signature verification to queue-backed architectures that scale to millions of events per day.
Concept Snapshot
- What It Is
- An HTTP callback endpoint that receives push-based event notifications from external systems, serving as a real-time data ingestion mechanism for ML pipelines.
- Category
- Data Ingestion
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: HTTP POST requests with JSON/XML payloads, headers (signatures, timestamps, event types). Outputs: acknowledged events routed to message queues, databases, or downstream pipeline stages.
- System Placement
- Sits at the very front of the data ingestion layer, upstream of data validation, feature extraction, and model serving or training components.
- Also Known As
- HTTP callback, reverse API, push notification endpoint, event receiver, web callback
- Typical Users
- ML Engineers, Backend Engineers, Data Engineers, Platform Engineers, DevOps Engineers
- Prerequisites
- HTTP protocol basics (methods, status codes, headers), REST API design, Message queues (SQS, Kafka, RabbitMQ), Cryptographic hashing (HMAC-SHA256), JSON schema validation
- Key Terms
- HMAC signatureidempotency keydead letter queueexponential backoffpayload validationwebhook secretevent typedelivery guaranteeat-least-once deliveryreplay attack
Why This Concept Exists
The Problem with Polling
Before webhooks, the only way to get data from an external system was polling -- making periodic API calls to check for new events. This approach has three fundamental problems for ML pipelines:
Problem 1: Latency. If you poll every 5 minutes, your ML system operates on data that's up to 5 minutes stale. For fraud detection at Razorpay processing thousands of transactions per second, 5 minutes is an eternity -- a fraudulent payment can complete, the money can move, and the damage is done before your model even sees the event.
Problem 2: Wasted compute. Most polling cycles return empty results. If a labeling team at an Indian AI startup completes annotations in bursts -- say, 100 labels at 2 PM and nothing until the next day -- your polling job runs 287 times with zero results for every one time it finds data. At scale, this burns through API rate limits and cloud costs for no value.
Problem 3: Scaling complexity. As the number of data sources grows, polling becomes a scheduling nightmare. Ten sources polling every minute means 14,400 API calls per day. A hundred sources means 144,000. Each needs rate limiting, error handling, and backoff logic. The operational burden grows linearly with source count.
The Webhook Solution
Webhooks invert the data flow. Instead of your system pulling data, the source pushes data to you the instant something happens. This is the "don't call us, we'll call you" pattern. The result is near-zero latency (events arrive within seconds of occurrence), zero wasted compute (you only process when there's actual data), and a receiver architecture that scales independently of the number of sources.
Why ML Pipelines Need This Specifically
ML systems have a unique relationship with freshness. A recommendation model trained on yesterday's click data is already degraded. A fraud model that doesn't see transactions in real time is useless. An NLP model fine-tuned on last week's support tickets misses emerging issues.
Webhooks enable event-driven ML -- pipelines that react to the world as it changes rather than on arbitrary schedules. When a user labels a data point, a webhook triggers re-training. When a payment is authorized, a webhook feeds the fraud scorer. When a model monitoring alert fires, a webhook kicks off a retraining pipeline.
Key Insight: Webhooks didn't become popular because they're elegant (they're actually quite messy in production). They became popular because the alternative -- polling -- fundamentally cannot deliver the freshness that modern ML systems demand.
Core Intuition & Mental Model
The Doorbell Analogy
Here's the simplest way to think about webhooks: polling is like walking to your front door every 5 minutes to check if a package arrived. A webhook is installing a doorbell -- the delivery person rings it when they're there, and you only get up when there's actually something at the door.
But here's where the analogy gets interesting for ML systems. Your doorbell (webhook endpoint) needs to handle some tricky situations: What if two delivery persons ring at the same time? What if someone rings pretending to be a delivery person but they're actually trying to break in? What if the doorbell rings but you're in the shower and can't answer immediately? What if the same delivery person rings three times because they weren't sure you heard the first time?
These map directly to the core webhook challenges: concurrency, authentication, availability, and idempotency.
The Mental Model: Thin Receiver, Fat Processor
The single most important architectural principle for production webhooks is: acknowledge fast, process later. Your webhook endpoint should do three things and nothing more:
- Verify the request is authentic (check the HMAC signature)
- Persist the raw payload to a durable queue or store
- Return 200 OK immediately
All the heavy lifting -- payload transformation, feature extraction, model inference, database writes -- happens asynchronously downstream. This pattern, sometimes called "thin receiver, fat processor", is what separates toy webhook implementations from production-grade ones.
Why? Because the webhook sender (Stripe, GitHub, Razorpay) is waiting for your response. Most providers have a timeout of 5-30 seconds. If you try to run ML inference in the request handler, you'll timeout, the provider will retry, and you'll process the same event multiple times. It's a cascade of bad outcomes.
Rule of Thumb: If your webhook handler takes more than 500ms to respond, you're doing too much work in it. Push the payload to a queue and respond immediately.
Technical Foundations
Formal Specification
A webhook system can be formally modeled as an asynchronous message delivery protocol between a producer (the external system generating events) and a consumer (your ML pipeline endpoint).
Definition: A webhook delivery is a tuple where:
- is the event payload (typically JSON)
- is the registered callback URL
- is the set of HTTP headers including authentication signatures
- is the delivery timestamp
Delivery Guarantee
Most webhook providers implement at-least-once delivery, meaning each event is delivered one or more times. Formally, for every event generated by , the consumer will receive at least one delivery attempt , but may receive multiple times:
This means exactly-once processing must be enforced on the consumer side through idempotency.
HMAC Signature Verification
The standard authentication mechanism uses HMAC-SHA256. Given a shared secret key and payload body , the signature is:
The consumer verifies authenticity by recomputing the HMAC over the received body and comparing:
To prevent replay attacks, a timestamp is included in the headers, and the consumer rejects any request where (typically seconds).
Idempotency Constraint
For a processing function and idempotency key , the system must satisfy:
That is, applying the same event multiple times produces the same result as applying it once. This is typically enforced by maintaining a set of processed event IDs and checking membership before processing.
Throughput Model
The effective throughput of a webhook receiver is bounded by:
where is the HTTP request handling capacity, is the downstream queue's write throughput, and is the average retry rate (fraction of events delivered more than once).
Internal Architecture
A production webhook ingestion system consists of four layers: an edge layer that terminates TLS and handles rate limiting, a receiver layer that authenticates and persists events, a queue layer that buffers events for async processing, and a processor layer that performs the actual ML pipeline work.
The key architectural insight is decoupling receipt from processing. The receiver must be fast and highly available (it's the public-facing endpoint), while the processor can be slower but more compute-intensive (it runs ML inference, writes to databases, triggers training jobs).
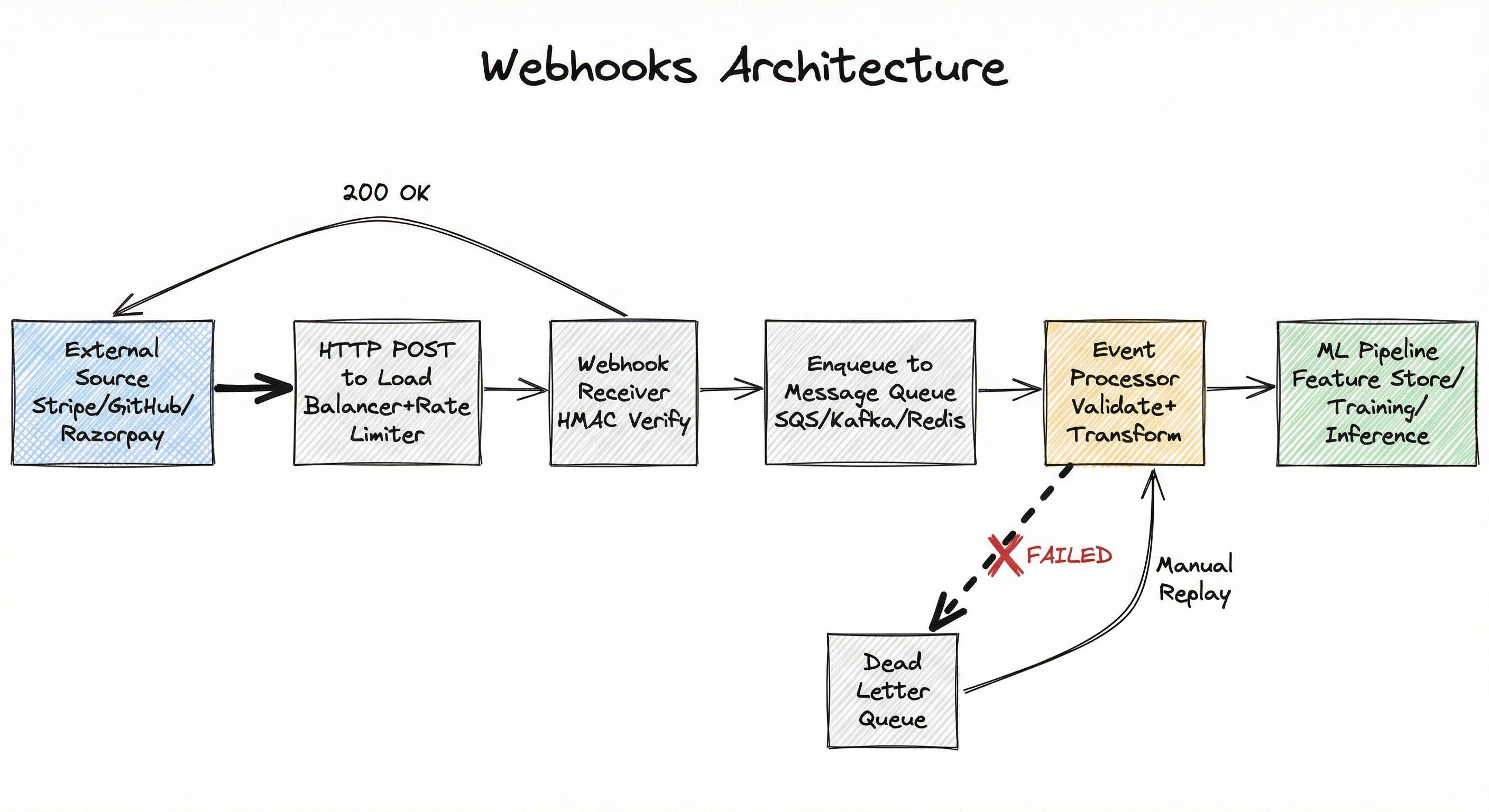
This architecture handles the fundamental tension of webhook systems: the sender expects a fast response (under 5 seconds), but ML workloads may take minutes or hours. The queue absorbs this impedance mismatch.
Key Components
Edge Layer (Load Balancer + Rate Limiter)
Terminates TLS connections, distributes traffic across receiver instances, and enforces rate limits to protect against DDoS or misconfigured senders. In AWS, this is typically an Application Load Balancer with WAF rules. For Indian deployments, CloudFront edge locations in Mumbai and Hyderabad reduce latency for domestic webhook sources.
Webhook Receiver
The core HTTP endpoint that accepts incoming webhook requests. Responsibilities: (1) extract signature from headers, (2) verify HMAC-SHA256 against the raw request body, (3) check timestamp freshness to prevent replay attacks, (4) persist the raw event payload to the message queue, (5) return HTTP 200 within the timeout window. Must be stateless for horizontal scaling.
Message Queue (Buffer Layer)
Durably stores events between receipt and processing. Absorbs traffic spikes (e.g., a Flipkart sale event triggering thousands of webhooks simultaneously) without backpressure on the receiver. Common choices: SQS for simplicity and auto-scaling, Kafka for high-throughput ordered streams, Redis Streams for low-latency use cases. The queue must guarantee at-least-once delivery.
Event Processor
Consumes events from the queue, validates payload schema against expected event types, transforms data into the format required by downstream ML components (feature extraction, normalization), and routes to the appropriate pipeline stage. Implements idempotency checks using a deduplication store (Redis or DynamoDB) to prevent double-processing of retried events.
Dead Letter Queue (DLQ)
Captures events that fail processing after a configured number of retries (typically 3-5 attempts with exponential backoff). Enables manual investigation and replay without blocking the main processing pipeline. Critical for debugging -- every failed event preserves the full original payload, headers, and failure reason.
Idempotency Store
A fast key-value store (Redis, DynamoDB) that tracks processed event IDs. Before processing any event, the processor checks this store. If the event ID exists, the event is acknowledged and skipped. TTL is set to match the provider's retry window (typically 24-72 hours) to prevent unbounded storage growth.
Data Flow
Inbound Path (Receipt): External source sends HTTP POST with JSON payload and HMAC signature in headers -> Load balancer routes to available receiver instance -> Receiver extracts and verifies HMAC signature against shared secret -> Timestamp is checked for freshness (reject if older than 5 minutes) -> Raw payload is persisted to message queue with metadata (source, event type, received timestamp) -> HTTP 200 returned to sender. Total time: <200ms.
Processing Path (Async): Queue consumer pulls event batch -> For each event, check idempotency store for duplicate -> If new, validate payload schema against event type definition -> Transform payload into pipeline-compatible format (extract features, normalize fields) -> Route to appropriate ML pipeline stage (training data store, feature store, inference endpoint) -> Mark event as processed in idempotency store -> Acknowledge message in queue. Total time: varies by downstream workload.
Failure Path: If processing fails after max retries, event moves to Dead Letter Queue -> Alert fires to on-call engineer -> After investigation and fix, events are replayed from DLQ in rate-limited batches to avoid thundering herd.
A left-to-right flow diagram showing: External Source (Stripe/GitHub/Razorpay) sending HTTP POST to a Load Balancer with Rate Limiter, which routes to a Webhook Receiver that verifies HMAC and persists events. The receiver enqueues to a Message Queue (SQS/Kafka/Redis) and returns 200 OK to the source. The queue feeds an Event Processor that validates and transforms data, routing to the ML Pipeline (Feature Store/Training/Inference). Failed events go to a Dead Letter Queue with manual replay back to the processor.
How to Implement
Two Implementation Strategies
Implementation patterns fall into two tiers based on scale and reliability requirements:
Tier 1: Direct receiver with queue backend -- a lightweight HTTP server (FastAPI, Express.js) that verifies signatures and pushes to a managed queue (SQS, Cloud Pub/Sub). Ideal for startups and teams processing fewer than 100K events per day. A team at a Bengaluru fintech startup can have this running in production within a day.
Tier 2: Managed webhook infrastructure -- platforms like Hookdeck, Svix, or AWS EventBridge that handle receipt, verification, retry, and routing as a service. Better for teams processing millions of events per day or integrating with dozens of webhook sources. Hookdeck's managed service starts at 150/month (~INR 12,600/month) for 1M events.
Cost Comparison: For 10 million webhook events per month on AWS:
- API Gateway + Lambda: ~2 (Lambda) + ~18/month (~INR 1,500/month)**
- Hookdeck managed: ~$75-150/month (~INR 6,300-12,600/month) but with built-in retries, monitoring, and deduplication
- Self-hosted on EC2: ~$35-70/month (~INR 2,900-5,900/month) for a t3.medium instance but with full operational overhead
The right choice depends on your team's operational maturity and whether the webhook receiver is a core competitive differentiator or plumbing you want to outsource.
Key Implementation Decisions
Regardless of tier, you must decide:
- Signature verification scheme: HMAC-SHA256 is the standard, but some providers use asymmetric signatures (Ed25519) or mTLS.
- Queue technology: SQS for simplicity, Kafka for ordering guarantees and replay, Redis Streams for ultra-low latency.
- Idempotency strategy: Event ID-based deduplication (most common) or conditional writes with timestamp comparison.
- Schema validation: Strict (reject malformed payloads) vs. permissive (accept and flag for review). Strict is safer for ML pipelines where garbage data can silently corrupt models.
import hashlib
import hmac
import json
import time
from typing import Optional
import boto3
from fastapi import FastAPI, Request, HTTPException, Header
from pydantic import BaseModel
app = FastAPI()
sqs = boto3.client("sqs", region_name="ap-south-1") # Mumbai region
WEBHOOK_SECRET = "whsec_your_shared_secret_here"
SQS_QUEUE_URL = "https://sqs.ap-south-1.amazonaws.com/123456789/ml-webhook-events"
TIMESTAMP_TOLERANCE = 300 # 5 minutes
def verify_hmac_signature(
payload_body: bytes,
signature_header: str,
timestamp_header: str,
secret: str,
) -> bool:
"""Verify HMAC-SHA256 signature with timestamp check."""
# Check timestamp freshness to prevent replay attacks
try:
timestamp = int(timestamp_header)
except (ValueError, TypeError):
return False
if abs(time.time() - timestamp) > TIMESTAMP_TOLERANCE:
return False
# Compute expected signature: HMAC-SHA256(secret, timestamp.body)
signed_content = f"{timestamp}.{payload_body.decode('utf-8')}"
expected_sig = hmac.new(
secret.encode("utf-8"),
signed_content.encode("utf-8"),
hashlib.sha256,
).hexdigest()
return hmac.compare_digest(expected_sig, signature_header)
@app.post("/webhooks/ingest")
async def receive_webhook(
request: Request,
x_webhook_signature: Optional[str] = Header(None),
x_webhook_timestamp: Optional[str] = Header(None),
x_webhook_id: Optional[str] = Header(None),
):
"""Receive webhook, verify signature, enqueue for async processing."""
# Step 1: Read raw body (must use raw bytes for HMAC verification)
raw_body = await request.body()
# Step 2: Verify HMAC signature
if not x_webhook_signature or not x_webhook_timestamp:
raise HTTPException(status_code=401, detail="Missing signature headers")
if not verify_hmac_signature(
raw_body, x_webhook_signature, x_webhook_timestamp, WEBHOOK_SECRET
):
raise HTTPException(status_code=401, detail="Invalid signature")
# Step 3: Enqueue raw payload to SQS for async processing
sqs.send_message(
QueueUrl=SQS_QUEUE_URL,
MessageBody=raw_body.decode("utf-8"),
MessageAttributes={
"webhook_id": {"DataType": "String", "StringValue": x_webhook_id or ""},
"received_at": {"DataType": "Number", "StringValue": str(int(time.time()))},
"source": {"DataType": "String", "StringValue": "external"},
},
MessageGroupId="webhook-events", # For FIFO queues
)
# Step 4: Return 200 immediately (thin receiver pattern)
return {"status": "accepted", "webhook_id": x_webhook_id}This is the thin receiver pattern in action. The endpoint does exactly three things: verifies the HMAC signature (including timestamp freshness to block replay attacks), enqueues the raw payload to SQS, and returns immediately. Notice we use await request.body() to get the raw bytes -- this is critical because parsing as JSON and re-serializing can subtly change the payload and break HMAC verification. The SQS queue is in ap-south-1 (Mumbai) to minimize latency for Indian webhook sources like Razorpay. The entire handler runs in under 100ms.
import json
import logging
from datetime import datetime, timedelta
from typing import Optional
import boto3
import redis
from pydantic import BaseModel, ValidationError
logger = logging.getLogger(__name__)
# Connections
redis_client = redis.Redis(host="redis.internal", port=6379, db=0)
sqs = boto3.client("sqs", region_name="ap-south-1")
MAIN_QUEUE_URL = "https://sqs.ap-south-1.amazonaws.com/123456789/ml-webhook-events"
DLQ_URL = "https://sqs.ap-south-1.amazonaws.com/123456789/ml-webhook-events-dlq"
IDEMPOTENCY_TTL = 72 * 3600 # 72 hours
MAX_RETRIES = 3
class PaymentEvent(BaseModel):
"""Schema for payment webhook events (e.g., Razorpay)."""
event_id: str
event_type: str
entity: str
payload: dict
created_at: int
class LabelEvent(BaseModel):
"""Schema for labeling completion events (e.g., Label Studio)."""
event_id: str
action: str
project_id: int
annotation: dict
created_at: str
EVENT_SCHEMAS = {
"payment": PaymentEvent,
"labeling": LabelEvent,
}
def is_duplicate(event_id: str) -> bool:
"""Check idempotency store for already-processed events."""
return redis_client.exists(f"webhook:processed:{event_id}") > 0
def mark_processed(event_id: str) -> None:
"""Mark event as processed with TTL."""
redis_client.setex(f"webhook:processed:{event_id}", IDEMPOTENCY_TTL, "1")
def route_to_pipeline(event_type: str, validated_payload: dict) -> None:
"""Route validated event to the appropriate ML pipeline stage."""
if event_type == "payment.authorized":
# Feed to real-time fraud detection model
send_to_feature_store(validated_payload)
trigger_fraud_inference(validated_payload)
elif event_type == "annotation.completed":
# Add to training data and check if retrain threshold is met
append_to_training_set(validated_payload)
check_retrain_trigger(validated_payload)
elif event_type == "model.alert":
# Monitoring alert -- trigger retraining pipeline
trigger_retraining_pipeline(validated_payload)
else:
logger.warning(f"Unknown event type: {event_type}, storing for review")
store_unknown_event(validated_payload)
def process_webhook_event(message: dict) -> None:
"""Process a single webhook event from the queue."""
body = json.loads(message["Body"])
attributes = message.get("MessageAttributes", {})
webhook_id = attributes.get("webhook_id", {}).get("StringValue", "")
# Step 1: Idempotency check
event_id = body.get("event_id") or webhook_id
if not event_id:
logger.error("Event missing ID, sending to DLQ")
send_to_dlq(message, reason="missing_event_id")
return
if is_duplicate(event_id):
logger.info(f"Duplicate event {event_id}, skipping")
return
# Step 2: Schema validation
event_source = body.get("entity", "unknown")
schema_class = EVENT_SCHEMAS.get(event_source)
if schema_class:
try:
validated = schema_class(**body)
except ValidationError as e:
logger.error(f"Schema validation failed for {event_id}: {e}")
send_to_dlq(message, reason=f"schema_validation_error: {str(e)}")
return
else:
validated = body # Accept unknown schemas but log warning
logger.warning(f"No schema defined for source: {event_source}")
# Step 3: Route to ML pipeline
try:
event_type = body.get("event_type", "unknown")
route_to_pipeline(event_type, body)
mark_processed(event_id)
logger.info(f"Successfully processed event {event_id} (type={event_type})")
except Exception as e:
logger.exception(f"Processing failed for {event_id}: {e}")
retry_count = int(attributes.get("retry_count", {}).get("StringValue", "0"))
if retry_count >= MAX_RETRIES:
send_to_dlq(message, reason=f"max_retries_exceeded: {str(e)}")
else:
requeue_with_backoff(message, retry_count + 1)
def poll_and_process():
"""Main processing loop -- polls SQS and processes events."""
while True:
response = sqs.receive_message(
QueueUrl=MAIN_QUEUE_URL,
MaxNumberOfMessages=10,
WaitTimeSeconds=20, # Long polling
MessageAttributeNames=["All"],
)
for message in response.get("Messages", []):
process_webhook_event(message)
sqs.delete_message(
QueueUrl=MAIN_QUEUE_URL,
ReceiptHandle=message["ReceiptHandle"],
)This is the fat processor counterpart to the thin receiver. It implements the three critical patterns for reliable webhook processing: (1) Idempotency via Redis-backed event ID deduplication with a 72-hour TTL matching typical provider retry windows, (2) Schema validation using Pydantic models to catch malformed payloads before they corrupt ML training data, and (3) Dead letter routing for events that fail processing after 3 retries. The route_to_pipeline function shows how different event types feed different parts of the ML system -- payment events go to fraud detection, annotation events go to training data, and monitoring alerts trigger retraining.
const express = require('express');
const crypto = require('crypto');
const { SQSClient, SendMessageCommand } = require('@aws-sdk/client-sqs');
const app = express();
const sqs = new SQSClient({ region: 'ap-south-1' });
const RAZORPAY_WEBHOOK_SECRET = process.env.RAZORPAY_WEBHOOK_SECRET;
const SQS_QUEUE_URL = process.env.SQS_QUEUE_URL;
// IMPORTANT: Use raw body for HMAC verification
app.use('/webhooks', express.raw({ type: 'application/json' }));
function verifyRazorpaySignature(rawBody, signature, secret) {
const expectedSignature = crypto
.createHmac('sha256', secret)
.update(rawBody)
.digest('hex');
return crypto.timingSafeEqual(
Buffer.from(expectedSignature, 'hex'),
Buffer.from(signature, 'hex')
);
}
app.post('/webhooks/razorpay', async (req, res) => {
try {
const signature = req.headers['x-razorpay-signature'];
if (!signature) {
return res.status(401).json({ error: 'Missing signature' });
}
// Verify Razorpay HMAC-SHA256 signature
if (!verifyRazorpaySignature(req.body, signature, RAZORPAY_WEBHOOK_SECRET)) {
console.warn('Invalid Razorpay webhook signature');
return res.status(401).json({ error: 'Invalid signature' });
}
const payload = JSON.parse(req.body.toString());
const eventId = payload.event_id || `rzp_${Date.now()}`;
// Enqueue to SQS for async processing
await sqs.send(new SendMessageCommand({
QueueUrl: SQS_QUEUE_URL,
MessageBody: req.body.toString(),
MessageAttributes: {
source: { DataType: 'String', StringValue: 'razorpay' },
event_type: { DataType: 'String', StringValue: payload.event || 'unknown' },
event_id: { DataType: 'String', StringValue: eventId },
},
}));
// Acknowledge immediately
return res.status(200).json({ status: 'ok' });
} catch (err) {
console.error('Webhook processing error:', err);
// Return 500 so Razorpay retries
return res.status(500).json({ error: 'Internal server error' });
}
});
app.listen(3000, () => console.log('Webhook receiver listening on port 3000'));This Node.js example shows a Razorpay-specific webhook receiver -- relevant for Indian ML teams building fraud detection or payment analytics. Two critical details: (1) We use express.raw() instead of express.json() for the webhook route because HMAC verification requires the exact raw bytes, not a parsed-and-reserialized JSON string. (2) We use crypto.timingSafeEqual() for signature comparison to prevent timing side-channel attacks. On error, we return 500 (not 200) so Razorpay knows to retry the delivery.
import hashlib
import hmac
import json
import subprocess
from fastapi import FastAPI, Request, HTTPException, Header
app = FastAPI()
GITHUB_WEBHOOK_SECRET = "your_github_webhook_secret"
def verify_github_signature(payload_body: bytes, signature_header: str) -> bool:
"""Verify GitHub webhook X-Hub-Signature-256."""
if not signature_header.startswith("sha256="):
return False
expected = hmac.new(
GITHUB_WEBHOOK_SECRET.encode("utf-8"),
payload_body,
hashlib.sha256,
).hexdigest()
return hmac.compare_digest(f"sha256={expected}", signature_header)
@app.post("/webhooks/github")
async def github_webhook(
request: Request,
x_hub_signature_256: str = Header(...),
x_github_event: str = Header(...),
x_github_delivery: str = Header(...),
):
raw_body = await request.body()
if not verify_github_signature(raw_body, x_hub_signature_256):
raise HTTPException(status_code=401, detail="Invalid signature")
payload = json.loads(raw_body)
ref = payload.get("ref", "")
repo = payload.get("repository", {}).get("full_name", "")
# Only trigger retraining on pushes to main that modify training data
if x_github_event == "push" and ref == "refs/heads/main":
modified_files = []
for commit in payload.get("commits", []):
modified_files.extend(commit.get("modified", []))
modified_files.extend(commit.get("added", []))
training_data_changed = any(
f.startswith("data/training/") or f.endswith(".parquet")
for f in modified_files
)
if training_data_changed:
# Trigger ML retraining pipeline (e.g., via Airflow, Prefect, or SageMaker)
trigger_retraining(
repo=repo,
commit_sha=payload["after"],
changed_files=[f for f in modified_files if f.startswith("data/")],
)
return {
"status": "retraining_triggered",
"commit": payload["after"][:8],
"changed_files_count": len(modified_files),
}
return {"status": "acknowledged", "event": x_github_event}
def trigger_retraining(repo: str, commit_sha: str, changed_files: list):
"""Trigger ML retraining pipeline via Prefect or Airflow API."""
import requests
requests.post(
"http://prefect-server:4200/api/deployments/trigger",
json={
"name": "model-retraining",
"parameters": {
"data_repo": repo,
"commit_sha": commit_sha,
"changed_files": changed_files,
},
},
timeout=10,
)This example demonstrates event-driven ML retraining triggered by GitHub webhooks. When someone pushes changes to training data files on the main branch, the webhook handler detects this, verifies the GitHub signature, inspects which files changed, and triggers a retraining pipeline (via Prefect in this case). This is the pattern used by MLOps teams that version training data in Git -- every data change automatically kicks off model retraining. The handler is smart about filtering: it only triggers retraining when actual training data files are modified, not for README updates or code changes.
# Webhook receiver deployment config (Kubernetes)
apiVersion: apps/v1
kind: Deployment
metadata:
name: webhook-receiver
labels:
app: ml-pipeline
component: webhook-ingestion
spec:
replicas: 3 # Minimum for HA
selector:
matchLabels:
app: webhook-receiver
template:
spec:
containers:
- name: receiver
image: ml-pipeline/webhook-receiver:v2.1
ports:
- containerPort: 8000
env:
- name: WEBHOOK_SECRET
valueFrom:
secretKeyRef:
name: webhook-secrets
key: hmac-secret
- name: SQS_QUEUE_URL
value: "https://sqs.ap-south-1.amazonaws.com/123456789/ml-webhook-events"
- name: MAX_BODY_SIZE
value: "1048576" # 1MB max payload
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "256Mi"
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 10
periodSeconds: 30
---
apiVersion: v1
kind: Service
metadata:
name: webhook-receiver
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "nlb"
spec:
type: LoadBalancer
ports:
- port: 443
targetPort: 8000
selector:
app: webhook-receiverCommon Implementation Mistakes
- ●
Parsing JSON before HMAC verification: Many frameworks (Express.js, Flask) automatically parse JSON request bodies. The HMAC signature is computed over the raw bytes, not the parsed-and-reserialized JSON. Even subtle differences like key ordering or whitespace will break verification. Always use the raw body for HMAC computation.
- ●
Doing heavy processing in the webhook handler: Running ML inference, database writes, or API calls in the request handler causes timeouts. Most providers wait 5-30 seconds for a response. If you exceed this, the provider retries, and you end up processing the same event multiple times. Always enqueue and respond immediately.
- ●
Missing idempotency checks: Webhook providers guarantee at-least-once delivery, meaning retries are expected behavior, not an error. Without idempotency checks, a payment event retried 3 times results in 3 entries in your training dataset -- silently corrupting your fraud detection model.
- ●
Hardcoding webhook secrets: Storing secrets in source code or environment files that get committed to Git. Use a secrets manager (AWS Secrets Manager, HashiCorp Vault, or Azure Key Vault). This is especially critical when webhook secrets are shared across teams at organizations like Zerodha or Razorpay.
- ●
Returning 200 on processing failure: If your handler encounters an error but returns 200, the provider considers the delivery successful and won't retry. Return 500 or 503 to signal that the delivery should be retried. Only return 200 after the payload is safely persisted to your queue.
- ●
Ignoring payload schema changes: Webhook providers evolve their payload schemas over time. If your processor assumes a rigid schema without version checking, a field rename or addition can break processing for all events. Use permissive parsing with known-field extraction rather than strict deserialization.
- ●
Not implementing request deduplication at the HTTP layer: Under high load, network issues can cause the same request to arrive at multiple receiver instances simultaneously. Without distributed deduplication (e.g., SQS FIFO deduplication ID), you process the same event on multiple workers.
When Should You Use This?
Use When
You need real-time or near-real-time data ingestion for your ML pipeline -- events must be processed within seconds, not minutes or hours (e.g., fraud detection on payment events from Razorpay)
The data source natively supports webhooks and provides HMAC-signed delivery (Stripe, GitHub, Shopify, Razorpay, Twilio, Label Studio, and most modern SaaS platforms)
Your ML system needs to react to external events -- new labels trigger retraining, new user activity updates recommendations, new documents trigger embedding generation
You want to minimize API rate limit consumption on the source system -- webhooks push data to you instead of you pulling, eliminating empty polling cycles
The event volume is bursty but manageable -- hundreds to millions of events per day, with spikes during sales events (Flipkart Big Billion Days) or peak hours
You are building an event-driven ML architecture where pipeline stages are triggered by data availability rather than fixed schedules
Multiple ML systems need to react to the same event -- a single webhook can fan out to fraud detection, analytics, and recommendation update pipelines simultaneously
Avoid When
You need to ingest bulk historical data -- webhooks deliver events one at a time as they occur. For backfilling 6 months of transaction history, use batch APIs or database exports instead
The data source doesn't support webhooks -- some legacy systems, internal databases, and government data portals (like certain Indian government APIs) only provide REST endpoints for polling
You need exactly-once processing guarantees without implementing idempotency -- webhooks inherently deliver at-least-once, and building reliable deduplication adds complexity
Your ML pipeline runs on a fixed schedule (e.g., nightly batch retraining) and doesn't benefit from real-time data -- the added infrastructure complexity of webhooks provides no value
The network environment is restrictive -- if your ML system runs in an air-gapped or heavily firewalled network that can't expose public endpoints, webhooks can't reach you
You need guaranteed ordering of events -- webhook delivery order is not guaranteed by most providers. If your ML pipeline requires strict temporal ordering, you'll need additional sequencing logic
The webhook payload doesn't contain enough data and you need to make follow-up API calls anyway -- this negates the latency benefit and you might as well poll
Key Tradeoffs
The Fundamental Tradeoff: Simplicity vs. Reliability
Webhooks are conceptually simple (receive an HTTP request, process it) but operationally complex. The complexity comes from the failure modes: what happens when your endpoint is down? When the sender retries and you process duplicates? When a traffic spike overwhelms your receiver?
Compare this to polling, which is operationally simple (a cron job that calls an API) but conceptually wasteful. Polling has predictable load, straightforward error handling, and no public endpoint to secure. But it trades freshness for simplicity.
| Dimension | Webhook | Polling |
|---|---|---|
| Latency | Seconds | Minutes to hours |
| Compute efficiency | High (only runs when data arrives) | Low (most cycles return empty) |
| Operational complexity | High (public endpoint, auth, idempotency) | Low (cron job, retry loop) |
| Failure handling | Complex (DLQ, replay, dedup) | Simple (retry on next poll) |
| Ordering guarantees | None (out-of-order delivery common) | Controllable (poll in sequence) |
| Cost at 10M events/month | ~INR 1,500 ($18) on AWS serverless | ~INR 4,200 ($50) in wasted API calls |
| Security surface | Large (public endpoint, DDoS risk) | Small (outbound calls only) |
The Second Axis: Build vs. Buy
Building a reliable webhook receiver requires implementing HMAC verification, idempotency, queue buffering, dead letter handling, and monitoring. Managed platforms like Hookdeck or Svix handle all of this but add cost and vendor dependency. For a small team at an Indian startup, the build-vs-buy decision often comes down to: can you afford to have a senior engineer spend 2-3 weeks building and maintaining webhook infrastructure, or should you pay $75-150/month for a managed solution?
Rule of Thumb: If you're integrating with fewer than 3 webhook sources and processing under 100K events/day, build your own thin receiver. Beyond that, seriously consider managed infrastructure.
Alternatives & Comparisons
Polling via REST APIs is the traditional alternative to webhooks. Choose polling when the data source doesn't support webhooks, when you need guaranteed ordering, or when your ML pipeline runs on a fixed schedule. Choose webhooks when you need real-time data delivery and the source supports them. Many production systems use both: webhooks for real-time events and polling as a fallback reconciliation mechanism to catch any missed deliveries.
Streaming platforms like Kafka or Kinesis provide persistent, ordered, replayable event streams -- properties that webhooks lack. Choose streaming when you need guaranteed ordering, replay capability, or when the event producer is an internal system you control. Choose webhooks when the data source is an external SaaS platform (Stripe, GitHub, Razorpay) that pushes events via HTTP. In practice, many architectures use webhooks as the ingestion point that feeds into a Kafka stream for downstream processing.
Cloud event triggers (AWS EventBridge, Google Cloud Eventarc) provide managed event routing with built-in filtering and fan-out. They are more structured and reliable than raw webhooks but only work within a cloud provider's ecosystem. Choose cloud event triggers for intra-cloud event routing. Choose webhooks when you need to receive events from external, cross-cloud, or third-party sources.
Data validation is not an alternative to webhooks but a complementary downstream component. In a well-designed pipeline, the webhook receiver handles receipt and authentication, then passes the raw payload to a validation layer that enforces schema constraints, data quality checks, and business rules before the data enters the ML pipeline. These two blocks almost always appear together.
Pros, Cons & Tradeoffs
Advantages
Near-zero latency data delivery -- events arrive within seconds of occurrence, enabling real-time ML use cases like fraud detection, dynamic pricing, and live recommendations that batch ingestion simply cannot support
Eliminates wasted compute from polling -- your system only processes when there's actual data to process. For a system that would otherwise poll 1,000 times to find 10 events, webhooks reduce compute waste by 99%
Standard HTTP protocol -- no proprietary SDKs, no special infrastructure. Any language or framework that can handle HTTP POST requests can receive webhooks. This makes webhooks the universal lingua franca of event-driven integration
Scales horizontally with ease -- since webhook receivers are stateless HTTP handlers, you can scale from 1 to 100 instances behind a load balancer without any coordination. A Kubernetes HPA can auto-scale based on request rate
Decouples data producers from consumers -- the external system (Stripe, GitHub) doesn't need to know anything about your ML pipeline. It just POSTs to a URL. This loose coupling means you can completely redesign your internal processing without changing the integration
Enables event-driven ML architectures -- webhooks are the trigger mechanism for reactive pipelines where model retraining, feature updates, and inference happen in response to real-world events rather than arbitrary schedules
Disadvantages
At-least-once delivery requires idempotency -- every webhook consumer must handle duplicate events, which adds infrastructure (dedup store) and logic (idempotency checks). Forgetting this is the #1 source of data quality issues in webhook-driven ML systems
Public endpoint creates a security surface -- your webhook URL is exposed to the internet. Without proper HMAC verification, rate limiting, and IP allowlisting, it's a vector for DDoS attacks, payload injection, and unauthorized data submission
No guaranteed delivery ordering -- events can arrive out of order, especially during retries. If your ML pipeline requires temporal ordering (e.g., processing user actions in sequence), you need additional sequencing logic or a downstream ordering buffer
Debugging is harder than polling -- when a webhook delivery fails, the error context is split between the sender's retry logs and your receiver's logs. Unlike polling where you control the entire flow, webhook debugging requires coordination with the sending platform
Receiver downtime means missed events -- if your endpoint is down and the sender exhausts its retry window (typically 24-72 hours), events are permanently lost. Polling-based systems can always catch up by re-reading from the API after recovery
Payload size limitations -- most webhook providers limit payloads to 1-5 MB, which can be insufficient for ML workloads involving images, audio, or large document batches. You often need a two-phase approach: webhook delivers metadata, then your system fetches the full payload via API
Failure Modes & Debugging
Signature verification failure on valid webhooks
Cause
The middleware or framework automatically parses the JSON body before the HMAC verification function receives the raw bytes. Re-serialization changes whitespace, key ordering, or Unicode escaping, causing the computed HMAC to differ from the sender's signature. This is the single most common webhook implementation bug.
Symptoms
All or most webhook deliveries are rejected with 401 errors. The sender's dashboard shows repeated delivery failures. The signature looks correct but hmac.compare_digest returns False. Switching to a different framework or middleware configuration mysteriously fixes the issue.
Mitigation
Always verify HMAC against the raw request body bytes, never parsed JSON. In Express.js, use express.raw({ type: 'application/json' }) for webhook routes. In FastAPI, use await request.body(). In Flask, use request.get_data(). Add a test that sends a known payload with a pre-computed signature to verify your implementation.
Silent duplicate processing
Cause
No idempotency mechanism implemented. The webhook provider retries delivery (due to network timeout, 5xx response, or explicit retry policy) and the same event is processed multiple times. For ML systems, this means duplicate training examples, double-counted features, or repeated inference calls.
Symptoms
Training datasets contain duplicate entries. Feature values are inflated (e.g., a user's purchase count is 3x actual). Model performance metrics don't match expectations. In fraud detection, the same transaction appears multiple times in the feature store.
Mitigation
Implement event ID-based deduplication using a fast key-value store (Redis with SETNX and TTL). Check for duplicates before processing. Set TTL to match the provider's maximum retry window (typically 72 hours). For extra safety, add a unique constraint on event_id in your database.
Receiver overwhelmed during traffic spikes
Cause
A sudden burst of events (e.g., Flipkart Big Billion Days sale, a marketing campaign triggering thousands of user signups, or a batch annotation job completing) exceeds the receiver's capacity. Without queue buffering, the receiver starts returning 503 errors, triggering exponential retries that make the situation worse.
Symptoms
HTTP 503 or 429 responses from the webhook endpoint. Provider dashboards show increasing delivery failures. Queue depth grows faster than processing capacity. CPU and memory utilization spike on receiver instances.
Mitigation
Always buffer through a message queue (SQS, Kafka) rather than processing inline. Use auto-scaling (Kubernetes HPA or AWS Lambda) on the receiver. Implement rate limiting at the edge layer to shed load gracefully. Pre-provision capacity before known traffic events (sale days, marketing campaigns).
Replay attacks from forged webhooks
Cause
An attacker captures a legitimate webhook payload and signature, then replays it hours or days later. Without timestamp verification, the HMAC signature is still valid because the payload hasn't changed. In ML systems, this can inject stale or malicious data into training pipelines.
Symptoms
Unexpected duplicate events with valid signatures but old timestamps. Anomalous data appearing in training sets. If the attacker modifies payloads while lacking the secret, HMAC verification catches it -- but replay attacks reuse unmodified payloads.
Mitigation
Include a timestamp in the signed content and reject requests where the timestamp differs from current time by more than 5 minutes. Most providers (Stripe, Svix) include timestamps in their signing scheme. Add this check as the first step in your verification function, before the HMAC computation.
Dead letter queue overflow and data loss
Cause
A persistent bug in the event processor causes all events of a certain type to fail. These events accumulate in the DLQ. If the DLQ has a retention policy (e.g., SQS's 14-day maximum) and the bug isn't fixed within that window, events are permanently lost.
Symptoms
DLQ depth grows continuously. CloudWatch or Prometheus alerts fire for DLQ depth exceeding threshold. Downstream ML models stop receiving certain event types. After the bug is fixed, a gap exists in the training data or feature store.
Mitigation
Configure DLQ retention to the maximum allowed (14 days for SQS). Set up aggressive alerts on DLQ depth (alert at 100 messages, page at 1,000). Archive DLQ messages to S3 before they expire so they can be replayed even after the retention window. Implement a DLQ replay mechanism with rate limiting.
Schema evolution breaks processing
Cause
The webhook provider adds new fields, renames existing fields, or changes data types in their payload schema without notice (or with insufficient notice). Your processor's strict schema validation rejects these modified payloads, routing them to the DLQ.
Symptoms
Sudden spike in schema validation errors for a specific event type. DLQ fills with events that have unexpected fields or missing expected fields. The provider's changelog shows a recent API update. Downstream ML models stop receiving fresh data.
Mitigation
Use additive-only schema validation: validate that required fields exist with expected types, but ignore unexpected additional fields. Subscribe to the provider's changelog and API deprecation notices. Version your event schemas and maintain backward-compatible parsers for at least 2 schema versions.
Placement in an ML System
Where Webhooks Fit in the ML Pipeline
Webhooks sit at the absolute front of the data ingestion layer. They are the first point of contact between external events and your ML system. Everything downstream depends on the webhook receiver's reliability and throughput.
In a real-time fraud detection pipeline (common at Indian fintechs like Razorpay, PhonePe, or Paytm), the flow is: Payment gateway fires webhook -> Receiver verifies and enqueues -> Feature extractor computes real-time features -> Fraud model runs inference -> Decision is returned within the SLA window (typically 100-500ms end-to-end).
In an MLOps retraining pipeline, the flow is: GitHub webhook fires on data push -> Receiver filters for training data changes -> Orchestrator (Prefect, Airflow) triggers retraining DAG -> Model is trained, evaluated, and deployed -> Monitoring webhook alerts if the new model degrades.
In a recommendation system update pipeline (think Swiggy restaurant recommendations), the flow is: Restaurant management system fires webhook when menu changes -> Receiver enqueues the update -> Feature pipeline recomputes restaurant embeddings -> Vector store is updated -> Next user query reflects the fresh data.
Key Insight: The webhook receiver is a reliability multiplier -- its uptime directly determines the freshness and completeness of data available to every downstream ML component. A receiver that drops 1% of events means your fraud model misses 1% of transactions, your training data has 1% gaps, and your recommendations are 1% stale.
Pipeline Stage
Data Ingestion
Upstream
- api-endpoint
- streaming-data-source
Downstream
- data-validation
- rate-limiter
- event-trigger
Scaling Bottlenecks
The primary bottleneck is receiver throughput during traffic spikes. A single FastAPI instance can handle roughly 2,000-5,000 webhook requests per second (depending on payload size and verification overhead). Beyond that, you need horizontal scaling.
The second bottleneck is queue write throughput. Standard SQS provides nearly unlimited throughput, but SQS FIFO queues are capped at 3,000 messages per second per queue (with batching). Kafka throughput depends on partition count and broker configuration -- typically 10,000-100,000 messages per second per partition.
The third bottleneck is idempotency store latency. Every event requires a Redis lookup (read + conditional write). At 10,000 events per second, Redis latency of 1ms per operation consumes 10 seconds of wall-clock time per second -- you'll need connection pooling and pipeline batching.
Some concrete numbers: For an Indian fintech processing Razorpay webhooks, expect ~100-1,000 events per second during peak hours, with 10x spikes during festival sales. A 3-instance receiver deployment behind an NLB with SQS buffering handles this comfortably. For a platform like Flipkart during Big Billion Days, expect 10,000-50,000 events per second -- this requires Kafka with multiple partitions and auto-scaling receiver pods.
Production Case Studies
Stripe's webhook system is the gold standard for event-driven payment processing. Their architecture publishes payment events (charges, refunds, disputes) as webhooks to merchant applications. Stripe signs every webhook with HMAC-SHA256, includes an idempotency key in each event, and retries failed deliveries with exponential backoff over 72 hours. Their published best practices directly inform how ML teams build fraud detection pipelines that consume payment events.
Stripe processes billions of webhook events monthly with 99.99%+ delivery success rate. Their architecture serves as the reference implementation that most webhook-consuming ML systems are designed against.
Razorpay, India's leading payment gateway, uses webhooks to notify merchants about payment lifecycle events -- authorization, capture, failure, and refund. Indian ML teams building fraud detection and payment analytics systems consume these webhooks as the primary data source. Razorpay signs webhooks with HMAC-SHA256 using a per-account webhook secret and supports filtering by event type to reduce unnecessary deliveries.
Razorpay's webhook system enables real-time fraud detection for merchants processing lakhs of transactions daily. The HMAC signing implementation prevents webhook spoofing attacks that could inject fake payment data into ML training pipelines.
GitHub webhooks are the backbone of CI/CD-triggered ML pipelines. When training data is version-controlled in Git repositories (a common pattern in MLOps), push webhooks trigger retraining pipelines. GitHub signs webhooks with HMAC-SHA256 via the X-Hub-Signature-256 header, includes a delivery GUID for idempotency, and expects a response within 10 seconds. MLOps platforms like CircleCI, Harness, and custom Prefect/Airflow deployments consume GitHub webhooks to automate model training, evaluation, and deployment.
GitHub webhooks enable event-driven MLOps for millions of repositories. The pattern of 'data push triggers retraining' has become standard practice, replacing scheduled cron-based retraining with reactive pipelines that respond to actual data changes.
During Black Friday/Cyber Monday 2024, Shopify's infrastructure processed 173 billion requests, with webhooks notifying merchant applications about orders, inventory changes, and customer events in real time. Shopify's webhook system uses Kafka as the internal backbone and delivers events via HTTP with HMAC verification. Merchant ML systems (demand forecasting, fraud detection, personalization) consume these webhooks to react to shopping behavior in real time.
Shopify's webhook infrastructure handled peak loads of 284 million requests per minute during BFCM 2024, demonstrating that queue-backed webhook architectures can scale to extreme burst traffic when properly designed.
Label Studio, an open-source data labeling platform widely used by Indian AI startups and research labs, fires webhooks when annotations are created, updated, or reviewed. ML teams configure these webhooks to trigger automated quality checks and incremental model retraining. When a batch of annotations is completed, the webhook feeds newly labeled data directly into the training pipeline, reducing the feedback loop from days (manual export) to minutes (automated webhook flow).
Teams using Label Studio webhooks report reducing their data-to-model feedback loop from 24-48 hours (manual CSV export and upload) to under 30 minutes (automated webhook-triggered retraining), significantly accelerating model iteration speed.
Tooling & Ecosystem
Managed webhook infrastructure for receiving, transforming, and routing webhooks. Provides built-in retries, rate limiting, event deduplication, and a debugging dashboard. Their open-source project Outpost (Apache-2.0) handles outbound webhook delivery with multi-tenant routing.
Enterprise-grade webhook sending and receiving platform. Open-source server implementation with built-in HMAC signing, retry logic, and monitoring dashboard. Available as both SaaS and self-hosted. The open-source webhook server is written in Rust for high performance.
High-performance Python web framework ideal for building webhook receivers. Native async support, automatic request validation via Pydantic, and OpenAPI webhook documentation support (since v0.99.0). The go-to choice for Python ML teams building webhook endpoints.
Tunneling tool that exposes local development servers to the internet for webhook testing. Supports built-in signature verification for 50+ webhook providers, request inspection, and replay. Essential for local development and debugging of webhook handlers.
Free online tool that generates a unique URL to receive and inspect webhook payloads. Useful for testing and debugging webhook integrations without writing any code. Shows headers, body, and timing for each received request.
Serverless event bus that can receive webhooks via API destinations and route them to AWS services (Lambda, SQS, Step Functions). Supports content-based filtering, schema registry, and event replay. Ideal for AWS-native ML pipelines.
Open-source outbound webhook and event destinations infrastructure. Delivers events to webhook endpoints, message queues (SQS, RabbitMQ), and event buses with at-least-once delivery guarantees. Written in Go with minimal dependencies (Redis + PostgreSQL).
Research & References
Kreuzberger, Kuhl & Hirschl (2023)IEEE Access, Vol. 11
Comprehensive MLOps reference that identifies event-driven data ingestion (including webhooks) as a critical component of continuous training pipelines. Defines the architectural role of trigger mechanisms in automated ML lifecycle management.
Shankar, Benschoten, Kejariwal, Lakshmanan & Xiong (2022)arXiv preprint
Proposes observability systems for production ML pipelines that monitor data ingestion endpoints (including webhooks) for anomalies in volume, schema drift, and latency. Directly relevant to webhook monitoring in ML systems.
Cardozo, Gomes & Coleti (2024)arXiv preprint
Systematic mapping study that analyzes MLOps architectural components including data ingestion triggers. Identifies event-driven ingestion as a key variability point in MLOps system design, with webhooks being the most common external trigger mechanism.
Hasan, Waseem, Liang, Ahmad & Ali (2024)arXiv preprint
Reviews MLOps practices from both academic and grey literature, identifying webhook-based data ingestion as a key enabler of continuous training pipelines. Highlights challenges including event ordering, idempotency, and integration testing.
Zhang, Chen, Ahmed & Hassan (2023)arXiv preprint
Case study examining model retraining practices including trigger mechanisms. Identifies event-driven triggers (such as webhooks from monitoring systems or data pipelines) as increasingly preferred over scheduled triggers for production ML systems.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a webhook ingestion system that feeds a real-time fraud detection model?
- ●
What is the difference between webhooks and polling? When would you choose one over the other for an ML pipeline?
- ●
How do you ensure exactly-once processing when webhook providers guarantee at-least-once delivery?
- ●
Explain HMAC signature verification for webhooks. Why is timing-safe comparison important?
- ●
How would you handle a sudden 100x spike in webhook events during a sale event (like Flipkart Big Billion Days)?
- ●
What happens to webhook events when your receiver is down for 2 hours? How do you recover?
Key Points to Mention
- ●
The thin receiver, fat processor pattern is non-negotiable for production webhooks. Acknowledge fast (under 500ms), process asynchronously via a queue. This is the first thing to mention in any webhook design discussion.
- ●
HMAC-SHA256 is the standard signature scheme used by 89% of webhook providers. Always verify against raw bytes, never parsed JSON. Use timing-safe comparison (
hmac.compare_digestin Python,crypto.timingSafeEqualin Node.js) to prevent timing side-channel attacks. - ●
Idempotency is the consumer's responsibility, not the provider's. Use event ID-based deduplication with a TTL matching the provider's retry window (typically 72 hours). Redis
SETNXwith TTL is the standard implementation. - ●
Dead letter queues are essential, not optional. Every failed event must be preserved for investigation and replay. Archive DLQ to durable storage (S3) before retention expires.
- ●
The queue acts as a shock absorber between bursty webhook delivery and steady downstream processing. SQS for simplicity, Kafka for ordering and replay. This is where you demonstrate distributed systems thinking.
Pitfalls to Avoid
- ●
Saying webhooks provide exactly-once delivery -- they provide at-least-once, and exactly-once processing is the consumer's responsibility through idempotency.
- ●
Proposing to process webhook events synchronously in the request handler without a queue -- this will timeout and cause cascading retries under any real load.
- ●
Forgetting to discuss security: HMAC verification, timestamp freshness checks, and replay attack prevention are table-stakes for production webhook receivers.
- ●
Ignoring the failure recovery story: what happens when your endpoint is down? How do you detect and replay missed events? This separates senior answers from junior ones.
- ●
Not mentioning monitoring: webhook endpoints need dashboards showing delivery success rate, signature verification failure rate, queue depth, processing latency, and DLQ growth.
Senior-Level Expectation
A senior candidate should design the complete webhook ingestion architecture: edge layer (load balancer + WAF + rate limiting), receiver layer (signature verification + queue persistence), processing layer (idempotency + schema validation + routing), and failure handling (DLQ + alerting + replay). They should discuss cost tradeoffs between serverless (API Gateway + Lambda) vs. container-based (ECS/EKS + SQS) deployments, and reason about capacity planning for known traffic events. They should also address operational concerns: how to rotate webhook secrets without downtime (dual-secret verification), how to handle schema evolution from providers, and how to monitor the health of the entire ingestion pipeline. The ability to discuss concrete numbers -- expected throughput, latency budgets, queue sizing, and cost projections in INR -- is what distinguishes a staff-level answer.
Summary
What We Covered
A webhook is an HTTP callback mechanism that pushes event data from external systems to your ML pipeline in real time. It solves the fundamental freshness problem that polling-based ingestion creates: instead of your pipeline operating on stale data from periodic API checks, webhooks deliver events within seconds of occurrence.
The production architecture follows the thin receiver, fat processor pattern: a lightweight HTTP endpoint verifies the HMAC-SHA256 signature, persists the raw payload to a message queue (SQS, Kafka, or Redis Streams), and returns 200 OK immediately. All heavy processing -- schema validation, idempotency checks, feature extraction, and routing to ML pipeline stages -- happens asynchronously downstream. This decoupling is what allows webhook systems to handle bursty traffic without dropping events or timing out.
The three non-negotiable implementation requirements are HMAC signature verification (authenticate every request using the raw body bytes, with timestamp freshness checks to prevent replay attacks), idempotency (deduplicate events using a Redis-backed event ID store, because at-least-once delivery means duplicates are expected, not exceptional), and dead letter queues (preserve failed events for investigation and replay, because silent data loss is unacceptable in ML systems where every missing event is a gap in training data or a missed inference opportunity).
Webhooks are the bridge between the outside world and your ML pipeline. They are conceptually simple -- just an HTTP POST -- but operationally demanding. The engineering challenge is not receiving the webhook; it's receiving it reliably, securely, and exactly once at scale. Master this, and you've built the foundation for event-driven ML systems that react to the real world in real time.