In today’s world, a booming word! and a thriving technology is unarguably Artificial Intelligence, Machine learning is a field under Artificial intelligence focused on developing algorithms. These algorithms allow computers to learn and generate various predictions using massive data. The very foundation of these algorithms has its roots in mathematics which enables complex problem solving. Mathematics is Undoubtedly an essential skill for those looking to build a career in machine learning field. This is an attempt to provide core mathematical concepts required for understanding and further developing machine learning algorithms.
mathematics helps learners with a toolkit of machine learning techniques that are important in creating data-efficient learning
Which Mathematical Concepts are Implemented in Data Science and Machine Learning?
Linear Algebra:
We can call it the lifeblood of machine learning! It plays a very important role in representing as well as manipulating data. Linear algebra is the study of vectors, matrices and linear transformation and Geometry provides a visual understanding of these concepts in machine learning, especially in high-dimensional spaces
Vectors and matrices:
Vectors represent data points or arrays and matrices represent datasets or tables. How is it related to machine learning you may ask?!, we understand for a fact that computers understand numbers and a way to represent them is vectors and matrices, for example in a dataset any feature is represented as a vector which is a one-dimensional array (although geometrically they do have magnitude and direction) and the dataset is represented as matrices, hence by default it becomes crucial to understand the operations on matrices like addition, multiplication, transposition and matrix decomposition, these understanding on a simple 3x3 matrices will enable an engineer to do various operations on a matrix or we can say a table or large dataset.
For example transposition: It flips a matrix around its diagonal. Useful for image processing or data cleaning. For example, an image can be represented as a matrix where each pixel is a value. Transposing this matrix would be useful for applying filters or even performing image recognition.
For a broader look at how linear algebra is applied in real-life scenarios across various fields, visit our blog on Linear Algebra’s Applications in Real Life.

Eigenvalues and Eigenvectors:
Eigenvalue is denoted by (λ), An eigenvalue of a square matrix A is a scalar (a single number), Eigenvector is denoted by (v), multiplication of Matrix with Eigenvector results into a scaled version of Eigenvector scaled by λ. for a square matrix A, an eigenvector v and corresponding eigenvalue λ satisfy Av=λv.
In the machine learning context, finding Eigenvalues and Eigenvectors helps us decompose the data into principal components, these are “Directions” of maximum variance in the data and ultimately this can be very useful in dimensionality reduction (i.e basically reducing the number of features in a dataset while retaining the essential information), this Principal component analysis (PCA) is used in feature selection where most important features are selected before model training and fitting functions.
Singular Value Decomposition (SVD):
SVD is a matrix factorization method that breaks down a matrix into three simpler matrices. important for dimensionality reduction and data compression. It helps identify patterns, reduce noise, and extract important features from data, which is useful in techniques like collaborative filtering and recommender systems.
Linear independence:
in simple words, none of the vectors can be formed by scaling and adding other vectors in the set is linearly independent. linear independence ensures that each feature in the dataset provides unique information for example if we have a population data set and there’s a column of gender and every data point represents the same gender, then the feature would not be as much useful for any sort of prediction, preventing redundancy and improving model performance. It is also important to find the rank of matrices, which affects their invertibility and the stability of algorithms like linear regression and matrix factorizations.
Matrix Equation:
Solving matrix equation is important for understanding transformations on spaces and covariance matrices,
Many algorithms like Linear regression can be shown with matrix operations: linear regression fits a line to a set of data points such that it minimizes the sum of squared differences between the observed values and the values predicted by the line usually called the Best fit line!
this involves solving linear equations in the form y=Xβ+ϵ , Estimation of Coefficients= β^=(XTX)−1XTy
Matrix representation of linear regression uses powerful linear algebra concepts to achieve efficient computation especially required while working with large datasets. and having numpy knowledge as it is a famous and widely used library is beneficial.
**Concepts of Calculus:
**Introductory Calculus:
To understand the optimization in machine learning algorithms, a solid foundation of differentiation, integration, and multivariable calculus is required. It deals with rates of change and accumulation of quantities especially in the context of machine learning while optimizing, multivariate calculus, including vector calculus plays a role in adjusting the parameters of a model such that it minimizes errors in prediction (technically finding the “Minima”).
For ease of understanding let's take an example of Linear regression on the prediction of property prices based on its size, here we intend to find the best-fit line that predicts the price of the property based on its size. The best-fit line can be expressed by the equation y=mx+b, where y is the predicted price, x is the size of the property, m is the “slope” of the line based on how price increases with size and b is the y-intercept, for simplicity of understanding we can say that b represents a price of the property with a size 0! (bias)
A common choice of the ”Error function” in such an example would be Mean squared error (MSE), which simply represents an average of squared differences between predicted prices and actual prices.
Equation of MSE
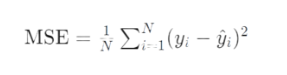
Now let's understand minimizing error with calculus, here we want to find the best “slope” of the line and bias/y-intercept
Derivatives will help us understand changes in error with respect to changes in slope and y_interccept, there is an iterative optimization algorithm to update/change slope and y-intercept in the direction that reduces the “error”, its called “Gradient descent”
There are 4 simple steps of gradient descent to perform:
- Initializing slope and y-intercept
- Calculating partial derivatives of MSE concerning slope and y-intercept
Partial derivatives of MSE
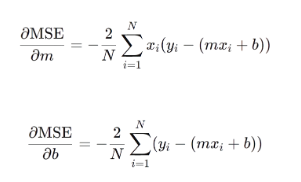
- Adjusting slope and y-intercept using (α) ~ a small positive number controlling the step size of adjustment.
- Repeating the process until the change in updated slope and y-intercept becomes low which indicates achieving optimal value
Backpropagation :
In neural networks, backpropagation is an important algorithm used for training. It uses chain rule from calculus for gradient descent implementation some text
- Forward pass: pass the input data through each layer. Each neuron performs a weighted sum of its inputs followed by an activation function.
- Error calculation:- Error computing at the output layer by simple comparison of Target values to the networks predicted values using loss function such as Mean squared error (MSE) it its a regression task or Cross-Entropy if its a Classification task
- Backpropagation (Backward pass):- to update the weights we propagate the error backward through the network.some text
- Computing gradients and updating weights:- using the chain rule compute the gradient of the loss function about each weight. This involves an important role of calculus, calculating partial derivatives of an error concerning the weights layer by layer, from the output layer, and moving backward to the input layer. Finally adjusting the weight in the error-reducing direction by subtracting the learning rate & Repeat forward/backward passes through the network until the error is optimally reduced.
- Regularization techniques such as L2 regularization are used during training to prevent overfitting and enhance generalization, all these concept together create a toolkit of machine learning , helping engineers attain efficiency while expanding depth knowledge.
Probability and Statistics:
The real-world data used for analysis and prediction sometimes have inherent uncertainty and probability and statistics help make conclusions about data and quantify the uncertainty and it makes probability and statistics an important part of Mathematics for Machine learning
Probability theory is the likelihood of an event occurring & statistics is analyzing and interpreting that data., probability distribution is formed by list of discrete random variable.
For ease of understanding let's take an example of a Medical Diagnosis, dissecting the process in 5 parts.
- Collecting details of people for Ebola disease with labels whether a person has Ebola disease or not as random variables along with symptoms , this data can be represented as probability distribution.
- Analyzing the collected data with the help of descriptive statistics, finding mean, variance, and distribution of features.
- The conditional probability of a person having Ebola given a person feels certain symptoms, is based on Baye’s theorem which helps us update the current belief based on new information.
Conditional Probability:
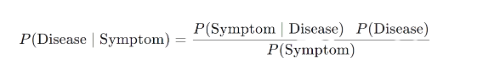
- Creating a simple probabilistic classifier based on Baye’s theorem
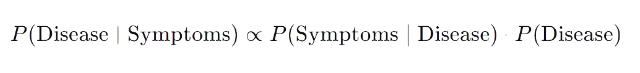
- Now we use the dataset and train the above model to count how often symptoms appear in a person having Ebola vs those who don't have it. And predict whether a person has Ebola or not for unseen data.
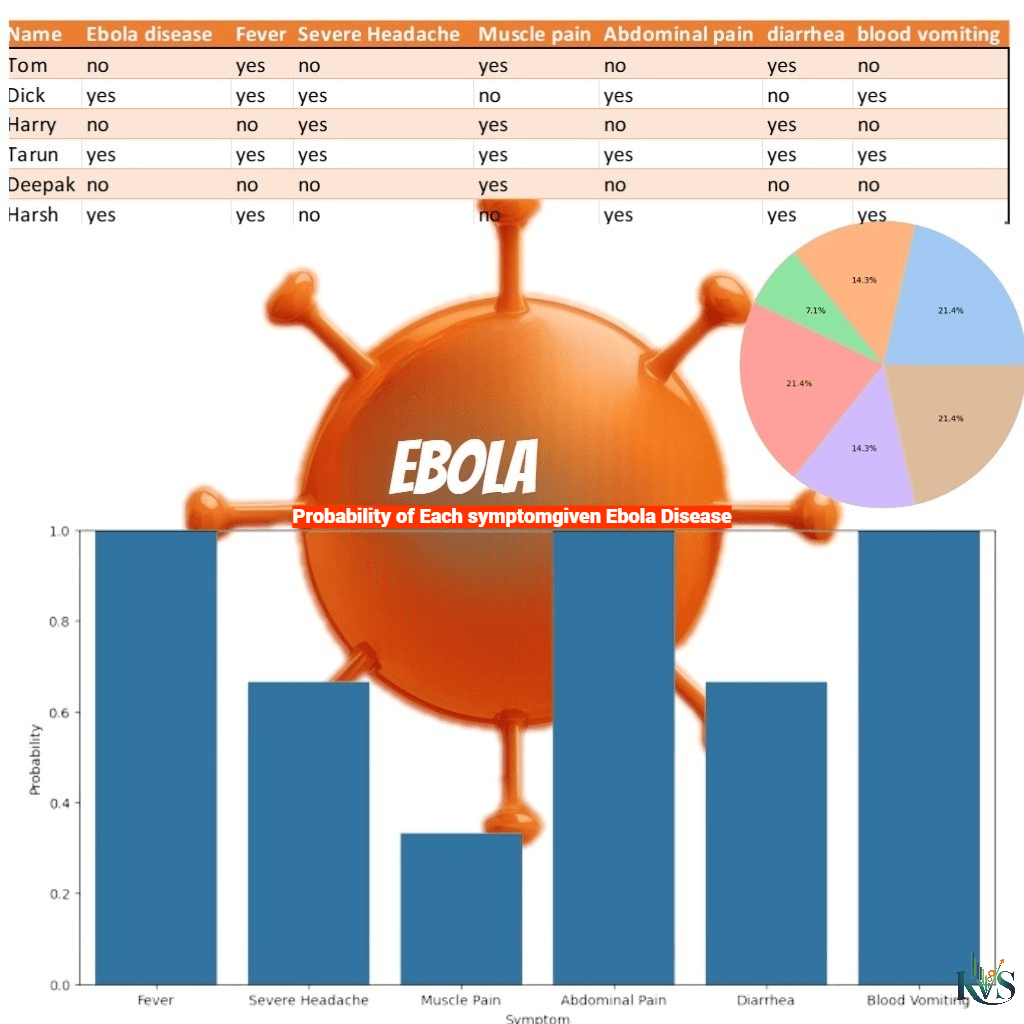
- Naive Bayes Models: Naive Bayes models rely on probability distributions to estimate the likelihood of each feature (symptom) occurring given a specific class (Ebola or no Ebola). Naive Bayes classifiers is based on Bayes' theorem and its used with strong (naive) independence assumptions between features.. It is a simple model but it can outperform more complex models, especially on small datasets.
- Gaussian Distribution (Normal distribution): This plays an important role in Gaussian Mixture Models (GMM), it's a type of soft clustering method in unsupervised learning. GMM assumes that data points are generated from a mixture of many Gaussian distributions with unknown parameters. This allows GMMs to perform modeling in complex data distributions and identify clusters that differ in shape, size, and density.
- Hypothesis Testing: A testing method that uses sample data to conclude a hypothesis about a population parameter. create a null hypothesis (no effect or difference) and an alternative hypothesis (an effect or difference exists). By calculating the p-value, we can define whether to accept alternate hypotheses or to reject it (it means whether to believe the new idea vs retain the old one!)
To dive deeper into the classical machine learning models and their mathematical foundations, check out our Notes: Classical Machine Learning blog.
Why one should have a strong math background?
- Derivations:- as we saw earlier in multivariate Calculus, a solid understanding of mathematical background especially in calculus is important in understanding derivatives and ingraining that practice to make it our second nature like a language is. Moreover, it is required for many of the machine learning algorithms like Support Vector Machines (SVMs) this would include optimization, Lagrange multipliers, and kernel functions. Getting a good hold of these derivations enables an engineer to know how the algorithm works and these concepts of math adds tremendous value to the practical experience,
- Reading research papers:- Computer science and more importantly data science and modern machine learning are evolving fast, to be able to know the latest updates in the research it is important to know how tor read a research paper which usually involves mathematical formulations, proofs, and experimental results. A deep understanding of math background helps understand these details and enables you to integrate them in your ongoing or upcoming project!
- Hyper parameter tuning:- in depth knowledge of mathematics is important for hyper parameter tuning, techniques like Grid search , random search and Bayesian optimization involves key concepts like optimization algorithms, this would ultimately improve the accuracy and performance of model.
What level of mathematical skill is required?
The requirement of mathematical understanding varies from job description to the other using different concepts for machine learning, but if we take a look at a Machine Learning engineer for example, they are responsible for designing, building, and deploying machine learning models. And all three key concepts require a strong foundation in mathematics, particularly in areas like linear algebra, calculus, and probability, level of mathematics is a little bit more than school math!. And these skills will be used in various central machine learning methods like**:**
- Supervised Learning - in this we train the model on labeled data to predict or classify new data points and its known example use cases are Image recognition and spam detection.
- Unsupervised Learning - this is mostly known for identifying hidden patterns, it's used for for clustering and dimensionality reduction.
- Semi-Supervised Learning - this combines labeled data with unlabeled data to improve learning accuracy, it's mostly used in data-efficient learning scenarios where labeled data is expensive to obtain.
- Reinforcement Learning- unlike supervised training in this method we train agents to make sequences of decisions through trial and error. One step closer to the target is considered a reward and a penalty for moving away from it, Widely applied in robotics, game-playing, and autonomous systems.
- Deep Learning- in field of machine learning, its a part that uses deep neural networks to model complex methods in massive datasets, its most known use case examples are image recognition, natural language processing, and speech recognition.
For a more hands-on approach to learning AI and machine learning, dive into cutting-edge topics, solve real-interview problems, and track your progress with Qnalab.
External Resources:-
If this article ignited the mathematician inside you!, the resources below will help you dive deeper into each of the topics covered here and mathematics of machine learning in general as well to expand your mathematical background
YouTube Channels
- 3Blue1Brown: Excellent visual explanations of mathematical concepts.
- StatQuest with Josh Starmer: Clear and engaging explanations of statistics and amazing understanding of machine learning concepts.
- Sentdex:- implementation of machine learning models & algorithms using Python programming
Books
- "Pattern Recognition and Machine Learning" by Christopher Bishop
- "Mathematics for Machine Learning" by Marc Peter Deisenroth, A. Aldo Faisal, and Cheng Soon Ong
Online Courses
- Coursera:- Probability & Statistics for Machine Learning & Data Science
- Coursera:- Machine Learning Specialization
Author
This article was written by Kartikey Vyas, and edited by our writers team.


