Agent Router in Machine Learning
An agent router is the decision-making layer in a multi-agent system that determines which specialized agent should handle a given task, query, or sub-task. Think of it as an intelligent dispatcher: it examines the incoming request, classifies the intent or required capability, and forwards the work to the agent best equipped to handle it.
In production ML systems, agent routers have become critical infrastructure. As organizations move from single monolithic LLM calls to constellations of specialized agents -- one for SQL generation, another for summarization, a third for code review -- someone (or something) needs to decide who does what. That "something" is the agent router.
The rise of multi-agent architectures in 2024-2025 has made routing a first-class engineering problem. Frameworks like LangGraph, CrewAI, AutoGen, and Amazon Bedrock Agents all provide routing primitives, and research papers like RouteLLM and MasRouter have formalized the problem of cost-effective, accurate agent selection.
From Swiggy's multi-agent customer support system routing tickets to specialized resolution agents, to Razorpay's AI-powered payment routing across gateways, agent routers are quietly powering some of the most sophisticated AI deployments in India and globally. The quality of your routing directly determines the quality ceiling of your entire multi-agent system.
Concept Snapshot
- What It Is
- A decision-making component that classifies incoming tasks or queries and dispatches them to the most appropriate specialized agent in a multi-agent system.
- Category
- Multi-Agent Systems
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: user query or task description, agent registry (capabilities, availability), optional context/history. Outputs: selected agent ID, confidence score, optional routing metadata.
- System Placement
- Sits between the user interface (or upstream orchestrator) and the pool of specialized downstream agents. Acts as the first decision point after a request enters the multi-agent system.
- Also Known As
- agent dispatcher, task router, intent router, agent selector, query router, agent gateway
- Typical Users
- ML engineers, backend engineers, AI platform engineers, solutions architects
- Prerequisites
- Multi-agent system concepts, Intent classification basics, Embedding similarity search, LLM function calling
- Key Terms
- intent classificationsemantic routingagent registryrouting accuracyfallback agentagent handoffconfidence thresholdrouting latency
Why This Concept Exists
The Problem: Monolithic Agents Don't Scale
Early LLM applications used a single agent -- one large prompt, one model, one set of tools. This worked fine for demos and simple chatbots. But as applications grew in scope, the single-agent approach hit a wall. Prompts became thousands of tokens long, tool lists grew unwieldy, and the agent started making poor tool-selection decisions because it was overloaded with responsibilities.
The solution? Specialization. Break the monolith into focused agents: a SQL agent that only writes queries, a research agent that only searches documents, a math agent that only solves computations. Each agent gets a tight prompt, a small tool set, and deep expertise in one domain. Accuracy improves dramatically.
But specialization creates a new problem: who decides which specialist to call?
The Routing Problem
Consider a customer support system for an Indian e-commerce platform. A user might ask about order tracking (logistics agent), request a refund (payments agent), ask about product specifications (catalog agent), or simply say "hello" (chitchat agent). Without a router, you'd either need one overloaded agent that handles everything poorly, or you'd force users to manually select a department -- a terrible user experience.
The agent router solves this by examining the incoming query and making a fast, accurate dispatch decision. It's the air traffic controller for your fleet of specialized agents.
Evolution of Routing Approaches
Routing has evolved through several generations:
Generation 1: Rule-based routing (keyword matching, regex patterns). Simple, fast, interpretable, but brittle. If a user says "Where is my order?" you match "order" to the logistics agent. But what about "I paid but nothing arrived"? No keyword for "order" there.
Generation 2: Intent classification (trained classifiers). A dedicated ML model predicts the intent category, which maps to an agent. More robust than rules, but requires labeled training data and retraining when new agents are added.
Generation 3: Semantic routing (embedding similarity). Encode example utterances for each agent into a shared vector space, then route by nearest-neighbor lookup. No training required -- just a few example utterances per route. Libraries like semantic-router from Aurelio AI pioneered this approach.
Generation 4: LLM-based routing (the LLM decides). Give the routing LLM a description of each agent and ask it to pick the right one. Most flexible, handles ambiguity well, but slower and more expensive. This is what LangGraph's conditional edges and Amazon Bedrock's supervisor mode use.
Key Insight: Most production systems use a hybrid approach -- fast semantic routing for clear-cut cases, LLM-based routing for ambiguous ones, and rule-based overrides for safety-critical paths. Swiggy's customer support system, for instance, combines rule-based routing with a dedicated lightweight LLM for agent assignment to achieve near-100% accuracy.
Core Intuition & Mental Model
The Airport Analogy
Imagine an international airport. Passengers arrive with different needs: some need to check in for domestic flights (Terminal 1), others for international flights (Terminal 2), some need the lounge (business class agent), and a few need emergency medical assistance (priority override).
The agent router is the information desk at the entrance. A good information desk doesn't need to know how to fly planes or serve food in the lounge -- it just needs to quickly and accurately understand what the passenger needs and point them to the right terminal.
If the information desk is slow, everyone queues up and the entire airport grinds to a halt. If it's inaccurate, passengers end up in the wrong terminal and have to be re-routed -- wasting everyone's time. The router is on the critical path for every single request.
The Core Promise
An agent router guarantees two things:
- Correct dispatch: The query reaches an agent that can actually handle it. A code question goes to the code agent, not the poetry agent.
- Fast dispatch: Routing decisions happen in milliseconds, not seconds. You don't want a 3-second routing delay before a 2-second agent response.
The deeper insight is that routing is itself a classification problem -- and classification is something ML systems are extremely good at. Whether you use embeddings, classifiers, or an LLM to make the routing decision, you're fundamentally asking: "Given this input, which category (agent) does it belong to?"
What a Router Does NOT Do
A router does not execute tasks. It does not generate SQL, write code, or search documents. It only decides who should. This separation of concerns is critical: the router stays lean and fast, while specialized agents handle the heavy lifting.
Similarly, a router is not an orchestrator. An orchestrator manages multi-step workflows, tracks state across agent invocations, and handles agent-to-agent communication. A router makes a single dispatch decision. In practice, a router is often a component within an orchestrator -- the orchestrator calls the router whenever it needs to decide the next step.
Technical Foundations
Formal Framework
Let be the set of available agents, and let be an incoming query or task. An agent router is a function:
that maps a query to an agent along with a confidence score .
Routing Strategies
Rule-Based Routing: A deterministic function where the mapping is defined by a set of conditional predicates :
The predicates are evaluated in priority order, and the first match wins.
Semantic Routing: Let be an embedding function and be the set of example utterances for agent . The routing decision is:
where is typically cosine similarity. The confidence score is the maximum similarity value achieved.
Classifier-Based Routing: A trained model outputs a probability distribution over agents:
with confidence .
LLM-Based Routing: The LLM receives the query and agent descriptions, then outputs a structured routing decision:
Routing Accuracy
The primary metric is routing accuracy: the fraction of queries dispatched to the correct agent. For a test set :
In practice, we also measure routing latency (time to make the dispatch decision, ideally for semantic routing, for LLM-based routing) and fallback rate (fraction of queries that fall through to the default/fallback agent).
Confidence-Gated Routing
A production-critical pattern is confidence-gated routing with a threshold :
This ensures that low-confidence routing decisions are sent to a fallback agent (often a general-purpose LLM) rather than risking a wrong dispatch. Tuning trades off coverage (fraction of queries handled by specialized agents) against accuracy.
Internal Architecture
A production agent router consists of several interconnected subsystems: an input preprocessor that normalizes and extracts features from the incoming query, a routing engine that makes the dispatch decision, an agent registry that maintains metadata about available agents, and a fallback/retry handler that manages routing failures.
The architecture supports multiple routing strategies in a cascading configuration -- fast, cheap methods (rule-based, semantic) are tried first, and expensive methods (LLM-based) are used only when the fast methods produce low-confidence results.
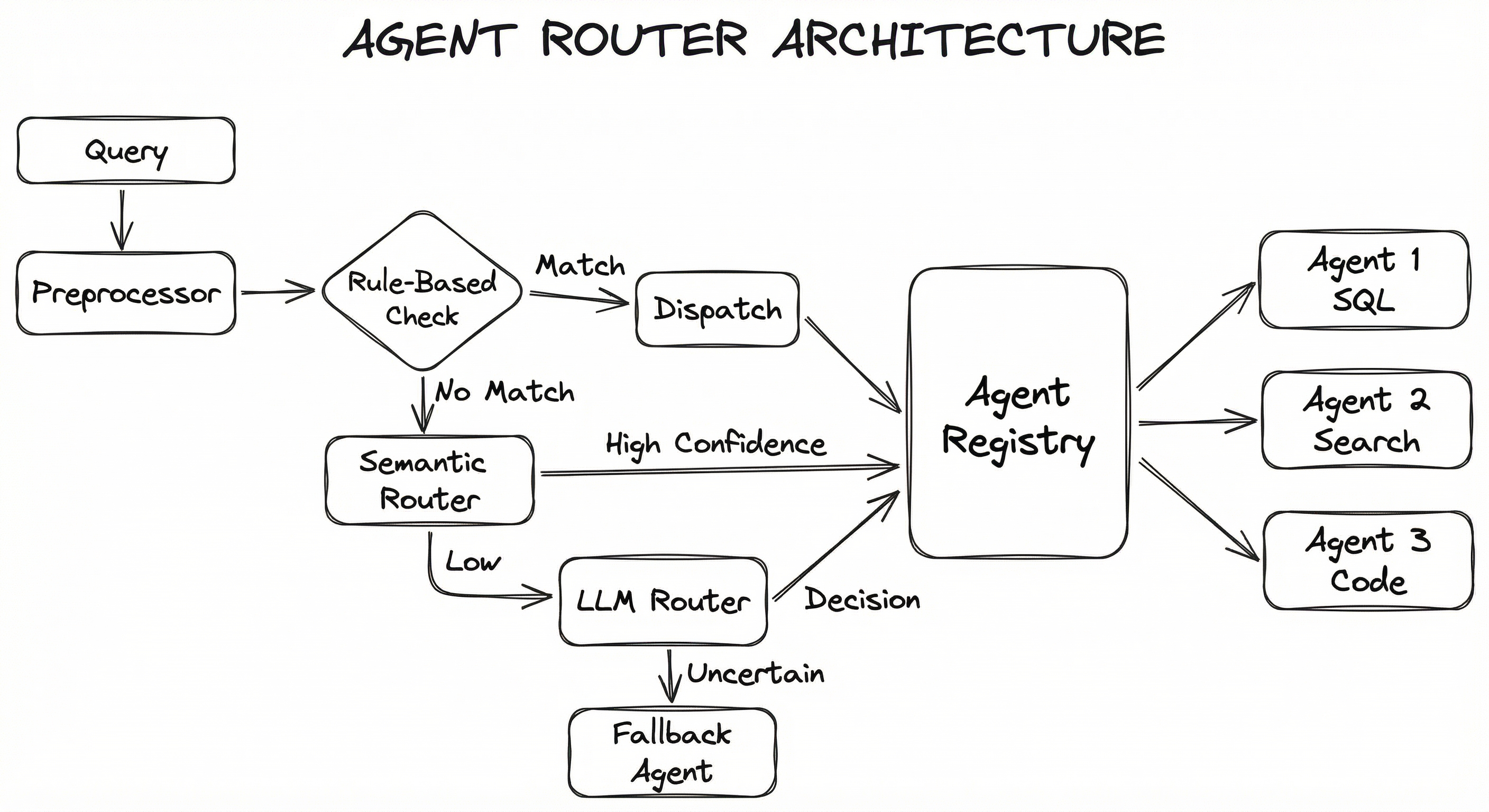
This cascading architecture is critical for balancing routing latency against accuracy. Rule-based checks resolve in microseconds, semantic routing in 5-20ms, and LLM-based routing in 200-800ms. By only escalating when needed, you keep the average routing latency low while maintaining high accuracy for ambiguous queries.
Key Components
Input Preprocessor
Normalizes the incoming query: lowercasing, language detection, entity extraction, and conversation history summarization. For multi-turn conversations, it may compress the context into a concise representation to keep routing fast. Also handles input validation and sanitization.
Rule-Based Router
The fastest routing layer. Evaluates deterministic predicates -- keyword matches, regex patterns, entity presence, or explicit user intent signals (e.g., the user clicked a 'Refund' button). Acts as a priority override for safety-critical or business-critical routing decisions.
Semantic Router
Encodes the query into an embedding vector and compares it against pre-computed embeddings of example utterances for each agent route. Returns the route with the highest similarity score. Typically uses a lightweight encoder like all-MiniLM-L6-v2 for sub-10ms latency.
LLM-Based Router
Uses a language model to reason about the query and select the appropriate agent from a description list. Handles ambiguous, multi-intent, or novel queries that semantic routing cannot resolve confidently. Typically uses a smaller, cheaper model (GPT-4o-mini, Claude Haiku, Gemini Flash) to minimize cost and latency.
Agent Registry
Maintains a catalog of all available agents with their capabilities, status (active/inactive), current load, and routing metadata (example utterances, descriptions, tool lists). Supports dynamic registration and deregistration of agents at runtime.
Confidence Gate
Evaluates the confidence score from the routing decision against a configurable threshold. If confidence is below threshold, the query is either escalated to a more capable routing method or sent to the fallback agent. Prevents low-confidence misroutes.
Fallback Handler
Catches queries that no specialized agent can handle with sufficient confidence. Routes to a general-purpose agent, queues for human review, or returns a clarification request to the user. Tracks fallback rates as a key health metric.
Load Balancer
When multiple agent instances serve the same capability, distributes requests across instances using strategies like round-robin, least-connections, or latency-based routing. Implements circuit breakers for unhealthy agent instances.
Data Flow
Request Path: A query enters the preprocessor, which normalizes it and extracts key features. The rule-based router checks for deterministic matches first (microsecond latency). If no rule matches, the semantic router encodes the query and finds the nearest agent route (5-20ms). If the semantic confidence is below threshold, the LLM-based router is invoked (200-800ms). Once an agent is selected, the agent registry is consulted for the agent's endpoint and current health status. If the target agent is healthy, the query is dispatched; if not, the load balancer redirects to a healthy instance or the fallback handler activates.
Feedback Path: After the agent processes the query, the routing decision and outcome are logged. Periodic analysis of routing logs identifies misroutes, which feed back into improving the router's example utterances, classifier training data, or LLM prompt.
A cascading flow diagram showing an incoming query passing through a preprocessor, then through three routing layers (rule-based, semantic, LLM-based) in order of increasing cost and capability. Each layer can dispatch directly to an agent via the agent registry, or escalate to the next layer. A fallback agent catches unresolved queries. The agent registry fans out to multiple specialized agents.
How to Implement
Choosing Your Routing Strategy
The implementation approach depends on your scale, latency requirements, and how often new agents are added:
Semantic routing (using libraries like semantic-router) is the sweet spot for most teams. It requires no training -- just define 5-15 example utterances per agent route and you're done. Routing latency is 5-20ms, and you can add new routes in minutes. This is what I'd recommend for any team starting out.
LLM-based routing (using LangGraph conditional edges, CrewAI hierarchical process, or Amazon Bedrock supervisor mode) is more flexible but slower and costlier. Each routing decision costs one LLM call -- at roughly 0.05 per decision for GPT-4o-mini or Claude Haiku. At 10,000 queries/day, that's 500/month (~INR 8,400-42,000/month) just for routing. Use it when queries are genuinely ambiguous or when you need the router to reason about multi-step task decomposition.
Classifier-based routing (fine-tuned BERT/DistilBERT) offers the best latency-accuracy tradeoff at scale but requires labeled training data (typically 100-500 examples per agent). If you have the data and the agents don't change frequently, this approach can achieve 95%+ accuracy at sub-5ms latency.
Hybrid cascading (rule -> semantic -> LLM) gives you the best of all worlds. Swiggy's customer support system uses exactly this pattern: rule-based routing for clear-cut intents, a lightweight LLM for ambiguous cases, achieving near-100% routing accuracy while keeping average latency low.
Cost Comparison: For a system handling 50,000 queries/day across 10 agents:
- Semantic routing: ~$5/month (embedding API costs) / ~INR 420/month
- Classifier routing: ~$0/month (self-hosted) + one-time training cost
- LLM routing (GPT-4o-mini): ~$500/month / ~INR 42,000/month
- Hybrid cascading: ~$50-100/month / ~INR 4,200-8,400/month (only 10-20% of queries escalate to LLM)
from semantic_router import Route, RouteLayer
from semantic_router.encoders import OpenAIEncoder
# Define routes with example utterances for each agent
sql_agent_route = Route(
name="sql_agent",
utterances=[
"Show me the top 10 customers by revenue",
"How many orders were placed last month?",
"Query the database for active subscriptions",
"Get the average order value by city",
"Write a SQL query to find duplicate records",
],
)
search_agent_route = Route(
name="search_agent",
utterances=[
"Find documents about machine learning best practices",
"Search for information about RAG pipelines",
"What does our documentation say about deployment?",
"Look up the API reference for authentication",
"Find relevant papers on transformer architectures",
],
)
code_agent_route = Route(
name="code_agent",
utterances=[
"Write a Python function to parse JSON",
"Debug this error in my code",
"Refactor this function to be more efficient",
"Generate unit tests for the payment module",
"Review this pull request for security issues",
],
)
chitchat_route = Route(
name="chitchat_agent",
utterances=[
"Hello, how are you?",
"What can you help me with?",
"Thanks for your help",
"Good morning",
"Tell me a joke",
],
)
# Initialize the encoder and route layer
encoder = OpenAIEncoder(name="text-embedding-3-small")
route_layer = RouteLayer(
encoder=encoder,
routes=[sql_agent_route, search_agent_route, code_agent_route, chitchat_route],
)
# Route a query
result = route_layer("How many users signed up this week?")
print(f"Routed to: {result.name}") # Output: sql_agent
print(f"Confidence: {result.similarity_score:.3f}")
# Route an ambiguous query
result = route_layer("Can you help me optimize this database query?")
print(f"Routed to: {result.name}") # Could be sql_agent or code_agentThe semantic-router library from Aurelio AI provides zero-training-required routing using embedding similarity. You define 5-15 example utterances per route, and the library encodes them into a shared vector space. At query time, it embeds the input and finds the nearest route by cosine similarity. This runs in 5-20ms and handles paraphrased or semantically equivalent queries well. The encoder can be swapped between OpenAI, Cohere, or local models like all-MiniLM-L6-v2 for fully offline routing.
from typing import Literal, TypedDict
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
import json
class AgentState(TypedDict):
query: str
routed_agent: str
response: str
confidence: float
AGENT_REGISTRY = {
"sql_agent": "Database queries, data analysis, SQL generation.",
"search_agent": "Documentation search, knowledge base lookup.",
"code_agent": "Code writing, debugging, refactoring, reviews.",
"general_agent": "General conversation and fallback.",
}
router_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def route_query(state: AgentState) -> AgentState:
"""LLM-based routing node."""
descs = "\n".join(f"- {k}: {v}" for k, v in AGENT_REGISTRY.items())
response = router_llm.invoke([
SystemMessage(content=f"Select the best agent.\nAgents:\n{descs}\nRespond JSON: {{\"agent\": \"name\", \"confidence\": 0.0-1.0}}"),
HumanMessage(content=state["query"]),
])
result = json.loads(response.content)
return {**state, "routed_agent": result["agent"], "confidence": result["confidence"]}
def confidence_gate(state: AgentState) -> Literal["specialized", "fallback"]:
return "fallback" if state["confidence"] < 0.7 else "specialized"
def dispatch(state: AgentState) -> str:
return state["routed_agent"]
# Build the graph
graph = StateGraph(AgentState)
graph.add_node("router", route_query)
for name in AGENT_REGISTRY:
graph.add_node(name, lambda s, n=name: {**s, "response": f"[{n}] {s['query']}"})
graph.set_entry_point("router")
graph.add_conditional_edges("router", confidence_gate, {"specialized": "dispatch", "fallback": "general_agent"})
graph.add_node("dispatch", lambda s: s)
graph.add_conditional_edges("dispatch", dispatch, {n: n for n in AGENT_REGISTRY})
for name in AGENT_REGISTRY:
graph.add_edge(name, END)
app = graph.compile()
result = app.invoke({"query": "How many active users?", "routed_agent": "", "response": "", "confidence": 0.0})
print(f"Routed to: {result['routed_agent']} (confidence: {result['confidence']:.2f})")This LangGraph implementation demonstrates LLM-based routing with a confidence gate. The router node uses GPT-4o-mini to analyze the query and select an agent. A conditional edge checks the confidence -- if below 0.7, the query goes to the fallback agent. The routing logic is explicit in the graph structure, making it easy to debug. In production, replace the stub agent lambdas with real implementations.
import re
from dataclasses import dataclass, field
from typing import Optional
import numpy as np
from sentence_transformers import SentenceTransformer
@dataclass
class RoutingResult:
agent_id: str
confidence: float
method: str # 'rule', 'semantic', 'llm', 'fallback'
latency_ms: float = 0.0
@dataclass
class AgentRoute:
agent_id: str
description: str
utterances: list[str] = field(default_factory=list)
keywords: list[str] = field(default_factory=list)
patterns: list[str] = field(default_factory=list)
is_active: bool = True
class CascadingRouter:
"""Production-grade cascading router: rules -> semantic -> LLM -> fallback."""
def __init__(
self,
routes: list[AgentRoute],
embedding_model: str = "all-MiniLM-L6-v2",
semantic_threshold: float = 0.75,
fallback_agent: str = "general_agent",
):
self.routes = {r.agent_id: r for r in routes}
self.semantic_threshold = semantic_threshold
self.fallback_agent = fallback_agent
# Pre-compute embeddings for semantic routing
self.encoder = SentenceTransformer(embedding_model)
self._build_utterance_index()
def _build_utterance_index(self):
"""Pre-compute embeddings for all route utterances."""
self.utterance_embeddings = {}
for agent_id, route in self.routes.items():
if route.utterances:
self.utterance_embeddings[agent_id] = self.encoder.encode(
route.utterances, normalize_embeddings=True
)
def route(self, query: str) -> RoutingResult:
"""Cascade through routing strategies."""
import time
start = time.perf_counter()
# Layer 1: Rule-based routing (fastest)
result = self._rule_based_route(query)
if result:
result.latency_ms = (time.perf_counter() - start) * 1000
return result
# Layer 2: Semantic routing
result = self._semantic_route(query)
if result and result.confidence >= self.semantic_threshold:
result.latency_ms = (time.perf_counter() - start) * 1000
return result
# Layer 3: LLM-based routing (most expensive)
result = self._llm_route(query)
if result and result.confidence >= 0.6:
result.latency_ms = (time.perf_counter() - start) * 1000
return result
# Layer 4: Fallback
elapsed = (time.perf_counter() - start) * 1000
return RoutingResult(
agent_id=self.fallback_agent,
confidence=0.0,
method="fallback",
latency_ms=elapsed,
)
def _rule_based_route(self, query: str) -> Optional[RoutingResult]:
"""Check keyword and regex patterns."""
query_lower = query.lower()
for agent_id, route in self.routes.items():
# Keyword matching
for kw in route.keywords:
if kw.lower() in query_lower:
return RoutingResult(agent_id=agent_id, confidence=1.0, method="rule")
# Regex patterns
for pattern in route.patterns:
if re.search(pattern, query, re.IGNORECASE):
return RoutingResult(agent_id=agent_id, confidence=1.0, method="rule")
return None
def _semantic_route(self, query: str) -> Optional[RoutingResult]:
"""Embedding similarity routing."""
query_emb = self.encoder.encode([query], normalize_embeddings=True)[0]
best_agent, best_score = None, -1.0
for agent_id, embs in self.utterance_embeddings.items():
scores = embs @ query_emb # cosine similarity (normalized)
max_score = float(np.max(scores))
if max_score > best_score:
best_score = max_score
best_agent = agent_id
if best_agent:
return RoutingResult(agent_id=best_agent, confidence=best_score, method="semantic")
return None
def _llm_route(self, query: str) -> Optional[RoutingResult]:
"""LLM-based routing for ambiguous queries."""
from openai import OpenAI
import json
client = OpenAI()
descriptions = "\n".join(
f"- {r.agent_id}: {r.description}"
for r in self.routes.values()
if r.is_active
)
response = client.chat.completions.create(
model="gpt-4o-mini",
temperature=0,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": f"Select the best agent for the query. Agents:\n{descriptions}\nRespond as JSON: {{\"agent\": \"id\", \"confidence\": 0.0-1.0}}"},
{"role": "user", "content": query},
],
)
result = json.loads(response.choices[0].message.content)
return RoutingResult(
agent_id=result["agent"],
confidence=result["confidence"],
method="llm",
)
# Usage
routes = [
AgentRoute(
agent_id="sql_agent",
description="Handles database queries and data analysis",
utterances=["Show me revenue data", "Count active users", "Query the orders table"],
keywords=["sql", "query", "database"],
patterns=[r"how many .*(users|orders|customers)"],
),
AgentRoute(
agent_id="refund_agent",
description="Processes refund requests and payment issues",
utterances=["I want a refund", "My payment failed", "Cancel my subscription"],
keywords=["refund", "cancel", "payment failed"],
patterns=[r"(refund|cancel).*(order|subscription|payment)"],
),
AgentRoute(
agent_id="search_agent",
description="Searches knowledge base and documentation",
utterances=["Find docs about APIs", "Search for deployment guide", "Look up auth docs"],
keywords=[],
patterns=[],
),
]
router = CascadingRouter(routes=routes, semantic_threshold=0.72)
result = router.route("I paid for my order but want my money back")
print(f"Agent: {result.agent_id}, Method: {result.method}, Confidence: {result.confidence:.2f}")
# Output: Agent: refund_agent, Method: semantic, Confidence: 0.85This production-grade cascading router implements the hybrid pattern used by companies like Swiggy. It tries three strategies in order of cost: (1) rule-based matching for clear-cut keywords and regex patterns (microseconds), (2) semantic similarity using sentence-transformers for paraphrased queries (5-20ms), and (3) LLM-based routing via GPT-4o-mini for genuinely ambiguous cases (200-800ms). Each layer has a confidence threshold -- queries only escalate if the cheaper layer isn't confident enough. The AgentRoute dataclass makes it easy to add new agents with just a description and example utterances.
import json
from dataclasses import dataclass
from collections import defaultdict
@dataclass
class RoutingTestCase:
query: str
expected_agent: str
category: str = "general" # for per-category analysis
def evaluate_router(router, test_cases: list[RoutingTestCase]) -> dict:
"""Evaluate routing accuracy with detailed breakdown."""
results = {
"total": len(test_cases),
"correct": 0,
"incorrect": 0,
"fallback_count": 0,
"method_distribution": defaultdict(int),
"per_agent_accuracy": defaultdict(lambda: {"correct": 0, "total": 0}),
"per_category_accuracy": defaultdict(lambda: {"correct": 0, "total": 0}),
"latencies_ms": [],
"misroutes": [],
}
for tc in test_cases:
result = router.route(tc.query)
is_correct = result.agent_id == tc.expected_agent
if is_correct:
results["correct"] += 1
else:
results["incorrect"] += 1
results["misroutes"].append({
"query": tc.query,
"expected": tc.expected_agent,
"actual": result.agent_id,
"confidence": result.confidence,
"method": result.method,
})
if result.method == "fallback":
results["fallback_count"] += 1
results["method_distribution"][result.method] += 1
results["per_agent_accuracy"][tc.expected_agent]["total"] += 1
results["per_category_accuracy"][tc.category]["total"] += 1
if is_correct:
results["per_agent_accuracy"][tc.expected_agent]["correct"] += 1
results["per_category_accuracy"][tc.category]["correct"] += 1
results["latencies_ms"].append(result.latency_ms)
# Compute summary metrics
results["accuracy"] = results["correct"] / results["total"]
results["fallback_rate"] = results["fallback_count"] / results["total"]
results["avg_latency_ms"] = sum(results["latencies_ms"]) / len(results["latencies_ms"])
results["p95_latency_ms"] = sorted(results["latencies_ms"])[int(0.95 * len(results["latencies_ms"]))]
for agent, stats in results["per_agent_accuracy"].items():
stats["accuracy"] = stats["correct"] / stats["total"] if stats["total"] > 0 else 0
return results
# Example test suite
test_cases = [
RoutingTestCase("How many orders were placed today?", "sql_agent", "data"),
RoutingTestCase("Show me the revenue breakdown by state", "sql_agent", "data"),
RoutingTestCase("I want my money back for order #12345", "refund_agent", "support"),
RoutingTestCase("Cancel my subscription immediately", "refund_agent", "support"),
RoutingTestCase("Find the API documentation for payments", "search_agent", "search"),
RoutingTestCase("What does our wiki say about deployments?", "search_agent", "search"),
# Edge cases - ambiguous queries
RoutingTestCase("The payment query is failing", "sql_agent", "ambiguous"),
RoutingTestCase("Help me with the refund process documentation", "search_agent", "ambiguous"),
]
# Run evaluation
# results = evaluate_router(router, test_cases)
# print(json.dumps(results, indent=2, default=str))Routing accuracy evaluation is non-negotiable in production. This test suite measures overall accuracy, per-agent accuracy (to catch agents that are consistently misrouted), per-category accuracy (to identify weak spots like ambiguous queries), fallback rate (how often the router gives up), latency percentiles, and detailed misroute logs. Run this as a regression test in CI whenever you modify routes, change the embedding model, or update the LLM prompt. A healthy system should maintain >95% routing accuracy and <5% fallback rate.
# Agent Router Configuration (YAML)
router:
strategy: cascading # rule -> semantic -> llm -> fallback
rule_engine:
enabled: true
priority: 1
semantic_engine:
enabled: true
priority: 2
model: all-MiniLM-L6-v2
threshold: 0.75
max_latency_ms: 50
llm_engine:
enabled: true
priority: 3
model: gpt-4o-mini
temperature: 0
threshold: 0.6
max_latency_ms: 1000
max_retries: 2
fallback:
agent_id: general_agent
log_level: warn
load_balancer:
strategy: least-connections # round-robin | least-connections | latency-based
health_check_interval_s: 30
circuit_breaker:
failure_threshold: 5
recovery_timeout_s: 60
agent_registry:
- id: sql_agent
description: "Database queries and data analysis"
utterances_file: routes/sql_agent.txt
keywords: [sql, query, database, table, count]
max_concurrency: 10
timeout_s: 30
- id: search_agent
description: "Knowledge base and document search"
utterances_file: routes/search_agent.txt
keywords: [search, find, lookup, documentation]
max_concurrency: 20
timeout_s: 15
- id: refund_agent
description: "Refund processing and payment issues"
utterances_file: routes/refund_agent.txt
keywords: [refund, cancel, payment, money back]
max_concurrency: 5
timeout_s: 45
monitoring:
log_all_routing_decisions: true
alert_on_fallback_rate_above: 0.10
alert_on_accuracy_below: 0.93
eval_dataset: tests/routing_eval.json
eval_schedule: dailyCommon Implementation Mistakes
- ●
Not implementing a fallback agent: Without a fallback, queries that don't match any route either error out or get sent to a random agent. Always have a general-purpose catch-all agent that can handle unexpected inputs gracefully.
- ●
Using a large, expensive LLM for every routing decision: Routing is on the critical path for latency. Using GPT-4 or Claude Opus for routing adds 1-3 seconds of latency and significant cost. Use GPT-4o-mini, Claude Haiku, or better yet, semantic routing for the fast path.
- ●
Too few example utterances per route: With semantic routing, having only 2-3 utterances per route leads to poor coverage of the query space. Use at least 10-15 diverse utterances per route, covering different phrasings, tones, and edge cases.
- ●
Ignoring multi-intent queries: A user might say "Refund my order and show me my account balance." A naive router picks one agent, losing the other intent. Production routers need to detect multi-intent queries and either split them or route to an orchestrator.
- ●
Not monitoring routing accuracy in production: Routing decisions are invisible to users -- they only see the final agent response. Without monitoring, you won't know when routing degrades. Log every routing decision with the method used, confidence score, and eventual outcome.
- ●
Hardcoding agent descriptions in prompts: When agents are added or removed, the router's LLM prompt becomes stale. Use a dynamic agent registry that the router queries at runtime, so the prompt always reflects the current agent pool.
- ●
Skipping confidence thresholds: Routing without a confidence gate means the router always picks something, even when it has no idea. This leads to silent misroutes that are difficult to diagnose. Always implement a confidence threshold with a fallback path.
When Should You Use This?
Use When
You have 3+ specialized agents and need automated dispatch based on query content or intent
Your multi-agent system handles diverse query types that require different capabilities (e.g., SQL, search, code generation, customer support)
You need to minimize routing latency while maintaining high accuracy -- cascading strategies let you trade off between these
New agents are added frequently and you need a routing mechanism that adapts without full retraining (semantic routing handles this with just new utterances)
You want to control cost by routing simple queries to cheaper models/agents and complex queries to more capable ones (a la RouteLLM)
Your system serves multiple domains or tenants, each with distinct agent pools that need independent routing
You need auditability: logging which agent handled each query and why the router chose it
Avoid When
You have only 1-2 agents -- the overhead of a routing layer is unnecessary; just use a single agent with multiple tools
All queries go to the same agent regardless of content (e.g., a single-purpose chatbot). There's nothing to route.
The user explicitly selects which agent to interact with via a UI (e.g., clicking a 'SQL Assistant' vs 'Code Assistant' tab). The routing decision is already made by the user.
Your agents are arranged in a fixed sequential pipeline (A -> B -> C), not a parallel selection. Use a workflow orchestrator instead of a router.
Query volume is extremely low (<100/day) and you can afford manual triage or a single general-purpose agent without specialization
Key Tradeoffs
The Fundamental Tradeoff: Speed vs. Accuracy vs. Cost
Every routing strategy occupies a point on a three-dimensional tradeoff surface:
| Strategy | Latency | Accuracy | Cost per Decision | Flexibility |
|---|---|---|---|---|
| Rule-based | ~0.1ms | High (for known patterns) | Free | Low -- brittle to novel phrasings |
| Semantic routing | 5-20ms | Good (85-95%) | ~$0.0001 (embedding call) | Medium -- add utterances for new routes |
| Classifier (fine-tuned) | 2-5ms | Excellent (93-98%) | Free (self-hosted) | Low -- requires retraining for new routes |
| LLM-based | 200-800ms | Excellent (90-97%) | $0.01-0.05 per query | High -- just update agent descriptions |
| Hybrid cascading | 5-100ms avg | Excellent (95-99%) | $0.001-0.01 per query | High |
Coverage vs. Precision
A low confidence threshold routes more queries to specialized agents (higher coverage) but increases the risk of misroutes (lower precision). A high threshold sends more queries to the fallback agent (lower coverage) but the specialized agents see only queries they can confidently handle (higher precision).
For customer-facing applications, precision matters more -- a misroute creates a frustrating user experience. For internal tools, coverage might matter more -- you'd rather have an imperfect specialized response than a generic one.
The Cold Start Problem
When you add a new agent, semantic and classifier-based routers have limited signal for the new route. LLM-based routing handles this gracefully (just add the new agent's description), but semantic routing needs at least 10-15 example utterances. Plan for a "warm-up" period when new agents may receive fewer queries than expected.
Alternatives & Comparisons
An orchestrator manages multi-step workflows involving multiple agents, tracking state and handling agent-to-agent communication. A router makes a single dispatch decision. In practice, an orchestrator often contains a router as a component -- the orchestrator decides the workflow, and the router decides which agent to invoke at each step. Choose a full orchestrator when you need multi-step reasoning; choose a standalone router when you only need single-step dispatch.
A supervisor monitors agent execution, validates outputs, and can override or re-route if an agent produces poor results. The router operates before agent execution (input routing), while the supervisor operates during and after (output validation). In Amazon Bedrock's architecture, 'supervisor with routing' combines both roles. Use a supervisor when you need output quality control; use a router when you need input dispatch.
Instead of routing to specialized agents, you could use a single agent with dynamically selected prompt templates. This is simpler but scales poorly -- as the number of use cases grows, a single agent's prompt becomes bloated and performance degrades. A router + specialized agents scales better beyond 3-4 distinct use cases.
A task decomposer breaks a complex request into sub-tasks before routing happens. It sits upstream of the router: first decompose, then route each sub-task. Use a task decomposer when user queries are complex and multi-faceted; use just a router when queries map cleanly to a single agent.
Pros, Cons & Tradeoffs
Advantages
Separation of concerns: Each agent focuses on one capability, leading to sharper prompts, better tool selection, and higher quality outputs. The router handles dispatch, not execution.
Scalable architecture: Adding a new agent requires only updating the agent registry and adding route examples -- no changes to existing agents. The system grows horizontally.
Cost optimization: By routing simple queries to cheaper models/agents and complex queries to expensive ones, you can reduce LLM costs by 40-70% without quality loss (as demonstrated by RouteLLM).
Latency control: Cascading routing strategies ensure that 80-90% of queries are routed in under 20ms, with only ambiguous queries incurring the latency of an LLM call.
Observability: Every routing decision can be logged with the method used, confidence score, and selected agent, enabling detailed analytics on query patterns and routing quality.
Graceful degradation: If a specialized agent is down or overloaded, the router can redirect to a fallback agent, maintaining system availability even during partial outages.
Multi-tenancy support: Different tenants or user segments can have different agent pools and routing configurations, enabling personalized routing strategies.
Disadvantages
Added latency on the critical path: Every request must pass through the router before reaching an agent. Even at 5-20ms, this adds up across millions of requests.
Routing errors compound: A misroute sends the query to an agent that can't handle it, producing a poor response that the user sees. Unlike internal errors, misroutes are often silent -- the agent returns something, just not something useful.
Maintenance overhead: The router needs its own monitoring, evaluation, and iterative improvement. Route utterances, confidence thresholds, and agent descriptions all need periodic tuning.
Multi-intent blind spot: Most routers assume one query maps to one agent. Multi-intent queries ("refund my order and check delivery status") require additional decomposition logic that simple routers don't provide.
Cold start for new routes: When a new agent is added, the router has limited signal for routing to it. Semantic and classifier-based routers need example data; LLM-based routers need prompt updates.
Single point of failure: If the router itself fails, no queries reach any agent. The router must be highly available, which adds operational complexity (redundancy, health checks, circuit breakers).
Failure Modes & Debugging
Systematic misroute for ambiguous queries
Cause
Queries that fall between two agents' domains -- e.g., "the payment query is failing" could be a database issue (SQL agent) or a payment issue (refund agent). The router consistently picks the wrong one because semantic overlap between routes is high.
Symptoms
Specific query categories show low routing accuracy while overall accuracy looks healthy. Users in certain segments report irrelevant responses. Per-agent misroute logs show a consistent pattern of confusion between two agents.
Mitigation
Add discriminative utterances that explicitly distinguish confusing cases. For semantic routing, increase the number of contrastive examples. For LLM routing, add clarifying instructions in the system prompt. Consider a secondary confirmation step for queries near the decision boundary.
Confidence threshold miscalibration
Cause
The confidence threshold () is set too high, sending too many queries to the fallback agent, or too low, allowing misroutes through. Thresholds are often set once and never tuned as query distributions shift.
Symptoms
Too high: fallback rate exceeds 20%, specialized agents are underutilized, users report generic responses. Too low: routing accuracy drops below 90%, agents receive queries outside their domain, error rates increase.
Mitigation
Analyze the confidence score distribution on a weekly basis. Plot the routing accuracy vs. threshold curve and choose at the knee point. Implement adaptive thresholds that adjust based on recent routing outcomes. Set up alerts when fallback rate exceeds 10%.
Agent registry staleness
Cause
An agent is added, removed, or updated but the router's registry is not updated. The LLM-based router has stale agent descriptions, or semantic routes reference agents that no longer exist.
Symptoms
Queries are routed to non-existent agents (causing errors) or new agents never receive traffic. In LLM-based routing, the model hallucinates agent names that aren't in the registry.
Mitigation
Implement a centralized agent registry with health checks. The router should dynamically fetch the current agent list at startup and periodically refresh. Add validation that the selected agent ID exists in the registry before dispatch.
Embedding model drift after update
Cause
The embedding model used for semantic routing is updated (e.g., from text-embedding-ada-002 to text-embedding-3-small), but the pre-computed utterance embeddings are not re-generated. The query embedding and utterance embeddings now live in incompatible vector spaces.
Symptoms
Semantic routing confidence scores drop across the board. Queries that previously routed correctly now go to the fallback agent. The issue appears suddenly after a deployment, not gradually.
Mitigation
Version-stamp all embeddings with the model that generated them. When the embedding model changes, trigger automatic re-encoding of all utterance embeddings. Add a CI check that verifies routing accuracy against a golden test set before deployment.
Cascading failure from router overload
Cause
The router itself becomes a bottleneck under high traffic. If using LLM-based routing, rate limits or latency spikes at the LLM provider cascade into routing timeouts, blocking all downstream agents.
Symptoms
End-to-end latency spikes dramatically. Timeout errors from the routing layer. All agents appear idle despite high incoming traffic. The router's request queue grows unboundedly.
Mitigation
Implement circuit breakers: if LLM-based routing latency exceeds a threshold (e.g., 2 seconds), bypass it and use the semantic router's result even at lower confidence. Add rate limiting at the router layer. Deploy the router with horizontal auto-scaling. Cache routing decisions for identical or near-identical queries.
Multi-intent query mishandling
Cause
A user submits a query with multiple intents ("Cancel my order and find me similar products") but the router is designed for single-intent dispatch. It picks one intent and drops the other.
Symptoms
Users report that only part of their request was addressed. Follow-up queries repeat the missed intent. Conversation-level satisfaction scores are low despite individual agent quality being high.
Mitigation
Add a multi-intent detection layer before routing. If multiple intents are detected, either: (a) decompose into sub-queries and route each independently, (b) route to an orchestrator agent that handles multi-step workflows, or (c) route to the highest-priority intent and queue the secondary intent for a follow-up turn.
Placement in an ML System
Where Does It Sit in the Pipeline?
In a multi-agent system, the agent router is the first decision point after a query enters the system. It sits between the user-facing interface (API gateway, chat widget, voice interface) and the pool of specialized agents.
The typical flow is:
- User submits query to the API gateway
- Preprocessor normalizes the query and extracts metadata
- Agent router classifies the query and selects a target agent
- Selected agent processes the query and returns a response
- (Optional) Supervisor validates the response quality
In more complex architectures with task decomposition, the flow becomes: user query -> task decomposer -> [sub-task 1 -> router -> agent, sub-task 2 -> router -> agent, ...] -> aggregator -> response.
The router is also critical in agentic loops where an agent can re-invoke the router to hand off to another agent mid-conversation. LangGraph's Command abstraction and OpenAI Swarm's handoff functions both support this pattern.
Key Insight: The router is both a performance gatekeeper (its latency adds to every request) and a quality gatekeeper (its accuracy determines whether the right agent handles the query). Both dimensions must be monitored.
Pipeline Stage
Orchestration / Serving
Upstream
- task-decomposer
- prompt-template
- user-interface
Downstream
- agent-orchestrator
- agent-supervisor
- langgraph-node
Scaling Bottlenecks
The primary bottleneck is routing latency, especially when LLM-based routing is in the critical path. At 10,000 QPS, even a 200ms LLM routing call means 2,000 concurrent requests to the LLM provider -- well above most rate limits.
Semantic routing scales much better: a single all-MiniLM-L6-v2 instance handles ~5,000 queries/second on a modern CPU. But the embedding model still needs memory (90MB for MiniLM) and compute.
The agent registry can become a bottleneck if it's backed by a remote database with high read latency. Cache the registry locally with a TTL of 30-60 seconds.
At very high scale (>100K QPS), consider deploying the router as a standalone microservice with horizontal auto-scaling, a local embedding model, and LLM routing only as an async fallback. Indian fintech companies like Razorpay process millions of payment routing decisions daily using similar architectures.
Production Case Studies
Swiggy built an enterprise-scale AI customer support system with Databricks that uses a hybrid routing approach: rule-based routing for clear intents combined with a dedicated lightweight LLM for agent assignment. Their initial approach of using a single LLM for agent assignment achieved 90% accuracy, but the goal was near-100%. By decoupling routing from task execution and using a specialized assignment model, they achieved the target accuracy. The system supports multi-agent architectures where a new agent instance is launched for each distinct disposition.
Near-100% routing accuracy for customer support ticket assignment. Reduced LLM inference costs by optimizing prompt length (removing emojis, reducing few-shot examples). Handles millions of customer interactions monthly across food delivery, Instamart, and Dineout.
Razorpay Optimizer is India's first AI-powered payments router, which routes payment transactions across multiple payment gateways to maximize success rates. While not an LLM agent router per se, it applies the same routing principles: classifying the incoming request (payment type, bank, amount) and dispatching to the gateway most likely to succeed. The router uses ML models trained on historical transaction data to predict gateway success probabilities in real-time.
Significant improvement in payment success rates for merchants using the multi-gateway approach. The AI router dynamically adapts to gateway health, bank-level success rates, and time-of-day patterns, reducing failed transactions.
Amazon Bedrock's multi-agent collaboration feature (GA March 2025) includes a supervisor with routing mode where a supervisor agent intelligently routes simple requests directly to specialized sub-agents, bypassing full orchestration. For complex queries, it falls back to full supervisor mode. This two-tier routing approach reduces latency for straightforward requests while maintaining flexibility for complex ones.
Organizations across financial services, healthcare, and customer support use Bedrock's routing to orchestrate specialized agents. The routing mode reduces average response latency by skipping unnecessary orchestration steps for simple queries.
The LMSYS team developed RouteLLM, a framework that trains router models to dynamically select between a stronger (expensive) and weaker (cheaper) LLM during inference. Using human preference data from Chatbot Arena, the routers learn to predict which model can handle a query adequately. The framework demonstrates that intelligent routing can achieve GPT-4-level quality while using GPT-4 for only a fraction of queries.
Over 2x cost reduction without compromising response quality on standard benchmarks. The routers demonstrate strong transfer learning -- they maintain performance even when the underlying strong and weak models are changed. Published at ICLR 2025.
Tooling & Ecosystem
Superfast decision-making layer for LLMs and agents from Aurelio AI. Routes queries using semantic vector space similarity rather than LLM generation. Supports multiple encoders (OpenAI, Cohere, HuggingFace, FastEmbed), vector store integrations (Pinecone, Qdrant), and local deployment. The go-to library for embedding-based agent routing.
Agent orchestration framework from LangChain that models workflows as state graphs with conditional edges for routing. The add_conditional_edges method enables dynamic agent selection based on state, and the Command abstraction supports agent handoffs with state transfer. The most widely used framework for building production multi-agent systems with explicit routing logic.
Open-source framework from LMSYS for serving and evaluating LLM routers. Trains routers on human preference data to dynamically select between strong and weak models, reducing costs by 2x+ without quality loss. Supports 4 router architectures out of the box. Published at ICLR 2025.
Multi-agent orchestration framework with a hierarchical process mode where a manager agent routes tasks to specialized crew members based on their roles and capabilities. Supports both low-code (visual builder) and pro-code (Python SDK) workflows. The allowed_agents parameter enables controlled delegation.
Microsoft's framework for building multi-agent systems using an actor-based model. Supports GroupChat with agent selection via the description field, semantic routers for intent-based routing, and asynchronous message-based communication. The v0.4 architecture introduced event-driven routing for scalable agent orchestration.
LLM gateway and proxy that provides routing, load balancing, and fallback across 100+ LLM providers. Supports latency-based routing, least-busy routing, cooldowns, circuit breakers, and Redis-backed distributed state. While primarily a model router, its patterns apply directly to agent routing infrastructure.
Managed multi-agent service from AWS with built-in supervisor with routing mode. The supervisor agent routes simple requests directly to sub-agents and uses full orchestration for complex queries. Supports parallel agent communication and integrated trace/debug console. GA as of March 2025.
Research & References
Ong, Elber-Dorozko, Sclar, Kryscinski, Dohan, Yogatama, Liang, Manning, Hashimoto (2024)ICLR 2025
Proposes training efficient router models that dynamically select between strong and weak LLMs using human preference data from Chatbot Arena. Achieves 2x+ cost reduction without quality loss and demonstrates transfer learning across model pairs.
Hu, Du, Guo, et al. (2025)ACL 2025
Introduces Multi-Agent System Routing (MASR) as a unified framework integrating collaboration mode determination, role allocation, and LLM routing through a cascaded controller network. Reduces overhead by up to 52% compared to SOTA methods.
Zhao, Wu, Feng, et al. (2024)NeurIPS 2024
Proposes dual contrastive learning (sample-LLM and sample-sample losses) to train a query-based router that assembles multiple LLMs. Outperforms individual top-performing LLMs by +2.76% on in-distribution tasks.
Wu, Bansal, Zhang, Wu, Li, Zhu, Jiang, Zhang, Wang (2023)COLM 2024
Introduces the AutoGen framework for multi-agent conversation with customizable agent roles, conversation patterns, and routing through GroupChat agent selection. Foundational work for Microsoft's multi-agent ecosystem.
Mehmood, Anwar, Castelan-Carlson, et al. (2024)arXiv preprint
Demonstrates that semantic routing outperforms standalone LLM prompting for intent classification by providing deterministic routing behavior and eliminating hallucination-induced misclassifications over extended use.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design an agent router for a customer support system with 15 specialized agents?
- ●
What are the tradeoffs between semantic routing and LLM-based routing?
- ●
How do you handle multi-intent queries in a routing system?
- ●
How would you measure and improve routing accuracy in production?
- ●
Design a routing system that balances cost, latency, and accuracy for a platform handling 100K queries/day.
- ●
How would you handle the cold start problem when adding a new agent to the system?
- ●
Explain how you would implement fallback and retry logic in an agent router.
Key Points to Mention
- ●
Always start with the cascading pattern: rules for deterministic cases, semantic for clear-cut cases, LLM for ambiguous cases. This is the production standard.
- ●
Routing accuracy is the primary metric, but always pair it with fallback rate, per-agent accuracy, and latency P95. A 95% overall accuracy might hide an 60% accuracy for a specific agent.
- ●
Confidence thresholds are critical: without them, the router always picks something, even when it shouldn't. Gate routing decisions and use a fallback agent for low-confidence cases.
- ●
The router is a single point of failure -- it must be highly available with circuit breakers, health checks, and horizontal scaling. If the router goes down, all agents become unreachable.
- ●
Cost-aware routing (RouteLLM pattern): route simple queries to cheap models and complex queries to expensive models. This can reduce LLM costs by 40-70% at scale.
- ●
Multi-intent detection is a real production concern -- mention task decomposition as the upstream solution.
Pitfalls to Avoid
- ●
Saying you'd use GPT-4 or Claude Opus for routing -- these are too slow and expensive for the routing layer. Always use a lightweight model or embedding-based approach.
- ●
Ignoring the fallback case -- never design a router without a catch-all agent for unrecognized queries.
- ●
Treating routing as a one-time setup -- routing needs continuous monitoring, evaluation, and improvement as query distributions and agent capabilities evolve.
- ●
Conflating routing with orchestration -- the router makes a single dispatch decision; the orchestrator manages multi-step workflows. Clarify this distinction.
- ●
Forgetting about latency -- routing is on the critical path for every request. A 1-second routing delay is unacceptable for real-time applications.
Senior-Level Expectation
A senior candidate should discuss the full routing lifecycle: strategy selection (rule/semantic/LLM/hybrid) with quantitative justification for the chosen approach, confidence calibration methodology, fallback chain design, multi-intent handling, the cold start problem for new agents, and operational concerns (monitoring, A/B testing routing strategies, capacity planning). They should reference specific architectures -- LangGraph's conditional edges, Amazon Bedrock's supervisor-with-routing mode, or the RouteLLM cost optimization pattern. The ability to reason about cost-performance tradeoffs at Indian startup budgets (where a $500/month routing cost for LLM calls is significant) separates senior engineers from mid-level ones. They should also discuss failure modes: what happens when the router itself fails, how to prevent cascading failures, and how to maintain routing quality as the agent pool evolves.
Summary
An agent router is the critical dispatch layer in multi-agent systems that classifies incoming queries and forwards them to the most appropriate specialized agent. It sits on the critical path of every request, making it both a performance gatekeeper (its latency adds to every interaction) and a quality gatekeeper (its accuracy determines whether the right specialist handles the job).
Production agent routers typically use a cascading strategy: rule-based checks for deterministic cases (microsecond latency), semantic routing via embedding similarity for clear-cut cases (5-20ms), and LLM-based routing for genuinely ambiguous queries (200-800ms). This hybrid approach, used by companies like Swiggy for customer support routing, achieves 95-99% routing accuracy while keeping average latency low and costs manageable. Key infrastructure patterns include confidence-gated routing with fallback agents, dynamic agent registries, load balancing across agent instances, and circuit breakers for resilience.
The field is rapidly maturing: research like RouteLLM (ICLR 2025) demonstrates 2x cost reduction through intelligent model routing, MasRouter (ACL 2025) formalizes multi-agent system routing as a unified optimization problem, and production platforms like Amazon Bedrock and LangGraph provide built-in routing primitives. Whether you're building a customer support system for an Indian e-commerce platform or a code assistance tool for a global engineering team, the agent router is the component that makes multi-agent architectures practical -- turning a collection of specialized agents into a coherent, responsive system.