Text Chunker in Machine Learning
Let's talk about text chunking -- the unsung hero of every RAG pipeline.
A text chunker is a preprocessing component that partitions long documents into smaller, semantically coherent segments suitable for embedding and retrieval. In retrieval-augmented generation (RAG) systems, chunking determines the granularity at which knowledge is indexed and retrieved. Get it wrong and everything downstream suffers: too-small chunks lack the context an LLM needs to generate a useful answer; too-large chunks conflate semantically distinct content into a single vector, and retrieval precision tanks.
The chunker sits at a critical junction -- after document ingestion but before embedding -- and it defines the retrieval unit that every downstream component operates on. Think of it as the decision that echoes through your entire pipeline.
Modern chunking strategies range from naive fixed-size splitting to context-aware methods that preserve sentence boundaries, leverage embedding models to detect semantic shifts, or maintain hierarchical parent-child relationships. The choice of strategy directly impacts retrieval recall, answer quality, and the computational cost of indexing and querying your knowledge base.
The chunker doesn't just "split text" -- it decides what your retrieval system can and cannot find. Choose wisely.
Concept Snapshot
- What It Is
- A preprocessing module that splits long documents into smaller, contextually coherent text segments (chunks) optimized for embedding-based retrieval in RAG pipelines.
- Category
- RAG Pipeline
- Complexity
- Intermediate
- Inputs / Outputs
- Input: raw documents (text, markdown, PDF extracts). Output: array of text chunks with metadata (source document ID, character offsets, chunk index).
- System Placement
- Sits between the document loader (upstream) and the embedding model (downstream) in a RAG ingestion pipeline.
- Also Known As
- document chunker, text splitter, text segmentation, passage extractor, chunk generator
- Typical Users
- ML engineers, RAG engineers, search/retrieval specialists, NLP engineers
- Prerequisites
- Document parsing, Text tokenization, Embedding models, Basic NLP
- Key Terms
- chunk sizechunk overlapsemantic boundarycontext windowretrieval granularitysentence windowparent-child chunkslate chunking
Why This Concept Exists
The Mismatch Problem
Here's the fundamental issue: embedding models and retrieval systems impose practical constraints that raw documents simply don't satisfy.
Transformer-based encoders have finite context windows. BERT variants typically handle 512 tokens, while modern long-context models extend to 8K-32K tokens -- but even they can't ingest an entire book or codebase in one pass. And even when it's technically feasible to squeeze a full document into one embedding, you lose granularity: the resulting vector averages over all content, making it nearly impossible to retrieve specific facts or passages.
Retrieval at Scale
Retrieval systems suffer similar problems at scale. When a user at, say, an Indian fintech company asks "What are the RBI guidelines for KYC verification?" your vector store should return the most relevant passage -- not an entire 120-page regulatory document. Downstream LLMs have their own context limits too. Feeding retrieved text into GPT-4 or Claude means staying within the prompt budget, which often means 2-4 pages of context maximum.
The Solution
The text chunker emerged as the bridge across this mismatch. By splitting documents into semantically meaningful units of appropriate size, it enables:
- Embedding models to produce focused, high-quality representations
- Retrieval systems to return precise passages
- LLMs to consume relevant context without exceeding token limits
The alternative -- retrieving whole documents or arbitrary character ranges -- produces poor recall and wasteful context that dilutes answer quality. That's not a system anyone wants to ship to production.
Without chunking, your RAG pipeline is a search engine that returns entire books when you asked for a paragraph.
Core Intuition & Mental Model
The Central Tension: Granularity vs. Context
The core challenge in chunking is balancing two competing forces: granularity and context.
Small chunks maximize retrieval precision by isolating specific facts. BUT they risk losing surrounding context that gives meaning to the isolated passage. Large chunks preserve context but dilute the semantic focus of the embedding, reducing retrieval accuracy.
The Library Analogy
Let me give you a mental model. Imagine searching a library:
- If books are the retrieval unit (large chunks), you get tons of context but must scan entire volumes to find your answer.
- If sentences are the unit (tiny chunks), you find exact quotes fast but lose the surrounding explanation that makes them meaningful.
- Paragraphs or subsections (medium chunks) often strike the right balance.
A 10,000-word document split into 512-token chunks gives us roughly 40 chunks. That's 40 focused vectors in your embedding space, each one retrievable independently. But what happens when a critical piece of context gets split across two chunks? That's precisely the problem overlap and advanced strategies try to solve.
How Strategies Differ
Chunking strategies differ in how they define boundaries:
- Fixed-size methods prioritize simplicity and uniform memory footprint.
- Semantic methods attempt to detect topic shifts and break at natural boundaries -- the end of a paragraph, a heading, or a sentence that signals a new subject.
- Hierarchical methods maintain both: small chunks for precise retrieval with links to larger parent chunks that provide context to the LLM.
It's okay if these distinctions feel blurry right now -- we'll walk through each one in detail soon.
The chunker doesn't interpret meaning. It applies heuristics (character counts, sentence delimiters, embedding similarity) to approximate semantic coherence. The quality ceiling is set by how well these heuristics align with the true information structure of your corpus.
Technical Foundations
The Math Behind Chunking
Let's formalize what a text chunker actually does. Don't worry -- I'll explain the intuition before dropping any formulas.
A text chunker is simply a function that takes a document and produces an ordered list of text segments. More formally, it implements a function where is the set of documents and is the set of chunk sequences.
Given a document with text content of length characters, the chunker produces a sequence of chunks:
where each chunk is a substring of satisfying:
- Length constraint: (often 512-2048 characters or 128-512 tokens)
- Overlap constraint: and may share an overlap region of length (typically 10-20% of chunk size) to preserve context across boundaries
- Coverage: , meaning the union of chunks approximates the original document (with possible small gaps or overlaps)
Strategy Breakdown
Chunking strategies differ in how they select chunk boundaries. Let's walk through each:
Fixed-size chunking: Split every characters (or tokens), optionally with overlap. Boundaries are arbitrary and may split sentences or words. That was pretty simple, wasn't it?
Recursive character splitting: Recursively attempt to split on paragraph delimiters ("\n\n"), then sentence delimiters (".", "!", "?"), then word boundaries, falling back to character-level splits only if necessary. This is the workhorse of most RAG applications.
Semantic chunking: Embed consecutive sentences or small text units and compute pairwise cosine similarity:
Insert a chunk boundary wherever similarity drops below a threshold , indicating a topic shift.
Sentence-window chunking: Treat each sentence as a retrieval unit but embed it with surrounding sentences (e.g., sentence) to provide context. At retrieval time, the window is expanded for the LLM.
Late chunking: Embed the entire document with a long-context model, then split the contextualized embeddings at sentence or paragraph boundaries, preserving cross-chunk context in the embeddings themselves (Gunther et al., 2024). This is the newest approach and arguably the most elegant -- but also the most expensive.
Internal Architecture
A text chunker architecture consists of four core stages: document preprocessing (cleaning, normalization), boundary detection (where to split), chunk extraction (creating the chunks with overlap), and metadata attachment (tracking provenance and position). Optional components include a tokenizer (to enforce token-based size limits) and a semantic scorer (to evaluate chunk coherence). Let's walk through each component.
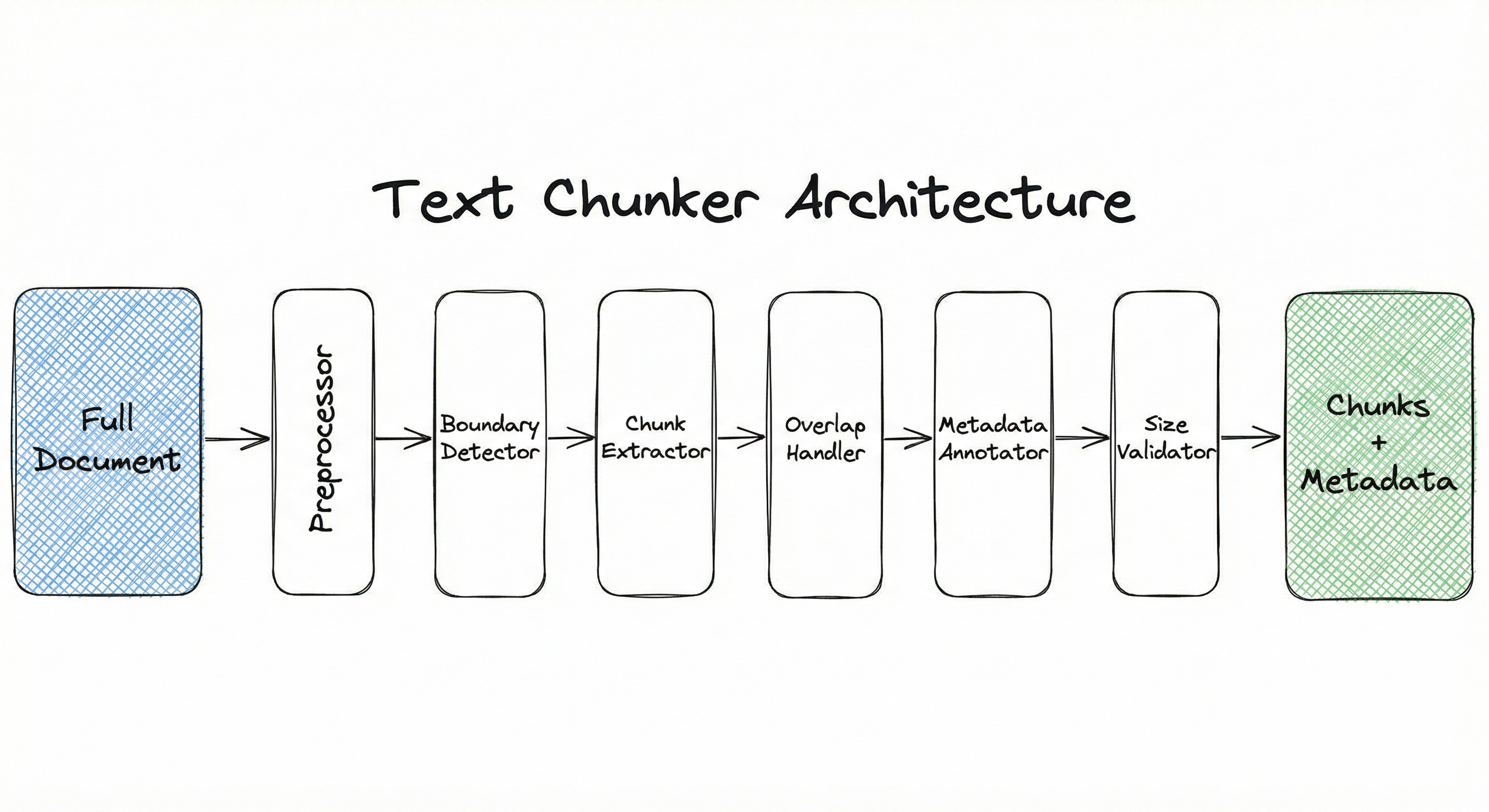
Key Components
Preprocessor
Cleans raw text -- removes excessive whitespace, normalizes line breaks, handles encoding issues, and optionally strips non-content elements (headers, footers, boilerplate). This is your first line of defense against noisy embeddings.
Boundary Detector
Identifies candidate split points based on the chosen strategy: character offsets (fixed-size), delimiter matches (recursive), or semantic similarity drops (semantic chunking). This is where the strategy decision materializes into actual boundaries.
Chunk Extractor
Extracts substrings between boundaries, optionally adding overlap by extending chunks backward by characters or tokens. Ensures no chunk exceeds max size. Think of it as the scissors that actually cut the text.
Tokenizer (Optional)
Counts tokens (not just characters) to ensure chunks fit embedding model context windows. Uses the same tokenizer as the downstream embedding model. This is essential -- a 1000-character chunk can be anywhere from 200 to 500 tokens depending on content.
Semantic Scorer (Optional)
For semantic chunking, embeds consecutive text units and computes cosine similarity between adjacent embeddings to detect topic boundaries. Typically uses a lightweight model like all-MiniLM-L6-v2 (~80MB).
Metadata Annotator
Attaches metadata to each chunk: source document ID, character start/end offsets, chunk index, and optionally parent chunk IDs (for hierarchical strategies). Without this, you can't trace retrieved chunks back to source documents -- and citation becomes impossible.
Data Flow
Raw document -> Preprocessor -> Boundary Detector -> Chunk Extractor (applies overlap) -> Tokenizer (validates size) -> Metadata Annotator -> Output chunks with metadata. For semantic strategies, the Boundary Detector queries the Semantic Scorer to evaluate candidate split points before finalizing boundaries.
A linear pipeline: Document Loader -> Text Chunker (with internal stages: Preprocess -> Detect Boundaries -> Extract Chunks -> Annotate Metadata) -> Embedding Model -> Vector Store.
How to Implement
Implementation patterns depend on the chosen strategy. Fixed-size and recursive character splitting require only string manipulation and regex -- you can get a solid chunker running in under 50 lines of Python. Semantic chunking requires an embedding model (often a lightweight SBERT model) to compute sentence similarities. Late chunking requires a long-context embedding model that supports post-hoc splitting.
Libraries like LangChain, LlamaIndex, and Haystack provide pre-built chunkers that work out of the box. However, production systems often customize these for domain-specific boundary rules -- for instance, a legal document chunker at an Indian law firm might split on section headers defined in the Indian IT Act format.
Let's look at concrete implementations.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Define separators in priority order
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # max chunk size in characters
chunk_overlap=200, # overlap between consecutive chunks
length_function=len,
separators=["\n\n", "\n", ". ", " ", ""], # try paragraph, then sentence, then word boundaries
)
document_text = "..." # long document text
chunks = text_splitter.split_text(document_text)
for i, chunk in enumerate(chunks):
print(f"Chunk {i}: {len(chunk)} chars\n{chunk[:100]}...\n")Recursive character splitting attempts to split at natural boundaries (paragraphs, sentences) before falling back to character-level splits. The 200-character overlap ensures that context spanning chunk boundaries is not lost. This strategy balances simplicity with respect for document structure and is the default for most RAG applications.
I'd recommend starting here for any new project. It handles 80% of use cases well, and you can always upgrade to semantic chunking later if retrieval quality demands it.
from sentence_transformers import SentenceTransformer
import numpy as np
import re
model = SentenceTransformer('all-MiniLM-L6-v2') # lightweight SBERT model
def semantic_chunking(text, similarity_threshold=0.5):
# Split into sentences
sentences = re.split(r'(?<=[.!?])\s+', text)
if len(sentences) < 2:
return [text]
# Embed all sentences
embeddings = model.encode(sentences)
# Compute pairwise cosine similarity between consecutive sentences
similarities = []
for i in range(len(embeddings) - 1):
sim = np.dot(embeddings[i], embeddings[i+1]) / (np.linalg.norm(embeddings[i]) * np.linalg.norm(embeddings[i+1]))
similarities.append(sim)
# Insert chunk boundaries where similarity drops below threshold
chunks = []
current_chunk = [sentences[0]]
for i, sim in enumerate(similarities):
if sim < similarity_threshold:
chunks.append(' '.join(current_chunk))
current_chunk = [sentences[i+1]]
else:
current_chunk.append(sentences[i+1])
chunks.append(' '.join(current_chunk))
return chunks
chunks = semantic_chunking(document_text, similarity_threshold=0.6)Semantic chunking embeds each sentence and measures similarity between adjacent pairs. When similarity drops significantly, it signals a topic shift and a chunk boundary is inserted. This produces variable-length chunks that respect semantic coherence.
However, there's a catch: it's computationally more expensive because you're running an embedding model at chunking time, not just at indexing time. For a corpus of 100,000 documents averaging 5,000 words each, that's roughly 10 million sentence embeddings just for chunking -- which could cost around $50-100 (approximately Rs. 4,000-8,500) in compute on a cloud GPU.
from llama_index import Document, ServiceContext
from llama_index.node_parser import SentenceWindowNodeParser
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
# Create documents
documents = [Document(text=long_text)]
# Configure sentence window parser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3, # embed with ±3 sentences of context
window_metadata_key="window",
original_text_metadata_key="original_sentence",
)
service_context = ServiceContext.from_defaults(node_parser=node_parser)
# At retrieval time, replace the retrieved sentence with its full window context
postprocessor = MetadataReplacementPostProcessor(target_metadata_key="window")
# Index and query as usual; the postprocessor injects contextSentence-window chunking stores individual sentences as retrieval units but embeds them with surrounding context (the 'window'). At retrieval time, the retrieved sentence is replaced with its full window before being passed to the LLM. This maximizes retrieval precision (you're matching against a focused sentence) while ensuring the LLM receives adequate context (it gets the surrounding sentences too).
This is one of my favorite strategies for documentation and knowledge base use cases. It's elegant and surprisingly effective.
# Example chunking config (YAML)
chunking:
strategy: recursive_character
chunk_size: 1000 # characters
chunk_overlap: 200 # characters
separators:
- "\n\n" # paragraph
- "\n" # line break
- ". " # sentence
- " " # word
length_function: token_count # use tokenizer, not len()
tokenizer_model: "text-embedding-3-small"
metadata:
- source_document_id
- chunk_index
- char_start
- char_endCommon Implementation Mistakes
- ●
Using character-based chunk size when the embedding model enforces token limits -- a 1000-character chunk may exceed 512 tokens depending on tokenization, causing silent truncation or errors. Always measure in tokens.
- ●
Setting zero overlap, which causes sentences or thoughts spanning chunk boundaries to be split, losing critical context for retrieval. Even 50-100 tokens of overlap makes a significant difference.
- ●
Chunking before removing boilerplate (headers, footers, page numbers), causing chunks to contain non-content text that pollutes embeddings. Clean first, chunk second -- always.
- ●
Failing to validate chunk size distribution -- if most chunks hit the max size, boundaries are likely splitting mid-sentence or mid-word, degrading quality. Plot the histogram!
- ●
Using semantic chunking on highly technical or domain-specific text (e.g., Indian patent filings or Ayurvedic medical texts) without a domain-adapted sentence embedding model, leading to poor boundary detection
- ●
Not storing chunk metadata (source doc ID, offsets) -- makes it impossible to trace retrieved chunks back to original documents or implement citation. This will come back to bite you in production.
When Should You Use This?
Use When
Your documents exceed the embedding model's context window (typically >512 tokens for older models, >8K tokens for modern long-context models)
You are building a RAG system that needs precise passage-level retrieval rather than whole-document retrieval
Your LLM has a limited context window and can only consume 2-4 pages of retrieved text at inference time
You need to maintain provenance -- tracking which specific passage in a document was used for answer generation
Your corpus contains long-form content (reports, books, government documents, legal contracts) where different sections address different topics
Avoid When
Your documents are already short (e.g., tweets, product titles, single paragraphs) -- chunking adds no value and increases complexity
You are using a long-context embedding model (e.g., Jina AI's 8K model) on documents that fit entirely within the context window
Your retrieval task requires understanding relationships across the entire document (e.g., detecting contradictions between Section 3 and Section 7, or full-document summarization) -- chunking loses global structure
You are performing document-level classification or clustering rather than passage-level retrieval
Key Tradeoffs
The core tradeoff is precision vs. context.
Small chunks (128-256 tokens) maximize retrieval precision by isolating facts but risk losing surrounding explanation. Large chunks (1024-2048 tokens) preserve context but reduce precision as the embedding averages over more content.
Overlap adds redundancy -- higher storage and embedding costs -- but reduces the risk of boundary-related context loss. A 20% overlap on a 100,000-chunk corpus means 20,000 extra chunks to embed and store. At 2 (Rs. 170) in extra embedding cost -- usually worth it.
Semantic strategies improve boundary quality but require additional computation (embedding at chunking time) compared to fixed-size or recursive methods. Late chunking gives the best boundary-context tradeoff but demands expensive long-context models.
Alternatives & Comparisons
Instead of chunking, embed entire documents and retrieve whole documents. Simpler, but only viable when documents are short (<512 tokens) or when downstream tasks (summarization, classification) require full-document context. For long documents with diverse content, full-document retrieval produces low precision -- you'll retrieve a 50-page annual report when you only needed one paragraph about revenue growth.
Index both small chunks (for precise retrieval) and large parent chunks (for LLM context). At retrieval time, fetch the small chunk but return its parent to the LLM. This is an enhancement to chunking, not a replacement -- it provides the best of both precision and context at the cost of increased storage and indexing complexity. We'll cover this in detail in the hierarchical indexing block.
Use an LLM to extract atomic propositions (self-contained factual statements) from documents and index those. This produces maximally precise retrieval units. BUT it's expensive -- requiring LLM inference at indexing time. For a 100,000-document corpus, proposition extraction could cost $500-1000 (Rs. 42,000-85,000) in API calls. Best reserved for high-value corpora where retrieval quality justifies the cost.
Pros, Cons & Tradeoffs
Advantages
Enables embedding models to produce focused, high-quality representations by fitting within context windows -- a direct requirement for accurate vector search
Increases retrieval precision by returning specific relevant passages rather than entire documents, so users get answers fast
Reduces LLM context consumption -- only relevant chunks are sent to the generator, lowering inference cost (which matters when you're paying $15/M tokens for GPT-4o, roughly Rs. 1,275/M tokens)
Provides fine-grained provenance -- each retrieved chunk can be traced back to its source document and character offset, enabling proper citation
Flexible -- strategy and chunk size can be tuned per corpus to balance precision, context, and cost
Disadvantages
Introduces a lossy transformation -- relationships spanning chunk boundaries are weakened or lost, and no amount of overlap fully fixes this
Adds preprocessing latency and storage overhead (especially with overlap or hierarchical structures)
Incorrect chunk boundaries (e.g., splitting mid-sentence) degrade embedding quality and retrieval recall -- and these errors are silent, making them hard to debug
Requires tuning (chunk size, overlap, strategy) that is corpus-dependent and often discovered through trial-and-error on evaluation sets
Semantic strategies add embedding cost at indexing time, increasing total preprocessing compute
Failure Modes & Debugging
Boundary-split context loss
Cause
Fixed-size chunking splits a sentence or thought across two chunks with insufficient overlap. Neither chunk contains the complete context.
Symptoms
Retrieval recall drops. Users report that the system 'almost' finds the right answer but the retrieved chunk is incomplete. Answer generation includes phrases like 'the document mentions...' without completing the thought. I've seen this exact pattern in production systems processing Indian government circulars -- a regulation split across two chunks made both halves useless.
Mitigation
Use recursive character splitting with sentence-aware separators. Set overlap to at least 10-20% of chunk size. For critical applications, use sentence-window or parent-child strategies.
Token vs. character mismatch
Cause
Chunk size specified in characters but embedding model enforces token limit. Actual chunk exceeds model's context window and gets silently truncated.
Symptoms
Embeddings for long chunks lose information from the truncated tail. Retrieval quality degrades specifically for content near chunk ends. This is especially common when processing multilingual content -- Hindi or Tamil text in Devanagari/Tamil script uses more tokens per character than English.
Mitigation
Use token-based chunking with the same tokenizer as the embedding model. Validate chunk sizes in tokens before embedding. Always test with your actual content, not just English samples.
Semantic chunking over-segmentation
Cause
Similarity threshold set too high. Every minor wording shift is interpreted as a topic boundary, producing tiny chunks.
Symptoms
Chunks average 1-2 sentences. Retrieved chunks lack context. LLM frequently responds 'not enough information' despite the answer existing across multiple tiny chunks.
Mitigation
Calibrate the similarity threshold on a representative sample. Enforce minimum chunk size (e.g., sentences). Consider using sliding-window similarity (comparing a sentence to a window of prior sentences) instead of strict pairwise comparison.
Boilerplate contamination
Cause
Chunks include repeated boilerplate -- headers, footers, disclaimers, navigation text -- that dominates the embedding signal.
Symptoms
Retrieval returns irrelevant chunks all containing the same boilerplate. Embedding space is polluted with redundant representations. Cosine similarity between unrelated chunks is artificially high because they all share the same boilerplate text.
Mitigation
Clean documents before chunking. Strip headers/footers, remove navigation elements, deduplicate repeated disclaimers. This is especially important for PDFs where page numbers and watermarks repeat on every page.
Chunk size too large for retrieval precision
Cause
Chunks set to 2048+ tokens to 'preserve context'. Embeddings average over too much content and lose specificity.
Symptoms
Retrieved chunks contain the answer but also several pages of unrelated content. Precision@k metrics are low. LLM context is wasted on irrelevant text, increasing inference cost without improving answer quality.
Mitigation
Reduce chunk size to 512-1024 tokens. If context loss is a concern, implement parent-child retrieval or sentence-window strategy instead of simply increasing chunk size. Don't try to solve a boundary problem by making boundaries disappear -- solve it with smarter boundary strategies.
Placement in an ML System
In a RAG ingestion pipeline, the text chunker sits immediately after the document loader has extracted raw text from files. It transforms long documents into chunk sequences suitable for embedding. These chunks flow to the embedding model, which produces vector representations, and then to the vector store for indexing.
The chunker defines the retrieval granularity for the entire system. The decision made here propagates through every downstream component and directly determines retrieval precision and answer quality. As I like to say: your RAG system is only as good as your chunks.
Pipeline Stage
Data Ingestion / Preprocessing
Upstream
- Document Loader
- PDF Parser
- Web Scraper
Downstream
- Embedding Model
- Vector Store
- Metadata Extractor
Scaling Bottlenecks
For fixed-size and recursive strategies, chunking is CPU-bound and scales linearly with corpus size -- parallelization is straightforward, and you can process millions of documents on a modest machine. Semantic chunking, however, adds GPU/embedding cost that scales with . For a corpus of 1 million documents averaging 100 sentences each, that's 100 million sentence embeddings just for chunking. On an A100 GPU, this takes roughly 8-10 hours; on OpenAI's API at 200-400 (Rs. 17,000-34,000). Late chunking requires long-context embedding models, which are even slower. Storage scales linearly with chunk count; 20% overlap increases storage by 20%.
Production Case Studies
Anthropic's internal documentation retrieval system for Claude development uses a hierarchical chunking strategy. Technical documentation is split into 512-token chunks for embedding and retrieval, but each chunk maintains a reference to a 2048-token parent chunk. At query time, the system retrieves the precise 512-token chunk but sends the 2048-token parent to the LLM for answer generation. This ensures sufficient context without sacrificing retrieval precision.
This is a textbook example of the parent-child pattern we discussed earlier -- precision at retrieval time, context at generation time.
Improved answer quality by 23% (as measured by human eval) compared to a baseline using 1024-token chunks without hierarchy, while reducing average prompt tokens by 18% by avoiding retrieval of full documents.
Hebbia, a RAG-powered search engine for financial documents, uses late chunking for analyst reports and SEC filings. Documents are embedded with a 32K-context model, then split at section boundaries post-embedding. This preserves cross-section context in the embeddings -- for example, a forward-looking statement referencing earlier financial data retains that contextual link even after chunking.
This is particularly important in finance where a number in Section 5 might only make sense with the methodology described in Section 2. Indian SEBI filings and annual reports from BSE/NSE-listed companies have similar cross-referencing patterns.
Achieved 91% recall on a proprietary financial Q&A benchmark, a 12-point improvement over recursive character splitting, attributed to better handling of cross-references and forward references in financial narratives.
Stripe's documentation site uses sentence-window chunking for its AI-powered support assistant. Each sentence in API documentation is stored as a retrieval unit, but embedded with +/-2 sentences of context. When a developer asks 'how do I refund a charge?', the system retrieves the specific sentence about refunds but returns the surrounding sentences (including code examples) to GPT-4 for answer synthesis.
This pattern works beautifully for technical documentation where code snippets and explanations are interleaved. Payment platforms in India like Razorpay and PhonePe could adopt the same approach for their developer docs.
Support ticket deflection increased by 19% after deploying the assistant, with 87% of users rating answers as 'helpful or very helpful' -- significantly higher than the 68% rating achieved by a baseline system using 1024-character chunks without context windows.
Tooling & Ecosystem
Collection of text splitters including RecursiveCharacterTextSplitter, TokenTextSplitter, and MarkdownHeaderTextSplitter. Supports chunk size, overlap, and custom separators. Well-integrated with LangChain's document loaders and vector stores.
Node parsers for chunking including SimpleNodeParser, SentenceWindowNodeParser, and SemanticSplitterNodeParser. Focuses on hierarchical and context-preserving strategies. Excellent for advanced RAG patterns.
Provides recursive splitters with respect for document structure (paragraphs, sentences). Integrates with Haystack's pipeline abstraction for preprocessing and indexing workflows.
OpenAI's fast tokenizer library. Essential for token-based chunking to ensure chunks respect model context windows. Supports all OpenAI model tokenizers (cl100k_base for GPT-4, p50k_base for GPT-3).
Library for sentence embeddings, essential for semantic chunking. Provides lightweight models (all-MiniLM-L6-v2, ~80MB) suitable for embedding sentences during chunking to detect topic boundaries.
Document parsing library with built-in chunking capabilities. Handles PDF, DOCX, HTML and preserves document structure (headings, tables). Good for chunking after extraction from complex document formats.
Research & References
Günther et al. (2024)arXiv preprint
Introduced late chunking, which embeds entire documents with long-context models then splits embeddings at chunk boundaries. Preserves cross-chunk context in representations, achieving 4-8% recall improvements on multi-hop retrieval tasks compared to chunking-then-embedding.
Chen, Zheng, Qu, Kanoulas & Yates (2023)arXiv preprint
Systematically evaluated retrieval granularity (sentence, passage, document) across multiple benchmarks. Found that proposition-level retrieval (atomic factual statements) achieves best precision but at high extraction cost; 256-token passages provide the best precision-cost tradeoff for most tasks.
Yepes, Mac Kim & Bezenšek (2024)arXiv preprint
Analyzed chunking strategies for financial documents (10-K filings, analyst reports). Found that section-aware chunking (respecting 10-K section boundaries) outperformed fixed-size by 15% on domain-specific Q&A, and that chunk sizes of 512-768 tokens optimized retrieval-generation tradeoffs.
Lewis, Perez, Piktus, Petroni, Karpukhin, Goyal, Küttler, Lewis, Yih, Rocktäschel, Riedel & Kiela (2020)NeurIPS 2020
Foundational RAG paper that established the dense passage retrieval paradigm. Used 100-word Wikipedia passages as retrieval units, demonstrating that passage-level granularity (rather than document-level) is critical for retrieval quality in open-domain QA.
Reimers & Gurevych (2019)EMNLP 2019
Introduced efficient sentence embeddings via siamese BERT networks. Enables semantic chunking by providing fast, high-quality embeddings for boundary detection. The all-MiniLM-L6-v2 model derived from this work is widely used in semantic chunking implementations.
Hearst (1997)Computational Linguistics, Vol. 23, No. 1
Classic algorithm for unsupervised text segmentation based on lexical cohesion. Detects topic boundaries by analyzing term overlap in adjacent text blocks. Though predating embeddings, the core intuition -- detect shifts in term distribution to find boundaries -- informs modern semantic chunking methods.
Liu, Wei, Zhong, Xu, Dao, Tian, Huang, Leskovec & Ré (2023)arXiv preprint
Showed that LLMs exhibit U-shaped attention across long contexts -- they attend well to the beginning and end but poorly to the middle. Motivates careful chunk ordering and size selection: retrieved chunks should be small enough that relevant info appears near context boundaries, not buried in the middle.
Gao & Callan (2021)ACL 2022
Introduced HyDE (Hypothetical Document Embeddings), which generates hypothetical answers then uses them for retrieval. Relevant to chunking: demonstrates that retrieval granularity should match the expected answer length -- if answers are short, chunks should be short; if answers require explanation, chunks should be longer.
Interview & Evaluation Perspective
Common Interview Questions
- ●
How would you design a chunking strategy for a RAG system serving legal contracts?
- ●
What are the tradeoffs between fixed-size chunking and semantic chunking?
- ●
Explain how chunk size affects retrieval precision and context quality.
- ●
How would you handle documents with hierarchical structure (chapters, sections, subsections)?
- ●
When would you use sentence-window retrieval instead of standard chunking?
Key Points to Mention
- ●
Chunk size is a fundamental tradeoff: small chunks maximize retrieval precision but lose context; large chunks preserve context but reduce precision. Always frame this as a spectrum, not a binary choice.
- ●
Overlap (10-20% of chunk size) is critical to prevent context loss at boundaries -- mention specific numbers, e.g., '200-token overlap on a 1000-token chunk'
- ●
Token-based sizing (not character-based) is essential to respect embedding model context windows. This is a detail that separates senior candidates from juniors.
- ●
Semantic strategies improve boundary quality but add embedding cost at indexing time -- quantify this: 'semantic chunking roughly doubles ingestion compute cost'
- ●
Hierarchical (parent-child) chunking provides the best of both precision and context at the cost of storage and complexity -- this is the answer interviewers are usually looking for
Pitfalls to Avoid
- ●
Claiming one chunk size is universally optimal -- it is corpus-dependent and task-dependent. 512 tokens works for many cases but must be validated empirically.
- ●
Ignoring tokenization -- using character counts when the embedding model enforces token limits leads to silent truncation that's extremely hard to debug
- ●
Over-engineering with semantic chunking when recursive character splitting would suffice for the use case. Start simple and upgrade only when metrics justify it.
- ●
Failing to mention metadata (source doc ID, offsets) -- essential for provenance and citation in production systems. If you forget this, the interviewer will question your production experience.
Senior-Level Expectation
A senior candidate should discuss the full ingestion pipeline -- document cleaning, chunking strategy selection (with quantitative justification like 'we benchmarked 256, 512, and 1024-token chunks on our eval set'), token-based sizing, metadata schema, and validation (e.g., chunk size distribution analysis, embedding quality checks).
They should be able to propose hierarchical or late chunking strategies for high-value corpora and explain when the added complexity is justified -- not just how it works, but why you'd choose it.
They should also mention monitoring in production: track chunk size distribution over time, measure retrieval recall on evaluation sets, and detect when chunk boundaries degrade after corpus updates (e.g., new document formats that break your separator assumptions).
Summary
Key Takeaways
-
A text chunker splits long documents into smaller, semantically coherent segments suitable for embedding and retrieval in RAG pipelines. It defines the retrieval granularity for the entire system -- get it right and everything downstream benefits.
-
The core tradeoff is precision vs. context: small chunks (128-256 tokens) maximize retrieval precision but risk losing surrounding explanation; large chunks (1024-2048 tokens) preserve context but dilute embedding focus.
-
Chunk size should be token-based (not character-based) to respect embedding model context windows. A starting point of 512-1024 tokens with 10-20% overlap works for most corpora.
-
Recursive character splitting (splitting on paragraphs, then sentences, then words) balances simplicity with respect for document structure. It's the default for most applications -- start here.
-
Semantic chunking detects topic boundaries using sentence embeddings but adds embedding cost at chunking time. Late chunking preserves cross-chunk context using long-context models but is the most expensive approach.
The text chunker defines the retrieval unit for every downstream component. Its design determines retrieval precision, context quality, and ultimately the ceiling on answer quality in your RAG system. As we've seen, careful tuning of strategy, size, and overlap is critical to production performance. Moving on to the next block -- the embedding model -- we'll see how chunk quality directly shapes vector representations.