We have all heard that this is the age of artificial intelligence and one way or another artificial intelligence is making a permanent place in our lives, whether we use it at home or the workplace, Artificial Intelligence (AI) has revolutionized the way we live, work, and interact with each other. Artificial Intelligence (AI) is revolutionizing industries with its ability to automate tasks, analyze large datasets, and make complex decisions. Central to this revolution are AI libraries and frameworks that provide the necessary tools and functionalities for developing sophisticated AI models and applications.
Definition and purpose of AI libraries
AI libraries are collections of pre-built algorithms and functions that allow developers to easily incorporate artificial intelligence capabilities into their applications. These libraries provide a wide range of tools and resources that make it easier for developers to create intelligent applications without having to spend valuable time and resources on building AI algorithms from scratch.
These libraries are typically developed and maintained by a dedicated team of researchers and engineers who are constantly working to refine and optimize the algorithms. They continuously update the libraries with the latest advancements and best practices in AI, ensuring that developers have access to cutting-edge technology.
One of the key benefits of using AI libraries is the speed and efficiency they bring to the development process. Developers can leverage pre-existing algorithms and models, saving them the time and effort required to develop and train their own AI models. This allows them to focus more on the unique aspects of their applications and ensure faster time-to-market.
Another important purpose of AI libraries is to foster innovation and creativity. By providing a foundation of pre-built algorithms, libraries empower developers to experiment and explore new possibilities in the realm of artificial intelligence. These libraries offer a wide range of functionalities and tools that enable developers to incorporate complex AI capabilities into their applications without having to build everything from scratch.
AI libraries promote collaboration and knowledge sharing within the AI community. Developers can contribute to these libraries by adding new algorithms, improving existing ones, or providing feedback and suggestions. This collaborative effort helps to advance the field of AI and enables developers to benefit from the collective expertise and insights of their peers.
Moreover, AI libraries also contribute to the overall quality and accuracy of AI applications. These libraries are built by experts in the field who have spent significant time and effort in refining and optimizing the algorithms. This means that developers can benefit from the expertise of the AI community and leverage tried and tested models that have been proven to deliver consistent and reliable results.
Strategic Responses to AI
The availability of AI libraries has prompted various strategic responses from businesses and organizations across different industries. These responses aim to harness the potential of AI to improve processes, drive innovation, and provide a competitive edge. Here are some strategic responses to AI-enabled by the accessibility of AI libraries:
1. Integration of AI capabilities in existing products and services
AI libraries enable businesses to integrate AI capabilities seamlessly into their existing products and services. By leveraging pre-built algorithms, companies can enhance their offerings with intelligent features such as voice recognition, image analysis, or personalized recommendations. This integration helps businesses improve their customer experience, optimize operations, and gain insights from data.
For example, e-commerce platforms can utilize AI libraries to implement recommendation systems that suggest relevant products to customers based on their browsing history and preferences. This not only helps increase sales but also provides a personalized shopping experience.
2. Streamlining internal processes
Organizations can leverage AI libraries to streamline internal processes, reducing manual effort and increasing efficiency. AI algorithms can automate repetitive tasks, perform data analysis, and provide insights that aid in decision-making.
For instance, companies can utilize AI libraries to develop chatbots that handle customer queries, reducing the need for manual customer support agents. These chatbots can utilize natural language processing algorithms from AI libraries to understand and respond to customer queries in real time. This not only improves customer service by providing instant support but also frees up valuable employee time to focus on more complex tasks.
Top AI and machine learning libraries
Scikit-Learn(Sklearn)
If you are entering the world of machine learning, Scikit-learn is like a trusty toolbox you would like to have with you. This public library has been built on top of NumPy, SciPy, and Matplotlib, and it's found a way to become an integral part of the machine learning community, both by budding enthusiasts and professionals. It provides an easy approach, from diving into complex data analysis to starting with simple predictive models. It is Open source, and commercially usable.
Scikit-learn markets itself as a “simple and efficient tool for data mining and data analysis” that is “accessible to everybody, and reusable in various contexts.”
User-Friendly and Versatile
- Simplicity at Its Best: Scikit-learn has an intuitive API that lets you work on your data and models easily, without diving into the depth of technical details.
- All-in-one package: It packs tools for classification, regression, clustering, dimensionality reduction, model selection, and preprocessing. Think of it as your one-stop shop for all things machine learning. Whether you’re clustering data sets, predicting stock prices, or recognizing patterns, Scikit-Learn has a tool for that. It’s like a treasure chest of algorithms that are ready to go with just a few lines of code.
Reliable and Efficient
- Performance-oriented: Built on NumPy and SciPy, Scikit-learn will assist in handling large datasets.
- Consistent API: Whether you are changing models or scaling a project, the consistent API helps you do so without any fuss.
From Learning to Production
- Education Excellence: If you want to learn machine learning, then the documentation in Scikit-learn is really clear and there are so many examples to help you out.
- Production Ready: The transition from research to production is smooth, thanks to Scikit-learn's robustness and its comprehensive feature set.
Use Cases:
Dimensionality Reduction( PCA ):
from sklearn.decomposition
import PCAimport matplotlib.pyplot as plt
# Generate synthetic data
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
# Apply PCA
pca = PCA(n_components=2)
principal_components = pca.fit_transform(X)
# Plot the principal components
plt.scatter(principal_components[:, 0], principal_components[:, 1], c=data.target, cmap='viridis')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset')
plt.show()Clustering:
<pre><code class="language-python">from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Generate synthetic data
from sklearn.datasets import make_blobs
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# Fit KMeans
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# Plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red', marker='X')
plt.show()</code></pre>Classification:
<pre><code class="language-python">from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load dataset
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2)
# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Predict and evaluate
predictions = model.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, predictions)}')</code></pre>Grid Search with Cross-Validation:
<pre><code class="language-python">from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# Load dataset
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2)
# Define parameter grid
param_grid = {'C': [0.1, 1, 10, 100],'gamma': [1, 0.1, 0.01, 0.001],'kernel': ['rbf']}
#Perform grid search
grid = GridSearchCV(SVC(), param_grid, refit=True, verbose=2, cv=5) grid.fit(X_train, y_train)
#Print best parameters and evaluate model
print(f'Best Parameters: {grid.best_params_}') predictions = grid.predict(X_test) print(classification_report(y_test, predictions))</code></pre>Regression:
<pre><code class="language-python">from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Load dataset
data = load_boston()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2)
# Train mode
lmodel = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
predictions = model.predict(X_test)
print(f'Mean Squared Error: {mean_squared_error(y_test, predictions)}')</code></pre>These examples showcase the versatility and power of Scikit-learn in handling various machine learning tasks, from data preprocessing and feature selection to model selection and evaluation.
Learning Resources:
The best way to learn Machine learning through Scikit-learn is to go through its documentation. It contains resources for Supervised, unsupervised, preprocessing, and everything, play with code on your Jupyter notebook, and make some interesting solutions to real-world problems, it will help you improve your technical skills
TensorFlow
Created by the Google Brain team and initially released to the public in 2015, TensorFlow is an open-source deep learning framework for numerical computation and large-scale machine learning. TensorFlow bundles together a slew of machine learning and deep learning models and algorithms (aka neural networks) and makes them useful through common programmatic metaphors. A convenient front-end API lets developers build applications using Python or JavaScript, while the underlying platform executes those applications in high-performance C++. TensorFlow also provides libraries for many other languages, although Python tends to dominate.
The most important thing to realize about TensorFlow is that, for the most part, the core is not written in Python: It's written in a combination of highly optimized C++ and CUDA (Nvidia's language for programming GPUs). Much of that happens, in turn, by using Eigen (a high-performance C++ and CUDA numerical library) and NVidia's cuDNN (a very optimized DNN library for NVidia GPUs, for functions such as convolutions).
TensorFlow is an open-source platform for machine learning using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) that flow between them. This flexible architecture describes machine learning algorithms as a graph of connected operations. They can be trained and executed on GPUs, CPUs, and TPUs across various platforms without rewriting code, ranging from portable devices to desktops to high-end servers. This means programmers of all backgrounds can use the same toolsets to collaborate, significantly boosting their efficiency. Developed initially by the Google Brain Team for the purposes of conducting machine learning and deep neural networks (DNNs) research, the system is general enough to be applicable in a wide variety of other domains as well.
How TensorFlow Works
Three distinct parts define the TensorFlow workflow, namely preprocessing of data, building the model, and training the model to make predictions. The framework inputs data as a multidimensional array called tensors and executes in two different fashions. The primary method is to build a computational graph that defines a data flow for training the model. The second, and often more intuitive method, is using eager execution, which follows imperative programming principles and evaluates operations immediately.
Using the TensorFlow architecture, training is generally done on a desktop or in a data center. In both cases, the process is sped up by placing tensors on the GPU. Trained models can then run on a range of platforms, from desktop to mobile and to cloud.
TensorFlow also contains many supporting features. For example, TensorBoard, allows users to visually monitor the training process, underlying computational graphs, and metrics for purposes of debugging runs and evaluating model performance. Tensorboard is the unified visualization tool for Tensorflow and Keras.
Keras is a high-level API that runs on top of TensorFlow. Keras furthers the abstractions of TensorFlow by providing a simplified API intended for building models for common use cases. The driving idea behind the API is being able to translate from an idea to a result in as little time as possible.
Benefits of TensorFlow
TensorFlow can be used to develop models for various tasks, including natural language processing, image recognition, handwriting recognition, and different computational-based simulations such as partial differential equations.
The key benefits of TensorFlow are in its ability to execute low-level operations across many acceleration platforms, automatic computation of gradients, production-level scalability, and interoperable graph exportation. By providing Keras as a high-level API and eager execution as an alternative to the dataflow paradigm on TensorFlow, it’s always easy to write code comfortably.
As the original developer of TensorFlow, Google still strongly backs the library and has catalyzed the rapid pace of its development. For example, Google has created an online hub for sharing the many different models created by users.
TensorFlow-Specific Business Use Cases
- Image processing and video detection:. Airplane manufacturing giant Airbus is using TensorFlow to extract and analyze information from satellite images to deliver valuable real-time information to clients.
- Time series algorithms: Kakao uses TensorFlow to predict the completion rate of ride-hailing requests.
- Tremendous scale capabilities: NERSC scaled a scientific deep learning application to more than 27,000 NVIDIA V100 Tensor Core GPUs using TensorFlow.
- Modeling: Using TensorFlow for deep transfer learning and generative modeling, PayPal has been able to recognize complex, temporarily varying fraud patterns while improving the experience of legitimate customers through expedited customer identification.
- Text recognition: SwissCom’s custom-built TensorFlow model improved business by classifying text, and determining the intent of customers upon receiving calls.
- Tweet prioritization: Twitter used TensorFlow to build its Ranked Timeline, ensuring that users don’t miss their most important tweets, even when following thousands of users.
Why TensorFlow Matters to You
Data scientists
The many different available routes to develop models with TensorFlow means that the right tool for the job is always available, expressing innovative ideas and novel algorithms as quickly as possible. As one of the most common libraries for developing machine learning models, it’s typically easy to find TensorFlow code from previous researchers when trying to replicate their work, preventing the loss of time to boilerplate and redundant code, and helping reduce development cost
Software developers
TensorFlow can run on a wide variety of common hardware platforms and operating environments. With the release of TensorFlow 2.0 in late 2019, it’s even easier to deploy TensorFlow models on a greater variety of platforms. The interoperability of models created with TensorFlow means that deployment is never a difficult task.
Use Case: Image Classification with a Neural Network
<pre><code class="language-python">import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
# Load dataset
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
# Build model
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')])
# Compile model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train model
model.fit(train_images, train_labels, epochs=5, validation_split=0.2)
# Evaluate model
test_loss, test_acc = model.evaluate(test_images, test_labels)print(f'Test Accuracy: {test_acc}')</code></pre>Use Case: Text Classification with RNN
<pre><code class="language-python">import tensorflow as tf
from tensorflow.keras import layers, models, datasets, preprocessing
# Load dataset
(train_texts, train_labels), (test_texts, test_labels) = datasets.imdb.load_data(num_words=10000)
maxlen = 500
train_texts = preprocessing.sequence.pad_sequences(train_texts, maxlen=maxlen)
test_texts = preprocessing.sequence.pad_sequences(test_texts, maxlen=maxlen)
# Build model
model = models.Sequential([
layers.Embedding(input_dim=10000, output_dim=128, input_length=maxlen),
layers.LSTM(128, return_sequences=True),
layers.LSTM(128),layers.Dense(1, activation='sigmoid')])
# Compile model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train model
model.fit(train_texts, train_labels, epochs=5, validation_split=0.2)
# Evaluate model
test_loss, test_acc = model.evaluate(test_texts, test_labels)
print(f'Test Accuracy: {test_acc}')</code></pre>Use Case: Custom Training Loop
<pre><code class="language-python">import tensorflow as tf
from tensorflow.keras import layers, models, datasets, optimizers
# Load dataset
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
# Build model
model = models.Sequential(
[layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')])
# Define optimizer and loss function
optimizer = optimizers.Adam()
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
# Custom training loop
epochs = 5
batch_size = 64
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(60000).batch(batch_size)
for epoch in range(epochs):
print(f'Starting epoch {epoch+1}')
for step, (x_batch, y_batch) in enumerate(train_dataset):
with tf.GradientTape() as tape:
logits = model(x_batch, training=True)
loss_value = loss_fn(y_batch, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
if step % 100 == 0:
print(f'Epoch {epoch+1}, Step {step}, Loss: {loss_value:.4f}')
# Evaluate model
test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(batch_size)
test_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy()
for x_batch, y_batch in test_dataset:
test_logits = model(x_batch, training=False)
test_acc_metric.update_state(y_batch, test_logits)
test_acc = test_acc_metric.result()
print(f'Test Accuracy: {test_acc:.4f}')</code></pre>Use Case: Model Deployment with TensorFlow Serving
<pre><code class="language-python">import tensorflow as tf
from tensorflow.keras import layers, models
# Build model
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')])
# Save model
model.save('my_model')
# TensorFlow Serving command (run in terminal):
# tensorflow_model_server --rest_api_port=8501 --model_name=my_model --
model_base_path="/path/to/my_model"</code></pre>Pandas
As an open-source software library built on top of Python specifically for data manipulation and analysis, Pandas offers data structure and operations for powerful, flexible, and easy-to-use data analysis and manipulation. Pandas strengthens Python by giving the popular programming language the capability to work with spreadsheet-like data enabling fast loading, aligning, manipulating, and merging, in addition to other key functions. Pandas are prized for providing highly optimized performance when back-end source code is written in C or Python.
Pandas rank among the most popular and widely used tools for so-called data wrangling, or munging. This describes a set of concepts and a methodology used when taking data from unusable or erroneous forms to the levels of structure and quality needed for modern analytics processing. Pandas excels in its ease of working with structured data formats such as tables, matrices, and time series data. It also works well with other Python scientific libraries.
How Pandas Works
Included in the Pandas open-source library are DataFrames, which are two-dimensional array-like data tables in which each column contains values of one variable and each row contains one set of values from each column. Data stored in a DataFrame can be of numeric, factor, or character types. Pandas DataFrames are also thought of as a dictionary or collection of series objects.
Data scientists and programmers familiar with the R programming language for statistical computing know that DataFrames are a way of storing data in grids that are easily overviewed. This means that Pandas is chiefly used for machine learning in the form of DataFrames.
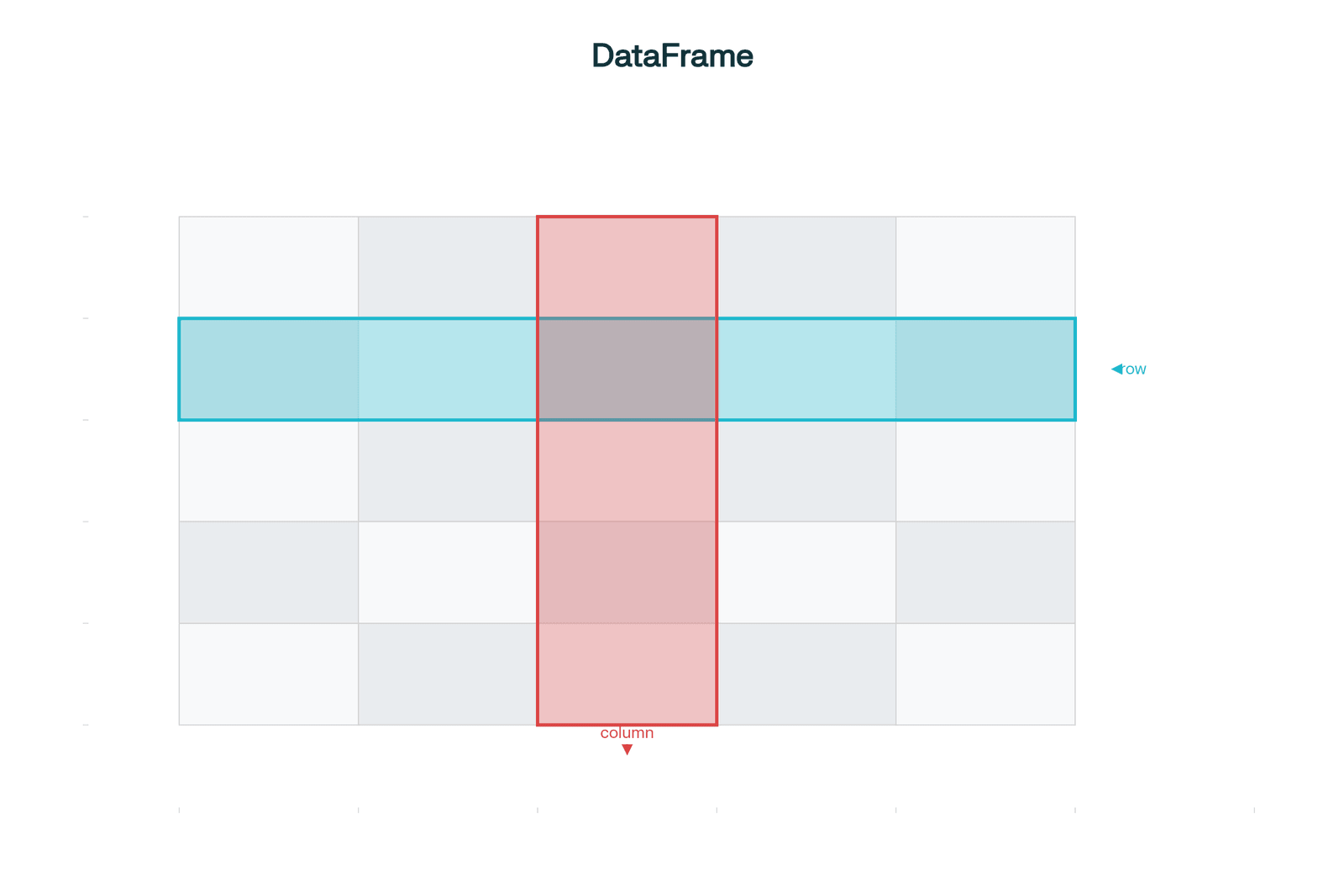
Pandas is well suited for working with several kinds of data, including:
- Tabular data with heterogeneously-typed columns, as in an SQL table or Excel spreadsheet
- Ordered and unordered (not necessarily fixed-frequency) time series data
- Arbitrary matrix data (homogeneously typed or heterogeneous) with row and column labels
Key benefits of the Pandas
Undoubtedly, pandas is a powerful data manipulation tool packaged with several benefits, including:
- Made for Python: Python is the world's most popular language for machine learning and data science.
- Less verbose per unit operations: Code written in pandas is less verbose, requiring fewer lines of code to get the desired output.
- Intuitive view of data: Pandas offers exceptionally intuitive data representation that facilitates easier data understanding and analysis.
- Extensive feature set: It supports an extensive set of operations from exploratory data analysis, dealing with missing values, calculating statistics, visualizing univariate and bivariate data, and much more.
- Works with large data: Pandas handles large data sets with ease. It offers speed and efficiency while working with datasets of the order of millions of records and hundreds of columns, depending on the machine.
Use case: Importing different files(CSV, Excel, Test, JSON files)
import pandas as pd
```python
#importing csv file
df = pd.read_csv("diabetes.csv")
#importing excel file
df = pd.read_excel('diabetes.xlsx')
#importing test files
df = pd.read_csv("diabetes.txt", sep="\s")
#importing json file
df = pd.read_json("diabetes.json")Use Case: Data Cleaning and Preparation
import pandas as pd
```python
# Create a DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Edward'],
'Age': [25, 30, None, 35, 40],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix']}
df = pd.DataFrame(data)
# Handling missing values
df['Age'].fillna(df['Age'].mean(), inplace=True)
# Removing duplicates
df.drop_duplicates(inplace=True)
# Transforming data formats
df['Age'] = df['Age'].astype(int)print(df)Use Case: Data Analysis and Manipulation
<pre><code class="language-python">#Create another DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Edward'],
'Age': [25, 30, 35, 35, 40],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix'],
'Salary': [70000, 80000, 50000, 60000, 90000]}
df = pd.DataFrame(data)
#Filtering data
filtered_df = df[df['Age'] > 30]
#Grouping data
grouped_df = df.groupby('Age').mean()
#Aggregating data
aggregated_df = df.agg({'Salary': ['mean', 'sum'], 'Age': ['max', 'min']})
print(filtered_df)
print(grouped_df)
print(aggregated_df)</code></pre>Other Use Cases of Pandas
- Time Series Analysis: Handle time series data with functionalities to resample, shift, and calculate rolling statistics.
- Data Visualization: Integrate with libraries like Matplotlib and Seaborn for plotting data directly from DataFrames.
- Input and Output Operations: Read from and write to various file formats like CSV, Excel, SQL databases, and JSON.
- Statistical Analysis: Perform descriptive statistics, correlation analysis, and hypothesis testing.
- Pivot Tables: Create pivot tables for summarizing and exploring complex datasets.
- Data Munging: Perform data wrangling tasks such as transforming, mapping, and converting data types.
Hugging Face
Hugging Face is a machine learning (ML) and data science platform and community that helps users build, deploy, and train machine learning models.
They describe themselves as:
“The AI community for building the future.”
It provides the infrastructure to demo, run, and deploy artificial intelligence (AI) in live applications. Users can also browse through models and data sets that other people have uploaded. Hugging Face is often called the GitHub of machine learning because it lets developers share and test their work openly.
The platform is important because of its open-source nature and deployment tools. It allows users to share resources, models, and research and to reduce model training time, resource consumption, and environmental impact of AI development.
Hugging Face is known for its Transformers Python library, which simplifies the process of downloading and training ML models. The library gives developers an efficient way to include one of the ML models hosted on Hugging Face in their workflow and create ML pipelines. The transformers library provides a unified API and pre-trained models for various NLP tasks such as text Classification, named entity recognition, question answering, text generation, and more.
The Transformers library simplifies the implementation of NLP models in several key ways:
- Abstraction of complexity: It abstracts away the complexity involved in initializing models, managing pre-processing pipelines, and handling tokenization.
- Pre-trained models: Providing the biggest collection of pre-trained models, they reduce the time and resources required to develop sophisticated NLP applications from scratch.
- Flexibility and modularity: The library is designed with modularity in mind, allowing users to plug in different components as required.
- Community and support: Hugging Face has fostered a strong community around its tools, with extensive documentation, tutorials, and forums.
- Continuous updates and expansion: The library is constantly updated with the latest breakthroughs in NLP, incorporating new models and methodologies as they are developed.
Key Features of the Hugging Face
- Transformers: Pre-trained models for many different NLP tasks.
- Datasets: Hundreds of available datasets for machine learning.
- Tokenizers: Hugging Face provides a range of user-friendly tokenizers, optimized for their Transformers library, which are key to the seamless preprocessing of text.
- Model Hub: Shared community space of pre-trained models. The Model Hub stands as the community's face, a platform where thousands of models and datasets are at your fingertips. It is an innovative feature that allows users to share and discover models contributed by the community, promoting a collaborative approach to NLP development.
- Integration: Easily can be integrated with other ML frameworks like TensorFlow and PyTorch.
Use case: Text classification
from transformers import pipeline
```python
# Initialize the text classification pipeline
classifier = pipeline('sentiment-analysis')
# Classify text
result = classifier("I love using Hugging Face!")
print(result)Use Case: Text generation
<pre><code class="language-python">from transformers import pipeline
# Initialize the text generation pipeline
generator = pipeline('text-generation', model='gpt-2')
# Generate text
result = generator("Once upon a time,")
print(result)</code></pre>Use case: Named Entity Recognition (NER)
from transformers import pipeline
```python
# Initialize the NER pipeline
ner = pipeline('ner')
# Perform NER
result = ner("Hugging Face is a company based in New York.")
print(result)Other Functionalities of the Hugging Face Library
- Summarization: Generate concise summaries of long texts, useful for quickly understanding large documents or articles.
- Translation: Translate text between different languages, enabling cross-lingual communication and content localization.
- Question Answering: Answer questions based on a given context, helpful for building AI assistants and chatbots.
- Text Embeddings: Generate vector representations of text for tasks like similarity comparison, clustering, and recommendation systems.
- Language Modeling: Train or fine-tune models for predicting the next word in a sequence, beneficial for autocomplete systems and text generation applications.
- Custom Model Training: Train custom models on specific datasets tailored to unique applications and domains, such as sentiment analysis or topic classification in specialized fields.
- Conversational AI: Build and deploy conversational agents or chatbots that can understand and respond to user inputs.
- Speech Recognition and Synthesis: Convert speech to text and text to speech, useful for voice assistants and accessibility tools.
- Token Classification: Identify specific tokens in text, like parts of speech or named entities, which is useful for detailed text analysis.
- Zero-Shot Classification: Classify text into categories without specific training data, leveraging pre-trained models for flexible and rapid deployment in various tasks.
- Sentence Similarity: Measure the similarity between two sentences, useful for plagiarism detection, duplicate detection, and semantic search.
- Paraphrasing: Rephrase sentences while retaining the original meaning, helpful for content rewriting and improving text diversity.
Open AI(API)
The OpenAI API allows developers to easily access a wide range of AI models developed by OpenAI. It provides a user-friendly interface that enables developers to incorporate advanced features powered by state-of-the-art OpenAI models into their applications. The API can be used for various purposes, including text generation, multi-turn chat, embeddings, transcription, translation, text-to-speech, image understanding, and image generation. Additionally, the API is compatible with curl, Python, and Node.js.
In simpler terms, the API is like a helper that lets you use OpenAI’s smart programs in your projects. For example, you can add cool features like understanding and creating text without having to know all the nitty-gritty details of the underlying models.
Key Features of OpenAI API
1. Pre-trained Models
OpenAI offers pre-trained models like GPT-3, DALL-E, and CLIP that can be used directly for various applications without the need for extensive training.
- GPT-3: A state-of-the-art language model capable of generating human-like text, answering questions, summarizing content, translating languages, and more.
- DALL-E: A model that generates images from textual descriptions, opening new possibilities for creative content generation.
- CLIP: A model that understands images and text together, enabling tasks like zero-shot classification, where it can recognize objects in images based on textual descriptions.
2. Customizable AI Models
While OpenAI provides powerful pre-trained models, it also allows customization to fit specific needs.
- Fine-Tuning: Customize models by fine-tuning them on specific datasets to improve performance on specialized tasks.
- Prompt Engineering: Tailor the behavior of models through carefully crafted prompts to get the desired output.
3. Simple AI Interface
The OpenAI API offers a simple and intuitive interface for developers to interact with the models.
- Easy Integration: The API can be easily integrated into various applications using standard HTTP requests.
- Comprehensive Documentation: Detailed documentation and examples are provided to help developers get started quickly.
- Libraries and SDKs: Official and community-supported libraries for various programming languages to simplify API usage.
4. Scalability
OpenAI's infrastructure supports scalable AI deployment, handling applications ranging from small-scale deep learning projects to large enterprise solutions.
- High Availability: Robust infrastructure ensures high availability and reliability of the API.
- Performance Optimization: Efficiently handles large volumes of requests with low latency, making it suitable for real-time applications.
- Usage Tiers: Different pricing and usage tiers to accommodate various needs, from hobbyists to large organizations.
Use Cases: Text Generation
import openai
```python
# Set up the OpenAI API key
openai.api_key = 'your-api-key'
# Generate text
response = openai.Completion.create(engine="text-davinci-003",prompt="Once upon a time,",max_tokens=50)
print(response.choices[0].text)Use Case: Question-Answering
<pre><code class="language-python">import openai
# Set up the OpenAI API key
openai.api_key = 'your-api-key'
# Define context and question
cotext = "Hugging Facpe is a company based in New York. It is known for its open-source libraries and pre-trained models for NLP tasks.
"question = "Where is Huggvisualization tooling Face based?"
# Answer the question
response = openai.Completion.create(
engine="text-davinci-003",
prompt=f"Context: {context}\nQuestion: {question}\nAnswer:",
max_tokens=50)
print(response.choices[0].text)</code></pre>Use Case: Chatbot Interaction
import openai
```python
# Set up the OpenAI API key
openai.api_key = 'your-api-key'
# Define user input
user_input = "Hello, who won the world series in 2020?"
# Generate chatbot response
response = openai.Completion.create(
engine="text-davinci-003",
prompt=f"User: {user_input}\nChatbot:",
max_tokens=50)
print(response.choices[0].text)Other Potential Use Cases
- Summarization: Generate concise summaries of long texts, useful for quickly understanding large documents or articles.
- Translation: Translate text between different languages, enabling cross-lingual communication and content localization.
- Content Creation: Generate creative content like articles, stories, and poems.
- Code Generation: Assist in writing code snippets or entire functions based on natural language descriptions.
- Data Analysis: Automate data analysis tasks by generating insights and reports from raw data.
- Education: Provide personalized learning experiences by generating educational content and answering questions.
- Customer Support: Automate customer support with AI-driven responses to common queries.
- Research Assistance: Summarize and provide insights from large volumes of research papers and articles.
- Interactive Applications: Enhance interactive applications with AI-driven features like dynamic storytelling and adaptive gameplay.
- Voice Assistance: Integrate speech recognition and synthesis for creating voice-based AI assistants.
OpenCV
OpenCV stands for Open Source Computer Vision. To put it simply, it is a library used for image processing. It is a huge open-source library used for computer vision applications, in areas powered by Artificial Intelligence or Machine Learning algorithms, and for completing tasks that need image processing. As a result, it assumes significance today in real-time operations in today’s systems. Using OpenCV, one can process images and videos to identify objects, faces, or even the handwriting of a human.
Written in C and C++, OpenCV is compatible with major operating systems such as GNU/Linux, macOS, Windows, iOS, and Android. There are interfaces for Python, Ruby, Matlab, and other languages. The OpenCV library includes more than 2500 algorithms, extensive documentation, and code samples for real-time Computer Vision. It contains a comprehensive Machine Learning library focused on statistical pattern recognition and clustering.
The software is written in optimized C and can take advantage of multi-core processors. This is known as multithreading.
Key Features of OpenCV
- Image Processing: Functions for filtering, transformations, and image enhancements.
- Video Analysis: Tools for capturing, processing, and analyzing video streams.
- Object Detection: Algorithms for detecting objects in images and videos.
- Machine Learning: Built-in machine learning algorithms for training and prediction tasks.
Use Case: Image Filtering
import cv2
```python
# Load an image
image = cv2.imread('input.jpg')
# Apply a Gaussian blur filter
blurred_image = cv2.GaussianBlur(image, (15, 15), 0)
# Save the result
cv2.imwrite('blurred_image.jpg', blurred_image)Use Case: Edge Detection
import cv2
```python
# Load an image
image = cv2.imread('input.jpg', 0) # Load in grayscale
# Apply Canny edge detection
edges = cv2.Canny(image, 100, 200)
# Save the result
cv2.imwrite('edges.jpg', edges)Use Case: Object Detection using Haar Cascades
import cv2
```python
# Load the pre-trained Haar cascade for face detection
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# Load an image
image = cv2.imread('input.jpg')
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Detect faces
faces = face_cascade.detectMultiScale(gray_image, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# Draw rectangles around the faces
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
# Save the result
cv2.imwrite('faces_detected.jpg', image)Other Potential Use Cases of OpenCV
- Video Capture and Processing: Capture video from cameras and process frames in real time.
- Feature Detection and Matching: Detect and match features between different images for tasks like image stitching and object recognition.
- Motion Tracking: Track moving objects in video sequences, useful for surveillance and sports analytics.
- Image Segmentation: Segment images into meaningful regions, useful for medical imaging and object extraction.
- Camera Calibration: Calibrate cameras to correct for lens distortion and improve measurement accuracy.
- 3D Reconstruction: Reconstruct 3D scenes from multiple images, useful for virtual reality and augmented reality applications.
- Image Stitching: Stitch multiple images together to create a panorama.
- Template Matching: Find occurrences of a template image within a larger image.
- Optical Flow: Estimate motion between two frames in a video sequence.
- OCR (Optical Character Recognition): Recognize and extract text from images, useful for digitizing documents.
NLTK(Natural Language Toolkit)
The Natural Language Toolkit (NLTK) is a comprehensive natural language processing (NLP) library in Python. It provides easy-to-use interfaces and a vast collection of libraries, tools, and resources for various NLP tasks.
It contains text-processing libraries for tokenization, parsing, classification, stemming, tagging, and semantic reasoning. It also includes graphical demonstrations and sample datasets as well as accompanied by a cookbook and a book that explains the principles behind the underlying language processing tasks that NLTK supports.
NLTK (Natural Language Toolkit) is the go-to API for NLP (Natural Language Processing) with Python. It is a really powerful tool to preprocess text data for further analysis like with ML models for instance.
Key Features of NLTK
- Text Processing: Tools for tokenizing, stemming, lemmatizing, and more.
- Corpora and Lexical Resources: Access to a wide range of text corpora and lexical resources.
- Text Classification: Algorithms for text classification and categorization.
- Syntax and Semantics: Tools for parsing and semantic analysis.
Use Case: Tokenization
<pre><code class="language-python">import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
# Download necessary data
nltk.download('punkt')
# Sample text
text = "Hello world. This is a test sentence."
# Word tokenization
words = word_tokenize(text)
print("Word Tokenization:", words)
# Sentence tokenization
sentences = sent_tokenize(text)
print("Sentence Tokenization:", sentences)</code></pre>Use Case: Part-of-Speech Tagging
<pre><code class="language-python">import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
# Download necessary data
nltk.download('averaged_perceptron_tagger')
# Sample text
text = "OpenAI is creating a general artificial intelligence."
# Tokenize text
words = word_tokenize(text)
# Part-of-Speech tagging
pos_tags = pos_tag(words)
print("Part-of-Speech Tags:", pos_tags)</code></pre>Use Case: Named Entity Recognition
<pre><code class="language-python">import nltk
from nltk.tokenize import word_tokenize
from nltk import ne_chunk
# Download necessary data
nltk.download('maxent_ne_chunker')
nltk.download('words')
# Sample text
text = "Barack Obama was born in Hawaii."
# Tokenize text
words = word_tokenize(text)
# Part-of-Speech tagging
pos_tags = nltk.pos_tag(words)
# Named Entity Recognition
named_entities = ne_chunk(pos_tags)
print("Named Entities:", named_entities)</code></pre>Other Potential Use Cases of NLTK
- Text Classification: Build and evaluate models for classifying text, such as spam detection or sentiment analysis.
- Text Cleaning and Preprocessing: Tools for cleaning and preprocessing text data, such as removing stop words and punctuation.
- Stemming and Lemmatization: Reduce words to their root forms for normalization.
- Corpora Access: Access to various text corpora for training and evaluation purposes.
- Syntactic Parsing: Parse sentences to analyze their grammatical structure.
- WordNet Integration: Use WordNet for lexical database queries, such as finding synonyms and antonyms.
- Concordance Generation: Generate concordances for words in text, useful for linguistic analysis.
- N-grams Generation: Create n-grams for text analysis and feature extraction.
- Language Modeling: Build language models for predicting the probability of sequences of words.
- Collocations Extraction: Identify collocations, which are pairs of words that occur together unusually often.
Numpy
NumPy is an open-source mathematical and scientific computing library for Python programming tasks. The name NumPy is shorthand for Numerical Python. The NumPy library offers a collection of high-level mathematical functions including support for multi-dimensional arrays, masked arrays, and matrices. NumPy also includes various logical and mathematical capabilities for those arrays such as shape manipulation, sorting, selection, linear algebra, statistical operations, random number generation, and discrete Fourier transforms.
The open-source python library relies on well-known packages implemented in another language (e.g. C or Fortran) to perform efficient computations, bringing the user both the expressiveness of Python and a performance similar to Matlab or Fortran.
As the core library for scientific computing, NumPy is the base for libraries such as Pandas, Scikit-learn, and SciPy. It’s widely used for performing optimized mathematical operations on large arrays.
A multidimensional array is a central data structure of a NumPy library, and generically represents a grid of values. NumPy’s ndarray, a homogeneous n-dimensional array object, describes a collection of elements or items of a similar type. Within these ndarrays, each item comprises the same size memory block, and each block is identified the same way. This enables efficient, fast, and easy manipulation of data for scientific computing.
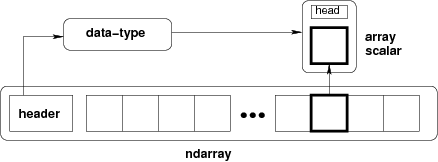
Figure based on the internal organization of NumPy arrays. Source: NumPy documentation, Copyright NumPy Developers, BSD 3-Clause Licens
Figure based on the internal organization of NumPy arrays. Source: NumPy documentation, Copyright NumPy Developers, BSD 3-Clause License
NumPy array operations are faster than Python Lists because NumPy arrays are compilations of similar data types and are packed densely in memory. By contrast, a Python List can have varying data types, placing additional constraints on the system while performing computations upon them.
Key Features of NumPy
- N-dimensional Array Object: Provides a powerful N-dimensional array object.
- Mathematical Functions: Functions for performing element-wise computations and operations on arrays.
- Linear Algebra: Tools for performing linear algebra operations.
- Random Number Generation: Facilities for generating random numbers.
- Integration with Other Libraries: Integrates seamlessly with libraries like Pandas, Scipy library, and Matplotlib.
Use Case: Array Creation, Manipulation, and Mathematical Operations
import numpy as np
```python
# Create arrays
array_1d = np.array([1, 2, 3, 4, 5])
array_2d = np.array([[1, 2, 3], [4, 5, 6]])p
rint("1D Array:", array_1d)print("2D Array:", array_2d)
# Indexing and slicing
print("First element of 1D array:", array_1d[0])
print("First row of 2D array:", array_2d[0, :])
print("Second column of 2D array:", array_2d[:, 1])
# Reshaping
reshaped_array = array_2d.reshape(3, 2)
print("Reshaped 2D Array:\n", reshaped_array)
# Mathematical operations
sum_array = np.add(array_1d, 5)
product_array = np.multiply(array_2d, 2)
print("Array after addition:", sum_array)
print("Array after multiplication:\n", product_array)Use Case: Statistical Operations, Linear Algebra, and Random Number Generation
<pre><code class="language-python">#Statistical operations
mean_value = np.mean(array_1d)
median_value = np.median(array_1d)
std_deviation = np.std(array_1d)
print("Mean:", mean_value)
print("Median:", median_value)
print("Standard Deviation:", std_deviation)
# Linear algebra operations
matrix_1 = np.array([[1, 2], [3, 4]])
matrix_2 = np.array([[5, 6], [7, 8]])
matrix_product = np.dot(matrix_1, matrix_2)
matrix_determinant = np.linalg.det(matrix_1)
matrix_inverse = np.linalg.inv(matrix_1)
print("Matrix Product:\n", matrix_product)
print("Matrix Determinant:", matrix_determinant)
print("Matrix Inverse:\n", matrix_inverse)
# Random number generation
random_array = np.random.rand(3, 3)
random_integers = np.random.randint(1, 10, size=(3, 3))
random_normal = np.random.normal(0, 1, size=(3, 3))
print("Random Array:\n", random_array)
print("Random Integers:\n", random_integers)
print("Random Normal Distribution:\n", random_normal)</code></pre>Use Case: Broadcasting, Sorting, and Complex Mathematical Functions
<pre><code class="language-python">#Broadcasting
array_a = np.array([1, 2, 3])
array_b = np.array([[10], [20], [30]])
broadcasted_sum = array_a + array_b
print("Broadcasted Sum:\n", broadcasted_sum)
#Sorting and searching
unsorted_array = np.array([3, 1, 2, 5, 4])
sorted_array = np.sort(unsorted_array)
indices = np.argsort(unsorted_array)
element_index = np.where(unsorted_array == 2)
print("Unsorted Array:", unsorted_array)
print("Sorted Array:", sorted_array)
print("Indices of Sorted Elements:", indices)
print("Index of Element '2':", element_index)
#Complex mathematical functions
angles = np.array([0, np.pi/2, np.pi])
sine_values = np.sin(angles)
log_values = np.log(array_1d)
print("Sine Values:", sine_values)
print("Logarithm Values:", log_values)</code></pre>Other Potential Use Cases of NumPy (without code)
- Fourier Transform: Perform Fourier transform for signal processing applications.
- Polynomials: Work with polynomials using NumPy's polynomial module.
- Histograms: Compute and plot histograms for data visualization.
- Financial Functions: Utilize financial functions like net present value (NPV) and internal rate of return (IRR).
- Integration with Pandas: Use NumPy arrays for efficient data manipulation with Pandas.
- Masked Arrays: Handle missing data with masked arrays.
- Custom UFuncs: Create custom universal functions (ufuncs) for element-wise operations.
Resources for further learning and development in AI libraries
- Online courses and tutorials: Actually, there are a lot of such resources in the area of AI libraries, for example, web courses and tutorials that cover topics including machine learning, deep learning, TensorFlow, and PyTorch, run by platforms like Udemy, Coursera, and edX. Some structured courses are provided with hands-on projects to practice with.
- Documentations and Guides: Most AI libraries have very detailed documentation and guides online. These will help you learn what a particular library can do, along with functionalities from its APIs and examples of their usage. Reading through the documentation can make one understand the capabilities of the library as well as how to best leverage these in his or her own projects.
- Open Source Community: Most AI libraries are bound to have a living open-source community, such as TensorFlow and PyTorch. These communities often have forums, discussion boards, and repositories on platforms like GitHub. Open-source communities expose you to some of the most experienced developers in the field, collaborate on projects, and stay up-to-date with what is going on in these domains.
- Books and Research Papers: Use books and research papers for a deep dive into AI libraries and their application. Many books are written on topics concerning machine learning. There are vast numbers of resources in AI libraries that can help further knowledge and development. Examples would be tutorials, documentation, and example code, along with community forums to learn, share ideas, and improve skills when using the power of AI libraries. Here is a selected sample:
- Online Communities and Forums: In addition to the open-source communities, there are several online communities(like AWS ML community) and forums dedicated to AI libraries. The likes of Stack Overflow and Reddit both have very active communities where developers can seek help and advice or share knowledge associated with the use of AI libraries. You are going to learn a lot not only from their experience but also get connected with people who think like you.
- Attending Meetups and Conferences: Meetups and conferences on AI libraries bring you current trends in the field. Such events often host talks, workshops, and networking sessions conducted by experts and practitioners. These provide a platform for sharing ideas, learning from others, and staying up to date on the fast-changing AI library.
- Kaggle: Kaggle provides a platform for hosting online competitions in the field of data science where its users can try their skills. Competitions involve an immense number of datasets and challenges that one can solve.
- Hackathons and Competitions: Participating in AI hackathons and competitions is a cool way to get practice using AI libraries. The problems they often stage introduce real-world challenges that would require a keen application of AI libraries to a particularly complex problem. Also, it's a good place to collaborate with other participants and get valuable feedback from subject experts themselves.
For a deeper understanding of how AI systems are developed, check out our blog on How to Build an AI System?. Additionally, to explore more on neural network models, visit NN Models. For insights on using AI with data manipulation, don't miss our post on Pandas AI.
Authors
This article is written by Gaurav Sharma, a member of 123 of AI, and edited by the 123 of AI team.


