CrewAI Agent in Machine Learning
CrewAI is an open-source, role-based multi-agent orchestration framework that models AI collaboration the way human teams actually work: by assigning specialized roles, goals, and backstories to individual agents, then coordinating them through structured processes to accomplish complex tasks autonomously.
The fundamental insight behind CrewAI is deceptively simple -- the same organizational principles that make human teams effective (clear role definitions, task delegation, shared context, and managerial oversight) can be applied to LLM-powered agents. Instead of building one monolithic prompt that tries to do everything, you decompose the problem into discrete roles (researcher, writer, analyst, reviewer) and let each agent focus on what it does best.
With over 40,000 GitHub stars and adoption by enterprises like PwC, DocuSign, PepsiCo, and Johnson & Johnson, CrewAI has become one of the most popular multi-agent frameworks in production. It powers over 2 billion agentic workflow executions and is used by an estimated 60% of Fortune 500 companies. Whether you are building a content pipeline for a Bengaluru-based edtech startup or orchestrating compliance workflows at a financial services firm, CrewAI provides the abstractions to go from prototype to production in weeks rather than months.
This guide covers everything you need to know: the core primitives (agents, tasks, crews), process types (sequential, hierarchical), memory and tool integration, production deployment patterns, cost analysis, and how CrewAI compares to alternatives like LangGraph and AutoGen.
Concept Snapshot
- What It Is
- A Python framework for orchestrating role-playing, autonomous AI agents that collaborate through structured processes to accomplish complex, multi-step tasks.
- Category
- Multi-Agent Systems
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: task descriptions, agent role definitions (YAML or Python), tool configurations, and LLM provider credentials. Outputs: structured task results, intermediate agent reasoning traces, and final crew output.
- System Placement
- Sits at the orchestration layer of an agentic AI system, above the LLM provider and tool integrations, and below the application-level business logic or API gateway.
- Also Known As
- CrewAI framework, crew-based agents, role-based multi-agent system, CrewAI orchestrator, multi-agent crew
- Typical Users
- ML Engineers, AI Application Developers, Backend Engineers, Solutions Architects, Product Engineers building agentic workflows
- Prerequisites
- LLM API usage (OpenAI, Anthropic, or local models), Basic understanding of prompt engineering, Python programming, Familiarity with agent-based AI concepts
- Key Terms
- agenttaskcrewrolegoalbackstorysequential processhierarchical processkickoffFlowsmemorytooldelegation
Why This Concept Exists
The Single-Agent Ceiling
The first generation of LLM applications followed a simple pattern: one prompt, one model, one response. This works beautifully for straightforward tasks -- summarize this document, translate this paragraph, answer this question. But it hits a hard ceiling when you need to accomplish complex, multi-step workflows that require different types of expertise.
Consider a real-world example: a startup in Hyderabad wants to automate its market research pipeline. The workflow involves (1) gathering competitor data from the web, (2) analyzing financial reports, (3) synthesizing findings into a structured report, and (4) reviewing the report for accuracy. A single LLM call cannot reliably do all four steps -- it loses context, hallucinates intermediate facts, and produces inconsistent formatting. You need decomposition.
The Multi-Agent Promise
Researchers at Stanford (Park et al., 2023) demonstrated that LLM agents with distinct personas and memory could simulate realistic social behaviors. Projects like CAMEL (Li et al., 2023), MetaGPT (Hong et al., 2023), and ChatDev (Qian et al., 2024) showed that assigning software engineering roles (product manager, architect, developer, QA) to separate LLM agents produced significantly better code than single-agent approaches. The pattern was clear: role specialization plus structured collaboration beats monolithic prompting.
But these early frameworks were primarily research prototypes. They lacked production essentials: robust error handling, memory persistence across sessions, easy tool integration, YAML-based configuration, and enterprise-grade observability.
Where CrewAI Fits In
CrewAI, created by Joao Moura and released in late 2023, was designed from the ground up to bridge the gap between academic multi-agent research and production deployment. It borrowed the role-based collaboration model from organizational theory -- where every team member has a clear role (what they do), goal (what they aim to achieve), and backstory (the context that shapes their behavior) -- and wrapped it in a developer-friendly Python API with sensible defaults.
The framework gained rapid adoption for several reasons: it was built independently of LangChain (reducing dependency bloat), it provided both sequential and hierarchical process types out of the box, and it offered a clear upgrade path from open-source to enterprise via CrewAI Enterprise and the Crew Control Plane.
Key Insight: CrewAI exists because single-agent prompting cannot reliably handle workflows that require diverse expertise, iterative refinement, and structured delegation. It provides the organizational primitives to model AI collaboration the way effective human teams operate.
Core Intuition & Mental Model
Think of It as Building a Team, Not Writing a Prompt
Here is the simplest way to understand CrewAI: instead of crafting one perfect prompt, you are hiring a small team. Each team member (agent) has a job title (role), a personal objective (goal), and relevant experience (backstory). You then hand them a list of tasks, specify who does what, and let them collaborate.
Imagine you are running a content agency in Mumbai. You would not ask one person to research a topic, write the article, design the graphics, and proofread the final piece. You would assemble a team: a Researcher who digs into sources, a Writer who crafts the narrative, a Designer who creates visuals, and an Editor who polishes the output. Each person receives the previous person's work and builds on it. That is exactly what a CrewAI crew does.
The Backstory Is Not Decoration -- It Is a Steering Mechanism
One of the most underappreciated aspects of CrewAI is the backstory field. New users often treat it as optional flavor text, but it fundamentally shapes agent behavior. A backstory like "You are a senior financial analyst with 15 years of experience at Goldman Sachs, specializing in emerging market equities" produces dramatically different output than "You are a research assistant." The backstory functions as a persistent system prompt that anchors the agent's persona throughout the entire task execution -- it constrains the solution space in useful ways.
Delegation as a First-Class Primitive
In many multi-agent frameworks, agents are peers that pass messages. CrewAI adds a crucial organizational concept: delegation. When an agent encounters a sub-problem outside its expertise, it can explicitly delegate to another agent in the crew. This mirrors how a lead engineer might hand off a database optimization question to a DBA. The hierarchical process type takes this further by introducing a manager agent that actively distributes tasks, reviews outputs, and re-delegates when quality is insufficient. Think of it as the difference between a flat startup and a structured enterprise team -- both work, but at different scales and for different problem types.
Mental Model: CrewAI = (Role specialization) + (Structured communication) + (Task delegation) + (Shared memory). If you understand how a well-run team operates, you already understand CrewAI's architecture.
Technical Foundations
Formal Abstractions
CrewAI's architecture can be expressed through four core primitives and their relationships.
Definition 1 (Agent): An agent is a tuple where is the role string, is the goal string, is the backstory string, is a set of available tools, is the underlying LLM, and indicates whether the agent can delegate tasks to other agents.
Definition 2 (Task): A task is a tuple where is the task description, is the expected output specification, is the assigned agent, and is the set of dependency tasks whose outputs are available as context.
Definition 3 (Crew): A crew is a tuple where is the set of agents, is the ordered set of tasks, is the process type, and is the optional memory configuration.
Definition 4 (Kickoff): The execution function takes a crew and an input context and produces an output . For sequential process:
where is the execution of task by its assigned agent , and each receives the accumulated context from all prior tasks.
For hierarchical process, a manager agent controls dispatch:
where is the execution ordering determined dynamically by the manager based on agent capabilities and task requirements.
Complexity Considerations
In sequential mode, the total LLM calls scale as where is the number of tasks and is the average number of tool-use iterations per task. In hierarchical mode, the manager adds an additional coordination calls, but enables parallel task dispatch when tasks are independent, potentially reducing wall-clock time from to where the DAG represents task dependencies.
Token Cost Model
The total token cost for a crew execution can be approximated as:
where and are the per-token costs for the LLM used by each task's assigned agent. For GPT-4o at 10 per million output tokens, a typical 5-task crew with 2,000 input and 1,000 output tokens per task costs roughly $0.0625 per execution (~INR 5.25).
Internal Architecture
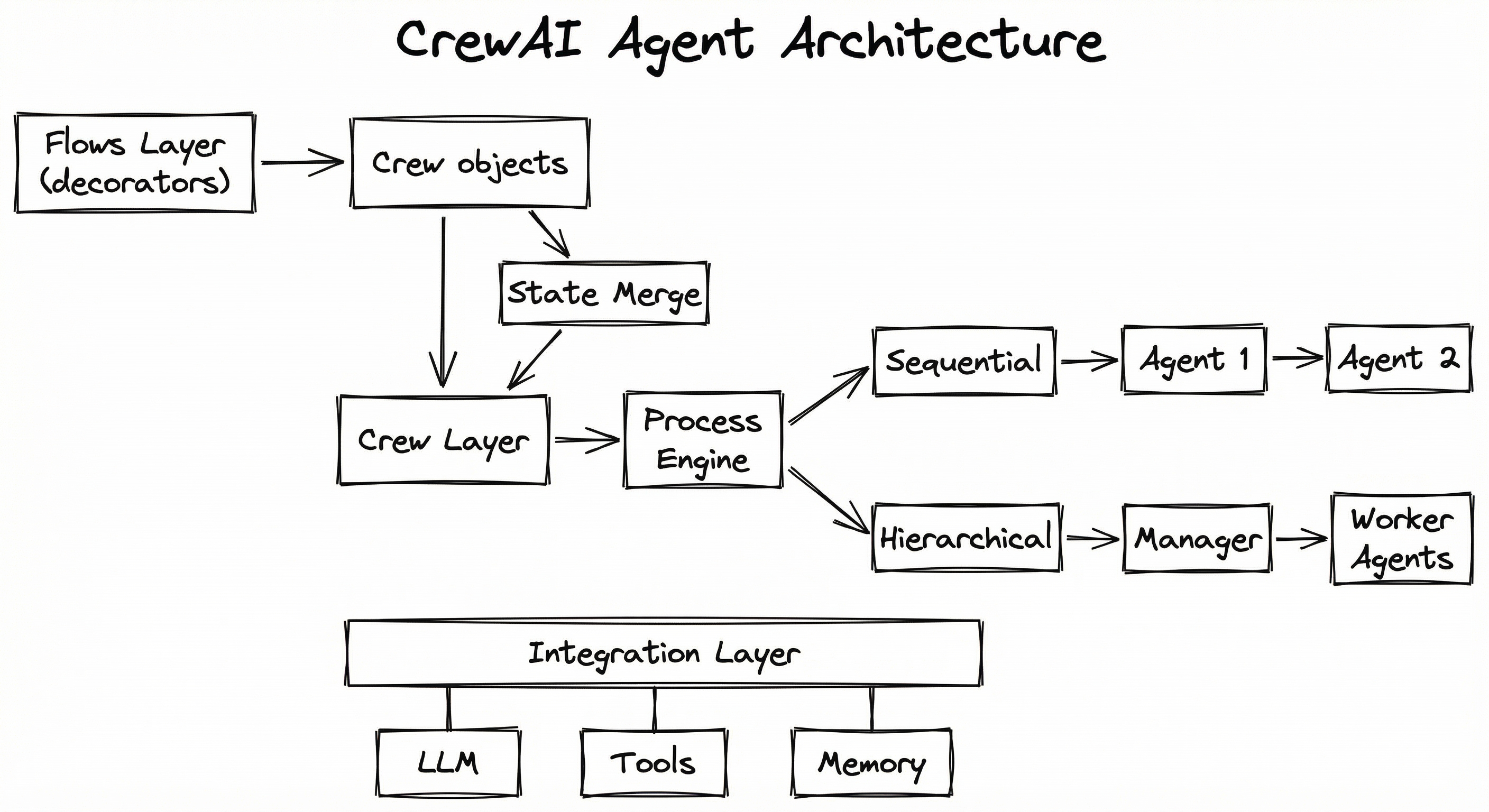
CrewAI's internal architecture follows a layered design with clear separation between agent definition, task orchestration, process execution, and external integrations.
At the top layer, the Crew object serves as the primary entry point. It holds references to all agents and tasks, manages the process lifecycle, and coordinates memory. Below that, the Process Engine implements the chosen execution strategy (sequential or hierarchical). The process engine interacts with individual Agent Executors that handle tool use, LLM calls, and output parsing for each agent. At the bottom layer, integrations connect to LLM providers (OpenAI, Anthropic, Ollama, Azure OpenAI), tool registries, and memory backends.
The Flows layer, introduced in 2024, adds an event-driven orchestration system on top of crews. Flows allow you to compose multiple crews into pipelines with conditional branching, loops, and state management -- think of it as the workflow engine that chains crews together the way Airflow chains tasks.
Key Components
Agent
The fundamental autonomous unit. Defined by a role (persona/job title), goal (what the agent aims to achieve), and backstory (contextual experience that shapes behavior). Each agent can be assigned specific tools and an LLM model. Agents can optionally delegate sub-tasks to other agents when allow_delegation=True.
Task
A discrete unit of work assigned to a specific agent. Each task has a description (what needs to be done), an expected_output (completion criteria), and optional context (dependencies on other tasks). Tasks can specify tool overrides and output format (JSON, Pydantic model, or free text).
Crew
The orchestration container that binds agents and tasks together. Configures the process type (sequential or hierarchical), memory settings, verbosity, and execution parameters. The crew.kickoff() method initiates execution.
Process Engine
Implements the execution strategy. Sequential: tasks execute in defined order, each receiving prior task outputs as context. Hierarchical: a manager agent dynamically assigns tasks to workers, reviews outputs, and re-delegates if quality is insufficient.
Memory System
Three-tier memory architecture: Short-term memory (ChromaDB-backed RAG for current execution context), Long-term memory (SQLite for cross-session task result persistence), and Entity memory (RAG-based tracking of named entities across conversations). Enabled via memory=True on the Crew object.
Tool Registry
Manages the tools available to agents. CrewAI provides built-in tools (web search, file I/O, code execution) and supports custom tools via the @tool decorator or BaseTool subclass. Tools can be assigned at agent level or task level for fine-grained control.
Flows
An event-driven orchestration layer for composing multiple crews into pipelines. Uses Python decorators (@start, @listen, @router) to define trigger conditions, conditional branching, and state management across crew executions. Flows enable building complex agentic applications beyond a single crew.
LLM Integration Layer
Connects agents to language model providers. Supports OpenAI, Anthropic Claude, Google Gemini, Azure OpenAI, Ollama (local models), and any OpenAI-compatible API. Each agent can use a different LLM, allowing cost optimization by routing simple tasks to cheaper models.
Data Flow
Sequential Process Data Flow:
crew.kickoff(inputs)is called with initial context- Task 1 is dispatched to Agent 1 with the input context
- Agent 1 invokes its LLM, optionally uses tools, and produces an output
- The output is stored in short-term memory and passed as context to Task 2
- This chain continues until all tasks complete
- The final task's output becomes the crew's result
Hierarchical Process Data Flow:
crew.kickoff(inputs)initializes the manager agent- The manager reviews all tasks and agent capabilities
- The manager delegates Task X to the most suitable agent
- The agent executes and returns output to the manager
- The manager validates the output quality; if insufficient, it re-delegates or provides feedback
- Steps 3-5 repeat for all tasks, potentially in parallel for independent tasks
- The manager compiles final results
Flows Data Flow:
- A Flow is triggered by
flow.kickoff() - Methods decorated with
@startexecute first - Methods decorated with
@listentrigger when their upstream methods complete @routermethods determine conditional branching paths- State is passed between methods via the Flow's state object
- Crews can be embedded as steps within a Flow
A four-layer architecture diagram. The top Flows Layer shows decorators feeding into multiple Crew objects that merge state. The Crew Layer shows a Crew Object connected to a Process Engine that branches into Sequential and Hierarchical processes. The Agent Layer shows Sequential feeding agents directly and Hierarchical feeding a Manager Agent that dispatches to Worker Agents. The Integration Layer shows agents connected to LLM Providers, Tool Registry, and Memory Backend.
How to Implement
Getting Started with CrewAI
CrewAI offers two implementation paths: a code-first approach using pure Python and a configuration-first approach using YAML files for agent and task definitions. The YAML approach is recommended for production systems because it separates configuration from logic, making it easier to modify agent behaviors without touching code.
The framework installs via pip (pip install crewai) and includes a CLI tool (crewai create crew my_project) that scaffolds a project with the recommended directory structure, including agents.yaml, tasks.yaml, and a crew.py file. This opinionated structure is intentional -- it forces clean separation of concerns from the start.
For Indian startups and cost-conscious teams, CrewAI supports any OpenAI-compatible API, which means you can use local models via Ollama (free), Azure OpenAI (often cheaper for Indian enterprises with Azure EA agreements), or providers like Together AI and Groq for cost-effective inference. A typical crew running 5 tasks on GPT-4o-mini costs approximately $0.005 per execution (~INR 0.42), making it feasible to run thousands of crew executions per day even on a tight budget.
from crewai import Agent, Task, Crew, Process
# Define agents with role, goal, and backstory
researcher = Agent(
role="Senior Market Research Analyst",
goal="Uncover emerging trends and competitive insights in the Indian fintech market",
backstory=(
"You are a seasoned market analyst with 12 years of experience tracking "
"the Indian fintech ecosystem. You've covered the rise of UPI, the growth "
"of Razorpay and PhonePe, and the regulatory shifts by RBI. You are known "
"for your data-driven, contrarian insights."
),
verbose=True,
allow_delegation=False,
llm="gpt-4o",
)
writer = Agent(
role="Content Strategist",
goal="Transform research findings into a compelling market brief for investors",
backstory=(
"You are a financial content strategist who has written for Bloomberg Quint "
"and The Ken. You excel at distilling complex fintech data into crisp, "
"actionable narratives that appeal to Series A and B investors."
),
verbose=True,
allow_delegation=False,
llm="gpt-4o",
)
# Define tasks
research_task = Task(
description=(
"Research the top 5 emerging trends in Indian fintech for 2026. "
"Focus on UPI market share shifts, BNPL regulation impacts, "
"and cross-border payment innovations. Use recent data from RBI "
"and NPCI reports."
),
expected_output="A detailed research brief with 5 trends, each supported by data points and sources.",
agent=researcher,
)
writing_task = Task(
description=(
"Using the research brief, write a 1500-word investor-facing market "
"analysis of Indian fintech trends. Include a competitive landscape "
"table and actionable investment themes."
),
expected_output="A polished market analysis document in markdown format.",
agent=writer,
context=[research_task], # This task receives the researcher's output
)
# Create and run the crew
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
process=Process.sequential,
verbose=True,
)
result = crew.kickoff()
print(result)This example demonstrates the core CrewAI pattern: define agents with specialized roles, create tasks with clear expected outputs, wire them together in a crew, and kick off execution. The context=[research_task] on the writing task ensures the writer receives the researcher's output. The sequential process guarantees the research completes before writing begins. Each agent's backstory is richly detailed -- this is not decoration but a critical steering mechanism that shapes the quality and style of the output.
# config/agents.yaml
researcher:
role: "Senior Market Research Analyst"
goal: "Uncover emerging trends and competitive insights in {industry}"
backstory: >
You are a seasoned market analyst with 12 years of experience.
You specialize in {industry} across the Indian market.
You are known for data-driven, contrarian insights backed by
primary sources like RBI circulars and SEBI filings.
llm: gpt-4o
max_iter: 15
allow_delegation: false
writer:
role: "Content Strategist"
goal: "Transform research into compelling {output_format} for {audience}"
backstory: >
You are a financial content strategist who has written for
Bloomberg Quint and The Ken. You distill complex data into
crisp, actionable narratives.
llm: gpt-4o-mini
allow_delegation: false
reviewer:
role: "Quality Assurance Editor"
goal: "Ensure factual accuracy, logical consistency, and professional tone"
backstory: >
You are a meticulous editor with a background in fact-checking
for financial publications. You catch errors that others miss.
llm: gpt-4o
allow_delegation: true
# config/tasks.yaml
research_task:
description: >
Research the top {num_trends} emerging trends in {industry}.
Focus on regulatory changes, market share shifts, and
technology innovations. Use recent data from official sources.
expected_output: "Detailed research brief with {num_trends} trends, each with data points."
agent: researcher
writing_task:
description: >
Using the research brief, write a {word_count}-word {output_format}
for {audience}. Include a competitive landscape table.
expected_output: "Polished {output_format} in markdown format."
agent: writer
context:
- research_task
review_task:
description: >
Review the {output_format} for factual accuracy, logical flow,
and professional tone. Flag any unsubstantiated claims.
Provide a final score out of 10.
expected_output: "Reviewed document with inline corrections and quality score."
agent: reviewer
context:
- writing_taskThe YAML configuration pattern separates agent and task definitions from execution logic. Notice the {industry}, {audience}, and {num_trends} placeholders -- these are populated at runtime via crew.kickoff(inputs={...}), making the same crew reusable across different domains. The writer uses gpt-4o-mini (cheaper) while the reviewer uses gpt-4o (more capable) -- a common cost optimization pattern where you allocate expensive models only to quality-critical tasks.
from crewai import Agent, Task, Crew, Process
# Worker agents
data_collector = Agent(
role="Data Collection Specialist",
goal="Gather structured data from APIs and web sources",
backstory="Expert at scraping and API integration with 8 years at a Bengaluru data analytics firm.",
tools=[web_search_tool, scraper_tool],
llm="gpt-4o-mini", # Cheaper model for data gathering
)
analyst = Agent(
role="Quantitative Analyst",
goal="Perform statistical analysis and identify actionable patterns",
backstory="IIT Bombay statistics graduate with 5 years at Zerodha's quant desk.",
tools=[code_execution_tool],
llm="gpt-4o", # More capable model for analysis
)
report_writer = Agent(
role="Report Author",
goal="Produce clear, well-structured analytical reports",
backstory="Former McKinsey consultant who writes reports that CXOs actually read.",
llm="gpt-4o-mini",
)
# Custom manager agent (optional -- CrewAI creates one by default)
manager = Agent(
role="Research Director",
goal="Coordinate the research team to produce high-quality deliverables on time",
backstory=(
"You are a seasoned research director who has managed teams of 20+ analysts. "
"You excel at task prioritization, quality control, and knowing when to "
"re-delegate work that doesn't meet standards."
),
llm="gpt-4o",
allow_delegation=True,
)
# Tasks (agent assignment is optional in hierarchical -- manager decides)
collect_task = Task(
description="Collect Q3 2025 revenue data for top 10 Indian SaaS companies.",
expected_output="Structured dataset with company name, revenue, growth rate, and source URL.",
)
analyze_task = Task(
description="Analyze revenue trends, compute CAGR, and identify top 3 outliers.",
expected_output="Statistical analysis with visualizations and key findings.",
)
report_task = Task(
description="Write a 2-page executive summary of the Indian SaaS market analysis.",
expected_output="Executive summary in markdown with tables and key recommendations.",
)
# Hierarchical crew with custom manager
crew = Crew(
agents=[data_collector, analyst, report_writer],
tasks=[collect_task, analyze_task, report_task],
process=Process.hierarchical,
manager_agent=manager,
memory=True, # Enable short-term, long-term, and entity memory
verbose=True,
)
result = crew.kickoff()
print(result.raw)In hierarchical mode, the manager agent dynamically decides which worker agent handles each task based on their roles and capabilities. Notice that tasks do not specify an agent -- the manager assigns them at runtime. The manager also validates outputs and can re-delegate if quality is insufficient. This pattern works well for complex workflows where task routing depends on intermediate results. The memory=True flag enables CrewAI's three-tier memory system, allowing agents to reference prior context within the execution.
from crewai.flow.flow import Flow, listen, start, router
from crewai import Crew
from pydantic import BaseModel
class MarketReportState(BaseModel):
industry: str = ""
research_quality_score: float = 0.0
research_output: str = ""
final_report: str = ""
class MarketReportFlow(Flow[MarketReportState]):
@start()
def gather_research(self):
"""First step: run the research crew."""
research_crew = Crew(
agents=[researcher_agent],
tasks=[research_task],
process="sequential",
)
result = research_crew.kickoff(
inputs={"industry": self.state.industry}
)
self.state.research_output = result.raw
return result.raw
@router(gather_research)
def evaluate_quality(self):
"""Route based on research quality."""
# Use a lightweight LLM call to score quality
score = evaluate_research_quality(self.state.research_output)
self.state.research_quality_score = score
if score >= 7.0:
return "proceed_to_writing"
else:
return "redo_research"
@listen("redo_research")
def refine_research(self):
"""Re-run research with enhanced instructions."""
enhanced_crew = Crew(
agents=[senior_researcher_agent],
tasks=[enhanced_research_task],
process="sequential",
)
result = enhanced_crew.kickoff(
inputs={
"industry": self.state.industry,
"prior_research": self.state.research_output,
}
)
self.state.research_output = result.raw
return result.raw
@listen("proceed_to_writing")
def write_report(self):
"""Final step: produce the report."""
writing_crew = Crew(
agents=[writer_agent, editor_agent],
tasks=[write_task, edit_task],
process="sequential",
)
result = writing_crew.kickoff(
inputs={"research": self.state.research_output}
)
self.state.final_report = result.raw
return result.raw
# Execute the flow
flow = MarketReportFlow()
flow.kickoff(inputs={"industry": "Indian fintech"})
print(flow.state.final_report)Flows extend CrewAI beyond single-crew execution into multi-crew pipelines with conditional logic. This example shows a quality gate pattern: research is evaluated, and if the score is below 7.0, it is re-run with a more capable agent before proceeding to the writing crew. The @start, @listen, and @router decorators define an event-driven DAG. The MarketReportState Pydantic model provides type-safe state management across the flow. This is the recommended pattern for production-grade agentic applications.
from crewai.tools import BaseTool
from pydantic import Field
import requests
class NSEStockPriceTool(BaseTool):
"""Fetch real-time stock price from NSE India."""
name: str = "NSE Stock Price Lookup"
description: str = (
"Fetches the current stock price for an Indian company listed on NSE. "
"Input should be the NSE stock symbol (e.g., 'RELIANCE', 'TCS', 'INFY')."
)
def _run(self, symbol: str) -> str:
try:
url = f"https://www.nseindia.com/api/quote-equity?symbol={symbol}"
headers = {
"User-Agent": "Mozilla/5.0",
"Accept": "application/json",
}
session = requests.Session()
session.get("https://www.nseindia.com", headers=headers)
response = session.get(url, headers=headers)
data = response.json()
price_info = data.get("priceInfo", {})
return (
f"Symbol: {symbol}\n"
f"Last Price: INR {price_info.get('lastPrice', 'N/A')}\n"
f"Change: {price_info.get('change', 'N/A')} "
f"({price_info.get('pChange', 'N/A')}%)\n"
f"Day High: INR {price_info.get('intraDayHighLow', {}).get('max', 'N/A')}\n"
f"Day Low: INR {price_info.get('intraDayHighLow', {}).get('min', 'N/A')}"
)
except Exception as e:
return f"Error fetching stock data for {symbol}: {str(e)}"
# Use the custom tool with an agent
nse_tool = NSEStockPriceTool()
financial_analyst = Agent(
role="Indian Equity Analyst",
goal="Analyze stock performance of Indian listed companies",
backstory="CFA charterholder with 10 years analyzing Indian equities at HDFC Securities.",
tools=[nse_tool],
llm="gpt-4o",
)Custom tools are a critical extension point in CrewAI. This example demonstrates building a tool that fetches real-time stock prices from NSE India -- directly relevant for Indian fintech applications. Tools are defined by subclassing BaseTool with a name, description (used by the agent's LLM to decide when to invoke the tool), and a _run method. The agent's LLM reads the tool description and autonomously decides when and how to invoke it during task execution.
# docker-compose.yaml for production CrewAI deployment
version: '3.8'
services:
crewai-app:
build: .
environment:
- OPENAI_API_KEY=${OPENAI_API_KEY}
- CREWAI_MEMORY=true
- CREWAI_VERBOSE=false
volumes:
- ./config:/app/config
- crew-memory:/app/.crewai
deploy:
resources:
limits:
memory: 2G
cpus: '1.0'
restart: unless-stopped
chromadb:
image: chromadb/chroma:latest
ports:
- "8000:8000"
volumes:
- chroma-data:/chroma/chroma
volumes:
crew-memory:
chroma-data:
# Estimated monthly costs (India, ap-south-1):
# - EC2 t3.medium: ~INR 2,500/month ($30)
# - LLM API (10K executions/day, GPT-4o-mini): ~INR 12,500/month ($150)
# - ChromaDB storage: ~INR 500/month ($6)
# Total: ~INR 15,500/month ($186)Common Implementation Mistakes
- ●
Skipping backstory detail: Treating the backstory as optional filler. The backstory is a persistent system prompt that fundamentally shapes agent behavior -- a generic backstory like 'You are a helpful assistant' produces generic output. Invest time writing rich, specific backstories with domain expertise and behavioral constraints.
- ●
Overly broad goals: Setting vague agent goals like 'Do research' instead of specific goals like 'Identify the top 5 regulatory risks for NBFC lending in India with supporting RBI circular references.' Broad goals lead to unfocused agent behavior and inconsistent outputs.
- ●
Using hierarchical process for simple workflows: The hierarchical process adds manager overhead (extra LLM calls, coordination latency). For linear, 2-4 task workflows, sequential process is simpler, cheaper, and more predictable. Reserve hierarchical for workflows with 5+ tasks and genuine delegation needs.
- ●
Ignoring token costs at scale: A single crew execution is cheap ($0.01-0.10), but running 10,000 executions per day adds up. Failing to assign cheaper models (GPT-4o-mini, Claude 3.5 Haiku) to simple tasks while reserving expensive models for critical tasks is a common cost mistake. For Indian startups, this can mean the difference between INR 25,000/month and INR 2,50,000/month.
- ●
No output validation: Assuming agent outputs are always correct. In production, you must validate outputs programmatically (schema checks, fact verification, safety filters) before passing them downstream. The Flows
@routerpattern is ideal for implementing quality gates. - ●
Circular delegation loops: Setting
allow_delegation=Trueon all agents without guard rails can cause infinite delegation loops where Agent A delegates to Agent B, which delegates back to Agent A. Usemax_iterto cap iterations and be intentional about which agents can delegate. - ●
Not leveraging memory for repeated workflows: Running the same crew type repeatedly without enabling memory means each execution starts from zero. Long-term memory allows agents to learn from past executions, improving quality over time.
When Should You Use This?
Use When
Your workflow naturally decomposes into distinct roles -- researcher, analyst, writer, reviewer, QA -- where each role benefits from a different persona and tool set
You need structured multi-step task execution with clear handoffs between agents, such as a content pipeline, compliance review chain, or customer support escalation flow
You want a framework that mirrors organizational hierarchies, with optional manager agents that coordinate task delegation and quality control
Your team prioritizes developer experience and rapid prototyping -- CrewAI's YAML configuration and CLI scaffolding get you from zero to working crew in under an hour
You need cross-session memory so that agents improve over time by learning from past executions (long-term memory via SQLite)
You are building for production and need enterprise features: observability, the Crew Control Plane, and managed deployment via CrewAI Enterprise
Your budget requires using different LLM tiers per agent (e.g., GPT-4o for critical analysis, GPT-4o-mini for data gathering) to optimize cost
You want to compose multiple crews into complex pipelines with conditional logic using Flows
Avoid When
Your task is a single-step LLM call (summarization, translation, classification) -- multi-agent overhead is unnecessary and adds latency and cost for no benefit
You need fine-grained, graph-level control over agent state transitions and conditional edges -- LangGraph provides more explicit workflow control for complex state machines
Your primary requirement is free-form, conversational multi-agent debate without structured task assignments -- AutoGen's conversation-driven architecture is a better fit
You are building a real-time, sub-second response system -- multi-agent coordination adds 5-30 seconds of latency per crew execution, making it unsuitable for synchronous API endpoints
You need deterministic, reproducible outputs for regulatory compliance -- LLM-based agents are inherently non-deterministic, and multi-agent systems amplify this variance
Your workflow has no natural role decomposition -- if one agent can do the job, adding more agents just adds cost and complexity
Key Tradeoffs
Simplicity vs. Control
CrewAI optimizes for developer experience at the cost of fine-grained control. The role-goal-backstory abstraction is intuitive and maps to how we think about human teams, but it hides the underlying prompt engineering. If you need to precisely control the system prompt, manage token windows, or implement custom retry logic at the agent level, you may find CrewAI's abstractions limiting compared to LangGraph's explicit graph API.
Cost vs. Quality
Every additional agent in a crew multiplies LLM calls. A 5-agent sequential crew makes at minimum 5 LLM calls per execution (more with tool use and delegation). At GPT-4o pricing, this is roughly 500-1,500/month (~INR 42,000-1,25,000/month). The cost-quality tradeoff can be optimized by:
| Strategy | Cost Impact | Quality Impact |
|---|---|---|
| Use GPT-4o-mini for non-critical agents | -60% token cost | Slight quality drop on complex tasks |
| Reduce agent count (combine similar roles) | -30-50% per execution | May lose specialization benefits |
| Cache common tool results | -20-40% tool call costs | No quality impact |
| Use local models via Ollama for dev/test | -95% during development | Lower quality, but fine for iteration |
Latency vs. Thoroughness
Sequential crews execute tasks one at a time, with total latency being the sum of all task latencies (typically 10-60 seconds for a 3-5 task crew). Hierarchical crews can parallelize independent tasks but add manager coordination overhead. For user-facing applications, consider running crews asynchronously and notifying users when results are ready, rather than making them wait.
Rule of Thumb: Start with 2-3 agents in sequential mode. Only add agents or switch to hierarchical when you can demonstrate measurable quality improvement that justifies the added cost and latency.
Alternatives & Comparisons
LangGraph provides a graph-based workflow model where agent interactions are nodes in a directed graph with explicit edges and conditional transitions. Choose LangGraph when you need fine-grained control over state transitions, complex branching logic, or persistent workflows with checkpointing. Choose CrewAI when you want a higher-level abstraction that models collaboration as roles and tasks rather than graph nodes -- CrewAI is faster to prototype but less flexible for unusual workflow topologies.
AutoGen emphasizes conversational collaboration where agents interact through natural-language chat, with strong support for human-in-the-loop patterns. Choose AutoGen for free-form debate, brainstorming, and scenarios where agents need to negotiate or challenge each other's outputs. Choose CrewAI when you want structured task assignment with clear role boundaries rather than open-ended conversation -- CrewAI's sequential and hierarchical processes provide more predictable execution paths.
A custom agent supervisor (often built with LangGraph or bare LLM calls) gives you maximum control over delegation logic and quality gates. Choose a custom supervisor when your orchestration requirements are highly domain-specific and no framework's abstractions fit. Choose CrewAI when you want the supervisor pattern out of the box via its hierarchical process, without building the coordination logic from scratch.
An agent router dispatches incoming requests to a single specialist agent based on intent classification, without inter-agent collaboration. Choose a router when tasks are independent and don't require multi-step collaboration. Choose CrewAI when tasks need to chain across multiple specialists, with each building on the previous agent's output.
Pros, Cons & Tradeoffs
Advantages
Intuitive role-based API that mirrors how human teams work -- defining agents with role, goal, and backstory is immediately understandable to developers without deep AI expertise. The learning curve is gentle.
YAML-based configuration separates agent definitions from execution logic, enabling non-technical stakeholders to modify agent behaviors without touching Python code. This is a significant operational advantage for enterprise deployments.
Built-in memory system with three tiers (short-term via ChromaDB, long-term via SQLite, entity memory via RAG) provides cross-session learning without requiring external memory infrastructure.
Flexible LLM assignment per agent allows cost optimization by routing simple tasks to cheaper models (GPT-4o-mini at 2.50/M) for quality-critical tasks.
Flows orchestration layer enables composing multiple crews into complex pipelines with conditional branching, quality gates, and state management -- bridging the gap from single-crew demos to production applications.
Enterprise-grade ecosystem including CrewAI Enterprise, the Crew Control Plane for observability, managed deployment, and partnerships with PwC, DocuSign, and other Fortune 500 companies.
Large community and ecosystem with 40K+ GitHub stars, 100K+ certified developers, and extensive examples and courses (including DeepLearning.AI). Getting help is easy.
Framework-independent implementation built from scratch without LangChain dependency, reducing bloat and dependency conflicts in production environments.
Disadvantages
Non-deterministic outputs -- LLM-based agents produce different results on each run, and multi-agent collaboration amplifies this variance. For workflows requiring reproducible outputs, this is a fundamental limitation.
Latency overhead from multi-agent coordination: a 5-task sequential crew typically takes 15-60 seconds, making it unsuitable for synchronous, user-facing API endpoints that need sub-second responses.
Token cost multiplication -- every additional agent and delegation step increases LLM API costs. A hierarchical crew with a manager adds 30-50% more LLM calls compared to sequential execution of the same tasks.
Debugging complexity increases with agent count: when a 5-agent crew produces incorrect output, tracing the root cause requires examining each agent's reasoning chain, tool calls, and inter-agent context passing.
Abstraction leakage in complex scenarios: CrewAI's high-level abstractions (role, goal, backstory) work well for standard workflows but can be frustrating when you need to precisely control system prompts, manage token windows, or implement custom error recovery logic.
Hierarchical process reliability: community feedback indicates that the hierarchical process with manager agents can be unpredictable, sometimes re-delegating excessively or failing to properly validate worker outputs. Sequential process is more battle-tested.
Failure Modes & Debugging
Infinite delegation loop
Cause
Multiple agents with allow_delegation=True delegate tasks back and forth without resolution, especially when task descriptions are ambiguous and agents cannot determine clear ownership.
Symptoms
Crew execution hangs or hits the max_iter limit. Token costs spike as agents generate delegation requests repeatedly. Verbose logs show agents saying 'I'll delegate this to...' in a circular pattern.
Mitigation
Set allow_delegation=False on most agents and only enable it on agents that genuinely need to delegate. Use max_iter (default 25) as a safety cap. In hierarchical mode, only the manager should delegate. Write unambiguous task descriptions that leave no room for role confusion.
Backstory-goal misalignment
Cause
An agent's backstory implies expertise in one domain but the goal asks for work in a different domain, causing the LLM to produce confused or low-quality output.
Symptoms
Agent outputs are generic, unfocused, or contain hallucinated expertise. The agent may ignore tool results and fall back to general knowledge because the persona does not match the task requirements.
Mitigation
Ensure backstory, role, and goal are coherent and mutually reinforcing. A backstory about financial analysis paired with a goal about code review will produce poor results. Review agent definitions as a unit, not independently.
Context window overflow
Cause
In sequential crews, each subsequent task receives accumulated context from all prior tasks. By task 5-6, the combined context can exceed the LLM's context window, causing truncation or errors.
Symptoms
Later tasks produce outputs that ignore early-stage context. Errors like 'maximum context length exceeded' appear in logs. Quality degrades noticeably in the final tasks of long crews.
Mitigation
Limit crew size to 3-5 tasks. Use output_json or output_pydantic to produce structured, compact outputs that consume fewer tokens when passed as context. For longer pipelines, use Flows to chain multiple smaller crews with summarized state passing.
Tool invocation failure cascade
Cause
An agent's tool call fails (API timeout, rate limit, invalid input), and the agent either retries indefinitely or produces hallucinated output instead of using the tool result.
Symptoms
Agent output contains fabricated data that should have come from a tool. Execution time spikes due to repeated retries. Downstream agents receive incorrect context and compound the error.
Mitigation
Implement tool-level error handling with clear fallback messages. Set max_iter to prevent infinite retries. Use max_retry_limit on the agent. In Flows, implement @router quality gates that check for tool-sourced data before proceeding.
Manager agent misallocation (hierarchical)
Cause
In hierarchical mode, the manager agent assigns a task to the wrong worker agent because agent roles are not sufficiently distinct or the manager's LLM makes a poor delegation decision.
Symptoms
Tasks are completed by agents lacking the relevant tools or expertise. Output quality is lower than expected. The manager may re-delegate the same task multiple times.
Mitigation
Make agent roles maximally distinct -- avoid overlapping role descriptions. Provide the manager with a clear backstory that includes knowledge of each worker's strengths. Consider using a stronger LLM (GPT-4o or Claude 3.5 Sonnet) for the manager while using cheaper models for workers.
Memory pollution across executions
Cause
Long-term memory stores results from previous crew executions. If earlier executions produced incorrect or outdated information, subsequent executions may retrieve and act on stale or wrong context.
Symptoms
Agents reference information that was not provided in the current execution. Outputs contain data from a previous, unrelated run. Quality is inconsistent across executions in ways that do not correlate with input changes.
Mitigation
Implement memory hygiene: periodically clear or prune long-term memory. Use execution-scoped memory namespaces to isolate different workflow types. Add metadata timestamps to memory entries and configure retrieval to prefer recent entries.
Placement in an ML System
Where Does CrewAI Sit in the ML System?
CrewAI operates at the orchestration layer of an agentic AI system. It sits above the LLM providers (OpenAI, Anthropic, local models) and tool integrations (search APIs, databases, code execution), and below the application-level business logic.
In a typical production architecture, the flow is: User Request -> API Gateway -> CrewAI Crew -> (LLM Calls + Tool Calls) -> Response. For asynchronous workflows, a task queue (Celery, SQS) sits between the API gateway and CrewAI, allowing crew executions to run in the background.
CrewAI interacts with several other system components:
- Upstream: An agent router may classify incoming requests and determine which crew to invoke. A memory store provides historical context.
- Downstream: Crews invoke tool executors for external actions (API calls, database queries, code execution). An agent supervisor or monitoring system tracks crew performance and cost.
- Complementary: LangGraph nodes may be used for low-level state management within individual agents, while CrewAI handles the higher-level multi-agent coordination.
Key Insight: CrewAI is not a replacement for your entire AI stack -- it is the coordination layer that ties together LLMs, tools, and memory into coherent multi-agent workflows. Think of it as the team manager, not the individual contributor.
Pipeline Stage
Orchestration / Agentic Layer
Upstream
- agent-router
- tool-executor
- memory-store
Downstream
- tool-executor
- memory-store
- agent-supervisor
Scaling Bottlenecks
The primary bottleneck is LLM API throughput. Each agent in a crew makes sequential LLM calls, and the total execution time is dominated by LLM response latency (typically 1-5 seconds per call). A 5-task crew with 3 tool-use iterations each makes ~15 LLM calls, taking 15-75 seconds total.
For high-throughput scenarios (e.g., processing 10,000 customer support tickets per day), you need horizontal scaling -- running multiple crew instances in parallel via task queues (Celery, Redis Queue, or cloud functions). Each crew instance is stateless (unless using shared memory), so scaling is linear: 10 workers = 10x throughput.
The second bottleneck is token cost scaling. At 125/day (~INR 10,500/day or ~INR 3.15 lakh/month). Switching non-critical agents to GPT-4o-mini (25/day (~INR 2,100/day).
Memory persistence (ChromaDB, SQLite) becomes a bottleneck at scale if many concurrent crew instances write simultaneously. For high-concurrency deployments, use a centralized memory backend (Redis, PostgreSQL) instead of file-based SQLite.
Production Case Studies
PwC selected CrewAI to power its Agent OS platform, a global enterprise system for structured orchestration, observability, and secure execution of AI agent workflows. CrewAI-powered agents were deployed across operations, client-facing workflows, and internal systems, with native agent-monitoring integrations providing visibility into task durations, tool selection, and human-versus-agent effort.
Code-generation accuracy improved from 10% to 70%. Complex document turnaround times were significantly reduced. PwC cited CrewAI's low barrier to entry for non-expert developers combined with deep API customization for advanced teams as a key selection factor.
DocuSign adopted CrewAI Flows for sales pipeline acceleration. Their workflow involves taking a lead, researching them, composing personalized outreach, validating quality, and sending -- a multi-agent pipeline they call the '3 Ps: Productivity, Personalization, Pipeline.' They evaluated all major frameworks and selected CrewAI for production.
Shipped in weeks with 14x less code than their previous implementation on another framework. The multi-agent approach enabled end-to-end sales pipeline automation with personalization at scale.
Yodaplus, an Indian IT services company, deployed CrewAI-based multi-agent systems for finance and retail use cases. In the finance domain, agents handled KYC document processing, credit risk analysis, and regulatory compliance checking. In retail, agents automated product catalog enrichment and customer inquiry routing.
Demonstrated that CrewAI's role-based architecture maps naturally to domain-specific workflows in Indian enterprise contexts, where regulatory requirements (RBI, SEBI) demand specialized agent expertise and auditable decision trails.
Andrew Ng's DeepLearning.AI partnered with CrewAI to create a production-focused course on multi-agent systems. The course covers practical patterns including blog post crews, customer support automation, and financial analysis pipelines, demonstrating CrewAI's use as a teaching and production framework.
Over 100,000 developers certified through CrewAI community courses, establishing CrewAI as a standard framework in the AI education ecosystem.
Tooling & Ecosystem
The core open-source framework. 40K+ GitHub stars. Includes agents, tasks, crews, sequential and hierarchical processes, Flows, memory, and tool integration. Install via pip install crewai.
Cloud-hosted platform for deploying, monitoring, and iterating multi-agent systems. Includes the Crew Control Plane for observability, execution analytics, and managed infrastructure. Plans from 120,000/year for enterprise.
Official collection of example crews covering content generation, research pipelines, customer support automation, financial analysis, and more. Essential reference for implementation patterns.
Graph-based agent orchestration framework by LangChain. The primary alternative to CrewAI for teams that need explicit state machine control over agent workflows. Supports persistent checkpointing and complex branching.
Conversation-driven multi-agent framework. Excels at debate-style collaboration, human-in-the-loop patterns, and rapid prototyping. The primary alternative for teams that prefer conversational over structured task-based coordination.
Local LLM runtime that integrates with CrewAI via OpenAI-compatible API. Enables running crews with zero API cost during development and testing. Supports Llama 3, Mistral, Gemma, and other open models.
Unified LLM API proxy that CrewAI can use to switch between 100+ LLM providers (OpenAI, Anthropic, Azure, Bedrock, Vertex AI) without code changes. Useful for cost optimization and provider failover.
Research & References
Wang, Ma, Feng, Wang, Lan, et al. (2025)arXiv preprint
Comprehensive survey of multi-agent collaboration mechanisms for LLMs, covering role-based architectures (CrewAI, MetaGPT, ChatDev), communication protocols, and coordination strategies. Provides a taxonomy of collaboration patterns relevant to understanding CrewAI's design choices.
Tran, Yang, Baral, et al. (2024)arXiv preprint (updated January 2026)
Identifies key challenges in multi-agent LLM systems including task allocation, robust reasoning through iterative debates, context management, and memory. Directly relevant to understanding the failure modes and design trade-offs in frameworks like CrewAI.
Hong, Zhuge, Chen, Zheng, Cheng, et al. (2023)ICLR 2024
Introduced role-based agent collaboration with standardized operating procedures (SOPs) for software development. MetaGPT's role assignment approach directly influenced CrewAI's design of agents with distinct roles, goals, and backstories.
Qian, Liu, Sun, Chen, Cong, et al. (2023)ACL 2024
Demonstrated that specialized LLM agents in software engineering roles (product manager, developer, tester) produce better code through chat-based collaboration. Established the paradigm of role-based agent teams that CrewAI extends to general-purpose workflows.
Guo, Chen, Wang, Yi, Yu, et al. (2024)arXiv preprint
Survey covering the landscape of LLM-based multi-agent systems, including agent architecture, communication mechanisms, and evaluation benchmarks. Provides comparative analysis of frameworks including CrewAI, AutoGen, and CAMEL.
Park, O'Brien, Cai, Morris, Liang, Bernstein (2023)UIST 2023
The foundational 'Smallville' paper that demonstrated LLM agents with distinct personas and memory can simulate realistic social behaviors. Established the theoretical basis for persona-driven agent design that CrewAI operationalizes through its role-goal-backstory pattern.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a multi-agent system to automate a complex research-and-reporting pipeline? Walk through agent roles, task decomposition, and process selection.
- ●
What are the key differences between CrewAI's sequential and hierarchical processes? When would you choose one over the other?
- ●
How does CrewAI's role-goal-backstory model affect agent output quality? Can you give an example where a poorly defined backstory leads to failure?
- ●
Compare CrewAI, LangGraph, and AutoGen. What are the strengths and weaknesses of each, and how do you decide which to use?
- ●
How would you optimize the cost of a CrewAI deployment that runs 50,000 crew executions per day?
- ●
Describe CrewAI's memory system. How do short-term, long-term, and entity memory work together?
- ●
What failure modes can occur in a hierarchical CrewAI crew, and how would you mitigate them?
Key Points to Mention
- ●
CrewAI models collaboration through role-based decomposition: each agent gets a role (persona), goal (objective), and backstory (experience context). The backstory is not decoration -- it is the primary behavioral steering mechanism.
- ●
Sequential process is simpler and more predictable; hierarchical process adds a manager agent for dynamic delegation and quality control but increases cost and can be less reliable.
- ●
Flows are the production-grade orchestration layer that chains multiple crews with conditional logic, quality gates, and state management -- essential for anything beyond a single crew demo.
- ●
Cost optimization requires differentiated LLM assignment: use GPT-4o or Claude Sonnet for quality-critical agents (analysis, review) and GPT-4o-mini or Haiku for commodity tasks (data gathering, formatting).
- ●
Memory is three-tiered: short-term (current execution context via ChromaDB), long-term (cross-session learning via SQLite), and entity memory (RAG-based entity tracking). Enable with
memory=True. - ●
At scale, the bottleneck is LLM API throughput and cost, not CrewAI itself. Horizontal scaling via task queues (Celery, SQS) is the standard pattern.
- ●
Always mention output validation -- production systems need quality gates between agents, not blind trust in LLM outputs.
Pitfalls to Avoid
- ●
Claiming CrewAI provides deterministic outputs -- multi-agent LLM systems are inherently non-deterministic. Acknowledge this and discuss mitigation strategies (structured output, validation, temperature control).
- ●
Treating all frameworks as equivalent -- CrewAI (role-based), LangGraph (graph-based), and AutoGen (conversation-based) have fundamentally different abstractions. Demonstrate you understand the architectural differences, not just the marketing.
- ●
Ignoring cost analysis -- multi-agent systems multiply LLM costs. An interviewee who cannot estimate per-execution cost (tokens x price x agents x iterations) will not be trusted with production deployments.
- ●
Describing only the happy path -- senior interviewers expect discussion of failure modes (delegation loops, context overflow, tool failures) and specific mitigation strategies.
- ●
Suggesting CrewAI for every problem -- if the task is a single-step LLM call, multi-agent is overkill. Demonstrate judgment about when NOT to use it.
Senior-Level Expectation
A senior or staff-level candidate should be able to: (1) architect a complete multi-agent system with clear role decomposition, tool integration, and memory strategy; (2) provide a detailed cost model including per-execution token costs, scaling projections, and optimization strategies (model tiering, caching, batching); (3) discuss the Flows layer for production pipeline orchestration with quality gates and conditional logic; (4) compare CrewAI's abstractions against LangGraph and AutoGen with specific technical trade-offs rather than surface-level comparisons; (5) design monitoring and observability for multi-agent systems (tracking per-agent latency, token usage, delegation patterns, and output quality metrics); and (6) reason about failure modes at scale -- what happens when one agent in a 10-agent crew consistently produces poor output? How do you detect and recover? In the Indian enterprise context, senior candidates should also discuss cost optimization strategies for high-volume deployments on constrained budgets, such as using Azure OpenAI on reserved capacity or Ollama for local inference during development.
Summary
Wrapping Up: What You Need to Remember About CrewAI
CrewAI is a role-based multi-agent orchestration framework that models AI collaboration the way effective human teams work. Its three core primitives -- agents (with role, goal, backstory), tasks (with description, expected output, context dependencies), and crews (with process type, memory, and execution control) -- provide an intuitive yet powerful abstraction for building complex agentic workflows.
The framework offers two process types: sequential (predictable, cost-efficient, best for linear workflows) and hierarchical (dynamic delegation via manager agent, best for complex workflows with 5+ agents). The Flows layer extends single-crew execution into multi-crew pipelines with conditional branching, quality gates, and persistent state -- this is where CrewAI becomes production-ready. Memory is three-tiered (short-term via ChromaDB, long-term via SQLite, entity memory via RAG), enabling agents to learn and improve across executions.
Compared to alternatives, CrewAI offers the most intuitive API for role-based decomposition, while LangGraph provides more explicit graph-level control and AutoGen excels at conversational collaboration. The choice is architectural: teams (CrewAI) vs. flowcharts (LangGraph) vs. meetings (AutoGen). With enterprise adoption by PwC, DocuSign, and PepsiCo, over 2 billion workflow executions, and a thriving open-source community of 40K+ GitHub stars, CrewAI has proven itself as a production-grade framework for multi-agent AI systems.
The One Thing to Remember: CrewAI's power comes from treating AI agents like team members, not like API endpoints. Rich role definitions, clear task boundaries, and structured processes produce dramatically better results than monolithic prompts -- just as well-organized human teams outperform lone generalists. Start with 2-3 agents in sequential mode, validate the quality improvement over a single-agent approach, and scale from there.