Token Counter in Machine Learning
Here is a question that every team building on LLMs eventually confronts: how many tokens is this prompt actually going to cost me? A token counter is the component that answers that question -- precisely, programmatically, and before you send a single API call. It sits at the intersection of cost control, context window management, and prompt engineering, turning the opaque process of tokenization into an observable, optimizable part of your ML pipeline.
Token counting sounds deceptively simple. After all, can't you just divide the character count by four and call it a day? You could, but that rough heuristic will betray you the moment you encounter code snippets, non-Latin scripts like Hindi or Tamil, JSON payloads, or emoji-laden user messages. The reality is that tokenization is model-specific, encoding-specific, and language-dependent -- and getting it wrong can mean silently truncated context, blown budgets, or failed API calls.
In production systems serving thousands of requests per minute -- whether that is a customer support chatbot for IRCTC, a code assistant for a Bengaluru startup, or a RAG pipeline at Flipkart -- the token counter is the guardrail that ensures every prompt fits within the model's context window, every response stays within budget, and every chunk is sized correctly for retrieval. It is the unsung plumbing that makes LLM applications economically viable at scale.
This guide covers everything from the mathematical foundations of BPE and SentencePiece to production-grade token budget allocation strategies, with real code, real costs (in both USD and INR), and real failure modes.
Concept Snapshot
- What It Is
- A utility that converts text into the specific token representation used by a target LLM and returns the exact token count, enabling context window management, cost estimation, and prompt optimization.
- Category
- LLM Operations
- Complexity
- Intermediate
- Inputs / Outputs
- Inputs: raw text (prompt, context, user message) + target model/encoding identifier. Outputs: token count (integer), optionally the token ID list and per-token cost estimate.
- System Placement
- Sits upstream of the LLM API call, typically invoked by the context assembler, prompt template engine, or rate limiter to validate that payloads fit within model constraints.
- Also Known As
- tokenizer, token estimator, token budget calculator, context window calculator, prompt token counter
- Typical Users
- ML Engineers, LLM Application Developers, Platform Engineers, DevOps/MLOps Engineers, Product Managers (cost forecasting)
- Prerequisites
- Basic understanding of LLMs and API usage, Familiarity with text encoding (UTF-8, Unicode), Understanding of context windows and prompt structure
- Key Terms
- BPESentencePiecetiktokentokencontext windowtoken budgetencodingvocabularysubwordtokenizer
Why This Concept Exists
The Invisible Tax on Every LLM Call
Every interaction with a large language model is fundamentally a token transaction. You send tokens in, you receive tokens back, and you pay for every single one of them. As of early 2026, GPT-4o charges 10.00 per million output tokens. Claude Sonnet 4.5 charges 15.00. Gemini 2.5 Pro charges 10.00. These numbers look small until you multiply them by millions of daily requests -- and then the difference between estimating token counts and knowing token counts can be tens of thousands of dollars per month.
But cost is only half the story. Every LLM has a hard limit on how many tokens it can process in a single request -- its context window. GPT-4o supports 128K tokens. Claude Sonnet 4.5 supports 200K tokens. Gemini 2.5 Pro supports 1M tokens. Exceed these limits and your API call fails outright. Stay well below them and you are leaving retrieval quality on the table by not including enough context.
Why Word Count Does Not Work
The naive approach -- estimating tokens from word count (the "divide by 0.75" rule) -- fails spectacularly in practice for several reasons:
- Code is token-dense: A Python function with special characters, indentation, and operators can use 2-3x more tokens per "word" than English prose.
- Non-Latin scripts are penalized: Hindi text in Devanagari script can use 3-5x more tokens per word than equivalent English text, because most tokenizer vocabularies are English-centric. A study evaluating tokenizer performance across official Indian languages found that GPT-4's tokenizer produces significantly more tokens for Telugu, Tamil, and Kannada compared to English for semantically equivalent content.
- Structured data is unpredictable: JSON, XML, and YAML have inconsistent token-to-character ratios depending on key names, nesting depth, and value types.
- Emoji and special characters: A single emoji can consume 2-5 tokens depending on the encoding.
The Evolution: From Offline Tool to Production Component
Token counting started as a developer convenience -- a way to check whether your prompt would fit before hitting the API. OpenAI's tiktoken library, released in late 2022, made this easy for GPT models. But as LLM applications matured from prototypes to production systems, token counting evolved from a manual check into an automated pipeline component.
Today, production token counters are embedded in middleware layers, invoked on every request to enforce budgets, optimize chunk sizes, route to cost-appropriate models, and generate usage analytics. They have become as essential to LLM operations as request logging is to web services.
Key Insight: A token counter is not just a utility function -- it is an observability and governance tool. Without accurate token counting, you cannot manage costs, enforce quotas, optimize prompts, or guarantee that your context window is used effectively.
Core Intuition & Mental Model
Tokens Are Not Words
Let us start with the most important mental model: a token is a chunk of text that a specific model treats as a single unit. For English text, a token is roughly three-quarters of a word on average. The word "tokenization" might be split into ["token", "ization"] -- two tokens. The word "the" is one token. The word "indistinguishable" might become ["ind", "ist", "ingu", "ishable"] -- four tokens.
Think of it like currency denomination. A hundred-rupee note is one "token" of value, but so is a ten-rupee coin. Different denominations represent different amounts, but each is a single unit in a transaction. Similarly, "the" and "ingu" are both single tokens despite representing very different amounts of meaning.
Why Not Just Use Characters?
You might ask: why not just work with individual characters? The answer is vocabulary efficiency. English has 26 letters, but the space of meaningful text patterns is enormous. Character-level models would need extremely long sequences to represent even short sentences, making them computationally expensive. Conversely, word-level tokenization creates huge vocabularies (hundreds of thousands of entries) and cannot handle misspellings, neologisms, or morphological variations.
Subword tokenization -- the approach used by BPE, WordPiece, and SentencePiece -- hits the sweet spot. It uses a vocabulary of 30K-200K tokens that covers common words as single tokens while decomposing rare words into meaningful subword pieces. This is the fundamental insight: frequent patterns get compact representations, rare patterns get decomposed into reusable parts.
The Counting Part
A token counter simply runs the tokenizer's encoding step and counts the resulting tokens. It does not need to decode them back into text. The critical requirement is that the counter uses exactly the same tokenizer and vocabulary as the target model. If you count tokens with GPT-4o's o200k_base encoding but send the request to Claude, your count will be wrong -- potentially by 10-30%.
Rule of Thumb: Never count tokens with one model's tokenizer and send to another. Each model family has its own tokenizer, and cross-model token estimates are unreliable. The only safe approach is to use the exact tokenizer for the exact model you are calling.
Technical Foundations
Tokenization as a Mapping Function
Formally, a tokenizer defines a mapping from a string of characters to a sequence of token IDs drawn from a fixed vocabulary :
where is the character alphabet (typically UTF-8 bytes or Unicode code points) and is the vocabulary of token IDs.
The token count of a string is simply the length of the tokenized sequence:
Byte Pair Encoding (BPE)
BPE is the most widely used tokenization algorithm in modern LLMs (GPT-4, GPT-4o, LLaMA, Mistral). It operates as follows:
- Initialize the vocabulary with all individual bytes (256 entries for byte-level BPE) or characters.
- Count all adjacent pairs of tokens in the training corpus.
- Merge the most frequent pair into a single new token and add it to the vocabulary.
- Repeat steps 2-3 for iterations until the desired vocabulary size is reached.
The merge rules are applied greedily during encoding. Given a string, BPE iteratively replaces the highest-priority pair until no more merges apply. The number of resulting tokens depends on how many merge rules match the input text.
The compression ratio for a corpus is:
For English text with a typical BPE vocabulary of 100K tokens, characters per token. For Hindi in Devanagari, can drop to due to under-representation in the training vocabulary.
SentencePiece and Unigram Model
SentencePiece, developed by Kudo and Richardson (2018), treats the input as a raw byte stream without assuming whitespace-delimited words. It supports both BPE and the Unigram language model:
In the Unigram model, each subword has a probability , and the tokenization of a sentence maximizes:
The optimal segmentation is found via the Viterbi algorithm in time, where is the string length and is the maximum token length.
Token Budget Constraint
In a production LLM system, the token counter enforces the context window constraint:
where is the model's context window size and is the maximum number of tokens reserved for the model's response. Violating this constraint results in a hard API error or silent truncation, depending on the provider.
Cost Function
The cost of an LLM API call is:
where and are the per-token prices. For GPT-4o as of early 2026: p_{\text{input}} = \2.50 / 10^6p_{\text{output}} = $10.00 / 10^6$.
Internal Architecture
A production token counter is rarely a standalone service -- it is an embedded utility within a broader LLM orchestration layer. The architecture typically involves a tokenizer registry that maps model identifiers to their specific tokenizer implementations, a counting engine that performs the actual encoding, and integration points with upstream components (prompt templates, context assemblers) and downstream components (rate limiters, cost trackers, API clients).
Here is how the components fit together in a typical production setup:
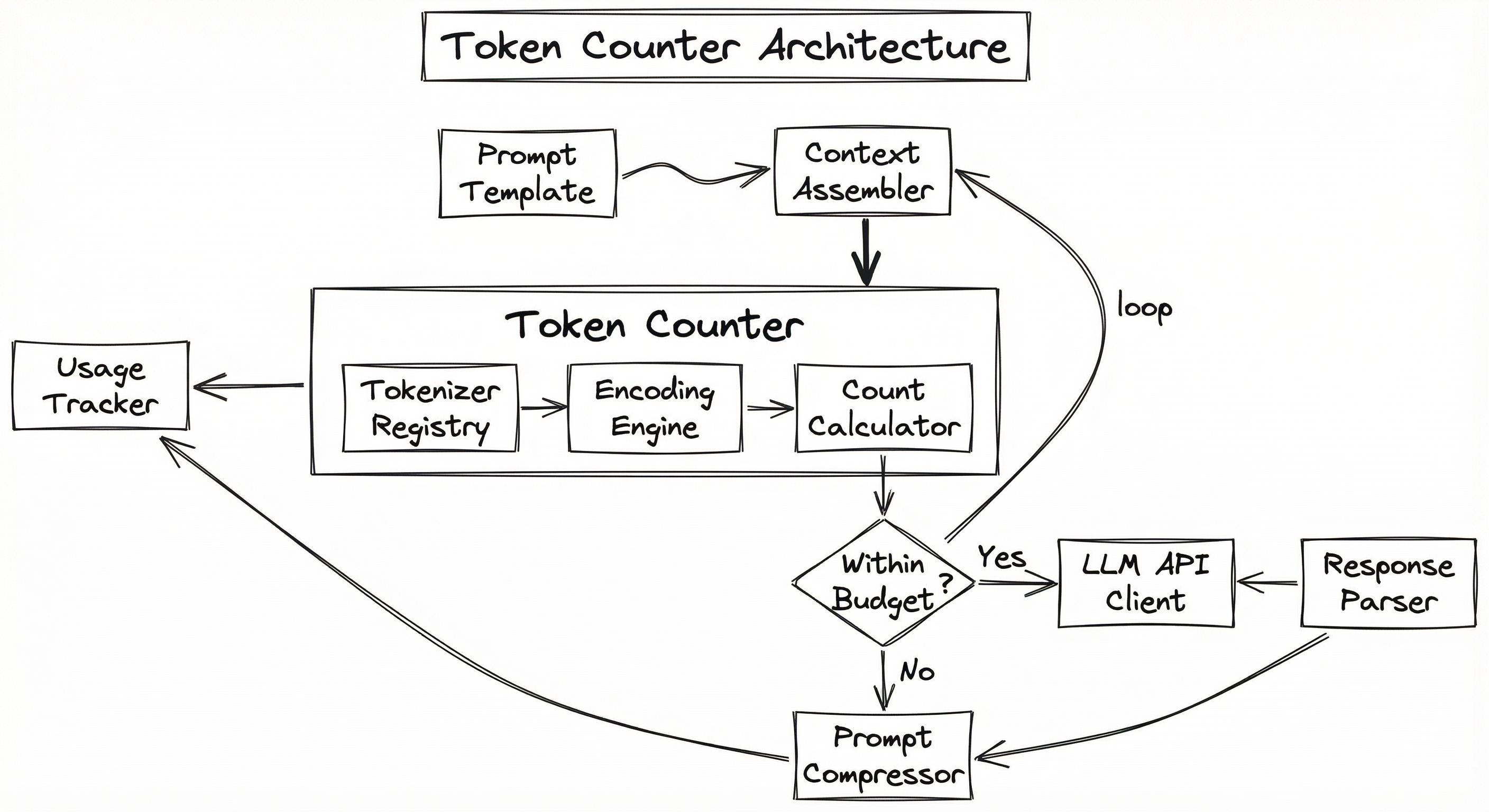
The token counter is invoked at multiple points in the request lifecycle: once during prompt assembly to ensure the payload fits, once after response receipt to log actual usage, and optionally during chunking to produce token-aligned text segments. In high-throughput systems processing thousands of requests per second, the tokenizer must be fast -- which is why libraries like tiktoken (Rust core) and HuggingFace tokenizers (Rust core with Python bindings) are implemented in compiled languages rather than pure Python.
Key Components
Tokenizer Registry
Maintains a mapping from model identifiers (e.g., gpt-4o, claude-sonnet-4-5, gemini-2.5-pro) to their corresponding tokenizer implementations and vocabulary files. Handles lazy loading of tokenizer assets and caches initialized tokenizer instances for reuse across requests. This is the source of truth for which encoding to use for which model.
Encoding Engine
Performs the actual text-to-token-ID conversion using the appropriate algorithm (BPE, Unigram, WordPiece). Accepts raw text and returns a list of integer token IDs. For BPE-based tokenizers, this involves applying merge rules in priority order. For Unigram-based tokenizers, this involves Viterbi decoding to find the maximum-probability segmentation.
Count and Cost Calculator
Takes the token ID list from the encoding engine and computes: (a) the raw token count, (b) the estimated cost based on the model's per-token pricing, and (c) the remaining budget given the context window limit. Supports both input and output token pricing models.
Budget Enforcer
Compares the counted tokens against configured limits -- context window size, per-request token caps, per-user daily quotas, and per-team monthly budgets. Returns a pass/fail decision and, on failure, provides guidance on how many tokens need to be trimmed. Integrates with rate limiters and cost governance systems.
Usage Tracker
Records token usage metrics for observability and billing. Logs input tokens, output tokens, model used, timestamp, user/team identifiers, and computed cost. Feeds into dashboards, alerting systems, and chargeback mechanisms. In multi-tenant SaaS applications, this is the foundation for usage-based billing.
Chunk Sizer
A specialized module that uses the token counter to split documents into chunks of a target token size (not character size). Critical for RAG pipelines where chunk size must align with the embedding model's maximum sequence length and the LLM's context window budget for retrieved passages.
Data Flow
Pre-Request Flow: Raw text components (system prompt, user query, retrieved context, conversation history) arrive at the context assembler. The token counter encodes each component independently and sums the counts. If the total exceeds the context window minus the reserved output tokens, the budget enforcer triggers truncation, summarization, or prompt compression. Once within budget, the assembled prompt is forwarded to the LLM API client.
Post-Response Flow: After the LLM responds, the usage tracker records both the input token count (pre-computed) and the output token count (returned by the API or computed locally). These metrics flow into the cost calculator for billing, the observability stack for monitoring, and the rate limiter for quota enforcement.
Chunking Flow: During document ingestion for RAG, the chunk sizer uses the token counter to split documents at token boundaries rather than character or word boundaries. This ensures that each chunk is exactly N tokens (e.g., 512 tokens for an embedding model with a 512-token context window), avoiding the waste of chunks that are too short or the truncation of chunks that are too long.
A flowchart showing text flowing from Prompt Template through Context Assembler to Token Counter, which branches to either LLM API Client (if within budget) or Prompt Compressor (if over budget, which loops back to Token Counter). The Token Counter internally consists of a Tokenizer Registry feeding an Encoding Engine feeding a Count and Cost Calculator. Post-response, a Usage Tracker receives data from both the Token Counter and the Response Parser.
How to Implement
Three Levels of Token Counting
Implementation approaches range from simple to production-grade:
Level 1: Direct library call -- Use tiktoken, transformers, or sentencepiece to count tokens for a specific model. This is what you do in a Jupyter notebook or a prototype. Five lines of code, zero infrastructure.
Level 2: Abstraction layer -- Build a TokenCounter class that wraps multiple tokenizer backends behind a unified interface, handles model-to-tokenizer mapping, and includes cost estimation. This is what you build when your application supports multiple models.
Level 3: Production middleware -- Embed token counting into your LLM gateway or proxy layer (like Portkey, LiteLLM, or a custom middleware). Token counting happens transparently on every request, feeding into budget enforcement, usage tracking, and auto-routing. This is what you build when token management is a business-critical concern.
The choice depends on your scale. A solo developer calling GPT-4o from a Flask app? Level 1 is fine. A platform team at a company like Razorpay or Zerodha building multi-model AI features across multiple product teams? You need Level 3.
Cost Context: At 100K requests/day with an average of 2,000 input tokens per request, you are processing 200M input tokens daily. At GPT-4o pricing (500/day (~INR 42,000/day or ~INR 12.6 lakh/month). A 20% reduction in token usage through better prompt engineering and context management saves ~INR 2.5 lakh/month. The token counter is the tool that makes this optimization measurable.
import tiktoken
def count_tokens_openai(text: str, model: str = "gpt-4o") -> dict:
"""Count tokens for OpenAI models using tiktoken."""
# Get the encoding for the specified model
encoding = tiktoken.encoding_for_model(model)
# Encode the text into token IDs
token_ids = encoding.encode(text)
token_count = len(token_ids)
# Pricing per million tokens (as of Feb 2026)
pricing = {
"gpt-4o": {"input": 2.50, "output": 10.00},
"gpt-4o-mini": {"input": 0.15, "output": 0.60},
"gpt-4.1": {"input": 2.00, "output": 8.00},
}
cost_per_million = pricing.get(model, {"input": 2.50, "output": 10.00})
estimated_input_cost_usd = (token_count / 1_000_000) * cost_per_million["input"]
return {
"model": model,
"encoding": encoding.name,
"token_count": token_count,
"token_ids": token_ids[:10], # First 10 for inspection
"estimated_input_cost_usd": round(estimated_input_cost_usd, 6),
"estimated_input_cost_inr": round(estimated_input_cost_usd * 84, 4),
}
# Example usage
text = "Explain how token counting works in large language models."
result = count_tokens_openai(text)
print(f"Token count: {result['token_count']}")
print(f"Encoding: {result['encoding']}")
print(f"Cost (USD): ${result['estimated_input_cost_usd']}")
print(f"Cost (INR): ₹{result['estimated_input_cost_inr']}")
# Compare across models
for model in ["gpt-4o", "gpt-4o-mini"]:
r = count_tokens_openai(text, model)
print(f"{model}: {r['token_count']} tokens, ${r['estimated_input_cost_usd']}")This example uses OpenAI's tiktoken library, which is the authoritative token counter for all GPT models. The library is written in Rust with Python bindings, making it extremely fast -- it can tokenize a megabyte of text in under a second. The encoding_for_model() function automatically selects the correct encoding: o200k_base for GPT-4o family models, cl100k_base for GPT-4 and GPT-3.5-turbo. Note the cost estimation: even a small 10-token prompt has a computable cost, and these micro-costs add up to real money at scale.
from transformers import AutoTokenizer
from typing import Optional
class MultiModelTokenCounter:
"""Token counter supporting any HuggingFace-compatible model."""
def __init__(self):
self._cache: dict[str, AutoTokenizer] = {}
def _get_tokenizer(self, model_name: str) -> AutoTokenizer:
if model_name not in self._cache:
self._cache[model_name] = AutoTokenizer.from_pretrained(model_name)
return self._cache[model_name]
def count(self, text: str, model_name: str) -> int:
tokenizer = self._get_tokenizer(model_name)
return len(tokenizer.encode(text))
def count_with_details(self, text: str, model_name: str) -> dict:
tokenizer = self._get_tokenizer(model_name)
encoded = tokenizer.encode(text)
tokens = tokenizer.convert_ids_to_tokens(encoded)
return {
"model": model_name,
"token_count": len(encoded),
"tokens_preview": tokens[:20],
"vocab_size": tokenizer.vocab_size,
"chars_per_token": round(len(text) / max(len(encoded), 1), 2),
}
def compare_models(self, text: str, model_names: list[str]) -> list[dict]:
"""Compare token counts across multiple models."""
results = []
for model in model_names:
result = self.count_with_details(text, model)
results.append(result)
return sorted(results, key=lambda x: x["token_count"])
# Usage
counter = MultiModelTokenCounter()
text = "मुंबई में आज का मौसम बहुत अच्छा है।" # Hindi text
models = [
"meta-llama/Llama-3.1-8B",
"mistralai/Mistral-7B-v0.1",
"google/gemma-2-2b",
]
for result in counter.compare_models(text, models):
print(f"{result['model']}: {result['token_count']} tokens "
f"({result['chars_per_token']} chars/token)")This example demonstrates multi-model token counting using HuggingFace's transformers library. The key insight is the compare_models method: different models tokenize the same text very differently, especially for non-English content. Hindi text might produce 15 tokens on one model and 45 on another due to vocabulary differences. The chars_per_token metric is particularly useful for identifying models that are inefficient for your specific language or domain. Note the tokenizer caching -- initializing a tokenizer is expensive (loading vocabulary files from disk or network), so always cache instances.
import tiktoken
from dataclasses import dataclass, field
from typing import Optional
@dataclass
class TokenBudget:
"""Represents the token allocation for a single LLM request."""
context_window: int # Total model context window
max_output_tokens: int # Reserved for response
system_prompt_tokens: int = 0
user_query_tokens: int = 0
context_tokens: int = 0
history_tokens: int = 0
@property
def total_input_tokens(self) -> int:
return (self.system_prompt_tokens + self.user_query_tokens +
self.context_tokens + self.history_tokens)
@property
def available_tokens(self) -> int:
return self.context_window - self.max_output_tokens - self.total_input_tokens
@property
def is_within_budget(self) -> bool:
return self.available_tokens >= 0
@property
def utilization_pct(self) -> float:
usable = self.context_window - self.max_output_tokens
return round((self.total_input_tokens / usable) * 100, 1) if usable > 0 else 0.0
class TokenBudgetManager:
"""Manages token budgets for LLM requests."""
MODEL_CONFIGS = {
"gpt-4o": {"window": 128_000, "encoding": "o200k_base"},
"gpt-4o-mini": {"window": 128_000, "encoding": "o200k_base"},
"gpt-4.1": {"window": 1_047_576, "encoding": "o200k_base"},
}
def __init__(self, model: str = "gpt-4o", max_output_tokens: int = 4096):
config = self.MODEL_CONFIGS[model]
self.encoding = tiktoken.get_encoding(config["encoding"])
self.model = model
self.budget = TokenBudget(
context_window=config["window"],
max_output_tokens=max_output_tokens,
)
def count(self, text: str) -> int:
return len(self.encoding.encode(text))
def allocate_system_prompt(self, text: str) -> int:
count = self.count(text)
self.budget.system_prompt_tokens = count
return count
def allocate_user_query(self, text: str) -> int:
count = self.count(text)
self.budget.user_query_tokens = count
return count
def allocate_context(self, chunks: list[str], max_tokens: Optional[int] = None) -> list[str]:
"""Add context chunks until budget or max_tokens is exhausted."""
max_tokens = max_tokens or self.budget.available_tokens
selected_chunks = []
tokens_used = 0
for chunk in chunks:
chunk_tokens = self.count(chunk)
if tokens_used + chunk_tokens > max_tokens:
break
selected_chunks.append(chunk)
tokens_used += chunk_tokens
self.budget.context_tokens = tokens_used
return selected_chunks
def get_budget_report(self) -> dict:
b = self.budget
return {
"model": self.model,
"context_window": b.context_window,
"max_output_tokens": b.max_output_tokens,
"system_prompt_tokens": b.system_prompt_tokens,
"user_query_tokens": b.user_query_tokens,
"context_tokens": b.context_tokens,
"history_tokens": b.history_tokens,
"total_input_tokens": b.total_input_tokens,
"available_tokens": b.available_tokens,
"utilization_pct": b.utilization_pct,
"is_within_budget": b.is_within_budget,
}
# Usage
manager = TokenBudgetManager(model="gpt-4o", max_output_tokens=4096)
manager.allocate_system_prompt("You are a helpful assistant for IRCTC.")
manager.allocate_user_query("What is the PNR status for ticket 2124567890?")
# Simulate RAG context chunks
chunks = [
"PNR 2124567890: Train 12301 Rajdhani Express, Delhi to Kolkata...",
"Current status: Confirmed, Coach B2, Berth 45, Departure 18:00...",
"Refund policy: Cancellation before 24 hours gets 75% refund...",
"Alternative trains: 12303 Poorva Express departs at 20:00...",
]
selected = manager.allocate_context(chunks)
report = manager.get_budget_report()
print(f"Using {report['total_input_tokens']} of {report['context_window']} tokens")
print(f"Utilization: {report['utilization_pct']}%")
print(f"Chunks included: {len(selected)} of {len(chunks)}")This is a production-grade token budget manager that treats the context window as a finite resource to be carefully allocated. The allocate_context method is especially important for RAG pipelines: it greedily fills the available token budget with retrieved chunks, stopping when adding the next chunk would exceed the limit. The utilization_pct metric is valuable for monitoring -- if your prompts consistently use less than 50% of the context window, you might be leaving retrieval quality on the table. If they consistently hit 90%+, you risk performance degradation (research suggests quality drops when utilization exceeds 85%).
import tiktoken
from typing import Generator
def chunk_by_tokens(
text: str,
chunk_size: int = 512,
chunk_overlap: int = 64,
model: str = "gpt-4o",
) -> Generator[dict, None, None]:
"""Split text into chunks of exactly `chunk_size` tokens.
Unlike character-based chunking, this ensures each chunk
is exactly the right size for the target model.
"""
encoding = tiktoken.encoding_for_model(model)
tokens = encoding.encode(text)
total_tokens = len(tokens)
if total_tokens <= chunk_size:
yield {
"text": text,
"token_count": total_tokens,
"chunk_index": 0,
"start_token": 0,
"end_token": total_tokens,
}
return
step = chunk_size - chunk_overlap
chunk_index = 0
for start in range(0, total_tokens, step):
end = min(start + chunk_size, total_tokens)
chunk_tokens = tokens[start:end]
chunk_text = encoding.decode(chunk_tokens)
yield {
"text": chunk_text,
"token_count": len(chunk_tokens),
"chunk_index": chunk_index,
"start_token": start,
"end_token": end,
}
chunk_index += 1
if end >= total_tokens:
break
# Usage
document = """India's Unified Payments Interface (UPI) processed over
15 billion transactions in December 2025, handling more than
₹23 lakh crore in value. PhonePe and Google Pay together account
for roughly 85% of UPI transaction volume. The system's success
has made it a model for real-time payment infrastructure globally,
with countries like Singapore, UAE, and France adopting
interoperable QR-code based systems inspired by UPI..."""
for chunk in chunk_by_tokens(document, chunk_size=128, chunk_overlap=16):
print(f"Chunk {chunk['chunk_index']}: {chunk['token_count']} tokens")
print(f" Preview: {chunk['text'][:80]}...")
print()Token-aware chunking is critical for RAG pipelines because character-based chunking produces chunks of unpredictable token lengths. A 1,000-character chunk might be 200 tokens of English prose or 400 tokens of Hindi text. This function guarantees each chunk is exactly chunk_size tokens (or fewer for the final chunk), with configurable overlap for context continuity across chunk boundaries. The overlap of 64 tokens (roughly 50 words) helps maintain coherence when retrieval returns adjacent chunks.
# Token counter configuration (YAML)
token_counter:
default_model: gpt-4o
cache_tokenizers: true
models:
gpt-4o:
encoding: o200k_base
context_window: 128000
pricing:
input_per_million: 2.50
output_per_million: 10.00
cached_input_per_million: 1.25
gpt-4o-mini:
encoding: o200k_base
context_window: 128000
pricing:
input_per_million: 0.15
output_per_million: 0.60
claude-sonnet-4-5:
tokenizer: anthropic # Use Anthropic's token counting API
context_window: 200000
pricing:
input_per_million: 3.00
output_per_million: 15.00
cached_input_per_million: 0.30
gemini-2.5-pro:
tokenizer: google # Use Google's token counting API
context_window: 1000000
pricing:
input_per_million: 1.25
output_per_million: 10.00
budget:
default_max_output_tokens: 4096
warn_at_utilization_pct: 85
hard_limit_utilization_pct: 95
quotas:
per_user_daily_tokens: 1000000
per_team_monthly_tokens: 100000000
alert_at_pct: 80Common Implementation Mistakes
- ●
Using the wrong tokenizer for the model: Counting tokens with
cl100k_base(GPT-4) when targeting GPT-4o (which useso200k_base) will give you incorrect counts. Always usetiktoken.encoding_for_model()to get the correct encoding automatically, and never hardcode encoding names. - ●
Estimating tokens from word count: The "1 token ~ 0.75 words" heuristic fails for code (2-3x more tokens per word), non-English text (up to 5x for Indic scripts), and structured data (JSON/XML). Always count tokens programmatically -- the cost of running the tokenizer is negligible compared to the cost of a wrong estimate.
- ●
Forgetting to count special tokens: Chat-formatted messages include special tokens (
<|im_start|>,<|im_end|>, role markers) that are not part of your visible text but consume tokens. For a typical chat API call, these overhead tokens add 3-10 tokens per message. At scale with multi-turn conversations, this adds up. - ●
Not accounting for output tokens in budget calculations: Teams allocate their entire context window to input and then wonder why the model's response is truncated. Always reserve tokens for the expected output length:
available_input = context_window - max_output_tokens. - ●
Initializing tokenizers on every request: Loading a tokenizer from disk or network takes 50-200ms. In a production pipeline processing hundreds of requests per second, this latency is unacceptable. Always cache tokenizer instances and reuse them across requests.
- ●
Assuming cross-model token count equivalence: Claude, GPT-4o, and Gemini all tokenize the same text differently. A 1,000-token prompt for GPT-4o might be 1,200 tokens for Claude and 900 for Gemini. If you switch models, recount everything.
When Should You Use This?
Use When
You are building any application that calls an LLM API and need to ensure prompts fit within context windows before making the call
You need to estimate and track LLM costs across multiple models, teams, or product features
You are implementing a RAG pipeline and need to size document chunks to exactly match embedding model or LLM token limits
Your application supports multiple LLM providers and you need to normalize token counting across different tokenization schemes
You need to implement per-user or per-team token quotas for a multi-tenant SaaS application
You are doing prompt engineering and need to measure the token impact of different prompt strategies
You are building an LLM gateway or proxy that needs to enforce token budgets and provide usage analytics
Avoid When
You are making one-off, manual API calls where eyeballing prompt length is sufficient -- adding a token counter to a Jupyter notebook experiment is over-engineering
Your prompts are static and well under the context window limit (e.g., a fixed 200-token classification prompt against a 128K context window) -- the margin is so large that counting adds no value
You are using a provider that handles token validation server-side and you have no cost or quota concerns -- though this is rare in production
The provider offers a built-in token counting endpoint and you do not need client-side pre-validation (e.g., Anthropic's token counting API for one-off checks)
Your application exclusively uses streaming responses where token-by-token output tracking replaces upfront counting
Key Tradeoffs
Accuracy vs. Speed
Exact token counting requires running the full tokenizer, which is in text length. For tiktoken with its Rust core, this is sub-millisecond for typical prompts (under 10K tokens). For pure Python tokenizers, it can be 10-50ms. In a pipeline that processes thousands of requests per second, even sub-millisecond overhead multiplied by three or four counting operations per request starts to matter.
Some teams use heuristic estimators -- e.g., len(text) / 4 for English -- as a fast first pass, and only run the full tokenizer when the estimate is within 10% of the limit. This two-tier approach reduces tokenizer invocations by 80-90% in systems where most prompts are well within budget.
Precision vs. Cross-Model Portability
Using the exact tokenizer for each model gives you perfect accuracy but creates a maintenance burden: you need to keep tokenizer versions in sync with model updates, handle models that do not have public tokenizers, and manage the dependency footprint. A "close enough" universal estimator (like using cl100k_base as an approximation for all models) reduces complexity but introduces 5-15% counting errors.
| Approach | Accuracy | Speed | Complexity | Best For |
|---|---|---|---|---|
| Exact tokenizer per model | 100% | Fast (Rust-backed) | High | Production systems with tight budgets |
| Heuristic estimation | 70-85% | Instant | Low | Quick checks, well-under-limit prompts |
| Universal approximation | 85-95% | Fast | Medium | Multi-model systems without strict limits |
| Provider API counting | 100% | Slow (network) | Low | One-off checks, pre-deployment validation |
Client-Side vs. Server-Side Counting
Counting tokens client-side (before the API call) lets you prevent wasted requests and manage budgets proactively. But some providers (Anthropic, Google) also return token counts in the API response, which gives you exact actuals for billing reconciliation. The best systems do both: pre-count to validate, post-count to verify.
Alternatives & Comparisons
A rate limiter controls the frequency of LLM API calls (requests per minute, tokens per minute), while a token counter measures the size of individual requests. They are complementary: the token counter tells you how big each request is, and the rate limiter ensures you do not exceed throughput limits. In practice, you need both -- the token counter feeds data to the rate limiter.
A response cache eliminates redundant LLM calls entirely by serving cached responses for repeated or similar queries. A token counter reduces the cost of new calls by optimizing prompt size. Caching is higher-ROI for high-repetition workloads (FAQ bots, classification), while token counting is essential for unique, context-heavy queries (RAG, code generation) where cache hit rates are low.
A text chunker splits documents into segments for processing, and ideally uses a token counter internally to produce token-aligned chunks. Without a token counter, chunkers operate on characters or words, which produces chunks of unpredictable token lengths. The token counter is a dependency of a good text chunker, not an alternative to it.
Pros, Cons & Tradeoffs
Advantages
Prevents hard API failures by validating that prompts fit within context windows before making the call -- a failed API call due to context overflow wastes latency and money
Enables precise cost tracking down to the individual request level, making it possible to attribute LLM spend to specific features, users, or teams -- essential for unit economics at companies like Razorpay or Swiggy building AI features
Supports multi-model optimization by revealing which model tokenizes your specific content most efficiently, allowing intelligent model routing (e.g., route Hindi-heavy queries to models with better Indic tokenization)
Enables token-aware chunking for RAG pipelines, ensuring document chunks are sized to exactly match embedding model limits rather than using imprecise character-based splitting
Provides the foundation for prompt optimization by making token counts measurable and comparable -- you cannot optimize what you do not measure, and token counting turns prompt engineering from guesswork into data-driven iteration
Supports budget enforcement and quota management in multi-tenant applications, preventing any single user or team from exhausting shared LLM resources
Fast and lightweight: Modern tokenizer libraries (tiktoken, HuggingFace tokenizers) are implemented in Rust and add sub-millisecond overhead per encoding operation
Disadvantages
Model-specific tokenizers create maintenance burden: Each model family requires its own tokenizer, and tokenizer updates (e.g., vocabulary changes between GPT-4 and GPT-4o) require code changes
Not all models have public tokenizers: Anthropic and Google do not publish their exact tokenizer implementations, forcing you to either use API-based counting (adds latency) or approximate with a similar tokenizer (loses accuracy)
Adds a processing step to every request: In latency-sensitive pipelines, even sub-millisecond tokenizer overhead across multiple components adds up
Token counts do not capture semantic value: A 1,000-token prompt is not inherently better or worse than a 500-token prompt; the token counter tells you size, not quality
Cross-model token counts are not comparable: 1,000 GPT-4o tokens and 1,000 Claude tokens represent different amounts of text, making cross-model cost comparison nuanced
Overhead for very short prompts: For simple, short prompts that are obviously well within the context window, the token counting step adds complexity with no practical benefit
Failure Modes & Debugging
Tokenizer version mismatch
Cause
The token counter uses an outdated tokenizer version that does not match the model's current encoding. For example, using cl100k_base (GPT-4) to count tokens for GPT-4o (which uses o200k_base). This happens when tokenizer libraries are not updated alongside model upgrades.
Symptoms
Token counts are consistently off by 5-20%. Prompts that should fit within the context window occasionally fail. Cost estimates diverge from actual bills. The errors are systematic but not catastrophic, making them hard to detect without explicit validation.
Mitigation
Pin tokenizer versions to model versions in your configuration. Set up automated tests that compare your token counter's output against the provider's API-reported token counts for a set of reference inputs. Alert on divergence greater than 1%. Update tiktoken and transformers libraries promptly when new model encodings are released.
Context window overflow from uncounted overhead
Cause
The token counter counts the visible text content but misses tokens added by the API layer: chat format tokens (<|im_start|>, <|im_end|>), role markers, separator tokens, and system-injected safety prefixes. These can add 50-200 tokens per request depending on the provider and message count.
Symptoms
API calls fail with context length exceeded errors even though your pre-counted tokens are within limits. The failures are intermittent -- they happen only when the prompt is near the context window boundary.
Mitigation
Account for message formatting overhead. OpenAI's cookbook provides exact formulas for chat message token overhead. As a safety margin, reserve 5-10% of the context window beyond your calculated needs. For multi-turn conversations, the overhead grows linearly with message count.
Multilingual token inflation
Cause
Non-English text -- especially in scripts with large character sets like Devanagari (Hindi), Tamil, Telugu, CJK, or Arabic -- is tokenized far less efficiently than English. A sentence that would be 20 tokens in English might become 60-100 tokens in Hindi. Teams that size their prompts based on English testing are surprised when Indic language inputs blow through token budgets.
Symptoms
Token budgets are exhausted much faster for non-English users. Context chunks for Hindi or Tamil documents fit fewer per request than English equivalents. Cost per query is 2-5x higher for non-English languages. Users in India report worse response quality because less context fits in the window.
Mitigation
Test token counts across all languages your application supports. Set language-specific chunk sizes (e.g., 256 tokens for Hindi content vs. 512 for English). Consider models with better multilingual tokenization (e.g., models trained on Indic data like AI4Bharat's IndicBERT use tokenizers optimized for Indian languages). Budget for the worst-case language, not English.
Silent truncation without counting
Cause
Some API configurations silently truncate input that exceeds the context window rather than raising an error. If the application does not pre-count tokens, critical context (retrieved documents, conversation history) may be silently dropped without any indication.
Symptoms
LLM responses become less relevant or hallucinate more frequently, but no errors are logged. The issue is intermittent -- it only occurs when prompts happen to exceed the window. User satisfaction drops but the engineering team sees no errors in monitoring.
Mitigation
Always pre-count tokens before API calls. Never rely on the provider to handle overflow gracefully. Log both pre-counted input tokens and API-reported input tokens, and alert on significant discrepancies. Implement explicit truncation with logging rather than allowing silent truncation.
Tokenizer initialization bottleneck
Cause
Tokenizer instances are created on every request instead of being cached. Loading tokenizer vocabulary files and merge rules from disk takes 50-500ms depending on the library and model. In a serverless or cold-start environment, this latency compounds with container spin-up time.
Symptoms
P99 latency spikes on the first request after deployment or cold start. Consistent 100-500ms overhead on every request in systems that do not cache tokenizer instances. High CPU usage from repeated tokenizer initialization.
Mitigation
Cache tokenizer instances at the module or application level. In serverless environments (AWS Lambda, Azure Functions), initialize tokenizers outside the handler function so they persist across invocations. Use lazy initialization with a thread-safe singleton pattern.
Cost estimation drift from stale pricing
Cause
Token pricing is hardcoded in the application and not updated when providers change their prices. LLM pricing has been highly volatile -- OpenAI has cut GPT-4o pricing multiple times since its launch, and Anthropic's Claude 4.5 family is significantly cheaper than Claude 3.5.
Symptoms
Cost dashboards and budget alerts are based on outdated pricing, leading to either over-budgeting (wasted allocation) or under-budgeting (surprise bills). Teams make model routing decisions based on stale cost data.
Mitigation
Externalize pricing configuration rather than hardcoding it. Use a configuration file or environment variables that can be updated without code changes. Consider pulling pricing from provider APIs where available. Set up quarterly pricing review reminders.
Placement in an ML System
Where the Token Counter Lives in the Pipeline
The token counter touches nearly every stage of an LLM application pipeline, but its primary home is in the pre-processing and orchestration layer -- the code that assembles prompts, validates them, and decides how to route them to the LLM.
In a RAG pipeline, the token counter is invoked at three points: (1) during document ingestion, to produce token-aligned chunks for the vector store; (2) during context assembly, to determine how many retrieved chunks fit within the remaining token budget; and (3) during cost tracking, to log the actual token usage of each request.
In a conversational AI system (like a customer support bot for Swiggy or a financial advisor for Zerodha), the token counter manages the conversation history: as the conversation grows, older messages must be summarized or dropped to stay within the context window. The token counter tells the system exactly when this pruning needs to happen.
In a multi-model routing system, the token counter enables cost-aware routing: a complex query that needs 50K tokens of context might be routed to Gemini 2.5 Pro (1M context window, 2.50/M input tokens), saving both money and avoiding potential overflow.
Integration Note: The token counter is a dependency of the context assembler, the rate limiter, the response cache (for key generation), and the cost tracker. It is one of the most cross-cutting components in an LLM application. Design it as a shared utility, not a one-off function buried in a single module.
Pipeline Stage
LLM Operations / Pre-Processing
Upstream
- prompt-template
- context-assembler
- text-chunker
Downstream
- rate-limiter
- response-cache
- embedding-model
Scaling Bottlenecks
The token counter itself is rarely the bottleneck -- modern tokenizer implementations in Rust (tiktoken at ~1M tokens/sec, HuggingFace tokenizers at similar throughput) are fast enough for virtually any production workload. The real bottleneck is the downstream LLM API call, which is 1000x slower than tokenization.
However, at extreme scale (millions of requests per second), tokenizer memory footprint matters. Each loaded tokenizer consumes 10-100MB of RAM for its vocabulary and merge tables. If you support 10+ models with distinct tokenizers, that is 1GB+ of resident memory just for tokenizer state. In memory-constrained environments (serverless functions with 512MB RAM), this can be a real constraint.
The other scaling consideration is token-aware chunking during ingestion: when processing millions of documents, the O(n) tokenization cost for each document adds up. Batch processing at 1M docs/hour with average doc length of 5,000 tokens requires ~5 billion tokenizer operations. Even at microsecond per operation, that is ~80 minutes of CPU time -- manageable on a single machine but worth parallelizing.
Production Case Studies
OpenRouter, a multi-model LLM routing platform, published a comprehensive study analyzing metadata from over 100 trillion tokens processed through their platform. Their token tracking infrastructure revealed that average prompt tokens per request quadrupled from ~1.5K to over 6K between 2024 and 2025, driven by the rise of agentic workflows and long-context RAG. Token counting across 200+ model providers required normalizing different tokenization schemes into a consistent measurement framework.
The study identified that programming tasks consistently represent 40-60% of all tokens processed. By tracking token usage patterns, OpenRouter enabled intelligent routing that saved users an estimated 30-40% on API costs through model selection optimization.
Portkey, a Mumbai-based AI gateway startup, built a production token tracking system that sits between applications and LLM providers. Their AI gateway counts tokens independently of provider-reported usage, normalizes counts across OpenAI, Anthropic, AWS Bedrock, and Google Vertex, and provides per-team, per-workload cost attribution. The system processes billions of tokens monthly across their customer base.
Portkey's token tracking infrastructure enables automated budget enforcement with usage caps, rate limits, and budget thresholds per team or workload. Customers report 20-40% cost reduction through visibility into token waste and intelligent model routing based on token usage patterns.
Delivery Hero (parent of Foodpanda, operating across India and Southeast Asia) used token counting and prompt optimization to build their product knowledge base with agentic AI. They meticulously crafted concise prompts to reduce token usage while maintaining output quality. For their title generation pipeline, they used knowledge distillation -- fine-tuning a smaller student model (GPT-4o-mini) to replicate a teacher model's output quality with significantly shorter, more efficient prompts.
The knowledge distillation approach reduced per-request token usage by approximately 60%, significantly lowering operational costs. The student model achieved comparable quality with much shorter prompts, enabling cost-effective scaling across millions of product listings.
Microsoft Research developed LLMLingua, a prompt compression framework that uses token-level analysis to reduce prompt sizes by up to 20x while maintaining task performance. The system employs a coarse-to-fine compression approach: a budget controller maintains semantic integrity under high compression ratios, and a token-level iterative algorithm models interdependence between compressed contents. Token counting is central to the framework -- it measures compression ratios and ensures compressed prompts still fit within target budgets.
LLMLingua achieved up to 20x compression with less than 5% accuracy loss across GSM8K, BBH, ShareGPT, and Arxiv-March23 benchmarks. The follow-up LLMLingua-2 is 3-6x faster and enables 1.6-2.9x end-to-end latency reduction at 2-5x compression ratios.
Tooling & Ecosystem
OpenAI's official BPE tokenizer library. Written in Rust with Python bindings, it is 3-6x faster than alternatives. Supports all OpenAI model encodings: o200k_base (GPT-4o family), cl100k_base (GPT-4, GPT-3.5-turbo). The authoritative tool for counting tokens for any OpenAI model.
Fast, general-purpose tokenizer library supporting BPE, WordPiece, Unigram, and more. Rust core with Python, Node.js, and Ruby bindings. Can tokenize a GB of text in under 20 seconds. Supports any model hosted on HuggingFace Hub, making it the go-to choice for open-source model token counting (LLaMA, Mistral, Gemma, etc.).
Google's language-independent subword tokenizer supporting both BPE and Unigram algorithms. Operates directly on raw Unicode text without whitespace assumptions, making it particularly effective for Indian languages and other non-Latin scripts. Used by T5, ALBERT, LLaMA, and many multilingual models.
Open-source AI gateway that provides transparent token counting, cost tracking, and usage analytics across 200+ LLM providers. Normalizes token counts across different providers and enables per-team budget enforcement. Built by a Mumbai-based team, with strong support for Indian deployment scenarios.
Unified interface for 100+ LLM providers with built-in token counting and cost tracking. Automatically selects the correct tokenizer for each model, normalizes token counts, and provides spend tracking per API key, user, and team. Useful as a drop-in proxy with token management built in.
OpenAI's interactive web-based tokenizer tool. Lets you paste text and see the exact token breakdown visually -- each token highlighted in a different color. Invaluable for debugging tokenization issues and building intuition about how text maps to tokens. No code required.
Microsoft's prompt compression toolkit that uses token-level analysis to compress prompts by up to 20x while preserving task performance. Integrates with token counting to measure compression ratios and ensure compressed prompts fit within target budgets. Essential for cost optimization in token-heavy RAG pipelines.
Research & References
Sennrich, Haddow & Birch (2016)ACL 2016
The foundational paper that introduced Byte Pair Encoding (BPE) for NLP. Adapted the BPE compression algorithm to segment words into subword units, enabling open-vocabulary neural translation. This paper established the subword tokenization paradigm used by virtually every modern LLM.
Kudo & Richardson (2018)EMNLP 2018 (System Demonstration)
Introduced SentencePiece, a language-independent tokenizer that operates on raw Unicode text without whitespace assumptions. Supports both BPE and Unigram algorithms. Especially important for multilingual and Indic language applications where whitespace-based pre-tokenization fails.
Jiang, Wu, Luo, Li, et al. (2023)EMNLP 2023
Proposed a coarse-to-fine prompt compression method achieving up to 20x compression with minimal performance loss. The framework uses token-level iterative compression guided by a budget controller, directly leveraging token counting for compression ratio management.
Pan, Wu, Jiang, et al. (2024)ACL 2024 (Findings)
Improved upon LLMLingua with a data distillation approach for task-agnostic prompt compression. Achieves 3-6x faster compression while being 1.6-2.9x faster end-to-end. Demonstrates that token-aware compression can be both efficient and faithful to the original content.
Han, Wang, Fang, Zhao, Ma & Chen (2024)ACL 2025 (Findings)
Introduced TALE, a framework that dynamically estimates token budgets based on task complexity to guide LLM reasoning. Reduces token usage by 68.9% on average with less than 5% accuracy loss by making LLMs aware of their token budget during chain-of-thought reasoning.
Multiple authors (2024)arXiv preprint
Evaluated tokenizer efficiency across all 22 official Indian languages for major LLM families. Found that current tokenizers produce significantly more tokens for Indic scripts compared to English, with implications for cost, latency, and context window utilization in Indian language applications.
Zouhar, Meister, Gastaldi, Du, Vieira, Salesky & Cotterell (2023)ACL 2023 (Findings)
Provided the first formal analysis of BPE's theoretical properties, including its greedy compression behavior and the conditions under which it produces optimal segmentations. Important for understanding why BPE token counts vary across different text types.
OpenRouter & a16z (2025)arXiv preprint
Analyzed metadata from 100+ trillion tokens processed through OpenRouter's multi-model platform. Found that average prompt length quadrupled to 6K tokens and programming tasks represent 40-60% of all tokens, highlighting the growing importance of accurate token counting at scale.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a token counting and budget management system for a multi-model LLM application?
- ●
Explain the difference between BPE, WordPiece, and SentencePiece tokenization. When does the choice matter for token counting?
- ●
A user reports that their Hindi-language queries are getting truncated. How would you diagnose and fix this?
- ●
How would you estimate LLM API costs for a product serving 1 million daily active users in India?
- ●
What happens if you count tokens with the wrong tokenizer? How would you detect and prevent this?
- ●
Design a token budget allocation strategy for a RAG pipeline with a 128K context window.
Key Points to Mention
- ●
Token counts are model-specific -- always use the exact tokenizer for the target model. Cross-model estimation introduces 5-30% error depending on the tokenizer families involved.
- ●
The token budget constraint is: system_tokens + user_tokens + context_tokens + reserved_output <= context_window. Violating this causes hard failures or silent truncation -- both are unacceptable in production.
- ●
Multilingual token inflation is a critical real-world concern: Hindi/Tamil/Telugu text can use 3-5x more tokens than English for equivalent content, directly impacting cost and quality for Indian users.
- ●
In production, token counting is not a one-off check -- it is continuous observability. Track token usage per request, per user, per feature, and per model. Alert on anomalies. Budget and forecast based on historical patterns.
- ●
Prompt compression (LLMLingua, etc.) and token-aware chunking are advanced techniques that depend on accurate token counting to function correctly.
- ●
The cost formula is straightforward () but the optimization space is rich: prompt caching (90% discount), batch APIs (50% discount), model routing, and prompt compression can reduce costs by 60-80%.
Pitfalls to Avoid
- ●
Saying that token count can be estimated from word count or character count -- this shows a fundamental misunderstanding of how tokenization works and immediately disqualifies you for senior roles.
- ●
Ignoring the multilingual dimension: if your system serves Indian users, you must address the Indic language token inflation problem. Interviewers from Indian companies (Flipkart, Swiggy, etc.) will specifically test for this.
- ●
Treating token counting as a pure engineering problem without connecting it to business impact -- the senior framing is always about cost, quality, and user experience.
- ●
Forgetting to account for output tokens when calculating context window budgets -- this is a surprisingly common error even among experienced engineers.
- ●
Claiming that all LLMs use the same tokenizer -- they do not, and the differences are significant.
Senior-Level Expectation
A senior candidate should demonstrate end-to-end thinking about token management as a system design problem, not just a library call. This means discussing: (1) how token counting integrates with the broader LLM orchestration layer (context assembly, rate limiting, cost tracking, model routing); (2) the multilingual challenge and how to handle it for Indian languages specifically; (3) cost optimization strategies beyond basic counting -- prompt caching (90% cost reduction on Anthropic), batch APIs (50% discount), prompt compression (2-20x reduction), and smart model routing; (4) observability and governance -- per-team quotas, usage dashboards, anomaly detection on token consumption patterns; (5) capacity planning -- given projected user growth and average tokens per request, what will your monthly LLM bill be in 6 months, and what levers do you have to control it? The ability to connect token-level technical details to rupee-level business impact is what separates staff engineers from senior engineers.
Summary
A token counter is a foundational component of any production LLM system, responsible for converting text into model-specific token representations and reporting the exact count. Far from being a simple utility function, it underpins cost management, context window enforcement, prompt optimization, and usage governance across the entire LLM application lifecycle.
The technical core is subword tokenization -- primarily BPE (used by GPT-4o, LLaMA, Mistral) and SentencePiece (used by T5, multilingual models). Different models use different tokenizers with different vocabularies, which means the same text produces different token counts across models. This model-specificity is the central challenge: you must always count with the exact tokenizer for your target model, and cross-model estimation introduces 5-30% error. For non-English text, especially Indian languages like Hindi, Tamil, and Telugu, the challenge is amplified by token inflation -- Indic scripts can use 2-5x more tokens than English for equivalent content, directly impacting cost and quality for Indian users.
In production, token counting integrates with every stage of the LLM pipeline: the context assembler uses it to fit prompts within the window, the text chunker uses it to produce token-aligned segments, the rate limiter uses it to enforce throughput quotas, and the cost tracker uses it to attribute spend to specific users, teams, and features. With LLM API costs running into lakhs of rupees per month for high-volume applications, the ability to measure, manage, and optimize token usage is not a nice-to-have -- it is a business-critical capability. The token counter is the instrument that makes this possible.