Task Decomposer in Machine Learning
A task decomposer is the component in a multi-agent system that takes a complex, high-level objective and breaks it into a structured set of smaller, executable subtasks -- each scoped enough for a single agent or tool to handle. It is, quite literally, the planning brain of an agentic pipeline.
Why does this matter? Because large language models, despite their impressive reasoning abilities, struggle with monolithic complex tasks. Ask GPT-4 to "build me a full-stack e-commerce app" in one shot and you'll get a mediocre sketch. Ask it to decompose that into 15 well-scoped subtasks -- define the database schema, set up authentication, build the product listing API, and so on -- then hand each to a specialized agent, and the output quality jumps dramatically.
Task decomposition sits at the heart of every serious multi-agent framework: LangGraph's hierarchical agent teams, CrewAI's crew planning, Microsoft AutoGen's conversational task splitting, and Google's Vertex AI Agent Builder all implement some form of it. The pattern is universal because the problem is universal: complex goals require divide-and-conquer.
In production systems across India and globally -- from Swiggy's multi-agent customer support to Flipkart's AI shopping concierge to Devin's autonomous software engineering -- task decomposition is the mechanism that transforms vague user intent into a concrete execution plan. Without it, multi-agent systems are just a collection of disconnected capabilities with no coordination.
Concept Snapshot
- What It Is
- A planning component that analyzes a complex task and produces a structured graph of smaller, executable subtasks with defined dependencies, inputs, outputs, and execution order.
- Category
- Multi-Agent Systems
- Complexity
- Advanced
- Inputs / Outputs
- Input: high-level task description (natural language or structured goal). Output: a directed acyclic graph (DAG) of subtasks with dependency edges, execution metadata, and agent assignments.
- System Placement
- Sits at the very beginning of a multi-agent pipeline, between the user request and the agent router or executor. It is the first component to process a task after intent parsing.
- Also Known As
- task planner, task splitter, hierarchical planner, goal decomposer, plan generator, subtask generator, work breakdown engine
- Typical Users
- ML engineers building multi-agent systems, AI platform architects, Backend engineers integrating agentic workflows, Product engineers designing AI-powered automation
- Prerequisites
- LLM prompting and chain-of-thought reasoning, Directed acyclic graphs (DAGs), Multi-agent system fundamentals, Basic graph theory (topological sorting), Prompt engineering patterns
- Key Terms
- DAGtopological sortdependency trackingparallel executionrecursive decompositionsubtask validationplan-and-solveleast-to-mosttask granularityexecution graph
Why This Concept Exists
The Monolithic Task Problem
LLMs are remarkably capable, but they have a well-documented failure mode: when given a task that requires coordinating many steps, maintaining state across operations, and handling branching logic, they tend to lose track of intermediate results, skip steps, or produce shallow outputs. This is not a model intelligence issue -- it is a working memory and context management issue.
Consider a realistic enterprise task: "Analyze our Q3 sales data, identify underperforming regions, generate improvement recommendations, create a presentation deck, and email it to the leadership team." A single LLM call will produce a vague, hand-wavy response. But decompose this into five discrete subtasks -- data retrieval, analysis, recommendation generation, deck creation, email dispatch -- and each becomes tractable for a specialized agent.
The Multi-Agent Coordination Challenge
The rise of multi-agent architectures created a new problem: how do you decide which agent does what, and in what order? If you have a researcher agent, a coder agent, a reviewer agent, and a presenter agent, someone needs to create the work breakdown structure. That "someone" is the task decomposer.
Without formal decomposition, multi-agent systems devolve into ad-hoc message passing where agents step on each other's work, duplicate effort, or deadlock waiting for inputs that no one is producing. The task decomposer eliminates this chaos by producing a dependency-aware execution plan upfront.
Evolution from Prompting to Planning
The intellectual lineage of task decomposition traces through several key innovations:
Chain-of-Thought (CoT) prompting (Wei et al., 2022) showed that asking models to "think step by step" improves reasoning. But CoT is linear -- it produces a chain, not a graph, and cannot express parallelism or conditional branching.
Least-to-Most Prompting (Zhou et al., 2022) introduced the idea of decomposing problems into progressively harder subproblems, solving each in sequence. This was a step toward true decomposition but still lacked the ability to express complex dependency structures.
Plan-and-Solve Prompting (Wang et al., 2023) explicitly separated the planning phase from the execution phase: first devise a plan, then execute it. This two-phase approach is the direct ancestor of modern task decomposers.
HuggingGPT (Shen et al., 2023) demonstrated a full pipeline where an LLM decomposes user requests into subtasks, selects models from Hugging Face for each subtask, executes them, and aggregates results. This was one of the first production-oriented demonstrations of LLM-driven task decomposition.
Today, frameworks like TDAG (Dynamic Task Decomposition and Agent Generation), LangGraph's hierarchical agent teams, and CrewAI's planning mode represent the state of the art -- producing DAG-structured plans with parallel execution, dynamic re-planning, and per-subtask agent instantiation.
Key Takeaway: Task decomposition exists because complex goals cannot be solved monolithically by a single agent. It converts unstructured objectives into structured execution plans that multi-agent systems can execute reliably and efficiently.
Core Intuition & Mental Model
The Project Manager Analogy
Think of a task decomposer as a senior project manager who receives a vague brief from a client -- "We need a new mobile app" -- and translates it into a detailed project plan with workstreams, milestones, dependencies, and team assignments. The PM doesn't write code or design UI; they figure out what needs to happen, in what order, and who should do it.
That's exactly what a task decomposer does for a multi-agent system. It receives a high-level goal, analyzes it, and produces a structured plan that downstream agents can execute independently.
Why DAGs, Not Lists?
A naive decomposition produces a flat list of subtasks: do A, then B, then C. But real-world tasks have parallelism and shared dependencies. If subtasks B and C both depend on A's output but are independent of each other, they can execute simultaneously. If subtask D depends on both B and C, it must wait for both to complete.
This is exactly a directed acyclic graph (DAG) -- the same structure used in build systems like Make, workflow engines like Airflow, and computation graphs in TensorFlow. The DAG captures the minimal ordering constraints, allowing maximum parallelism without violating dependencies.
A good task decomposer doesn't just split work -- it discovers the critical path through the task graph. The critical path determines the minimum possible execution time, and everything off the critical path can be parallelized.
The Goldilocks Problem of Granularity
Decompose too coarsely, and subtasks remain too complex for individual agents. Decompose too finely, and you create an explosion of trivial subtasks with massive coordination overhead. The art of task decomposition is finding the right granularity -- subtasks that are self-contained enough to be handled by a single agent call, but meaningful enough that the output moves the overall task forward.
A useful heuristic: each subtask should be completable in a single LLM call (or a single tool invocation). If it needs multiple rounds of reasoning, it probably needs further decomposition. If it is so trivial that any agent could handle it without specialization, it has probably been over-decomposed.
Technical Foundations
Formal Framework
Let denote a high-level task described in natural language. A task decomposer is a function that maps to a directed acyclic graph where:
- Each vertex represents a subtask with attributes: description , required capabilities , expected inputs , and expected outputs
- Each directed edge represents a dependency: subtask requires the output of subtask before it can begin execution
Execution Semantics
The execution order of the subtask DAG is determined by topological sorting. A topological sort of produces a linear ordering such that for every edge , vertex appears before in .
Subtasks with no unresolved dependencies (in-degree zero in the remaining graph) can execute in parallel. The maximum parallelism at any step is:
where is the subgraph of remaining unexecuted subtasks at time .
Critical Path Analysis
The critical path is the longest path through the DAG when each subtask has an estimated execution time :
Minimizing the makespan requires both good decomposition (short critical path) and effective parallelization (wide DAG where possible).
Decomposition Quality Metrics
We can evaluate a decomposition along several axes:
- Completeness: Does the union of subtask outputs cover all requirements of ? Formally,
- Minimality: Are there redundant subtasks? , removing would leave some requirement uncovered
- Granularity Score: Average complexity of subtasks, measured by estimated token count or tool invocations per subtask
- Parallelism Factor: -- ratio of total work to wall-clock time under maximal parallelism
Recursive Decomposition
For deeply complex tasks, decomposition can be applied recursively. If a subtask exceeds a complexity threshold , it is itself decomposed:
This produces a hierarchical task graph -- a tree of DAGs -- where leaf nodes are atomic, executable subtasks and internal nodes are composite tasks that expand into sub-DAGs.
Internal Architecture
A production task decomposer consists of four major subsystems: a task analyzer that parses and understands the input goal, a plan generator that produces the subtask DAG, a dependency resolver that validates and optimizes the graph structure, and a plan validator that checks feasibility before handing off to execution. Here is the architecture:
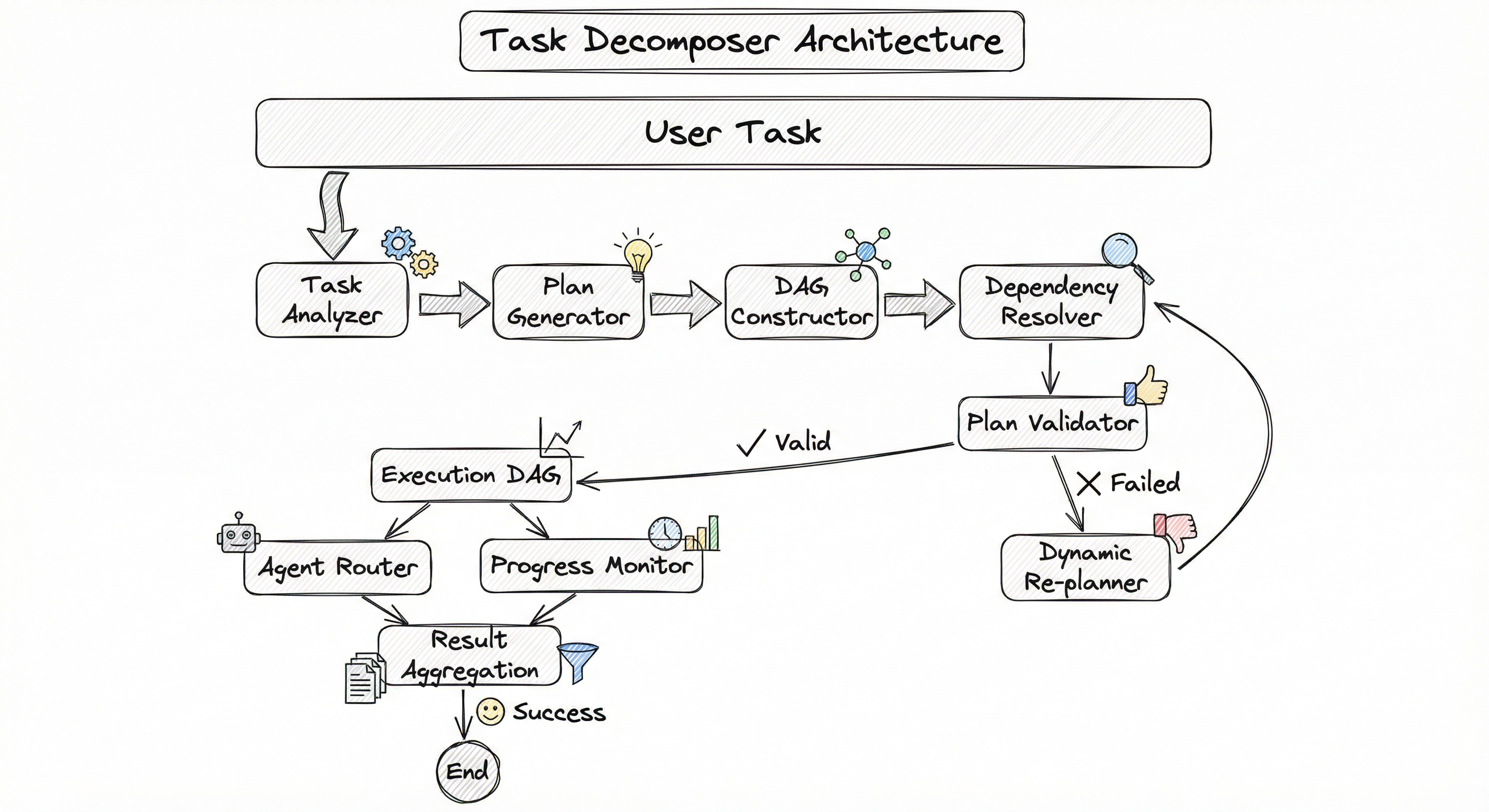
The plan generator is typically an LLM prompted with the task description, available agent capabilities, and decomposition guidelines. The output is a structured representation (usually JSON) of subtasks and their dependencies. The dependency resolver then validates the DAG properties (acyclicity, connectivity, type compatibility between outputs and inputs) and applies optimizations like merging trivially sequential subtasks or splitting overly broad ones.
The re-planning loop is critical for production systems. When a subtask fails or produces unexpected output, the dynamic re-planner can modify the remaining DAG without restarting from scratch -- adjusting downstream dependencies, inserting retry nodes, or rerouting work to alternative agents.
Key Components
Task Analyzer
Parses the incoming task description, extracts key entities, identifies the task type (creative, analytical, technical, etc.), estimates complexity, and determines whether decomposition is needed at all. Simple tasks bypass decomposition entirely.
Plan Generator (LLM-based)
The core decomposition engine. Uses an LLM with structured output (JSON mode) to generate subtasks, their descriptions, expected inputs/outputs, estimated durations, and inter-subtask dependencies. Prompted with available agent capabilities to ensure subtasks are assignable.
DAG Constructor
Converts the LLM's structured output into a formal directed acyclic graph. Validates acyclicity (detects and breaks cycles), ensures all subtask inputs have a producing subtask or are available from the original task context, and assigns unique IDs to each node.
Dependency Resolver
Optimizes the DAG by identifying parallelizable branches, computing the critical path, resolving implicit dependencies (e.g., two subtasks that both need access to the same resource), and applying topological sorting to determine execution order.
Plan Validator
Runs feasibility checks: Are all required agent types available? Do estimated costs fit within budget? Does the critical path fit within the time constraint? Are there subtasks with no clear agent assignment? Returns the plan or triggers re-planning.
Progress Monitor
Tracks the execution state of each subtask in the DAG (pending, running, completed, failed). Detects stalled subtasks, triggers timeouts, and notifies the dynamic re-planner when intervention is needed.
Dynamic Re-planner
Handles mid-execution plan modifications. When a subtask fails, produces unexpected output, or the task requirements change, the re-planner modifies the remaining DAG -- inserting retries, swapping agents, adding compensating subtasks, or pruning unreachable branches.
Data Flow
Planning Phase: The user's task enters the Task Analyzer, which enriches it with metadata (complexity score, task type, required capabilities). The enriched task is passed to the Plan Generator (LLM), which outputs a structured subtask list with dependencies. The DAG Constructor builds the graph, the Dependency Resolver optimizes it, and the Plan Validator checks feasibility. If validation fails, the system loops back to the Plan Generator with feedback.
Execution Phase: The validated DAG is handed to the Agent Router, which assigns each subtask to the appropriate agent. The Progress Monitor watches execution in real-time. Completed subtask outputs flow into dependent subtasks as inputs (following DAG edges). If a subtask fails, the Dynamic Re-planner modifies the remaining DAG and execution continues.
Aggregation Phase: Once all leaf nodes in the DAG have completed, a final aggregation step combines subtask outputs into the overall task result. This may involve an LLM-based synthesizer that merges partial results into a coherent whole.
A top-to-bottom flowchart showing: User Task flowing into Task Analyzer, then Plan Generator (LLM), DAG Constructor, Dependency Resolver, Plan Validator with a validation gate. Valid plans flow to the Execution DAG which connects to both the Agent Router and Progress Monitor. The Progress Monitor has a failure detection path leading to a Dynamic Re-planner that feeds back into the DAG Constructor. Successful completion flows to Result Aggregation.
How to Implement
Implementation Approaches
Task decomposition can be implemented at three levels of sophistication:
Level 1: Prompt-based decomposition -- A single LLM call with a well-crafted prompt that outputs a structured plan. This is the simplest approach, used by most prototypes and suitable for straightforward tasks. The decomposition quality is entirely dependent on prompt engineering.
Level 2: Framework-integrated decomposition -- Using a multi-agent framework (LangGraph, CrewAI, AutoGen) that provides built-in planning primitives. These frameworks handle the DAG construction, agent assignment, and execution orchestration, letting you focus on defining agent capabilities and decomposition strategies.
Level 3: Custom decomposition engine -- Building a dedicated planning service with recursive decomposition, dynamic re-planning, cost optimization, and integration with your specific agent registry. This is what companies like Cognition (Devin) and Swiggy build for production systems.
For most teams, Level 2 is the sweet spot. You get robust decomposition without building the entire planning infrastructure from scratch.
Cost Note: A single GPT-4o decomposition call for a moderately complex task costs approximately 100-300/month (~INR 8,400-25,200/month) just for the planning calls -- a small fraction of the total agent execution cost, which typically runs 10-50x higher.
import json
from openai import OpenAI
from typing import TypedDict
from dataclasses import dataclass, field
@dataclass
class Subtask:
id: str
description: str
agent_type: str
dependencies: list[str] = field(default_factory=list)
inputs: list[str] = field(default_factory=list)
outputs: list[str] = field(default_factory=list)
estimated_seconds: int = 30
@dataclass
class TaskPlan:
original_task: str
subtasks: list[Subtask]
critical_path: list[str] = field(default_factory=list)
DECOMPOSITION_PROMPT = """
You are a task decomposition engine for a multi-agent system.
Available agent types:
- researcher: Searches the web, reads documents, gathers information
- coder: Writes, debugs, and reviews code
- analyst: Analyzes data, generates insights, creates charts
- writer: Produces written content, summaries, reports
- reviewer: Validates outputs, checks quality, suggests improvements
Given the following task, decompose it into subtasks.
For each subtask, specify:
- id: unique snake_case identifier
- description: clear, actionable description
- agent_type: which agent type should handle this
- dependencies: list of subtask IDs that must complete first
- inputs: what data this subtask needs
- outputs: what data this subtask produces
- estimated_seconds: rough time estimate
Rules:
1. Each subtask must be completable in a single agent call
2. Maximize parallelism: only add dependencies when truly needed
3. Ensure the subtask graph is a DAG (no cycles)
4. Every subtask output that is needed downstream must be listed
5. Aim for 3-15 subtasks depending on complexity
Return valid JSON with this schema:
{"subtasks": [{"id": "...", "description": "...", "agent_type": "...", "dependencies": [...], "inputs": [...], "outputs": [...], "estimated_seconds": N}]}
Task: {task}
"""
def decompose_task(task: str, model: str = "gpt-4o") -> TaskPlan:
client = OpenAI()
response = client.chat.completions.create(
model=model,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": "You are a task decomposition engine. Always respond with valid JSON."},
{"role": "user", "content": DECOMPOSITION_PROMPT.format(task=task)},
],
temperature=0.2,
)
raw = json.loads(response.choices[0].message.content)
subtasks = [Subtask(**s) for s in raw["subtasks"]]
plan = TaskPlan(original_task=task, subtasks=subtasks)
plan.critical_path = compute_critical_path(plan)
return plan
def compute_critical_path(plan: TaskPlan) -> list[str]:
"""Compute the critical path through the subtask DAG."""
task_map = {s.id: s for s in plan.subtasks}
# Longest path via dynamic programming
memo: dict[str, tuple[int, list[str]]] = {}
def longest_path(task_id: str) -> tuple[int, list[str]]:
if task_id in memo:
return memo[task_id]
task = task_map[task_id]
if not task.dependencies:
result = (task.estimated_seconds, [task_id])
else:
best_time, best_path = 0, []
for dep_id in task.dependencies:
dep_time, dep_path = longest_path(dep_id)
if dep_time > best_time:
best_time, best_path = dep_time, dep_path
result = (best_time + task.estimated_seconds, best_path + [task_id])
memo[task_id] = result
return result
# Find the task with the longest path (no task depends on it = sink node)
all_deps = {d for s in plan.subtasks for d in s.dependencies}
sinks = [s.id for s in plan.subtasks if s.id not in all_deps]
if not sinks:
sinks = [s.id for s in plan.subtasks]
best_time, best_path = 0, []
for sink in sinks:
time, path = longest_path(sink)
if time > best_time:
best_time, best_path = time, path
return best_path
# Example usage
if __name__ == "__main__":
plan = decompose_task(
"Research the top 5 vector databases, compare their performance, "
"write a technical blog post with benchmarks, and create a summary slide deck."
)
print(f"Task: {plan.original_task}")
print(f"Subtasks: {len(plan.subtasks)}")
print(f"Critical path: {' -> '.join(plan.critical_path)}")
for s in plan.subtasks:
print(f" [{s.id}] ({s.agent_type}) {s.description}")
print(f" deps: {s.dependencies}, est: {s.estimated_seconds}s")This is a complete, runnable task decomposer that uses GPT-4o's structured JSON output mode. The decompose_task function sends the task to the LLM with a prompt specifying available agent types and decomposition rules. The LLM returns a JSON object with subtasks, dependencies, and metadata. The compute_critical_path function uses dynamic programming to find the longest path through the DAG, which determines the minimum execution time. The temperature is set low (0.2) to get consistent, deterministic decompositions.
import asyncio
from dataclasses import dataclass, field
from enum import Enum
from typing import Any, Callable, Awaitable
class SubtaskStatus(Enum):
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
@dataclass
class SubtaskState:
id: str
description: str
agent_type: str
dependencies: list[str]
status: SubtaskStatus = SubtaskStatus.PENDING
result: Any = None
error: str | None = None
class DAGExecutor:
def __init__(self, agent_registry: dict[str, Callable[..., Awaitable[Any]]],
max_concurrency: int = 5, max_retries: int = 2):
self.agents = agent_registry
self.semaphore = asyncio.Semaphore(max_concurrency)
self.max_retries = max_retries
self.states: dict[str, SubtaskState] = {}
self.events: dict[str, asyncio.Event] = {}
async def execute(self, subtasks: list[dict]) -> dict[str, Any]:
for st in subtasks:
self.states[st["id"]] = SubtaskState(**st)
self.events[st["id"]] = asyncio.Event()
await asyncio.gather(*[self._run(st["id"]) for st in subtasks],
return_exceptions=True)
return {sid: s.result for sid, s in self.states.items()
if s.status == SubtaskStatus.COMPLETED}
async def _run(self, sid: str) -> None:
state = self.states[sid]
# Wait for dependencies
for dep in state.dependencies:
await self.events[dep].wait()
if self.states[dep].status == SubtaskStatus.FAILED:
state.status = SubtaskStatus.FAILED
state.error = f"Dependency {dep} failed"
self.events[sid].set()
return
dep_outputs = {d: self.states[d].result for d in state.dependencies}
agent_fn = self.agents.get(state.agent_type)
if not agent_fn:
state.status = SubtaskStatus.FAILED
self.events[sid].set()
return
for attempt in range(self.max_retries + 1):
try:
async with self.semaphore:
state.status = SubtaskStatus.RUNNING
state.result = await agent_fn(task=state.description, inputs=dep_outputs)
state.status = SubtaskStatus.COMPLETED
break
except Exception as e:
if attempt == self.max_retries:
state.status = SubtaskStatus.FAILED
state.error = str(e)
else:
await asyncio.sleep(2 ** attempt)
self.events[sid].set()
# Usage
async def main():
async def researcher(task, inputs): return f"Researched: {task}"
async def writer(task, inputs): return f"Wrote based on: {inputs}"
executor = DAGExecutor({"researcher": researcher, "writer": writer})
results = await executor.execute([
{"id": "r1", "description": "Research A", "agent_type": "researcher", "dependencies": []},
{"id": "r2", "description": "Research B", "agent_type": "researcher", "dependencies": []},
{"id": "w1", "description": "Write report", "agent_type": "writer", "dependencies": ["r1", "r2"]},
])
print(results) # r1 and r2 run in parallel, w1 waits for both
asyncio.run(main())This DAG executor implements parallel subtask execution with dependency tracking. Each subtask waits on asyncio.Event objects for its dependencies, enabling automatic parallel execution of independent subtasks. A semaphore controls concurrency, exponential backoff handles retries, and dependency outputs are automatically passed as inputs to downstream subtasks. In the example, r1 and r2 execute in parallel, and w1 starts only after both complete.
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
import json
class PlannerState(TypedDict):
task: str
subtasks: list[dict]
current_subtask_idx: int
results: dict[str, str]
final_output: str
llm = ChatOpenAI(model="gpt-4o", temperature=0.2)
def decompose_node(state: PlannerState) -> PlannerState:
"""LLM-based task decomposition node."""
response = llm.invoke([
SystemMessage(content=(
"Decompose the following task into 3-8 sequential subtasks. "
"Return JSON: {\"subtasks\": [{\"id\": \"step_1\", "
"\"description\": \"...\", \"agent_type\": \"...\"}]}"
)),
HumanMessage(content=state["task"]),
])
subtasks = json.loads(response.content)["subtasks"]
return {
**state,
"subtasks": subtasks,
"current_subtask_idx": 0,
"results": {},
}
def execute_subtask_node(state: PlannerState) -> PlannerState:
"""Execute the current subtask using an LLM agent."""
idx = state["current_subtask_idx"]
subtask = state["subtasks"][idx]
context = json.dumps(state["results"], indent=2)
response = llm.invoke([
SystemMessage(content=(
f"You are a {subtask['agent_type']} agent. "
f"Complete this subtask using the context from previous steps.\n"
f"Previous results: {context}"
)),
HumanMessage(content=subtask["description"]),
])
new_results = {**state["results"], subtask["id"]: response.content}
return {
**state,
"results": new_results,
"current_subtask_idx": idx + 1,
}
def should_continue(state: PlannerState) -> str:
"""Check if there are more subtasks to execute."""
if state["current_subtask_idx"] < len(state["subtasks"]):
return "execute"
return "aggregate"
def aggregate_node(state: PlannerState) -> PlannerState:
"""Combine all subtask results into final output."""
response = llm.invoke([
SystemMessage(content="Synthesize all subtask results into a cohesive final output."),
HumanMessage(content=json.dumps(state["results"], indent=2)),
])
return {**state, "final_output": response.content}
# Build the LangGraph
graph = StateGraph(PlannerState)
graph.add_node("decompose", decompose_node)
graph.add_node("execute_subtask", execute_subtask_node)
graph.add_node("aggregate", aggregate_node)
graph.add_edge(START, "decompose")
graph.add_edge("decompose", "execute_subtask")
graph.add_conditional_edges("execute_subtask", should_continue, {
"execute": "execute_subtask",
"aggregate": "aggregate",
})
graph.add_edge("aggregate", END)
app = graph.compile()
# Run
result = app.invoke({
"task": "Analyze the Indian e-commerce market and write a strategy memo",
"subtasks": [],
"current_subtask_idx": 0,
"results": {},
"final_output": "",
})
print(result["final_output"])This LangGraph implementation demonstrates the decompose-execute-aggregate pattern. The graph has three node types: (1) decompose_node uses the LLM to break the task into subtasks, (2) execute_subtask_node processes one subtask at a time with context from previous results, and (3) aggregate_node synthesizes all results. The conditional edge should_continue loops execution until all subtasks are complete. This is a sequential execution pattern -- for parallel execution, you would use LangGraph's Send API to fan out subtasks to parallel branches.
from crewai import Agent, Task, Crew, Process
# Define specialized agents
researcher = Agent(
role="Senior Market Researcher",
goal="Find accurate, up-to-date market data and competitive intelligence",
backstory="You are an expert market researcher with 15 years of experience "
"analyzing technology markets in India and globally.",
verbose=True,
allow_delegation=False,
)
analyst = Agent(
role="Data Analyst",
goal="Transform raw research into actionable insights with quantitative backing",
backstory="You are a quantitative analyst who excels at finding patterns "
"in data and creating compelling visualizations.",
verbose=True,
allow_delegation=False,
)
writer = Agent(
role="Technical Writer",
goal="Produce clear, well-structured technical content",
backstory="You are a technical writer who specializes in making complex "
"topics accessible to engineering leadership.",
verbose=True,
allow_delegation=False,
)
# Define tasks with explicit dependencies
research_task = Task(
description=(
"Research the current state of AI agent frameworks in 2026. "
"Cover LangGraph, CrewAI, AutoGen, and OpenAI Agents SDK. "
"Include pricing, features, community size, and production readiness."
),
expected_output="Structured research report with data on each framework",
agent=researcher,
)
analysis_task = Task(
description=(
"Analyze the research data to identify the best framework for "
"an Indian fintech startup building a customer support automation system. "
"Consider cost (budget: INR 5 lakh/month), scalability, and Hindi language support."
),
expected_output="Comparative analysis with recommendation and justification",
agent=analyst,
context=[research_task], # dependency: waits for research_task
)
writing_task = Task(
description=(
"Write a technical decision document based on the analysis. "
"Include an executive summary, comparison table, recommendation, "
"migration plan, and cost projections in INR."
),
expected_output="Complete technical decision document (1500-2000 words)",
agent=writer,
context=[research_task, analysis_task], # depends on both
)
# Create crew with planning enabled
crew = Crew(
agents=[researcher, analyst, writer],
tasks=[research_task, analysis_task, writing_task],
process=Process.sequential,
planning=True, # enables automatic plan generation before execution
verbose=True,
)
result = crew.kickoff()
print(result)This CrewAI example demonstrates framework-level task decomposition. With planning=True, CrewAI automatically generates a step-by-step plan before agents start working. The context parameter on each Task defines explicit dependencies -- analysis_task cannot start until research_task completes, and writing_task waits for both. This is a practical pattern for teams that want task decomposition without building custom DAG infrastructure. Note the India-specific context: the analysis task includes INR budget constraints and Hindi language requirements.
# Task decomposer configuration (YAML)
decomposer:
model: gpt-4o
temperature: 0.2
max_subtasks: 15
min_subtasks: 3
max_depth: 3 # recursive decomposition depth limit
complexity_threshold: 500 # tokens; subtasks above this get re-decomposed
available_agents:
- type: researcher
capabilities: [web_search, document_reading, data_extraction]
cost_per_call_usd: 0.05
- type: coder
capabilities: [code_generation, debugging, code_review]
cost_per_call_usd: 0.08
- type: analyst
capabilities: [data_analysis, visualization, statistical_testing]
cost_per_call_usd: 0.06
- type: writer
capabilities: [content_writing, summarization, editing]
cost_per_call_usd: 0.04
execution:
max_concurrency: 5
subtask_timeout_seconds: 120
max_retries: 2
retry_backoff: exponential
replanning:
enabled: true
trigger_on: [subtask_failure, timeout, unexpected_output]
max_replans: 3
budget:
max_total_cost_usd: 1.00 # ~INR 84
max_subtask_cost_usd: 0.20Common Implementation Mistakes
- ●
Over-decomposition: Splitting tasks into 20+ trivial subtasks that each produce a single sentence. This creates massive coordination overhead and the LLM spends more tokens on planning than executing. Rule of thumb: if a subtask takes fewer than 50 tokens to complete, it's too granular.
- ●
Under-decomposition: Leaving subtasks so broad that they're essentially the original task with a different name. If a subtask description is longer than 2-3 sentences, it probably needs further decomposition.
- ●
Ignoring parallelism: Creating a purely sequential chain when many subtasks are independent. This is the most common mistake -- teams default to a linear pipeline when a DAG with parallel branches would be 2-5x faster. Always ask: "Does subtask B really need subtask A's output?"
- ●
Missing dependency edges: Assuming subtasks are independent when they share implicit state (e.g., both need to read from the same database, or subtask C references data that subtask A generates). This causes race conditions or incomplete context in downstream subtasks.
- ●
No validation of decomposition output: Trusting the LLM's decomposition blindly without checking for cycles, disconnected components, or subtasks that reference nonexistent agent types. Always validate the DAG structure programmatically before execution.
- ●
Static decomposition for dynamic tasks: Creating the full plan upfront and never revising it, even when subtask results reveal that the plan needs adjustment. Production systems must support dynamic re-planning.
- ●
Inconsistent granularity: Mixing very coarse subtasks ("build the entire frontend") with very fine ones ("add a semicolon to line 42") in the same decomposition. This makes progress tracking and resource allocation unreliable.
When Should You Use This?
Use When
Your task involves multiple distinct steps that require different skills or tools (e.g., research + analysis + writing + review)
You are building a multi-agent system where different agents have specialized capabilities and need coordinated execution
The task has inherent parallelism -- independent subtasks that can execute simultaneously to reduce wall-clock time
Tasks are complex enough that a single LLM call produces shallow or incomplete results, but a structured plan yields better outputs
You need auditability and progress tracking -- decomposition creates a clear execution log showing what happened at each step
Your system must handle partial failures gracefully -- if one subtask fails, the rest can continue or the plan can be adjusted
Tasks arrive with variable complexity and you need adaptive processing (simple tasks bypass decomposition, complex ones get full planning)
Avoid When
The task is simple enough to be handled in a single LLM call -- adding decomposition overhead for a straightforward question is wasteful
Latency is the primary constraint and the task must complete in under 2 seconds -- decomposition adds 1-3 seconds of planning overhead
You have a fixed, well-known workflow that never changes -- use a static pipeline (like an Airflow DAG) instead of dynamic LLM-based decomposition
The cost budget is extremely tight -- each decomposition call costs $0.01-0.03, and for high-volume simple tasks this adds up quickly
Task types are highly repetitive and can be handled by pattern matching or template-based routing rather than LLM planning
You don't have specialized agents -- if every subtask goes to the same general-purpose LLM, decomposition adds coordination cost without capability differentiation
Key Tradeoffs
Planning Time vs. Execution Quality
The fundamental tradeoff is planning overhead vs. execution quality. A decomposition call adds 1-5 seconds and $0.01-0.05 to every task. For tasks that complete in 10+ seconds with multiple agents, this overhead is negligible and the quality improvement is substantial. For sub-second tasks, the overhead dominates.
| Factor | Without Decomposition | With Decomposition |
|---|---|---|
| Latency (simple task) | 2-5s | 5-10s (slower) |
| Latency (complex task) | 30-60s | 15-30s (faster via parallelism) |
| Quality (simple task) | High | Similar (no benefit) |
| Quality (complex task) | Low-Medium | High (significant improvement) |
| Cost per task | $0.02-0.10 | $0.05-0.50 (planning + execution) |
| Failure recovery | No (all-or-nothing) | Yes (subtask-level retry) |
| Auditability | Low | High (step-by-step log) |
Static vs. Dynamic Decomposition
Static decomposition (plan once, execute) is simpler and faster but cannot adapt when subtask results reveal unexpected information. Dynamic decomposition (re-plan during execution) is more robust but adds complexity and cost. Most production systems use a hybrid approach: static decomposition with dynamic re-planning triggered only on failure or anomaly.
Depth vs. Breadth of Decomposition
Recursive decomposition (depth) produces very fine-grained subtasks that are easy to execute but expensive to coordinate. Shallow decomposition (breadth) produces fewer, coarser subtasks that are cheaper to coordinate but may still be complex. The optimal depth depends on your agents' capabilities -- if your agents can handle moderately complex tasks, shallow decomposition (depth 1-2) is usually sufficient.
Alternatives & Comparisons
A planning module uses iterative reasoning (ReAct loop) where the agent plans one step at a time, executes it, observes the result, and plans the next step. Task decomposer, by contrast, generates the full plan upfront before any execution begins. Use a planning module when the task is exploratory and the next step depends heavily on previous results. Use a task decomposer when you can anticipate the full structure of the work and want to maximize parallelism.
An agent router dispatches tasks to appropriate agents based on classification, but it does not decompose the task. It assumes the incoming task is already scoped for a single agent. Use an agent router when tasks arrive pre-decomposed or are naturally atomic. Use a task decomposer when tasks are complex and need to be broken into multiple agent-sized pieces before routing.
An agent supervisor monitors and coordinates agent execution, handling retries, load balancing, and quality checks. It is a runtime component that operates after decomposition. A task decomposer is a planning-time component that generates the execution plan. These two work together: the decomposer creates the plan, the supervisor ensures it executes correctly.
Chain-of-thought prompting embeds implicit decomposition within a single LLM call by asking the model to "think step by step." This is lighter weight but limited: it cannot express parallelism, doesn't produce a formal execution graph, and cannot assign different agents to different steps. Use CoT for simple reasoning tasks. Use a task decomposer when you need structured multi-agent execution.
Pros, Cons & Tradeoffs
Advantages
Enables true parallelism in multi-agent execution -- independent subtasks run simultaneously, reducing wall-clock time by 2-5x for complex tasks compared to sequential processing
Improves output quality for complex tasks by ensuring each subtask is handled by a specialized agent with focused context, rather than overloading a single agent with the entire problem
Provides granular failure recovery -- when one subtask fails, only that subtask needs to be retried or re-planned, not the entire task. This dramatically improves system reliability
Creates a clear audit trail -- the decomposition graph shows exactly what was planned, what executed, and what produced each piece of the final output. Essential for compliance and debugging
Supports cost optimization -- by assigning subtasks to agents of appropriate capability (expensive model for complex reasoning, cheap model for simple formatting), you can reduce overall cost by 30-60%
Enables adaptive complexity handling -- simple tasks bypass decomposition while complex tasks get full planning, allowing the system to be efficient across the difficulty spectrum
Makes multi-agent coordination explicit -- instead of agents discovering coordination needs at runtime (which leads to chaos), the decomposer defines the coordination structure upfront
Disadvantages
Adds planning latency of 1-5 seconds per task, which is unacceptable for real-time applications requiring sub-second responses
Increases total cost due to the additional LLM call for decomposition -- approximately 300-1,500/month (~INR 25,000-1.26 lakh/month) at 10K tasks/day
LLM decomposition is non-deterministic -- the same task may produce different decompositions across runs, making testing and reproducibility challenging. Mitigation: use low temperature (0.1-0.2) and structured output formats
Decomposition quality is bounded by the LLM's understanding of the task domain -- if the model doesn't understand the domain, it will produce poor decompositions. No amount of prompt engineering fully compensates for domain ignorance
Coordination overhead grows with subtask count -- each additional subtask adds context passing, status tracking, and potential failure points. Beyond 15-20 subtasks, the overhead starts to dominate execution time
Recursive decomposition can explode if depth limits are not enforced -- a task that keeps decomposing creates exponentially many subtasks, consuming budget and time without proportional quality improvement
Failure Modes & Debugging
Cyclic dependency generation
Cause
The LLM generates a subtask plan where task A depends on B and B depends on A (or longer cycles). This happens more frequently with complex tasks where relationships are ambiguous, or when the prompt doesn't explicitly instruct the model to avoid cycles.
Symptoms
The DAG executor deadlocks -- subtasks wait indefinitely for dependencies that can never resolve. If cycle detection is not implemented, the system hangs silently. With detection, you get an error but no valid plan.
Mitigation
Always validate the decomposition output with a topological sort before execution. If the sort fails, the graph has cycles. Implement an automated cycle-breaking heuristic (remove the lowest-confidence edge in each cycle) and re-validate. Add explicit instructions to the decomposition prompt: "Ensure no circular dependencies."
Orphaned subtask outputs
Cause
A subtask produces output that no downstream subtask consumes, and this output was actually critical for the final result. The decomposer failed to create the dependency edge connecting the producer to the consumer.
Symptoms
The final aggregated result is missing key information. Individual subtask results look correct in isolation, but the synthesis is incomplete. This is particularly insidious because no errors are raised -- the system appears to work correctly.
Mitigation
Implement a coverage validator that checks whether the union of all subtask outputs covers the requirements of the original task. Use a lightweight LLM call to verify: "Given these subtask outputs, is the original task fully addressed?" Add explicit output-to-input wiring in the decomposition schema.
Granularity mismatch
Cause
The decomposer produces subtasks at wildly inconsistent granularity -- one subtask is "design the entire system architecture" while another is "capitalize the first letter of the title." This happens when the prompt lacks granularity guidelines.
Symptoms
Some agents finish in 100ms while others take 60+ seconds. The critical path is dominated by the coarse subtask, negating any parallelism benefits. Progress bars are meaningless because completion percentage doesn't correlate with actual progress.
Mitigation
Add granularity constraints to the decomposition prompt: "Each subtask should require approximately 100-500 tokens of output." Implement a post-decomposition validation step that estimates subtask complexity (via token count heuristic or LLM assessment) and triggers re-decomposition for outliers.
Context loss across subtask boundaries
Cause
Important context from earlier subtasks is not properly propagated to dependent subtasks. The decomposer specifies the dependency but the executor only passes a summary or ID rather than the full context needed.
Symptoms
Downstream subtasks produce outputs that are technically correct but don't reference or build upon earlier work. The final result feels disjointed -- like it was written by different people who never talked to each other.
Mitigation
Implement explicit context passing where each subtask's full output (not just a reference) is available to dependent subtasks. Use a shared context store that subtasks can read from and write to. Consider a context compression step for very long intermediate outputs to fit within token limits.
Infinite re-planning loop
Cause
A subtask repeatedly fails, triggering re-planning, which produces a plan that also fails in the same way. The re-planner doesn't have enough information to produce a fundamentally different approach, so it keeps generating similar failing plans.
Symptoms
The system burns through budget with repeated decomposition and execution calls, never completing the task. Logs show a repeating pattern of plan-execute-fail-replan cycles.
Mitigation
Enforce a maximum re-plan count (typically 2-3). After the limit, escalate to a human or fall back to a simpler execution strategy (e.g., single-agent mode). Each re-plan should include the failure reason from the previous attempt so the LLM can try a genuinely different approach.
Agent capability mismatch
Cause
The decomposer assigns a subtask to an agent type that doesn't have the required capabilities. For example, assigning a code execution subtask to a researcher agent, or a database query to a writing agent.
Symptoms
Subtasks fail with capability errors, produce irrelevant outputs, or succeed but with poor quality because the agent is operating outside its specialization.
Mitigation
Pass the agent capability registry to the decomposition prompt so the LLM knows exactly what each agent type can do. Implement a post-decomposition validation step that checks each subtask's requirements against the assigned agent's capabilities. Reject plans with mismatches.
Placement in an ML System
Where Does the Task Decomposer Sit?
The task decomposer is the first planning component in a multi-agent pipeline. It sits between the user's intent (parsed by an intent classifier or received as a prompt) and the execution layer (agent router, supervisor, and individual agents).
In a LangGraph-based system, the decomposer is typically the first node in the graph, feeding into a fan-out pattern that dispatches subtasks to parallel agent branches. In CrewAI, it manifests as the planning=True flag that generates a plan before the crew starts working. In AutoGen, it's the initial conversation between the user proxy and the assistant that establishes the work breakdown.
The decomposer directly determines the quality ceiling of the entire multi-agent execution. A bad decomposition -- missing steps, wrong agent assignments, unnecessary sequential dependencies -- produces bad results regardless of how capable the individual agents are. This makes it arguably the most critical component in the entire pipeline.
Key Insight: The task decomposer is to multi-agent systems what the query planner is to databases. Just as a database query planner translates SQL into an optimized execution plan, the task decomposer translates a user goal into an optimized multi-agent execution plan. And just as a bad query plan makes even powerful hardware useless, a bad task decomposition wastes even the most capable agents.
Pipeline Stage
Planning / Orchestration
Upstream
- prompt-template
- planning-module
- intent-classifier
Downstream
- agent-router
- agent-supervisor
- langgraph-node
- tool-executor
Scaling Bottlenecks
The primary bottleneck is LLM latency for the decomposition call. Each decomposition requires a single LLM inference that typically takes 1-5 seconds for GPT-4o and 2-8 seconds for more capable models. At 1,000 concurrent tasks, you need significant LLM throughput.
For recursive decomposition, the bottleneck compounds: a depth-3 decomposition with branching factor 5 could require up to LLM calls just for planning. At 0.62 (~INR 52) per task before any execution begins.
The second bottleneck is context window pressure. Complex tasks with many subtasks require passing the full plan context to the executor, which can consume 2,000-5,000 tokens. With 15 subtasks, each having description, inputs, and outputs, the plan itself may approach 3,000-4,000 tokens.
Scaling strategy: Cache decompositions for similar tasks using semantic similarity matching. If a new task is >0.92 similar to a previously decomposed task, reuse the plan structure with parameter substitution. This can reduce decomposition calls by 40-60% in systems with repetitive task patterns.
Production Case Studies
Devin, the AI software engineer built by Cognition Labs, uses hierarchical task decomposition as its core planning mechanism. When given a software engineering task, Devin enters "Planner" mode, decomposes the task into subtasks (understand requirements, set up environment, write code, run tests, debug failures, commit changes), and executes them sequentially with re-planning on failure. The system demonstrated the power of structured decomposition for complex, multi-step engineering work.
Devin resolved 13.86% of real GitHub issues end-to-end on the SWE-bench benchmark, compared to 1.96% for the previous state of the art -- a 7x improvement largely attributed to its planning and decomposition capabilities. In a Nubank migration case study, Devin delivered 8-12x faster migration with 20x cost reduction.
Swiggy built a multi-agent customer support system using Databricks where complex customer queries (order issues involving multiple items, partial refunds, and redelivery) are decomposed into distinct agent tasks. Each disposition (refund processing, order tracking, restaurant communication) launches a separate agent instance, enabling clear functional separation and modular task handling. The architecture uses task decomposition to convert a single customer complaint into multiple coordinated agent actions.
The multi-agent architecture with task decomposition enabled Swiggy to handle complex multi-intent conversations with better code isolation, self-contained agents, and the flexibility to control each task with a dedicated agent. The system serves enterprise-scale customer support across Food, Instamart, and Dineout verticals.
LangChain's Deep Agents architecture, built on LangGraph, implements explicit task decomposition as a first-class primitive. Unlike reactive loop-based agents, Deep Agents use a built-in planning tool (similar to a todo list) to break tasks into manageable steps, spawn specialized sub-agents for isolated execution, and maintain persistent memory via a virtual file system. This represents the current state of the art in framework-level task decomposition for production agentic systems.
Deep Agents demonstrated that explicit planning and decomposition significantly improve reliability on complex, multi-step tasks compared to reactive agent loops. The architecture supports spawning sub-agents that maintain clean context separation, reducing the hallucination and context confusion problems that plague monolithic agents.
Microsoft Research's AutoGen framework uses multi-agent conversation as its task decomposition mechanism. Rather than a single planning call, AutoGen decomposes tasks through structured dialogue between a user proxy agent and assistant agents. The conversational decomposition approach allows tasks to be refined iteratively, with the assistant proposing a breakdown, the user proxy validating it, and the plan evolving through multiple turns. This has been applied to domains including mathematics, coding, supply-chain optimization, and online decision-making.
AutoGen demonstrated that conversational task decomposition produces more adaptive plans than single-shot decomposition, particularly for tasks where the full scope is not known upfront. The framework has been adopted by thousands of developers and is the basis for AutoGen Studio, a no-code tool for building multi-agent systems.
Tooling & Ecosystem
The leading agent orchestration framework. Supports hierarchical agent teams with explicit task decomposition, conditional routing, parallel fan-out, and stateful execution. The Send API enables dynamic subtask dispatch to parallel branches. Best for building custom decomposition logic with full control over the execution graph.
Multi-agent framework with built-in planning (planning=True) that automatically decomposes tasks before crew execution. Supports role-based agent specialization, explicit task dependencies via context, and both sequential and hierarchical process modes. Best for teams that want decomposition without building custom infrastructure.
Multi-agent conversation framework where task decomposition emerges through structured dialogue between agents. Supports nested conversations, sub-agent spawning, and group chat patterns for collaborative planning. Best for tasks where decomposition needs to be iterative and conversational.
OpenAI's official agent orchestration SDK with built-in handoff patterns, tool governance, and tracing. Supports multi-agent workflows where a coordinator agent decomposes tasks and hands off subtasks to specialized agents. Includes observability tools for debugging decomposition quality.
Google's managed platform for building and deploying AI agents with visual orchestration (Agent Designer). Supports multi-agent collaboration where specialized agents discover each other's capabilities dynamically. Agent Engine handles deployment, scaling, and management in production.
Traditional workflow orchestration tools that execute predefined DAGs. While they don't do LLM-based dynamic decomposition, they are the right choice when your task structure is known in advance and doesn't change between runs. Prefect's dynamic task mapping is a middle ground between static and fully dynamic decomposition.
Research & References
Shen, Song, Tan, Li, Lu, Zhuang (2023)NeurIPS 2023
Introduced a full pipeline where an LLM decomposes user requests into subtasks, selects AI models from Hugging Face for each subtask, orchestrates execution, and aggregates results. One of the first demonstrations of LLM-driven task decomposition for multi-model orchestration.
Yao, Yu, Zhao, Shafran, Griffiths, Cao, Narasimhan (2023)NeurIPS 2023
Generalized chain-of-thought into a tree structure where each thought is a coherent reasoning unit. Enabled deliberate search over decomposition strategies with backtracking. Improved GPT-4's Game of 24 success rate from 4% (CoT) to 74% (ToT).
Besta, Blach, Kubicek, Gerstenberger, Gianinazzi, Gajber, Lehmann, Podstawski, Niewiadomski, Nyczyk, Hoefler (2024)AAAI 2024
Extended Tree of Thoughts to arbitrary graph structures where LLM thoughts can be combined, refined, and looped. Modeled task decomposition as DAG construction with merging and feedback edges. Achieved sorting quality improvements of up to 62% over Tree of Thoughts.
Wang, Xu, Yan, Lam (2023)ACL 2023
Proposed explicitly separating the planning phase ("devise a plan to solve the problem") from the execution phase ("carry out the plan"). This two-phase approach directly inspired modern task decomposers that generate plans before execution.
Zhou, Schärli, Hou, Wei, Scales, Wang, Schuurmans, Cui, Bousquet, Le, Chi (2023)ICLR 2023
Introduced decomposing problems into progressively harder subproblems, solving each with the benefit of previous answers. Demonstrated that easy-to-hard decomposition enables models to solve problems significantly harder than their training examples.
Qian, Ye, Zhang, Lin, Wu, Liu, Zheng, Luo (2024)Neural Networks, 2025
Proposed dynamic task decomposition into DAG structures with per-subtask agent generation -- creating specialized agents on-the-fly for each decomposed subtask. Outperformed static multi-agent systems on diverse benchmarks by approximately 2.5-3 points.
Wu, Bansal, Zhang, Wu, Li, Zhu, Jiang, Zhang, Wang (2023)COLM 2024
Introduced the multi-agent conversation paradigm where task decomposition happens through structured dialogue between customizable, conversable agents. Demonstrated effectiveness across mathematics, coding, decision-making, and entertainment domains.
Deshmukh, Walia, Hegde, Chadha (2024)arXiv preprint
Proposed a comprehensive agentic system that decomposes user queries into DAG-structured tasks with an Orchestrator, Delegator, ToolManager, and GraphExecutor. Introduced novel evaluation metrics for decomposition quality and tool selection accuracy.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a task decomposition system for a multi-agent pipeline that handles 10,000 tasks per day?
- ●
Explain the tradeoff between static (upfront) decomposition and dynamic (iterative) decomposition. When would you choose each?
- ●
How do you handle failures in the middle of a multi-step plan? What happens to subtasks that depend on the failed one?
- ●
What data structure would you use to represent a decomposed task plan, and how would you determine execution order?
- ●
How would you evaluate the quality of a task decomposition -- what metrics would you track?
- ●
Design a task decomposer for an Indian e-commerce platform where customers can ask complex multi-intent questions like 'Track my order, apply for a refund on the damaged item, and reorder the same product with a coupon.'
Key Points to Mention
- ●
Task decomposition produces a DAG, not a list -- this distinction is critical because it enables parallel execution and proper dependency tracking. Mention topological sorting for execution order.
- ●
The critical path determines minimum execution time. Good decomposition minimizes the critical path length while maximizing parallelism on non-critical branches.
- ●
Decomposition quality has three dimensions: completeness (all requirements covered), minimality (no redundant subtasks), and appropriate granularity (each subtask is single-agent-scoped).
- ●
Production systems need dynamic re-planning -- the ability to modify the remaining DAG when a subtask fails, rather than restarting the entire plan.
- ●
The decomposition prompt must include the agent capability registry so the LLM can produce actionable plans with valid agent assignments.
- ●
Cost-aware decomposition is essential for production: assign expensive models (GPT-4o) to complex reasoning subtasks and cheap models (GPT-4o-mini) to simple formatting subtasks.
Pitfalls to Avoid
- ●
Describing decomposition as just "breaking a task into steps" without discussing dependency structure, parallelism, or the DAG representation. Interviewers want to see graph thinking.
- ●
Ignoring the cost of decomposition itself -- every planning call costs money and time. A senior engineer should discuss when decomposition is worth the overhead and when it isn't.
- ●
Assuming the LLM's decomposition is always correct -- always mention validation (cycle detection, completeness checking, agent capability matching) as a required step.
- ●
Forgetting about failure recovery -- a real system must handle subtask failures gracefully, not just the happy path.
- ●
Over-engineering the decomposition for simple tasks. A senior engineer knows when to say "this task doesn't need decomposition, just route it directly to an agent."
Senior-Level Expectation
A senior/staff-level candidate should discuss the full lifecycle: complexity estimation to decide whether decomposition is needed, decomposition strategy selection (flat vs. recursive, static vs. dynamic), DAG construction with cycle validation and critical path analysis, agent assignment based on capability matching and cost optimization, execution orchestration with parallel dispatch and dependency-gated synchronization, progress monitoring with timeout and failure detection, dynamic re-planning strategies, and evaluation of decomposition quality over time. They should also address practical concerns like decomposition caching for repeated task patterns (common in customer support at scale), cost budgeting (especially relevant for Indian startups with tight margins), and the tradeoff between decomposition depth and coordination overhead. Bonus points for discussing how to test decomposition quality -- building evaluation datasets of tasks with known-good decompositions and measuring structural similarity.
Summary
Wrapping Up
The task decomposer is the planning brain of any multi-agent system. It takes complex, high-level goals and transforms them into structured execution plans -- directed acyclic graphs of subtasks with explicit dependencies, agent assignments, and execution metadata.
The key concepts to remember:
-
Decomposition produces a DAG, not a list. This enables parallel execution of independent subtasks, proper dependency tracking, and critical path optimization. The parallelism factor -- ratio of total work to wall-clock time -- is the primary efficiency metric.
-
Granularity is the central design decision. Each subtask should be scoped for a single agent call: complex enough to produce meaningful output, simple enough to complete reliably. The heuristic is 100-500 tokens of output per subtask.
-
Production systems require dynamic re-planning. When subtasks fail, the decomposer must be able to modify the remaining DAG without restarting from scratch. This means maintaining execution state, detecting failures, and generating alternative plans with context from the failure.
-
Not every task needs decomposition. Simple, single-step tasks should bypass the decomposer entirely. A complexity classifier at the entry point routes tasks adaptively -- only complex tasks get the full planning treatment.
The tooling ecosystem is mature: LangGraph for custom decomposition logic, CrewAI for built-in planning, AutoGen for conversational decomposition, and managed platforms like Vertex AI Agent Builder for enterprise deployments. The choice depends on your control requirements, team expertise, and scale.
The task decomposer is to multi-agent systems what the project manager is to software teams. The agents do the work, but the decomposer ensures they're doing the right work, in the right order, with the right information. Without it, you have a collection of capable agents with no coordination. With it, you have a system that can tackle problems none of them could solve alone.