Output Parser in Machine Learning
Here is the uncomfortable truth about large language models: they are spectacular at generating text, but terrible at following formatting instructions consistently. Ask GPT-4o for a JSON object, and nine times out of ten you will get a perfectly formed response. That tenth time? You will get a chatty preamble like "Sure! Here's the JSON you requested:" followed by a code block, or a trailing comma that breaks your JSON.parse() call, or a hallucinated field that does not exist in your schema. In production, that tenth time will happen at 3 AM on a Saturday, and your entire pipeline will grind to a halt.
An output parser is the component that sits between the raw text output of an LLM and the rest of your application, transforming unstructured (or semi-structured) text into validated, typed, programmatically usable data structures. It is the bridge between the probabilistic, free-form world of language models and the deterministic, schema-driven world of software engineering.
Output parsers have evolved from simple regex extractors into sophisticated systems that combine prompt engineering, schema enforcement, constrained decoding, and automatic retry logic. They are now a first-class concern in every production LLM application -- from Razorpay's KYC document extraction pipeline to Zomato's AI customer support bot that processes over 1,000 messages per minute.
If you are building anything beyond a chatbot demo -- if your LLM output feeds into a database, an API, a decision engine, or another model -- you need an output parser. Full stop.
Concept Snapshot
- What It Is
- A component that transforms raw LLM text output into validated, structured data formats (JSON, Pydantic models, TypeScript types, XML, or custom schemas) with error handling and retry logic.
- Category
- LLM Operations
- Complexity
- Intermediate
- Inputs / Outputs
- Input: raw text string from an LLM completion. Output: validated, typed data structure (dict, Pydantic model, dataclass, Zod object) conforming to a predefined schema.
- System Placement
- Sits immediately after the LLM inference call and before any downstream business logic, database writes, API calls, or agent action execution.
- Also Known As
- structured output extractor, response parser, schema enforcer, output formatter, structured generation layer
- Typical Users
- ML Engineers, Backend Engineers, LLM Application Developers, AI/ML Platform Teams
- Prerequisites
- Basic LLM API usage (completions, chat), JSON and JSON Schema fundamentals, Python type systems (Pydantic, dataclasses), Prompt engineering basics
- Key Terms
- structured outputconstrained decodingJSON modeschema validationPydanticZodfunction callingtool useretry logicgrammar-guided generationoutput fixing
Why This Concept Exists
The Free-Text Problem
LLMs are autoregressive text generators. They predict the next token based on probability distributions learned from training data. Nothing in this process inherently guarantees that the output will be valid JSON, that a date field will actually contain a date, or that an enum field will contain one of the allowed values. The model "wants" to be helpful and conversational -- which is exactly what you do not want when you need a clean {"status": "approved", "confidence": 0.87} to feed into your downstream service.
Let us quantify this. Before OpenAI introduced structured outputs in August 2024, their own benchmarks showed that prompting alone achieved roughly 35% schema compliance for complex JSON schemas. That means 65% of responses had some structural issue -- missing fields, wrong types, extra commentary, or outright malformed JSON. For a production system processing thousands of requests per hour, a 65% failure rate is catastrophic.
The Evolution: From Regex to Constrained Decoding
The history of output parsing tracks the maturation of LLM applications:
Phase 1 (2022-early 2023): Regex and string manipulation. Early LLM apps used re.findall() and string splitting to extract structured data from model outputs. Fragile, unmaintainable, and broke constantly whenever the model changed its phrasing. Everyone who built an LLM app in this era has war stories about regex parsers.
Phase 2 (mid 2023): Framework-level parsers. LangChain introduced PydanticOutputParser, StructuredOutputParser, and OutputFixingParser. These injected format instructions into the prompt and used Pydantic for validation. A massive improvement, but still relied on the model "choosing" to follow instructions -- which it sometimes did not.
Phase 3 (late 2023-2024): Provider-native structured outputs. OpenAI launched JSON mode (November 2023), then full structured outputs with strict schema adherence (August 2024). Anthropic added tool use and structured outputs for Claude. Google added JSON mode to Gemini. The providers moved schema enforcement from the application layer into the inference layer.
Phase 4 (2024-present): Constrained decoding engines. Libraries like Outlines, XGrammar, and Guidance moved enforcement even deeper -- into the token sampling process itself. By masking invalid tokens during generation, these systems guarantee 100% structural validity without relying on the model's "willingness" to comply.
Key Insight: The trend is clear -- structured output enforcement is moving deeper into the stack, from post-hoc parsing to prompt engineering to API-level enforcement to token-level constrained decoding. Each layer adds reliability but also constraints. Understanding where enforcement happens is the key to choosing the right approach for your system.
Core Intuition & Mental Model
The Translator Analogy
Think of an output parser as a simultaneous translator at a UN summit. The LLM is a brilliant delegate who speaks in flowing, nuanced prose. Your application backend is a bureaucrat who only understands forms filled in triplicate. The output parser listens to the delegate's speech and fills out the form -- faithfully capturing the meaning while enforcing the rigid structure the bureaucrat requires.
Sometimes the delegate rambles, goes off-topic, or uses ambiguous phrasing. A good translator (parser) handles this gracefully -- asking for clarification (retry), inferring intent from context (output fixing), or flagging when the message simply cannot be translated into the required form (validation error).
Two Fundamentally Different Approaches
Here is the mental model that will save you hours of confusion: output parsers fall into two camps, and the distinction matters enormously.
Approach 1: Parse after generation (post-hoc). Let the LLM generate freely, then parse and validate the output. This is what LangChain's PydanticOutputParser, OpenAI's JSON mode, and most regex-based approaches do. The model generates text; you try to extract structure from it. If it fails, you retry or fix.
Approach 2: Constrain during generation (inline). Modify the token sampling process to prevent the model from ever generating invalid tokens. This is what Outlines, XGrammar, and OpenAI's strict structured outputs do. The model literally cannot produce malformed output because invalid tokens are masked at each decoding step.
Approach 1 is easier to set up but has a non-zero failure rate. Approach 2 guarantees structural validity but can be more complex to deploy and may slightly affect generation quality (because you are restricting the model's "creative freedom" at the token level).
Rule of Thumb: For API-based models (OpenAI, Anthropic, Google), use provider-native structured outputs -- it is Approach 2 handled for you. For self-hosted models, use Outlines or XGrammar. Fall back to Approach 1 (Pydantic parsing + retry) only when constrained decoding is not available.
Technical Foundations
Formal Framework
Let us define the output parsing problem precisely.
Given:
- An LLM that produces a text output (where is the token vocabulary)
- A schema defining a set of valid structured outputs
- A prompt that includes instructions for the desired output format
An output parser is a function:
where represents a parsing failure. The parser maps raw text to a valid structured output or signals failure.
Schema Compliance Rate
The key metric for output parsers is the schema compliance rate :
where is the total number of LLM outputs processed. For production systems, you want . With constrained decoding, by construction.
Constrained Decoding: The Token Masking Formulation
In constrained decoding, at each generation step , the model produces a probability distribution over the vocabulary . A grammar mask defines the set of tokens that are valid at step given the current parse state. The constrained distribution is:
This renormalization ensures the model only samples from structurally valid continuations. The overhead per token is the cost of computing , which XGrammar reduces to under 40 microseconds per token through vocabulary partitioning and persistent stack optimizations.
Retry Budget and Expected Cost
For post-hoc parsing with retry, the expected cost of obtaining a valid output with per-attempt success probability and maximum retries is:
where is the cost per LLM call. If (90% first-attempt success) and , the expected cost multiplier is approximately -- an 11% overhead. But if (the pre-structured-outputs era), the multiplier jumps to -- you are paying 2.5x for every output. That is why constrained decoding (where ) is not just technically elegant -- it directly saves money.
Internal Architecture
A production output parser system consists of several interconnected layers that work together to transform raw LLM text into validated structured data. The architecture must handle the happy path (well-formed output) efficiently while providing robust fallback mechanisms for malformed outputs.
Here is how these components connect:
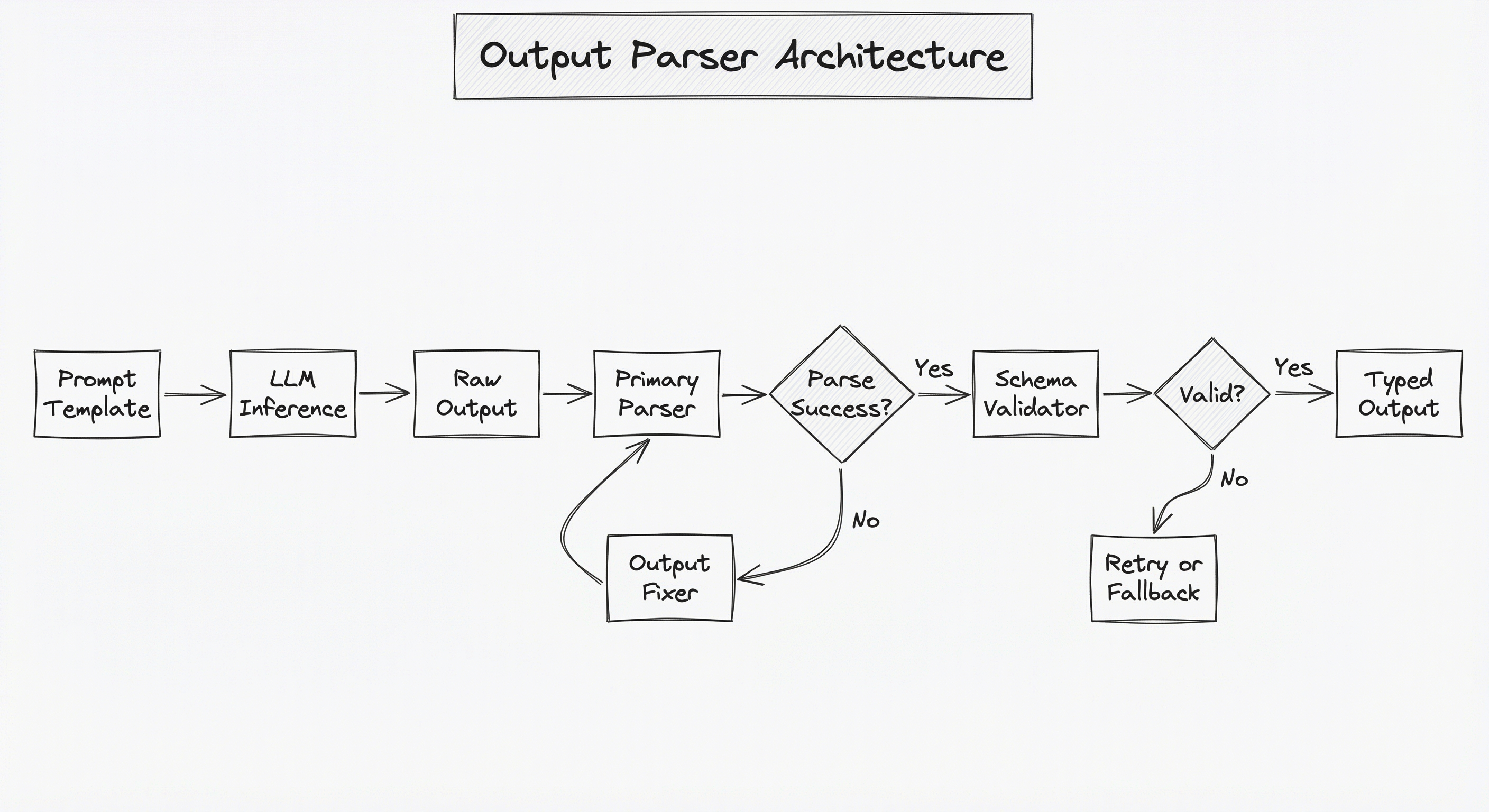
The system operates in three phases: generation-time enforcement (schema instructions in prompt, JSON mode, constrained decoding), parse-time extraction (JSON parsing, regex extraction, XML parsing), and validation-time checking (Pydantic/Zod schema validation, type coercion, custom validators). Each phase catches progressively subtler errors.
Key Components
Schema Definition Layer
Defines the expected output structure using Pydantic models (Python), Zod schemas (TypeScript), JSON Schema, or custom EBNF grammars. This single source of truth drives both prompt injection (telling the LLM what format to use) and response validation (checking the LLM actually complied). Tools like Instructor and the Vercel AI SDK derive prompt instructions automatically from the schema definition.
Prompt Injection Engine
Converts the schema definition into natural-language format instructions that are appended to the user prompt. For example, LangChain's PydanticOutputParser generates instructions like: "The output should be formatted as a JSON instance that conforms to the JSON schema below..." More sophisticated engines like Instructor use function-calling APIs to pass the schema directly to the model without polluting the prompt.
Inference-Time Enforcer
Operates at the LLM provider or serving layer. Includes OpenAI's response_format: {type: 'json_schema'}, Anthropic's strict tool use, and self-hosted constrained decoding engines (Outlines, XGrammar, llama.cpp grammars). This is the strongest enforcement layer -- it prevents invalid tokens from being generated in the first place.
Primary Parser
Extracts structured data from the raw LLM text output. Handles JSON extraction (including stripping markdown code fences and preamble text), XML parsing, regex-based extraction, and delimiter-based splitting. Must be resilient to common LLM quirks like trailing commas, single quotes instead of double quotes, and comments in JSON.
Schema Validator
Validates the parsed data against the schema definition. Performs type checking, range validation, enum enforcement, required field verification, and custom business rule validation. Pydantic V2 and Zod provide detailed error messages that can be fed back to the LLM for self-correction.
Output Fixer / Retry Controller
Handles validation failures through a configurable retry strategy. Options include: (1) syntactic fixing with json_repair or regex cleanup, (2) LLM-based repair where the malformed output and error message are sent back to the model, and (3) full retry with enhanced instructions. The retry controller tracks attempt count, latency budget, and cost accumulation to decide when to escalate to a fallback.
Fallback and Dead Letter Queue
When all retries are exhausted, routes the failed output to a fallback handler. Options include returning a default value, using a simpler/more reliable model, queueing for human review, or raising an exception. In production, failed outputs should be logged to a dead letter queue for debugging and reprocessing.
Data Flow
The data flows through the system in a loop-capable pipeline:
Happy Path: Prompt with schema -> LLM (with JSON mode/constrained decoding) -> Raw JSON text -> JSON.parse() -> Pydantic/Zod validation -> Typed output -> Downstream consumer.
Retry Path: Prompt -> LLM -> Raw text -> Parse failure or validation failure -> Error message + original output -> Appended to prompt as correction context -> LLM (retry) -> Parse -> Validate -> (repeat up to N times).
Fallback Path: After N failed retries -> Dead letter queue + alert -> Fallback response (default value, human review queue, or graceful degradation).
The key architectural decision is where to place the enforcement boundary. Provider-native structured outputs (OpenAI, Anthropic) eliminate the parse-and-retry loop entirely for schema-compliant outputs, reducing the architecture to a single pass in most cases. For self-hosted models, the constrained decoding engine (Outlines, XGrammar) serves the same function at the inference layer.
A flowchart showing the output parsing pipeline: starting with a Prompt Template that feeds into LLM Inference, producing Raw Output Text. This flows to a Primary Parser, which either succeeds (going to Schema Validator) or fails (going to an Output Fixer that loops back). The Schema Validator either produces a valid Typed Structured Output for downstream consumption, or triggers a Retry loop (with error feedback in the prompt) back to LLM Inference. After exhausting retries, outputs go to a Fallback / Dead Letter Queue.
How to Implement
Choosing Your Implementation Strategy
The implementation approach depends on three factors: your LLM provider (API-based vs. self-hosted), your programming language (Python vs. TypeScript vs. others), and your reliability requirements (can you tolerate occasional failures, or do you need 100% compliance?).
For API-based models, the landscape has consolidated around a few proven patterns:
-
OpenAI Structured Outputs (
response_formatwithjson_schema): Guarantees 100% schema compliance using constrained decoding on their servers. Available for GPT-4o and later models. This is the gold standard for OpenAI users. -
Anthropic Tool Use / Structured Outputs: Claude supports structured outputs via tool definitions with
strict: true, using constrained sampling with compiled grammar artifacts. Available for Claude Sonnet 4.5 and Opus 4.1. -
Instructor library: A lightweight wrapper that works across 15+ providers (OpenAI, Anthropic, Google, Mistral, Ollama, etc.). Defines schemas as Pydantic models and handles retries automatically. Over 3 million monthly downloads -- the de facto standard for multi-provider structured output in Python.
-
Vercel AI SDK + Zod: The TypeScript equivalent. Uses Zod schemas that get converted to JSON Schema, sent to the model, and validated on return. Excellent developer experience with full type inference.
For self-hosted models, constrained decoding is the way to go:
-
Outlines (dottxt-ai): Python library that guarantees structured output via grammar-guided generation. Supports JSON Schema, regex, and arbitrary context-free grammars.
-
XGrammar (mlc-ai): High-performance constrained decoding engine achieving up to 100x speedup over alternatives. Under 40 microseconds per token overhead.
-
llama.cpp grammars: Built-in GBNF grammar support for the llama.cpp ecosystem.
Cost Consideration: Using Instructor with GPT-4o-mini for structured extraction costs approximately 0.60 per 1M output tokens (~INR 12.5 and ~INR 50 respectively). With retry logic averaging 1.1 calls per request, that is roughly 83/month (~INR 7,000/month) -- very manageable.
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List, Optional
from enum import Enum
class Sentiment(str, Enum):
POSITIVE = "positive"
NEGATIVE = "negative"
NEUTRAL = "neutral"
class ProductReview(BaseModel):
"""Structured representation of a product review."""
product_name: str = Field(description="Name of the product being reviewed")
sentiment: Sentiment = Field(description="Overall sentiment of the review")
rating: float = Field(ge=1.0, le=5.0, description="Rating from 1.0 to 5.0")
key_pros: List[str] = Field(description="List of positive aspects mentioned")
key_cons: List[str] = Field(description="List of negative aspects mentioned")
purchase_verified: Optional[bool] = Field(
default=None, description="Whether the purchase is verified"
)
summary: str = Field(
max_length=200, description="One-sentence summary of the review"
)
# Patch the OpenAI client with Instructor
client = instructor.from_openai(OpenAI())
# Extract structured data from free-text review
review_text = """
Bought the boAt Rockerz 450 headphones from Flipkart during the Big Billion Days
sale for INR 999. Sound quality is surprisingly good for the price - punchy bass
and clear mids. Battery lasts about 12 hours which is decent. The padding on the
ear cups could be better though, gets uncomfortable after 2 hours. Build quality
feels a bit plasticky. Overall great value for money if you're on a budget.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
max_retries=3,
messages=[
{
"role": "user",
"content": f"Extract a structured review from this text:\n\n{review_text}",
}
],
)
print(review.model_dump_json(indent=2))
# {
# "product_name": "boAt Rockerz 450",
# "sentiment": "positive",
# "rating": 3.8,
# "key_pros": ["Good sound quality", "Punchy bass", "12-hour battery", "Great value"],
# "key_cons": ["Uncomfortable after 2 hours", "Plasticky build quality"],
# "purchase_verified": null,
# "summary": "Solid budget headphones with good sound and battery, but comfort and build could improve."
# }Instructor wraps the OpenAI client to add Pydantic-based schema enforcement with automatic retries. The response_model parameter tells Instructor to: (1) convert the Pydantic model to a JSON Schema, (2) pass it to OpenAI via function calling or structured outputs, (3) parse the response into a validated Pydantic instance, and (4) automatically retry up to max_retries times if validation fails, including the error message in the retry prompt. The Field descriptors serve double duty -- they validate the output AND provide semantic hints to the model about what each field should contain.
from openai import OpenAI
from pydantic import BaseModel
from typing import List
client = OpenAI()
class KYCExtraction(BaseModel):
"""Extracted KYC information from an identity document."""
document_type: str # e.g., "Aadhaar", "PAN", "Passport"
full_name: str
document_number: str
date_of_birth: str # ISO format YYYY-MM-DD
address: str
is_valid: bool
confidence_score: float
extraction_notes: List[str]
# Using the parse method for guaranteed structured output
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": "You are a KYC document parser. Extract structured information from document text. Use ISO date format.",
},
{
"role": "user",
"content": """OCR text from document:
INCOME TAX DEPARTMENT GOVT OF INDIA
Permanent Account Number Card
RAJESH KUMAR SHARMA
BQAPS1234K
Date of Birth: 15/08/1990
Father's Name: SURESH KUMAR SHARMA""",
},
],
response_format=KYCExtraction,
)
kyc_data = completion.choices[0].message.parsed
print(f"Document: {kyc_data.document_type}")
print(f"Name: {kyc_data.full_name}")
print(f"PAN: {kyc_data.document_number}")
print(f"Valid: {kyc_data.is_valid}")
# Document: PAN
# Name: RAJESH KUMAR SHARMA
# PAN: BQAPS1234K
# Valid: TrueOpenAI's parse method provides guaranteed schema compliance -- the response will always match your Pydantic model because it uses constrained decoding on OpenAI's servers. No retries needed. The compliance rate goes from ~35% (prompting alone) to 100% (strict mode). This is the most reliable approach for OpenAI users, though it is only available on GPT-4o-2024-08-06 and later models.
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import List
class RestaurantRecommendation(BaseModel):
"""Structured restaurant recommendation."""
restaurant_name: str = Field(description="Name of the restaurant")
cuisine_type: str = Field(description="Primary cuisine type")
price_range_inr: str = Field(description="Price range per person in INR")
rating: float = Field(ge=1.0, le=5.0)
must_try_dishes: List[str] = Field(description="Top 3 dishes to try")
vegetarian_friendly: bool
reasoning: str = Field(description="Why this restaurant is recommended")
# Create the parser
parser = PydanticOutputParser(pydantic_object=RestaurantRecommendation)
# Build prompt with auto-injected format instructions
prompt = ChatPromptTemplate.from_messages([
("system", "You are a food recommendation expert for Indian cities."),
("user", "{query}\n\n{format_instructions}"),
])
# Chain: prompt -> LLM -> parser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
chain = prompt | llm | parser
# Invoke
result = chain.invoke({
"query": "Recommend a great biryani place in Hyderabad for a family dinner",
"format_instructions": parser.get_format_instructions(),
})
print(result.restaurant_name) # e.g., "Paradise Biryani"
print(result.price_range_inr) # e.g., "INR 300-500"
print(result.must_try_dishes) # e.g., ["Hyderabadi Dum Biryani", ...]LangChain's PydanticOutputParser takes a post-hoc parsing approach: it generates format instructions from the Pydantic model, injects them into the prompt, and then parses the LLM's text output back into a Pydantic instance. This works with any LLM (not just OpenAI) but does not guarantee compliance -- the model might still produce malformed output. For production use, pair this with OutputFixingParser or RetryWithErrorOutputParser to handle failures gracefully.
import { generateObject } from 'ai';
import { openai } from '@ai-sdk/openai';
import { z } from 'zod';
// Define the output schema with Zod
const OrderSchema = z.object({
items: z.array(
z.object({
name: z.string().describe('Name of the food item'),
quantity: z.number().int().positive(),
priceINR: z.number().positive().describe('Price in Indian Rupees'),
specialInstructions: z.string().optional(),
})
),
deliveryAddress: z.string(),
estimatedTotalINR: z.number().positive(),
isVegetarian: z.boolean(),
paymentMethod: z.enum(['UPI', 'card', 'COD', 'wallet']),
});
// Type is automatically inferred from the schema
type Order = z.infer<typeof OrderSchema>;
async function parseOrder(userMessage: string): Promise<Order> {
const { object } = await generateObject({
model: openai('gpt-4o-mini'),
schema: OrderSchema,
prompt: `Extract a structured food order from this message: ${userMessage}`,
});
// 'object' is fully typed as Order
return object;
}
// Usage
const order = await parseOrder(
'I want 2 butter naans, 1 dal makhani, and 1 paneer tikka. ' +
'Deliver to Koramangala 4th Block, Bangalore. Pay with UPI. ' +
'Make the naan extra crispy please.'
);
console.log(order.items[0].name); // "Butter Naan"
console.log(order.paymentMethod); // "UPI"
console.log(order.estimatedTotalINR); // e.g., 650The Vercel AI SDK translates Zod schemas into JSON Schema, sends them to the model, and validates the response -- all in one call. The .describe() method on Zod fields provides semantic hints to the model without polluting your TypeScript types. The result is fully typed: TypeScript knows that order.items is an array of objects with specific fields. This is the standard approach for Next.js and TypeScript-based LLM applications.
import outlines
from pydantic import BaseModel, Field
from typing import List
from enum import Enum
class TicketPriority(str, Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
CRITICAL = "critical"
class SupportTicket(BaseModel):
"""Structured support ticket extracted from customer message."""
category: str = Field(description="Issue category")
priority: TicketPriority
summary: str = Field(max_length=200)
affected_service: str
requires_escalation: bool
suggested_tags: List[str]
# Load a local model with Outlines
model = outlines.models.transformers("mistralai/Mistral-7B-Instruct-v0.3")
# Create a generator that is GUARANTEED to produce valid SupportTicket JSON
generator = outlines.generate.json(model, SupportTicket)
# Generate -- output is always valid, no retries needed
prompt = """Extract a structured support ticket from this customer message:
Customer: My UPI payments through PhonePe keep failing since yesterday.
I've tried 5 times and each time it says 'transaction declined'.
My account has sufficient balance. This is urgent as I need to pay
my electricity bill before the deadline tonight.
"""
ticket = generator(prompt)
print(ticket.priority) # TicketPriority.HIGH
print(ticket.category) # "Payment Failure"
print(ticket.requires_escalation) # TrueOutlines uses constrained decoding to guarantee 100% schema compliance. At each token generation step, it computes a mask of valid tokens based on the current parse state of the JSON schema and prevents the model from sampling invalid tokens. This means the output is always valid -- no parsing errors, no retries, no dead letter queues. The tradeoff is that you need to run the model locally (or on your own GPU infrastructure), and the constrained decoding adds a small per-token overhead (typically 1-5% of total generation time).
import json
import json_repair
from pydantic import BaseModel, ValidationError
from openai import OpenAI
from typing import TypeVar, Type, Optional
import logging
logger = logging.getLogger(__name__)
T = TypeVar("T", bound=BaseModel)
def robust_parse(
client: OpenAI,
model: str,
prompt: str,
schema: Type[T],
max_retries: int = 3,
fix_with_llm: bool = True,
) -> Optional[T]:
"""Production-grade output parser with multi-layer fallback.
Layer 1: Direct JSON parsing
Layer 2: JSON repair (fix trailing commas, quotes, etc.)
Layer 3: LLM-based output fixing
Layer 4: Full retry with error context
"""
schema_json = json.dumps(schema.model_json_schema(), indent=2)
last_error = None
for attempt in range(max_retries):
# Build prompt with error context on retries
messages = [{"role": "user", "content": prompt}]
if attempt > 0 and last_error:
messages.append({
"role": "user",
"content": (
f"Your previous response failed validation with error: "
f"{last_error}\n\nPlease fix and return valid JSON matching "
f"this schema:\n{schema_json}"
),
})
response = client.chat.completions.create(
model=model,
messages=messages,
response_format={"type": "json_object"},
)
raw_text = response.choices[0].message.content
# Layer 1: Direct parse
try:
data = json.loads(raw_text)
return schema.model_validate(data)
except json.JSONDecodeError as e:
logger.warning(f"Attempt {attempt+1}: JSON parse failed: {e}")
# Layer 2: JSON repair
try:
repaired = json_repair.loads(raw_text)
return schema.model_validate(repaired)
except (ValidationError, Exception) as repair_err:
logger.warning(f"Attempt {attempt+1}: Repair failed: {repair_err}")
last_error = str(repair_err)
except ValidationError as e:
logger.warning(f"Attempt {attempt+1}: Validation failed: {e}")
# Layer 3: LLM-based fixing
if fix_with_llm and attempt < max_retries - 1:
try:
fix_response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": (
f"Fix this JSON to match the schema.\n\n"
f"JSON: {raw_text}\n\n"
f"Errors: {e}\n\n"
f"Schema: {schema_json}\n\n"
f"Return ONLY valid JSON, no explanation."
),
}
],
response_format={"type": "json_object"},
)
fixed_data = json.loads(fix_response.choices[0].message.content)
return schema.model_validate(fixed_data)
except Exception as fix_err:
logger.warning(f"LLM fix failed: {fix_err}")
last_error = str(fix_err)
else:
last_error = str(e)
logger.error(f"All {max_retries} attempts failed for schema {schema.__name__}")
return None # Caller should handle None (dead letter queue, default, etc.)This production pattern implements a multi-layer fallback strategy: (1) try direct JSON parsing, (2) attempt syntactic repair with json_repair, (3) use the LLM itself to fix validation errors, (4) retry from scratch with error context in the prompt. Each layer handles a different class of failure -- syntactic errors, type mismatches, missing fields, and fundamental misunderstandings. The function returns None when all attempts fail, allowing the caller to implement application-specific fallback logic (default values, human review queue, etc.).
# Production output parser configuration (YAML)
output_parser:
primary_strategy: "provider_structured_output" # or "constrained_decoding", "post_hoc_parsing"
provider_config:
openai:
response_format: "json_schema"
strict: true
anthropic:
tool_use_strict: true
retry:
max_attempts: 3
backoff_ms: [100, 500, 2000] # exponential backoff
fix_with_llm: true
fix_model: "gpt-4o-mini" # cheaper model for fixing
validation:
framework: "pydantic_v2" # or "zod", "json_schema"
coerce_types: true
strip_extra_fields: true
fallback:
strategy: "dead_letter_queue" # or "default_value", "raise_exception"
dlq_table: "failed_outputs"
alert_threshold: 0.05 # alert if >5% failure rate
monitoring:
track_compliance_rate: true
track_retry_count: true
track_parse_latency: true
log_failed_outputs: trueCommon Implementation Mistakes
- ●
Not using provider-native structured outputs when available: Many teams still use regex parsing or prompt-based JSON extraction with OpenAI models when
response_formatwith strict JSON Schema is available and guarantees 100% compliance. Check your provider's docs before building a custom parser. - ●
Defining schemas that are too complex for the model: A schema with 30 nested fields, recursive types, and complex union types will confuse smaller models even with constrained decoding. Start with flat, simple schemas and increase complexity gradually. GPT-4o can handle complex schemas; GPT-4o-mini struggles with deeply nested ones.
- ●
Ignoring the cost of retries in your budget: If your first-attempt success rate is 80%, you are paying 1.25x per output on average. With 3 retries at 80% per-attempt, you still have a 0.8% overall failure rate (0.2^3 = 0.008). Model this explicitly in your cost projections, especially at scale. For a Flipkart-scale system processing 1M extractions/day, that 0.8% is 8,000 failures daily.
- ●
Using temperature > 0 for structured extraction: Higher temperature increases output diversity, which is great for creative writing but terrible for schema compliance. For structured output tasks, always set
temperature=0(or as close to 0 as your provider allows). This single setting change can improve compliance from 85% to 95%+. - ●
Forgetting to handle partial/streaming outputs: If you are streaming LLM responses for lower time-to-first-token, the output parser needs to handle incomplete JSON gracefully. Instructor supports streaming with
Partial[T]types; the Vercel AI SDK supportsstreamObject. Do not try toJSON.parse()a stream. - ●
Putting the schema in the system prompt instead of using function calling / tool use: Embedding the schema as text in the system prompt forces the model to parse format instructions from natural language. Using the function calling API or tool use passes the schema as structured metadata that the model is specifically trained to handle. The latter is almost always more reliable.
- ●
Not versioning your schemas: When you change a Pydantic model (add a field, change a type), existing cached or queued outputs may fail validation. Use explicit schema versioning and backward-compatible changes (optional fields with defaults) to avoid breaking your pipeline during deployments.
When Should You Use This?
Use When
Your LLM output feeds into any programmatic system -- a database write, an API call, a downstream model, or an agent's action executor. Basically, any time a non-human consumer needs to read the output.
You are extracting structured entities from unstructured text (names, dates, amounts, categories from documents, emails, support tickets, etc.).
Your application requires type-safe, validated responses -- for example, a fintech app extracting transaction details where a wrong type could cause a financial error.
You are building an LLM-powered agent that needs to produce structured tool calls, function arguments, or action parameters.
You need consistent output formats across multiple LLM providers or models (e.g., you want to switch between GPT-4o and Claude without changing your parsing logic).
You are operating at scale (>1K requests/hour) where even a 1% failure rate means dozens of broken requests that need human intervention.
Your compliance or audit requirements demand that LLM outputs conform to specific schemas (healthcare, finance, legal domains).
Avoid When
Your LLM output is consumed directly by humans (chatbot responses, creative writing, summaries) and does not need programmatic processing. Let the model speak freely.
You are building a prototype or hackathon project where occasional malformed outputs are acceptable and you can just retry manually. Do not over-engineer for demo day.
The output is a single, simple value (yes/no, a number, a category from a small set) that can be extracted with a simple string match or regex. You do not need Pydantic for a boolean.
You are using an LLM for text-to-text tasks (translation, rewriting, summarization) where the output is inherently unstructured prose.
The cost of implementing and maintaining a robust parser exceeds the cost of occasional manual corrections -- typically only true for very low-volume (<100 requests/day) internal tools.
Your downstream consumer already handles free-text input (e.g., a search engine that takes natural language queries). Adding a structured output layer would be unnecessary complexity.
Key Tradeoffs
The Reliability-Flexibility Tradeoff
The strongest enforcement mechanisms (constrained decoding, OpenAI strict mode) guarantee 100% schema compliance but restrict the model's output to exactly what the schema allows. If the model has useful information that does not fit your schema, it gets dropped. Weaker mechanisms (prompt-based instructions) give the model more flexibility but introduce failure risk.
| Approach | Compliance Rate | Latency Overhead | Model Flexibility | Provider Lock-in |
|---|---|---|---|---|
| Prompt-only instructions | 35-85% | None | High | None |
| JSON mode (no schema) | 90-95% | ~5ms | Medium | Low |
| Structured outputs (strict) | ~100% | ~10-50ms (first call) | Low | High |
| Constrained decoding (Outlines/XGrammar) | 100% | 1-5% of generation time | Low | None (self-hosted) |
| Post-hoc parsing + retry | 95-99.9% | 0-3x (retry cost) | High | None |
The Cost-Reliability Tradeoff
More reliable approaches often cost more. OpenAI's structured outputs use additional compute for constrained decoding (reflected in slightly higher latencies). Post-hoc retry approaches add cost proportional to the failure rate. Constrained decoding on self-hosted models requires GPU infrastructure.
For an Indian startup on a tight budget, here is the decision tree:
- < 1K requests/day: Use Instructor with
max_retries=2on GPT-4o-mini. Total cost: ~INR 1,000/month. - 1K-100K requests/day: Use OpenAI structured outputs (strict mode). Total cost: ~INR 10,000-50,000/month.
- > 100K requests/day: Self-host with Outlines or XGrammar on an A100 GPU. Total cost: ~INR 2-3 lakh/month for a single GPU instance, but no per-request API charges.
The Portability Tradeoff
Provider-native structured outputs lock you into that provider. Instructor and LangChain provide abstraction layers, but the behavior is not identical across providers. If multi-provider support matters (e.g., you want to fail over from OpenAI to Anthropic), invest in a parser that works across providers with a consistent retry strategy.
Alternatives & Comparisons
A prompt template can include format instructions that ask the LLM to produce structured output, but without a parser to validate and extract the response, you are relying entirely on the model's compliance. This works for simple formats with capable models but fails at scale. Use a prompt template for the instruction layer, but always pair it with an output parser for the validation layer.
Guardrails (like Guardrails AI) provide a superset of output parsing functionality -- they validate structure, but also check for content safety, factual accuracy, PII leakage, and other semantic properties. If you only need structural validation, an output parser is simpler and faster. If you also need content validation (toxicity checks, hallucination detection), guardrails are the broader solution. Many production systems use both: an output parser for structure, guardrails for content.
Function calling / tool use is increasingly used as a structured output mechanism -- you define a 'tool' that takes your desired schema as parameters, and the model 'calls' it to produce structured output. This blurs the line between output parsing and tool execution. The key difference: a tool executor actually invokes functions with side effects; an output parser just extracts and validates data. If you are already using tool use for agent actions, leveraging it for structured output is elegant. If you just need data extraction, a dedicated output parser is cleaner.
Pros, Cons & Tradeoffs
Advantages
Type safety and validation: Output parsers enforce schemas at runtime, catching type errors, missing fields, and constraint violations before malformed data propagates through your system. A single uncaught
nullin a financial calculation can cost real money.Automatic retry and self-healing: Libraries like Instructor and LangChain's
RetryWithErrorOutputParserautomatically retry failed parses, feeding error messages back to the LLM. This creates a self-correcting loop that dramatically improves reliability without manual intervention.Provider abstraction: Tools like Instructor work across 15+ LLM providers with the same Pydantic model definition. You can switch from OpenAI to Anthropic to a self-hosted model without changing your schema or parsing logic.
Constrained decoding guarantees 100% compliance: With Outlines, XGrammar, or OpenAI strict mode, structurally invalid output is mathematically impossible. No retries, no fallbacks, no dead letter queues -- just correct output, every time.
Developer experience improvements: In TypeScript (Zod + AI SDK) and Python (Pydantic + Instructor), the parsed output is fully typed with IDE autocomplete, documentation, and compile-time checks. This reduces bugs and accelerates development.
Cost optimization through reduced retries: Higher first-attempt compliance means fewer LLM calls, which directly reduces API costs. Moving from 80% to 100% compliance saves 20-25% on inference costs at scale.
Disadvantages
Constrained decoding can degrade generation quality: By masking tokens at each step, constrained decoding may force the model into low-probability token sequences, potentially reducing the semantic quality of the output. Research (CRANE, 2025) shows this can reduce reasoning accuracy by up to 10% in some benchmarks.
Additional latency: Schema compilation, grammar construction, and validation add overhead. OpenAI's structured outputs add ~10-50ms on the first call (grammar compilation, cached for 24 hours). Outlines adds 1-5% to total generation time. For latency-sensitive applications (real-time chat), this matters.
Schema design complexity: Designing schemas that are expressive enough to capture the LLM's output but simple enough for the model to follow is an art. Overly complex schemas (deep nesting, union types, recursive structures) increase failure rates with smaller models.
Provider lock-in for native structured outputs: OpenAI's structured outputs API, Anthropic's strict tool use, and Gemini's JSON mode each have different capabilities and limitations. Building on one provider's native features creates switching costs.
Maintenance overhead for schema evolution: As your application evolves, schemas change. Each change requires updating the Pydantic model, regenerating format instructions, testing compliance, and potentially re-validating historical outputs. Schema versioning is a real operational burden.
Not effective for inherently ambiguous outputs: Some LLM outputs are genuinely ambiguous -- a sentiment could be positive or neutral, an entity boundary could go either way. Forcing these into rigid schemas creates false precision. The parser will produce a valid output, but the output may not be the right one.
Failure Modes & Debugging
Chatty preamble / postamble contamination
Cause
The LLM adds conversational text before or after the structured output, such as "Sure! Here is the JSON:" or "I hope this helps!" This is especially common with instruction-tuned models that are trained to be conversational, and when the prompt does not explicitly say "output ONLY the JSON."
Symptoms
JSON.parse() or json.loads() fails with a syntax error because the raw output starts with text, not a {. The error message typically points to an unexpected character at position 0.
Mitigation
Use provider-native JSON mode or structured outputs (which suppress preamble by design). For post-hoc parsing, implement a JSON extraction step that scans the output for the first { and last } and parses only that substring. The json_repair library handles many of these cases automatically. Better yet, use function calling / tool use, which returns JSON without preamble.
Schema non-compliance with valid JSON
Cause
The LLM produces syntactically valid JSON that does not match the expected schema -- wrong field names, missing required fields, extra fields, wrong types (string instead of number), or enum values outside the allowed set. This is the most common failure mode with prompt-based parsing.
Symptoms
JSON parsing succeeds but Pydantic or Zod validation raises a ValidationError listing the specific field-level violations. The LLM "understood" JSON but not your specific schema.
Mitigation
Use strict structured outputs (OpenAI, Anthropic) or constrained decoding (Outlines) to prevent this class of failure entirely. For post-hoc parsing, implement retry with the validation error message included in the prompt: "Your output had these validation errors: {errors}. Please fix and return valid JSON."
Token limit truncation
Cause
The structured output exceeds the model's max_tokens limit and gets cut off mid-JSON, producing an incomplete (and thus unparseable) output. Common when extracting large arrays or deeply nested objects. GPT-4o-mini with a 16K output limit can still truncate a sufficiently large structured response.
Symptoms
JSON parsing fails with an "unexpected end of input" error. The output ends abruptly, often mid-string or mid-array. If using streaming, the stream ends without a complete object.
Mitigation
Set max_tokens generously (at least 2x your expected output size). For large extractions, use chunking: split the extraction into smaller, independent sub-tasks that each produce a small output, then merge results. Monitor the finish_reason field in API responses -- length indicates truncation.
Retry loop exhaustion (infinite retry spiral)
Cause
The LLM consistently fails to produce valid output even after multiple retries, and the retry logic keeps calling the model without giving up. This can happen with ambiguous prompts, schemas the model fundamentally cannot satisfy, or when the error feedback confuses the model further.
Symptoms
Latency spikes to 5-10x normal (multiple sequential LLM calls). API costs spike unexpectedly. Logs show repeated validation errors with the same or similar error messages. If not caught, this can drain your API budget in minutes.
Mitigation
Always set a hard retry limit (typically 2-3 retries). Implement exponential backoff between retries. Add a total latency budget that aborts even if retries remain. Log and alert on retry rate > 5%. After exhaustion, route to a dead letter queue -- do not silently drop the failure.
Semantic hallucination in structured fields
Cause
The output is structurally valid (passes schema validation) but contains factually incorrect or hallucinated values. For example, an entity extraction parser returns a valid {"company": "Infosys", "revenue": "$50B"} when the actual revenue is $18B. The parser sees valid types and is satisfied.
Symptoms
No parsing or validation errors are raised. Downstream systems consume incorrect data silently. The issue is only caught during manual review, user complaints, or downstream metric degradation.
Mitigation
Output parsers alone cannot catch semantic errors -- they only enforce structural validity. Layer semantic validation on top: cross-reference extracted values against known databases, use guardrails for factual consistency checks, or implement confidence scoring. For critical applications (finance, healthcare), add a human-in-the-loop verification step.
Constrained decoding quality degradation
Cause
Aggressive token masking in constrained decoding forces the model into low-probability token paths, degrading the semantic quality of generated content. This is especially problematic for open-ended fields (descriptions, summaries) within otherwise structured output.
Symptoms
Structured output is always valid, but free-text fields within the schema are lower quality -- more repetitive, less coherent, or factually weaker than unconstrained generation. Hard to detect without quality benchmarks.
Mitigation
Use the CRANE approach: alternate between unconstrained generation (for reasoning and content quality) and constrained generation (for structural correctness). Or use a two-pass approach: generate freely first, then use a second pass to extract structure from the free-text output.
Placement in an ML System
Where Does the Output Parser Sit?
The output parser sits at a critical junction in the LLM pipeline -- immediately after inference and before any downstream consumption. Think of it as the quality gate between the probabilistic LLM world and the deterministic application world.
In a RAG pipeline, the output parser structures the LLM's generated answer into a format the frontend can render (e.g., extracting citations, confidence scores, and source references as separate fields rather than embedding them in prose).
In an agent system, the output parser transforms the LLM's reasoning into structured action commands that the tool executor can dispatch. When Claude decides to call a function, the output parser ensures the function arguments match the expected schema before invocation.
In a data extraction pipeline (think Razorpay extracting KYC details from Aadhaar/PAN scans, or Swiggy extracting menu items from restaurant photos), the output parser is the core value-creation step -- transforming unstructured input into database-ready records.
The output parser's reliability directly determines the reliability of everything downstream. A 99% parser compliance rate means 1 in 100 downstream operations receives garbage input. At Zomato's scale of 1,000+ messages per minute, that is 10+ failures every minute. This is why output parsing is not an afterthought -- it is a first-class system design concern.
Pipeline Stage
Post-Inference / LLM Operations
Upstream
- prompt-template
- token-counter
Downstream
- guardrails
- agent-orchestrator
- tool-executor
Scaling Bottlenecks
The primary bottleneck is retry cost at scale. If your first-attempt compliance rate is 90% and you process 1M outputs/day, that is 100K retries -- each costing an additional LLM call. At GPT-4o-mini pricing (0.60/1M output tokens), each retry costs roughly 80/day (~INR 6,700/day) in pure retry overhead, or about $2,400/month (~INR 2 lakh/month).
For constrained decoding on self-hosted models, the bottleneck shifts to GPU compute for grammar compilation and token masking. XGrammar's benchmarks show under 40 microseconds per token, but at high throughput (thousands of concurrent requests), this overhead becomes measurable.
The second bottleneck is schema compilation latency. OpenAI's structured outputs compile the JSON Schema into a grammar on first use, adding 10-50ms. This is cached for 24 hours, but if you have hundreds of different schemas, cache misses become frequent.
- Maximize first-attempt compliance: Use the strongest enforcement available (strict mode, constrained decoding) to minimize retries.
- Use cheaper models for retry: If the primary model fails, retry with GPT-4o-mini instead of GPT-4o -- it is 30x cheaper and often sufficient for fixing.
- Cache compiled schemas: For self-hosted constrained decoding, pre-compile and warm the grammar cache during deployment.
- Batch similar extractions: If you have many documents with the same schema, batch them to amortize schema compilation cost.
Production Case Studies
Zomato built Zia, an AI customer support chatbot using Together AI's optimized Llama models. A critical component of Zia's architecture is a structured output transformation layer that converts JSON API responses into natural language for the LLM, and then parses the LLM's structured action outputs back into API calls. This bidirectional parsing pipeline handles order status queries, refund processing, and issue categorization at scale.
Doubled customer satisfaction (CSAT) scores, reduced average response time to under 10 seconds, and scaled to over 1,000 messages per minute. The structured output layer ensures every customer interaction produces a valid action (refund, escalate, resolve) with correct parameters.
OpenAI introduced Structured Outputs in August 2024, moving schema enforcement from the application layer into the inference engine via constrained decoding. Their internal benchmarks showed that schema compliance improved from 35% (prompting alone) to 100% (strict mode) across a suite of complex JSON schemas. The feature was motivated by customer feedback that unreliable JSON output was the #1 pain point in production LLM applications.
100% schema compliance for supported models (GPT-4o and later). Eliminated the need for retry logic in most structured output use cases, reducing application complexity and inference costs for millions of API users.
Robinhood uses Guardrails AI to validate and parse LLM outputs in their financial applications. Every LLM response that touches financial data (account summaries, transaction categorizations, investment recommendations) passes through structured validation that enforces both schema correctness and financial accuracy constraints. The output parser ensures amounts are valid numbers, account references exist, and regulatory disclosures are present.
Achieved reliable AI behavior in production financial applications where incorrect structured outputs could result in regulatory violations or financial losses. Near-zero latency impact (10-50ms) for validation on top of LLM inference.
dottxt developed Outlines, the open-source library for constrained structured generation, and the companion outlines-core Rust library (in collaboration with Hugging Face). Outlines introduced grammar-guided generation for JSON Schema, regex patterns, and arbitrary context-free grammars, enabling guaranteed structured output from any locally-hosted LLM. Their coalescence optimization makes constrained decoding up to 5x faster than naive implementations.
Over 9,000 GitHub stars and widespread adoption in the self-hosted LLM ecosystem. Outlines-core (the Rust port) provides portable constrained decoding that integrates with vLLM, llama.cpp, and other serving frameworks, making structured output a commodity feature for self-hosted models.
Tooling & Ecosystem
The most popular Python library for structured LLM output extraction. Built on Pydantic, supports 15+ providers (OpenAI, Anthropic, Google, Mistral, Ollama, etc.), with automatic retry, streaming partial objects, and validation. Over 3 million monthly downloads.
Grammar-guided structured generation library that guarantees 100% schema compliance via constrained decoding. Supports JSON Schema, regex, and context-free grammars. Works with any locally-hosted model via transformers or vLLM integration.
High-performance constrained decoding engine achieving up to 100x speedup over alternatives. Under 40 microseconds per token overhead for JSON Schema enforcement. Developed by the MLC-AI team. Portable across serving backends.
TypeScript SDK for building AI applications with structured output support via Zod schemas. The generateObject function converts Zod schemas to JSON Schema, sends them to the model, and returns fully typed, validated objects. Works with OpenAI, Anthropic, Google, and other providers.
Framework-level output parsers including PydanticOutputParser, StructuredOutputParser, OutputFixingParser, and RetryWithErrorOutputParser. Part of the LangChain ecosystem for building LLM applications. Supports prompt injection of format instructions and multi-layer retry.
Open-source framework that combines structured output validation with content safety checks. Defines expected output format via Pydantic or RAIL specs, then validates and optionally corrects LLM responses. Adds ~10-50ms latency. 5.9K+ GitHub stars.
Lightweight AI engineering framework by Prefect for structured data extraction. Provides high-level functions (marvin.extract, marvin.classify, marvin.generate) that handle schema definition, prompt construction, and output parsing in a single call. Uses Pydantic AI under the hood in v3.0.
Lightweight Python library for repairing malformed JSON strings. Handles common LLM output issues: trailing commas, single quotes, comments, unquoted keys, missing brackets. Fast and reliable for syntactic fixing before schema validation.
Research & References
Geng, Liu, et al. (2025)arXiv preprint
Introduces JSONSchemaBench, a benchmark of 10K real-world JSON schemas across 10 datasets. Evaluates six constrained decoding frameworks (Guidance, Outlines, llama.cpp, XGrammar, OpenAI, Gemini) and reveals significant variation in compliance rates across schema complexity levels.
Dong, Ruan, et al. (2024)arXiv preprint
Proposes vocabulary partitioning and persistent stack optimizations for constrained decoding, achieving up to 100x speedup over existing solutions. Under 40 microseconds per token for JSON Schema enforcement.
Park, Hahn, et al. (2024)arXiv preprint
Demonstrates that naive grammar-constrained decoding distorts the LLM's probability distribution, and proposes ASAp (Adaptive Sampling with Approximate expected futures) to guarantee grammatical output while preserving the model's conditional distribution.
Xu, Yang, et al. (2025)arXiv preprint
Shows that constrained decoding can hurt reasoning quality by up to 10%, and proposes alternating between unconstrained reasoning and constrained output generation to recover accuracy. A critical finding for anyone using structured outputs with chain-of-thought.
Scholak, Bahdanau, et al. (2023)arXiv preprint
Demonstrates that grammar-constrained decoding can replace task-specific finetuning for structured NLP tasks (SQL generation, semantic parsing), achieving competitive accuracy with zero-shot inference by constraining the output grammar at decoding time.
Beurer-Kellner, Fischer, Vechev (2023)PLDI 2023
Introduces LMQL, a query language for LLMs that combines natural language prompting with programmatic constraints and control flow. Achieves 26-85% cost savings by reducing redundant token generation through constraint-aware decoding.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a reliable structured output pipeline for an LLM application that processes 100K requests/day?
- ●
What is the difference between JSON mode, structured outputs (strict), and constrained decoding? When would you use each?
- ●
How would you handle a scenario where the LLM consistently fails to produce valid output for a complex schema?
- ●
Explain the tradeoffs between enforcing structure at the prompt level vs. the decoding level vs. post-hoc validation.
- ●
How would you design the retry strategy for an output parser in a latency-sensitive application?
- ●
What happens to output quality when you use constrained decoding? How would you mitigate quality degradation?
Key Points to Mention
- ●
The compliance rate spectrum: prompting alone (~35%) -> JSON mode (~90-95%) -> structured outputs / constrained decoding (100%). Always quantify where your approach sits on this spectrum.
- ●
Retry cost is a direct function of first-attempt compliance: at and 3 retries, expected cost multiplier is 1.11x; at it is 2.54x. Model this explicitly.
- ●
Constrained decoding (Outlines, XGrammar) moves enforcement into the token sampling loop, masking invalid tokens. This guarantees structural validity but can degrade content quality -- cite the CRANE paper's finding of up to 10% reasoning accuracy drop.
- ●
Schema design is as important as the parser: keep schemas flat and simple for smaller models, use
Field(description=...)for semantic hints, and version your schemas for backward compatibility. - ●
In production, output parsers need monitoring: track compliance rate, retry rate, parse latency, and failure patterns. Alert on compliance rate drops -- they often indicate upstream prompt or model changes.
- ●
For Indian fintech/healthtech applications, mention the regulatory requirement for structured, auditable LLM outputs -- the RBI and SEBI increasingly expect explainable AI decisions, which requires structured output at minimum.
Pitfalls to Avoid
- ●
Saying 'just use regex to parse JSON from the LLM output' -- this signals a lack of awareness of modern structured output tools and the failure modes of regex-based parsing.
- ●
Claiming constrained decoding has no downsides -- the CRANE and Grammar-Aligned Decoding papers show real quality tradeoffs that a senior engineer should acknowledge.
- ●
Ignoring the cost dimension: in an interview for an Indian startup, not mentioning the INR cost per extraction and how retry rates affect the bottom line is a missed opportunity.
- ●
Conflating structural validity with semantic correctness: a parser can produce a perfectly valid JSON object with completely hallucinated values. Always clarify this boundary.
- ●
Over-engineering for a simple use case: if the interviewer describes a low-volume prototype, recommending a full Outlines + grammar compilation + dead letter queue setup is tone-deaf. Match the solution to the scale.
Senior-Level Expectation
A senior or staff-level candidate should discuss the full lifecycle: schema design (Pydantic/Zod with descriptive fields and sensible defaults), enforcement strategy selection (based on provider, model, and scale), retry policy design (with cost modeling and latency budgets), monitoring and alerting (compliance rate, retry rate, failure patterns), and graceful degradation (dead letter queues, fallback values, human-in-the-loop). They should be able to reason about the cost implications at Indian startup scale -- for example, calculating that a 10% compliance drop at 500K requests/day means 50K extra LLM calls, costing approximately INR 3,500/day in pure retry overhead on GPT-4o-mini. The candidate should also discuss schema evolution strategy, multi-provider portability, and the semantic validity gap (structural correctness != factual correctness). Bonus points for mentioning constrained decoding research (XGrammar, Grammar-Aligned Decoding, CRANE) and the tradeoff between structural guarantees and reasoning quality.
Summary
An output parser is the critical bridge between the free-form, probabilistic world of LLM text generation and the structured, deterministic world of software applications. It transforms raw model output into validated, typed data structures -- JSON objects, Pydantic models, Zod types, or custom schemas -- that downstream systems can consume reliably.
The field has evolved rapidly through four phases: regex-based extraction (fragile), framework-level parsers like LangChain (better but still probabilistic), provider-native structured outputs from OpenAI and Anthropic (near-guaranteed compliance), and constrained decoding engines like Outlines and XGrammar (mathematically guaranteed compliance at the token level). The key tradeoff is between structural reliability and generation quality -- constrained decoding guarantees valid output but can degrade reasoning quality by up to 10%, a finding that every production team should factor into their design.
For production LLM applications, the output parser is not an afterthought -- it is a first-class system design concern. The choice of parsing strategy (post-hoc vs. constrained, retry budget, schema complexity) directly impacts cost, latency, reliability, and downstream data quality. At Indian startup scale, the difference between a 80% and 100% first-attempt compliance rate can mean INR 5,000-50,000/month in retry overhead alone. The recommendation is clear: use provider-native structured outputs when available, constrained decoding for self-hosted models, and Instructor or the Vercel AI SDK as your abstraction layer. Always monitor compliance rate, retry rate, and failure patterns -- and remember that structural validity is a necessary but not sufficient condition for output quality. The parser guarantees the format; the model (and your prompt) determine the substance.