
Why are repositories the “hidden gems” of good resources to learn Machine Learning?
"Talk is cheap. Show me the code."
– Linus Torvalds
Machine Learning and Computer Science are perhaps the only fields where we can get the most hands on experience and validation of the topics that we study about , all of it for the most part takes a decent laptop,an internet connection, and a curiosity to learn.
Machine Learning algorithms and their applications prove as a valuable resource,hence used by a wide range of Expert Systems analytics applictaions and industry experts ,some applications include predictive models of product sales , image classification for NSFW content, natural language processing with binary classification for email spam detection etc.
Overview of Machine Learning Resources: Cutting the Clutter
- There is an abundance of material available on machine learning, from courses on on LLM and GPT spammed with buzzwords to plain rigorous theoretical courses without any or mediocre implementations to courses .
- It's not a lack of resources; rather, it's about navigating the enormous sea of them.
- R and Python are two programming languages that are used in machine learning. Libraries and frameworks from ML sources are also used.
- It takes a lot of work to maintain and update these libraries, and researchers, programmers, annotation writers, and debuggers , people with MLops capabilities, feedback and improvement are all needed. for the good functioning of these libraries.
- The utility of a resource depends on the current level of skill and the desired outcome of that the learner wants. Level up your current skills and interview preparation with QnA Lab.
- An ML based application can be made without getting much into the theory and learning more about MLops and development whereas devising new theoretical methods for solving current problems would require high level expertise in theoretical concepts of ML , suffice to say there is a need of both these skills to be valued equally and there is no “one size fits all path “ for learning ML.
- Repositories are places where diverse perspectives regarding every aspect of the method are shared, implemented along with raising issues , trying out new variants of existing methods , sharing compute resources and quality data and sharing insights generated from the data to re-itrate the process,this ensures transparency , and equal access of ML resources.
- This blog offers a thorough overview of the machine learning process, examined by the subject matter experts of 123ofAI who have contributed in research in institutes like Stanford and Ivy League Universities.
- To summarize open sources ML repositories are a great resource to learn as they offer:some text
- Cooperation and Exchange through open source offerings
- Transparency and Reproducibility of models.
- Accessibility and Learning Opportunities through forum discussions
- Community Support and Collaboration by resolving issues
- Deployment and Integration of models in an hands on approach.
If you're looking to complement your repository-based learning, explore our comprehensive list of Top 10 ML Books, which provide both theoretical insights and practical applications to solidify your understanding of ML
Criteria for Selecting the Top 10 Repositories across range of topics:
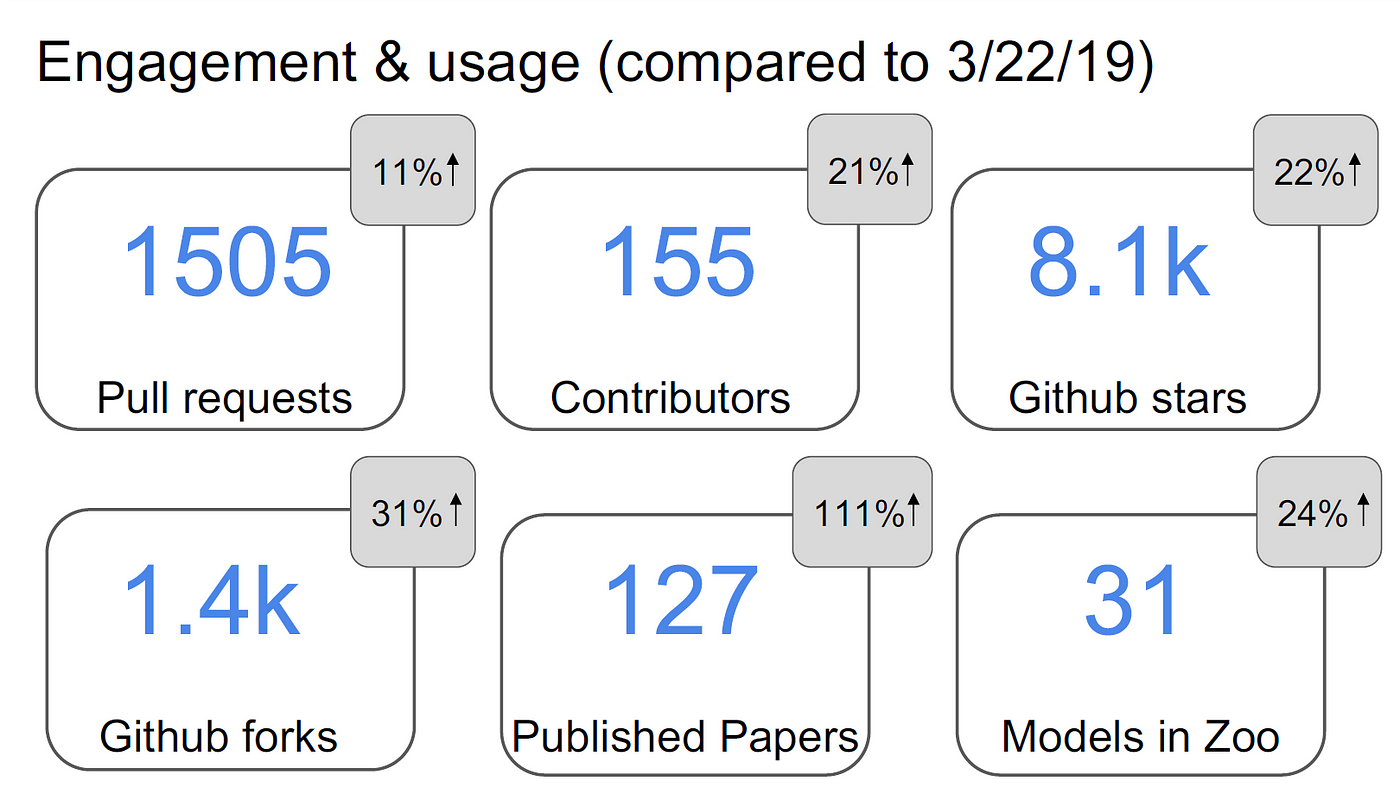
Widely Used and Highly Rated Repositories across range of topics:
- Number of Stars: A repository's popularity can be inferred from the number of stars it has. Users mark as interesting or helpful repositories.
- The number of forks indicates how many users have duplicated the repository, frequently in order to make changes or use it as the foundation for a new project. Higher popularity is typically indicated by more forks.
- Total number of Watchers: Users who have signed up to get updates on activity in the repository are known as Watchers. More viewers , comments from the researchers, hobbyists and the coders and subject matter experts key features of the specific niche to the indicate a greater level of interest in the project.
- Number of Contributors and their expertise: A repository's popularity within the community can be inferred from the number of unique contributors to it, their expertise in ml and coding and the subject matter to which the ml techniques are applied. More contributors typically equate to greater interest and acceptance.
To dive deeper into essential libraries for machine learning, explore our blog on AI Libraries, where we cover tools like TensorFlow, Hugging Face, and others to enhance your learning.
Key Features of Active Community and Developer Support
Preference Measures
Number of Issues: An active user base that reports defects and requests new features for the project may be indicate a higher number of open issues.
Number of Pull Requests: A high pull request count indicates that people are actively adding enhancements and code changes to the repository, which may be an indication of user preference and uptake.
Commit Frequency: Active and favored projects may be indicated by repositories with a high frequency of commits, particularly those from several authors.
Deliver Frequency: A project's ability to consistently deliver new features and bug fixes can indicate its user base values and the contributors who maintain it.
Documentation Quality: Users may find it simpler to accept and favor a project if it has well-documented repositories with concise examples and tutorials.
In addition to the metrics mentioned above, content of the repos and their age is important to determine their relevance and importance.
Metrics for Content, Comprehension, & Continuity of Code
- Breadth of Topics: A repository's inclusion of topics indicates both the depth and the scope of its contribution to the field of machine learning. Broad topic range repositories, such those on computer vision, natural language processing, and deep learning, are probably more influential and thorough.
- Depth of Content : A repository's depth of content indicates how detailed it is and how much it contributes to machine learning methods. Users are likely to find repositories with comprehensive instructions, examples, and tutorials more beneficial and educational.
- Documentation Quality: Users may find it simpler to accept and favor a project if it has well-documented repositories with concise examples and tutorials.
Code Quality: Metrics measuring code quality, like code complexity and coverage, can reveal the general caliber of the repository as well as the degree to which it adds to the body of knowledge on machine learning. - The repository's age: A repository's maturity and degree of contribution to the field of machine learning can be inferred from its age. Actively updated and maintained older repositories are probably more significant and affect the community more broadly.
Top 10 Machine Learning Repositories
1: ML-For-Beginners by Microsoft
Benefits of Microsoft's ML for Beginners Program: Extensive 12-week course covering traditional machine learning methods and Scikit-learn.
- Project-based learning increases engagement and improves concept retention.
- Some lessons have video walkthroughs hosted on the Microsoft Developer YouTube channel.
- Flexible learning approach that allows learners to complete individual lessons or the entire 12-week cycle.
- Multi-language support (Python and R).
Drawbacks of Microsoft's ML for Beginners:
- Limited emphasis on deep learning
- Dependency on Scikit-learn, which may not be appropriate for all learners
- Limited customization choices
- No real-time assessment or feedback
- A lack of engagement
2: Awesome Machine Learning by Joseph Misiti
Benefits:
- Comprehensive List: The repository is an extensive resource for ml practitioners, offering a carefully selected list of ml frameworks, tools, and applications,hence giving an overview of a wide range of topics reinforcement learrning and various other machine learning systems.
- Easy Contribution: Users can ensure that the list is accurate and up-to-date by contacting the maintainer or providing pull requests through the repository.
Drawbacks of the Repo:
- Outdated Information: There's a chance that some of the information in the repository is out of date because it doesn't reflect the most recent changes or advancements in the ML community.
- Deprecation Issues: The repository contains deprecated tools that might not be appropriate for ongoing projects or might need more work to keep compatible.
3.100 Days of Machine Learning:
The "100 Days of ML Code" GitHub repository is a thorough machine learning challenge where participants commit to learning and applying different machine learning topics for 100 days, at least one hour per day. For a variety of methods, including support vector machines, naive Bayes classifier, K-nearest neighbors, logistic regression, linear regression, and more, the repository offers thorough explanations and code implementations.
Benefits:
- Extensive Coverage: The repository includes information on a broad range of subjects, ranging from deep learning and natural language processing to more complex subjects like decision trees and linear regression.
- Daily Progress Tracking: The learning journey may be easily followed and reviewed thanks to the daily logs, which offer a thorough description of the progress made.
- Code Implementation: The repository is a useful tool for individuals who want to learn by doing because it contains code implementations for a variety of algorithms and strategies.
Drawbacks:
- Information Overload: It can be challenging to concentrate on particular subjects due to the overwhelming amount of information and code implementations available.
- Absence of Context: Some of the ideas and code snippets may be hard to understand without other information or prior experience if there isn't enough context.
- Lack of a Clear Structure: It is difficult to navigate and locate particular subjects or code implementations in the repository due to its unclear structure.
4. DAIR.ai
Dair.ai combines code with educational ones and advanced research insights, and tutorials: That's what sets it apart from the vast majority of code-heavy repositories that are sometimes just too advanced for the uninitiated. It attempts to put an effortless road to reading through a myriad of machine-learning topics, starting from the very basics of natural language processing (NLP) terminating with state-of-the-art deep learning models. A good place for those wishing a proper conceptual framework and practice to do some investigations and learn computer programming.
Benefits:
- Cutting-Edge Research Insights: Dair.ai often highlights recent developments in machine learning, focusing on the latest papers and findings from top conferences like NeurIPS, ACL, and ICML.
- Hands-On Learning: The repository contains Jupyter notebooks and code examples to help learners implement cutting-edge research in a practical manner.
- Collaborative Community: With an active presence on platforms like Twitter and Medium, Dair.ai also fosters discussions that further enhance community learning.
- Comprehensive NLP Resources: NLP is a key area of focus, with detailed breakdowns of key algorithms, datasets, and state-of-the-art models such as BERT, GPT, and T5.
- Open-Source Spirit: Consistent with the open-source philosophy, Dair.ai encourages contributions from the global community, which adds to the repository’s depth and diversity.
Drawbacks:
- Complexity for Beginners: While the educational resources are extensive, some of the advanced research implementations may feel overwhelming for those just starting in AI/ML.
- Narrow Focus on NLP: A significant portion of the repository is dedicated to NLP, which might be limiting for those seeking expertise in other areas like computer vision or reinforcement learning.
- Lack of Structure: Due to the wide range of resources, navigating the repository can sometimes feel overwhelming, especially for learners trying to follow a clear curriculum.
5. Aishwaryanr’s GitHub Repository: A Deep Dive into Generative AI and More
Aishwaryanr’s GitHub repository offers a rich collection of resources for those interested in generative AI, making it a valuable resource for learners, researchers, and practitioners alike.
The repository focuses on Generative AI and spans a wide range of topics, offering everything from theoretical insights to hands-on coding tutorials. It’s an ideal space for users who want to delve into this burgeoning area of AI, especially in large language models (LLMs), neural networks, deep learning, and transformer models.
Key Features:
- Comprehensive Guide: This repository is an evolving guide to generative AI, featuring curated resources from top papers, frameworks, and research institutes.
- Research-Driven: The repository focuses on the latest trends and developments in AI, making it a go-to for keeping up with cutting-edge technologies.
- Hands-On Learning: There are numerous Jupyter notebooks and code examples, allowing users to interact with pre-built models and explore how generative AI can be applied in real-world scenarios.
- Interview Prep Material: Another highlight is the repository’s section on interview preparation, where you’ll find key topics, example problems, and solutions for technical interviews focused on machine learning and AI.
Strengths:
- Breadth of Topics: Covers essential areas like neural networks, GANs, transformers, and LLMs like GPT and BERT.
- Interactive Notebooks: Multiple Jupyter notebooks allow for hands-on exploration of generative AI, ensuring learners don’t just read about models—they can run and modify them.
- Up-to-date: With frequent updates, users can stay informed on the latest tools and models.
- Community Engagement: The repository encourages user contributions, fostering a collaborative learning environment.
Drawbacks:
- Focus on Generative AI: While highly informative, the repository may not serve those looking for more general or non-generative AI topics like reinforcement learning or classic machine learning algorithms.
- Intermediate to Advanced: The materials, while comprehensive, may be a bit overwhelming for absolute beginners.
Author
This article was written by Sahil Shenoy, and edited by our writers team.


