Agent Supervisor in Machine Learning
The Agent Supervisor is the central coordination layer in hierarchical multi-agent systems. It acts as a manager that receives a complex task, decomposes it into subtasks, delegates each subtask to the most appropriate specialist agent, monitors execution progress, validates outputs, and synthesizes final results -- all while enforcing budgets, timeouts, and quality thresholds.
Why does this matter now? Because single LLM agents hit a ceiling on complex, multi-step tasks. Research from UC Berkeley shows that multi-agent systems outperform single agents by up to 90%, but they also consume 15x more tokens. Without a supervisor to coordinate, monitor costs, and enforce quality, multi-agent systems devolve into expensive chaos.
The supervisor pattern has become the dominant architecture for enterprise agentic AI. From Databricks' Agent Bricks to LangGraph's langgraph-supervisor library to CrewAI's hierarchical process, every major framework now provides first-class support for supervisor-based coordination. Swiggy uses a multi-agent supervisor architecture for customer support on Databricks. Razorpay deployed agentic payment flows with OpenAI. The pattern has moved from research curiosity to production necessity.
This guide covers the complete agent supervisor lifecycle: what it is, when to use it, how to implement it, and -- critically -- how to prevent the failure modes that cause multi-agent systems to spiral out of control in production.
Concept Snapshot
- What It Is
- A meta-agent that oversees, coordinates, and quality-controls a team of specialist agents by decomposing tasks, delegating work, validating outputs, and managing budgets and escalation policies.
- Category
- Multi-Agent Systems
- Complexity
- Advanced
- Inputs / Outputs
- Inputs: complex user request or task specification, available agent registry, budget/policy constraints. Outputs: synthesized final response, execution trace, cost report, agent performance metrics.
- System Placement
- Sits at the top of a hierarchical multi-agent system, between the user-facing interface (upstream) and the specialist worker agents (downstream). In some architectures, supervisors themselves can be nested under higher-level supervisors.
- Also Known As
- manager agent, orchestrator agent, coordinator agent, lead agent, meta-agent, triage agent
- Typical Users
- ML Engineers, AI Platform Engineers, Backend Engineers, Solutions Architects, Technical Product Managers
- Prerequisites
- LLM function calling / tool use, Prompt engineering, Basic agent design patterns, State management concepts, Error handling and retry strategies
- Key Terms
- task decompositionagent delegationoutput validationescalation policytoken budgetagent registryexecution tracehierarchical coordinationhandoff protocolquality gate
Why This Concept Exists
The Single-Agent Ceiling
A single LLM agent -- even one equipped with tools -- struggles with tasks that span multiple domains or require long chains of reasoning. Ask one agent to "analyze our Q3 sales data, compare it with competitor pricing from the web, draft a strategy memo, and create a slide deck," and you'll watch it lose context, hallucinate intermediate results, or simply exhaust its context window.
The fundamental issue is that a single agent's context window is a shared, finite resource. Every tool call result, every intermediate thought, every error recovery attempt competes for the same token budget. By the time a complex task reaches step 5 of 8, the agent has often forgotten the nuances of step 1.
Why Not Just Use Multiple Independent Agents?
The naive solution -- "just run multiple agents in parallel" -- creates a different set of problems. Without coordination, agents duplicate work, produce conflicting outputs, or operate on stale state. Imagine three agents independently querying the same database, each making slightly different assumptions. You get three different answers and no way to reconcile them.
This is the coordination problem that distributed systems engineers have wrestled with for decades. Multi-agent LLM systems face the exact same challenges: consistency, resource contention, failure propagation, and result aggregation.
The Supervisor as a Solution
The agent supervisor pattern borrows from organizational theory: a manager doesn't do the detailed work but ensures the right people do the right work in the right order. The supervisor maintains a global view of the task state, allocates work based on agent capabilities, enforces quality standards, and handles exceptions.
Microsoft's Magentic-One system demonstrated this elegantly in 2024: an Orchestrator agent plans, tracks progress, and re-plans to recover from errors while directing four specialist agents. The system achieved state-of-the-art performance on complex benchmarks precisely because the orchestrator could adapt the plan in real-time based on what the specialists discovered.
Key Insight: The supervisor pattern exists because complex tasks require both specialization (deep expertise per subtask) and coordination (global awareness across subtasks). No single agent can provide both simultaneously within a finite context window.
Core Intuition & Mental Model
The Film Director Analogy
Think of an agent supervisor like a film director. The director doesn't operate the camera, act in scenes, or edit footage. Instead, the director holds the vision for the entire film and coordinates specialists -- the cinematographer, actors, editors, sound designers -- to realize that vision. The director decides what scene to shoot next, notices when an actor's performance doesn't match the tone, and calls for re-takes when quality falls short.
The agent supervisor works identically. It holds the task plan (the "script"), delegates scenes to specialist agents (the "crew"), reviews their outputs (the "dailies"), and decides whether to accept, retry, or escalate. The supervisor never does the detailed work itself -- its job is coordination, quality control, and decision-making.
Why the Supervisor Needs Its Own LLM
A common misconception is that the supervisor can be a simple rule-based router. In practice, the supervisor needs its own LLM because the delegation decisions are contextual and adaptive. Should the research agent handle this query, or is it really a data analysis task? Did the coding agent's output actually solve the problem, or did it produce syntactically correct but logically wrong code? These judgment calls require reasoning, not just pattern matching.
That said, the supervisor's LLM doesn't need to be the most powerful model available. A capable mid-tier model (like GPT-4o-mini or Claude 3.5 Haiku) can often handle supervision effectively, while the specialist agents use more powerful models for their domain-specific tasks. This asymmetry is a key cost optimization strategy -- you'll see it throughout this guide.
The Core Loop
Every supervisor follows the same fundamental loop: Plan -> Delegate -> Monitor -> Validate -> Synthesize. The plan decomposes the task. Delegation assigns subtasks to specialists. Monitoring tracks progress and catches failures early. Validation ensures outputs meet quality thresholds. Synthesis combines validated outputs into the final response. This loop may execute multiple times as the supervisor re-plans based on intermediate results.
Technical Foundations
Formal Model
Let us define the agent supervisor formally. Consider a multi-agent system where:
- is the supervisor agent with access to a planning LLM and a global state
- is the set of specialist agents, each with capabilities and cost profile
- is the incoming task specification
- is the supervision policy governing delegation, validation, and escalation
Task Decomposition
The supervisor first decomposes into an ordered set of subtasks:
where each subtask has a dependency graph with and edge indicating that depends on the output of .
Agent Assignment
For each subtask , the supervisor selects an agent using an assignment function:
This maximizes the capability-to-cost ratio, preferring agents that are both well-suited to the task and cost-efficient.
Budget Constraint
The supervisor enforces a total budget across all agent invocations:
where is the estimated token cost of agent executing subtask . The BAMAS framework formalizes this as an Integer Linear Programming problem to find the cost-optimal agent set.
Quality Gate
Each agent output passes through a validation function:
where is a quality scoring function (which may itself use an LLM-as-judge), is the acceptance threshold, and is the maximum retry count.
Complexity Analysis
The supervisor's coordination overhead scales as in the worst case, where is the number of subtasks and is the number of candidate agents. In practice, agent registries and capability tags reduce this to near-constant lookup time. The dominant cost is the LLM inference for planning and validation, which typically consumes 10-20% of the total system token budget.
Internal Architecture
A production agent supervisor consists of six interconnected subsystems: a task planner that decomposes incoming requests, an agent registry that maintains the capability catalog, a delegation engine that routes subtasks, a monitoring layer that tracks execution state, a validation engine that enforces quality gates, and a synthesis module that aggregates final outputs. The supervisor itself runs as a stateful agent with its own LLM and persistent memory across the task lifecycle.
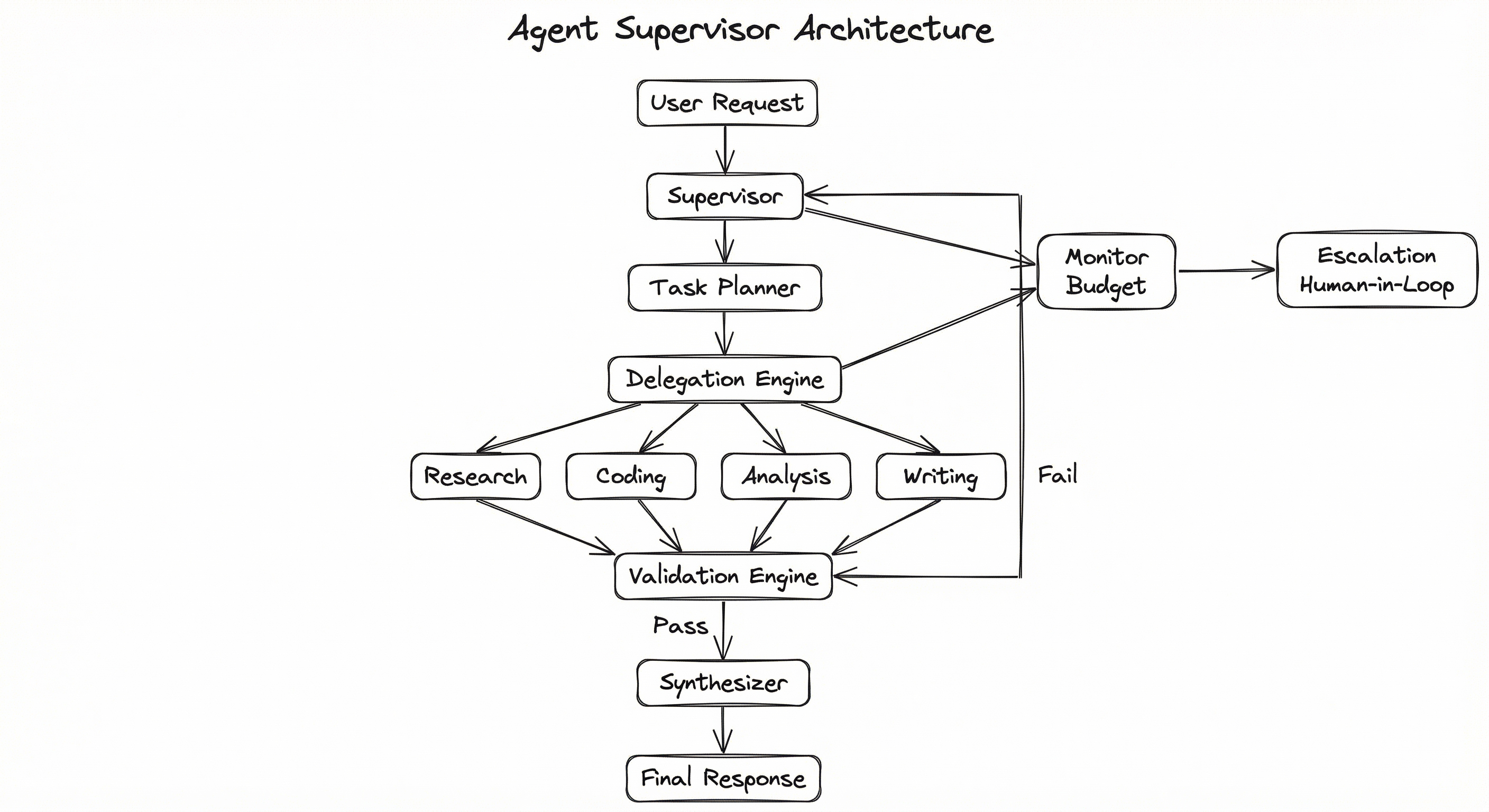
The architecture supports both sequential delegation (subtask A must complete before subtask B starts) and parallel delegation (independent subtasks execute concurrently via scatter-gather). Most production systems use a hybrid: a DAG of subtasks with both serial dependencies and parallel branches. LangGraph models this naturally as a state graph, while CrewAI's hierarchical process handles it through the manager agent's delegation logic.
Key Components
Task Planner
Analyzes the incoming request and produces a structured execution plan -- a DAG of subtasks with dependencies, estimated complexity, and required capabilities. The planner may consult the agent registry to understand what's available before planning. This is typically the first LLM call in the supervisor loop.
Agent Registry
Maintains a catalog of available specialist agents with their capabilities, tool access, cost profiles (token-per-task estimates), reliability scores, and current availability. Think of it as a service registry in microservices architecture. In LangGraph, this is defined by the list of agents passed to create_supervisor(). In CrewAI, it's the Crew definition.
Delegation Engine
Routes each subtask to the appropriate specialist agent based on the task planner's assignments. Handles the actual invocation -- passing context, instructions, and constraints to the worker agent. Manages parallel execution for independent subtasks using scatter-gather patterns.
Monitoring & Budget Tracker
Tracks real-time execution state: which subtasks are in progress, completed, or failed. Monitors cumulative token consumption against the budget ceiling. Emits alerts when approaching budget thresholds (e.g., 80% consumed). Logs execution traces for debugging and observability.
Validation Engine
Evaluates each agent's output against quality criteria before accepting it. May use rule-based checks (format validation, length constraints), LLM-as-judge scoring, or domain-specific validators (code compilation, SQL execution). Decides whether to accept, retry with feedback, or escalate.
Escalation Handler
Activated when an agent fails repeatedly, budget limits are reached, or the supervisor encounters ambiguity it cannot resolve. Routes to human-in-the-loop review, falls back to a more capable (and expensive) model, or gracefully degrades by returning a partial result with an explanation of what couldn't be completed.
Synthesizer
Aggregates validated outputs from all specialist agents into a coherent final response. Handles deduplication, conflict resolution (when agents produce contradictory results), and formatting. This is typically the last LLM call in the supervisor loop.
Data Flow
Task Ingestion: A user request arrives at the supervisor. The supervisor's LLM analyzes it and invokes the Task Planner to produce a subtask DAG.
Delegation Phase: The Delegation Engine walks the DAG, dispatching ready subtasks (those with all dependencies satisfied) to specialist agents. Independent subtasks run in parallel; dependent subtasks wait.
Execution & Monitoring: Each specialist agent executes its subtask using its own tools and LLM. The Monitor tracks progress, token consumption, and wall-clock time. If an agent exceeds its individual timeout or budget allocation, the monitor signals the supervisor.
Validation Loop: As each agent returns its output, the Validation Engine scores it. Accepted outputs are stored in the shared state. Failed outputs trigger a retry -- the supervisor provides feedback to the agent and re-delegates. After retries, the Escalation Handler takes over.
Synthesis: Once all subtasks are validated, the Synthesizer combines outputs into the final response, resolving any conflicts and ensuring coherence. The supervisor returns the result alongside an execution trace and cost summary.
A hierarchical flowchart showing: User Request flows to Supervisor Agent, which connects to Task Planner, then Delegation Engine. The Delegation Engine fans out to four specialist agents (Research, Coding, Analysis, Writing). All agent outputs converge at the Validation Engine, which either passes to the Synthesizer (producing the Final Response) or loops back to the Supervisor on failure. A parallel path shows the Supervisor connected to a Monitor & Budget Tracker, which escalates to a Human-in-Loop handler when budget is exceeded.
How to Implement
Three Implementation Approaches
There are three mainstream approaches to implementing an agent supervisor in 2026:
Approach 1: LangGraph Supervisor -- The most flexible option. LangGraph models the supervisor as a state graph where the supervisor node decides which agent to invoke next based on the current state. The langgraph-supervisor library provides a create_supervisor() factory that wires up the routing, state management, and handoff logic. Best for teams that need fine-grained control over the execution flow.
Approach 2: CrewAI Hierarchical Process -- The most opinionated option. CrewAI's process=Process.hierarchical automatically creates a manager agent that delegates tasks to crew members based on their defined roles and tools. You can also supply a manager_agent to customize the supervisor's behavior. Best for teams that want a production-ready supervisor with minimal boilerplate.
Approach 3: Custom Implementation -- Build the supervisor loop directly using an LLM provider's function calling API. The supervisor is a standard agent with tools like delegate_to_agent, check_agent_status, validate_output, and synthesize_results. Best for teams with unique requirements that don't fit neatly into a framework.
Cost Note: A typical multi-agent supervisor system processing a complex enterprise query consumes 50,000-200,000 tokens across all agents. At GPT-4o pricing (10/1M output), that's 1.50 per complex query (~INR 21-126). With GPT-4o-mini for the supervisor and specialist agents on cheaper tasks, costs drop to 0.10 per query (~INR 1.7-8.4). For a startup in Bengaluru processing 10,000 queries/day, that's the difference between 25/day (~INR 2,100/day).
from langgraph_supervisor import create_supervisor
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
import time
# Define specialist agents with their tools
@tool
def search_web(query: str) -> str:
"""Search the web for information."""
# Actual implementation would use Tavily, SerpAPI, etc.
return f"Search results for: {query}"
@tool
def run_sql_query(query: str) -> str:
"""Execute a SQL query against the analytics database."""
# Actual implementation would connect to your DB
return f"Query results for: {query}"
@tool
def generate_chart(data: str, chart_type: str) -> str:
"""Generate a visualization from data."""
return f"Chart generated: {chart_type} with data"
# Create specialist agents
research_agent = create_react_agent(
model=ChatOpenAI(model="gpt-4o", temperature=0),
tools=[search_web],
name="researcher",
prompt="You are a research specialist. Find accurate, up-to-date information."
)
analysis_agent = create_react_agent(
model=ChatOpenAI(model="gpt-4o", temperature=0),
tools=[run_sql_query, generate_chart],
name="analyst",
prompt="You are a data analyst. Query databases and create visualizations."
)
writing_agent = create_react_agent(
model=ChatOpenAI(model="gpt-4o", temperature=0),
tools=[],
name="writer",
prompt="You are a technical writer. Synthesize information into clear reports."
)
# Create the supervisor with a cheaper model for coordination
supervisor = create_supervisor(
agents=[research_agent, analysis_agent, writing_agent],
model=ChatOpenAI(model="gpt-4o-mini", temperature=0),
prompt=(
"You are a project supervisor coordinating a team of specialists. "
"Decompose the user's request into subtasks and delegate to the "
"appropriate agent. Validate each output before proceeding. "
"If an agent's output is unsatisfactory, provide specific feedback "
"and ask them to retry (max 2 retries). "
"Always synthesize a final coherent response."
),
)
# Compile and run
app = supervisor.compile()
# Execute with budget tracking
start = time.time()
result = app.invoke({
"messages": [
{"role": "user", "content": "Analyze our Q3 sales trends and compare with industry benchmarks. Produce a summary report."}
]
})
elapsed = time.time() - start
print(f"Completed in {elapsed:.1f}s")
print(f"Agent turns: {len(result['messages'])}")
for msg in result["messages"]:
if hasattr(msg, "name"):
print(f" [{msg.name}]: {msg.content[:100]}...")This example demonstrates the core LangGraph supervisor pattern. The key architectural decisions are: (1) using a cheaper model (gpt-4o-mini) for the supervisor while giving specialist agents gpt-4o -- the supervisor needs routing intelligence, not deep domain expertise; (2) the supervisor prompt includes explicit retry logic with a max retry count; (3) agents are created with create_react_agent which gives them the ReAct (Reason + Act) loop for tool use. The create_supervisor() factory from langgraph-supervisor handles the state graph construction, message routing, and turn management automatically.
from crewai import Agent, Task, Crew, Process
from crewai.llm import LLM
# Define the custom supervisor/manager agent
manager = Agent(
role="Project Supervisor",
goal="Coordinate the team to deliver high-quality analysis reports. "
"Validate all outputs before accepting them. Escalate to human "
"review if confidence is below 0.7.",
backstory="You are a senior project manager with 15 years of experience "
"coordinating cross-functional teams. You never accept mediocre "
"work and always verify facts before including them.",
llm=LLM(model="gpt-4o-mini"),
allow_delegation=True,
verbose=True,
)
# Define specialist agents
researcher = Agent(
role="Senior Research Analyst",
goal="Find accurate market data and industry benchmarks",
backstory="Expert in market research with access to financial databases",
llm=LLM(model="gpt-4o"),
tools=[], # Add your research tools here
)
data_analyst = Agent(
role="Data Analyst",
goal="Analyze numerical data and produce statistical insights",
backstory="Quantitative analyst skilled in SQL, Python, and statistics",
llm=LLM(model="gpt-4o"),
tools=[], # Add your analysis tools here
)
writer = Agent(
role="Report Writer",
goal="Create clear, executive-ready reports from technical analysis",
backstory="Technical writer experienced in business communications",
llm=LLM(model="gpt-4o"),
)
# Define tasks
research_task = Task(
description="Research Q3 2025 industry benchmarks for the SaaS sector "
"in India. Include revenue growth rates, churn rates, and "
"CAC/LTV ratios from credible sources.",
expected_output="Structured research report with cited data points",
agent=researcher,
)
analysis_task = Task(
description="Compare our Q3 metrics against the industry benchmarks. "
"Identify areas where we outperform and underperform. "
"Calculate statistical significance where possible.",
expected_output="Comparative analysis with tables and key findings",
agent=data_analyst,
context=[research_task], # Depends on research output
)
report_task = Task(
description="Synthesize the research and analysis into an executive "
"summary report. Include key metrics, trends, and "
"3-5 actionable recommendations.",
expected_output="Executive report (500-800 words) with recommendations",
agent=writer,
context=[research_task, analysis_task],
)
# Create the crew with hierarchical process
crew = Crew(
agents=[researcher, data_analyst, writer],
tasks=[research_task, analysis_task, report_task],
process=Process.hierarchical,
manager_agent=manager,
verbose=True,
memory=True, # Enable shared memory across agents
max_rpm=30, # Rate limit: max 30 requests per minute
)
# Execute
result = crew.kickoff()
print(result)CrewAI's hierarchical process provides a more opinionated supervisor pattern. Key design choices here: (1) the manager_agent is explicitly defined with a cheaper LLM, detailed instructions for quality validation, and a confidence threshold for human escalation; (2) tasks have context dependencies creating a DAG -- the analysis task waits for research, and the report waits for both; (3) memory=True enables shared memory so the supervisor and agents maintain context across the workflow; (4) max_rpm=30 enforces rate limiting to prevent runaway API costs. CrewAI automatically handles the delegation, retry, and synthesis logic through the manager agent.
import json
import time
from dataclasses import dataclass, field
from enum import Enum
from typing import Any
from openai import OpenAI
client = OpenAI()
class AgentStatus(Enum):
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
ESCALATED = "escalated"
@dataclass
class BudgetTracker:
max_tokens: int = 500_000
max_cost_usd: float = 2.0
consumed_tokens: int = 0
consumed_cost: float = 0.0
warning_threshold: float = 0.8
def record(self, input_tokens: int, output_tokens: int, model: str):
"""Record token usage and compute cost."""
pricing = {
"gpt-4o": {"input": 2.50 / 1e6, "output": 10.0 / 1e6},
"gpt-4o-mini": {"input": 0.15 / 1e6, "output": 0.60 / 1e6},
}
rates = pricing.get(model, pricing["gpt-4o"])
cost = input_tokens * rates["input"] + output_tokens * rates["output"]
self.consumed_tokens += input_tokens + output_tokens
self.consumed_cost += cost
@property
def budget_remaining(self) -> float:
return self.max_cost_usd - self.consumed_cost
@property
def over_warning(self) -> bool:
return self.consumed_cost >= self.max_cost_usd * self.warning_threshold
@property
def over_budget(self) -> bool:
return self.consumed_cost >= self.max_cost_usd
@dataclass
class SubTask:
id: str
description: str
assigned_agent: str
status: AgentStatus = AgentStatus.PENDING
result: str = ""
retries: int = 0
max_retries: int = 2
@dataclass
class SupervisorState:
task: str
subtasks: list[SubTask] = field(default_factory=list)
budget: BudgetTracker = field(default_factory=BudgetTracker)
execution_log: list[dict] = field(default_factory=list)
def call_agent(agent_name: str, instruction: str, model: str, budget: BudgetTracker) -> dict:
"""Execute a specialist agent and track costs."""
if budget.over_budget:
return {"status": "budget_exceeded", "output": ""}
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": f"You are a {agent_name} specialist."},
{"role": "user", "content": instruction},
],
temperature=0,
max_tokens=2000,
)
usage = response.usage
budget.record(usage.prompt_tokens, usage.completion_tokens, model)
return {
"status": "completed",
"output": response.choices[0].message.content,
"tokens": usage.prompt_tokens + usage.completion_tokens,
}
def validate_output(output: str, task_desc: str, budget: BudgetTracker) -> dict:
"""Use LLM-as-judge to validate agent output quality."""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a quality reviewer. Score the output 0-10 and provide specific feedback."},
{"role": "user", "content": f"Task: {task_desc}\n\nOutput:\n{output}\n\nScore 0-10 and explain."},
],
temperature=0,
max_tokens=500,
)
budget.record(response.usage.prompt_tokens, response.usage.completion_tokens, "gpt-4o-mini")
content = response.choices[0].message.content
# Parse score from response (simplified)
try:
score = int([c for c in content.split() if c.isdigit()][0])
except (IndexError, ValueError):
score = 5
return {"score": score, "feedback": content}
def run_supervisor(task: str, budget_usd: float = 2.0) -> dict:
"""Main supervisor loop with budget enforcement and escalation."""
state = SupervisorState(task=task, budget=BudgetTracker(max_cost_usd=budget_usd))
# Step 1: Plan -- decompose task into subtasks
plan_response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": (
"You are a task planner. Decompose the user request into "
"2-4 subtasks. Return JSON: [{\"id\": \"t1\", "
"\"description\": \"...\", \"agent\": \"research|analysis|writing\"}]"
)},
{"role": "user", "content": task},
],
temperature=0,
response_format={"type": "json_object"},
)
state.budget.record(
plan_response.usage.prompt_tokens,
plan_response.usage.completion_tokens,
"gpt-4o-mini"
)
plan = json.loads(plan_response.choices[0].message.content)
subtasks = plan.get("subtasks", plan.get("tasks", []))
for st in subtasks:
state.subtasks.append(SubTask(
id=st["id"], description=st["description"], assigned_agent=st["agent"]
))
# Step 2: Execute subtasks with validation loop
for subtask in state.subtasks:
if state.budget.over_budget:
subtask.status = AgentStatus.ESCALATED
state.execution_log.append({
"subtask": subtask.id, "event": "budget_exceeded",
"remaining": state.budget.budget_remaining,
})
continue
while subtask.retries <= subtask.max_retries:
subtask.status = AgentStatus.RUNNING
result = call_agent(
agent_name=subtask.assigned_agent,
instruction=subtask.description,
model="gpt-4o" if subtask.assigned_agent != "writing" else "gpt-4o-mini",
budget=state.budget,
)
if result["status"] == "budget_exceeded":
subtask.status = AgentStatus.ESCALATED
break
# Validate
validation = validate_output(result["output"], subtask.description, state.budget)
state.execution_log.append({
"subtask": subtask.id, "attempt": subtask.retries + 1,
"score": validation["score"], "tokens": result.get("tokens", 0),
})
if validation["score"] >= 7:
subtask.result = result["output"]
subtask.status = AgentStatus.COMPLETED
break
else:
subtask.retries += 1
subtask.description += f"\n\nPrevious attempt feedback: {validation['feedback']}"
if subtask.status == AgentStatus.RUNNING:
subtask.status = AgentStatus.FAILED
# Step 3: Synthesize
completed = [st for st in state.subtasks if st.status == AgentStatus.COMPLETED]
escalated = [st for st in state.subtasks if st.status == AgentStatus.ESCALATED]
return {
"completed_subtasks": len(completed),
"escalated_subtasks": len(escalated),
"total_cost_usd": round(state.budget.consumed_cost, 4),
"total_tokens": state.budget.consumed_tokens,
"execution_log": state.execution_log,
"results": {st.id: st.result for st in completed},
}
# Usage
report = run_supervisor(
task="Research the Indian SaaS market size in 2025 and write a one-page summary.",
budget_usd=1.50,
)
print(json.dumps(report, indent=2))This custom implementation exposes the full supervisor machinery that frameworks like LangGraph abstract away. The BudgetTracker enforces hard cost limits with a warning threshold at 80%. The validate_output function uses LLM-as-judge to score agent outputs on a 0-10 scale, with a threshold of 7 for acceptance. The retry loop appends validation feedback to the subtask description, giving agents specific guidance on how to improve. Escalated subtasks (budget exceeded or max retries hit) are tracked separately so the caller can route them to human review. This pattern costs roughly 0.50 per complex query at GPT-4o-mini pricing (~INR 8-42).
# Agent Supervisor Configuration (YAML)
supervisor:
model: gpt-4o-mini
temperature: 0
max_planning_tokens: 2000
retry_policy:
max_retries_per_subtask: 2
backoff_seconds: [1, 3]
validation:
method: llm-as-judge
model: gpt-4o-mini
acceptance_threshold: 7 # out of 10
escalation:
trigger: budget_exceeded | max_retries | low_confidence
target: human-in-loop
fallback_model: gpt-4o # escalate to more capable model first
agents:
- name: researcher
model: gpt-4o
tools: [web_search, document_retrieval]
max_tokens_per_call: 4000
cost_weight: 1.0
- name: analyst
model: gpt-4o
tools: [sql_query, python_exec, chart_gen]
max_tokens_per_call: 4000
cost_weight: 1.2
- name: writer
model: gpt-4o-mini
tools: []
max_tokens_per_call: 6000
cost_weight: 0.3
budget:
max_total_tokens: 500000
max_cost_usd: 2.00
warning_threshold: 0.8
per_agent_cap_pct: 0.4 # no single agent can consume >40% of budget
observability:
trace_backend: langsmith # or phoenix, langfuse
log_level: INFO
emit_cost_metrics: true
alert_on_escalation: trueCommon Implementation Mistakes
- ●
Using the same expensive model for supervision and specialist work: The supervisor primarily routes and validates -- it doesn't need GPT-4 or Claude Opus. Using GPT-4o-mini or Claude Haiku for the supervisor and reserving expensive models for specialist agents can cut total costs by 40-60%.
- ●
No budget enforcement: Without token/cost limits, a supervisor caught in a retry loop can burn through hundreds of dollars in minutes. The BAMAS paper showed that cost can vary by 200% across different agent topologies for the same task. Always set hard budget caps.
- ●
Passing entire conversation history to every agent: Each specialist should receive only the context relevant to its subtask, not the full conversation. Bloated context wastes tokens and confuses agents. The supervisor should extract and forward only the relevant state.
- ●
Missing validation between agent steps: Blindly forwarding one agent's output to the next without validation propagates errors through the chain. A single hallucinated data point from the research agent will contaminate the analysis and the final report. Validate at every handoff.
- ●
Hardcoded agent assignments instead of capability-based routing: If you hardcode "always send SQL tasks to Agent B," you lose the ability to handle novel task types or gracefully degrade when an agent is unavailable. Use capability descriptions and let the supervisor's LLM match tasks to agents dynamically.
- ●
No execution trace or observability: When a multi-agent pipeline produces a wrong answer, you need to trace which agent introduced the error. Without structured logging of each delegation, validation score, and retry, debugging is nearly impossible. Log everything.
When Should You Use This?
Use When
Your task requires multiple distinct capabilities (research + coding + writing + analysis) that no single agent can handle well within one context window
You need quality control and validation between processing steps -- the supervisor can catch errors before they propagate downstream
Your system must enforce budget constraints -- the supervisor tracks cumulative token consumption and can halt or degrade gracefully before costs spiral
You need an audit trail showing which agent produced which output and what validation was applied -- critical for compliance-heavy domains (fintech, healthcare)
The task has a natural decomposition into parallel subtasks that benefit from concurrent execution via scatter-gather
You're building an enterprise assistant that routes queries across multiple domain-specific agents (HR, IT, Finance, Sales) based on intent classification
You need escalation to human reviewers when agent confidence is low or when stakes are high -- the supervisor is the natural escalation point
Avoid When
The task is simple enough for a single agent with tools. If one ReAct agent can handle it in 2-3 tool calls, a supervisor adds unnecessary latency and cost
You need real-time, sub-second responses. The supervisor loop adds 2-5 seconds of overhead per delegation round-trip. For latency-critical applications (autocomplete, real-time chat), a single agent or a simple router is better
Your agents need to collaborate peer-to-peer with rich bidirectional communication. The supervisor pattern enforces a hub-and-spoke topology; if agents need to negotiate directly, consider a peer-to-peer or blackboard architecture instead
You have fewer than 3 specialist agents. With only 2 agents, the coordination overhead of a supervisor rarely pays for itself -- a simple sequential chain or conditional branch suffices
Your budget is extremely tight and every token counts. The supervisor itself consumes tokens for planning, delegation, and validation. Research shows supervisor overhead is typically 10-20% of total system cost
You're in an early prototype phase and don't yet know what agents you need. Start with a single agent, identify the failure modes, then introduce a supervisor when the failure modes are coordination-related
Key Tradeoffs
Quality vs. Latency
The supervisor's validation loop is the primary quality mechanism -- but each validation step adds a round-trip to the LLM. A three-agent pipeline with validation at each step means the supervisor makes at least 7 LLM calls (1 plan + 3 delegations + 3 validations). At 1-2 seconds per LLM call, you're looking at 7-15 seconds of wall-clock time. For interactive applications, you may need to relax validation (skip it for low-stakes subtasks) or use async streaming to provide incremental results.
Cost vs. Reliability
Using a cheap model for the supervisor saves money but increases the risk of poor delegation decisions or missed quality issues. Using an expensive model for the supervisor improves coordination quality but can double the total cost. The sweet spot, based on production reports from teams at Databricks and LangChain, is: mid-tier model for supervision (GPT-4o-mini, Claude Haiku), high-tier model for complex specialist work (GPT-4o, Claude Sonnet), top-tier model only for escalation fallback.
| Supervisor Model | Specialist Model | Approx Cost/Query | Quality | Latency |
|---|---|---|---|---|
| GPT-4o-mini | GPT-4o-mini | 0.05 (~INR 1.7-4.2) | Medium | 5-8s |
| GPT-4o-mini | GPT-4o | 0.75 (~INR 21-63) | High | 8-15s |
| GPT-4o | GPT-4o | 1.50 (~INR 42-126) | Highest | 10-20s |
Centralized vs. Distributed Control
The supervisor pattern is inherently centralized -- the supervisor is a single point of failure and a potential bottleneck. If the supervisor's context window fills up (from tracking many subtasks), it degrades. For systems with more than 8-10 specialist agents, consider a hierarchical supervisor pattern where multiple mid-level supervisors each manage 3-5 agents, coordinated by a top-level supervisor.
Alternatives & Comparisons
An orchestrator uses deterministic code (state machines, DAGs) to route between agents, while a supervisor uses an LLM to make routing decisions dynamically. Choose the orchestrator when the workflow is well-defined and predictable. Choose the supervisor when the task decomposition requires judgment and adaptability. Many production systems use both: an orchestrator for the happy path and a supervisor for exception handling.
A router classifies the incoming request and dispatches it to a single specialist agent -- there's no multi-step coordination or output validation. Think of it as a one-shot dispatcher. The supervisor goes further: it decomposes complex tasks into multiple subtasks, delegates to multiple agents, and synthesizes results. Use a router when each query maps cleanly to one agent; use a supervisor when queries require multi-agent collaboration.
A task decomposer breaks a complex task into subtasks but doesn't execute or coordinate them -- it's a planning-only component. The supervisor includes task decomposition as one of its capabilities but also handles delegation, monitoring, validation, and synthesis. Use a standalone decomposer when you have a separate execution engine; the supervisor bundles decomposition with execution management.
A LangGraph node is a single processing step in a state graph. The supervisor is typically implemented as a special LangGraph node that controls the routing logic, but it's architecturally distinct -- it's the decision-making node that determines which other nodes to execute next. Think of the supervisor as the conductor; LangGraph nodes are the musicians.
Pros, Cons & Tradeoffs
Advantages
Handles complex, multi-domain tasks that exceed any single agent's capabilities by decomposing them into specialist subtasks and coordinating execution across a team
Built-in quality control through validation gates at each handoff point -- the supervisor catches errors before they propagate, significantly improving end-to-end accuracy
Budget enforcement and cost predictability -- the supervisor tracks cumulative token consumption and can halt, degrade gracefully, or escalate before costs spiral out of control
Natural escalation path to human review -- when agent confidence is low or retries are exhausted, the supervisor provides a clean handoff point to human-in-the-loop workflows
Observability and auditability -- the supervisor's execution trace shows exactly which agent produced which output, enabling debugging, compliance reporting, and performance optimization
Modular agent management -- specialist agents can be added, removed, or upgraded independently without redesigning the entire system. Microsoft's Magentic-One demonstrated this: agents can be swapped without additional prompt tuning
Adaptive re-planning -- when a subtask fails or produces unexpected results, the supervisor can revise the plan in real-time, unlike static DAG-based orchestration
Disadvantages
Latency overhead -- the supervisor loop adds 2-5 seconds per delegation round-trip. A 3-agent pipeline with validation can take 10-20 seconds end-to-end, making it unsuitable for real-time interactive use cases
Token cost of supervision -- the supervisor itself consumes 10-20% of the total token budget for planning, delegation prompts, and validation. For high-volume applications, this overhead adds up significantly
Single point of failure -- if the supervisor hallucinates a bad plan or misroutes a subtask, the entire pipeline fails. The supervisor's quality is the ceiling for the whole system
Context window pressure -- as the number of subtasks and agents grows, the supervisor must track more state in its context window. Beyond 8-10 active subtasks, supervisor quality degrades noticeably
Debugging complexity -- a failing multi-agent supervisor system has possible failure points (n agents, m subtasks). Without robust tracing and observability, root cause analysis is painful
Cold start and planning latency -- the initial task decomposition step adds 1-3 seconds before any work begins, even for tasks where the decomposition is obvious
Failure Modes & Debugging
Infinite delegation loop
Cause
The supervisor delegates a task to an agent, the agent returns a vague or incomplete response, the supervisor re-delegates to the same or another agent without providing clearer instructions, creating an unbounded loop that burns tokens rapidly.
Symptoms
Token consumption spikes without progress. The execution trace shows the same subtask being retried 5+ times with marginally different phrasing. Costs escalate 10-50x beyond expected.
Mitigation
Enforce a hard max_retries per subtask (typically 2-3). On each retry, append specific validation feedback to the agent's prompt. After max retries, escalate to a more capable model or human review. Always set a hard budget cap that terminates the entire pipeline.
Supervisor hallucination in task planning
Cause
The supervisor's LLM fabricates subtasks that don't map to the original request, assigns tasks to non-existent agents, or creates circular dependencies in the task DAG.
Symptoms
Subtasks appear unrelated to the user's request. Agent assignment references capabilities that don't exist. The execution stalls on a dependency that can never be satisfied.
Mitigation
Validate the task plan against the agent registry before execution -- reject any plan that references unknown agents. Use structured output (JSON mode) for the planning step to enforce schema compliance. Include the agent capability list directly in the supervisor's system prompt.
Context contamination across agents
Cause
The supervisor passes too much context from one agent's output to the next, including irrelevant details, intermediate reasoning, or even hallucinations from a previous step.
Symptoms
Downstream agents repeat or build upon errors from upstream agents. The final output contains contradictions or traces of intermediate reasoning that should have been filtered out.
Mitigation
The supervisor should extract and forward only the validated, relevant portions of each agent's output. Implement a context filter between agents that strips intermediate reasoning and retains only the factual output. The validation step should explicitly check for hallucinated content before passing outputs downstream.
Budget exhaustion before critical subtasks
Cause
Early subtasks consume a disproportionate share of the budget (e.g., a research agent that retrieves and processes too many documents), leaving insufficient budget for later critical subtasks like synthesis.
Symptoms
The supervisor escalates or skips the final synthesis step. The user receives partial results with missing analysis or incomplete conclusions. The execution trace shows >60% of budget consumed by the first subtask.
Mitigation
Implement per-subtask budget caps (e.g., no single subtask can exceed 40% of total budget). Prioritize subtasks so that critical ones execute first. Use a two-pass approach: first pass with budget-conscious models to estimate complexity, second pass with full models for execution.
Validation model disagrees with specialist model
Cause
The supervisor uses a weaker model for validation (e.g., GPT-4o-mini) that incorrectly rejects high-quality output from a stronger specialist model (e.g., GPT-4o), creating a bottleneck where correct work is repeatedly flagged as inadequate.
Symptoms
High-quality agent outputs consistently score below the acceptance threshold. Subtasks hit max retries despite producing correct results. The stronger model keeps regenerating essentially the same correct answer.
Mitigation
Calibrate the validation threshold empirically on a held-out set. Consider using the same model tier for validation as for specialist work on high-stakes subtasks. Alternatively, use rule-based validation (format checks, length constraints, factual lookups) instead of LLM-as-judge for objective quality criteria.
Agent capability drift after model update
Cause
The underlying LLM model is updated (e.g., GPT-4o gets a minor version bump) and a specialist agent's behavior changes subtly -- it may handle certain task types differently or produce outputs in a different format.
Symptoms
Validation scores drop gradually across all tasks assigned to the affected agent. The supervisor starts escalating more frequently. The change correlates with a model version update rather than any code change.
Mitigation
Pin model versions in production (gpt-4o-2025-08-06 not gpt-4o). Maintain an evaluation suite that runs on model updates. Implement canary deployments for model version changes -- route 5% of traffic to the new version and compare metrics before full rollout.
Placement in an ML System
Where Does the Supervisor Sit?
In an agentic AI pipeline, the supervisor sits between the user-facing API (or chat interface) and the specialist agent pool. The user's request arrives at the supervisor, which acts as the single entry point for the entire multi-agent system.
In enterprise architectures (like Databricks' Agent Bricks or Google ADK), the supervisor is often the top-level agent in a hierarchical multi-agent system. It coordinates specialized sub-agents that may themselves be supervisors of smaller teams -- creating a tree-structured organization similar to a corporate org chart.
For Razorpay's agentic payment system, the supervisor routes payment-related intents to specialized agents (refund handler, fraud detector, compliance checker) while maintaining a unified conversation state. For Swiggy's AI support system on Databricks, the supervisor coordinates agents handling order tracking, restaurant queries, and refund processing.
Architectural Insight: The supervisor is the control plane of your multi-agent system, while the specialist agents are the data plane. Keep the control plane lightweight and fast. The supervisor should make decisions, not do work.
Pipeline Stage
Orchestration / Serving
Upstream
- agent-router
- task-decomposer
- human-in-loop
Downstream
- crewai-agent
- langgraph-node
- agent-orchestrator
Scaling Bottlenecks
The primary bottleneck is LLM inference latency at the supervisor level. Every delegation decision, validation check, and synthesis step requires a round-trip to the LLM. With 5+ subtasks, the supervisor alone may make 12-15 LLM calls, each taking 1-3 seconds.
Concurrent task handling is another scaling concern. If the supervisor manages long-running tasks that overlap in time, its context window fills with state from multiple active workflows. At 10+ concurrent workflows, a single supervisor instance becomes unreliable.
Some concrete numbers from production systems: a LangGraph supervisor handling 3 agents with validation processes roughly 30 requests per minute on a single instance. Scaling to 1,000 RPM requires ~33 supervisor instances with load balancing and shared state (e.g., Redis-backed checkpoints). At that scale, supervisor coordination costs approximately $0.05 per request (~INR 4.2), representing 15% of total system cost.
Production Case Studies
BASF adopted Databricks' Multi-Agent Supervisor architecture for their Marketmind project in Sales & Marketing. The supervisor coordinates multiple domain-specific agents (Genie Spaces, agent endpoints, Unity Catalog functions) to handle complex cross-domain queries. The architecture provides built-in access controls ensuring end users only access the sub-agents and data they're authorized for.
Unified enterprise assistant that routes queries across multiple specialized domains with governance controls. Reduced the need for multiple single-purpose chatbots into one supervised multi-agent interface.
Swiggy partnered with Databricks to build an enterprise-scale AI agent for customer support. The system progressed from initial prototypes through model selection to advanced multi-agent systems with real-time monitoring and CRM integration. A supervisor agent coordinates specialist agents handling order tracking, restaurant queries, refund processing, and delivery status updates.
Enterprise-grade AI customer support system serving millions of orders with multi-agent coordination, real-time monitoring, and seamless CRM integration across Swiggy's delivery and Instamart platforms.
Microsoft's Magentic-One system uses a lead Orchestrator agent that directs four specialist agents (WebSurfer, FileSurfer, Coder, ComputerTerminal) to solve complex tasks. The Orchestrator plans, tracks progress, and re-plans to recover from errors. The modular design allows agents to be added or removed without additional prompt tuning.
Achieved statistically competitive performance to state-of-the-art on three diverse agentic benchmarks (GAIA, AssistantBench, WebArena) while demonstrating that the supervised architecture is robust to individual agent failures.
Razorpay partnered with NPCI and OpenAI to launch Agentic Payments on ChatGPT, a pilot initiative integrating AI into India's digital commerce ecosystem. The system uses a supervisor-like coordination layer where an AI agent manages payment workflows including intent detection, fraud screening, compliance checks, and UPI transaction execution through Razorpay's MCP server.
First company in India to adopt Model Context Protocol (MCP) for payments, enabling AI-driven commerce flows that coordinate multiple payment processing agents under a unified supervisor.
Tooling & Ecosystem
Official LangGraph library for creating hierarchical multi-agent systems. Provides create_supervisor() factory that wires up routing, state management, and handoff logic for a supervisor coordinating specialist agents built with create_react_agent.
Framework for orchestrating autonomous AI agents. The Process.hierarchical mode automatically creates a manager agent that delegates tasks, validates outputs, and coordinates crew members. Supports custom manager_agent configuration for fine-grained supervisor control.
Multi-agent framework using an actor model for orchestration. Supports supervisor patterns through GroupChat with a custom speaker selection policy. Powers Magentic-One's Orchestrator pattern. Includes AutoGen Studio for no-code multi-agent development.
Google's open-source framework for building multi-agent systems. Supports hierarchical agent structures with CoordinatorAgent that delegates to specialist sub_agents using AutoFlow routing. Optimized for Gemini but model-agnostic.
Production-ready evolution of OpenAI's experimental Swarm framework. Supports agent handoffs, tool use, and triage patterns that implement supervisor-like coordination. Recommended replacement for Swarm for all production use cases.
Enterprise multi-agent supervisor for Databricks. Coordinates Genie Spaces, agent endpoints, Unity Catalog functions, and MCP servers. Includes built-in access controls, evaluation, and Mosaic AI monitoring for production governance.
Observability and evaluation platform for LLM applications. Provides execution traces, cost tracking, and quality metrics essential for debugging and monitoring agent supervisor systems. Integrates natively with LangGraph supervisors.
Research & References
Wu, Bansal, Zhang, Wu, Li, Zhu, Jiang, Zhang, Wang, et al. (2023)COLM 2024
Foundational paper introducing the AutoGen framework for multi-agent conversation, enabling customizable agents that converse to solve tasks using combinations of LLMs, human inputs, and tools. Established the architectural patterns that supervisor-based systems build upon.
Fourney, Bansal, Mozannar, Tan, Salinas, Zhu, et al. (2024)arXiv preprint
Presented a multi-agent system with an Orchestrator lead agent that plans, tracks progress, and re-plans while directing four specialist agents. Demonstrated state-of-the-art performance on GAIA, AssistantBench, and WebArena benchmarks with a modular, supervisor-based architecture.
Cemri, Pan, Yang, et al. (2025)ICLR 2025
Identified 14 unique failure modes across 1,600+ annotated traces from 7 multi-agent frameworks. The MAST taxonomy organizes failures into specification/design failures, inter-agent misalignment, and task verification/termination issues -- essential reading for anyone designing supervisor validation logic.
Yang, Luo, Liu, Lou, Chen (2025)arXiv preprint
Proposed a framework that selects cost-optimal agent sets using Integer Linear Programming and determines collaboration topologies via reinforcement learning. Directly addresses the budget management challenge in supervised multi-agent systems.
Multiple authors (2024)arXiv preprint
Examines multi-agent collaboration patterns for enterprise use cases, including supervisor agent architectures with action groups and tool access. Provides evaluation frameworks for measuring multi-agent system effectiveness in production settings.
Han, Zhang, et al. (2024)arXiv preprint
Comprehensive survey of challenges in LLM-based multi-agent systems including agent coordination, communication protocols, scalability, and evaluation. Identifies open problems in supervisor design including context management and failure recovery.
Multiple authors (2025)arXiv preprint
Evaluates hybrid coordination approaches combining orchestrator control with directed peer communication. Provides scaling laws and architectural guidelines for multi-agent systems, showing how supervisor patterns compare with decentralized approaches at different scales.
Interview & Evaluation Perspective
Common Interview Questions
- ●
Design a multi-agent system where a supervisor coordinates research, coding, and writing agents to produce a technical report. How would you handle failures and budget constraints?
- ●
What is the difference between the supervisor pattern and peer-to-peer agent coordination? When would you choose each?
- ●
How would you implement output validation between agent steps in a supervised multi-agent pipeline?
- ●
A multi-agent system is producing inconsistent results. Walk me through how you would debug it.
- ●
How would you estimate and control the token cost of a supervised multi-agent system that processes 100K requests per day?
- ●
Design an escalation policy for a customer support supervisor agent at a company like Swiggy or Flipkart.
Key Points to Mention
- ●
The supervisor pattern provides centralized coordination, quality control, and budget enforcement -- its three core value propositions. Always mention all three.
- ●
Use asymmetric model tiers: cheap model for supervision (GPT-4o-mini), expensive model for specialist work (GPT-4o), top-tier model only for escalation. This can cut costs by 40-60%.
- ●
The supervisor loop is Plan -> Delegate -> Monitor -> Validate -> Synthesize. Each step is a potential failure point that needs specific mitigation.
- ●
Research from BAMAS shows that cost varies by 200% across different agent topologies for the same task. The supervisor's topology selection is itself a critical optimization problem.
- ●
The UC Berkeley study found 14 distinct failure modes in multi-agent systems. A well-designed supervisor mitigates at least 8 of them through validation gates and retry logic.
- ●
Always discuss observability: execution traces, per-agent cost metrics, validation scores, and escalation rates. You can't improve what you can't measure.
Pitfalls to Avoid
- ●
Treating the supervisor as omniscient -- it's an LLM with the same limitations as any other agent (hallucination, context window constraints, prompt sensitivity). It just has a different role.
- ●
Ignoring the latency implications -- a supervisor adds 5-15 seconds of end-to-end latency compared to a single agent. Always quantify this in your design.
- ●
Proposing a supervisor for a task that a single agent can handle. The interviewer is testing whether you know when NOT to use the pattern.
- ●
Forgetting to discuss budget enforcement and cost estimation. Enterprise deployments care deeply about cost predictability.
- ●
Describing the supervisor without mentioning the validation/quality-gate mechanism. Delegation without validation is just a router, not a supervisor.
Senior-Level Expectation
A senior or staff-level candidate should be able to architect the full supervisor system: (1) task decomposition strategy with dependency graph construction, (2) agent registry design with capability matching, (3) multi-tier model selection with cost-quality tradeoff analysis, (4) validation pipeline with LLM-as-judge calibration, (5) budget enforcement with per-subtask caps and graceful degradation, (6) escalation policy hierarchy (retry -> better model -> human), (7) observability stack (traces, cost metrics, quality dashboards), and (8) scaling strategy (horizontal supervisor instances with shared state). They should also discuss failure mode taxonomy, referencing specific patterns from the MAST research. Bonus points for discussing cost projections in both USD and INR, demonstrating awareness of deployment economics for Indian startups vs. enterprise deployments.
Summary
The Agent Supervisor is the coordination backbone of hierarchical multi-agent LLM systems. It addresses the fundamental tension between specialization (deep expertise per subtask) and coordination (global awareness across subtasks) that no single agent can resolve within a finite context window.
The core architecture follows a Plan -> Delegate -> Monitor -> Validate -> Synthesize loop. The supervisor decomposes complex tasks into a DAG of subtasks, assigns each to the most capable and cost-efficient specialist agent, monitors execution against budget and time constraints, validates outputs through quality gates (LLM-as-judge or rule-based), and synthesizes validated results into a coherent final response. When agents fail or quality falls short, the supervisor retries with specific feedback, escalates to more capable models, or routes to human review.
Production adoption is accelerating across frameworks (LangGraph, CrewAI, AutoGen, Google ADK) and enterprises (Databricks BASF Marketmind, Swiggy's AI support, Razorpay's agentic payments). The key engineering challenges are cost management (supervisor overhead is 10-20% of total tokens; total costs vary 200% by topology), latency (5-15 seconds for a typical 3-agent pipeline), and failure handling (the MAST taxonomy identifies 14 distinct failure modes in multi-agent systems). The design pattern of using a cheaper model for supervision while reserving expensive models for specialist work can cut costs by 40-60% without significant quality degradation -- a critical optimization for startups operating on tight budgets.
The agent supervisor doesn't do the work -- it ensures the right work gets done, by the right agents, at the right quality, within the right budget. That coordination intelligence is what separates a reliable multi-agent system from an expensive token bonfire.