Re-Ranker in Machine Learning
Let's talk about re-rankers — the unsung heroes that quietly turn mediocre search results into great ones.
Imagine you ask your retriever for the top 100 documents related to your query. It does a decent job — most of the relevant stuff is somewhere in that list. But is the best document at position 1? Or is it buried at position 37? This is exactly the problem a re-ranker solves.
A re-ranker is a second-stage scoring model that receives a candidate set of documents from an upstream retriever and reorders them by estimated relevance to your query. Unlike first-stage retrievers — which must evaluate millions of candidates in sub-linear time — re-rankers operate over a small shortlist (typically 20 to 200 documents) and can therefore afford computationally expensive architectures that model fine-grained, token-level interactions between query and document.
The canonical architecture here is the cross-encoder: a transformer that ingests the concatenation of query and candidate passage, processes them through joint self-attention layers, and outputs a scalar relevance score. This joint encoding captures lexical and semantic interactions that bi-encoder retrieval, by design, simply cannot represent.
The practical impact? Substantial. Appending a cross-encoder re-ranker to a bi-encoder retriever routinely improves NDCG@10 by 10 to 25 percentage points on standard benchmarks such as MS MARCO and TREC Deep Learning tracks (Nogueira and Cho, 2019). More recently, large language models have been repurposed as zero-shot listwise re-rankers, producing permutation-based orderings that rival or exceed supervised cross-encoders on out-of-distribution queries (Sun et al., 2023).
Re-rankers are now a near-universal component in production retrieval-augmented generation (RAG) systems, enterprise search engines, and recommendation pipelines. If you're building any system where the quality of the top-3 or top-5 results matters — and let's be honest, it almost always does — you'll want a re-ranker in your pipeline.
Concept Snapshot
- What It Is
- A scoring model that takes a query and a short list of candidate documents from an upstream retriever and reorders them by relevance, using architectures (cross-encoders, late-interaction models, or LLMs) that are too expensive for full-corpus search but deliver substantially higher ranking accuracy.
- Category
- RAG Pipeline
- Complexity
- Advanced
- Inputs / Outputs
- **Inputs**: a query string and a list of candidate documents (typically 20-200 passages retrieved by a first-stage retriever). **Outputs**: the same documents reordered by relevance score, or a truncated top-k subset with associated confidence scores.
- System Placement
- Sits immediately after the first-stage retriever (bi-encoder, BM25, or hybrid search) and before the context assembler or LLM generator in a RAG pipeline. In multi-stage pipelines, multiple re-rankers may be cascaded in order of increasing cost and accuracy.
- Also Known As
- cross-encoder ranker, neural re-ranker, second-stage ranker, passage re-ranker, relevance scorer
- Typical Users
- ML engineers, search engineers, NLP engineers, RAG system developers, information retrieval researchers
- Prerequisites
- Bi-encoder retrieval, Transformer architecture, Embedding models, Vector stores, Information retrieval metrics (NDCG, MRR, MAP)
- Key Terms
- cross-encoderbi-encoderlate interactionpointwise rankingpairwise rankinglistwise rankingNDCG@kMRRknowledge distillationmulti-stage retrievalquery-document interaction
Why This Concept Exists
The Fundamental Bottleneck of First-Stage Retrieval
Let's start with a question: if semantic search already gives us relevant results, why do we need a re-ranker on top?
Here's the thing. First-stage retrievers face an intractable scaling constraint: they must score every document in a corpus that may contain millions or billions of entries. Bi-encoders resolve this by pre-computing document embeddings and reducing retrieval to approximate nearest neighbor search. That's elegant and fast.
BUT — and this is a big but — this independence assumption means that query tokens and document tokens never directly attend to each other. The resulting similarity score is a coarse, single-vector comparison that cannot capture fine-grained relevance signals such as negation, entity co-reference, or conditional relationships between query terms and passage content.
A Concrete Example
Consider the query "countries that have NOT adopted the euro" and a passage about "countries that adopted the euro." A bi-encoder may assign high similarity because both texts occupy similar semantic regions. However, a cross-encoder will correctly identify the negation and score the passage as irrelevant.
This distinction is not a limitation of any specific model — it's a fundamental consequence of the representation bottleneck inherent in independent encoding. You simply can't squeeze all the nuance of a document into a single 768-dimensional vector and expect perfect relevance matching.
The Numbers Tell the Story
Re-rankers exist to close this precision gap. By operating over a small candidate set (the output of the first stage), they can afford the quadratic self-attention cost of joint query-document encoding.
Nogueira and Cho (2019) demonstrated that fine-tuning BERT as a cross-encoder passage re-ranker improved MRR@10 on MS MARCO from 0.167 (BM25 baseline) to 0.365 — a relative improvement exceeding 100 percent. That's not an incremental gain; that's a paradigm shift.
This two-stage retrieve-then-rerank paradigm has since become the standard architecture for production search and RAG systems. It beautifully balances the efficiency of approximate retrieval with the accuracy of full cross-attention scoring.
Key Takeaway: Re-rankers exist because relevance is fundamentally relational — it depends on the interaction between query and document, not on either one in isolation. Bi-encoders approximate this interaction; cross-encoders model it directly.
Core Intuition & Mental Model
Trading Compute for Precision
Here's the core idea, and it's surprisingly simple: a re-ranker trades computational cost for ranking precision by allowing every query token to attend to every document token through joint self-attention.
Where a bi-encoder compresses each input independently into a single vector and computes relevance as a dot product, a cross-encoder re-ranker feeds the concatenated pair through a shared transformer. This enables the model to learn token-level relevance patterns:
- Which query words are satisfied by which document phrases
- Whether negations or qualifiers alter relevance
- How entity mentions interact across the two texts
Relevance Is Relational
The key insight — and I really want you to internalize this — is that relevance is fundamentally a relational property between two texts, not a property of either text in isolation. A document about "machine learning" isn't inherently relevant; it's relevant with respect to a specific query. Cross-encoders model this relation directly, while bi-encoders approximate it through independent compression.
A Mental Model That Sticks
Let me give you an analogy. First-stage retrieval is like scanning book titles on a library shelf to find candidates. Re-ranking is like opening each candidate book, reading the relevant chapter, and deciding which ones actually answer your question.
The shelf scan must be fast — sub-linear in the number of books. But the reading step can be thorough because you're only examining a handful of candidates. That's the retrieve-then-rerank paradigm in a nutshell.
That was pretty simple, wasn't it?
Core Intuition: Bi-encoders ask "how similar are these two embeddings?" Cross-encoders ask "given this specific query, how relevant is this specific document?" The second question is harder to answer — but it's also the right question.
Technical Foundations
The Math Behind Re-Ranking
Alright, let's get formal. Don't worry — I'll explain the intuition before every formula.
A re-ranker defines a scoring function that estimates the relevance of document to query . There are three principal formulations, each with different cost-quality profiles.
1. Pointwise Ranking
The simplest approach: independently score each pair. A cross-encoder implements this as:
where is the pooled representation from a transformer that ingests , and is the sigmoid function. The model is trained with binary cross-entropy against relevance labels.
MonoBERT (Nogueira and Cho, 2019) is the canonical pointwise cross-encoder. It's simple, effective, and still widely used in production.
2. Pairwise Ranking
Instead of scoring documents independently, what if we asked: "which of these two documents is more relevant?" The model receives a query and two documents and predicts which is more relevant:
Pairwise approaches require comparisons for candidates, which limits practical deployment. However, they produce more calibrated relative orderings because every prediction is a direct comparison.
3. Listwise Ranking
Here's where things get interesting. The model receives a query and the entire candidate list and directly outputs a permutation or probability distribution over rankings.
RankGPT (Sun et al., 2023) implements listwise reranking by prompting an LLM to sort passage identifiers by relevance, producing a permutation such that:
MonoT5 (Nogueira et al., 2020) bridges pointwise and listwise by generating relevance tokens ("true" / "false") for each pair, then sorting by the probability assigned to "true."
4. Late Interaction (The Middle Ground)
ColBERT (Khattab and Zaharia, 2020) and ColBERTv2 (Santhanam et al., 2022) represent a clever middle ground: query and document are encoded independently into multi-vector representations (one vector per token), and relevance is computed as the sum of maximum similarities between query token vectors and document token vectors:
This is called MaxSim. It allows document representations to be pre-computed while still capturing token-level interactions at query time. It's faster than a full cross-encoder but more expressive than a single-vector dot product.
Summary: Pointwise is simple and scalable. Pairwise is more calibrated but . Listwise captures global context but needs LLMs. Late interaction pre-computes documents but still matches tokens. Pick your tradeoff.
Internal Architecture
A re-ranker module in a retrieval pipeline consists of three logical stages: candidate reception (receiving the shortlist from the first-stage retriever), scoring (applying the re-ranking model to each candidate or to the full list), and output assembly (sorting candidates by score and truncating to top-k).
The scoring stage is the computational bottleneck, and its cost profile differs dramatically across architectures:
- Cross-encoders: forward passes, each processing the full query-document pair
- Late-interaction models: MaxSim computations over pre-computed token embeddings
- LLM listwise re-rankers: one or a few forward passes over the full list encoded as a prompt
Let's walk through each component.
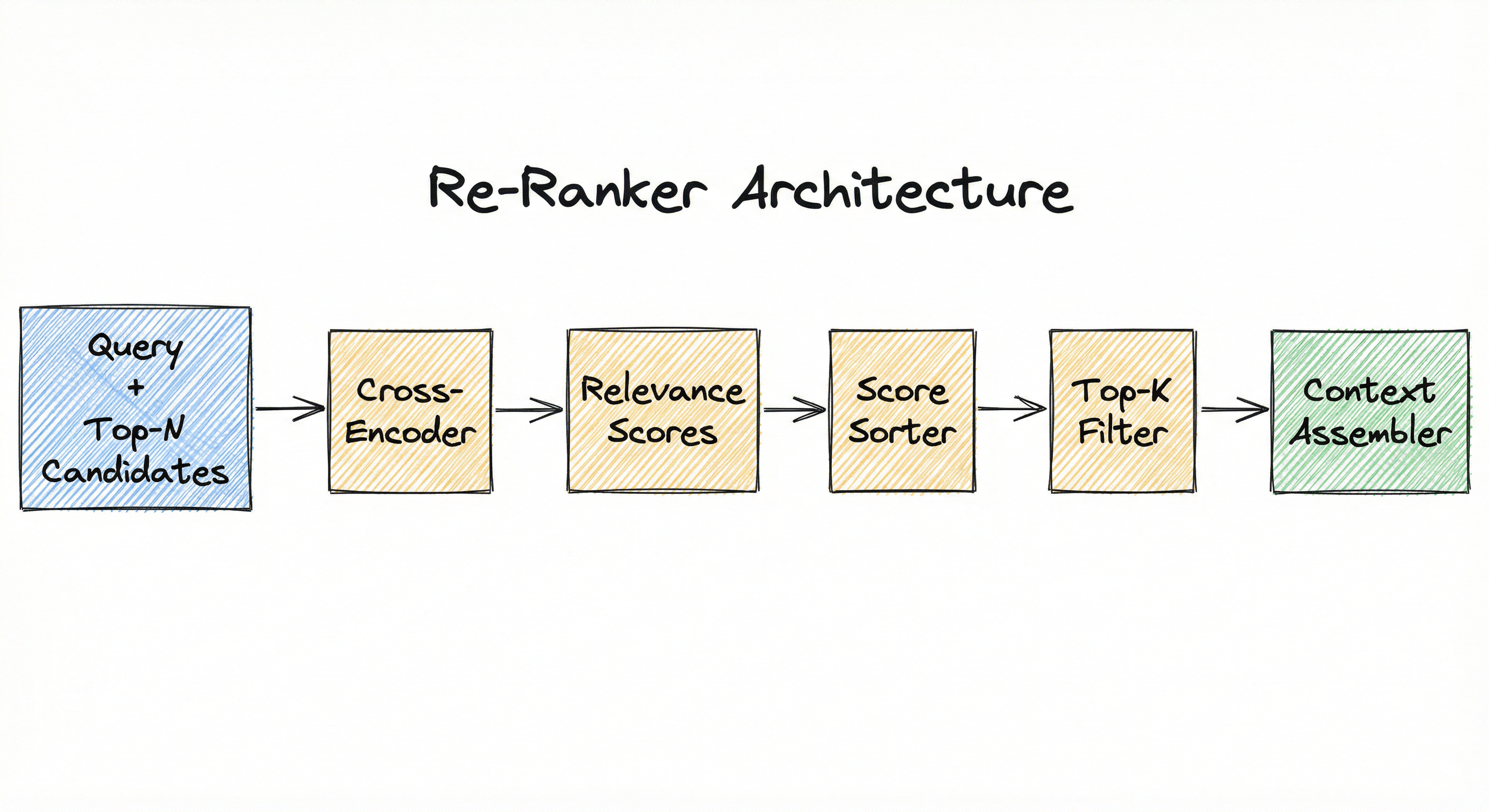
Key Components
Candidate Reception Layer
Receives the top-N documents from the upstream retriever (bi-encoder, BM25, or hybrid) along with their initial scores and metadata. Normalizes formats and prepares query-document pairs for scoring.
Scoring Engine (Cross-Encoder)
Tokenizes pairs, runs them through a transformer encoder, and produces a scalar relevance score per candidate. This is the dominant re-ranking architecture in production systems.
Scoring Engine (Late Interaction)
Computes token-level MaxSim scores between pre-computed document token embeddings and query token embeddings produced at query time.
Scoring Engine (LLM Listwise)
Formats the candidate list as a structured prompt and instructs an LLM to output a relevance-sorted permutation of passage identifiers.
Score Aggregation and Output
Sorts candidates by re-ranker score, applies score normalization if needed (e.g., softmax for calibrated probabilities), truncates to top-k, and passes results to the downstream context assembler or LLM generator.
Data Flow
User query --> First-stage retriever returns top-N candidates --> Re-ranker tokenizes and scores each (query, document) pair (or the full list for listwise models) --> Candidates sorted by re-ranker score --> Top-k results passed to context assembler or LLM generator.
A directed pipeline: 'Query' --> 'First-Stage Retriever (BM25 / Bi-Encoder)' --> 'Top-N Candidates' --> 'Re-Ranker (Cross-Encoder / Late Interaction / LLM)' --> 'Scored & Sorted Candidates' --> 'Top-K Output' --> 'Context Assembler / LLM Generator'. A feedback arrow from 'Re-Ranker' to 'Score Aggregation' merges with optional first-stage scores.
How to Implement
Let's get practical. Re-ranker implementations fall into three categories:
- Lightweight cross-encoders using the sentence-transformers library with pre-trained models from the SBERT ecosystem
- API-based re-rankers from providers like Cohere and Jina — great for teams without GPU infrastructure
- LLM-based listwise re-rankers using frameworks like RankLLM or vLLM
The choice depends on your latency requirements, infrastructure maturity, and whether you need zero-shot generalization to novel domains or can fine-tune on labeled data. Let's dive into each with working code examples.
from sentence_transformers import CrossEncoder
import numpy as np
# Load a pre-trained cross-encoder fine-tuned on MS MARCO
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', max_length=512)
query = "What are the effects of climate change on coral reefs?"
# Candidate passages from first-stage retriever
candidates = [
"Coral reefs are declining worldwide due to rising ocean temperatures caused by climate change.",
"The Great Barrier Reef is located off the coast of Queensland, Australia.",
"Ocean acidification, driven by increased CO2 absorption, weakens coral skeletons and inhibits growth.",
"Climate change refers to long-term shifts in global temperatures and weather patterns.",
"Bleaching events caused by thermal stress have destroyed 14% of the world's coral since 2009."
]
# Score each (query, candidate) pair
pairs = [[query, candidate] for candidate in candidates]
scores = model.predict(pairs)
# Sort by descending relevance score
ranked_indices = np.argsort(scores)[::-1]
for rank, idx in enumerate(ranked_indices):
print(f"Rank {rank+1} (score: {scores[idx]:.4f}): {candidates[idx][:80]}...")The sentence-transformers CrossEncoder class wraps a HuggingFace transformer model fine-tuned for relevance classification. The model tokenizes , runs a forward pass, and outputs a scalar score via a classification head.
The ms-marco-MiniLM-L-6-v2 model is a popular production choice: it achieves strong NDCG@10 on MS MARCO while being compact enough (22M parameters) for low-latency inference. Note that each candidate requires a separate forward pass, so latency scales linearly with the number of candidates. Batch them!
import cohere
co = cohere.ClientV2(api_key="your-api-key")
query = "What are the effects of climate change on coral reefs?"
documents = [
"Coral reefs are declining worldwide due to rising ocean temperatures caused by climate change.",
"The Great Barrier Reef is located off the coast of Queensland, Australia.",
"Ocean acidification, driven by increased CO2 absorption, weakens coral skeletons.",
"Climate change refers to long-term shifts in global temperatures.",
"Bleaching events caused by thermal stress have destroyed 14% of coral since 2009."
]
# Rerank with Cohere Rerank API
response = co.rerank(
model="rerank-v3.5",
query=query,
documents=documents,
top_n=3 # Return only top 3 results
)
for result in response.results:
print(f"Rank {result.index} (score: {result.relevance_score:.4f}): "
f"{documents[result.index][:80]}...")Cohere Rerank provides a managed cross-encoder API that abstracts away model hosting, GPU provisioning, and batching. The rerank-v3.5 model supports 100+ languages and accepts up to 1,000 documents per request.
API-based re-ranking is ideal for teams without GPU infrastructure or when rapid prototyping is the priority. The tradeoff is per-query cost (pricing per search unit — roughly 100/day (~Rs 8,400/day) just for re-ranking — manageable, but worth considering as you scale.
from openai import OpenAI
import re
client = OpenAI(api_key="your-api-key")
def listwise_rerank(query: str, passages: list[str], window_size: int = 10) -> list[int]:
"""Rerank passages using LLM listwise sorting (RankGPT-style)."""
# Build numbered passage list for the prompt
passage_block = "\n".join(
f"[{i+1}] {p[:300]}" for i, p in enumerate(passages[:window_size])
)
prompt = f"""I will provide a query and a list of passages.
Rank the passages by relevance to the query from most to least relevant.
Output ONLY the passage numbers in order, separated by ' > '.
Query: {query}
Passages:
{passage_block}
Ranking:"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0,
max_tokens=200
)
# Parse the ranking from the response
ranking_text = response.choices[0].message.content.strip()
ranked_indices = [int(x.strip()) - 1 for x in re.findall(r'\d+', ranking_text)]
return ranked_indices
# Usage
query = "What are the effects of climate change on coral reefs?"
passages = ["..."] # Your retrieved passages
ranked_order = listwise_rerank(query, passages)
reranked_passages = [passages[i] for i in ranked_order]This implements the RankGPT approach (Sun et al., 2023) where an LLM is prompted to produce a relevance-ordered permutation of passage identifiers. The sliding window technique processes passages in overlapping windows when the candidate count exceeds the context window.
This zero-shot approach requires no training data and generalizes well to novel domains. However, it incurs high latency (1-5 seconds per query) and cost (~$0.05/query or Rs 4.2/query with GPT-4). For production, consider distilled open-source alternatives like RankZephyr (Pradeep et al., 2023) served via vLLM — same quality, fraction of the cost.
Common Implementation Mistakes
- ●
Setting N too low for the re-ranker — if the first-stage retriever misses relevant documents in its top-N, the re-ranker cannot recover them. Start with N=100 and tune based on recall@N of your retriever. I've seen teams debug their re-ranker for weeks when the real problem was retriever recall.
- ●
Using a cross-encoder as a first-stage retriever over the full corpus — cross-encoders require forward passes and cannot pre-compute document representations, making full-corpus scoring prohibitively expensive. On a corpus of 10M documents, that's 10 million forward passes per query. Not happening.
- ●
Ignoring the max sequence length of the cross-encoder — when query + document exceeds the model's token limit (typically 512), truncation silently discards document content. Use models with longer context windows or truncate documents strategically (keep the first and last paragraphs).
- ●
Failing to batch cross-encoder inference — scoring candidates sequentially instead of in batches wastes GPU utilization and inflates latency by 3-10x. Always batch. Always.
- ●
Applying a short-passage re-ranker to long documents — a model trained on MS MARCO (60-word passages) has never seen long inputs during training and quality degrades. Chunk your documents first, then re-rank the chunks.
- ●
Not evaluating end-to-end impact — a re-ranker that improves NDCG@10 by 5 points may not improve downstream RAG answer quality if the context assembler already selects the right passages. Always measure what matters to the user, not just the intermediate metric.
When Should You Use This?
Use When
Your first-stage retriever (BM25 or bi-encoder) returns relevant documents within top-100 but fails to rank them correctly in the top-5 or top-10 — this is the classic re-ranking use case
You're building a RAG system where the quality of the top-3 retrieved passages directly determines answer correctness — and let's be honest, this is most RAG systems
Query-document relevance depends on fine-grained interactions (negation, entity co-reference, conditional clauses) that bi-encoders simply cannot capture
You have a latency budget for an additional 50-500ms of scoring beyond the first-stage retrieval
Out-of-domain generalization is important and you need zero-shot reranking without training data — this is where LLM-based reranking really shines
Avoid When
Your total latency budget is under 50ms and even a lightweight cross-encoder adds unacceptable overhead — think autocomplete or real-time typeahead
The first-stage retriever already achieves high NDCG@10 (>0.70) and additional reranking yields diminishing returns — measure before you add complexity
Your candidate set is very large (>1,000 documents) and you cannot afford the linear cost of cross-encoder scoring — consider a cheaper intermediate stage first (like ColBERT)
Ranking correctness is less important than recall — for example, when the downstream consumer can process all retrieved documents regardless of order
Your application requires fully explainable ranking decisions and the opacity of neural re-rankers is unacceptable for regulatory reasons (common in Indian financial services under RBI/SEBI compliance)
Key Tradeoffs
The fundamental tradeoff is latency versus ranking precision — and let me give you concrete numbers.
A lightweight cross-encoder like ms-marco-MiniLM-L-6-v2 scores 50 passages in approximately 60ms on a GPU, improving NDCG@10 by 10-25 points over bi-encoder retrieval alone. Hosting cost? About $0.50/hour (~Rs 42/hour) on an AWS g4dn.xlarge instance.
Larger models (BERT-large cross-encoders) push precision further but require 200-400ms. LLM-based listwise re-rankers (GPT-4, RankZephyr) achieve the highest zero-shot quality but cost 1-5 seconds and 10-100x more per query — roughly $0.05/query (Rs 4.2/query) with GPT-4.
Late-interaction models (ColBERTv2) offer a middle ground: faster than cross-encoders because document representations are pre-computed, but slightly lower accuracy because interactions are limited to per-token maximum similarity rather than full cross-attention.
Knowledge distillation from LLM teachers into compact cross-encoders (Rank-DistiLLM, 2024) is the emerging best practice — near-LLM quality at cross-encoder latency and cost. This is probably where you should invest if you're building for production.
Rule of Thumb: Start with a MiniLM cross-encoder. If it's not good enough, try an LLM re-ranker. If the LLM re-ranker works but costs too much, distill it into a cross-encoder. That's the playbook.
Alternatives & Comparisons
A bi-encoder computes query and document embeddings independently and retrieves via vector similarity. It's 100-1000x faster than a cross-encoder for scoring but sacrifices 10-25 NDCG points because it cannot model token-level query-document interactions. When latency is paramount and ranking precision is secondary, bi-encoder retrieval without re-ranking is viable — but you're leaving quality on the table.
Hybrid search combines lexical and semantic retrieval signals via score fusion (e.g., Reciprocal Rank Fusion). It improves recall over either method alone but does not model query-document interactions as deeply as a cross-encoder re-ranker. Think of hybrid search as a better first stage — it's complementary to re-ranking, not a replacement. The ideal pipeline is hybrid retrieval followed by cross-encoder re-ranking.
ColBERTv2 stores per-token document embeddings and computes relevance via MaxSim at query time. It's faster than full cross-attention because document encodings are pre-computed, but uses more storage than single-vector bi-encoders (one vector per token — roughly 7 GB for the MS MARCO passage corpus after compression). ColBERT can serve as either a retriever or a re-ranker; as a re-ranker, it's faster but slightly less accurate than a full cross-encoder.
Feature-based learning-to-rank models use handcrafted features (BM25 score, PageRank, click-through rate) and gradient-boosted trees to rank candidates. They're fast and interpretable but require extensive feature engineering and cannot learn novel textual relevance signals from raw text. Neural re-rankers have largely superseded them for text-heavy ranking tasks. However, feature-based rankers remain common in e-commerce (Flipkart, Amazon) and ad ranking where structured features like price, seller rating, and delivery speed dominate over text relevance.
Pros, Cons & Tradeoffs
Advantages
Dramatically improves ranking precision: cross-encoders routinely add 10-25 NDCG@10 points over first-stage retrieval, directly improving RAG answer quality
Captures fine-grained interactions: cross-encoders model full token-level interactions between query and document — negation, entity co-reference, and conditional relevance that bi-encoders fundamentally miss
Strong zero-shot generalization: LLM-based re-rankers (RankGPT, RankZephyr) work well on novel domains without any training data — incredibly valuable when you don't have labeled relevance judgments
Fully modular: re-rankers can be added to or removed from an existing retrieval pipeline without modifying upstream or downstream components — plug and play
Knowledge distillation pathway: you can compress large re-ranker capabilities into compact, low-latency models suitable for production — getting the best of both worlds
Good transfer learning: MS MARCO-trained cross-encoders transfer surprisingly well to many domains, reducing the need for expensive domain-specific training data
Disadvantages
Adds latency: 50-500ms for cross-encoders, 1-5 seconds for LLM-based re-rankers, on top of first-stage retrieval time — this can be a dealbreaker for real-time applications
Linear cost scaling: cross-encoder scoring cost scales linearly with candidate count — re-ranking 200 documents costs 4x more than 50 documents, with proportionally more GPU time
Cannot recover missed documents: re-rankers reorder but do not retrieve — if the first-stage retriever missed a relevant document entirely, the re-ranker will never see it
High per-query cost for LLM re-rankers: API pricing (~50K/month (Rs 42L/month) just for re-ranking
Expensive training data: supervised cross-encoders require relevance judgments (query-document pairs with labels) that are costly to collect — expect Rs 2-5 per judgment from annotation services
Impractical for ultra-low-latency: latency makes re-rankers unsuitable for autocomplete, real-time typeahead search, or any interaction where users expect sub-50ms responses
Failure Modes & Debugging
Retriever recall ceiling
Cause
The first-stage retriever fails to include relevant documents in its top-N candidates, so the re-ranker never sees them. This is the most common and most frustrating failure mode.
Symptoms
Re-ranker produces high-confidence scores for irrelevant documents; NDCG@10 after re-ranking is no better than without it; users report missing results that they know should exist.
Mitigation
Increase the candidate count N passed to the re-ranker. Monitor recall@N of the first-stage retriever independently — this is your ceiling. Use hybrid retrieval (BM25 + dense) to maximize recall before re-ranking. If recall@100 is below 90%, fix your retriever before investing in a better re-ranker.
Truncation-induced information loss
Cause
Query plus document exceeds the cross-encoder's maximum token limit (typically 512 tokens), and relevant content in the truncated tail is silently lost.
Symptoms
Re-ranker systematically ranks shorter passages higher than longer ones regardless of content relevance; passages with key information in later paragraphs are scored lower than expected.
Mitigation
Use cross-encoders with longer context windows (e.g., models fine-tuned with 1024 or 2048 max length). Pre-chunk long documents so each chunk fits within the limit. A pragmatic trick: keep the first 200 tokens and last 100 tokens, dropping the middle — key information tends to cluster at the beginning and end of documents.
Domain shift degradation
Cause
Cross-encoder was trained on MS MARCO (web search passages) but deployed on a domain with different vocabulary, document structure, or relevance criteria (legal, medical, scientific, or Indian vernacular content).
Symptoms
Re-ranker performs well on general English queries but poorly on domain-specific queries; NDCG improvement over the retriever is minimal or even negative for specialized topics; code-mixed queries (Hinglish, Tanglish) perform especially poorly.
Mitigation
Fine-tune the cross-encoder on domain-specific relevance data. If labeled data is scarce, use LLM-based re-rankers (RankGPT) which generalize better zero-shot, or distill an LLM re-ranker into a domain-adapted cross-encoder. For Indian language support, consider multilingual cross-encoders or Cohere's multilingual rerank-v3.5.
Latency budget exceeded
Cause
Candidate count N is too large, model is too heavy, or GPU resources are underprovisioned, causing re-ranking latency to exceed the pipeline SLA.
Symptoms
P95 latency spikes above acceptable thresholds; timeout errors in the retrieval pipeline; users perceive slow search responses.
Mitigation
Reduce N, switch to a smaller distilled cross-encoder (MiniLM-L-6 instead of BERT-large), enable batched inference, or implement early exit strategies. For extreme latency constraints, replace the cross-encoder with a late-interaction model (ColBERTv2). FlashRank provides CPU-only ONNX-optimized inference under 50ms for resource-constrained environments.
Score miscalibration across queries
Cause
Cross-encoder scores are not calibrated across different queries — a score of 0.8 for query A may indicate weaker relevance than 0.6 for query B.
Symptoms
Threshold-based filtering (e.g., 'only show results with score > 0.5') produces inconsistent behavior: some queries return too many results, others too few.
Mitigation
Use rank-based selection (top-k) rather than score-based thresholding. If scores must be comparable across queries, apply per-query softmax normalization or train with calibration objectives. This is a subtle but important distinction — I've seen production systems break because someone hardcoded a score threshold.
Positional bias in LLM listwise re-rankers
Cause
LLMs exhibit known positional biases — they tend to favor passages at the beginning or end of the prompt context window, regardless of relevance (the "lost in the middle" phenomenon).
Symptoms
Re-ranking quality varies depending on the initial order of passages in the prompt; shuffling the input order changes the output ranking substantially.
Mitigation
Apply the sliding window approach from RankGPT (Sun et al., 2023) that processes passages in overlapping windows and aggregates rankings. Use multiple passes with shuffled orderings and aggregate via voting. RankZephyr (Pradeep et al., 2023) was specifically trained to reduce positional bias.
Cost explosion at scale
Cause
LLM-based re-ranking with API models (GPT-4) at high query volumes leads to unsustainable API costs; or GPU costs for self-hosted cross-encoders exceed budget.
Symptoms
Monthly inference costs grow linearly with query volume; cost-per-query exceeds the revenue or value generated by the search system. For an Indian startup doing 500K queries/day with GPT-4 re-ranking, monthly costs can hit $75K (~Rs 63L/month).
Mitigation
Distill the LLM re-ranker into a compact cross-encoder using knowledge distillation (Rank-DistiLLM approach). Reduce candidate count N. Implement caching for repeated or similar queries — you'd be surprised how many queries in production are near-duplicates. Use tiered re-ranking: cheap model for most queries, expensive model only for high-value or ambiguous queries.
Placement in an ML System
In a RAG pipeline, the re-ranker sits between the first-stage retriever (which returns a broad set of candidates from the vector store or BM25 index) and the context assembler (which selects and formats the top passages for the LLM generator).
The re-ranker's output directly determines which passages the LLM sees, making it a critical quality gate. If the re-ranker gets the top-3 wrong, the LLM gets the wrong context, and the answer suffers. It's that simple.
In multi-stage cascades, a lightweight cross-encoder may first reduce 200 candidates to 50, followed by a heavier LLM-based re-ranker that selects the final top-5. In search engines (think Google, Bing, or Indian platforms like JioSaavn and Flipkart), the re-ranker sits between the retrieval backend and the results rendering layer.
Pipeline Stage
Post-Retrieval
Upstream
- Vector Store
- BM25 Index
- Hybrid Search
- Embedding Model
Downstream
- Context Assembler
- LLM Generator
- Answer Extraction
- Search Results UI
Production Case Studies
Google deployed BERT-based neural re-ranking in its search pipeline in 2019, representing what the company called one of the biggest improvements to search in five years. The BERT re-ranker scores query-passage pairs to improve the ranking of the top search results, particularly for longer, more conversational queries where understanding the full context of words like 'to' and 'for' matters for relevance.
Google reported that the BERT-based re-ranker improved search quality for approximately 10% of English-language queries, particularly complex queries with prepositions and contextual nuance that lexical matching could not resolve. Given Google processes ~8.5 billion searches per day, that's roughly 850 million queries per day benefiting from neural re-ranking.
Nogueira and Cho's seminal paper demonstrates a simple re-implementation of BERT for query-based passage re-ranking using cross-encoders. The system passes a query and document simultaneously to a transformer network, which outputs a single relevance score, with the advantage of performing attention across both the query and document.
Achieved state of the art on TREC-CAR dataset and was the top entry in MS MARCO passage retrieval task leaderboard, outperforming previous state of the art by 27% (relative) in MRR@10.
JioSaavn, one of India's largest music streaming platforms with over 100 million monthly active users, employs a multi-stage retrieval and re-ranking pipeline for music and podcast search. The first stage uses a combination of metadata-based retrieval and embedding-based search over song and podcast embeddings. A neural re-ranker then scores candidate results by modeling the interaction between the user query and item metadata (title, artist, lyrics snippets, tags), with particular attention to transliterated queries (Hindi queries in English script) and multi-language searches that are uniquely common in the Indian market.
The re-ranking stage improved click-through rates on search results by approximately 18%, with the largest gains on transliterated and code-mixed queries (e.g., Hinglish queries like 'mere dil mein aaj kya hai song') where lexical matching alone performs poorly due to inconsistent spelling conventions. This is a great example of re-ranking solving a problem that better retrieval alone cannot fix.
Elastic integrated cross-encoder re-ranking directly into Elasticsearch via the text_similarity_reranker and the Elastic Learned Sparse EncodeR (ELSER). Enterprise customers deploy Elasticsearch with a two-stage pipeline: BM25 or dense retrieval as the first stage, followed by a cross-encoder re-ranker hosted via the Elastic inference API. This enables organizations to add neural re-ranking to existing Elasticsearch deployments without replacing their search infrastructure — critical for enterprise adoption.
Enterprise customers reported 15-30% improvements in search relevance (measured by NDCG@10) after enabling re-ranking, with the largest gains in internal knowledge base search and customer support ticket retrieval where queries are often verbose and semantically complex. Several Indian enterprises, including major IT services companies, have adopted this pattern for internal documentation search.
Tooling & Ecosystem
Python library providing pretrained cross-encoder models and a simple predict() API for scoring query-document pairs. Includes models fine-tuned on MS MARCO (ms-marco-MiniLM-L-6-v2, ms-marco-electra-base) and NLI datasets. The most widely used open-source re-ranking toolkit.
Managed re-ranking API supporting 100+ languages. The rerank-v3.5 model accepts up to 1000 documents per request and handles long documents (up to 4096 tokens). No GPU infrastructure required. Pricing is per search unit.
Neural re-ranker available as both an API and self-hosted model. The jina-reranker-v2-base-multilingual model supports 100+ languages and 1024-token context. Offers a free tier and competitive pricing for production workloads.
Late-interaction retrieval and re-ranking model that pre-computes per-token document embeddings and computes MaxSim at query time. ColBERTv2 uses residual compression to reduce storage by 6-10x. The PLAID engine further optimizes retrieval speed via centroid-based pruning.
Python toolkit for reproducible listwise re-ranking with LLMs. Implements RankGPT, RankVicuna, and RankZephyr approaches. Supports both API-based (GPT-4, Claude) and self-hosted (vLLM-served) models for listwise re-ranking.
High-throughput LLM serving engine with PagedAttention. Used to self-host open-source re-ranking LLMs (RankZephyr, RankVicuna) with 3-5x higher throughput than naive HuggingFace inference. Essential for production LLM-based re-ranking at scale.
Ultra-lightweight Python library for re-ranking that runs on CPU without PyTorch or GPU dependencies. Uses ONNX-optimized cross-encoder models for sub-50ms re-ranking. Ideal for edge deployment and resource-constrained environments.
Collection of pre-trained cross-encoder models on the HuggingFace Hub, including MS MARCO-trained rankers (MiniLM, ELECTRA, DeBERTa variants) and NLI-trained models. Directly loadable via sentence-transformers or HuggingFace Transformers.
Research & References
Nogueira & Cho (2019)arXiv preprint
Introduced MonoBERT, the first cross-encoder re-ranker based on BERT for passage ranking. Fine-tuning BERT on MS MARCO with binary relevance labels improved MRR@10 from 0.167 (BM25) to 0.365, establishing the cross-encoder as the dominant re-ranking architecture. This paper catalyzed the era of pretrained-transformer-based neural re-ranking.
Nogueira, Jiang, Pradeep & Lin (2020)EMNLP 2020 Findings
Proposed MonoT5, which frames passage re-ranking as a text-to-text problem: given 'Query: q Document: d Relevant:', the model generates 'true' or 'false'. The probability assigned to 'true' serves as the relevance score. MonoT5-3B achieved state-of-the-art results on MS MARCO and TREC-DL, demonstrating that encoder-decoder architectures are effective re-rankers and opening the path to generative re-ranking.
Reimers & Gurevych (2019)EMNLP 2019
Established the distinction between bi-encoders (independent encoding, suitable for retrieval) and cross-encoders (joint encoding, suitable for re-ranking) that underpins modern two-stage retrieval pipelines. Showed that cross-encoders achieve substantially higher accuracy on semantic textual similarity tasks but require comparisons, motivating the retrieve-then-rerank architecture.
Santhanam, Khattab, Potts & Zaharia (2022)NAACL 2022
Introduced residual compression for ColBERT's per-token document embeddings, reducing the MS MARCO passage index from 154 GB to approximately 7 GB while maintaining retrieval effectiveness. ColBERTv2 demonstrated that late-interaction models can approach cross-encoder accuracy while enabling pre-computed document representations, making them suitable as both retrievers and efficient re-rankers.
Sun, Yan, Ma, Ren, Yin & Ren (2023)arXiv preprint
Proposed RankGPT, demonstrating that LLMs (GPT-3.5, GPT-4) can perform zero-shot listwise passage re-ranking by generating permutations of passage identifiers. Using a sliding window strategy to handle long candidate lists, GPT-4 achieved state-of-the-art NDCG@10 on TREC Deep Learning tracks, surpassing supervised cross-encoders on several benchmarks without any task-specific training.
Pradeep, Sharifymoghaddam & Lin (2023)arXiv preprint
Distilled listwise re-ranking capabilities from GPT-4 into RankZephyr, a 7B-parameter open-source LLM. RankZephyr matched or exceeded GPT-4's NDCG@10 on TREC Deep Learning and BEIR benchmarks while being self-hostable at a fraction of the cost. Demonstrated that listwise re-ranking is an emergent capability that can be transferred via distillation to smaller models.
Hofstatter, Althammer, Schroder, Sertkan & Hanbury (2020)arXiv preprint
Introduced Margin-MSE loss for distilling ranking knowledge from a cross-encoder teacher into efficient bi-encoder and ColBERT student models. This cross-architecture distillation approach enables training fast retrievers that approximate cross-encoder quality, forming the basis for cost-effective multi-stage retrieval pipelines.
Yates, Nogueira & Lin (2021)arXiv preprint
Provided a comprehensive analysis of multi-stage retrieval pipelines, benchmarking combinations of BM25, bi-encoder, cross-encoder, and MonoT5 re-rankers across MS MARCO and TREC datasets. Established best practices for cascade design: how many candidates to pass between stages, when to add additional re-ranking stages, and diminishing returns analysis.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is the difference between a bi-encoder and a cross-encoder? Why can't we use a cross-encoder for first-stage retrieval?
- ●
How would you design a two-stage retrieval pipeline with a re-ranker for a RAG system handling 10M documents?
- ●
Compare pointwise, pairwise, and listwise re-ranking approaches. What are the tradeoffs?
- ●
How does ColBERT's late interaction differ from a full cross-encoder? When would you choose one over the other?
- ●
An LLM-based re-ranker gives great results but costs $0.05 per query (~Rs 4.2). How would you reduce the cost while preserving quality?
- ●
Your re-ranker improves NDCG@10 on benchmarks but doesn't improve RAG answer quality. What could be wrong?
Key Points to Mention
- ●
Re-rankers model token-level query-document interactions via cross-attention, capturing fine-grained relevance signals (negation, co-reference) that bi-encoders miss due to independent encoding — this is the fundamental reason they exist
- ●
The retrieve-then-rerank paradigm separates efficiency (first stage, sub-linear) from precision (second stage, linear in candidate count), making the overall system both scalable and accurate
- ●
Cross-encoder latency scales linearly with candidate count — the choice of is a critical quality-latency tradeoff that must be tuned empirically based on retriever recall@N
- ●
LLM-based listwise re-rankers (RankGPT) achieve strong zero-shot performance but at 10-100x the cost of cross-encoders; knowledge distillation (RankZephyr) can close this gap
- ●
Re-rankers cannot recover documents that the first-stage retriever missed — recall@N of the retriever is the ceiling for re-ranker effectiveness. Always check this first.
- ●
MS MARCO-trained cross-encoders transfer well to many domains, but fine-tuning or LLM-based re-ranking is needed for specialized domains (medical, legal, multilingual, Indian vernacular)
Pitfalls to Avoid
- ●
Claiming a cross-encoder can replace the first-stage retriever — it absolutely cannot scale to millions of documents due to scoring cost per query
- ●
Ignoring the re-ranker's dependency on the retriever's recall — optimizing the re-ranker while the retriever misses relevant documents is a wasted effort (I've seen this mistake at every level of seniority)
- ●
Treating all re-ranking approaches as interchangeable — pointwise, pairwise, listwise, and late-interaction have fundamentally different cost profiles and quality characteristics
- ●
Overlooking the max sequence length constraint — most cross-encoders truncate at 512 tokens, silently losing document content without any warning
- ●
Assuming LLM re-rankers always outperform cross-encoders — supervised cross-encoders often win on in-domain tasks where training data is available
Senior-Level Expectation
A senior candidate should discuss the full multi-stage cascade design: choosing the candidate count based on retriever recall@N analysis, selecting the re-ranker architecture based on latency SLA and quality requirements, evaluating end-to-end impact on downstream tasks (not just ranking metrics), implementing knowledge distillation to compress expensive models, and operating the re-ranker in production (GPU autoscaling, batching, caching, monitoring NDCG drift).
They should quantify tradeoffs with concrete numbers: N=50 at 60ms vs. N=200 at 250ms vs. LLM re-ranking at 3s, and justify the choice for a given use case. They should also discuss cost — a cross-encoder on a g4dn.xlarge costs ~5,000/day (~Rs 4.2L/day).
Bonus points if they mention monitoring for distribution shift (query patterns change over time, degrading re-ranker effectiveness) and A/B testing re-ranker changes against end-to-end metrics rather than just NDCG.
Summary
Let's bring it all together.
-
A re-ranker is a second-stage model that reorders retrieved candidates by scoring fine-grained query-document interactions, improving ranking precision where first-stage retrievers are limited by their independent encoding constraint
-
Cross-encoders (MonoBERT, MiniLM) concatenate query and document through joint self-attention, achieving 10-25 NDCG@10 points improvement over bi-encoder retrieval at a cost of 50-400ms per query
-
Late-interaction models (ColBERTv2) pre-compute per-token document embeddings and use MaxSim scoring, offering a speed-accuracy middle ground between bi-encoders and cross-encoders
-
LLM-based listwise re-rankers (RankGPT, RankZephyr) produce permutation-based orderings with strong zero-shot generalization but incur 1-5 second latency and higher cost per query (~$0.05 / Rs 4.2 per query with GPT-4)
-
Knowledge distillation from LLM teachers into compact cross-encoders is the emerging best practice for production systems that need both quality and efficiency
-
Re-rankers are bounded by first-stage recall: they reorder but do not retrieve, so improving retriever recall@N is a prerequisite for re-ranker effectiveness
The Bottom Line: A re-ranker is the precision layer in a multi-stage retrieval pipeline. It bridges the gap between efficient but approximate first-stage retrieval and the exact relevance judgments needed for high-quality RAG and search applications. If you're building a production RAG system and you're not using a re-ranker, you're almost certainly leaving quality on the table.