Importance of Understanding Backpropagation and Gradient Descent
Understanding backpropagation and gradient descent is crucial as they form the backbone of training neural networks. These concepts enable the adjustment of model parameters to minimize errors, making them essential for developing accurate and efficient AI systems. Mastering these techniques is fundamental for anyone aiming to delve deeper into machine learning and AI, ensuring a strong foundation for advanced topics.
Purpose of the Blog
This blog aims to demystify backpropagation and gradient descent, fundamental yet vital topics in AI and machine learning. By providing clear explanations and practical insights, it serves as a comprehensive resource for learners, laying the groundwork for more advanced studies in the field.
Loss Function and Mean Squared Error
When a machine learning model tries to learn from data, it uses these features and assigns weights to them. This process allows the model to understand the importance of each feature in making accurate predictions. However, to make these predictions useful and accurate, we need a way to measure how well the model is performing. This is where the concept of a loss function comes into play.
Loss Function
A loss function is a mathematical way of measuring the difference between the actual output and the predicted output of the model. Think of it as a measure of error. The goal of training a machine learning model is to minimize this error, so the predictions become as close to the actual values as possible.
There are different types of loss functions depending on the problem at hand:
- For classification problems, where the goal is to categorize data into distinct labels (like differentiating between cars and bikes), we often use loss functions like cross-entropy loss.
- For regression problems, where the goal is to predict a continuous value (like predicting house prices), mean squared error (MSE) is a commonly used loss function.
Mean Squared Error (MSE)
In regression problems, the MSE is a popular choice because it measures the average of the squares of the errors between predicted and actual values. This method emphasizes larger errors more than smaller ones, which is useful for improving the accuracy of predictions.
Formula:
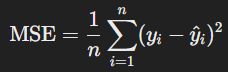
where y subscript i is the actual value and y hat superscript i are the predicted values, and n is the number of observations.
What is Gradient Descent?
Definition and Basic Concept
Gradient descent is a powerful optimization algorithm used in machine learning to minimize a loss function and improve model performance. The basic idea is to iteratively adjust the model's parameters (weights) to reduce the error between the predicted outputs and the actual values. By doing this, we can find the optimal set of weights that minimizes the loss function and enhances the accuracy of the model.
Gradient
Gradient descent relies on backpropagation to determine the direction for optimization. It utilizes the gradients calculated through backpropagation to identify the direction that leads to the minimum point of the loss function. Specifically, we focus on the negative gradient because it points in the direction of the steepest descent. By following the negative gradient, we move downward along the slope, ultimately leading us to the minimum point. For example:
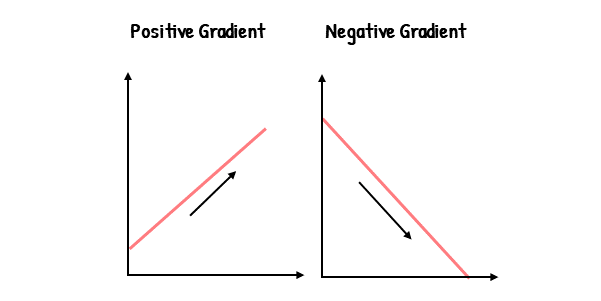
The Step Size
The step size for navigating the cost function is determined by the learning rate.
Learning Rate
The learning rate is a hyperparameter that defines the step size at each iteration of gradient descent, influencing the speed at which we descend the slope.
The step size is crucial for balancing optimization time and accuracy. It is denoted by the parameter alpha (α). A smaller α corresponds to a smaller step size, while a larger α corresponds to a larger step size. If the step size is too large, we risk overshooting the minimum point, leading to inaccurate results. Conversely, if the step size is too small, the optimization process may become excessively slow, resulting in wasted computational resources.
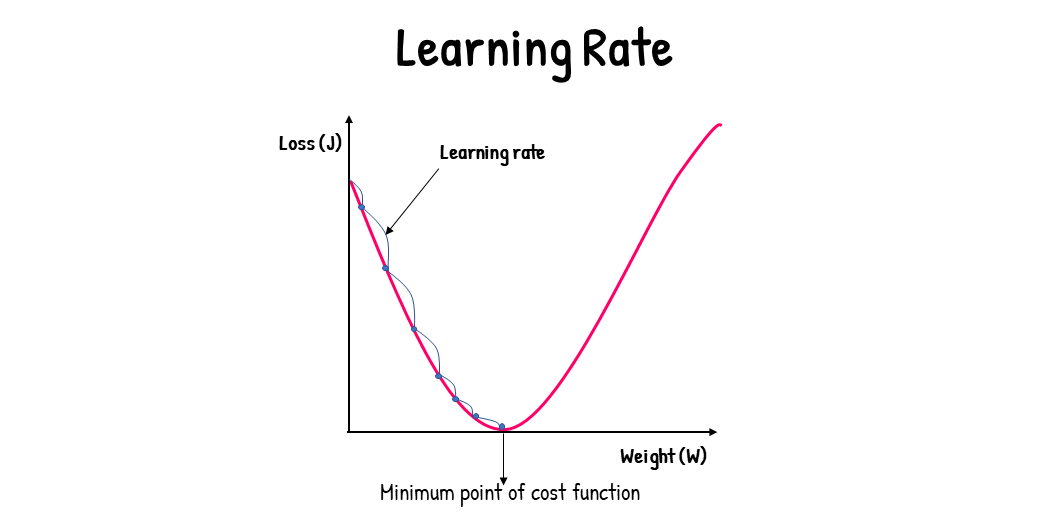
The step size is assessed and adjusted based on the cost function's behavior. A higher gradient of the cost function indicates a steeper slope, allowing the model to learn faster with a high learning rate. A high learning rate results in a larger step size, while a low learning rate results in a smaller step size. If the gradient of the cost function reaches zero, the model ceases to learn.
For a deeper dive into the essential mathematical principles that power machine learning algorithms, check out our article on Mathematics in Machine Learning, where we break down the core mathematical concepts necessary to understand and implement machine learning models effectively.
Role in Optimizing Machine Learning Models
In machine learning, models learn patterns from data to make predictions. The quality of these predictions depends on how well the model's parameters are tuned. Gradient descent helps in this tuning process by finding the values of the parameters that minimize the loss function, which measures the difference between the actual and predicted values.
Types of Gradient Descent
There are three main types of gradient descent, each with its own advantages and use cases:
Let's dive into each of these in detail.
Batch Gradient Descent
Definition: Batch gradient descent uses the entire training dataset to calculate the gradient of the loss function and update the weights.
Process:
- Compute the gradient of the loss function using all training examples.
- Update the weights using the average gradient.
- Repeat the process until convergence.
Formula:
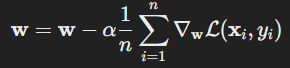
where:
- w are the weights,
- α is the learning rate,
- n is the number of training examples,
- L is the loss function,
- xi and yi are the features and outcomes of the i-th example.
Advantages:
- Convergence to the global minimum for convex loss functions.
- Smooth and stable updates.
Disadvantages:
- Computationally expensive for large datasets.
- Requires significant memory to handle the entire dataset.
Stochastic Gradient Descent (SGD)
Definition: Stochastic gradient descent updates the weights using only one training example at a time. This results in more frequent updates compared to batch gradient descent.
Process:
- Randomly shuffle the training data.
- For each training example, compute the gradient of the loss function.
- Update the weights using the gradient of the single example.
- Repeat the process for each training example.
Formula:
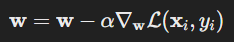
where:
- w are the weights,
- α is the learning rate,
- L is the loss function, and
- xi and yi are the features and outcomes of the i-th example.
Advantages:
- Faster updates, leading to quicker initial convergence.
- Handles large datasets efficiently.
Disadvantages:
- Updates are noisy and can cause fluctuations in the loss function.
- May converge to suboptimal solutions due to high variance in updates.
Mini-Batch Gradient Descent
Definition: Mini-batch gradient descent strikes a balance between batch gradient descent and SGD by using a small, random subset of the training data (mini-batch) to compute the gradient.
Process:
- Divide the training data into small batches.
- For each mini-batch, compute the gradient of the loss function.
- Update the weights using the average gradient of the mini-batch.
- Repeat the process for each mini-batch.
Formula:
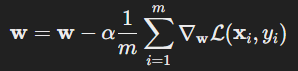
where:
- w are the weights,
- α is the learning rate,
- n is the number of training examples,
- L is the loss function,
- xi and yi are the features and outcomes of the i-th example.
Advantages:
- Reduces the variance of updates compared to SGD.
- More efficient than batch gradient descent for large datasets.
- Often results in faster convergence compared to both batch and stochastic gradient descent.
Disadvantages:
- Requires careful tuning of mini-batch size.
- Updates are still noisy but less so than SGD.
Conclusion
Gradient descent is a cornerstone optimization technique in machine learning, helping models learn by minimizing the loss function. Understanding its different types and their applications is crucial for building efficient and accurate machine learning models. Whether using batch, stochastic, or mini-batch gradient descent, the goal remains the same: iteratively refine the model's parameters to make better predictions.
Beyond optimization, understanding why your model makes certain predictions is equally important. Check out our Understanding the “Why”: A Practical Guide to Model Explainability to learn how to interpret and explain the decisions made by your machine learning models.
What is Backpropagation?
Backpropagation is a training algorithm used for training feedforward neural networks. It plays an important part in improving the predictions made by neural networks. This is because backpropagation is able to improve the output of the neural network iteratively.
In a feedforward neural network, the input moves forward from the input layer to the output layer. Backpropagation helps improve the neural network’s output. It does this by propagating the error backward from the output layer to the input layer.
Step-by-Step Process of Backpropagation
- Initialization:
Initialize the weights and biases of the neural network with small random values. - Forward Pass:
Input data is fed into the input layer.
Each neuron in a layer calculates its weighted sum zl of the outputs a^(l-1) from the previous layer (l−1) using the formula:
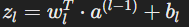
The weighted sum is then passed through an activation function (σ) to introduce non-linearity and generate the neuron's activation function:
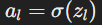
- Compute Cost:The loss function (L) is used to calculate the error between the predicted output (aL) and the actual target value (y).
- Backward Pass:
Calculate the gradient of the cost function with respect to each weight and bias using the chain rule. This involves:- Calculating the error at the output layer.
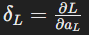
For each hidden layer (l<L), compute the error signal (δl) using the chain rule:
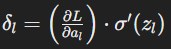
5. Update Weights and Biases:
Once we have the error signal (δl) for each layer, calculate the gradients of the loss function with respect to the weights (wl) and biases (bl) in each layer
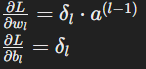
Update the weights and biases using the learning rate (α) according to the gradient descent formula:
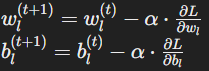
where t represents the current iteration.
**6. Iterate**:
Steps 2-7 are repeated for all training examples in a mini-batch or the entire dataset (depending on the chosen gradient descent variant). This process continues for multiple epochs (complete passes through the training data) until
the loss function converges or a stopping criterion is met.Role in Training Neural Networks
- Error Reduction: Backpropagation systematically reduces the error by adjusting the weights and biases, leading to improved model predictions.
- Efficiency: It efficiently computes the gradients for each layer in the neural network, making the training process feasible for deep networks.
- Generalization: By minimizing the cost function, backpropagation helps the neural network generalize well to new, unseen data.
Historical Context and Significance
- Development: The backpropagation algorithm was popularized by the seminal paper "Learning representations by back-propagating errors" by Rumelhart, Hinton, and Williams in 1986. However, the basic principles were known earlier.
- Significance: Backpropagation revolutionized the field of artificial intelligence and machine learning by making the training of multi-layer neural networks practical. It enabled the development of deep learning models that have since achieved state-of-the-art performance in various domains, including image recognition, natural language processing, and game playing.
Relationship Between Backpropagation and Gradient Descent
By understanding backpropagation, we gain insight into how neural networks learn and improve over time, which is essential for developing advanced machine learning models.
Backpropagation and gradient descent work in tandem to train neural networks. Here's how they collaborate:
- Backpropagation's Role: It efficiently calculates the gradients of the loss function with respect to all weights and biases in the network. These gradients provide crucial information about how adjustments to the network's parameters will affect the overall error. Backpropagation essentially computes the direction in which the weights and biases should be adjusted to minimize the loss function.
- Gradient Descent's Role: Gradient descent leverages the gradients calculated by backpropagation to iteratively update the weights and biases in the direction that minimizes the loss function. It acts as an optimizer, using the backpropagated error signal as a guide to steer the learning process.
Flow of Data and Error in a Neural Network:
- Forward Pass: During the forward pass, data flows from the input layer to the output layer. At each layer:
The weighted sum of the previous layer's outputs is calculated.
The activation function transforms this sum into the neuron's activation. - Error Calculation: Once the predicted output is obtained, the loss function measures the difference between the prediction and the actual target value.
- Backward Pass: The error signal propagates backward through the network:
The output layer's error signal is calculated using the derivative of the loss function.
The chain rule is applied layer by layer to compute the error signal for each hidden layer, considering the activation function's derivative in that layer. - Weight and Bias Update: The error signals are used to calculate the gradients for each weight and bias. These gradients indicate how much each parameter has contributed to the overall error.
- Gradient Descent Step: Gradient descent uses the learning rate and the calculated gradients to update the weights and biases in a way that reduces the loss function.
Together, backpropagation and gradient descent create a powerful learning mechanism for neural networks. Backpropagation efficiently calculates the gradients, and gradient descent utilizes them to iteratively refine the network's parameters, leading to improved performance over time.
Key Differences Between Backpropagation and Gradient Descent
Purpose and Function
Backpropagation aims to calculate the gradient of the loss function with respect to the network's weights, providing the necessary gradients to adjust the weights and biases in a multi-layer neural network. It serves as the mechanism for error propagation and gradient computation within the network. On the other hand, gradient descent's purpose is to optimize the loss function by adjusting the model parameters (weights and biases). It uses the gradients calculated via backpropagation to iteratively update the parameters to minimize the loss, acting as the optimization algorithm that guides the training process.
Processes Involved
In backpropagation, the forward pass computes activations and outputs, followed by error calculation to determine the loss or error. The backward pass then computes gradients of the loss with respect to each weight and bias using the chain rule, allowing for gradient computation necessary for updating the weights and biases. Gradient descent begins with the initialization of weights and biases. It then updates gradients using the values obtained from backpropagation, iterating this process for multiple epochs over the dataset until the loss function converges or a stopping criterion is met.
Applications in Different Contexts
Backpropagation is primarily used in training deep neural networks, making it suitable for supervised learning tasks such as classification and regression. It is also utilized in reinforcement learning to train value functions and policies. Conversely, gradient descent is used across various machine learning algorithms, not limited to neural networks. It is applicable in linear regression, logistic regression, and support vector machines (SVMs). Additionally, it adapts well to unsupervised learning methods like clustering, for example, in K-means clustering.
Mathematical Formulation of Gradient Descent
Gradient descent minimizes a loss function L(θ), where θ represents the model parameters. The general update rule for gradient descent is:

- θt: Parameters at iteration t.
- α: Learning rate.
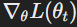
- Gradient of the loss function with respect to θ at iteration t.
- For a simple linear regression model y=wx+by with MSE as the loss function:
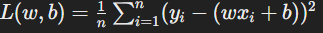
- The gradients are:
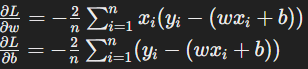
Derivation of Backpropagation Equations
For a neural network with L layers, the backpropagation equations are derived using the chain rule. Let:
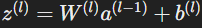
- Weighted input to layer l.
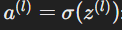
- Activation at layer l.
- The output error at the final layer L:
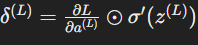
- For each layer l:
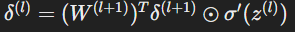
- The gradients with respect to the weights and biases are:
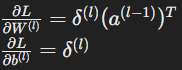
Example with a Simple Neural Network
Consider a simple neural network with one input layer, one hidden layer, and one output layer.
Suppose:
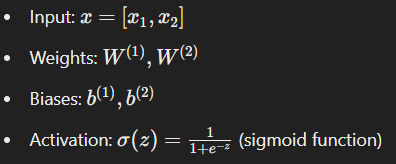
Forward Pass:
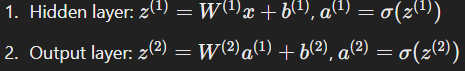
Loss Calculation:
- Suppose the true label is y, and the output is a^(2). Using MSE:
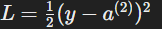
Backward Pass:
- Output layer error:
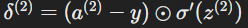
- Hidden layer error:
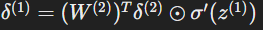
- Gradients:
Weights and biases for the output layer:
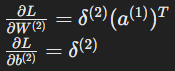
- Weights and biases for the hidden layer:
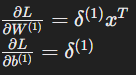
- Weight Update:
Using gradient descent with learning rate α:
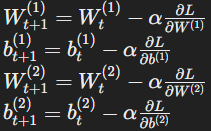
This process is repeated iteratively for all training examples until the network converges to an optimal solution.
Common Issues Faced During Gradient Descent and Backpropagation
When implementing gradient descent and backpropagation, practitioners often encounter several challenges:
- Vanishing Gradients:
Problem: Gradients become extremely small, hindering the weight updates, especially in deep networks.
Solution: Use activation functions like ReLU instead of sigmoid or tanh. Employ techniques like batch normalization and gradient clipping. - Exploding Gradients:
Problem: Gradients grow exponentially during backpropagation, leading to unstable updates.
Solution: Implement gradient clipping to limit the gradient values. Use careful weight initialization strategies. - Overfitting:
Problem: The model performs well on training data but poorly on unseen data.
Solution: Apply regularization techniques (L1, L2), dropout, and data augmentation. Monitor training with validation sets. - Slow Convergence:
Problem: Training takes a long time to reach optimal values.
Solution: Adjust learning rates, use learning rate schedules or adaptive learning rate methods like Adam, RMSprop.
Techniques to Address Vanishing and Exploding Gradients
- Vanishing Gradients:
Activation Functions: Use ReLU (Rectified Linear Unit) or its variants (Leaky ReLU, Parametric ReLU).
Batch Normalization: Normalizes the input of each layer, stabilizing the learning process.
Weight Initialization: Use methods like He initialization for ReLU, which can help maintain gradient magnitude. - Exploding Gradients:
Gradient Clipping: Limits the gradients to a maximum value during backpropagation.
Weight Initialization: Xavier initialization can help in preventing gradients from becoming too large.
Smaller Learning Rates: Use smaller learning rates to avoid large updates that can cause instability.
Conclusion
Recap of Key Points
Understanding and implementing backpropagation and gradient descent are essential for training neural networks. Backpropagation calculates the gradients necessary for updating weights, while gradient descent optimizes these parameters to minimize the loss function. Despite challenges such as vanishing and exploding gradients, various techniques and strategies can be employed to address these issues and improve model performance.
Importance of Both Techniques in the Field of AI
Backpropagation and gradient descent are foundational techniques in machine learning and AI, enabling the training of deep neural networks and the development of accurate predictive models. Mastering these techniques is crucial for anyone aspiring to work in AI and machine learning.
Encouragement for Further Learning and Experimentation
Continued learning and experimentation are key to mastering these concepts. By exploring advanced topics and experimenting with different models and datasets, you can deepen your understanding and contribute to the growing field of AI.
For a more hands-on approach to learning AI and machine learning, dive into cutting-edge topics, solve real-interview problems, and track your progress with Qnalab.
Links to Relevant Research Papers and Articles
- "Learning representations by back-propagating errors" by Rumelhart, Hinton, and Williams (1986)
- "Adam: A Method for Stochastic Optimization" by Kingma and Ba (2014)
- "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift" by Ioffe and Szegedy (2015)
Author
This article was written by SHOUVIK DEY, and edited by our writers team.


