Summarizer in Machine Learning
A summarizer is an NLP component that condenses long text into a shorter version while preserving the essential meaning, key facts, and salient arguments. It sits at the heart of any system that needs to distill information -- whether that is compressing a 50-page legal contract into a one-page brief, turning a two-hour earnings call transcript into bullet points, or generating the "TL;DR" for a Slack thread.
Summarization comes in two fundamental flavors: extractive (selecting and stitching together existing sentences from the source) and abstractive (generating entirely new sentences that paraphrase the original content). Modern systems increasingly blur this line, using extractive methods to select candidate passages and then abstractive models to rewrite them into fluent, coherent summaries.
The rise of large language models has transformed summarization from a research benchmark into a production necessity. From Inshorts condensing Indian news articles into 60-word cards, to enterprise platforms summarizing customer support tickets for agents, to RAG pipelines compressing retrieved context before feeding it to a generator -- summarizers are everywhere. Understanding the tradeoffs between extraction and abstraction, the right model for your latency and cost budget, and how to evaluate output quality is essential for any ML engineer building information-dense applications.
Concept Snapshot
- What It Is
- An NLP component that condenses source text into a shorter representation while preserving key information, using either extractive (sentence selection) or abstractive (novel generation) techniques.
- Category
- Natural Language Processing
- Complexity
- Intermediate
- Inputs / Outputs
- Input: one or more source documents (raw text, tokenized sequences, or structured passages). Output: a shorter text summary (single sentence to multi-paragraph) with optional metadata like confidence scores and source attributions.
- System Placement
- Sits downstream of tokenizers and text preprocessors; upstream of context assemblers, prompt templates, or end-user interfaces in ML pipelines.
- Also Known As
- text summarizer, document summarizer, auto-summarization engine, TL;DR generator, condensation module, digest generator
- Typical Users
- ML Engineers, NLP Engineers, Data Scientists, Product Engineers, Content Platform Developers
- Prerequisites
- Tokenization and text preprocessing, Transformer architecture fundamentals, Sequence-to-sequence models, Attention mechanisms, Basic information retrieval concepts
- Key Terms
- extractive summarizationabstractive summarizationROUGE scoreBERTScoreseq2seqencoder-decoderTextRankchain of densitymap-reduce summarizationfaithfulnesshallucination
Why This Concept Exists
The Information Overload Problem
Humans are drowning in text. A single enterprise might generate 10,000 customer support tickets per day, each averaging 500 words. That is 5 million words daily -- no human team can read all of it. Legal teams review contracts that run 100+ pages. Analysts digest earnings call transcripts exceeding 15,000 words. Researchers face thousands of papers published monthly on arXiv alone.
Manual summarization does not scale. A skilled human summarizer processes roughly 5,000 words per hour with high quality. At that rate, summarizing a day's worth of support tickets would require 1,000 person-hours -- an impossibility for any operations team.
From Rule-Based Heuristics to Neural Generation
Early summarization systems were purely extractive, using statistical heuristics: sentences at the beginning of documents, sentences containing high-frequency terms, or sentences connected to many others in a graph. Luhn's 1958 method -- arguably the first automatic summarizer -- simply scored sentences by the frequency of "significant" words.
The TextRank algorithm (2004) brought graph-based ranking to summarization, treating sentences as nodes and using PageRank-style voting to identify the most "central" sentences. This was a leap forward, but extractive methods inherently suffer from coherence problems -- you are stitching together sentences written in different contexts.
Abstractive summarization became practical with sequence-to-sequence models. The attention mechanism (Bahdanau et al., 2015) and the copy mechanism (See et al., 2017) allowed models to both generate novel words and copy important terms from the source. Then came the transformer era: BART (2019), T5 (2019), and PEGASUS (2019) established new state-of-the-art results on every major summarization benchmark.
The LLM Inflection Point
Today, large language models like GPT-4, Claude, and Gemini can produce remarkably fluent summaries with zero-shot or few-shot prompting -- no fine-tuning required. This has democratized summarization: any developer can call an API and get a reasonable summary. But it has also raised the bar. Production systems now need to worry about faithfulness (does the summary contain only information from the source?), controllability (can you specify length, style, and focus?), and cost (LLM API calls at scale get expensive fast).
Key Takeaway: Summarizers exist because information grows faster than human attention. The evolution from frequency heuristics to TextRank to transformers to LLMs reflects the field's relentless pursuit of summaries that are not just shorter, but genuinely faithful and useful.
Core Intuition & Mental Model
Two Ways to Summarize -- and Why It Matters
Imagine you are taking notes in a lecture. Extractive summarization is like highlighting sentences in the textbook -- you are selecting existing content. Abstractive summarization is like writing the notes in your own words -- you are generating new text that captures the meaning.
Extractive methods are safer: they cannot hallucinate information that is not in the source, because every word in the output came from the input. But they are often clunky -- sentences ripped from different paragraphs may not flow well together, and they cannot combine ideas from multiple passages into a single concise statement.
Abstractive methods are more powerful: they can rephrase, compress, and synthesize. A 200-word paragraph can become a single elegant sentence. But they carry the risk of hallucination -- generating plausible-sounding claims that are not supported by the source document. This is the central tension in summarization: fluency vs. faithfulness.
The Mental Model: Compression With a Fidelity Guarantee
Think of summarization as lossy compression for natural language. Just as JPEG reduces image file size by discarding imperceptible visual details, a summarizer reduces text length by discarding less important information. The compression ratio (input length / output length) is typically 5:1 to 20:1 for single-document summarization.
But unlike JPEG, where the quality metric is well-defined (PSNR, SSIM), summarization quality is fuzzy. A summary can be fluent but unfaithful, or faithful but unreadable. The best summarizers optimize along multiple axes simultaneously: informativeness (did it capture the key points?), faithfulness (did it avoid making things up?), coherence (does it read well?), and conciseness (is it appropriately short?).
Expert Insight: When someone says "our summarizer works great," always ask: great by what metric? ROUGE scores can be high even when summaries hallucinate. Faithfulness evaluation is the harder and more important problem in production.
Technical Foundations
Mathematical Formulation
Let be a source document consisting of sentences. A summarizer produces a summary subject to a length constraint .
Extractive Summarization selects a subset of indices and constructs where preserves document order. The optimization objective is:
where measures sentence importance and controls the redundancy penalty (Maximal Marginal Relevance).
Abstractive Summarization generates token by token using a conditional language model:
where are the model parameters, typically a transformer encoder-decoder. The model is trained to maximize log-likelihood over reference summaries:
Evaluation: ROUGE Metrics
The standard evaluation framework is ROUGE (Recall-Oriented Understudy for Gisting Evaluation). For a candidate summary and reference summary :
where denotes n-grams of length . The most commonly reported variants are:
- ROUGE-1: Unigram overlap -- captures content coverage
- ROUGE-2: Bigram overlap -- captures fluency and phrase-level matching
- ROUGE-L: Longest common subsequence -- captures sentence-level structure
State-of-the-art models on CNN/DailyMail achieve approximately ROUGE-1: 44-47, ROUGE-2: 21-23, ROUGE-L: 40-43.
Beyond ROUGE: Semantic Evaluation
BERTScore computes token-level cosine similarity between contextual embeddings of the candidate and reference:
where and are precision and recall computed by greedily matching each token in the candidate to the most similar token in the reference (and vice versa) using BERT embeddings. BERTScore correlates more strongly with human judgments than ROUGE, particularly for abstractive summaries where paraphrasing is common.
Internal Architecture
A production summarization system is more than a single model -- it is a pipeline that handles document preprocessing, chunking for long inputs, model inference, post-processing, and quality validation. Here is the typical architecture:
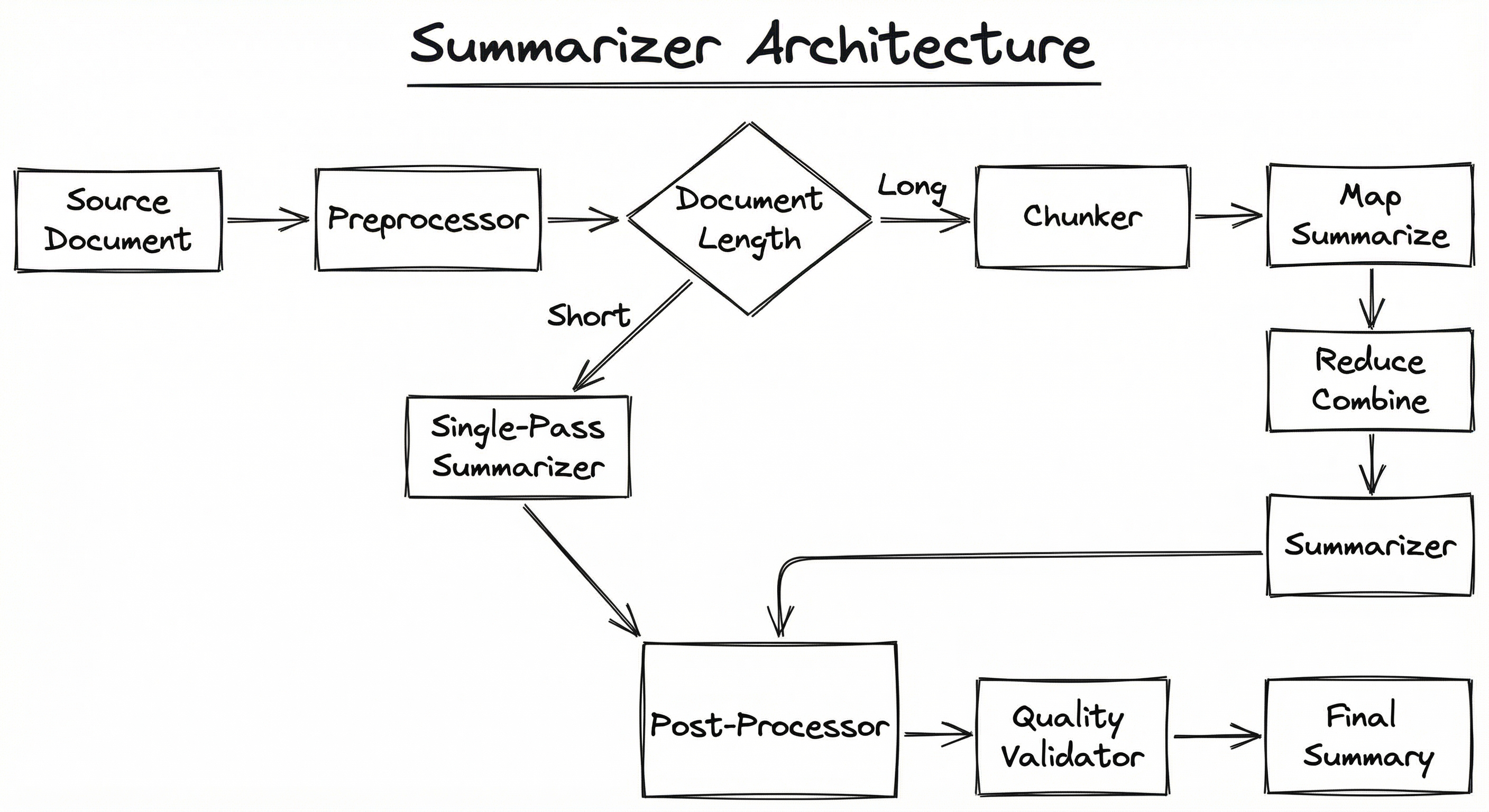
The architecture branches based on document length. Short documents (under the model's context window) go through a single forward pass. Long documents are split into chunks, each chunk is summarized independently (the "map" step), and the chunk summaries are combined into a final summary (the "reduce" step). This map-reduce pattern is the standard approach for handling documents that exceed model context limits -- whether you are using a fine-tuned BART model with a 1024-token window or an LLM with a 128K-token window that you want to use cost-efficiently.
Key Components
Preprocessor / Tokenizer
Cleans input text (removes boilerplate, normalizes whitespace, handles encoding), segments into sentences, and tokenizes. For extractive methods, sentence boundaries are critical. For abstractive methods, subword tokenization (BPE, SentencePiece) prepares input for the encoder.
Document Chunker
Splits long documents into overlapping segments that fit within the model's maximum input length. Chunk boundaries should respect sentence or paragraph boundaries to avoid splitting semantic units. Typical chunk sizes are 512-1024 tokens with 10-20% overlap.
Extractive Selector
Scores and ranks sentences by importance using graph-based methods (TextRank), embedding similarity (BERT-based), or learned classifiers. Selects top-k sentences while minimizing redundancy. Used standalone or as a pre-filter for abstractive models.
Abstractive Generator
A sequence-to-sequence transformer (BART, T5, PEGASUS) or an LLM (GPT-4, Claude, Gemini) that generates novel summary text conditioned on the source. Controls output length via max_length, min_length, and length_penalty parameters.
Map-Reduce Orchestrator
Manages the two-phase summarization of long documents: dispatches chunks to the summarizer in parallel (map phase), collects intermediate summaries, and feeds them back for final consolidation (reduce phase). May use iterative refinement instead of a single reduce step.
Post-Processor
Cleans generated output: removes repeated phrases, fixes grammatical artifacts from beam search, ensures proper sentence boundaries, and formats the summary according to application requirements (bullet points, paragraphs, specific length).
Quality Validator
Checks the summary for factual consistency against the source document using NLI-based detectors (SummaC, AlignScore) or LLM-as-judge. Flags or rejects summaries that contain hallucinated information. This is the most underinvested component in most production systems.
Data Flow
Single-Document Flow: Source text enters the preprocessor, gets tokenized and (if needed) chunked. Each chunk passes through the summarizer model. If multiple chunks exist, their summaries are combined in the reduce step. The post-processor cleans the output, and the quality validator checks factual consistency before the summary is returned.
Multi-Document Flow: Multiple source documents are first deduplicated and clustered by subtopic. Each cluster is summarized independently, then cluster summaries are merged into a coherent multi-document summary. This requires additional logic for handling contradictions between sources and ensuring balanced coverage.
RAG Integration Flow: In a RAG pipeline, the summarizer sits between the retriever and the prompt template. Retrieved passages are summarized to fit within the LLM's context window, maximizing the amount of relevant information that can be passed to the generator while staying within token budgets.
A directed flow from Source Document through Preprocessor to a decision point based on document length. Short documents go directly to the Single-Pass Summarizer. Long documents are chunked, each chunk is summarized (map phase), and results are combined (reduce phase) before going to the summarizer. Output passes through Post-Processor and Quality Validator to produce the Final Summary.
How to Implement
Choosing Your Approach
Implementation strategy depends on three factors: latency requirements, cost budget, and quality bar.
Option 1: Fine-tuned transformer models (BART, T5, PEGASUS). Best when you have domain-specific training data, need low latency (<500ms), and want predictable per-query costs. A facebook/bart-large-cnn model on a single GPU processes ~50 documents/second. Cost: ~INR 25,000/month ($300/month) for a GPU instance.
Option 2: LLM API-based summarization (GPT-4o, Claude, Gemini). Best for rapid prototyping, zero-shot quality on diverse domains, and when you do not have training data. Cost: ~30-120 (~INR 2,500-10,000).
Option 3: Hybrid extractive-then-abstractive. Use an extractive pre-filter (TextRank, BERT-based scoring) to select the most important passages, then feed those to an abstractive model. This reduces input length by 3-5x, cutting LLM API costs proportionally while maintaining quality.
For Indian startups operating under tight compute budgets, Option 1 with a fine-tuned T5-small or T5-base offers the best cost-quality tradeoff. For enterprise applications where quality is paramount, Option 2 with GPT-4o-mini or Claude 3.5 Haiku provides excellent results at reasonable cost.
Cost Note: Summarizing 10,000 documents/day (avg 3000 tokens each) with GPT-4o-mini costs approximately 135/month (~INR 11,300/month). With a fine-tuned BART-large on a single A10G GPU, the same workload costs ~$25/month (~INR 2,100/month) in compute but requires upfront fine-tuning effort.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
import networkx as nx
import re
def textrank_summarize(text: str, num_sentences: int = 3) -> str:
"""Extractive summarization using TextRank with sentence embeddings."""
# Split into sentences
sentences = re.split(r'(?<=[.!?])\s+', text.strip())
if len(sentences) <= num_sentences:
return text
# Encode sentences using a lightweight model
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
# Build similarity matrix
sim_matrix = cosine_similarity(embeddings)
np.fill_diagonal(sim_matrix, 0) # No self-loops
# Apply PageRank
graph = nx.from_numpy_array(sim_matrix)
scores = nx.pagerank(graph, alpha=0.85, max_iter=100)
# Select top sentences (preserve original order)
ranked_indices = sorted(scores, key=scores.get, reverse=True)
selected = sorted(ranked_indices[:num_sentences])
return ' '.join(sentences[i] for i in selected)
# Usage
text = """India's digital payments ecosystem has seen remarkable growth.
UPI processed 12.02 billion transactions in October 2024 alone.
PhonePe and Google Pay dominate with a combined 85% market share.
The Reserve Bank of India continues to expand the infrastructure.
Rural adoption remains a challenge despite government incentives.
New features like UPI Lite and credit-on-UPI are driving further adoption."""
print(textrank_summarize(text, num_sentences=2))This example demonstrates extractive summarization using TextRank with modern sentence embeddings instead of traditional TF-IDF. The all-MiniLM-L6-v2 model from sentence-transformers produces 384-dimensional embeddings that capture semantic similarity far better than bag-of-words approaches. The PageRank algorithm then identifies the most "central" sentences -- those most similar to all other sentences in the document. This approach requires no training data and works across domains.
from transformers import pipeline, BartForConditionalGeneration, BartTokenizer
import torch
# Option 1: Quick setup with pipeline API
summarizer = pipeline(
"summarization",
model="facebook/bart-large-cnn",
device=0 if torch.cuda.is_available() else -1
)
text = """The Indian Space Research Organisation (ISRO) successfully launched
the Chandrayaan-3 mission, which achieved a historic soft landing on the
lunar south pole on August 23, 2023. India became the fourth country to
land on the Moon and the first to land near the south pole. The Pragyan
rover deployed from the Vikram lander conducted multiple experiments
including thermal measurements and seismic activity detection. The mission
cost approximately Rs 615 crore (about $75 million), making it one of the
most cost-effective lunar missions in history. The success was celebrated
across India and positioned ISRO as a leader in cost-effective space
exploration. The data collected continues to provide insights about the
lunar surface composition and potential water ice deposits."""
result = summarizer(
text,
max_length=80,
min_length=30,
do_sample=False,
num_beams=4,
length_penalty=2.0,
no_repeat_ngram_size=3
)
print(result[0]['summary_text'])
# Option 2: Fine-grained control with model + tokenizer
model = BartForConditionalGeneration.from_pretrained("facebook/bart-large-cnn")
tokenizer = BartTokenizer.from_pretrained("facebook/bart-large-cnn")
inputs = tokenizer(
text,
return_tensors="pt",
max_length=1024,
truncation=True
)
summary_ids = model.generate(
inputs["input_ids"],
max_length=80,
min_length=30,
num_beams=4,
length_penalty=2.0,
no_repeat_ngram_size=3,
early_stopping=True
)
print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))Two approaches to using BART for abstractive summarization. The pipeline API is the quickest way to get started -- two lines of code for a working summarizer. The model + tokenizer approach gives you full control over generation parameters. Key parameters: num_beams=4 uses beam search for better quality, length_penalty=2.0 encourages longer outputs (reduce for shorter summaries), and no_repeat_ngram_size=3 prevents the model from repeating trigrams. The facebook/bart-large-cnn checkpoint is fine-tuned on CNN/DailyMail and works well for news-style summarization out of the box.
from openai import OpenAI
import json
client = OpenAI() # Uses OPENAI_API_KEY env variable
def chain_of_density_summarize(
article: str,
iterations: int = 5,
target_words: int = 80,
model: str = "gpt-4o-mini"
) -> dict:
"""Chain of Density summarization: iteratively increases entity density."""
prompt = f"""Article: {article}
You will generate {iterations} increasingly concise, entity-dense summaries
of the above article. Each summary should be approximately {target_words} words.
Guidelines:
- Summary 1: Write a sparse summary covering only 1-2 main entities.
- Each subsequent summary: Identify 1-3 informative entities from the article
that are MISSING from the previous summary. Add them by:
(a) Replacing less specific phrases with more specific ones
(b) Fusing multiple sentences to make room
(c) Compressing existing information
- NEVER increase the summary length. Every word must earn its place.
- NEVER drop entities mentioned in earlier summaries.
- An entity is a real-world object: named events, people, organizations,
specific numbers, dates, technical terms.
Return a JSON array of {iterations} objects, each with keys:
"summary": the summary text,
"missing_entities": list of entities added in this iteration,
"density_score": number of entities per 100 words
"""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.3,
response_format={"type": "json_object"}
)
result = json.loads(response.choices[0].message.content)
return result
# Usage
article = """India's Unified Payments Interface (UPI) has revolutionized
digital payments in the country. In 2024, UPI processed over 130 billion
transactions worth Rs 200 lakh crore ($2.4 trillion). PhonePe leads with
48% market share, followed by Google Pay at 37%. The National Payments
Corporation of India (NPCI) has expanded UPI internationally, with
singapore, UAE, France, and Sri Lanka now accepting UPI payments.
The RBI introduced UPI Lite for small transactions under Rs 500 without
PIN verification, processing 300 million transactions monthly.
Credit-on-UPI, launched in partnership with RuPay, has seen 15 million
users adopt the feature within six months."""
result = chain_of_density_summarize(article)
for i, step in enumerate(result.get("summaries", [result])):
print(f"\n--- Iteration {i+1} ---")
print(step.get("summary", step))Chain of Density (CoD) prompting, introduced by Adams et al. (2023), produces summaries that are more entity-dense and abstractive than vanilla prompting. The key insight is that iterative refinement forces the model to prioritize information more carefully with each pass. Human evaluators on CNN/DailyMail preferred CoD summaries at step 3 (out of 5) -- a sweet spot between sparsity and information overload. This technique works with any capable LLM and requires no fine-tuning. Cost per summarization with GPT-4o-mini: approximately $0.001 (~INR 0.08) per article.
from transformers import pipeline
import torch
from typing import List
import re
class MapReduceSummarizer:
"""Summarize documents longer than the model's context window."""
def __init__(
self,
model_name: str = "facebook/bart-large-cnn",
chunk_size: int = 900,
chunk_overlap: int = 100,
map_max_length: int = 150,
reduce_max_length: int = 200
):
self.summarizer = pipeline(
"summarization",
model=model_name,
device=0 if torch.cuda.is_available() else -1
)
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.map_max_length = map_max_length
self.reduce_max_length = reduce_max_length
def _split_into_chunks(self, text: str) -> List[str]:
"""Split text into overlapping chunks at sentence boundaries."""
sentences = re.split(r'(?<=[.!?])\s+', text.strip())
chunks = []
current_chunk = []
current_length = 0
for sentence in sentences:
words = len(sentence.split())
if current_length + words > self.chunk_size and current_chunk:
chunks.append(' '.join(current_chunk))
# Keep last few sentences for overlap
overlap_sentences = []
overlap_len = 0
for s in reversed(current_chunk):
if overlap_len + len(s.split()) > self.chunk_overlap:
break
overlap_sentences.insert(0, s)
overlap_len += len(s.split())
current_chunk = overlap_sentences
current_length = overlap_len
current_chunk.append(sentence)
current_length += words
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
def summarize(self, text: str) -> str:
"""Map-reduce summarization pipeline."""
chunks = self._split_into_chunks(text)
if len(chunks) == 1:
result = self.summarizer(
chunks[0],
max_length=self.reduce_max_length,
min_length=50,
do_sample=False
)
return result[0]['summary_text']
# Map phase: summarize each chunk
print(f"Map phase: summarizing {len(chunks)} chunks...")
chunk_summaries = []
for i, chunk in enumerate(chunks):
result = self.summarizer(
chunk,
max_length=self.map_max_length,
min_length=30,
do_sample=False
)
chunk_summaries.append(result[0]['summary_text'])
# Reduce phase: combine chunk summaries
combined = ' '.join(chunk_summaries)
print(f"Reduce phase: combining {len(chunk_summaries)} summaries...")
# If combined summaries are still too long, recurse
if len(combined.split()) > self.chunk_size:
return self.summarize(combined)
result = self.summarizer(
combined,
max_length=self.reduce_max_length,
min_length=50,
do_sample=False
)
return result[0]['summary_text']
# Usage
summarizer = MapReduceSummarizer()
long_document = "..." # Your long document here
print(summarizer.summarize(long_document))This map-reduce implementation handles documents of arbitrary length by recursively chunking and summarizing. The overlap between chunks (100 tokens by default) ensures that context at chunk boundaries is not lost. The recursion in the reduce phase handles cases where even the combined chunk summaries exceed the model's context window -- rare but possible for very long documents (50,000+ words). This is the same pattern used by LangChain's MapReduceDocumentsChain but implemented from scratch for transparency and customization.
from rouge_score import rouge_scorer
from bert_score import score as bert_score
import numpy as np
def evaluate_summary(
candidate: str,
reference: str,
verbose: bool = True
) -> dict:
"""Evaluate a summary using ROUGE and BERTScore metrics."""
# ROUGE scores
scorer = rouge_scorer.RougeScorer(
['rouge1', 'rouge2', 'rougeL', 'rougeLsum'],
use_stemmer=True
)
rouge_results = scorer.score(reference, candidate)
# BERTScore
P, R, F1 = bert_score(
[candidate],
[reference],
model_type="microsoft/deberta-xlarge-mnli",
lang="en",
verbose=False
)
results = {
"rouge1_f1": rouge_results['rouge1'].fmeasure,
"rouge2_f1": rouge_results['rouge2'].fmeasure,
"rougeL_f1": rouge_results['rougeL'].fmeasure,
"bertscore_precision": P.item(),
"bertscore_recall": R.item(),
"bertscore_f1": F1.item()
}
if verbose:
print("=== ROUGE Scores ===")
for key in ['rouge1', 'rouge2', 'rougeL']:
r = rouge_results[key]
print(f" {key}: P={r.precision:.4f} R={r.recall:.4f} F1={r.fmeasure:.4f}")
print(f"\n=== BERTScore ===")
print(f" P={P.item():.4f} R={R.item():.4f} F1={F1.item():.4f}")
return results
# Example
reference = "India's ISRO achieved a historic lunar south pole landing with Chandrayaan-3 at a cost of $75 million."
candidate = "ISRO's Chandrayaan-3 mission successfully landed near the Moon's south pole, making India the first country to achieve this feat, at a cost of approximately Rs 615 crore."
results = evaluate_summary(candidate, reference)This evaluation function computes both ROUGE (lexical overlap) and BERTScore (semantic similarity). ROUGE is the standard metric reported in papers and leaderboards, but BERTScore with DeBERTa-xlarge correlates better with human judgments -- it gives credit to paraphrases that ROUGE misses. For production monitoring, track ROUGE-L F1 as the primary metric and BERTScore F1 as a secondary signal. A ROUGE-L F1 above 0.35 and BERTScore F1 above 0.85 typically indicates acceptable quality for news-style summarization.
# Summarization pipeline config (YAML)
pipeline:
name: document-summarizer
strategy: map-reduce # options: single-pass, map-reduce, refine
preprocessor:
max_input_tokens: 100000
sentence_splitter: spacy # options: spacy, nltk, regex
clean_html: true
remove_boilerplate: true
chunker:
chunk_size_tokens: 900
overlap_tokens: 100
respect_sentence_boundaries: true
model:
name: facebook/bart-large-cnn
device: cuda:0
quantization: int8 # options: none, int8, int4
generation:
max_length: 150
min_length: 40
num_beams: 4
length_penalty: 2.0
no_repeat_ngram_size: 3
early_stopping: true
quality:
faithfulness_checker: summac # options: summac, alignscore, llm-judge
min_rouge_l: 0.30
max_hallucination_score: 0.15
reject_on_failure: false # log warning instead of rejecting
monitoring:
log_rouge_scores: true
log_latency_p99: true
alert_on_quality_drop: true
evaluation_sample_rate: 0.05 # evaluate 5% of outputsCommon Implementation Mistakes
- ●
Ignoring input length limits: Feeding a 10,000-token document into a BART model with a 1024-token limit silently truncates the input. The model summarizes only the beginning, missing critical information from the middle and end. Always check
model.config.max_position_embeddingsand implement chunking for longer inputs. - ●
Treating ROUGE as a quality guarantee: A ROUGE-1 F1 of 0.45 tells you the summary has good unigram overlap with the reference, but it says nothing about factual accuracy. Models can achieve high ROUGE scores while hallucinating specific numbers, dates, or causal relationships. Always pair ROUGE with faithfulness evaluation.
- ●
Using greedy decoding for abstractive models: Greedy decoding (selecting the highest-probability token at each step) produces repetitive, degenerate summaries. Use beam search with
num_beams=4andno_repeat_ngram_size=3as a baseline. For more diverse summaries, try nucleus sampling withtop_p=0.9. - ●
Not controlling output length explicitly: Without
min_lengthandmax_lengthconstraints, models may produce summaries that are too short (a single generic sentence) or too long (barely shorter than the input). Always set explicit length bounds based on your application requirements. - ●
Applying the same summarizer across all domains without evaluation: A model fine-tuned on CNN/DailyMail news articles will underperform on legal documents, medical records, or code documentation. Domain transfer is not free -- evaluate on your target domain and fine-tune if quality is insufficient.
- ●
Neglecting post-processing: Abstractive models sometimes generate incomplete sentences (especially with aggressive
max_lengthtruncation), repeated phrases, or formatting artifacts. A simple post-processing step that removes incomplete trailing sentences and deduplicates content significantly improves perceived quality.
When Should You Use This?
Use When
You need to condense long documents (reports, articles, transcripts) into digestible formats for end users or downstream systems
Your RAG pipeline retrieves more context than fits in the LLM's prompt -- a summarizer compresses retrieved passages to maximize information density within token budgets
Customer support teams need quick overviews of long ticket histories or conversation threads before responding
You are building a news aggregation or content curation platform (like Inshorts or Google News) that needs automated digest generation
Legal, medical, or financial documents need to be summarized for non-expert stakeholders while preserving key facts
Multi-document settings require synthesizing information from multiple sources into a single coherent overview
You want to generate meeting notes, podcast summaries, or video transcriptions in a shorter form
Avoid When
The source text is already short (under 100 words) -- summarization adds latency and cost with minimal benefit. Just display the original.
Exact wording matters (legal clauses, regulatory language, medical dosage instructions) -- any paraphrasing risks changing the meaning, and extractive methods may miss critical context
You need structured information extraction (entity extraction, relation extraction) rather than a prose summary -- use an NER or IE pipeline instead
The input is highly technical with domain-specific terminology that your summarizer has not been trained on -- output quality will be poor and potentially dangerous (e.g., medical summaries with wrong drug names)
Real-time latency requirements are under 50ms -- even fast summarization models add 100-500ms per document. Consider pre-computing summaries offline instead.
The task is better served by keyword extraction or topic labeling rather than full prose summarization
Key Tradeoffs
Extractive vs. Abstractive
| Dimension | Extractive | Abstractive |
|---|---|---|
| Faithfulness | High (words come from source) | Lower (may hallucinate) |
| Fluency | Variable (stitched sentences) | High (generated prose) |
| Compression ratio | 3:1 to 5:1 typical | 5:1 to 20:1 achievable |
| Latency | 10-50ms (no generation) | 100ms-5s (model dependent) |
| Cost | Low (CPU inference) | Higher (GPU or API) |
| Training data needed | None (unsupervised) | Significant (supervised) |
Fine-Tuned Models vs. LLM APIs
Fine-tuned models (BART, T5, PEGASUS) offer lower latency (50-200ms), predictable costs ($25-100/month for a GPU), and domain specialization. But they require training data, model management, and cannot generalize to new domains without retraining.
LLM APIs (GPT-4o, Claude, Gemini) offer zero-shot versatility, better instruction following (control length, style, format), and no infrastructure management. But they are more expensive at scale ($100-500/month at moderate volume), have higher latency (1-10s), and raise data privacy concerns for sensitive content.
The Sweet Spot for Most Teams
Start with an LLM API for prototyping and validation. Once you have confirmed that summarization adds value to your product and you have collected evaluation data, fine-tune a smaller model (T5-base, BART-base) for cost efficiency. Keep the LLM as a fallback for edge cases that the fine-tuned model handles poorly.
Alternatives & Comparisons
A text classifier assigns labels to documents (topic, sentiment, priority) but does not generate shorter representations of the content. If you need a categorical understanding of a document rather than a condensed version, classification is the right tool. However, summarization and classification are often used together -- classify first, then summarize within each category.
A context assembler selects and arranges retrieved passages for an LLM prompt. While it performs a form of content selection (similar to extractive summarization), it focuses on fitting within token budgets and maintaining relevance ordering rather than producing human-readable summaries. Use a summarizer when the output needs to be coherent prose; use a context assembler when the output feeds directly into an LLM.
Prompt templates can include summarization instructions (e.g., 'Summarize the following in 3 bullet points'), effectively embedding summarization as part of a larger LLM call. This works for simple cases but lacks the modularity, caching, and quality monitoring of a dedicated summarizer component. For production systems, separate the summarization step from the generation step.
The tokenizer is a prerequisite for the summarizer, not an alternative. It converts raw text into tokens that the summarization model can process. If your goal is simply to truncate text to fit a token budget without preserving meaning, a tokenizer with truncation is simpler than a summarizer -- but the result will be much lower quality.
Pros, Cons & Tradeoffs
Advantages
Massive time savings: Reduces hours of reading to seconds of scanning. A 10,000-word document becomes a 200-word summary in under a second with a fine-tuned model.
Enables downstream processing: Summarized text fits within LLM context windows, reduces embedding costs, and improves retrieval precision in RAG pipelines.
Scalable information access: Democratizes access to long, complex documents -- non-expert stakeholders can understand legal contracts, research papers, or financial reports through summaries.
Flexible granularity: Can produce anything from a single-sentence headline to a multi-paragraph executive summary, controlled by generation parameters.
Domain adaptability: Fine-tuned models can specialize in legal, medical, scientific, or financial summarization with domain-specific training data, achieving quality that matches human experts.
Cost-effective at scale: A single GPU running BART can summarize 50+ documents per second. Even LLM APIs at $0.001/summary are far cheaper than human summarizers (INR 500-2000 per human-written summary).
Disadvantages
Hallucination risk: Abstractive models may generate plausible-sounding facts not present in the source. This is especially dangerous in medical, legal, and financial domains where accuracy is non-negotiable.
Evaluation is hard: ROUGE captures lexical overlap but not semantic accuracy or faithfulness. Human evaluation is expensive (INR 200-500 per evaluation). BERTScore helps but is not sufficient alone.
Long document handling is complex: Most transformer models have context limits (1024 tokens for BART, 512 for base T5). Map-reduce strategies add complexity, latency, and potential information loss at chunk boundaries.
Domain transfer is not free: A model trained on news articles will struggle with medical discharge summaries, legal briefs, or code documentation. Fine-tuning requires labeled data that may not exist for your domain.
Loss of nuance: Summarization inherently discards information. Critical qualifying statements ('under certain conditions', 'except in cases of') may be dropped, changing the meaning of the remaining content.
Position bias: Many models disproportionately weight the beginning of the document (lead bias), under-representing important information in the middle or end. This is a known weakness of models trained on news data.
Failure Modes & Debugging
Factual Hallucination
Cause
The abstractive model generates specific claims (numbers, names, dates, causal relationships) that are not present in or are contradicted by the source document. This happens because the model's language prior overrides the conditioning on the input -- it generates what sounds plausible rather than what the source says.
Symptoms
Summary contains invented statistics, incorrect attributions, or fabricated quotes. Often detected only by human review or NLI-based consistency checks. Particularly common when the model encounters ambiguous or underspecified input.
Mitigation
Use faithfulness detection tools (SummaC, AlignScore, or LLM-as-judge). Implement a post-generation verification step that checks each claim against the source. For high-stakes domains, use extractive-then-abstractive pipelines to limit the generation space. Set num_beams >= 4 to reduce hallucination via beam search.
Input Truncation Without Warning
Cause
Source document exceeds the model's maximum input length. The tokenizer silently truncates the input, and the model summarizes only the visible portion -- typically the beginning of the document.
Symptoms
Summaries consistently reflect only the first section of long documents. Key information from later sections is completely absent. Users report that summaries 'miss the point' of documents where the conclusion or recommendation appears at the end.
Mitigation
Always compare len(tokenizer.encode(text)) against model.config.max_position_embeddings. If input exceeds the limit, use map-reduce chunking or switch to a long-context model (LED, Longformer, or an LLM with 128K+ context). Log truncation events as warnings.
Repetitive or Degenerate Output
Cause
Greedy decoding or low-diversity beam search causes the model to enter a loop, generating the same phrase repeatedly. More common with smaller models, low temperature, or when the input is noisy or out-of-distribution.
Symptoms
Summary contains repeated sentences or phrases (e.g., 'The report states that the report states that...'). Output may also degenerate into a single repeated token.
Mitigation
Set no_repeat_ngram_size=3 to block trigram repetition. Use num_beams=4 or higher. If using sampling, set top_p=0.9 and temperature=0.7. Add a post-processing step that detects and removes repeated n-grams.
Lead Bias (Position Bias)
Cause
Models trained primarily on news articles (CNN/DailyMail, XSum) learn that the most important information appears in the first few sentences -- the inverted pyramid structure. When applied to non-news documents (reports, papers, conversations), this bias causes the model to over-represent the introduction and under-represent later sections.
Symptoms
Summaries of academic papers focus on the abstract/introduction and miss results and conclusions. Summaries of meeting transcripts cover only the first agenda item. Summaries of legal documents focus on preamble clauses and miss operative provisions.
Mitigation
Fine-tune on domain-specific data where key information appears throughout the document. Use extractive pre-selection that explicitly samples from all document sections. For LLM-based summarization, instruct the model to cover all sections equally in the prompt.
Entity Confusion in Multi-Document Settings
Cause
When summarizing multiple documents that discuss different entities with similar names or overlapping events, the model may conflate information -- attributing claims from Document A to entities in Document B.
Symptoms
Summary attributes actions or statements to the wrong person, organization, or event. Particularly common when documents discuss related but distinct topics (e.g., multiple quarterly earnings reports from different companies).
Mitigation
Preprocess multi-document inputs with entity disambiguation. Add document-level metadata tags so the model can track source attribution. Use per-document summarization followed by a merge step rather than concatenating all documents into a single input.
Quality Degradation Under Domain Shift
Cause
A summarizer trained or prompted for one domain (e.g., news) is applied to a different domain (e.g., medical records, legal contracts, code documentation) where vocabulary, structure, and importance criteria differ significantly.
Symptoms
ROUGE scores drop 15-30% compared to in-domain evaluation. Summaries miss domain-specific key information. Technical terms are paraphrased incorrectly or omitted. Users in the target domain report summaries as 'unhelpful' or 'missing the point'.
Mitigation
Evaluate on your target domain before deploying. If quality is insufficient, fine-tune on domain-specific data (even 1000 examples can make a significant difference with PEGASUS). For LLM-based systems, include domain-specific few-shot examples in the prompt.
Placement in an ML System
Where Does a Summarizer Sit in the ML Pipeline?
In a RAG pipeline, the summarizer typically sits between the retriever and the context assembler. After relevant passages are retrieved from a vector store, the summarizer compresses them to fit within the LLM's context window. This is especially valuable when retrieval returns 20+ passages but the prompt template only has room for 5 -- summarizing the top 20 into a condensed form preserves more information than simply truncating to the top 5.
In a content platform (news, research, e-commerce), the summarizer sits in the serving layer, generating summaries on-demand or during batch processing. Flipkart might summarize product reviews for display on product pages; Inshorts condenses full news articles into 60-word cards for mobile consumption.
In a customer support system, the summarizer processes conversation history before it is shown to an agent or fed into a response-generation model. Freshworks or Zendesk-style platforms use summarization to give agents quick context on long ticket threads.
Key Insight: The summarizer is a compression layer. It appears wherever there is a mismatch between available information and the capacity of the next consumer -- whether that consumer is a human, an LLM, or a downstream model.
Pipeline Stage
Post-Processing / Serving
Upstream
- tokenizer
- text-classifier
- document-loader
Downstream
- context-assembler
- prompt-template
- embedding-model
Scaling Bottlenecks
The primary bottleneck is GPU compute for abstractive summarization. A single BART-large model on an A10G GPU processes ~50 documents/second for short inputs (512 tokens). For map-reduce over 10-chunk documents, throughput drops to ~5 documents/second per GPU.
LLM API rate limits become the bottleneck for API-based systems. GPT-4o at 30K tokens/minute limits you to ~15 long-document summaries per minute. At 10,000 documents/day, you need careful request scheduling and batching.
Memory is the bottleneck for extractive methods at scale. Building a TextRank similarity matrix for a 10,000-sentence document requires memory -- ~400MB for embeddings alone. For very long documents, hierarchical approaches are necessary.
Some concrete numbers for a system processing 50,000 documents/day:
- Fine-tuned BART-large on 4x A10G GPUs: ~INR 80,000/month ($960/month)
- GPT-4o-mini API: ~INR 19,000/month ($225/month) but higher latency
- Hybrid extractive pre-filter + BART: 2x A10G GPUs, ~INR 40,000/month ($480/month)
Production Case Studies
Inshorts, one of India's most popular news apps with 10M+ downloads, developed Rapid60 -- an AI-backed algorithm trained on 500,000+ manually-produced summaries that automatically condenses full-length news articles into 60-word 'shorts'. The system generates over 100K summaries per month, blending AI output with editorial oversight for the top 20% most-read content.
The company achieved operational profitability with revenue growing from INR 3 crore (14M) in 2019-20. The AI summarization pipeline handles 80% of content, freeing editorial staff to focus on high-impact stories.
Google Cloud published a detailed reference architecture for long-document summarization using Gemini models with iterative refinement and map-reduce patterns. The system handles documents exceeding 100,000 tokens by splitting into chunks, summarizing with Gemini Flash, and consolidating with a refinement pass. Deployed on Vertex AI Workflows for orchestration.
The architecture demonstrates production-grade long-document summarization with configurable chunk strategies, achieving consistent quality across documents ranging from 10K to 500K tokens while managing API costs through model selection (Gemini Flash for chunks, Gemini Pro for final consolidation).
Researchers from Salesforce, MIT, and Columbia developed the Chain of Density prompting technique for LLM-based summarization. The method iteratively refines summaries to increase entity density without increasing length. Human evaluators on CNN/DailyMail preferred CoD summaries over vanilla GPT-4 summaries, selecting the 3rd iteration as the optimal density level.
CoD summaries were rated as more abstractive, exhibiting more fusion and less lead bias than standard GPT-4 summaries. The technique has been widely adopted in production summarization systems using LLM APIs, becoming a de facto prompting standard for high-quality summarization.
The BBC's article corpus (2010-2017) was used to create the XSum (Extreme Summarization) dataset -- 226,711 articles each paired with a single-sentence summary. This dataset pushed the field toward highly abstractive summarization, as the one-sentence summaries cannot be produced by simple sentence extraction. It remains a key benchmark for evaluating summarization models.
XSum became one of the most widely used summarization benchmarks alongside CNN/DailyMail. State-of-the-art ROUGE-1 scores improved from ~29 (pre-transformer) to ~47 (PEGASUS) on this dataset, demonstrating the dramatic impact of pre-trained models on abstractive summarization quality.
Tooling & Ecosystem
The go-to library for summarization model inference and fine-tuning. Provides pre-trained BART, T5, PEGASUS, LED, and dozens of other summarization models with a unified pipeline('summarization') API. Supports GPU acceleration, quantization, and easy model switching.
Lightweight Python library for extractive summarization. Implements TextRank, LexRank, LSA, Luhn, and KL-Sum algorithms. Excellent for quick extractive baselines with no GPU required. Ideal for prototyping or low-resource environments.
Provides ready-made chains for stuff, map-reduce, and refine summarization strategies using any LLM backend (OpenAI, Anthropic, local models). Handles document splitting, prompt templating, and chain orchestration. Best for LLM-based summarization workflows.
Google's official ROUGE implementation in Python. Computes ROUGE-1, ROUGE-2, ROUGE-L, and ROUGE-Lsum with optional stemming. The de facto standard for reproducible summarization evaluation.
Computes semantic similarity between candidate and reference summaries using contextual embeddings. Correlates more strongly with human judgments than ROUGE, especially for abstractive summaries. Supports multiple backbone models including DeBERTa.
Google's PEGASUS model implementation, pre-trained with Gap Sentences Generation (GSG) -- a self-supervised objective specifically designed for summarization. Achieves strong results on 12 diverse benchmarks, particularly excels in low-resource settings (state-of-the-art with only 1000 examples).
Factual consistency evaluation tool for summarization. Uses NLI models to detect hallucinations by checking whether each sentence in the summary is entailed by the source document. Essential for production systems where faithfulness matters.
Research & References
Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, Zettlemoyer (2020)ACL 2020
Introduced BART, a denoising autoencoder that combines a bidirectional encoder (like BERT) with an autoregressive decoder (like GPT). Achieved state-of-the-art on CNN/DailyMail and XSum summarization benchmarks with up to 3.5 ROUGE improvement over prior work.
Zhang, Zhao, Saleh, Liu (2020)ICML 2020
Proposed Gap Sentences Generation (GSG), a pre-training objective tailored for summarization where important sentences are masked and the model learns to generate them. Achieved state-of-the-art on all 12 evaluated summarization benchmarks and showed remarkable few-shot performance with only 1000 training examples.
Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li, Liu (2020)JMLR 2020
Introduced T5, which frames all NLP tasks as text-to-text problems. The systematic study of pre-training objectives, model architectures, and data strategies established T5 as a versatile foundation for summarization and many other tasks.
Adams, Peskoff, Weston, Suhr, Iyyer, Cohan (2023)EMNLP 2023
Introduced Chain of Density prompting where GPT-4 iteratively produces summaries with increasing entity density. Human evaluators preferred CoD summaries at step 3 (of 5), finding them more abstractive and less lead-biased than vanilla GPT-4 summaries.
Beltagy, Peters, Cohan (2020)arXiv preprint
Introduced an attention mechanism that scales linearly with sequence length, enabling processing of documents with thousands of tokens. The Longformer Encoder-Decoder (LED) variant achieved state-of-the-art on long-document summarization benchmarks (arXiv, PubMed).
See, Liu, Manning (2017)ACL 2017
Introduced the copy mechanism for neural summarization, allowing models to both generate new words and copy words from the source. The pointer-generator architecture and coverage mechanism became foundational building blocks for subsequent summarization models.
Mihalcea, Tarau (2004)EMNLP 2004
Proposed an unsupervised graph-based ranking algorithm for text extraction, applying PageRank to sentence graphs for extractive summarization. Remains widely used as a strong unsupervised baseline and a component in hybrid summarization systems.
Zhang, Fabbri, Choubey, Gu, Radev (2024)TACL 2024
Comprehensive evaluation of LLMs (GPT-3.5, GPT-4, Claude, LLaMA) on news summarization. Found that LLMs produce more coherent and faithful summaries than fine-tuned models, but ROUGE scores can be misleading -- LLM summaries are preferred by humans despite sometimes having lower ROUGE scores.
Interview & Evaluation Perspective
Common Interview Questions
- ●
What is the difference between extractive and abstractive summarization? When would you choose each?
- ●
How do you handle summarization of documents that exceed the model's context window?
- ●
Explain the ROUGE metric and its limitations. What alternatives exist?
- ●
How would you detect and mitigate hallucinations in an abstractive summarizer?
- ●
Design a summarization system for a news app like Inshorts that needs to condense articles into 60-word summaries at scale.
- ●
Compare BART, T5, and PEGASUS for summarization. What are the architectural differences and when would you choose each?
- ●
How would you evaluate whether your summarizer is production-ready? What metrics and processes would you put in place?
- ●
Describe the map-reduce approach to long-document summarization. What are the tradeoffs?
Key Points to Mention
- ●
The extractive-abstractive spectrum is not binary -- modern systems often use extractive pre-selection followed by abstractive rewriting. This combines the faithfulness of extraction with the fluency of abstraction.
- ●
ROUGE measures lexical overlap, not semantic accuracy. A summary can score high on ROUGE while hallucinating facts. Always supplement with faithfulness metrics (SummaC, BERTScore, human evaluation).
- ●
PEGASUS's Gap Sentences Generation pre-training objective makes it the strongest model for summarization when fine-tuning data is limited (<1000 examples). BART is the best general-purpose choice. T5 offers flexibility across tasks.
- ●
Map-reduce summarization handles long documents but introduces information loss at chunk boundaries and in the reduction step. The refine strategy (iteratively updating a running summary) can produce more coherent results at the cost of sequential processing.
- ●
Chain of Density prompting produces higher-quality LLM summaries than vanilla prompting and requires no fine-tuning -- essential knowledge for production LLM-based summarization systems.
- ●
Position bias (lead bias) is a real problem: models trained on news over-weight early sentences. For non-news domains, this must be explicitly addressed through training data or prompting strategies.
Pitfalls to Avoid
- ●
Treating summarization as a solved problem because LLMs can generate fluent summaries -- faithfulness, controllability, and cost-efficiency are unsolved engineering challenges.
- ●
Reporting only ROUGE scores without discussing their limitations. Senior interviewers will push back on ROUGE-only evaluation.
- ●
Ignoring the latency and cost implications of different approaches. Always frame the solution in terms of the production constraints: 'For 10K docs/day at <200ms p99, a fine-tuned BART-base on GPU costs INR 25K/month.'
- ●
Failing to discuss post-processing and quality validation as part of the system. The model is one component; the system includes preprocessing, chunking, inference, post-processing, and monitoring.
- ●
Assuming one model fits all domains. Domain-specific fine-tuning or few-shot prompting is almost always needed for production quality.
Senior-Level Expectation
A senior candidate should discuss the full system design: document preprocessing and chunking strategy, model selection with quantitative justification (not just 'I would use BART'), output quality validation (faithfulness checking, ROUGE monitoring, human evaluation loops), latency and cost analysis at the expected scale, and graceful degradation strategies (fallback from abstractive to extractive if the model produces low-confidence output). They should also address operational concerns: how to handle model updates without downtime, how to detect quality regressions in production, and how to build evaluation datasets for a new domain. The ability to reason about the tradeoff between LLM API costs and self-hosted model costs -- especially in the context of Indian startup budgets -- distinguishes senior engineers from mid-level ones. A staff-level candidate would additionally discuss multi-document summarization, cross-lingual summarization for India's multilingual context, and how summarization quality metrics feed into broader product KPIs.
Summary
A summarizer is the information compression layer in ML systems, transforming long documents into concise representations while preserving key facts, arguments, and nuance. The field spans a spectrum from extractive methods (TextRank, BERT-based sentence scoring) that select existing sentences to abstractive methods (BART, T5, PEGASUS, LLMs) that generate novel text. Modern production systems increasingly use hybrid approaches -- extractive pre-selection followed by abstractive rewriting -- to balance faithfulness with fluency.
The practical engineering of summarization involves navigating several interconnected tradeoffs: extractive vs. abstractive (safety vs. fluency), fine-tuned models vs. LLM APIs (cost and latency vs. versatility), and quality vs. speed (beam search with faithfulness checking vs. single-pass generation). For long documents, map-reduce and refine strategies handle inputs that exceed model context windows, while techniques like Chain of Density prompting push LLM-based summarization quality beyond vanilla prompting. Evaluation remains a core challenge: ROUGE measures lexical overlap but misses semantic accuracy, BERTScore captures meaning better but ignores faithfulness, and factual consistency checkers (SummaC, AlignScore) address hallucination but add latency.
In production, the summarizer is wherever there is a mismatch between available information and the capacity of the next consumer. Whether compressing retrieved passages for a RAG pipeline's context window, condensing news articles into 60-word cards for an Inshorts-like app, or generating ticket summaries for customer support agents -- the summarizer bridges the gap between information abundance and attention scarcity. Choose your approach based on your domain, scale, and quality requirements; start with an LLM API for validation, then optimize toward fine-tuned models as your understanding of the problem matures.