
As machine learning models become more complex, questions about their decision-making become more urgent—especially in sensitive areas like healthcare, finance, and even criminal justice. This demand for explainability typically unfolds at two levels: why did the model make this specific prediction? (local) versus how does the model behave overall? (global). While these are often talked about separately, both are crucial if we want to trust and verify modern AI systems. To learn more about Model Selection, check out this blog.
Understanding Local Explainability: A Microscope on a Single Prediction
Local explainability zeroes in on one data point (or a small set of points) to answer, “How and why did the model arrive at this result?” Imagine you’re a data scientist at a bank, where a machine learning model decides whether to approve or deny a customer’s loan application. A customer named Alice was denied. Naturally, Alice wants to know why. With local explainability tools:
- LIME (Local Interpretable Model-Agnostic Explanations) might approximate the behavior of the complex model around Alice’s data (her credit score, income, debt-to-income ratio, etc.) by fitting a simple surrogate model (like a tiny linear regressor). You would then see which features locally influenced that denial.
- SHAP (Shapley Additive Explanations) would assign a “Shapley value” to each of Alice’s features, indicating how much each one pushed the final prediction higher or lower than a baseline.
- For deep learning tasks, you might use Grad-CAM or Integrated Gradients to visually highlight why a particular image was classified one way or which words in a text influenced a sentiment analysis.
In all these approaches, the explanations focus on Alice’s specific data. If her debt-to-income ratio is unusually high compared to her peer group, the model’s local explanation might say, “This ratio accounts for the largest negative impact on your approval probability.” This clarity is vital for individuals directly affected by a prediction—be it a denied loan, a missed medical diagnosis, or a flagged insurance claim.
Why It Matters
- User-Facing Rationale: Telling users exactly how the model arrived at their specific outcome.
- Debugging: If a model misclassifies a single data point, local explainability helps data scientists see which features or signals might have led astray.
- Ethical & Regulatory Needs: In many sectors, decisions that affect people’s lives must come with an explanation.
To learn more about why explainability matters in AI, check out our [Understanding the “Why”: A Practical Guide to Model Explainability](http://Understanding the “Why”: A Practical Guide to Model Explainability) blog.
Global Explainability: A Bird’s-Eye View of the Model
While local explanations zoom in on singular cases, global explainability looks at the model’s entire decision-making across a dataset. Instead of focusing on why a particular loan was denied, you ask broader questions: “Which features does the model generally rely on the most? How do predictions typically shift when a feature’s value changes? Does the model exhibit bias toward certain demographics?”
- Permutation Feature Importance might show that, over the entire dataset, Credit Score is the feature most crucial in determining whether a loan gets approved, followed by Annual Income, and so on.
- Partial Dependence Plots (PDP) or Accumulated Local Effects (ALE) reveal how the model’s predictions, on average, shift if a feature (like debt-to-income ratio) goes from low to high.
- Global Surrogate Models can replicate the black-box model’s predictions with a more interpretable model (like a small decision tree) to approximate how the original model behaves on a large scale.
Why It Matters
- Auditing and Compliance: Many industries (like finance) require not just individual explanations, but evidence that the model is fair and consistent overall.
- High-Level Validation: Subject-matter experts can confirm if it makes sense that debt-to-income ratio or credit score is the biggest factor.
- Bias Detection: If a global method reveals that the model systematically penalizes users below a certain age or from certain zip codes, you may have discovered potential discrimination that needs addressing.
The Strengths and Limitations of Each Approach
Local Strengths
- Precision: Pinpoints the exact reasons for a single outcome, which is often what users or regulators demand.
- Actionability: Tells an individual or a data scientist precisely which changes could alter that specific decision (e.g., “lower your debt-to-income ratio by 5% to be approved”).
Local Limitations
- Scope: Local explanations do not describe the model’s overall behavior. A model might rely heavily on one feature for some instances, but a different feature for others.
- Possible Instability: If a model’s decision boundary is highly nonlinear, small sampling changes can yield varying local explanations.
Global Strengths
- Big Picture: Lets you see consistent patterns or wide-reaching biases across thousands (or millions) of predictions.
- Auditing and Strategy: If you notice a certain feature is near-irrelevant globally, you might decide to drop or refine it, saving data collection cost.
Global Limitations
- Averages Can Mislead: If subgroups behave differently, a global explanation might conceal key nuances.
- No Individual Reasoning: Telling a denied applicant, “Globally, credit score is the most important feature” does not help them understand their unique situation.
Real-World Example #1: Credit Scoring Revisited
Imagine you have a random forest that predicts whether someone will default. Globally, you learn that Credit Score explains about 40% of your model’s decision power (highest of all features). Meanwhile, Income explains 25%, Employment Length 10%, and the rest is shared among minor factors. Partial Dependence Plots show that once Credit Score is above 720, the model becomes much more likely to predict no default.
However, John’s loan application is denied, and he wants to know why. You switch to a local explanation method (LIME or SHAP) and discover that for John’s specific combination of features (score=680, debt-to-income=39%), the model heavily penalizes his high debt-to-income ratio. Interestingly, even though Credit Score is globally the most important, in John’s case, the Debt-to-Income Ratio overshadowed his credit score—locally.
This difference highlights how crucial it is to combine both local and global explainability for a truly complete picture.
Real-World Example #2: Healthcare Diagnostics
Consider a deep learning model designed to detect early signs of diabetic retinopathy from retina scans. At a global level, hospital administrators want to be sure that the model relies on legitimate medical features—such as subtle lesions or microaneurysms—rather than patient age or certain demographic information. By performing permutation feature importance and global surrogates, they confirm the network focuses on clinically relevant patterns.
However, for a single patient, a specialist might want a local explanation (e.g., Grad-CAM) to see exactly which region of the retina scan triggered a “disease present” prediction. If the heatmap highlights a suspicious lesion, the doctor can decide whether the model is correct—or if it’s being misled by an artifact (like lighting or camera glare). Thus, local explainability reassures the physician about why this particular patient was flagged, while global explainability assures the hospital that the model’s overall behavior is sound.
Bringing Them Together
- Global First: Start by evaluating how the model behaves on the whole. Determine if the model is consistent with domain knowledge and if high-level biases or feature importance patterns appear.
- Then Go Local: For edge cases, exceptions, or user complaints, zoom in and see precisely which features determined that prediction.
- Iterate: Often, local explanations reveal anomalies that prompt deeper global investigations. Conversely, global patterns might suggest focusing local explanations on certain types of instances.
For more on selecting the right features, visit our Feature Selection blog.
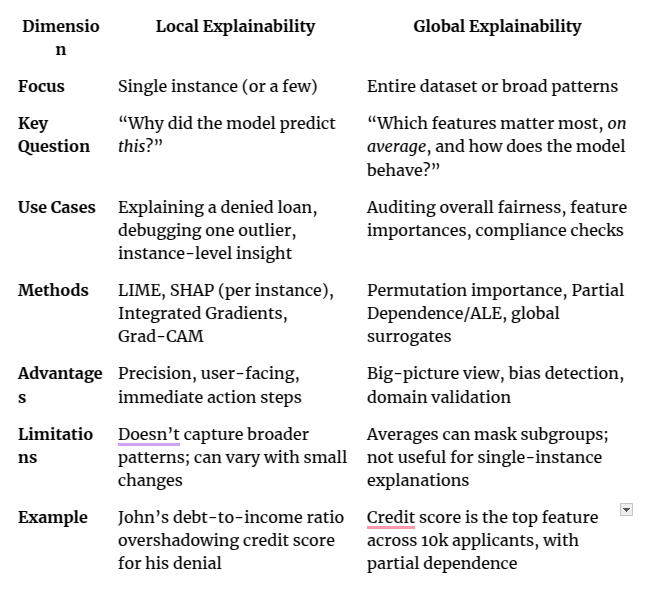
Comparative Table: Local vs. Global Explainability
Conclusion: Two Lenses, One Goal
In the evolving landscape of AI, explainability cannot be boiled down to a single method or a single perspective. Local explanations serve the immediate needs of debugging individual predictions and providing user-level transparency, while global explanations guide broader audits, policy decisions, and ethical oversight.
By integrating both, you gain:
- Trust: Users see how each individual outcome was generated, and organizations see global fairness and reliability.
- Diagnostics: Fine-grained local insights and big-picture global patterns reinforce each other.
- Compliance: Many regulations demand proof that the AI system is both consistently fair (global) and can explain individual outcomes (local).
Ultimately, both local and global explainability are indispensable tools in building accountable, transparent AI that can withstand scrutiny from users, stakeholders, and regulators alike.
Authors
This article is written by Gaurav Sharma, a member of 123 of AI, and edited by the 123 of AI team.


