Planning Module in Machine Learning
Here is the central truth about autonomous AI agents: they are only as effective as their ability to plan. A planning module is the cognitive core of an agentic system -- the component responsible for taking a high-level goal, decomposing it into a structured sequence of executable subtasks, and orchestrating their execution in the right order.
Without planning, an LLM agent is just a chatbot that can call tools. With planning, it becomes something closer to a junior engineer: it can reason about dependencies, estimate what information it needs, decide which tools to use, and adapt when things go wrong. That distinction is everything.
Planning modules sit at the intersection of classical AI planning (think STRIPS, PDDL, hierarchical task networks) and modern LLM-based reasoning (chain-of-thought, Tree of Thought, ReAct). The field has evolved rapidly since 2023, driven by the realization that raw LLM intelligence is not enough -- you need structured decomposition to handle complex, multi-step tasks reliably.
From Google's Gemini Deep Research breaking down research queries into browsable sub-investigations, to Swiggy's AI assistant planning multi-step food orders across restaurants, planning modules are becoming the backbone of every serious agentic deployment. If you are building agents in production, this is the component you will spend the most time getting right.
Concept Snapshot
- What It Is
- A component within an agentic AI system that takes a high-level goal and produces a structured, ordered plan of subtasks that can be executed by downstream tool executors or sub-agents.
- Category
- Agentic Systems
- Complexity
- Advanced
- Inputs / Outputs
- Inputs: user goal/query, available tools/capabilities, current state, optional memory/context. Outputs: ordered list of subtasks with dependencies, resource assignments, and success criteria.
- System Placement
- Sits between the agent orchestrator (upstream) and the tool executor or ReAct loop (downstream) in an agentic pipeline.
- Also Known As
- task planner, task decomposer, agent planner, goal decomposition module, plan generator
- Typical Users
- ML Engineers, AI Agent Developers, Backend Engineers, Product Engineers building AI features
- Prerequisites
- Large Language Models (prompting, chain-of-thought), Agent architectures (ReAct, tool use), Basic graph theory (DAGs, topological sort), Prompt engineering
- Key Terms
- task decompositionhierarchical planningTree of Thoughtchain-of-thoughtplan-and-solvePDDLreplanninggoal-directed planningplan verificationDAG
Why This Concept Exists
The Fundamental Problem: LLMs Cannot Reliably Execute Multi-Step Tasks in One Shot
If you ask GPT-4o to "research food delivery competition in India, compare unit economics across Swiggy, Zomato, and Zepto, and produce a strategic recommendation" -- as a single prompt -- you get a mediocre, surface-level response. The model hallucinates numbers, skips sub-analyses, and produces something that looks comprehensive but isn't.
Why? Complex tasks have implicit dependencies that a single forward pass cannot resolve. You need to identify competitors, gather financial data for each, normalize metrics, compare, then synthesize. Each step depends on the previous one. A planning module makes these dependencies explicit.
The Classical AI Roots
Planning is not a new problem. STRIPS (1971) formalized planning as search over state spaces defined by preconditions and effects. PDDL became the standard formalism. Hierarchical Task Networks (HTNs) introduced decomposing abstract tasks into concrete sub-tasks -- exactly what modern LLM planners do, with neural networks instead of symbolic reasoners.
The irony: classical planners are provably optimal for well-defined domains but useless for open-ended tasks. You cannot write a PDDL domain for "plan a weekend trip to Goa."
The LLM Revolution in Planning
Starting in 2022-2023, researchers found that LLMs could generate coherent task decompositions when prompted correctly. Chain-of-thought prompting (Wei et al., 2022) showed that "think step by step" dramatically improved multi-step reasoning. Plan-and-Solve (Wang et al., 2023) formalized this: first generate a plan, then execute each step.
The real breakthrough was recognizing that plans must be dynamic. Static plans fail because the world changes -- APIs error out, searches yield nothing, sub-tasks are harder than expected. Modern planning modules incorporate replanning: observe results, detect failures, revise on the fly. This separates toy demos from production agents.
Key Insight: A planning module creates a living document that adapts as the agent learns. The best plans are hypotheses, not prescriptions.
Core Intuition & Mental Model
The Restaurant Kitchen Analogy
Think of a planning module like the head chef in a busy restaurant kitchen. A customer order comes in: "Paneer Butter Masala with garlic naan and gulab jamun." The head chef does not personally cook everything. Instead, they:
- Decompose the order into parallel workstreams (curry station, bread station, dessert station)
- Sequence the tasks correctly (start the gulab jamun first because it needs to chill, fire the naan last so it arrives hot)
- Assign each subtask to the right specialist
- Monitor progress and replan if something goes wrong (the paneer is out? Switch to dal makhani and inform the customer)
A planning module does exactly the same thing for an AI agent. It receives a complex goal, breaks it into subtasks, determines the right ordering and parallelization, assigns subtasks to appropriate tools or sub-agents, and adapts when execution does not go as expected.
Why Single-Step Reasoning Fails
Here is the core intuition for why planning matters: the complexity of a task grows exponentially with the number of steps, but the reliability of each step is less than 100%. If each step has a 90% success rate and your task requires 10 sequential steps, your overall success rate is . That is why you need a planner that can detect failures at each step and course-correct.
Planning modules address this by making the agent's reasoning explicit and inspectable. Instead of hoping the LLM gets everything right in one shot, you get a structured plan where each step can be validated, retried, or replaced independently. This is the same principle that makes software engineering work -- you do not write a 10,000-line function, you decompose it into testable modules.
The Spectrum of Planning Approaches
Planning approaches exist on a spectrum from fully upfront to fully reactive:
- Upfront planning: Generate the entire plan before executing anything. Simple, but brittle -- if step 3 fails, the entire plan may be invalid.
- Interleaved planning: Plan a few steps, execute them, observe results, plan the next steps. More robust, but slower due to repeated LLM calls.
- Reactive planning: No explicit plan -- just decide the next action based on current state (this is what basic ReAct does). Fast, but lacks global coherence.
The sweet spot for most production systems is interleaved planning with replanning on failure -- plan 3-5 steps ahead, execute them, and revise the plan based on what you learn. This balances cost, latency, and reliability.
Technical Foundations
Formal Framework for Task Planning
Let's formalize what a planning module does. I'll build up from simple to complete.
Goal Specification: A planning problem begins with a goal expressed in natural language, a set of available tools , and an initial state representing the agent's current knowledge.
Plan Definition: A plan is a directed acyclic graph (DAG) where each node represents a subtask and each edge represents a dependency (subtask must complete before can begin).
Each subtask is a tuple:
Plan Quality: A good plan minimizes total execution time while maximizing the probability of achieving the goal. We can express this as:
where is the minimum acceptable success probability.
Task Decomposition Formally
Task decomposition is a recursive function that maps a complex task to a set of simpler subtasks:
The decomposition is valid if and only if:
- Completeness: Completing all subtasks achieves the original goal:
- Feasibility: Each subtask is executable by at least one available tool:
- Consistency: No subtask contradicts another: when depends on
Replanning as State-Conditioned Regeneration
When a subtask fails with error , the replanner generates a revised plan conditioned on the current state:
This is fundamentally different from retrying the same plan -- the replanner has access to everything the agent has learned so far and can adjust the strategy accordingly.
Complexity Considerations
Classical planning in PDDL is PSPACE-complete in the general case. LLM-based planning sidesteps formal complexity by using the model's world knowledge as a heuristic, but this comes at the cost of no completeness or optimality guarantees. This is an important tradeoff to understand: LLM planners are fast and flexible but can miss valid plans or produce suboptimal ones.
Practical Note: In production, we care less about theoretical optimality and more about good-enough plans that can be executed and revised quickly. A plan that is 80% optimal but executable in 2 seconds beats a provably optimal plan that takes 30 seconds to compute.
Internal Architecture
A production planning module consists of five interconnected subsystems: a goal parser that interprets the user's intent, a decomposition engine that breaks goals into subtasks, a dependency resolver that determines execution order, a plan validator that checks feasibility before execution, and a replanning engine that revises plans when subtasks fail.
The architecture follows a plan-observe-replan loop: generate an initial plan, execute subtasks one at a time (or in parallel where dependencies allow), observe the results, and revise the remaining plan if needed. This loop continues until the goal is achieved or the agent determines the goal is unachievable.
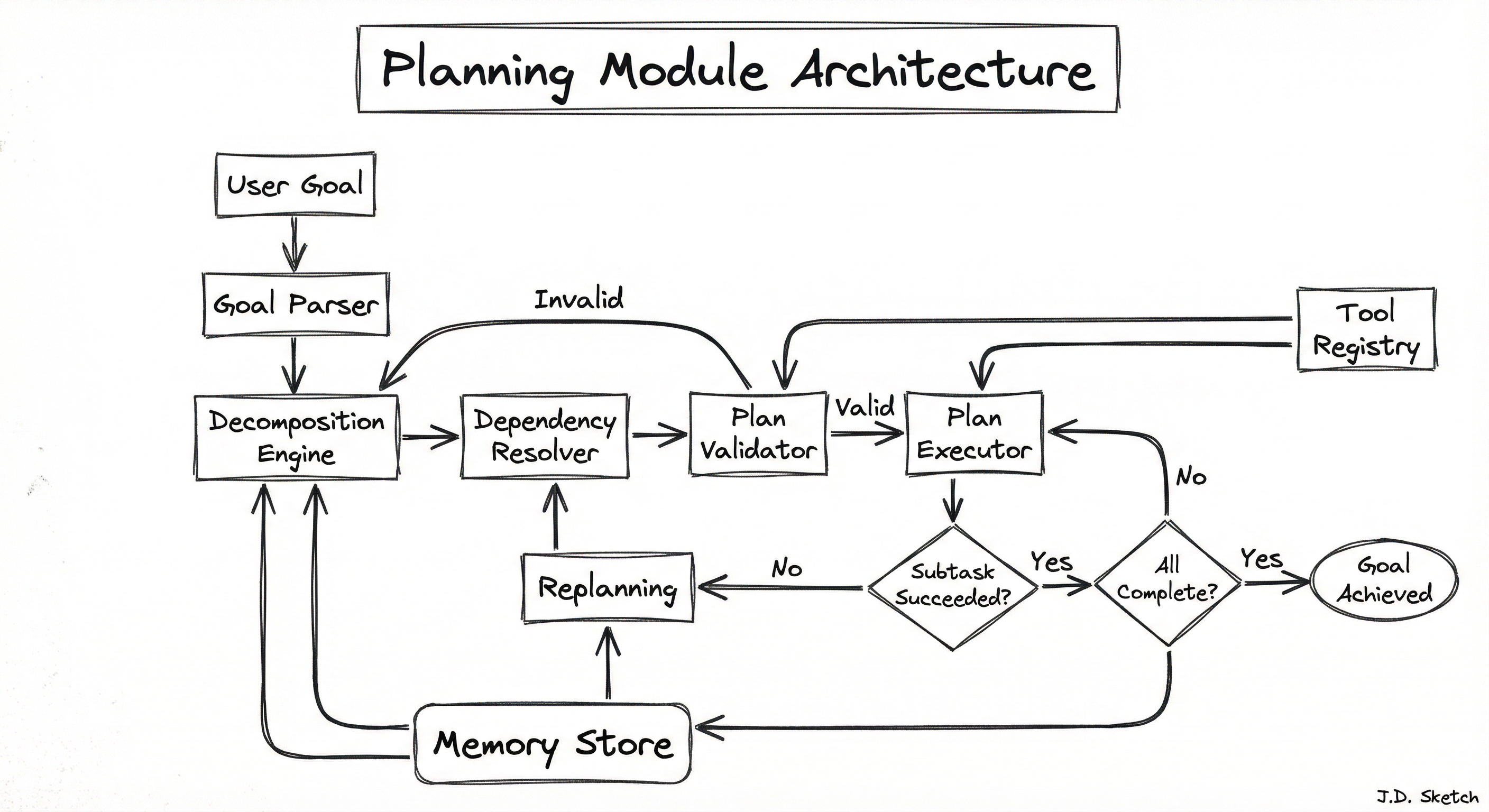
Key Components
Goal Parser
Interprets the user's natural language goal and extracts structured intent: the desired outcome, any constraints, preferences, and implicit requirements. For example, parsing "Book a flight from Delhi to Bangalore for under INR 5,000 next Friday" into a structured goal with destination, budget constraint, and date requirement.
Decomposition Engine
The core LLM-powered component that breaks a high-level goal into a sequence of subtasks. Supports multiple strategies: linear decomposition (step-by-step), hierarchical decomposition (nested sub-goals), and adaptive decomposition (decompose only as needed). Uses chain-of-thought or Tree of Thought prompting internally.
Dependency Resolver
Constructs a DAG (Directed Acyclic Graph) from the subtask list by analyzing which subtasks depend on outputs from others. Identifies parallelizable subtasks and determines the critical path. Uses topological sorting to produce a valid execution order.
Plan Validator
Checks the generated plan for feasibility before execution: are all required tools available? Are subtask inputs satisfiable from upstream outputs? Are there circular dependencies? Does the plan address all aspects of the original goal? Can optionally use a separate LLM call for semantic validation.
Replanning Engine
Activated when a subtask fails or produces unexpected results. Receives the current execution state, completed subtask results, and the error signal. Generates a revised plan that accounts for what has been learned, potentially taking an entirely different approach to achieve the goal.
Plan Memory Interface
Connects to the agent's memory store to retrieve relevant past plans, successful strategies for similar goals, and learned heuristics. This allows the planner to improve over time -- if a particular decomposition strategy worked well for similar tasks before, reuse it.
Data Flow
Planning Phase: The user goal enters the Goal Parser, which produces a structured intent. The Decomposition Engine receives this intent along with the tool registry (available capabilities) and any relevant context from the Memory Store. It generates a list of subtasks via LLM prompting. The Dependency Resolver analyzes these subtasks and constructs an execution DAG. The Plan Validator checks feasibility and either approves the plan or sends it back for revision.
Execution Phase: The Plan Executor dispatches subtasks to the Tool Executor in dependency order, running independent subtasks in parallel where possible. After each subtask completes, the result is evaluated against the success criteria.
Replanning Phase: If a subtask fails, the Replanning Engine receives the full execution context -- what succeeded, what failed, and why. It generates a revised plan from the current state, which goes through the Dependency Resolver and Validator again before execution resumes.
Key Design Decision: The decomposition and replanning engines are separate because they solve different problems. Decomposition works from a blank slate; replanning works from a partially completed state with new information. Combining them into a single component leads to confused prompts and worse plans.
A flowchart showing the user goal flowing through Goal Parser, Decomposition Engine, Dependency Resolver, and Plan Validator before reaching the Plan Executor. A feedback loop from the Executor goes through a success check -- if the subtask fails, it routes to the Replanning Engine which feeds back into the Dependency Resolver. The Memory Store connects bidirectionally to both the Decomposition Engine and Replanning Engine. The Tool Registry feeds into both the Validator and Executor.
How to Implement
Implementation Approaches
There are three primary approaches to implementing a planning module, each with distinct tradeoffs:
Approach 1: Prompt-Based Planning -- Use a single LLM call with a carefully crafted system prompt that instructs the model to output a structured plan (JSON or numbered list). This is the simplest approach and works well for tasks with 3-7 subtasks. Cost: one LLM call for planning (~$0.01-0.05 per plan with GPT-4o, roughly INR 0.85-4.20).
Approach 2: Multi-Turn Planning with Validation -- Use multiple LLM calls: one for initial decomposition, one for dependency analysis, one for validation. More robust but 3x the cost and latency. Recommended for complex tasks with 8+ subtasks or when plan quality is critical.
Approach 3: Hybrid Classical + LLM Planning -- Use the LLM to translate the natural language goal into a formal representation (like PDDL), then use a classical planner for optimal plan generation, and translate back. This is the LLM+P approach (Liu et al., 2023). Best for well-structured domains like logistics, scheduling, or workflow automation.
For most production systems in India -- whether you are building an AI agent for Razorpay's merchant onboarding or Flipkart's customer service -- Approach 2 hits the sweet spot. The extra cost of validation LLM calls (roughly INR 3-5 per plan) is negligible compared to the cost of executing a bad plan that wastes downstream API calls and user time.
Cost Breakdown: A typical agentic task with planning costs 3-5 LLM calls for the planner (plan generation + validation + potential replan) plus 5-15 LLM calls for execution. At GPT-4o pricing (15/M output tokens), a complex 10-step task costs approximately 0.01-0.03 (INR 0.85-2.50).
from typing import List
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
class SubTask(BaseModel):
id: int = Field(description="Unique subtask identifier")
description: str = Field(description="What this subtask accomplishes")
tool: str = Field(description="Which tool to use")
depends_on: List[int] = Field(default_factory=list)
success_criteria: str = Field(description="How to verify success")
class Plan(BaseModel):
goal: str
subtasks: List[SubTask]
reasoning: str = Field(description="Why this decomposition was chosen")
PLANNER_PROMPT = ChatPromptTemplate.from_messages([
("system", """You are a task planning specialist. Decompose the goal into subtasks.
Available tools: {tools}
Rules: each subtask uses one tool, specify dependencies, minimize steps,
independent subtasks should NOT depend on each other (enables parallelism)."""),
("human", "Goal: {goal}\nContext: {context}")
])
llm = ChatOpenAI(model="gpt-4o", temperature=0)
planner = PLANNER_PROMPT | llm.with_structured_output(Plan)
def generate_plan(goal: str, tools: List[str], context: str = "") -> Plan:
plan = planner.invoke({"goal": goal, "tools": ", ".join(tools), "context": context})
_validate_dag(plan)
return plan
def _validate_dag(plan: Plan) -> None:
"""Ensure no circular dependencies via DFS."""
visited, in_stack = set(), set()
adj = {st.id: st.depends_on for st in plan.subtasks}
def dfs(node):
if node in in_stack: raise ValueError(f"Cycle at subtask {node}")
if node in visited: return
in_stack.add(node)
for dep in adj.get(node, []): dfs(dep)
in_stack.discard(node); visited.add(node)
for st in plan.subtasks: dfs(st.id)
def _topological_sort(plan: Plan) -> List[int]:
in_degree = {st.id: len(st.depends_on) for st in plan.subtasks}
queue = [sid for sid, deg in in_degree.items() if deg == 0]
order = []
while queue:
node = queue.pop(0); order.append(node)
for st in plan.subtasks:
if node in st.depends_on:
in_degree[st.id] -= 1
if in_degree[st.id] == 0: queue.append(st.id)
return order
def execute_with_replanning(plan: Plan, max_replans: int = 3) -> dict:
results, replan_count = {}, 0
for subtask_id in _topological_sort(plan):
subtask = next(s for s in plan.subtasks if s.id == subtask_id)
dep_results = {d: results[d] for d in subtask.depends_on}
try:
results[subtask.id] = execute_subtask(subtask, dep_results)
except Exception as e:
if replan_count >= max_replans:
raise RuntimeError(f"Max replans exceeded: {e}")
replan_count += 1
ctx = f"Done: {results}. Failed: {subtask.description}. Error: {e}"
new_plan = generate_plan(plan.goal, ["search", "calculator"], ctx)
return execute_with_replanning(new_plan, max_replans - 1)
return results
def execute_subtask(subtask: SubTask, dep_results: dict) -> str:
print(f"Executing [{subtask.id}]: {subtask.description} via {subtask.tool}")
return f"Result of subtask {subtask.id}" # Replace with real tool dispatch
# Usage
plan = generate_plan(
goal="Compare Reliance vs TCS stock performance over 6 months",
tools=["search", "calculator", "code_executor", "chart_generator"],
context="Indian retail investor, large-cap focus"
)
results = execute_with_replanning(plan)This implementation demonstrates the complete plan-and-execute pattern. The Plan and SubTask Pydantic models enforce structure on the LLM's output via structured output (function calling). The _validate_dag function catches circular dependencies before execution. The execute_plan_with_replanning function runs subtasks in topological order and recursively replans when a subtask fails, passing the full execution context to the planner so it can make informed revisions. The topological sort ensures correct dependency ordering while allowing identification of parallelizable subtasks (those with in-degree 0 at the same time).
import asyncio
from typing import List, Tuple
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
class PlanCandidate(BaseModel):
strategy: str = Field(description="High-level strategy name")
steps: List[str] = Field(description="Ordered list of steps")
reasoning: str
risk_factors: List[str]
class PlanEvaluation(BaseModel):
feasibility_score: float = Field(description="0-1")
completeness_score: float = Field(description="0-1")
efficiency_score: float = Field(description="0-1")
critique: str
llm = ChatOpenAI(model="gpt-4o", temperature=0.7) # Diversity
evaluator_llm = ChatOpenAI(model="gpt-4o", temperature=0) # Consistency
async def tree_of_thought_plan(goal: str, tools: List[str], n_candidates: int = 3):
# Phase 1: Generate diverse strategies
gen_prompt = ChatPromptTemplate.from_messages([
("system", f"Generate {n_candidates} DIFFERENT strategies. Tools: {', '.join(tools)}"),
("human", "Goal: {goal}")
])
Candidates = type("C", (BaseModel,), {
"__annotations__": {"candidates": List[PlanCandidate]}
})
resp = await (gen_prompt | llm.with_structured_output(Candidates)).ainvoke({"goal": goal})
# Phase 2: Evaluate in parallel
eval_prompt = ChatPromptTemplate.from_messages([
("system", "Critically assess this plan. Score 0-1 per dimension."),
("human", "Goal: {goal}\nStrategy: {strategy}\nSteps: {steps}")
])
evaluator = eval_prompt | evaluator_llm.with_structured_output(PlanEvaluation)
evals = await asyncio.gather(*[
evaluator.ainvoke({"goal": goal, "strategy": c.strategy,
"steps": '\n'.join(f'{i+1}. {s}' for i,s in enumerate(c.steps))})
for c in resp.candidates
])
# Phase 3: Weighted selection
scored = [
(c, 0.4*e.feasibility_score + 0.35*e.completeness_score + 0.25*e.efficiency_score)
for c, e in zip(resp.candidates, evals)
]
best, score = max(scored, key=lambda x: x[1])
print(f"Selected: {best.strategy} (score: {score:.2f})")
return best
# Usage
best = asyncio.run(tree_of_thought_plan(
goal="Build churn prediction pipeline for 10M-user Indian telecom",
tools=["data_query", "feature_engineer", "model_trainer", "evaluator", "deployer"]
))This implements the Tree of Thought planning pattern: generate multiple candidate plans (the 'branches'), evaluate each independently (the 'pruning'), and select the best one. The key insight is using a higher temperature (0.7) for generation to produce diverse strategies, but a low temperature (0) for evaluation to get consistent scoring. The evaluation runs in parallel via asyncio.gather, keeping latency manageable. The composite score weights feasibility highest (0.4) because an elegant but infeasible plan is worthless. This pattern costs ~4 LLM calls (1 generation + 3 evaluations) but produces significantly more robust plans for complex tasks.
from typing import List, Optional, Dict, Any
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
class TaskAttempt(BaseModel):
success: bool
result: Optional[str] = None
error: Optional[str] = None
class DecomposedTask(BaseModel):
subtasks: List[str] = Field(description="2-4 simpler subtasks")
reasoning: str
llm = ChatOpenAI(model="gpt-4o", temperature=0)
def adapt_execute(task: str, context: Dict[str, Any] = None,
max_depth: int = 3, depth: int = 0) -> str:
"""ADaPT: only decompose when direct execution fails."""
context = context or {}
indent = " " * depth
print(f"{indent}[Depth {depth}] Attempting: {task[:80]}...")
# Step 1: Try direct execution
attempt = _try_execute(task, context)
if attempt.success:
return attempt.result
# Step 2: Max depth? Return partial
if depth >= max_depth:
return f"PARTIAL: {attempt.error}"
# Step 3: Decompose and recurse
decomposer = ChatPromptTemplate.from_messages([
("system", "Break this failed task into 2-4 simpler subtasks.\nError: {error}"),
("human", "Task: {task}")
]) | llm.with_structured_output(DecomposedTask)
decomposition = decomposer.invoke({"task": task, "error": attempt.error})
subtask_results = {}
for i, subtask in enumerate(decomposition.subtasks):
result = adapt_execute(subtask, {**context, **subtask_results},
max_depth, depth + 1)
subtask_results[f"subtask_{i+1}"] = result
return _synthesize(task, subtask_results)
def _try_execute(task: str, context: Dict) -> TaskAttempt:
resp = (ChatPromptTemplate.from_messages([
("system", "Complete this task. If too complex, respond CANNOT_COMPLETE."),
("human", "Task: {task}\nContext: {context}")
]) | llm).invoke({"task": task, "context": str(context)})
if "CANNOT_COMPLETE" in resp.content:
return TaskAttempt(success=False, error=resp.content)
return TaskAttempt(success=True, result=resp.content)
def _synthesize(task: str, results: Dict[str, str]) -> str:
resp = (ChatPromptTemplate.from_messages([
("system", "Synthesize subtask results for the original task."),
("human", f"Task: {task}\nResults: {results}")
]) | llm).invoke({})
return resp.content
# Usage
result = adapt_execute(
task="Analyze feasibility of same-day delivery for D2C brand in Jaipur, Lucknow, Kochi",
max_depth=3
)This implements the ADaPT (As-Needed Decomposition and Planning) pattern from Prasad et al. (2024). The key principle is: only decompose when you have to. The agent first tries to execute the task directly. If it fails (because the task is too complex), it decomposes into 2-4 simpler subtasks and recursively attempts each one. This is more efficient than always decomposing upfront because simple tasks get executed in one shot, while complex tasks are progressively broken down to the right granularity. The max_depth parameter prevents infinite recursion -- in practice, 2-3 levels of decomposition handle most tasks.
# Planning module configuration (YAML)
planning:
model: gpt-4o
temperature: 0.0 # Deterministic planning
max_subtasks: 12
max_replan_attempts: 3
decomposition:
strategy: adaptive # options: upfront, interleaved, adaptive
max_depth: 3
min_subtask_granularity: "single_tool_call"
validation:
enabled: true
check_circular_deps: true
check_tool_availability: true
semantic_validation: true # Extra LLM call to validate plan coherence
replanning:
enabled: true
trigger: on_failure # options: on_failure, on_low_confidence, always
carry_forward_results: true
max_strategy_changes: 2
tree_of_thought:
enabled: false # Enable for critical tasks
n_candidates: 3
evaluation_weights:
feasibility: 0.4
completeness: 0.35
efficiency: 0.25
cost_controls:
max_planning_tokens: 4000
max_total_tokens: 50000
prefer_mini_model_for_simple_tasks: trueCommon Implementation Mistakes
- ●
Over-decomposition: Breaking tasks into too many tiny subtasks (15+ steps) when 5-7 would suffice. Each subtask adds an LLM call for execution, increasing cost and latency linearly. A 20-step plan for a simple research query costs 20x more than it should. Rule of thumb: if a subtask takes one tool call, it is at the right granularity.
- ●
Missing dependency specification: Generating a flat list of steps without specifying which depend on which. This prevents parallelization and makes replanning nearly impossible because the planner cannot determine which downstream steps are affected by a failure.
- ●
Stateless replanning: Replanning without passing the results of already-completed subtasks. The replanner re-generates the entire plan from scratch, causing the agent to repeat work it has already done. Always pass the full execution state to the replanner.
- ●
Single-strategy planning: Generating only one plan and committing to it. For critical tasks, generating 2-3 candidate plans and evaluating them (Tree of Thought style) produces significantly more robust outcomes at the cost of 2-3 extra LLM calls.
- ●
Ignoring tool capabilities in plan generation: The planner generates subtasks that no available tool can execute. Always include the tool registry in the planning prompt so the LLM knows what is achievable.
- ●
No plan validation before execution: Executing a generated plan without checking for circular dependencies, missing tools, or infeasible steps. A 30-second validation step can save minutes of wasted execution.
- ●
Hardcoding decomposition depth: Using a fixed number of decomposition levels regardless of task complexity. Simple tasks get over-decomposed; complex tasks get under-decomposed. Use adaptive decomposition (ADaPT) instead.
When Should You Use This?
Use When
Your agent needs to handle tasks that require 3+ sequential steps with dependencies between them
Tasks are open-ended or user-specified (not hardcoded workflows) -- the agent must figure out what to do, not just how
Execution failures are common and the agent needs to adapt its approach (API errors, missing data, tool limitations)
You need to optimize for parallelism -- some subtasks can run concurrently and you want to exploit that
The task domain is broad enough that a single ReAct loop would wander without a high-level plan
You need audit trails and explainability -- a structured plan can be shown to users for approval before execution
Your agent operates in a human-in-the-loop setting where users want to review and modify the plan before it executes
Avoid When
The task is simple enough for a single tool call or a basic ReAct loop (1-2 steps). Adding planning overhead to a simple lookup is wasteful.
You have a fixed, predefined workflow that never changes. Use a state machine or DAG orchestrator instead -- planning adds unnecessary LLM cost and non-determinism.
Latency is extremely critical (sub-second response required). Planning adds 1-3 seconds of LLM inference time before any execution begins.
Your budget is extremely tight and every LLM call counts. Planning typically adds 2-4 LLM calls on top of execution calls.
The task domain is narrow and well-defined enough that rule-based decomposition (if-else logic) works reliably. Do not use an LLM when a dictionary lookup suffices.
You need deterministic, reproducible behavior. LLM-based planning is inherently non-deterministic -- the same goal may produce different plans on different runs.
Key Tradeoffs
The Core Tradeoff: Plan Quality vs. Latency and Cost
Every planning call adds latency and cost before any actual work begins. A simple plan generation takes 1-2 seconds with GPT-4o. Tree of Thought planning with 3 candidates and evaluation takes 3-5 seconds. For user-facing applications, this delay is noticeable.
| Approach | Planning Latency | Cost per Plan | Plan Quality | Best For |
|---|---|---|---|---|
| No planning (pure ReAct) | 0ms | $0 | Low for complex tasks | Simple, 1-2 step tasks |
| Single-shot planning | 1-2s | ~$0.02 (INR 1.7) | Medium | 3-7 step tasks |
| Multi-turn with validation | 3-5s | ~$0.06 (INR 5) | High | 8+ step critical tasks |
| Tree of Thought | 4-8s | ~$0.15 (INR 12.5) | Highest | Complex tasks where first-plan failure is costly |
| Hybrid LLM+Classical | 2-4s | ~$0.03 (INR 2.5) | High (optimal in domain) | Well-structured planning domains |
The Second Tradeoff: Flexibility vs. Reliability
Upfront planning produces a complete plan but is brittle to execution surprises. Interleaved planning adapts to new information but costs more (multiple planning calls) and can lose global coherence. The production sweet spot is plan-then-replan: generate a full plan upfront, execute it, and only invoke the replanner when a subtask fails or produces unexpected output.
The Hidden Tradeoff: Decomposition Granularity
Fine-grained decomposition (many small subtasks) is more robust to individual failures but costs more to plan and execute. Coarse-grained decomposition (few large subtasks) is cheaper but each failure is harder to recover from because you lose more progress. For most tasks, aim for 5-8 subtasks where each subtask maps to 1-2 tool calls.
Alternatives & Comparisons
ReAct (Reasoning + Acting) interleaves thinking and tool use without an explicit upfront plan. It's simpler, faster for short tasks (1-3 steps), and requires no planning overhead. But for tasks requiring 5+ steps, ReAct tends to lose coherence, repeat actions, or miss steps. Use ReAct for simple interactive tasks; use a planning module when the task has clear sub-goals and dependencies.
A task decomposer is a subset of a planning module -- it handles only the decomposition step without dependency resolution, validation, or replanning. If your execution framework already handles ordering and error recovery, a standalone task decomposer may be sufficient and simpler to implement.
An agent orchestrator manages the lifecycle of the entire agent (routing, state management, tool dispatch) and may include planning as one of its capabilities. If you need a full agent framework, the orchestrator is the right abstraction. If you need to add structured planning to an existing agent, a standalone planning module is more modular.
Pros, Cons & Tradeoffs
Advantages
Dramatically improves complex task completion rates -- ADaPT showed up to 28% higher success rates on multi-step tasks compared to flat execution, and Tree of Thought achieved 74% on Game of 24 vs. 4% for chain-of-thought alone.
Enables parallel execution by identifying independent subtasks through dependency analysis. A 10-step plan with 3 parallelizable pairs executes in ~7 steps of wall-clock time instead of 10.
Provides explainability and auditability -- the structured plan can be logged, shown to users for approval, and analyzed post-hoc to understand agent behavior. Essential for regulated industries.
Makes replanning systematic rather than ad-hoc. When a subtask fails, the replanner knows exactly what has been completed, what failed, and what remains, producing targeted fixes rather than starting over.
Reduces token waste compared to ReAct on complex tasks. A planned agent makes 5-8 focused tool calls; an unplanned agent may make 15-20 wandering attempts before converging.
Supports human-in-the-loop workflows naturally. Users can review, modify, or approve plans before execution begins, keeping humans in control of agent behavior.
Disadvantages
Adds 1-5 seconds of latency before any execution begins, which is noticeable in interactive applications. Users see the agent 'thinking' before it starts working.
Increases LLM cost by 2-5 additional calls per task for planning, validation, and potential replanning. At scale (millions of tasks/month), this adds up: ~$200-500/month (INR 17,000-42,000) for a moderately busy agent.
Plans can be wrong -- LLMs may generate plausible-sounding but infeasible or incomplete plans. Without validation, a bad plan wastes more resources than no plan because the agent commits to a flawed strategy.
Non-deterministic by nature -- the same goal may produce different plans on different runs, making testing and debugging harder. You cannot write simple unit tests that assert a specific plan structure.
Decomposition quality degrades for unfamiliar domains -- if the LLM lacks knowledge about the task domain, it produces generic or incorrect decompositions. Planning is only as good as the model's world knowledge.
Overhead is not justified for simple tasks -- adding planning to a 1-2 step task wastes time and money. You need a routing mechanism to decide which tasks actually need planning.
Failure Modes & Debugging
Hallucinated subtasks
Cause
The LLM generates subtasks that reference tools or capabilities that do not exist in the agent's toolkit, or assumes access to data that is not available. This happens when the tool registry is not included in the planning prompt or the model confabulates capabilities.
Symptoms
Execution fails immediately when the agent tries to dispatch a subtask to a non-existent tool. The error log shows ToolNotFoundError or similar. The plan looks coherent on paper but cannot be executed.
Mitigation
Always include the full tool registry (names and descriptions) in the planning prompt. Add a plan validation step that checks every subtask's tool assignment against the available tools before execution begins. Reject plans that reference unknown tools and regenerate.
Infinite replanning loop
Cause
The replanner generates a new plan that fails for the same reason as the original, triggering another replan. This typically happens when the fundamental issue is not a plan problem but a tool or data availability problem that no plan can solve.
Symptoms
The agent enters a cycle of plan-fail-replan-fail with no progress. LLM costs spike. The task never completes. Logs show the same or similar errors repeating across replan attempts.
Mitigation
Set a hard limit on replan attempts (typically 2-3). After the limit, escalate to human intervention or return a partial result with an explanation. Track the type of failure across replans -- if the same error repeats, stop replanning and report the underlying issue.
Over-decomposition cascade
Cause
The planner breaks a task into too many subtasks (15+), each of which may also be over-decomposed in adaptive planning, leading to an explosion of LLM calls. Often caused by vague goals that the planner interprets too broadly.
Symptoms
Extremely high token usage and cost for a single task. Execution takes minutes instead of seconds. Many subtasks produce trivial or redundant results. The final synthesized output is not meaningfully better than a single well-prompted LLM call.
Mitigation
Set a maximum subtask count per decomposition level (8-12). Implement cost circuit breakers that abort execution if token usage exceeds a threshold. Pre-process vague goals with a clarification step before planning.
Dependency misspecification
Cause
The planner fails to correctly identify dependencies between subtasks. Two subtasks that should be sequential are marked as independent (causing data availability errors when the second runs), or independent subtasks are marked as dependent (preventing parallelization).
Symptoms
Subtasks fail because their input data is not yet available from upstream tasks. Or execution is slower than expected because parallelizable tasks run sequentially. DAG validation passes but runtime behavior is incorrect.
Mitigation
Add a dedicated dependency validation step: for each subtask, explicitly verify that all referenced inputs are available from upstream subtask outputs. Use a separate LLM call to review and correct the dependency graph. Include concrete input/output specifications in each subtask definition.
Goal drift during replanning
Cause
After multiple replans, the revised plan drifts from the original goal. The replanner focuses on fixing the immediate failure but loses sight of the big picture. Each replan introduces small deviations that compound.
Symptoms
The agent completes its (revised) plan successfully, but the final output does not address the user's original goal. The plan looks internally consistent but has subtly shifted focus.
Mitigation
Always include the original goal verbatim in every replan prompt. Add a goal-alignment check after replanning: use an LLM call to verify that the revised plan still addresses the original goal. Track goal coverage metrics across replans.
Stale context in long-running plans
Cause
For plans that take minutes to execute (e.g., multi-step research tasks), the context gathered by early subtasks may become stale or irrelevant by the time later subtasks use it. External data sources may have changed.
Symptoms
Later subtasks produce inconsistent results that contradict information gathered by earlier subtasks. The final synthesis contains contradictions or outdated information.
Mitigation
Add freshness timestamps to subtask results. For long-running plans, implement a context refresh mechanism that re-validates critical data points before dependent subtasks execute. Set maximum plan execution time limits.
Placement in an ML System
Where Does the Planning Module Sit?
In a typical agentic architecture, the planning module sits between the agent orchestrator (which manages the overall agent lifecycle, routing, and state) and the tool executor (which dispatches individual subtask actions to tools like search APIs, code interpreters, or databases).
Upstream, the planning module receives the user's goal (possibly refined by a goal parser or clarification step) and context from the memory store (relevant past interactions, successful plan templates, domain knowledge). It also receives the tool registry -- the list of available tools and their capabilities.
Downstream, the planning module outputs a structured plan (DAG of subtasks) to the tool executor for dispatch. If the agent uses a ReAct loop for individual subtask execution, the planning module feeds subtasks into the loop one at a time. If the agent has a human-in-the-loop component, the plan is first presented for approval before execution begins.
Integration Pattern: The planning module is typically invoked once per user goal (initial planning) and then again only on subtask failure (replanning). It is NOT called on every agent step -- that would be the ReAct loop's job. Think of the planning module as the strategic layer and the ReAct loop as the tactical layer.
Pipeline Stage
Orchestration / Agent Runtime
Upstream
- agent-orchestrator
- memory-store
Downstream
- tool-executor
- react-loop
- human-in-loop
Scaling Bottlenecks
The primary bottleneck is LLM inference latency and cost. Each planning call requires 500-2000 tokens of input (goal + tools + context) and 200-800 tokens of output (the plan). At 1000 tasks/hour, that is 1-2 million tokens/hour just for planning, costing roughly $5-15/hour (INR 420-1260/hour) with GPT-4o.
The second bottleneck is replanning frequency. If 20% of tasks require replanning, your effective LLM cost increases by 40-60% (replanning prompts are longer because they include execution context). Monitoring replan rates and addressing root causes (tool reliability, better initial plans) is critical.
At very high scale (10,000+ tasks/hour), consider plan caching: if similar goals recur, cache successful plan templates and adapt them rather than generating from scratch. This can reduce planning LLM calls by 30-50% for repetitive workloads.
Production Case Studies
Google's Gemini Deep Research (launched December 2024) uses a planning module to decompose complex research queries into a multi-step research plan. When a user asks a complex question, Gemini generates a structured research plan, presents it for user approval, then executes each step by searching the web, reading sources, and synthesizing findings. The plan explicitly shows which sub-questions will be investigated, in what order, and which can be parallelized.
Gemini Deep Research became one of Google's most-used AI features within months of launch, demonstrating that exposing the plan to users (for review and modification) significantly increases trust and adoption. The planning module handles queries that would require 20-30 minutes of manual research in 2-5 minutes.
Swiggy integrated AI agents that use task planning to handle complex user requests like "order dinner for 4 people with one vegetarian, one person who is gluten-free, keeping the budget under INR 2000." The planning module decomposes this into subtasks: identify dietary constraints, search restaurants matching all constraints, filter by budget, select items that satisfy each person's requirements, and assemble the cart. In January 2026, Swiggy further integrated MCP (Model Context Protocol) to enable external AI assistants to plan and execute multi-step orders.
The AI-powered ordering assistant handles constraint satisfaction that would require 10-15 minutes of manual browsing in under 30 seconds. Multi-step planned interactions show 3x higher completion rates compared to single-turn chatbot interactions.
Microsoft's AutoGen framework implements a multi-agent conversation system where a planning agent decomposes complex tasks and distributes subtasks across specialized agents (coder, executor, critic). The planner coordinates the conversation flow, determines when to invoke each specialist, and handles replanning when an agent's output does not meet quality criteria. Used internally for code generation, data analysis, and document processing workflows.
AutoGen-based systems demonstrated significant improvements on complex coding tasks (HumanEval, MATH benchmarks) by decomposing problems into sub-problems handled by specialized agents. The planning layer reduced redundant computation by 40% compared to single-agent approaches by avoiding repeated work through structured task assignment.
Flipkart's internal AI agents for seller onboarding use task planning to decompose the onboarding process into structured steps: verify business documents, validate product catalog format, check pricing compliance, generate product descriptions, and set up inventory management. The planning module adapts the onboarding workflow based on seller category (fashion vs. electronics vs. groceries), each of which has different compliance requirements.
Automated planning reduced average seller onboarding time from 5 days to under 24 hours. The adaptive planning module handles 15+ different seller category workflows without hardcoded rules, reducing engineering maintenance effort by approximately 60%.
Tooling & Ecosystem
The leading open-source framework for building stateful, multi-step agent workflows as graphs. Includes built-in support for plan-and-execute patterns, human-in-the-loop plan approval, state persistence, and replanning. The plan-and-execute tutorial is a direct implementation of a planning module.
Multi-agent framework with a dedicated planning agent that generates step-by-step plans shared across the crew before execution. Agents receive both their specific task and the overall plan, enabling coordinated multi-agent execution. Used by 60% of Fortune 500 companies as of 2025.
Multi-agent conversation framework from Microsoft Research. Supports task decomposition via specialized planner agents, nested conversations for hierarchical planning, and human-in-the-loop patterns. Recently released AutoGen Studio for no-code agent workflow building.
OpenAI's official SDK for building agents with function calling. While not a dedicated planning framework, its structured output and function calling capabilities are the building blocks for implementing custom planning modules. The Responses API supports multi-step agent workflows.
LlamaIndex provides Workflows for building multi-step agent pipelines with built-in planning capabilities. Includes query planning for complex RAG scenarios where multiple data sources need to be queried in a specific order. Good for planning within data-intensive agent tasks.
One of the original autonomous agent projects, AutoGPT features built-in task planning and decomposition. Given a high-level objective, it generates a hierarchical task structure, creates sub-plans for each sub-goal, and executes them with self-monitoring. Useful as a reference implementation.
Research & References
Yao, Yu, Zhao, Shafran, Griffiths, Cao & Narasimhan (2023)NeurIPS 2023
Introduced the Tree of Thoughts (ToT) framework that generalizes chain-of-thought by exploring multiple reasoning paths as a tree, with LLM-based evaluation for branch selection. Achieved 74% on Game of 24 vs. 4% for standard CoT.
Wang, Xu, Lan, Hu, Lan, Lee & Lim (2023)ACL 2023
Proposed the Plan-and-Solve (PS) prompting strategy: first devise a plan to divide the task into subtasks, then execute them sequentially. Consistently outperformed zero-shot CoT across math reasoning benchmarks.
Wei, Wang, Schuurmans, Bosma, Ichter, Xia, Chi, Le & Zhou (2022)NeurIPS 2022
The foundational paper on chain-of-thought prompting, showing that providing step-by-step reasoning examples dramatically improves LLM performance on arithmetic, commonsense, and symbolic reasoning tasks. The intellectual ancestor of all modern planning approaches.
Yao, Zhao, Yu, Du, Shafran, Narasimhan & Cao (2022)ICLR 2023
Introduced the ReAct pattern of interleaving reasoning traces with tool-use actions. While not a planning module per se, ReAct established the agent loop pattern that planning modules build upon -- reasoning traces serve as implicit micro-plans.
Shen, Song, Tan, Li, Lu, Zhuang, Chen, Zhang & Ding (2023)NeurIPS 2023
Demonstrated a four-stage pipeline (task planning, model selection, task execution, response generation) where an LLM planner decomposes complex AI tasks into subtasks and assigns each to a specialized model from Hugging Face. A landmark example of LLM-as-planner architecture.
Wang, Xie, Jiang, Mandlekar, Xiao, Zhu, Fan & Anandkumar (2023)arXiv preprint (ICML 2023 Workshop)
Built an autonomous Minecraft agent with automatic curriculum planning, a growing skill library, and iterative prompting. Demonstrated that planning with progressive skill acquisition enables lifelong learning -- 3.3x more unique items and 15.3x faster milestone achievement.
Shinn, Cassano, Gopinath, Narasimhan & Yao (2023)NeurIPS 2023
Proposed verbal self-reflection as a mechanism for agents to learn from planning failures without weight updates. The agent reflects on why a plan failed and incorporates that reflection into the next planning attempt. Improved task completion by 22% in AlfWorld.
Liu, Jiang, Zhang, Liu, Zhang, Biswas & Stone (2023)arXiv preprint
Hybrid approach combining LLM natural language understanding with classical PDDL planners. The LLM translates problems to PDDL, a classical planner finds optimal solutions, and the LLM translates back. Achieves provably optimal plans for structured domains.
Huang, Yu, Ma, Zhong, Feng, Wang, Chen, Peng, Feng, Qin & Liu (2024)arXiv preprint
Comprehensive survey of LLM agent planning methods, categorizing approaches into task decomposition, plan selection, external module-aided planning, reflection, and memory-augmented planning. Essential reading for understanding the landscape.
Prasad, Koller, Hartmann, Clark, Sabharwal, Bansal & Khot (2024)NAACL 2024 Findings
Introduced adaptive decomposition that recursively breaks down tasks only when direct execution fails. Achieved 28% higher success rates on ALFWorld and 33% on TextCraft compared to fixed decomposition approaches.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a planning module for an AI agent that handles customer support tickets across multiple product categories?
- ●
Compare and contrast upfront planning vs. interleaved planning vs. reactive (ReAct) approaches. When would you use each?
- ●
Your agent's plans keep failing at step 4 out of 7. How do you debug and fix this?
- ●
How would you implement replanning that does not repeat already-completed work?
- ●
Explain the tradeoff between plan granularity (number of subtasks) and execution reliability.
- ●
How does Tree of Thought planning differ from chain-of-thought, and when is the extra cost justified?
- ●
Design a planning module for an agent that helps Indian retail investors build diversified portfolios.
Key Points to Mention
- ●
Plans should be DAGs, not linear sequences -- this enables parallelization and makes dependency reasoning explicit. Always mention topological sorting for execution order.
- ●
Replanning is not retrying -- replanning generates a new strategy conditioned on everything the agent has learned from partial execution. It carries forward completed results and adapts.
- ●
Cost awareness matters: a planning call costs roughly 20K-150K/month (INR 17-125 lakh/month). Discuss optimization strategies like plan caching.
- ●
The ADaPT principle (decompose only when necessary) is generally better than always-decompose because it avoids over-decomposition for simple tasks while still handling complex ones.
- ●
Plan validation before execution is a cheap insurance policy. One extra LLM call to validate catches circular dependencies, missing tools, and goal misalignment before expensive execution begins.
- ●
Connect planning to classical AI roots (STRIPS, PDDL, HTN) to show depth. Mention LLM+P as a bridge between neural and symbolic planning.
Pitfalls to Avoid
- ●
Treating planning as optional or 'nice to have' -- for complex tasks (5+ steps), the absence of planning is the #1 cause of agent failure.
- ●
Conflating planning with prompting. Chain-of-thought is a reasoning technique; a planning module is an architectural component with decomposition, validation, execution, and replanning.
- ●
Ignoring the cost dimension -- claiming you would 'always use Tree of Thought' without acknowledging the 4x cost increase shows a lack of production awareness.
- ●
Describing plans as static sequences rather than adaptive DAGs. Static plans are brittle; production systems need replanning.
- ●
Forgetting to mention the tool registry. A plan is only useful if the planner knows what tools are available.
Senior-Level Expectation
A senior/staff candidate should be able to design a complete planning subsystem: goal parsing with structured extraction, multi-strategy decomposition (adaptive vs. upfront based on task complexity), DAG construction with parallel execution, plan validation with tool registry checks, replanning with state carryover, cost optimization (plan caching, model selection based on task complexity), and monitoring (replan rates, plan quality metrics, cost per task). They should discuss failure modes proactively (goal drift, over-decomposition, infinite replan loops) and propose mitigations without being prompted. Bonus: connecting to classical AI planning (PDDL, HTN) and discussing when hybrid approaches outperform pure LLM planning. The ability to reason about cost-quality tradeoffs at scale -- especially under the budget constraints typical of Indian startups -- demonstrates genuine production experience.
Summary
The planning module is the strategic brain of an AI agent system -- the component that transforms a vague, high-level goal into a structured, executable plan of subtasks. Without it, agents are limited to reactive, one-step-at-a-time reasoning that fails on complex, multi-step tasks. With it, agents can decompose problems, identify dependencies, exploit parallelism, and systematically adapt when things go wrong.
The field has evolved rapidly from simple chain-of-thought prompting (2022) through Tree of Thought deliberation and Plan-and-Solve decomposition (2023) to adaptive, failure-aware replanning systems (2024-2025). The key architectural principles are: represent plans as DAGs (not linear sequences) to enable dependency reasoning and parallelization; validate plans before execution to catch infeasible steps early; implement replanning with state carryover so the agent does not repeat completed work; and match planning complexity to task complexity (do not use Tree of Thought for a simple lookup, do not use single-shot planning for a 15-step research task).
In production, the cost of planning is typically 10-20% of total task cost but yields 2-3x improvements in task completion rates for complex goals. The practical tradeoffs -- latency vs. plan quality, granularity vs. robustness, upfront vs. adaptive decomposition -- are the engineering decisions that separate demo-quality agents from production-ready ones. Whether you are building a customer support agent for Razorpay, a research assistant for a Bangalore AI startup, or an automated onboarding workflow for Flipkart sellers, the planning module is where you will invest the most design effort and see the highest returns.