Cache Layer in Machine Learning
A cache layer is an in-memory data store that sits between your ML serving infrastructure and its backing data sources -- feature stores, databases, model servers -- to deliver pre-computed features and predictions at sub-millisecond latency. In machine learning systems, caching is not a nice-to-have optimization; it is the difference between a 200ms recommendation response and a 5ms one.
Why does this matter so much for ML specifically? Because ML inference requests are expensive. A single prediction might require fetching 50-200 features from a feature store, each feature potentially involving a database read. At 10,000 QPS, that is 500K to 2M database reads per second -- a recipe for infrastructure meltdown and ballooning cloud bills. A well-designed cache layer intercepts the vast majority of those reads and serves them from RAM.
From DoorDash caching feature store lookups to Netflix pre-computing personalized recommendations into EVCache, every production ML system at scale relies on a caching layer. In the Indian context, think of Swiggy caching restaurant-level features for real-time delivery time estimation, or Razorpay caching fraud detection features to keep payment latency under 100ms. The cache layer is the unsung hero that makes real-time ML economically viable.
Concept Snapshot
- What It Is
- An in-memory data store that accelerates ML feature retrieval and prediction serving by keeping frequently accessed data close to the compute layer, reducing latency and backend load.
- Category
- Storage
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: feature vectors, prediction results, model outputs, computed aggregations. Outputs: cached values on hit; cache miss triggers a fallback read from the backing store.
- System Placement
- Sits between the model serving layer (or application layer) and the persistent feature store, database, or model inference endpoint.
- Also Known As
- caching layer, in-memory cache, hot storage, feature cache, prediction cache, look-aside cache, read-through cache
- Typical Users
- ML Engineers, Backend Engineers, Platform Engineers, SRE / DevOps Engineers, Data Engineers
- Prerequisites
- Key-value stores, Feature stores, Model serving fundamentals, Distributed systems basics, TTL and eviction policies
- Key Terms
- cache hit rateTTLeviction policyLRULFUwrite-throughwrite-backcache stampedecache invalidationdistributed cacheconsistent hashing
Why This Concept Exists
The Latency Tax of Real-Time ML
Every ML prediction request triggers a cascade of data lookups. A fraud detection model at Razorpay might need the user's transaction history (last 30 days), merchant risk score, device fingerprint features, and geographic velocity signals -- all before it can produce a single fraud probability. Without caching, each of those features requires a round-trip to a database or feature store. At P99, that is 5-20ms per feature lookup, and with 50 features, you are looking at 250ms to 1 second just for feature assembly. Add inference time on top, and your payment flow grinds to a halt.
A cache layer collapses that feature retrieval time to 0.1-1ms for cached features. That is a 100-1000x improvement. And since most features change infrequently -- a user's historical transaction patterns do not shift every second -- cache hit rates of 90-99% are achievable in practice.
The Cost Imperative
Beyond latency, there is a raw cost argument. Database reads are expensive. A Redis cluster serving 100K QPS costs roughly $500-800/month (~INR 42,000-67,000/month) on AWS. The equivalent database capacity to handle those reads directly -- with replication and IOPS provisioning -- would cost 5-10x more. DoorDash reported that their feature store was one of their largest infrastructure cost centers, and caching was the primary lever they used to bring costs under control.
Two Decades of Evolution
Caching is not new -- Memcached launched in 2003, Redis in 2009. But the application of caching to ML workloads has evolved significantly:
Phase 1 (2010-2016): Simple key-value caching of model predictions. If the same user requests recommendations twice, serve the cached result.
Phase 2 (2017-2021): Feature-level caching emerged alongside feature stores. Systems like Feast + Redis allowed caching individual features, enabling cache sharing across multiple models that consume the same features.
Phase 3 (2022-present): Multi-layered caching architectures -- request-local caches, in-process caches (Caffeine, Guava), distributed caches (Redis, Memcached), and CDN-level caches -- each tier optimized for different access patterns and staleness tolerances.
Key Insight: Caching in ML systems is not just about speed -- it is about making real-time ML economically viable. Without caching, most companies simply cannot afford the infrastructure to serve ML predictions at scale.
Core Intuition & Mental Model
The Library Analogy
Imagine a library where every time someone asks a question, the librarian walks to the warehouse three blocks away to retrieve the answer. That is your feature store without a cache. Now imagine the librarian keeps a small desk with the 100 most commonly requested books. For 95% of questions, the answer is right there on the desk -- no warehouse trip needed. That desk is your cache layer.
The brilliance of this approach is that ML workloads have extreme locality. In a recommendation system, a small fraction of users and items account for the majority of traffic. The top 1% of Swiggy restaurants might serve 30% of all orders. The top 10% of Flipkart products account for 60% of views. Caching exploits this power-law distribution ruthlessly.
What a Cache Layer Does NOT Do
A cache layer does not replace your database or feature store. It is a performance accelerator, not a source of truth. The moment you start treating the cache as authoritative, you have introduced a consistency nightmare. The cache can go down, entries can be evicted, and stale data can be served -- all by design. Your system must handle cache misses gracefully, always falling back to the backing store.
Another critical distinction: a cache layer does not make bad data faster. If your feature engineering pipeline produces incorrect features, caching them will serve incorrect features at blazing speed. Garbage in, garbage out -- just at sub-millisecond latency.
The Two Fundamental Tradeoffs
Every caching decision reduces to two tensions:
- Freshness vs. Speed: Longer TTLs mean higher hit rates but staler data. Shorter TTLs mean fresher data but more cache misses and higher backend load.
- Memory vs. Coverage: Caching everything maximizes hit rates but costs a fortune in RAM. Caching selectively saves money but requires careful analysis of access patterns.
The art of cache layer design is finding the sweet spot on both axes for your specific workload.
Technical Foundations
Formal Model
A cache layer implements a function that maps keys to values from a backing store with the following properties:
Cache hit: If , return in time.
Cache miss: If , fetch , optionally store , and return .
Hit Rate
The cache hit rate over requests is:
For most ML serving workloads, a hit rate is acceptable, is good, and is excellent. Uber reports hit rates above 99.9% for their CacheFront system.
Effective Latency
The effective average latency of a cached system is:
where is cache access latency (~0.1-1ms) and is backing store latency (~5-50ms). At , , :
That is a 13.5x improvement over the uncached 20ms.
TTL and Staleness
Each cached entry has an expiration time . The maximum staleness of any served value is bounded by the TTL:
XFetch: Probabilistic Early Recomputation
The XFetch algorithm (Vattani et al., 2015) prevents cache stampedes by having each request probabilistically decide to recompute before expiry. The probability of recomputing at time is:
where is a tuning parameter (typically the inverse of the recomputation time ). As approaches , the probability increases, and exactly one request is likely to trigger recomputation before expiry.
Consistent Hashing
For distributed caches with nodes, consistent hashing maps keys to nodes using a hash ring. When a node is added or removed, only keys need to be remapped, compared to for naive modular hashing. This is critical for cache cluster resizing without causing mass cache invalidation.
Internal Architecture
A production cache layer for ML systems typically comprises multiple tiers, each optimized for different access patterns and consistency requirements. The architecture follows a layered approach where requests pass through increasingly expensive storage tiers until a hit is found.
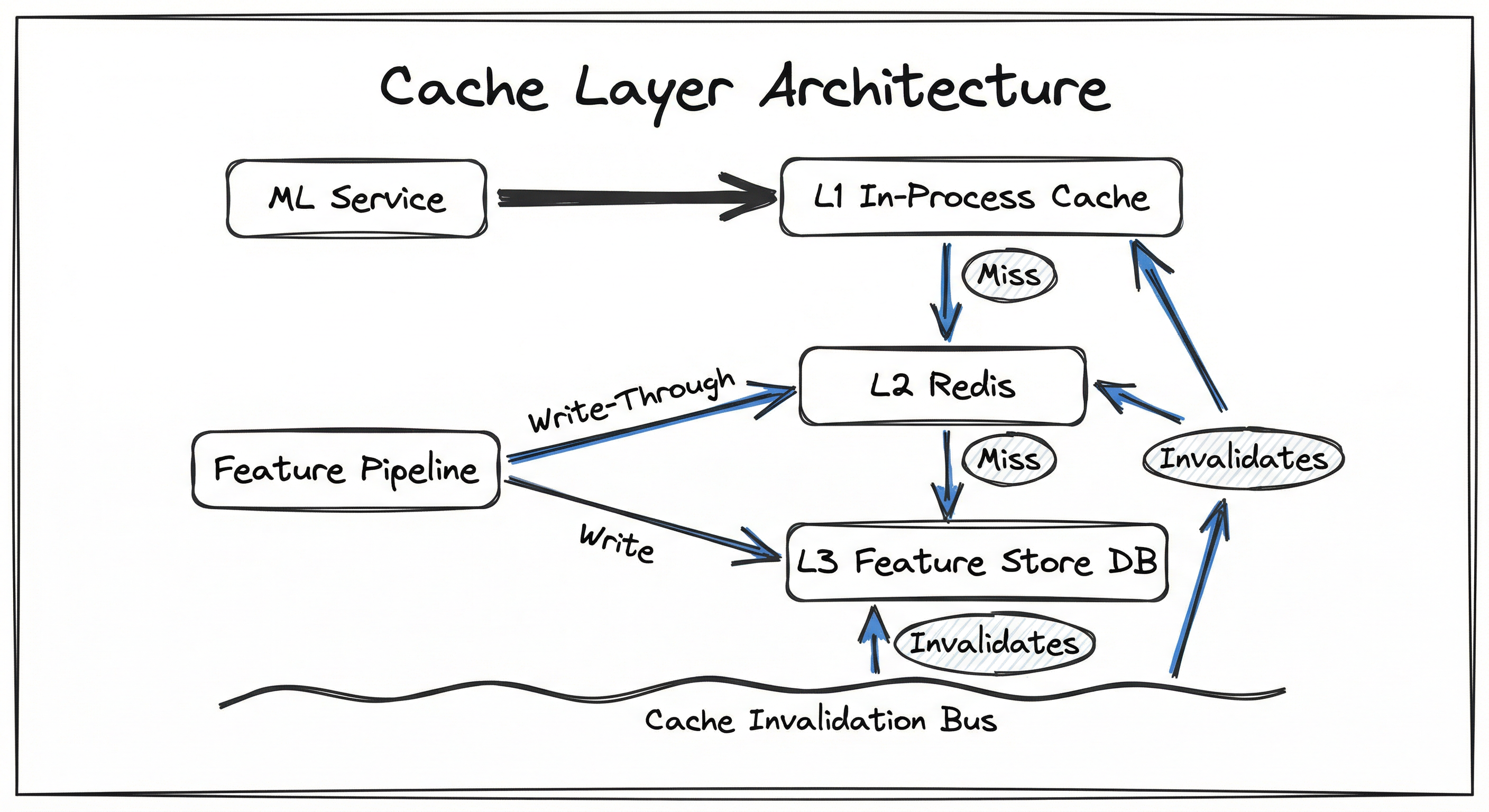
The L1 in-process cache (Caffeine, Guava, or a simple HashMap) lives within the ML service's JVM or Python process. It has zero network overhead and serves the hottest keys at nanosecond latency. However, it is local to each process instance and cannot be shared across pods.
The L2 distributed cache (Redis, Memcached, or Dragonfly) is a network-accessible shared cache. All ML service instances read from and write to this tier. It provides millisecond latency with cluster-wide visibility -- when one pod populates a cache entry, all pods benefit.
The L3 backing store (feature store like Feast, a database like DynamoDB or Cassandra) is the source of truth. It is consulted only on L2 misses. Writes flow through a feature pipeline that updates both the backing store and the cache.
Key Components
L1 In-Process Cache
A JVM heap or Python dict-based cache local to each service instance. Stores the hottest keys with TTLs of seconds to minutes. Zero network latency. Implementations include Caffeine (Java), cachetools (Python), or Guava (Java). DoorDash uses Caffeine as their L1 cache in their feature store client.
L2 Distributed Cache (Redis / Memcached)
A network-accessible, shared in-memory store. Handles the bulk of cache traffic. Supports rich data structures (Redis), TTL-based expiration, and cluster mode for horizontal scaling. This is the primary cache tier in most ML systems.
Cache Client / SDK
A client library embedded in the ML service that implements the caching protocol: check L1, then L2, then L3 on miss. Handles serialization, consistent hashing, circuit breaking on cache failures, and metrics emission (hits, misses, latency).
Cache Invalidation Bus
A messaging system (Kafka, Redis Pub/Sub, or CDC streams) that propagates invalidation events when source data changes. Ensures cached entries are evicted or refreshed when the underlying features are updated by the feature pipeline.
Cache Warmup Service
A batch or streaming process that pre-populates the cache with frequently accessed features before traffic arrives. Critical for cold-start scenarios (new deployment, cache flush) and for preventing a thundering herd on the backing store. Netflix pre-warms petabytes of EVCache data before live events.
Monitoring & Alerting
Prometheus/Grafana dashboards tracking cache hit rate, miss rate, eviction rate, memory utilization, P50/P99 latency, and hot key detection. Alerts trigger when hit rate drops below threshold (e.g., <90%) or memory pressure exceeds safe limits.
Data Flow
- ML service receives an inference request and needs features for a given entity (e.g., user_id=12345).
- L1 check: The cache client checks the in-process cache. If hit, return immediately (~100ns).
- L2 check: On L1 miss, the client queries Redis/Memcached. If hit, populate L1 and return (~0.5-2ms).
- L3 fallback: On L2 miss, the client reads from the feature store or database. The result is written back to L2 (and L1), then returned (~5-50ms).
Two strategies are common:
Write-through: The feature pipeline writes to both the backing store and the cache synchronously. Guarantees cache freshness but adds write latency.
Write-behind (write-back): The pipeline writes to the cache first and asynchronously flushes to the backing store. Lower write latency but risks data loss if the cache node fails before flush.
Write-around: The pipeline writes only to the backing store. The cache is populated lazily on the next read. Avoids cache pollution from infrequently accessed features but causes a miss on the first read after an update.
When a feature value changes, a CDC event or explicit invalidation message is published to the invalidation bus. All cache tiers subscribing to that key's topic evict or refresh the entry.
A three-tier architecture: L1 in-process cache inside the ML service, L2 distributed Redis cache, and L3 feature store/database as the backing store. Arrows show read path (left to right through tiers on miss), write path (feature pipeline writing through to L2 and L3), and invalidation path (invalidation bus pushing evictions to both L1 and L2).
How to Implement
Choosing Your Cache Technology
The two dominant choices are Redis and Memcached, with Dragonfly emerging as a modern contender. Redis offers rich data structures (hashes, sorted sets, streams), persistence options, Lua scripting, and pub/sub -- making it the default choice for most ML caching workloads. Memcached is simpler, multi-threaded by default, and slightly more memory-efficient for pure key-value workloads. Netflix's EVCache is built on Memcached and handles 400M ops/second across 22,000 nodes.
Dragonfly is a newer entrant that claims 25x throughput over single-process Redis while maintaining API compatibility. It uses a multi-threaded, shared-nothing architecture that is well-suited for modern multi-core servers.
For ML feature caching specifically, Redis is the most common choice because features are often stored as hash maps (one hash per entity, one field per feature), and Redis hashes provide field-level access without deserializing the entire feature vector.
Implementation Patterns
There are three primary patterns for integrating caching into ML serving:
-
Feature-level caching: Cache individual features keyed by entity ID + feature name. Allows selective TTLs per feature (e.g., 5 minutes for real-time features, 1 hour for batch features). This is what DoorDash and most feature store integrations use.
-
Prediction-level caching: Cache the final model output keyed by a hash of the input features. Effective when the same inputs recur frequently (e.g., same user viewing the same product page). Mercari documents this as their "Prediction Cache Pattern."
-
Embedding caching: Cache computed embeddings keyed by entity ID. Avoids re-running the embedding model for repeated entities. Common in recommendation systems and RAG pipelines.
Cost Note: A Redis cluster with 3 nodes (r6g.xlarge on AWS) costs approximately 370/month (~INR 31,000/month) with 26 GB is often sufficient.
import redis
import json
import hashlib
from typing import Dict, Optional, List
class MLFeatureCache:
"""Multi-tier feature cache for ML serving."""
def __init__(self, redis_url: str = "redis://localhost:6379",
default_ttl: int = 300):
self.redis = redis.Redis.from_url(redis_url, decode_responses=True)
self.local_cache: Dict[str, dict] = {} # L1 in-process cache
self.default_ttl = default_ttl # seconds
def _cache_key(self, entity_type: str, entity_id: str) -> str:
return f"features:{entity_type}:{entity_id}"
def get_features(self, entity_type: str, entity_id: str,
feature_names: List[str]) -> Dict[str, Optional[str]]:
"""Retrieve features with L1 -> L2 -> miss fallback."""
key = self._cache_key(entity_type, entity_id)
# L1: Check in-process cache
if key in self.local_cache:
cached = self.local_cache[key]
result = {f: cached.get(f) for f in feature_names}
if all(v is not None for v in result.values()):
return result
# L2: Check Redis
pipe = self.redis.pipeline()
pipe.hmget(key, *feature_names)
pipe.ttl(key)
values, ttl = pipe.execute()
result = dict(zip(feature_names, values))
if all(v is not None for v in result.values()):
# Populate L1 cache
self.local_cache[key] = result
return result
# L3: Cache miss -- caller must fetch from feature store
return {f: v for f, v in result.items()} # partial results
def set_features(self, entity_type: str, entity_id: str,
features: Dict[str, str],
ttl: Optional[int] = None) -> None:
"""Write features to L1 + L2 (write-through)."""
key = self._cache_key(entity_type, entity_id)
ttl = ttl or self.default_ttl
pipe = self.redis.pipeline()
pipe.hset(key, mapping=features)
pipe.expire(key, ttl)
pipe.execute()
# Populate L1
self.local_cache[key] = features
def invalidate(self, entity_type: str, entity_id: str) -> None:
"""Invalidate both cache tiers."""
key = self._cache_key(entity_type, entity_id)
self.redis.delete(key)
self.local_cache.pop(key, None)
# Usage
cache = MLFeatureCache(redis_url="redis://cache.internal:6379", default_ttl=600)
# Write features after feature pipeline computes them
cache.set_features("user", "u_12345", {
"avg_order_value": "542.30",
"order_count_30d": "12",
"preferred_cuisine": "north_indian",
"fraud_risk_score": "0.03"
}, ttl=300)
# Read features during inference
features = cache.get_features("user", "u_12345", [
"avg_order_value", "order_count_30d", "fraud_risk_score"
])This example implements a two-tier caching client with an L1 in-process dictionary and an L2 Redis hash. Features are stored as Redis hashes keyed by entity type and ID, allowing retrieval of individual features via HMGET. The set_features method implements write-through by updating both tiers. The get_features method checks L1 first, falls back to L2, and returns partial results on a miss so the caller knows which features to fetch from the backing store.
import redis
import json
import hashlib
import time
import math
import random
from typing import Optional, Callable, Any
class PredictionCache:
"""Cache ML predictions with XFetch stampede prevention."""
def __init__(self, redis_url: str = "redis://localhost:6379"):
self.redis = redis.Redis.from_url(redis_url, decode_responses=True)
def _prediction_key(self, model_name: str, input_hash: str) -> str:
return f"pred:{model_name}:{input_hash}"
def _hash_input(self, model_input: dict) -> str:
"""Deterministic hash of model input for cache key."""
serialized = json.dumps(model_input, sort_keys=True)
return hashlib.sha256(serialized.encode()).hexdigest()[:16]
def get_or_predict(
self,
model_name: str,
model_input: dict,
predict_fn: Callable[[dict], Any],
ttl: int = 60,
beta: float = 1.0
) -> Any:
"""
Return cached prediction or compute and cache.
Uses XFetch algorithm for stampede prevention.
beta: controls early recomputation aggressiveness.
beta=1.0 is standard; higher values recompute earlier.
"""
input_hash = self._hash_input(model_input)
key = self._prediction_key(model_name, input_hash)
# Check cache
cached = self.redis.hgetall(key)
if cached:
value = json.loads(cached["value"])
expiry = float(cached["expiry"])
delta = float(cached["delta"]) # recomputation time
now = time.time()
# XFetch: probabilistic early recomputation
# P(recompute) = exp(-lambda * (expiry - now))
# where lambda = beta / delta
gap = expiry - now
if gap > 0:
xfetch_threshold = delta * beta * math.log(random.random())
if gap + xfetch_threshold > 0:
return value # Serve cached, no recompute
# Either expired or XFetch triggered early recompute
# Compute prediction
start = time.time()
prediction = predict_fn(model_input)
delta = time.time() - start
# Store with metadata for XFetch
pipe = self.redis.pipeline()
pipe.hset(key, mapping={
"value": json.dumps(prediction),
"expiry": str(time.time() + ttl),
"delta": str(delta)
})
pipe.expire(key, ttl + 60) # Redis TTL slightly longer
pipe.execute()
return prediction
# Usage
cache = PredictionCache("redis://cache.internal:6379")
def fraud_model_predict(features: dict) -> dict:
"""Simulate model inference (replace with actual model call)."""
# In production: model.predict(features)
return {"fraud_probability": 0.03, "risk_level": "low"}
result = cache.get_or_predict(
model_name="fraud_detector_v2",
model_input={"user_id": "u_12345", "amount": 1500, "merchant": "m_789"},
predict_fn=fraud_model_predict,
ttl=30, # 30 second TTL for fraud predictions
beta=1.0
)This implements the XFetch algorithm (Vattani et al., 2015) for probabilistic cache stampede prevention. Instead of all requests discovering an expired entry simultaneously and hammering the model server, XFetch causes one request to proactively recompute the prediction before it expires. The beta parameter controls how aggressively early recomputation happens -- higher values mean earlier recomputation, reducing the chance of a stampede but slightly increasing compute cost. The prediction, its expiry time, and its computation duration (delta) are all stored together so that the XFetch probability can be computed on each read.
import redis
from redis.sentinel import Sentinel
from redis.exceptions import ConnectionError, TimeoutError
import time
from functools import wraps
from typing import Optional
class CircuitBreaker:
"""Simple circuit breaker for cache resilience."""
CLOSED = "closed" # Normal operation
OPEN = "open" # Cache disabled, bypass to backing store
HALF_OPEN = "half_open" # Testing if cache recovered
def __init__(self, failure_threshold: int = 5,
recovery_timeout: int = 30):
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.failures = 0
self.state = self.CLOSED
self.last_failure_time = 0
def record_success(self):
self.failures = 0
self.state = self.CLOSED
def record_failure(self):
self.failures += 1
self.last_failure_time = time.time()
if self.failures >= self.failure_threshold:
self.state = self.OPEN
def can_execute(self) -> bool:
if self.state == self.CLOSED:
return True
if self.state == self.OPEN:
if time.time() - self.last_failure_time > self.recovery_timeout:
self.state = self.HALF_OPEN
return True
return False
return True # HALF_OPEN: allow one request through
class ResilientMLCache:
"""Production-grade cache with Sentinel failover and circuit breaker."""
def __init__(self, sentinel_hosts: list, service_name: str = "mymaster"):
self.sentinel = Sentinel(
sentinel_hosts,
socket_timeout=0.5,
socket_connect_timeout=0.5
)
self.service_name = service_name
self.breaker = CircuitBreaker(failure_threshold=5, recovery_timeout=30)
def _get_master(self):
return self.sentinel.master_for(
self.service_name, socket_timeout=0.5
)
def get(self, key: str) -> Optional[str]:
if not self.breaker.can_execute():
return None # Circuit open: skip cache, go to backing store
try:
master = self._get_master()
value = master.get(key)
self.breaker.record_success()
return value
except (ConnectionError, TimeoutError) as e:
self.breaker.record_failure()
return None # Graceful degradation: treat as cache miss
def set(self, key: str, value: str, ttl: int = 300) -> bool:
if not self.breaker.can_execute():
return False
try:
master = self._get_master()
master.setex(key, ttl, value)
self.breaker.record_success()
return True
except (ConnectionError, TimeoutError) as e:
self.breaker.record_failure()
return False
# Usage with Redis Sentinel for HA
cache = ResilientMLCache(
sentinel_hosts=[
("sentinel-1.internal", 26379),
("sentinel-2.internal", 26379),
("sentinel-3.internal", 26379),
],
service_name="ml-feature-cache"
)This production-grade example combines Redis Sentinel for automatic failover with a circuit breaker pattern. When the cache experiences consecutive failures (network partition, node crash), the circuit breaker opens and all cache operations gracefully degrade to returning None -- effectively bypassing the cache and falling through to the backing store. After a recovery timeout, the breaker enters a half-open state and tests one request. This prevents a failing cache from adding latency to every request. Redis Sentinel provides automatic master election and failover, ensuring high availability without manual intervention.
# Redis Cluster configuration for ML feature caching
# redis.conf (production settings)
maxmemory 26gb
maxmemory-policy allkeys-lfu
# LFU tuning for ML workloads
lfu-log-factor 10
lfu-decay-time 1
# Persistence (RDB snapshots for warm restart)
save 900 1
save 300 10
# Network
timeout 0
tcp-keepalive 300
tcp-backlog 511
# Slow log for debugging
slowlog-log-slower-than 10000
slowlog-max-len 128
# Cluster mode
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 15000
---
# Application-level cache config (YAML)
cache:
l1:
type: caffeine
max_size: 10000
ttl_seconds: 30
l2:
type: redis-cluster
nodes:
- redis-1.internal:6379
- redis-2.internal:6379
- redis-3.internal:6379
default_ttl_seconds: 300
connection_pool_size: 50
socket_timeout_ms: 500
circuit_breaker:
failure_threshold: 5
recovery_timeout_seconds: 30
feature_ttls:
batch_features: 3600 # 1 hour for batch-computed features
streaming_features: 60 # 1 min for real-time streaming features
static_features: 86400 # 24 hours for rarely changing features
prediction_cache: 30 # 30 seconds for cached predictions
warmup:
enabled: true
entity_types: ["top_users", "top_merchants"]
warmup_on_deploy: trueCommon Implementation Mistakes
- ●
Treating the cache as source of truth: The cache is a performance layer, not a data store. If the cache goes down, your system must still function by falling through to the backing store. Any system that breaks on cache failure has a critical architecture flaw.
- ●
Uniform TTL across all features: Different features have different staleness tolerances. A user's lifetime order count can be cached for hours, but a real-time fraud risk score should have a TTL of seconds. Use per-feature TTL policies, not a blanket value.
- ●
Ignoring cache stampede (thundering herd): When a hot key expires, hundreds of concurrent requests discover the miss simultaneously and all hit the backing store. Use probabilistic early recomputation (XFetch), distributed locks, or request coalescing to prevent this.
- ●
No circuit breaker on cache failures: If the Redis cluster goes down and you retry every cache operation with a timeout, you add latency to every request instead of saving it. Implement a circuit breaker that bypasses the cache during outages.
- ●
Caching large serialized objects instead of granular features: Storing a 50KB JSON blob per user forces deserialization of the entire object even when you need a single feature. Use Redis hashes with one field per feature for granular access.
- ●
Not monitoring cache hit rate in production: A cache with 60% hit rate is worse than no cache at all (you pay the overhead of cache checks on every request with marginal benefit). Monitor hit rates and alert when they drop below 85-90%.
- ●
Forgetting to invalidate on model version changes: If you cache predictions keyed by input features and deploy a new model version, stale predictions from the old model will be served until TTL expires. Include the model version in the cache key.
When Should You Use This?
Use When
Your ML serving latency is dominated by feature retrieval (>50% of total request time) -- caching can eliminate most of that cost
Your feature access patterns exhibit high locality: a small fraction of entities account for the majority of requests (power-law distribution)
The same prediction inputs recur frequently (e.g., same user viewing the same product page within minutes)
Your feature store or database is a cost bottleneck and you need to reduce read IOPS by 5-10x
You are serving real-time ML predictions at >1,000 QPS where every millisecond of latency matters (ad ranking, fraud detection, recommendations)
Your features have known staleness tolerances -- batch features that update hourly can tolerate a 10-minute cache without quality degradation
You need to survive backend failures gracefully: a cache layer provides a buffer that can serve stale data while the feature store recovers
Avoid When
Your features change on every request (e.g., real-time sensor data that is unique per timestamp) -- cache hit rate will be near zero, and you are paying overhead for nothing
Your data requires strict consistency guarantees (e.g., account balance in a banking system) where even seconds of staleness could cause incorrect decisions
Your traffic is uniformly distributed across entities with no hot keys -- caching provides diminishing returns when there is no locality to exploit
Your total dataset fits in the ML service's memory and can be loaded directly -- an in-process lookup is always faster than a Redis round-trip
You have fewer than 100 QPS and your backing store can easily handle the load -- the operational complexity of a cache layer is not justified
Your model inputs are highly unique (e.g., free-text queries in a search system) where the probability of an exact cache hit is negligible
Key Tradeoffs
Freshness vs. Performance
The fundamental tradeoff in caching is between data freshness and cache hit rate. Longer TTLs yield higher hit rates and lower backend load, but stale features can degrade model accuracy. For ML systems, this tradeoff is nuanced because different features have different staleness sensitivity:
| Feature Type | Example | Staleness Tolerance | Recommended TTL |
|---|---|---|---|
| Static attributes | User age, merchant category | Hours to days | 4-24 hours |
| Batch aggregates | 30-day order count | Minutes to hours | 10-60 minutes |
| Streaming features | Orders in last 5 min | Seconds | 10-60 seconds |
| Predictions | Fraud score for a transaction | Seconds | 15-60 seconds |
Memory Cost vs. Coverage
Redis memory is expensive relative to disk storage. A rough comparison:
| Storage Tier | Cost per GB/month (AWS) | Latency |
|---|---|---|
| Redis (r6g.xlarge) | ~$14/GB (~INR 1,170/GB) | 0.1-1ms |
| DynamoDB (on-demand) | ~$0.25/GB (~INR 21/GB) | 5-10ms |
| S3 | ~$0.023/GB (~INR 1.9/GB) | 50-200ms |
You want to cache the working set -- the subset of features actively needed for serving -- not the entire feature store. If your feature store has 100M entities but only 5M are active daily, cache those 5M. That might be 5M * 1KB = 5GB, costing ~$70/month (~INR 5,850/month) in Redis.
Operational Complexity
Adding a cache layer introduces another failure point, consistency challenges, and monitoring requirements. For a small team (2-3 engineers), starting with a managed Redis service (AWS ElastiCache, Azure Cache for Redis, or Redis Cloud) reduces operational burden significantly. Self-hosting Redis on Kubernetes is feasible but requires expertise in cluster management, backup strategies, and failover testing.
Alternatives & Comparisons
A response cache sits at the API gateway or CDN layer and caches entire HTTP responses (including ML predictions). It is simpler to implement but coarser-grained -- you cannot cache individual features, only complete responses. Use a response cache when the same API endpoint is called with identical parameters repeatedly (e.g., trending recommendations). Use a feature-level cache layer when different models share features or when you need granular TTLs per feature.
A feature store is the source-of-truth for ML features, providing both offline (batch) and online (low-latency) serving. Many feature stores like Feast use Redis internally as their online store. A cache layer sits in front of the feature store to further reduce latency and cost. If you are already using Feast with Redis as the online store, an additional L1 in-process cache is the natural next optimization.
Some model serving frameworks (NVIDIA Triton, TF Serving) offer built-in response caching. This is convenient for prediction caching but typically limited to a single model and single node. A dedicated cache layer provides cross-model cache sharing, distributed caching across nodes, and richer invalidation strategies.
Time-series databases (InfluxDB, TimescaleDB) are optimized for temporal data writes and range queries, not for point lookups. If your ML features are primarily time-series (sensor data, event counts), a time-series DB may serve as both storage and serving layer. But for mixed feature types with high QPS point lookups, a Redis cache layer on top of any backing store is still faster.
Pros, Cons & Tradeoffs
Advantages
Sub-millisecond feature retrieval: Redis serves 100K+ ops/second with P99 latency under 1ms, enabling real-time ML predictions that would be impossible with direct database access. This is the primary reason cache layers exist in ML systems.
Dramatic cost reduction: By absorbing 90-99% of reads, a cache layer can reduce feature store/database costs by 5-10x. DoorDash reported that caching was their primary lever for controlling feature store infrastructure costs.
Backend protection during traffic spikes: During flash sales (Flipkart Big Billion Days) or viral events, the cache absorbs traffic bursts that would overwhelm the backing store. The cache acts as a shock absorber for your database.
Graceful degradation on backend failures: If the feature store goes down temporarily, the cache can serve stale (but usable) features while the backend recovers. This turns a hard outage into a soft degradation.
Cross-model feature sharing: Multiple ML models often consume overlapping features. A centralized cache means feature values computed for one model's request benefit all subsequent models, reducing redundant computation.
Reduced cold-start latency: Pre-warming the cache with popular entity features means the first request for a popular item is served from cache, not from a cold database read. Netflix pre-warms EVCache data before live events to ensure zero cold-start latency.
Disadvantages
Cache invalidation complexity: Phil Karlton famously said there are only two hard things in computer science: cache invalidation and naming things. In ML systems, the problem is compounded because features change at different rates and through different pipelines.
Memory cost at scale: Redis stores everything in RAM, which is 50-100x more expensive per GB than disk storage. A 50GB Redis cluster on AWS costs ~$700/month (~INR 58,500/month). At petabyte scale (Netflix), caching infrastructure becomes a major cost center itself.
Consistency risks with stale features: Serving cached features that are out of date can silently degrade model accuracy. A fraud model using a 10-minute-old risk score might miss a rapidly evolving attack pattern. The staleness is invisible to the model.
Operational overhead: Running a distributed Redis cluster requires monitoring, alerting, backup, failover testing, and capacity planning. A cache outage that is not handled gracefully (via circuit breakers) can cascade into a full system outage.
Cache stampede risk: Hot keys with identical TTLs can cause thundering herd effects that overwhelm the backend on expiration. Requires explicit mitigation (XFetch, locks, jitter) that adds implementation complexity.
Debugging difficulty: Cached data adds a layer of indirection to debugging. When model predictions are wrong, you need to determine whether the issue is in the model, the features, or a stale cache entry. Cache-related bugs are notoriously hard to reproduce.
Failure Modes & Debugging
Cache Stampede (Thundering Herd)
Cause
A popular cache key expires, and hundreds of concurrent requests simultaneously discover the miss and all query the backing store. The backing store is overwhelmed, leading to cascading timeouts and failures.
Symptoms
Sudden spike in backing store QPS coinciding with cache key expiration. Latency spikes across all requests. Potential database connection pool exhaustion. Feature store error rates climb sharply for 5-30 seconds, then recover (until the next hot key expires).
Mitigation
Implement probabilistic early recomputation (XFetch algorithm) so one request refreshes the cache before expiration. Alternatively, use a distributed lock (Redis SET NX EX) so only one request recomputes while others wait or serve stale data. Add TTL jitter (randomize TTL by +/-10%) to prevent synchronized expirations. For extremely hot keys, use background refresh where a dedicated worker continuously refreshes the value before it expires.
Hot Key Overload
Cause
A single cache key (e.g., a viral product, a trending topic, a celebrity user) receives disproportionate traffic that overwhelms the Redis node responsible for that key's hash slot.
Symptoms
One Redis node shows significantly higher CPU and network utilization than peers. Latency for requests touching the hot key degrades while other keys remain fast. In Redis Cluster, the specific hash slot becomes a bottleneck.
Mitigation
Implement local caching (L1) for hot keys so requests are served from process memory without hitting Redis. Use key replication by appending a random suffix (e.g., key:0 through key:9) and reading from a random replica. Some Redis proxies (Twemproxy, Envoy) support automatic hot key detection and local caching.
Silent Stale Data Serving
Cause
Cache entries outlive their useful freshness period due to overly long TTLs or missing invalidation events. The feature pipeline updates the backing store, but the cache is not notified.
Symptoms
Model accuracy degrades gradually but no errors are raised. A/B test metrics drift. Features that should reflect recent user behavior show stale values. This is particularly dangerous for fraud detection and risk scoring where timeliness is critical.
Mitigation
Implement CDC-based invalidation (change data capture) that publishes events when the backing store is updated. Add cache-vs-source comparison monitoring that periodically samples cached values and compares them to the backing store, alerting on staleness. Use per-feature TTLs aligned to the feature's update frequency. DoorDash runs a shadow mode that compares cache results to source-of-truth for validation.
Cache Avalanche (Mass Expiration)
Cause
A large number of cache entries were written at the same time with the same TTL, causing them all to expire simultaneously. This is different from a stampede (single hot key) -- an avalanche involves many keys expiring at once.
Symptoms
Cache hit rate drops precipitously (from 95% to 20%) in a short window. Backing store experiences a massive read spike. The system may recover as entries are re-populated, only to repeat the cycle at the next mass expiration.
Mitigation
Add TTL jitter: instead of TTL = 300s, use TTL = 300 + random(-30, 30). This spreads expirations over a 60-second window instead of a single instant. For bulk cache warmup operations, stagger the writes over a period rather than writing everything at once.
Cache Penetration (Querying Non-Existent Keys)
Cause
Requests for entities that do not exist in the backing store (e.g., a deleted user, an invalid ID) always result in cache misses, bypassing the cache entirely and hitting the database on every request. Malicious actors can exploit this pattern.
Symptoms
High cache miss rate for specific key patterns. Backing store load remains high despite good overall cache hit rates. If exploited by an attacker, this becomes a denial-of-service vector.
Mitigation
Cache negative results (null markers) with a short TTL (e.g., 60 seconds) so repeated lookups for non-existent entities are served from cache. Implement a Bloom filter in front of the cache to reject lookups for keys that definitely do not exist without touching the cache or database.
Cache Node Failure Without Circuit Breaker
Cause
A Redis node or cluster becomes unreachable (network partition, OOM kill, hardware failure), and the application retries every cache operation with a timeout, adding latency to every request instead of failing fast.
Symptoms
All request latencies increase by the cache timeout duration (e.g., 500ms). The system appears degraded even though the backing store is healthy. Error logs fill with Redis connection timeouts.
Mitigation
Implement a circuit breaker that opens after N consecutive failures, bypassing the cache entirely and falling through to the backing store. Use Redis Sentinel or Redis Cluster for automatic failover. Set aggressive connection timeouts (200-500ms) so cache failures are detected quickly.
Placement in an ML System
Where Does the Cache Layer Sit?
In an ML serving pipeline, the cache layer sits at the intersection of feature retrieval and model inference. When an ML service receives a prediction request, it first needs to assemble the input features. The cache layer intercepts this feature retrieval step, serving features from memory instead of querying the feature store or database.
For prediction caching, the cache sits after model inference, storing the output keyed by the input. Subsequent identical requests skip inference entirely. This is particularly effective for recommendation systems where the same user-item pair is scored multiple times during a session.
The cache layer also plays a critical role in feature store architecture. Tools like Feast use Redis as their online serving store, essentially making the cache the primary read path. In this configuration, the offline store (data warehouse) is the source of truth, features are materialized to Redis by a feature pipeline, and the ML service reads exclusively from Redis during inference.
Architectural Principle: The cache layer should be transparent to the model. The model receives features regardless of whether they came from L1, L2, or L3. Cache logic lives in the feature retrieval client, not in the model code. This separation of concerns makes it possible to tune caching independently of model development.
Pipeline Stage
Serving / Feature Retrieval
Upstream
- feature-store
- model-serving
- time-series-db
Downstream
- model-serving
- response-cache
Scaling Bottlenecks
The primary bottleneck is memory. Redis stores all data in RAM, and the working set size determines your cluster size and cost. At 1M entities with 1KB of features each, that is 1GB -- comfortable on a single node. At 100M entities, you need 100GB distributed across multiple nodes.
At very high QPS (>500K ops/second), network bandwidth between the ML service and Redis becomes the bottleneck. Each HMGET command for 10 features might return 1-2KB. At 500K QPS, that is 500MB-1GB/second of network throughput. Solutions include connection pooling, pipelining multiple commands, and using Redis Cluster to distribute load.
Even with a large cluster, a single hot key can bottleneck one node. This is common in ML systems where popular entities (trending products, viral content) have extreme request concentration. L1 in-process caching is the primary mitigation.
A single Redis node (r6g.xlarge, 4 vCPUs, 26 GB) on AWS can handle ~200K-300K ops/second. A 3-node Redis Cluster with replicas can handle ~500K-900K ops/second. Netflix's EVCache (Memcached-based) handles 400M ops/second across 22,000 nodes. Uber's CacheFront serves over 150M reads per second.
Production Case Studies
DoorDash implemented a three-tier cache architecture for their ML feature store: (1) request-local cache (HashMap bound to request lifecycle), (2) in-process cache (Caffeine with JVM-level sharing), and (3) distributed Redis cache. Their feature store supports billions of daily requests for features across customers, merchants, and delivery drivers. By adding client-side caching in front of their Redis-backed feature store, they achieved a significant reduction in direct feature store reads.
70% improvement in feature store performance (measured by read reduction). Significant cost savings on their largest infrastructure cost center. Runtime controls allow per-layer TTL tuning and shadow-mode validation against the source of truth.
Netflix built EVCache, a globally distributed caching system based on Memcached, to power their recommendation and personalization systems. EVCache handles pre-computed recommendations, watch history, session metadata, and personalized artwork. The system is replicated across multiple AWS regions with Kafka-based global replication. For live events, Netflix pre-warms petabytes of cache data to ensure zero cold-start latency when millions of users tune in simultaneously.
400 million operations per second across 22,000 Memcached instances. 14.3 PB of cached data. Cache hit rates routinely exceed 99%. Sub-millisecond read latency for personalized recommendations that load instantly when users open the app.
Uber developed CacheFront, an integrated caching layer that sits in front of their Docstore (document database). CacheFront is used to serve ML features for real-time pricing, ETA estimation, and fraud detection. The system uses Redis with a CDC (change data capture) pipeline for cache invalidation, ensuring that cached features stay fresh as underlying data changes. They evolved from eventually consistent invalidation (TTL + CDC) to stronger consistency guarantees as more latency-sensitive ML workloads adopted the system.
Over 150 million reads per second served from cache. Cache hit rates above 99.9% for most use cases. Enabled real-time ML serving for pricing and ETA that processes millions of ride requests globally.
Razorpay uses Redis for caching fraud detection features and payment routing decisions in their ML pipeline. Their architecture employs randomized TTLs to prevent cache stampedes during high-traffic events like festival sales. Redis also serves as a rate limiter deployed as a sidecar, protecting downstream ML model servers from overload. The cache layer is critical for maintaining sub-100ms payment processing latency while running multiple ML models (fraud detection, risk scoring, dynamic routing) in the critical path.
Payment processing latency maintained under 100ms with ML-based fraud detection and risk scoring in the critical path. Redis caching enables processing of billions of rupees in transactions during peak festival seasons (Diwali, year-end sales) without degradation.
Tooling & Ecosystem
The de facto standard in-memory data store for ML caching. Supports strings, hashes, sorted sets, streams, pub/sub, and Lua scripting. Redis hashes are ideal for feature-level caching (one hash per entity, one field per feature). Cluster mode supports horizontal scaling with consistent hashing. Available as managed services on all major clouds (ElastiCache, Azure Cache, GCP Memorystore).
A modern Redis/Memcached-compatible in-memory store with a multi-threaded, shared-nothing architecture. Claims 25x throughput over single-process Redis and 30% better memory efficiency. Fully compatible with Redis APIs, making it a drop-in replacement. Particularly attractive for ML workloads that need high throughput on a single node without the complexity of Redis Cluster.
Simple, high-performance, distributed memory caching system. Multi-threaded by default, making it efficient on modern multi-core servers. Netflix's EVCache is built on Memcached and handles 400M ops/second. Best for pure key-value workloads where Redis's rich data structures are not needed.
High-performance, near-optimal in-process caching library for Java. Uses the Window TinyLFU eviction policy that achieves near-optimal hit rates. DoorDash uses Caffeine as their L1 in-process cache for feature store lookups. Essential for the local cache tier in multi-layer architectures.
Python library providing LRU, LFU, TTL, and other cache implementations. Useful as an L1 in-process cache for Python-based ML services. Lightweight alternative to Redis for local caching with memoization decorators.
Open-source feature store that uses Redis as its default online serving store. Feast materializes features from the offline store (data warehouse) into Redis, providing sub-millisecond feature retrieval. The Feast + Redis combination is the most common feature serving architecture in production ML systems.
Netflix's distributed caching solution built on Memcached. Provides global replication, zone-aware routing, and automatic failover. Handles 400M ops/second at Netflix scale. Open-sourced but primarily designed for Netflix's AWS infrastructure.
Multi-threaded Redis fork maintained by Snapchat. Offers higher throughput than single-threaded Redis on multi-core machines while maintaining full Redis API compatibility. Supports active replication for high availability.
Research & References
Vattani, Chierichetti & Lowenstein (2015)PVLDB, Vol. 8, No. 8
Introduced the XFetch algorithm for probabilistic early cache recomputation. Proves that an exponential distribution-based approach is optimal for preventing stampedes, and the approach is simple to implement in production systems. The foundational paper for cache stampede prevention.
Nishtala, Fugal, Grimm et al. (2013)USENIX NSDI 2013
Describes Facebook's deployment of Memcached as a distributed key-value store handling billions of requests per second. Introduces lease-based solutions for stale sets and thundering herds, and regional replication strategies. Foundational reference for large-scale caching architecture.
Netflix Engineering (2023)Netflix Tech Blog
Describes EVCache's global architecture including cross-region replication via Kafka, zone-aware routing, and petabyte-scale cache warmup strategies. Documents how Netflix serves 400M ops/second with sub-millisecond latency for personalized recommendations.
Karger, Lehman, Leighton et al. (1997)ACM STOC 1997
The original consistent hashing paper that provides the mathematical foundation for distributed cache key distribution. Ensures that adding or removing cache nodes only redistributes keys, critical for elastic cache clusters.
Huang, Guo, Huang et al. (2013)ACM SOSP 2013
Analyzes cache behavior at Facebook scale, quantifying the relationship between cache size, hit rate, and workload characteristics. Provides empirical evidence for power-law access distributions and their implications for cache sizing in large-scale systems.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a caching layer for a feature store serving 10 ML models at 50K QPS?
- ●
Explain the difference between write-through, write-back, and write-around caching. When would you use each in an ML system?
- ●
What is a cache stampede and how would you prevent it?
- ●
How do you handle cache invalidation when features are updated by a batch pipeline?
- ●
If your Redis cluster goes down, what happens to your ML serving pipeline? How would you design for this failure?
- ●
How would you determine the optimal TTL for different types of ML features?
- ●
Walk me through how you would debug a situation where model predictions are wrong and you suspect stale cached features.
Key Points to Mention
- ●
Multi-tier caching (L1 in-process + L2 distributed + L3 backing store) is the production pattern. DoorDash, Netflix, and Uber all use this approach. Know the tradeoffs of each tier.
- ●
Cache hit rate is the primary metric -- quantify it. Above 95% is good, above 99% is excellent. Below 85% means your caching strategy needs rework. Always back claims with numbers.
- ●
TTLs should be per-feature, not uniform. Batch features tolerate minutes to hours of staleness; streaming features need seconds. Always align TTL with the feature's update frequency and the model's staleness sensitivity.
- ●
Cache stampede prevention is a must-discuss for any high-QPS system. XFetch (probabilistic early recomputation) is the gold standard. Distributed locks are an alternative but add latency.
- ●
Circuit breakers are essential -- a failing cache should degrade gracefully (serve from backing store), not add latency to every request. This is the most commonly missed detail in cache layer designs.
- ●
Cost modeling matters: calculate Redis memory cost per entity, multiply by working set size, compare to the backing store cost you are eliminating. Show that caching is economically justified.
Pitfalls to Avoid
- ●
Saying 'just add Redis' without discussing invalidation strategy, TTL design, failure handling, and monitoring. Caching is a system design problem, not a single technology choice.
- ●
Ignoring cache consistency altogether. While perfect consistency is not required, you need to articulate your staleness bounds and explain why they are acceptable for your ML workload.
- ●
Forgetting to discuss what happens on cache failure. If your entire system breaks when Redis goes down, you have a single point of failure, not a cache layer.
- ●
Proposing a single TTL for all features. This signals a lack of understanding of ML feature characteristics. Different features have wildly different update frequencies and staleness tolerances.
- ●
Not considering hot keys. In ML systems, popular entities (top users, trending products) can create extreme key-level load imbalance that breaks naive caching strategies.
Senior-Level Expectation
A senior/staff-level candidate should be able to design a complete multi-tier caching architecture with specific technology choices for each tier, per-feature TTL policies with justification based on feature update frequencies, cache invalidation via CDC or event-driven pipelines, hot key mitigation strategies, and detailed failure handling (circuit breakers, graceful degradation, cache warmup after outages). They should estimate cache sizing and cost (in INR or USD), discuss consistency tradeoffs specific to the ML use case (e.g., 'a 5-minute stale fraud score is unacceptable, but a 30-minute stale user preference vector is fine'), and reference real-world patterns from companies like DoorDash, Netflix, or Uber. The ability to reason about the second-order effects of caching -- how a cache shapes traffic patterns, how cache-dependent systems behave during outages, how TTL choices affect model accuracy -- is what separates senior architects from mid-level engineers.
Summary
Recap
A cache layer is the performance backbone of production ML serving systems. It provides sub-millisecond access to ML features and predictions by keeping frequently accessed data in memory (Redis, Memcached, or Dragonfly), eliminating the latency and cost of repeated database reads. The multi-tier architecture -- L1 in-process cache, L2 distributed cache, L3 backing store -- is the industry standard, used by DoorDash, Netflix, Uber, and virtually every company running ML at scale.
The key design decisions are TTL strategy (per-feature TTLs aligned to update frequency and staleness tolerance), invalidation mechanism (CDC-based, event-driven, or TTL-only), stampede prevention (XFetch probabilistic early recomputation or distributed locking), and failure handling (circuit breakers for graceful degradation when the cache is unavailable). Getting these right means the difference between a cache that saves 90% of your infrastructure cost and one that introduces subtle bugs from stale data.
The cache layer is not glamorous -- it does not have the intellectual appeal of a novel model architecture or the visibility of a user-facing feature. But it is the component that makes real-time ML economically viable. Without it, serving ML predictions at scale would require 5-10x more database infrastructure, pushing latencies into unacceptable ranges and costs into unsustainable territory. As Phil Karlton warned, cache invalidation is hard. But getting it right is what separates production ML systems from research prototypes.